 Shushi Namba
Shushi Namba Akie Saito1
Akie Saito1 Wataru Sato
Wataru Sato
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol., 23 May 2024
Sec. Emotion Science
Volume 15 - 2024 | https://doi.org/10.3389/fpsyg.2024.1281857
This article is part of the Research TopicInsights in Emotion ScienceView all 12 articles
The rapid detection of neutral faces with emotional value plays an important role in social relationships for both young and older adults. Recent psychological studies have indicated that young adults show efficient value learning for neutral faces and the detection of “value-associated faces,” while older adults show slightly different patterns of value learning and value-based detection of neutral faces. However, the mechanisms underlying these processes remain unknown. To investigate this, we applied hierarchical reinforcement learning and diffusion models to a value learning task and value-driven detection task that involved neutral faces; the tasks were completed by young and older adults. The results for the learning task suggested that the sensitivity of learning feedback might decrease with age. In the detection task, the younger adults accumulated information more efficiently than the older adults, and the perceptual time leading to motion onset was shorter in the younger adults. In younger adults only, the reward sensitivity during associative learning might enhance the accumulation of information during a visual search for neutral faces in a rewarded task. These results provide insight into the processing linked to efficient detection of faces associated with emotional values, and the age-related changes therein.
The ability to efficiently determine the emotional significance of facial expressions is crucial for adaptive behavior in social interactions (Stins et al., 2011; Heerdink et al., 2015). Efficient detection of faces with positive emotional value is important for social behaviors and relationships. Similarly, rapid detection of faces displaying negative, threatening emotions can enable an individual to avoid a dangerous situation and preserve resources.
The adaptive qualities of emotional expressions appear to influence attention (Hansen and Hansen, 1988; Fenske and Raymond, 2006; Craig et al., 2014). However, this idea has led to several controversies in the field of psychology (Puls and Rothermund, 2018; Tannert and Rothermund, 2020). For example, there is conjecture regarding the physical and emotional significance of faces providing emotional information (Horstmann et al., 2006; Calvo and Nummenmaa, 2008; Horstmann et al., 2012). To control for perceptual properties when investigating the detection of faces with emotional information, Saito et al. (2022a) employed inherently neutral faces associated with positive or negative values as target stimuli in a visual search task. They based their paradigm on an associative learning task in which neutral stimuli (e.g., colors) were linked with a reward or punishment (Anderson et al., 2011; Wentura et al., 2014; Muller et al., 2016). They found that the reaction time (RT) during a visual search for neutral faces associated with a reward or punishment was reduced compared with that for neutral faces not associated with feedback. In other words, emotional significance facilitated attentional capture during a visual search task.
Given the aging of many contemporary societies, the cognition of older adults has been a major research focus (Ziaei and Fischer, 2016). Older people exhibit a “positivity effect,” i.e., they tend to focus their attention on pleasant stimuli (Reed et al., 2014). However, studies on this topic have yielded inconsistent results. For example, a recent study (Saito et al., 2020) found that both young and older participants readily attended to angry facial expressions. In contrast, older participants did not show this tendency for happy facial expressions. In addition, in an associative learning task combined with a visual search paradigm, Saito et al. (2022b) found that positive (reward) and negative (punishment) outcomes in the associative learning task facilitated attention in the visual search task for successful young and older learners, although there were no differences in emotional valence.
Although previous studies have demonstrated rapid detection of neutral faces associated with an emotional value (Saito et al., 2022a,b), the mechanism underlying the relationship between associative learning and visual search attention remains unclear. Visual search performance has been investigated in successful and unsuccessful learners. However, several scholars have pointed out that such binary groupings are statistically undesirable (DeCoster et al., 2009; Reinhart, 2015). The RT, as a dependent variable, is inherently right-skewed. Analysis of variance (ANOVA), which assumes a normal data distribution, is also inappropriate for this type of study. Another problem is that classification errors are generally analyzed separately from RT, making it impossible to assess the speed-accuracy trade-off. Furthermore, the RTs regarding the relationship between associative learning rate and visual search performance were not compared between the groups because the groups were distinguished using a binary classification scheme based on the associative learning performance (Saito et al., 2022a,b).
Computational modeling using behavioral data has potential for elucidating the mechanisms of human psychological processes (Lee and Wagenmakers, 2014). The reinforcement learning model (Rescorla and Wagner, 1972; Hertwig et al., 2004) can be used to quantitatively evaluate learning rate parameters in learning tasks, and to reveal their associations with other variables and obtain insight into the mechanisms of human behaviors (e.g., Dombrovski et al., 2010; Kwak et al., 2014; Suzuki et al., 2023). Given the above findings, reinforcement learning is likely to be useful for examining performance in learning tasks that involve associative learning; they allow the identification of factors that contribute to success in learning tasks, such as sensitivity to feedback ( ) or reliance on a model ( ).
The diffusion model (Ratcliff, 1978; Ratcliff and Rouder, 1998; Ratcliff and McKoon, 2008; Forstmann et al., 2016) can be used to describe the distribution of RTs associated with the detection of emotional faces (Tipples, 2019; Sawada et al., 2022). The diffusion model includes four main parameters. The threshold separation ( ) is the distance between two choices (i.e., target presence and absence), z denotes the starting point (which is related to prior bias in two-choice tasks), and is the drift rate (speed with which evidence is accumulated in relation to a specific response, i.e., toward the upper or lower threshold). The non-decision time (t0) is based on all time components unrelated to the information accumulation process. RTs tend to be classified as fast or slow in experimental tasks. However, more in-depth metrics can be obtained, such as the speed with which information is accumulated ( ), the amount of information required ( ), and the time required to arrive at a judgement (t0). Analysis of such metrics can reveal the mechanisms underlying psychological processes. Indeed, Sawada et al. (2022) used the diffusion model to estimate cognitive parameters in a visual search task requiring participants to detect angry and happy expressions, and their anti-expressions, within a crowd of neutral faces. Regardless of valence, for emotional facial expressions was rapid, values were large, and t0 values were small. These results suggest that efficient detection of facial expressions is characterized by the faster and more cautious accumulation of information through enhanced attentional allocation.
When investigating the relationships among different behavioral task performance indices, a computational modeling approach can be used to maximize the amount of information obtained. By fitting a reinforcement learning model to associative learning data and a diffusion model to visual search data, and then examining the relationship between the resulting parameters, further insight can be obtained into the mechanisms underlying the detection of faces with emotional meaning.
In this study, we explored the psychological processes underlying the rapid detection of faces with emotional meaning by investigating the relationship between associative learning and visual search data. Moreover, we investigated developmental changes by comparing young and older participants. We applied the hierarchical reinforcement learning and diffusion models to data collected in previous studies (Saito et al., 2022a,b) (Figure 1). Then, we checked the relationships between the resulting parameters using both models. Learning success in associative learning tasks was quantitatively represented by changes in learning rates on a continuum, instead of a binary classification. We also calculated three psychologically meaningful parameters ( , , and t0) instead of the RT. This study is the first to investigate the relationships among the above parameters.
