
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Sustain. Food Syst., 05 November 2021
Sec. Sustainable Food Processing
Volume 5 - 2021 | https://doi.org/10.3389/fsufs.2021.642786
 Nicholas J. Watson1*
Nicholas J. Watson1* Alexander L. Bowler1Ahmed Rady1Oliver J. Fisher1Alessandro Simeone2,3Josep Escrig4Elliot Woolley5
Alexander L. Bowler1Ahmed Rady1Oliver J. Fisher1Alessandro Simeone2,3Josep Escrig4Elliot Woolley5 Akinbode A. Adedeji6
Akinbode A. Adedeji6Food and drink is the largest manufacturing sector worldwide and has significant environmental impact in terms of resource use, emissions, and waste. However, food and drink manufacturers are restricted in addressing these issues due to the tight profit margins they operate within. The advances of two industrial digital technologies, sensors and machine learning, present manufacturers with affordable methods to collect and analyse manufacturing data and enable enhanced, evidence-based decision making. These technologies will enable manufacturers to reduce their environmental impact by making processes more flexible and efficient in terms of how they manage their resources. In this article, a methodology is proposed that combines online sensors and machine learning to provide a unified framework for the development of intelligent sensors that work to improve food and drink manufacturers' resource efficiency problems. The methodology is then applied to four food and drink manufacturing case studies to demonstrate its capabilities for a diverse range of applications within the sector. The case studies included the monitoring of mixing, cleaning and fermentation processes in addition to predicting key quality parameter of crops. For all case studies, the methodology was successfully applied and predictive models with accuracies ranging from 95 to 100% were achieved. The case studies also highlight challenges and considerations which still remain when applying the methodology, including efficient data acquisition and labelling, feature engineering, and model selection. This paper concludes by discussing the future work necessary around the topics of new online sensors, infrastructure, data acquisition and trust to enable the widespread adoption of intelligent sensors within the food and drink sector.
Food and drink is the world's largest manufacturing sector with annual global sales of over £6 trillion (Department for Business Energy and Industrial Strategy, 2017). In the UK alone, the food and drink sector contributes over £28 billion to the economy and employs over 400,000 workers (Food and Drink Federation Statistics at a Glance, 2021). One of the biggest challenges facing the sector is how to produce nutritious, safe and affordable food whilst minimising the environmental impacts. It has been reported that global food and drink production and distribution consumes approximately 15% of fossil fuels and is responsible for 28% of greenhouse emissions (Department for Business Energy and Industrial Strategy, 2017). Manufacturing is experiencing the fourth industrial revolution (often labelled Industry 4.0 or digital manufacturing) which is the use of Industrial Digital Technologies (IDTs) such as robotics, sensors, and artificial intelligence within manufacturing environments. Key to the fourth industrial revolution is the enhanced collection and use of data to enable evidence-based decision making. Although IDTs have been shown to deliver productivity, efficiency and sustainability benefits in many manufacturing sectors, their adoption has been much slower in food and drink. This has often been attributed to the characteristics of the sector, which is extremely dynamic, producing high volumes of low-value products with limited resources to commit to process innovation. As data is the key component of digital manufacturing, there is a need for appropriate sensing technologies to collect this data.
Although many simple sensors exist, such as those for temperature and pressure measurements, there is a shortage of solutions for cost-effective, advanced technologies which can provide actionable information on the properties of materials streams (e.g., feedstocks, products, and waste) and the manufacturing processes. Data mining and Machine Learning (ML) techniques may be used to analyse sensor measurements and generate actionable information. Machine learning methods develop models which learn from a training data set and are capable of fitting complex functions between input and output data. Machine learning models are highly suited to food and drink manufacturing environments because the sector manufactures high volumes of products and therefore generates high volumes of data available to develop models.
The focus of this article is a methodology for combining sensor measurements and ML to improve the environmental sustainability of food and drink manufacturing processes. The article will begin with a summary of sustainability challenges and relevant sensor and ML research. Following this, the methodology for combining sensors measurements and ML will be presented and then applied to four industrially relevant case studies. These case studies will highlight the benefits and key considerations of the methodology in addition to any challenges which still remain.
The rapid increase in the consumption of processed foods together with the production of complex, multicomponent food products (e.g., breaded chicken breasts) driven by ever-changing consumer demand (e.g., new dietary requirements, low effort meals, etc.) makes the food industry one of the most energy-intensive manufacturing sectors (Ladha-Sabur et al., 2019). Additionally, the crop and animal production part of food supply needs to tackle challenges in land use, resource consumption due to extended season growing, waste production, use of chemicals and transport emissions (Food and Agriculture Organization of the United Nations, 2017). Within the factory, practically every sustainability challenge resolves around two core issues: resource (material, energy, water, and time) inefficiency and inherent waste production. For example, lead times are often longer than order times so manufacturers regularly over-produce which often leads to waste.
There are challenges around improving the energy efficiency of common processes such as refrigeration (Tsamos et al., 2017), drying (Sun et al., 2019), and frying (Su et al., 2018) whilst other processes such as washing and cleaning are hugely water-intensive (Simeone et al., 2018). Within food and drink manufacturing, examples of IDT use to improve resource efficiency include forecasting energy consumption to inform mitigation measures (Ribeiro et al., 2020), reducing energy consumption in drying (Sun et al., 2019), reducing the amount of product lost by automating product quality testing (García-Esteban et al., 2018) and reducing water consumption in agriculture via Industrial Internet of Things (IIoT) monitoring (Jha et al., 2019). Although time is rarely discussed in sustainable manufacturing discussions, it is a key aspect as reducing the time of a process reduces its resource demand and the associated overheads (e.g., lighting and heating a factory). Monitoring time can also enable more efficient use and scheduling of manufacturing assets.
The UK manufacturing sector is directly responsible for the production of about 1.5 million tonnes of food waste annually post-farm gate, of which 50% is estimated as wasted food and the rest being inedible parts (Parry et al., 2020). As waste is an inherent part of the raw food, avoidance options are not always available and, due to its low value, the waste is not normally managed in the most sustainable manner (Garcia-Garcia et al., 2019a). There are opportunities to take a systematic approach to industrial food waste management to reduce the proportions sent to landfill, shown in Garcia-Garcia et al. (2017, 2019b), and research has shown potential for the valorisation of food waste to further recover economic and environmental value (Garcia-Garcia et al., 2019a). There are examples utilising IDTs to track food waste during production which has led to reduced levels of food waste (Jagtap and Rahimifard, 2019; Jagtap et al., 2019; Garre et al., 2020). One example saw reductions of food waste by 60% by capturing waste data during manufacturing in real-time and sharing it with all the stakeholders in a food supply chain (Jagtap and Rahimifard, 2019). Another example used ML to predict deviations in production, reducing uncertainties related to the amount of waste produced (Garre et al., 2020). These examples demonstrate that increased monitoring and modelling of food and drink production systems increases their sustainability.
Online sensors are a cornerstone technology of digital manufacturing as they generate real-time data on manufacturing processes and material streams. There are several contradictory definitions of what is meant by “online” sensors. For this work, we define online sensor as sensors that directly measure the material or process, in real time, without the need for a bypass loop or sample removal for further analysis. A survey on the state of the food manufacturing sector identified that digital sensors and transmitters were the most likely hardware components to be purchased in 2019 (Laughman, 2019). The expected rise in the industrial deployment of sensors is driven by several factors; they are considerably cheaper than other IDTs (e.g., robots) and can often be retrofitted onto existing equipment reducing disruption to existing manufacturing processes. Historically, the main sensors that are used in manufacturing processes monitor simple properties such as temperature, pressure, flow rate and fill level. Although these are essential for process monitoring and control, more advanced sensing technologies are required to provide detailed information on manufacturing processes and key material properties.
Sensors have been used to monitor resource consumption in single unit operations or entire food production systems (Ladha-Sabur et al., 2019). In addition, sensors have been used to measure and optimise the performance of unit operations that have a large carbon footprint (Pereira et al., 2016). A particular focus on the use of sensors within food and drink manufacturing is for monitoring the key quality parameters of products (e.g., Takacs et al., 2020). Although these measurements are primarily used for safety and quality control, this also impacts on the sustainability of the process as any product deemed to be of unacceptable quality is often sent to waste or reworked into another product, requiring the use of additional resources. Other sensors performing measurements, such as weight, have also been developed to directly monitor waste generated in food production processes (Jagtap and Rahimifard, 2019).
Many different types of sensors techniques exist, these are characterised by technical features including sensing modality, spatial measurement mode (point, line, area, or volume), resolution, accuracy, and speed of data acquisition and analysis. Other aspects which must be taken into account include the sensor's cost and ability to autonomously and non-invasively perform real-time measurements in production environments. Although many different sensing techniques exist, the most popular ones within food and drink manufacturing include visible imaging (Wu and Sun, 2013; Tomasevic et al., 2019), Near-Infrared (NIR) spectroscopy (Porep et al., 2015; McGrath et al., 2021), hyperspectral imaging (Huang et al., 2014; Saha and Manickavasagan, 2021), X-ray (Mathanker et al., 2013; de Medeiros et al., 2021), Ultrasonic (US) (Mathanker et al., 2013; Fariñas et al., 2021), microwave (Farina et al., 2019), and terahertz (Ok et al., 2014; Ren et al., 2019). The majority of previous work has focused on sensing the properties of the food materials but sensors have also been deployed to monitor processes such as mixing (Bowler et al., 2020a) and the fouling of heat exchangers (Wallhäußer et al., 2012). The majority of previously reported work is laboratory-based but advanced sensors are becoming more widely deployed within production environments with the most popular being optical and x-ray methods.
The key for sensors to work effectively in industrial environments is not to focus on adapting high precision lab-based analytical methods but to determine what is the key information required to make a manufacturing decision and identify the most suitable cost-effective sensing solution. For example, to determine if a piece or processing equipment is clean a sensor should be deployed which can determine if fouling is present on surface. Although more advanced sensing technologies could determine the composition and volume of fouling, these are not required to make the required manufacturing decision. Sensor techniques also experience the benefits of another key IDT: the IIoT. The IIoT enables sensors to be connected to the internet which reduces the cost and size of hardware required on-site and enables the sensors to benefit from enormous computing resources available in the cloud.
For any sensor technology, there is a need for suitable methods to process the recorded sensor measurement and produce information about the material or process being monitored. For many sensors, first principle models can be utilised based on a sound scientific understanding of its mode of operation. However, for more complex sensing technologies and measurement environments, it is often difficult to develop first-principles models, as they need to account for many factors which affect the sensor's measurement. This is especially challenging when using sensors to monitor highly complex and variable biological materials in production environments which are extremely noisy with constantly changing environmental conditions (e.g., atmospheric light and temperature).
An alternative to first-principle methods are DDMs, a subset of empirical modelling that encompasses the fields of computational intelligence and ML (Solomatine et al., 2008). Computational intelligence are nature inspired computational approaches to problem-solving (Saka et al., 2013). Whereas, ML focuses on the development of algorithms and models that can access data and use it to learn for themselves (Coley et al., 2018). It is this capability that makes ML suited to intelligent sensor development. It should be noted that the prediction performance of ML models is only as good as the data used to train the model, but performance can continuously be improved as more or better data becomes available (Goodfellow et al., 2016). Machine learning is experiencing more widespread use within manufacturing primarily due to the ever-increasing amount of data generated by IIoT devices and constant improvements in computing power required to process these vast quantities of data. Machine learning models can be used for a variety of tasks, but the two most popular are classification and regression. Classification tasks are used to select a class of output (e.g., is a measured food of acceptable quality or not) whereas regression models output a numerical value (e.g., sucrose content in a potato). Machine learning methods are further categorised based on their learning approach, primarily either supervised or unsupervised methods. Supervised ML methods have a training dataset with input data for known outputs and these methods can be used to address classification and regression problems. Unsupervised methods do not have known outputs and use clustering methods, such as Principle Component Analysis (PCA) or k-means clustering, to identify structures which may exist within the data.
The majority of previous research that utilises ML to analyse sensor data has used supervised methods, with the most popular including Artificial Neural Networks (ANN), Support Vector Machines (SVM), Decision Trees (DT), and K-Nearest Neighbours (KNN) (Zhou et al., 2019; Bowler et al., 2020b). These standard methods are often called base, weak or shallow learners. The most recent advances in ML are generally in the area of deep learning, which can overcome limitations of earlier shallow networks that prevented efficient training and abstractions of hierarchical representations of multi-dimensional training data (Shrestha and Mahmood, 2019). There are a variety of different deep learning methods but often they include multi-layer neural networks and can automate the feature selection process using methods such as Convolution Neural Networks (CNN) (Liu et al., 2018). Deep learning does come with drawbacks however, such as high training time, overfitting and increased complexity (Shrestha and Mahmood, 2019). An alternative to deep learning is to improve base-learners predictive capabilities through ensemble methods that combine numerous base learners with techniques such as bagging or boosting to improve overall model prediction performance (Hadavandi et al., 2015).
