 Darshini Mahendran
Darshini Mahendran Gabrielle Gurdin1
Gabrielle Gurdin1 Christina Tang
Christina Tang Bridget T. McInnes
Bridget T. McInnes
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Res. Metr. Anal., 12 July 2021
Sec. Emerging Technologies and Transformative Paradigms in Research
Volume 6 - 2021 | https://doi.org/10.3389/frma.2021.688353
This article is part of the Research TopicInformation Extraction from Bio-Chemical TextView all 8 articles
Chemical patents are an essential source of information about novel chemicals and chemical reactions. However, with the increasing volume of such patents, mining information about these chemicals and chemical reactions has become a time-intensive and laborious endeavor. In this study, we present a system to extract chemical reaction events from patents automatically. Our approach consists of two steps: 1) named entity recognition (NER)—the automatic identification of chemical reaction parameters from the corresponding text, and 2) event extraction (EE)—the automatic classifying and linking of entities based on their relationships to each other. For our NER system, we evaluate bidirectional long short-term memory (BiLSTM)-based and bidirectional encoder representations from transformer (BERT)-based methods. For our EE system, we evaluate BERT-based, convolutional neural network (CNN)-based, and rule-based methods. We evaluate our NER and EE components independently and as an end-to-end system, reporting the precision, recall, and F1 score. Our results show that the BiLSTM-based method performed best at identifying the entities, and the CNN-based method performed best at extracting events.
Chemical patents are a significant source of information about novel chemicals and chemical reactions. New chemical compound discovery plays a vital role in the chemical and pharmaceutical industry, and chemical patents are the first venue this information is disclosed (He et al., 2021). Unfortunately, there has been a rapid growth of chemical patents in recent years, and with the increasing volume, the manual cataloging of these chemicals and chemical reactions is become laborious and time-intensive, making it difficult for researchers to keep up with the current state of the art. This has created an urgent need for automated solutions to extract information from patents in order to expedite the work of synthetic chemists (Lowe and Mayfield, 2020). Furthermore, these databases allow for the discovery of new chemical and synthetic pathways (Wang et al., 2001; Bort et al., 2020).
A chemical reaction typically includes an ordered sequence of reaction and workup steps that transforms a starting material into an end product (He et al., 2021). The process of extracting these steps consists of two key tasks: chemical named entity recognition (NER) and event extraction (EE). NER is the automatic identification of entities involved in a chemical reaction, and EE is the automatic identification and classification of event steps that link entities together. Here, the entities are names of chemical compounds labeled based on their role in a reaction and conditions associated with the reaction, such as yield and temperature (Copara et al., 2020), and the event is the relation between the entities that describe the steps taken to create the final product. To identify the entities and trigger words, we explored bidirectional long short-term memory (BiLSTM)-based and bidirectional encoder representations from transformer (BERT)-based (Devlin et al., 2018) methods each combined with a conditional random field (CRF) output layer for the final prediction. To identify the events, we explored rule-based, convolutional neural network (CNN)-based, and BERT-based methods. We evaluated our methods on the CLEF ChEMU-2020 dataset (He et al., 2021) where we also participated in the challenge (Mahendran et al., 2020). We evaluated each of the methods on their individual tasks (NER and EE) independently, and as an end-to-end system. We reported the precision, recall, and F1 score finding our best method (BiLSTM + CRF) for NER obtained an overall relaxed precision of 0.95 and exact precision of 0.87, relaxed recall of 0.99 and exact recall of 0.85, and a relaxed F1 score of 0.97 and an exact F1 score of 0.87. Our best method for EE (CNN-based) obtained an overall precision of 0.81, recall of 0.54, and F1 score of 0.65.
The remainder of the study is as follows. First, we discuss the current literature on extracting chemical reactions for patents. Second, we describe our NER and EE methods. Third, we discuss and analyze the results of our NER and EE separately, and then the results of combining them into an end-to-end system. Finally, we discuss the conclusions and future work of our research.
The extraction of chemical reaction properties and events from unstructured text is essential due to the increasing volume of information. We define properties as the entities associated with the reaction, and the events as sequence of steps that transform a starting material into an end product. Here, we discuss the previous literature within this domain.
He et al. (2021) used a CRF-based model for NER and a rule-based system for EE. For NER, they developed the BANNER NER system (Leaman and Gonzalez, 2008) which uses lexical, syntactic, and contextual features in a CRF model. For EE, they used a co-occurrence–based method where they created two dictionaries:
Copara et al. (2020) and Malarkodi et al. (2020) each developed a NER system to identify chemical entities from patents. Copara et al. (2020) used a BERT-based method assessing five variations of the BERT language models, including a domain-specific model called ChemBERTa. The models have a fully connected layer on top of the hidden states of each token and fine-tuned on the ChEMU dataset, using the training and development sets provided. Malarkodi et al. (2020) investigated using CRFs and multilayer perceptrons (MLPs), and they used word-level features, grammatical features, and functional term features.
Lowe and Mayfield (2020), Zhang and Zhang (2020), Ruas et al. (2020), and Dönmez et al. (2020) developed both NER and EE systems to extract chemical entities, and their trigger words, and subsequently link the trigger words to the entities to identify events. However, only Lowe and Mayfield (2020) and Zhang and Zhang (2020) conducted an end-to-end evaluation.
Lowe and Mayfield (2020) proposed a method utilizing parsing information with grammar rules for both NER and EE. For NER, they used ChemicalTagger (Hawizy et al., 2011) for efficient matching against extensive grammars that describe entity types to recognize chemicals and physical quantities, and then used regular expressions to recognize the remainder of the entity types and trigger words. For EE, they associated all of the entities within a phrase to its corresponding trigger word, with some predefined exception rules.
Zhang and Zhang (2020) proposed a hybrid combination of deep learning models and pattern-based rules for both NER and EE. In their work, a new language model, named Patent_BioBERT, was generated by pretraining the patent texts over BioBERT (Lee et al., 2019). For NER, they fine-tuned Patent_BioBERT on a BiLSTM + CRF and post-processed the output utilizing a set of pattern rules. For EE, they built a binary classifier by fine-tuning Patent_BioBERT to recognize relations between the trigger words and entities. They also designed post-processing rules based on patterns observed in the training data and applied them to recover some of these false-negative relations.
Ruas et al. (2020) proposed a BERT-based method for NER and EE. For NER, they first used a rule-based tokenizer for text tokenization and then a BERT-based model to extract the entities evaluating both BioBERT and BERT. For EE, they first performed sentence segmentation masking the trigger words, and the segment is then fed into a BERT model to classify the relation. Dönmez et al. (2020) proposed a BERT-based method for NER and a rule-based method for EE. For NER, they used the pretrained BERT model, BioBERT, to detect the entities and trigger words. For RE, if there is a trigger word in the same sentence as an entity, the event is identified based on a set of rules.
In this work, we analyze and benchmark different approaches for both NER and EE. For NER, we explore a BiLSTM + CRF and a BioBERT-based method. For EE, we explore a rule-based method that utilizes the colocation information, a CNN-based method that divides a sentence into segments and processes each segment unit separately, and two BERT-based methods. We evaluate the methods for NER and EE individually as well as an end-to-end system, conducting a thorough analysis of our results to identify the areas in which each approach does well and falls short.