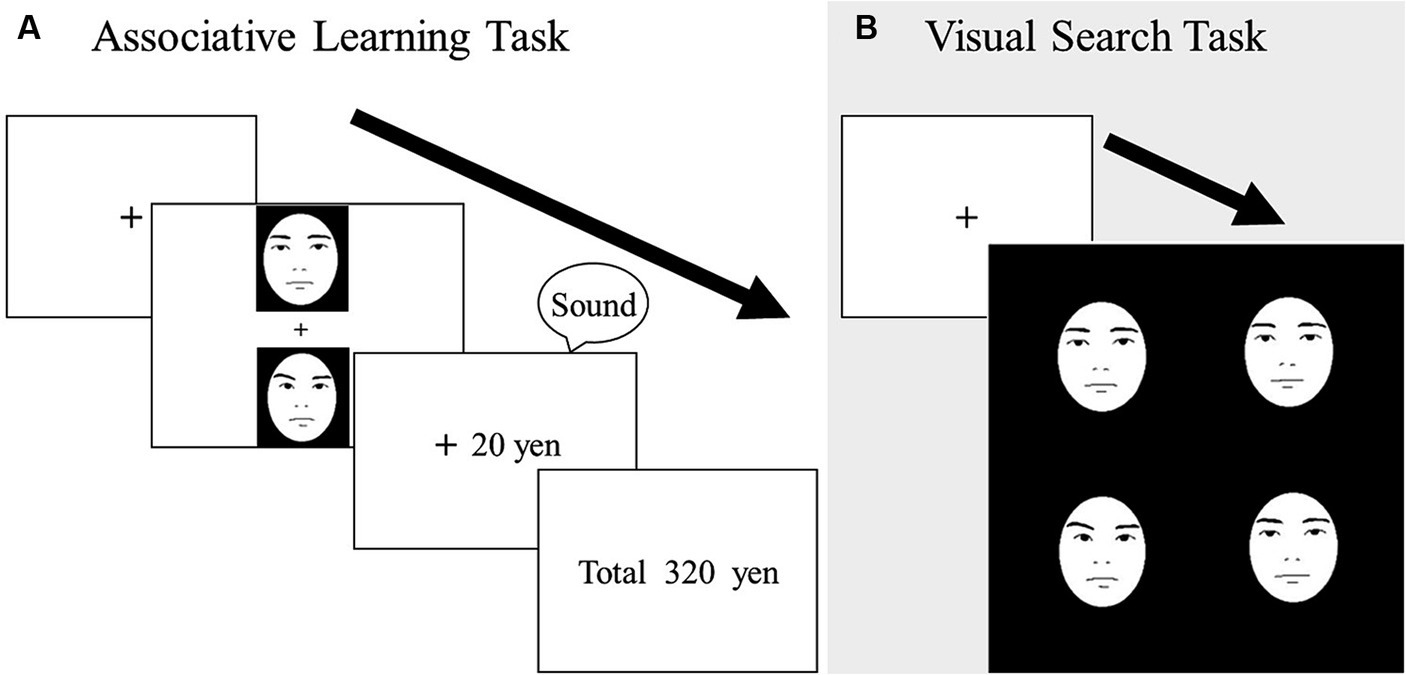
Figure 1. Schematic illustrations of trials in the learning task (A) and visual search task (B). In the learning task, participants chose one face from each pair to maximize their earnings. In the visual search task, participants identified one discrepant face embedded among distractor faces. Actual stimuli were photographic faces.
We tested three hypotheses using computational models. The first hypothesis was informed by the previous finding that people tend to avoid negative situations rather than to show approach behavior to positive ones. Kahneman and Tversky (1979) explained this asymmetry between gain and loss using prospect theory. Katahira et al. (2011) revealed that the negative reward value of negative pictures was larger than the positive reward value of positive pictures. Thus, we expected the learning rate in the associative learning task to be higher in both younger and older participants for punishment trials than reward trials. In terms of developmental changes, Saito et al. (2020) reported that older participants showed markedly reduced sensitivity to positive expressions compared with younger participants. Thus, our hypotheses are as follows: 1–1. Learning rate parameters will be higher for punishment trials than reward trials. 1–2. Older participants will have low learning rates for rewards. In the visual search paradigm, we expected the younger group to exhibit superior performance compared with the older group (Salthouse, 2000). Accordingly, we hypothesized that each diffusion model parameter value will be higher in the younger participants than in the older ones. Finally, based on a straightforward interpretation of Saito et al. (2022b), we predicted that the in RT will be linked to the learning rates. The relationships between other parameters were investigated in an exploratory manner.
We recruited 29 young adult participants (13 women; mean ± SD age = 22.6 ± 2.1 years), all of whom were either undergraduate or graduate students at Kyoto University. We also recruited 32 older participants (16 women; mean ± SD age = 73.5 ± 5.3 years) from a local human resource center in Kyoto. All participants were paid for their participation. The sample size was determined by a priori power analysis, using a frequentist approach with an assumed level because the data had been used in previous studies (Saito et al., 2022a,b). All participants provided written informed consent to take part in the study, which was approved by the ethics committee of the Unit for Advanced Studies of the Human Mind at Kyoto University and conducted in accordance with institutional ethical guidelines and the Declaration of Helsinki.
Seven grayscale images of male faces with neutral expressions were selected from a database containing 65 faces of Japanese individuals (Sato et al., 2019). One face was used as a distractor in the visual search task, and the others were used as targets in the associative learning and visual search tasks. The images were adjusted for brightness and contrast using Photoshop 5.0 (Adobe, San Jose, CA) and the mean luminance was equalized using MATLAB R2017b (MathWorks, Natick, MA). The stimuli were controlled in terms of both attractiveness and distinctiveness. The detection speed was not significantly different between the target faces in the visual search task according to the results of preliminary experiments (F(5,35) = 2.18, p = 0.079). All stimuli were cut into ellipses to exclude distinctive factors (e.g., hairstyle and facial contours), and had subtended visual angles of 3.5° horizontally × 4.5° vertically.
Three pairs of faces were used. The face pairs were fixed throughout the learning task. Each pair was allocated to one of the three value conditions (reward, punishment, or zero outcome), and this allocation was counterbalanced across participants. In the reward and punishment conditions, one face in each pair was designated as the target. Selecting the target resulted in a monetary reward (20 yen increase in each trial) or punishment (20 yen decrease in each trial) in 80% of trials (zero outcomes for the other 20%). The nontarget image in each pair was assigned the reverse probability pattern (i.e., 20% probability of monetary reward or punishment). In the zero-outcome condition, one face was the target, but the monetary outcome was always zero regardless of whether the participants selected the target or nontarget. This condition was set as a control condition to compare the learning conditions (reward and punishment). The target face statuses in each condition were counterbalanced across the participants. Each participant experienced 1 of 24 stimulus presentation combinations in the learning task.
The same three face pairs from the associative learning task were used in the visual search task. The face classified as the target in each condition in the associative learning task was also the target in this task. An additional face with a neutral expression was used as a distractor. The search display was a square (11.0° × 11.0°) within which faces were presented in four positions at 4° intervals. One target face and three identical distractor faces were presented in each of the four positions in the target-present condition. Each target face was presented 8 times in each of the four positions, so that each target was presented 32 times in total. In the target-absent condition, the four identical distractor faces appeared in all of the positions.
The participants were seated in a chair with a chin rest fixed 80 cm from the monitor. The experimental room was soundproofed and dimly lit.
The participants took part in a betting game, in which they were asked to choose a face from each stimulus pair based on their “gut feeling” and register their response by pressing the corresponding button on a response box. The goal of the task was to maximize their earnings. Because the participants were not told which of the paired faces was the target, they had to make a guess about which face would be more likely to lead to a reward. They were informed that the money they earned would be paid after the experiment, and were asked to try and earn as much money as possible. Each trial began with the presentation of a fixation cross for 500 m, followed by a pair of faces. The faces in the pair were positioned 2.5° above or below the fixation cross (0.9° × 0.9°), such that they appeared in the center of the screen. The positions of the target and nontarget faces were pseudo-randomized. After the participant made a response, a “reward” message (plus 20 yen, minus 20 yen, or 0 yen) was presented on the screen, and a sound indicated whether the answer was correct or incorrect (no sound for 0 yen). Then, the amount of money earned was displayed on the screen for 1,800 ms. Each face pair was presented 10 times (total of 30 trials) in one block, and there were 10 blocks in the main experiment, resulting in 300 trials. To prevent the consecutive presentation of identical face pairs in the same position, the presentation order of the face pairs was pseudo-randomized. Prior to the experiment, the participants completed 30 practice trials to familiarize themselves with the task.
Before the experiment, the participants were informed that no monetary reward or punishment would occur in this task. In each trial, a fixation cross was shown for 500 ms, followed by a stimulus array containing four faces (Figure 1B) that did not have any facial movements (i.e., neutral faces). The participants were instructed to indicate whether one of the faces was dissimilar from the others, or if all four faces were the same, by pressing the corresponding button on the response box as quickly and accurately as possible. The allocation of the response buttons was counterbalanced across participants. Each block included 24 target-present trials (8 trials each in the reward, punishment, and zero-outcome conditions) and 24 target-absent trials. The main experiment consisted of four blocks, such that the total number of trials was 192. To prevent the consecutive presentation of identical targets in the same position, the order of trial presentation was pseudo-randomized in each block. There was no time limit. Before the experiment, the participants completed 24 practice trials.
In the associative learning task, two younger participants (−220 ~ −140 yen) and 10 older participants (−440 ~ −20 yen) had net negative amounts. Regardless of whether a negative or positive amount of money was earned, all participants received the same predetermined monetary bonus in the learning task (1,000 Japanese yen) after they had been debriefed.
To determine whether the learning conditions affected face selection, and whether that effect differed depending on age, we performed three-way mixed ANOVA with factors of learning condition (reward, punishment and zero), trial block (1–20, 21–40, 41–60, 61–80, and 81–100), and age (younger and older). For post-hoc tests, p-values were adjusted using the Holm-Bonferroni sequentially rejective procedure (Holm, 1979). Learning was assumed to have occurred, if there was a performance difference between the first 20 and final 20 trials.
