 Nádia Moura
Nádia Moura Pedro Dias
Pedro Dias Lurdes Veríssimo
Lurdes Veríssimo Patrícia Oliveira-Silva
Patrícia Oliveira-Silva Sofia Serra
Sofia Serra
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
SYSTEMATIC REVIEW article
Front. Psychol., 09 October 2024
Sec. Performance Science
Volume 15 - 2024 | https://doi.org/10.3389/fpsyg.2024.1467434
This article is part of the Research TopicWomen in Performance ScienceView all 4 articles
Assessment is a crucial aspect of music performance. In pedagogical contexts, an effective assessment process can measure student achievement and inform instructional decisions that contribute to improving teaching and learning. However, music performance assessment is particularly challenging due to its inherent subjectivity, involving personal expression and interpretation, which can lead to divergent opinions. In this PRISMA systematic review (registration DOI: 10.17605/OSF.IO/CSM8Q), we aimed to delimit and analyze solo music performance assessment systems found in the literature to date, including their corresponding evaluation categories and descriptive criteria, rating methodology, and target audience. A search in three main scientific databases (Web of Science, Scopus, ERIC) was conducted using keywords associated with the topic of assessment in the field of solo music performance. Ultimately, 20 papers were selected and examined, resulting in 26 original assessment systems for analysis. Regarding sample characteristics, we found that studies mainly focused on evaluating high school and university students, with music teachers and faculty members serving as primary evaluators. Many assessment systems were designed to be applicable across various instruments, although some were tailored to specific instruments (e.g., piano, voice) and families (e.g., brass, woodwind). Systems typically structured evaluation around technical, interpretative/expressive, and various musical feature categories (e.g., pitch, rhythm, intonation), further elaborated with descriptive items. While five-point Likert scales were commonly used, recent studies indicated a shift towards rubrics for detailed feedback, which aids examiners’ understanding and supports student progress. No differentiation was found in assessment criteria based on students’ learning stages, suggesting an area for improvement in refining these assessment methods. This study identifies gaps and proposes improvements in existing assessment systems, providing a foundation for educators and policymakers to enhance curriculum design and instructional practices in music education.
Assessment is an integral dimension of music performance, both in educational and professional contexts. The assessment process is defined by Payne et al. (2019, p. 43) as “the collection, analysis, interpretation, and applied response to information about student performance or program effectiveness in order to make educational decisions resulting in continual improvement.” Therefore, achieving effective assessments is of extreme relevance, as they do not only provide an overview of the student’s progress in comparison to the expected skills and knowledge projected for a given outcome or learning level, enabling students and teachers to reorganize practices but also reveal areas upon which curricular adaptations can be implemented (Mustul and Aksoy, 2023; Payne et al., 2019; Tabuena et al., 2021).
However, developing reliable systems for music performance assessment presents multiple challenges. First, each musical instrument requires specific skills (e.g., string instrumentalists develop bowing technique, and wind instrumentalists develop breathing technique), demanding that assessment tasks be tailored to each instrument’s unique requirements (Russell, 2014). Second, although ensuring jury expertise, human-based performance evaluation models carry high degrees of subjectivity, often due to poor descriptions (Giraldo et al., 2019; Thompson and Williamon, 2003; Wesolowski et al., 2016). Third, many instrumental and vocal assessment systems put emphasis on pitch and tempo accuracy, neglecting other important dimensions such as interpretation and sound quality (Giraldo et al., 2019). Ultimately, performance-oriented education receives less attention that general classroom music education, resulting in limited research in this area. Considering the identified challenges, it is crucial that systematic reviews provide a framework for addressing these issues.
In a preliminary database search, four narrative reviews were found about the topic of music performance assessment: three articles (Lerch et al., 2020; McPherson and Thompson, 1998; Zdzinski, 1991) and one book chapter (Russell, 2014). In such reviews, multiple assessment systems were identified, including generalized systems applicable to all instruments (Mills, 1991; Russell, 2010b, 2015; Stanley et al., 2002; Thompson and Williamon, 2003; Wesolowski, 2012, 2021; Winter, 1993) and instrument-specific systems (Abeles, 1973; Bergee, 2003; Wrigley, 2005; Wrigley and Emmerson, 2013). Russell (2014) highlighted the role of four nuclear evaluation categories, common to most studies, which significantly predict evaluators’ assessment accuracy: tone and intonation, articulation, rhythmic accuracy, and interpretation or musical effect. There are other studies, however, presenting a dicotomical distinction between categories related to instrumental and vocal technical skills (e.g., accuracy of notes, of rhythm) and interpretation (e.g., dynamics, suitable sense of styles, sense of performance, bodily communication) (Davidson and Coimbra, 2001; Mills, 1991; Stanley et al., 2002). In fact, a subsequent study demonstrated that both technique and musical expression contributed to increases in assessments of overall performance quality, with technique alone also contributing to rating increases in musical expression (Russell, 2015). Nonetheless, as stated by Lerch et al. (2020), the selection of evaluation parameters is highly dependent on the proficiency level of the students and can also vary depending on the culture and musical style of the music being performed. The reviews also called attention to the wide range of rating scales was implemented across studies (McPherson and Thompson, 1998; Zdzinski, 1991), including qualitative (e.g., in Russell, 2010a, strongly agree/agree/disagree/strongly disagree) and quantitative classifications (e.g., in Thompson and Williamon, 2003, ratings from 1 to 10), as well as a variety of assessment levels (e.g., Mills, 1991, uses four levels, while Wrigley and Emmerson, 2013, use seven levels). Earlier reviews advocated for the need to increase reliability and validity of assessment procedures, highlighting the promising results of more systematic approaches, such as the facet-factorial (Zdzinski, 1991) and the importance of considering the influence of personal, cultural, and social biases on the jury (McPherson and Thompson, 1998). These considerations inspired follow-up research related to judge reliability (Bergee, 2003; Hewitt and Smith, 2004; Smith, 2004, to name a few). The more recent review by Lerch et al. (2020), focused on computerized music analysis, presented an overview of the tools and methods which can be used to automatically assess performance parameters not only for evaluation purposes but also for analysis, modelling, and software development. The authors underscore the relevance of developing accessible and reliable automated systems to improve objectivity in performance assessment, a quest that has been long mentioned (McPherson and Thompson, 1998; Zdzinski, 1991). Russell (2014) also corroborated the potential of technology in music assessment, if its equal availability is ensured for all students.