The CLEF ChEMU-2020 dataset contains patents annotated with chemical entities and events explaining the sequence of steps that lead a starting material through a chemical reaction to an end product (Nguyen et al., 2020). It includes ten entities and two event classes. Table 1 displays the definitions of each entity and trigger word label in detail. Table 2 shows the event statistics of the training dataset. The dataset includes two trigger words (REACTION_STEP and WORKUP), and an event consists of a trigger word and an entity. Events are divided into two classes: ARG1 and ARGM. The ARG1 event label corresponds to relations between a trigger word and chemical compound entities. The ARGM event label corresponds to the relations between a trigger word and temperature, time, or yield entities. Figure 1 shows an example of a sentence from the CLEF ChEMU-2020 dataset (He et al., 2021) that explains the relationship between an entity and a trigger word.

TABLE 1. Definitions of entities and trigger words of the dataset.
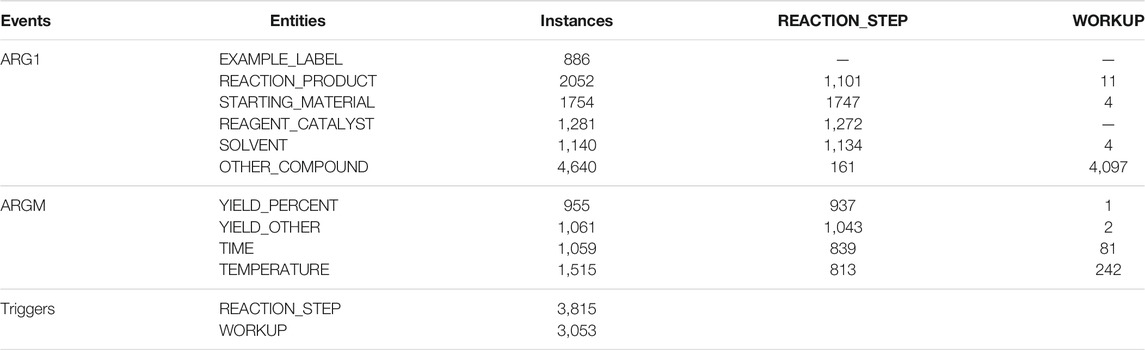
TABLE 2. Number of entity types and trigger words in the training data and their event relations.

FIGURE 1. An example from the CLEF ChEMU-2020 dataset that shows the entities, trigger words, and events.
This section describes the underlying methodology of our NER and EE systems.
We evaluate using BiLSTMs and a BERT to identify the chemical entities and their trigger words. In this section, we describe each of these in detail.
For our BiLSTM method, we use BiLSTM units with a CRF output layer (BiLSTM + CRF). An LSTM (Huang et al., 2015) is a type of recurrent neural network (RNN). It has two sources of input: the current state and the past states. This allows the cell to connect the previous observations, such as words in a sentence, and learn the dependencies of these words over arbitrarily long distances. The LSTM identifies what information should be passed to the next component, allowing only the relevant information. With BiLSTMs, data are processed in both directions with two separate hidden layers to enable the system to exploit context in both directions. We use a linear-chain CRF to assign the final class probability. CRF is a sequence-learning algorithm that incorporates the interdependence between labels into model induction and prediction. This allows the model to use the preceding label predictions to inform what labels are most likely to follow or to occur close together.
We represent our input into the BiLSTM + CRF using pretrained word embeddings (Mikolov et al., 2013) in combination with character embeddings (Gridach, 2017). We use the pretrained ChemPatent embeddings (Nguyen et al., 2020) that are trained over a collection of 84,076 full patent documents (1B tokens). The word and character embeddings are then concatenated and then passed through the network. The character embeddings are learned using a BiLSTM layer and concatenated onto the word embeddings. The character embeddings are valuable for alleviating the problem of “out of vocabulary” (OOV) terms for the model. In the case of chemical patents, many tokens are long chemical names that do not show up in the dataset used to train word embeddings, such as the reaction product 3-Isobutyl-5-methyl-1-(oxetane-2-ylmethyl)-6-[(2-oxoimidazolidin-1-yl)methyl]thieno[2,3-d]pyrimidine-2,4(1H,3H)-dione.
For our BERT method, we use BERT’s embedding representation into a feed-forward neural network with a CRF output layer. BERT is a contextualized word embedding model trained over a large corpus for masked language modeling and next sentence prediction tasks. Devlin et al. (2018) showed that this pretrained model could then be fine-tuned for other NLP tasks, including NER, by adding a simple classification layer. We evaluated BERT and several other additions for extracting chemical reaction parameters from chemical patents. Our architecture consists of an 1) alternate WordPiece labeling component, 2) BioBERT feature representation, and 3) a simple feed-forward layer into a CRF output layer for the final prediction.
Alternate WordPiece labeling: BERT tokenization involves splitting some tokens into “WordPieces” referred to as subwords, which alleviates the problem of OOV words. However, this creates a complication when doing token-level classification like NER; as per Devlin et al. (2018) recommendation, we only classify the first WordPiece by masking the rest and applying an “X” label.
BioBERT: BioBERT (Lee et al., 2019) is a BERT model that was further pretrained over biomedical text. In our work, the input to BioBERT is a single text sentence that is broken into subwords. An input representation is constructed by integrating the token, segment, and positional embeddings. Lee et al. (2019) started by loading the BERT-based cased weights and then training over PubMed abstracts and PubMed Central articles. For our experiments, we loaded the BioBERT v1.1 weights and then fine-tuned the model identically to standard BERT.
Classification layers: The system takes the output of the BioBERT layers, and passes it through a simple dense feed-forward layer and then into the CRF layer for the final classification. The CRF layer allows for the dependencies between the labels to be incorporated into the final prediction.
Since a chemical reaction step involves action and chemical compound(s) on which the action takes effect, we treat EE as a two-stage task: 1) identification of a trigger word that indicates a chemical reaction step and 2) identification of the relation between a trigger word and chemical compound(s) that is (are) linked to the trigger word.
To identify the trigger words, we use our NER system BiLSTM + CRF method described in Section 4.1.1. To identify the relations between the trigger words and the entities, we explore three methods: 1) rule-based method, 2) convolutional neural network(CNN)-based method, and 3) BERT-based methods: BERT_cased and BioBERT (Lee et al., 2019). In this section, we describe each of the methods in detail.
For our rule-based method, we utilize the colocation information between the trigger word and the chemical entity to determine if a relation should exist. We use a breadth-first search algorithm to find the trigger word’s closest occurrence on either side of the entity and all the closest occurrences of the trigger words within a sentence. Then, for each entity in the dataset, we traverse both sides until the trigger word’s most immediate occurrence is found using the provided span values of the entities. We apply different traversal techniques and determine the best traversal technique. The following are the traversal techniques we explore: traverse left-only, traverse right-only, traverse left-first-then-right, and vice versa. In this work, we report the best results, which used the left-only traversal where we traverse to the left side of the entity mention finding the closest occurrence of the trigger words.
For our CNN-based method, we split the sentence into segments and pass each segment into its respective CNN architecture, joining the resulting weights into a softmax layer for classification. CNNs are a form of deep neural networks and consist of four main layers (Nguyen and Grishman, 2015): 1) an embedding layer, 2) a convolution layer, 3) a pooling layer, and 4) a feed-forward layer. The convolution layer acts as a filter and learns what features to extract from the input. The max-pooling layer uses the position information to identify the most significant features from the convolution filter’s output. Finally, the feed-forward layer performs classification.
