 Yingying Ni
Yingying Ni Wei Ni
Wei Ni- 1School of Media & Communication Shanghai Jiao Tong University, Shanghai, China
- 2Department of Critical Care Medicine, Sir Run Run Shaw Hospital, Hangzhou, Zhejiang, China
Objective: This study proposes an emotion correlation-enhanced sentiment analysis model (ECO-SAM), a sentiment correlation modeling-based multi-label sentiment analysis model.
Methods: The ECO-SAM utilizes a pre-trained BERT encoder to obtain semantic embedding of input texts and then leverages a self-attention mechanism to model the semantic correlation between emotions. Additionally, it utilizes a text emotion matching neural network to make sentiment analysis for input texts.
Results: The experiment results in public datasets demonstrate that compared to baseline models, the ECO-SAM obtains the precision score increasing by 13.33% at most, the recall score increasing by 3.69% at most, and the F1 score increasing by 8.44% at most. Meanwhile, the modeled sentiment semantics are interpretable.
Limitations: The data modeled by the ECO-SAM are limited to text-only modality, excluding multi-modal data that could enhance classification performance. Additionally, the training data are not large-scale, and there is a lack of high-quality large-scale training data for fine-tuning sentiment analysis models.
Conclusion: The ECO-SAM is capable of effectively modeling sentiment semantics and achieving excellent classification performance in many public sentiment analysis datasets.
1 Introduction
Sentiment analysis is a significant task in natural language processing that aims to mine the emotional tendencies of given texts, thereby helping to gain a deeper understanding of the text content and its potential impact. Currently, with the rise of public social media platforms such as Sina Weibo and Twitter, sentiment analysis techniques have shown important roles in social sentiment analysis and event tracking (Mujahid et al., 2021; Omar and Abd El-Hafeez, 2023). Relevant researchers use sentiment analysis algorithms to identify the emotional tendencies of massive social media platform users’ posts, thereby comprehensively analyzing the trend of public opinion and taking corresponding measures. The sentiment analysis technology itself has also expanded from the traditional simple binary classification task to the multi-classification task, that is, identifying the specific emotions contained in the text, such as happy, sad, like, and angry.
However, compared to the traditional binary sentiment analysis, the multi-label sentiment analysis task faces challenges such as data sparsity, class imbalance, and difficulty in modeling emotional semantics. To this end, researchers have proposed various multi-label text emotion classification models based on statistics, machine learning, and deep learning techniques. For example, sentiment analysis models based on emotional dictionaries (Wu et al., 2019; Acerbi et al., 2023; Duan et al., 2021a) identify the emotional categories of texts by matching the retrieved words in the emotional dictionary. Text emotion dictionary models based on Naive Bayes and support vector machines (Neethu and Rajasree, 2013) use statistical learning methods to analyze and model word frequency statistical features to recognize the probability of text emotions. With the widespread application of deep learning in the field of natural language understanding (Vaswani et al., 2023; Mikolov et al., 2013; Yadav and Vishwakarma, 2020; Beridge et al., 2022), deep learning text emotion recognition models represented by recurrent neural networks (RNN) (Zhang et al., 2019) and large-scale pre-trained models (pre-trained model) (Duan et al., 2021b; Cortiz, 2021) have made significant progress in the identification of specific text emotion categories by relying on the powerful capabilities of deep learning in semantic representation modeling.
To efficiently mine and utilize semantic correlation between emotions to enhance multi-label sentiment analysis, in this study, we propose an emotion correlation-enhanced sentiment analysis model (ECO-SAM). Inspired by the widely used self-attention mechanism for language modeling and the basic emotion theory, we first design a novel attention-based emotion correlation modeling module that could automatically learn the semantic correlation between emotions from data and obtain correlation-enhanced emotion embedding representation. Next, we transform the multi-label sentiment analysis problem into an information retrieval problem, which aims to find the most suitable emotions from the emotion candidate list for a given query text. Then, we design an emotion-matching module that uses neural networks to learn the matching function between emotion and text embedding from data. Finally, we demonstrate the effectiveness of ECO-SAM via extensive experiments on two public sentiment analysis datasets. The experiment results unveil that the ECO-SAM obtains the precision score increasing by 13.33% at most, the recall score increasing by 3.69% at most, and the F1 score increasing by 8.44% at most. Meanwhile, the modeled sentiment semantics are interpretable.
2 Related work
2.1 Basic emotion theory
The basic emotion theory was proposed by American psychologist Ekman (1972). The theory believes that humans have six basic emotions: happiness, sadness, fear, anger, surprise, and disgust. These basic emotions are considered to be universally present across cultures and species. Based on the basic emotion theory, Ekman (1972) found some universality of emotional expressions through observing the facial expressions of people in different cultures. Izard (1977) expanded the basic emotion theory, discussing the relationship between basic emotions and the relationship between emotion and cognition. The study proposed a model of the emotional system, describing the relationships between basic emotions and how they interact and regulate each other. For example, the author pointed out that there is a close relationship between “anger” and “disgust,” while “happiness” and “sadness” have an antagonistic relationship. Russell (1980) proposed the circular emotion theory, which expanded the basic emotion theory and emphasized the construction and subjective experience of emotions, implying the idea of modeling the association between emotions. Cowen and Keltner (2017) explored how people describe and distinguish different emotional experiences in self-reports. The study found more fine-grained emotional experiences compared to the basic emotion theory, expanding the understanding of emotions and breaking through the traditional concept of basic emotions. It shows that emotions are complex and diverse and can be described and captured through multiple discrete emotion categories and continuous gradients.
In summary, the basic emotion theory first proposed the six basic elements of emotion. Relevant scholars have delved deeper into the construction of emotions and the relationships between emotions based on the basic emotion theory and developed a gradually more comprehensive emotional theory framework.
2.2 Sentiment analysis
Sentiment analysis is a text classification task that aims to identify the emotional category of a text based on its semantic features. According to the different distribution of emotion labels, sentiment analysis can be divided into emotion polarity classification (binary), emotion category classification (multi-class), and emotion label classification (multi-label). Sentiment analysis models include rule-based emotion dictionary methods (Wu et al., 2019; Acerbi et al., 2023; Xu et al., 2021), statistical machine learning-based methods (Neethu and Rajasree, 2013; Rastogi et al., 2021), and deep learning-based methods (Yadav and Vishwakarma, 2020; Duan et al., 2021a; Cortiz, 2021; Zhang et al., 2019; Ahmed et al., 2022). The rule-based emotion dictionary method is an unsupervised approach that uses emotion dictionaries to obtain the emotion values of emotional words in the document and then determines the overall emotional tendency of the document through weighted calculation. This method does not consider the connections between words, nor does it consider the changes in the emotional tendency of words due to the context.