To build a reinforcement learning model, we established a modified multiple-armed bandit model (Hertwig et al., 2004; Ahn et al., 2017) based on the Rescorla-Wagner (delta) model in which the learning rates for reward and punishment were distinguished (Rescorla and Wagner, 1972). Because there was no feedback in the zero condition, the estimates were not uniquely determined; we used only the data for the reward and punishment conditions. Thus, we estimated four main parameters: the learning rate for reward ( ), learning rate for punishment ( ), inverse temperature for reward ( ), and inverse temperature for punishment ( ). First, we set four expected values for the four choices (target face choice in reward conditions, nontarget face choice in reward conditions, target face choice in punishment conditions, and nontarget face choice in punishment conditions). Next, we calculated prediction error (PE) by subtracting the monetary outcome (+1, 0, −1) from the expected value (EV) for each choice. After that, the following updating rule was formulated.
To calculate the action probabilities, we used the softmax choice rule with the inverse temperature parameter ( ), which reflects how individuals’ choices are made deterministically with respect to the value of the alternative choices (Kaelbling et al., 1996). An increase in the inverse temperature corresponds to a preference for model dependent choices, whereas a decrease in the inverse temperature reflects a tendency toward more random decisions. The learning rates represent the sensitivity of feedback in a learning task, where close to 1 places more weight on recent outcomes.
In addition, we applied Bayesian hierarchical modeling (Lee and Wagenmakers, 2014), which can delineate individual differences and similarities among participants and thus enhance the accuracy of statistical inferences (Gelman and Hill, 2006; Driver and Voelkle, 2018; Namba et al., 2022). The number of iterations was set to 5,000, the number of burn-in samples to 5,000, and the number of chains to four. The R-hat value for all parameters was 1.0, indicating convergence of the four chains (Stan Development Team, 2020). The details of the model, including the prior distributions, are described in the Supplementary material.1
To determine whether the learning conditions affected visual search performance (i.e., RT and accuracy), and whether that effect differed by age, we performed two-way mixed ANOVA including learning condition (reward, punishment and zero) and age (younger and older). Similar to the associative learning tasks, p-values were adjusted using the Holm-Bonferroni sequentially rejective procedure. We were concerned with the difference between the reward, punishment, and no feedback conditions in the target-present trials, rather than the difference between the target-present and absent conditions. Thus, we focused on the target-present condition in the visual search task.
To build the hierarchical drift-diffusion model, we applied a response-fitting model that use two outputs: same or dissimilar. We extracted the three main parameters from the behavioral data using the hierarchical drift diffusion model: , and t0. For parameter estimation, we calculated individual-level parameters (and the within-condition covariance structure) for in the different learning conditions (reward, punishment, and zero), and we calculated a population-level parameter for t0. z was fixed at 0.5. This was due to the need to constrain parameters for stable convergence (Kinosada, 2019). We determined whether the values of R-hat were close to 1 (values closer to 1 indicate greater convergence) and calculated the variation between the four chains (smaller variance reflects greater convergence). The number of iterations was set to 5,000, and the number of burn-in samples was set to 5,000. The diffusion model, including the prior distributions, was described in detail in (see Footnote 1).
Finally, we explored the correlations among the underlying parameters for each participant. Since no sample size calculation or a priori power analysis was conducted, we used conservative criteria, i.e., r > 0.30 (Cohen, 2013). All analyses were performed using R ver. 3.6.1 (R Core Team, 2019), with the “anovakun,” “bayesplot,” “brms,” “cmdstanr,” “posterior,” “rstan,” “tidyverse” packages (Bürkner, 2017; Gabry et al., 2019, 2023; Wickham et al., 2019; Stan Development Team, 2020; Bürkner et al., 2023; Iseki, 2023).
First, we checked the learning curves for the young and older participants, as shown in Figure 2. A visual inspection of the performance of the younger and older participants indicated good learning outcomes in both groups, although the younger participants exhibited more efficient learning. Three-way mixed ANOVA was performed to evaluate the effects of age, learning and trial block. There was no main effect of age or trial block, and interaction effect between age and trial block (Fs < 0.35, ps > 0.55, ηG2s < 0.002), but the main effect of learning condition was significant (F(2, 110) = 49.61, p < 0.001, ηG2 = 0.32). Participants in the reward condition performed significantly better than those in the zero and punishment conditions, and participants in the zero condition performed better than those in the punishment condition (ts > 4.36, ps < 0.001). There was also an interaction effect between trial block and learning condition (F(8, 440) = 13.43, p < 0.001, ηG2 = 0.05). The post hoc test showed significant differences between trial blocks in the reward and punishment conditions (Fs > 14.22, ps < 0.001, ηG2s > 0.06), but there was no difference between trial blocks in the zero condition (F(4, 220) = 0.38, p = 0.82, ηG2 = 0.00). In the reward condition, the selection rate was significantly higher in the last 20 trials than in the first 20 trials (t = 5.04, p < 0.001), but the opposite was true in the punishment condition (t = 5.30, p < 0.001). This indicates that associative learning for reward and punishment occurred in both participants. In addition, there was an interaction effect between age and learning condition (F(7, 43) = 7.43, p = 0.001, ηG2 = 0.07). The post hoc test showed significant differences between younger and older participants in the reward and punishment conditions (Fs > 9.25, ps < 0.004, ηG2s > 0.10), with the effects being smaller in older than younger participants, but there was no difference in the zero condition (F(1,55) = 0.02, p = 0.88, ηG2 = 0.00). Moreover, the performance of younger participants significantly differed among the conditions; performance was best in the reward condition, followed by the zero condition and finally by the punishment condition (ts > 5.40, ps < 0.001). Older participants performed worse in the punishment condition than the other two learning conditions (ts > 2.76, ps < 0.02), but the reward condition did not differ from the zero condition (t = 1.35, p = 0.19). In summary, the younger participants were able to learn reward and punishment contingencies in the associative learning task, and the older participants were able to learn punishment contingencies in the associative learning task but not reward contingencies.

Figure 2. (A) Mean (± standard error) proportion of target faces selected by younger participants for each block (1–20) in the reward, punishment and zero conditions. (B) Mean (± standard error) proportion of target faces selected by older participants for each block (1–20 trials) in the reward, punishment, and zero conditions.
Next, as shown in Table 1 and Figure 3, we assessed the results for the reinforcement learning model parameters. There was a small difference in learning rate between the reward and punishment trials among the younger participants. Specifically, the learning rates were higher for punishment trials. For the inverse temperature parameters, both groups had higher values for the reward compared with punishment trials. We performed the posterior predictive check, comparing simulated and real data (Supplementary Figure S12).
