 Yujia Chen
Yujia Chen Jiangdan Liu2†
Jiangdan Liu2†- 1School of Computer Science and Information Engineering, Harbin Normal University, Harbin, China
- 2School of Economics, Beijing International Studies University, Beijing, China
- 3Institute of Advanced Materials and Technology, University of Science and Technology Beijing, Beijing, China
Stock market analysis is helpful for investors to make reasonable decisions and maintain market stability, and it usually involves not only quantitative data but also qualitative information, so the analysis method needs to have the ability to deal with both types of information comprehensively. In addition, due to the inherent risk of stock investment, it is necessary to ensure that the analysis results can be traced and interpreted. To solve the above problems, a stock market analysis method based on evidential reasoning (ER) and hierarchical belief rule base (HBRB) is proposed in this paper. First, an evaluation model is constructed based on expert knowledge and ER to evaluate stock market sentiment. Then, a stock market decision model based on HBRB is constructed to support investment decision making, such as buying and selling stocks and holding positions. Finally, the Shanghai Stock Index from 2010 to 2019 is used as an example to verify the applicability and effectiveness of the proposed stock market analysis method for investment decision support. Experimental research demonstrates that the proposed method can help analyze the stock market comprehensively and support investors to make investment decisions effectively.
1. Introduction
The stock market is an important place for investment and trading. Its structure and trading activities are complex and influential. It is the thermometer of national economic development (Jin and Guo, 2021). The factors that affect the volatility of the stock market are very complex, showing highly nonlinear and dynamic characteristics (Barra et al., 2020), which increases the difficulty and risk of investment. Therefore, for investors to obtain greater returns and avoid investment risks, it is necessary to conduct a reasonable analysis of the stock market (de Oliveira et al., 2011; Chen et al., 2018; Feng et al., 2019).
Many scholars have researched the analysis of the stock market. Broadly speaking, there are two typical approaches of studying the stock market in literature: the seminal and widely studied approach is to make use of statistical analysis, financial theories and knowledge for stock market analysis, while the latest advance in the fields is to explore the use of machine learning and Artificial Intelligence (AI) techniques. Most of the statistical analysis is based on quantitative data. For example, Arashim (2022) proposed an ARMA-GARCH model to analyze the daily stock index of the Nasdaq Stock Exchange. Al-Ani and Zubaidi (2021) used the Kolmogorov–Smirnov test, normality test and Heteroskedasticity test to verify the expected risk of the Iraqi stock market. He et al. (2020) used OLS regression and quantile regression to study the relationship between investor sentiment and stock market volatility. Salman and Ali (2021) studied the impact of COVID-19 on the stock market through conventional t tests and nonparametric Mann–Whitney tests.
With the development of machine learning and AI techniques, scholars have applied relevant algorithms to stock market prediction, such as neural networks, support vector machines (SVM), and Bayesian models. The research on analyzing stocks based on machine learning can be further divided into two categories: regression and classification. Regression analysis focuses on predicting future stock prices by training a large amount of historical data. From the point of view of forecasting stock prices, Zheng and He (2021) proposed a hybrid forecasting model based on principal component analysis (PCA) and a recurrent neural network (RNN) to predict airline stock prices. Chen et al. (2021) constructed a machine learning hybrid model and selected 19 technical indicators to quantitatively predict stock prices. The above algorithms have advantages in solving the high-dimensional feature problem, which is also consistent with the multi-feature data in the field of stock prediction. However, when this method is applied to large-scale training samples, it will consume a lot of computer memory and computing time. Cheng and Chen (2018) proposed a fuzzy time series forecasting model based on weighted association rules to predict the price of gold in financial markets. Classification studies focus on predicting stock trends, which will be divided into two categories: up or down. Common classification algorithms are KNN, support vector machines (SVM), and random forests (RF). From the point of view of trend prediction, Yuan et al. (2020) proposed using feature selection and a machine learning integrated algorithm to predict the trend of China’s stock market. After comparison with many methods, the RF model shows some advantages in predicting the long-term stock price trend. Malagrino et al. (2018) took the closing direction of an index as the changing trend of the closing price of a certain trading day compared with the closing price of the previous day and predicted such a changing trend in combination with a Bayesian network. Ananthi and Vijayakumar (2021) judge the selling or buying trading behavior after predicting the stock market trend through candlestick pattern detection and the KNN algorithm. Xiao et al. (2020) combined SVM with the traditional ARIMA model to predict the direction of stock price fluctuations. Although algorithms such as SVM have been successfully used to predict financial time series, there are some limitations to these methods. For example, stock market data is characterized by huge noise, non-smoothness and complex dimensionality (Kara et al., 2011). The algorithm often shows unpredictable performance on noisy data. It imposes a significant challenge in predicting stock trends. For investors, the ultimate purpose of analyzing the stock market is to make investment decisions. In fact, this is a problem of classification. In practice, this is a matter of classification. Therefore, it is necessary to study an efficient classification algorithm to analyze stocks.
