 Melanie Trypke
Melanie Trypke Ferdinand Stebner
Ferdinand Stebner Joachim Wirth
Joachim Wirth- 1Institute of Educational Science, University of Osnabrück, Osnabrück, Germany
- 2Institute of Educational Research, Ruhr University Bochum, Bochum, Germany
Regarding the redundancy effect in multimedia learning environments, more consistency is needed in the theoretical assumptions and investigation of this effect. Current research lacks a comprehensive account of different redundant scenarios in which materials facilitate or inhibit learning and provides little conceptual guidance on how learning processes are affected by different types of redundancy. Theoretical assumptions refer to redundancy as a contentual overlap of information provided by the learning material; in this case, processing duplicated information strains the learners’ limited cognitive capacities. Other assumptions refer to the role of processing limitations in working memory channels, including separate processing for visual and verbal information. In this case, an ineffective combination of sources leads to an overload of the limited working memory capacity. This paper reviews empirical research on the redundancy effect (63 studies) and classifies two types of redundancy: (1) content redundancy, and (2) working memory channel redundancy. From an instructional psychology perspective, the analyses reveal four different implementations of redundant scenarios: (1) adding narration to visualizations, (2) adding written text to visualizations, (3) adding written text to narration, and (4) adding written text to narrated visualizations. Regarding the effects of the two redundancy types within these scenarios, analyses indicate positive effects of content redundancy (affected by learners’ prior knowledge), negative effects of working memory channel redundancy (regarding visualizations and written text), and positive effects of working memory channel redundancy (regarding narration and written text). Moreover, results point to factors that might moderate the effect of redundancy and illustrate interactions with existing multimedia effects. Overall, this review provides an overview of the state of empirical research and reveals that the consideration of both redundancy types provides further explanations in this field of research.
1. Introduction
Research in multimedia learning has investigated multimedia effects and derived principles for designing multimedia learning environments (Mayer, 2014). One of the most prominent effects is the redundancy effect, which appears when different sources of learning material provide redundant information. In investigations of this effect, two theories have played a crucial role: cognitive load theory (CLT; Chandler and Sweller, 1991) and the Cognitive Theory of Multimedia Learning (CTML; Mayer et al., 2001). According to CLT, the redundancy effect occurs when different sources provide the same or unnecessary information (Chandler and Sweller, 1991; Kalyuga et al., 1999). When differentiating between the same and unnecessary information concerning redundancy, the key factor is relevance. The same information refers to repeating information related to the learning task. As an example, Chandler and Sweller (1991) pointed to self-explanatory diagrams accompanied by textual instructions that redescribe the content of the diagrams. In this example, the textual instructions do not provide additional information or explanation; they merely repeat the same information. By contrast, unnecessary information refers to information unrelated to the learning content for example, by adding background music or entertaining graphics to self-explanatory diagrams (CTML call these “seductive details”). At this point, it is important to consider that CLT suggests that redundant information (both the same and unnecessary) interferes with learning and should be eliminated. From a CTML perspective the elimination of unnecessary information (seductive details) aligns with the coherence principle. According to CTML, the redundancy effect refers “to any multimedia situation in which learning from animation (or illustration) and narration is superior to learning from the same materials along with printed text that matches the narration” (Mayer et al., 2001, p. 153).
Both CLT and CTML hold that redundancy impedes learning, though they make different theoretical assumptions (which will be further discussed in section two). Numerous studies support this idea (e.g., Kalyuga et al., 1999; Mayer et al., 2001; Jamet and Bohec, 2007; Austin, 2009). However, many studies report empirical results suggesting that redundancy enhances learning (e.g., Adegoke, 2017) or has no effect on learning (e.g., Chu, 2006). According to Kalyuga and Sweller (2014), there might be two reasons for these contradictory findings. One might be that researchers use the same term—redundancy—to investigate different variations of the effect, such as complementary redundancy1 (e.g., Fenesi and Kim, 2014), partial redundancy2 (e.g., Roscoe et al., 2015), or concise redundancy3 (e.g., Wu, 2011). The other reason might be that some studies implement redundancy between narration and written text (e.g., Diao and Sweller, 2007), others among visualization, narration, and written text (e.g., Mayer and Johnson, 2008), and still others between visualization and written text (e.g., Torcasio and Sweller, 2010). In alignment with Kalyuga et al. (2003), we think that the assumptions of CLT and CTML complement each other and clarify different aspects of redundancy. To consider both perspectives, we suggest distinguishing between two different types of redundancy concerning the content in the learning material (e.g., providing duplicated or unnecessary information) and the included working memory channels to deal with this information.
Therefore, this literature review examines various redundant scenarios to clarify whether differences in content, working memory channels, or both might account for the heterogeneous findings in this research field.
The idea of different types of redundancy has been introduced previously (see Hsia, 1974; Kalyuga et al., 2003; Bohec and Jamet, 2008; Mayer, 2009; Dooley, 2015). However, while earlier classifications emphasized total or partial duplications of spoken and written text (Bohec and Jamet, 2008; Dooley, 2015), the borders of information processing capacity (Miller, 1956; Hsia, 1974), or the logical relationships among different sources of information (Low et al., 2013; Kalyuga, 2014), we propose to look more closely at different redundant scenarios.
To define our two types of redundancy, we focus on cognitive processes localized in the working memory (Schnotz, 2005). Imagine a multimedia environment where learners receive an animation about lightning formation accompanied by a narration that redescribes the content of the animation. A redundancy effect could occur at the cognitive processing level, as cognitive resources are unnecessarily used to determine that the information was duplicated (content redundancy). The same applies to unnecessary information; for instance, learners receive an animation about lightning formation accompanied by background music (not related to the learning content), or learners receive a written text about lightning formation accompanied by entertaining pictures (not related to the learning content). In this case, cognitive resources are unnecessarily used to determine that the information was irrelevant.
The second type of redundancy affects working memory channels. Imagine a situation where learners receive narration and written text. A redundancy effect would affect the processing channel for verbal information in working memory because the narration competes with the written text (Mayer, 2009). Another scenario includes the presentation of visualization and written text; because the two sources are both perceived visually, a redundancy effect could affect the cognitive processing of working memory channels because visualization and written text “compete for limited cognitive resources in the visual channel” (Mayer and Johnson, 2008, p. 124).
Furthermore, it must be considered that these types of redundancy can occur in combination. Imagine a multimedia environment containing visualization and written text. If both sources provide identical information, we have content redundancy and working memory channel redundancy. By contrast, if the visualization and written text contain different information (e.g., the written text complements or supplements information), we have working memory channel redundancy without content redundancy. For instance, learners receive an animation on how to assemble a piece of furniture. The animation would show each step of the assembly process, e.g., how to attach two parts, while the written text would provide more detailed instructions on how much pressure to apply or how to tighten the screws.
Since redundancy must be considered by anyone involved in designing multimedia materials (including instructional designers and educators), this review synthesizes existing research, applying current insights to different variations of the effect on a theoretical level. The distinction of two redundancy types combines the assumptions of CLT and CTML and enables us to categorize the implementations among different studies. This leads to an opportunity to fill gaps in the current understanding and highlight areas that need further research. On a practical level, this categorization enables us to elucidate factors that influence the effectiveness of redundant information and its relation to other principles of multimedia learning, which leads to implications for the design of instructional materials in terms of how to optimize the use of redundant information, for example, when to use which type of redundancy and when a type might be counterproductive.
2. Theoretical derivation of the two redundancy types
In the following, we describe the theoretical assumptions that provide the basis for the derivation of our proposed redundancy types. Regarding our classification, the assumptions of CLT (Chandler and Sweller, 1991; Sweller, 2010) align with our concept of “content redundancy” (e.g., the duplication of relevant information).
Cognitive load theory is an instructional theory about cognitive information processing demands on human working memory during learning and problem-solving. Research in this area focuses on the limited capacity of working memory, aiming to identify the most effective design recommendations for learning environments (Sweller et al., 2011). According to CLT, the redundancy effect occurs when two sources provide identical or unnecessary information or when multiple pieces of information that can be understood independently are presented concurrently (e.g., Chandler and Sweller, 1991; Kalyuga et al., 1999; Kalyuga, 2014). Before CLT established this definition of redundancy, prior studies investigated the split-attention effect (e.g., Tarmizi and Sweller, 1988). Both the redundancy effect and the split-attention effect deal with multiple sources of information (e.g., visualization and written text) and the associated increase in extraneous cognitive load (Sweller et al., 2011). However, unlike the redundancy effect, the split-attention effect only occurs if two sources of information are unintelligible in isolation but are each essential to achieving the learning goal (Sweller et al., 2011).4 In cases of redundancy, learners must process unnecessary information, since some information is either identical to already-processed information or unnecessary for learning (CTML refers to the exclusion of unnecessary information as the “coherence principle”; Mayer and Fiorella, 2014). Overall, according to CLT, redundancy of any kind is harmful to learning, but the extent of detriment depends on the complexity of the learning material. The complexity of learning material derives from the degree of element interactivity (Sweller, 2010). If elements of the learning material are interrelated, they must be stored and processed simultaneously in working memory. In this case, CLT implies a high level of element interactivity and high working memory requirements for information processing (Sweller, 2010). If redundant information is added to learning material that contains high element interactivity, it is more likely to be detrimental because it adds extraneous cognitive load that may overload working memory capacity. In contrast, when element interactivity is low, additional redundant information may not lead to an overload of working memory capacity.
Our understanding of working memory channel redundancy aligns with the assumptions of the CTML (Mayer, 2014) because it focuses on processing information from multiple sources in the same working memory channel. Regarding verbal redundancy, CTML also includes the concept of content redundancy when it refers to narration with duplicated written text.
Cognitive theory of multimedia learning is a theory of learning from instructional messages, and it aims to develop instructional design guidelines that enable active processing in learners and promote the construction of meaningful internal representations of learning content. This perspective (Mayer, 2009) uses the term redundancy in a more restricted way and represents a subset of CLT’s broad definition (Mayer et al., 2001). For CTML, the redundancy effect occurs when information is presented via visualization, narration, and written text (Moreno and Mayer, 2002). In such cases, redundancy presumably harms learning because “(a) the visual channel can become overloaded by having to visually scan between pictures and on-screen text, and (b) because learners expend mental effort in trying to compare the incoming streams of printed and spoken text” (Mayer, 2009, p. 118). Mayer et al. (2001) and Moreno and Mayer (2002) identified evidence for this assumption. They indicated that learners perform worse when learning with visualization, narration, and written text than with visualization and narration only. However, Mayer and Johnson (2008) revised their definition of redundancy after demonstrating the benefits of embedding written keywords from a narrated text into visual displays. These benefits were limited to improved performance on a memory test. The most common explanation for these results is that adding written keywords instead of the full written text to the visual part of multimedia instruction can guide learners’ attention toward relevant information (Mayer, 2014).
Further, CTML defines a subclass of redundant information, verbal redundancy. Verbal redundancy refers to the presentation of identical words in both written text and narration, with no visualizations (Mayer, 2009). Research on verbal redundancy indicates that the simultaneous presentation of verbal information as written text and narration results in improved learning performance over narration alone, if the written information is short (e.g., Moreno and Mayer, 2002). Overall, according to CTML, redundancy has varying effects on learning. According to the findings on verbal redundancy, adding written text to narration supports learning, but this effect depends on learners’ prior knowledge and the degree of information overlap (Adesope and Nesbit, 2012). In contrast, adding written text to narration and visualization leads to a negative redundancy effect when the written text duplicates words that are already present in the narration (Mayer et al., 2001).