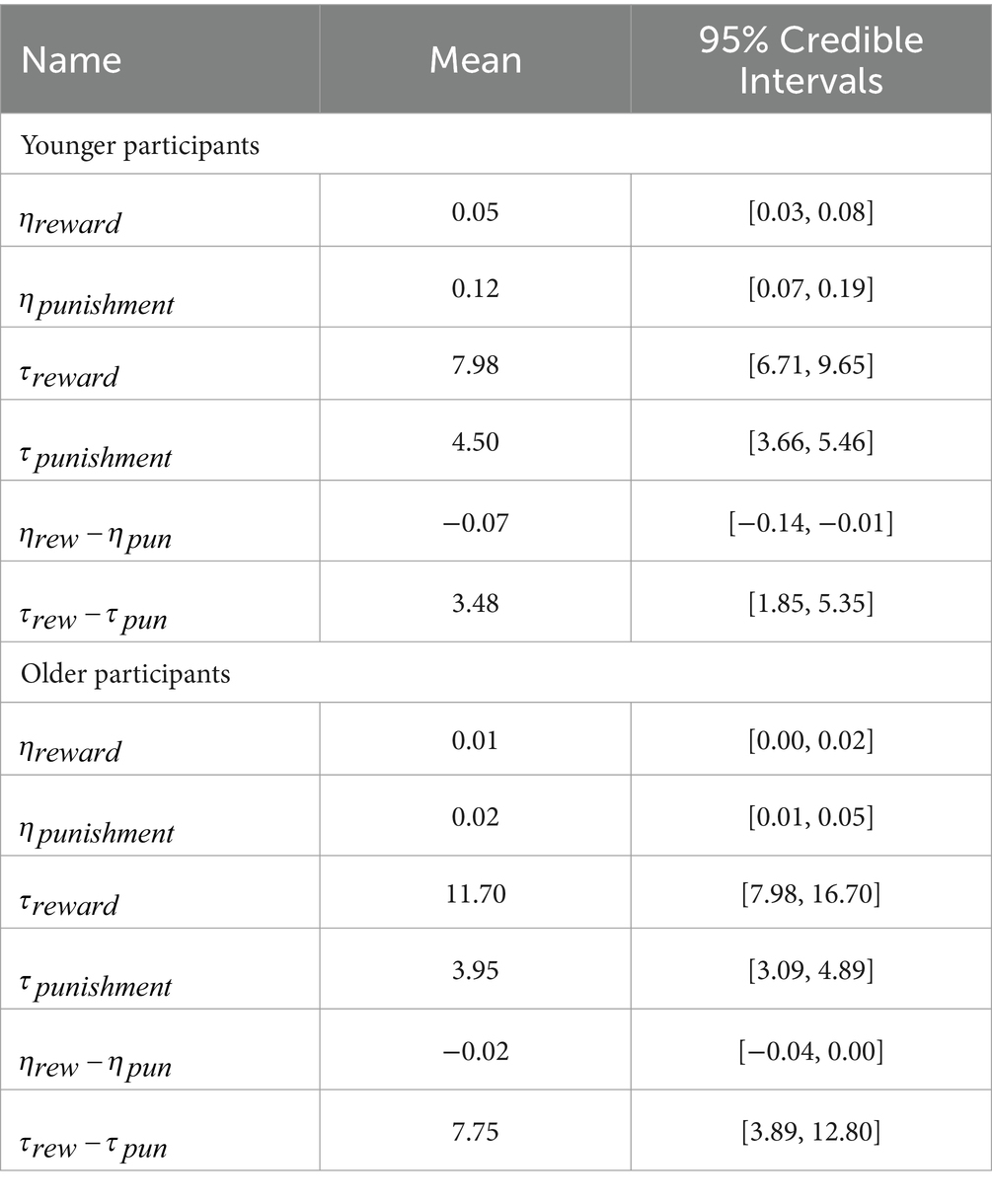
Table 1. All parameters in the reinforcement-learning model.
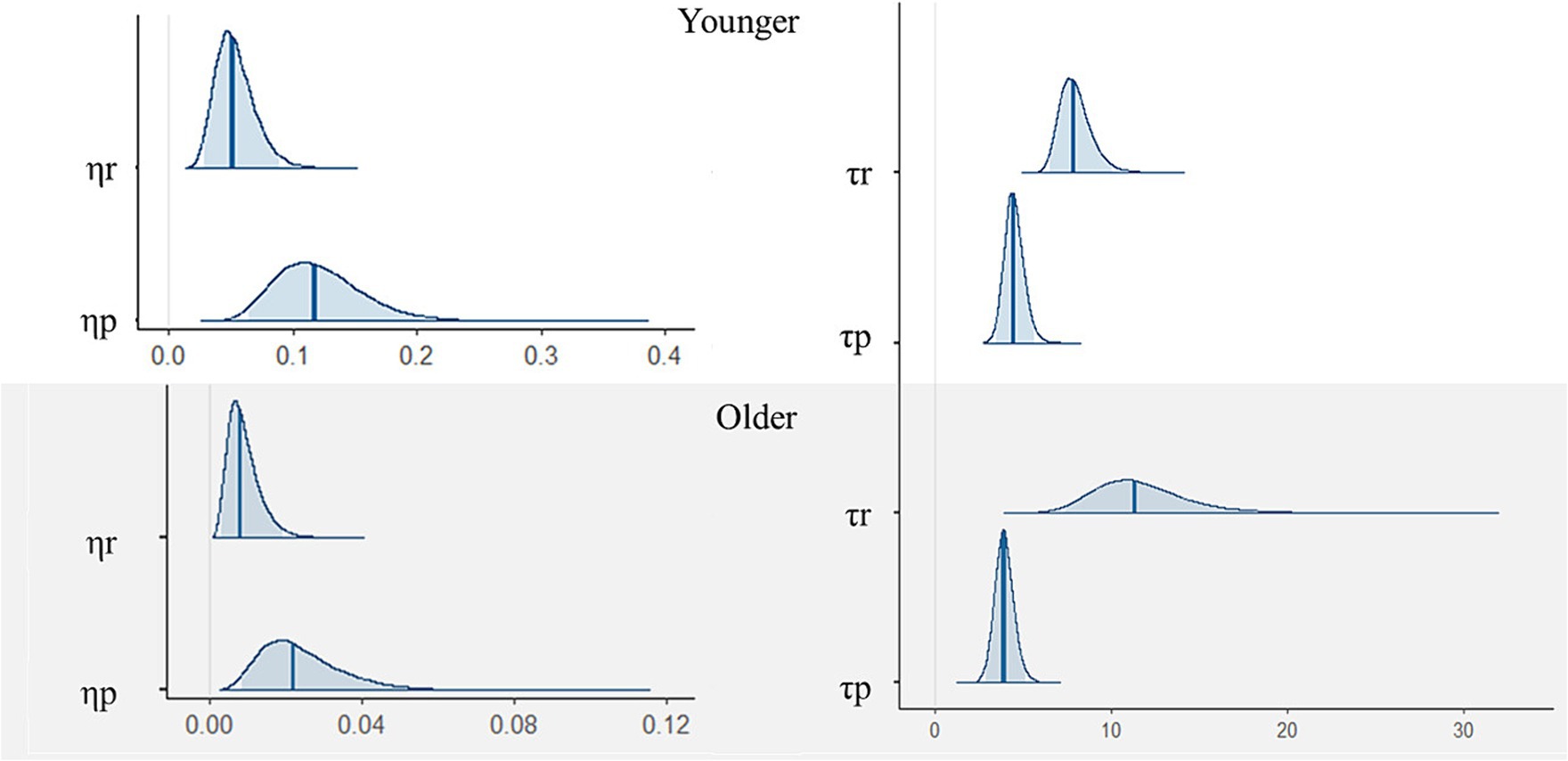
Figure 3. Posterior distributions of each parameter of the reinforcement learning model among younger (upper) and older participants (lower). Blue bars are expected a posteriori values and transparent blue regions are 95 credible intervals. = the learning rates, τ = the inverse temperature, ∗r = for reward, ∗p = for punishment.
Figure 4 shows the posterior distributions of each parameter difference between younger and older participants. There were differences between the younger and older participants in learning rates but not inverse temperatures. Specifically, younger participants had higher learning rates than older ones (reward: mean of group difference = 0.04, 95% credible interval [CI] = [0.02, 0.07]; punishment: mean of group difference = 0.10, 95% CI = [0.04, 0.16]). There were no differences in inverse temperatures between the younger and older participants (reward: mean of group difference = −3.71, 95% CI = [−8.80, 0.38]; punishment: mean of group difference = 0.55, 95%CI = [−0.72, 1.84]).
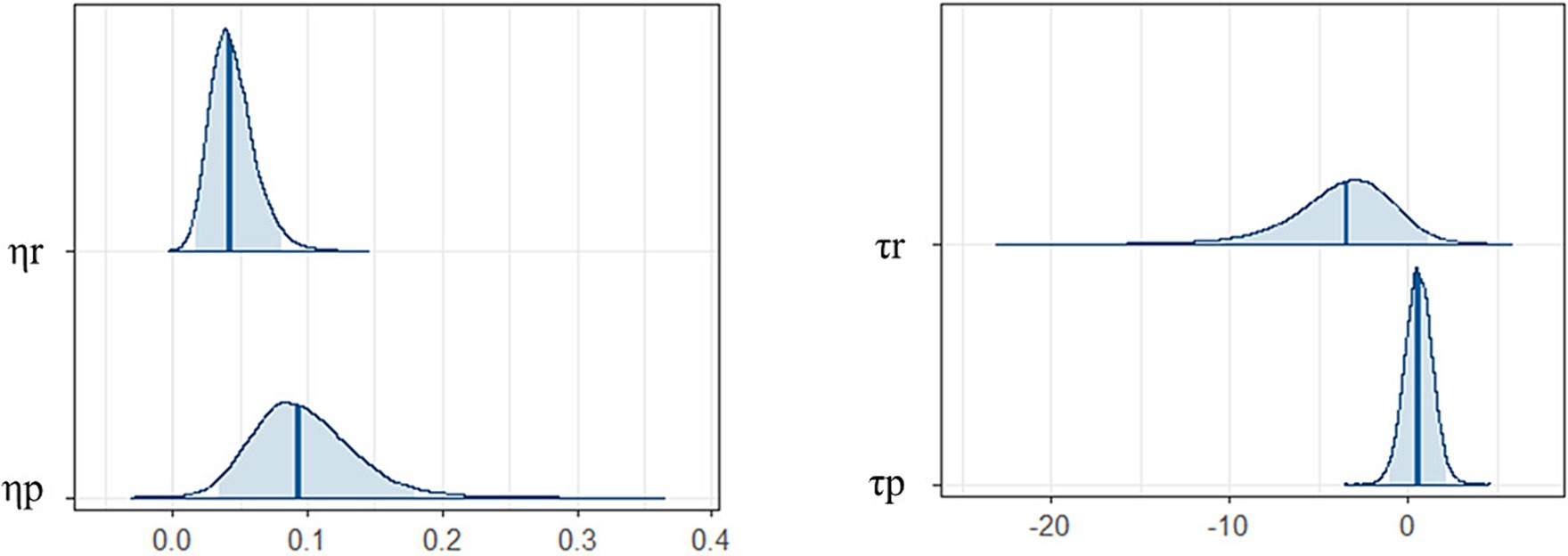
Figure 4. Posterior distributions of each parameter difference between younger and older participants. Blue bars are expected a posteriori values and transparent blue regions are 95% credible intervals. Positive values are a relatively large component of younger participants, while negative values are a relatively large component of older participants. = the learning rates, τ = the inverse temperature, *r = for reward, *p = for punishment.