Through the above analysis of literature, the following challenges and limitations should be considered rigorously in the process of stock analysis. First, in the process of making investment decisions, investors need to analyze crossings and fluctuations between indicator lines. For example, a gold cross is regarded as an important signal to buy a stock, while most of the above research performances analysis from a quantitative perspective and ignores the piece of qualitative information. Second, the stock market is complex and nonlinear, so the model performance should be measured appropriately in the process of analysis (He et al., 2020). Finally, most stock analysis methods based on machine learning are data-driven models. The analysis process is not interpretable, and the results are not traceable.
Based on the above analysis, it is of great significance to construct an effective market analysis model to cover both stages of evaluating the stock market and making investment decisions such as buying and selling stocks. During the stock market evaluation process, investors must consider many factors, including both quantitative and qualitative information. In order to comprehensively analyze the above information, this paper adopts a evaluation method based on evidential reasoning (ER) proposed by Yang et al. (2006). The ER is a multi-attribute decision analysis method based on evidence (Kong et al., 2015). The stock market can be reasonably assessed. In the comprehensive decision-making of the stock market, the idea of the belief rule base (BRB) is adopted. This method was proposed by Yang and Xu (2013) BRB is based on IF-THEN rule. Expert knowledge can be used to constrain these rules and set the initial parameters of the model. As a result, the relationship between the inputs and outputs is explained. BRB itself can be seen as an expert system that can effectively deal with problems such as fuzzy uncertainty and probabilistic uncertainty. The BRB model can establish a complex nonlinear relationship between input and output according to the financial mechanism (Zhou et al., 2016). Different from machine learning algorithms such as neural networks and SVM, the reasoning process of BRB can be verified and explained (Hossain et al., 2018). ER and BRB are homologous methods. Therefore, the original physical meaning will not be destroyed, and the information will not be lost in use. The modeling method based on ER and BRB is also applied to medical analysis (Kong et al., 2012), fault diagnosis (Cheng et al., 2022), natural gas pipeline leak assessment (Feng et al., 2021) and so on.
In this paper, a method based on the ER algorithm and hierarchical BRB is proposed to analyze the stock market, and the main contributions can be summarized as follows:
1. In this paper, an interpretable stock analysis model based on ER and hierarchical BRB is proposed. The reasoning process of the model is causal, and the results can be traced back (Cao et al., 2021). In stock analysis, the process is transparent and the results are more convincing.
2. The proposed stock market evaluation model can deal with both quantitative and qualitative information. It can comprehensively consider the subjective uncertainty of qualitative indicators and the probabilistic uncertainty of quantitative indicators.
3. To comprehensively analyze the stock market, a hierarchical BRB model based on the weight of attributes is proposed in this paper. The accuracy of the model can be improved through top-level training of data. Besides, the model is extensible, and the problem of rule explosion in multiple attributes is reduced.
The structure of the paper is as follows. In Section 2, the key tasks in stock market analysis are formulated. In Section 3, a stock market analysis model is constructed. In Section 4, the validity of the constructed model is verified. A summary of the full text and future work are given in Section 5.
2. Problem formulation
The constructed stock market analysis model mainly comprehensively analyzes multiple types of technical indicators to provide investors with investment decisions, such as whether they should sell stocks, buy stocks or hold positions in the current situation. Feature extraction and evaluation of the current stock market quotation are also required before comprehensive decision making. The key tasks are described below.
Task 1: Feature extraction of stock market data
In the process of market analysis, the data of the stock market cannot reflect the situation of the stock market, and it is necessary to mine the internal characteristics of different indicators. Therefore, selecting a set of appropriate features from a large number of data is the most important problem to be solved. The process of feature extraction is described as follows.
where denotes the feature extracted at moment , denotes the feature extraction method, and is the time period. There are many types of common stock technical indicators, such as moving averages (MA), moving average convergence divergence (MACD), relative strength index (RSI), on balance volume (OBV), etc. In this paper, three types of indicators, MA, MACD and stochastic Indicator (KDJ), are selected for stock analysis.
Task 2: Processing of quantitative and qualitative information
Before making an investment decision, a primary analysis of stock market quotation based on different types of indicator data is performed. Market quotation is quantified in preparation for making investment recommendations. The stock market has the characteristics of uncertainty and nonlinearity. At the same time, both quantitative information and qualitative information are included in the analysis process. How to construct a model that can deal with both qualitative and quantitative data and nonlinearly reflect the results of stock market evaluation is a problem that needs to be solved, which is described as follows:
where is the output of the stock market evaluation model at time and the value is between 1 and 5. The larger the value is, the more depressed the market is, and the stock should be sold at this time. denotes the nonlinear conversion process from stock market index data to stock market evaluation results. denotes the parameters set according to the actual situation of the stock market. The parameters set contains the weights of the attributes. Based on the extracted features, three ER models are constructed in this paper, and the stock market evaluation results of each model are , , .
Task 3: Comprehensive multi-index stock market analysis
When investors actually analyze the stock market, they often need to consider many factors comprehensively. In addition, a large amount of financial knowledge and investment experience needs to be incorporated to obtain reasonable and reliable investment recommendations. Therefore, the problems of how the model can combine expert knowledge to achieve multi-attribute decision making and provide investors with reasonable recommendations are to be addressed. The process is described as follows.
where means to provide investors with trading recommendations on date , and the trading recommendations include five aspects: buy all positions, buy half positions, hold a position, sell half positions, and sell all positions. denotes the nonlinear transformation process from the results of single-type technical index analysis to the results of comprehensive analysis. denotes the parameters set of the model, which includes the weight of attributes and the weight of rules.