2.1. Research questions
Based on the theoretical assumptions, we can provide a theoretical rationale for the two redundancy types. To investigate the implementation of content and working memory channel redundancy, we must consider the perspectives of instructional and cognitive psychology. From an instructional psychology perspective, we need to analyze different implementations of redundant presentation formats (e.g., image and written text, or narration and written text) and the content among these sources (e.g., duplicated or unnecessary information). From a cognitive psychology perspective, we must consider various learning and processing activities in working memory channels related to the different presentation formats.
Furthermore, it is necessary to consider interactions with existing multimedia effects. Various studies have found that level of expertise is one of the main factors moderating the redundancy effect (e.g., Lee et al., 2006). For example, information essential for learners with low prior knowledge may be ineffective (or even harmful) for knowledgeable learners (e.g., Kalyuga et al., 2000). This is called the expertise reversal effect (Kalyuga, 2014). According to our classification, the information might be content redundant to expert learners. Another factor is explained by the signaling effect (Van Gog, 2014), which refers to situations in which cues guide learners’ attention to relevant information. For example, Adesope and Nesbit (2012) showed that the implementation of narrations accompanied by short written keywords fosters learning, despite combining content and working memory channel redundancy. In contrast, narrations accompanied by identical written text impaired learning. These findings support the assumption that multimedia instructions do not have to reduce demands on cognitive processing as much as possible but should instead provide a level of processing that is neither too low (boring) nor too high (cognitive overload). In the case of Adesope and Nesbit (2012), results indicate by repeating certain information, learners can better identify what is essential to the task, which promotes efficient processing.
Based on these considerations, this review focuses on the following research questions:
1. How do studies implement the two types of redundancy?
2. Do both types of redundancy hamper learning?
3. How do the types of redundancy interact with other effects in multimedia learning?
3. Method
3.1. Literature search and coding procedures
We searched for empirical research published between January 1, 1991, and January 1, 2021. We consulted the following databases: Web of Science, Google Scholar, ERIC, ScienceDirect and PsycInfo. We used the search terms redundancy effect, redundancy principle, redundancy, redundancy effect in multimedia learning, and multimedia instruction for all databases in the fields of title, abstract, keywords, and full text (see Table 1).

Table 1. Keywords literature search.
After the initial database searches, focused searches were conducted (see Figure 1). In the first search phase, we used the following inclusion criteria: studies that had a (quasi-) experimental design, explained their research methods, focused on the research field of multimedia learning, and were written in German or English. A screening of titles and abstracts revealed that most hits were not relevant, as many articles did not investigate the redundancy effect in multimedia learning. After eliminating irrelevant search matches, 219 articles that met all preliminary criteria remained. The next search steps (phases 2–4) included more detailed inclusion criteria to increase the comparability of the studies: studies were selected that mentioned a theoretical approach for redundancy, contained a redundant treatment and non-redundant control condition (or compared different levels of redundancy), assigned participants randomly to groups, and reported a post-test (first test after intervention). After a full-text reading, 54 articles presenting 63 studies were included in this review. Studies were excluded if they involved no empirical study, conducted a meta-analysis or review, lacked a treatment group, lacked a full set of data, involved no theoretical approach for redundancy, or were conducted in a different research field than multimedia learning (e.g., computer science or medical studies). To analyze the implementation of the two redundancy types in the studies, we developed a coding form (see Supplementary Tables S1–S2). To conduct an interrater agreement, 14 (22.2%) of the studies coded by the first coder were randomly selected to be coded by an independent coder. Per cent agreements ranged between 86 and 100% (an overview of per cent agreements is presented in the Supplementary Table S3).
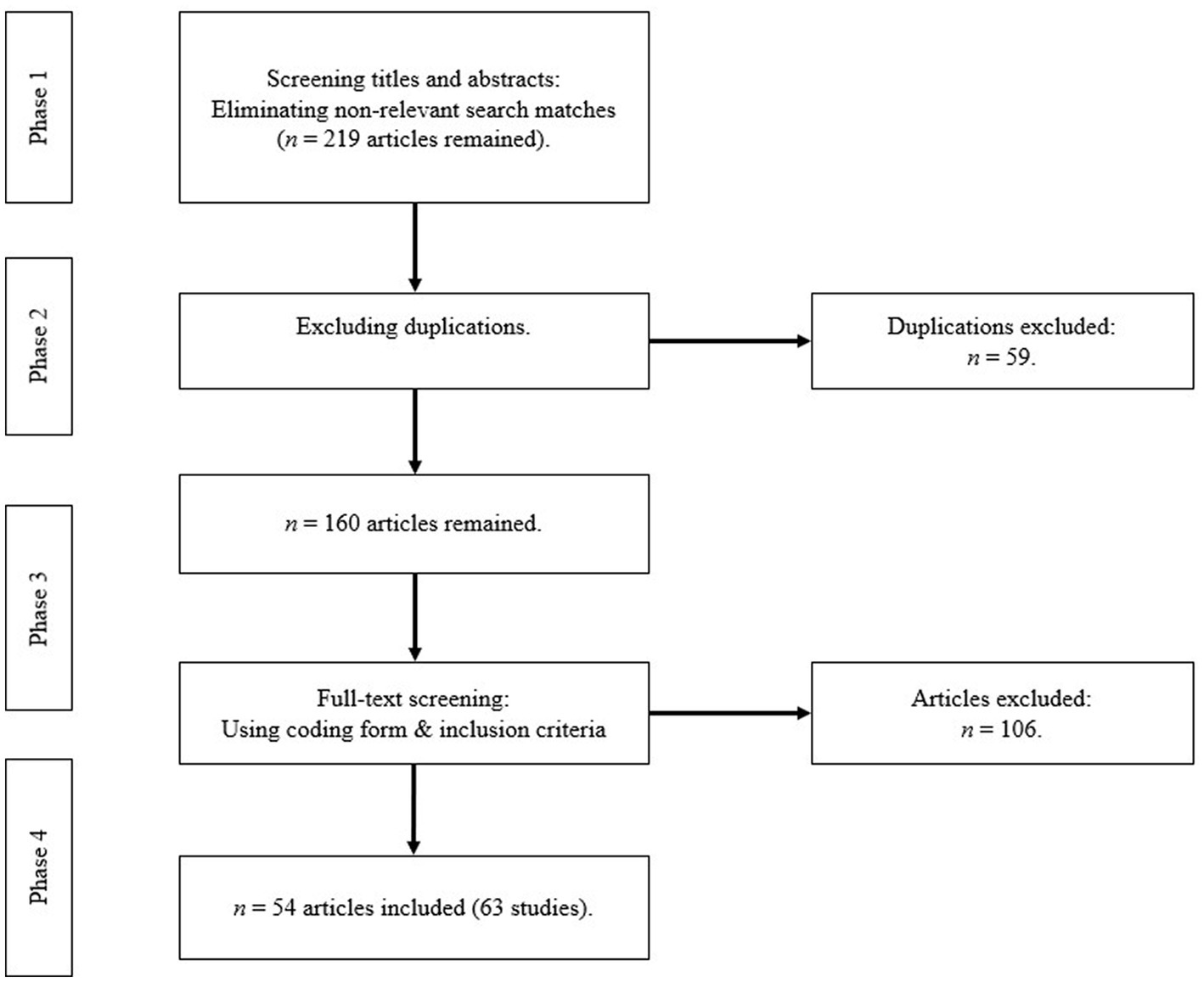
Figure 1. Selection process.
4. Results
4.1. Implementation of the two redundancy types
This section illustrates the implementation of various redundant scenarios and moderating factors. To analyze the implementation of content redundancy, we focus on the provided content in the learning materials. It should be noted that it was not possible to analyze the learning materials used by the studies directly. In many studies, no information about the learning materials was available. Therefore, we relied on the authors’ statements to analyze whether some information in the materials was duplicated or unnecessary (see Supplementary Table S1). We coded the studies according to the following categories: 1 = content redundancy between visualization and textual information; 2 = content redundancy between narration and written text; 3 = no content redundancy between visualization and textual information; 4 = no content redundancy between narration and written text; and 5 = content redundancy is not mentioned.
To investigate the implementation of working memory channel redundancy, we analyzed the treatment conditions of the studies. We were able to identify four different redundant scenarios (see Supplementary Table S2) and coded the studies using the following categories: 1 = adding narration to visualizations (no working memory channel redundancy); 2 = adding written text to visualizations (working memory channel redundancy regarding visualizations and written text); 3 = adding written text to narration (working memory channel redundancy regarding written text and narration); and 4 = adding written text to narrated visualizations (working memory channel redundancy regarding visualization, narration, and written text). Table 2 illustrates the distribution of studies according to these redundant scenarios.
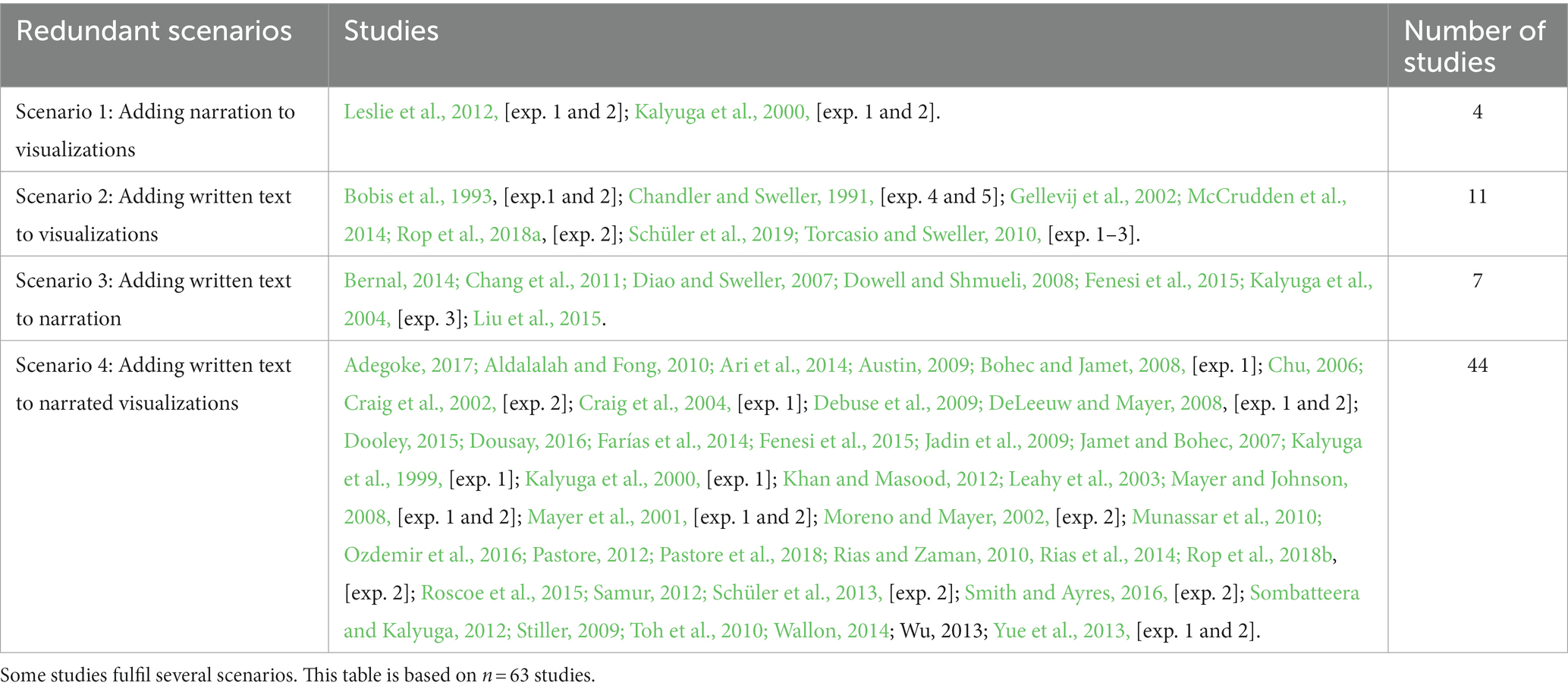
Table 2. Implementation of four redundant scenarios.
