 Vania Sena1†
Vania Sena1† Amangeldi Kenjegaliev
Amangeldi Kenjegaliev Aliya Kenjegalieva
Aliya Kenjegalieva
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Res. Metr. Anal. , 10 August 2022
Sec. Research Policy and Strategic Management
Volume 7 - 2022 | https://doi.org/10.3389/frma.2022.805116
This article is part of the Research Topic Explaining the Productivity Gap Between Frontier Firms and Laggards View all 4 articles
This paper proposes a new methodology that combines standard production theory with Multiple-Criteria Decision Analysis (MCDA) methods to rank banks based on their capability of using investment in new technologies to reduce the other inputs' usage, for a given level of output. Banks are first ranked based on their investment in innovation (innovation rank); afterwards, we calculate the overall rank by combining two factors of production, viz. labor and assets, using the PROMETHEE II approach that belongs to the family of the outranking methods. We then use directional efficiency measures to measure the banks' efficiency by means of relation between two ranks, for a given level of the outputs. We apply the methodology to a sample of US and EU banks sourced from Orbis BankFocus. The key findings suggest there are four types of banks in our sample: (a) banks whose innovation rank is positively correlated with the overall rank; (b) banks exhibiting a negative correlation between two ranks: their overall ranks are low while still exhibiting high innovation ranks; (c) banks with high overall rank but low innovation rank and (d) banks with the worst ranks both for the innovation rank and the overall rank. The least efficient banks belong to this group.
Over the last twenty years, the banking sector has invested in digital technologies (Rishi and Saxena, 2004) that have changed their production processes and the way they interact with customers. Digital technologies are a type of innovation that allow banks to process and transmit information easily. As a result, banks have been able to expand the range of products they offer as well as the menu of ancillary services associated to them. However, the impact of investment in digital technologies is not only limited to the outputs of the banks. Like any other type of innovation, digital technologies reduce the demand for other types of inputs such as labor and capital: indeed, tasks which were routinely performed by employees of a branch can now be performed by bots or other information processing technologies. As the demand for labor reduces, there is less need for a bank to invest in physical buildings and as a result, the demand for fixed assets decreases as well.
The impact of the investment in digital technologies on the demand of the other inputs creates some theoretical difficulties when trying to model banks' production process and measuring their efficiency. Indeed, digital technologies (like any other types of innovation) tend to be considered inputs of the banks' production function. However, investment in digital technologies does not behave like any other inputs with the result that assumptions such as strong disposability of inputs may not be realistic when modeling production function where investment in digital technologies is one of the inputs. Indeed, on the one hand, the increase of the expenditure on digital technologies may lead to an increase of the outputs for a given level of inputs' usage. On the other hand, the same increase of the innovation expenditure may lead to a decrease of the inputs' usage for a given level of output. As a result, it is unclear whether we can assume that banks can still produce the same amount of outputs if all the inputs shrink simultaneously. This conceptual weakness creates problems when using standard methodologies for the measurement of efficiency. For instance, Data Envelopment Analysis (DEA) relies on strong disposability of inputs and any attempt to remove this assumption (for instance, by introducing the concepts of weak disposability) has led to other issues (see Podinovski et al., 2009).
To circumvent this problem when measuring the efficiency of banks while allowing for the investment in digital technologies as an input of the production function, we propose a new methodology that combines standard production theory with MCDA methods to rank banks based on their capability of using investment in digital technologies to reduce the other inputs' usage, for a given level of output. We start by considering a directional distance function which is a standard representation of a technology and is related to both the input distance function (which assumes that outputs are exogenous) and the output distance function (which assumes the exogeneity of the inputs). Assuming that outputs are exogenous, banks have two types of inputs: (a) labor and capital, that can be decreased for a given level of outputs in the case of inefficient banks and (b) expenditure in digital technologies that may have to stay constant (or increase) for a given level of output even in the case of inefficient banks. To capture the fact that contractions of inputs may be associated to increases of the remaining input, we propose to replace the inputs with ranks which capture the fact that the inputs move in different directions.
To do so, the investment in innovation is separated from the other inputs. Banks are first ranked according to the size of investment in innovation (innovation rank); afterwards, we calculate the overall rank by combining two factors of production, viz. labor and assets, using the PROMETHEE II approach (Brans et al., 1986) that belongs to the family of the outranking methods. We then use directional efficiency measures to measure the banks' efficiency by means of relation between two ranks, for a given level of the outputs. We would expect that improvements along the overall rank (i.e., reduction in the inputs' usage) may be accompanied by proportional improvements along the innovation rank. However, if this is not the case, then the innovation ranks are not identical for banks with equivalent overall ranks implying that increases in the investment in digital technologies does not translate in an equivalent reduction of the inputs' usage for a given level of outputs.
To exemplify our approach, we consider three models. The first one focuses on investment on intangible assets as a proxy of innovation (proxied by intangible assets). The second one focuses on non-performing loans (a ratio of impaired loans to gross customer loans and advances) and allows to illustrate how our approach can be used for other types of variables. Finally, the third model focuses on a sample drawn from a Gaussian distribution. We have chosen the latter two as a robustness check of our approach. For example, non-performing loans have significant impact on bank performance and asset quality (see for example Simoens and Vennet, 2021). Deteriorations in non-performing loans reduces bank competitiveness and performance. Hence, we expect the least productive banks to have the lowest ranks both for non-performing loans and the overall performance (and vice versa in the case of the most efficient bank). Our approach builds on Ishizaka et al. (2018) although to the best of our knowledge, combining MCDA methods with standard production theory to measure efficiency in the banking industry has never been done.
The remainder of the paper is organized as follows. In the next section, we discuss production technology set and provide details of the directional distance function. In section on production technology and ranks, we introduce our ranked distance function. First, we will explain how to obtain our ranks: the innovation rank and the overall rank. Then we focus on the ranked distance function that we use in this paper. Section Empirical analysis: data, operationalization and methodology is devoted to data and data analysis. Section Estimation results focuses on our results and the robustness checks. Finally, the last section “Conclusions” offers final remarks.
As standard in the operational research literature, we begin from defining the technology available to the DMUs. The technology is characterized by an attainable set T (i.e., the production frontier) that includes all combinations of inputs and outputs that are technically achievable. Now, let an entity b with b = 1, .., B has a vector xb with K inputs, indexed k = 1, …, K, at its disposal. Let yb be a vector of U outputs, indexed u = 1, …, U that the entity b produces.
The production technology, in that case, is characterized by:
where T describes a set of input vectors that are feasible for each output vector (Glass et al., 2020). It is usually assumed that (a) T is convex, (b) T is closed, and (c) there is free disposability of inputs and outputs (see Chambers et al., 1998; Daraio and Simar, 2005; Atkinson and Tsionas, 2016; Kuosmanen and Johnson, 2017; and Layer et al., 2020).