3. Construction of stock analysis model
To solve the above tasks, a stock market analysis model is constructed in this section. Stock analysis model mainly includes stock market evaluation model and stock market comprehensive decision-making model. The overall structure of the model is described in Section 3.1. The technical indicators selected for this paper are presented in Section 3.2. In Section 3.3, the process of implementing the stock market analysis model is described in detail.
3.1. The overall structure of the model
The overall structure mainly includes four parts: feature extraction, stock market evaluation model, stock market comprehensive decision-making model and optimization model. The structure of the stock analysis is shown in Figure 1.
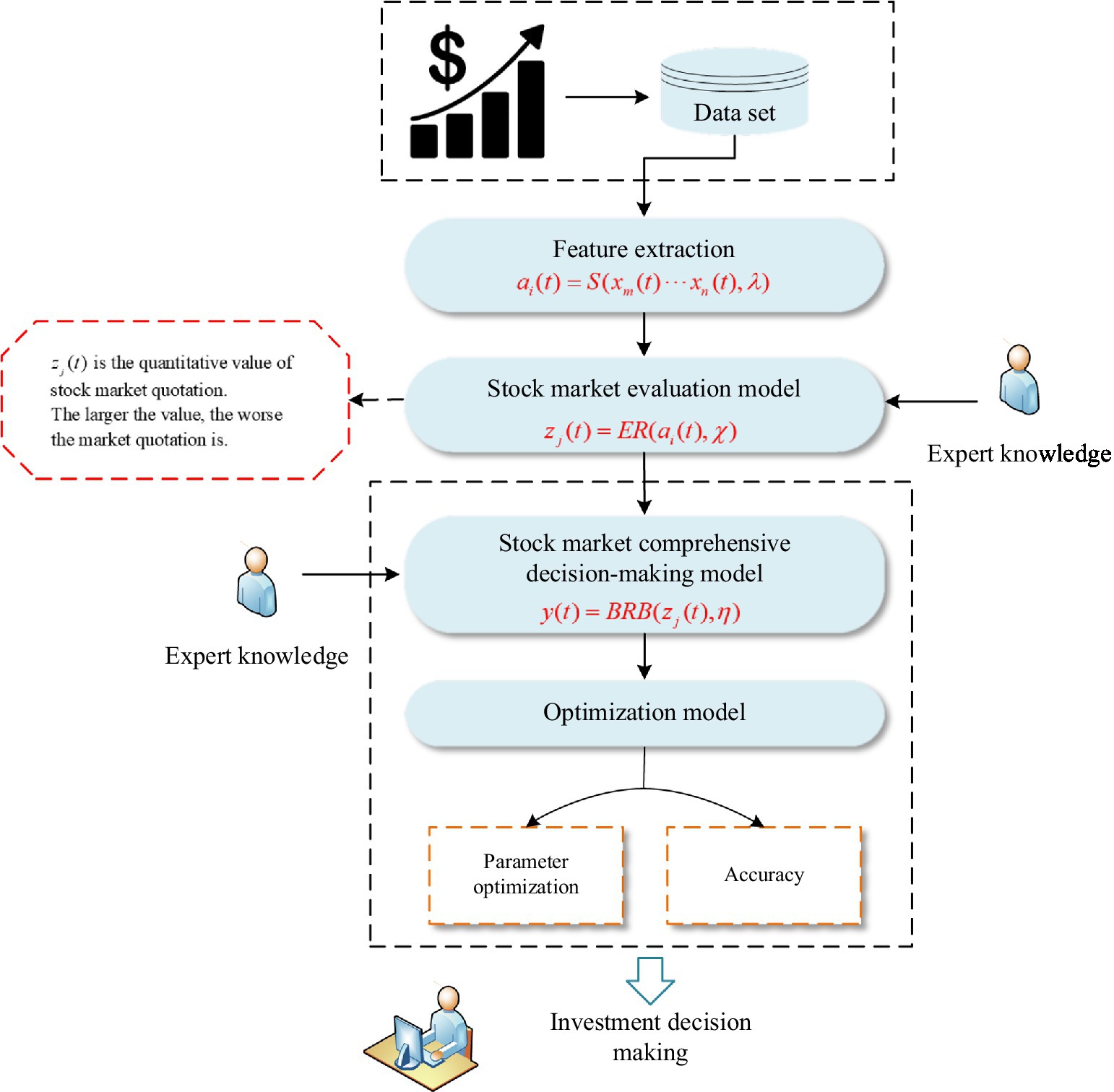
Figure 1. The structure of the stock analysis model.
First, the model analyzes the relationship between various technical indicators according to the stock mechanism for feature extraction. Second, based on the features extracted above, a stock market evaluation model is constructed. This model is used to assess whether the stock market sentiment is optimistic. Next, when the stock market evaluation is completed, a stock market comprehensive decision-making model is constructed. The model takes the evaluation results as input, and the model can output investment decisions. Among them, investment decisions include buying stocks, holding stocks and selling stocks. Finally, to improve the accuracy of the analysis results, an optimization model is constructed, and the model parameters are continuously optimized.