Common emotion dictionaries include English dictionaries such as General Inquirer, SentiWordNet, Opinion Lexicon, and MPQA (Chatterjee et al., 2019), as well as Chinese dictionaries such as HowNet (Fu et al., 2017), NTUSD (Chen et al., 2022), and the Chinese emotion lexicon ontology (Deng et al., 2017). The statistical machine learning-based method is a supervised approach that trains machine learning classification models on text data with emotion labels and then applies the trained machine learning classification models to text emotion prediction tasks. For example, Gaye et al. (2021) proposed a text emotion recognition model based on support vector machines (SVMs), dividing the emotion analysis process into two strategies and four methods. Ghourabi et al. (2020) proposed a text emotion recognition method based on Naive Bayes, establishing a three-layer tree-structured emotion recognition structure. In addition, Patel and Urry (2024) proposed a text emotion recognition method that combines deep semantic and surface-level grammar, applicable to aspect-level sentiment analysis.
The deep learning-based method is also a supervised approach, training neural network classification models on text data with emotion labels, and utilizing the strong fitting ability of neural networks to accurately predict text emotion categories. For example, Grandjean et al. (2008) proposed a sentiment analysis model based on convolutional neural networks, where the dual convolutional layer structure can extract features from sentences of any length. Ji et al. (2019) proposed a sentiment analysis model based on deep belief networks, solving the problem of sparse text features. With the rise of large language models (LLMs) (Zhao et al., 2023; Elyoseph et al., 2023; Liu et al., 2023), the pre-trained LLM-based methods have emerged in sentiment analysis and achieved excellent performance on large-scale datasets. For instance, Valderrama et al. (2024) used the BERT model to obtain more complete text semantic representations, thereby more accurately predicting text emotion categories. Sailunaz et al. (2018) compared the sentiment analysis capabilities of various large language models in the research on user behaviors of spreading others’ privacy information on social networks. Gao et al. (2021) proposed to use prompt learning to enhance the classification performance of pre-trained models when the data volume is relatively small. In the multi-modal emotion recognition scenario, Zhu et al. (2020) proposed a sentiment analysis model based on improved ResNet to analyze and improve the accuracy of image emotion classification. Currently, deep learning models play a pivotal role in accurate sentiment analysis. As shown in Table 1, we count and list current state-of-the-art sentiment analysis methods based on previous research.
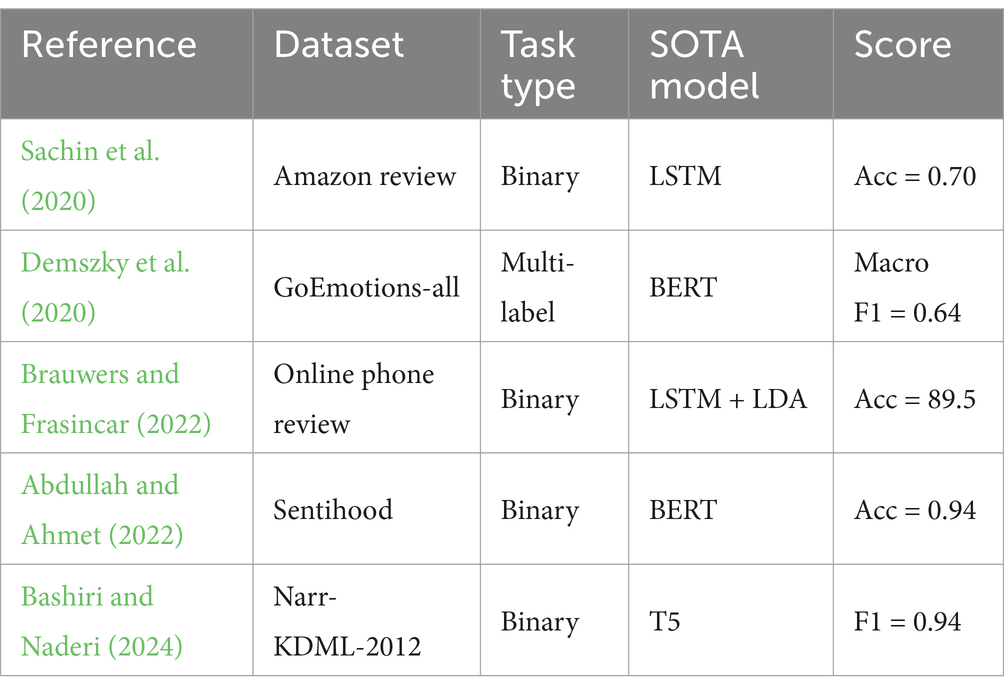
Table 1. Current state-of-the-art (SOTA) sentiment analysis methods.
2.3 Deep learning and attention mechanism
The attention mechanism was first proposed by Bahdanau et al. (2016), which is a deep learning technique used to model the semantic association and related representation between different parts of the semantic sequence. In natural language processing, the attention mechanism is often used to model the semantic association between the context in the corpus, thereby achieving the correspondence between the model output results and the context in tasks such as text generation and text classification. The transformer model proposed by Vaswani et al. (2023) is a representative model using a self-attention mechanism. The transformer model has strong semantic representation and text output capabilities and is the foundation of many text classifiers and text sentiment recognition methods.
3 Sentiment analysis based on emotion correlation modeling
Existing sentiment analysis methods struggle to model the important role of emotion correlation in emotion recognition. Therefore, this study first proposes a text sentiment analysis method based on emotion correlation modeling (ECO-SAM). Subsequently, the superiority of the ECO-SAM in sentiment analysis and emotion correlation modeling is demonstrated on the Weibo text sentiment analysis dataset. Finally, the ECO-SAM is applied to text emotion analysis under a given topic.
