 Habtamu Setegn Ngusie1*
Habtamu Setegn Ngusie1* Getanew Aschalew Tesfa2
Getanew Aschalew Tesfa2 Asefa Adimasu Taddese3
Asefa Adimasu Taddese3 Ermias Bekele Enyew4
Ermias Bekele Enyew4 Tilahun Dessie Alene5Gebremeskel Kibret Abebe6
Tilahun Dessie Alene5Gebremeskel Kibret Abebe6 Agmasie Damtew Walle7
Agmasie Damtew Walle7 Alemu Birara Zemariam8
Alemu Birara Zemariam8- 1Department of Health Informatics, School of Public Health, College of Medicine and Health Sciences, Woldia University, Woldia, Ethiopia
- 2School of Public Health, College of Medicine and Health Science, Dilla University, Dilla, Ethiopia
- 3Department of Sport, Physical Education and Health (SPEH), Academy of Wellness and Human Development, Faculty of Arts and Social Sciences, Hong Kong Baptist University, Kowloon, Hong Kong SAR, China
- 4Department of Health Informatics, College of Medicine and Health Science, Wollo University, Dessie, Ethiopia
- 5Department of Pediatric and Child Health, School of Medicine, College of Medicine and Health Science, Wollo University, Dessie, Ethiopia
- 6Department of Emergency and Critical Care Nursing, School of Nursing, College of Medicine and Health Sciences, Woldia University, Woldia, Ethiopia
- 7Department of Health Informatics, College of Medicine and Health Science, Debre Berhan University, Debre Berhan, Ethiopia
- 8Department of Pediatrics and Child Health Nursing, School of Nursing, College of Medicine and Health Science, Woldia University, Woldia, Ethiopia
Background: Sub-Saharan Africa faces high neonatal and maternal mortality rates due to limited access to skilled healthcare during delivery. This study aims to improve the classification of health facilities and home deliveries using advanced machine learning techniques and to explore factors influencing women's choices of delivery locations in East Africa.
Method: The study focused on 86,009 childbearing women in East Africa. A comparative analysis of 12 advanced machine learning algorithms was conducted, utilizing various data balancing techniques and hyperparameter optimization methods to enhance model performance.
Result: The prevalence of health facility delivery in East Africa was found to be 83.71%. The findings showed that the support vector machine (SVM) algorithm and CatBoost performed best in predicting the place of delivery, in which both of those algorithms scored an accuracy of 95% and an AUC of 0.98 after optimized with Bayesian optimization tuning and insignificant difference between them in all comprehensive analysis of metrics performance. Factors associated with facility-based deliveries were identified using association rule mining, including parental education levels, timing of initial antenatal care (ANC) check-ups, wealth status, marital status, mobile phone ownership, religious affiliation, media accessibility, and birth order.
Conclusion: This study underscores the vital role of machine learning algorithms in predicting health facility deliveries. A slight decline in facility deliveries from previous reports highlights the urgent need for targeted interventions to meet Sustainable Development Goals (SDGs), particularly in maternal health. The study recommends promoting facility-based deliveries. These include raising awareness about skilled birth attendance, encouraging early ANC check-up, addressing financial barriers through targeted support programs, implementing culturally sensitive interventions, utilizing media campaigns, and mobile health initiatives. Design specific interventions tailored to the birth order of the child, recognizing that mothers may have different informational needs depending on whether it is their first or subsequent delivery. Furthermore, we recommended researchers to explore a variety of techniques and validate findings using more recent data.
Introduction
Ensuring universal access to high-quality healthcare services, particularly for maternal and child health, is a crucial global goal rooted in the principles of primary healthcare (1, 2). Within the realm of maternal health, this objective involves providing comprehensive and easily accessible healthcare services tailored specifically to women of reproductive age. These services encompass essential components such as ANC, health facility delivery, and postnatal care (3, 4).
By placing a strong emphasis on primary healthcare, we can significantly enhance the wellbeing of both mothers and children through the provision of essential, accessible, and affordable healthcare services (3, 4). However, despite these intentions, challenges remain in the provision of maternal healthcare services, especially in developing regions. Notably, limited access to health facility delivery and inadequate ANC visits contribute to suboptimal health outcomes in East Africa (5–8).
Extensive research has established a clear link between health facility delivery and maternal and neonatal mortality rates (9, 10). In particular, home deliveries, which often lack access to skilled healthcare professionals and emergency obstetric care, expose mothers and newborns to increased risks of adverse outcomes (11, 12). Complications during childbirth such as postpartum hemorrhage, obstructed labor, infections, birth asphyxia, and neonatal sepsis pose substantial threats to the health and survival of both mothers and infants (13, 14). Furthermore, the absence of immediate interventions in home settings can lead to delays in recognizing and managing these complications, thereby exacerbating their severity and contributing to poorer health outcomes (15).
Given that childbirth complications are a leading cause of maternal and neonatal mortality, delivering in health facilities emerges as a prominent solution. The World Health Organization (WHO) identifies severe bleeding (mainly postpartum), infections (typically after delivery), high blood pressure during pregnancy (pre-eclampsia and eclampsia), complications from delivery, and unsafe abortions as responsible for 75% of maternal deaths (16). For instance, severe postpartum hemorrhage alone accounts for 27.1% of maternal fatalities globally, while obstructed labor contributes 17.9% (17).
Moreover, postpartum infections are a major cause of maternal death, with ~5 million cases of pregnancy-related infections reported annually, resulting in around 75,000 deaths (18). Additionally, gestational diabetes affects about 20 million births each year (19), and hypertensive disorders in pregnancy lead to ~76,000 maternal and 500,000 prenatal deaths globally each year (20). Epidemiological studies further report that the prevalence of hypertensive disorders in pregnancy ranges from 5.2 to 8.2% for gestational hypertension and from 0.2 to 9.2% for preeclampsia (21).
As of 2023, about 1.2 million pregnant women worldwide were living with HIV (22), with mother-to-child transmission accounting for 9% of new infections (23). For neonates, premature births, birth complications (such as birth asphyxia and trauma), neonatal infections, and congenital anomalies collectively account for nearly 40% of deaths in children under five (24). Therefore, delivering in health facilities is one of the safest methods to manage these complications and mitigate their severity, ultimately protecting the lives of both mothers and their newborns. Access to skilled healthcare professionals and emergency obstetric care in health facilities significantly reduces the risks associated with childbirth complications, underscoring the vital role of health facility delivery in improving maternal and neonatal health outcomes.
In the context of Sub-Saharan Africa, particularly alarming rates of neonatal and maternal mortality persist due to inadequate health facility delivery. For example, in 2017, the region reported a maternal mortality ratio of 542 per 100,000 live births, highlighting the urgent need for intervention (7, 8). Additionally, in 2018, Sub-Saharan Africa recorded the highest neonatal mortality rate among regions defined by the SDGs, with 28 deaths occurring per 1,000 live births (25, 26).
To address these pressing challenges, the WHO, in collaboration with governments and partners, has implemented various initiatives in Sub-Saharan Africa. These initiatives focus on developing and implementing comprehensive maternal and child health programs, promoting community-based interventions, enhancing emergency obstetric care services, and encouraging skilled birth attendance (27, 28). Despite these efforts, a significant proportion of women in East Africa still choose home births (29, 30).
The choice of delivery location is influenced by a wide array of factors. These factors encompass residence (31), age (31, 32), education level of mothers and husband (33), ANC visit (34), wealth status (34), religion (31), women's occupation (31), husband occupation (32), sex of household head (35), media access (29, 31), the timing of the first ANC check (36, 37), number of pregnancies (38), age at first marriage (39), preceding birth interval (40), distance from a health facility (33, 41), mobile phone ownership (42), and birth order (42, 43).
While previous studies have examined the factors influencing the choice of delivery location using Demographic and Health Survey (DHS) data from various countries (29, 44), a deeper understanding requires the utilization of advanced machine learning algorithms and data science techniques. Such an approach enables the discovery of hidden patterns and relationships that may not be easily discernible through traditional statistical methods.
Consequently, we propose a study aimed at evaluating the potential improvements in classification performance achieved by employing a diverse range of advanced machine learning and data science techniques to distinguish between home and health facility deliveries. Additionally, the study will investigate the key factors that influence the decision-making process among childbearing women in East Africa when choosing between these two delivery options.
Related works
The topic of health facility vs. home delivery among women of reproductive age has been extensively studied in various contexts (30, 31, 35, 40, 44–57). While traditional statistical methods have been commonly utilized, researchers have recognized their limitations in capturing complex relationships and interactions among multiple influencing factors (58). To address these shortcomings, machine learning techniques have been increasingly applied, yielding promising results in predicting delivery locations and improving health outcomes for mothers and newborns.
For instance, a study conducted in Zanzibar employed logistic regression, LASSO regression, random forest, and artificial neural networks to predict delivery locations, achieving accuracy rates between 68 and 77% (59). Another study in Zanzibar focused on evaluating the vulnerability of algorithms used in community health worker-led maternal health programs, emphasizing the critical need for accurate data monitoring strategies to effectively target high-risk women (60).
In Afghanistan, a web-based predictive model utilizing machine learning algorithms, particularly random forest, achieved an impressive accuracy of 84.23%. This highlights the potential for targeted interventions to enhance the utilization of skilled child delivery services and reduce maternal and child mortality rates (61). Similarly, a study in Ethiopia that explored determinants of skilled delivery service utilization developed a predictive model using the J48 algorithm, demonstrating exceptional accuracy of 98% (62).
Despite these advancements, significant research gaps remain in the exploration and application of advanced machine learning algorithms, data balancing techniques, and tuning methods, particularly when applied to large datasets. Previous studies have often been constrained by their reliance on relatively small datasets, which limits the generalizability of their findings.
To bridge this research gap, our study aims to conduct a comprehensive investigation by leveraging a relatively large dataset. We will explore and experiment with 12 cutting-edge advanced machine learning algorithms, along with various data balancing techniques and tuning methods, to enhance accuracy and precision in distinguishing between health facility and home deliveries.
Method
Data source
This study utilized secondary data from the most recent Demographic and Health Surveys (DHS) conducted in 12 East African countries: Ethiopia (2016), Kenya (2022), Uganda (2016), Tanzania (2022), Burundi (2017), Rwanda (2015), Madagascar (2021), Mozambique (2015), Zimbabwe (2015), Zambia (2018), Malawi (2016), and Comoros (2012). For each country, the most recent DHS data was used; if multiple surveys were available, the latest one was taken. The data was obtained from the official DHS Program database (URL: https://dhsprogram.com/data/available-datasets.cfm). Ethical approval was obtained from the Institutional Review Board for the DHS Program to ensure compliance with research guidelines.
The DHS Program has conducted standardized cross-sectional surveys in over 90 countries, gathering comprehensive and representative data on aspects such as population, health, HIV, and nutrition. These surveys employed a multi-stage stratified sampling approach, where participants were selected from households within designated clusters. Sampling strata were created based on urban and rural sectors, and enumeration areas were chosen using probability proportional to size. Within the selected enumeration areas, households were chosen using equal probability systematic sampling (63).
The study specifically targeted childbearing women in East Africa, those between the ages of 15 and 49 who had given birth within the past 5 years. The analysis included a substantial sample size of 86,009 individuals across the 12 countries mentioned. The dataset used in the study consisted of 19 distinct features that were taken into account during the analysis.