One of the most flexible approaches in productivity literature is a directional distance function introduced by Chambers et al. (1998) and based on Luenberger's (1992) benefit function. Given a directional vector of inputs and outputs, the directional distance is defined as:
In this case, the distance from the efficient frontier is estimated in an additive way and the direction to the frontier is defined by dx and dy. This approach is popular among researchers because it explicitly allows to set some elements in the directional vector equal to zero (see for example Fare and Grosskopf, 2010). In a recent paper, Daraio and Simar (2014) point out that the efficient frontier is uniquely defined by the boundary of the attainable set T (where all the inputs and outputs are involved), but the distance to the frontier depends on the chosen direction. The direction can be different for each entity (like in the radial cases) or it can be the same for all the decision-making units. According to Daraio and Simar (2014), this way of measuring the distance is very flexible and generalizes the “oriented” radial measures proposed by Farrell (1957).
There is a large empirical literature on how to measure efficiency of organizations using frontier analysis (see for example, Chambers et al., 1998; Fare and Grosskopf, 2010; Duygun et al., 2013, 2016; Glass et al., 2014; Glass and Glass, 2018). Frontiers can be computed using either econometric techniques or Data Envelopment Analysis (DEA) (Banker et al., 1984). Econometric techniques assume that the most productive firms are located on the production curve. However, often these estimations are imprecise and prone to errors (Land et al., 1993; Fernandez et al., 2000; Layer et al., 2020). On the contrary, DEA is a very intuitive technique that measures DMU's efficiency as the ratio between the sum of the weighted output levels and the sum of the weighted input levels. The advantages of DEA over econometric techniques are multiple: first, it does not require any assumption on the functional form of the distance frontier. Second, it can accommodate multiple inputs and outputs. However, several authors have pointed out that one limitation of DEA is that it assumes strong (free) disposability of inputs and outputs. The assumption of free disposability of outputs means that for any levels of inputs, it is possible to reduce the level of outputs freely; conversely, free disposability of inputs implies that for a given level of outputs, inputs can be increased freely. The assumption of strong disposability is incorporated in the constant (CRS) and variable (VRS) returns-to-scale DEA models (Banker et al., 1984).
The assumption of strong disposability of inputs and/or outputs is unrealistic in some contexts. A lot of literature has focused on the case of undesirable outputs whose reduction has to be accompanied by a decrease of desirable outputs. However, this is also true in the case of inputs: for instance, an expansion of some inputs may be costly if DMUs are required to invest in some other inputs simultaneously. Traditionally, these cases are accommodated by introducing the assumption of weak disposability of inputs (Shephard, 1970). The assumption of weak input disposability states that, if a vector of outputs is produced from a vector of inputs, then the same vector of outputs can be produced if we scale up all components of the input vector in the same proportion. This assumption is problematic on two counts: first, at a theoretical level. Kuosmanen and Podinovski (2009) show that in these cases the production technology is a convex set. Second, the assumption may not be useful for DMUs which have to simultaneously increase some inputs while decreasing others, to be able to produce the same level of outputs. For instance, when modeling the production technology of commercial banks, assuming that labor and capital may decrease freely for a given level of outputs may be problematic as such decreases are usually the result of increases of the investments in digital technologies—inputs of the commercial banks' production technology. In these cases, alternative methodologies may be needed to model these technologies.
Our approach starts from the observation that there are industries where DMUs have to minimize some inputs (say, I_min) while maximizing others (I_max) for a given level of outputs; if so, we can identify the optimal combination of I_min and I_max, for each DMU and for given outputs. As in the case of the frontier analysis, we can calculate the optimal combination of I_min and I_max for the whole industry and this will give us a benchmark against which assess the performance of each DMU in the industry. Our approach starts by splitting inputs into two groups i.e., inputs that need to be reduced and inputs that need to be expanded. As we deal with multiple inputs in each case, we propose to convert them into ranks which will be used instead of the inputs. The use of ranks strips measurement units from the variables, reduces the dimension of the dataset and avoids the need of additional assumptions to measure efficiency.
In the case of one variable, the rank is defined as
Since the rank in (3), rb1, is based on a single variable, the DMU with the largest value is allocated the rank rb1 = 1. However, if we have inputs with different measurement units and scales, we need to use alternative methodologies to calculate the ranks. In these cases, MCDA methods which allow to rank multiple alternatives based on a number of decision criteria are particularly useful as they allow to collapse multi-dimensional datasets into a single index.
One of them is an outranking method that uses a pairwise comparison of alternatives via a preference index so that an alternative x is claimed to outrank another alternative y if, and only if, x is at least as good as y and there is no strong argument to contradict this assertion. For our analysis, we use the PROMETHEE II approach (Brans et al., 1986). Assume that a set of criteria be zb = (xb2, …, xbK) where xb2, …, xbK are K − 1 inputs. The comparison among alternative combinations of inputs is in terms of preferences. According to Brans et al. (1986), the preference function for each element i in zb is given by Pi(b, c), where b ≠ c. This function represents the preference intensity of the DMU b over the DMU c with respect to element i. For each criterion the preference function is a non-decreasing function of
Brans et al. (1986) report six types of generalized criteria evaluations. We use a modified usual criterion since it gives us binary outcome and we only need to decide between two types: either Pi(b, c) = 0 if Φ {b(i) − c(i)} ≤ 0 or Pi(b, c) = 1 if Φ {b(i) − c(i)} > 0 (i.e., strict preference of b over c).
Each element i is given a weight, w(i), which indicates the relative importance of it for a decision maker. In the absence of a preferred choice the criterion weight is w(i) = (K − 1)−1. Then the preference index, 𝔓, is given as
As Brans et al. (1986) note, 𝔓(b, c) is a combined intensity preference for the entity b over the entity c taking into account all element i in zb. The resulting outcome takes the value between 0 [weak preference of the entity b over the entity c if 𝔓(b, c) close to 0] and 1 [strong preference of the entity b over c if 𝔓(b, c) close to 1].
For each entity b the outranking character (outflow) is given by
The outflow computed in (6) indicates preference of c ∈ B compared to b. Equivalently for outranked character (entering flow) of b is:
The inflow computed in (14) indicates preference of b compared to c ∈ B with the net flow being equal to:
For each pair of DMUs, we have two possibilities:
This partial ranking approach transforms separate distributions of each element in into a single composite variable with a uniform distribution regardless of the asymmetries in the original distributions. Therefore, we can derive an overall rank defined as:
Once rb1 and 𝔎b are calculated, they can be replaced into (9):
We can also set signs of our directionalcan also set signs of our directional vector by vector by choosing to sort ranks in ascending or descending orders. This is done by transforming individual distribution of variables into a single uniform distribution regardless of asymmetries in the original distributions. Therefore, this model significantly reduces dimensionality of datasets and increases computational capacity compared to the mathematical programming models or the nonparametric maximum likelihood models typically used in the literature (see for instance, Banker and Morey, 1986; Seiford and Thrall, 1990; and Kumbhakar et al., 2007). The directional vector in our case is d = (db, db1) = (−1, −γb). There are negative signs because both ranks are sorted in an ascending order, i.e., 1 is allocated to the most preferred entity and so on for the rest of the decision-making units. The magnitude of the direction db1, is that shows the level of association between the individual rank and the overall rank for the entity b, and scales the overall rank proportionally to the individual rank. The ranks for an entity that is located on the frontier curve is given by reff, 1 and 𝔎eff.