In our architecture, we perform a binary classification for each trigger word–entity pair to identify whether a relation exists between the trigger word and the entity. First, we identify and extract the sentence where a trigger word–entity pair lies, and based on where the text spans are located in the sentence, we divide the sentence into five segments: 1) preceding—tokenized words before the first concept, 2) concept 1—tokenized words in the first concept, 3) middle—tokenized words between the two concepts, 4) concept 2—tokenized words in the second concept, and 5) succeeding—tokenized words after the second concept. A segment is represented by a matrix of
For our BERT-based methods, we explore two BERT-contextualized embedding representations. BERT is a transformer-based attention model which trains in both directions. Here, we use BERT-contextualized embeddings and feed them into a simple feed-forward neural network. We explore two BERT-based models: BERT_cased and BioBERT.
• BERT_cased: general BERT models trained on a large corpus of English data: Book-Corpus (800 M words) and Wikipedia (2,500 M words) in a self-supervised manner (without human annotation). Here, we used the model with 2 heads, 12 layers, 768 hidden units/layers, and a total of 110 M parameters.
• BioBERT: general BERT model, further trained over a corpus of biomedical research articles from PubMed1 abstracts and PubMed Central2 article full texts.
In this architecture, we first extract the sentences that contain a trigger word and entity arguments. Next, as our feature extraction component, we pass the sentences through the pretrained BERT models to extract the features. Then, we feed the output into a dropout layer and finally into a fully connected dense layer for classification. As with our CNN-based method, we treat the EE as a binary classification task building a separate model for each trigger word–entity pair.
In this work, we used our NER and EE frameworks: MedaCy and RelEx.
MedaCy3 is a python-based framework developed to automatically identify the experimental parameters associated with the reaction, including the trigger words. RelEx4 is a python-based framework developed to automatically link the trigger words with the experimental parameters to provide the sequence of steps within the reaction. MedaCy contains a number of supervised multi-label sequence classification algorithms for NER. RelEx contains rule-based, deep learning–based, and BERT-based algorithms to identify relations between entities.
MedaCy: we used PyTorch (Paszke et al., 2019) for the implementation of the BiLSTM + CRF and BioBERT + CRF architectures. The models were trained for 40 epochs and optimized using stochastic gradient descent. Tokenization was conducted using the SpaCy tokenizer. The labels are strictly the entity types.
RelEx: we used Keras (Charles, 2013) for the implementation of the CNN architecture. We experimented with different sliding window sizes, filter sizes, and loss functions for fine-tuning, and in this work, small filter sizes generated the best results. We applied the dropout technique on the output of the convolution layer to regularize the model. We used Adam and rmsprop optimizers to minimize our loss function. We utilized SpaCy tokenizer (Schatz and Weber, 2015) and Keras tokenizer5 for the rule-based and the CNN-based method, respectively. We trained the models for 5–10 epochs to avoid over-fitting. We used the HuggingFaceTransformers to build the BERT models from Tensorflow 2.0, and used BertTokenizer (Devlin et al., 2018) and AutoTokenizer (Alsentzer et al., 2019) for tokenization.
We report the precision, recall, and F1 scores. Precision is the ratio between correctly predicted mentions over the total set of predicted mentions for a specific entity, recall is the ratio of correctly predicted mentions over the actual number of mentions, and F1 is the harmonic mean between precision and recall. We also report both the exact and relaxed results for each entity category for our NER and end-to-end evaluation. In the exact evaluation, two annotations are equal only if they have the same tag with exactly matching spans. With the relaxed evaluation, two annotations are equal if they share the same tag and their spans overlap.
In this section, we present and discuss the results of our NER and EE systems evaluated independently and then as a complete end-to-end system.
Table 3 shows the exact and relaxed precision (P), recall (R), and F1 (F) scores obtained over the test set for our BiLSTM + CRF with the ChEMU patent embeddings and our BioBERT + CRF methods.
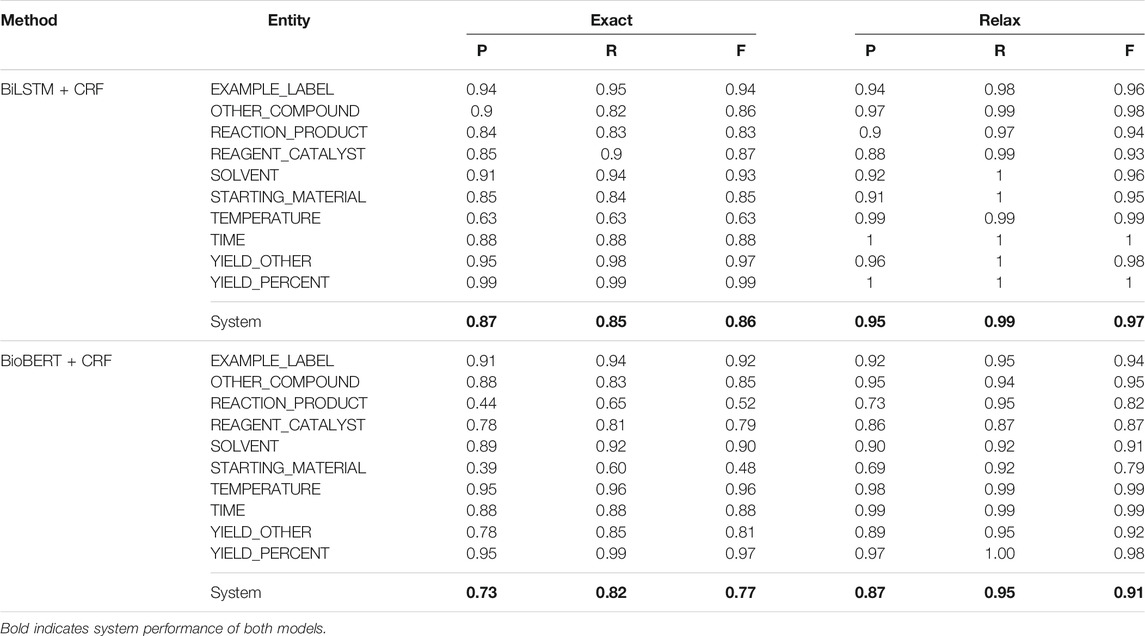
TABLE 3. Precision (P), recall (R), and F1 (F) results for our NER system.
In the BiLSTM + CRF results, the exact F-1 score was high
In the BioBERT + CRF results, the model performed on par with the BiLSTM + CRF except for REACTION_PRODUCT and STARTING_MATERIAL. The relaxed results indicate that the model is labeling a portion of the entity and can identify most of them; however, the precision is relatively low. BioBERT initially obtains a label for each subword token. These are then combined to provide both token-level predictions, which are fed into the CRF layer to obtain the final entity-level predictions. This allows for dependencies between the entities to be taken into consideration for sequence labeling. The BioBERT results indicate that it is getting most of an entity but not all of it; this suggests that post-processing of the labels can be improved in the future to obtain a full exact match.
