 Santos Orejudo
Santos Orejudo Raquel Lozano-Blasco
Raquel Lozano-Blasco Pablo Bautista2
Pablo Bautista2
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol., 15 May 2024
Sec. Personality and Social Psychology
Volume 15 - 2024 | https://doi.org/10.3389/fpsyg.2024.1383134
This article is part of the Research TopicAdvancing Understanding and Mitigating Antisocial and Bullying Behaviors: Insights and Strategies for School-Based InterventionView all 7 articles
Introduction: The construct of collective intelligence assumes that groups have a better capacity than individuals to deal with complex, poorly defined problems. The digital domain allows us to analyze this premise under circumstances different from those in the physical environment: we can gather an elevated number of participants and generate a large quantity of data.
Methods: This study adopted an emotional perspective to analyze the interactions among 794 adolescents dealing with a sexting case on an online interaction platform designed to generate group answers resulting from a certain degree of achieved consensus.
Results: Our results show that emotional responses evolve over time in several phases of interaction. From the onset, the emotional dimension predicts how individual responses will evolve, particularly in the final consensus phase.
Discussion: Responses gradually become more emotionally complex; participants tend to identify themselves with the victim in the test case while increasingly rejecting the aggressors.
The construct of collective intelligence has become increasingly popular in a variety of scientific domains, as it provides a theoretical and empirical framework that allows researchers to analyze how groups can perform better than individuals. Many studies have been conducted in a small-group environment where participants collectively generate a product that researchers can compare with an equivalent product resulting from individual actions or answers. Sharing a common methodology, the studies by Woolley et al. (2010), Engel et al. (2014), Meslec et al. (2016), Aggarwal and Woolley (2018), Aggarwal et al. (2019), Woolley and Aggarwal (2020) are a good example of the practical application of the premise of collective intelligence. Although those studies have nevertheless received a certain amount of criticism, researchers who have applied other methods have reached similar conclusions (Navajas et al., 2018; Toyokawa et al., 2019; Pescetelli et al., 2021).
This paradigm of dealing with collaborative group tasks in small groups featuring face-to-face interaction is fundamentally transformed when interactions are transferred to the Internet environment: a “digital space,” as designated by Pescetelli et al. (2021). One of the most important differences between face-to-face and online interaction is that the online environment allows researchers to considerably improve the number of individuals participating and collaborating in tasks. They can thus ascertain whether a large number of jointly interacting people might improve the chance of resolving the open, complex problems that confront humanity today (Lorenz et al., 2011; Hamada et al., 2020). The crowd intelligence construct provides us with a theoretical and empirical framework to approach such problem-solving processes on a collaborative basis in large groups; it is assumed, however, that the participants do not necessarily need to interact with one another to reach the solution (Hamada et al., 2020). One of the major research interests in this field is to ascertain under which conditions group performance can be optimized (Becker et al., 2017; Yahosseini and Moussaïd, 2020; Pescetelli et al., 2021). Key issues in such empirical analyses of the productions of large groups include: (1) ascertaining which is the most adequate method to aggregate potential solutions with the ultimate purpose of confirming that the collective product is better than the individual solution, and (2) studying how such products can be operationalized and quantified. One frequent solution is to devise estimation tasks that are easy to quantify; such tasks, however, seem to be far removed from the more complex, open kind of tasks with which human beings are usually faced in natural settings (Geifman and Raban, 2015).
Another key issue in the study of collaborative tasks is establishing a series of conditions that allow participants to interact with one another to achieve the best solution to a problem. Indeed, if overall performance needs to be improved, such collaborative interaction is a necessary condition (Gürçay et al., 2015; Navajas et al., 2018; Toyokawa and Gaissmaier, 2022), but it also serves as a differentiating factor among diverse types of collective intelligence processes (Hamada et al., 2020). As mentioned above, face-to-face interactions are limited to a reduced number of people, usually four to six individuals; in such contexts, the ideal number of participants in a group is five (Navajas et al., 2018). The number can be increased in some instances, as in particularly demanding tasks that require a more enhanced degree of coordination among members and a more significant amount of incentive (Mao et al., 2016). In the online environment, however, interactive spaces can gather elevated quantities of individuals who can interact with one another to analyze a problem or simply share their experiences regarding a particular product. Their outlook evolves naturally through interactions in a dynamic system (Almaatouq et al., 2020). The task of analyzing and understanding what goes on in such “digital spaces” is thus more complex.
This context thus poses two empirical questions. How does large-group interaction take place in such digital contexts? Is it truly possible to achieve quality solutions to particular problems via online interactions? Both of these issues ultimately lead us to analyze the nature of such interactions (Navajas et al., 2018; Massari et al., 2019) along with further key issues, including social influence processes (Gürçay et al., 2015; Becker et al., 2017; Toyokawa et al., 2019) and the participants’ level of involvement (Hamada et al., 2020). It is also important to define and establish the type of problem/task to be solved (Geifman and Raban, 2015; Sulik et al., 2022). An additional element worthy of study resides in the design of the task itself: the key issue is to ascertain whether the system foresees for the group to produce a consensual solution to the problem or whether the solution should be generated a posteriori through aggregation mechanisms that are external to the group (Yahosseini and Moussaïd, 2020).
A considerable number of complex issues are thus involved. Our study aims to analyze the interactions that arise when a large number of people (in our case, close to 800 individuals) jointly explore a task in an interactive environment on an online platform until they propose solutions. One key issue lies in resolving how the productions of a significant number of people should be quantified or measured, since their interactions can only be quantified as a series of thousands of individual events. We thus propose to study how those interactions evolve in the context of a large group that is dealing with an ethical problem consisting in the analysis of a case of cyberbullying. We chose and designed this case with the purpose of encouraging engagement on the part of the participants, who were asked to emit judgments about “what happened.” We propose to study the situation using big data tools designed to analyze emotions (Aggarwal, 2022; Trisna and Jie, 2022; Chan et al., 2023).
It is also essential to grasp the nature of the interactive environment in which a task is carried out. The IT environments in which large group interactions take place can have many different characteristics and goals, ranging from social media (on which information can be shared) to collaborative environments such as Wikipedia (Holtz et al., 2018). Certain tools are specifically designed to create collaborative environments in which information can be shared, joint solutions can be reached, and consensus mechanisms can be established (Geifman and Raban, 2015). This is also the case on the Collective Intelligence platform we used in this study: its characteristics are described further below and can also be consulted in Orejudo et al. (2022).
This study’s objective was to analyze how information spreads in an online interaction environment designed according to the principles of collective intelligence. We hypothesize that the emotional dimension plays a key role in this process and predicts how information spreads within that environment.
In the field of social behavior, the construct of Collective Intelligence (CI) has become increasingly popular, starting with the study by Woolley et al. (2010) published in the journal Science. The underlying supposition in collective intelligence is that when people work together as a group (intragroup level) on tasks of various kinds, the group’s level of performance is superior to the mean of the performances of its individuals (intrapersonal) on the same tasks. One of the most interesting results of this study is the idea of the “c” factor. Based on the traditional idea of the g-factor of intelligence, the researchers found that the factor analysis carried out on the performance of the groups on the different tasks suggested a single factor that explained most of the variance in the results, the so-called “c” factor. A series of studies by that research team have confirmed that results achieved in face-to-face contexts and in online environments are similar (Engel et al., 2014; Meslec et al., 2016). Other investigations have been conducted featuring tasks of dissimilar nature (Woolley and Aggarwal, 2020); further studies have sought to ascertain what kind of conditions exert a significant influence on results.
Those studies were criticized by other authors (Starkey, 2012; Rowe et al., 2021). After conducting a meta-analysis of CI studies based on the Woolley paradigm, Rowe et al. (2021) called certain results into question, particularly those related to what is known as the c-factor. They pointed out that the level of individual or group performance on tasks can be highly determined by contextual factors and by the nature of the task itself: this, in turn, would limit the validity of the c-factor. In order to take the importance of contextual factors into account, it is necessary to describe them more closely. Woolley et al. (2015) provided an important contribution by proposing two analysis levels: top-down factors (those related to the participants in the task) and bottom-up factors (those related to the conditions in which the interaction takes place). Among personal or top-down factors, the first studies focused on the sex variable, ascribing a greater degree of emotional competency to women. For a group to function well, emotional competency is key: it improves the group’s cohesion and plays a pivotal role in conflict management situations (Curşeu et al., 2015). Other authors have added further considerations related to emotional intelligence (Hjertø and Paulsen, 2016), social sensitivity, and cognitive diversity (Woolley et al., 2010; Aggarwal et al., 2019). Independent replications of the Woolley studies have extended our knowledge regarding these variables: not all results could be replicated. For instance, Bates and Gupta (2017) ascribed greater importance to the individual characteristics of a group’s members than to the group’s heterogeneity per se.
Among possible bottom-up factors, interaction among group members is regarded as a necessary condition for collective intelligence to emerge (De Vincenzo et al., 2017; Bernstein et al., 2018; Dai et al., 2020). Indeed, within the paradigm established by Woolley et al. (2010), the condition of interaction is essential, as the final product is achieved by a group. The level of participation of group members is also relevant. Woolley and Aggarwal (2020) found that groups where turn-taking was more varied tended to perform better, whereas performance was inferior in groups where only certain participants monopolized conversational turn-taking. Bernstein et al. (2018) found that a group’s creativity and the quality of its responses to a previously poorly defined task tended to improve considerably when intermittent interactions were introduced within the group. In their analysis of decision-making contexts, De Vincenzo et al. (2017) found that intermediate transitions were the ones most prone to improve a group’s overall performance. In tasks of an individual nature tackled by a group, Navajas et al. (2018) confirmed that the estimations emitted by participants in the group are better than those emitted by individuals: even one sole previous interaction in the group suffices to improve performance with regard to similar tasks carried out on an individual level.
The interactions within the group emerge from a learning process that is essentially social in nature (Woolley and Aggarwal, 2020). Navajas et al. (2018) found that this specifically occurs when small groups interact with one another, share opinions, contrast differing points of view, and reach agreements. However, other social factors can impact behavior within the group. For instance, factors associated with social prestige can lead to extreme behaviors or can lead the other members to participate less: this is the so-called herd effect, which is more likely to occur in large groups (Fontanari, 2018; Toyokawa et al., 2019; Yahosseini and Moussaïd, 2020; Sulik et al., 2022). Further factors, such as leadership or physical proximity, can act as key elements of social influence (Kabo, 2018). The relevance of social influence has been experimentally proven. For example, the study by Salganik et al. (2006) showed that social influence can determine purchase habits to a greater degree than the quality of the product.