According to Fernandez et al. (2000), the frontier is not known exactly and estimation usually leads to the two-sided error terms (see also Layer et al., 2020). On the other hand, Land et al. (1993) note that the most productive decision-making units close to the frontier are assumed to represent frontier decision-making units. Instead, in γb we assume an ideal condition where there is a hypothetical decision-making unit that is located on the frontier. In this case the individual rank for this entity is reff, 1 = 1 and the overall rank is 𝔎eff = 1.
In the literature, the distance β(xb, yb:dx) is calculated using linear programming or maximum likelihood estimation methods. To obtain the ranked equivalent to β(xb, yb:dx, dy), i.e., the ranked distance K(𝔎b, rb1:d) in equation 11, we use the following
Subject to
K(𝔎b, rb1:d) is a locus i.e., if γb = 1, the difference between the best rank and the worst rank is the same for both ranks (single rank and overall rank). If γb is larger than 1, then reduction of the gap between worst rank and better rank in innovation (in other words spend more in intangibles) implies an even larger reduction in the gap between worst and better ranks in the overall rank. If γb is smaller than 1, then we are in the opposite situation.
We source the data from Orbis BankFocus (formerly Bankscope)1. We include all available financial institutions as long as they are parent or holding companies because the majority of investment in innovation2 is usually performed by parent companies. For example, Goldman Sachs Group recorded $4 bn of intangible assets while its daughter bank Goldman Sachs Bank recorded only $65 mln, as reported by BankFocus for 2019. Moreover, from an accounting point of view, bank accounts are typically consolidated within the holding company's consolidated financial statements. In the case of unconsolidated reports, the proportion of intangible assets of the subsidiary company in the parent's holdings usually is negligible.
To identify the parent company, we have selected financial institutions whose ultimate owners can be identified within the database. Additionally, as in Kenjegalieva et al. (2009) and Tsionas et al. (2015), we carefully scrutinized accounting standards to avoid duplicate data for the same bank. Orbis database reports two different accounting standards: GAAP and IFRS. We use US GAAP accounting standard for American banks and IFRS accounting standard for European banks.
The full sample consists of a dataset covering the period from 2010 to 2019. Our data consist of four input variables: total assets, number of employees, other intangible assets (proxy for innovation) and mortgage servicing rights (MSRs); and two output variables: gross loans and NPL ratio (bad output). A list of these variables with their definitions are provided in Table 1 and descriptive statistics in Table 2A. We normalize input variables with gross loans and then standardized them with the sample mean of each input. In total we have data for 1,887 US banks and 388 EU banks. Data for MSRs available only for 64 US banks. Hence, we assume MSRs are equal to zero for the rest of the US financial intermediaries. Since the US financial intermediaries capitalize MSRs with other intangible assets, we subtracted MSRs from other intangible assets.3

Table 1. List of variables and their definitions.

Table 2. Data analysis: descriptive statistics and independent samples test between US and EU banks.
We consider three specifications: (1) innovation (proxied by intangible assets), (2) non-performing loans (a ratio of impaired loans to gross customer loans and advances) and (3) a sample drawn from a Gaussian distribution. For the former two specifications, we omit a bank-year observation where there was a missing observation within a single variable. As a result, the final sample sizes for these two specifications are smaller than the full sample and differ between each other and vary from year to year.
The methodology applied to the specifications are operationalised in the following way:
Step 1: Calculate an individual rank (rb1) based on the investment in intangible assets in Model 1. We do the same for the non-performing loans in Model 2 and for one of the random variables in Model 3.
Step 2: Use the Promethee outranking method to generate the overall rank. We use the number of employees and total assets as the input variables.
Step 3: This is the final step when we use (12) and (13) to get K(𝔎b, rb1:d) and γb.
Before proceeding to estimation of the two models, we examine the data for the US and EU banks. We expect that due to globalization, financial markets in both regions converge. Therefore, we compare the first moments of each variable between two regions. We use an independent samples test to check whether the means of the variables for the US and EU banks are statistically different from each other (and Welch, 1947; see Imbens and Kolesár, 2016). This test assumes equal variance of the variables across the two samples; we test whether the variances are indeed equal by using the Levene's test (Levene, 1960; Brown and Forsythe, 1974).
The results of the independent samples test are presented in Table 2B. This table shows that the means of the variables in the US and EU are statistically different from each other. The results are consistent under both assumptions on variances. For example, the t-statistics for “Employees” computed with assumption of the equal variances is −47.284 (see Table 2B, column 5). At the same time, t-statistics computed under the assumption of unequal variances is −46.567. In both cases, they are significant at 1% level. Additionally, column 8 in Table 2B indicates that the mean difference for “Employees” is −1.875 and std. error differences are 0.039 and 0.040, respectively. Comparable results are obtained for “Total Assets,” “Other Intangible Assets,” and “Non-Performing Loans.” The Levene's test also shows that the variances of the variables across the two data-sets are statistically different.
Observation of the mean differences (Table 2B, Column 8) indicates that all variables, at the sample mean, are larger for the EU banks compared to the US banks. One interesting point to note is that the magnitude of the mean difference for “Non-Performing Loans” is much larger than for the rest of the variables. This result possibly suggests that the US banks are more competitive than EU banks and they maximize their efficiency by utilizing technologies (such as ICT) that reduce other costs including non-performing loans.
Table 3 reports the results of Model 1 that focuses on innovation expenditure. One of the key parameters to focus on, along with the distance K(𝔎b, rb1:d), is γ that shows the magnitude of the change in the overall rank in response to the unit change of the innovation rank. Since we ranked innovation in ascending order, underperforming units are at the bottom of the sample (in terms of ranks). However, inspection of K(𝔎b, rb1:d) in Table 3 indicates that inefficient units do not have the worst individual or overall ranks (see respective panels A and B, Table 2). A combination of the ranks suggests the units are inefficient. For example, for the US banks K(𝔎b, rb1:d) = 416 and γ = 0.947 in 2019, and this outcome translates into the individual rank of 417 and the overall rank of 394 compared to the maximum possible rank of 422 in that year. Similar results are observed for the rest of the banks and years in the US as well as the EU.