4.1.1. Scenario 1: adding narration to visualizations
Scenario one illustrates four studies (6.4%) implementing content redundancy between narration and visualizations (see Table 3). In this case, both sources provide the same duplicated information. This scenario does not include working memory channel redundancy because both sources are processed in different working memory channels.
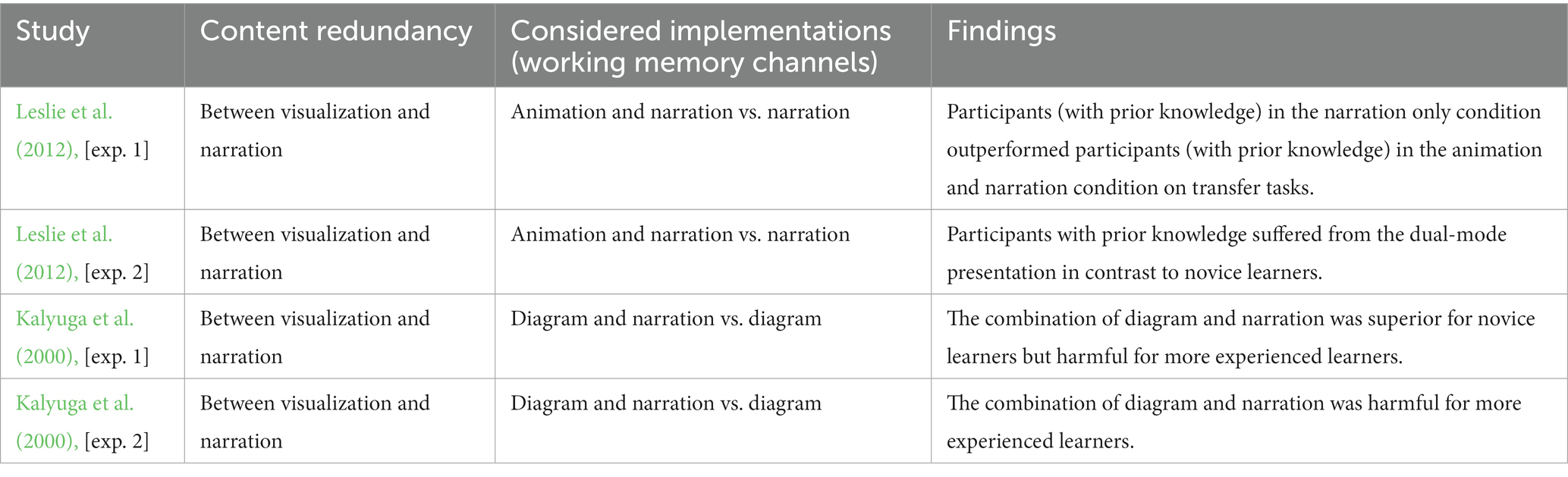
Table 3. Adding narration to visualizations.
Leslie et al. (2012) used learning materials on magnetism and light and compared the learning performance of younger participants (no prior knowledge) and older participants (medium prior knowledge) in two experiments. The participants received either animation and narration or narration only. The authors mentioned that the animation and narration provided the same information. Therefore, these sources were understandable in isolation (content redundancy). After differentiating their sample by age, the results indicated that older participants in the narration only condition outperformed older participants in the animation and narration condition on transfer tasks. In contrast, the differences among younger participants were not significant.
Kalyuga et al. (2000) [exp. 1] compared different instructional formats using inexperienced learner. Results indicated that learning from a fusion diagram accompanied by narration (content redundancy) was superior to a diagram only. This finding illustrated an advantage of dual-mode presentation techniques. However, after additional training, results were reversed, indicating that the advantage of the diagram plus narration disappeared, and the effectiveness of the diagram only increased on a performance test. These results were confirmed by Kalyuga et al. (2000) [exp. 2], showing that the combination of diagram and narration was essential for novice learners but harmful for more experienced learners.
4.1.2. Moderating factors
Since only four studies investigate this scenario, moderating factors are limited. These studies indicate that learners’ prior knowledge moderates the effect of content redundancy (Leslie et al., 2012). All studies explained their results in light of the expertise reversal effect, which states that “information beneficial for novice learners became redundant for more knowledgeable learners” (Kalyuga, 2014, p. 577). The negative effect of content redundancy was found in participants with prior knowledge because the duplicated information became redundant and interfered with learning. Positive effects of visualization and narration were attributed to the expansion of limited working memory capacities by dual-mode presentations.
Overall, content redundancy hinders learning if participants have high prior knowledge. Therefore, it can be concluded that the positive effect of dual-mode presentations disappears due to content redundancy. In contrast, it might be possible that novice learners benefit from content redundancy or, in the case of Leslie et al. (2012), that content redundancy does not have negative effects.
4.1.3. Scenario 2: adding written text to visualizations
Scenario two addresses 11 studies (17.5%) that implemented content redundancy and working memory channel redundancy (see Table 4). In this case, content redundancy exists because visualization and written text duplicate information or one source provides unnecessary information (unrelated to the learning content). Working memory channel redundancy exists because the visual channel can become overloaded by the need to scan between visualizations and written text.
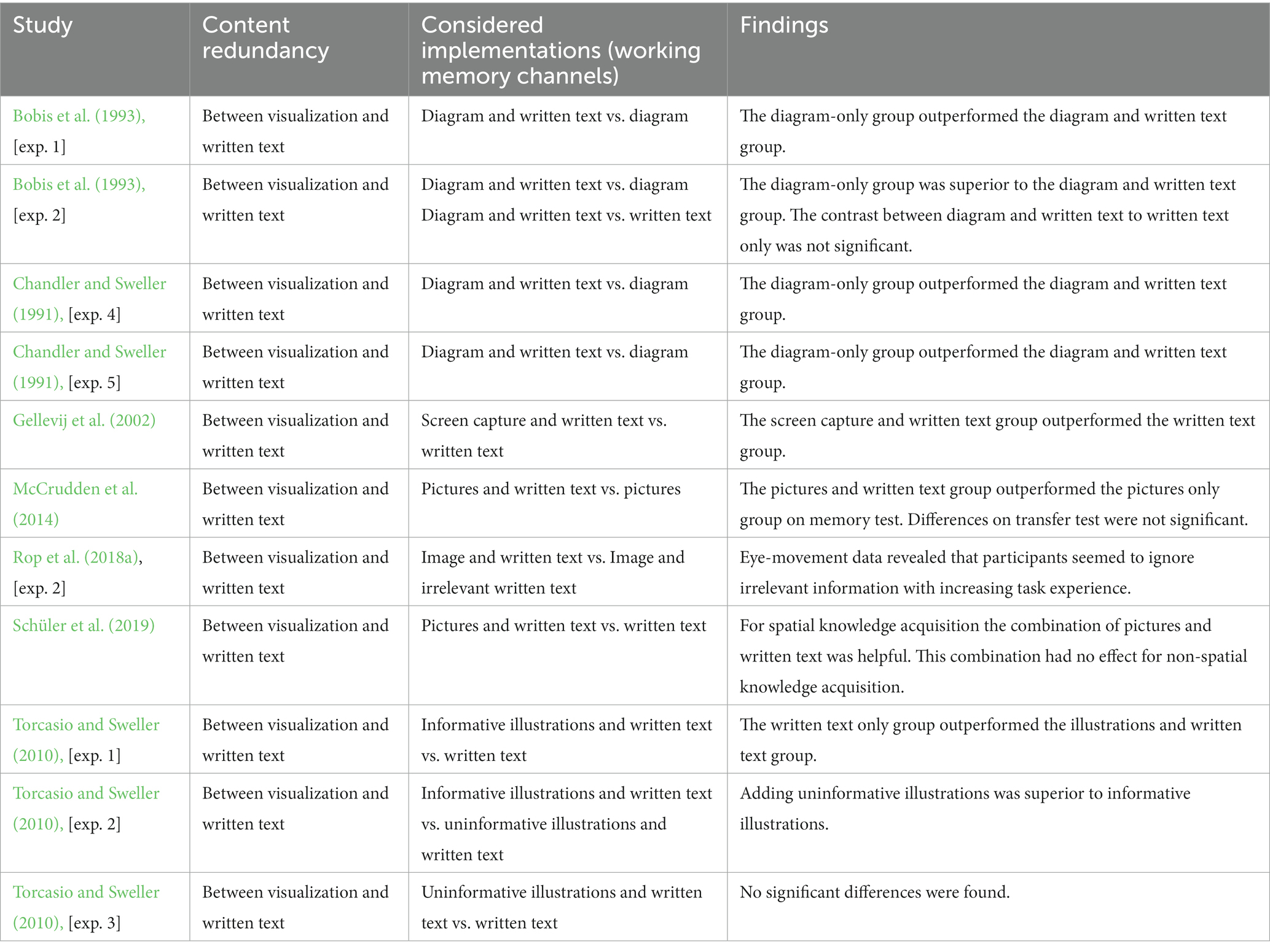
Table 4. Adding written text to visualizations.
Some of the studies found negative effects showing that participants in a visualization only condition outperformed participants in a visualization and written text condition (Bobis et al., 1993 [exp. 1 and 2]; Chandler and Sweller, 1991 [exp. 4 and 5]). Other studies reported negative effects showing that participants in a written text-only condition outperformed participants in a visualization and written text condition (Gellevij et al., 2002; Torcasio and Sweller, 2010; Schüler et al., 2019 [exp. 1]). These effects were attributed to the fact that redundant materials led participants to devote mental resources to processing unnecessary information.
Torcasio and Sweller (2010) investigated the reading abilities of children. In their second experiment, they confirmed that the content of information determines whether the redundancy effect occurs. The results indicated that informative images accompanied by written text interfere with learning, unlike uninformative images accompanied by written text. In experiment three, participants received either uninformative images accompanied by a written text or written text only. Results indicated no significant differences. Since the images in this study were unrelated to the written text, the authors assumed that participants may have been able to ignore them. Rop et al. (2018a) reported comparable findings for irrelevant written text, indicating that participants seemed to ignore irrelevant information.
Furthermore, Tocasio and Sweller mentioned the low complexity of the written text. They assumed that the extraneous load retrieved by the uninformative images was not high enough to overload working memory capacity. As illustrated in experiment two, they concluded that informative images relevant to the text are more likely to invoke a redundancy effect.
By contrast, Gellevij et al. (2002) compared visualizations and written text to written text-only. They showed that content redundancy combined with working memory channel redundancy can lead to positive effects. A positive effect was also found by McCrudden et al. (2014), who investigated the effect of a written text accompanied by images that either duplicated segments of the text or did not. The results indicated that including images that duplicate text segments increased achievement scores on a memory test.