Machine learning methods have been successfully combined with sensor data for a variety of applications within the food and drink manufacturing sector. The majority of this work has focused on optical techniques. Vision camera systems have utilised ML models for applications such as fruit and vegetable sorting (Mahendran et al., 2015), defect detection (Liu et al., 2018), poultry inspection (Chao et al., 2008), and quality assessment (Geronimo et al., 2019), adulteration of meat (Al-Sarayreh et al., 2018), quality inspection of baked products (Du et al., 2012), adulteration detection in spices (Oliveira et al., 2020), and curing of bacon (Philipsen and Moeslund, 2019). The majority of previous work has focused on combining sensors and ML to monitor the food materials being manufactured and commercial solutions are now available for applications such as potato grading (B-Hive, 2020). In addition, vision systems utilising ML have been combined with other IDTs such as robots for applications such as autonomous fruit harvesting (Yu et al., 2019). Although the majority of previous work combining sensors and ML has focused on optical systems (imaging and spectroscopic), research has been performed using data from other sensor instruments. For example, X-ray measurements have been combined with ML for the internal inspection of fruit (Van De Looverbosch et al., 2020). Several articles reviewing ML research within food and drink are available which the reader may refer to Liakos et al. (2018), Rehman et al. (2019), Zhou et al. (2019), and Sharma et al. (2020).
Many different approaches have been developed to standardise the data modelling process including CRISP-DM and Analytics Solutions Unified Method for Data Mining/predictive analytics (ASUM-DM) from Microsoft (Angée et al., 2018). However, many of these methods are focussed on general data-driven modelling projects and not specific to ML modelling of sensor data in food and drink production environments. As previously discussed, the transition to Industry 4.0 means that there is a growing variety of online sensors available to monitor production environments. Developing these sensors has considerations around precision of measurements, cost, positioning, and deployment in industrial environments, which will impact the volume and granularity of data available to develop a ML model. While undertaking the projects in the reported case studies, the need for a unifying methodology between the two areas became apparent. Figure 1 presents a methodology for combining sensor measurements and ML to create intelligent sensors to address the specific challenge of efficient resource use within food and drink manufacturing. The methodology has been devised as a synthesis of the methodologies applied in the reported case studies and hence is grounded in the practical application of the problem. While this methodology has been developed for the food and drink industry, it may be adapted for other industries and applications.
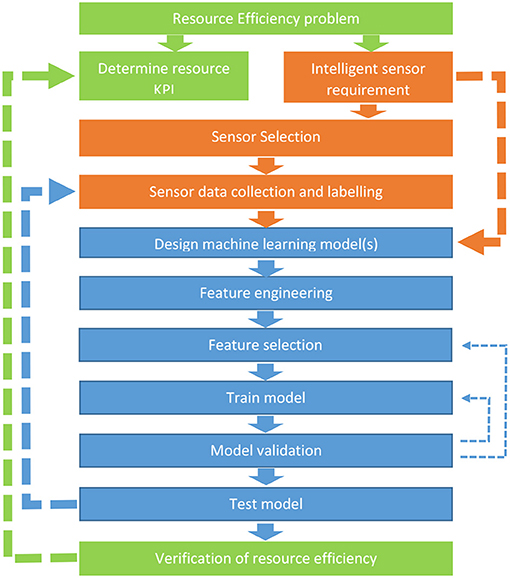
Figure 1. Intelligent sensing process for resource efficiency. The steps in the green boxes are directly related to the resource efficiency problem, the orange boxes to the sensor aspects and the blue to the machine learning process. Solid arrows indicate the main direction of methodology, thick dashed lines indicate scenarios that require a return to a previous step and thin dashed arrows indicate stages that will undergo iterative improvement.
The intelligent sensor developer should first define the specific resource problem to be addressed, similar to the business need step in other data modelling methodologies (Azevedo and Santos, 2008). Specific resources challenges may include minimising the consumption of resources utilised during the process in addition to emissions and waste generated. The problem should be well-defined, take into consideration the scope of influence of a company (e.g., if they alter the composition of their waste streams, what impact might this have on available treatments) and also ensure that any related economic and social implications are considered.
Decide the metrics that will be used to monitor the resource and how it will be measured. Metrics may include the amount of resources utilised or waste generated.
The developer must specify the required output from the predictive model. This could be a value related to a key quality parameter of a product predicted through a regression model (e.g., moisture content) or to determine if the product contains damage or is of acceptable quality or not through a classification model. Alternatively, the purpose of the model could be to predict something related to a unit operation (process). This could include predicting whether the process had reached its end-point or not (classification) or the predicted time remaining (regression) until optimal end-point. It could also include identifying if a fault has occurred in the process (anomaly detection) to determine if an intervention is required.
Although obvious, the developer must ensure that when selecting a sensor its sensing modality can record data sufficient to achieve the intelligent sensor requirement. For example, if the requirement is to determine the grade of a fruit or vegetable-based on size, the sensor must produce information on size and an imaging system would be appropriate. If the requirement is to determine a property such a moisture content, then a sensor sensitive to changes in moisture, such as NIR or dielectric, should be used. A sensor may be required to provide predictions on the internal aspect of food, so sensors capable of measuring internally such as X-ray, US, and electrical methods would be required. For certain applications, choice of sensing technologies may be limited, whereas for others there may be many. The developer should select from the appropriate technologies based on technical specifications, such as accuracy, precision, and resolution in addition to other factors such as size, cost and ease of installation and use. Food safety is an essential aspect of food and drink production, therefore any sensor should be easy to clean and not present any safety or contamination risks.
At this stage, the developer must collect and label the sensor data required to train the ML models. Considerations need to be made in terms of the volume of sensor data and how representative it is of the system under investigation. Regarding volume, the developer must decide between the trade-off that always exists: ML models generally perform better with more data, but this comes with time costs associated with collecting and labelling the data. With ML it is important that the data set is appropriate for the modelling approach to be used. For example, when developing classification models, it is important to collect enough data for each output class to ensure effective performance. If only a small number of samples is expected in one class (e.g., rejections based on a rare quality defect), an anomaly detection model may be more suitable. If supervised ML methods are to be used, the recorded data requires a label to determine its class for classification models or value for regression models. There are different ways to label the data that the developer should consider. Often labelling is completed by humans, which can be extremely costly in terms of time and disruptions to production processes. Labelling of data is one of the primary challenges with utilising ML methods within production environments. If labelling of all collected data is not possible, semi-supervised or unsupervised methods should be explored in addition to domain adaption and transfer learning. The latter two are methods that apply a model trained in one or more “source” domains to a different, but related, “target” domain (Pan et al., 2011). However, they rely on a trained model already existing.
Once the data is collected the developer needs to partition it into training, validation, and test sets. Training data is used to train the models and validation is used to tune the model hyperparameters and the model input variables. A hyperparameter is an adjustable algorithm parameter (e.g., number of layers and nodes in an ANN) that must be either manually or automatically tuned in order to obtain a model with the optimal performance (Zeng and Luo, 2017). The test data is finally used to evaluate the performance of the model with data that was not used for any of the training and validation processes. Test data provides an unbiased evaluation of the final model fit on data outside of the training data set.
Partitioning of the data may vary depending on the volume of data available and how representative the data is to the system being modelled with (Clement et al., 2020) splitting their dataset into 70% training, 15% validation and 15% test.
In the first step of the modelling stage the developer must determine the most suitable ML algorithm(s) to use. A range of different ML algorithms exist, and it is often difficult to determine the most suitable one for a specific application. Often ML practitioners will assess a range of different algorithms to determine which results in the best performance based on the validation set. Once the algorithm has been selected, the developer must also determine model hyperparameters. Developers often initially set hyperparameters based on their own past experience, similar work available in the literature or initial prototype models.
The developer will be required to use domain knowledge to extract variables from raw recorded sensor signals and process them so that they are in a suitable modelling format (Kuhn and Johnson, 2020). Feature extraction methods tend to be unique to each different sensor and could be based on the physical interpretation of the recorded signal or an appropriate signal transformation. Feature engineering is not always necessary, as certain ML techniques, such as CNNs, automate this step. However, these techniques often require significantly larger volumes of data.
Of the engineered features, the developer must determine if there are redundant or useless features which harm the learning process (Kuhn and Johnson, 2020). Feature selection is important as a high degree of dimensionality within input variables can cause overfitting in ML models. Overfitting is the generation of a model that corresponds too closely or exactly to the training dataset (and sometimes noise), which negatively impacts future predictions (Srivastava et al., 2014). The developer may use one or both of two categories of feature selection techniques. Firstly, supervised selection involves examining input variables in conjunction with a trained model where the effect of adding or removing variables can be assessed against model performance at predicting the target variable. The tuning of model input variables is incorporated into the model validation stage. The second approach, called unsupervised selection, performs statistical tests on the input variables (e.g., the correlation between variables) to determine which are similar or do not convey significant information. An example of this is to use PCA. This creates a projection of the data resulting in entirely new input features, or principal components.
At this stage, the developer will train the ML model. Initially model parameters (such as node weights on ANN) should be assigned values using methods such as random initialisation, random seeds or fixed values (e.g., all zeros). The training dataset is used to determine the values for these parameters that most accurately fit the data through an optimisation algorithm. Optimisation algorithms are used to find the model parameters that minimise the cost function (measure of model prediction error). A range of different optimisation algorithms exists and are generally selected as the one that is most appropriate for a specific ML algorithm. For example, stochastic gradient descent and adaptive moment estimation are two common optimisation algorithms used when training a neural networks (Kingma and Ba, 2014). Similar to the primarily ML algorithm, the optimisation algorithms have several hyperparameters, including batch size and number of epochs, which will affect the success of training stage (Kingma and Ba, 2014).
The developer must next utilise validation techniques to tune the model features and hyperparameters and generate an initial assessment of the model's performance. Depending on whether a classification or regression model has been developed, different performance metrics will be used by the developer. For regression models the developer should use a combination of Coefficient of Determination (R2), Root Mean Squared Error (RMSE), and Mean Absolute Percentage Error (MAPE). Whereas, for classification models the developer may pick from classification accuracy and error, sensitivity, and specificity. It is important to use a range of assessment metrics, as relying on only one metric may give a false indication of the model's performance. K-fold cross-validation is recommended for tuning the model features and hyperparameters to avoid overfitting and selection bias (Krstajic et al., 2014). In k-fold cross-validation, the data is divided into k subsets and the model training and validation is repeated k times. Each time, one of the k subsets is used as the validation data and the remaining subsets to train the model. The average error across all k trials is computed. There are variations of k-fold cross validation aimed at further reducing the chance of overfitting and selection bias. These include leave one out, stratified, repeated, and nested cross-validation (Krstajic et al., 2014).
The developer should test the model on data not used in any part of the model training or hyperparameter tuning to indicate its performance on new data. Test data is only used once the model learning stage is complete to provide an unbiased evaluation of the model's ability to fit new data. Again, a range of assessment metrics should be used. If the model's performance on the test data does not meet the manufacturer's requirements, then the developer should return to an earlier stage in the process (e.g., sensor selection or data collection). If there is uncertainty to what extent the training data is representative of the manufacturing system (e.g., unknown if the temperature measurements extends to the maximum temperature range of the system), it is recommended to perform further evaluation of the model on additional unseen data (Fisher et al., 2020).
At the final stage, the developer should apply the model to monitor the resource problem and deploy it to achieve more efficient resource utilisation. If the model does not deliver this, different steps of the process may need to be reapplied. For example, choosing alternative key quality parameters for the intelligent sensor to predict.
The remainder of this article will focus on four case studies which combine sensors and ML for a variety of applications within food and drink manufacturing. The case studies use optical and/or US sensors and will demonstrate how the intelligent sensing methodology can improve sustainability in the manufacturing process. In addition, the case studies highlight some of the challenges of using ML methods. A summary of the case studies with their key features is presented in Table 1.
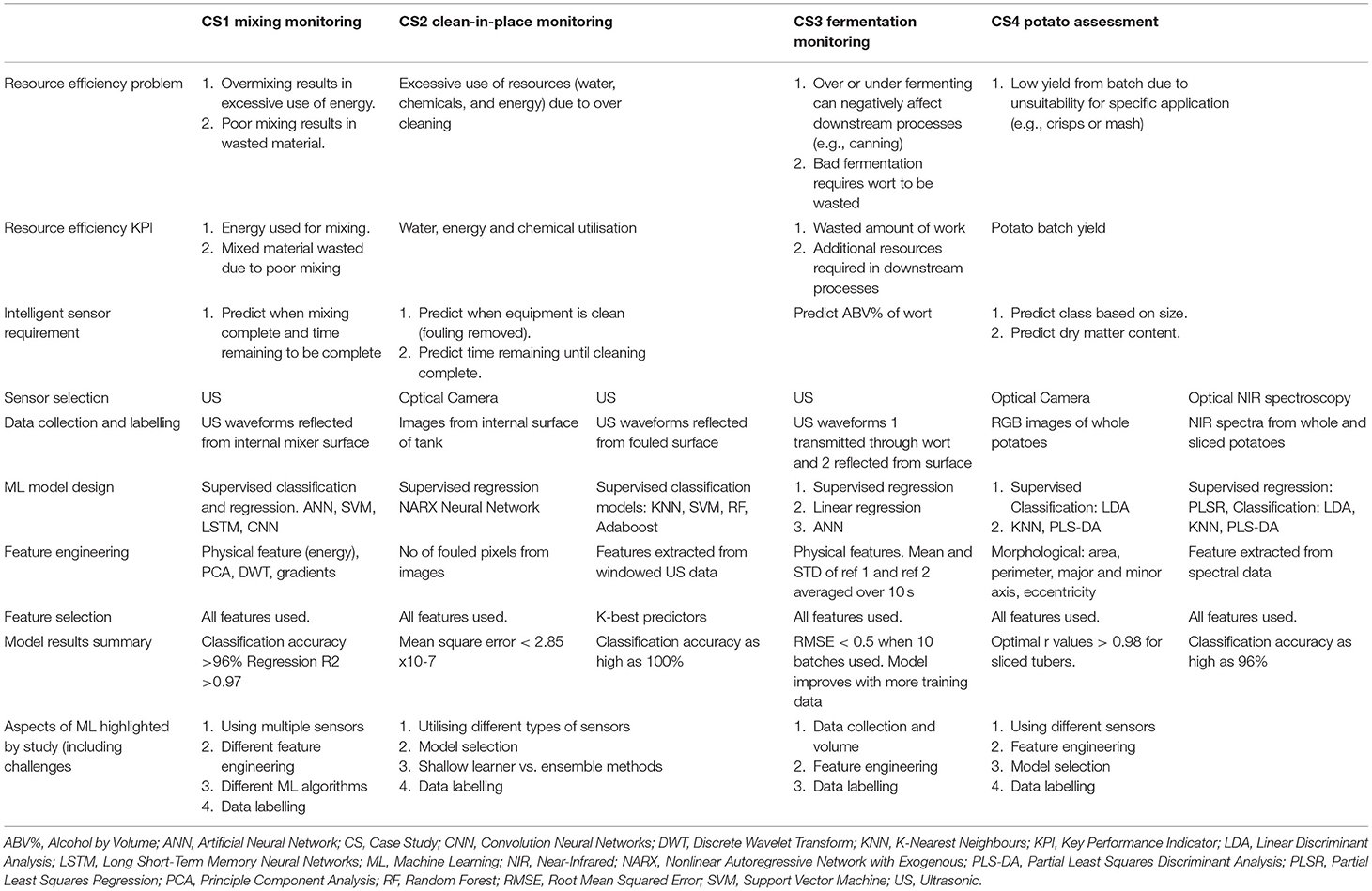
Table 1. Key features of the four intelligent sensing case studies.