3.2. Feature extraction
The most directly and easily available technical indicators in stock data include opening price, closing price, highest price and lowest price. To analyze the stock market comprehensively from different perspectives, a large number of technical indicators have been introduced on this basis. From a functional perspective, technical indicators can be generally divided into the following three categories: trend indicators, overbought and oversold indicators, and energy indicators.
The trend indicator is used to judge the changing trend of stock prices. It can eliminate the effect of short-term changes and other accidental factors on the change of stock price. The common trend indicators are the moving average (MA) (Tanaka-Yamawaki and Tokuoka, 2007), moving average convergence divergence (MACD) (Wang and Kim, 2018) and so on. The overbought and oversold trading indicator is not only an indicator to judge the trend of market price and the phenomenon of overbought and oversold but also a technical indicator for short-term investment. The common overbought and oversold indicators are the Williams percent range and stochastic oscillator (KDJ). Energy indicators refer to the observation of stock price changes mainly from the perspective of volume. For example, on balance volume (OBV) and volume ratio (VR) are all energy indicators.
In this paper, MA, MACD and KDJ are selected to analyze the stock market. The reasons are as follows: first, MA has the characteristics of trend and smoothness, which is an important reference to judge the trend of stock prices. Second, MACD not only has the advantage of MA but also reacts more significantly to recent price changes (Aguirre et al., 2020). Third, MA and MACD have lags (Anghel, 2015; Wu and Diao, 2015), so this paper also analyzes the KDJ. This type of indicator can quickly and intuitively analyze the market and make judgments on buying and selling. Figure 2 shows the system of selected indicators. The following is the calculation method of the indicator.
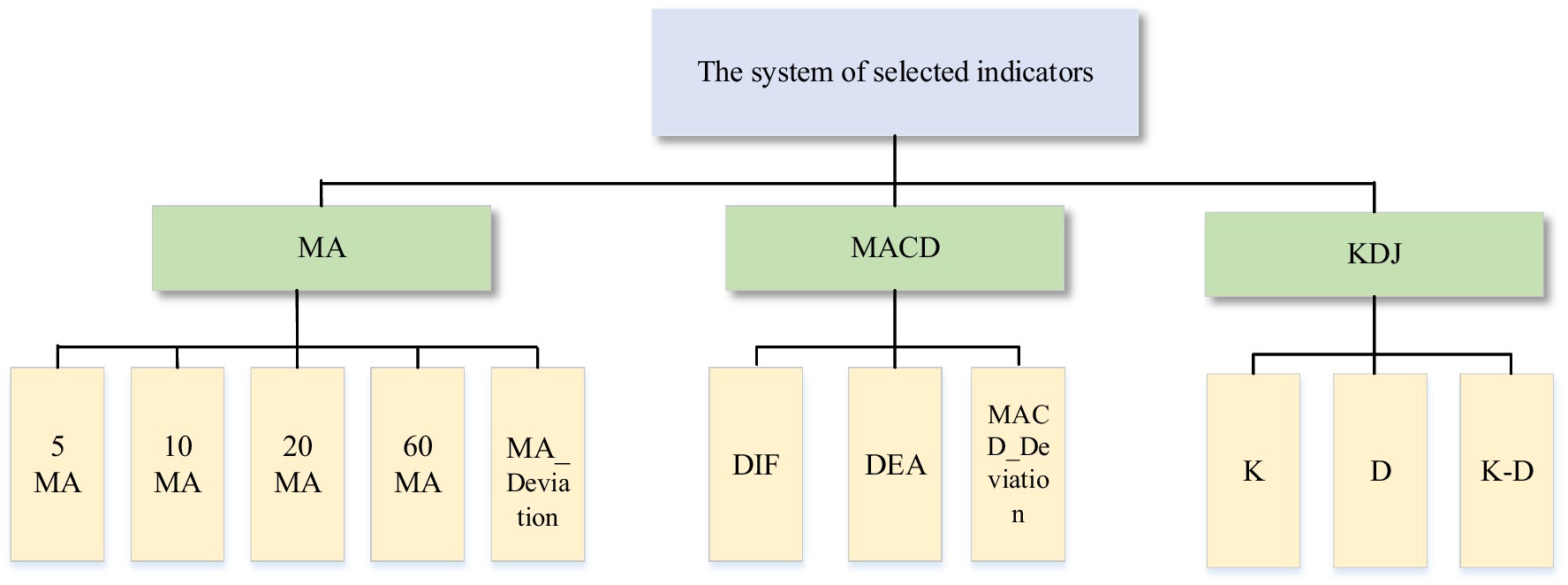
Figure 2. The system of selected indicators.
3.2.1. Moving average
A moving average is the arithmetic average of the closing prices of a number of consecutive days, which is used as a tool of price trend. Another measure is deviation, which is the degree of deviation between the closing price and a particular moving average. The formulas are as follows:
where represents the period of the indicator. represents the closing price on the day, and represents the MA deviation rate on days.