Hence, the absence of a systematic literature review in solo music performance assessment, coupled with the diverse array of instruments, methods, and rating scales identified in this preliminary research, reinforces the need to delimit and characterize evaluation procedures. This systematic review aims to provide a systematized overview of valuable evidence for academics and educators in this field. It builds on previous studies by critically examining generalized and instrument-specific systems, aiming to integrate their strengths while addressing their limitations. Specifically, its goal is to critically analyze solo music performance assessment systems found in the literature to date, including their corresponding evaluation categories, descriptive criteria, rating methodology, and target audience. We intend to establish a generally accepted set of standards and criteria to measure solo performance quality, if possible, adjusted for different musician populations (e.g., basic and advanced learning levels). The main research question driving this study is “What solo music performance assessment systems are reported and implemented in the literature, and how are they characterized?.” This is followed by the specific questions: “What are the main categories of assessment, and which are given the most importance?,” “Within each category, what descriptive items/criteria are provided to the evaluators?,” “What rating methods are adopted (e.g., qualitative or quantitative, type and size of scales)?,” and “How do assessment systems differ between the types of population being evaluated (e.g., children, professionals)?”
This systematic review followed the PRISMA updated guidelines (Preferred Reporting Items for Systematic Reviews and Meta-Analyses, Page et al., 2021). Registration in the OSF (Open Science Framework) was also performed (Registration DOI: 10.17605/OSF.IO/CSM8Q).
The current systematic review covered studies that developed and/or implemented music performance assessment systems, analyzing their methodological design (categories/items for assessment, criteria, and rating scales). Given the qualitative nature of our research question, we used the PEO framework: Population – music performers and students, including children, adolescents, higher education students and professionals (no limitations were imposed due to the scarce existing research); Exposure – the process of performance assessment was considered as the exposure; Outcome – assessment systems and corresponding categories, items, criteria, and rating scales.
Inclusion criteria were established to focus on peer-reviewed articles and reviews that provide detailed descriptions of music performance assessment systems, ensuring the inclusion of rigorous and validated studies. The language criteria was expanded to include articles written in Portuguese, as this is the native language of all authors and there are multiple journals using it as primary language. Exclusion criteria, such as the omission of articles referring to general music education rather than performance assessment, were applied to maintain the specificity and relevance of our review. Based on these considerations, the specific inclusion and exclusion criteria applied in this review are as follows:
Inclusion criteria adopted:
1. Articles with relevant data on the theme of music performance assessment and with descriptions of the assessment systems;
2. Reviews or original research articles published in peer-reviewed journals;
3. Articles written in English or Portuguese;
4. Articles that report evaluations targeted at performers or music students (children, adolescents, higher education students, professionals).
Exclusion criteria adopted:
1. Articles referring to assessment systems of general music education rather than music performance;
2. Articles that were marked as “retracted”;
3. Letters to the editor and grey literature.
Web of Science (all databases), Scopus, and Education Resources Information Center (ERIC) were the chosen databases for our literature search due to their coverage of peer-reviewed articles in the fields of education, social sciences, and music performance. These databases are recognized for their extensive indexing of high-quality academic journals, ensuring that our review encompasses a wide range of relevant studies. The electronic search was conducted on March 18, 2024, using the expression: (“music* perform*” OR “music play*”) AND [title] (analys* OR assess* OR evaluat* OR rat* OR exam* OR criteri* OR jury OR judge*). The previous keywords were chosen to capture a broad spectrum of terms related to music performance assessment while ensuring specificity to our research focus in instrumental and vocal music performance. Filters were applied to limit the results to research articles and reviews in English and Portuguese.
Outputs were exported to a reference manager software (Mendeley; © 2024 Elsevier Ltd), and duplicates were removed. The selection process was conducted following three stages. In the screening stage, two researchers independently analyzed titles and abstracts following the eligibility criteria to exclude irrelevant references. When eligibility was ambiguous, the full text of the reference was obtained. In the inclusion stage, the same researchers critically appraised the full texts of the selected references for eligibility, and all relevant references were included in the review. Also, at this point, an examination of the bibliography of each study was performed to identify additional relevant studies complying with the inclusion criteria (backward citation searching). The screening and inclusion stages were replicated for the citation searching. In the case of disagreement over the eligibility of studies, a discussion was carried out between the researchers until a consensus was reached.
Researchers then extracted the data from the included references into a Microsoft Excel sheet. The following information was retrieved: author, year, journal, aim, type of study, sample characteristics (age, learning level, musical instruments, context of implementation), assessment system characteristics (name, categories, items, preponderance of items in the final score, criteria, rating methods), results, and limitations (if applicable). Following, data synthesis was conducted through both qualitative and quantitative methods to provide a comprehensive analysis of the findings, including the presentation of tables and summarizing the studies’ evidence through a qualitative approach.
The selection process is summarized in Figure 1, presenting the PRISMA flow diagram.

Figure 1. Flow diagram (based on PRISMA statement, Page et al., 2021) summarizing the search procedure.
A total of 1,113 studies were identified and 754 were retained after the duplicate’s removal. In the screening stage, 700 publications were excluded because they did not fulfil the criteria for inclusion and exclusion, resulting in 53 publications for full-text analysis. Two publications were not fully available online, so publishers and authors were contacted via email, from whom we did not get a response, resulting in a final number of 51 publications. After careful analysis, 37 studies were excluded: 21 studies presented replications or extensions of assessment rubrics originally presented in other included studies (i.e., applying them to ensembles, student self-evaluation, among others), six studies consisted of theoretical articles which, although regarded performance evaluation, did not provide descriptions of assessment systems, six studies implemented single rating assessment systems without specific dimensions or criteria (e.g., single overall rating from 1 to 100), and four studies did not focus on performance assessment (e.g., were focused on listeners’ emotional perceptions).
At this stage, we arrived at 14 publications to include in the review. However, through backward citation searching, we identified 10 additional publications potentially meeting our inclusion criteria. Three of these were impossible to retrieve online and the author informed us that electronic copies of the works were not available. Hence, we analyzed the full text of seven publications. One study was excluded because it presented a replication of the assessment rubric used in another included article, leading us to a total of six publications to add to the review. The systematic review included 20 studies: 18 empirical research articles, one theoretical article, and one narrative literature review. Nineteen studies were written in English and one was written in Portuguese.