Most, if not all, food manufacturing processes use material mixing at some stage. Mixing is not only used for combining materials, but also to suspend solids, provide aeration, promote mass and heat transfer, and modify material structure (Bowler et al., 2020a). Inefficient mixing can result in off-specification products (waste) and excessive energy consumption. Therefore, this case study focuses on developing an intelligent sensor which could be used to inform on the mixing process KPIs: energy consumption and wasted mixing material. Due to the prevalence of mixing within factories, the optimisation of this process provides significant potential for improving manufacturing sustainability.
To address the resource efficiency problem, the intelligent sensor requirement was to predict (A) when the materials were fully mixed (mixing endpoint) and (B) time remaining until mixing endpoint. Therefore, classification ML models were developed to classify whether a mixture was non-mixed or fully mixed, and regression ML models were built to predict the time remaining until mixing completion. In a factory, the intelligent sensor prediction of the time remaining would provide additional benefits of better scheduling of batch processes and therefore improved productivity. Furthermore, prevention of under-mixing would eliminate product rework or disposal, and the prevention of over-mixing would minimise excess energy use.
There are many sensor techniques available which can monitor mixing processes in a factory (e.g., electrical resistance tomography or NIR spectroscopy), but each have benefits and downsides which limit them to specific applications (Bowler et al., 2020a). An US sensor was selected for this work due to being in-line, meaning they directly measure the mixture with no manual sampling required and so are suitable in automatic control systems. The sensors are also low-cost, non-invasive, and are capable of monitoring opaque systems. This case study demonstrates the benefits of using multiple sensors, within the intelligent sensor methodology, to monitor a mixing process and also investigates different feature engineering methods and ML algorithms.
The data to train the intelligent sensor was collected from a honey-water blending mixing system. Two magnetic transducers of 1 cm2 active element surface area with 5 MHz resonance (M1057, Olympus) were externally mounted to the bottom of a 250 ml glass mixing vessel (Figures 2A,B). An overhead stirrer with a cross-blade impeller was used to stir the mixture. As honey is miscible in water, the sensors follow a change in component concentration at the measurement area as the mixture homogeneity increases. The transducers were attached to adhesive magnetic strips on the outside of the vessel with coupling gel applied between the sensor and strip. The transducers were used in pulse-echo mode to both transmit and receive the US signal. The sensing technique used in this work monitors the sound wave reflected from the vessel wall and mixture interface, which is dependent on the magnitude of the acoustic impedance mismatch between the neighbouring materials (McClements, 1995). Therefore, no transmission of the sound wave through the mixture is required. In industrial mixtures, there are typically many components present which create many heterogeneities for the sound wave to travel through. This causes the sound wave to undergo scattering, reflection, and attenuation during transmission. Combined with the large mixing vessel sizes in factories, this makes transmission-based techniques difficult to use without high power, and therefore high cost, transducers. A limitation of the non-transmission technique used in this work becomes the local material property measurement. Therefore, two sensors were used to monitor the mixing process to compare the effect of sensor positioning. One sensor was attached in the centre of the vessel base, and another was mounted offset from the centre, Figure 2B.
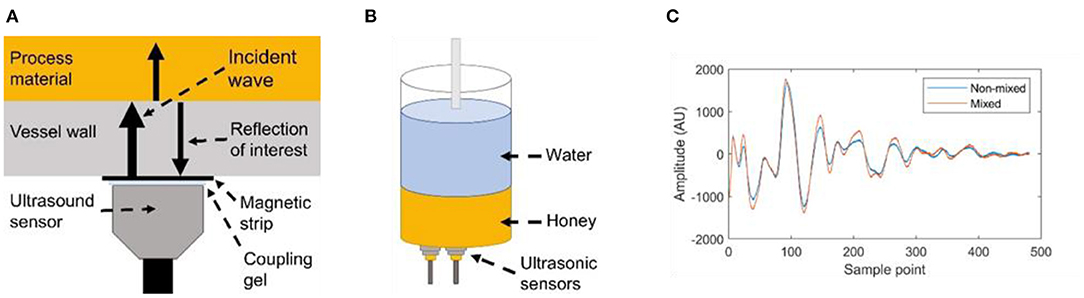
Figure 2. (A) A depiction of the sound wave reflecting from the vessel wall and mixture interface. (B) A diagram of the honey-water blending system. (C) An example of the ultrasonic waveform displaying the difference between a non-mixed honey-water system and a fully-mixed system.
Two different volumes of honey were used for the experiments: 20 and 30 ml. A constant volume of 200 ml tap water was used throughout. The impeller speed was also set to values of either 200 or 250 rpm. These four parameter permutations were repeated three times across 1 day whilst varying the laboratory thermostat set point to produce a temperature variation from 19.3 to 22.1°C. Therefore, 12 runs were completed in total. This allowed an investigation of the ML models ability to generalise across process parameters. The labelled training data for ML model development was obtained by filming the mixing process with a video camera to determine the time at which the honey had fully dissolved.
A focus of this case study was to investigate the level of feature engineering required for acceptable prediction accuracy. Regarding the design of ML models, ANNs, SVMs, Long Short-Term Memory Neural Networks (LSTMs) shallow ML algorithms were compared with CNNs that use representation learning. Shallow learning requires manual feature engineering and selection for model development, and therefore typically requires some specialist domain knowledge of ultrasound and/or the mixing system from the operator. In contrast, CNNs automatically extract features, requiring no operator input. The features compared for shallow ML model development were full-waveform features, such as the waveform energy; principle components, using the amplitude at each sample point in a waveform; and frequency components of the waveform after applying the Discrete Wavelet Transform (DWT). A flow diagram detailing the ML feature engineering process is presented in Figure 3. Each run was held back sequentially for testing, and a model was developed using the remaining runs as training data.
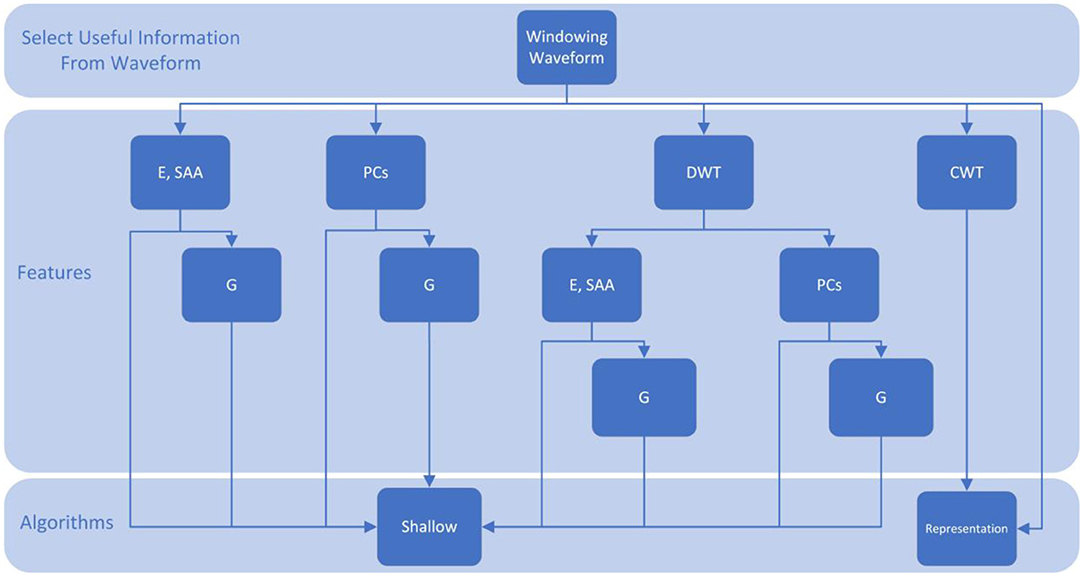
Figure 3. A flow diagram presenting the feature engineering methodology employed. CWT, Continuous Wavelet Analysis; DWT, Discrete Wavelet Analysis; E, Waveform energy; G, Feature gradient; PCs, Principal Components; SAA, Sum Absolute Amplitudes.
To classify whether the honey-water mixing was complete, the highest accuracy was 96.3% (Table 2). This was achieved using the central sensor and an LSTM with the waveform energy, Sum Absolute Amplitudes (SAA), and their gradients as features. Performing data fusion between both sensors produced no improvement in classification accuracy over the central sensor alone, sometimes producing lower classification accuracies due to overfitting. This is because the last position for the honey to dissolve was the centre of the mixing vessel base, where the central sensor was located. High classification accuracy was achieved by being able to use data from previous time-steps. This was achieved using LSTMs, which store representations of every previous time-step; ANNs using feature gradients features; or time-domain CNNs which use stacking of 25 previous time-steps.

Table 2. A selection of prediction accuracy results for the honey-water blending experiments.
An R2-value of 0.974 to predict the time remaining until mixing completion for the honey-water blending was achieved using both sensors with time-domain input CNNs. Using both sensors produced the highest prediction accuracies, owing to the non-central sensor having greater resolution near the beginning of the process, and the central sensor having a greater resolution at the end (Figure 4). Again, the ability to use previous time-steps as features was necessary for high prediction accuracy.
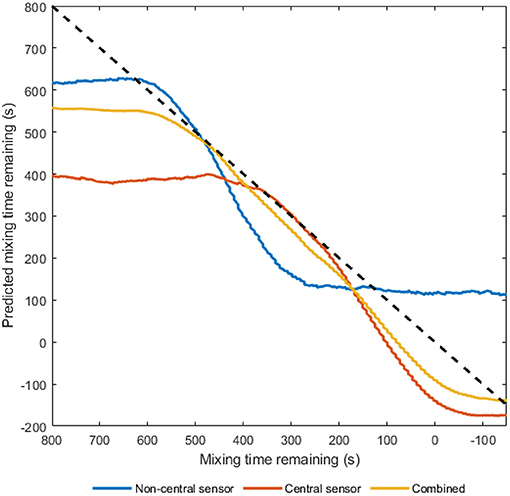
Figure 4. A comparison between regression accuracies for predicting the time remaining until mixing completion for the honey-water batter mixing. The results displayed are from the non-central sensor, central sensor, and combining sensor outputs all using a time-domain input CNN.
SVMs performed worst overall, most likely because of overfitting due to their convex optimisation problem leading to a global minima. Global cost minimisation may lead to poor prediction ability when the test data process parameters lie outside of the bounds of the training data. As a k-fold testing procedure is used in this work, testing on data lying outside of the process parameter space used in training is unavoidable. In comparison, ANNs only converge to local minima, which may have aided their ability to generalise to test data outside the parameter space of training.
The use of sensors and ML to monitor mixing processes relies on the availability of a set of complete labelled data. In a factory, a reference measurement is often not available, and if one is available it is typically obtained via manual sampling and off-line analysis, providing only a small set of labelled data. Therefore, techniques which can develop reliable ML models with limited labelled training data must be investigated. Two methods to achieve this are transfer learning and semi-supervised learning. Transfer learning involves leveraging knowledge used on a source domain to aid prediction of a target domain. For example, training a ML model on a lab-scale mixing system with a reference measurement to obtain a complete set of labelled data, and then combining this knowledge with the unlabelled data on the full-scale mixing system. On the other hand, semi-supervised learning can use unsupervised ML methods on the labelled data in conjunction with unlabelled runs to extract features, and then utilise a self-training procedure.
The purpose of this case study was to develop an intelligent sensor to reduce resource consumption (energy) and waste (off-specification product) during the mixing process. The predictions from the multi-sensor classification models all achieved prediction accuracies above 95% and the regression models R2-values above 97% with acceptable errors. This demonstrates the potential of combining ultrasonic sensors with ML to monitor and optimise mixing processes and deliver environmental benefits.