Study variables and measurements
In this study, the variable of interest was health facility delivery, defined as women giving birth in healthcare facilities, including government, private, and non-government health institutions. Reproductive-age women who delivered in these facilities were categorized as “health facility delivery” (coded as 1), while those who gave birth outside of healthcare facilities were categorized as “home delivery” (coded as 0) (63). The study considered several independent variables after reviewing the literature, including place of residence, religion, media exposure, sex of household head, birth order number, birth interval, timing of the first ANC check, number of children in the family, current marital status, ANC visit, working status of the mother, owns the mobile telephone, wealth status, age of household head, husband/partner educational level, age of the mother, education level of mothers, and distance from health facilities.
Data preprocessing
The first step in machine learning is data pre-processing, which involves preparing and transforming the data to make it understandable for computers (64). In this study, the machine learning process focused on the outcome variable of delivery location, along with various independent variables outlined in the above subsection.
Our machine learning workflow involved a continuous improvement process for our models. We selected and engineered features, chose the appropriate model, trained the model, evaluated its performance, optimized its parameters through cross-validation, selected the top-performing final model, and deployed it to predict the place of delivery (65). We refined our models through an iterative approach, continuously making improvements. Figure 1 visually represents the steps in our workflow, but it may not include all the recurring tasks that were executed.
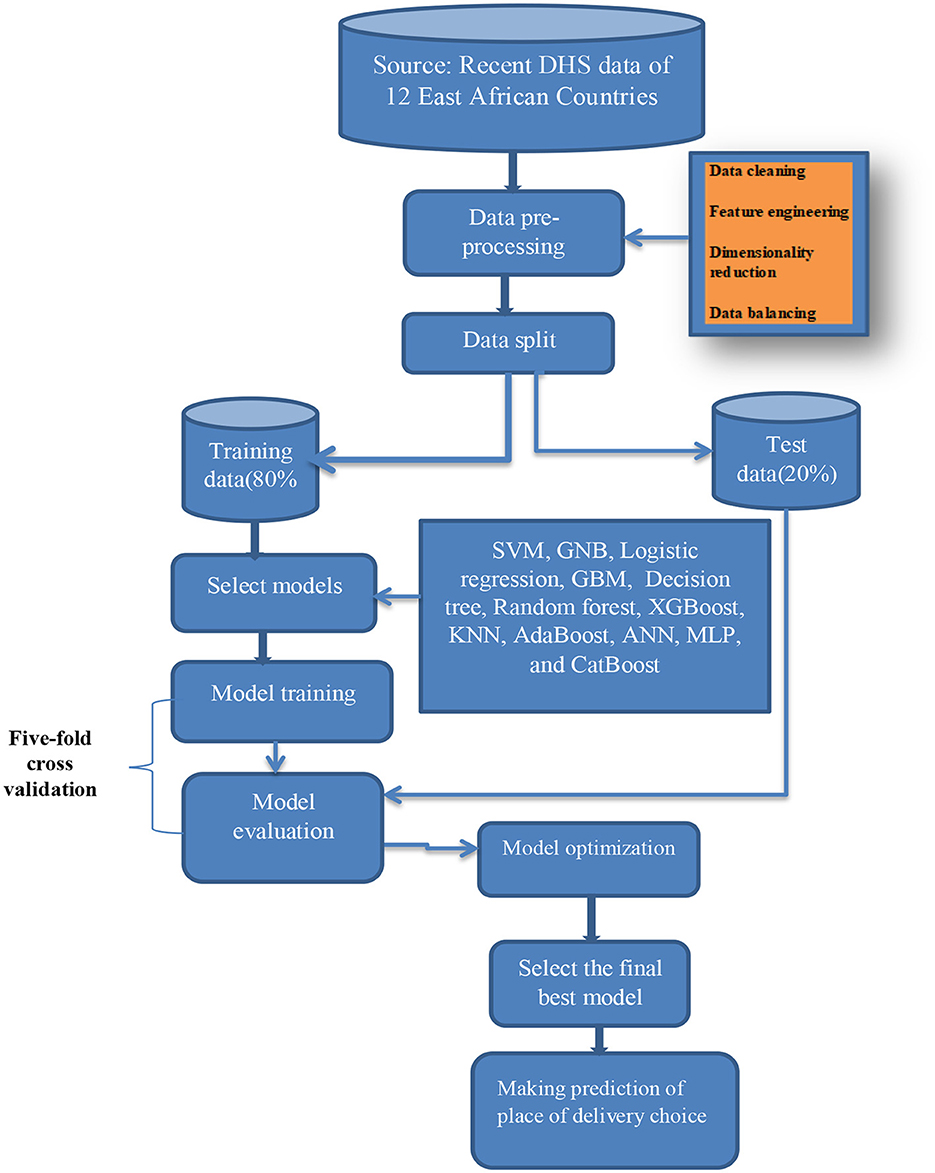
Figure 1. Study work flow diagram. ANN, Artificial Neural Network; GNB, Gaussian Naive Bayes; GBM, Gradient Boosting Machines; KNN, K-Nearest Neighbors; MLP, Multi-Layer Perceptron; SVM, Support Vector Machine; XGBoost, Extreme Gradient Boosting.
Data cleaning
During the data analysis process, a comprehensive data cleaning approach was employed to ensure the quality and integrity of the dataset. In this study, no redundant data entries were identified.
The missing rate for all variables in our study was found to be below 10%. To address missing values, the K-Nearest Neighbors (KNN) imputation technique was utilized. KNN imputation is a widely adopted method that leverages information from neighboring data points to impute missing values. KNN was chosen for its ability to utilize surrounding information, handle different data types, preserve structure, and its established reliability in missing value imputation (66, 67).
To identify outliers, we utilized various visualization techniques such as scatter plots, box plots, and histograms. Few outliers were removed based on the recommendation of the DHS guideline (63). Additionally, we assessed multicollinearity by examining the correlation matrix, considering a correlation value exceeding 0.8 between two variables as indicative of high correlation (68, 69). Our analysis confirmed that no multicollinearity was observed among the variables in this study.
As shown in Figure 2, the highest correlation was observed between marital status and husband's education, and there was also some correlation between the number of children and the mother's age; however, all correlations remained below 0.8. Therefore, no significant multicollinearity was detected among the variables.
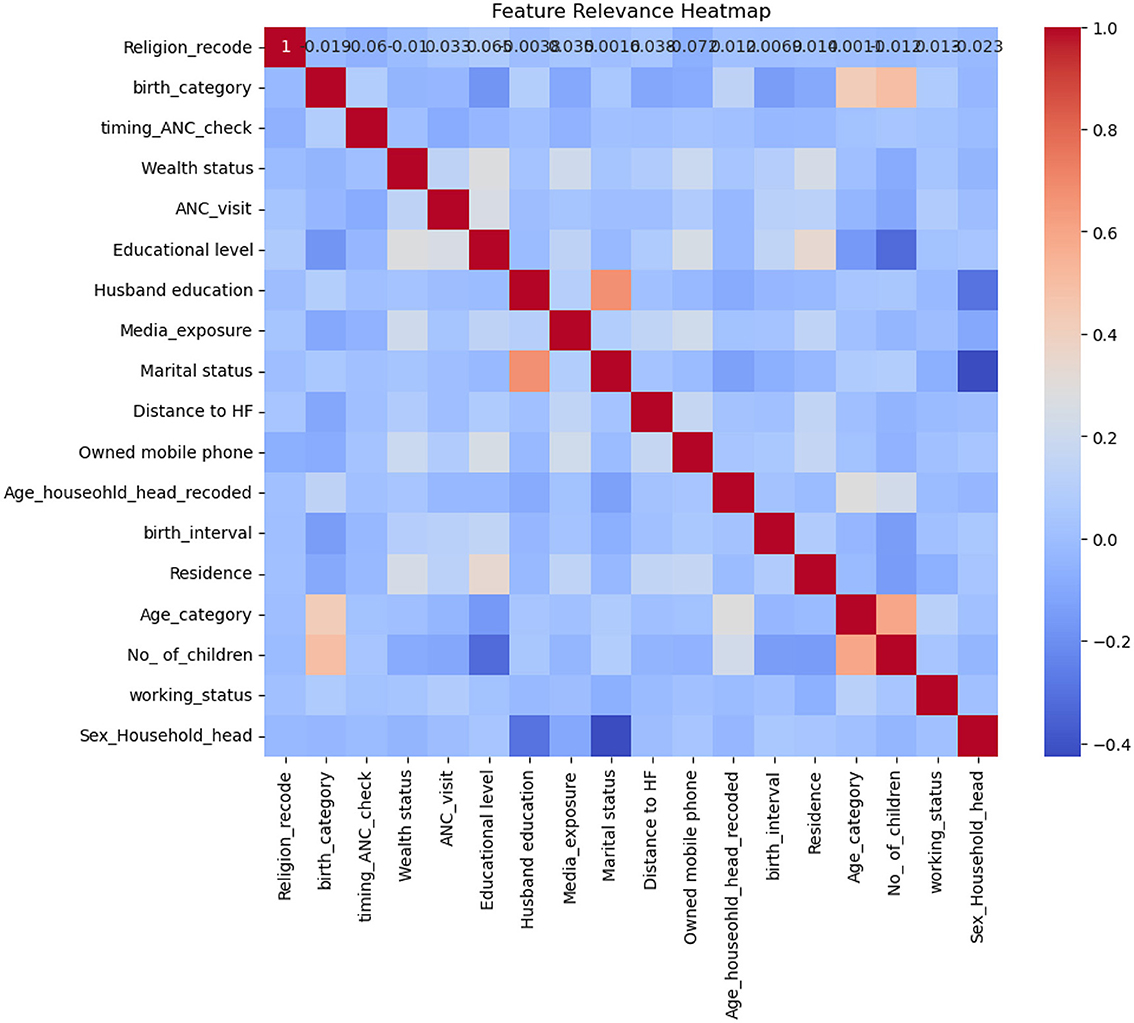
Figure 2. Heat map of the correlation matrix showing feature relevance.
Feature engineering
Feature engineering is the process of selecting, acquiring, and transforming the most relevant features from the available data to build machine learning models that are both precise and efficient (70). In our research, we used one-hot encoding to encode nominal categorical variables and label encoding for ordinal categorical variables (71).
Dimensionality reduction
In our study, we focused on enhancing model performance and simplifying the dataset through various dimensionality reduction techniques. These techniques included univariate selection, recursive feature elimination (RFE), random forest feature elimination, principal component analysis (PCA), lasso regression, and Boruta-based feature selection (72). After conducting thorough experimentation and comparing the results across different feature selection methods, we determined that the Boruta-based approach stood out as the most effective in terms of accuracy and robustness.
One of the key advantages of the Boruta algorithm is its ability to evaluate feature importance by comparing their performance against randomly generated shadow features. This approach ensures a comprehensive and unbiased assessment of feature significance, allowing only the most informative features to be selected for our predictive model. Moreover, the Boruta algorithm successfully distinguishes true signals from noise by comparing features against shadow features, resulting in a more reliable and robust feature selection process (73, 74).
