 Eric Grunenberg
Eric Grunenberg Heinrich Peters2
Heinrich Peters2 Sandra C. Matz
Sandra C. Matz
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Soc. Psychol., 29 January 2024
Sec. Computational Social Psychology
Volume 1 - 2023 | https://doi.org/10.3389/frsps.2023.1290295
This article is part of the Research TopicComputational Social PsychologyView all 6 articles
Assessing the psychological characteristics of job applicants—including their vocational interests or personality traits—has been a corner stone of hiring processes for decades. While traditional forms of such assessments require candidates to self-report their characteristics via questionnaire measures, recent research suggests that computers can predict people's psychological traits from the digital footprints they leave online (e.g., their Facebook profiles, Twitter posts or credit card spending). Although such models become increasingly available via third-party providers, the use of external data in the hiring process poses considerable ethical and legal challenges. In this paper, we examine the predictability of personality traits from models that are trained exclusively on data generated during the recruiting process. Specifically, we leverage information from CVs and free-text answers collected as part of a real-world, high-stakes recruiting process in combination with natural language processing to predict applicants' Big Five personality traits (N = 8,313 applicants). We show that the models provide consistent moderate predictive accuracy when comparing the machine learning-based predictions with the self-reported personality traits (average r = 0.25), outperforming recruiter judgments reported in prior literature. Although the models only capture a comparatively small part of the variance in self-reports, our findings suggest that they might still be relevant in practice by showing that automated predictions of personality are just as good (and sometimes better) at predicting key external criteria for job matching (i.e., vocational interests) as self-reported assessments.
The future of work is changing rapidly: Automation, digitalization, and globalization are predicted to drive a shift in both our concept of work and the workforce itself (Spencer, 2018; Acemoglu and Restrepo, 2019). In the next 10–15 years, entire industries are predicted to vanish, others will emerge, and some will reinvent themselves. Job markets around the world will face large scale workforce transitions: More and more people will be searching for new jobs due to skill or organizational mismatches (Manyika et al., 2017). Many of these job seekers will be matched by third-party HR services such as online job boards and agencies (Lund et al., 2016). These platforms need scalable solutions to process applicants' data and match them to potential jobs.
Recent research suggests that predictive modeling using machine learning (ML) offers a promising approach to replacing time-consuming self-reports by predicting organizationally relevant traits about job seekers (e.g., cognitive ability, personality, or interests). Notably these assessments are not only relatively accurate but also cheap, unobtrusive, and scalable (Matz and Netzer, 2017; Azucar et al., 2018; Stachl et al., 2021). However, most of the existing research on ML-based assessments of personality has either focused on later stage hiring procedures, such as interviews (e.g., Hickman et al., 2022, 2023) or relied on personal data obtained from social media (e.g., Kosinski et al., 2013; Park et al., 2015; Youyou et al., 2015; Hickman et al., 2019). While digital footprints extracted from social media data are often easy to access (e.g., Facebook Likes or status updates, Tweets, or LinkedIn profiles; Kosinski et al., 2015), they have several limitations when it comes to their application in the recruiting process. First, research on personality prediction from assessment center interviews indicates that personality prediction models trained on social media do not necessarily generalize well on data from personnel selection settings (Hickman et al., 2019, 2022, 2023). Second, using social media data in general might be problematic: Applicants might not have active social media profiles, might vary in the amount of data available or might be opposed to recruiters invading their privacy by accessing their social media profiles and seemingly unrelated personal data (Matz and Netzer, 2017; Yarbrough, 2018; Matz et al., 2020).
In this paper, we suggest an alternative approach that does not rely on external data, but instead leverages information that is generated early in the recruiting process itself. Specifically, we show that (i) ML-based models trained on readily available short text excerpts and CVs native to a third-party recruiting agency can predict Big Five personality traits and (ii) that these ML-based personality assessments in turn predict vocational interests with similar accuracy as self-reported personality. Taken together, our results suggest that companies and third-party services can benefit from considering predictive models trained on internal recruiting data to assess candidates' psychological characteristics, respecting candidates' privacy, and ultimately use these insights to proactively match them to suitable jobs.
The combination of automation, digitalization and globalization has led to major changes in (i) the workplace, (ii) employment structures, and (iii) the meaning of work individuals expect from their professions (Acemoglu and Restrepo, 2020, 2019; Anderson et al., 2017; Makridakis, 2017). Studies expect that by 2030 up to 375 million people might need to switch occupational sectors and re-train due to automation. At the same time, people's expectations regarding their work are changing (Manyika et al., 2017). Especially among younger adults there is a growing demand for meaningful work as well as a healthy work-life balance (Twenge et al., 2010; Lub et al., 2016; Anderson et al., 2017).
The shifting nature of work has two important implications for recruiting. First, job seekers have access to a wider pool of jobs and change jobs more frequently than before. Second, companies have access to a wider pool of applicants but might have to hire more frequently and assure that the applicants they hire derive meaning from the jobs they enter. Together, these shifts lead to a more dynamic, complex job market that requires efficient and scalable matching between job seekers (and their preferences) and companies (with their job requirements; i.e., person-job fit; Kristof, 1996; Kern et al., 2019; Wilmot and Ones, 2021). Consequently, digital intermediaries such as online job boards, platforms, and agencies (both as proprietary part of organizations and as third-party services) will play an increasingly important role in the recruiting process as they streamline the matching between applicants and jobs (Allen et al., 2007; Manyika et al., 2017; Cardoso et al., 2021; Schaarschmidt et al., 2021).
The matching process typically considers two types of information: (1) applicants' formal characteristics, including education, prior job experience, current location, or expected salary and (2) applicants' “softer” but less superficial psychological characteristics such as motivation, personality, organizational values, or vocational interests. Personality traits are among the most prominent psychological characteristics considered in the hiring process (Salgado and de Fruyt, 2017). They capture relatively stable individual differences in the way that people think, feel and behave. The most prominent taxonomy of personality is the Five Factor Model (Goldberg, 1993)—or Big Five.
The Big Five have been associated with a wide variety of organizational outcomes, including job performance (Barrick and Mount, 1991; Barrick et al., 2001; Wilmot and Ones, 2021), leadership (Judge et al., 2002; Bono and Judge, 2004), team member effectiveness (Mount et al., 1998; Bell, 2007), and counterproductive work behavior (Berry et al., 2007), for a comprehensive overview, see Barrick and Mount (2012). What is more, research on person-job- and person-organization-fit suggests that individuals are more motivated by and perform better in jobs that match their personality characteristics (Kristof-Brown and Guay, 2011; Ostroff and Zhan, 2012; Wilmot and Ones, 2021).
An important consideration for the use of softer psychological criteria in the recruiting process, is the ease with which such information can be obtained. Traditionally, psychological characteristics have been assessed with self-report questionnaires (Funder, 2009), which require applicants to indicate how much they agree with different statements (e.g., “I am the life of the party” as a measure of Extraversion). In the context of scalable recruiting intermediaries the use of self-reports is often hindered by the fact that applicants might not be motivated to complete lengthy assessments (Ryan and Ployhart, 2000; Hausknecht et al., 2004). This is particularly true for proactive matching approaches that provide proactive recommendations to candidates. Consequently, if psychological factors are to be integrated into scalable matching algorithms, there is a need to facilitate psychometric assessments that do not rely on direct input from the user. A promising approach to assessing organizationally relevant characteristics such as personality traits within digital recruitment and recommendation systems is the application of automated ML-based predictions from text. ML approaches promise a scalable and efficient alternative to self-reports or human judgments (e.g., Sajjadiani et al., 2019, 2022; Goretzko and Israel, 2022; Hickman et al., 2022). Text is a nearly universal part of application platforms, which typically collect text in the form of CVs, cover letters, self-descriptions, or text data on online profiles. Compared to questionnaire responses, free text allows applicants to express themselves in an unrestrained way and has been shown to be predictive of personality traits within and outside of selection contexts (e.g., Liu et al., 2015; Park et al., 2015; Harrison et al., 2019; Hickman et al., 2019, 2023; Kern et al., 2019). For example, research has demonstrated that computational models are able to render fast and relatively accurate predictions of personality from people's social media posts (Schwartz et al., 2013; Park et al., 2015; Kern et al., 2019; Peters and Matz, 2023), predict self- and other-reported personality from applicants' video interviews (Hickman et al., 2019, 2022, 2023) or CEOs' personality from transcripts of earning calls (Harrison et al., 2019).
The present research aims to test the performance of ML models in predicting personality traits from text data native to the recruiting process. Focusing on text data generated during the recruiting process makes it possible to leverage the power of predictive models while simultaneously respecting the applicant's privacy and conforming to legal requirements (Matz and Netzer, 2017; Matz et al., 2020; Goretzko and Israel, 2022). We will quantify the predictive performance of our models in two ways. First, the models' construct validity will be measured as the correlation between predicted and self-reported scores. Second, the models' criterion validity will be quantified by correlating the personality predictions with a central external criterion for job matching and preselection (Nye, 2022; Wegmeyer and Speer, 2022): vocational interests (Holland, 1959, 1997). While not as commonly discussed as other constructs (Wegmeyer and Speer, 2022), vocational interests have been shown to be valid predictors of important work-related outcomes such as full-time employment, job stability and income beyond personality and cognitive ability (Stoll et al., 2017). When applied in preselection contexts so that job-interest congruence is achieved, they further have been shown to predict, among others, choice stability (Hunter and Hunter, 1984; Assouline and Meir, 1987), job and job choice satisfaction (Hoff et al., 2020), as well as relevant performance outcomes (van Iddekinge et al., 2011; Nye et al., 2012, 2017), making them a prime construct for preselection and matching.