Confusion matrices for the BiLSTM + CRF and BERT + CRF over the testing dataset are shown in Figure 2. Rows in the matrix represent annotated entities, and columns represent predicted entities. For instance, in the BiLSTM + CRF, the bottom right corner of each matrix is darker because of the large number of OTHER_COMPOUND (O.C) entities in the dataset. The colors in the matrix indicate the density of the entities and the system annotations. The matrix shows that the majority of mislabeling for both models occurred when many of the specific entity labels, such as STARTING_MATERIAL (S.M.), REAGENT_CATALYST (R.C.), REACTION_PRODUCT (R.P.), and SOLVENT (S), were predicted to be OTHER_COMPOUND (O.C.), as all four of those entities are chemicals. We believe this is due to two main reasons. The first reason is obvious; there is a significantly larger number of training instances for OTHER_COMPOUND than the other entities. However, the second reason is that OTHER_COMPOUND is quite a broad category referring to any chemical that is not one of the other four entities. Therefore, if the context surrounding the chemical is not sufficient to place it in the STARTING_MATERIAL, REAGENT_CATALYST, REACTION_PRODUCT, or SOLVENT label, it defaults to the broader OTHER_COMPOUND label.
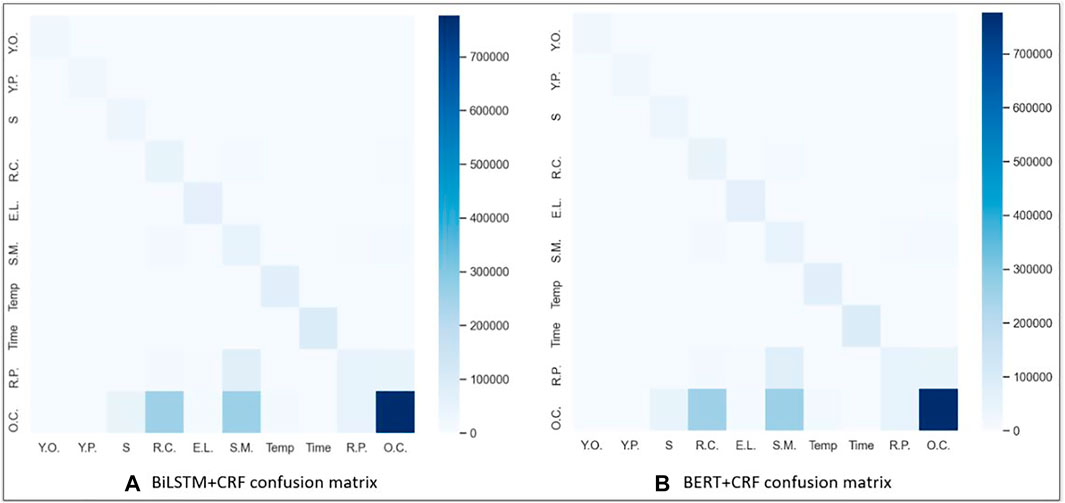
FIGURE 2. Confusion matrix using (A) BiLSTM + CRF and (B) BERT + CRF results. Keys for the acronyms are as follows: EXAMPLE_LABEL (E.L.), REACTION_PRODUCT (R.P.), STARTING_MATERIAL (S.M.), REAGENT_CATALYST (R.C.), SOLVENT (S), OTHER_COMPOUND (O.C.), YIELD_PERCENT (Y.P.), YIELD_OTHER (Y.O.), TIME (Time), and TEMPERATURE (Temp).
Table 4 shows a comparison between the top results reported by the CLEF ChEMU-2020 challenge using the CLEF-2020 dataset, baseline, and our NER methods. Baseline is a CRF-based NER system called BANNER (Leaman and Gonzalez, 2008) provided by the ChEMU organizers using the CLEF-2020 dataset. From the overall results of our models, we can see the BiLSTM + CRF method trained using patent embeddings returned the best relaxed results over both the BioBERT + CRF and the CRF baseline, obtaining a 97% system-wide relaxed + score, however, scoring slightly lower on the exact results than on the baseline. Melaxtech (Zhang and Zhang, 2020) fine-tuned the BioBERT over the patent texts and a BiLSTM + CRF for NER; they outperformed other systems, achieving a high F1-score of 0.96. VinAI (Dao and Nguyen, 2020), Lasige BioTM (Ruas et al., 2020), and BiTeM (Copara et al., 2020) performed equally and better than our methods under exact match. Our BiLSTM + CRF method outperformed the baseline and other methods under relaxed match, achieving higher recall. As discussed in the related work (Section 2), MelaxTech, BiTeM, and LasigBioTM developed BERT-based systems; MelaxTech also used a BiLSTM + CRF as VinAI. AU-KBC built systems using CRFs and MLP.
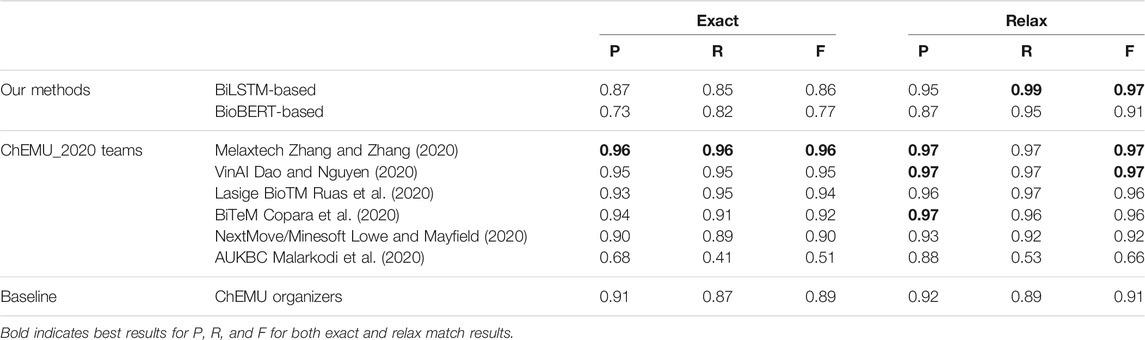
TABLE 4. Our best results in comparison with the top results of the ChEMU-2020 competition for NER. Baseline is provided by the organizers of the ChEMU-2020 challenge.
Table 5 shows the exact match precision (P), recall (R), and F1 (F) scores obtained for the EE system. The triggers were identified using our BiLSTM + CRF method trained over the ChemPatent embeddings, and the events were identified using our rule-based method, our CNN-based method, and our two BERT-based methods. The results show that the CNN-based method obtained a higher overall F1 score than the other methods. When training with CNN, the overall precision of the predictions is high, but the recall is low; this result shows that CNN failed to classify all instances but was able to classify most of the predicted instances correctly. This is primarily due to the limited number of training instances for many of the WORKUP relations. For example, SOLVENT, REACTION_PRODUCT, and STARTING_MATERIAL all have less than 11 instances in the training data.