Cleaning the internal surfaces of processing equipment is important to ensure equipment remains hygienic and operating under optimal conditions. Cleaning of processing equipment is generally performed by automated systems, called Clean-in-Place (CIP). Clean-in-place systems clean via a combination of mechanical force and high-temperature fluids (including cleaning chemicals) and feature several steps including initial rinse, detergent wash, post detergent rinse, and sterilisation. The environmental costs of cleaning are primarily from the water and energy used [up to 30% of the energy use in dairy production (Eide et al., 2003) and 35% of water use in beer production (Pettigrew et al., 2015)]. Therefore, this case study aims to develop an intelligent sensor that would monitor the KPIs: water, energy, and chemical consumption in industrial deployed CIP systems.
Most CIP processes suffer from over-cleaning, as they are designed around worst-case cleaning scenarios. Improvements to CIP processes are possible by identifying when each stage is complete so that the next stage can begin immediately, thereby eliminating unnecessary cleaning and minimising the associated environmental impacts. To achieve this, sensor technologies are required to identify when the objective of each cleaning stage has been performed. This will result in improvements to the CIP system KPIs. The two stages which require the most monitoring are the pre-rinse and the detergent wash. Previous research has been undertaken to monitor industrial CIP using various sensor technologies [electrical (Chen et al., 2004), optical (Simeone et al., 2018), acoustic (Pereira et al., 2009), US (Escrig et al., 2019)]. These sensor methods vary in terms of their cost, complexity, and operating parameters such as speed of data acquisition and spatial area monitored. No single sensor method is suitable for monitoring all the different types of equipment used within food production so a range of different sensor and data analysis methods should be studied.
This case study demonstrates the benefits of utilising multiple sensor technologies (optical and US) to monitor cleaning processes and compares different ML algorithms required to interpret the sensor data.
The intelligent sensor for CS2 is required to predict (A) if fouling is present on a surface (classification) and (B) the time remaining until the surface is free from fouling (regression). As part of the sensor selection stage, two sensors were investigated, namely optical (ultraviolet) and US.
Optical sensor data was collected from a two-tank (CIP and process) system. Each tank had a 600 mm internal diameter and 315 mm height. The CIP tank included the cleaning water and chemicals, and the process tank was fouled and used for the cleaning experiments. The fluids in the CIP tank were pumped through a spray ball (Tank S30 dynamic) located in the centre and at the top of the process tank. The bottom internal surface of the process tanked was fouled with 150 g of melted white chocolate. This was allowed to cool and dry before the cleaning was performed using the fluids (water with 2% sodium hydroxide at 55C). The experiments continued until all the fouling was removed. The cleaning experiments were repeated three times to increase the statistical reliability. An 18W 370 nm ultraviolet lamp and a digital camera (Nikon D330 DSLR and a 10–20 mm F4-5.6 EX DC HSM wide-angle zoom) were placed in bespoke openings of the process tank lid. Images (2000*2992 pixels) of the internal surface were recorded every 5 s during the cleaning process. The experimental rig setup is shown in Figures 5A,B. A bespoke image processing method including baseline subtraction, colour channel separation, and thresholding was developed to determine the surface and volume of fouling (Simeone et al., 2018).
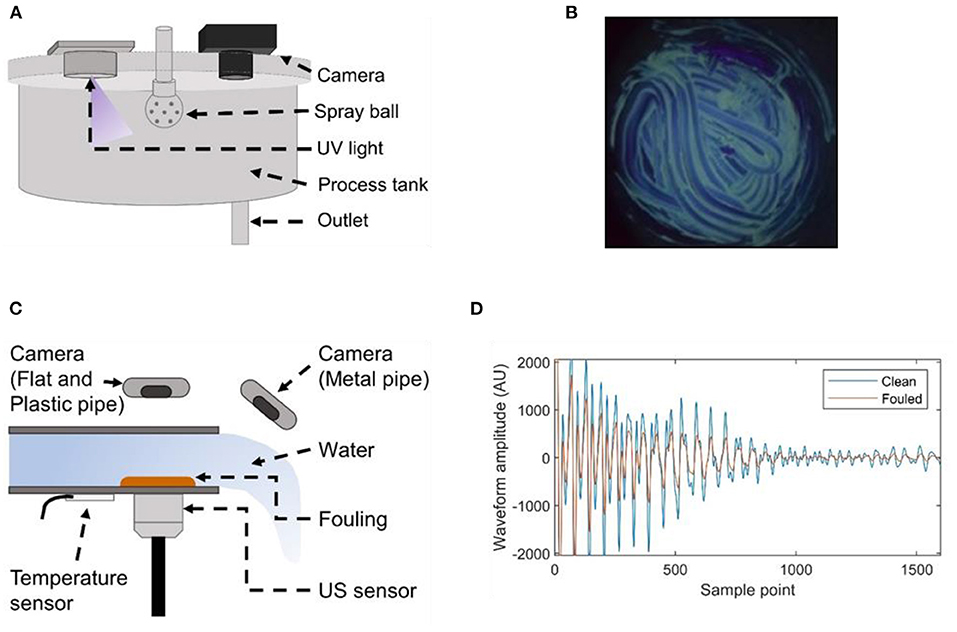
Figure 5. Experimental setups for optical (A) and ultrasonic measurements (C) and examples of the data recorded by the optical (B) and ultrasonic sensors (D).
When designing the ML model within the intelligent sensor, a Non-linear Autoregressive Network with Exogenous (NARX) neural network was developed to predict the cleaning time remaining from the volume of fouling calculated from the images. A NARX neural network is a non-linear autoregressive exogenous model used for prediction of time series data (Xie et al., 2009). Feature engineering was performed to extract the number of fouled pixels from each image. Readers are referred to the authors' previous work for the comprehensive feature engineering process used (Simeone et al., 2018). As only one feature was extracted, feature selection was not necessary. Different training datasets were developed by combining image processing results from the three cleaning experiments. Different network architectures were studied including 3, 6, 10, 15, and 20 hidden layer nodes. A Bayesian Regularisation algorithm (MacKay, 1992) was used for training and the predicted output was the cleaning time remaining. The model performance was evaluated using the RMSE between the predicted time and the actual time.
Ultrasonic data was collected from three test sections. A rectangular rig with a 1.2 mm thick SS340 bottom plate (300 mm by 40 mm) and clear PMMA sides (40 mm height) and two circular pipes constructed of PMMA and SS316 were used. The pipes had approximate dimensions of length 300 mm, internal diameter 20 mm and wall thickness 2 mm. Three materials (tomato paste, gravy, and concentrated malt) were used to foul the test sections. The materials were chosen because of their different compositions, which is known to affect surface adhesion and cleaning behaviour (Wilson, 2018). For both experimental rigs, 15 g of fouling material was placed in the centre of the plate for the flat rig, 30 mm from the exit of the pipes. Cleaning was performed by water, with a fluid temperature of either 12 or 45°C and flowrate of 6 m/s, until all of the surface fouling was removed. Seven repeats were performed for all combinations of fouling rig, temperature and fouling material. The US and temperature data were recorded using the same equipment as CS1. For the circular pipes, different US transducers were used (2 MHz Yushi) and these were glued to the bottom of the pipes. In both configurations, the US transducers were located on the external bottom surfaces in the location the fouling was placed. A camera (Logitech® C270 3MP) was also used to record images of the cleaning processes (Figure 5C). An example of a recorded US wave form can be seen in Figure 5D. The camera was placed above the rig in the same location as the fouling for the flat rig and slightly above the exit of the pipe rigs. For all configurations, the camera location was adjusted to optimise the view of the fouling and cleaning process. Ultrasonic and temperature data were recorded every 4 s and camera images were recorded every 20 s. The camera images were used to label the recorded US data as either dirty (fouling present) or clean (no fouling present).
Supervised classification ML techniques were developed to predict if the pipe section was dirty or clean from the recorded US measurements. The intelligent sensor ML model was developed by evaluating several ML models: KNN, SVM, Random Forests (RF), and Adaboost (using decisions trees as base learning). The performance of the algorithms was assessed by comparing the predicted class (dirty or clean) to the actual condition. Separate models were developed for the flat rig, PMMA pipe and SS316 pipe. For these models, the majority of the experimental data was used in the training data set. However, for each fouling material and temperature combination, two experimental runs were excluded from the training dataset and used for testing the models. Input features were engineered from the US waveforms. Feature selection was performed using a K-best predictors method and the number of input features varied for experimental geometry and classification method.
Figure 6 displays the results of the predicted cleaning time remaining from the NARX neural network trained with the results of the image processing and the actual cleaning time. The figure shows that the model gives an accurate prediction of the cleaning time remaining for diverse datasets. This achievement is valuable to the manufacturer as it ensures cleaning operations are only performed while fouling remains and reduces the economic and environmental cost of the process, supporting a more effective production scheduling. The results in Figure 6 indicate that most errors in the prediction are at the beginning of the cleaning processes, but this error reduces as the cleaning continues. The reason must be found in the initial delay (2 images) and the limited number of images. As the cleaning proceeds, the continuous addition of training samples in the NARX model and the decay of the delay effect drastically reduce the prediction performance error.
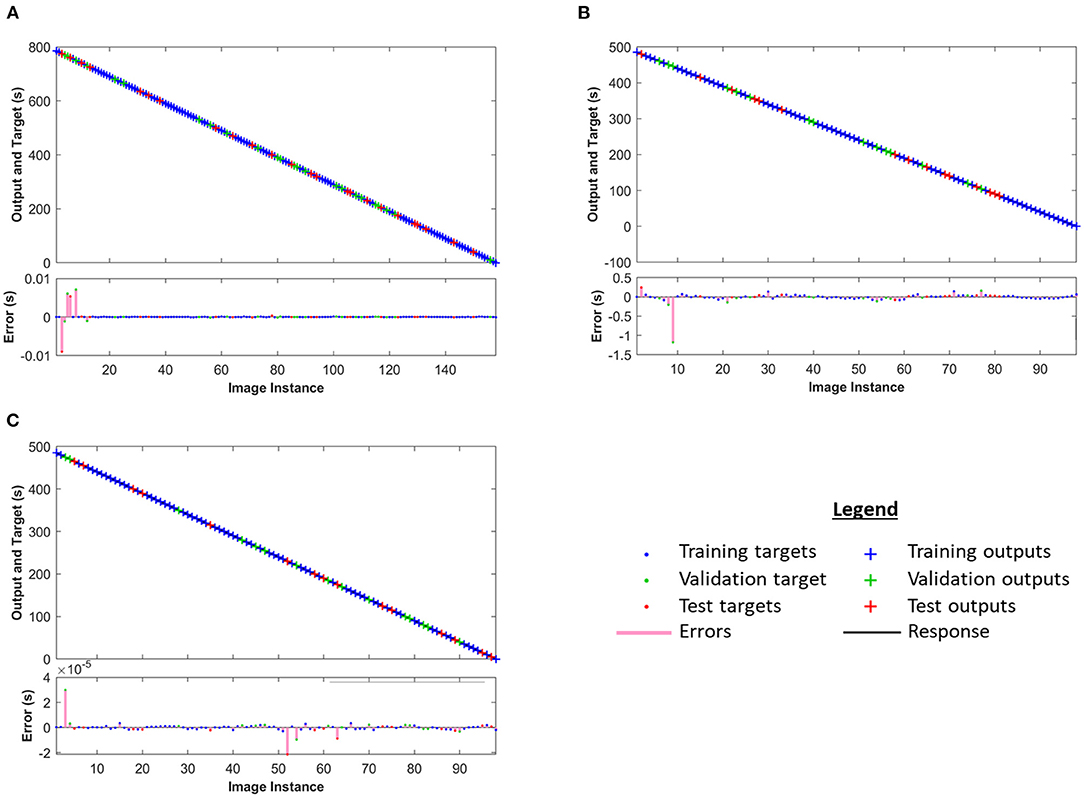
Figure 6. Predictions of cleaning time remaining from Nonlinear Autoregressive Network with Exogenous (NARX) neural network training on (A) dataset 1, (B) dataset 2, and (C) dataset 1+2.
Table 3 presents the average classification prediction accuracy for the two test runs experiments at 45°C for all fouling materials. All ML methods had strong prediction performance (>97%) except for the SVM which often predicted the test section was dirty when it was clean. It is not clear why the SVM produced worse prediction and the lack of explainability is one of the challenges which often faces users of ML methods. The results show that all the ML models performed well except for the SVM in the flat rig and there was no clear advantage of using the more complex ensemble methods RF and Adaboost.
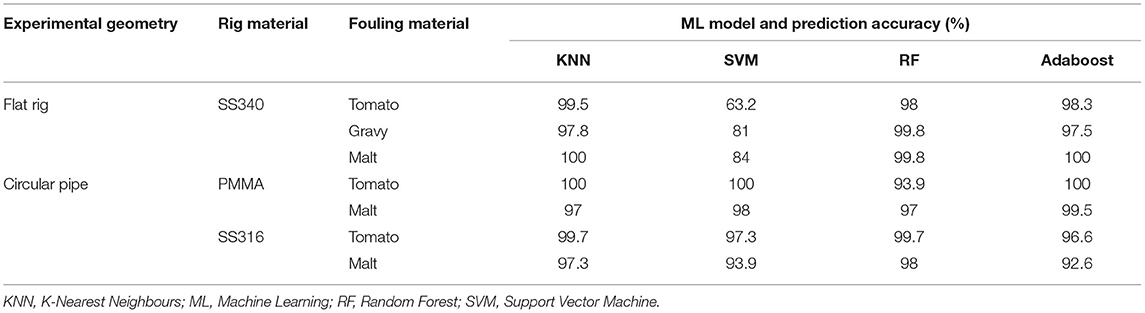
Table 3. Comparison of classification prediction accuracy for different fouling materials, experimental geometry, material of construction, and ML method for test runs at 45°C.