Building on the existing literature, we pursue the following research questions:
RQ1: How accurately can the Big Five personality traits be predicted from ML-based models using linguistic features extracted from job seekers' CVs and short text responses that were obtained as part of the recruiting process?
RQ2: Can the ML-based personality scores predict vocational interests with a similar accuracy as self-report personality scores?
To address the two research questions, we leverage a combination of open- and closed-vocabulary approaches and train a series of supervised ML models. We compare the performance of models trained on features extracted from (a) applicants' CVs, (b) short free text responses, and (c) a combined model with features from both data sources to a baseline model that utilizes information about the applicant's gender. Subsequently, we analyze correlational patterns of self-report and ML-based personality scores with self-report vocational interests.
We describe our sampling plan, all data exclusions, all manipulations, and all measures in the study. This study was not preregistered. The analysis code is available in the OSF-repository of this project (https://osf.io/gxae9/). Given that the data are highly sensitive and proprietary, they can only be made available upon reasonable request. Data were analyzed using Python, version 3.7.3 (see respective Method section for specific packages). Given that the study relies on secondary data, we did not preregister the design or analyses.
The data for this study was provided by an intermediary recruiting platform that operates in Australia and aims to place high-performing undergraduate and graduate students in high-quality part-time jobs. To use their services, students are required to set up a general profile that is displayed to possible employers. In the profile set-up process, applicants submit information about themselves including a CV, short textual answers to questions relating to one's planned development trajectory, as well as broadly defined vocational interests. In addition, students are asked to take a short personality test. As part of the sign-up process, students provide consent that their data can be used for research purposes.
The original dataset consisted of 9,280 applicants. For our study, we excluded participants using the following criteria: (i) incomplete personality assessments, (ii) fewer than six words in the short-answer free text responses, and (iii) duplicated applicants. This reduced the original dataset to 8,313 applicants (51.4% male, 47.9% female, 1% other).
A total of 7,864 (95%) applicants uploaded documents to the CV section of their profile. Text data was extracted using the pdfplumber (version 0.05.28) Python package for all the 7,734 of the pdfs that were machine readable. A manual inspection of the documents revealed that some of the documents contained short test files with only a few words while others included research articles of extreme length. To only capture actual CVs, we excluded all files containing fewer than 50 words or more than 10,000 words. This procedure resulted in a final corpus of 7,691 CV documents with an average number of 561.33 (SD = 289.91) words per document.
As part of the profile creation process, applicants were asked to answer the question “In a few sentences, please tell us about something you would like to learn more about and why? (150–200 words)” in written form. On average, applicants in our sample wrote 94.87 words (SD = 59.67; see Appendix A for examples).
Personality was assessed using the Mini-IPIP (Donnellan et al., 2006), a 20-item version of the 50-item International Personality Item Pool (Goldberg et al., 2006). The Mini-IPIP measures the Big Five with four items per personality trait. Participants were asked to rate the items on a 5-point Likert scale (0 = “Strongly disagree”, 4 = “Strongly agree”). Table 1 displays means, standard deviations, and internal consistencies.
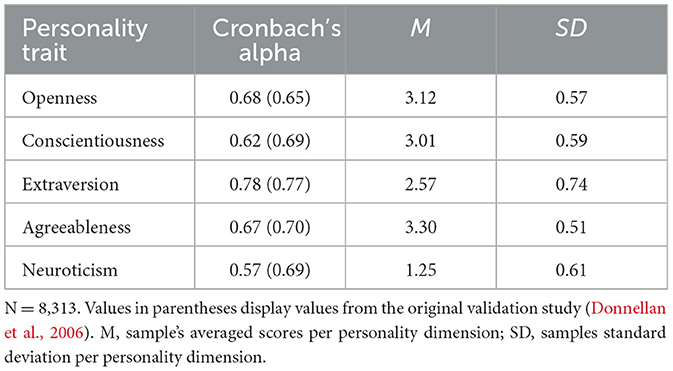
Table 1. Cronbach's alpha, average scores and standard deviation of the big five personality traits.
Vocational interest data was available for a subset of n = 3,469 of applicants. Applicants were asked to select their interests from a set of eight pre-defined categories using a “tick-all-that-apply” format: Design, marketing, programming, finance, analytics, operations, accounting, and HR. On average, applicants selected 3.46 categories (SD = 1.65; see Appendix Table B1 for choice frequencies across all categories).
The development and validation of our prediction models was based on two major steps: (1) Preprocessing and feature extraction and (2) training and validation. Figure 1 illustrates the process visually.
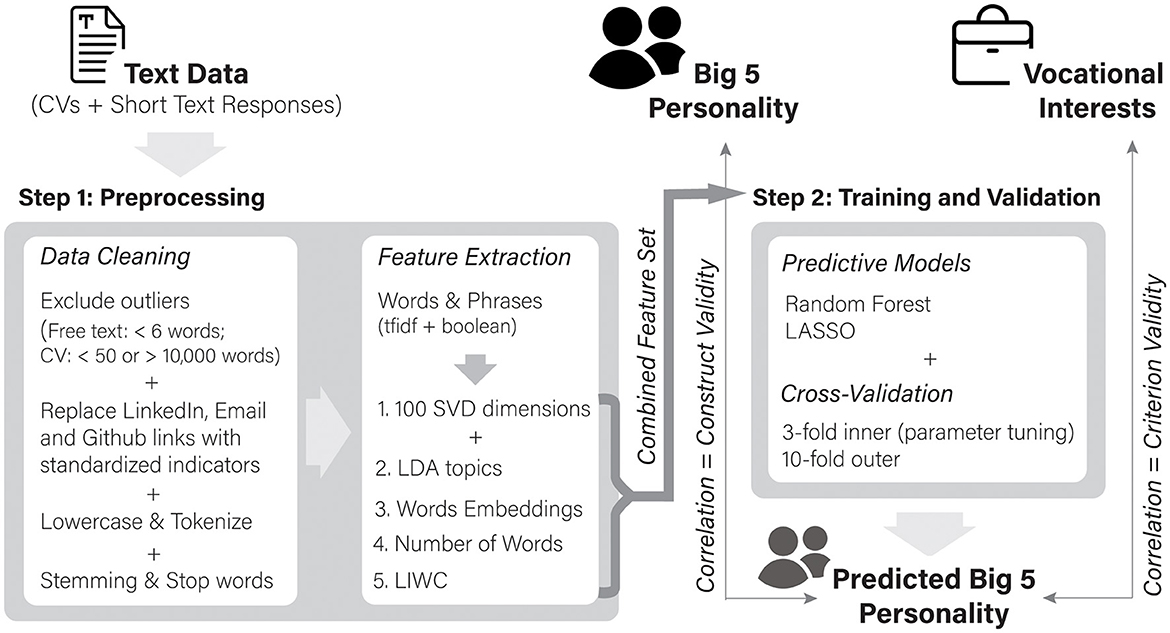
Figure 1. Process flow diagram illustrating the modeling approach used to build the ML-based models predicting personality.
Our text-based models extended the feature extraction process by Park et al. (2015) by combining closed- with open-vocabulary approaches. Specifically, we extracted four types of language features: (1) words and phrases, (2) topics, (3) LIWC-features, and (4) word embeddings. In addition, we also included the length of the answers as a feature. The final feature set included 694 predictors.
For the purpose of feature extraction, we transformed all text input to lowercase and split the text into tokens (i.e., single words). Afterwards, we removed stop words (i.e., very frequent words like a, the, or is) and stemmed the words using the Porter stemmer integrated in the Python package nltk (version 3.4.5; Bird et al., 2009). For the CVs, we replaced references to LinkedIn profiles, email addresses and GitHub repositories with the tokens “LINKEDIN,” “EMAILADDRESS,” and “GITHUB” to allow them to be included as features in the frequency-based feature extraction methods. For the feature extraction using LIWC, the unprocessed answers were directly fed into the LIWC software, which also examines linguistic styles that are extracted based on stopwords (Pennebaker et al., 2015).
After preprocessing, we first extracted word frequencies and short phrases using scikit-learn (version 0.21.2; Pedregosa et al., 2011). Phrases refer to combinations of words that occur next to each other (n-grams). Parallel to Park et al. (2015) we included phrases up to three words (e.g., “My name is”). These frequencies were then weighted based on their term frequency-inverse document frequency (tf-idf). Tf-idf weighting can be used to determine how important a word is in a document that is part of a larger corpus. Tf-idf values are high for words with a high term frequency (i.e., occur often in a specific document) and a low document frequency in the whole corpus (i.e., does not occur often in general). In addition to these tf-idf weighted frequencies, we added a binary representation of each of the extracted frequency features indicating if an applicant used a word or a phrase at least once in his answer. Since the number of features generated by considering words and word combinations reached into the hundred thousands, we decided to limit the number of extracted features to 10,000 (5,000 tf-idf weighted features and 5,000 binary features). These two sets of features were extracted by each considering the top 5,000 features ordered by term frequency. Given the limited sample size of our data, we subsequently applied Singular Value Decomposition, a method for dimensionality reduction (Golub and Reinsch, 1970) to each of the feature sets of 5,000 features reducing each of them to 100 features.