By incorporating the features selected by the Boruta algorithm, we observed improved accuracy and robustness in predicting the place of delivery. Prediction accuracy was measured using metrics such as accuracy, precision, recall, F1-score, and AUC, while 5-fold cross-validation was employed to assess robustness. This underscores the practical benefits of the Boruta-based feature selection method within the context of our dataset.
Boruta algorithm graph visualized the importance of variables, highlighting significant variables in green, unimportant variables in red, and tentative variables in yellow (75). In our comprehensive analysis, the Boruta algorithm graph (Figure 3) showed all variables are important. Consequently, we used all variables to predict the place of delivery and explore data patterns through association rule mining.
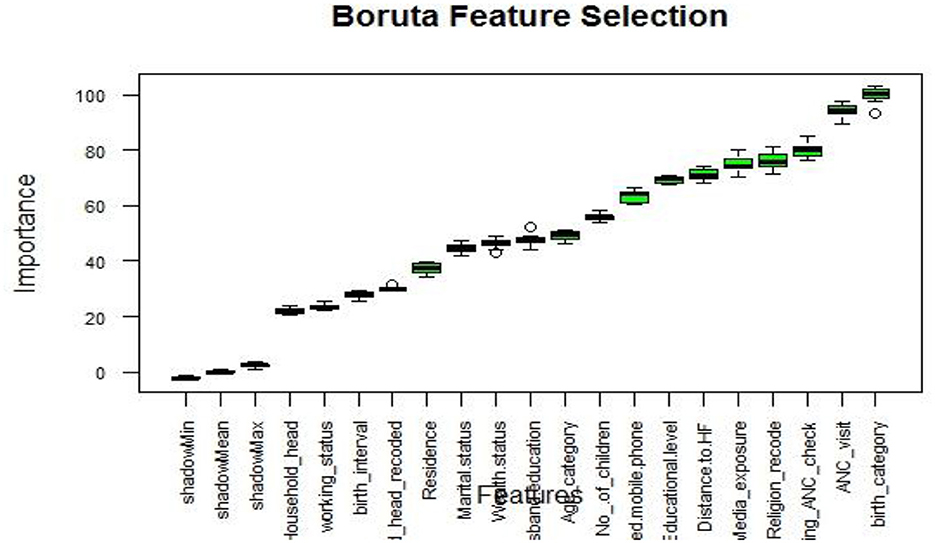
Figure 3. Feature selection using Boruta algorithm.
Data balancing
To address the class imbalance, it's helpful to experiment with various data balancing methods and select the most effective one for the specific dataset (76–78). To address the issue of class imbalance in our dataset, which consists of a binary outcome variable and categorical independent variables (with a few of them being binary), we conducted an extensive review of scientific literature (79, 80) and experimented with seven different data balancing methods. These methods were carefully selected based on their appropriateness for our specific dataset. The techniques we employed are as follows: Under-sampling, Over-sampling, Adaptive Synthetic Sampling (ADASYN), Synthetic Minority Oversampling Technique (SMOTE), SMOTE-ENN (Edited Nearest Neighbor), SMOTE-Tomek, and NearMiss algorithm.
By conducting a comprehensive assessment of model performance, and considering various metrics, we compared machine learning algorithms trained on balanced data using these different balancing techniques. This process enabled us to identify the most effective approach for addressing the class imbalance in our dataset. We selected the balancing technique that demonstrated superior performance for further experimentation and final prediction.
In this study, we compared the performance of each machine learning algorithm across different data balancing techniques. The results showed that SMOTE-ENN significantly outperformed the other methods, demonstrating a substantial advantage over them. Consequently, we chose the SMOTE-ENN technique for further analysis and optimization (see Table 1 for more details).
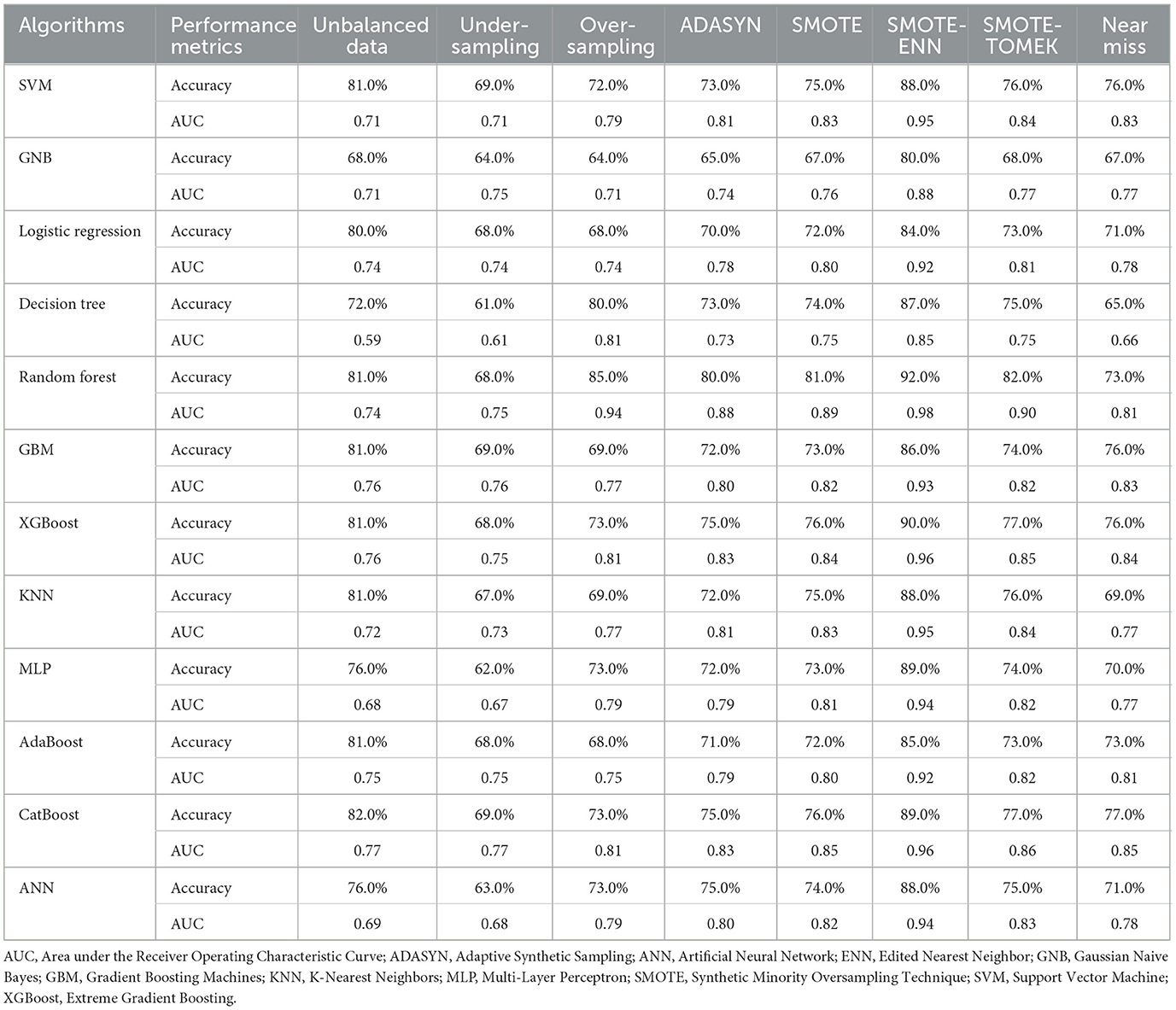
Table 1. Comparison of data balancing techniques across each machine learning algorithms.
Additionally, Supplementary material 1 provides a detailed graphical comparison of the performance of machine learning algorithms across various data balancing techniques and in the context of imbalanced data.
Model selection and development
In our research, we focused on predicting the place of delivery. We aimed to classify the place of delivery into two groups: “health facility delivery” and “home delivery.” To ensure accurate predictions, we needed to select suitable classifiers capable of effectively handling this classification task.
To accomplish this, we used the scikit-learn version 1.3.2 packages in Python, implemented within Jupyter Notebook. We employed 12 advanced machine learning algorithms to evaluate their predictive capabilities in distinguishing the place of delivery. The selection of these algorithms was based on their suitability for classification tasks and the nature of our dataset (81–83).
The algorithms we utilized include SVM with kernel methods, Gaussian Naive Bayes (GNB), logistic regression, decision tree, random forest, gradient boosting machines (GBM), eXtreme Gradient Boosting (XGBoost), AdaBoost, KNN algorithm, CatBoost Classifier, multilayer perceptron (MLP) neural network, and artificial neural networks (ANN) using TensorFlow. By incorporating a diverse set of algorithms, we aimed to explore different modeling approaches and assess their effectiveness in predicting the place of delivery (82).
Model training, evaluation, and optimization
In our study, we employed a straightforward method of dividing the data into two sets: an 80% (68,807 cases) training set and a 20% (17,202 cases) testing set. To assess the performance of each predictive model, we used various measurements, such as accuracy, precision, recall/sensitivity, F1-score, specificity, and AUC. Using these metrics, we conducted a comprehensive evaluation of each predictive model, considering overall correctness, accurate positive predictions, identification of positive instances, balance, and discriminatory ability (84).
In addition, we conducted a comprehensive analysis of the hyperparameters to optimize and enhance the model's performance. During model optimization, we systematically explored grid search, random search, and Bayesian optimization to identify the optimal hyperparameter settings. We compared the results from these techniques to determine which configurations yielded the highest performance. It is recommended to experiment with different tuning techniques and select the one that demonstrates superior performance (85, 86). To ensure robust performance evaluation, we employed cross-validation techniques and compared different options such as 3-, 5-, and 10-fold validations. Upon analysis, we found that 5-fold cross-validation provided the best results for our specific dataset. Therefore, we utilized the 5-fold cross-validation approach to ensure reliable and accurate performance evaluation (87).
To improve the model's accuracy and reliability, we carried out model calibration. By fine-tuning the model through calibration, we enhanced its predictive capabilities, resulting in more precise forecasts of the desired outcome (88).
Moreover, we compared different kernel methods specifically for the SVM model. We experimented with five commonly used types of kernel methods: linear kernel, polynomial kernel, radial basis function (RBF) kernel, sigmoid kernel, and Gaussian kernel (89). After conducting evaluations, we determined that the polynomial kernel method exhibited the highest performance for SVM, and thus we selected and employed it. Our objective was to select the kernel function that produced the best results for the SVM model through a thorough evaluation and comparison process.
Model interpretability
To enhance the interpretability of our model, we utilized association rule mining techniques to uncover hidden patterns and relationships within the dataset. This involved applying the widely adopted Apriori algorithm, specifically designed for association rule mining. Through this algorithm, we identified frequent item sets and extracted meaningful association rules using measures such as lift and confidence. The lift measure quantified the strength of associations between variables, revealing the influence of one variable on the occurrence of another. Confidence, on the other hand, indicated the reliability of association rules by showing how often the consequent variable appeared when the antecedent variable was present (90–92).
Furthermore, we employed the final top-performing machine learning model to select relevant features for prediction. This process allowed us to evaluate the importance of different features and choose those that had the greatest impact on the model's performance. By incorporating feature relevance selection, we improved the interpretability of our model, emphasizing the influential variables in making predictions.