3.2.2. Moving average convergence divergence
MACD is a technical indicator that reflects the aggregation and separation between the 12-day exponential moving average (EMA) and the 26-day exponential moving average. It is an important indicator to judge when to buy and sell. Differential value (DIF) is the difference between the 12-day EMA and the 26-day EMA. Difference exponential average (DEA) is the average DIF over 9 days. The formulas are as follows:
where represents the closing price of the day. and represent the 12-day exponential moving average and the 26-day exponential moving average, respectively. and represent exponential moving average of the previous days. indicates the deviation of the MACD from the 60-day moving average on that day, where denotes the MACD value of the previous days.
3.2.3. Stochastic indicator
When calculating the KDJ indicator, the row stochastic value (RSV) of the day is calculated first, and then the K and D values are calculated according to this value. The calculation formulas are as follows:
where represents the closing price of the day. and represent the lowest and highest prices on the th day, respectively. and are the K and D values of the th day, respectively.
3.3. Implementation of the model
A stock market evaluation model based on ER and a stock market comprehensive decision-making model based on hierarchical BRB are constructed. According to the selected features, the stock market evaluation model is further divided into three parts: the ER_MA model, ER_MACD model and ER_KDJ model. The implementation process of the stock analysis model is shown in Figure 3.
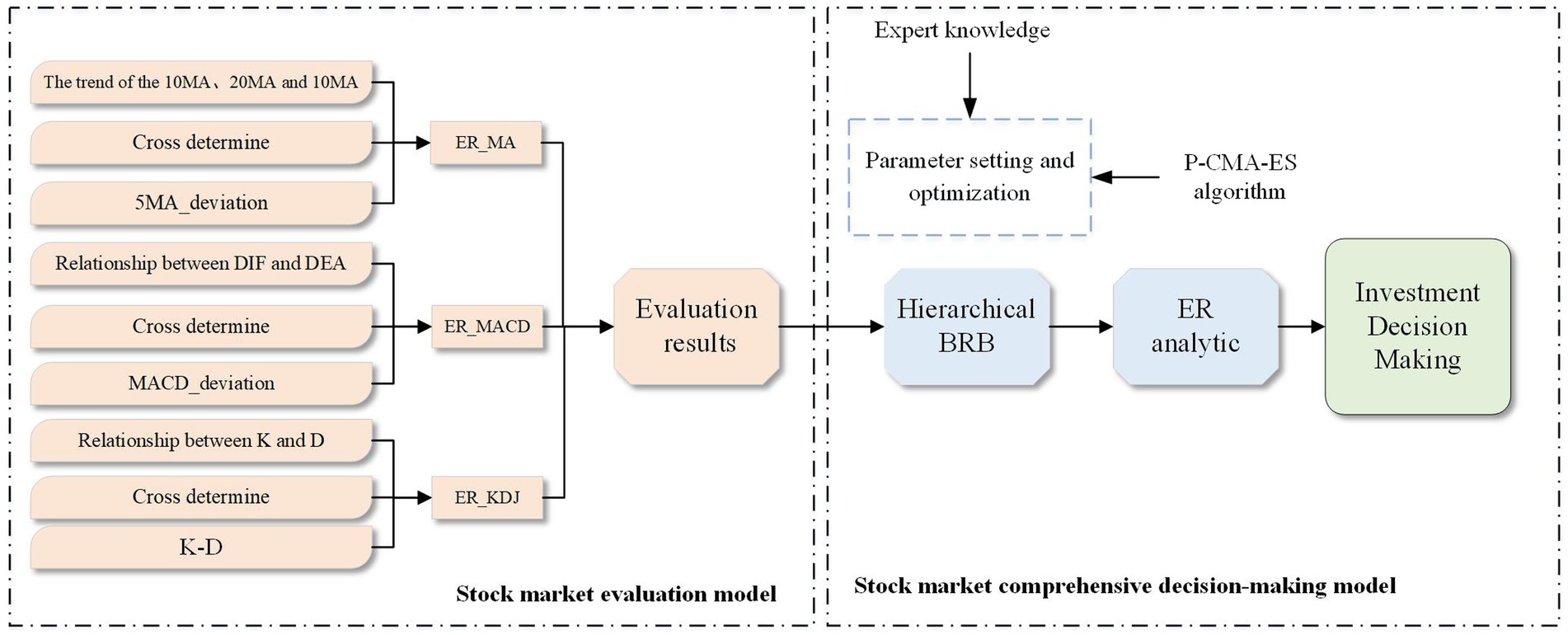
Figure 3. The implementation process of the stock analysis model.
3.3.1. Stock market evaluation model
This section mainly refers to the indicators MA (5 MA, 10 MA, 20 MA, and 60 MA), MACD (DIF, DEA) and KDJ (K, D) to evaluate the situation of the stock market. The following is the structure of the model and the reasoning process of the model.
3.3.1.1. The structure of the model
Based on the ER iterative algorithm, three models, ER_MA, ER_MACD, and ER_KDJ, are constructed. The model outputs an assessment of the stock market sentiment. The results of this assessment contain three categories: positive (P), intermediate (M) and negative (N). The following are definitions of model attributes.