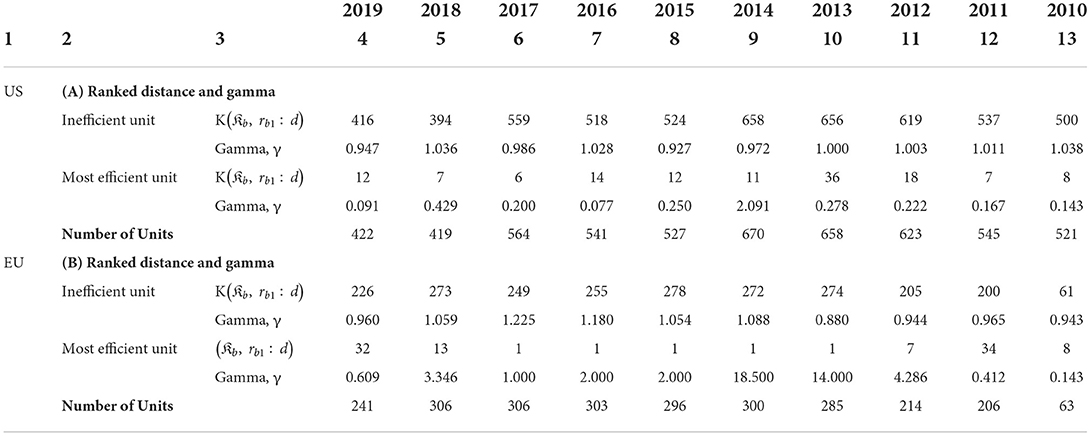
Table 3. K(𝔎b, rb1:d) and gamma in the model with innovation for US and EU banks.
While K(𝔎b, rb1:d) of inefficient units depend on the number of banks during analyzed period, we expect K(𝔎b, rb1:d) to be close to unity for the most efficient units. Table 3 indicates that this is not always the case. For instance, the efficient bank's K(𝔎b, rb1:d) in the US is as worse as 14; nonetheless the value of γ is 0.077 (in 2016) and converted into ranks they give 15 and 1 (out of 541) for the individual and overall ranks, respectively. At the same time, the efficient EU banks' worst K(𝔎b, rb1:d) is observed in 2011 with K(𝔎b, rb1:d) = 34 and γ = 0.412. In general, K(𝔎b, rb1:d) for the efficient unit is lowest in the US than in the EU (particularly so at the beginning of the period). At the same time, for the EU K(𝔎b, rb1:d) = 1 can be observed for several periods. We conjecture that this result is due to the strong competition preventing banks in the top tier from having the highest ranks.
From panels A and B of Table 3, it can be observed that γs for inefficient units both in the US and the EU fluctuates around 1. Moreover, in 2013, γ equals one in the US. This indicates that in order to reach the frontier point the bank needs to have equi-proportional changes in both ranks. The maximum absolute value for γ in the US is observed in 2010 (γ = 1.038). For the EU banks the variation in γ is slightly higher than for the US banks but broadly similar. Among the most efficient units, we find a large variation in γ. For example, the lowest absolute value of γ is equal to 0.077 for the efficient US bank in 2016 and for the EU banks it is 0.143 in 2010. The largest γ across two economies is in the EU with γ = 18.500 in 2014. For the US banks the largest γ is observed in 2014 with γ = 2.091.
In spite of (𝔎b, rb1:d) and γ show the fastest path to reff, 1 = 1 and Keff = 1, Figures 1, 2 indicate that distribution of ranks are uniform and independent of each other. Given the same overall rank, ranks for innovation are different across banks. Our results indicate that there are four types of banks in our sample. First, the banks where the innovation rank is positively correlated with the overall rank, i.e., the high overall rank is correlated with high innovation rank. These banks are located in the SW quadrant. The second type of banks exhibits a negative correlation between two ranks: their overall ranks are low while still exhibiting high innovation ranks. They can be observed in the WN quadrant. The third type of banks have high overall rank but low innovation rank. Finally, the fourth group in NE quadrant have the worst ranks both for the innovation rank and the overall rank. The least efficient banks belong to this group. For example, banks located in South-West (SW) and North-East (NE) quadrants show that their innovation ranks are in line with their overall ranks. These are the best and the worst banks, respectively. However, an interesting picture can be observed from West-North (WN) and East-South (ES) quadrants. Banks located in WN quadrant have high innovation ranks, that is comparable with banks from SW quadrant, nonetheless they have low overall ranks.
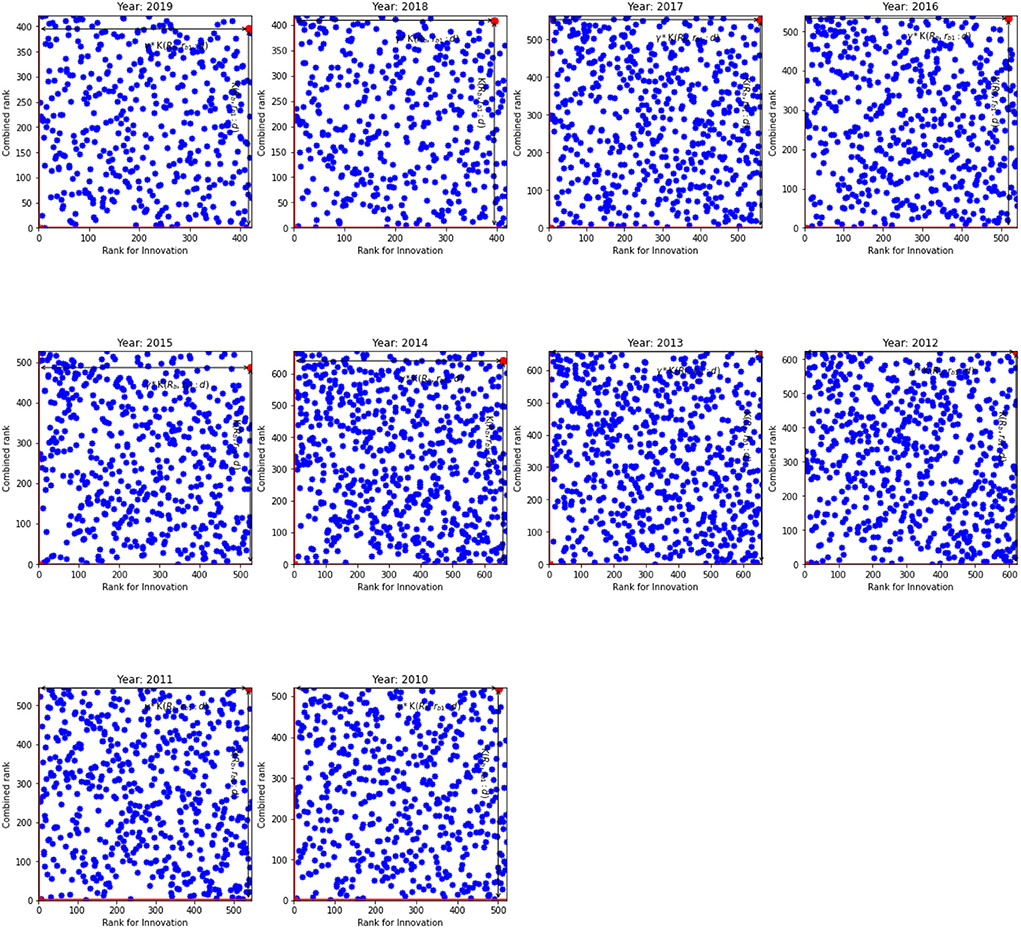
Figure 1. The innovation rank against combined rank for the US. K(𝔎b, rb1:d) and γ*K(𝔎b, rb1:d) for the inefficient unit.