To check the performance of the visual search task, we performed two-way mixed ANOVA including age and learning condition. It should be noted that this ANOVA analysis was a preliminary analysis to measure the tendency of the data. Regarding RT, there were main effects of age and learning condition (Fs > 4.45, ps < 0.02, ηG2s > 0.01). Younger participants (mean = 0.97) showed shorter RTs than older participants (mean = 1.58; t = 8.77, p < 0.001). Regarding the effect of learning condition, RT was significantly shorter in the reward condition than in the zero condition (t = 2.96, p = 0.01), and there was a trend toward a difference between the punishment and zero conditions (t = 1.78, p = 0.08). There was no interaction effect between age and learning condition (F(2, 110) = 2.03, p = 0.14, ηG2 = 0.005). Regarding accuracy, no significant main or interaction effects were found (Fs < 0.80, ps > 0.45, ηG2s < 0.006). In summary, in the visual search task, the younger participants were faster than the older ones. Moreover, the RT in the reward condition, but not in the punishment condition, was significantly different to that in the zero condition over the two age groups.
As described above, we computed the three drift diffusion parameters (α, ν, t0) from the visual search data for the younger and older participants. Figure 5 shows the α values, i.e., the threshold of accumulated evidence for all conditions (two groups: younger and older; three conditions: reward, punishment, and zero). Visual inspection indicated no differences among the reward, punishment, and zero conditions, but there were differences between the younger and older participants only for the zero condition ( : mean of group difference = −0.14, 95% credible interval [CI] = [−0.31, 0.02]; : mean of group difference = −0.15, 95% credible interval [CI] = [−0.30, 0.01]; : mean of group difference = −0.17, 95% credible interval [CI] = [−0.34, −0.01]). These results indicate that the older participants needed more information before they made a response regarding the value-driven unlearned faces. The posterior predictive check was further confirmed using reaction time values in the simulated and real data of younger and older participants [Supplementary Figure S2; (see Footnote 2)].
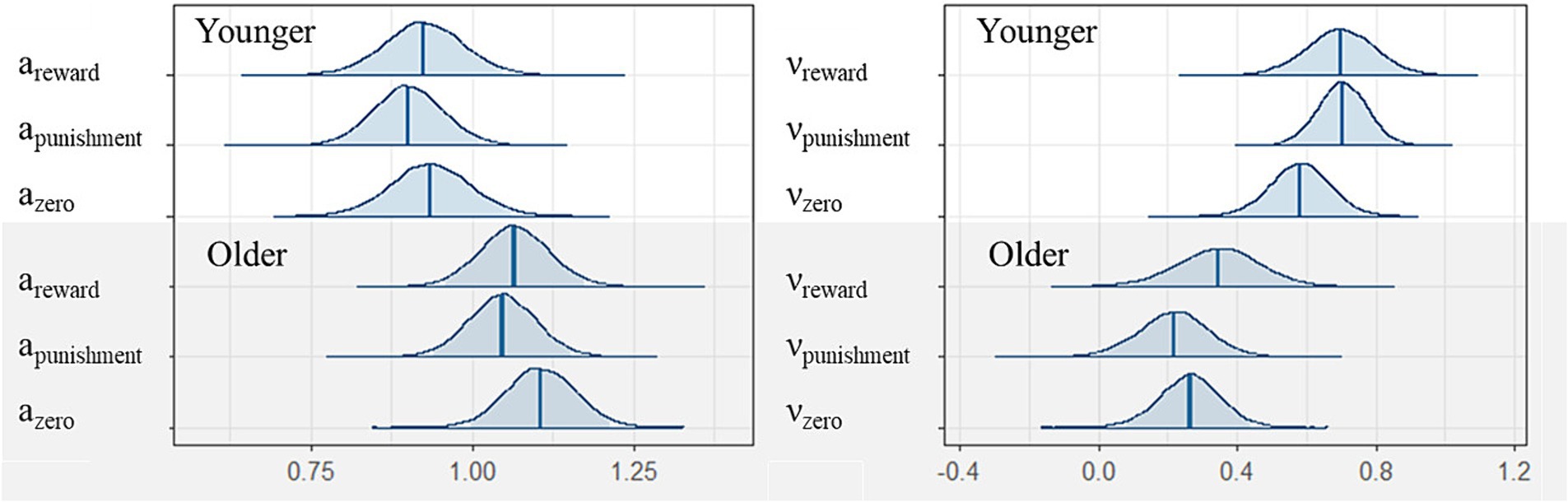
Figure 5. Posterior density plot of the group means of the six parameters as produced in the group (y = younger, o = older) and conditions (reward, punishment, and zero). Left: the threshold separation (α), right: the drift rate (ν).
Figure 5 shows the results for ν, i.e., the speed at which the participants accumulated evidence before making a response. Even in the younger group, although visual inspection indicated that the positive and negative learning conditions had a relatively higher ν compared with the zero condition, performance did not differentiate positive and negative learning conditions from the zero condition ( : mean of group difference = 0.12, 95% credible interval [CI] = [−0.05, 0.28]; : mean of group difference = 0.12, 95% credible interval [CI] = [−0.07, 0.31]). There were differences between the younger and older participants ( : mean of group difference = 0.35, 95% credible interval [CI] = [0.05, 0.66]; : mean of group difference = 0.49, 95% credible interval [CI] = [0.24, 0.74]; : mean of group difference = 0.32, 95% credible interval [CI] = [0.08, 0.57]).
t0 is based on all time components unrelated to the information accumulation process, as stated previously. There were differences between the younger and older participants ( : mean = 0.36, 95% credible interval [CI] = [0.35, 0.36]; : mean = 0.50, 95% credible interval [CI] = [0.49, 0.52]; : mean of group difference = −0.15, 95% credible interval [CI] = [−0.16, −0.13]). In other words, older participants needed more time both before and after information accumulation than younger adults.
To avoid the influence of outliers, we explored the Spearman’s rank correlation coefficients among the underlying parameters for each participant. We extracted the mode value (most probable value) for each individual parameter. Tables 2, 3 show the relationships between associative learning and visual search parameters. In younger participants, only the learning rate in rewarded associative learning trials was correlated with the ν for faces in the reward condition (r = 0.38, p = 0.04). However, there were no other correlations between the associative learning and visual search task parameters (|r|s < 0.35, ps < 0.07). For older participants, there were no correlations between the associative learning and visual search task parameters (|r|s < 0.32, ps < 0.10).