4.1.4. Moderating factors
Torcasio and Sweller (2010) named the content and the complexity of information as moderating factors. They claimed that if a visualization is related to textual information, a negative redundancy effect is likely. Schüler et al. (2019) confirmed the importance of duplicated content and elucidated a further moderating factor: the knowledge that must be acquired. They compared materials with pictures corresponding with a written text to those with only pictures or only written text. The written text contained spatial or visual information that was also provided in the pictures. For the post-tests, learners needed to acquire spatial and non-spatial information. Results indicated that the learning of spatial information increased if pictures and written text contained the same spatial information, but that increase was not significant compared to learners receiving only pictures. Regarding visual information, learning increased if pictures and written text contained the same visual information, but the increase compared to learners receiving pictures only was also not significant. In contrast, a combination of pictures and spatial text hindered the acquisition of visual knowledge. McCrudden et al. (2014) identified the signaling principle (see text-based cueing; Van Gog, 2014) as a further moderating factor. They explained that the inclusion of duplicated text segments guided learners’ attention to the relevant aspects of the learning material (see Jeung et al., 1997). Therefore, content redundancy combined with working memory channel redundancy may benefit learning if the written text guides learners’ attention. This finding also aligns with the spatial contiguity principle (Mayer and Fiorella, 2014), which claims that integrating written text into a visualization promotes learning.
A further moderating factor was found in a study by Bobis et al. (1993). They demonstrated the importance of the non-redundant condition. Their study illustrated a negative redundancy effect, comparing a lesson with visualization and written text to one with visualization-only. In contrast, they found that the difference between a combination of visualization and written text and written text-only was not significant.
Overall, most studies revealed that the combination of content redundancy and working memory channel redundancy regarding visualization and written text has negative effects. However, these negative effects are influenced by non-redundant control conditions, the type of duplicated content, the complexity of information, and the knowledge that needs to be acquired. Furthermore, the positive impacts of signals and spatial contiguity can overcome the negative effects. Adding unnecessary information seems not to hamper learning if it does not overload working memory capacity.
4.1.5. Scenario 3: adding written text to narration
Scenario three encompasses seven studies (11.1%) that implemented content redundancy and working memory channel redundancy (see Table 5). In this case, content redundancy is given because the narration and written text contain duplicated information. Working memory channel redundancy is given because the narration competes with the written text in working memory. From a CTML perspective, these studies investigated verbal redundancy (Mayer, 2009).
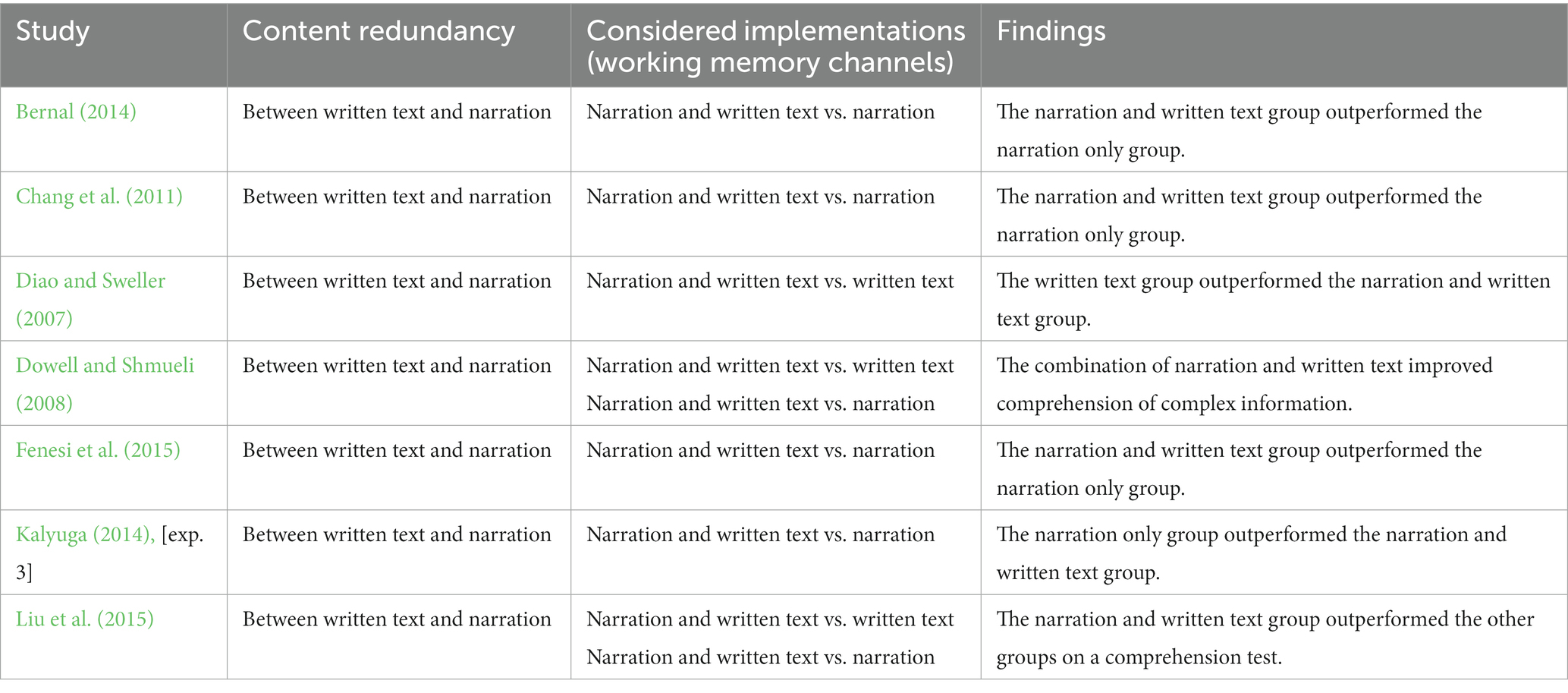
Table 5. Adding written text to narrations.
Kalyuga et al. (2004) [exp. 3] found that the combination of narration and written text had negative effects compared to narration-only. Similarly, Diao and Sweller (2007) illustrated the negative effects of the combination of narration and written text compared to written text only. By contrast, subsequent studies found positive effects (Dowell and Shmueli, 2008; Chang et al., 2011; Bernal, 2014; Fenesi et al., 2015; Liu et al., 2015). For example, Bernal (2014) investigated the learning of English as a foreign language. Learners received narration and written text with the written text containing either a full text or keywords. The control groups received either narration or the full-text version of the written text. The results revealed that learners who received narration with written keywords outperformed learners receiving only narration or only written text on a text-sound association task. The difference between the group that received narration accompanied by a full text and those who received only a written text was not significant. Since the findings of these studies are not homogeneous, we seek possible moderating factors.
4.1.6. Moderating factors
Besides the influence of prior knowledge on the redundancy effect a further moderating factor is the degree of content overlap between narration and written text. Kalyuga et al. (2004) [exp. 3] found that a high degree of content overlap between narration and written text impeded learning. This result aligns with the findings of the meta-analysis on the verbal redundancy effect, which shows that narrations accompanied by identical written text impaired learning (e.g., Adesope and Nesbit, 2012).
Fenesi et al. (2015) found another moderating factor in working memory capacity as it relates to age. They compared narration accompanied by an identical written text to narration-only. After splitting their sample by age (younger participants, Mage = 18.75; older participants, Mage = 72.36), they found a positive effect. The results indicated that older participants profit from the combination of content redundancy and working memory channel redundancy regarding written text and narration. In contrast, younger participants showed no significant differences between the redundant and the narration only conditions. The authors assumed that older participants have age-related reductions in working memory for which the redundant presentation may have compensated.
As Kalyuga (2012) elaborated, the degree to which learners can control the pace of the learning material might influence the effect of redundancy. Bernal (2014) varied learning material by presenting it as either learner-paced or system-paced. She found no significant difference between the redundant and non-redundant conditions but found a significant advantage for the learner-paced conditions. This finding aligns with Kalyuga et al. (2004) [exp. 3], who found that narration and identical written text had a negative effect when presented simultaneously in a system-paced format. The moderating effect of pacing will be further discussed in section 4.1.8.
Liu et al. (2015) illustrated that written text can compensate for the transient structure of narration. They revealed differences dependent on whether the narration and identical written text are compared to narration-only or to written text-only. Results indicated that narration and identical written text increased learning compared to narration-only, but when compared to written text-only, the positive effect only applied for a recall test. Chang et al. (2011) and Dowell and Shmueli (2008) confirmed that the combination of narration with identical written text was superior to narration-only. They stated that the negative effect of the transient structure of narrations may be compensated by additional written text.
Another moderating factor is the complexity of the provided information. Dowell and Shmueli’s (2008) initial analyses revealed no significant differences until they considered the complexity of the information. When provided with highly complex information, participants in the written text and narration condition outperformed the narration-only condition.
Overall, the combination of content redundancy and working memory channel redundancy regarding written text and narration seems beneficial for learning. This positive effect is mainly moderated by prior knowledge (favoring low prior knowledge). These results confirm research insights regarding verbal redundancy that find that the benefit increases when the content overlap of narration and written text is low (favoring short written texts). The combination is also helpful when learning complex information, as the written text can compensate for the transient structure of narration. These results indicate that people with a lower working memory capacity particularly benefit from this combination. Finally, the results also show that it is beneficial to give learners control of the pace of the learning material.
4.1.7. Scenario 4: adding written text to narrated visualizations
Scenario four contains 44 (69.8%) studies that implemented content redundancy and working memory channel redundancy in higher complexity. Content redundancy can occur among all three sources (e.g., all sources provide identical information), between visualization and textual information, or between narration and written text only. Working memory channel redundancy can occur because working memory can become overloaded by visually scanning between visualizations and written text and comparing the incoming streams of written text and narration.
In contrast to the previous sections, studies in this scenario still offer a high level of heterogeneity. Only three of the remaining 44 studies (6.8%) report content redundancy among all sources (see Table 6): visualization, narration, and written text (Leahy et al., 2003 [exp. 2],Farías et al., 2014; Rop et al., 2018b [exp. 2]). Therefore, an extensive analysis of the effects of redundancy is limited to these studies.

Table 6. Duplicated information between written text and narrated visualizations.
Farías et al. (2014) investigated the learning of lexical items. They compared two groups each receiving narrated verbs accompanied by identical written text, with one of those groups also receiving additional images (illustrating the action of the verb). The results indicated that, regarding retention and transfer tasks, the group receiving additional images outperformed the group with only narration and written text. Like Kalyuga et al. (2003), the authors suspected that the processing of the redundant resource occurred within available working memory capacity because learning verbs induces low element interactivity. Leahy et al. (2003) investigated learning with a complex temperature line graph. They compared two groups, each receiving self-explanatory diagram accompanied by written text, with one of those groups also receiving an additional narration (identical to the written text). Results indicated that learners with the diagram and written text outperformed those with the diagram, narration, and written text. Rop et al. (2018b) investigated the effect of irrelevant images when participants learn words from an artificial language. Groups either received matching or mismatching images accompanied by narration and written text. Results indicated that the initial negative effect of mismatching images disappeared if participants gained experience with the task.
Analyses of the remaining 41 studies revealed a subset of eight studies investigating the variation of the degree of content overlap between narration and written text (see Table 7). However, these studies did not consider content redundancy between the visualization and textual information.