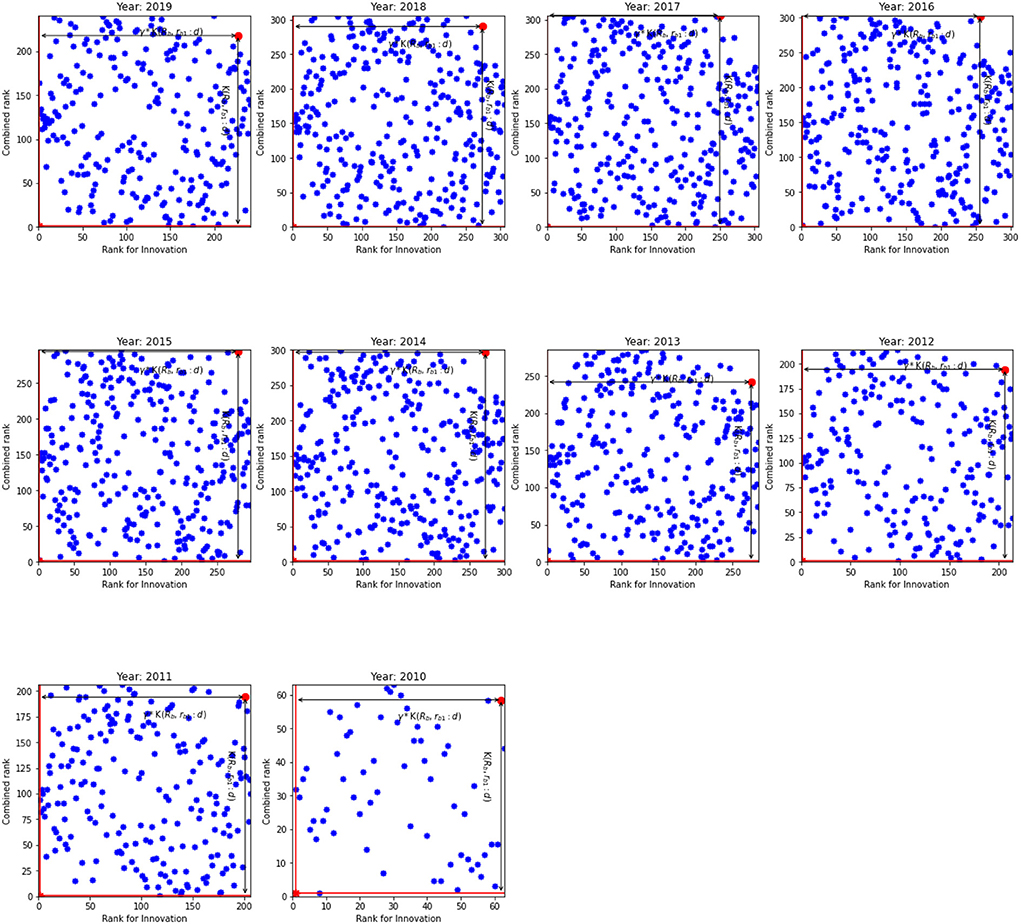
Figure 2. The innovation rank against combined rank for the EU. K(𝔎b, rb1:d) and γ*K(𝔎b, rb1:d) for the inefficient unit.
Moreover, we find that the inefficient units do not have the worst individual or combined ranks. Rather a combination of them scores the units as inefficient. Similar results are observed for all years in the US as well as the EU. At the same time, we expect K(𝔎b, rb1:d) of the efficient units to be close to unity. However, our results indicate that this is not the case. In general, the K(𝔎b, rb1:d) for the efficient units are worse in the US than in the EU.
In case of non-performing loans (NPL), K(𝔎b, rb1:d) for inefficient units behaves similar as in spec 1 (see Table 4). In other words, the worst ranked banks do not have the lowest K(𝔎b, rb1:d). However, γ for the inefficient unit in NPLs is closer to unity than γ for the inefficient unit in innovation. Moreover, there is less variation in γ. This result indicates that, in general, a change in one of the ranks is accompanied by a proportional change in the other rank.

Table 4. K(𝔎b, rb1:d) and gamma in the model with non-performing loans for US and EU banks.
Table 4 also shows the results for efficient units. Distances in the most efficient units for non-performing loans are much closer to the frontier point. For example, while K(𝔎b, rb1:d) for innovation was relatively far from 1 [the closest to one is K(𝔎b, rb1:d) = 7], for NPL this value equals to 0.5. At the same time, there is a variation in the behavior of γ but it is mostly <1. Exception happened when γ was equal to 12 and this indicates that there was a large difference between the two ranks in 2010.
The results for non-performing loans given in Table 4 broadly resemble the results in Table 3. However, a visual inspection of Figures 3, 4 show that the relationship between the NPL rank and the overall rank differs from the relationship between the innovation rank and the overall rank observed in Figures 1, 2. Indeed, there is a positive linear relationship between the NPL rank and the combined rank: as the NPL rank improves so does the combined rank. This relationship can be seen in Figure 3 that shows the NPL rank and the combined rank for the US. It shows that most banks are located along the primary diagonal line. The most inefficient unit is in NE quadrant and the most efficient bank at the bottom of the diagonal line (SW quadrant).