Another characteristic of large groups is the wide diversity of responses generated through interaction: this becomes an essential element of the process. Response diversity is the necessary condition for creative solutions to appear; at the same time, however, it can represent a risk in the attempt to reach a consensus (Klieger, 2016; Mann and Helbing, 2017; Yahosseini and Moussaïd, 2020; Pescetelli et al., 2021; Sulik et al., 2022). One of the most relevant issues is ascertaining under which conditions such response diversity can become the basis for the emergence of collective intelligence (Sulik et al., 2022). On the one hand, we need to grasp how such diversity emerges. On the other hand, it is necessary to determine what kind of conditions can work in favor of achieving consensus. Thus, in the first case, the herd effect, or, on the other hand, a low degree of participation on the part of certain group members, can be two of the factors that would hinder response diversity. Toyokawa et al. (2019) suggest that the nature of the task can also impact the diversity of responses: more open tasks lead to a broader variety of responses, while more closed tasks lead to a more reduced variety. On the other hand, certain authors propose that a productive way of taking advantage of diversity is to have an agent working inside the system who plays the role of “facilitator,” i.e., who controls and orients the group in its realization of the task (Bigham et al., 2018). In digital environments, the facilitator task is delegated to an automatic system (Gimpel et al., 2020). Such systems are difficult to design. The social prestige of responses is one of the elements that work most in favor of consensus. Still, nothing guarantees that responses that enjoy considerable social prestige are necessarily the best (Lorenz et al., 2011). An attempt to improve this system would consist in ensuring a genuinely collective generation and distribution of responses while optimizing the participation of all agents involved in the task. This approach can be carried out in real-time, as was the case in the system applied in the current study (Orejudo et al., 2022).
As mentioned above, this study belongs to a series of studies on the subject of collective intelligence in online environments. Such environments allow researchers to generate a series of interactions within large groups of people. However, the systems employed can be thoroughly different, and their design determines how the interaction is produced. The Collective Intelligence platform1 on which our study was carried out has been designed and developed by researchers. Its goal is to generate an interaction model that allows for the emergence of high-quality solutions to the tasks in question (Orejudo et al., 2022). To achieve this, the platform is designed to seek to address some of the problems that emerge in large-group interactions: for example, the emergence of extreme responses, the copying of responses emitted by prestigious members of the group, the proliferation of multiple solutions, and even the fact that certain participants provide no response whatsoever. The system divides the procedure into successive work phases that can be grouped into three main blocks: an individual work phase (Phase 1), several small-group work phases (Phases 2, 3, 4, and 5), and two final phases oriented toward establishing consensus (Phases 6 and 7).
In the first phase, each participant works alone on the task (Phase 1). Once this has occurred, the system generates interactive dynamics among the participants, exposing each one of them to the information/responses generated by four “neighbors.” After viewing the four neighbors’ answers, the user can modify his/her response or choose to copy one of his/her neighbors’ responses. This all occurs in Phases 2, 3, 4, and 5. All phases are anonymous, thereby preventing that the prestige enjoyed by certain participants might condition the interaction (Bernstein et al., 2018). Using the possibilities made available by computation, each phase presents the user with a different set of “neighbors,” thereby ensuring that information is distributed throughout the entire network. This successive set of phases in small groups has the purpose of generating interactions with a manageable number of neighbors to ensure that participants do not suffer from information overload (Garg et al., 2022); it is also designed for information to be distributed all across the network by means of neighbor rotation in each phase. An environment is thus achieved with a number of participants that guarantees good solutions: five (Navajas et al., 2018; Toyokawa et al., 2019); moreover, the information can be spread across the network in a broader dispersion than would be achieved in small groups, thus avoiding another limitation associated with face-to-face interactions: turn-taking, i.e., when turns are monopolized by a limited number of participants (Mann and Helbing, 2017).
Phases 6 and 7 have the goal of achieving consensus and allowing participants to take the popularity of responses into account as an additional mechanism that enables them to evaluate their own contributions. The system generates a response popularity indicator designed to resemble the prestige effect: in this case, the “prestige” factor emerges through participants’ tendential preference for certain responses during the entire interactive process (Phases 2, 3, 4, and 5). The function of this indicator is to provide participants with feedback as a basis for a consent mechanism that will lead to a set of adequate solutions ranked by participants, while avoiding the factor of group member prestige that would have conditioned their participation and choices. This mechanism of facilitation (Lorenz et al., 2011) modulates the heterogeneity of responses by applying a popularity system. In the final two phases of interaction, once the responses have circulated through the network and have been evaluated by participants, a progressive procedure of response selection emerges, eliminating less frequent responses and exposing participants to the most popular ones. The basic supposition is that after that interaction procedure, the most popular responses in the network will be of high quality (Orejudo et al., 2022). That pruning method thus acts as a virtual moderator of the entire group, transferring a portion of the process of the previously described moderator role to AI (Bigham et al., 2018).
The system is flexibly designed, with the purpose of allowing researchers to previously establish the duration of each of the seven phases of each work session, the percentage of interchanges that take place in the group phases (Phases 2 to 5), and the number of response eliminations that take place in the consensus phases (Phases 6 and 7). Moreover, the system collects and stores all participant interventions each time they elaborate or copy an idea and introduce it into the system by choosing the “Save Answer” option. The resulting data generated by the platform can thus be analyzed, identifying which participant made the contribution and at which moment in time.
One of the situations we encounter in studies of collective intelligence (CI) is the emergence of a large quantity of responses, particularly when the number of participants is elevated, and the task is open (Toyokawa et al., 2019). This leads to a methodological difficulty in analyzing the interaction dynamics generated by participants in a CI process, even when the task is designed to produce consensus (Orejudo et al., 2022). Sentiment analysis (Lozano-Blasco et al., 2021) can offer a valid alternative if we want to analyze the emotional dimension of a text.
Sentiment analysis is a procedure that allows us to understand people’s opinions or attitudes regarding a situation, a product, a service, or a concept, as expressed in a written text (Ceron et al., 2013; Yu et al., 2013). Sentiment analysis initially emerged in a business context, with the goal of finding hidden information in user comments that served as a basis for their business strategies and decisions (Aggarwal, 2022). In other words, sentiment analysis is a social thermometer that measures the feelings/emotions of users, uncovering tendencies in their opinions and comments on social networks (Chan et al., 2023). Specialized software is available for the procedure (Fang et al., 2018).
Sentiment analysis is capable of analyzing a text – a tweet, a post, or a video – in order to determine whether it transmits a positive, negative, or neutral feeling (Aggarwal, 2022). Certain specific tools allow the researcher to determine further variables, including the emotional diversity of a text, its objectivity, or its degree of irony (Trisna and Jie, 2022). It is even possible to elicit which are the most predominant emotions in a text, as shown in Plutbick’s theory (Plutchik, 2001; Trisna and Jie, 2022). Sentiment analysis can likewise identify subjects and themes by grouping them into clusters.
These software products are based on natural language processing (NLP) (Fang et al., 2018). Although such categorization can be done manually, the most common current approach is the application of automated computational methods that are not externally supervised, such as Google Cloud Natural Language API and IBM Watson Natural Language Understanding (Hu and Liu, 2004; Yu et al., 2013). Two types of sentiment analysis can be distinguished: (a) analysis based on the wordlists that associate specific words with a certain feeling or emotion, and (b) analysis based on automatic learning using algorithms that learn to identify feelings (Jiang et al., 2011; Syahrul and Dwi, 2017). As a final result, each text receives a numerical value associated with a quantitative value, which can be emotional polarity or the degree of subjectivity (Jiang et al., 2011; Syahrul and Dwi, 2017).
Regardless of the chosen method, the analysis of interaction always represents a considerable challenge (Evans et al., 2011). When the task is of an emotional nature, researchers have the viable option of applying means of analyzing large quantities of data through emotional evaluation. In this study, we propose to use sentiment analysis to analyze moral judgments emitted about a prototypical case of cyberbullying.
Cyberbullying is a bullying subtype that is carried out in an online environment and fulfills the characteristics of intentionality, abuse of power, and reiteration (Patchin and Hinduja, 2006; Smith et al., 2008). However, the complexity of identifying these characteristics in online environments (which are in constant evolution, and which presuppose the perpetrator’s connection to a device with an Internet connection) implies that this phenomenon is different from mere aggression (Patchin and Hinduja, 2015). Among the multiple typologies of cyberbullying, we find one that is particularly frequent among adolescents: sexting, a type of cyberbullying focused on spreading images or videos with sexual content on the Internet without the owner’s consent (Lounsbury et al., 2011). The prevalence of sexting in adolescence is around 36% (Gámez-Guadix et al., 2017).
Scientific research highlights the relevance of emotional responses to cyberbullying in both aggressors and victims (Hemphill et al., 2015; Arató et al., 2020; Lo Cricchio et al., 2021; Jiang et al., 2022). Emotional competencies have been identified as protective factors against cyberbullying (Guerra et al., 2021). Guerra et al. (2021) and Jiang et al. (2022) associate low levels of emotional competency and emotional control with the realization of acts of cyberaggression (Guerra et al., 2019). The emotions provoked in victims of cyberbullying have been well-identified: anger, fear, sadness, and stress (Hemphill et al., 2015).
The perpetuation of cyberbullying is also associated with low levels of empathetic responsibility (Arató et al., 2020) and a high degree of moral disconnect from the perpetrated act (Paciello et al., 2020; Lo Cricchio et al., 2021). The cyberbully uses such mechanisms to inhibit feelings of remorse (Wang et al., 2016) or pain in the face of the victim’s suffering (Leduc et al., 2018). Inversely, low levels of moral disconnect and high levels of empathetic responsibility are directly linked with non-implication in acts of cyberbullying since people with such levels understand the harm that can be done to other human beings (Perren and Gutzwiller-Helfenfinger, 2012; Wang et al., 2016; Arató et al., 2020; Paciello et al., 2020).
Emotional response also plays a role in the spectators, i.e., those who observe the act of cyberaggression and can either defend the victim, attack them, or maintain a neutral position (Machackova and Pfetsch, 2016). Spectators who support the aggressor are normalizing their opinions about cyberbullying: they are upholding the appearance of such behavior on the Internet (Machackova and Pfetsch, 2016). Conversely, those spectators who defend the victim are showing high levels of affective and cognitive empathy with them (Machackova and Pfetsch, 2016). Nevertheless, the issue of whether someone tends to support the aggressor, or the victim is apparently more closely associated with temporal, technical, or psychological proximity with the implied person: for instance, a social connection with either the victim, the aggressor, or the other spectators (Pfetsch, 2016). In line with the latter author, it is worthwhile to point out that exposure to acts of cyberaggression leads to greater levels of stress and negative emotions than prosocial or neutral interactions among peers (Caravita et al., 2016). The role of the spectator is key in our study’s approach since, in our case, the participants who are analyzing the case of cyberbullying have not directly taken part in it. However, they are associated with it in their position as spectators since their responses to the task help us to determine whether their emotional implication lies with the victim or with the aggressors.
This study thus pursues the goal of verifying whether the emotional dimension of participants’ responses when faced with an ethical task on the platform Collective Learning (see Footnote 1) tends to vary in function of the phase in which the interaction takes place. Sentiment analysis via automated software is a method that has been successfully applied in other studies that analyzed interactions in virtual interactive environments where an elevated number of participants emit a large number of responses (Lozano-Blasco et al., 2021). That option of sentiment analysis could thus be transferred to an interactive environment such as the one featured here. We therefore hypothesize that the emotional dimension of responses will gradually change along the experiment’s successive phases, and that said emotional dimension will have a significant relationship with the other dimensions applied to analysis response, which are: (1) the frequency with which each response appears, (2) the number of times each response is copied by participants, and (3) response length as an indicator of response complexity (Orejudo et al., 2022). Moreover, we assume that those three indicators will be interrelated: the model chosen to depict the relationship among variables can well be the path model, as appears below.