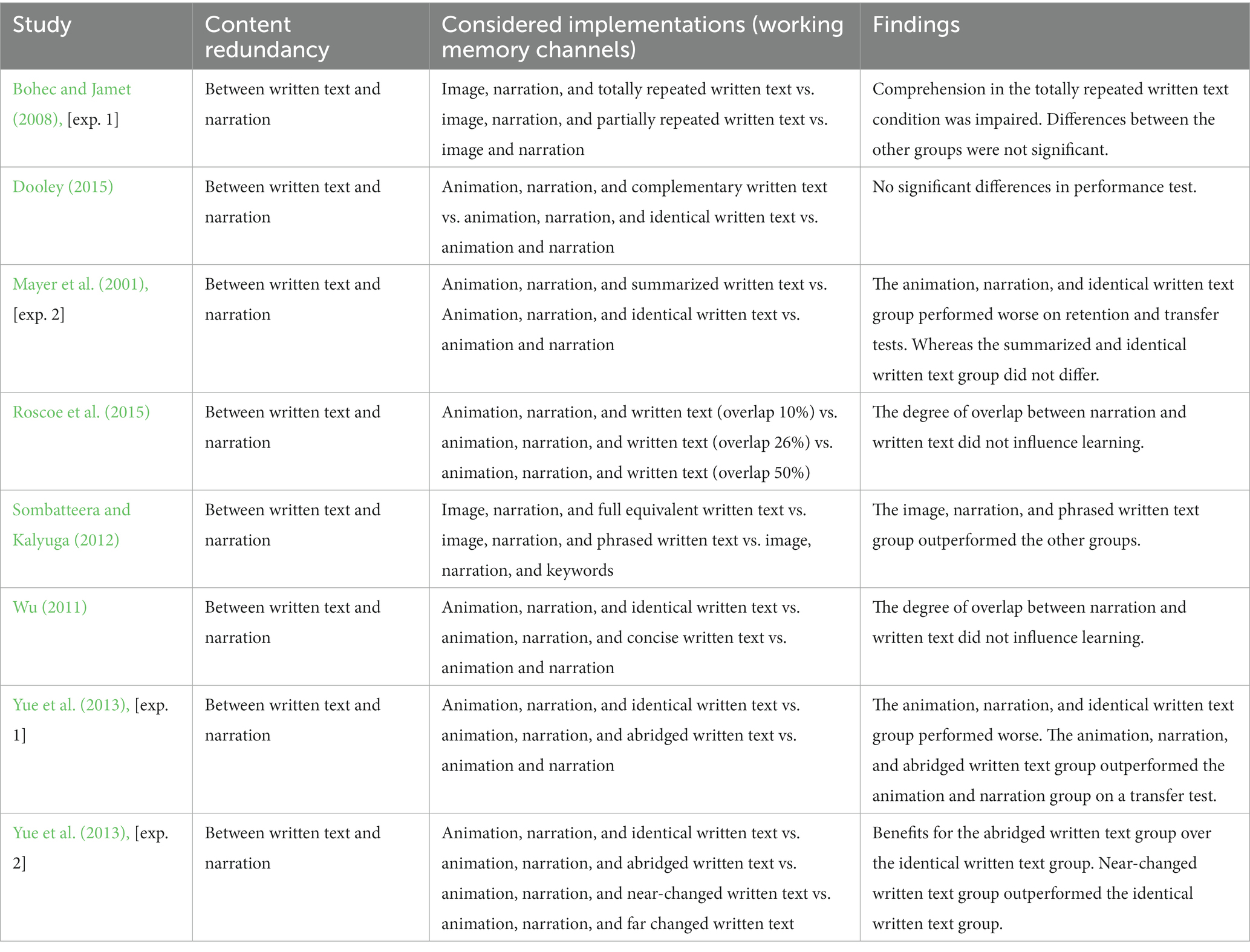
Table 7. Varying the degree of overlap between written text and narration.
Results of Bohec and Jamet (2008), Mayer et al. (2001), Sombatteera and Kalyuga (2012), and Yue et al. (2013) [exp. 1 and 2], indicated negative effects of adding identical written text to narrated visualizations. Furthermore, Sombatteera and Kalyuga (2012), and Yue et al. (2013) [exp. 1 and 2], found positive effects of short compared to identical written text. In contrast, Dooley (2015), Roscoe et al. (2015), and Wu (2011) found that of the degree of overlap between written text and narration accompanied by visualizations had no effect.
The results of the remaining 33 studies that only report redundancy between narration and written text show high heterogeneity (see Table 8). Some studies indicated positive effects (e.g., Mayer and Johnson, 2008; Ari et al., 2014; Adegoke, 2017 [exp. 1 and 2]; Munassar et al., 2010; Toh et al., 2010; Samur, 2012), while others indicated negative effects (e.g., Kalyuga et al., 1999 [exp. 1]; Kalyuga et al., 2000 [exp. 1]; Mayer et al., 2001 [exp. 1 and 2]; Austin, 2009 [exp. 1]; Aldalalah and Fong, 2010; Rias and Zaman, 2010; Khan and Masood, 2012), and still others showed no significant differences (e.g., Moreno and Mayer, 2002 [exp. 2]; Craig et al., 2004 [exp. 1]; Debuse et al., 2009; Jadin et al., 2009).
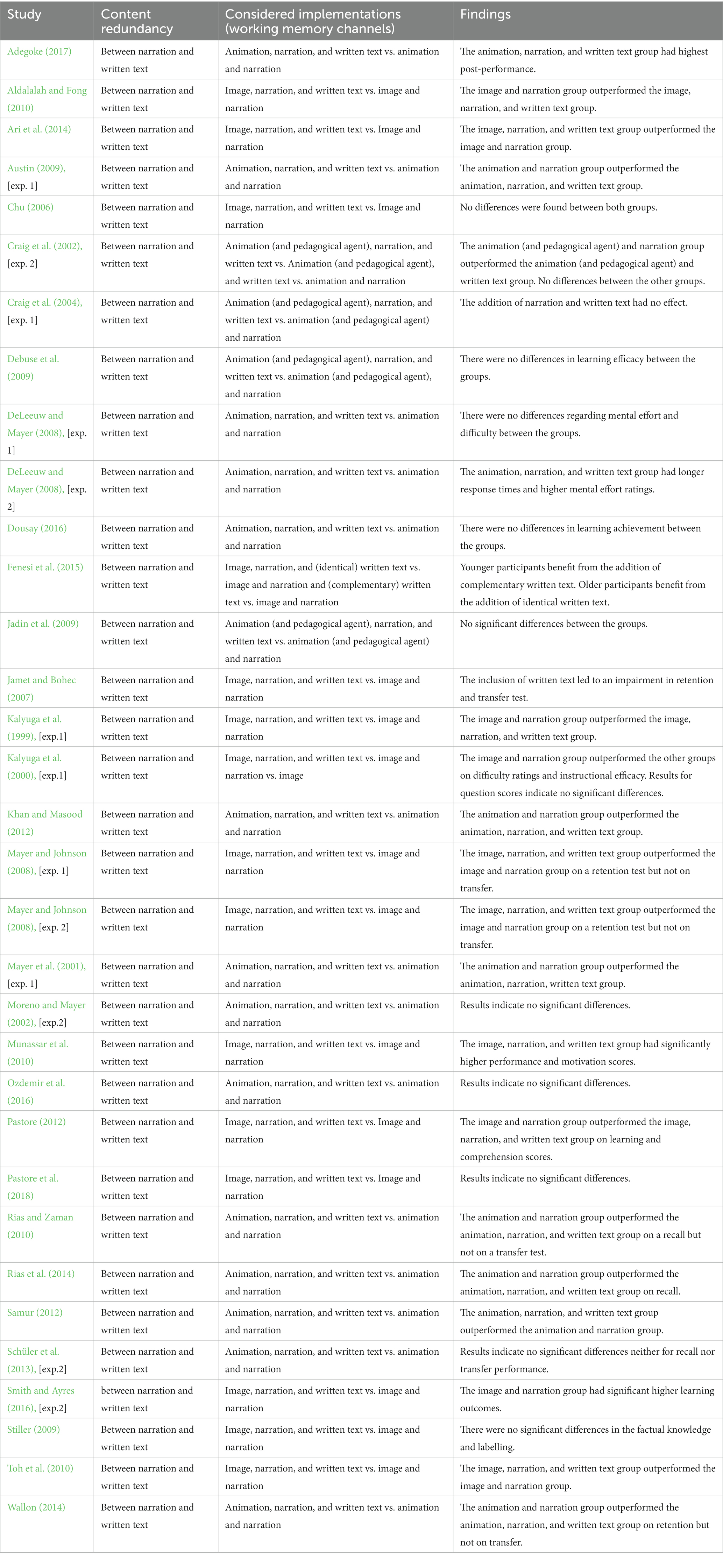
Table 8. Adding written text to narrated visualizations.
4.1.8. Moderating factors
Studies that implemented content redundancy among visualization, narration, and written text identified element interactivity as a moderating factor (Leahy et al., 2003; Farías et al., 2014). The duplication of information seems beneficial when element interactivity is low. In such cases, working memory capacity is not overloaded despite the redundancy. In contrast, when element interactivity is high, the duplication of information across all sources seems detrimental to learning.
For studies that report only on content redundancy between narration and written text, we cannot assess the extent to which, for example, the visualization also contained duplicated information because most studies did not publish their learning materials in detail. However, we assume there is at least a small overlap. For example, Austin (2009) [exp. 1] mentioned content redundancy only between written text and narration. However, an illustration of the learning material reveals that there also seems to be content redundancy between the visualization and textual information. The negative effect of using visualization, narration, and written text compared to visualization and narration may be caused by the working memory overload of needing to scan between visualization and written text and compare the incoming streams of written text and narration. Combined with content redundancy, it might be possible that the positive effect of combining narration and written text disappears when a visualization is added. From this perspective, the different types of redundancy and their moderating factors interact with each other.
Further examples were found in the studies by Mayer et al. (2001) [exp. 1 and 2], who compared animation with narration accompanied by either summarized or duplicated written text in lightning formation learning materials. The results indicated negative effects on retention and transfer tests, whether the written text was short or long. This contradicts the findings in Section 4.1.6, which showed a positive effect of content redundancy combined with working memory channel redundancy (regarding narration and written text), especially when the written text was short. We assume that a possible redundancy between the animation and written text may have overshadowed the possible positive effects of written text and narration. The findings of Moreno and Mayer (2002) [exp. 2] support this assumption. They compared animation, narration, and written text to animation and narration. Initial analyses revealed no significant differences among the conditions. However, they illustrated that content redundancy combined with working memory channel redundancy (regarding narration and written text) helped learners when the presentation was sequential and the animation was not presented simultaneously with the textual information.
Kalyuga et al. (1999) [exp. 1] and Kalyuga et al. (2000) [exp. 1] deliberately excluded content redundancy between visualizations and textual information. Results indicated that, regarding learning and cognitive load, participants learning from visualization and narration outperformed participants learning from visualization, narration, and written text. Since the textual information and visualization were both essential for understanding, the authors assumed that the negative effect was caused by split attention.
Debuse et al. (2009) and Jadin et al. (2009) included pedagogical agents as visualizations. These studies showed insignificant differences between learning materials with visualization, narration, and written text and those with visualization and narration. We suggest the following explanations for these findings. One possibility is that the positive effect of the combination of narration and written text dissipates with the addition of the pedagogical agent. Another possible explanation is that the learning materials need to be complex to cause an overload of working memory capacity. A third explanation derives from the type of visualization. If the visualization contains information unnecessary for learning (e.g., pictures of a person), it may be that learners can ignore this information. Rop et al. (2018a) [exp. 2] confirmed learners’ ability to ignore unnecessary information in learning materials. They indicated that the negative effect of narration and written text accompanied by mismatching pictures disappeared when participants were familiar with the tasks. On the other hand, inexperienced participants could not ignore unnecessary information, and their learning decreased. Therefore, the ability to ignore unnecessary information is moderated by learners’ prior knowledge.