Results
Descriptive results of the background characteristics
The study extensively analyzed the descriptive and socio-demographic characteristics of 86,009 women of reproductive age. Among the participants, the highest percentage, which represented 39,639 individuals (46.09%), were between the ages of 25 and 34. In terms of their place of residence, the majority of the study participants, comprising 64,548 individuals (75.1%), came from rural areas. For more detailed information, please refer to Table 2.

Table 2. Individual characteristics of reproductive age group women in East African countries (n = 86,009).
Prevalence of health facility delivery in East Africa
Based on the analysis of the recent DHS dataset in our study, as described in the methodology section, it was revealed that the overall prevalence of health facility delivery among women of reproductive age in East Africa was 83.71% (95% CI: 83.48, 83.93). Notably, Ethiopia had the lowest rate of health facility delivery, with only 38.05% (95% CI: 36.92, 39.18) of women accessing such services. Conversely, Malawi had the highest prevalence of health facility delivery, with 94.35% (95% CI: 93.95, 94.74) of women delivering at a health facility. For a more comprehensive breakdown of health facility-based deliveries in each country, please refer to Figure 4.
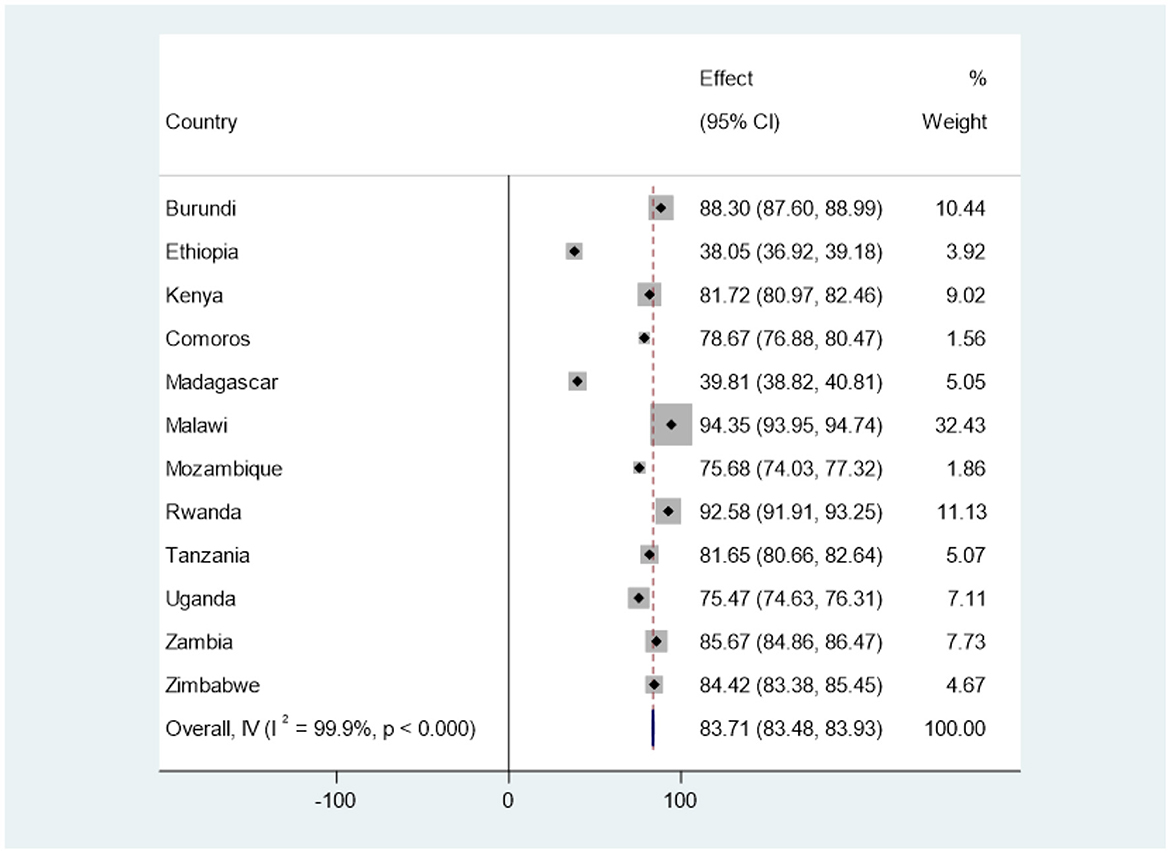
Figure 4. The prevalence of health facility delivery among reproductive age women in East Africa countries using forest tree plot.
Machine learning analysis of the place of delivery
In this subsection, we present the performance of each machine learning algorithm both before and after optimization.
Comparative analysis of machine learning models using balanced data
As outlined in the methodology, we selected SMOTE-ENN for further analysis and optimization due to its significant effectiveness. The analysis of the balanced data using SMOTE-ENN revealed that Random Forest was the top-performing algorithm, followed by CatBoost and XGBoost. The ROC curve value for SMOTE-ENN is presented in Figure 5. For detailed performance metrics, please refer to Supplementary material 1.
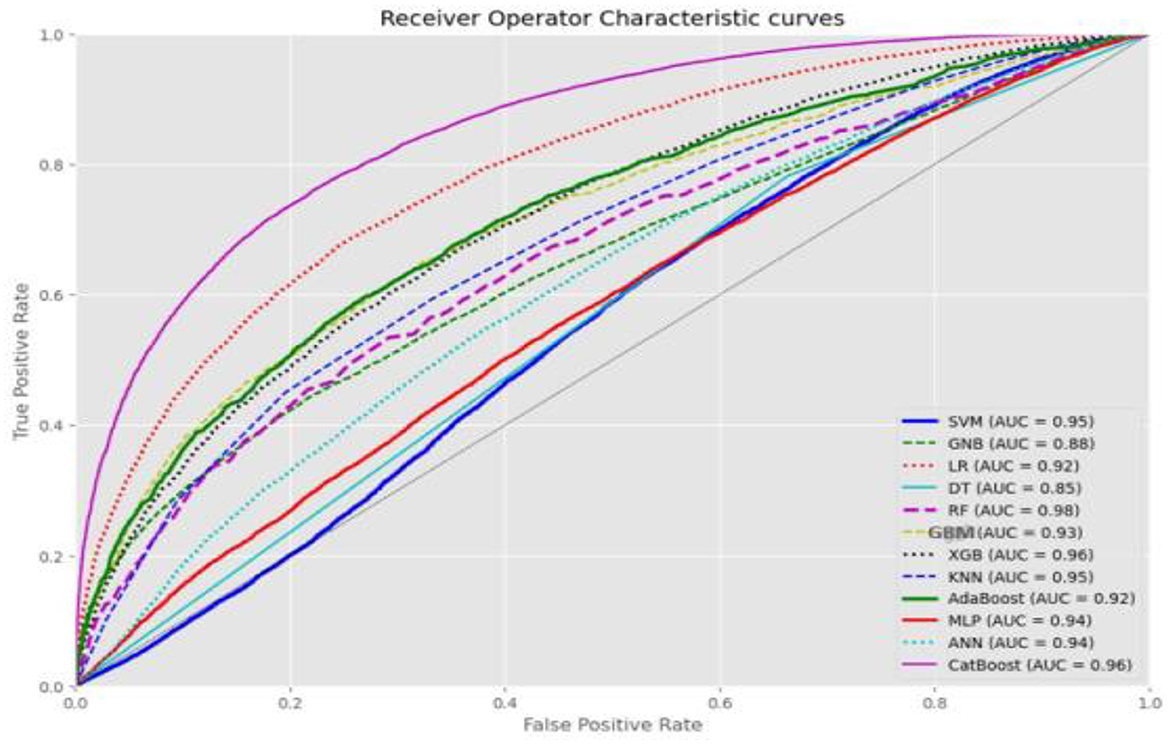
Figure 5. ROC curve value of each machine learning algorithm using balanced data.
Performance comparisons of optimized machine learning models
We compared the performance of 12 machine learning algorithms for predicting the place of delivery using three different tuning techniques. We employed techniques such as grid search, random search, and Bayesian optimization for tuning the model. The results demonstrated excellent performance across all 12 algorithms, although performance varied depending on the tuning technique.
In the grid search technique, the random forest algorithm achieved the highest performance metrics, with an AUC of 0.98 and an accuracy of 92.0%. The KNN and GBM closely followed with accuracies of 92.0 and 91.0%, respectively, and corresponding AUC values of 0.96 and 0.97. Most algorithms achieved an AUC above 0.90, except for GNB and decision trees, which had AUC values of 0.88 and 0.86, respectively.
In the random search technique, the random forest algorithm demonstrated superior performance metrics, with an AUC of 0.98 and an accuracy of 93.0%. The XGBoost and CatBoost algorithms closely followed with accuracies of 92.0% and AUC values of 0.97. Similar to the grid search results, most algorithms achieved an AUC above 0.90, except for GNB and decision trees, which had AUC values of 0.88.
Using the Bayesian optimization technique, the SVM and CatBoost algorithms showcased the best performance metrics, in which both of those algorithms scored an accuracy of 95% and AUC of 0.98. The KNN and MLP algorithms closely followed, achieving accuracies of 90.0% with respective AUC values of 0.96 and 0.95. Most algorithms achieved an AUC above 0.90, except for GNB and GBM, which had AUC values of 0.88 and 0.84, respectively.
Overall, the comprehensive evaluation demonstrated excellent performance across all 12 machine learning algorithms, with consistent and comparable results. Different tuning techniques yielded the best outcomes for different algorithms, with random search, grid search, and Bayesian optimization showing notable performance in specific cases.
The top-performing algorithms were obtained using Bayesian optimization tuning. Although variations in performance were observed, no single technique consistently outperformed all aspects of the machine learning algorithms. The top-performing algorithms across all metrics were SVM and CatBoost with Bayesian optimization tuning, both scoring an accuracy of 95%, an AUC of 0.98, and showing insignificant differences in comprehensive analysis of metrics performance such as accuracy, precision, recall/sensitivity, F1-score, specificity, and AUC (see Figure 6).