3.1 An overview of ECO-SAM
The framework of the proposed ECO-SAM algorithm is shown in Figure 1. The framework consists of three modules: the text encoder module, the attention text correlation modeling module, and the emotion matching module. The text encoder module uses the large-scale pre-trained model BERT to encode the text input into a high-dimensional text semantic vector. The attention text correlation modeling module uses the attention mechanism to transform the trainable emotion inherent feature vectors and output feature vectors containing emotion correlations, while also outputting an emotion correlation matrix. The emotion classification neural network module matches the text semantic vector with each emotion-correlated emotion feature vector and calculates the probability of the text containing that emotion. The algorithm finally outputs the probability of emotion containment.
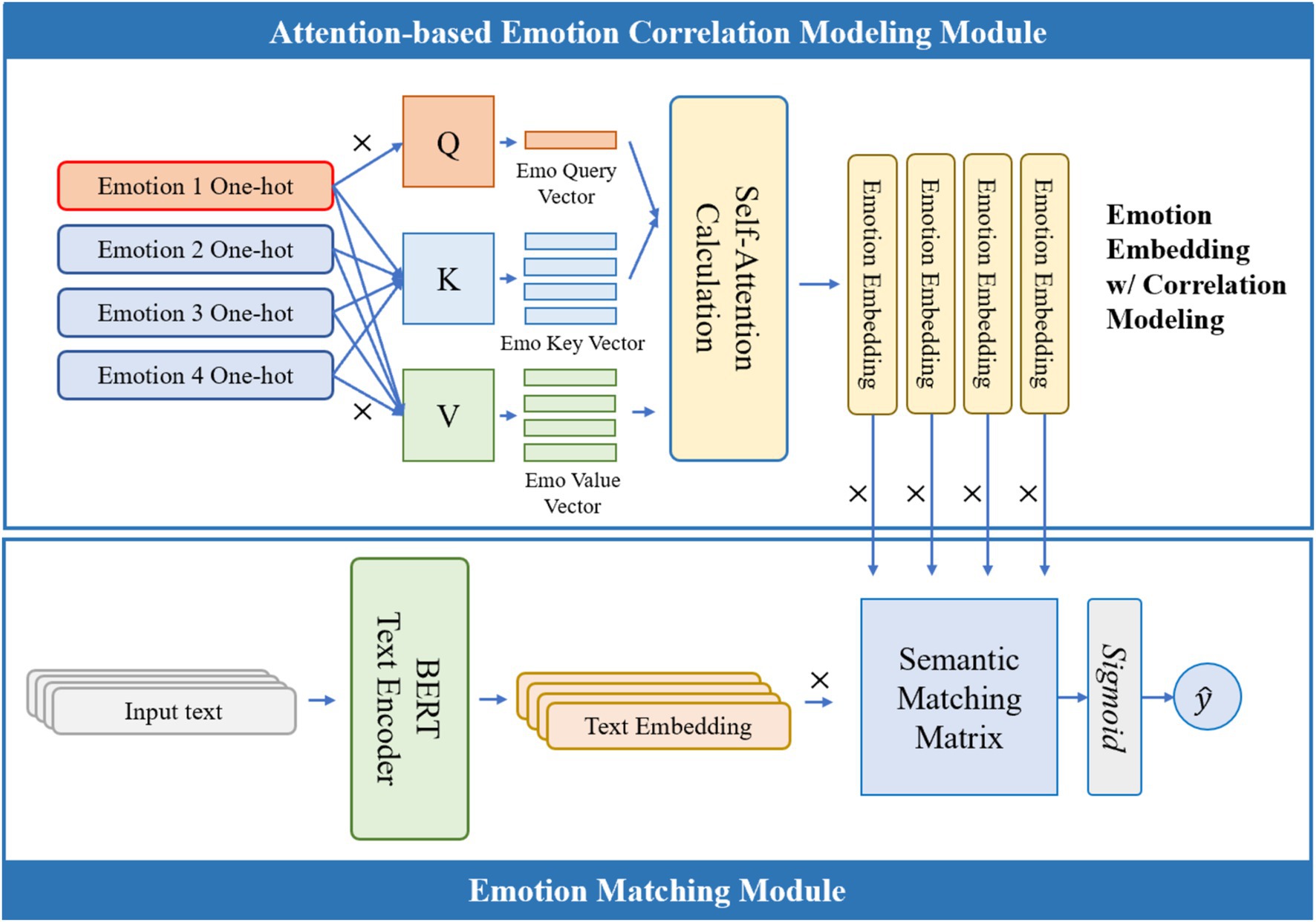
Figure 1. Structure of ECO-SAM.
In the training stage, the model’s emotion inherent feature vectors, attention text correlation modeling module, and emotion classification neural network are trained using a multi-label text emotion recognition dataset. In the inference stage, the parameters of ECO-SAM are frozen to achieve end-to-end sentiment analysis.
3.2 BERT text encoder
The BERT text encoder in the ECO-SAM (Cui et al., 2021) is a large-scale pre-trained text encoding model based on BERT (Vaswani et al., 2023). This module utilizes a masked language model (MLM) to generate deep bidirectional language representations. Experiments in the original BERT study (Vaswani et al., 2023) have demonstrated that BERT achieved state-of-the-art performance on 11 natural language processing tasks, which substantiates the efficacy of the BERT module in text semantic representation.
Formally, let the original text input be a character sequence , then the encoding process of BERT can be formalized as shown in Equation 1:
where , is the text semantic representation vector. The represents the dimension of the text semantic representation vector defined by BERT. In general, D .
3.3 Attention-based emotion correlation modeling module
The attention-based emotion correlation modeling module uses the self-attention mechanism to model the semantic correlation of emotions, thereby addressing the lack of research on emotion correlation in existing studies. Specifically, the self-attention mechanism adopts the query-key-value (QKV) pattern. Each emotion in the framework has a trainable query vector, key vector, and value vector (the value vector corresponds to the inherent emotion feature vector in Figure 1). First, for a target emotion, its query vector is obtained, and the cosine similarity between the query vector and the key vector of each other emotion is calculated. The similarity with each other emotion reflects the semantic dependence of the target emotion, i.e., the extent to which the semantic representation of the target emotion depends on that particular emotion. Then, the feature vector containing the emotion correlation of the target emotion is calculated. This vector is the weighted average of the inherent feature vectors (value vectors) of each emotion, with the weights being the calculated semantic dependence. Finally, Pearson’s correlation coefficient between the feature vectors containing emotion correlations is calculated and the emotion correlation matrix is output.