The second feature set we extracted is based on topics. Topics refer to clusters of semantically related words that are generated through Latent Dirichlet Allocation (LDA; Blei et al., 2003). We fitted the LDA model using the LatentDirichletAllocation function implemented via scikit-learn (version 0.21.2; Pedregosa et al., 2011), setting the number of topics to 100. This created a document-topic matrix with documents as rows and the usage of each topic per document as columns, resulting in a feature set of 100 topic features.
LIWC analyzes text data by first comparing the words of a text against predefined categories (e.g., the word “hate” is associated with the categories Affective Processes, Negative Emotion and Anger) and then creating category-based frequency scores. Based on this procedure, LIWC creates a matrix of 93 output variables, including single linguistic styles and broader summary variables, which we all included in our feature set. For a complete list of the LIWC2015 scales see the official LIWC2015 language manual (Pennebaker et al., 2015).
Embedding methods convert symbolic, abstract representations of meaning such as words and images into numeric vector representations. These vectors capture the underlying semantic relations between the symbolic representations. The intuition behind word embeddings is reflected by the idea that the meaning of a word can be deducted by analyzing the sets of words that commonly surround it across many different contexts. The result is an n-dimensional feature space representing the meaning of word in relation to other words (Lawson and Matz, 2022).
We used the pre-trained 300-dimensional vector package “en_core_web_md” from Stanford's GloVe Project (Pennington et al., 2014) which is implemented in the Python package spaCy (Version 2.0.12; Montani et al., 2022) and includes vector representations for 20,000 different words and accounts for conjunctions of words by mapping its vectors against 650,000 keys. We implemented these pre-trained embeddings by making use of spaCy's function to create document vectors. Document vectors are created by first extracting vector representations for the single words in a document and then calculating the mean vector for each of the 300 dimensions over all words in a document. The resulting feature set is a 300-dimensional set of vectors with one 300-dimensional vector for each document.
The combined feature set of 694 features was used to train a Random Forest regression model predicting personality scores. The Random Forest algorithm is an ensemble machine learning technique that models non-linear relationships (Breiman, 2001). The algorithm simultaneously constructs multiple decision trees by randomly drawing subsets of input data (features) and then aggregating these trees to improve predictive accuracy. We trained a total of three models: First, the free text-model, trained on the 694 features extracted from the free texts. Second, the CV-model, trained on the 694 features from the CVs. And third, a combined model, trained on a stacked feature set including both the features extracted from the free texts and the CVs with 1,388 features. To provide an additional reference point against which our language-based personality predictions could be evaluated, we also trained a linear regression model using gender as the sole predictor (baseline model).
To analyze the robustness of our findings we additionally performed the same analyses with linear Lasso models (Tibshirani, 1996, see Appendix C for more details). To keep the discussion of our findings concise, we only report the findings for the Random Forest models in the main manuscript and report the findings for the Lasso models in the Supplementary material. As expected, the more complex non-linear Random Forest models outperformed the Lasso models, but notably the difference in accuracy was found to be relatively small suggesting that even simple linear models capture a considerable amount of variance in personality traits. All algorithms were implemented using the scikit-learn package in Python (version 0.21.2; Pedregosa et al., 2011).
To train and evaluate our models in an iterative process, we applied a nested resampling strategy (Stachl et al., 2020). This strategy nests multiple repeating resampling loops in each other, separating the fitting process and the hyperparameter tuning process. We used two nested loops: An inner loop for hyperparameter tuning in which we applied 3-fold cross validation and an outer loop for the fitting of the models using the selected hyperparameters in which we applied 10-fold cross-validation. For the hyperparameter tuning of the Random Forest models we implemented a random search with the default configuration of 100 iterations. For the Lasso models we used a grid search to find the optimal value for the penalization parameter λ (see Appendix Table C1 for hyperparameter ranges). Performance was evaluated by correlating the self-report personality scores with the predicted personality scores from the outer loop.
Figure 2 displays the Pearson correlations between the predicted and self-report personality scores for the Random Forest models (see Appendix Table D1 for a table of Random Forests results and Appendix Table D2 for the results from the Lasso models). All three text-based Random Forest models showed accuracies that were significantly different from zero and outperformed the baseline model (average correlation of baseline r = 0.06). Averaged across the five traits, personality could be predicted with an accuracy of r = 0.18 from the free text data, r = 0.24 from the CV data and r = 0.25 from the combination of both data sources. For all three text-based models, the highest performance was achieved for the dimension of Extraversion (free text: r = 0.22, CV: r = 0.33, combined: r = 0.33).
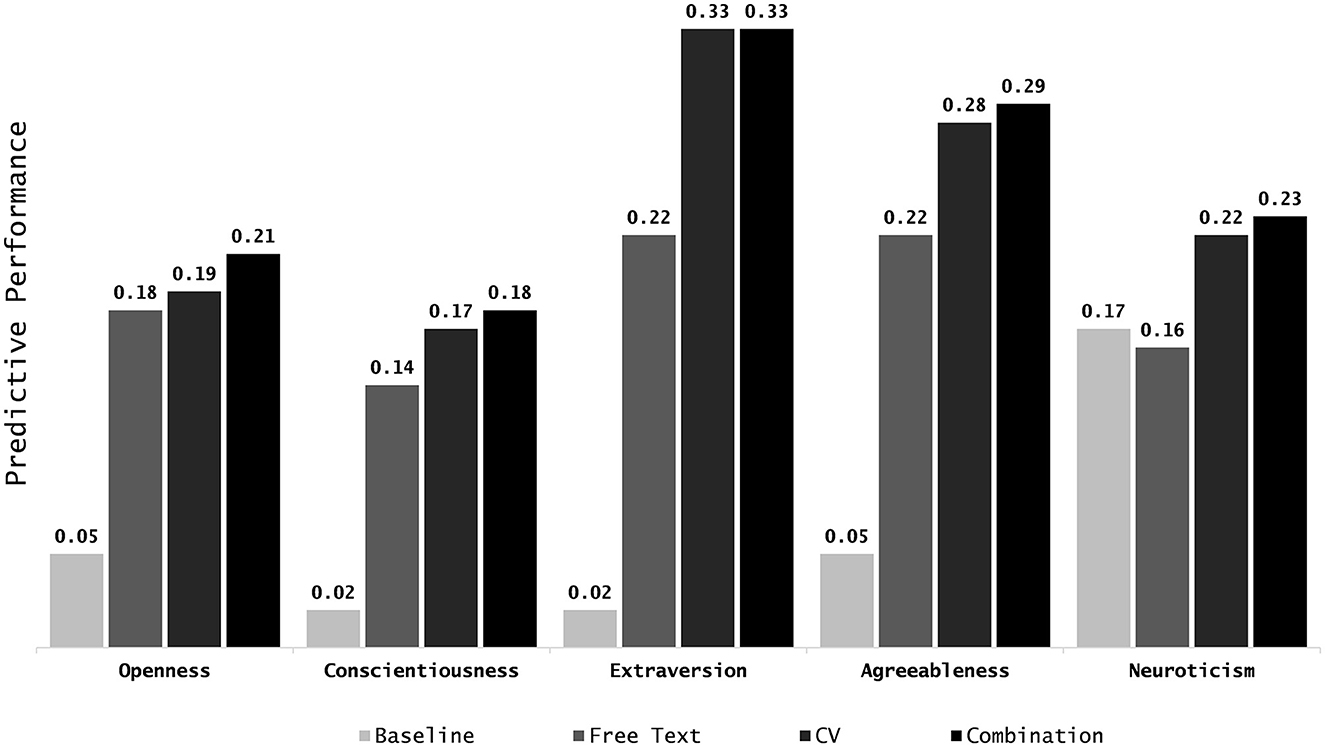
Figure 2. Bar charts comparing the predictive performance of the different Random Forest models per Big Five personality trait. Predictive performance is defined as correlation between self-report and predicted personality. From left to right within one trait: (1) Baseline model, (2) free text model, (3) CV model, and (4) combined model.
To benchmark the predictive accuracies of our models to current best practices, we compared them to the accuracy of human judges (see Figure 3). Prior research suggests that recruiters regularly infer personality from CVs, but do so inaccurately (Cole et al., 2009; Burns et al., 2014; Apers and Derous, 2017). Cole et al. (2009) found that when presented with written CVs, recruiters were only able to judge Extraversion better than chance (r = 0.15). A similar pattern was replicated in research on personality judgments based on LinkedIn profiles that include both free text sections and CVs. Both, van de Ven et al. (2017) and Roulin and Levashina (2019) found that judges were only able to judge Extraversion better than chance (Roulin and Levashina, 2019: r = 0.20; van de Ven et al., 2017: r = 0.29). Our models outperform these accuracies of human judges by (a) making better than chance predictions for all five personality dimensions, and surpassing the highest reported average human accuracy both, (b) across traits (r = 0.08; Roulin and Levashina, 2019), and (c) for a single trait dimension (Extraversion r = 0.29; van de Ven et al., 2017).