A total of 794 students studying in their first year of bachillerato level (higher secondary education) in Zaragoza (Spain) participated in this experiment. Bachillerato is a non-obligatory level chosen by students who want to continue with university. It consists of two academic years. In the first year, students tend to be 16–17 years old. At the end of the second year, they take the tests that allow them access to university. As our study was anonymous, we did not ask for any age or sex data in order to guarantee maximum anonymity; at any rate, in the Spanish educational system, most of the students who enter bachillerato are 17 years old. In terms of sex, national statistics show very similar percentages. In 2018, 53.1% were girls, and 46.9% were boys (Ministerio de Educación y Formación Profesional, 2020).
To carry out the study, we invited all educational centers in the city of Zaragoza offering bachillerato level to participate in a collective intelligence experiment. The invitation was sent through the Aragon Government Department of Education, i.e., the very entity in charge of organizing education at that level. All centers that agreed to participate under the conditions we proposed (anonymous student participation, student disposal to carry out the task for 2 h and having one computer per student) were included in the experiment. A total of 19 educational centers were allowed access to participate, with students stemming from 33 different class groups. The participating class group with the most students had 33 members, and there were 14 in the smallest.
The students who participated in this experiment were successfully confronted with two tasks: one consisted of an ethical dilemma, and the other was a mathematical problem. For further details regarding the mathematical task, the reader can consult Orejudo et al. (2022). In the ethical dilemma, lasting about 1 h, the students were asked to analyze a cyberbullying situation: concretely, a sexting case. A girl (Pilar) takes an intimate photo of herself for her boyfriend (Alex), who, in turn, sends it to a male friend (Quino), rising to a challenge. Quino ends up posting it, and the photo thus becomes public. Three questions are asked: (1) What do you think about Pilar taking a photo of herself and sending it to her boyfriend? (2) Should Alex have sent the photo to Quino? (3) Should Quino have posted Pilar’s photo? These questions encourage the participants to answer by formulating open texts without word limits.
The system recorded each participant’s chosen response to each of the three questions in the course of all seven phases of the experiment. Each participant was allowed to record more than one response per question, one response, or none. A total of 2,897 responses were registered for Question 1, a total of 3,852 answers for Question 2, and 3,864 answers for Question 3. From the participants’ responses, we extrapolated the following variables:
Variables related to the emotional dimension, obtained through the Meaning Cloud program in its demo version2:
• Polarity of the analyzed element, expressing an emotional tendency that is either strongly positive (P+, 4 points), positive (2 points), neutral or no polarity (zero points), negative (−2 points), or strongly negative (−4 points)
• Agreement: establishes the agreement among the emotions detected in the text, sentence, or segment to which it refers. It has two possible values: agreement [1 point (Example: “I think that’s a bad idea”)] when the different elements have the same polarity, or disagreement (0) when there is no such polarity agreement (“There is nothing wrong with sending photos of yourself to people you trust. What is problematic is sending photos that could cause you problems to other people. No matter how much you trust that person, you can never be sure that the photo is safe, because your phone could be hacked, stolen or you could end up making a serious mistake because of a silly challenge”).
• Subjectivity: identifies the subjectivity of the text. It has two possible values: objective (0) (It’s something she should not have done, although I do not think she’s the one with the problem, as it’s her boyfriend who has shared it without her consent) when the text has no marks of subjectivity, or subjective when they exist (1) (“Everyone can do what they think is right, and if they have confidence in it, I do not see it as wrong”).
• Irony: indicates the presence of irony indicators in the text, with two options: non-ironic or ironic. As can be seen in the results section, the system does not have any detection of ironic responses in the participants’ productions.
• Confidence: represents the degree of confidence associated with the sentiment analysis conducted on the text. Its value is an integer ranging from 0 to 100, according to the system’s score.
Those data are completed by further variables collected by the Collective Learning platform:
• Phase: the phase (1, 2, 3, 4, 5, or 6–7) in which each response appeared on the platform (see our above description of phase characteristics in Section 1.3).
• Number of copies: the number of times each response was copied by other participants.
• Final frequency obtained by each response at the end of the experiment (Phases 6–7).
• Length: number of characters of each response. The same indicator has been used in other studies by Orejudo et al. (2022): response length is related to the response’s ethical depth and complexity. This parameter is collected on an Excel spreadsheet by applying the Length formula.
Once participating centers had been selected, each center designated a teacher as the local coordinator of the activity. After having accepted to serve as coordinators, those selected teachers attended two training sessions in which they learned about the conditions of the experiment, the way the platform works, and the mode of coordination allowing for all centers to carry out the task synchronously.
Participants’ families were informed through a letter about the study’s purpose and procedure, ensuring participants’ anonymity. In the same letter, the volunteers were informed of their participation and the possibility of excluding from the activity those students whose families did not agree to their involvement or who themselves did not consent to participate. Thus, only students willing to participate in the experiment received the code to access the platform. This study was carried out in accordance with the recommendations of the Council of the British Educational Research Association (BERA) (2011) in the second edition of their Ethical Guidelines for Educational Research. Subjects received no compensation for participating in the study. Compliance with the standards of the Declaration of Helsinki on human experimentation was guaranteed at all times. Furthermore, the entire research program containing this experiment, along with further ones to be carried out in the near future, was approved and validated by the Committee of Ethics in Research of the Government of Aragón (CEICA: Comité de Ética de la Investigación de la Comunidad Autónoma de Aragón).
To compare results among phases, we conducted a one-factor analysis of variance for each quantitative dependent variable, taking the phase as the factor. The two last phases (6 and 7) were analyzed together, given that the system calculated frequencies for those two phases in continuous mode. In Table 1, we provide the values stemming from the Brown-Forsythe robust statistic, as the supposition of equality among variances could not be guaranteed in all cases. For the three dichotomous variables under consideration – Agreement, Subjectivity, and Irony – we calculated the relationship among phases by means of contingency tables, providing the Chi-square Pearson correlation value to contrast the hypothesis of association, and Cramer’s V to quantify it.
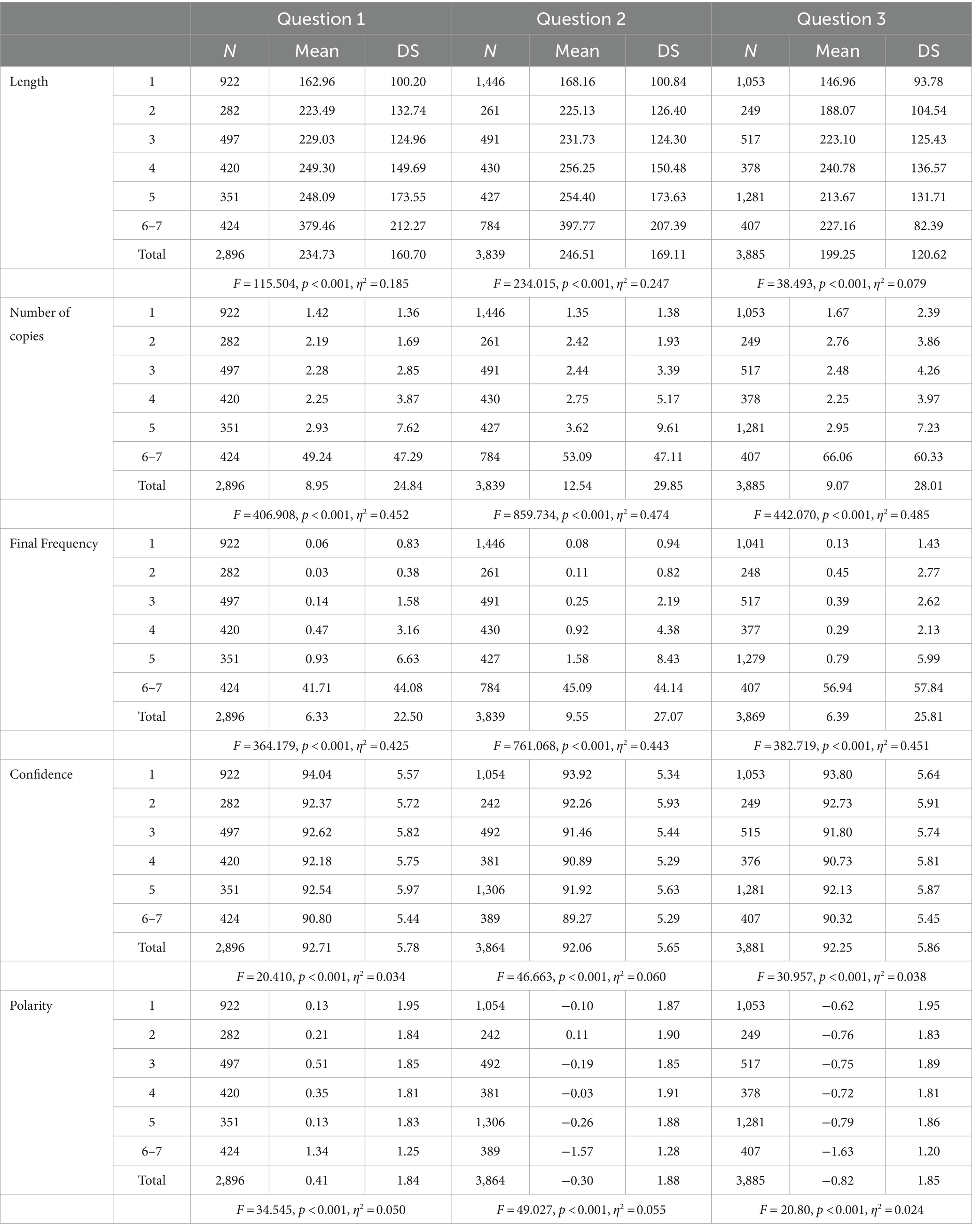
Table 1. Descriptives by phases.
We then applied path analysis to establish a model of relationships among variables. Path analysis allows the researcher to establish direct relationships among variables and mediating relationships, thereby obtaining an estimation of direct and indirect effects (Byrne, 2010). In this specific case, we considered four exogenous variables related to the responses’ emotional dimensions. We hypothesized that those four exogenous variables, in turn, would partially predict response length. The dimensions of emotions and length, the phase in which each response appeared, and, finally, length and phase would have an impact on the number of copies and the final frequency of responses. We hypothesized those mediating relationships, but also a direct relationship between each exogenous variable, on the one hand, and each endogenous variable and each mediating variable, on the other. The model likewise assumes a relationship between estimation errors of final frequency and the number of copies, given that a relationship between those two variables is expected. The hypothetical model is depicted in Figure 1. As an estimation method, we used ADF through the AMOS 26 statistical program, which provides the ADF option when normal distribution of variables cannot be assumed. Furthermore, we used the goodness-of-fit indicators usually applied in such cases, with their respective cutting-off points (Byrne, 2010).