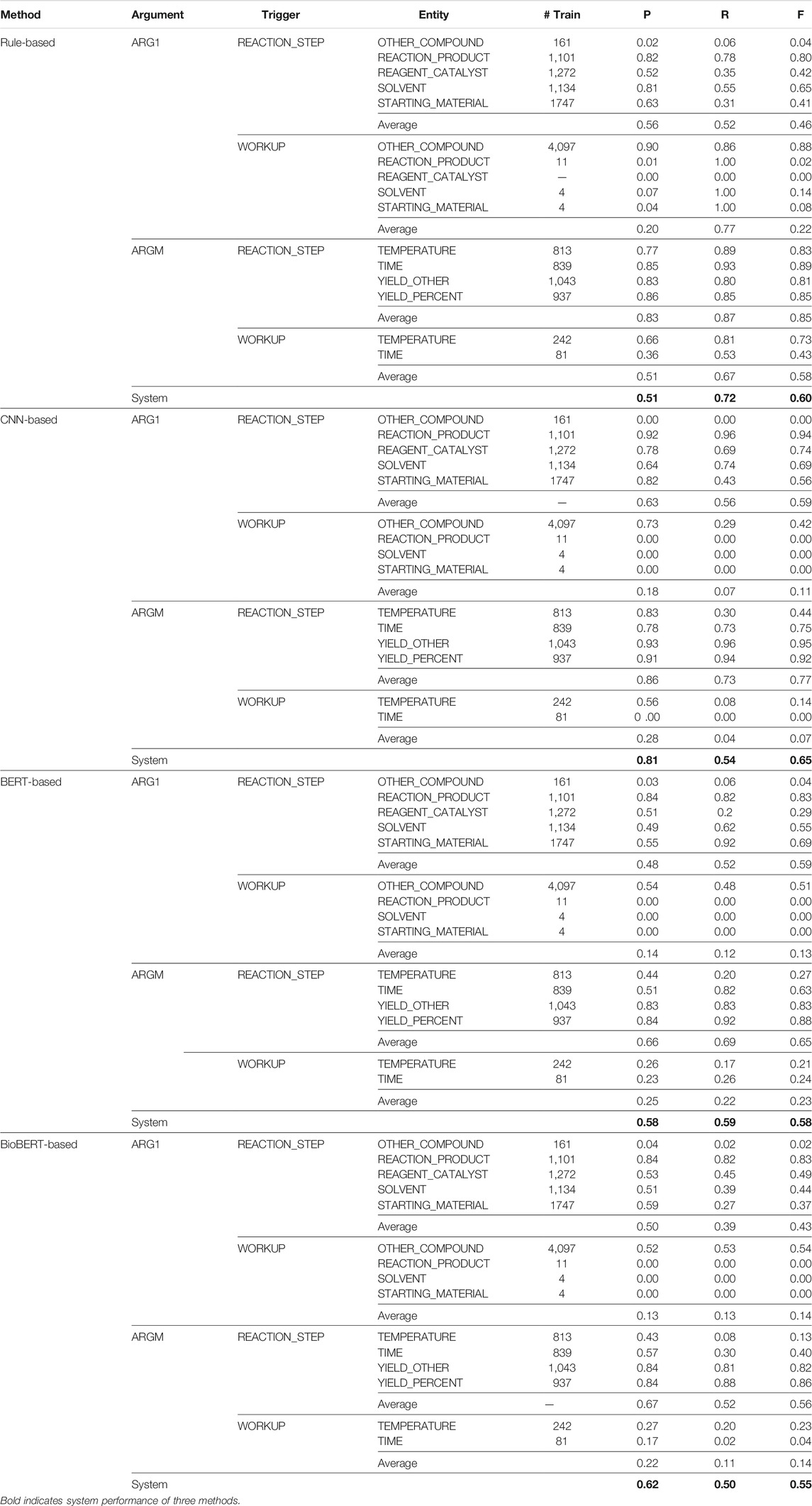
TABLE 5. Precision (P), recall (R), and
We can also see that each event class performance (trigger word–entity pair) in the CNN-based method is proportional to the number of instances in the training set. For example, event classes REACTION_STEP—REAGENT_CATALYST, and REACTION_STEP–STARTING_MATERIAL have more training instances and obtain a high F1 score, whereas the event classes WORKUP-SOLVENT and WORKUP-STARTING_MATERIAL have a very few instances and obtain an F1 score of zero. The rule-based method obtains comparatively high recall but low precision. It predicts all the closest occurrences of the trigger words of the entity compounds in the traversal area; however, many predictions are false positives. Since the number of instances in the training set does not affect the rule-based methods, the event classes that have few instances perform better. For example, the event classes WORKUP-TIME and REACTION_STEP-OTHER_COMPOUND obtained zero F1 score with the CNN-based method but performed better with the rule-based method, obtaining F1 scores of 0.43 and 0.88, respectively.
Both BERT-based methods obtain mediocre results compared to other rule-based and CNN-based methods, which we find surprising. The precision of both BERT-based methods is higher than that of the rule-based method but lower than that of the CNN-based method, and the recall is lower than that of the rule-based method but higher than that of the CNN-based method. We assume the reasons behind these findings are the BERT-based methods utilize contextualized embeddings which improve the number of the predictions (high recall), but the CNN-based method utilizes domain-related, non-contextualized patent embeddings that improve the number of true positives (high precision). Also, BERT-based methods take only the sentence where the trigger word–entity pair is located as the input, whereas the CNN-based method breaks the sentence into segments and processes each segment separately. Therefore, the CNN-based method considers the positional information of the entities results in more true positives. If we compare the BERT-based methods with each other, we can see the BERT_cased method obtained a higher recall and an overall F1 score, whereas the BioBERT-based method obtained a high precision. Since the BioBERT embeddings are trained over biomedical research articles, comparatively, they classify most of the predicted instances correctly.
Each trigger word category shows the arithmetic mean for both trigger word classes for each entity argument class. We can see the CNN-based method performs well with the REACTION_STEP classes and poor with WORKUP classes. This is mainly because of the number of instances in each event class. Comparatively, most of the REACTION_STEP classes have more instances for the CNN to train than most WORKUP classes. This is the same reason the rule-based method performs better with the WORKUP classes. BERT-based method results are similar to those of the CNN-based method; they perform well with the REACTION_STEP classes compared to the WORKUP classes. Since both BERT-based and CNN-based methods are supervised learning methods, they need more instances for each class to improve the results.
Table 6 shows a detailed error analysis our EE methods. We report the number of true positives (tp), false positives (fp), and false negatives (fn), and also “fpm” and “fnm,” two metrics that represent the number of false positives and false negatives of the trigger words predicted.