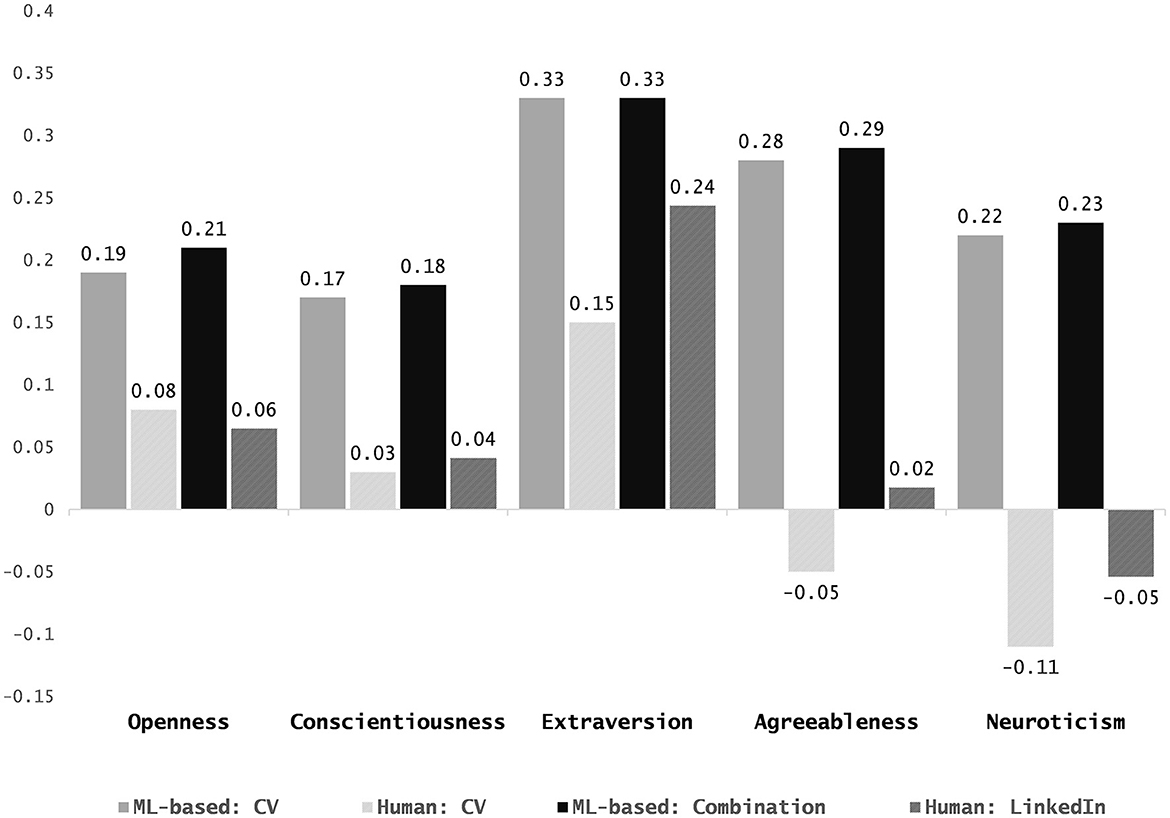
Figure 3. Bar charts comparing the predictive performance of the Random Forest models against the performance of human raters on similar material reported in prior research. Predictive performance is defined as correlation between self-report and predicted personality. From left to right within one personality trait: (1) ML-based CV model, (2) human performance rating personality from CVs (Cole et al., 2009), (3) combined ML-based model, and (4) human performance rating personality from LinkedIn profiles (calculated as weighted mean from results from Roulin and Levashina, 2019 and van de Ven et al., 2017).
Table 2 displays correlations between vocational interests and the four assessment approaches to personality: Self-report personality, the free text Random Forest model, the CV Random Forest model, and the combined Random Forest model. Supporting the validity of our predictive models, all text-based models showed similar correlational patterns with the vocational interests as the self-reported personality traits, with no difference in direction of any of the significant correlations. In fact, the predicted scores of all computational models showed higher average correlations with vocational interests (free text r = 0.09; CV and combined model r = 0.14) than the self-report personality scores (r = 0.05). See Appendix Table D3 for the respective Lasso results.
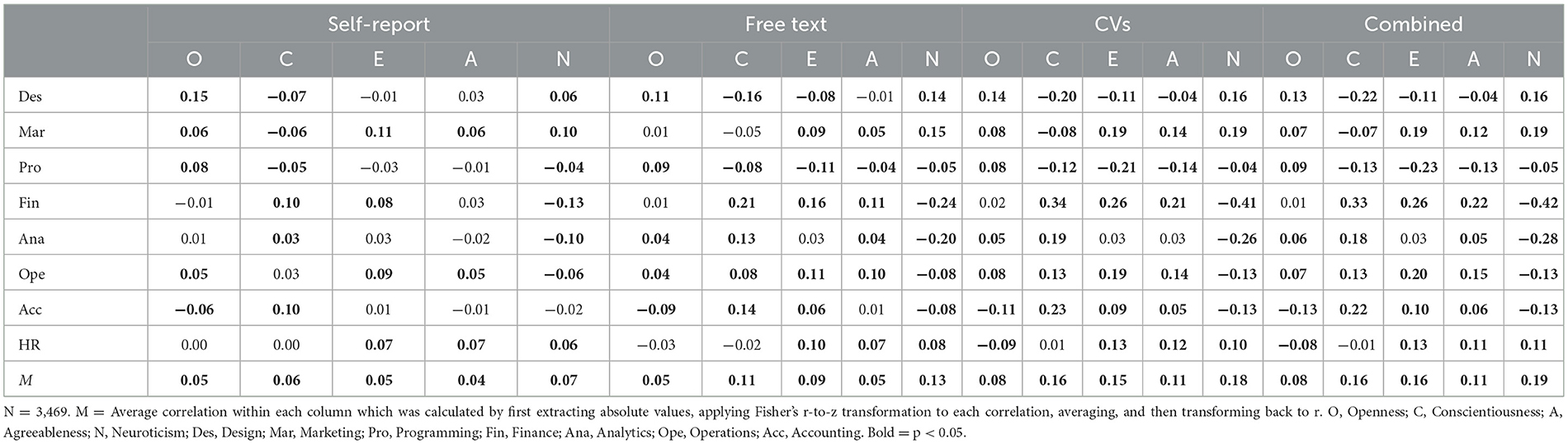
Table 2. Correlation of the big five self-report personality traits and random forest ML-based models with indications of vocational interests.
Figure 4 shows that the vast majority of correlations between the five personality traits and eight vocational interests (90%) are stronger for ML-based than self-reported personality traits (i.e., observations located in the upper diagonal).
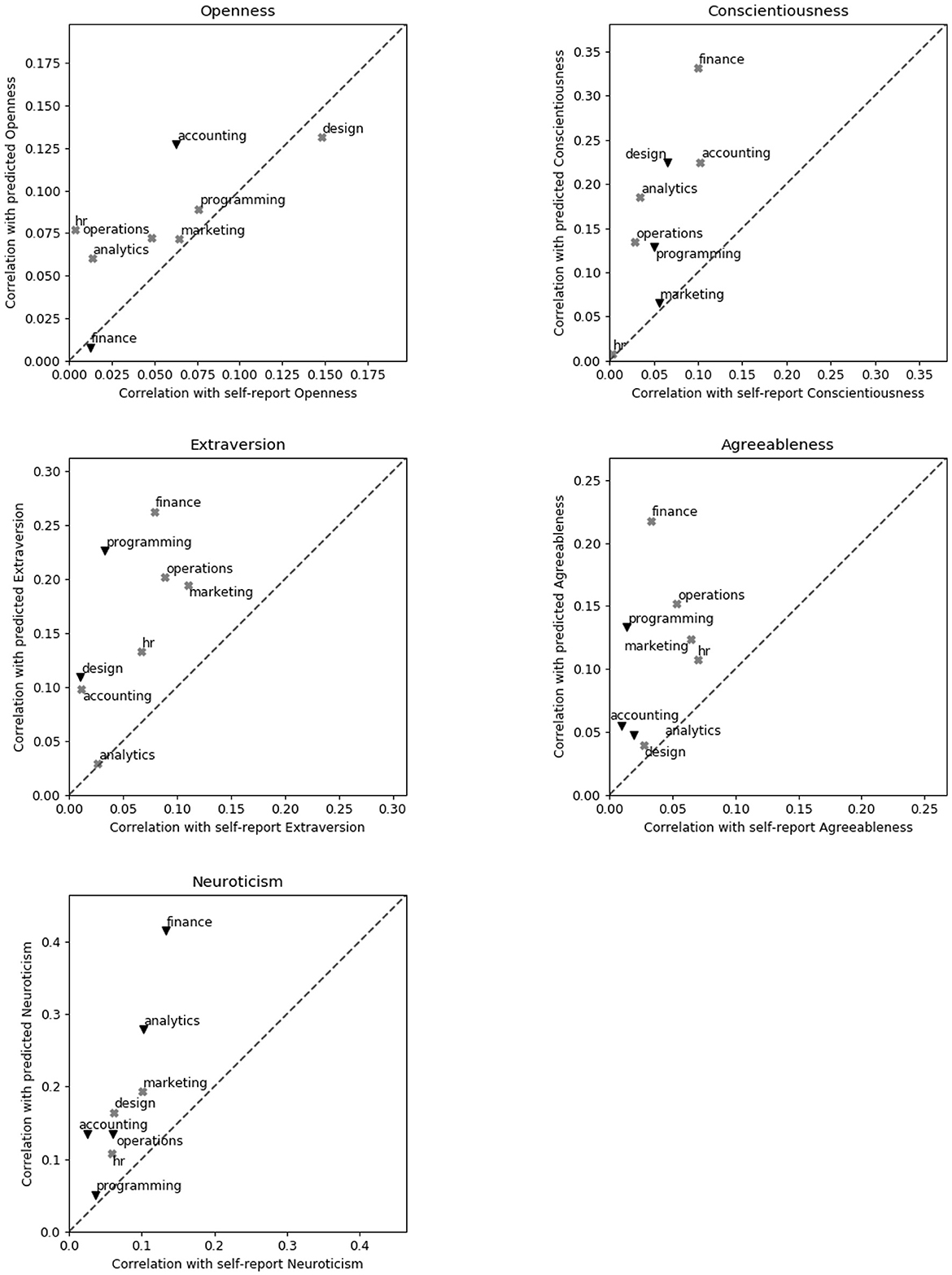
Figure 4. Scatterplots displaying absolute correlation between predicted and self-report personality scores and self-report vocational interest categories for the combined Random Forest model. Dots positioned above the diagonal line display cases in which the ML-based personality traits correlated stronger with vocational interests than the self-report models. Positive correlations are displayed as gray “X”s and negative correlations are displayed as black triangles. Differences in direction of the correlations between predicted and self-report personality scores only occurred with non-significant correlations. In these cases, the displayed mark represents the direction of the correlation of the predicted personality scores with the self-report vocational interest categories.