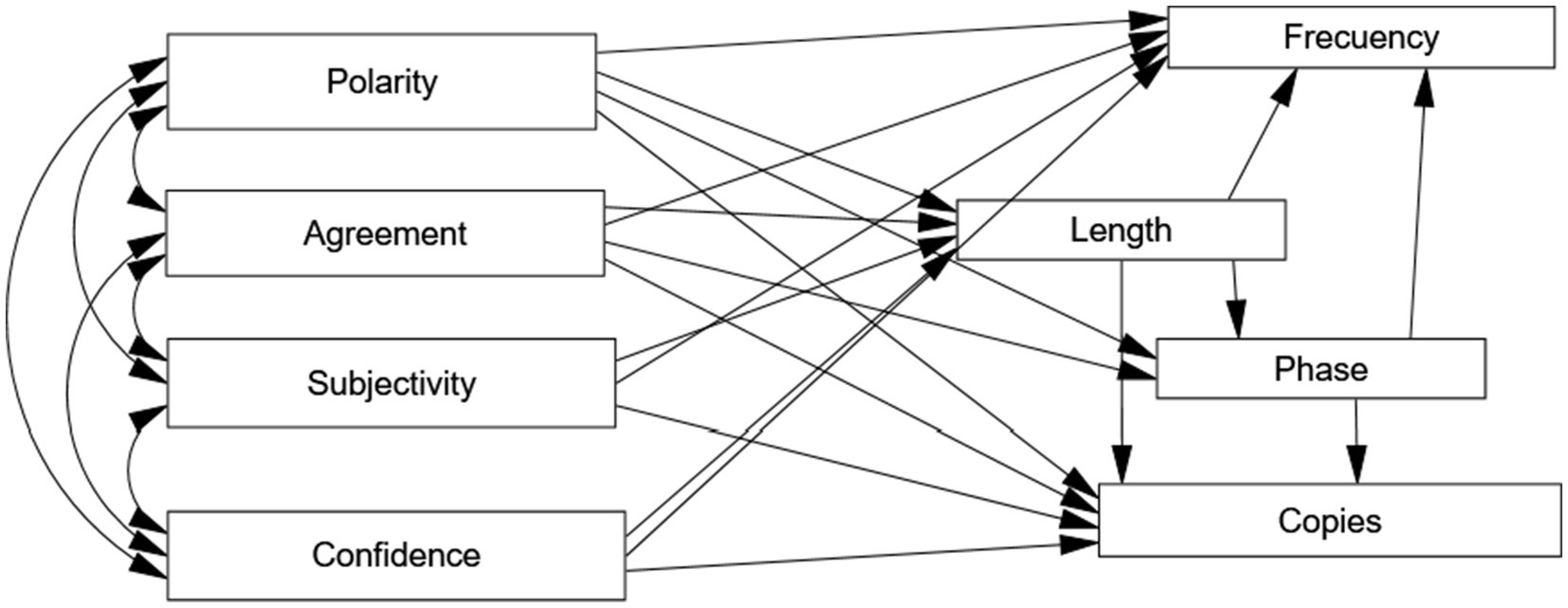
Figure 1. Path diagram.
As can be observed in Table 1, participant activity in this experiment was not equally distributed along all its successive phases, nor was the response typology always equal. Thus, for the total of three questions, we found a response rate > 1 per participant in Phase 1 (the individual phase) since we had a total of 794 participants. That response rate decreased gradually and notably in Phases 2, 3, 4, and 5 (the phases of interaction with four neighbors: four real-time colleagues whose answers could be viewed by the participant). Then, in Phases 6 and 7, the response rate increases once again (these are the phases in which each participant is allowed to view the group’s most frequent responses). All three questions followed a similar pattern in this respect, although Questions 2 and 3 elicited more responses than Question 1 (see Table 1).
Those differences according to work phase can also be observed in the type of response emitted by the participants. The response length variable increased significantly in the answers appearing in Phases 6–7, and a similar increase can be observed in the transition from Phase 1 (individual work) to Phases 2, 3, 4, and 5 (work in tandem with one’s “neighbors”). The same pattern can be observed in the number of copies made of each response. Responses still present in Phases 6–7 were much more frequently copied than those that appeared in Phase 1, the individual phase. The latter were copied less than the responses appearing in collaborative phases 2, 3, 4, and 5. In terms of final frequency, we only found differences among responses appearing in Phases 6–7 and the remainder (Phases 1, 2, 3, 4, and 5). In all three questions, we observe considerable size effects according to the Eta-square value, and those size effects are associated with the considerable differences that can be noted between Phase 6–7 and the previous ones.
In Table 1, we can compare phases in terms of the program’s own Confidence in its evaluation of responses and the Polarity assigned to them. In the Confidence variable, we find the same pattern as in the ones mentioned above: Phase 1 (individual) generates the greatest degree of Confidence, followed by less Confidence in the 4-neighbor group phases (2, 3, 4, and 5) and even less Confidence in Phases 6–7. Although the response in Phases 6–7 is the one to which the least degree of Confidence can be ascribed according to the system, the mean still lies around 90 points for each of the three responses. Regarding Polarity, we note the following evolution of responses: a notable increment of the positive value from Phase 1 (0.13) to Phase 6–7 (1.34) and an increment of the negative value on Question 2 (−0.15 in the first phase to −1.62 in the last) and of the negative value on Question 3 (−0.62 in the first phase to −1.63 in the last).
The dichotomous variables of Subjectivity and Agreement also evolve notably along successive phases (Table 2). Differences are statistically significant in all three questions. In Phase 1, responses are more objective and have a greater degree of internal agreement, whereas in Phase 6–7 they are more subjective and with a lesser degree of internal agreement. That change occurs progressively in the intermediate phases (2, 3, 4, and 5), where participants work in tandem with their neighbors. Moreover, in Table 2, we can once more observe significant differences among the three questions in terms of these two variables (Subjectivity and Agreement). Ever since the first, individual phase, Question 1 is the one featuring the greatest degree of internal disagreement in the responses (39.7% for Question 1 vs. 33.3% for Question 2 and 34.2% for Question 3). Answers to Question 1 also display a greater degree of subjectivity (74% for Question 1 vs. 54.9% for Question 2 and 48% for Question 3). These differences among questions are maintained during the collaborative phases (2, 3, 4, and 5). However, by the time we reach Phase 6–7, they have become narrower between Questions 1 and 2, while Question 3 remains an outlier (Phase 6–7, Agreement, 72.9% for Question 1, 73.6 for Question 2, and 65.8% for Question 3; Subjectivity, 89.2% for Question 1, 84.2 for Question 2, and 71.0% for Question 3). In terms of irony, no notable differences can be observed, given that the majority of responses lack any sort of irony.
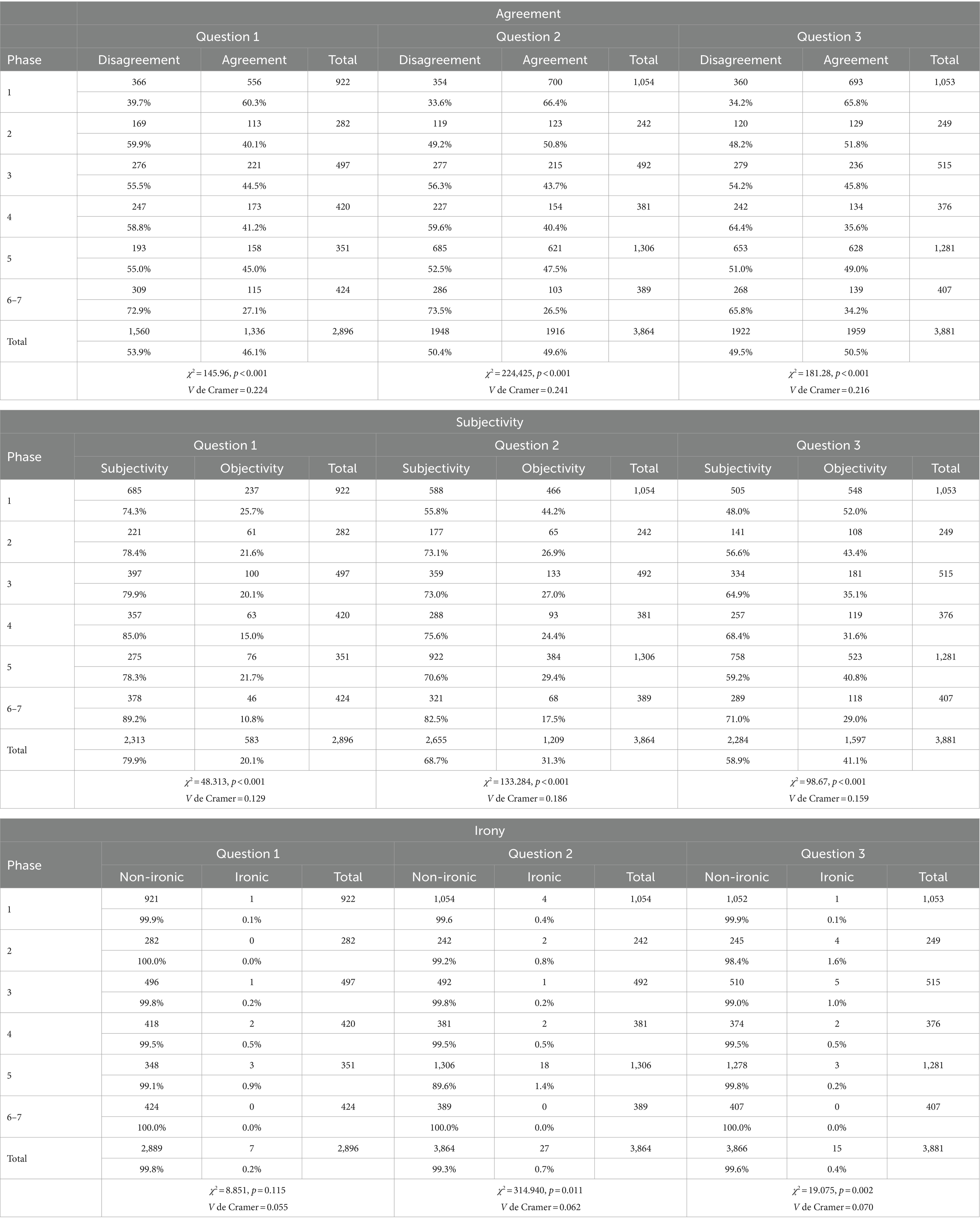
Table 2. Agreement, subjectivity, and irony contingency table by phase.
Table 3 displays the estimations of regression weights for the path models generated by each question. In all three cases, we were able to find models that adequately fit the data (P1, χ2 = 16.494, d.f. = 6; p = 0.011; χ2/DF = 2.749; RMSEA = 0.028; CFI = 0.998; P2: χ2 = 3.827; d.f. = 4; p = 0.430; χ2/DF = 0.957; RMSEA = 0.000; CFI = 1.00; P3: χ2 = 3.968, d.f. = 2; p = 0.138; χ2/DF = 1.984; RMSEA = 0.016; CFI = 1.00), excluding regression weights that were not statistically significant (represented by zeros in this table). In all three cases, we obtained a good estimation of response length (41.7, 32.9, and 31.7%). In all three questions, the Confidence variable was the best predictor (γp1 = −0.323, γp2 = −0.434, γp3 = −0.264), followed by Agreement for Question 1 (γ = −0.263) and Subjectivity for Questions 2 (γ = −0.236) and 3 (γ = −0.244).