These results are promising and indicate that the combination of US sensors and ML can be used to determine when surface fouling has been removed. Although, the challenge remains to develop a representative dataset in industrial environments. In the laboratory work, it was possible to label the recorded US data using images as the experimental rigs had either clear sides or an open end. This would not be possible in industrial environments and alternative methods must be developed to label the data (e.g., semi-supervised or transfer learning). In addition, the current US system is a point measurement, so the presence of fouling can only be determined at one location. Although, this can be overcome by deploying multiple sensors, which is possible due to the decreasing cost of hardware.
The optical and US intelligent sensors developed both serve to improve CIP systems resource efficiency by predicting CIP endpoint and cleaning time remaining to prevent over-cleaning. Furthermore, CS2 highlights that different sensors need to be deployed in different types of equipment to monitor the same process and accep1le results can be achieved with a range of different ML algorithms.
Fermentation is a unit operation used in the production of numerous alcoholic beverages including beer, wine and cider. Beer fermentation generally takes several days, and monitoring can determine the optimal process endpoint or identify any problems during the process. The purpose of fermentation is to produce ethanol, so monitoring its concentration during the process is essential (Schöck and Becker, 2010). Traditionally ethanol concentration (the wort Alcohol by Volume ABV%) is monitored via offline measurements using density metres or refractometers. Offline techniques are not ideal, as they require sample preparation by human operators, waste material and often are not real-time, increasing the risk of over or under fermenting.
Case study 3 aims to address the resource efficiency problem resulting from over or under fermenting, which can negatively affect downstream processes (e.g., canning) and to detect when a fermentation has encountered a problem and should be stopped, wasting the wort. An intelligent sensor developed to predict ABV% of the wort in real-time would help to prevent over or under fermentation and identify any problems with the fermentation. This would provide key information related to resource utilisation and waste generation sustainability KPIs.
When considering sensor selection, multiple technologies have been developed with capabilities of making ABV% measurements during fermentation via auto sampling or bypass systems including techniques using piezoelectric mems (Toledo et al., 2018), Hybrid electronic tongues (Kutyła-Olesiuk et al., 2012), High-Performance Liquid Chromatography (HPLC) (Liu et al., 2001) and Infrared Imaging (Lachenmeier et al., 2010). Fully online methods have also been developed including NIR (Svendsen et al., 2016; Vann et al., 2017), FT-NIR (Veale et al., 2007) and dispersive Raman spectroscopy (Shaw et al., 1999). An US sensor was chosen for this CS due to affordability compared to other options, as well as the additional benefits of US sensors discussed in CS1 (Bowler et al., 2021).
Ultrasonic measurements have been used to monitor ABV% during beer fermentation (Becker et al., 2001; Resa et al., 2004, 2009; Hoche et al., 2016). The wort is a three-component liquid mixture (ethanol, water and sugar) with dissolved CO2 and CO2 bubbles, meaning at least two separate measurements are required to calculate the ABV%. The previous research using US sensors to monitor fermentation used a variety of different signal and data processing methods to solve this problem. The most popular methods use either US velocity measurements at different temperatures (Becker et al., 2001) or a combination of US velocity with other measurements such as density (Resa et al., 2004, 2009; Hoche et al., 2016). However, multiple measurements at a single point in time are not required when using ML as time-series features can be incorporated into the models.
This case study will develop an intelligent sensor using US measurements to monitor the ABV% in beer fermentation at lab and production scale. The case study will demonstrate a different feature engineering strategy to the other case studies, which utilised US measurements and discuss some of the challenges associated with generating and labelling a suitable training dataset.
Fermentation monitoring was performed at two different scales to explore some of the topics around the intelligent sensor methodology. Lab-scale (~20 l) fermentations were performed using a Coopers Real Ale brew kit and tap water. Fermentation monitoring was also performed in a 2,000 L fermenter at the Totally Brewed brewery in Nottingham, UK. Twelve fermentations were monitored at lab scale and five at production scale. The production scale fermentations included three batches of Slap in the Face and two batches of Guardians of the Forest. For both lab and production scale, the wort formulation and fermentation conditions were kept consistent between runs although process variations are present due to variable atmospheric conditions.
In CS1 and CS2, the US system recorded a single reflected US wave from an interface of interest. In CS3 it was decided to also calculate the US velocity in the wort so a probe was designed which would propagate a wave through a known distance of wort (Figure 7A). This probe design resulted in US waves reflected from two different interfaces been recorded (Figure 7B). The probe used a Sonatest 2MHZ immersion transducer and a RTD PT1000 thermocouple to measure temperature. For the brewery fermentations, a sample was removed every 2 h (except through the night) and the ABV% was calculated using a hydrometer. For the lab-scale fermentations, the ABV% was recorded using a Tilt hydrometer in addition to removing a sample every 2 h and performing measurements using a density metre.
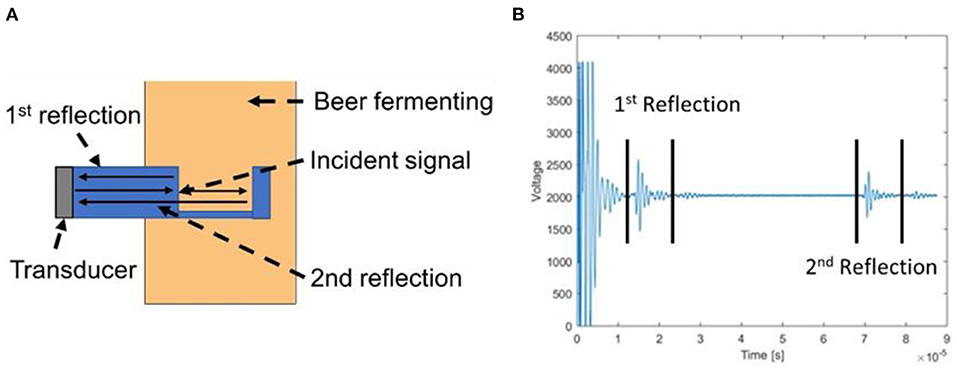
Figure 7. Ultrasonic (US) wave propagation and recorded signal. (A) US wave propagation path through the fermenter. (B) The recorded US signal with the 1st and 2nd reflections highlighted.
The data collection process was identical for lab and brewery fermentations. From the beginning of the fermentation, 10 s of data was recorded every 5 min. This 10 s of data included approximately 36 recorded US waveforms (Figure 7B) and 36 temperature recordings. For the lab-scale fermentations, the density was also recorded with the Tilt every 5 min. Data collection continued until after the fermentations were complete.
Supervised regression ML models were developed to predict the ABV% from the US and temperature measurements recorded during the fermentation. The ABV% recorded from the Tilt and sample measurements provided data labels for the ML models. Machine learning models were only developed for the lab fermentations, as insufficient repeated fermentations and data labelling were possible at the brewery. As 36 US waveforms were recorded in a 10-s time frame, it was also possible to engineer features calculated from the 10-s block of data. These included the mean and standard deviation of the amplitude of each reflection. The standard deviation of the second reflection amplitude was identified as a key feature, as this would be most affected by CO2 bubbles in the wort that would reflect or scatter the US waves. The full list of features used for the ML models included: US velocity, mean amplitude first reflection, mean amplitude second reflection, standard deviation of the amplitude of the second reflection, temperature, and time since yeast pitched.
Regarding the ML model design, linear regression and ANN algorithms were developed to predict the ABV% during fermentation from the US measurements. For the linear regression model 11 randomly selection lab fermentations were used to train the model and the other used for testing. The linear regression model solved directly using the linear least-squares method. A NARX neural network was developed with a single hidden layer. For this model eight, randomly selected fermentations were used for training, three for validation and one for testing. The values of the weight and the biases were calculated using the Levenberg–Marquardt learning function implemented via MATLAB functions. The maximum number of iterations was set to 1,000. To evaluate the linear regression and neural network models the RMSE was calculated between the predicted and actual value for ABV%. A second study was performed where different neural network models were developed with the number of fermentations used for training varying from 1 to 10.
Figure 8 displays the mean amplitude of the first and second US wave reflections during fermentation at the brewery. The amplitude data of the first reflection is different for all five batches of beer although the general trend is an increase in amplitude during fermentation. The amplitude data of the second reflection appears more variable up to day two/three of fermentation. This is due to the CO2 bubbles being produced that interfere with the second reflection as it travels through the wort. It had been expected that the amplitude reflections would be distinct between the two beers; however, no such observation occurred. This suggests that, if more batch data was obtained, it may be possible to train the sensor by combining both datasets.
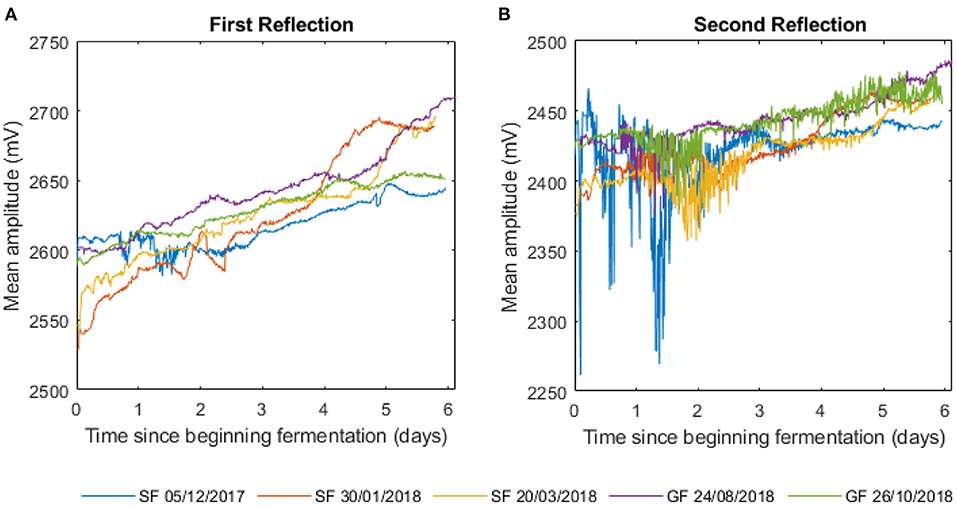
Figure 8. Amplitude data collected from five batches of beer fermented at the brewery, three are Slap in the Face beer (SF) and two are the Guardians of the Forest (GF) beer. (A) The first ultrasonic wave reflection mean amplitude and (B) the second ultrasonic wave reflection mean amplitude.
Figure 9 presents the results from the ML models developed from the lab fermentation data. Both the linear regression and neural network models produce reasonable predictions of the ABV% during the fermentation. The neural network provides a slightly better prediction although both models predict the final ABV% value to within 0.2%. Figure 9B shows the RMSE between the actual ABV value and the predicted value from the neural network as a function of the number of fermentations used to in the training dataset. As the number of batches increases, the models make better predictions and the RMSE reduces. In these experiments, a maximum of 10 batches were used and the RMSE had not reached a stable value which suggests a further reduction in error would be possible if data from additional fermentations was utilised. In this case, the modeller (or engineer) needs to decide as a trade-off exists. Data from more fermentations improves the model predictions but also delays the times until the model can be used. A sensible approach would be to update the models as more data becomes available. However, this comes with an additional development cost from labelling the data and employing expertise to retrain the model. Another method would be to determine an acceptable error for the model and stop when that was achieved.
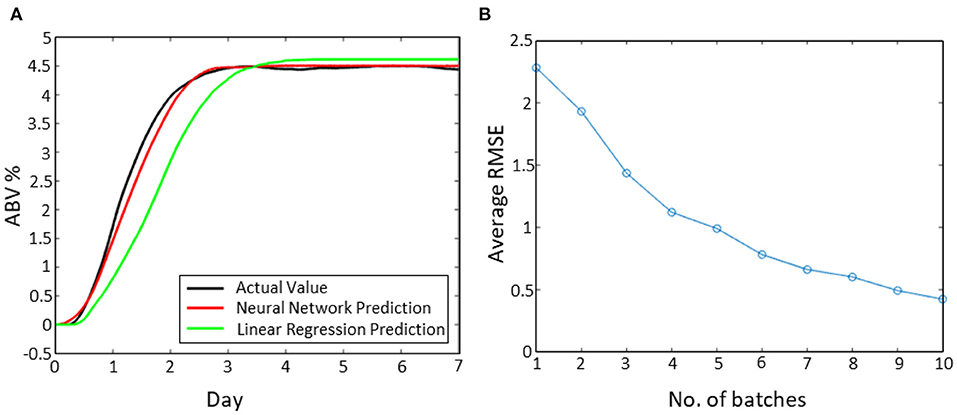
Figure 9. Machine learning results from the lab fermentation experiments. (A) Prediction of the Alcohol by Volume (ABV%) from an Artificial Neural Network (ANN) compared to a linear regression model and the actual measured value. (B) The Root Mean Squared Error (RMSE) of the predictions as a function of number of batches used in the training dataset.
This case study has developed an intelligent sensor to monitor ABV% in real-time during beer fermentation. The measurements from the sensor will help to prevent over or under fermenting in breweries and the associated resource lost. Furthermore, it highlighted the challenges of developing a dataset for training when a particular product is made infrequently and the challenge of labelling that data. The case study has demonstrated the benefits of using model input data from two different time frames (one from a fixed point in time and the second averaged over time) and demonstrated the benefit of having a larger training data set on model performance.
