EDITORIAL
Published on 03 Feb 2023
Editorial: Machine learning for biological sequence analysis
doi 10.3389/fgene.2023.1150688
- 1,795 views
- 8 citations
8,382
Total downloads
32k
Total views and downloads
EDITORIAL
Published on 03 Feb 2023
ORIGINAL RESEARCH
Published on 19 Jan 2023

ORIGINAL RESEARCH
Published on 06 Jan 2023
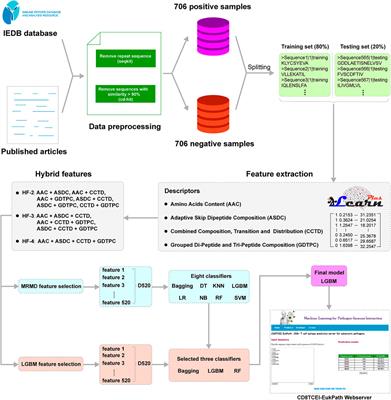
ORIGINAL RESEARCH
Published on 14 Dec 2022
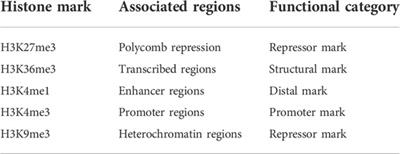
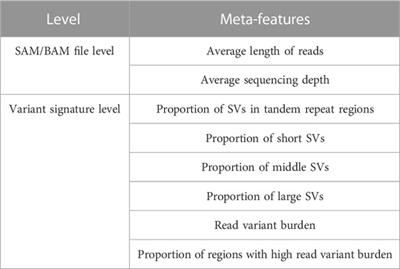
ORIGINAL RESEARCH
Published on 29 Nov 2022

ORIGINAL RESEARCH
Published on 17 Nov 2022
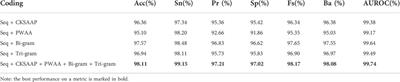
ORIGINAL RESEARCH
Published on 09 Nov 2022
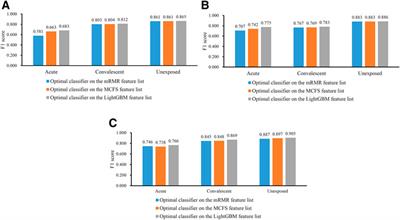
ORIGINAL RESEARCH
Published on 18 Oct 2022
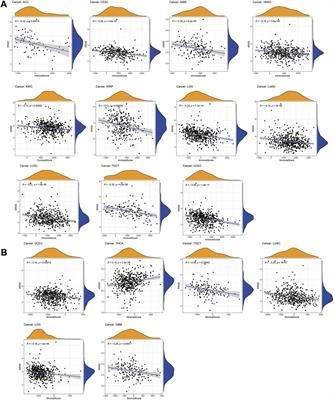
ORIGINAL RESEARCH
Published on 12 Sep 2022
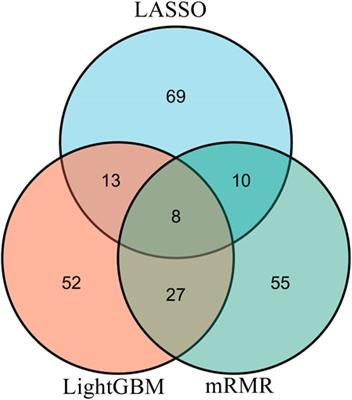
ORIGINAL RESEARCH
Published on 12 Sep 2022
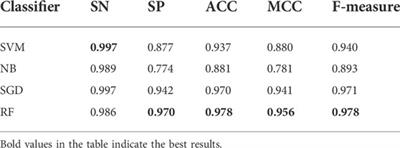
METHODS
Published on 15 Aug 2022
ORIGINAL RESEARCH
Published on 22 Jul 2022