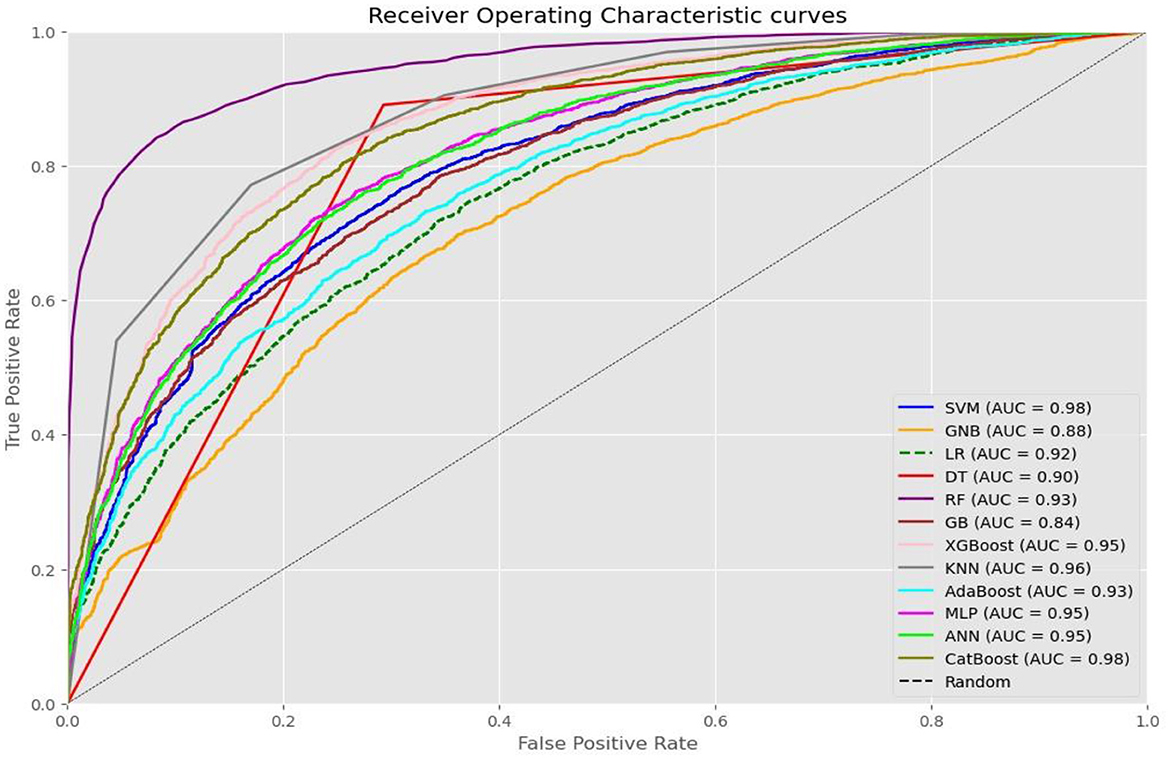
Figure 6. A ROC curve value of each machine learning algorithm after optimized using Baysian optimization technique.
To get a detailed comparison of the 12 machine learning algorithms and how they performed in the three different tuning techniques, please refer to Table 3. You can also find graphical representations of the algorithm performance in each tuning technique in Supplementary material 2.
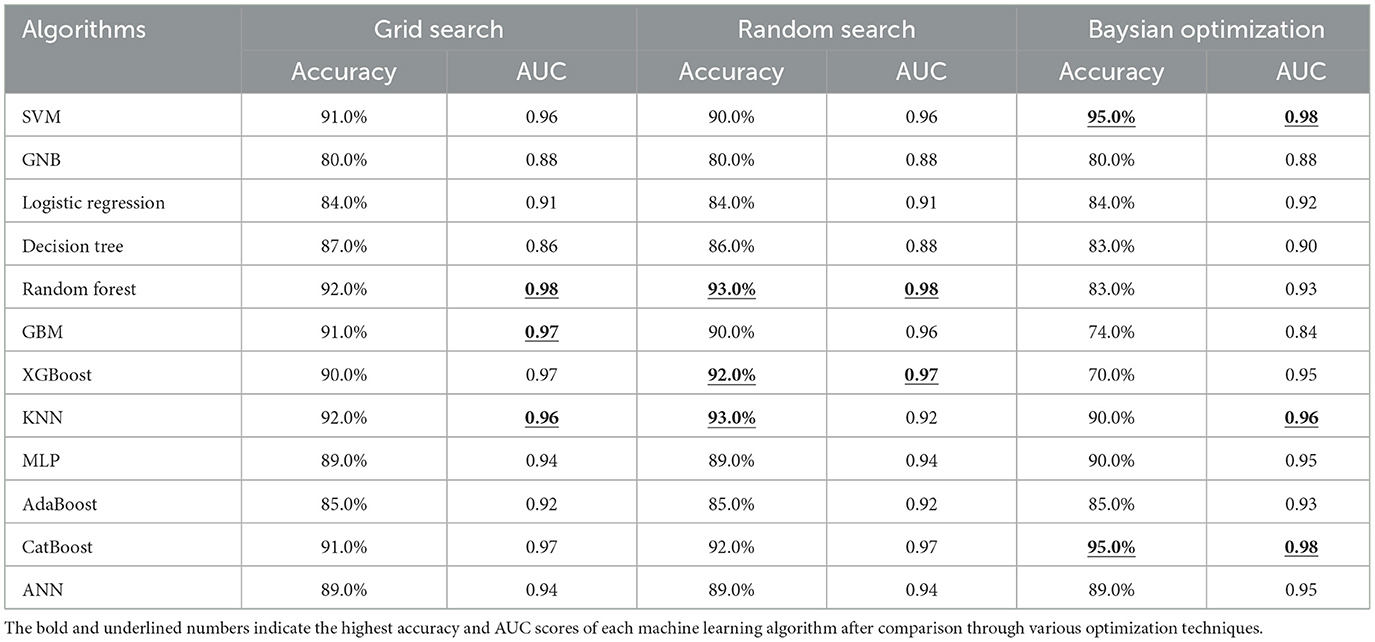
Table 3. Accuracy and AUC value of the selected machine algorithms after data balancing and optimized with across different hyperparameter tuning techniques.
Model interpretability and feature relevance
Association rule mining
By employing the Apriori algorithm, our study discovered seven influential association rules based on their lift values and confidence. Significantly, the consistent presence of variables such as maternal and paternal education levels, timing of the first ANC checkup during the first trimester (early ANC visit), wealth status, having marital status, mobile phone ownership, religious affiliation (Jehova or traditional), having media exposure, and giving birth for the first time indicated their strong association with the likelihood of facility delivery.
The top seven association rules and their corresponding lift values are as follows:
1. If mothers have a higher education level and their husbands also have a higher education level, the probability of giving birth at a facility is 97.4% (confidence = 0.974 and lift = 1.226).
2. If mothers have a higher education level and attend their first ANC checkup in the first trimester, the probability of giving birth at a facility is 95.8% (confidence = 0.958 and lift = 1.205).
3. If mothers are in the middle level of economic status and their husbands have a higher education level, the probability of giving birth at a facility is 95.5% (confidence = 0.955 and lift = 1.202).
4. If mothers and their husbands have a higher educational level and the mothers are married, the probability of giving birth at a facility is 96.7% (confidence = 0.967 and lift = 1.216).
5. If mothers have a higher educational level, own a mobile phone, and follow the Jehova religion, the probability of giving birth at a facility is 97.6% (confidence = 0.976 and lift = 1.228).
6. If mothers have a higher education level, have access to media, and follow the Jehova religion, the probability of giving birth at a facility is 97.5% (confidence = 0.975 and lift = 1.217).
7. If mothers have a higher education level, are giving birth for the first time, and follow a traditional religion, the probability of giving birth at a facility is 96.8% (confidence = 0.968 and lift = 1.219).
Evaluation of feature relevance
We used the CatBoost algorithm to analyze the importance of features in predicting the place of delivery. Choosing CatBoost over SVM, despite their equal prediction performance in this study, was due to CatBoost's interpretability advantage. Unlike SVM, CatBoost allows for direct interpretation of feature importance.
Accordingly, the top seven importance variables for this prediction were religion, birth order category, timing of the first ANC checkup, wealth status, ANC visit, highest educational level of mother, and husband education level (see Figure 7).
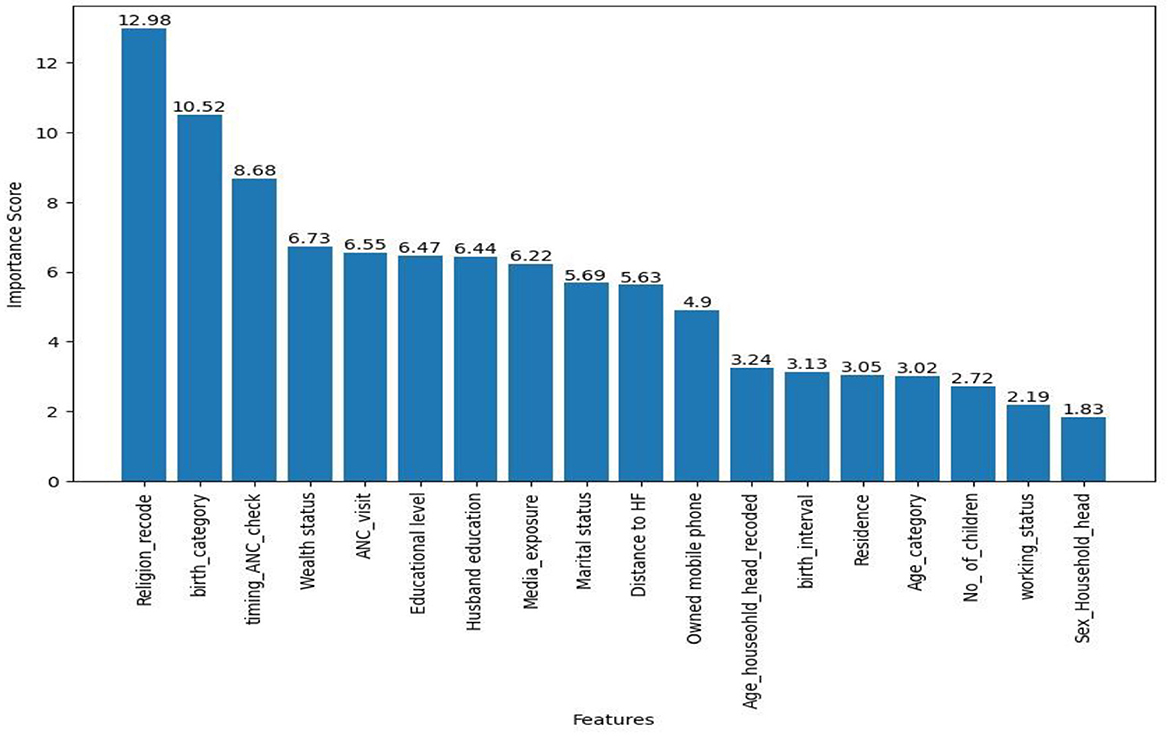
Figure 7. CatBoost based feature relevance.
Discussion
In our research study conducted using recent DHS data of East African countries, we evaluated 12 advanced machine learning algorithms using different techniques to balance the data and fine-tune the hyperparameters. Our extensive experimentation enabled us to take the possible best performance metrics score of each algorithm after comparison in each data balancing and tuning technique.
Our analysis revealed that the overall prevalence of health facility delivery among women of reproductive age in East Africa was found to be 83.71% (95% CI: 83.48, 83.93). This figure is slightly lower than the previously reported rate of 87.49% (30). The discrepancy may stem from the different timeframes in which the surveys were conducted across countries. The decline in health facility deliveries signals the need for urgent measures to meet SDGs aimed at reducing maternal mortality.
Ethiopia exhibited the lowest health facility delivery rate at 38.05%, while Malawi had the highest at 94.35%. The challenges in Ethiopia may relate to insufficient medical care and human resources to serve over 120 million people (93).
Out of the 12 algorithms that were evaluated and compared, SVM and CatBoost after being optimized using Bayesian optimization tuning emerged as the top performers in predicting the place of delivery, in which both of those algorithms scored an accuracy of 95%, and AUC of 0.98. Furthermore, a comprehensive analysis of various performance metrics indicated that there was no significant difference between these two algorithms, highlighting their comparable capabilities in predicting the place of delivery. It is worth noting that the performance of these algorithms in our study surpasses that of previous research on predicting the place of delivery (59–61). This variation could be attributed to the unique nature of our dataset, which involved a larger sample size and different features. Additionally, our study focused on extensively experimenting with various data balancing and tuning techniques, which may have contributed to the improved performance as noted by previous scholarly findings in this field (76, 77, 85, 86).