This paper set out to address two critical questions related to the feasibility and value of using ML-based predictions of personality in preselection and job matching contexts: How accurately can personality be predicted from textual information obtained early and solely in the recruiting process (construct validity)? And how do the predicted personality scores relate to relevant external criteria, such as applicants' vocational interests (criterion validity)?
Providing support for the construct validity of the suggested approach (RQ1), our findings suggest that applicants' personality traits can be predicted from text data obtained early in the recruiting process. All three text-based models—free text response, CV and combined—showed significant correlations and outperformed the demographic baseline model. The highest average performance was obtained by the combined model (r = 0.25), followed by the CV model that is just marginally less performant (r = 0.24) but stronger than the free text model (r = 0.18).
While the accuracies obtained by our text-based models are on par with or superior to those observed for other digital footprints, including music preferences (average r = 0.17; Nave et al., 2018), Flickr Pictures (average r = 0.18; Segalin et al., 2017) and spending records (average r = 0.21; Gladstone et al., 2019), as well as specific language cues from hiring interviews (average r = 0.19; Hickman et al., 2023), they are lower than those observed for social media data, including both Facebook Likes (r = 0.45; Youyou et al., 2015) and Facebook status updates (r = 0.41; Park et al., 2015). There are multiple explanations for this finding. First, the accuracy of computational models depends on the amount and richness of the data. While our sample of 8,313 applicants and around 660 words per applicant is unique, it is still considerably smaller than the Facebook samples which included data from more than 71,000 users with an average of about 4,100 words per user (e.g., Park et al., 2015). Second, there are important differences in the type of information used. Facebook statuses consist of information people intentionally share with other people and therefore reflect content such as opinions and emotions. In contrast, in a recruiting setting, applicants (a) are prompted to respond to a specific question and submit specific material (e.g., CVs) and (b) know that their information will be reviewed with regard to a hiring decision. Thus, their answers are more restricted and do not allow for a free expression of their personality.
Notably, our models still substantially outperformed accuracies that have been reported for human judges (Cole et al., 2009; Apers and Derous, 2017; van de Ven et al., 2017; Roulin and Levashina, 2019). This comparison not only has practical implications, but also shows that relevant cues for personality judgments are available in application materials. Whereas, human judges are known to be able to judge the Big Five personality traits of strangers from cues found in physical and online spaces (e.g., bedrooms or online social media profiles Gosling et al., 2002; Naumann et al., 2009; Back et al., 2010; Küfner et al., 2010), prior work has suggested that recruiters struggle to make valid personality judgments based on application material for all Big 5 traits but for Extraversion (Cole et al., 2009; Apers and Derous, 2017; van de Ven et al., 2017; Roulin and Levashina, 2019).
One possible explanation for this finding is that the application context is characterized by relatively strict and widely understood norms about the structure and content of its materials (Apers and Derous, 2017). These norms and expectations restrict the richness of expression in the application documents and reduce the availability of relevant cues for personality judgments. For instance, a possible explanation for the challenge of human judges assessing Conscientiousness in application materials (Cole et al., 2009; Apers and Derous, 2017; van de Ven et al., 2017; Roulin and Levashina, 2019) compared to social media profiles (Marcus et al., 2006; Back et al., 2010; Hall et al., 2014) is that, unlike social media's more socially focused self-presentation contexts, the expectation of neatness and accuracy in application materials may prompt candidates to engage in more extensive error-checking behavior. This behavior then minimizes the variance in otherwise overtly available cues for Conscientiousness such as the existence of spelling or grammatical errors. However, the fact that our models were able to predict personality with some degree of accuracy suggests that application materials indeed contain personality cues that might be overlooked by human judges. This finding underscores the potential of ML methods to discover patterns in complex data sources and to complement human workers in their day-to-day tasks.
Providing support for the criterion validity of our text-based models (RQ2), the predicted personality scores showed consistent correlational patterns with vocational interests that were aligned with the correlations observed for the self-reported personality scores (see Table 2). What is more, the observed correlations of the predicted personality scores with the vocational interests were found to be higher (average r = 0.15) than the self-report personality scores (average r = 0.05). These findings are aligned with the results of prior research finding that predicted personality scores correlate more strongly with certain external variables than self-report personality (Park et al., 2015; Youyou et al., 2015). A potential explanation for this phenomenon is that the predictive models might only capture a specific part of the variance in the outcome (i.e., self-report personality scores) that is pertinent to the training data. First, the applied ML models inherently aim to capture stable patterns in the features that are predictive of the outcome. As noise in both, the features and the outcome, should not be stable but random, the resulting predictions should not include some of the noise inherent to the variance of the self-report personality scores. Second, since the models were trained on features extracted from application materials, the predicted personality score might capture individual differences that are more directly work-related and therefore show stronger associations with vocational interests than self-report personality scores. If this trend can be replicated using different types of training data, the use of predicted personality scores may not only add value by being more efficient and scalable, but also by representing less noisy and more domain-relevant constructs than broad self-report personality scores.
Our findings showcase that psychological characteristics and preferences of job candidates can be predicted using readily available data native to the recruiting process early on without the need to access external third-party information. Insights into these characteristics are critical when it comes to matching the right candidate to the right job, thereby reducing the risk of quick turnover, and lowering overall hiring costs. In contrast to previous work that relies on social media data to predict psychological characteristics (e.g., Park et al., 2015; Youyou et al., 2015), our approach offers several advantages with regard to privacy and legal concerns. Because our models exclusively rely on information that was voluntarily shared by participants in the context of the recruiting process for the purpose of evaluating their fit for a given job, they are aligned with recent conceptualizations of privacy as contextual integrity (Nissenbaum, 2004): A person's privacy is upheld if the flow and use of data is aligned with the expectations that the individual has about how their data is being used.
Importantly, we do not mean to overstate the accuracies of our predictive models. While our findings suggest that ML-based predictions are likely to outperform the judgments made by human managers and are superior to self-reports in predicting vocational interests, the absolute accuracies are still moderate at best. Given the importance of hiring decisions for both companies and applicants, we therefore caution against the use of such predictive models as final decision-making tools. Instead, they could be used to assists managers in asking the right questions during the interview stage, or to proactively recommend and preselect relevant job openings to candidates. This approach would be aligned with recent updates to privacy legislation such as the General Data Protection Regulation (GDPR), which restrict the use of profiling when it comes to making automated decisions on the bases of such profiles (European Parliament and European Council, 2016).
The present study comes with a number of limitations that should be addressed by future research. First, the data for this study stems from a highly selective sample. It was collected as part of a recruiting process aimed at placing high-performing students into high-quality student jobs (e.g., student jobs at consulting firms, IT firms, banks). As a case in point, this restriction resulted in smaller standard deviations in personality scores compared to the original validation study of the Mini-IPIP (Donnellan et al., 2006). While this restriction suggests that the predictive performance of ML-based models was conservatively estimated in the current study and might be higher in more heterogeneous samples, future research should address this question on the generality of our results empirically. What is more, future research should explore potential moderators of the models' predictive performance. For example, future work could investigate the effect of sample size and amount of information per applicant on predictive performance.