Formally, one-hot encoding is used to mark each emotion. Let denotes the emotion feature inherent vector matrix, denotes the evaluation query vector matrix, and denotes the emotion key vector matrix. In the prediction of emotion probabilities, this module first calculates the emotion feature using and the one-hot emotion vector , as shown in Equation 2. Meanwhile, it obtains the query and key vectors for each emotion, as shown in Equation 3 and Equation 4:
Subsequently, the semantic dependence similarity between the target emotion and each emotion is calculated using Equation 5:
Finally, the emotion-semantic embedding with correlation modeling for the target emotion is calculated, as presented in Equation 6:
The resulting calculation is the emotion vector representation that contains the emotion dependence relationship, which is used in the subsequent steps to recognize the emotion of the text.
3.4 Emotion matching module
The emotion matching module uses a neural network to compute the degree of matching between the text semantic representation and the emotion-semantic representation, thereby predicting the probability of each emotion in the text. Specifically, given the semantic representation vector of a sentence and the semantic representation vector of an emotion, this module uses a quadratic form neural network to predict the probability of the text emotion, as shown in Equation 7:
where is the eigenvalue decomposition of the semantic matching matrix . The above eigenvalue decomposition transformation implies that this neural network prediction process is equivalent to applying the same linear transformation to the text semantic vector and the emotion-semantic vector and then taking the element-wise weighted average, with the weights being the eigenvectors. The training process of the neural network is equivalent to optimizing the linear transformation and the eigenvectors, so that the predicted probability of text emotion is close to the true data label.
3.5 Loss function
Since the sentiment analysis problem addressed by the ECO-SAM is a multi-label classification problem, the cross-entropy loss is used as the loss function, as shown in Equation 8. During the model training process, the training objective of the ECO-SAM is to minimize the loss function value:
where represents all the trainable parameters in the ECO-SAM. N represents the number of samples (text samples in the training set). represents the number of possible emotion categories. represents whether the text contains the emotion, where indicates the text contains the emotion , and indicates otherwise. represents the probability predicted by the ECO-SAM that the text contains each emotion.
4 Text emotion recognition experiment
4.1 Experimental setup
This experiment compares the proposed multi-label sentiment analysis model, ECO-SAM, with various baseline text emotion prediction models using the public Weibo dataset. The goal is to verify the accuracy of the ECO-SAM in sentiment analysis and its ability to model emotion feature correlations. For the experimental datasets, this study used two publicly available datasets: NLPCC2014 and GoEmotions (Demszky et al., 2020). This module takes three inputs for emotion k: the feature inherent vector, query vector, and the corresponding key vectors for all emotions. Each text contains up to two emotions. The GoEmotions dataset consists of 58,000 text data from the English forum Reddit, with the original data containing 27 fine-grained emotion categories. Based on the basic emotion theory, we screened out the 7 emotions consistent with the NLPCC2014 dataset as well as the neutral case as the target of sentiment analysis and selected 32,445 valid samples. Next, we split each dataset into training, validation, and test sets in the ratio of 70%:10%:20%, respectively.
In terms of the experiment setting, all models implemented using Python 3.8, with the deep learning framework being PyTorch, and the operating system being Linux. The hardware configuration for running the experiments is a server with two 2.10GHz Intel Xeon E5-2620 v4 CPUs and one NVIDIA Tesla-A100 GPU.
4.2 Text emotion prediction experiment
The main experiments in this study include emotion prediction experiments and emotion feature correlation analysis. Finally, the ECO-SAM emotion prediction model is applied to sentiment analysis. In the emotion prediction experiment, the following baseline models are used:
Random: Random prediction. For each emotion, the text has a 1/2 probability of being classified into that emotion category. Whether an emotion prediction model performs better than random prediction is a basic criterion for its usability.
cnsenti (Deng and Nan, 2022): Chinese Sentiment, an emotion prediction model based on the HowNet emotion dictionary of Chinese Knowledge Network.
SVM (Mullen and Collier, 2004): Support Vector Machine, an emotion prediction model based on support vectors. In the experiment, BERT is used to encode the text into semantic vectors, which are then used as input to the SVM.
LSTM (Hochreiter and Schmidhuber, 1997): Long short-term memory is a type of recurrent neural network (RNN) architecture designed to address the vanishing gradient problem in traditional RNNs. LSTMs are particularly effective at learning long-term dependencies in data, making them well-suited for applications such as sentiment analysis and time series analysis.
BiLSTM (Graves and Schmidhuber, 2005): It is an extension of the traditional LSTM architecture that processes input sequences in both forward and backward directions. This bidirectional approach provides a more comprehensive understanding of the sequence.
BERT (Devlin et al., 2019) is a pre-trained transformer-based language model. BERT can encode raw texts into semantic vectors with rich information for downstream tasks. For the text emotion prediction task, we use a fully connected neural network as the downstream output layer.
T5 (Raffel et al., 2020): It is a transformer-based language model proposed by Google that unifies various NLP tasks by framing them all as text-to-text problems, where both input and output are text strings.
The results of the text emotion prediction experiment are shown in Table 2. Considering the characteristics of the multi-label classification task, the evaluation metrics are Micro Precision, Micro Recall, and Micro F1 Score. The higher the score for each of these evaluation metrics, the higher the accuracy of the model’s text emotion prediction.
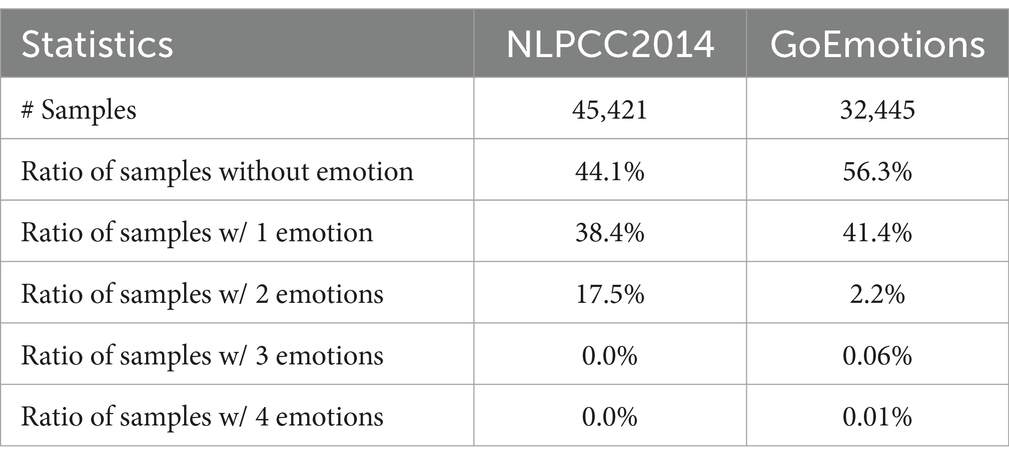
Table 2. Statistics of datasets after preprocessing.