On the other hand, the performance of the top-performing algorithms in our study was lower compared to previous research in Ethiopia (62) that focused on predicting skilled delivery. This disparity could be attributed to differences in dataset characteristics and the methodology employed for feature selection. While the previous Ethiopian study solely utilized variables identified as significant in the multivariable logistic regression for developing their model, we employed the Boruta algorithm feature selection technique after comparing various techniques. This difference in feature selection methodology could potentially explain the variation in the performance of the machine learning algorithms.
Our findings implied the effectiveness of SVM and CatBoost when optimized with Bayesian optimization tuning. SVM combines the strengths of effective classification with the efficiency of Bayesian optimization for hyperparameter optimization, resulting in improved predictions. Similarly, CatBoost, designed for categorical data, performs well when paired with Bayesian optimization tuning due to its ability to handle categorical features and benefit from optimization capabilities. This finding is supported by several studies conducted by different researchers who analyze the strengths and weaknesses of each algorithm (94–96).
Association rule mining analysis led us to identify seven strong rules with confidence above 95.0% that provide insights into the factors influencing facility-based deliveries. One consistent finding is that higher education levels of both mothers and their husbands are strongly associated with an increased probability of delivering at a facility. This association can be explained by the fact that education equips individuals with knowledge about the benefits of skilled birth attendance and the risks associated with home deliveries. Educated individuals are more likely to understand the importance of accessing healthcare facilities for safe deliveries and are empowered to make informed decisions. The finding is supported by previous studies (33).
The findings indicate that early ANC checkups are a significant predictor consistently identified in the association rules. This suggests that early ANC visits influence women's decisions regarding facility delivery. During these visits, expectant mothers receive essential information about the importance of skilled birth attendance and are encouraged to deliver in healthcare facilities. Notably, this finding aligns with a study conducted in Southern Ethiopia (37), though it contradicts results from a study based on the Mini Ethiopian DHS (36).
We also find that wealth status plays a role in determining the probability of delivering at a health facility. The middle level of economic status is associated with facility delivery, highlighting the role of financial resources in accessing and utilizing maternal healthcare services. This could be due to women with good economic status being more likely to afford the costs associated with facility deliveries, including transportation, medical fees, and other related expenses. Additionally, they may have access to better healthcare facilities, which further encourages facility-based deliveries. This finding is supported by previous studies elsewhere in the world (34).
Being married is found to enhance the chances of opting for facility delivery. This could be because married women often have a partner who can assist them in decision-making regarding childbirth, which may influence their choice to select facility delivery. This finding is supported by previous studies conducted in Northern Ethiopia, which highlight the potential link between marital status and the utilization of maternal health services (97).
Mobile phone ownership is significantly associated with facility delivery. This correlation likely stems from mobile phones' ability to provide access to health-related information, helping women gather crucial knowledge about the benefits of facility delivery and the services available. While ownership does not necessarily imply internet access or that one has a smartphone only, it still enhances communication with healthcare providers through features such as voice calls and text messaging. This functionality enables women to seek advice and assistance during their decision-making process. This finding aligns with a previous study conducted elsewhere (42).
Religious affiliation, specifically being a follower of Jehovah or traditional religions, is also associated with a higher likelihood of facility delivery. This finding suggests the importance of considering religious factors in public health interventions and highlights the need for targeted, culturally sensitive strategies to enhance health facility delivery in diverse religious communities. The finding is supported by studies elsewhere in the world (31).
Media exposure is consistently linked to a higher probability of delivering at a health facility. This could be due to media platforms, such as radio, television, or the internet, playing a crucial role in disseminating information about the benefits of facility delivery, available services, and success stories. Exposure to such messages creates awareness and helps women make informed choices regarding their place of delivery. This finding is supported by previous studies elsewhere in the world (29, 31).
According to the top seven association rules identified in this study, give a first-order child increase the likelihood of facility-based deliveries. This finding is supported by studies conducted elsewhere (42, 43). A possible explanation is that first-time mothers may be more aware of the potential complications associated with home deliveries, leading them to choose facility-based care for their childbirth.
Strengths and limitations of the study
This study has several notable strengths. It conducted a comprehensive evaluation of 12 advanced machine learning algorithms using a relatively large dataset, thoroughly examining their performance. Additionally, extensive experimentation with various data balancing and hyperparameter tuning techniques was undertaken to optimize each algorithm's effectiveness, enhancing the reliability of the findings. The study also identified key factors associated with facility-based deliveries, providing valuable insights for interventions and strategies.
However, certain limitations must be considered when interpreting the results. Firstly, the study relied on existing survey data, which may have inherent limitations and gaps in capturing some relevant variables. Another limitation is the lack of exploration of ensemble techniques, which combine multiple models to improve predictive accuracy. The study utilized DHS data starting from 2012, which may affect its applicability and highlights the opportunity for further validation with more recent data. Lastly, the exclusive use of the Apriori algorithm for constructing association rules presents a limitation.
Conclusion
The analysis of various machine learning algorithms, alongside various techniques, revealed that the SVM and CatBoost algorithms excelled in accurately identifying health facility-based deliveries. These results underscore the effectiveness of machine learning models as valuable tools for healthcare providers and policymakers, enabling them to identify women at risk of delivering outside healthcare facilities and design targeted interventions to promote safe deliveries.
The overall prevalence of facility-based deliveries stands at 83.71%, indicating a slight decline from previous reports. This trend highlights the urgent need for targeted interventions to meet SDGs, particularly in maternal health.
Furthermore, the investigation into factors influencing facility-based deliveries through association rule mining identified several key determinants, including education level, early ANC visits, wealth status, marital status, mobile phone ownership, religious affiliation, media exposure, and giving birth for the first time. By addressing these factors through tailored interventions and policies, stakeholders can enhance health outcomes for mothers and children in East Africa.
This study recommends promoting facility-based deliveries through a variety of strategies: raising awareness about skilled birth attendance, encouraging early ANC visits, addressing financial barriers with targeted support programs, implementing culturally sensitive interventions, and utilizing media campaigns and mobile health initiatives. Additionally, interventions should be designed with consideration for the birth order of the child, recognizing that mothers may have different informational needs depending on whether it is their first or subsequent delivery.
Future research should consider additional contextual factors to develop a comprehensive understanding of influences on the place of delivery. Researchers are also encouraged to explore alternative algorithms for constructing association rules and to experiment with model ensembling techniques to optimize algorithm performance. Incorporating more recent and diverse datasets will further enhance the relevance and applicability of findings. By adopting these approaches, researchers can improve the accuracy and robustness of their predictions.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found at: the data used for this study can be accessed from the DHS website upon request to the appropriate authority (URL: https://dhsprogram.com/data/available-datasets.cfm). Additionally, the source code used for this study can be shared upon reasonable request from the correspondence author.
Ethics statement
We obtained approval from the DHS Program to access and utilize their data for our study, which was obtained from: https://www.dhsprogram.com. The data provided by the DHS is anonymized. As a result, no institutional ethical review was required, as the data adheres to regulations that safeguard the rights and privacy of human subjects.
Author contributions
HN: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. GT: Writing – review & editing, Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Software, Writing – original draft. AT: Conceptualization, Formal analysis, Investigation, Methodology, Project administration, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. EE: Conceptualization, Data curation, Funding acquisition, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. TA: Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. GA: Conceptualization, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. AW: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. AZ: Conceptualization, Formal analysis, Funding acquisition, Investigation, Methodology, Software, Supervision, Writing – original draft, Writing – review & editing, Validation.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Acknowledgments
We would like to thank the measure DHS program for providing the dataset.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpubh.2024.1439320/full#supplementary-material
Abbreviations
ADASYN, Adaptive Synthetic Sampling; ANC, Anta Natal Care; ANN, Artificial Neural Network; AUC, Area under the Receiver Operating Characteristic Curve; DHS, Demographic Health Survey; FPR, False Positive Rate; GBM, Gradient Boosting Machines; GNB, Gaussian Naive Bayes; MLP, Multi-Layer Perceptron; KNN, K-Nearest Neighbors; PCA, Principal Component Analysis; RBF, Radial Basis Function; RFE, Recursive Feature Elimination; SDGs, Sustainable Development Goals; SVM, Support Vector Machine; SMOTE, Synthetic Minority Over-Sampling Technique; SMOTE-ENN, Synthetic Minority Over-Sampling Technique with Edited Nearest Neighbor; TPR, True Positive Rate; XGBoost: eXtreme Gradient Boosting; KNN, K-Nearest Neighbors; ROC, Receiver Operating Characteristic Curve; WHO, World Health Organization; XGBoost, Extreme Gradient Boosting.
References
1. World Health Organization. A Vision for Primary Health Care in the 21st Century: Towards Universal Health Coverage and the Sustainable Development Goals. Geneva: World Health Organization (2018).
2. World Health Organization. Primary Health Care on the Road to Universal Health Coverage: 2019 Global Monitoring Report. Geneva: World Health Organization (2021).
3. Bitton A, Ratcliffe HL, Veillard JH, Kress DH, Barkley S, Kimball M, et al. Primary health care as a foundation for strengthening health systems in low-and middle-income countries. J Gen Intern Med. (2017) 32:566–71. doi: 10.1007/s11606-016-3898-5
4. De Maeseneer J, Willems S, De Sutter A, Van de Geuchte I, Billings M. Primary Health Care as a Strategy for Achieving Equitable Care: a Literature Review Commissioned By the Health Systems Knowledge Network. Ottawa, ON: International Development Research Centre (2007).
5. Srivastava A, Avan BI, Rajbangshi P, Bhattacharyya S. Determinants of women's satisfaction with maternal health care: a review of literature from developing countries. BMC Pregn Childb. (2015) 15:1–12. doi: 10.1186/s12884-015-0525-0
6. Makaula P, Funsanani M, Mamba KC, Musaya J, Bloch P. Strengthening primary health care at district-level in Malawi-determining the coverage, costs and benefits of community-directed interventions. BMC Health Serv Res. (2019) 19:1–14. doi: 10.1186/s12913-019-4341-5
7. Azevedo MJ, Azevedo MJ. The state of health system (s) in Africa: challenges and opportunities. Histor Perspect State Health Health Systems in Africa. (2017) 2:1–73. doi: 10.1007/978-3-319-32564-4_1
8. Mekonnen T, Dune T, Perz J. Maternal health service utilisation of adolescent women in sub-Saharan Africa: a systematic scoping review. BMC Pregn Childb. (2019) 19:1–16. doi: 10.1186/s12884-019-2501-6
9. Chinkhumba J, De Allegri M, Muula AS, Robberstad B. Maternal and perinatal mortality by place of delivery in sub-Saharan Africa: a meta-analysis of population-based cohort studies. BMC Publ Health. (2014) 14:1–9. doi: 10.1186/1471-2458-14-1014
10. Chaka EE, Mekurie M, Abdurahman AA, Parsaeian M, Majdzadeh R. Association between place of delivery for pregnant mothers and neonatal mortality: a systematic review and meta-analysis. Eur J Publ Health. (2020) 30:743–8. doi: 10.1093/eurpub/ckz060
11. Atukunda EC, Mugyenyi GR, Obua C, Musiimenta A, Najjuma JN, Agaba E, et al. When women deliver at home without a skilled birth attendant: a qualitative study on the role of health care systems in the increasing home births among rural women in southwestern Uganda. Int J Women's Health. (2020) 2020:423–34. doi: 10.2147/IJWH.S248240
12. Dahab R, Sakellariou D. Barriers to accessing maternal care in low income countries in Africa: a systematic review. Int J Environ Res Public Health. (2020) 17:4292. doi: 10.3390/ijerph17124292
13. Melo P, Coomarasamy A, Coomarasamy A. Pregnancy and Childbirth Risks: Clinical and Legal Perspectives. Research Handbook on Patient Safety and the Law. Cheltenham: Edward Elgar Publishing (2023). p. 237-56.