3.3.1.1.1. ER_MA model
The technical indicator of the MA type is an indicator that describes the trend state of stock prices. In the process of stock trading evaluation, 10MA, 20MA and 60MA are arranged from top to bottom, that is, 10MA > 20MA > 60MA, which reflects the trend of positive development of the stock market. It also means that this is the time to buy the stock. If it is arranged in the opposite direction, it is a negative signal, indicating the timing of selling. Similarly, the golden cross and dead cross are the key points to judge buying and selling. In the ER_MA model, the golden cross and the dead cross need to be based on two indicators: 5 MA and 10 MA. When 5MA crosses 10MA from bottom to top, the intersection is the golden cross. When there is a golden cross, the stock market will have some room to rise, which is a positive signal and the best time to buy. In contrast, it is a dead cross. Attributes can be divided into three levels, namely, negative signal, intermediate signal and positive signal. The attributes are shown in Table 1.
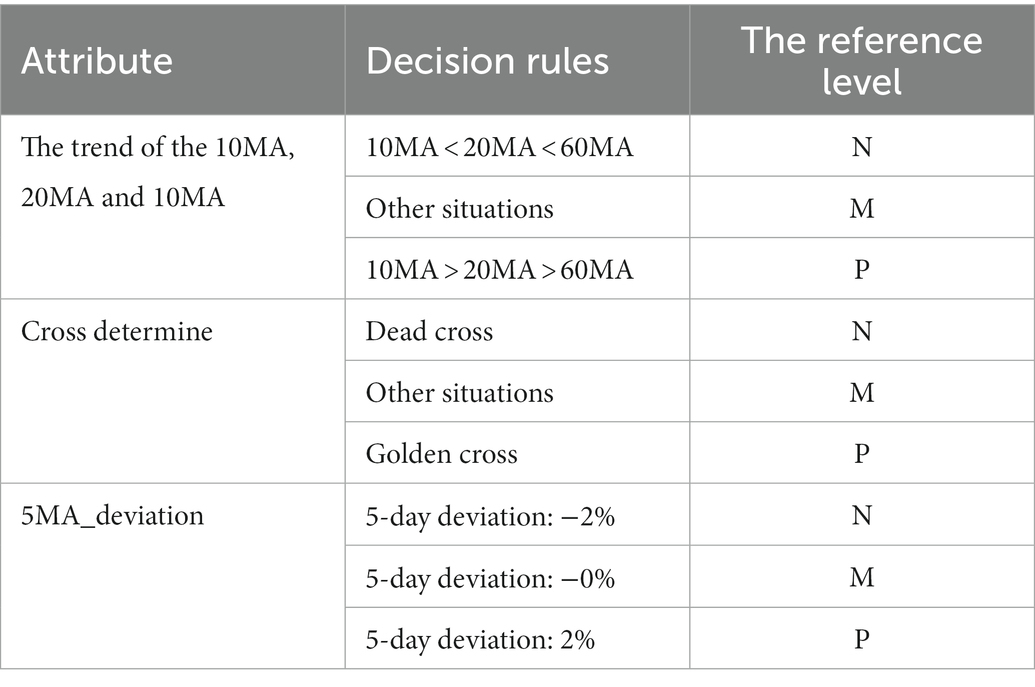
Table 1. ER_MA model attributes.
3.3.1.1.2. ER_MACD model
The technical indicator of MACD type is a famous trend indicator. The DIF and DEA indicators are referenced in the model. When DIF > 0 and DEA > 0, a positive trend is shown in the stock market, which is the buy signal. When DIF < 0 and DEA < 0, a negative trend appears in the stock market, which is a sell signal. In the MACD model, when DIF breaks through DEA from the bottom up, the golden cross is formed, which is the buy signal. When DIF breaks through DEA from top to bottom, a dead cross is formed, which is a sell signal. The attributes are shown in Table 2.
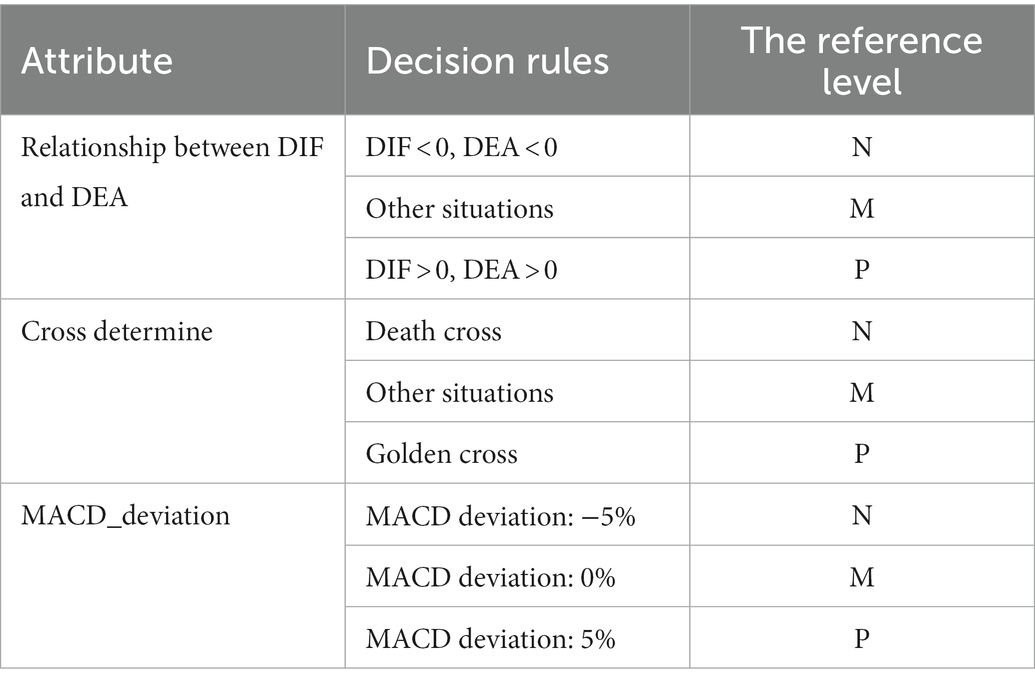
Table 2. ER_MACD model attributes.