Overall, Scenario 4 illustrates the high complexity of redundant multimedia learning environments indicating all studies combined visualization, narration, and written text; however, the implementations and results differed. Studies differed in the correspondence between visualizations and textual information, control conditions, length of text, and type of visualization (e.g., animation, images, pedagogical agents). Due to a lack of information on the learning materials, we could not provide a differentiated assignment of the various types of redundancy. Therefore, we recommend that future studies provide more detailed information on their learning materials and report how content redundancy was realized among all sources. Strictly speaking, each type of redundancy is an independent variable, and several are (unconsciously) varied in the existing studies. For example, without assessing the extent of content redundancy, we cannot analyze whether the effects of redundancy are due to unconsidered types of redundancy or other moderating effects. Nevertheless, we assume that the moderating factors presented in Sections 4.1.2, 4.1.4, and 4.1.6 also affect the studies in this scenario.
5. Summary, discussion, and recommendations
This review extends current insights into the redundancy effect by presenting an alternative classification that describes and characterizes different implementations of redundancy in multimedia learning environments. Overall, this review illustrates the need for a refinement of the term redundancy, as other authors have previously demanded (e.g., Baldwin, 1968; Bohec and Jamet, 2008; Dooley, 2015; Schroeder and Cenkci, 2018). This review began by distinguishing between the different theoretical assumptions of CLT and CTML regarding the redundancy effect in multimedia learning. CLT describes redundancy in a “broader “sense and relates to the logical relations of the learning content; redundancy harms learning if identical information is provided in multiple forms, if different pieces of information do not relate to each other, or if the information is unrelated to the learning content. For CTML, the redundancy effect occurs when information is presented via visualization, narration, and written text (Moreno and Mayer, 2002). In such cases, redundancy harms learning because “(a) the visual channel can become overloaded by having to visually scan between pictures and on-screen text, and (b) because learners expend mental effort in trying to compare the incoming streams of printed and spoken text” (Mayer, 2009, p. 118). Concerning these theoretical assumptions, we classify two types of redundancy: (1) content redundancy and (2) working memory channel redundancy. To investigate the implementation of these redundancy types, we reviewed empirical research on the redundancy effect of 63 studies.
In the following, the results are summarized and discussed in light of our research questions.
5.1. Research question 1: how do studies implement the two types of redundancy?
Studies implemented content redundancy by providing duplicated or unnecessary information among different sources (e.g., animation and narration). According to working memory channel redundancy, studies illustrated two ways of implementations: working memory channel redundancy regarding visualizations and written text and working memory channel redundancy regarding narration and written text. Overall, the implementation of both redundancy types was realized via four different scenarios: (1) adding narration to visualizations, (2) adding written text to visualizations, (3) adding written text to narration, and (4) adding written text to narrated visualizations.
5.2. Research question 2: do both types of redundancy hamper learning?
The implementation of content redundancy (identical information in the visualization and narration) indicates that content redundancy on its own hinders learning when participants have high prior knowledge. Novice learners, by contrast, may benefit from content redundancy, or at least that it appears content redundancy does not have negative effects. We recommend that instructions contain content redundancy when intended for novice learners, and the material is highly complex. If learners are struggling to understand complex novel information, providing content redundancy can help them to integrate the new information and reduces the cognitive effort for schema construction (e.g., an animation showing the different parts of a plant and their functions should be narrated if learners have low prior knowledge or have visual impairments). For low-complexity material, presenting the information once clearly and concisely may be sufficient for novice learners. Moreover, we recommend removing content redundancy (e.g., exclude narration from an animation) in low-complexity learning materials for learners with prior knowledge.
The analyses of the four scenarios reveal that studies implemented different types of redundancy simultaneously. Most studies that implement content redundancy combined with working memory channel redundancy (regarding visualizations and written text) reveal negative effects. However, these negative effects are influenced by the type of non-redundant condition, the type of duplicated content, and the knowledge that needs to be acquired. Furthermore, the positive aspects of signals can overcome the negative effects of this combination. For example, if learners receive an animation showing the process of photosynthesis accompanied by written text, we recommend the following: for learners with prior knowledge, include keywords if the animation is highly complex. In contrast, for low complexity, we recommend excluding the keywords. When learners have no prior knowledge, we recommend including short content-redundant written text that summarizes each step of the process if the animation is highly complex. When the animation has low complexity, the integration of keywords may be sufficient for novices. We further suggest integrating the written text into the visualization. However, Bobis et al. (1993) demonstrated that an integrated format is only beneficial if both sources are essential for learning. If the learning material has a low complexity but nevertheless contains a high degree of contentual overlap (not essential) the positive effect disappears.
Content redundancy combined with working memory channel redundancy (regarding narration and written text) seems beneficial for learning. Results align with findings on the verbal redundancy effect (Mayer, 2009). They are mainly moderated by text length (favoring short written texts), the complexity of information (favoring higher complexity), and the compensating function of written text (favoring the opportunity to re-read information missed in the narration). If complex knowledge needs to be acquired (particularly if learners struggle with reading or have visual impairments), we recommend removing redundancy regarding narration and written text when a text is lengthy or adding keywords instead of long written text to the narration. We also recommend giving learners control over the pace of the learning material. Furthermore, results indicate that learners with a lower working memory capacity particularly benefit from this combination.
Most studies implemented a combination of visualization, narration, and written text. Results indicate inconsistent results and interactions between the redundancy types. For content redundancy across all sources, results indicate that the combination of visualization, narration, and written text was helpful when dealing with complex learning material. When studies considered only content redundancy regarding narration and written text and excluded content redundancy regarding visualization and textual information, the results illustrate that learning is impaired when a visualization contains essential (not duplicated) information. In this case, we recommend excluding written text to avoid split attention. When the visualization contains unnecessary information (not related to the learning content), we recommend excluding the visualization, especially for learners with low levels of prior knowledge because they are unable to ignore irrelevant information in learning materials. In addition, the negative effect of redundancy regarding visualization and written text overshadows the positive effects of content redundancy regarding narration and written text. We recommend including visualizations, narrations, and written texts only when they are essential for understanding and when the visualization is highly complex. We further recommend implementing a short written text when the learning material is highly complex, and learners have low levels of prior knowledge. We also suggest integrating the short written text into the visualization. Otherwise, we recommend removing either the visualization or the written text. Overall, we recommend that future studies provide more detailed information on how content redundancy was implemented across different sources.
5.3. Research question 3: how do the types of redundancy interact with other effects in multimedia learning?
In line with Kalyuga (2012), our results indicate that the expertise reversal effect (Kalyuga, 2014) moderates the negative effect of content redundancy. It seems that novice learners benefit from redundant information. In contrast, content redundancy impedes learning for learners with high levels of prior knowledge (e.g., Leslie et al., 2012). Furthermore, the positive effects of content redundancy seem more likely when presenting information in different sensory modalities (e.g., animation and narration) what is moderated by the modality effect (Mayer, 2009). The negative effects of content redundancy combined with working memory channel redundancy (regarding visualization and written text) are moderated by either the split-attention effect (Ayres and Sweller, 2014) or the seductive details effect (Harp and Mayer, 1998). The positive effects seem to be moderated by the multimedia effect (Mayer, 2014), signaling effect (Van Gog, 2014), and spatial contiguity effect (Mayer and Fiorella, 2014). The signaling effect (Van Gog, 2014) also moderates the positive effects of content redundancy combined with working memory channel redundancy (regarding narration and written text). The verbal redundancy effect (Mayer, 2009), transient information effect (Jiang and Sweller, 2021), and expertise reversal effect (Kalyuga, 2014) moderate the negative effects of this combination.
6. Directions for further research
Although this review addressed some gaps in redundancy research, new questions arise. One question concerns the interactions between the different types of redundancy. Since many studies have not considered content redundancy in visual and textual information, the question remains whether working memory channel redundancy combined with content redundancy strengthens or weakens the negative effects. Another question arises regarding the quantity of content overlap. As Roscoe et al. (2015) show, the degree of content overlap between narration and written text varies significantly. Determining the overlap between visualization and textual information is much more difficult. For example, a written text may provide additional information not visible in the visualization, in which case there would be no content redundancy. However, often a text contains both identical and additional information. Future studies should pay attention to this issue and report which information is presented in the text and the visualization. One possibility for such an investigation would be to analyze which information tested in the post-test was duplicated. A first study by Albers et al. (2023) addressed this issue, illustrating that content redundancy (providing identical content) increases learning and decreases cognitive load, whereas content redundancy combined with working memory channel redundancy impedes learning and increases cognitive load. However, further research is required. Another question that arises is whether there is an influence on which information is presented in which format. For example, Hegarty (2014) has already shown that dynamic information can be better processed when presented via visualization. On the other hand, verbal information serves better when linear structures (e.g., sequences of events) must to be learned. These findings are also relevant for redundancy research. Imagine having the same information in both visualization and written text. In this case, the complexity of the information is moderated by the presentation format: if a visualization has low complexity while a written text is highly complex, we will likely see different redundancy effects depending on the control condition. If the visualization is the control condition, we will probably see a negative effect of redundancy because the visualization was already essential for understanding, and the addition of complex written text hampers learning. By contrast, if the written text is the control condition, we will likely see a positive effect because the learner will benefit from the addition of the visualization. This example shows that aspects of element interactivity must be considered. Element interactivity describes “the degree of interconnectedness between essential elements of information that should be considered in working memory at the same time” (Kalyuga, 2011, p. 2). If elements can be processed in isolation—if they do not interact—element interactivity is low. On the other hand, if elements cannot be processed in isolation—if they interact with each other—element interactivity is high (Sweller, 2010). Our review has shown that complexity (element interactivity) has a moderating effect on all types of redundancy. Future studies should examine the redundancy types separately, starting with low element interactivity, and observe how the effects change when element interactivity increases. As indicated by Sweller (2010), element interactivity reflects intrinsic cognitive load for novice learners. In contrast, for expert learners, the interacting elements are unnecessary and induce extraneous cognitive load. As suggested by Kalyuga (2014), learning material should be adapted to different levels of expertise. Therefore, future studies could provide a self-paced setting that includes the option of fading out different sources of information.
7. Limitations
One limitation of this review is that it includes only studies that explicitly investigated the redundancy effect and mentioned a theoretical approach to redundancy. Further analyses should investigate study designs to identify what types of redundancy are investigated instead of focusing only on the theoretical background. For example, Fenesi et al. (2016) investigated the split-attention effect and the coherence effect. They compared a complementary presentation (narration with relevant visualizations) with a split-attention presentation (narration with relevant visualizations and identical on-screen text). Based on our classification, this is an investigation of the redundancy effect. Other examples include Harskamp et al. (2007), Herrlinger et al. (2017), and Stebner et al. (2017), and even studies that investigate the seductive details effect (e.g., Lehmann and Seufert, 2017).
A further limitation is that this review provides only a first impression of the methodological similarities and differences in this area, while other important aspects—for instance, individual differences among learners (e.g., intelligence, spatial ability), different post-tests formats (e.g., retention, transfer, cognitive load, motivation), virtual reality learning environments (Baceviciute et al., 2022)—were not considered.
Another limitation is that the included studies vary greatly in how much detail they provided about the design of their learning materials. For instance, we noticed that many studies did not give specifics about the implementation of content redundancy between visualization and textual information; we were able to distinguish only whether content redundancy was implemented.