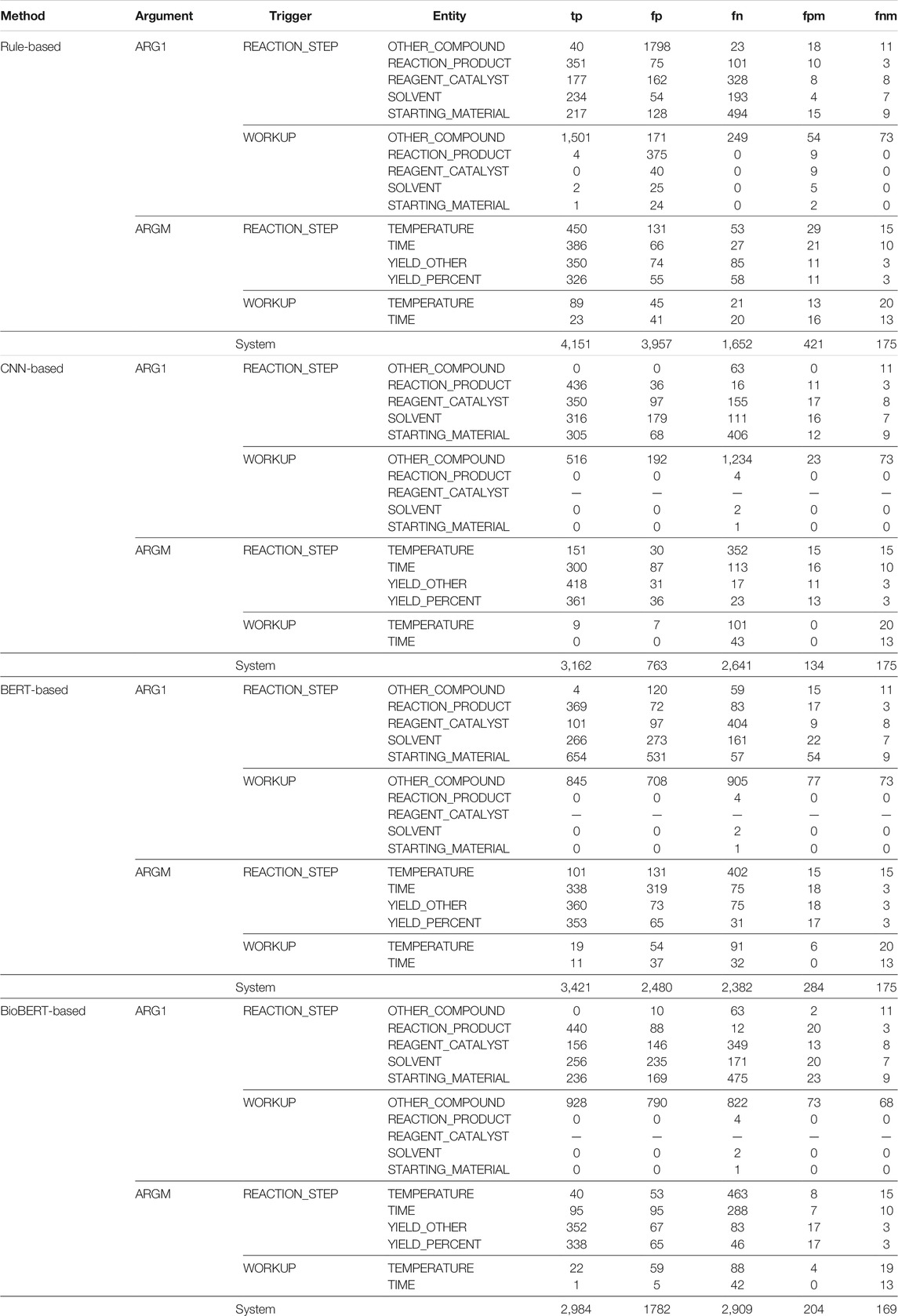
TABLE 6. Error analysis for the event extraction (EE) system where trigger words are trained with ChemPatent embeddings.
The results are consistent with the previous observations from Table 5. We can see that REACTION_STEP classes performed better than the WORKUP classes. It is safe to say that class imbalance plays a significant role in the miss-annotation of the instances. The results also show that the rule-based method significantly over annotates given the number of false positives. For example, the rule-based method identified 379 instances of the WORKUP-REACTION_PRODUCT event class, with only four being true positives. Despite having significant training instances in the REACTION_STEP classes, we can see an equally high number of false positives as true positives. This is mainly because extracting events is often trickier, regardless of the sentence pattern. For example, the following sentences show a trigger word–REACTION_PRODUCT pair in each.
1. After cooling, the solid was collected by filtration and washed with cold dichloromethane to give N-(4-(2-oxo-1,2,3,4-tetrahydroquinolin-6-yl)thiazol-2-yl)oxazole-5-carboxamide (0.121 g, 87%) as a beige solid.
2. {Methyl 4-[(6-bromo-2-phenyl-3-propylquinolin-4-yl)carbonyl]aminobicyclo[2.2.2]octane-1-carboxylate 150 mg (0.40 mmol) of the compound from example 38 A were dissolved in 1.4 ml (19.8 mmol) of thionyl chloride.
In the first sentence, the entity REACTION_PRODUCT N-(4-(2-oxo-1,2,3,4-tetrahydroquinolin-6-yl)thiazol-2-yl)oxazole-5-carboxamide is related to the trigger word give, but in the second sentence, the entity REACTION_PRODUCT {Methyl 4-[(6-bromo-2-phenyl-3-propylquinolin-4-yl)carbonyl]aminobicyclo[2.2.2]octane-1-carboxylate is not related to the trigger word dissolved. Despite the similar sentence structure, the results are not similar. These kinds of instances make the EE in this dataset quite hard.
In our EE methods, we utilized the trigger words predicted from our NER methods and the ground truth entities as the trigger words, respectively. From the metrics “fpm” and “fnm” for a trigger word–entity pair, we can see that when the number of “fpm” and “fnm” of a trigger word increases, the performance of the trigger word–entity pair decreases. We believe this is because the prediction of the trigger word–entity pair depends on the trigger word predicted by the biLSTM + CRF model described in Section 4.1.
Table 7 shows a comparison between the top results reported by the CLEF ChEMU-2020 challenge using the CLEF-2020 dataset, the co-occurrence baseline provided by the organizers of the challenge, and the overall results of our EE methods. The overall results show that all three of our systems obtain a higher precision and F1 score than the baseline but not recall. Since the baseline method is a rule-based method based on the co-occurrence information, it obtains a high recall but low precision. Here, all systems outperform the baseline in terms of the F1 score, and Melaxtech (Zhang and Zhang, 2020) obtained the overall best performance using a hybrid combination of deep learning models and pattern-based rules for EE. As discussed in Section 2, NextMove/Minesoft Lowe and Mayfield (2020) proposed a method utilizing parsing information with grammar rules, and BOUN_REX (Dönmez et al., 2020) utilized a set of rules to identify the events. All teams performed better than our methods, except for the recall of Dönmez et al. (2020).
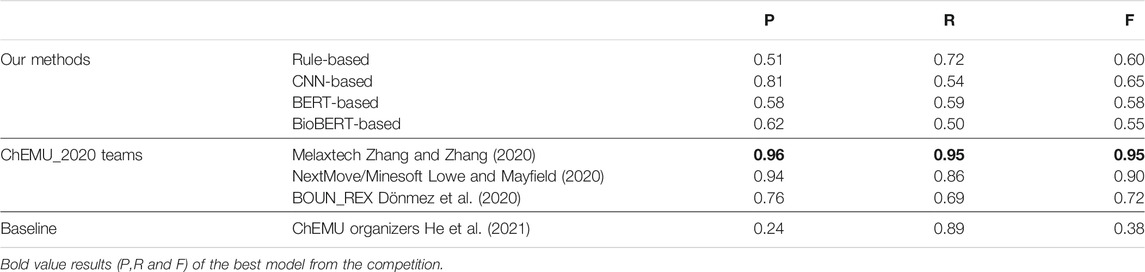
TABLE 7. Our best results in comparison with the top results of the ChEMU-2020 competition for event extraction (EE). Baseline is provided by the organizers of the ChEMU-2020 challenge.
An end-to-end system addresses both NER and EE; therefore, we combine our NER and EE methods to form a two-stage method. First, we use our BiLSTM + CRF method with the ChEMU patent embeddings, which produced the best results with NER to identify the entity arguments and trigger words. Then we use our CNN-based method with the ChEMU patent embeddings and the two BERT-based methods with the BERT contextualized embeddings to extract the events. From both the NER and EE results, we observed the precision of the deep-learning based methods is higher than that of the rule-based approach. Therefore, we decided to experiment only with deep-learning methods for the end-to-end system. Table 8 shows the exact and relax match precision (P), recall (R), and F1 (F) scores obtained for our three methods and shows a comparison between the top results reported by the ChEMU-2020 challenge participants using the CLEF-2020 dataset, the co-occurrence baseline provided by the organizers of the challenge, and the overall results of our end-to-end methods.