Potato Dry Matter (DM) directly affects the quality of fried potato products, and consequently, the profit that the farmer and food processor can achieve. The higher the DM ratio is, the more output of fried or dehydrated products (Storey, 2007). Additionally, the DM content and distribution affect the bruise susceptibility during harvest, which in turn influences crop waste and the quality of cooked or processed products (Storey, 2007). The ideal DM range in potatoes is 14–37% depending mainly on cultivar, preharvest, and storage conditions (Burton, 1966).
The DM in potato tubers is usually determined by measuring the specific gravity, using the weight in air and the weight in water or by using a hydrometer (Storey, 2007). Such methods are destructive, resulting in loss of resource, along with being time-consuming and not suitable for online application. To resolve this problem, CS4 developed an intelligent sensor to predict the DM in tubers without wasting material. Furthermore, CS4 developed an intelligent sensor to classify the tubers based on size. Grading the tuber by size provides the market with high-quality tubers, which reduces the cost of transport by eliminating tubers of unacceptable sizes. Predictions from these sensors enable monitoring of CS4's KPI: tuber wastage.
Two sensor technologies were selected, NIR spectroscopy and colour vision cameras. Near infrared spectroscopy is a technology where an estimation of the chemical content of the material is obtained through the interaction of light and the sample using reflectance, transmittance, or interference configurations. NIR has already been applied at the commercial level (Rady and Guyer, 2015). Colour vision systems are already established in food and agricultural applications and these systems are efficiently used to detect extremal defects, diseases, and shapes of fruits, vegetables, and other food products (Santos et al., 2012; Rady et al., 2021). Such systems generate quick, accurate, and objective features of the studied materials in a non-invasive, and cost-effective manner (Zou and Zhao, 2015). Applying colour vision for size-based potatoes is generally not a new concept. However, in developing countries where the postharvest losses might reach a level of 30% (COMCEC, 2016), such systems are not available for all growers or packing houses. Colour-based systems are relatively cheap and work effectively on detecting external features. Both technologies were considered, as NIR systems are usually point-based and able to detect chemical composition, whereas colour imaging systems provide information in the spatial domain (Chen et al., 2002; Nicolaï et al., 2007).
The intelligent sensor for CS4 must predict (A) potato DM content (regression) and (B) class based on size (classification).
To generate a dataset to train the NIR sensor, potato samples were acquired from a farm in England, United Kingdom. The samples were the Eurostar variety and there were 91 tubers in total. Tested samples included whole tubers and sliced samples with 9 ± 1 mm thickness. Each sliced sample was obtained using a manual potato cutter and the desired slice was the third one cut from the stem side. To estimate the DM ratio for tubers, the specific gravity was first estimated by hydrostatic weighing (Storey, 2007).
In this study, two different NIR diffuse reflectance sensors were utilised to measure the samples. The first sensor was the NIRONE S2.0 (Spectral Engines, Oulu, Finland), which acquires signals in the range of 1,550–1,950 nm. The second sensor was the NIRONE S2.5 (Spectral Engines, Oulu, Finland) which operates in the range of 2,000–2,450 nm. The spectrum of each sample was the average of three measured readings. Figure 10A shows examples of the experimental set up for such sensors.
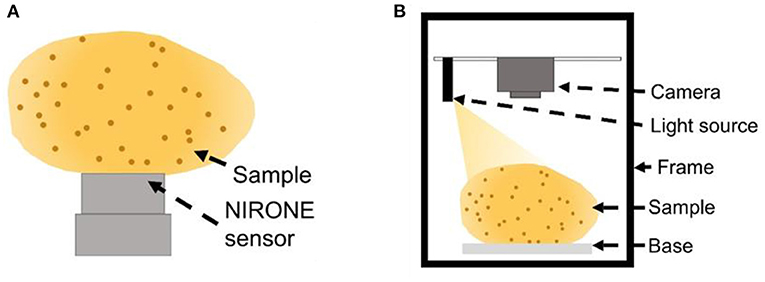
Figure 10. Schematic diagram for measuring potato samples using (A) NIRONE sensors (S2.0 or S2.5) and (B) RGB camera.
As part of the data collection and labelling stage, the NIR spectra obtained from each samples (Is) was first normalised using the intensity obtained from a white reflectance reference (Ir), and the background, or dark, intensity (Id) as follows:
The spectra for each sample was then pre-processed to overcome the noise originating from electronic sources and variations due to temperature change. The spectral pre-processing techniques applied in this CS included mean centring, smoothing using 1st derivative, smoothing using 2nd derivative, smoothing using Savitzky-Golay, and Multiplicative Scattering Correction (MSC). To obtain a uniform distribution of the DM ratios a logarithmic transformation was applied.
The ML model was designed using Partial Least Squares Regression (PLSR). Cross-validation (four-fold) was applied on the pre-processed data to obtain the optimal prediction model based on the values of the correlation coefficient (r), Root Mean Square Error of Cross-Validation (RMSEcv), and the ratio between the standard deviation and the RMSEcv (RPD).
Classification of samples based on DM ratio was also implemented. The threshold DM was chosen as the median value of the data (21.79%). Several classification algorithms were applied including Linear Discriminant Analysis (LDA), KNN, and Partial Least Squares Discriminant Analysis (PLS-DA) (Rady et al., 2019). Cross-validation was applied to the pre-processed data for DM classification.
Data was collected to train the optical sensor by measuring tuber samples obtained from a farm in Alexandria, Egypt. Two potato cultivars were included in this dataset, Cara and Spunta. Cara tubers are more spherical and less elliptical than Spunta tubers. Samples were not cleaned and only rotted and damaged tubers were discarded. For each cultivar, 200 tubers were imaged such that each subgroup represent one size group, small and large. The measurement system, as shown in Figure 10B, contains a colour or RGB camera (Fuji FinePix S5700, FujiFilm, Minato-ku, Tokyo, Japan), a LED light lamp (12 W), and a black wooden box. The light and the camera were placed 25, and 30 cm, respectively, vertically above the sample surface and the light was 60° inclined with respect to the horizontal direction. Each sample was imaged twice, once on each side.
Feature engineering was first performed so that each raw image was segmented to obtain the tuber shape only. Segmentation was based on the HSV colour space along using the hue coordinate with a threshold hue value of 0.20. After obtaining the segmented colour image, the features were extracted. Extracted features included morphological: area, perimeter, major and minor axis, and eccentricity (Gonzalez and Woods, 2006). Regarding feature selection, all the features were included due to the limited number of features.
The design of the ML model used LDA algorithm to classify the size of the samples. Samples in each cultivar were divided into each group based on visual observation and there were four classes in total (2 cultivar and two size groups). 10-fold cross-validation was employed during the training and validation stages.
Table 4 reports the regression results of DM for whole tubers and sliced samples. In the case of the whole tubers, the optimal r(RPD) values were 93% (3.33%), and 96% (4.48) for the NIRONE S2.0 and NIRONE, S2.5, respectively. In the case of sliced samples, the r(RPD) values were 96% (2.58) for the NIRONE S2.0, and 98% (3.74) for NIRONE S2.5. These results are considered comparable to those listed by previous studies using NIR, who achieved optimal r(RMSEcv) values of 92% (1.52%) (Dull et al., 1989), 88 (1.3%) (Scanlon et al., 1999), 85% (0.002) (Kang et al., 2003), 90% (0.004) (Chen et al., 2005), and 97% (0.91%) (Helgerud et al., 2012).
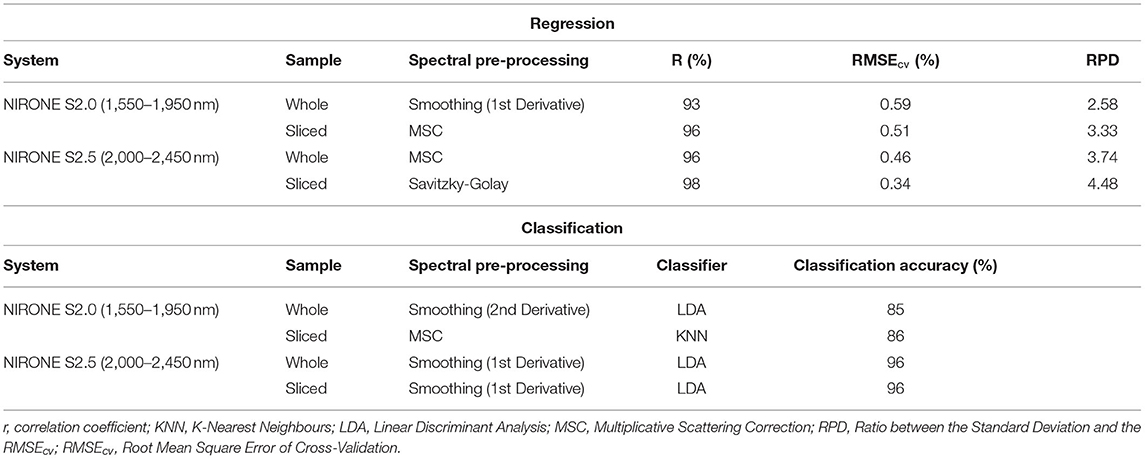
Table 4. Best regression and classification results of dry matter for whole tubers and sliced samples obtained from different utilised NIR sensors.
Table 4 reports the performance of the optimal classification models based on the DM value stated earlier (21.79%). The classification accuracy values for whole tubers were 85% for NIRONE S2.0, and 96% for NIRONE S2.5. While the values for the sliced samples were 86 and 96% for the NIRONE S2.0 and NIRONE S2.5, respectively. These results were obtained by LDA, and KNN classifiers along with smoothing using 1st or 2nd derivatives, and MSC. Classification provides a rapid evaluation of the DM in potatoes and is suitable for assessing the use of the tubers without the need to accurately calculate the DM value. Generally, the sliced samples resulted in better prediction and classification performance than whole tubers, which is possibly due to the skin condition effecting the whole tubers results.
Results for the classification models are reported in Table 5. The overall classification accuracy was 92.5% using LDA, whereas the individual accuracy values were 82, 92, 95, and 93% for small Cara, large Cara, small Spunta, and large Spunta, respectively.

Table 5. Classification results, confusion matrix and classification accuracy, for evaluating potato tuber size using a colour imaging system.
This case study has developed intelligent sensors to predict (A) potato DM and (B) class, based on size. The predictions made by these sensors will mean poor quality potatoes are detected earlier in the supply chain, reducing resource lost processing them downstream. Furthermore, CS4 demonstrated that the combination of non-invasive sensors and ML methods can be used to monitor potato quality.
The manufacturing of food and drink has a significant impact on the planet in terms of natural resources utilised and waste and emissions generated. Industrial digital technologies have the capability to reduce this impact by making processes more intelligent and efficient. The food and drink manufacturing sector has been slow to adopt digital technologies partly due to the lack of cost-effective sensing technologies capable of monitoring the key properties of materials and production processes in challenging industrial environments. One challenge is converting sensor data into actionable information on the material or process being monitored. The article presents an intelligent sensor methodology that utilises data-driven modelling approaches, such as ML, to make predictions, from sensor measurements, which monitor environmental sustainability KPIs within the food and drink manufacturing processes. Furthermore, it was demonstrated that ML can be used with affordable optical and US sensors to deliver sustainability benefits for a variety of applications within the sector.
The intelligent sensor methodology was applied to four food and drink case studies. All case studies demonstrated how the methodology may be employed to solve industrial resource efficiency problems as well as highlighting key challenges in developing ML models, including data acquisition and labelling. As the digital revolution continues, it is anticipated that intelligent sensors will play a greater role in the future of food and drink to increase resources efficiency and reduce the carbon footprint of this essential sector. In order to speed up the implementation of intelligent sensors and the benefits they may provide, future work should address:
• New online sensors: As ML enables processing and analysis of new data types, more IIoT sensors will continue to be developed that measure new types of food and drink material and production data. The introduction of a greater number of sensors into food and drink production lines will require considerations regarding the topic of sensor fusion, which is combining different sensor data such that the resulting information has less uncertainty than would be possible when these sources were used individually. Furthermore, there is the need for an economic case that will demonstrate the benefits of introducing new sensors to production lines. Additionally, with the increased number of sensors, thought should be given to the how the paper's intelligent sensor methodology may be automated by applying the techniques developed in the field of automated ML. When developing new sensors, work must address issues of general relevance to all sensor devices, such as energy consumption, latency, security, reliability, and affordability, but from a food and drink sector perspective.
• Infrastructure: Food and drink production systems are made up of multiple different stages and unit operations. Provision of an integrated and interoperable data management environment, allowing for data from multiple sources to be securely accessed and used by industrial operators, and managing the safety of any operation influenced by such data is essential.
• Data acquisition: CS3 demonstrated that acquiring sufficient labelled data to train the ML models within the sensors is challenging within some food and drink production environments. Further work should address the potential of transfer learning or semi-supervised methods to overcome data shortages due to production lines making a variety of food or drink products.
• Trust: Core to intelligent sensors are the ML models that turn the sensor data into meaningful, actionable information. These models are typically referred to as black-box models, meaning it is not possible to know how they reached their output. This lack of transparency may be a barrier in deploying intelligent sensors, as factory operators and managers may not trust the sensor predictions without understanding how they were reached.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
AB, JE, AR, AS, and OF: data collection and analysis. All authors: paper concept, paper writing, and paper reviewing.