14. Zinjani S. Common Medical Conditions in the Neonates. Clinical Anesthesia for the Newborn and the Neonate. Berlin: Springer (2023). p. 49–70.
15. Bhutta ZA, Das JK, Bahl R, Lawn JE, Salam RA, Paul VK, et al. Can available interventions end preventable deaths in mothers, newborn babies, and stillbirths, and at what cost? Lancet. (2014) 384:347–70. doi: 10.1016/S0140-6736(14)60792-3
16. World Health Organization. Maternal Mortality: Why Do Women Die? Geneva: World Health Organization (2020). Available at: https://www.who.int/news-room/fact-sheets/detail/maternal-mortality (accessed May 26, 2024).
17. Say L, Chou D, Gemmill A, Tunçalp Ö, Moller A-B, Daniels J, et al. Global causes of maternal death: a WHO systematic analysis. Lancet Glob Health. (2014) 2:e323–e33. doi: 10.1016/S2214-109X(14)70227-X
18. Miller AE, Morgan C, Vyankandondera J. Causes of puerperal and neonatal sepsis in resource-constrained settings and advocacy for an integrated community-based postnatal approach. Int J Gynecol Obstetr. (2013) 123:10–5. doi: 10.1016/j.ijgo.2013.06.006
19. Wang H, Li N, Chivese T, Werfalli M, Sun H, Yuen L, et al. IDF diabetes atlas: estimation of global and regional gestational diabetes mellitus prevalence for 2021 by International Association of Diabetes in Pregnancy Study Group's Criteria. Diabet Res Clin Pract. (2022) 183:109050. doi: 10.1016/j.diabres.2021.109050
20. Salam RA, Das JK, Ali A, Bhaumik S, Lassi ZS. Diagnosis and management of preeclampsia in community settings in low and middle-income countries. J Fam Med Prim Care. (2015) 4:501–6. doi: 10.4103/2249-4863.174265
21. Umesawa M, Kobashi G. Epidemiology of hypertensive disorders in pregnancy: prevalence, risk factors, predictors and prognosis. Hypertens Res. (2017) 40:213–20. doi: 10.1038/hr.2016.126
22. World Health Organization. HIV—Estimated Percentage of Pregnant Women Living With HIV Who Received Antiretrovirals for Preventing Mother-to-Child Transmission. Geneva: World Health Organization. The Global Health Observatory (2023). Available at: https://www.who.int/data/gho
23. UNAIDS U. Global Plan Towards the Elimination of New HIV Infections Among Children By 2015. Geneva: UNAIDS (2011).
24. World Health Organization Newborn Mortality. Geneva: World Health Organization (2023). Available at: https://www.who.int/news-room/fact-sheets/detail/newborn-mortality (accessed June 12, 2024).
25. Sharrow D, Hug L, You D, Alkema L, Black R, Cousens S, et al. Global, regional, and national trends in under-5 mortality between 1990 and 2019 with scenario-based projections until 2030: a systematic analysis by the UN Inter-agency Group for Child Mortality Estimation. Lancet Glob Health. (2022) 10:e195–206. doi: 10.1016/S2214-109X(21)00515-5
26. Coll-Seck A, Clark H, Bahl R, Peterson S, Costello A, Lucas T. Framing an agenda for children thriving in the SDG era: a WHO-UNICEF-Lancet Commission on child health and wellbeing. Lancet. (2019) 393:109–12. doi: 10.1016/S0140-6736(18)32821-6
27. Brizuela V, Tunçalp Ö. Global initiatives in maternal and newborn health. Obstetr Med. (2017) 10:21–5. doi: 10.1177/1753495X16684987
28. Souza JP, Gülmezoglu AM, Vogel J, Carroli G, Lumbiganon P, Qureshi Z, et al. Moving beyond essential interventions for reduction of maternal mortality (the WHO Multicountry Survey on Maternal and Newborn Health): a cross-sectional study. Lancet. (2013) 381:1747–55. doi: 10.1016/s0140-6736(13)60686-8
29. Ketemaw A, Tareke M, Dellie E, Sitotaw G, Deressa Y, Tadesse G, et al. Factors associated with institutional delivery in Ethiopia: a cross sectional study. BMC Health Serv Res. (2020) 20:1–6. doi: 10.1186/s12913-020-05096-7
30. Tesema GA, Tessema ZT. Pooled prevalence and associated factors of health facility delivery in East Africa: mixed-effect logistic regression analysis. PLoS ONE. (2021) 16:e0250447. doi: 10.1371/journal.pone.0250447
31. Tadele N, Lamaro T. Utilization of institutional delivery service and associated factors in Bench Maji zone, Southwest Ethiopia: community based, cross sectional study. BMC Health Serv Res. (2017) 17:1–10. doi: 10.1186/s12913-017-2057-y
32. Weldemariam S, Kiros A, Welday M. Utilization of institutional delivery service and associated factors among mothers in North West Ethiopian. BMC Res Notes. (2018) 11:1–6. doi: 10.1186/s13104-018-3295-8
33. Kebede A, Hassen K, Nigussie Teklehaymanot A. Factors associated with institutional delivery service utilization in Ethiopia. Int J Women's Health. (2016) 2016:463–75. doi: 10.2147/IJWH.S109498
34. Exavery A, Kanté AM, Njozi M, Tani K, Doctor HV, Hingora A, et al. Access to institutional delivery care and reasons for home delivery in three districts of Tanzania. Int J Equity Health. (2014) 13:1–11. doi: 10.1186/1475-9276-13-48
35. Ahinkorah BO. Non-utilization of health facility delivery and its correlates among childbearing women: a cross-sectional analysis of the 2018 Guinea demographic and health survey data. BMC Health Serv Res. (2020) 20:1–10. doi: 10.1186/s12913-020-05893-0
36. Tariku M, Enyew DB, Tusa BS, Weldesenbet AB, Bahiru N. Home delivery among pregnant women with ANC follow-up in Ethiopia; evidence from the 2019 Ethiopia mini demographic and health survey. Front Publ Health. (2022) 10:862616. doi: 10.3389/fpubh.2022.862616
37. Woldesemayat MWaE. Determinants of home delivery among women in rural pastoralist community of Hamar District, Southern Ethiopia: a case-control study. Risk Manag Healthc Policy. (2020) 13:2159. doi: 10.2147/RMHP.S268977
38. Hagos S, Shaweno D, Assegid M, Mekonnen A, Afework MF, Ahmed S. Utilization of institutional delivery service at Wukro and Butajera districts in the Northern and South Central Ethiopia. BMC Pregn Childb. (2014) 14:1–11. doi: 10.1186/1471-2393-14-178
39. Abeje G, Azage M, Setegn T. Factors associated with Institutional delivery service utilization among mothers in Bahir Dar City administration, Amhara region: a community based cross sectional study. Reprod Health. (2014) 11:1–7. doi: 10.1186/1742-4755-11-22
40. Tesema GA, Mekonnen TH, Teshale AB. Individual and community-level determinants, and spatial distribution of institutional delivery in Ethiopia, 2016: Spatial and multilevel analysis. PLoS ONE. (2020) 15:e0242242. doi: 10.1371/journal.pone.0242242
41. Tegegne TK, Chojenta C, Loxton D, Smith R, Kibret KT. The impact of geographic access on institutional delivery care use in low and middle-income countries: systematic review and meta-analysis. PLoS ONE. (2018) 13:e0203130. doi: 10.1371/journal.pone.0203130
42. Tessema ZT, Tiruneh SA. Spatio-temporal distribution and associated factors of home delivery in Ethiopia. Further multilevel and spatial analysis of Ethiopian demographic and health surveys 2005-2016. BMC Pregn Childb. (2020) 20:1–16. doi: 10.1186/s12884-020-02986-w
43. Fekadu GA, Ambaw F, Kidanie SA. Facility delivery and postnatal care services use among mothers who attended four or more antenatal care visits in Ethiopia: further analysis of the 2016 demographic and health survey. BMC Pregn Childb. (2019) 19:1–9. doi: 10.1186/s12884-019-2216-8
44. Gebremichael SG, Fenta SM. Determinants of institutional delivery in Sub-Saharan Africa: findings from Demographic and Health Survey (2013-2017) from nine countries. Trop Med Health. (2021) 49:45. doi: 10.1186/s41182-021-00335-x
45. Zegeye B, Ahinkorah BO, Idriss-Wheelr D, Oladimeji O, Olorunsaiye CZ, Yaya S. Predictors of institutional delivery service utilization among women of reproductive age in Senegal: a population-based study. Archiv Publ Health. (2021) 79:1–11. doi: 10.1186/s13690-020-00520-0
46. Ajayi AI, Akpan W. Maternal health care services utilisation in the context of “Abiye” (safe motherhood) programme in Ondo State, Nigeria. BMC Publ Health. (2020) 20:1–9. doi: 10.1186/s12889-020-08512-z
47. Habonimana D, Batura N. Empirical analysis of socio-economic determinants of maternal health services utilisation in Burundi. BMC Pregn Childb. (2021) 21:1–11. doi: 10.1186/s12884-021-04162-0
48. Kangbai DM, Bandoh DA, Manu A, Kangbai JY, Kenu E, Addo-Lartey A. Socio-economic determinants of maternal health care utilization in Kailahun District, Sierra Leone, 2020. BMC Pregn Childb. (2022) 22:276. doi: 10.1186/s12884-022-04597-z
49. Bolarinwa OA, Fortune E, Aboagye RG, Seidu A-A, Olagunju OS, Nwagbara UI, et al. Health facility delivery among women of reproductive age in Nigeria: does age at first birth matter? PLoS ONE. (2021) 16:e0259250. doi: 10.1371/journal.pone.0259250
50. Dankwah E, Zeng W, Feng C, Kirychuk S, Farag M. The social determinants of health facility delivery in Ghana. Reprod Health. (2019) 16:1–10. doi: 10.1186/s12978-019-0753-2
51. Boah M, Mahama AB, Ayamga EA. They receive antenatal care in health facilities, yet do not deliver there: predictors of health facility delivery by women in rural Ghana. BMC Pregn Childb. (2018) 18:1–10. doi: 10.1186/s12884-018-1749-6
52. Zhang X, Anser MK, Ahuru RR, Zhang Z, Peng MY-P, Osabohien R, et al. Do predictors of health facility delivery among reproductive-age women differ by health insurance enrollment? a multi-level analysis of Nigeria's data. Front Publ Health. (2022) 10:797272. doi: 10.3389/fpubh.2022.797272
53. Chernet AG, Dumga KT, Cherie KT. Home delivery practices and associated factors in Ethiopia. J Reprod Infertil. (2019) 20:102. doi: 10.1186/s12905-020-0892-1
54. Ahinkorah BO, Seidu A-A, Budu E, Agbaglo E, Appiah F, Adu C, et al. What influences home delivery among women who live in urban areas? Analysis of 2014 Ghana Demographic and Health Survey data. PLoS ONE. (2021) 16:e0244811. doi: 10.1371/journal.pone.0244811
55. Regassa LD, Tola A, Weldesenbet AB, Tusa BS. Prevalence and associated factors of home delivery in Eastern Africa: further analysis of data from the recent Demographic and Health Survey data. SAGE Open Med. (2022) 10:20503121221088083. doi: 10.1177/20503121221088083
56. Tiruneh SA, Lakew AM, Yigizaw ST, Sisay MM, Tessema ZT. Trends and determinants of home delivery in Ethiopia: further multivariate decomposition analysis of 2005–2016 Ethiopian Demographic Health Surveys. Br Med J Open. (2020) 10:e034786. doi: 10.1136/bmjopen-2019-034786
57. Tessema ZT, Tesema GA. Pooled prevalence and determinants of skilled birth attendant delivery in East Africa countries: a multilevel analysis of Demographic and Health Surveys. Ital J Pediatr. (2020) 46:1–11. doi: 10.1186/s13052-020-00943-z
58. Rajula HSR, Verlato G, Manchia M, Antonucci N, Fanos V. Comparison of conventional statistical methods with machine learning in medicine: diagnosis, drug development, and treatment. Medicina. (2020) 56:455. doi: 10.3390/medicina56090455
59. Fredriksson A, Fulcher IR, Russell AL, Li T, Tsai Y-T, Seif SS, et al. Machine learning for maternal health: predicting delivery location in a community health worker program in Zanzibar. Front Digit Health. (2022) 4:855236. doi: 10.3389/fdgth.2022.855236
60. Tsai Y-T, Fulcher IR, Li T, Sukums F, Hedt-Gauthier B. Predicting facility-based delivery in Zanzibar: the vulnerability of machine learning algorithms to adversarial attacks. Heliyon. (2023) 9:e16244. doi: 10.1016/j.heliyon.2023.e16244
61. Nasrat N, Babakerkhell MD, Gawhari GS, Ahmadi AR. Implementation of a predictive model for skilled child delivery service use in Afghanistan. In: 2021 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech). Kabul: IEEE (2021).