Since GoEmotions is an English dataset, the baseline model cnsenti, which is based on the Chinese dictionary, is unable to recognize the text emotions in this dataset. From the above experimental results, it can be seen that the ECO-SAM proposed in this study outperforms the existing text emotion prediction baseline models in terms of precision, recall, and F1 score, with the highest increase in precision being 13.33%, the highest increase in recall being 3.69%, and the highest increase in F1 score being 8.44%. This proves that the ECO-SAM can predict text emotions more accurately compared to existing models (Table 3).
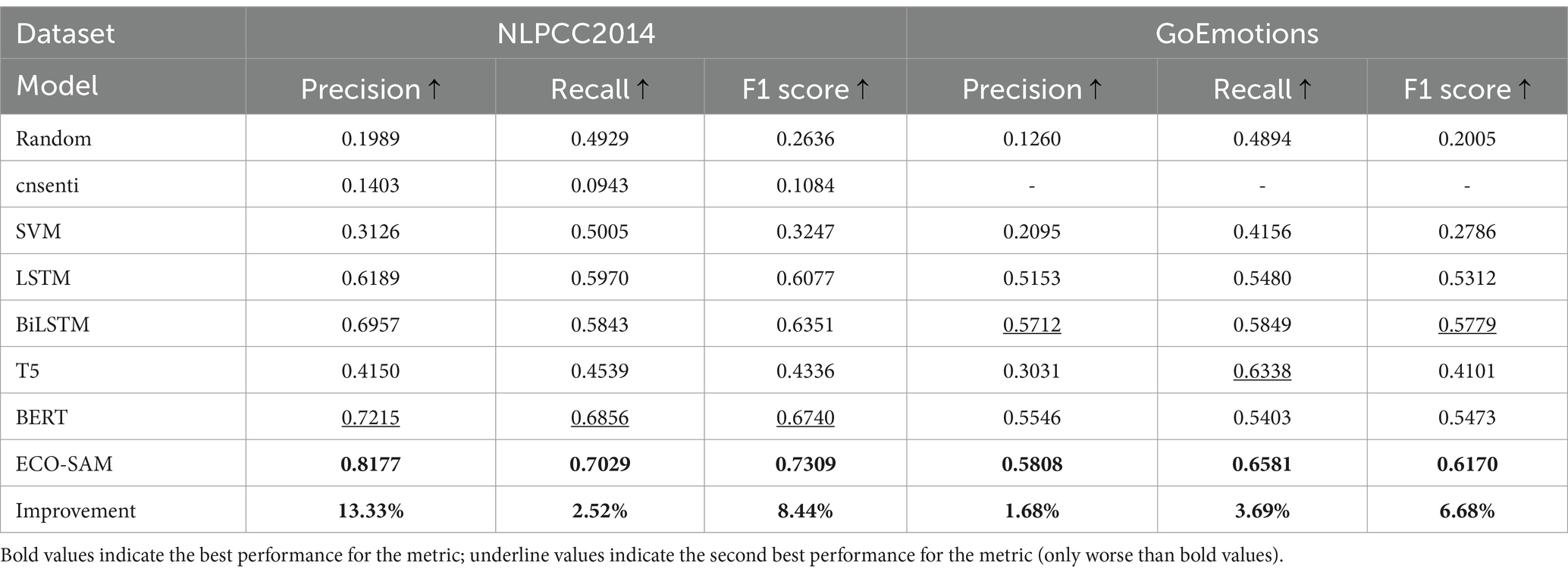
Table 3. Experiment results of sentiment analysis.
Furthermore, among the baseline models, the BERT method also significantly outperforms other existing methods. The comparison between the BERT and cnsenti shows that the text emotion prediction model based on BERT pre-trained language encoding has better performance on Weibo emotion prediction than the traditional model based on rules and emotion dictionaries. The comparison between BERT and SVM shows that the text emotion prediction algorithm based on neural networks has better performance on Weibo emotion prediction than the algorithm based on SVM. Compared to the best baseline model BERT, our proposed ECO-SAM method further improves the performance of the text emotion prediction model based on BERT pre-trained language encoding through an innovative emotion feature modeling module.
4.3 Visualization experiment: emotion feature correlation modeling experiment
This section uses the NLPCC2014 dataset as an example to analyze the ability of the ECO-SAM to model emotional semantic similarity. The ECO-SAM text emotion prediction model improves the accuracy of text emotion prediction by modeling the correlation between emotion features through the attention-based emotion modeling module. This experimental stage mainly focuses on the modeling results of the emotional feature correlation in the ECO-SAM. In the ECO-SAM, emotional features are represented as , where k represents the emotion category sequence number. For any two emotions k1 and k2, this experiment uses Pearson’s correlation coefficient of the emotion features as the measure of emotion feature correlation, denoted as . This correlation coefficient ranges between −1 and 1. When , the two emotion features are positively correlated (similar); when , the two emotion features are uncorrelated (independent); when , the two emotion features are negatively correlated (semantically opposite). The results of the emotion feature correlation calculation are shown in the following figure, which includes seven emotions: anger, disgust, fear, happiness, like, sadness, and surprise. The brighter the color of each square in the figure, the greater the correlation value, and the stronger the association between the two emotions. According to Figure 2, the three emotions most strongly associated with each emotion are as follows:
• Anger: Disgust (0.99), Surprise (0.50), Fear (0.39).
• Disgust: Anger (0.99), Surprise (0.46), Fear (0.34).
• Fear: Surprise (0.97), Anger (0.39), Sadness (0.38).
• Happiness: Like (0.55), Surprise (0.48), Fear (0.37).
• Like: Happiness (0.55), Sadness (0.31), Anger (0.24).
• Sadness: Fear (0.38), Anger (0.35), Like (0.31).
• Surprise: Fear (0.97), Anger (0.50), Happiness (0.48).