Second, to ensure the fairness of predictions of our models, future work should investigate whether factors inherent to the person might influence predictive accuracy and potentially lead to algorithmic bias (Cowgill and Tucker, 2020). Empirically this bias could manifest in different ways. First, the predictive models might predict different score levels of personality traits for different subgroups (e.g., native vs. non-native speakers, race, and gender) despite them sharing the same ground-truth levels for the respective personality construct. Second, the models might produce different levels of predictive accuracy across subgroups (Tay et al., 2022). For example, it is possible that the accuracy of our text-based models is lower for non-native speakers who do not have access to the full vocabulary of a native speaker and might therefore find it harder to express their personalities. This can be true even when both groups share the same levels for the latent personality constructs. To uncover such biases, future research should first identify relevant subgroups and then perform subgroup analyses investigating whether differences exist in the distribution of the predicted personality scores or the models' accuracy across these subgroups.
Moreover, future research should implement interpretable ML approaches to identify potential biases and develop a better understanding of which aspects of application materials are predictive of certain personality judgments (Molnar, 2022). In our case, the relatively small dataset made it necessary to reduce the complexity of the text data by applying a dimensionality reduction step via SVD. However, larger datasets would offer the option to process the text data at the level of n-grams, therefore retaining the ability to meaningfully interpret model outputs. One option to integrate an interpretable ML approach into the modeling pipeline would be to include permutation-based feature importance measures (Breiman, 2001) into the outer-loop of the cross-validation approach. These feature importance metrics are calculated by evaluating the change in predictive performance subsequent to random permutation (i.e., shuffling) of the values of a feature. This procedure makes it possible to determine how important each feature is for the predictive performance of the model. In a first step, the extracted feature importance metrics could then be used to understand how the models integrate the extracted language feature into a prediction. In a second step, they could also be used to analyze whether the information the model relies on when making its predictions varies across different subgroups (e.g., gender and native speaker).
An alternative approach could be the extraction of SHAP values (Lundberg and Lee, 2017). SHAP values are rooted in cooperative game theory and, while generally being computationally more expensive, come with the advantage that they allow for global and local explanation. That is, whereas permutation feature importance measures are usually used to explain the decision rules of a model across all of its predictions (global explanation), SHAP values are designed to also provide explanations for every individual prediction (i.e., every applicant in our dataset; local explanation). Having access to local explanations might bring additional benefits in the context of recruiting as recruiters could see how the information from the application material was used in the personality prediction for specific applicants. Having access to local explanations could help to identify potential biases in the models at a more fine-grained level. Equally, local explanations could also be used to transparently demonstrate that applicants have been treated fairly and that the predictions were not driven by biases if for example mandated in a lawsuit. As of today, these bias analyses and more would potentially also be required to adhere to the proposed EU AI Act (AI Act, 2021). Exact assessments are not possible as the AI Act to this date is still under discussion and has not yet been passed into legislature.
Third, this study only considered two types of text data: free text responses and CVs. Future research should investigate how different types of text data from the recruiting process such as cover letters or letters of reference can be leveraged in prediction models. An intriguing question is how recruiting processes could be designed to produce even richer, more predictive data sources, for example by comparing different questions, asking for more free text answers or requiring applicants to produce more text in conversations with chat bots.
Fourth, in line with prior research we found that the predicted personality values correlate higher with certain external variables than self-report personality (Park et al., 2015; Youyou et al., 2015). An investigation of the unique contributions of ML-based personality models over self-report assessment, especially as a function of their training data, could (a) help map the advantages of the predicted constructs over self-report-assessed constructs and (b) uncover possible blind-spots of self-reports. To further investigate this phenomenon, research could map predicted personality scores from models trained on different types of training data and their self-report counterparts to different external criteria. For example, for the case of predicted personality scores in recruiting settings, predicted personality scores based on work-related and work-unrelated data sources should be mapped to a variety of different external criteria such as cognitive ability, job satisfaction or job performance.
Fifth, we applied a combined approach of open- and closed-vocabulary extraction approaches. Since the field of natural language processing is constantly evolving, new methods such as contextualized word embeddings like BERT (Devlin et al., 2018) or more recently large language models (Touvron et al., 2023) become available to researchers at increasingly narrow intervals. Future research should investigate how models can be improved by including these new methods.
Sixth, to better understand the practical implications of our results, future research should examine the downstream value of implementing ML-based personality prediction models in real-world recruiting contexts, for example, in a recommendation system that proactively matches candidates to jobs. Are applicants matched using ML-based predictions of personality more likely to receive an initial response from the employer? Are they more likely to be hired for the job after going through the full interview process? Are they happier and more productive in their job? And are they less likely to leave? Providing answers to these questions will be critical for showing the real value of our predictive models.
In this paper, we demonstrated the feasibility of using automated predictions of personality in applied preselection and recruiting settings. We extended existing research by showing that (i) personality traits can be predicted from text data generated early in the recruiting process (rather than later or from external third-party data, such as social media profiles) and that (ii) such automated personality assessments are able to predict important external criteria such as vocational interests. Our findings highlight an opportunity for organizations to utilize automated assessments of personality in their recruitment processes without running the risk of violating participants' privacy and encountering legal challenges. Based on the observed accuracies of our models, we caution against the use of such predictive models to make final hiring decisions, but instead encourage their application as managerial decision-making aids and input into proactive job recommendations.
The code and results of the analyses presented in this study can be found in an online repository (https://osf.io/gxae9/).
The requirement of ethical approval was waived by Columbia Business School's IRB as this study relied only on secondary data. The studies were conducted in accordance with the local legislation and institutional requirements.
EG: Conceptualization, Formal analysis, Visualization, Writing–original draft, Writing–review & editing. HP: Conceptualization, Formal analysis, Writing–review & editing. MF: Conceptualization, Data curation, Writing–review & editing. MB: Resources, Supervision, Writing–review & editing. SM: Conceptualization, Resources, Supervision, Visualization, Writing–review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This research was supported by a scholarship by the German Academic Scholarship Foundation and by the Bundesministerium für Bildung und Forschung (Federal Ministry of Education and Research, Germany; Project Number: 01GK1801A). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript and the authors did not report any conflict of interest.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frsps.2023.1290295/full#supplementary-material
Acemoglu, D., and Restrepo, P. (2020). Robots and jobs: evidence from US labor markets. J. Polit. Econ. 128, 2188–2244. doi: 10.1086/705716
Acemoglu, D., and Restrepo, P. (2019). “Artificial intelligence, automation, and work,” in National Bureau of Economic Research Conference Report. The Economics of Artificial Intelligence: An Agenda, eds A. Agrawal, A. Goldfarb, and J. Gans (Chicago, IL: The University of Chicago Press), 197–236.
AI Act (2021). Proposal for a Regulation of the European Parliament and of the Council Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act) and Ammending Certain Union Legeslative Acts. Belgium: Brussels.
Allen, D. G., Mahto, R. V., and Otondo, R. F. (2007). Web-based recruitment: effects of information, organizational brand, and attitudes toward a web site on applicant attraction. J. Appl. Psychol. 92, 1696–1708. doi: 10.1037/0021-9010.92.6.1696
Anderson, H. J., Baur, J. E., Griffith, J. A., and Buckley, M. R. (2017). What works for you may not work for (Gen)Me: limitations of present leadership theories for the new generation. Leadership Quart. 28, 245–260. doi: 10.1016/j.leaqua.2016.08.001
Apers, C., and Derous, E. (2017). Are they accurate? Recruiters' personality judgments in paper versus video resumes. Comput. Hum. Behav. 73, 9–19. doi: 10.1016/j.chb.2017.02.063
Assouline, M., and Meir, E. I. (1987). Meta-analysis of the relationship between congruence and well-being measures. J. Vocat. Behav. 31, 319–332. doi: 10.1016/0001-8791(87)90046-7
Azucar, D., Marengo, D., and Settanni, M. (2018). Predicting the Big 5 personality traits from digital footprints on social media: a meta-analysis. Pers. Indiv. Diff. 124, 150–159. doi: 10.1016/j.paid.2017.12.018
Back, M. D., Stopfer, J. M., Vazire, S., Gaddis, S., Schmukle, S. C., Egloff, B., et al. (2010). Facebook profiles reflect actual personality, not self-idealization. Psychol. Sci. 21, 372–374. doi: 10.1177/0956797609360756
Barrick, M. R., and Mount, M. K. (1991). The big five personality dimensions and job performance: a meta-analysis. Person. Psychol. 44, 1–26. doi: 10.1111/j.1744-6570.1991.tb00688.x
Barrick, M. R., and Mount, M. K. (2012). “Nature and use of personality in selection,” in Oxford Handbook of Personnel Assessment and Selection, eds N. Schmitt (Oxford: Oxford University Press), 225–251.
Barrick, M. R., Mount, M. K., and Judge, T. A. (2001). Personality and performance at the beginning of the new millennium: what do we know and where do we go next? Int. J. Select. Assess. 9, 9–30. doi: 10.1111/1468-2389.00160
Bell, S. T. (2007). Deep-level composition variables as predictors of team performance: a meta-analysis. J. Appl. Psychol. 92, 595–615. doi: 10.1037/0021-9010.92.3.595
Berry, C. M., Ones, D. S., and Sackett, P. R. (2007). Interpersonal deviance, organizational deviance, and their common correlates: a review and meta-analysis. J. Appl. Psychol. 92, 410–424. doi: 10.1037/0021-9010.92.2.410
Bird, S., Klein, E., and Loper, E. (2009). Natural Language Processing with Python (1st Edn). Sebastopol, CA: O'Reilly Media.