Out of the three narrative reviews initially found, two were removed from this systematic review considering that one study (McPherson and Thompson, 1998) reported assessment systems already included under their original empirical research articles, and the other study (Lerch et al., 2020) did not provide information on assessment systems and primarily focused on computer-assisted assessment of sound features. However, we kept one review (Zdzinski, 1991) because it presented additional assessment systems that were deemed relevant to our review.
The characteristics of the participants are shown in Table 1.
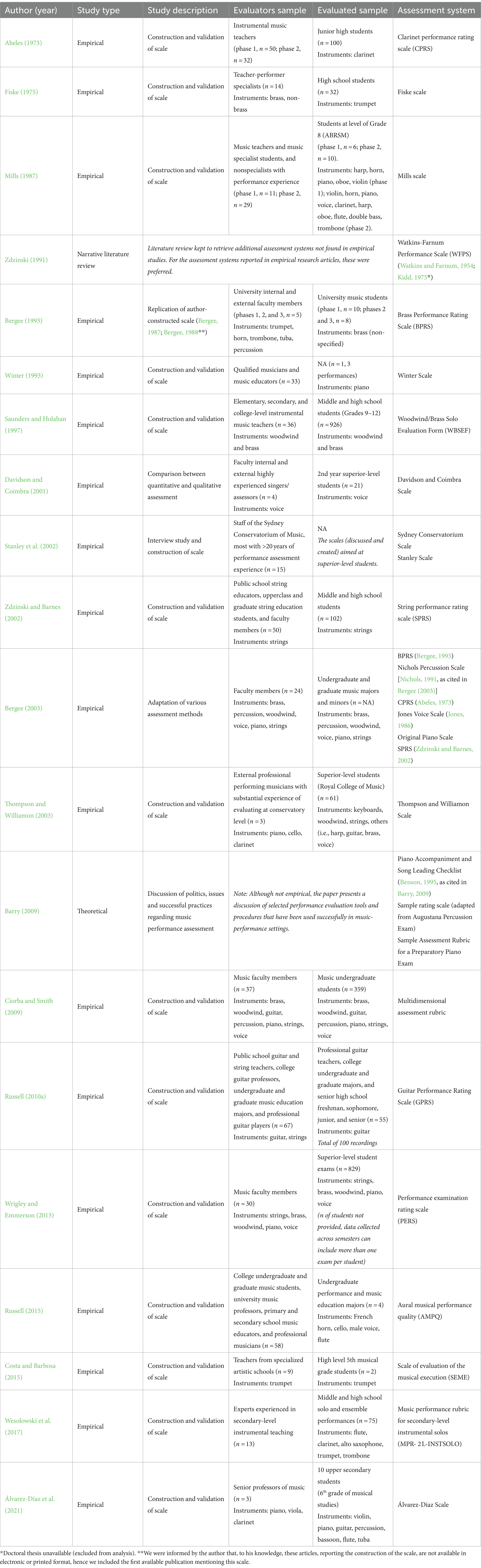
Table 1. Details of included studies—characteristics, samples and methods.
Across studies, the number of evaluated participants ranged from one (Winter, 1993) to 926 (Saunders and Holahan, 1997), and the number of evaluator participants ranged from three (Álvarez-Díaz et al., 2021) to 67 (Russell, 2010a). Studies reported performance assessments of students from: junior high only (n = 1), middle and high school (n = 4), grade 8 ABRSM (Associated Board of the Royal Schools of Music) (n = 1), upper secondary music students (n = 2), superior-level/university music students (n = 7), a combination of professionals, university, and high school students (n = 1), or not specified/not applicable (n = 4). Performances in the following instruments were included: clarinet only (n = 1), trumpet only (n = 2), piano only (n = 1), voice only (n = 1), guitar only (n = 1), brass (n = 1), woodwind and brass (n = 2), strings (n = 1), a combination of instruments from varied families and voice (n = 7), or not specified/not applicable (n = 3).
Evaluator participants were instrumental music teachers (n = 4), teacher-performer specialists (n = 3), faculty members (n = 6), a combination of instrumental teachers, graduate students, and faculty members (n = 4), a combination of instrumental teachers and nonspecialists with performative experience (n = 1), and not specified/not applicable (n = 2). The instrumental expertise of the evaluators was voice only (n = 1), guitar only (n = 1), trumpet only (n = 1), brass (n = 1), woodwind and brass (n = 1), strings (n = 1), mixed panel (varied instrumental families) (n = 6), or not specified/not applicable (n = 8). Nine studies specifically adopted evaluators with high levels of expertise in the corresponding instrument or instrumental family (e.g., brass) being evaluated.
A summary of the 26 assessment systems extracted from the 20 publications analyzed in this review, including names, authors, years of publication, as well as structural characteristics, is presented in Table 2.

Table 2. Details of assessment systems retrieved from included studies—categories, items and criteria.
Most assessment systems were designed for application across instruments (n = 11) but there were also family-specific (n = 6), and instrument-specific (clarinet, n = 1; guitar, n = 1; trombone, n = 1; percussion, n = 2; voice, n = 1; piano, n = 3) systems.
The first-level assessment categories ranged from two (Benson, 1995, as cited in Barry, 2009; Stanley et al., 2002; Wrigley and Emmerson, 2013) to 12 categories (Mills, 1987) across studies, although most recurrently three, four or five categories were implemented. Technical-related categories were the most frequent (19 studies used the term technique, whereas others defined it as command of instrument, instrumental control, or instrumental competence). Expressive-related categories were also recurrent, emerging under the terms interpretation (14 studies), expression (5), musical understanding (4), musical communication (1), musicality (3), musicianship (3), and artistry (1). Following, we found tone/timbre/sound quality (15), intonation/pitch/melodic accuracy (14), rhythm (13) and tempo (11), articulation (8), dynamics (6), and phrasing (3). While some studies considered rhythm and tempo as separate categories (e.g., Abeles, 1973), others joined them (e.g., Bergee, 1993). Four studies included an additional category related to overall quality. Eight systems further comprised categories related to presentation, confidence, visual, stage presence, and audience communication. Five systems included one category related to the adequacy of the interpretation regarding the musical style and epoque. Two studies included categories of body communication and posture. Moreover, the Álvarez-Díaz Scale (2021) was the only system to consider the difficulty of the repertoire as a category, and the Woodwind/Brass Solo Evaluation Form (Saunders and Holahan, 1997) provided a reduced version for musical scales’ assessment. In instrument- and family-specific systems, idiosyncratic categories were identified, including diction and language facility (for voice), sticking or grip (for percussion), air support, tongue, or vibrato (for winds), memorization, fingering, or pedaling (for piano), and vibrato (for strings).