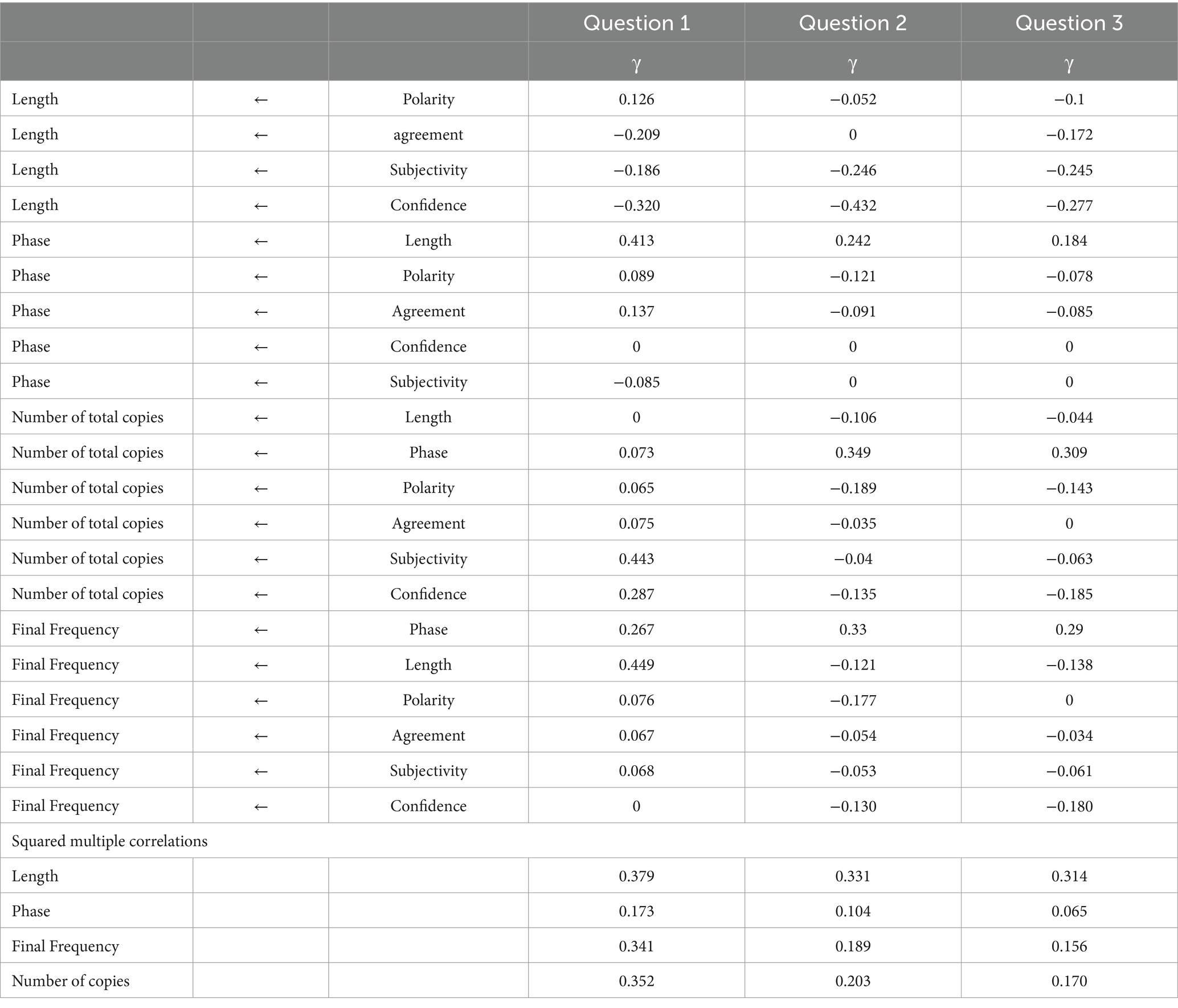
Table 3. Results from path analyses.
The prediction of the phase in which the final response appears is more efficacious for Question 1 (28.2%) than for Questions 2 and 3(10.7 and 6.7%, respectively). Among all predictors, Length is the most relevant one (γp1 = 0.473, γp2 = 0.246, γp3 = 0.173). Polarity also appears with a certain relevant weight in all three questions, but with a different sign in Question 1 than in the two others (γp1 = 0.123, γp2 = −0.110, γp3 = −0.084). The two remaining variables, Final Frequency and Number of Copies, are now much better explained for Question 1; moreover, Length and Phase are the two most relevant variables for all questions, as can be observed once again in Table 3. Nevertheless, exogenous variables are also statistically significant, especially Polarity and Confidence in Questions 2 and 3.
The overall relevance of each variable is shown in Table 4, which gathers the total set of effects of each variable within the model. Many of those effects are indirect, i.e., occurring via mediating variables. Thus, Confidence has an indirect effect on Questions 1 and 2 in the Phase variable (γp1 = −0.153, γp2 = −0.107, γp3 = −0.046), on Question 1 in the Final Frequency variable (γp1 = −0.219, γp2 = 0.021, γp3 = −0.015), and on the Number of Copies (γp1 = −0.205, γp2 = 0.013, γp3 = −0.014). We observe similar results for the remaining emotional variables, i.e., Subjectivity, Agreement, and Polarity, with indirect weights, particularly in Question 1.
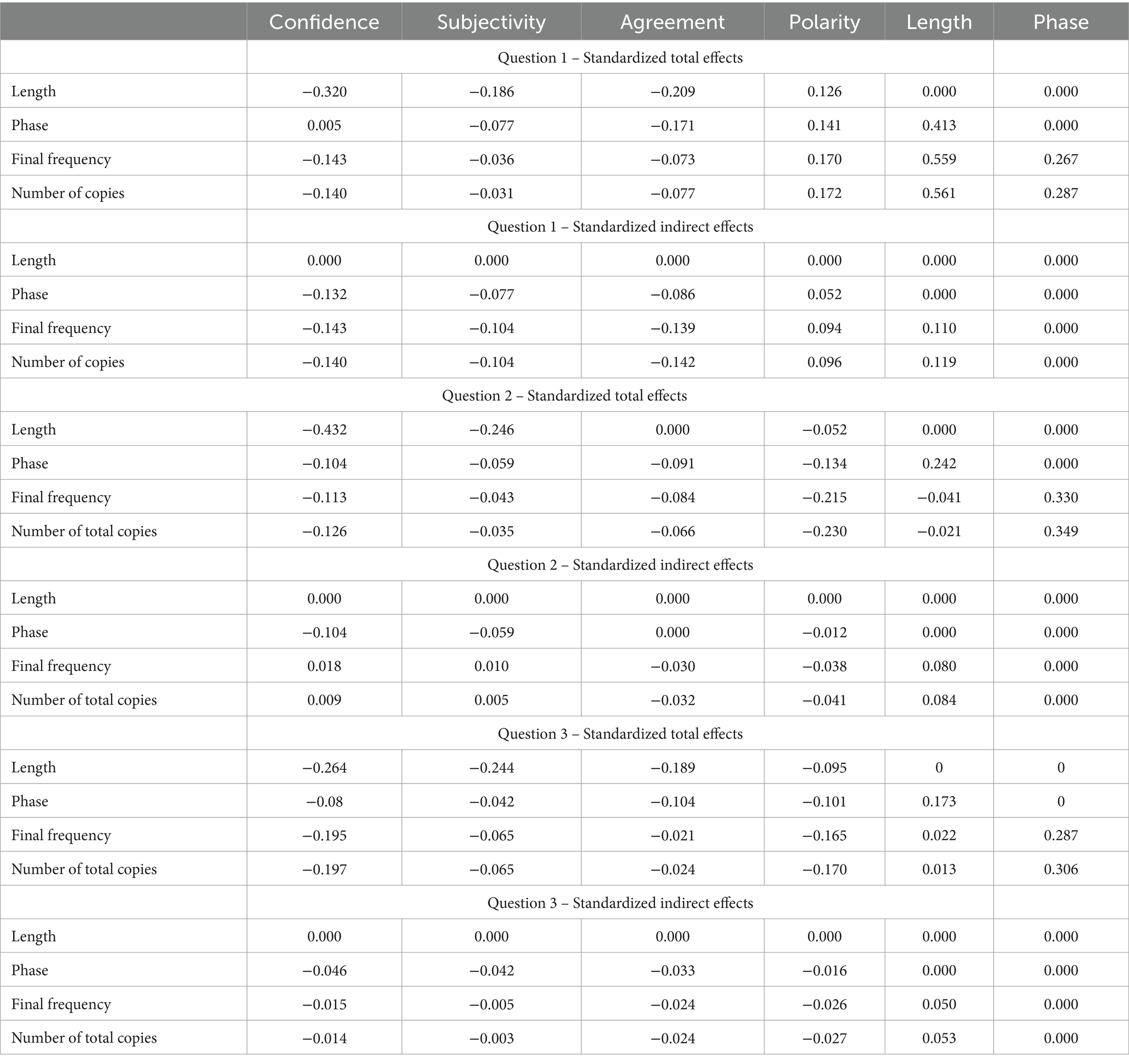
Table 4. Path model total and indirect effects.
This study’s goal was to analyze the evolution of responses generated by 794 participants who were asked to fulfill the task of analyzing a cyberbullying situation on a Collective Intelligence platform designed to encourage joint collaboration in the elaboration of responses aiming for consensus. The platform’s features are designed to maximize interaction elements that play a key role in the emergence of collective intelligence. as described in our Introduction section.
In the course of the process generated on the platform. The responses’ emotional dimension evolved with clear gradual differences between the initial individual phase (Phase 1). the middle phases of work in small groups (Phases 2, 3, 4, and 5) and the final phases where consensus was sought across the board (Phases 6 and 7). Apart from that relationship with the phases, we found a direct relationship with three further indicators of activity on the platform: (1) length of responses, (2) the final frequency with which certain responses appeared, and (3) the number of times they were copied throughout the system. Moreover, responses evolved differently along time according to the question. The role of the main characters in the ethical case – victim and aggressors – determined that evolution to a large extent.
Regarding these results, it is important to bear in mind that participants’ responses depend on the way the activity on the platform is organized. Phase 1 corresponds with individual work in which participants make their first contribution to the task set before them. In the next four phases (Phases 2, 3, 4, and 5), users share their responses with four “neighbors.” In each of those four phases, the neighbors are different, as well as the conditions under which the responses are displayed (the fixed answers at first, then real-time permutation and permutation of users). This design has the goal of ensuring that interaction among users should take place with a sufficient quantity of information that enables the participants in each group to analyze the responses. It also ensures that responses (thus information) can be distributed throughout the system in its entirety. In this process two aspects are key: the number of participants in each interaction “among neighbors” (five) and the system of permutation of users, designed to rotate user positions and contacts, thus enabling users to go on distributing the information that gradually emerges. This model guarantees interaction, which is key in the emergence of collective intelligence (Navajas et al., 2018). Moreover, the choice to reduce all interaction groups to only five users ensures that each user is confronted with a manageable amount of information. The herd effect is reduced, because the limitation to five neighbors encourages all users to participate actively. As we mentioned in the Introduction section, studies in the field of collective intelligence have found that reduced groups work best (Woolley et al., 2010; Navajas et al., 2018; Toyokawa et al., 2019; Pescetelli et al., 2021). Nevertheless. the design of the Collective Learning platform improves upon the model of local work in small groups, given that it manages to spread the information throughout the digital space, ensuring that all participants are allowed to collaborate in seeking the solution for the problem that has been posed: participant neighbor positions rotate and each one of them, in turn, acts as a new node in a series of successive interactions. This strategy optimizes the potential for interaction within the digital space (Almaatouq et al., 2020; Yahosseini and Moussaïd, 2020; Pescetelli et al., 2021).