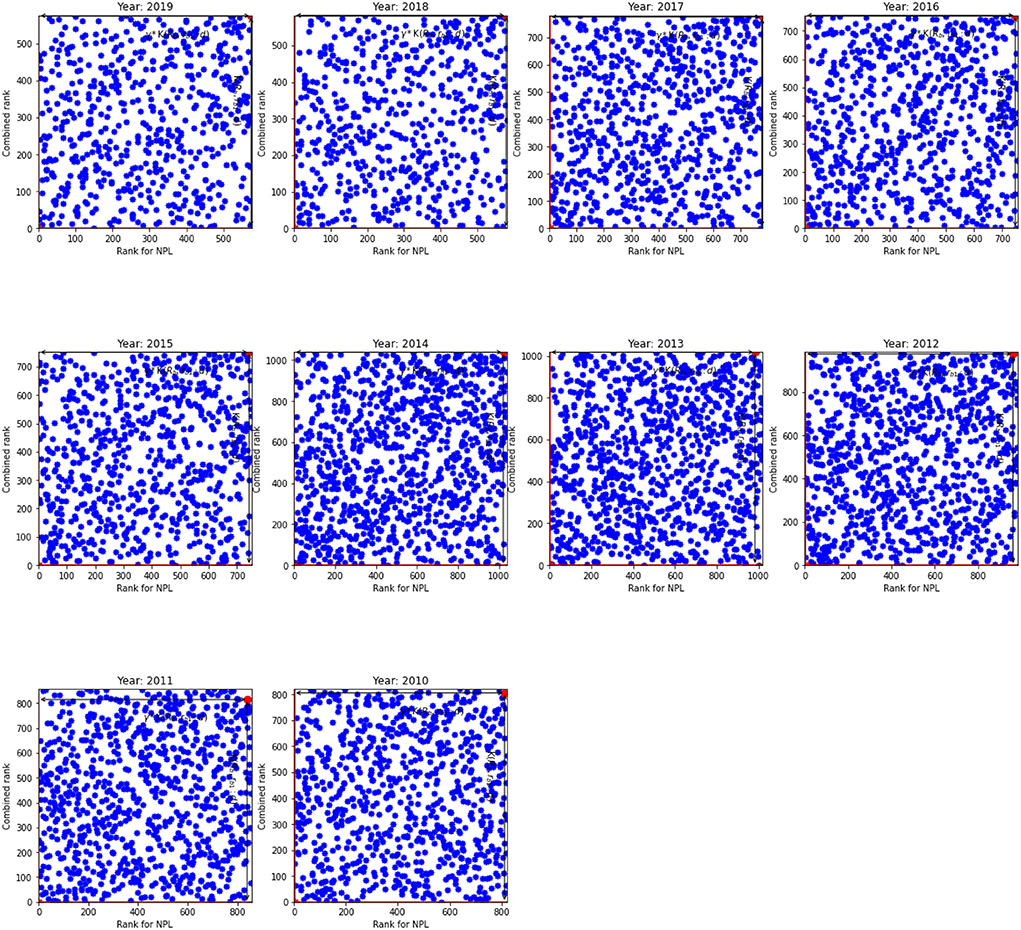
Figure 3. The NPL rank against combined rank for the US. K(𝔎b, rb1:d) and γ*K(𝔎b, rb1:d) for the inefficient unit.
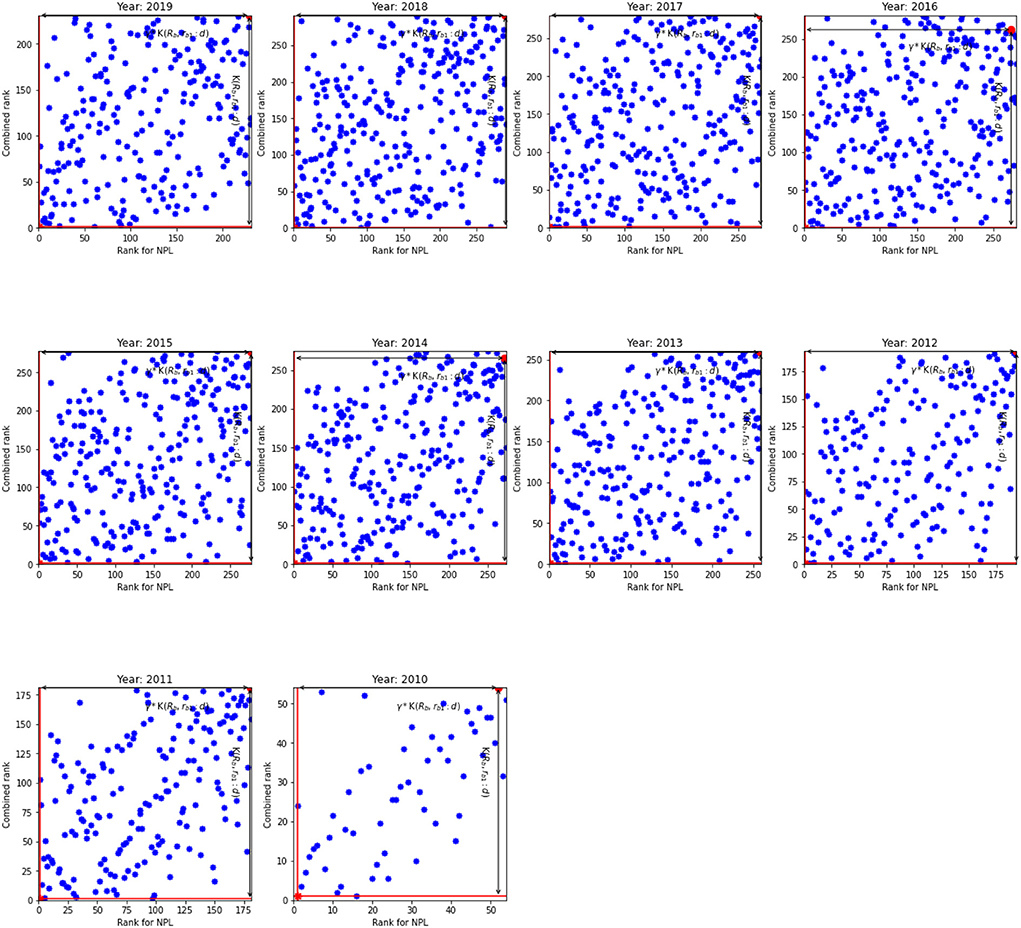
Figure 4. The NPL rank against combined rank for the EU. K(𝔎b, rb1:d) and γ*K(𝔎b, rb1:d) for the inefficient unit.
Overall, the number of analyzed banks in the EU is much lower than the number of banks in the US: by approximately four to five times. As a result, we observe relatively low number of banks in the upper and lower diagonals (WN and ES quadrants) and hence, the diagonal line is more prominent for the EU than for the US banks. Based on the results for non-performing loans, we argue that the banks that are able to screen out risky borrowers efficiently—therefore, they have higher NPL ranks—are able to reduce costs without affecting the quality of loans and hence they are more competitive that leads to improvement in the overall rank. In addition, smaller NPL ratio means that banks need less provision for future loan losses that increases their loan base; and leads to lower interest rates and whence they can provide cheaper loans.
In this section we provide results of the model with randomly generated variables. Each variable has mean zero but differs in the variance. We split the simulated data into ten distinct periods to emulate the actual data. Table 5 shows outcome of this model. According to the table the inefficient units do not have the worst ranks. This is similar to previous specifications, whereas a combination of overall and individual ranks marks the units as inefficient. For instance, K(𝔎b, rb1:d) = 233 and γ=0.940 for the period 10 that suggests that the overall rank is 219 and individual rank is 234. Dynamics of the parameter γ, according to Table 5, show that γ gravitates around unity and indicates a proportional change in ranks. Additionally, Table 5 shows the results for the efficient units. Distances K(𝔎b, rb1:d) in the most efficient units varies from 1 to 24 with γs as low as 0.27 and as high as 18. Since we are using random sample, Figure 5 shows that the units are scattered randomly across the graphs. Overall, the results are similar to results from models 1 and 2.