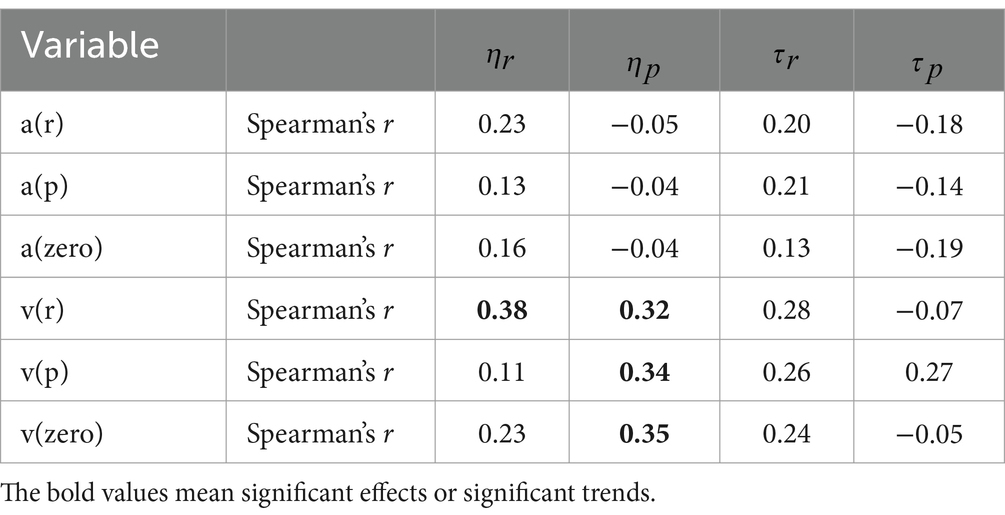
Table 2. Spearman’s rank correlation coefficients between the underlying mode parameters from the reinforcement-learning and drift diffusion models for younger participants.
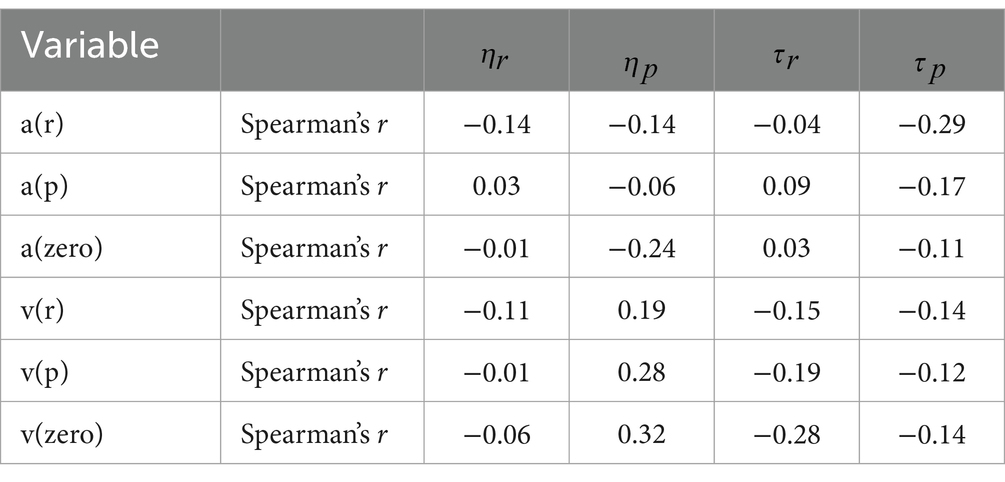
Table 3. Spearman’s rank correlation coefficients between the underlying mode parameters from the reinforcement-learning and drift diffusion models for older participants.
This study explored the psychological processes underlying the rapid detection of faces with emotional meaning by investigating the relationship between associative learning data and visual search data. First, we found that the learning rates for reward and punishment were higher for younger than older participants (Figure 4). This was consistent with the simple learning performances revealed by Figure 2. The results also showed that learning rate parameter values were higher for punishment than reward trials in younger participants only. Older participants did not show different learning rates between reward and punishment trials. This result is consistent with previous studies showing that aging reduces sensitivity to negative faces and information (Mill et al., 2009; Zhao et al., 2016; Richoz et al., 2018). Our results suggest that the sensitivity of learning feedback might decrease with age.
Both the younger and older participants in this study showed higher inverse temperatures for reward than for punishment, and there was no difference between younger and older participants for this parameter (Figure 4). The inverse temperature parameter reflects the degree to which an individual retains their previous learning history (Katahira, 2015). Thus, both younger and older participants could have kept learning history and learning rate updates in the reward trials than punishment trials. However, the younger participants may have adjusted for this difference in sensitivity (i.e., higher learning rate for punishment than reward). Our reinforcement learning model shed light on the associative learning process in both younger and older participants.
For the visual search paradigm, ν was larger and t0 was smaller in the younger group than in the older group, consistent with our hypothesis. This result is consistent with Saito et al. (2022a), who revealed that RT in visual search tasks differs between younger and older adults. This finding further demonstrates that the younger group had superior efficiency in terms of information accumulation (ν) compared to the older group. Additionally, the perceptual time leading to motion onset (t0) was shorter in the younger group. Aging might reduce the speed with which information accumulates and attention is allocated to value-associated faces. Only in the zero condition, the older participants needed more information before they made a response (α) compared to the younger participants. This could be interpreted as that the older participant’s learning in the associative learning task affected the amount of information needed before they made a response, even if only slightly, so that they no longer differed from the younger participants. Figure 5 also shows that the threshold parameters for the value-driven conditions in the older participants were closer to the left than in the zero condition. The decline in performance among older participants is amenable to decomposition across distinct components as the current study indicated. The identification and elucidation of requisite interventions tailored to these specific components entail the pursuit of future research investigations.
We hypothesized that the ν for RT would be linked to each learning rate parameter. However, our results only partially supported this prediction, with the data from the younger participants in the reward condition. The result implies that sensitivity to reward in an associative learning task facilitates the accumulation of information in a visual search task for younger, but not older, participants. During an experiment in which a learning task and visual search were performed in relatively rapid succession, short term reward sensitivity was advantageous, although this effect diminished with age. This finding suggests that, in the context of building social relationships, more efficient accumulation of reward information is required in earlier stages of development. It is important to note that no such relationship was found between t0 and . In the older participants, there were no correlations between the parameters from the two computational models. Thus, further research using a visual search task with more appropriate connections to associative learning tasks needs to be designed. Recently, Pedersen et al. (2017) attempted to combine the drift diffusion and reinforcement learning models. By directly applying the combined model to one learning task, we can expect to gain insight into the relationships between the mathematical parameters. The current study is the first to provide insight into how younger and older adults detect neutral faces that are associated with positive values.
Our findings have theoretical implications. The current results revealed the associations between computational parameters (i.e., learning rate and drift rate) underlying observable behavioral responses during value learning and value-driven detection of neutral faces in young participants. Several previous studies that used computational modeling have shown that the computational parameters reflect latent cognitive processes and are tightly linked to activity in specific brain regions. For example, a recent neuroimaging study reported that the drift rate estimated from face evaluation behaviors using a drift-diffusion model was associated with amygdala activity (Calabro et al., 2023). We expect our findings to provide insights into the neural mechanisms for value-driven detection of neutral faces and their aging patterns, which should be investigated in future computational neuroimaging studies.
Our findings may also have practical implications. A previous study has suggested that computational parameters classified clinical and non-clinical populations better than behavioral measures (Wiecki et al., 2015). A recent study reported that the RT performance of value-driven detection of neutral faces was associated with participants’ autistic traits (Saito et al., 2023). Collectively, our findings suggest that the computational modeling of the task may be helpful for the classification of individuals with autism spectrum disorder and those with typical development. Also, because the present study revealed the computational underpinnings of the effect of aging on value learning and value-driven detection of neutral faces, the same approach may provide information about pathological aging, such as dementia (cf. Irwin et al., 2018). Further research is warranted to test the task of value-driven detection of neutral faces and its computational modeling for clinical populations.
This study had several limitations. First, the number of younger participants with successful learning outcomes was greater than that of older participants. The 8:2 feedback ratio used in the associative learning task was difficult for older adults, but may have been too easy for younger adults, thus making it difficult to compare associative learning performance in the visual search task. In the posterior predictive check [Supplementary Figure S1; (see Footnote 2)], the observed data for the older adults who failed to learn had a poor fit with the reinforcement learning model. This also poses a risk of the interpretability of the parameters of reinforcement learning models in the participants who failed to learn. Modification of the feedback ratio in the associative learning task or improving the reinforcement model, which can account for learning failures, is important for future research. The current study compared younger and older participants but factors other than age might contribute the observed differences/relationships. For example, attention is related to intelligence (Schweizer and Moosbrugger, 2004), and it is likely that young participants from Kyoto University and older participants from a local human resource center differ in attributes other than age, such as IQ (Chamorro-Premuzic and Furnham, 2008). The effects of age should be pursued with adequate control of factors that may cause interpretable outcomes. Future studies including older participants should use the Mini-Mental State Examination (Folstein et al., 1975) or other neuropsychological tests to explore whether general cognitive functions are preserved. In addition, the present study applied the diffusion model with a constrained number of trials (i.e., 32), which raises concerns about stable parameter estimates. Even when using only 24 trials, there was a sufficient correlation in the three-parameter diffusion model between the real and predicted values in the systematic simulation (Lerche et al., 2017). Notably, for detecting the condition differences, the noise of parameter estimation might not necessarily be critical. It also holds true that a larger trial count often improves parameter estimation, with the result that future research endeavors may demand the use of more trials and larger sample sizes to enhance the depth and scope of inquiry. Finally, as facial stimuli, the current study used only young male faces with neutral expressions, which may have biased the results considering that male faces tend to be viewed more negatively than female faces (Craig and Lee, 2020). Although emotional recognition performance for the facial expressions of older people is reportedly lower regardless of the observer’s age (Riediger et al., 2011), further studies are needed to determine whether this lower performance is applicable to older faces with neutral expressions.