8. Conclusion
This review provides new contributions that have emerged in response to the research questions: It combines different theoretical assumptions of CLT and CTML and their implementation in the studies. In addition, it indicates that the empirical investigation of redundancy is sufficiently different among the studies (e.g., various combinations of modalities, different methods for presenting information, and different degrees of contentual overlap). On the one hand, this review enables scientists to classify their research on the redundancy effect and provides conceptual guidance on how to consider redundancy when designing a study. On the other hand, it illustrates educators’ options to consider redundancy during the development of learning material (not only digital but conventional lectures). Theoretically, it offers a way to define redundancy more precisely using a differentiation between two redundancy types: content redundancy and working memory channel redundancy. Empirically this review illustrates that redundancy (especially content redundancy) can support learning when used appropriately in the learning process. However, the benefits must depend on how it is applied. Too much redundancy (e.g., narration and identical written text) or redundancy presented in an unhelpful way increases extraneous cognitive load and impedes learning. Moreover, this review provides guidance to decide which types of redundancy to use or avoid, e.g., based on the complexity of the learning material, the learners’ prior knowledge or interacting multimedia effects. Moreover, it addresses practical problems in this research area (e.g., no specifics about implementing content redundancy between visualization and textual information and a lack of information on the learning materials). Finally, the review demonstrated perspectives for future studies (e.g., comparing various types of redundancy experimentally).
Author contributions
MT and JW contributed to conception and design of the review. MT took the lead in writing the first draft of the manuscript. FS and JW provided critical feedback and helped to shape the manuscript. MT, FS, and JW contributed to the interpretation of the results, provide approval for publication of the content, and agree to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved. All authors contributed to the article and approved the submitted version.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2023.1148035/full#supplementary-material
Footnotes
1. ^Complementary redundancy: narration paired with images and written text.
2. ^Partial redundancy: presentations with a low correspondence between written text and narration.
3. ^Concise redundancy: shortened form of written text combined with a visualization.
4. ^Note that CLT and CTML define the split-attention effect differently. CTML suggests avoiding split attention by integrating words spatially and temporally in a visualization (see spatial and temporal contiguity principle in Mayer and Fiorella, 2014). CTML further suggests distributing information across different modalities to relieve cognitive processing systems (e.g., using spoken rather than written text when adding words to a picture or animation). This effect is called the "modality effect" (Mayer, 2014). In contrast, CLT considers the logical relations among information from multiple sources. From this perspective, the modality effect only occurs under conditions where the split-attention effect occurs (Low et al., 2013)—for instance, if two pieces of information from multiple sources are unintelligible in isolation but essential for learning.
References
*Adegoke, B. A. (2010). Integrating animations, narratives and textual information for improving physics learning. Electron. J. Res. Educ. Psychol. 8, 725–748. doi: 10.25115/ejrep.v8i21.1391
Adesope, O. O., and Nesbit, J. C. (2012). Verbal redundancy in multimedia learning environments. A meta-analysis. J. Educ. Psychol. 104, 250–263. doi: 10.1037/a0026147
Albers, F., T rypke, M., Stebner, F., Wirth, J., and Plass, J. L. (2023). Different types of redundancy and their effect on learning and cognitive load. Br. J. Educ. Psychol. 00, e12592–e12514. doi: 10.1111/bjep.12592
*Aldalalah, O. M., and Fong, S. F. (2010). Effects of modality and redundancy principles on the learning and attitude of a computer-based music theory lesson among Jordanian primary pupils. Int. Educ. Stud. 3, 52–64. doi: 10.5539/ies.v3n3p52
*Ari, F., Raymond, F., Fethi, A. I., Cheon, J., Crooks, S. M., Paniukov, D., et al. (2014). The effects of verbally redundant information on student learning. An instance of reverse redundancy. Comput. Educ. 76, 199–204. doi: 10.1016/j.compedu.2014.04.002
*Austin, K. A. (2009). Multimedia learning. Cognitive individual differences and display design techniques predict transfer learning with multimedia learning modules. Comput. Educ. 53, 1339–1354. doi: 10.1016/j.compedu.2009.06.017
Ayres, P., and Sweller, J. (2014). “The Split-attention principle in multimedia learning” in The Cambridge Handbook of Multimedia Learning (Cambridge Handbooks in Psychology). ed. R. Mayer (Cambridge: Cambridge University Press), 206–226.
Baceviciute, S., Lucas, G., Terkildsen, T., and Makransky, G. (2022). Investigating the redundancy principle in immersive virtual reality environments: an eye-tracking and EEG study. J. Comput. Assist. Learn. 38, 120–136. doi: 10.1111/jcal.12595
Baldwin, T. F. (1968). Redundancy in simultaneously presented audio-visual message elements as a determinant of recall. Final report. ED 031 933 (ERIC January 1970). Available at: https://files.eric.ed.gov/fulltext/ED038027.pdf
*Bernal, A. M. E. (2014). Effects of text, audio and learner control on text-sound association and cognitive load of EFL learners. unpublished doctoral dissertation, Arizona State University.
*Bobis, J., Sweller, J., and Cooper, M. (1993). Cognitive load effects in a primary school geometry task. Learn. Instr. 3, 1–21. doi: 10.1016/S0959-4752(09)80002-9
*Bohec, O. L., and Jamet, E. (2008). “Levels of verbal redundancy, note-taking and multimedia learning” in Understanding Multimedia Documents. eds. J. F. Rouet, R. Lowe, and W. Schnotz (Berlin: Springer).
*Chandler, P., and Sweller, J. (1991). Cognitive load theory and the format of instruction. Cogn. Instr. 8, 293–332. doi: 10.1207/s1532690xci0804_2
*Chang, C. C., Lei, H., and Tseng, J. S. (2011). Media presentation mode, English listening comprehension and cognitive load in ubiquitous learning environments: modality effect or redundancy effect? Australas. J. Educ. Technol. 27, 633–654. doi: 10.14742/ajet.942
*Chu, S. L. (2006). Investigating the effectiveness of redundant text and animation in multimedia learning environments. doctoral dissertation, University of Central Florida.
Craig, S. D., Driscoll, D. M., and Gholson, B. (2004). Constructing knowledge from dialog in an intelligent tutoring system: interactive learning, vicarious learning, and pedagogical agents, Norfolk, VA: Association for the Advancement of Computing in Education (AACE). J. Educ. Multimed. Hypermedia 13, 163–183. Available at: https://www.learntechlib.org/primary/p/24271/ (Accessed April 21, 2023).
*Craig, S. D., Gholson, B., and Driscoll, D. M. (2002). Animated pedagogical agents in multimedia educational environments. Effects of agent properties, picture features and redundancy. J. Educ. Psychol. 94, 428–434. doi: 10.1037/0022-0663.94.2.428
*Debuse, J. C. W., Hede, A., and Lawley, M. (2009). Learning efficacy of simultaneous audio and on-screen text in online lectures. Australas. J. Educ. Technol. 25, 748–762. doi: 10.14742/ajet.1119
*DeLeeuw, K. E., and Mayer, R. E. (2008). A comparison of three measures of cognitive load: evidence for separable measures of intrinsic, extraneous, and germane load. J. Educ. Psychol. 100, 223–234. doi: 10.1037/0022-0663.100.1.223
*Diao, Y., and Sweller, J. (2007). Redundancy in foreign language reading comprehension instruction: concurrent written and spoken presentations. Learn. Instr. 17, 78–88. doi: 10.1016/j.learninstruc.2006.11.007
*Dooley, A. M. (2015). A comparison of three levels of verbal redundancy in multimedia learning and its effects on memory retention and transfer in legal professionals. doctoral dissertation.
*Dousay, T. A. (2016). Effects of redundancy and modality on the situational interest of adult learners in multimedia learning. Educ. Technol. Res. Dev. 64, 1251–1271. doi: 10.1007/s11423-016-9456-3
*Dowell, J., and Shmueli, Y. (2008). Blending speech output and visual text in the multimodal interface. Hum. Factors 50, 782–788. doi: 10.1518/001872008X354165
*Farías, M., Obilinovic, K., Orrego, R., and Gregersen, T. (2014). Evaluating types and combinations of multimodal presentations in the retention and transfer of concrete vocabulary in EFL learning. Rev. Signos 47, 3–4. doi: 10.4067/S0718-09342014000100002
Fenesi, B., and Kim, J. A. (2014). Learners misperceive the benefits of redundant text in multimedia learning. Front. Psychol. 5, 1–7. doi: 10.3389/fpsyg.2014.00710
Fenesi, B., Kramer, E., and Kim, J. A. (2016). Split-attention and coherence principles in multimedia instruction can rescue performance for learners with lower working memory capacity. Appl. Cogn. Psychol. 30, 691–699. doi: 10.1002/acp.3244
*Fenesi, B., Vandermorris, S., Kim, J. A., Shore, D. I., and Heisz, J. J. (2015). One size does not fit all: older adults benefit from redundant text in multimedia instruction. Front. Psychol. 6, 1–9. doi: 10.3389/fpsyg.2015.01076
*Gellevij, M., Van Der Meij, H., De Jong, T., and Pieters, J. (2002). Multimodal versus unimodal instruction in a complex learning context. J. Exp. Educ. 70, 215–239. doi: 10.1080/00220970209599507
Harp, S. F., and Mayer, R. E. (1998). How seductive details do their damage: a theory of cognitive interest in science learning. J. Educ. Psychol. 90, 414–434. doi: 10.1037/0022-0663.90.3.414
Harskamp, E. G., Mayer, R. E., and Suhre, C. (2007). Does the modality principle for multimedia learning apply to science classrooms? Learn. Instr. 17, 465–477. doi: 10.1016/j.learninstruc.2007.09.010
Hegarty, M. (2014). “Multimedia learning and the development of mental models” in The Cambridge Handbook of Multimedia Learning. ed. R. E. Mayer (Cambridge: Cambridge University Press), 673–701.
Herrlinger, S., Höffler, T. N., Opfermann, M., and Leutner, D. (2017). When do pictures help learning from expository text? Multimedia and modality effects in primary schools. Res. Sci. Educ. 47, 685–704. doi: 10.1007/s11165-016-9525-y
Hsia, H. J. (1974). Audiovisual between-channel redundancy and its effects upon immediate recall and short-term memory [conference presentation]. Annu. Meeting Assoc. Educ. Journal, 1–24.
*Jadin, T., Gruber, A., and Batinic, B. (2009). Learning with e-lectures: the meaning of learning strategies. J. Educ. Technol. Soc. 12, 282–288. Available at: https://www.learntechlib.org/p/75419/
*Jamet, E., and Bohec, O. L. (2007). The effect of redundant text in multimedia instruction. Contemp. Educ. Psychol. 32, 588–598. doi: 10.1016/j.cedpsych.2006.07.001
Jeung, H.-J., Chandler, P., and Sweller, J. (1997). The role of visual indicators in dual sensory mode instruction. Educ. Psychol. 17, 329–343. doi: 10.1080/0144341970170307
Jiang, D., and Sweller, J. (2021). “The transient information principle in multimedia learning” in The Cambridge Handbook of Multimedia Learning Cambridge Handbooks in Psychology. eds. R. Mayer and L. Fiorella (Cambridge: Cambridge University Press), 268–274.
Kalyuga, S. (2011). Cognitive load theory: how many types of load does it really need? Educ. Psychol. Rev. 23, 1–19. doi: 10.1007/s10648-010-9150-7
Kalyuga, S. (2012). Instructional benefits of spoken words: a review of cognitive load factors. Educ. Res. Rev. 7, 145–159. doi: 10.1016/j.edurev.2011.12.002
Kalyuga, S. (2014). “The expertise reversal principle in multimedia learning” in The Cambridge Handbook of Multimedia Learning. ed. R. E. Mayer (Cambridge: Cambridge University Press), 576–597.