The most common logic adopted across studies was to select a small set of first-level categories and further expand them into multiple second-level items. However, four studies presented different organizations. Mills’ categories (1987) consisted of 12 statements (e.g., performer hardly knew the piece), which were transposed into 12 bipolar items (e.g., the performer hardly knew/was familiar with the piece). Costa and Barbosa (2015) also presented differing categorical terminologies (materials: sensorial and manipulative, expression: personal and vernacular, shape: speculative and idiomatic, value: symbolic and systematic). Nevertheless, these categories become closer to others in their more objective item form (e.g., tuning, sound quality, notion of musical style). The Watkins-Farnum Performance Scale (1954) also derived significantly from other methodologies, as it consisted of 14 exercises of increasing difficulty in varied musical features (e.g., pitch, rhythm, slurring/articulation, among others) which are played orderly by the evaluated participants. Evaluators score each exercise’s performance by considering the participants’ errors, producing a final score for the test. When participants score zero on two consecutive exercises, they stop the test (see Table 2 for more information). On the other hand, Davidson and Coimbra (2001) arrived at three main a posteriori categories (body communication, technical accuracy, artistry) based on evaluators’ ratings and qualitative comments and open-ended responses.
The second-level items ranged from 10 (Stanley et al., 2002) to 44 items (Russell, 2015) across studies, with each of the previous categories commonly being expanded onto multiple items. Three systems did not present items as two comprised a direct rating per category (Fiske, 1975; Stanley et al., 2002) and the other, although mentioning that each category was defined by three items to keep evaluations short, did not provide descriptions in the corresponding article (Bergee, 2003). Items are reported in detail in Table 2.
The rating scales retrieved can be organized into three types: rating scales (n = 19), rubrics (n = 4), checklists (n = 2), and combined checklist and rubric (n = 1). Unlike traditional rating scales, rubrics provide detailed information for each score level.
In terms of the number of levels within these scales, the distribution is as follows: 14 systems used 5-point scales (qualitative, n = 10; qualitative rubric, n = 2; quantitative, n = 1; A – E system, n = 1), four used 4-point scales (qualitative, n = 2; qualitative rubric, n = 1; position only, n = 1), one adopted a 2 to 4-point qualitative rubric depending on the category; two used 6-point scales (qualitative, n = 1; qualitative rubric, n = 1), one used a 7-point qualitative scale, one used a 10-point quantitative scale, and one did not provide information. Two studies combined qualitative rating scales with single overall quantitative scores in 10-point and 13-letter scales. Additionally, the WFPS resulted in scores under a 12-point scale. This diverse range of rating scales highlights the variability in assessment approaches and underscores the need for standardization to ensure consistent and reliable evaluations across different studies.
Our review primarily focuses on the methods of performance assessment methods. In this sense, for all studies, the primary outcome of all publications comprised the development, validation, and/or implementation of a music performance assessment. Nonetheless, we present below some of the most relevant complementary findings across studies. Table 3 synthesizes the objectives and findings for each study.

Table 3. Objectives and synthesized findings of included studies.
Five studies (and seven assessment systems) (Abeles, 1973; Bergee, 1993, 2003; Jones, 1986; Nichols, 1991, as cited in Bergee, 2003; Russell, 2010a; Zdzinski and Barnes, 2002) used facet-factorial approaches, defined as conceptualizing the behavior as multidimensional and selecting scale items through factor analysis, validating the method as an effective technique for the construction of rating scales. These studies collected a pool of initial items (range: 90–99) generated by experts, to which factorial techniques were applied to produce a final version of the measurement instrument that included items with high factor loadings (range: 27–32). Zdzinski and Barnes (2002) found that the factor grouping slightly differed from those in Abeles (1973) and Bergee (1993), most likely due to instrument-specific technical requirements. For example, for strings, tone and articulation were grouped in the same factor (Zdzinski and Barnes, 2002); for brass, tone and intonation were grouped and technique was accommodated in another factor (Bergee, 1993); and for woodwinds, separate factors were established for tone, articulation, and intonation (Abeles, 1973). The SPRS was the only system that included vibrato items in a separate factor. Similarly, the Jones Scale (Jones, 1986) yielded a different factor structure with Interpretation/Musical Effect as common and other factors consisting of Tone/Musicianship, Technique, Suitability/Ensemble, and Diction. The piano scale developed by Bergee (2003) consisted of only three factors (Interpretation/Musical Effect, Rhythm/Tempo, and Technique).
Wrigley and Emmerson (2013) developed PERS models for five instrument families (piano, voice, strings, brass, woodwind) distilling acceptable levels of reliability (internal reliability alphas ranging from 0.81 to 0.98) and construct validity. Their results also confirmed the importance of using instrument-specific scales, as, although the authors found consistency between instrument departments at the general factor of evaluation, they also found considerable variation between dimension constructs, which can be attributable to instrumental idiosyncrasies. Moreover, this was the only work identified in which the same author team developed evaluation systems for five instrumental families. Wesolowski et al. (2017) recently applied the Multifaceted Rasch Partial Credit Measurement Model to create a 30-item solo wind performance assessment rubric. In summary, Rasch techniques enable construct-irrelevant factors, such as individual characteristics of persons, raters, or items, to not interfere between observed data and predictions of the model, accounting for multiple issues related to individual variability observed in facet-factorial approaches. The scale displayed overall good psychometric qualities (reliability, precision, and validity).
Regarding assessment systems transversal to multiple instruments, Mills (1987) found that a bipolar scale effectively explained a high proportion of variance in overall ratings. Ciorba and Smith (2009) developed a multidimensional assessment rubric, applicable across instruments and university years, that revealed moderate to high levels of agreement among judges and was influential in measuring students’ achievement, as proved by the positive correlation between performance achievement and participants’ year in university (freshman, sophomore, junior, and senior). Recently, Álvarez-Díaz et al. (2021) also validated a unidimensional assessment rubric applicable across instruments.
Russell (2015) introduced novel findings regarding the weight of each performance dimension, demonstrating a positive causal relationship between technique and musical expression. Technique showed direct effects on the ratings of overall quality and musical expression, while musical expression demonstrated direct effects on overall quality only, suggesting that deficiencies in technique will not only influence assessments of it but also of musical expression and the overall perception of performance quality.