In conclusion, we used reinforcement learning and drift diffusion models to compare the value learning process and value-driven detection of neutral faces between younger and older adults. The learning rates in the associative learning task, and the ν and t0 values in the visual search task, were higher in younger than in older participants. Sensitivity to learning feedback may decrease with age. During value-driven detection of neutral faces among young adults, we found that only the sensitivity to reward in the associative learning task promoted efficient accumulation of information during a visual search for neutral faces in younger but not in older adults. The parameter values of our mathematical model shed light on the contributing factors underlying the rapid detection of faces with emotional meaning in younger and older adults. Specifically, the sensitivity to feedback in the associative learning task, the speed of information accumulation and the perceptual time leading to motion onset in the visual search tasks, and the relationship between the speed of information accumulation and feedback sensitivity to reward, decreases with age. The current study underscored the significance of computational modeling in elucidating the cognitive process behind value-driven behavior and contributed to a deeper understanding of aging and related conditions, offering avenues for future investigation and potential interventions in both neuroscience and clinical contexts.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in the article/Supplementary material.
The studies involving humans were approved by all participants provided written informed consent to take part in the study, which was approved by the ethics committee of the Unit for Advanced Studies of the Human Mind at Kyoto University and conducted in accordance with institutional ethical guidelines and the Declaration of Helsinki. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
SN: Investigation, Visualization, Writing – original draft, Writing – review & editing. AS: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Resources, Writing – review & editing. WS: Conceptualization, Funding acquisition, Project administration, Supervision, Validation, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by funds from the Japan Science and Technology Agency Core Research for Evolutional Science and Technology (grant number JPMJCR17A5).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2024.1281857/full#supplementary-material
Ahn, W. Y., Haines, N., and Zhang, L. (2017). Revealing neurocomputational mechanisms of reinforcement learning and decision-making with the hBayesDM package. Comput. Psychiatr. 1, 24–57. doi: 10.1162/CPSY_a_00002
Anderson, B. A., Laurent, P. A., and Yantis, S. (2011). Value-driven attentional capture. Proc. Natl. Acad. Sci. 108, 10367–10371. doi: 10.1073/pnas.1104047108
Bürkner, P. C. (2017). Brms: an R package for Bayesian multilevel models using Stan. J. Stat. Softw. 80, 1–28. doi: 10.18637/jss.v080.i01
Bürkner, P., Gabry, J., Kay, M., and Vehtari, A. (2023). “Posterior: tools for working with posterior distributions.” Available at: https://mc-stan.org/posterior/.
Calabro, R., Lyu, Y., and Leong, Y. C. (2023). Trial-by-trial fluctuations in amygdala activity track motivational enhancement of desirable sensory evidence during perceptual decision-making. Cereb. Cortex 33, 5690–5703. doi: 10.1093/cercor/bhac452
Calvo, M. G., and Nummenmaa, L. (2008). Detection of emotional faces: salient physical features guide effective visual search. J. Exp. Psychol. Gen. 137, 471–494. doi: 10.1037/a0012771
Chamorro-Premuzic, T., and Furnham, A. (2008). Personality, intelligence and approaches to learning as predictors of academic performance. Pers. Individ. Differ. 44, 1596–1603. doi: 10.1016/j.paid.2008.01.003
Craig, B. M., Becker, S. I., and Lipp, O. V. (2014). Different faces in the crowd: a happiness superiority effect for schematic faces in heterogeneous backgrounds. Emotion 14, 794–803. doi: 10.1037/a0036043
Craig, B. M., and Lee, A. J. (2020). Stereotypes and structure in the interaction between facial emotional expression and sex characteristics. Adapt. Human Behav. Physiol. 6, 212–235. doi: 10.1007/s40750-020-00141-5
DeCoster, J., Iselin, A. M., and Gallucci, M. (2009). A conceptual and empirical examination of justifications for dichotomization. Psychol. Methods 14, 349–366. doi: 10.1037/a0016956
Dombrovski, A. Y., Clark, L., Siegle, G. J., Butters, M. A., Ichikawa, N., Sahakian, B. J., et al. (2010). Reward/punishment reversal learning in older suicide attempters. Am. J. Psychiatry 167, 699–707. doi: 10.1176/appi.ajp.2009.09030407
Driver, C. C., and Voelkle, M. C. (2018). Hierarchical bayesian continuous time dynamic modeling. Psychol. Methods 23, 774–799. doi: 10.1037/met0000168
Fenske, M. J., and Raymond, J. E. (2006). Affective influences of selective attention. Curr. Dir. Psychol. Sci. 15, 312–316. doi: 10.1111/j.1467-8721.2006.00459.x
Folstein, M. F., Folstein, S. E., and McHugh, P. R. (1975). “Mini-mental state”: a practical method for grading the cognitive state of patients for the clinician. J. Psychiatr. Res. 12, 189–198. doi: 10.1016/0022-3956(75)90026-6
Forstmann, B. U., Ratcliff, R., and Wagenmakers, E. J. (2016). Sequential sampling models in cognitive neuroscience: advantages, applications, and extensions. Annu. Rev. Psychol. 67, 641–666. doi: 10.1146/annurev-psych-122414-033645
Gabry, J., Češnovar, R., and Johnson, A. (2023). Cmdstanr: R interface to 'CmdStan'. Available at: https://mc-stan.org/cmdstanr/, https://discourse.mc-stan.org.
Gabry, J., Simpson, D., Vehtari, A., Betancourt, M., and Gelman, A. (2019). Visualization in Bayesian workflow. J. R. Stat. Soc. Ser. A Stat. Soc. 182, 389–402. doi: 10.1111/rssa.12378
Gelman, A., and Hill, J. (2006). Data analysis using regression and multilevel/hierarchical models. Cambridge, UK: Cambridge university press.
Hansen, C. H., and Hansen, R. D. (1988). Finding the face in the crowd: an anger superiority effect. J. Pers. Soc. Psychol. 54, 917–924. doi: 10.1037/0022-3514.54.6.917
Heerdink, M. W., van Kleef, G. A., Homan, A. C., and Fischer, A. H. (2015). Emotional expressions as social signals of rejection and acceptance: evidence from the affect misattribution paradigm. J. Exp. Soc. Psychol. 56, 60–68. doi: 10.1016/j.jesp.2014.09.004
Hertwig, R., Barron, G., Weber, E. U., and Erev, I. (2004). Decisions from experience and the effect of rare events in risky choice. Psychol. Sci. 15, 534–539. doi: 10.1111/j.0956-7976.2004.00715.x
Horstmann, G., Borgstedt, K., and Heumann, M. (2006). Flanker effects with faces may depend on perceptual as well as emotional differences. Emotion 6, 28–39. doi: 10.1037/1528-3542.6.1.28
Horstmann, G., Lipp, O. V., and Becker, S. I. (2012). Of toothy grins and angry snarls—open mouth displays contribute to efficiency gains in search for emotional faces. J. Vis. 12:7. doi: 10.1167/12.5.7
Irwin, K., Sexton, C., Daniel, T., Lawlor, B., and Naci, L. (2018). Healthy aging and dementia: two roads diverging in midlife? Front. Aging Neurosci. 10:275. doi: 10.3389/fnagi.2018.00275
Iseki, R. (2023). Anovakun version 4.8.9. Available at: http://riseki.php.xdomain.jp/index.php?ANOVA%E5%90%9B
Kaelbling, L. P., Littman, M. L., and Moore, A. W. (1996). Reinforcement learning: a survey. J. Artif. Intell. Res. 4, 237–285. doi: 10.1613/jair.301
Kahneman, D., and Tversky, A. (1979). Prospect theory: an analysis of decision under risk. Econometrica 47, 263–292. doi: 10.2307/1914185
Katahira, K. (2015). The relation between reinforcement learning parameters and the influence of reinforcement history on choice behavior. J. Math. Psychol. 66, 59–69. doi: 10.1016/j.jmp.2015.03.006
Katahira, K., Fujimura, T., Okanoya, K., and Okada, M. (2011). Decision-making based on emotional images. Front. Psychol. 2:311. doi: 10.3389/fpsyg.2011.00311
Kinosada, Y. (2019). Compare parameters across conditions for within-participant factors in the experiment (in Japanese). Available at: https://das-kino.hatenablog.com/entry/2019/12/22/222333
Kwak, Y., Pearson, J., and Huettel, S. A. (2014). Differential reward learning for self and others predicts self-reported altruism. PLoS One 9:e107621. doi: 10.1371/journal.pone.0107621
Lee, M. D., and Wagenmakers, E.-J. (2014). Bayesian cognitive modeling: a practical course. Cambridge, UK: Cambridge University Press.