Kalyuga, S., Ayres, P., Chandler, P., and Sweller, J. (2003). The expertise reversal effect. Educ. Psychol. 38, 23–31. doi: 10.1207/S15326985EP3801_4
*Kalyuga, S., Chandler, P., and Sweller, J. (1999). Managing split-attention and redundancy in multimedia instruction. Appl. Cogn. Psychol. 13, 351–371. doi: 10.1002/(SICI)1099-0720(199908)13:4<351::AID-ACP589>3.0.CO;2-6
*Kalyuga, S., Chandler, P., and Sweller, J. (2000). Incorporating learner experience into the design of multimedia instruction. J. Educ. Psychol. 92, 126–136. doi: 10.1037/0022-0663.92.1.126
*Kalyuga, S., Chandler, P., and Sweller, J. (2004). When redundant on-screen text in multimedia technical instruction can interfere with learning. Hum. Factors 46, 567–581. doi: 10.1518/hfes.46.3.567.50405
Kalyuga, S., and Sweller, J. (2014). “The redundancy principle in multimedia learning”, in The Cambridge Handbook of Multimedia Learning, ed. R. E. Mayer (Cambridge: Cambridge University Press), 247–262. doi: 10.1017/CBO9781139547369.013
*Khan, F. M., and Masood, M. (2012). Effectiveness of visual animation-narration presentation on student's achievement in the learning of meiosis. Procedia. Soc. Behav. Sci. 46, 5666–5671. doi: 10.1016/j.sbspro.2012.06.493
*Leahy, W., Chandler, P., and Sweller, J. (2003). When auditory presentations should and should not be a component of multimedia instruction. Appl. Cognit. Psychol. 17, 401–418. doi: 10.1002/acp.877
Lee, H., Plass, J. L., and Homer, B. D. (2006). Optimizing cognitive load for learning from computer-based science simulations. J. Educ. Psychol. 98, 902–913. doi: 10.1037/0022-0663.98.4.902
Lehmann, J., and Seufert, T. (2017). The influence of background music on learning in the light of different theoretical perspectives and the role of working memory capacity. Front. Psychol. 8:1902. doi: 10.3389/fpsyg.2017.01902
*Leslie, K. C., Low, R., Jin, P., and Sweller, J. (2012). Redundancy and expertise reversal effects when using educational technology to learn primary school science. Educ. Technol. Res. Dev. 60, 1–13. doi: 10.1007/s11423-011-9199-0
*Liu, T. C., Lin, Y. C., Gao, Y., Yeh, S. C., and Kalyuga, S. (2015). Does the redundancy effect exist in electronic slideshow assisted lecturing? Comput. Educ. 88, 303–314. doi: 10.1016/j.compedu.2015.04.014
Low, R., Jin, P., and Sweller, J. (2013). “Some instructional consequences of logical relations between multiple sources of information” in Learning Through Visual Displays. eds. G. Schraw, M. T. McCrudden, and D. Robinson (Charlotte, North Carolina: IAP Information Age Publishing), 23–45.
Mayer, R. E. (Ed.). (2014). The Cambridge Handbook of Multimedia Learning. Cambridge: Cambridge University Press.
Mayer, R., and Fiorella, L. (2014). “Principles for reducing extraneous processing in multimedia learning: coherence, signaling, redundancy, spatial contiguity, and temporal contiguity principles” in The Cambridge Handbook of Multimedia Learning. ed. R. Mayer (Cambridge: Cambridge University Press), 279–315.
*Mayer, R. E., Heiser, J., and Lonn, S. (2001). Cognitive constraints on multimedia learning: when presenting more material results in less understanding. J. Educ. Psychol. 93, 187–198. doi: 10.1037/0022-0663.93.1.187
*Mayer, R. E., and Johnson, C. I. (2008). Revising the redundancy principle in multimedia learning. J. Educ. Psychol. 100, 380–386. doi: 10.1037/0022-0663.100.2.380
*McCrudden, M. T., Hushman, C. J., and Marley, S. C. (2014). Exploring the boundary conditions of the redundancy principle. J. Exp. Educ. 82, 537–554. doi: 10.1080/00220973.2013.813368
Miller, G. A. (1956). The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychol. Rev. 63, 81–97. doi: 10.1037/h0043158
*Moreno, R., and Mayer, R. E. (2002). Verbal redundancy in multimedia learning: when reading helps listening. J. Educ. Psychol. 94, 156–163. doi: 10.1037/0022-0663.94.1.156
*Munassar, W., Yahaya, W., and Chong, S. C. (2010). When is the redundancy principle effective in the multimedia learning of a foreign language? J. Institutional Res. South East Asia 8, 16–36.
*Ozdemir, M., Izmirli, S., and Sahin-Izmirli, O. (2016). The effects of captioning videos on academic achievement and motivation: reconsideration of redundancy principle in instructional videos. J. Educ. Technol. Soc. 19, 1–10.
*Pastore, R. S. (2012). The effects of time-compressed instruction and redundancy on learning and learners’ perceptions of cognitive load. Comput. Educ. 58, 641–651. doi: 10.1016/j.compedu.2011.09.018
Pastore, R., Briskin, J., and Asino, T. (2018). The effects of the multimedia, modality, and redundancy principles in a computer based environment on adult learners. In E. Langran and J. Borup (Eds.), Proceedings of Society for Information Technology and teacher education international conference (pp. 1663–1668). Association for the Advancement of Computing in Education (AACE).
*Rias, R. M., and Zaman, H. B. (2010). “Investigating the redundancy effect in multimedia learning on a computer science domain”, International Symposium in Information Technology (ITSim), 1, 1–4. doi: 10.1109/ITSIM.2010.5561341
*Rias, R. M., Zaman, H. B., and Manap, A. A. (2014). Applying redundancy and animation in a multimedia learning application on a computer science domain [conference paper]. Knowledge management international conference (KMICe) Langkawi, Malaysia. Available at: http://www.kmice.cms.net.my/ProcKMICe/KMICe2014/PDF/PID94.pdf
*Rop, G., Schüler, A., Verkoeijen, P. P. J. L., Scheiter, K., and van Gog, T. (2018a). Effects of task experience and layout on learning from text and pictures with or without unnecessary picture descriptions. J. Comput. Assist. Learn. 34, 458–470. doi: 10.1111/jcal.12287
*Rop, G., van Wermeskerken, M., de Nooijer, J. A., Verkoeijen, P. P. J. L., and van Gog, T. (2018b). Task experience as a boundary condition for the negative effects of irrelevant information on learning. Educ. Psychol. Rev. 30, 229–253. doi: 10.1007/s10648-016-9388-9
*Roscoe, R. D., Jacovina, M. E., Harry, D., Russell, D. G., and McNamara, D. S. (2015). Partial verbal redundancy in multimedia presentations for writing strategy instruction. Appl. Cogn. Psychol. 29, 669–679. doi: 10.1002/acp.3149
*Samur, Y. (2012). Redundancy effect on retention of vocabulary words using multimedia presentation. Br. J. Educ. Technol. 43, E166–E170. doi: 10.1111/j.1467-8535.2012.01320.x
Schnotz, W. (2005). “An integrated model of text and picture comprehension” in The Cambridge Handbook of Multimedia Learning. ed. R. E. Mayer (Cambridge: Cambridge University Press), 49–69.
Schroeder, N. L., and Cenkci, A. T. (2018). Spatial contiguity and spatial split-attention effects in multimedia learning environments. A meta-analysis. Educ. Psychol. Rev. 30, 679–701. doi: 10.1007/s10648-018-9435-9
*Schüler, A., Pazzaglia, F., and Scheiter, K. (2019). Specifying the boundary conditions of the multimedia effect. The influence of content and its distribution between text and pictures. Br. J. Psychol. 110, 126–150. doi: 10.1111/bjop.12341
*Schüler, A., Scheiter, K., and Gerjets, P. (2013). Is spoken text always better? Investigating the modality and redundancy effect with longer text presentation. Comput. Hum. Behav. 29, 1590–1601. doi: 10.1016/j.chb.2013.01.047
*Smith, A., and Ayres, P. (2016). Investigating the modality and redundancy effects for learners with persistent pain. Educ. Psychol. Rev. 28, 401–424. doi: 10.1007/s10648-014-9293-z
*Sombatteera, S., and Kalyuga, S. (2012). When dual sensory mode with limited text presentation enhance learning. Procedia. Soc. Behav. Sci. 69, 2022–2026. doi: 10.1016/j.sbspro.2012.12.160
Stebner, F., Kühl, T., Höffler, T. N., Wirth, J., and Ayres, P. (2017). The role of process information in narrations while learning with animations and static pictures. Comput. Educ. 104, 34–48. doi: 10.1016/j.compedu.2016.11.001
*Stiller, K. D. (2009). Mono-und bimodale Textpräsentationen zu Bildern in Hypermedia-Systemen. Psychol. Erzieh. Unterr. 56, 49–63. https://www.reinhardt-journals.de/index.php/peu/article/view/686
Sweller, J. (2010). Element interactivity and intrinsic, extraneous, and germane cognitive load. Educ. Psychol. Rev. 22, 123–138. doi: 10.1007/s10648-010-9128-5
Tarmizi, R. A., and Sweller, J. (1988). Guidance during mathematical problem solving. J. Educ. Psychol. 80, 424–436. doi: 10.1037/0022-0663.80.4.424
*Toh, S. C., Munassar, W. A. S., and Yahaya, W. A. J. W. (2010). “Redundancy effect in multimedia learning: A closer look” in Proceedings of ASCILITE - Australian Society for Computers in Learning in Tertiary Education Annual Conference 2010, 988–998, Australasian Society for Computers in Learning in Tertiary Education. Available at: https://www.learntechlib.org/p/45503/ (Accessed April 20, 2023).
*Torcasio, S., and Sweller, J. (2010). The use of illustrations when learning to read: a cognitive load theory approach. Appl. Cogn. Psychol. 24, 659–672. doi: 10.1002/acp.1577
Van Gog, T. (2014). “The signaling (or cueing) principle in multimedia learning” in The Cambridge handbook of multimedia learning. ed. R. E. Mayer (Cambridge: Cambridge University Press), 263–278.
*Wallon, R. C. (2014). Does the redundancy principle of multimedia learning hold in the secondary science classroom? Master’s thesis, University of Illinois.
*Wu, Y. F. (2011). An exploration of concise redundancy in online multimedia learning. doctoral dissertation, University of Northern Colorado.
Keywords: redundancy effect, cognitive load theory, cognitive theory of multimedia learning, multimedia instruction, review
Citation: Trypke M, Stebner F and Wirth J (2023) Two types of redundancy in multimedia learning: a literature review. Front. Psychol. 14:1148035. doi: 10.3389/fpsyg.2023.1148035
Edited by:
Juan Cristobal Castro-Alonso, University of Birmingham, United KingdomReviewed by:
Jose Hanham, Western Sydney University, AustraliaMeng-Chun Tsai, National Penghu University of Science and Technology, Taiwan
Copyright © 2023 Trypke, Stebner and Wirth. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Melanie Trypke, bWVsYW5pZS50cnlwa2VAdW9zLmRl
†ORCID: Melanie Trypke, https://orcid.org/0000-0002-6970-5741
Ferdinand Stebner, https://orcid.org/0000-0001-9187-1722
Joachim Wirth, https://orcid.org/0000-0003-2414-9144