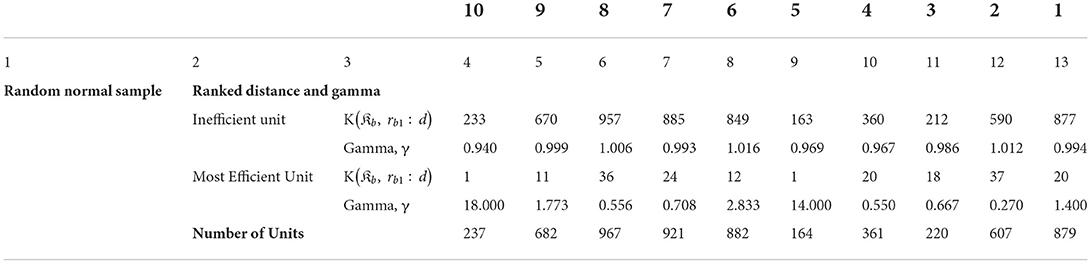
Table 5. K(𝔎b, rb1:d) and gamma in the model with random samples from a normal distribution.
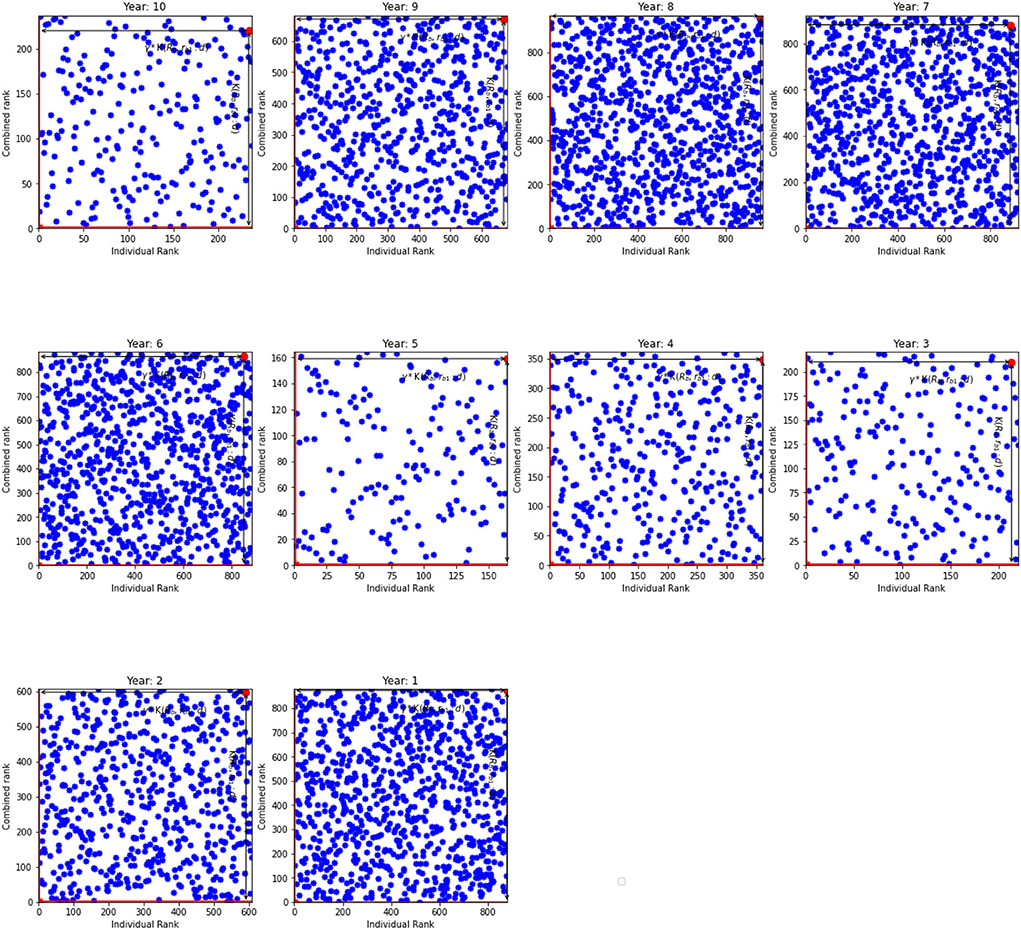
Figure 5. The individual rank against combined rank (from random normal samples). K(𝔎b, rb1:d) and γ*K(𝔎b, rb1:d) for the inefficient unit.
In this paper, we have proposed a new methodology that combines standard production theory with MCDA methods to rank banks based on their capability of using investment in digital technologies to reduce the other inputs' usage, for a given level of output. To capture the fact that contractions of inputs may be associated to increases of the remaining input, we propose to replace the inputs with ranks which capture the fact that the inputs move in different directions.
To exemplify the methodology, we have applied it to a sample of US and EU banks sourced from Orbis BankFocus for 2010 to 2019. We have considered three models. The first one focuses on investment on intangible assets as a proxy of innovation (proxied by intangible assets). The second one focuses on non-performing loans (a ratio of impaired loans to gross customer loans and advances) and allows to illustrate how our approach can be used for other types of variables while the third model focuses on a sample drawn from a Gaussian distribution. Results suggest that banks can be sorted in four groups according to their capability of using investment in new technologies to reduce other inputs' usage, for a given level of output.
Our methodology can help banks to quantify the impact of their investment in digital technologies and can take actions that improve its impact. Conversely, financial investors and other stakeholders can use it to detect how efficiently the bank can utilize its digital technologies. And, since these activities have direct implications on future financial standing of the bank, the results can help forecast banks' future financial performance.
The original contributions presented in the study are included in the article/supplementary materials, further inquiries can be directed to the corresponding authors.
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. ^This database is used, for example, by Fiordelisi et al. (2011) and Tsionas et al. (2015) to obtain data for EU-15 and EU-26 countries, respectively.
2. ^See for example accounting rules on other intangible assets in IFRS – IAS 38, FASB ASC – Topic 350 and FRS102 – Section 18, but cf. SFFAS 10.
3. ^We would like to thank an anonymous reviewer for pointing to this issue.