3.3.1.1.3. ER_KDJ model
The technical indicator of KDJ type is an indicator that describes the signals of stock buying and selling. The values of K and D are usually between 0 and 100. When the values of K and D are greater than 80, the market is overbought. When the values of K and D are less than 20, the market is oversold. The K value is greater than the D value; that is, when the K line breaks through the D line upwards, the golden cross point is formed, which is the buy signal. The K value is less than the D value; that is, when the K line falls below the D line, the dead cross point is formed, which is a sell signal. Attributes can be divided into three levels, namely, negative signal, intermediate signal and positive signal. The attributes are shown in Table 3.
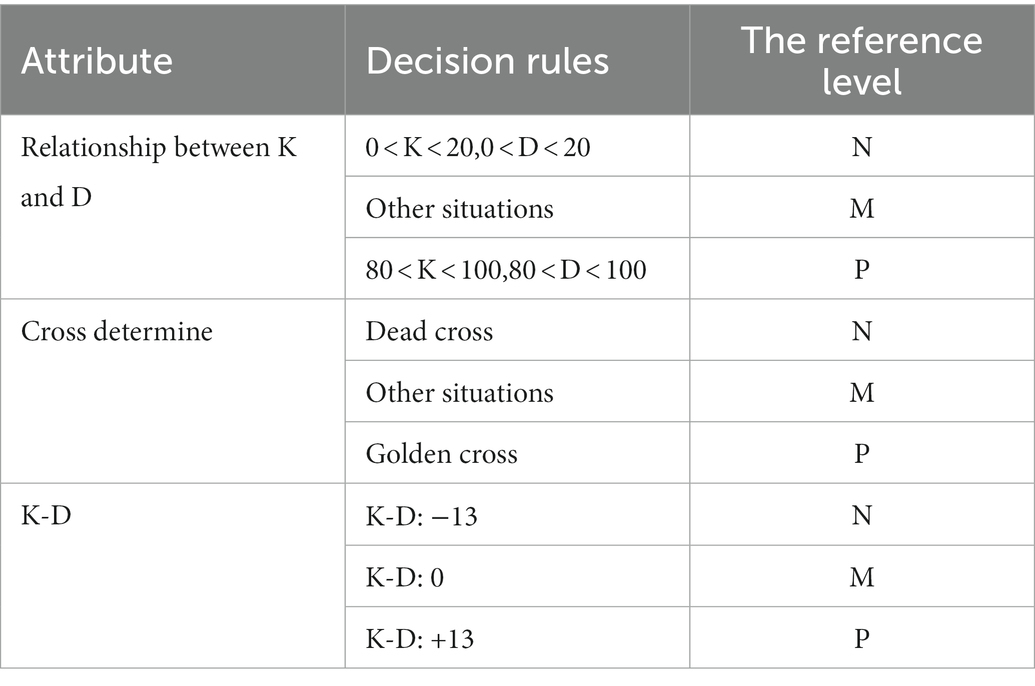
Table 3. ER_KDJ model attributes.
3.3.1.2. Reasoning process
Combined with expert knowledge, the fusion process of multiple indicators is as follows:
Step 1: Initialize the confidence of the evaluation level of financial indicators.
There are M indicators under the model, in which represents all the levels at which the indicators can be evaluated, namely, . Then, represents the degree of belief that the technical indicator is rated as , which is described as:
Step 2: Integrate the information of various financial indicators.
The ER is established based on the Dempster rule, which can be used for data fusion (Yang and Xu, 2013). The ER algorithm can assign residual support to any single propositions and the frame of discernment, while Dempster’s combination rule allocates all residual support to the frame of discernment. ER provides an efficient way of expressing information, where uncertainty can be transformed into basic probability mass by certain rules (Zhou et al., 2021). The information is expressed in the form of a belief distribution and can be transmitted without loss in the process of evidence combination. The following is the process of evidence combination.
First, the belief degrees needs to be transformed into a basic probability mass (Feng et al., 2019). The formula is as follows:
where represents the basic probability mass of the level of the indicator, and represents the weight of the indicator. is denoted as the basic probability mass not assigned to the rank set, and . denotes the basic probability mass of the missing indicator. In cases where the expert is unable to give precise rules or where some of the input data is not available, the results of the rules will be incomplete. Therefore, the incompleteness should be taken into account in the reasoning process. denotes the degree of incompleteness of the indicator.