This work was supported by the Innovate UK projects 103936 and 132205 and EPSRC projects EP/P001246/1, EP/S036113/1, and EP/R513283/1.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Al-Sarayreh, M., Reis, M. M., Yan, W. Q., and Klette, R. (2018). Detection of red-meat adulteration by deep spectral–spatial features in hyperspectral images. J. Imaging 4:63. doi: 10.3390/jimaging4050063
Angée, S., Lozano-Argel, S. I., Montoya-Munera, E. N., Ospina-Arango, J. D., and Tabares-Betancur, M. S. (2018). “Towards an improved ASUM-DM process methodology for cross-disciplinary multi-organization big data and analytics projects,” in Proceedings of the Communications in Computer and Information Science, (Chicago, US) 613–624.
Azevedo, A., and Santos, M. F. (2008). “KDD, semma and CRISP-DM: a parallel overview,” in Proceedings of the MCCSIS'08 - IADIS Multi Conference on Computer Science and Information Systems; Proceedings of Informatics 2008 and Data Mining 2008, (Amsterdam, The Netherlands) 182–185.
Becker, T., Mitzscherling, M., and Delgado, A. (2001). Ultrasonic velocity– a noninvasive method for the determination of density during beer fermentation. Eng. Life Sci. 1, 61–67. doi: 10.1002/1618-2863(200108)1:2<61::aid-elsc61>3.0.co;2-d
B-Hive (2020). B-Hive Develops UK's First Potato Protein Extraction Process. Available online at: https://www.b-hiveinnovations.co.uk/news/b-hive-develops-uks-first-potato-protein-extraction-process (accessed December 1, 2020).
Bowler, A., Escrig, J., Pound, M., and Watson, N. (2021). Predicting alcohol concentration during beer fermentation using ultrasonic measurements and machine learning. Fermentation 7:34. doi: 10.3390/fermentation7010034
Bowler, A. L., Bakalis, S., and Watson, N. J. (2020a). A review of in-line and on-line measurement techniques to monitor industrial mixing processes. Chem. Eng. Res. Des. 153, 463–495. doi: 10.1016/j.cherd.2019.10.045
Bowler, A. L., Bakalis, S., and Watson, N. J. (2020b). Monitoring mixing processes using ultrasonic sensors and machine learning. Sensors 20:1813. doi: 10.3390/s20071813
Burton, W.G., (1966). The potato. A survey of its history and of factors influencing its yield, nutritive value, quality and storage., (Edn 2 (revised)). Netherlands: H. Veenman en Zonen N.V.
Chao, K., Yang, C.-C., Kim, M. S., and Chan, D. E. (2008). High throughput spectral imaging system for wholesomeness inspection of chicken. Appl. Eng. Agric. 24, 475–485. doi: 10.13031/2013.25135
Chen, J. Y., Zhang, H., Miao, Y., and Matsunaga, R. (2005). NIR measurement of specific gravity of potato. Food Sci. Technol. Res. 11, 26–31. doi: 10.3136/fstr.11.26
Chen, X. D., Li, D. X. Y., Lin, S. X. Q., and Necati, O. (2004). On-line fouling/cleaning detection by measuring electric resistance — equipment development and application to milk fouling detection and chemical cleaning monitoring. Science 61, 181–189. doi: 10.1016/S0260-8774(03)00085-2
Chen, Y. R., Chao, K., and Kim, M. S. (2002). Machine vision technology for agricultural applications. Comput. Electron. Agric. 36, 173–191. doi: 10.1016/S0168-1699(02)00100-X
Clement, C. L., Kauwe, S. K., and Sparks, T. D. (2020). Benchmark AFLOW data sets for machine learning. Integr. Mater. Manuf. Innov. 9, 153–156. doi: 10.1007/s40192-020-00174-4
Coley, C. W., Green, W. H., and Jensen, K. F. (2018). Machine learning in computer-aided synthesis planning. Acc. Chem. Res. 51, 1281–1289. doi: 10.1021/acs.accounts.8b00087
COMCEC (2016). COMCEC Coordination Office Reducing Postharvest Losses in the OIC Member Countries COMCEC COORDINATION OFFICE September 2016 Standing Committee for Economic and Commercial Cooperation of the Organization of Islamic Cooperation (COMCEC); Ankara, Turkey, 2016. p.15-18.
de Medeiros, A. D., Bernardes, R. C., da Silva, L. J., de Freitas, B. A. L., dos Dias, D. C. F., and da Silva, C.B. (2021). Deep learning-based approach using X-ray images for classifying Crambe abyssinica seed quality. Ind. Crops Prod. 164:113378. doi: 10.1016/j.indcrop.2021.113378
Du, C. J., Cheng, Q., and Sun, D. W. (2012). Computer vision in the bakery industry. Comput. Vis. Technol. Food Beverage Ind. 422–450. doi: 10.1533/9780857095770.3.422
Dull, G. G., Birth, G. S., and Leffler, R. G. (1989). Use of near infrared analysis for the nondestructive measurement of dry matter in potatoes. Am. Potato J. 66, 215–225. doi: 10.1007/BF02853444
Eide, M. H., Homleid, J. P., and Mattsson, B. (2003). Life cycle assessment (LCA) of cleaning-in-place processes in dairies. LWT Food Sci. Technol. 36, 303–314. doi: 10.1016/S0023-6438(02)00211-6
Escrig, J., Woolley, E., Rangappa, S., Simeone, A., and Watson, N. J. (2019). Clean-in-place monitoring of different food fouling materials using ultrasonic measurements. Food Control 104, 358–366. doi: 10.1016/J.FOODCONT.2019.05.013
Farina, L., Scapaticci, R., Tobon Vasquez, J. A., Rivero, J., Litman, A., Crocco, L., et al. (2019). “Microwave imaging technology for in-line food contamination monitoring,” in Proceedings of the 2019 IEEE International Symposium on Antennas and Propagation and USNC-URSI Radio Science Meeting, APSURSI 2019, (Atlanta, US) 817–818.
Fariñas, L., Contreras, M., Sanchez-Jimenez, V., Benedito, J., and Garcia-Perez, J. V. (2021). Use of air-coupled ultrasound for the non-invasive characterization of the textural properties of pork burger patties. J. Food Eng. 297:110481. doi: 10.1016/j.jfoodeng.2021.110481
Fisher, O. J., Watson, N. J., Escrig, J. E., Witt, R., Porcu, L., Bacon, D., et al. (2020). Considerations, challenges and opportunities when developing data-driven models for process manufacturing systems. Comput. Chem. Eng. 2020:106881. doi: 10.1016/j.compchemeng.2020.106881
Food and Agriculture Organization of the United Nations (2017). The Future of Food and Agriculture: Trends and Challenges. Rome.
Food Drink Federation Statistics at a Glance (2021). Available online at: https://www.gdalabel.org.uk/statsataglance.html (accessed December 1, 2020).
García-Esteban, J. A., Curto, B., Moreno, V., González-Martín, I., Revilla, I., and Vivar-Quintana, A. (2018). “A digitalization strategy for quality control in food industry based on Artificial Intelligence techniques,” in Proceedings of the 2018 IEEE 16th International Conference on Industrial Informatics (INDIN), (Porto, Portugal) 221–226.
Garcia-Garcia, G., Stone, J., and Rahimifard, S. (2019a). Opportunities for waste valorisation in the food industry – A case study with four UK food manufacturers. J. Clean. Prod. 211, 1339–1356. doi: 10.1016/J.JCLEPRO.2018.11.269
Garcia-Garcia, G., Woolley, E., and Rahimifard, S. (2019b). Identification and analysis of attributes for industrial food waste management modelling. Sustainability 11:2445. doi: 10.3390/su11082445
Garcia-Garcia, G., Woolley, E., Rahimifard, S., Colwill, J., White, R., and Needham, L. (2017). A methodology for sustainable management of food waste. Waste Biomass Valorization 8, 2209–2227. doi: 10.1007/s12649-016-9720-0
Garre, A., Ruiz, M. C., and Hontoria, E. (2020). Application of machine learning to support production planning of a food industry in the context of waste generation under uncertainty. Oper. Res. Perspect. 7:100147. doi: 10.1016/j.orp.2020.100147
Geronimo, B. C., Mastelini, S. M., Carvalho, R. H., Barbon Júnior, S., Barbin, D. F., Shimokomaki, M., et al. (2019). Computer vision system and near-infrared spectroscopy for identification and classification of chicken with wooden breast, and physicochemical and technological characterization. Infrared Phys. Technol. 96, 303–310. doi: 10.1016/j.infrared.2018.11.036
Gonzalez, R. C., and Woods, R. E. (2006). Color image processing. In Digital Image Processing, 3rd Edn. (Pearson: New York, US) 2006. pp. 416-482
Hadavandi, E., Shahrabi, J., and Shamshirband, S. (2015). A novel Boosted-neural network ensemble for modeling multi-target regression problems. Eng. Appl. Artif. Intell. 45, 204–219. doi: 10.1016/J.ENGAPPAI.2015.06.022
Helgerud, T., Segtnan, V. H., Wold, J. P., Ballance, S., Knutsen, S. H., Rukke, E. O., et al. (2012). Near-infrared spectroscopy for rapid estimation of dry matter content in whole unpeeled potato tubers. J. Food Res. 1, 55–65. doi: 10.5539/jfr.v1n4p55
Hoche, S., Krause, D., Hussein, M. A., and Becker, T. (2016). Ultrasound-based, in-line monitoring of anaerobe yeast fermentation: model, sensor design and process application. Int. J. Food Sci. Technol. 51, 710–719. doi: 10.1111/ijfs.13027
Huang, H., Liu, L., and Ngadi, M. O. (2014). Recent developments in hyperspectral imaging for assessment of food quality and safety. Sensors 14, 7248–7276. doi: 10.3390/s140407248
Jagtap, S., Bhatt, C., Thik, J., and Rahimifard, S. (2019). Monitoring potato waste in food manufacturing using image processing and internet of things approach. Sustainability 11:3173. doi: 10.3390/su11113173
Jagtap, S., and Rahimifard, S. (2019). The digitisation of food manufacturing to reduce waste – Case study of a ready meal factory. Waste Manage. 87, 387–397. doi: 10.1016/j.wasman.2019.02.017
Jha, K., Doshi, A., Patel, P., and Shah, M. (2019). A comprehensive review on automation in agriculture using artificial intelligence. Artif. Intell. Agric. 2, 1–12. doi: 10.1016/j.aiia.2019.05.004
Kang, S., Lee, K.-J., Choi, W., Son, J.-R., Choi, D.-S., and Kim, G. (2003). “A near-infrared sensing technique for measuring the quality of potatoes,” in Proceedings of the 2003 ASAE Annual Meeting, (Las Vegas, US) 033137.
Kingma, D. P., and Ba, J. A. (2014). “A method for stochastic optimization,” in Proceedings of the ICLR 2015 (San Diego, CA), 1–15.
Krstajic, D., Buturovic, L. J., Leahy, D. E., and Thomas, S. (2014). Cross-validation pitfalls when selecting and assessing regression and classification models. J. Cheminform. 6, 1–15. doi: 10.1186/1758-2946-6-10
Kuhn, M., and Johnson, K. (2020). Feature Engineering and Selection: A Practical Approach for Predictive Models, 1st Edn. Milton, ON: CRC Press.
Kutyła-Olesiuk, A., Zaborowski, M., Prokaryn, P., and Ciosek, P. (2012). Monitoring of beer fermentation based on hybrid electronic tongue. Bioelectrochemistry 87, 104–113. doi: 10.1016/j.bioelechem.2012.01.003
Lachenmeier, D. W., Godelmann, R., Steiner, M., Ansay, B., Weigel, J., and Krieg, G. (2010). Rapid and mobile determination of alcoholic strength in wine, beer and spirits using a flow-through infrared sensor. Chem. Cent. J. 4, 5–18. doi: 10.1186/1752-153X-4-5
Ladha-Sabur, A., Bakalis, S., Fryer, P. J., and Lopez-Quiroga, E. (2019). Mapping energy consumption in food manufacturing. Trends Food Sci. Technol. 86, 270–280. doi: 10.1016/j.tifs.2019.02.034
Laughman, C. (2019) State of Food Manufacturing Survey. Available online: https://www.foodengineeringmag.com/articles/98519-state-of-food-manufacturing-survey (accessed on Nov 16, 2020).