The results in these small-group phases (Phases 2 to 5) yield similar response patterns for the three questions that made up the task. Compared to Phase 1, the number of responses in Phases 2, 3, 4, and 5 was reduced, thereby implying that the participants were indeed carrying out the task: they were analyzing the other participants’ answers. The fruit of their analysis, in turn, generated new solutions. In the course of Phases 2, 3, 4, and 5, we thus observe that chosen and emergent responses gradually started to lengthen (as shown by the Length variable). Moreover, they gradually tended to be copied more times (i.e., the averages of the number of copies and the final frequency are directly related to the phase in which the responses appear). The emotional polarity of responses also tends to vary, curiously, we ascertain that in Phase 1, polarity is positive; it turns negative in Phases 2 and 3, and also starts to increment. These results might indicate that the platform is achieving the objective we set ourselves: the aim of facilitating an environment that guarantees the spread of information across the entire group. This seems to derive from the direct relationship between the phase in which the response is elaborated and its greater diffusion across the network, observed in the Number of Copies and the Final Frequency, as well as in the fact that the number of neighbors we chose for this experiment (groups of 5) guaranteed a diversity of responses that was sufficient to ensure and encourage response evolution. The conditions we chose also seem to have allowed for an adequate amount of time for the group to develop: the group, as a unit of synchronized analysis, requires such a minimum amount of time to confront ideas and positions through interaction and interchange in order to achieve a maximum degree of cooperation and interdependency in the final consensus. The platform supports and encourages the collective construction of a solution from a perspective of co-responsibility (Palacín and Aiger, 2014; Sierra-Pérez et al., 2021).
Phases 6 and 7 are the phases of consensus and maximum interdependence. To achieve that state, the platform calculates in real time the frequency of each response within the system, and it progressively presents the participants with the “Top 10” answers (the most frequent ones). At the same time, it generates an opposite effect by eliminating the least frequent responses. Users who had chosen less popular answers now have the option of deciding whether they develop a new response of their own pen (Phase 6) or if they decide to adopt one of the Top 10 answers as their own. The mechanism is designed to inspire users to seek consensus: among other methods, it represents an alternative designed to reduce the diversity of responses observed elsewhere and the conditions that lead to such diversity (De Vincenzo et al., 2017; Mann and Helbing, 2017; Massari et al., 2019; Sulik et al., 2022). However, compared to other mechanisms of social influence, this system does not start to function until the responses are elaborated and distributed throughout the network, thereby limiting the initial effect of popularity (Lorenz et al., 2011; Bernstein et al., 2018). The nature of responses is an indication of the importance of structuring the group’s activity by imposing a series of successive phases in time (individual phase, interactive phases, then group phase) in order to encourage the group’s emergent maturity and the synchronicity of its responses, achieved via group consensus. Interaction enhances a user network’s potential for “listening,” for generating discrepancies. For harmonizing points of view, and for strengthening agreements (Palacín and Aiger, 2014; Sierra-Pérez et al., 2021). From an emotional perspective, we observe that the two last phases produce a response pattern that is clearly different from the previous ones. The adopted responses are now even longer and have an elevated degree of final frequency within the system. Of course, the system’s mechanism already tended to encourage such responses; now, however, their emotional dimensions are even more pronounced than in the previous ones; their positive or negative polarity is likewise more extreme than before. In this final phase, the system has fulfilled its purpose: that of reducing the number of responses and proposing a consensus solution. It could be argued. However, that this process has led to a response that is somewhat extreme from an emotional point of view, reflecting a certain “polarization effect” that can easily emerge when small groups interact with the same task (Navajas et al., 2018). However, in a task/situation such as the one proposed herein, the emotional tendency can be viewed as something more positive than negative: it favors a positioning close to the victim’s interests, rejecting those of the aggressors (Machackova and Pfetsch, 2016). It would thus seem that the dynamic generated by the system has exerted a homogenizing effect while producing a response that is formulated with a greater degree of complexity or richness in terms of argumentation. This can be seen in the greater length of favored responses, but also in further indicators stemming from the sentiment analysis: the degree of Confidence in estimations. The responses’ internal agreement among themselves, and the degree of subjectivity.
These indicators, on the whole, present a profile that seems to indicate that a response of greater complexity has been achieved, thereby confirming that a process that aims to generate collective intelligence should produce quality solutions. Moreover, the process itself should also offer a learning experience for those who participate in it (Bernstein et al., 2018; Orejudo et al., 2022). The data resulting from this study gave us a series of clues regarding such complexity from an emotional vantage point. Thus, on the one hand. we have found that the length of responses increases along the successive phases: in the case of all three questions, the path model directly relates that aspect of length with the four emotional dimensions under consideration. Which. taken as a whole, have the capacity to explain a remarkable percentage of responses: 37.9% (for Question 1), 33.1% (for Question 2), and 31.4% (for Question 3).
Moreover, four of the emotional dimensions (except irony) provided by the sentiment analysis tool have significant relationships among themselves and vary in the same manner from one phase to the next. This, in turn, supports our hypothesis that complexity gradually emerges in the course of the system’s successive interaction phases. Emotional valence is increasingly clearly defined as either positive or negative. Two further indicators, Subjectivity and Disagreement, are related, on the one hand, to the responses’ emotional content and, on the other, to the internal structure of the texts that make up those responses. Those three indicators (Emotional Valence, Subjectivity, and Disagreement) are joined by Confidence, which is based on the reliability of the system’s categorization, and which might be associated with less complexity. At any rate, our hypothesis that emotional dimensions can play a relevant role in the interactions that occur on this collective intelligence platform is confirmed by (1) the pattern of responses produced through the experiment, (2) their direct relationship with the Phase variable, (3) the latter’s direct relationship with Length, and (4) the relationship between Length and Final Frequency and Number of Copies. Our data analysis also confirms that the sentiment analysis tool is adequate for the analysis of large quantities of data such as those generated here, or even those generated by interactions on social networks (Karagozoglu and Fabozzi, 2017; Ferchaud et al., 2018; Lozano-Blasco et al., 2021; Zuheros et al., 2023).
The different Polarity valences – positive for Question 1 but negative for Questions 2 and 3 – likewise seem to suggest that these participants have gone through the real process of analyzing the task, as reflected by the successive responses the interaction system has generated. They respond as if they had authentically witnessed the occurrences, achieving a great degree of emotional implication with the actors in the ethical case and also experiencing a certain degree of emotional activation (Caravita et al., 2016). Participants responded by choosing the side of the victim, a choice which generates higher levels of cognitive and emotional empathy with the victim than with the aggressors, as also tends to occur in real-life scenarios (Machackova and Pfetsch, 2016). The group dynamic further accentuated the empathetic response, from a cognitive perspective. Bautista et al. (2022) had already ascertained that the same task and situation tended to improve participants’ moral reasoning capacities. Social neuroscience studies have used group somatic markers (measured by group electrodermal activity) to show that (1) a group needs a certain amount of time to synchronize the act of “listening to one another,” (2) group processes imply improved attention levels in the individual, and (3) emotional activation somewhat attenuates a group’s overall listening capacity (Aiger, 2013). The rate of change tends to accelerate when the group is able to carry out a process of cognitive-emotional revaluation (Vicente et al., 2006) in the phases of cooperation and maximum interdependence (which, in our study, had their equivalent in the final consensus phases. i.e., Phases 6 and 7).
Our results lead us to reflect upon the educational value that might be inherent in contexts of interaction, such as the environment provided by our experiment. Other authors in the field already find a great degree of educational potential in interactive large-group contexts. Large groups allow for their members to construct authentic learning communities; participants can pool and share their resources and they can also create collaborative/cooperative spaces such as the one described herein (Castellanos et al., 2017; Chen, 2018; Ciccone, 2019; Tenorio et al., 2021). Moreover, since such interactive projects take place in “virtual” spaces, the environment is familiar to adolescent users and akin to the type of online space where they are often confronted with threatening risks, such as cyberbullying. Thus, within a virtual space, adolescents can start acquiring the necessary competencies that help them adapt to online environments in general, such as messaging platforms and social networks (Cebollero-Salinas et al., 2022). Such collective intelligence makes it possible to gather a sizeable “crowd” to resolve relevant issues. The system presented in this paper is capable of managing up to 5.000 participants simultaneously in one project. The user can thus feel that they are part of a learning community, or of a collective that takes up joint action when faced with the same problems. This idea of a collective could be a further variable that plays a certain role in the productivity of groups facing a task, such as the group of users featured in this study. An additional advantage found in environments such as this one can be seen in the occasion that it offers for real-time interaction. By adding a fixed time limit, such virtual platforms can provide a consensus mechanism that delivers certain guarantees. We are aware that such group phenomena do not always guarantee success; it is thus essential to describe under which conditions collective intelligence is capable of producing quality solutions (Bigham et al., 2018; Orejudo et al., 2022). The current investigation provides a solid basis for the ongoing study of complexity in collective intelligence. Moreover, certain features of the platform – such as the possibility of modulating the rate of interchange in the small-group work phases, or of choosing the number of responses eliminated in the final consensus rounds – can give rise to different scenarios which, in turn, offer additional alternatives that could be of educational use. If the platform presented herein were programmed to act as a knowledge management system by modifying structures and group processes plus introducing the use of feedback (which, in turn, affects interventions) and by incorporating the aspect of social abilities, it could be reckoned among the leading alternatives in terms of group management designed to efficiently conduct tasks while ensuring that a group can serve as an instrument of change, thanks to the advantages of CI (Collective Intelligence).
However, we should still ask ourselves whether the final consensus phases (Phases 6 and 7) represent the type of interaction that allows users to have a learning experience. From the vantage point of our research, we cannot guarantee it, since social influence seems to be the major factor in these two final stages. But at least the participants are also engaged in social learning, as they are selecting the options they consider best among all the options they had previously been dealing with (Navajas et al., 2018). Other crowd intelligence studies assume that learning is acquired by merely sharing such information, analyzing it and evaluating it (Toyokawa et al., 2014; Hertz et al., 2021); we thus likewise assume that information is being actively processed and that such processing requires a certain amount of previous activity in formulating a response to the question. This, in turn, involves decision-making. Which brings us to the vicinity of active learning theories.