In a literature review, Zdzinski (1991) discussed that despite the widespread application of the Watkins-Farnum Performance Scale (1954) in music performance research up to date, studies have shown moderate and low validity coefficients (e.g., 0.63, 0.40, 0.12) when comparing the WFPS with other scales. Moreover, the WFPS is based on calculating a score derived from bar-by-bar performance errors (e.g., rhythm, pitch), which poses multiple drawbacks: (a) the final score does not allow for differentiation of errors as they are summed; (b) only one point (corresponding to one error) can be deducted by measure regardless of the number of errors occurring; and (c) the score does not include parameters such as musicality, phrasing, or intonation. The author also highlighted that systematic and criteria-based assessment systems such as the ones by Abeles (1973) or Bergee (1993), yielded promising results in terms of reliability and validity. Saunders and Holahan (1997) and Barry (2009) also emphasize that, although more challenging to build, criteria-specific rating scales have superior diagnostic validity than Likert-type rating scales and traditional open-ended rating forms. In line with these findings, Costa and Barbosa (2015) discovered that variability within trumpet judges increased in evaluations without pre-defined criteria, although it was generally high in both free and criteria-based evaluation models. In fact, multiple studies reported high correlations between performance assessment categories (Álvarez-Díaz et al., 2021; Ciorba and Smith, 2009; Fiske, 1975; Thompson and Williamon, 2003), underscoring that, although the unique contribution of each score to the composite may be limited, the comparison of scores in different dimensions presents a profile of student achievement that can be transposed into valuable feedback related to specific performative skills and lead to plans for future instruction to address areas of weakness.
From a complementary perspective, Davidson and Coimbra (2001) found that, although assessors demonstrated high degrees of correlation in grades, their criteria were implicit rather than explicit. Assessors seemed to share a code of assessment criteria but lacked articulation and delimitation, suggesting that they were uncertain of what their own or others’ beliefs drove decisions. In the interview study by Stanley et al. (2002), examiners at a tertiary music conservatorium presented mixed opinions regarding criteria-based assessments. While some felt using criteria facilitated the focus on essential assessment issues and was helpful in articulating desired performance characteristics in feedback to students, others believed criteria-based assessment represented a narrow view that tended to interfere with their holistic assessments of music performance. Discussions with examiners led to the adaptation of the conservatorium’s assessment system, considering their preference for fewer criteria so that more time could be dedicated to writing detailed comments (Stanley et al., 2002).
Regarding mediator factors in performance assessment, studies reported no differences between brass and non-brass judges (Fiske, 1975), nor between music specialists and nonspecialists (Mills, 1987). Nevertheless, in Mills (1987), the constructs used did not require possessing musical knowledge (e.g., the performance was hesitant/fluent). Fiske (1975) also found that technique was rated differently between wind and nonwind judges (Fiske, 1975), and Thompson and Williamon (2003) reported evidence of bias according to examiners’ instrumental expertise. Bergee (1993) found high inter-judge reliability for faculty and peer evaluation panels, demonstrating consistent agreement on all factors but rhythm-tempo; self-evaluation, however, correlated poorly with faculty and peer evaluation. No differences were found between levels of evaluative experience or between teaching assistants and faculty members (Bergee, 2003). In fact, Winter (1993) found that the prior training received by music adjudicators was more significant in producing consistent and accurate assessments than the previous experience in such a role. Finally, Bergee (2003) found that inter-judge reliability was consistently good regardless of panel size, although permutations of two and three evaluators tended to exhibit more variability, greater range, and less uniformity than did groups of four and five. Hence, the author recommended using at least five adjudicators for performance evaluation. Furthermore, the same study found no effects of videotaped (versus live) performances or prior knowledge of performers.
This systematic review summarized solo music performance assessment methods reported in published scientific research for over 50 years. Significant heterogeneity was observed between the included studies regarding the assessment systems used to evaluate performances, allowing for the retrieval and analysis of 26 different systems reported across 20 publications. We found 11 generalized, six family-, and nine instrument-specific scales, among the identified systems. Some studies advocate for adopting family- and instrument-specific scales that consider the idiosyncrasies related to instrumental and vocal technique. For example, in assessing vocal performance, diction and language facility are relevant skills (Jones, 1986), just as breathing, air support, and tongue are for winds (Bergee, 1993; Wesolowski et al., 2017) or vibrato for strings (Zdzinski and Barnes, 2002). The argument for instrumental scales is further supported by findings such as rating differences between wind and nonwind judges in the technical dimension (Fiske, 1975), evidence of bias according to examiners’ instrumental expertise (Thompson and Williamon, 2003), substantial variability between instrument departments on the level of dimension constructs (Wrigley and Emmerson, 2013), and factor grouping of assessment items varying between instrumental families [e.g., the String Performance Rating Scale by Zdzinski and Barnes, 2002 yielded a different factorial organization than the Clarinet Performance Rating Scale by Abeles, 1973]. On the contrary, generalized scales seem to facilitate the standardization of assessment practices across instrumental and vocal departments and foster the development of a common criteria vocabulary among examiners, a previously identified deficiency (Davidson and Coimbra, 2001). After carefully considering examiners’ opinions, requesting fewer criteria and more space for subjective comments, one tertiary music conservatorium replaced a family-directed assessment system with a set of common assessment criteria (Stanley et al., 2002). Generalized systems have been successful in contexts where direct comparisons are desired, for instance, in measuring students’ achievement throughout university years (Ciorba and Smith, 2009), in multi-instrument competitions (Álvarez-Díaz et al., 2021), or in music performance assessment by non-experts (Mills, 1987). We conclude that, as posed by Barry (2009), there is no “one-size-fits-all approach to music evaluation” and that, depending on the context, function of the assessment, and institutional culture, both generalized and instrument-oriented methods can be effectively implemented.