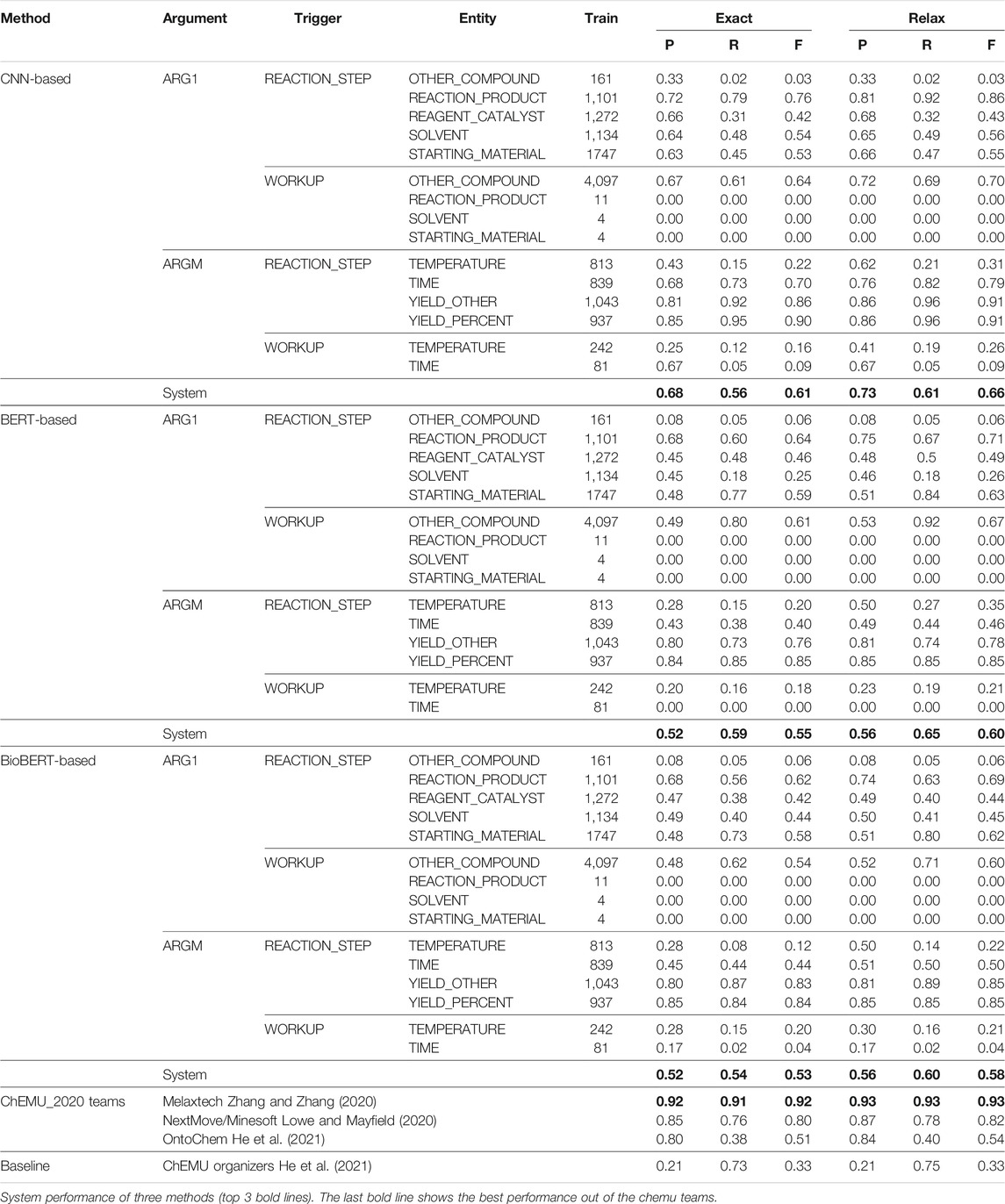
TABLE 8. Precision (P), recall (R), and
The average performance of the end-to-end system runs slightly lower than the EE system due to the error propagation from our NER. However, we can see the exact match performance of the methods is consistent with the results of our EE-independent evaluation (Table 5). Overall, the CNN-based method obtained a higher exact and relax precision and F1 score than both the BERT-based methods; however, the BERT_cased method obtained comparatively high recall. We believe the CNN-based method obtained a higher precision than the BERT-based method due to the word embeddings used and the input representation format. ChEMU patent embeddings are trained over patents specifically, and the domain-related information in the patent embeddings provides a better representation of the terms than the contextualized embeddings used in the BERT-based methods. Also, BERT-based methods do not take the positional information of the entities into account, whereas the CNN-based method does. Both BERT-based methods obtain similar precision and F1 scores, but the BERT_cased method obtains higher recall. The relaxed end-to-end system results show a slight increase in recall and a slight decrease in precision compared to the EE-independent evaluation. Relaxed BiLSTM-CRF scores are comparatively similar to the ground truth (precision—0.95, recall—0.99, and F-score—0.97) for the relaxed evaluation. Hence, the borders of the relaxed NER predictions of the BiLSTM + CRF can include the entity names within the context. We believe these accounts for the slight increase in the recall and slight decrease in precision from the EE evaluation. In addition, both tasks use our BiLSTM + CRF model to identify the trigger words. Since the performance of the trigger word prediction strongly influences the performance of the trigger word–entity pair prediction, we would expect to see a similar performance for both tasks.
Comparing our results, previous works, and baseline shows that both methods obtain a higher precision and F1 score than the baseline, but not recall. The baseline (He et al., 2021) used a CRF-based model for NER and a rule-based system for EE. All systems outperform the baseline in terms of the F1 score under both relax and exact matches. Melaxtech (Zhang and Zhang, 2020) outperformed all other systems using a BiLSTM + CRF for NER and a BERT-based method for EE similar to our methods. However, they performed post-processed steps utilizing a set of pattern rules which increased the performance. Thus, we can see that the recall in most of the participants’ systems of the ChEMU_2020 challenge is substantially lower than their precision. However, the recall of our methods is higher than that of our precision.
We explored a BiLSTM + CRF and a BioBERT + CRF method to extract entities and trigger words from the patents. Our results showed that the BiLSTM + CRF method using word embeddings trained over chemical patents obtained the highest results across all entities. We believe utilizing domain-related, non-contextualized patent embeddings improved the performance of utilizing the BERT-contextualized embeddings for word representation, indicating that additional fine-tuning of BERT may be required. The BiLSTM + CRF errors primarily occurred due to the models mislabeling entities annotated as OTHER_COMPOUND for more specific labels, like REACTION_PRODUCT or STARTING_MATERIAL. Additionally, the way that our method predicts entity labels may have contributed to errors with labeling entity spans fully. In the future, we plan to focus on better distinguishing between different types of chemical compounds. We explored rule-based, CNN-based, and two BERT-based methods to extract events from chemical reactions, using our BiLSTM + CRF method with the ChEMU patent embeddings to identify the trigger words. Our results showed that the CNN-based method using word embeddings trained over chemical patents obtained the highest results. In addition, the CNN-based and BERT-based methods obtained comparatively higher precision, especially with the REACTION_STEP classes, as those classes have more instances to train on. Meanwhile, as the rule-based method does not require training, it performed better with WORKUP classes, obtaining a higher recall than the other two methods. In the future, we plan to explore building a hybrid model with both CNN- and rule-based methods to increase performance. Also, we plan to explore graph-based CNNs to facilitate diverse input data representation to improve performance. In addition, we treated the end-to-end system as two independent stages where we perform first NER and then EE. In the future, we plan to explore utilizing a joint learning model to learn both entities better, and trigger words and events simultaneously.