Lerche, V., Voss, A., and Nagler, M. (2017). How many trials are required for parameter estimation in diffusion modeling? A comparison of different optimization criteria. Behav. Res. Methods 49, 513–537. doi: 10.3758/s13428-016-0740-2
Mill, A., Allik, J., Realo, A., and Valk, R. (2009). Age-related differences in emotion recognition ability: a cross-sectional study. Emotion 9, 619–630. doi: 10.1037/a0016562
Muller, S., Rothermund, K., and Wentura, D. (2016). Relevance drives attention: attentional bias for gain-and loss-related stimuli is driven by delayed disengagement. Q. J. Exp. Psychol. 69, 752–763. doi: 10.1080/17470218.2015.1049624
Namba, S., Sato, W., Nakamura, K., and Watanabe, K. (2022). Computational process of sharing emotion: an authentic information perspective. Front. Psychol. 13:849499. doi: 10.3389/fpsyg.2022.849499
Pedersen, M. L., Frank, M. J., and Biele, G. (2017). The drift diffusion model as the choice rule in reinforcement learning. Psychon. Bull. Rev. 24, 1234–1251. doi: 10.3758/s13423-016-1199-y
Puls, S., and Rothermund, K. (2018). Attending to emotional expressions: no evidence for automatic capture in the dot-probe task. Cogn. Emot. 32, 450–463. doi: 10.1080/02699931.2017.1314932
R Core Team (2019). R: a language and environment for statistical computing. Vienna: R Foundation for Statistical Computing.
Ratcliff, R. (1978). A theory of memory retrieval. Psychol. Rev. 85, 59–108. doi: 10.1037/0033-295X.85.2.59
Ratcliff, R., and McKoon, G. (2008). The diffusion decision model: theory and data for two-choice decision tasks. Neural Comput. 20, 873–922. doi: 10.1162/neco.2008.12-06-420
Ratcliff, R., and Rouder, J. N. (1998). Modeling response times for two-choice decisions. Psychol. Sci. 9, 347–356. doi: 10.1111/1467-9280.00067
Reed, A. E., Chan, L., and Mikels, J. A. (2014). Meta-analysis of the age-related positivity effect: age differences in preferences for positive over negative information. Psychol. Aging 29, 1–15. doi: 10.1037/a0035194
Reinhart, A. (2015). Statistics done wrong: the woefully complete guide. San Francisco, CA: No Starch Press.
Rescorla, R. A., and Wagner, A. R. (1972). “A theory of Pavlovian conditioning: variations in the effectiveness of reinforcement and non-reinforcement” in Classical conditioning II: current research and theory. eds. A. H. Black and W. F. Prokasy (New York: Appleton-Century-Crofts).
Richoz, A. R., Lao, J., Pascalis, O., and Caldara, R. (2018). Tracking the recognition of static and dynamic facial expressions of emotion across the life span. J. Vis. 18:5. doi: 10.1167/18.9.5
Riediger, M., Voelkle, M. C., Ebner, N. C., and Lindenberger, U. (2011). Beyond “happy, angry, or sad?”: age-of-poser and age-of-rater effects on multi-dimensional emotion perception. Cogn. Emot. 25, 968–982. doi: 10.1080/02699931.2010.540812
Saito, A., Sato, W., and Yoshikawa, S. (2020). Older adults detect happy facial expressions less rapidly. R. Soc. Open Sci. 7:191715. doi: 10.1098/rsos.191715
Saito, A., Sato, W., and Yoshikawa, S. (2022a). Rapid detection of neutral faces associated with emotional value among older adults. J. Gerontol. B Psychol. Sci. Soc. Sci. 77, 1219–1228. doi: 10.1093/geronb/gbac009
Saito, A., Sato, W., and Yoshikawa, S. (2022b). Rapid detection of neutral faces associated with emotional value. Cogn. Emot. 36, 546–559. doi: 10.1080/02699931.2021.2017263
Saito, A., Sato, W., and Yoshikawa, S. (2023). Brief research report: autistic traits modulate the rapid detection of punishment-associated neutral faces. Front. Psychol. 14:1284739. doi: 10.3389/fpsyg.2023.1284739
Salthouse, T. A. (2000). Aging and measures of processing speed. Biol. Psychol. 54, 35–54. doi: 10.1016/S0301-0511(00)00052-1
Sato, W., Hyniewska, S., Minemoto, K., and Yoshikawa, S. (2019). Facial expressions of basic emotions in japanese laypeople. Front. Psychol. 10:259. doi: 10.3389/fpsyg.2019.00259
Sawada, R., Sato, W., Nakashima, R., and Kumada, T. (2022). How are emotional facial expressions detected rapidly and accurately? A diffusion model analysis. Cognition 229:105235. doi: 10.1016/j.cognition.2022.105235
Schweizer, K., and Moosbrugger, H. (2004). Attention and working memory as predictors of intelligence. Intelligence 32, 329–347. doi: 10.1016/j.intell.2004.06.006
Stan Development Team . (2020). Stan modeling language users guide and reference manual, version 2.21.2. Available at: https://mc-stan.org
Stins, J. F., Roelofs, K., Villain, J., Kooijman, K., Hagenaars, M. A., and Beek, P. J. (2011). Walk to me when I smile, step back when I’m angry: emotional faces modulate whole-body approach–avoidance behaviors. Exp. Brain Res. 212, 603–611. doi: 10.1007/s00221-011-2767-z
Suzuki, S., Zhang, X., Dezfouli, A., Braganza, L., Fulcher, B. D., Parkes, L., et al. (2023). Individuals with problem gambling and obsessive-compulsive disorder learn through distinct reinforcement mechanisms. PLoS Biol. 21:e3002031. doi: 10.1371/journal.pbio.3002031
Tannert, S., and Rothermund, K. (2020). Attending to emotional faces in the flanker task: probably much less automatic than previously assumed. Emotion 20, 217–235. doi: 10.1037/emo0000538
Tipples, J. (2019). Recognising and reacting to angry and happy facial expressions: a diffusion model analysis. Psychol. Res. 83, 37–47. doi: 10.1007/s00426-018-1092-6
Wentura, D., Muller, P., and Rothermund, K. (2014). Attentional capture by evaluative stimuli: gain-and loss-connoting colors boost the additional-singleton effect. Psychon. Bull. Rev. 21, 701–707. doi: 10.3758/s13423-013-0531-z
Wickham, H., Averick, M., Bryan, J., Chang, W., McGowan, L. D. A., François, R., et al. (2019). Welcome to the Tidyverse. J. Open Source Softw. 4:1686. doi: 10.21105/joss.01686
Wiecki, T. V., Poland, J., and Frank, M. J. (2015). Model-based cognitive neuroscience approaches to computational psychiatry: clustering and classification. Clin. Psychol. Sci. 3, 378–399. doi: 10.1177/2167702614565359
Zhao, M.-F., Zimmer, H. D., Shen, X., Chen, W., and Fu, X. (2016). Exploring the cognitive processes causing the age-related categorization deficit in the recognition of facial expressions. Exp. Aging Res. 42, 348–364. doi: 10.1080/0361073X.2016.1191854
Keywords: facial expression detection, associative learning, diffusion model, emotional value, gerontology
Citation: Namba S, Saito A and Sato W (2024) Computational analysis of value learning and value-driven detection of neutral faces by young and older adults. Front. Psychol. 15:1281857. doi: 10.3389/fpsyg.2024.1281857
Edited by:
Florin Dolcos, University of Illinois at Urbana-Champaign, United StatesReviewed by:
Kentaro Katahira, National Institute of Advanced Industrial Science and Technology (AIST), JapanCopyright © 2024 Namba, Saito and Sato. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Shushi Namba, bmFzaHVzaGlAaGlyb3NoaW1hLXUuYWMuanA=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.