Regarding the main assessment categories, most assessment systems adopted a structure comprising one technical category, one interpretative/expressive category, and multiple musical feature categories (e.g., pitch, rhythm, intonation). Additionally, eight systems reserved one category for stage presence, and even fewer encompassed categories for aesthetics and epoque adequacy, and body behavior. Although this structure seems reasonable, one may reflect on how technique relates to both musical effect execution and interpretation. Musical execution and communication are only attainable if the performer possesses substantial skill levels in their instrument, supporting the priority to developing a precise technique in music education settings (Gellrich and Parncutt, 1998; McPherson, 2022). For example, clarinet players’ finger movements in pressing and releasing keys, together with breathing, determine the timing of tone onsets (also known as tempo or rhythmic accuracy in the categories of assessment systems) (Palmer et al., 2009). Similarly, violin players need to master upper body movements to express melodic continuity through timing (rubato), a common marker of personal interpretation (Huberth et al., 2020). Russell (2015) findings further support this notion, showing that technique directly impacts the ratings of overall quality and musical expression, while musical expression solely impacts the overall quality. Hence, technical deficiencies affect not only on technique ratings but also on the perception of musical expression and the overall performance quality. In accordance, Álvarez-Díaz et al. (2021) attributed the higher assessment weights (30% each) to the technical level and performance quality, followed by the difficulty of chosen pieces (20%), stylistic coherence, and stage presence (10% each). This categorical intertwinement has also been noted through inter-category correlations in several studies (Álvarez-Díaz et al., 2021; Ciorba and Smith, 2009; Fiske, 1975; Thompson and Williamon, 2003). Considering these findings, we believe it is worth reflecting on the weight given to the technical category in relation to others and to what extent it could be pertinent to aggregate skills related to musical features, such as pitch, intonation, or articulation, in this sector.
By analyzing the rating scales implemented, we identified that most assessment systems used 5-point Likert qualitative scales, which reflect the evaluators’ level of agreement with a set of assessment elements. However, we noted that, gradually, more recent studies started replacing these with rubrics, which provide detailed descriptions for each level of the achievement scale. Such descriptions constitute beneficial feedback for the evaluated individuals, as they present a clearly defined set of descriptors related to learning expectations, providing both a measure of the present performance and information to improve future performances (Ciorba and Smith, 2009). Moreover, rubric descriptors also facilitate the examiners’ role by delimiting the expected outcomes for each level, again promoting the much-needed common understanding of assessment criteria (Wesolowski, 2012). In terms of the number of levels within scales, consensus among authors appeared challenging to reach. Most kept to traditional 5-point Likert scales (e.g., Bergee, 2003; Saunders and Holahan, 1997), while some selected even numbered scales (e.g., 4-point) to eliminate neutral categories by forcing positively or negatively positioned responses (Mills, 1987; Wesolowski et al., 2017), and others adopted 1–10 quantitative scales due to their direct relation with the 100-point scale frequently used in music educational contexts (Thompson and Williamon, 2003). Research has shown that scales with more than 10 points result in decreased reliability, although they provide respondents with increased precision levels (Preston and Colman, 2000), and that 5-point scales can produce inconsistent answer scores (Toepoel and Funke, 2018). Curiously, seven-point scales seem to be the best compromise (Krosnick and Fabrigar, 1997; Maitland, 2009), and they were only adopted in the PERS (Wrigley and Emmerson, 2013). Nevertheless, it is crucial to highlight that, in developing rubrics, implementing a high number of levels can be challenging, as it becomes more difficult to define differences between expected outcome descriptors.
One surprising finding regards the almost imperceivable differences in assessment criteria between diverging types of populations. Most of the studies focused on either high schoolers or university students, representing distinct performance levels. Hence, we expected that, at the item level, descriptions would be adapted to the expected skill competence for each learning stage. However, the descriptions were general to the extent to which most items were applicable to multiple populations. For example, when presented with the following item: command of instrument is (select one option) below minimum expectations/demonstrates potential for musical growth/has achieved a point where musical maturity is possible/is proficient/demonstrates potential for professional success (Ciorba and Smith, 2009), judges are unable to infer what is, indeed, the expected command of instrument for the student at hand. For example, for a beginner saxophone player, producing sound without squeaking would be a good demonstration of the command of the instrument, while for a superior-level student, it could be the ability to play harmonics while maintaining intonation and timbre quality. Barry (Barry, 2009) introduces a fine example of a rubric adapted for a preparatory piano exam in which descriptors are objective and level-appropriate (e.g., not yet – student misses standard fingering more than once; almost – student misses standard fingerings once; … exceeds standard – student develops more efficient fingering practice). Without a doubt, music performance assessment, unlike more objective disciplines, is particularly defying due to the involvement of expressive decisions and response divergence (Wesolowski, 2012). Moreover, it has been discussed that music educators, in particular, face challenges in systematically documenting and quantifying the essential concepts and skills they want their students to acquire and demonstrate at different levels of performance achievement (Payne et al., 2019; Wesolowski, 2015). Therefore, we postulate that the level of accuracy the assessment systems lacked in determining the specific goals for each learning stage may be a reflection of the path music education has yet to pursue to reform outdated practices and adopt more effective, efficient, and clearly defined methods for measuring student growth, aligning with other general education policies.
Two main limitations were identified in this work. First, we included only reviews and original research published in peer-reviewed journals. Citation searches revealed that numerous studies on music performance assessment exist in grey literature, such as doctoral dissertations and institutional pedagogical guidelines. However, many assessment systems initially presented in these were later converted into articles by the same authors or implemented by others. Therefore, we focused this review on published, peer-reviewed works to ensure validity and scientific rigor, even though it may have implicated discarding additional publications. Second, our review’s scope limits our ability to draw conclusions about the efficacy of the assessment systems reported. We focused on their construction, characterization, and validation rather than analyzing replication studies. While the assessment systems analyzed generally reported good reliability and consistency in their original studies, subsequent research might have identified weaknesses. For instance, Zdzinski (1991) noted in his literature review that multiple post hoc studies using the Watkins-Farnum Performance Scale (1954) had already revealed moderate and low validity coefficients compared to other scales. Future research should map the use of various assessment systems post-implementation, providing insights into their frequency of use and into additional validity results.
In conclusion, this review documents the major progress in music performance assessment simultaneously underscores the imperative for continued research to address persistent gaps and improve existing methodologies. We investigated music performance assessment systems found in scientific literature, analyzing their corresponding evaluation categories and descriptive criteria, rating methodology, and target audience. A total of 51 full-text publications were assessed for eligibility, which were reduced to 20 articles that met the inclusion criteria.