62. Tesfaye B, Atique S, Azim T, Kebede MM. Predicting skilled delivery service use in Ethiopia: dual application of logistic regression and machine learning algorithms. BMC Med Inform Decis Mak. (2019) 19:1–10. doi: 10.1186/s12911-019-0942-5
63. USAID. Guide to DHS Statistics DHS-7 (Version 2). (2020). Available at: https://dhsprogram.com/data/Guide-to-DHS-Statistics/index.cfm (accessed November 24, 2023).
64. Kadhim AI. An evaluation of preprocessing techniques for text classification. Int J Comput Sci Inform Secur. (2018) 16:22–32.
65. Warnett SJ, Zdun U. Architectural design decisions for the machine learning workflow. Computer. (2022) 55:40–51. doi: 10.1109/MC.2021.3134800
66. Pujianto U, Wibawa AP, Akbar MI. K-nearest neighbor (k-NN) based missing data imputation. In: 2019 5th International Conference on Science in Information Technology (ICSITech). Yogyakarta: IEEE (2019).
67. Beretta L, Santaniello A. Nearest neighbor imputation algorithms: a critical evaluation. BMC Med Inform Decis Mak. (2016) 16:197–208. doi: 10.1186/s12911-016-0318-z
68. Liu X, Lei S, Wei Q, Wang Y, Liang H, Chen L. Machine learning-based correlation study between perioperative immunonutritional index and postoperative anastomotic leakage in patients with gastric cancer. Int J Med Sci. (2022) 19:1173. doi: 10.7150/ijms.72195
69. Anand H, Vinodchandra S. Applying correlation threshold on Apriori algorithm. In: 2013 IEEE International Conference ON Emerging Trends in Computing, Communication and Nanotechnology (ICECCN). Tirunelveli: IEEE (2013).
70. Zheng A, Casari A. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists. Sebastopol, CA: O'Reilly Media, Inc. (2018).
71. Al-Shehari T, Alsowail RA. An insider data leakage detection using one-hot encoding, synthetic minority oversampling and machine learning techniques. Entropy. (2021) 23:1258. doi: 10.3390/e23101258
72. Rawat S, Rawat A, Kumar D, Sabitha AS. Application of machine learning and data visualization techniques for decision support in the insurance sector. Int J Inform Manag Data Insights. (2021) 1:100012. doi: 10.1016/j.jjimei.2021.100012
73. Pudjihartono N, Fadason T, Kempa-Liehr AW, O'Sullivan JM. A review of feature selection methods for machine learning-based disease risk prediction. Front Bioinformat. (2022) 2:927312. doi: 10.3389/fbinf.2022.927312
74. Rudnicki WR, Wrzesień M, Paja W. All relevant feature selection methods and applications. Feat Select Data Pat Recogn. (2015) 2015:11–28. doi: 10.1007/978-3-662-45620-0_2
75. Chen R-C, Dewi C, Huang S-W, Caraka RE. Selecting critical features for data classification based on machine learning methods. J Big Data. (2020) 7:52. doi: 10.1186/s40537-020-00327-4
76. Hasan M, Rabbi MF, Sultan MN, Nitu AM, Uddin MP. A novel data balancing technique via resampling majority and minority classes toward effective classification. Telecommun Comput Electr Contr. (2023) 21:1308–16. doi: 10.12928/telkomnika.v21i6.25211
77. Domingues I, Amorim JP, Abreu PH, Duarte H, Santos J. Evaluation of oversampling data balancing techniques in the context of ordinal classification. In: 2018 International Joint Conference on Neural Networks (IJCNN). Rio de Janeiro: IEEE (2018).
78. Ngusie HS, Mengiste SA, Zemariam AB, Molla B, Tesfa GA, Seboka BT, et al. Predicting adverse birth outcome among childbearing women in Sub-Saharan Africa: employing innovative machine learning techniques. BMC Publ Health. (2024) 24:2029. doi: 10.1186/s12889-024-19566-8
79. Mooijman P, Catal C, Tekinerdogan B, Lommen A, Blokland M. The effects of data balancing approaches: a case study. Appl Soft Comput. (2023) 132:109853. doi: 10.1016/j.asoc.2022.109853
80. Arora M, Dhawan S, Singh K. Data driven prognosis of cervical cancer using class balancing and machine learning techniques. EAI Endor Trans Energy Web. (2020) 7:e2. doi: 10.4108/eai.12-4-2021.169183
81. Ali MM, Paul BK, Ahmed K, Bui FM, Quinn JM, Moni MA. Heart disease prediction using supervised machine learning algorithms: performance analysis and comparison. Comput Biol Med. (2021) 136:104672. doi: 10.1016/j.compbiomed.2021.104672
82. Dhall D, Kaur R, Juneja M. Machine learning: a review of the algorithms and its applications. Proc ICRIC 2019 Recent Innov Comput. (2020) 2020:47–63. doi: 10.1007/978-3-030-29407-6_5
83. Austin PC, Tu JV, Ho JE, Levy D, Lee DS. Using methods from the data-mining and machine-learning literature for disease classification and prediction: a case study examining classification of heart failure subtypes. J Clin Epidemiol. (2013) 66:398–407. doi: 10.1016/j.jclinepi.2012.11.008
84. Jiang T, Gradus JL, Rosellini AJ. Supervised machine learning: a brief primer. Behav Ther. (2020) 51:675–87. doi: 10.1016/j.beth.2020.05.002
85. Raschka S. Model evaluation, model selection, and algorithm selection in machine learning. arXiv preprint arXiv:181112808. (2018). doi: 10.48550/arXiv.1811.12808
86. Yu T, Zhu H. Hyper-parameter optimization: a review of algorithms and applications. arXiv preprint arXiv:200305689. (2020). doi: 10.48550/arXiv.2003.05689
87. Xu Y, Goodacre R. On splitting training and validation set: a comparative study of cross-validation, bootstrap and systematic sampling for estimating the generalization performance of supervised learning. J Anal Test. (2018) 2:249–62. doi: 10.1007/s41664-018-0068-2
88. Dormann CF. Calibration of probability predictions from machine-learning and statistical models. Glob Ecol Biogeogr. (2020) 29:760–5. doi: 10.1111/geb.13070
89. Roman I, Santana R, Mendiburu A, Lozano JA. In-depth analysis of SVM kernel learning and its components. Neural Comput. Appl. (2021) 33:6575–94. doi: 10.1007/s00521-020-05419-z
90. Al-Maolegi M, Arkok B. An improved Apriori algorithm for association rules. arXiv preprint arXiv:14033948. (2014). doi: 10.5121/ijnlc.2014.3103
91. Hussein N, Alashqur A, Sowan B. Using the interestingness measure lift to generate association rules. J Adv Comput Sci Technol. (2015) 4:156. doi: 10.14419/jacst.v4i1.4398
92. Bao F, Mao L, Zhu Y, Xiao C, Xu C. An improved evaluation methodology for mining association rules. Axioms. (2021) 11:17. doi: 10.3390/axioms11010017
93. Assefa Y, Van Damme W, Williams OD, Hill PS. Successes and challenges of the millennium development goals in Ethiopia: lessons for the sustainable development goals. Br Med J Glob Health. (2017) 2:e000318. doi: 10.1136/bmjgh-2017-000318
94. Cho G, Yim J, Choi Y, Ko J, Lee S-H. Review of machine learning algorithms for diagnosing mental illness. Psychiat Investig. (2019) 16:262. doi: 10.30773/pi.2018.12.21.2
95. Hancock JT, Khoshgoftaar TM. CatBoost for big data: an interdisciplinary review. J Big Data. (2020) 7:1–45. doi: 10.1186/s40537-020-00369-8
96. Kumar PS, Kumari A, Mohapatra S, Naik B, Nayak J, Mishra M. CatBoost ensemble approach for diabetes risk prediction at early stages. In: 2021 1st Odisha International Conference on Electrical Power Engineering, Communication and Computing Technology (ODICON). Bhubaneswar: IEEE (2021).
Keywords: association rule mining, feature relevance, health facility delivery, home delivery, machine learning algorithms
Citation: Ngusie HS, Tesfa GA, Taddese AA, Enyew EB, Alene TD, Abebe GK, Walle AD and Zemariam AB (2024) Predicting place of delivery choice among childbearing women in East Africa: a comparative analysis of advanced machine learning techniques. Front. Public Health 12:1439320. doi: 10.3389/fpubh.2024.1439320
Received: 27 May 2024; Accepted: 11 November 2024;
Published: 27 November 2024.
Edited by:
Md. Akhtarul Islam, Khulna University, BangladeshReviewed by:
Umesh Ghimire, Indiana University, United StatesRicardo Valentim, Federal University of Rio Grande do Norte, Brazil
Copyright © 2024 Ngusie, Tesfa, Taddese, Enyew, Alene, Abebe, Walle and Zemariam. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Habtamu Setegn Ngusie, aGFidGFtdWhpM0BnbWFpbC5jb20=