Publicly available datasets were analyzed in this study. These data can be found here: http://chemu.eng.unimelb.edu.au/.
DM and BM are the primary authors of the manuscript. DM, GG, and BM contributed to the software developed within this work. DM, GG, BM, NL, and CT all contributed to the analysis of the results. All authors contributed to writing and editing the manuscript.
This work was funded by the National Science Foundation under Grant no. 1651957, and the Jeffress Trust Awards Program in Interdisciplinary Research.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
1https://www.ncbi.nlm.nih.gov/pubmed/.
2https://www.ncbi.nlm.nih.gov/pmc/.
3https://github.com/NLPatVCU/MedaCy/.
4https://github.com/NLPatVCU/RelEx/tree/CLEF_2020.
5https://github.com/keras-team/keras.
Alsentzer, E., Murphy, J. R., Boag, W., Weng, W.-H., Jin, D., Naumann, T., et al. (2019). Publicly Available Clinical Bert Embeddings. arXiv preprint arXiv:1904.03323, 72.
Bort, W., Baskin, I. I., Sidorov, P., Marcou, G., Horvath, D., Madzhidov, T., et al. (2020). Discovery of Novel Chemical Reactions by Deep Generative Recurrent Neural Network, London: Nature.
Charles, P. (2013). Project Title. Available at: https://github.com/charlespwd/project-title.
Copara, J., Naderi, N., Knafou, J., Ruch, P., and Teodoro, D. (2020). Named Entity Recognition in Chemical Patents Using Ensemble of Contextual Language Models. arXiv pSreprint arXiv:2007.12569.
Dao, M. H., and Nguyen, D. Q. (2020). Vinai at Chemu 2020: An Accurate System for Named Entity Recognition in Chemical Reactions from Patents, Thessaloniki, Greece: Working Notes of CLEF 2020-Conference and Labs of the Evaluation Forum, 22-25.
Devlin, J., Chang, M., Lee, K., and Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. CoRR abs/1810.04805, 278.
Dönmez, H., Köksal, A., Ozkirimli, E., and Ozgür, A. (2020). Boun-rex at Clef-2020 Chemu Task 2: Evaluating Pretrained Transformers for Event Extraction, Thessaloniki, Greece: Working Notes of CLEF 2020-Conference and Labs of the Evaluation Forum, 22-25.
Gridach, M. (2017). Character-level Neural Network for Biomedical Named Entity Recognition. J. Biomed. Inform. 70, 85–91. doi:10.1016/j.jbi.2017.05.002
Hawizy, L., Jessop, D. M., Adams, N., and Murray-Rust, P. (2011). Chemicaltagger: A Tool for Semantic Text-Mining in Chemistry. J. Cheminform 3, 17. doi:10.1186/1758-2946-3-17
He, J., Nguyen, D. Q., Akhondi, S. A., Druckenbrodt, C., Thorne, C., Hoessel, R., et al. (2021). “Chemu 2020: Natural language processing methods are effective for information extraction from chemical patents. Frontiers in Research Metrics and Analytics, 6, 12. doi:10.3389/frma.2021.654438
Huang, Z., Xu, W., and Yu, K. (2015). Bidirectional Lstm-Crf Models for Sequence Tagging. arXiv preprint arXiv:1508.01991.
Leaman, R., and Gonzalez, G. (2008). Banner: an Executable Survey of Advances in Biomedical Named Entity Recognition. Pac. Symp. Biocomput. 13, 652–663.
Lee, J., Yoon, W., Kim, S., Kim, D., Kim, S., So, C. H., et al. (2019). Biobert: a Pre-trained Biomedical Language Representation Model for Biomedical Text Mining. Bioinformatics 36 (4), 1234–1240. doi:10.1093/bioinformatics/btz682
Lowe, D., and Mayfield, J. (2020). “Extraction of Reactions from Patents Using Grammars,” in Central Europe Workshop Proceedings (CEUR-WS).
Mahendran, D., Gurdin, G., Lewinski, N., Tang, C., and McInnes, B. T. (2020). Nlpatvcu Clef 2020 Chemu Shared Task System Description, Thessaloniki, Greece: Working Notes of CLEF 2020-Conference and Labs of the Evaluation Forum, 22-25.
Malarkodi, C., Pattabhi, R., and Sobha, L. D. (2020). Clrg Chemner: A Chemical Named Entity Recognizer@ Chemu Clef 2020, Thessaloniki, Greece: Working Notes of CLEF 2020-Conference and Labs of the Evaluation Forum, 22-25.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., and Dean, J. (2013). “Distributed Representations of Words and Phrases and Their Compositionality,” in Advances in neural information processing systems, December 5–10, 2013, (Lake Tahoe:NIPS), 3111–3119.
Nguyen, D. Q., Zhai, Z., Yoshikawa, H., Fang, B., Druckenbrodt, C., Thorne, C., et al. (2020). “Chemu: Named Entity Recognition and Event Extraction of Chemical Reactions from Patents,” in European Conference on Information Retrieval, April 14–17, 2020. (NOVA, Portuguese:Springer International Publishing, University Lisbon), 572–579. doi:10.1007/978-3-030-45442-5_74
Nguyen, T. H., and Grishman, R. (2015). “Relation Extraction: Perspective from Convolutional Neural Networks,” in Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, June 2015, (Denver, Colarado:ACL). 39–48.
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., et al. (2019). “Pytorch: An Imperative Style, High-Performance Deep Learning Library,” in Advances in Neural Information Processing Systems 32. Editors H. Wallach, H. Larochelle, A. Beygelzimer, F. d Alche-Buc, E. Fox, and R. Garnett (Vancouver, Canada: Curran Associates, Inc.), 8024–8035.
Ruas, P., Lamurias, A., and Couto, F. M. (2020). Lasigebiotm Team at Clef2020 Chemu Evaluation Lab: Named Entity Recognition and Event Extraction from Chemical Reactions Described in Patents Using Biobert Ner and Re, Thessaloniki, Greece: Working Notes of CLEF 2020-Conference and Labs of the Evaluation Forum, 22-25.
Schatz, S. N., and Weber, R. J. (2015). Adverse Drug Reactions. Accp (American College of Clinical Pharmacy), 5326.
Keywords: named entity recognition, event extraction, relation extraction, information extraction, chemical natural language processing
Citation: Mahendran D, Gurdin G, Lewinski N, Tang C and McInnes BT (2021) Identifying Chemical Reactions and Their Associated Attributes in Patents. Front. Res. Metr. Anal. 6:688353. doi: 10.3389/frma.2021.688353
Received: 30 March 2021; Accepted: 31 May 2021;
Published: 12 July 2021.
Edited by:
Karin Verspoor, RMIT University, AustraliaReviewed by:
Hong-Jie Dai, National Kaohsiung University of Science and Technology, TaiwanCopyright © 2021 Mahendran, Gurdin, Lewinski, Tang and McInnes. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Darshini Mahendran, bWFoZW5kcmFuZEB2Y3UuZWR1
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.