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent dirichlet allocation. J. Mach. Learn. Res. 3, 993–1022. doi: 10.5555/944919.944937
Bono, J. E., and Judge, T. A. (2004). Personality and transformational and transactional leadership: a meta-analysis. J. Appl. Psychol. 89, 901–910. doi: 10.1037/0021-9010.89.5.901
Burns, G. N., Christiansen, N. D., Morris, M. B., Periard, D. A., and Coaster, J. A. (2014). Effects of applicant personality on resume evaluations. J. Bus. Psychol. 29, 573–591. doi: 10.1007/s10869-014-9349-6
Cardoso, A., Mourão, F., and Rocha, L. (2021). The matching scarcity problem: when recommenders do not connect the edges in recruitment services. Expert Syst. With Appl. 175, 114764. doi: 10.1016/j.eswa.2021.114764
Cole, M. S., Feild, H. S., Giles, W. F., and Harris, S. G. (2009). Recruiters' inferences of applicant personality based on resume screening: do paper people have a personality? J. Bus. Psychol. 24, 5–18. doi: 10.1007/s10869-008-9086-9
Cowgill, B., and Tucker, C. E. (2020). Algorithmic Fairness and Economics. New York City, NY: Columbia Business School Research Paper.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
Donnellan, M. B., Oswald, F. L., Baird, B. M., and Lucas, R. E. (2006). The mini-IPIP scales: tiny-yet-effective measures of the Big Five factors of personality. Psychol. Assess. 18, 192–203. doi: 10.1037/1040-3590.18.2.192
European Parliament and European Council (2016). EU General data protection regulation (EU-GDPR). Off. J. Eur. Union 119.
Funder, D. C. (2009). Persons, behaviors and situations: an agenda for personality psychology in the postwar era. J. Res. Person. 43, 120–126. doi: 10.1016/j.jrp.2008.12.041
Gladstone, J. J., Matz, S. C., and Lemaire, A. (2019). Can psychological traits be inferred from spending? Evidence from transaction data. Psychol. Sci. 30, 1087–1096. doi: 10.1177/0956797619849435
Goldberg, L. R. (1993). The structure of phenotypic personality traits. Am. Psychol. 48, 26–34. doi: 10.1037/0003-066X.48.1.26
Goldberg, L. R., Johnson, J. A., Eber, H. W., Hogan, R., Ashton, M. C., Cloninger, C. R., et al. (2006). The international personality item pool and the future of public domain personality measures. J. Res. Person. 40, 84–96. doi: 10.1016/j.jrp.2005.08.007
Golub, G. H., and Reinsch, C. (1970). Singular value decomposition and least squares solutions. Numerische Mathematik 14, 403–420. doi: 10.1007/BF02163027
Goretzko, D., and Israel, L. S. F. (2022). Pitfalls of machine learning-based personnel selection: fairness, transparency, and data quality. J. Pers. Psychol. 21, 37–47. doi: 10.1027/1866-5888/a000287
Gosling, S. D., Ko, S. J., Mannarelli, T., and Morris, M. E. (2002). A room with a cue: personality judgments based on offices and bedrooms. J. Person. Soc. Psychol. 82, 379–398. doi: 10.1037/0022-3514.82.3.379
Hall, J. A., Pennington, N., and Lueders, A. (2014). Impression management and formation on Facebook: a lens model approach. New Media Soc. 16, 958–982. doi: 10.1177/1461444813495166
Harrison, J. S., Thurgood, G. R., Boivie, S., and Pfarrer, M. D. (2019). Measuring CEO personality: developing, validating, and testing a linguistic tool. Strat. Manag. J. 40, 1316–1330. doi: 10.1002/smj.3023
Hausknecht, J. P., Day, D. V., and Thomas, S. C. (2004). Applicant reactions to selection procedures: an updated model and meta-analysis. Pers. Psychol. 57, 639–683. doi: 10.1111/j.1744-6570.2004.00003.x
Hickman, L., Bosch, N., Ng, V., Saef, R., Tay, L., and Woo, S. E. (2022). Automated video interview personality assessments: reliability, validity, and generalizability investigations. J. Appl. Psychol. 107, 1323–1351. doi: 10.1037/apl0000695
Hickman, L., Saef, R., Ng, V., Woo, S. E., Tay, L., and Bosch, N. (2023). Developing and evaluating language-based machine learning algorithms for inferring applicant personality in video interviews. Hum. Resource Manag. J. doi: 10.1111/1748-8583.12356
Hickman, L., Tay, L., and Woo, S. E. (2019). Validity evidence for off-the-shelf language-based personality assessment using video interviews: convergent and discriminant relationships with self and observer ratings. Pers. Assess. Decis. 5, 3. doi: 10.25035/pad.2019.03.003
Hoff, K. A., Song, Q. C., Wee, C. J., Phan, W. M. J., and Rounds, J. (2020). Interest fit and job satisfaction: a systematic review and meta-analysis. J. Vocat. Behav. 123, 103503. doi: 10.1016/j.jvb.2020.103503
Holland, J. L. (1959). A theory of vocational choice. J. Couns. Psychol. 6, 35–45. doi: 10.1037/h0040767
Holland, J. L. (1997). Making Vocational Choices: A Theory of Vocational Personalities and Work Environments (3rd Edn.). Odessa, FL: Psychological Assessment Resources.
Hunter, J. E., and Hunter, R. F. (1984). Validity and utility of alternative predictors of job performance. Psychol. Bull. 96, 72–98. doi: 10.1037/0033-2909.96.1.72
Judge, T. A., Bono, J. E., Ilies, R., and Gerhardt, M. W. (2002). Personality and leadership: a qualitative and quantitative review. J. Appl. Psychol. 87, 765–780. doi: 10.1037/0021-9010.87.4.765
Kern, M. L., McCarthy, P. X., Chakrabarty, D., and Rizoiu, M.-A. (2019). Social media-predicted personality traits and values can help match people to their ideal jobs. Proc. Natl. Acad. Sci. 116, 26459–26464. doi: 10.1073/pnas.1917942116
Kosinski, M., Matz, S. C., Gosling, S. D., Popov, V., and Stillwell, D. J. (2015). Facebook as a research tool for the social sciences: opportunities, challenges, ethical considerations, and practical guidelines. Am. Psychol. 70, 543–556. doi: 10.1037/a0039210
Kosinski, M., Stillwell, D. J., and Graepel, T. (2013). Private traits and attributes are predictable from digital records of human behavior. Proc. Natl. Acad. Sci. 110, 5802–5805. doi: 10.1073/pnas.1218772110
Kristof, A. L. (1996). Person-organization fit: an integrative review of its conceptualizations, measurement, and implications. Pers. Psychol. 49, 1–49. doi: 10.1111/j.1744-6570.1996.tb01790.x
Kristof-Brown, A., and Guay, R. P. (2011). “Person–environment fit,” in APA Handbook of Industrial and Organizational Psychology: Vol. 3: Maintaining, Expanding, and Contracting the Organization, eds S. Zedeck (Washington, DC: American Psychological Association), 3–50.
Küfner, A. C., Back, M. D., Nestler, S., and Egloff, B. (2010). Tell me a story and I will tell you who you are! Lens model analyses of personality and creative writing. J. Res. Pers. 44, 427–435. doi: 10.1016/j.jrp.2010.05.003
Lawson, M. A., and Matz, S. C. (2022). Hiring women into senior leadership positions is associated with a reduction in gender stereotypes in organizational language. Proc. Natl. Acad. Sci. 119, 1–11. doi: 10.1073/pnas.2026443119
Liu, P., Tov, W., Kosinski, M., Stillwell, D. J., and Qiu, L. (2015). Do Facebook status updates reflect subjective well-being? Cyberpsychol. Behav. Soc. Network. 18, 373–379. doi: 10.1089/cyber.2015.0022
Lub, X. D., Bal, P. M., Blomme, R. J., and Schalk, R. (2016). One job, one deal…or not: Do generations respond differently to psychological contract fulfillment? Int. J. Hum. Resource Manag. 27, 653–680. doi: 10.1080/09585192.2015.1035304
Lund, S., Manyka, J., and Robinson, K. (2016). Managing Talent in a Digital Age (McKinseyQuarterly). McKinsey Global Institute.
Lundberg, S., and Lee, S.-I. (2017). “A unified approach to interpreting model predictions,” in Advances in Neural Information Processing Systems, eds I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Red Hook, NY: Curran Associates, Inc.).
Makridakis, S. (2017). The forthcoming Artificial Intelligence (AI) revolution: its impact on society and firms. Futures 90, 46–60. doi: 10.1016/j.futures.2017.03.006
Manyika, J., Lund, S., Chui, M., Bughin, J., Woetzel, J., Batra, P., et al. (2017). Jobs Lost, Jobs Gained: Workforce Transitions in a Time of Automation. McKinsey Global Institute.
