EDITORIAL
Published on 30 Apr 2019
Editorial: Mining Scientific Papers: NLP-enhanced Bibliometrics
doi 10.3389/frma.2019.00002
- 27,678 views
- 35 citations
10k
Total downloads
110k
Total views and downloads
EDITORIAL
Published on 30 Apr 2019
ORIGINAL RESEARCH
Published on 07 Feb 2019
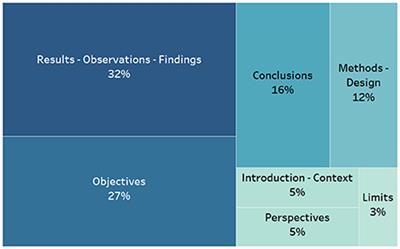
ORIGINAL RESEARCH
Published on 07 Feb 2019
ORIGINAL RESEARCH
Published on 25 Oct 2018

ORIGINAL RESEARCH
Published on 19 Sep 2018

ORIGINAL RESEARCH
Published on 13 Jul 2018
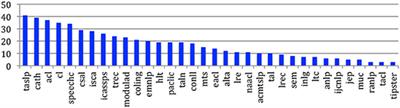
ORIGINAL RESEARCH
Published on 15 Jun 2018
ORIGINAL RESEARCH
Published on 15 May 2018