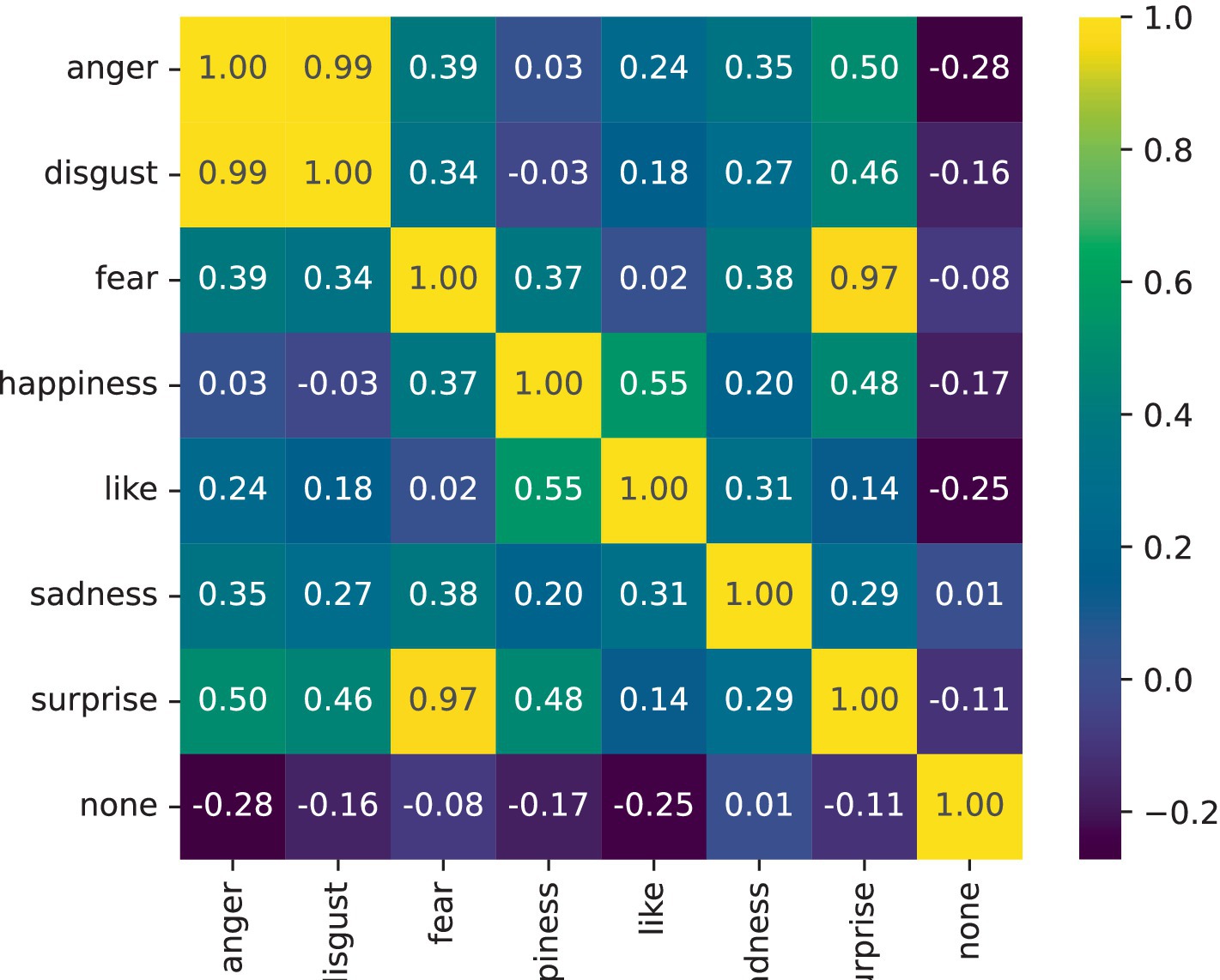
Figure 2. Heatmap of the correlation of emotion features.
The above results show that different types of emotions, due to their semantic differences, either exhibit strong correlations or are mutually independent of each other. Some emotions, due to the consistency of their semantics, often exhibit a relatively strong clustering feature. For example, “anger” and “disgust” are both negative emotions, and their semantic correlation reaches 0.99. They also have relatively strong correlations with “fear,” indicating that the above four emotions are similar in semantic connotation, which is consistent with people’s intuition. At the same time, “happiness” and “like” have a relatively strong correlation, indicating that the two intuitively positive emotions also have similar semantic connotations. In addition, “surprise” has a relatively high semantic similarity with positive emotions such as “happiness,” as well as with negative emotions such as “fear.” This suggests that “surprise” as an emotion that an individual perceives due to sudden changes tends to be neutral. In other words, “surprise” can coexist with positive emotions (such as “pleasant surprise”) and also with negative emotions (such as “horrifying surprise”).
5 Discussion
The significance of this research is as follows: First, at the theoretical level, this study organically combines basic emotion theory and deep learning technology, innovatively proposes a large-scale pre-trained text emotion recognition method (ECO-SAM), and verifies the method’s accurate text emotion recognition and emotion-semantic correlation modeling capabilities through large-scale experiments on real datasets. In the task of sentiment analysis, accuracy is a core issue in related research and is also an important technical guarantee for public opinion monitoring. Therefore, the high performance of ECO-SAM in the experiments is undoubtedly of great significance for enhancing the effectiveness of public opinion monitoring. Second, by leveraging the emotion -semantic correlation modeling capability of ECO-SAM, this study also analyzes the correlation relationships between different emotions within this topic, providing important data references for related public opinion monitoring.
At the same time, this research still has some limitations. First, due to the limitations of available data, the training corpus built using the ECO-SAM is still not sufficient to fully unleash the model’s maximum performance, and the data volume needs to be further increased in future research. Second, in terms of text semantic parsing capability, the performance of the ECO-SAM method in recognizing the emotions of texts with large implicit information such as irony and sarcasm still needs to be improved. In the future research plan, on the one hand, we can further improve the text emotion recognition capability through methods such as expanding the dataset and optimizing the model architecture. On the other hand, with the rise of large language models (LLMs) (such as ChatGPT), we can combine the advantages of LLMs in text generation and emergent capabilities, as well as the advantages of ECO-SAM in strong semantic modeling and low computational cost, to develop more efficient sentiment analysis techniques. Furthermore, the topic and user distribution on online social platforms are complex and rich in information. How to leverage the rich topic and user information to assist text emotion recognition and public opinion monitoring, and explore the downstream applications of emotion recognition and emotion-semantic modeling, we also believe, is an important future research direction.