Liakos, K. G., Busato, P., Moshou, D., Pearson, S., and Bochtis, D. (2018). Machine learning in agriculture: a review. Sensors 18, 1–29. doi: 10.3390/s18082674
Liu, Y. C., Wang, F. S., and Lee, W. C. (2001). On-line monitoring and controlling system for fermentation processes. Biochem. Eng. J. 7, 17–25. doi: 10.1016/S1369-703X(00)00100-5
Liu, Z., He, Y., Cen, H., and Lu, R. (2018). Deep feature representation with stacked sparse auto-encoder and convolutional neural network for hyperspectral imaging-based detection of cucumber defects. Trans. ASABE 61, 425–436. doi: 10.13031/trans.12214
MacKay, D. J. C. (1992). “Bayesian interpolation,” in Maximum Entropy and Bayesian Methods. 1992. 4, p.415-447. doi: 10.1162/neco.1992.4.3.415
Mahendran, R., Gc, J., and Alagusundaram, K. (2015). Application of computer vision technique on sorting and grading of fruits and vegetables. J. Food Process. Technol. S1, 1–7. doi: 10.4172/2157-7110.S1-001
Mathanker, S. K., Weckler, P. R., and Bowser, T. J. (2013). X-ray applications in food and agriculture: a review. Trans. ASABE 56, 1227–1239. doi: 10.13031/trans.56.9785
McClements, D. J. (1995). Advances in the application of ultrasound in food analysis and processing. Trends Food Sci. Technol. 6, 293–299. doi: 10.1016/S0924-2244(00)89139-6
McGrath, T. F., Haughey, S. A., Islam, M., and Elliott, C. T. (2021). The potential of handheld near infrared spectroscopy to detect food adulteration: results of a global, multi-instrument inter-laboratory study. Food Chem. 353:128718. doi: 10.1016/j.foodchem.2020.128718
Nicolaï, B. M., Beullens, K., Bobelyn, E., Peirs, A., Saeys, W., Theron, K. I., et al. (2007). Nondestructive measurement of fruit and vegetable quality by means of NIR spectroscopy: a review. Postharvest Biol. Technol. 46, 99–118. doi: 10.1016/j.postharvbio.2007.06.024
Ok, G., Park, K., Kim, H. J., Chun, H. S., and Choi, S.-W. (2014). High-speed terahertz imaging toward food quality inspection. Appl. Opt. 53, 1406–1412. doi: 10.1364/ao.53.001406
Oliveira, M. M., Cruz-Tirado, J. P., Roque, J. V., Teófilo, R. F., and Barbin, D. F. (2020). Portable near-infrared spectroscopy for rapid authentication of adulterated paprika powder. J. Food Compos. Anal. 87:103403. doi: 10.1016/j.jfca.2019.103403
Pan, S. J., Tsang, I. W., Kwok, J. T., and Yang, Q. (2011). Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 22, 199–210. doi: 10.1109/TNN.2010.2091281
Parry, A., Harris, B., Fisher, K., and Forbes, H. (2020). UK Progress Against Courtauld 2025 Targets and UN Sustainable Development Goal 12.3. Banbury.
Pereira, A., Mendes, J., and Melo, L. F. (2009). Monitoring cleaning-in-place of shampoo films using nanovibration technology. Sensors Actuat. B Chem. 136, 376–382. doi: 10.1016/j.snb.2008.11.043
Pereira, L. A. M., Piza, L. V., Vicente, M., Arce, A. I. C., de Silva, A. C. S., Tech, A. R. B., et al. (2016). Construction of an experimental pilot-scale electric oven using wireless sensor instrumentation for baked food evaluation. Food Bioprod. Process. 100, 214–220. doi: 10.1016/j.fbp.2016.07.004
Pettigrew, L., Blomenhofer, V., Hubert, S., Groß, F., and Delgado, A. (2015). Optimisation of water usage in a brewery clean-in-place system using reference nets. J. Clean. Prod. 87, 583–593. doi: 10.1016/j.jclepro.2014.10.072
Philipsen, M. P., and Moeslund, T. B. (2019). “Intelligent injection curing of bacon,” in Proceedings of the Procedia Manufacturing, (Limerick, Ireland) 148–155.
Porep, J. U., Kammerer, D. R., and Carle, R. (2015). On-line application of near infrared (NIR) spectroscopy in food production. Trends Food Sci. Technol. 46, 211–230. doi: 10.1016/j.tifs.2015.10.002
Rady, A., Fischer, J., Reeves, S., Logan, B., and Watson, N. J. (2019). The effect of light intensity, sensor height, and spectral pre-processing methods when using NIR spectroscopy to identify different allergen-containing powdered foods. Sensors 20:230. doi: 10.3390/s20010230
Rady, A. M., and Guyer, D. E. (2015). Rapid and/or nondestructive quality evaluation methods for potatoes: a review. Comput. Electron. Agric. 117, 31–48. doi: 10.1016/j.compag.2015.07.002
Rady, A. M., Guyer, D. E., and Watson, N. J. (2021). Near-infrared spectroscopy and hyperspectral imaging for sugar content evaluation in potatoes over multiple growing seasons. Food Anal. Methods 14, 581–595. doi: 10.1007/s12161-020-01886-1
Rehman, T. U., Mahmud, M. S., Chang, Y. K., Jin, J., and Shin, J. (2019). Current and future applications of statistical machine learning algorithms for agricultural machine vision systems. Comput. Electron. Agric. 156, 585–605. doi: 10.1016/j.compag.2018.12.006
Ren, A., Zahid, A., Fan, D., Yang, X., Imran, M. A., Alomainy, A., et al. (2019). State-of-the-art in terahertz sensing for food and water security – A comprehensive review. Trends Food Sci. Technol. 85, 241–251. doi: 10.1016/j.tifs.2019.01.019
Resa, P., Elvira, L., and de Espinosa, F. (2004). Concentration control in alcoholic fermentation processes from ultrasonic velocity measurements. Food Res. Int. 37, 587–594. doi: 10.1016/j.foodres.2003.12.012
Resa, P., Elvira, L., Montero De Espinosa, F., González, R., and Barcenilla, J. (2009). On-line ultrasonic velocity monitoring of alcoholic fermentation kinetics. Bioprocess Biosyst. Eng. 32, 321–331. doi: 10.1007/s00449-008-0251-3
Ribeiro, A. M. N. C., do Carmo, P. R. X., Rodrigues, I. R., Sadok, D., Lynn, T., and Endo, P. T. (2020). Short-term firm-level energy-consumption forecasting for energy-intensive manufacturing: a comparison of machine learning and deep learning models. Algorithms 13:274. doi: 10.3390/a13110274
Saha, D., and Manickavasagan, A. (2021). Machine learning techniques for analysis of hyperspectral images to determine quality of food products: a review. Curr. Res. Food Sci. 4, 28–44. doi: 10.1016/j.crfs.2021.01.002
Saka, M. P., Doğan, E., and Aydogdu, I. (2013). Analysis of swarm intelligence–based algorithms for constrained optimization. Swarm Intell. Bioinspired Comput. 2013, 25–48. doi: 10.1016/B978-0-12-405163-8.00002-8
Santos, D., Nunes, L. C., De Carvalho, G. G. A., Gomes, M. D. S., De Souza, P. F., Leme, F. D. O., et al. (2012). Laser-induced breakdown spectroscopy for analysis of plant materials: a review. Spectrochim. Acta B Spectrosc. 71, 3–13. doi: 10.1016/j.sab.2012.05.005
Scanlon, M. G., Pritchard, M. K., and Adam, L. R. (1999). Quality evaluation of processing potatoes by near infrared reflectance. J. Sci. Food Agric. 79, 763–771. doi: 10.1002/(SICI)1097-0010(199904)79:5<763::AID-JSFA250>3.0.CO;2-O
Schöck, T., and Becker, T. (2010). Sensor array for the combined analysis of water-sugar-ethanol mixtures in yeast fermentations by ultrasound. Food Control 21, 362–369. doi: 10.1016/j.foodcont.2009.06.017
Sharma, R., Kamble, S. S., Gunasekaran, A., Kumar, V., and Kumar, A. (2020). A systematic literature review on machine learning applications for sustainable agriculture supply chain performance. Comput. Oper. Res. 119:104926. doi: 10.1016/j.cor.2020.104926
Shaw, A. D., Kaderbhai, N., Jones, A., Woodward, A. M., Goodacre, R., Rowland, J. J., et al. (1999). Noninvasive, on-line monitoring of the biotransformation by yeast of glucose to ethanol using dispersive Raman spectroscopy and chemometrics. Appl. Spectrosc. 53, 1419–1428. doi: 10.1366/0003702991945777
Shrestha, A., and Mahmood, A. (2019). Review of deep learning algorithms and architectures. IEEE Access 7, 53040–53065. doi: 10.1109/ACCESS.2019.2912200
Simeone, A., Deng, B., Watson, N., and Woolley, E. (2018). Enhanced clean-in-place monitoring using ultraviolet induced fluorescence and neural networks. Sensors 18, 1–21. doi: 10.3390/s18113742
Solomatine, D., See, L. M., and Abrahart, R. J. (2008). “Data-driven modelling: concepts, approaches and experiences,” in Practical Hydroinformatics. Water Science and Technology Library, eds R. J. Abrahart, L. M. See, and D. P. Solomatine (Berlin: Springer), 17–31.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958.
Storey, M. (2007). “The harvested crop,” in eds D. Vreugdenhil, J. Bradshaw, C. Gebhardt, F. Govers, D. K. L. Mackerron, M. A. Taylor, and H. A. Ross (Amsterdam: Elsevier), 441–470.
Su, Y., Zhang, M., Adhikari, B., Mujumdar, A. S., and Zhang, W. (2018). Improving the energy efficiency and the quality of fried products using a novel vacuum frying assisted by combined ultrasound and microwave technology. Innov. Food Sci. Emerg. Technol. 50, 148–159. doi: 10.1016/j.ifset.2018.10.011
Sun, Q., Zhang, M., and Mujumdar, A. S. (2019). Recent developments of artificial intelligence in drying of fresh food: a review. Crit. Rev. Food Sci. Nutr. 59, 2258–2275. doi: 10.1080/10408398.2018.1446900
Svendsen, C., Cieplak, T., and Van Den Berg, F. W. J. (2016). Exploring process dynamics by near infrared spectroscopy in lactic fermentations. J. Near Infrared Spectrosc. 24, 443–451. doi: 10.1255/jnirs.1244
Takacs, R., Jovicic, V., Zbogar-Rasic, A., Geier, D., Delgado, A., and Becker, T. (2020). Evaluation of baking performance by means of mid-infrared imaging. Innov. Food Sci. Emerg. Technol. 61:102327. doi: 10.1016/J.IFSET.2020.102327
Toledo, J., Ruiz-Díez, V., Pfusterschmied, G., Schmid, U., and Sánchez-Rojas, J. L. (2018). Flow-through sensor based on piezoelectric MEMS resonator for the in-line monitoring of wine fermentation. Sensors Actuat. B Chem. 254, 291–298. doi: 10.1016/j.snb.2017.07.096
Tomasevic, I., Tomovic, V., Milovanovic, B., Lorenzo, J., Ðorđevi,ć, V., and Karabasil, N.. (2019). Comparison of a computer vision system vs. traditional colorimeter for color evaluation of meat products with various physical properties. Meat Sci. 148, 5–12. doi: 10.1016/j.meatsci.2018.09.015
Tsamos, K. M., Ge, Y. T., Santosa, I.D., Tassou, S. A., Bianchi, G., and Mylona, Z. (2017). Energy analysis of alternative CO2 refrigeration system configurations for retail food applications in moderate and warm climates. Energy Convers. Manag. 150, 822–829. doi: 10.1016/j.enconman.2017.03.020
Van De Looverbosch, T., Rahman Bhuiyan, M. H., Verboven, P., Dierick, M., Van Loo, D., De Beenbouwer, J., et al. (2020). Nondestructive internal quality inspection of pear fruit by X-ray CT using machine learning. Food Control 113:107170. doi: 10.1016/j.foodcont.2020.107170
Vann, L., Layfield, J. B., and Sheppard, J. D. (2017). The application of near-infrared spectroscopy in beer fermentation for online monitoring of critical process parameters and their integration into a novel feedforward control strategy. J. Inst. Brew. 123, 347–360. doi: 10.1002/jib.440
Veale, E. L., Irudayaraj, J., and Demirci, A. (2007). An on-line approach to monitor ethanol fermentation using FTIR spectroscopy. Biotechnol. Prog. 23, 494–500. doi: 10.1021/bp060306v
Wallhäußer, E., Hussein, M. A., and Becker, T. (2012). Detection methods of fouling in heat exchangers in the food industry. Food Control 27, 1–10. doi: 10.1016/j.foodcont.2012.02.033
Wilson, D. I. (2018). Fouling during food processing – progress in tackling this inconvenient truth. Curr. Opin. Food Sci. 23, 105–112. doi: 10.1016/j.cofs.2018.10.002
Wu, D., and Sun, D. W. (2013). Colour measurements by computer vision for food quality control - A review. Trends Food Sci. Technol. 29, 5–20. doi: 10.1016/j.tifs.2012.08.004
Xie, H., Tang, H., and Liao, Y. H. (2009). “Time series prediction based on narx neural networks: an advanced approach,” in Proceedings of the Proceedings of the 2009 International Conference on Machine Learning and Cybernetics, (Baoding, China) 1275–1279.
Yu, Y., Zhang, K., Yang, L., and Zhang, D. (2019). Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 163:104846. doi: 10.1016/j.compag.2019.06.001
Zeng, X., and Luo, G. (2017). Progressive sampling-based Bayesian optimization for efficient and automatic machine learning model selection. Heal. Inf Sci. Syst. 5, 1–21. doi: 10.1007/s13755-017-0023-z
Keywords: digital manufacturing, sensors, machine learning, food and drink manufacturing, intelligent manufacturing, industry 4.0, industrial digital technologies
Citation: Watson NJ, Bowler AL, Rady A, Fisher OJ, Simeone A, Escrig J, Woolley E and Adedeji AA (2021) Intelligent Sensors for Sustainable Food and Drink Manufacturing. Front. Sustain. Food Syst. 5:642786. doi: 10.3389/fsufs.2021.642786
Received: 16 December 2020; Accepted: 01 October 2021;
Published: 05 November 2021.
Edited by:
Jeremy Graham Frey, University of Southampton, United KingdomReviewed by:
Marta Prado, International Iberian Nanotechnology Laboratory (INL), PortugalCopyright © 2021 Watson, Bowler, Rady, Fisher, Simeone, Escrig, Woolley and Adedeji. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Nicholas J. Watson, bmljaG9sYXMud2F0c29uQG5vdHRpbmdoYW0uYWMudWs=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.