This study has certain limitations. First, we analyzed responses entirely independently of who the authors of those responses were. There thus must have been participants who emitted several responses per phase, contrasted with others who emitted one sole response, or none. The analysis system we employed ascribes the same value to original responses as to those that are copied from other authors in the system. Copied responses are maintained in the system as often as they appear, without applying a process of filtering out duplicates (which would have helped correct the degree of bias). We nevertheless opted to maintain that analysis strategy as it is more ecological: all responses were shared across the network, independently of their origin. Another approach would have consisted in taking each response only once into account, or only to allow one response per participant. It would have entailed that low-frequency responses would have been handled equally in the initial phases. Indeed, in those initial phases, participants seem to familiarize themselves rapidly with the system and seem to be re-recording their own responses on more than one occasion, as is suggested by the high frequency of responses in the individual phase. At any rate, the analysis strategy we chose to apply was in proportion to our research goal, which was to analyze the emotional dimension of responses generated on the platform. At the same time, we were proposing a data analysis based on automatized AI tools that analyze natural language, thereby gathering the entire dynamic generated by the system. Other analysis possibilities admittedly exist, such as evaluating the quality of final responses (Bigham et al., 2018) as a valid option to solve a problem, or studying the degree of creativity that the process gradually produces. In any case, the evolution of AI is creating new possibilities in record time. For now, chatpgt is already emerging as an option to tackle this task efficiently, and may be integrated into platforms such as Collective Learning in the near future. Furthermore, we have refrained from analyzing the responses from the vantage point of participants, although that aspect could have improved our grasp of the phenomena under study. For example, we could have analyzed the response patterns that appear in successive phases, or we could have analyzed who were the participants who intervened in the consensus phases, or how the process of social influence acts in a context of entire anonymity such as this one, or which emotional responses are chosen by participants when they interact with others, when they are exposed to the Top 10, or when the system eliminates their responses because the group has had a low degree of acceptance for them. Hertz et al. (2021) and Toyokawa and Gaissmaier (2022) do go more into depth on this level of individual differences: they highlight the importance that such differences can have when responses are displayed to the group and when decisions are taken. Such aspects will need to be taken into account in the future.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving humans were approved by Research Ethics Committee of the Autonomous Community of Aragon (CEICA). C.P. – C.I. PI22/216. The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation in this study was provided by the participants’ legal guardians/next of kin.
SO: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Supervision, Validation, Writing – original draft, Writing – review & editing. RL-B: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. PB: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Resources, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. MA: Conceptualization, Formal analysis, Investigation, Methodology, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing.
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This study was part of the R&D&I project TED2021-130302B-C21: Digital transformation and critical thinking in students through online interaction on the THINKUB platform for collective intelligence, funded by MCIN/AEI/10.13039/501100011033 and by the European Union NextGenerationEU/PRTR.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Aggarwal, C. C. (2022). “Opinion mining and sentiment analysis” in Machine learning for text. ed. C. C. Aggarwal (Cham: Springer International Publishing), 491–514.
Aggarwal, I., and Woolley, A. W. (2018). Team creativity. Cognition. And cognitive style diversity. Manag. Sci. 65, 1586–1599. doi: 10.1287/mnsc.2017.3001
Aggarwal, I., Woolley, A. W., Chabris, C. F., and Malone, T. W. (2019). The impact of cognitive style diversity on implicit learning in teams. Front. Psychol. 10:112. doi: 10.3389/fpsyg.2019.00112
Aiger, M. (2013). Patrones electrodérmicos de la actividad grupal. Universitat de Barcelona. Available at: http://hdl.handle.net/10803/134062
Almaatouq, A., Noriega-Campero, A., Alotaibi, A., Krafft, P. M., Moussaid, M., and Pentland, A. (2020). Adaptive social networks promote the wisdom of crowds. Proc. Natl. Acad. Sci. USA 117, 11379–11386. doi: 10.1073/pnas.1917687117
Arató, N., Zsidó, A. N., Lénárd, K., and Lábadi, B. (2020). Cybervictimization and cyberbullying: the role of socio-emotional skills. Front. Psych. 11:248. doi: 10.3389/fpsyt.2020.00248
Bates, T. C., and Gupta, S. (2017). Smart groups of smart people: evidence for IQ as the origin of collective intelligence in the performance of human groups. Intelligence 60, 46–56. doi: 10.1016/j.intell.2016.11.004
Bautista, P., Cano-Escoriaza, J., Vicente, E., Cebollero-Salinas, A., and Orejudo, S. (2022). Improving adolescent moral reasoning versus cyberbullying: an online big group experiment by means of collective intelligence. Comput. Educ. 189:104594. doi: 10.1016/j.compedu.2022.104594
Becker, J., Brackbill, D., and Centola, D. (2017). Network dynamics of social influence in the wisdom of crowds. Proc. Natl. Acad. Sci. USA 114, E5070–E5076. doi: 10.1073/pnas.1615978114
Bernstein, E., Shore, J., and Lazer, D. (2018). How intermittent breaks in interaction improve collective intelligence. Proc. Nat. Acad. Sci. USA 115, 8734–8739. doi: 10.1073/pnas.1802407115
Bigham, J. P., Bernstein, M. S., and Adar, E. (2018). “Human-computer interaction and collective intelligence” in Handbook of collective intelligence. eds. E. T. W. W. Malone and M. S. Bernstein (Cambridge, Massachusetts, London: The MIT Press), 57–83.
British Educational Research Association (BERA) (2011). Ethical guidelines for educational research. Available at: https://www.bera.ac.uk/publication/bera-ethical-guidelines-for-educational-research-2011
Byrne, B. M. (2010). Structural equation Modeling with AMOS. Basic concepts. Applications and programming. New York, Routledge: Taylor & Francis Group.
Caravita, S. C., Colombo, B., Stefanelli, S., and Zigliani, R. (2016). Emotional. Psychophysiological. And behavioral responses elicited by the exposition to cyberbullying situations: two experimental studies. Psicol. Educ. 22, 49–59. doi: 10.1016/j.pse.2016.02.003
Castellanos, J., Haya, P. A., and Urquiza-Fuentes, J. (2017). A novel group engagement score for virtual learning environments. IEEE Trans. Learn. Technol. 10, 306–317. doi: 10.1109/TLT.2016.2582164
Cebollero-Salinas, A., Cano-Escoriaza, J., and Orejudo, S. (2022). Are emotional e-competencies a protective factor against habitual digital behaviors (media multitasking. Cybergossip. Phubbing) in Spanish students of secondary education? Comput. Educ. 181:104464. doi: 10.1016/j.compedu.2022.104464
Ceron, A., Curini, L., Iacus, S. M., and Porro, G. (2013). Every tweet counts? How sentiment analysis of social media can improve our knowledge of citizens’ political preferences with an application to Italy and France. New Media Soc. 16, 340–358. doi: 10.1177/1461444813480466
Chan, J. Y. L., Bea, K. T., Leow, S. M. H., Phoong, S. W., and Cheng, W. K. (2023). State of the art: a review of sentiment analysis based on sequential transfer learning. Artif. Intell. Rev. 56, 749–780. doi: 10.1007/s10462-022-10183-8
Chen, S. (2018). Literacy and connected learning within a participatory culture: linkages to collective intelligence efficacy and civic engagement. Asia Pac. Educ. Res. 27, 167–175. doi: 10.1007/s40299-018-0375-4
Ciccone, M. (2019). Teaching adolescents to communicate (better) online: best practices from a middle school classroom. J. Media Lit. Educ. 11, 167–178. doi: 10.23860/JMLE-2019-11-2-9
Curşeu, P. L., Pluut, H., Boroş, S., and Meslec, N. (2015). The magic of collective emotional intelligence in learning groups: no guys needed for the spell! Br. J. Psychol. 106, 217–234. doi: 10.1111/bjop.12075
Dai, A., Zhao, Z., Li, R., Zhang, H., and Zhou, Y. (2020). Evaluation mechanism of collective intelligence for heterogeneous agents’ group. IEEE Access 8, 28385–28394. doi: 10.1109/ACCESS.2020.2971278
De Vincenzo, I., Giannoccaro, I., Carbone, G., and Grigolini, P. (2017). Criticality triggers the emergence of collective intelligence in groups. Phys. Rev. E 96:022309. doi: 10.1103/PhysRevE.96.022309
Engel, D., Woolley, A. W., Jing, L. X., Chabris, C. F., and Malone, T. W. (2014). Reading the mind in the eyes or reading between the lines? Theory of mind predicts collective intelligence equally well online and face-to-face. PLoS One 9:e115212. doi: 10.1371/journal.pone.0115212
Evans, M. A., Feenstra, E., Ryon, E., and McNeill, D. (2011). A multimodal approach to coding discourse: collaboration. Distributed cognition. And geometric reasoning. Int. J. Comput. Support. Collab. Learn. 6, 253–278. doi: 10.1007/s11412-011-9113-0
Fang, Y., Tan, H., and Zhang, J. (2018). Multi-strategy sentiment analysis of consumer reviews based on semantic fuzziness. IEEE Access 6, 20625–20631. doi: 10.1109/ACCESS.2018.2820025
Ferchaud, A., Grzeslo, J., Orme, S., and LaGroue, J. (2018). Parasocial attributes and YouTube personalities: exploring content trends across the most subscribed YouTube channels. Comput. Hum. Behav. 80, 88–96. doi: 10.1016/j.chb.2017.10.041
Fontanari, J. F. (2018). Reputation blackboard systems. Cogn. Syst. Res. 50, 29–35. doi: 10.1016/j.cogsys.2018.03.008
Gámez-Guadix, M., De Santisteban, P., and Resett, S. (2017). Sexting entre adolescentes españoles: prevalencia y asociación con variables de personalidad. Psicothema 29, 29–34. doi: 10.7334/psicothema2016.222
Garg, K., Kello, C. T., and Smaldino, P. E. (2022). Individual exploration and selective social learning: balancing exploration-exploitation trade-offs in collective foraging. J. R. Soc. Interface 19:20210915. doi: 10.1098/rsif.2021.0915
Geifman, D., and Raban, D. R. (2015). Collective problem-solving: the role of self-efficacy. Skill. And prior knowledge. Int. J. Skills Life. Learn. 11, 159–178. doi: 10.28945/2319
Gimpel, H., Graf-Drasch, V., Laubacher, R. J., and Wöhl, M. (2020). Facilitating like Darwin: supporting cross-fertilisation in crowdsourcing. Decis. Support. Syst. 132:113282. doi: 10.1016/j.dss.2020.113282
Guerra, J., León, B., Yuste, R., López, V., and Mendo, S. (2019). Emotional intelligence and psychological well-Beingin adolescents. Int. J. Environ. Res. Public Health 16:1720. doi: 10.3390/ijerph16101720
Guerra, J., Yuste, R., López, V., and Mendo, S. (2021). Efecto modelador de la competencia emocional en los perfiles de ciberacoso. Ann. Psychol. 37, 202–209. doi: 10.6018/analesps.338071
Gürçay, B., Mellers, B. A., and Baron, J. (2015). The power of social influence on estimation accuracy. J. Behav. Decis. Mak. 28, 250–261. doi: 10.1002/bdm.1843
Hamada, D., Nakayama, M., and Saiki, J. (2020). Wisdom of crowds and collective decision-making in a survival situation with complex information integration. Cogn. Res. Princ. Implic. 5:48. doi: 10.1186/s41235-020-00248-z
Hemphill, S. A., Tollit, M., Kotevski, A., and Heerde, J. A. (2015). Predictors of traditional and cyber-bullying victimization: a longitudinal study of Australian secondary school students. J. Interpers. Violence 30, 2567–2590. doi: 10.1177/0886260514553636
Hertz, U., Bell, V., and Raihani, N. (2021). Trusting and learning from others: immediate and long-term effects of learning from observation and advice. Proc. R. Soc. B Biol. Sci. 288:20211414. doi: 10.1098/rspb.2021.1414
Hjertø, K. B., and Paulsen, J. M. (2016). Beyond collective beliefs: predicting team academic performance from collective emotional intelligence. Small Group Res. 47, 510–541. doi: 10.1177/1046496416661236
Holtz, P., Kimmerle, J., and Cress, U. (2018). Using big data techniques for measuring productive friction in mass collaboration online environments. Int. J. Comput.-Support. Collab. Learn. 13, 439–456. doi: 10.48550/arXiv.1406.7551
Hu, M., and Liu, B. (2004). Mining and summarizing customer reviews. In Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining (168–177).