6 Conclusion
Online social platforms are highly susceptible to large-scale controversial network issues, many of which can easily escalate into emotionally charged irrational propagation. Existing sentiment analysis models have difficulty in modeling emotion correlation, and the accuracy of emotion prediction needs to be improved. To solve the above problems, this study first conducted extensive and in-depth-related research and innovatively proposed an emotion correlation-enhanced sentiment analysis model (ECO-SAM) based on basic emotion theory and deep learning technology, to achieve accurate text emotion recognition and emotion correlation modeling on online social platforms. The large-scale comparative experiments on the real text emotion recognition Chinese dataset NLPCC2014 and the English dataset GoEmotions verified the accurate text emotion recognition capability of the ECO-SAM. Emotion recognition comparative experiments showed that the ECO-SAM improved the precision, recall, and F1 score of text emotion recognition by 13.33, 3.69, and 8.44%, respectively, compared to the optimal baseline method BERT, effectively improving the accuracy of text emotion recognition. The emotion feature correlation experiment showed that emotions with similar emotional colors (positive/negative) have relatively strong semantic correlations; the “surprise” emotion has a relatively high semantic correlation with both positive emotions and negative emotions, acting as a bridge between the two in the emotion correlation graph.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found at: https://github.com/qweraqq/NLPCC2014_sentiment.
Author contributions
YN: Writing – original draft, Writing – review & editing, Conceptualization, Investigation, Project administration. WN: Data curation, Formal analysis, Resources, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by Zhejiang Provincial Health Science and Technology Program Project (2021KY757) and Special Anti-epidemic Project of Zhejiang Provincial Department of Education (Y202043731).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abdullah, T., and Ahmet, A. (2022). Deep learning in sentiment analysis: recent architectures. ACM Comput. Surv. 55, 1–37. doi: 10.1145/3548772
Acerbi, A., Kerhoas, D., Webber, A. D., McCabe, G., Mittermeier, R. A., and Schwitzer, C. (2023). Sentiment analysis of the twitter response to Netflix's our planet documentary. Conserv. Biol. 37:e14060. doi: 10.1111/cobi.14060
Ahmed, M. Z. I., Sinha, N., Phadicar, S., and Ghaderpour, E. (2022). Automated feature extraction on AsMap for emotion classification using EEG. Sensors 22:2346. doi: 10.3390/s22062346
Bahdanau, D., Cho, K., and Bengio, Y. (2016). Neural machine translation by jointly learning to align and translate. Available at: https://ar5iv.labs.arxiv.org/html/1409.0473.
Bashiri, H., and Naderi, H. (2024). Comprehensive review and comparative analysis of transformer models in sentiment analysis. Knowl. Inf. Syst. 66, 7305–7361. doi: 10.1007/s10115-024-02214-3
Beridge, C., Zhou, Y., Robillard, J. M., and Kaye, J. (2022). Companion robots to mitigate loneliness among older adults: perception of benefit and possible deception. Front. Psychol. 14:1106633. doi: 10.3389/fpsyg.2023.1106633
Brauwers, G., and Frasincar, F. (2022). A survey on aspect-based sentiment classification. ACM Comput. Surv. 55, 1–37. doi: 10.1145/3503044
Chatterjee, A., Gupta, U., Chinnakotla, M. K., Srikanth, R., Galley, M., and Agrawal, P. (2019). Understanding emotions in text using deep learning and big data. Comput. Hum. Behav. 93, 309–317. doi: 10.1016/j.chb.2018.12.029
Chen, Y., Yuan, J., You, Q., and Luo, J. (2022). “TextFooler adversarial Chinese text classification: dataset and benchmark” in Findings of the association for computational linguistics. ed. J. Luo (Florida: Association for Computational Linguistics), 3265–3279.
Cortiz, D. (2021). “Exploring transformers models for emotion recognition: a comparision of BERT, DistilBERT, RoBERTa, XLNET and ELECTRA,” In Proceedings of the 2022 3rd international conference on control, robotics and intelligent system. Association for Computing Machinery. 230–234.
Cowen, A. S., and Keltner, D. (2017). Self-report captures 27 distinct categories of emotion bridged by continuous gradients. Proc. Natl. Acad. Sci. 114, E7900–E7909. doi: 10.1073/pnas.1702247114
Cui, Y., Che, W., Liu, T., Qin, B., Yang, Z., Wang, S., et al. (2021). Pre-training with whole word masking for Chinese BERT. IEEE/ACM Trans. Audio Speech Lang. Process. 29, 3504–3514. doi: 10.1109/TASLP.2021.3124365
Devlin, J., Chang, M. W., Lee, K., and Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.Vol 1 (Long and Short Papers), Assoc. Comput. Linguist. 4171–4186. doi: 10.18653/v1/N19-1423
Demszky, D., Movshovitz-Attias, D., Ko, J., Cowen, A., Nemade, G., and Ravi, S. (2020). GoEmotions: a dataset of fine-grained emotions. In D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault (Eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Florida: Association for Computational Linguistics.
Deng, X., and Nan, P. (2022). Cntext: a Python tool for text mining. Available at: https://github.com/hiDaDeng/cntext (Accessed September, 2022).
Deng, S., Sinha, A. P., and Zhao, H. (2017). Adapting sentiment lexicons to domain-specific social media texts. Decis. Support. Syst. 94, 65–76. doi: 10.1016/j.dss.2016.11.001
Duan, R., Cui, Z., Ao, X., Li, Y., Zhang, Y., Yu, Y., et al. (2021a). Sentiment classification algorithm based on the cascade of BERT model and adaptive sentiment dictionary. Wirel. Commun. Mob. Comput. 2021:6625984. doi: 10.1155/2021/6625984
Duan, R., Zhu, Z., Zhou, F., and Xie, X. (2021b). Sentiment classification algorithm based on the cascade of BERT model and adaptive sentiment dictionary. Wirel. Commun. Mob. Comput. 2021:6660990. doi: 10.1155/2021/6660990
Ekman, P. (1972). Emotion in the human face: Guide-lines for research and an integration of findings. Oxford: Pergamon Press.