Atkinson, S., and Tsionas, M. (2016). Directional distance functions: optimal endogenous directions. J. Econom. 190, 301–314. doi: 10.1016/j.jeconom.2015.06.006
Banker, R. D., Charnes, A., and Cooper, W. W. (1984). Some models for estimating technical and scale inefficiencies in data envelopment analysis. Manag. Sci. 30, 1078–1092. doi: 10.1287/mnsc.30.9.1078
Banker, R. D., and Morey, R. C. (1986). Efficiency analysis for exogenously fixed inputs and outputs. Oper. Res. 34, 513–521. doi: 10.1287/opre.34.4.513
Brans, J. P., Vincke, P. H., and Mareschal, B. (1986). How to select and how to rank projects: the Promethee method. Eur. J. Oper. Res. 24, 228–238. doi: 10.1016/0377-2217(86)90044-5
Brown, M. B., and Forsythe, A. B. (1974). Robust tests for the equality of variances. J. Am. Stat. Assoc. 69, 364–367. doi: 10.1080/01621459.1974.10482955
Chambers, R. G., Chung, Y., and Fare, R. (1998). Profit, directional distance functions and Nerlovian efficiency. J. Optimization Theory Appl. 98, 351–364. doi: 10.1023/A:1022637501082
Daraio, C., and Simar, L. (2005). Introducing environmental variables in nonparametric frontier models: a probabilistic approach. J. Productivity Anal. 24, 93–121. doi: 10.1007/s11123-005-3042-8
Daraio, C., and Simar, L. (2014). Directional distances and their robust versions: computational and testing issues. Eur. J. Oper. Res. 237, 358–369. doi: 10.1016/j.ejor.2014.01.064
Duygun, M., Sena, V., and Shaban, M. (2013). Schumpeterian competition and efficiency among commercial banks. J. Bank. Finance 37, 5176–5185. doi: 10.1016/j.jbankfin.2013.07.003
Duygun, M., Sena, V., and Shaban, M. (2016). Trademarking activities and total factor productivity: some evidence for British commercial banks using a metafrontier approach. J. Bank. Finance 72, S70–S80. doi: 10.1016/j.jbankfin.2016.04.017
Fare, R., and Grosskopf, S. (2010). Directional distance functions and slacks-based measures of efficiency. Eur. J. Oper. Res. 200, 320–322. doi: 10.1016/j.ejor.2009.01.031
Farrell, M. J. (1957). The measurement of productive efficiency. J. R. Stat. Soc. A 120, 253–281. doi: 10.2307/2343100
Fernandez, C., Koop, G., and Steel, M. (2000). A Bayesian analysis of multiple-output production frontiers. J. Econom. 98, 47–79. doi: 10.1016/S0304-4076(99)00074-3
Fiordelisi, F., Marquez-Ibanez, D., and Molyneux, P. (2011). Efficiency and risk in European banking. J. Bank. Finance 35, 1315–1326. doi: 10.1016/j.jbankfin.2010.10.005
Glass, A., and Glass, K. (2018). A spatial productivity index in the presence of efficiency spillovers: evidence for U.S. banks, 1992-2015. Eur. J. Oper. Res. 273, 1165–1179. doi: 10.1016/j.ejor.2018.09.011
Glass, A., Glass, K., and Kenjegaliev, A. (2020). Comparisons of deposit types and implications of the financial crisis: evidence for U.S. banks. Int. J. Finance Econ. 27, 641–664. doi: 10.1002/ijfe.2172
Glass, A., Glass, K., and Sickles, R. (2014). Estimating efficiency spillovers with state level evidence for manufacturing in the US. Econ. Lett. 123, 154–159. doi: 10.1016/j.econlet.2014.01.037
Imbens, G. W., and Kolesár, M. (2016). Robust standard errors in small samples: some practical advice. Rev. Econ. Stat. 98, 701–712. doi: 10.1162/REST_a_00552
Ishizaka, A., Resce, G., and Mareschal, B. (2018). Visual management of performance with PROMETHEE productivity analysis. Soft Comput. 22, 7325–7338. doi: 10.1007/s00500-017-2884-0
Kenjegalieva, K., Simper, R., Weyman-Jones, T., and Zelenyuk, V. (2009). Comparative analysis of banking production frameworks in eastern European financial markets. Eur. J. Oper. Res. 198, 326–340. doi: 10.1016/j.ejor.2008.09.002
Kohlbeck, M. (2004). Investor valuations and measuring bank intangible assets. J. Account. Auditing Finance. 19, 29–60. doi: 10.1177/0148558X0401900104
Kumbhakar, S. C., Park, B. U., Simar, L., and Tsionas, E. G. (2007). Nonparametric stochastic frontiers: a local maximum likelihood approach. J. Econom. 137, 1–27. doi: 10.1016/j.jeconom.2006.03.006
Kuosmanen, T., and Johnson, A. (2017). Modeling joint production of multiple outputs in stoned: directional distance function approach. Eur. J. Oper. Res. 262, 792–801. doi: 10.1016/j.ejor.2017.04.014
Kuosmanen, T., and Podinovski, V. (2009). Weak disposability in nonparametric production analysis: reply to Fare and Grosskopf. Am. J. Agric. Econ. 91, 539–545. doi: 10.1111/j.1467-8276.2008.01238.x
Land, K. C., Lovell, C. A. K., and Thore, S. (1993). Chance-constrained data envelopment analysis. Managerial Decis. Econ. 14, 541–554. doi: 10.1002/mde.4090140607
Layer, K., Johnson, A. L., Sickles, R. C., and Ferrier, G. D. (2020). Direction selection in stochastic directional distance functions. Eur. J. Oper. Res. 280, 351–364. doi: 10.1016/j.ejor.2019.06.046
Levene, H. (1960). Robust tests for equality of variances. In: I. Olkin, editor. Contributions to Probability and Statistics (Palo Alto, CA: Stanford University Press), 278–92.
Luenberger, D. G. (1992). Benefit functions and duality. J. Math. Econ. 21, 461–481. doi: 10.1016/0304-4068(92)90035-6
Podinovski, V. V., Førsund, F. R., and Krivonozhko, V. E. (2009). A simple derivation of scale elasticity in data envelopment analysis. Eur. J. Oper. Res. 197, 149–153. doi: 10.1016/j.ejor.2008.06.015
Rishi, M., and Saxena, S. (2004). Technological innovations in the Indian banking industry: the late bloomer. Account. Hist. Rev. 14, 339–353. doi: 10.1080/0958520042000277801
Seiford, L. M., and Thrall, R. M. (1990). Recent developments in DEA: the mathematical programming approach to frontier analysis. J. Econom. 46, 7–38. doi: 10.1016/0304-4076(90)90045-U
Shephard, R. W. (1970). Theory of Cost and Production Functions, Princeton. New Jersey, NJ: Princeton University Press.
Simoens, M., and Vennet, R. V. (2021). Bank performance in Europe and the US: a divergence in market-to-book ratios. Finance Res. Lett. 40:101672. doi: 10.1016/j.frl.2020.101672
Tsionas, E. G., Assaf, A. G., and Matousek, R. (2015). Dynamic technical and allocative efficiencies in European banking. J. Bank. Finance 52, 130–139. doi: 10.1016/j.jbankfin.2014.11.007
Keywords: efficiency, distance function, innovation, ranks, MCDA
Citation: Sena V, Kenjegaliev A and Kenjegalieva A (2022) Innovation and efficiency in financial institutions. Front. Res. Metr. Anal. 7:805116. doi: 10.3389/frma.2022.805116
Received: 29 October 2021; Accepted: 18 July 2022;
Published: 10 August 2022.
Edited by:
Luigi Aldieri, University of Salerno, ItalyReviewed by:
Travis Davidson, Ohio University, United StatesCopyright © 2022 Sena, Kenjegaliev and Kenjegalieva. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Amangeldi Kenjegaliev, YS5rZW5qZWdhbGlldkBodWxsLmFjLnVr
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.