ORIGINAL RESEARCH
Published on 11 May 2022
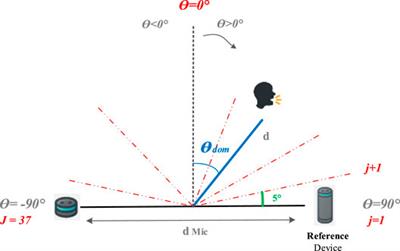
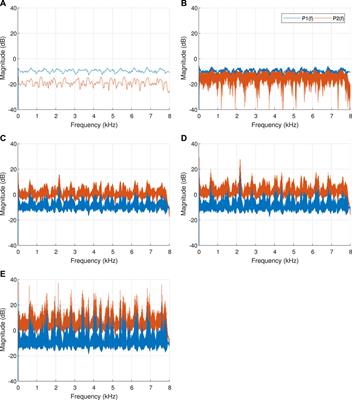
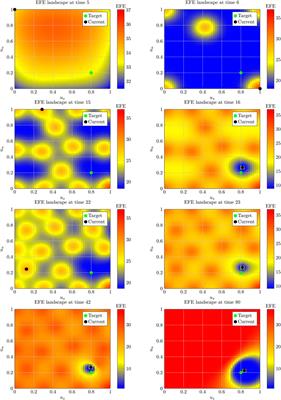
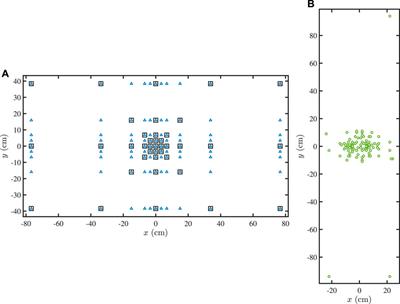
Constant-Beamwidth Kronecker Product Beamforming With Nonuniform Planar Arrays
doi 10.3389/frsip.2022.829463
- 1,651 views
- 8 citations
1,986
Total downloads
10k
Total views and downloads
ORIGINAL RESEARCH
Published on 11 May 2022
ORIGINAL RESEARCH
Published on 17 Mar 2022
ORIGINAL RESEARCH
Published on 11 Mar 2022
ORIGINAL RESEARCH
Published on 07 Mar 2022