Marcus, B., Machilek, F., and Schütz, A. (2006). Personality in cyberspace: personal web sites as media for personality expressions and impressions. J. Pers. Soc. Psychol. 90, 1014–1031. doi: 10.1037/0022-3514.90.6.1014
Matz, S. C., Appel, R. E., and Kosinski, M. (2020). Privacy in the age of psychological targeting. Curr. Opin. Psychol. 31, 116–121. doi: 10.1016/j.copsyc.2019.08.010
Matz, S. C., and Netzer, O. (2017). Using big data as a window into consumers' psychology. Curr. Opin. Behav. Sci. 18, 7–12. doi: 10.1016/j.cobeha.2017.05.009
Molnar, C. (2022). Interpretable Machine Learning: A Guide for Making Black Box Models Explainable (2nd Edn.).
Montani, I., Honnibal, M., van Landeghem, S., Boyd, A., Peters, H., O'Leary McCann, P., et al. (2022). Explosion/spaCy: v3.4.4 [Computer Software]. Geneva: Zenodo.
Mount, M. K., Barrick, M. R., and Stewart, G. L. (1998). Five-Factor Model of personality and performance in jobs involving interpersonal interactions. Human Perform. 11, 145–165. doi: 10.1207/s15327043hup1102andamp;3_3
Naumann, L. P., Vazire, S., Rentfrow, P. J., and Gosling, S. D. (2009). Personality judgments based on physical appearance. Pers. Soc. Psychol. Bull. 35, 1661–1671. doi: 10.1177/0146167209346309
Nave, G., Minxha, J., Greenburg, D., Kosinski, M., Stillwell, D. J., and Rentfrow, P. (2018). Musical preferences predict personality: evidence from active listening and Facebook likes. Psychol. Sci. 29, 1659. doi: 10.1177/0956797618761659
Nye, C. D. (2022). Assessing Interests in the twenty-first-century workforce: building on a century of interest measurement. Ann. Rev. Org. Psychol. Org. Behav. 9, 415–440. doi: 10.1146/annurev-orgpsych-012420-083120
Nye, C. D., Su, R., Rounds, J., and Drasgow, F. (2012). Vocational interests and performance: a quantitative summary of over 60 years of research. Persp. Psychol. Sci. J. Assoc. Psychol. Sci. 7, 384–403. doi: 10.1177/1745691612449021
Nye, C. D., Su, R., Rounds, J., and Drasgow, F. (2017). Interest congruence and performance: revisiting recent meta-analytic findings. J. Vocat. Behav. 98, 138–151. doi: 10.1016/j.jvb.2016.11.002
Ostroff, C., and Zhan, Y. (2012). “Person–environment fit in the selection process,” in Oxford Handbook of Personnel Assessment and Selection, eds N. Schmitt (Oxford: Oxford University Press), 252–273.
Park, G., Schwartz, H. A., Eichstaedt, J. C., Kern, M. L., Kosinski, M., Stillwell, D. J., et al. (2015). Automatic personality assessment through social media language. J. Pers. Soc. Psychol. 108, 934–952. doi: 10.1037/pspp0000020
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830. doi: 10.5555/1953048.2078195
Pennebaker, J. W., Boyd, R. L., Jordan, K., and Blackburn, K. (2015). The Development and Psychometric Properties of LIWC2015. Austin, TX: University of Texas at Austin.
Pennington, J., Socher, R., and Manning, C. (2014). “GloVe: global vectors for word representation,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), eds A. Moschitti, B. Pang, and W. Daelemans (Association for Computational Linguistics), 1532–1543.
Peters, H., and Matz, S. (2023). Large language models can infer psychological dispositions of social media users. arXiv preprint arXiv:2309.08631.
Roulin, N., and Levashina, J. (2019). LinkedIn as a new selection method: psychometric properties and assessment approach. Pers. Psychol. 72, 187–211. doi: 10.1111/peps.12296
Ryan, A. M., and Ployhart, R. E. (2000). Applicants' perceptions of selection procedures and decisions: a critical review and agenda for the future. J. Manag. 26, 565–606. doi: 10.1177/014920630002600308
Sajjadiani, S., Daniels, M. A., and Huang, H.-C. (2022). The social process of coping with work-related stressors online: a machine learning and interpretive data science approach. Pers. Psychol. doi: 10.1111/peps.12538. [Epub ahead of print].
Sajjadiani, S., Sojourner, A. J., Kammeyer-Mueller, J. D., and Mykerezi, E. (2019). Using machine learning to translate applicant work history into predictors of performance and turnover. J. Appl. Psychol. 104, 1207–1225. doi: 10.1037/apl0000405
Salgado, J. F., and de Fruyt, F. (2017). “Personality in personnel selection,” in Handbooks in Management. The Blackwell Handbook of Personnel Selection, eds A. Evers, N. Anderson, and O. Voskuijl (Hoboken, NJ: Blackwell), 174–198.
Schaarschmidt, M., Walsh, G., and Ivens, S. (2021). Digital war for talent: how profile reputations on company rating platforms drive job seekers' application intentions. J. Vocat. Behav. 131, 103644. doi: 10.1016/j.jvb.2021.103644
Schwartz, H. A., Eichstaedt, J. C., Kern, M. L., Dziurzynski, L., Ramones, S. M., Agrawal, M., et al. (2013). Personality, gender, and age in the language of social media: the open-vocabulary approach. PLoS ONE 8, e73791. doi: 10.1371/journal.pone.0073791
Segalin, C., Perina, A., Cristani, M., and Vinciarelli, A. (2017). The pictures we like are our image: continuous mapping of favorite pictures into self-assessed and attributed. IEEE Trans. Affect. Comp. 8, 268–285. doi: 10.1109/TAFFC.2016.2516994
Spencer, D. A. (2018). Fear and hope in an age of mass automation: debating the future of work. New Technol. Work Empl. 33, 1–12. doi: 10.1111/ntwe.12105
Stachl, C., Boyd, R. L., Horstmann, K. T., Khambatta, P., Matz, S. C., and Harari, G. M. (2021). Computational personality assessment. Pers. Sci. 2, e6115. doi: 10.5964/ps.6115
Stachl, C., Pargent, F., Hilbert, S., Harari, G. M., Schoedel, R., Vaid, S., et al. (2020). Personality research and assessment in the era of machine learning. Eur. J. Pers. 34, 613–631. doi: 10.1002/per.2257
Stoll, G., Rieger, S., Lüdtke, O., Nagengast, B., Trautwein, U., and Roberts, B. W. (2017). Vocational interests assessed at the end of high school predict life outcomes assessed 10 years later over and above IQ and Big Five personality traits. J. Pers. Soc. Psychol. 113, 167–184. doi: 10.1037/pspp0000117
Tay, L., Woo, S. E., Hickman, L., Booth, B. M., and D'Mello, S. (2022). A conceptual framework for investigating and mitigating Machine Learning Measurement Bias (MLMB) in psychological assessment. Adv. Methods Pract. Psychol. Sci. 5, 251524592110613. doi: 10.1177/25152459211061337
Tibshirani, R. (1996). Regression shrinkage and selection via the Lasso. J. Royal Stat. Soc. B. 58, 267–288. doi: 10.1111/j.2517-6161.1996.tb02080.x
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., et al (2023). LLaMA: Open and Efficient Foundation Language Models. Available online at: https://arxiv.org/pdf/2302.13971 (accessed December 11, 2023).
Twenge, J. M., Campbell, S. M., Hoffman, B. J., and Lance, C. E. (2010). Generational differences in work values: leisure and extrinsic values increasing, social and intrinsic values decreasing. J. Manag. 36, 1117–1142. doi: 10.1177/0149206309352246
van de Ven, N., Bogaert, A., Serlie, A., Brandt, M. J., and Denissen, J. J. (2017). Personality perception based on LinkedIn profiles. J. Manag. Psychol. 32, 418–429. doi: 10.1108/JMP-07-2016-0220
van Iddekinge, C. H., Roth, P. L., Putka, D. J., and Lanivich, S. E. (2011). Are you interested? A meta-analysis of relations between vocational interests and employee performance and turnover. J. Appl. Psychol. 96, 1167–1194. doi: 10.1037/a0024343
Wegmeyer, L. J., and Speer, A. B. (2022). Understanding, detecting, and deterring faking on interest inventories. Int. J. Select. Assess. 30, 562–578. doi: 10.1111/ijsa.12398
Wilmot, M. P., and Ones, D. S. (2021). Occupational characteristics moderate personality–performance relations in major occupational groups. J. Vocat. Behav. 131, 1–18. doi: 10.1016/j.jvb.2021.103655
Yarbrough, J. R. (2018). Is cybervetting ethical? An overview of legal and ethical issues. J. Ethical Legal Issues 11, 1–23.
Keywords: natural language processing, machine learning, job matching, personality, vocational interests
Citation: Grunenberg E, Peters H, Francis MJ, Back MD and Matz SC (2024) Machine learning in recruiting: predicting personality from CVs and short text responses. Front. Soc. Psychol. 1:1290295. doi: 10.3389/frsps.2023.1290295
Received: 07 September 2023; Accepted: 17 November 2023;
Published: 29 January 2024.
Edited by:
Michal Kosinski, Stanford University, United StatesReviewed by:
Matthew Hibbing, University of California, Merced, United StatesCopyright © 2024 Grunenberg, Peters, Francis, Back and Matz. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Eric Grunenberg, ZXJpYy5ncnVuZW5iZXJnQHVuaS1tdWVuc3Rlci5kZQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.