EDITORIAL
Published on 24 Apr 2023
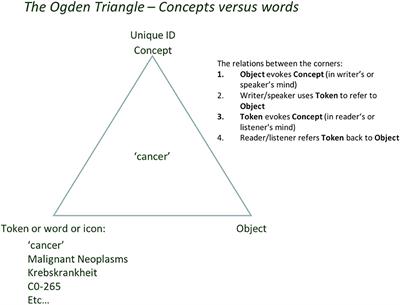
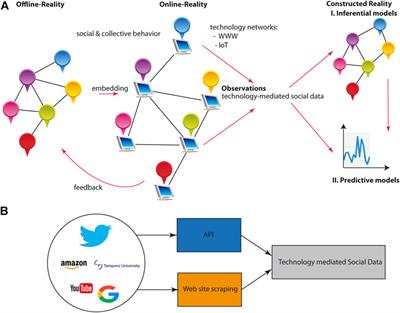
Editorial: Data science and artificial intelligence for (better) science
doi 10.3389/frma.2023.1177903
- 6,458 views
4,038
Total downloads
30k
Total views and downloads
EDITORIAL
Published on 24 Apr 2023
CONCEPTUAL ANALYSIS
Published on 18 Jul 2022
PERSPECTIVE
Published on 11 May 2022
PERSPECTIVE
Published on 22 Apr 2022
PERSPECTIVE
Published on 22 Apr 2021