The literature review identified 26 assessment systems for detailed analysis. Most studies evaluated high school and university students, with evaluators primarily being music teachers and faculty members. About one-third of the studies assessed a heterogeneous group of instrumental and vocal performances, while the others focused on specific instruments/voice or instrumental families. Consequently, most assessment systems were designed for use across various instruments, though some were family- or instrument-specific. Many systems followed a structural logic including one technical category, one interpretative/expressive category, and multiple musical feature categories (e.g., pitch, rhythm, intonation), further expanded into descriptive items. Five-point Likert qualitative scales were most common, though recent studies showed a trend towards rubrics for detailed feedback, facilitating both examiners comprehension and student progress. Interestingly, no differences were found in assessment criteria for students at different learning stages. Research efforts should be directed toward developing and validating assessment criteria specific to different proficiency stages. Customizing assessment tools to meet the needs of beginners, intermediate, and advanced students is crucial. It allows educators, researchers, and curriculum developers to offer more relevant and constructive feedback, a contribution that is crucial for fostering individual growth and progress in music performance. Also, this strategy ensures that assessment methods are suitably challenging and developmentally appropriate for each level of a student’s educational journey.
By delimiting and characterizing the existing assessment systems, this study represents a novel contribution for educators and policymakers looking to enhance curriculum design and instructional practices in music education, as well as for researchers aiming to design science-based, objective performance assessment studies. With continued efforts in these areas, we can look forward to a future where music performance assessments are more reliable, equitable, and truly support and enhance the musical journey of every student.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
NM: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Validation, Writing – original draft, Writing – review & editing. PD: Conceptualization, Validation, Writing – review & editing. LV: Conceptualization, Validation, Writing – review & editing. PO-S: Validation, Writing – review & editing. SS: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Supervision, Writing – original draft, Writing – review & editing.
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This research was funded by the Fundação para a Ciência e Tecnologia (Portugal) under the IC&DT project with reference 2022.05771.PTDC.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Abeles, H. F. (1973). A facet-factorial approach to the construction of rating scales to measure complex behaviors. J. Educ. Meas. 10, 145–151. doi: 10.1111/j.1745-3984.1973.tb00792.x
Álvarez-Díaz, M., Muñiz-Bascón, L. M., Soria-Alemany, A., Veintimilla-Bonet, A., Fernández-Alonso, R., Alvarez-Diaz, M., et al. (2021). On the design and validation of a rubric for the evaluation of performance in a musical contest. Int. J. Music. Educ. 39, 66–79. doi: 10.1177/0255761420936443
Barry, N. H. (2009). Evaluating music performance: politics, pitfalls, and successful practices. Coll. Music. Symp. 49, 246–256. Available at: http://www.jstor.org/stable/41225250
Benson, C . (1995). “Comparison of Students and Teachers’ Evaluations and Overall perceptions of Students’ Piano Performances,” Texas Music Education Research. Available at: https://www.tmea.org/OSOCollege/Researcbben1995.pdf (Accessed November 7, 2008).
Bergee, M. J. (1987). An application of the facet-factorial approach to scale construction in the development of a rating scale for euphonium and tuba music performance. Doctoral dissertation, University of Kansas. ProQuest dissertations and theses.
Bergee, M. J. (1988). Use of an objectively constructed rating scale for the evaluation of brass juries: A criterion-related study. Dy. Missouri. J. Res. Music Educ. 5, 6–15.
Bergee, M. J. (1989). An investigation into the efficacy of using an objectively con- structed rating scale for the evaluation of university-level single-reed juries. Mus.J. Res Music Educ. 26, 74–91.
Bergee, M. J. (1993). A comparison of faculty, peer, and self-evaluation of applied Brass jury performances. J. Res. Music. Educ. 41, 19–27. doi: 10.2307/3345476
Bergee, M. J. (2003). Faculty interjudge reliability of music performance evaluation. J. Res. Music. Educ. 51, 137–150. doi: 10.2307/3345847
Ciorba, C. R., and Smith, N. Y. (2009). Measurement of instrumental and vocal undergraduate performance juries using a multidimensional assessment rubric. J. Res. Music. Educ. 57, 5–15. doi: 10.1177/0022429409333405
Costa, M. C., and Barbosa, J. F. (2015). The assessment of trumpet’s instrumental performance by teachers: issues and challenges. Per Musi 31, 134–148. doi: 10.1590/permusi2015a3108
Davidson, J. W., and Coimbra, D. D. C. (2001). Investigating performance evaluation by assessors of singers in a music college setting. Music. Sci. 5, 33–53. doi: 10.1177/102986490100500103
Fiske, H. E. (1975). Judge-group differences in the rating of secondary school trumpet performances. J. Res. Music. Educ. 23, 186–196. doi: 10.2307/3344643
Gellrich, M., and Parncutt, R. (1998). Piano technique and fingering in the eighteenth and nineteenth centuries: bringing a forgotten method Back to life. Br. J. Music Educ. 15, 5–23. doi: 10.1017/S0265051700003739
Giraldo, S., Waddell, G., Nou, I., Ortega, A., Mayor, O., Perez, A., et al. (2019). Automatic assessment of tone quality in violin music performance. Front. Psychol. 10, 1–12. doi: 10.3389/fpsyg.2019.00334
Hewitt, M. P., and Smith, B. P. (2004). The influence of teaching-career level and primary performance instrument on the assessment of music performance. J. Res. Music. Educ. 52, 314–327. doi: 10.1177/002242940405200404
Huberth, M., Davis, S., and Fujioka, T. (2020). Expressing melodic grouping discontinuities: evidence from violinists’ rubato and motion. Music. Sci. 24, 494–514. doi: 10.1177/1029864919833127
Jones, H. (1986). An application of the facet-factorial approach to scale construction in the development of a rating scale for high school vocal solo performance (adjudication, evaluation, voice). Doctoral dissertation, University of Oklahoma. ProQuest dissertations and theses.
Kidd, R. L. (1975). The construction and validation of a scale of trombone performance skills. University of Illinois at Urbana-Champaign.
Krosnick, J. A., and Fabrigar, L. R. (1997). “Designing rating scales for effective measurement in surveys” in Survey measurement and process quality. eds. L. Lyberg, P. Biemer, M. Collins, and E. Al (Hoboken, New Jersey: Wiley), 141–164.
Lerch, A., Arthur, C., Pati, A., and Gururani, S. (2020). An interdisciplinary review of music performance analysis. Transac. Int. Soc. Music Inform. Retrieval 3, 221–245. doi: 10.5334/tismir.53
Maitland, A. (2009). How many scale points should I include for attitudinal questions? Surv. Pract. 2, 1–4. doi: 10.29115/sp-2009-0023
McPherson, G. E. (2022). The Oxford handbook of music performance: development and learning, Proficiencies, performance practices, and psychology, vol. 1: Oxford University Press.