Jiang, L., Yu, M., Zhou, M., Liu, X., and Zhao, T. (2011). Target-dependent twitter sentiment classification. In Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies (151–160).
Jiang, Q., Zhao, F., Xie, X., Wang, X., Nie, J., Lei, L., et al. (2022). Difficulties in emotion regulation and cyberbullying among Chinese adolescents: a mediation model of loneliness and depression. J. Interpers. Violence 37:NP1105-NP1124. doi: 10.1177/0886260520917517
Kabo, F. (2018). The architecture of network collective intelligence: correlations between social network structure. Spatial layout and prestige outcomes in an office. Philos. Trans. R. Soc. B Biol. Sci. 373, 1–9. doi: 10.1098/rstb.2017.0238
Karagozoglu, A. K., and Fabozzi, F. Z. (2017). Volatility wisdom of social media crowds. J. Portf. Manag. 43, 136–151. doi: 10.3905/jpm.2017.43.2.136
Klieger, A. (2016). The use of social networks to employ the wisdom of crowds for teaching. TechTrends 60, 124–128. doi: 10.1007/s11528-016-0020-0
Leduc, K., Conway, L., Gomez-Garibello, C., and Talwar, V. (2018). The influence of participant role. Gender. And age in elementary and high-school children's moral justifications of cyberbullying behaviors. Comput. Hum. Behav. 83, 215–220. doi: 10.1016/j.chb.2018.01.044
Lo Cricchio, M. G., García-Poole, C., Te Brinke, L. W., Bianchi, D., and Menesini, E. (2021). Moral disengagement and cyberbullying involvement: a systematic review. Eur. J. Dev. Psychol. 18, 271–311. doi: 10.1080/17405629.2020.1782186
Lorenz, J., Rauhut, H., Schweitzer, F., and Helbing, D. (2011). How social influence can undermine the wisdom of crowd effect. Proc. Natl. Acad. Sci. USA 108, 9020–9025. doi: 10.1073/pnas.1008636108
Lounsbury, K., Mitchell, K. J., and Finkelhor, D. (2011). The true prevalence of “Sexting”. Durham, NH: Crimes against Children Research Center.
Lozano-Blasco, R., Latorre-Martínez, M. P., and Cortes-Pascual, A. (2021). Analizing teens an analysis from the perspective of gamers in Youtube. Sustain. For. 13:11391. doi: 10.3390/su132011391
Machackova, H., and Pfetsch, J. (2016). Bystanders’ responses to offline bullying and cyberbullying: the role of empathy and normative beliefs about aggression. Scand. J. Psychol. 57, 169–176. doi: 10.1111/sjop.12277
Mann, R. P., and Helbing, D. (2017). Optimal incentives for collective intelligence. Proc. Natl. Acad. Sci. USA 114, 5077–5082. doi: 10.1073/pnas.1618722114
Mao, A., Mason, W., Suri, S., and Watts, D. J. (2016). An experimental study of team size and performance on a complex task. PloS one 11:e0153048. doi: 10.1371/journal.pone.0153048
Massari, G. F., Giannoccaro, I., and Carbone, G. (2019). Are distrust relationships beneficial for group performance? The influence of the scope of distrust on the emergence of collective intelligence. Int. J. Prod. Econ. 208, 343–355. doi: 10.1016/j.ijpe.2018.12.005
Meslec, N., Aggarwal, I., and Curşeu, P. L. (2016). The insensitive ruins it all: compositional and compilational influences of social sensitivity on collective intelligence in groups. Front. Psychol. 7:676. doi: 10.3389/fpsyg.2016.00676
Ministerio de Educación y Formación Profesional (2020). Igualdad en cifras MEFP 2020. Aulas por la igualdad. Secretaría General Técnica. Available at: https://www.educacionyfp.gob.es/dam/jcr:914e956e-9241-49c5-b9a6-d99d6eade751/igualdad-en-cifras-2020-online.pdf
Navajas, J., Niella, T., Garbulsky, G., and Sigman, M. (2018). Aggregated knowledge from a small number of debates outperforms the wisdom of large crowds. Nat. Hum. Behav. 2, 126–132. doi: 10.1038/s41562-017-0273-4
Orejudo, S., Cano-Escoriaza, J., Cebollero-Salinas, A. B., Bautista, P., Clemente-Gallardo, J., Rivero, A., et al. (2022). Evolutionary emergence of collective intelligence in large groups of students. Front. Psychol. 13:848048. doi: 10.3389/fpsyg.2022.848048
Paciello, M., Tramontano, C., Nocentini, A., Fida, R., and Menesini, E. (2020). The role of traditional and online moral disengagement on cyberbullying: do externalising problems make any difference? Comput. Hum. Behav. 103, 190–198. doi: 10.1016/j.chb.2019.09.024
Palacín, M., and Aiger, M. (2014). “Group communication,” in Psychosocial aspects of communication. eds. Martínez-Pecino, R., and Guerra, J. M. (Madrid. Pirámide), 193–206.
Patchin, J. W., and Hinduja, S. (2006). Bullies move beyond the schoolyard. Youth Violence Juv. Justice 4, 148–169. doi: 10.1177/1541204006286288
Patchin, J. W., and Hinduja, S. (2015). Measuring cyberbullying: implications for research. Aggress. Violent Behav. 23, 69–74. doi: 10.1016/j.avb.2015.05.013
Perren, S., and Gutzwiller-Helfenfinger, E. (2012). Cyberbullying and traditional bullying in adolescence: differential roles of moral disengagement. Moral emotions. And moral values. Eur. J. Dev. Psychol. 9, 195–209. doi: 10.1080/17405629.2011.643168
Pescetelli, N., Rutherford, A., and Rahwan, I. (2021). Modularity and composite diversity affect the collective gathering of information online. Nat. Commun. 12:3195. doi: 10.1038/s41467-021-23424-1
Pfetsch, J. (2016). “Who is who in cyberbullying? Conceptual and empirical perspectives on bystanders in cyberbullying” in A social-ecological approach to cyberbullying. ed. M. F. Wright (Hauppauge: Nova Publishing), 121–149.
Plutchik, R. (2001). The nature of emotions: human emotions have deep evolutionary roots. A fact that may explain their complexity and provide tools for clinical practice. Am. Sci. 89, 344–350. doi: 10.1511/2001.28.344
Rowe, L. I., Hattie, J., and Hester, R. (2021). G versus c: comparing individual and collective intelligence across two meta-analyses. Cogn. Res. Princ. Implic. 6:26. doi: 10.1186/s41235-021-00285-2
Salganik, M. J., Dodds, P. S., and Watts, D. J. (2006). Experimental study of inequality and unpredictability in an artificial cultural market. Science 311, 854–856. doi: 10.1126/science.1121066
Sierra-Pérez, J., Aiger, M., and López-Forniés, I. (2021). Conceptualization in the circular economy: analysing the influence of thinking profiles in creative groups. J. Clean. Prod. 316:128287. doi: 10.1016/j.jclepro.2021.128287
Smith, P. K., Mahdavi, J., Carvalho, M., Fisher, S., Russell, S., and Tippett, N. (2008). Cyberbullying: its nature and impact in secondary school pupils. J. Child Psychol. Psychiatry 49, 376–385. doi: 10.1111/j.1469-7610.2007.01846.x
Starkey, C. J. (2012). Releasing your inner leader: spinning 21st-century standards-driven evaluations and professional development into stronger school relationships. Knowledge Quest 40, 10–13.
Sulik, J., Bahrami, B., and Deroy, O. (2022). The diversity gap: when diversity matters for knowledge. Perspect. Psychol. Sci. 17, 752–767. doi: 10.1177/17456916211006070
Syahrul, M., and Dwi, M. (2017). Aspect-based sentiment analysis to review products using Naïve Bayes. AIP Conf. Proc. 1867:020060. doi: 10.1063/1.4994463
Tenorio, T., Isotani, S., Bittencourt, I. I., and Lu, Y. (2021). The state-of-the-art on collective intelligence in online educational technologies. IEEE Trans. Learn. Technol. 14, 257–271. doi: 10.1109/TLT.2021.3073559
Toyokawa, W., and Gaissmaier, W. (2022). Conformist social learning leads to self-organised prevention against adverse bias in risky decision making. eLife 11:e75308. doi: 10.7554/eLife.75308
Toyokawa, W., Kim, H. R., and Kameda, T. (2014). Human collective intelligence under dual exploration-exploitation dilemmas. PLoS One 9:e95789. doi: 10.1371/journal.pone.0095789
Toyokawa, W., Whalen, A., and Laland, K. N. (2019). Social learning strategies regulate the wisdom and madness of interactive crowds. Nat. Hum. Behav. 3, 183–193. doi: 10.1038/s41562-018-0518-x
Trisna, K. W., and Jie, H. J. (2022). Deep learning approach for aspect-based sentiment classification: a comparative review. Appl. Artif. Intell. 36:2014186. doi: 10.1080/08839514.2021.2014186
Vicente, R., Cornejo, J. M., and Barbero, F. (2006). La evaluación de la actividad grupal. El análisis de la actividad grupal (AAG) y la aplicación DSCLIMA del Sistema SOCIOS. Anu. Psicol. 37, 299–320.
Wang, X., Lei, L., Liu, D., and Hu, H. (2016). Moderating effects of moral reasoning and gender on the relation between moral disengagement and cyberbullying in adolescents. Personal. Individ. Differ. 98, 244–249. doi: 10.1016/j.paid.2016.04.056
Woolley, A. W., and Aggarwal, I. (2020). “Collective intelligence and group learning,” in Handbook of group and organizational learning. eds. L. Argote and J. M. Levine (New York, NY: Oxford University Press).
Woolley, A. W., Aggarwal, I., and Malone, T. W. (2015). Collective intelligence and group performance. Curr. Dir. Psychol. Sci. 24, 420–424. doi: 10.1177/0963721415599543
Woolley, A. C., Chabris, C. F., Pentland, A., Hashmi, N., and Malone, T. W. (2010). Evidence for a collective intelligence factor in the performance of human groups. Science 330, 686–688. doi: 10.1126/science.1193147
Yahosseini, K. S., and Moussaïd, M. (2020). Comparing groups of independent solvers and transmission chains as methods for collective problem-solving. Sci. Rep. 10:3060. doi: 10.1038/s41598-020-59946-9
Yu, Y., Duan, W., and Cao, Q. (2013). The impact of social and conventional media on firm equity value: a sentiment analysis approach. Decis. Support. Syst. 55, 919–926. doi: 10.1016/j.dss.2012.12.028
Keywords: collective intelligence, collective learning, sentiment analysis, cyberbullying, platform, online experiment
Citation: Orejudo S, Lozano-Blasco R, Bautista P and Aiger M (2024) Interaction among participants in a collective intelligence experiment: an emotional approach. Front. Psychol. 15:1383134. doi: 10.3389/fpsyg.2024.1383134
Edited by:
Mahwish Kamran, Iqra University, PakistanReviewed by:
Sohni Siddiqui, Technical University of Berlin, GermanyCopyright © 2024 Orejudo, Lozano-Blasco, Bautista and Aiger. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Montserrat Aiger, bW9udHNlYUB1bml6YXIuZXM=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.