Elyoseph, Z., Hadar-Shoval, D., Asraf, K., and Lvovsky, M. (2023). ChatGPT outperforms humans in emotional awareness evaluations. Front. Psychol. 14:1199058. doi: 10.3389/fpsyg.2023.1199058
Fu, X., Liu, W., Xu, Y., Yu, C., and Wang, T. (2017). Combine HowNet lexicon to train phrase recursive autoencoder for sentence-level sentiment analysis. Neurocomputing 241, 18–27. doi: 10.1016/j.neucom.2017.01.079
Gao, T., Fisch, A., and Chen, D. (2021). Making pre-trained language models better few-shot learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (pp. 3816–3830). Pennsylvania: Association for Computational Linguistics.
Gaye, B., Zhang, D., and Wulamu, A. (2021). Improvement of support vector machine algorithm in big data background. Math. Probl. Eng. 2021, 1–9. doi: 10.1155/2021/5594899
Ghourabi, A., Mahmood, M. A., and Alzubi, Q. M. (2020). A hybrid CNN-LSTM model for SMS spam detection in Arabic and English messages. Fut. Internet 12:156. doi: 10.3390/fi12090156
Grandjean, D., Sander, D., and Scherer, K. R. (2008). Conscious emotional experience emerges as a function of multilevel, appraisal-driven response synchronization. Conscious. Cogn. 17, 484–495. doi: 10.1016/j.concog.2008.03.019
Graves, A., and Schmidhuber, J. (2005). Framewise phoneme classification with bidirectional LSTM networks. In Proceedings 2005 IEEE International Joint Conference on Neural Networks, Florida: Association for Computational Linguistics. 2047–2052.
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
Ji, H., Rong, W., Liu, J., Ouyang, Y., and Xiong, Z. (2019). LSTM based semi-supervised attention framework for sentiment analysis. In Proceedings of the 2019 IEEE Conference on Leicester: IEEE.
Liu, F., Li, X., Liu, R., and Zeng, J. (2023). Linguistic expressions of negative stances: a conversation analysis of turn-medial particle dai in Jishou dialect. Front. Psychol. 14:1018648. doi: 10.3389/fpsyg.2023.1018648
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., and Dean, J. (2013). “Distributed representations of words and phrases and their compositionality,” in Proceedings of the 26th international conference on neural information processing systems. Curran Associates Inc. 2, 3111–3119.
Mujahid, M., Lee, E., Rustam, F., Washington, P. B., Ullah, S., Reshi, A. A., et al. (2021). Sentiment analysis and topic modeling on tweets about online education during COVID-19. Appl. Sci. 11:8438. doi: 10.3390/app11188438
Mullen, T., and Collier, N. (2004). Sentiment analysis using support vector machines with diverse information sources. In Proceedings of the 2004 Conference on empirical methods in natural language. Florida: Association for Computational Linguistics
Neethu, M. S., and Rajasree, R. (2013). Sentiment analysis in twitter using machine learning techniques. In 2013 fourth international conference on computing, communications and networking technologies (ICCCNT) (pp. 1–5). IEEE. Tiruchengode.
Omar, A., and Abd El-Hafeez, T. (2023). Quantum computing and machine learning for Arabic language sentiment classification in social media. Sci. Rep. 13:17305. doi: 10.1038/s41598-023-44113-7
Patel, P., and Urry, H. L. (2024). Discrete and dimensional approaches to affective forecasting errors. Front. Psychol. 15:1412398. doi: 10.3389/fpsyg.2024.1412398
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., et al. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21, 1–67.
Rastogi, A., Singh, R., and Ather, D. (2021). Sentiment analysis methods and applications–a review. In 2021 10th international conference on System Modeling & Advancement in research trends (SMART) (pp. 391–395). Moradabad: IEEE.
Russell, J. A. (1980). A circumplex model of affect. J. Pers. Soc. Psychol. 39, 1161–1178. doi: 10.1037/h0077714
Sachin, S., Tripathi, A., Mahajan, N., Aggarwal, S., and Nagrath, P. (2020). Sentiment analysis using gated recurrent neural networks. SN Comput. Sci. 1:76. doi: 10.1007/s42979-020-0076-y
Sailunaz, K., Dhaliwal, M., Rokne, J., and Alhajj, R. (2018). Emotion detection from text and speech: a survey. Soc. Netw. Anal. Min. 8:28. doi: 10.1007/s13278-018-0505-2
Valderrama, C. E., Gomes Ferreira, M. G., Mayor Torres, J. M., Garcia-Ramirez, A. R., and Camorlinga, S. G. (2024). Editorial: machine learning approaches to recognize human emotions. Front. Psychol. 14:1333794. doi: 10.3389/fpsyg.2023.1333794
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2023). Attention is all you need. Available at: https://arxiv.org/abs/1706.03762 (Accessed August, 2023).
Wu, J., Guo, R., Shi, Z., and Liu, Y. (2019). Chinese micro-blog sentiment analysis based on multiple sentiment dictionaries and semantic rule sets. IEEE Access 7, 183924–183939. doi: 10.1109/ACCESS.2019.2960655
Xu, L., Li, L., Jiang, Z., Wang, Y., Ren, F., and Chen, F. (2021). A novel emotion lexicon for Chinese emotional expression analysis on Weibo: using grounded theory and semi-automatic methods. IEEE Access 9, 92757–92768. doi: 10.1109/ACCESS.2020.3009292
Yadav, A., and Vishwakarma, D. K. (2020). Sentiment analysis using deep learning architectures: a review. Artif. Intell. Rev. 53, 4335–4385. doi: 10.1007/s10462-019-09794-5
Zhang, T., Zheng, W., Cui, Z., Zong, Y., Yan, J., and Yan, K. (2019). Spatial-temporal recurrent neural network for emotion recognition. IEEE Trans. Cybern. 49, 839–847. doi: 10.1109/TCYB.2017.2788081
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., et al. (2023). A survey of large language models. Available at: https://arxiv.org/abs/2303.18223 (Accessed October, 2024).
Keywords: text classification, sentiment analysis, natural language processing, attention mechanism, emotion theory
Citation: Ni Y and Ni W (2024) A multi-label text sentiment analysis model based on sentiment correlation modeling. Front. Psychol. 15:1490796. doi: 10.3389/fpsyg.2024.1490796
Edited by:
Sébastien Lallé, Sorbonne Universités, FranceReviewed by:
Isabella Poggi, Roma Tre University, ItalySuvdaa Batsuuri, National University of Mongolia, Mongolia
Copyright © 2024 Ni and Ni. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wei Ni, bml3ZWk5OTY2QDE2My5jb20=