McPherson, G. E., and Thompson, W. F. (1998). Assessing music performance: issues and influences. Res. Stud. Music Educ. 10, 12–24. doi: 10.1177/1321103X9801000102
Mills, J. (1987). Assessment of solo musical performance - a preliminary study. Bull. Counc. Res. Music. Educ. 91, 119–125.
Mills, J. (1991). Assessing musical performance musically. Educ. Stud. 17, 173–181. doi: 10.1080/0305569910170206
Mustul, O., and Aksoy, Y. (2023). Opinions of lecturers in music education department about assessment and evaluation of the violin and viola exams. Rast Müzikoloji Dergisi 11, 289–307. doi: 10.12975/rastmd.20231127
Nichols, J. P. (1991). A factor analysis approach to the development of a rating scale for snare drum performance. Dialogue Instrumental Music Educ. 15, 11–31.
Page, M. J., McKenzie, J. E., Bossuyt, P. M., Boutron, I., Hoffmann, T. C., Mulrow, C. D., et al. (2021). The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ 372. doi: 10.1136/bmj.n71
Palmer, C., Koopmans, E., Loehr, J. D., and Carter, C. (2009). Movement-related feedback and temporal accuracy in clarinet performance. Music. Percept. 26, 439–449. doi: 10.1525/mp.2009.26.5.439
Payne, P. D., Burrack, F., Parkes, K. A., and Wesolowski, B. (2019). An emerging process of assessment in music education. Music. Educ. J. 105, 36–44. doi: 10.1177/0027432118818880
Preston, C. C., and Colman, A. M. (2000). Optimal number of response categories in rating scales: reliability, validity, discriminating power, and respondent preferences. Acta Psychol. 104, 1–15. doi: 10.1016/s0001-6918(99)00050-5
Russell, B. E. (2010a). The development of a guitar performance rating scale using a facet-factorial approach. Bull. Counc. Res. Music. Educ. 184, 21–34. doi: 10.2307/27861480
Russell, B. E. (2010b). The empirical testing of musical performance assessment paradigm. Doctoral dissertation, University of Miami
Russell, J. A. (2014). Assessment in instrumental music. Oxford Handbook Topics Music. doi: 10.1093/oxfordhb/9780199935321.013.100
Russell, B. E. (2015). An empirical study of a solo performance assessment model. Int. J. Music. Educ. 33, 359–371. doi: 10.1177/0255761415581282
Saunders, T. C., and Holahan, J. M. (1997). Criteria-specific rating scales in the evaluation of high school instrumental performance. J. Res. Music. Educ. 45, 259–272. doi: 10.2307/3345585
Smith, B. P. (2004). Five judges’ evaluation of audiotaped string performance in international competition. Bull. Counc. Res. Music. Educ. 160, 61–69. Available at: https://www.jstor.org/stable/40319219
Stanley, M., Brooker, R., and Gilbert, R. (2002). Examiner perceptions of using criteria in music performance assessment. Res. Stud. Music Educ. 18, 46–56. doi: 10.1177/1321103X020180010601
Tabuena, A. C., Morales, G. S., and Perez, M. L. A. C. (2021). Music assessment techniques for evaluating the students’ musical learning and performance in the Philippine K-12 basic education curriculum. Harmonia 21, 192–203. doi: 10.15294/harmonia.v21i2.32872
Thompson, S. A. M., and Williamon, A. (2003). Evaluating evaluation: musical performance assessment as a research tool. Music. Percept. 21, 21–41. doi: 10.1525/mp.2003.21.1.21
Toepoel, V., and Funke, F. (2018). Sliders, visual analogue scales, or buttons: influence of formats and scales in mobile and desktop surveys. Math. Popul. Stud. 25, 112–122. doi: 10.1080/08898480.2018.1439245
Watkins, J. G., and Farnum, S. E. (1954). The Watkins-Farnum performance scale. A standardised achievement test for all band instruments, Minnesota, Winona: Hal Leonard Publishing.
Wesolowski, B. C. (2012). Understanding and developing rubrics for music performance assessment. Music. Educ. J. 98, 36–42. doi: 10.1177/0027432111432524
Wesolowski, B. C. (2015). Tracking student achievement in music performance: developing student learning objectives for growth model assessments. Music. Educ. J. 102, 39–47. doi: 10.1177/0027432115589352
Wesolowski, B. C. (2021). An examination of differential item functioning in a rubric to assess solo music performance. Music. Sci. 25, 161–175. doi: 10.1177/1029864919859928
Wesolowski, B. C., Amend, R. M., Barnstead, T. S., Edwards, A. S., Everhart, M., Goins, Q. R., et al. (2017). The development of a secondary-level solo wind instrument performance rubric using the multifaceted Rasch partial credit measurement model. J. Res. Music. Educ. 65, 95–119. doi: 10.1177/0022429417694873
Wesolowski, B. C., Wind, S. A., and Engelhard, G. (2016). Examining rater precision in music performance assessment: an analysis of rating scale structure using the multifaceted rash partial credit model. Music. Percept. 33, 662–678. doi: 10.1525/mp.2016.33.5.662
Winter, N. (1993). Music performance assessment: a study of the effects of training and experience on the criteria used by music examiners. Int. J. Music. Educ. os-22, 34–39. doi: 10.1177/025576149302200106
Wrigley, W. J., and Emmerson, S. B. (2013). Ecological development and validation of a music performance rating scale for five instrument families. Psychol. Music 41, 97–118. doi: 10.1177/0305735611418552
Zdzinski, S. F. (1991). Measurement of solo instrumental music performance: a review of literature. Bull. Council Res. Music Educ. Summer 1991, 47–58.
Keywords: instrumental and vocal performance evaluation, judges, rating scales, music pedagogy, music competitions, western classical music, systematic review
Citation: Moura N, Dias P, Veríssimo L, Oliveira-Silva P and Serra S (2024) Solo music performance assessment criteria: a systematic review. Front. Psychol. 15:1467434. doi: 10.3389/fpsyg.2024.1467434
Edited by:
Maria Varvarigou, Mary Immaculate College, IrelandReviewed by:
Claudia Bullerjahn, Justus-Liebig-University Giessen, GermanyCopyright © 2024 Moura, Dias, Veríssimo, Oliveira-Silva and Serra. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Nádia Moura, bm1vdXJhQGZsLnVjLnB0; Sofia Serra, c29maWEuc2VycmFAdWEucHQ=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.