Then, the rules are combined by using ER and described as follows.
where and respectively denote the basic probability mass assigned to the evaluation level and the basic probability mass assigned to the identification framework after the combination of rules.
Finally, the combined belief degree is calculated. It can be described as follows:
Step 3: Utility Computing
The evaluation results of the model were quantified using the following utility formula.
where denotes the set of utilities.
Remark 2: ER algorithm has the ability to deal with qualitative and quantitative information comprehensively. The evaluation results are based on formulaic reasoning and are traceable.
3.3.2. Stock market comprehensive decision-making model
The three types of stock indicators MA, MACD and KDJ obtained under the ER algorithm can quantify the status of the stock market, but the evaluation results are inferred by a type indicator. The volatility of the stock market is often influenced by the interaction of many factors. A comprehensive decision-making model for the stock market needs to be constructed. The utility results of the MA model, the MACD model and the KDJ model are used as the premise attributes to construct a hierarchical BRB model.
3.3.2.1. The structure of the model
To solve the rule explosion problem when multiple attributes are input, a hierarchical BRB model can be considered. The model is a bottom-up structure and is easily extensible. The main idea is to arrange the weights of attributes from low to high. Except for the first layer model, the attributes with lower weights and the results of the upper layer are selected as input each time until the final state is reached. In this paper, a two-layer BRB model is constructed. Figure 4 is the structure of the hierarchical BRB model and the rule expression is profiled as:
where represents the rule of the layer model. represents the output result, which is also used as the input information of the next layer. represents the reference level of the output result, and (j = 1, 2…, N) represents the belief degree of the level. represents the rule weight, represents the attribute weight, and .
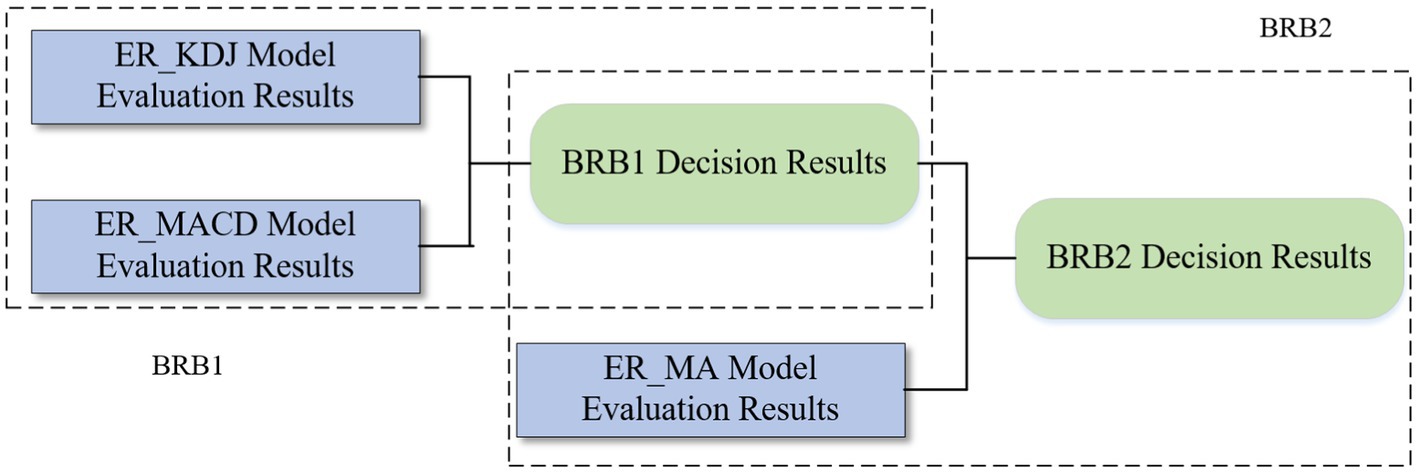
Figure 4. The structure of the hierarchical BRB model.
3.3.2.1.1. Construction of the first layer model BRB1
The importance of the three stock evaluation models is from high to low: ER_MA model, ER_MACD model, and ER_ KDJ model. Therefore, the MACD utility and KDJ utility are selected as the prerequisite attributes of the first-layer BRB model. The reference points are defined as follows:
is the MACD utility reference point, and is the KDJ utility reference point. The result is the trading degree of the stock, and the reference point of can be five reference points: buy all positions (BA), buy half positions (BH), hold a position (Hold), sell half positions(SH), and sell all positions (SA), which can be described as:
where is the rule in model BRB1. represents the belief of the level corresponding to the rule. represents the weight of this rule. and represent attribute and weights.
3.3.2.1.2. Construction of the second layer model BRB2
The result obtained by the BRB1 model and the utility of the MA model are used as the prerequisite attributes to construct the second-layer model BRB2. The reference points are defined as follows:
is the MA utility reference point, and is the reference point. The result represents the final stock trading situation, and the reference point of can be five reference points: buy all positions (BA), buy half positions (BH), hold a position (Hold), sell half positions (SH), and sell all positions (SA). In the BRB2 model, there are 15 belief rules, which are described as:
where is the rule in the BRB2 model. represents the belief of the level corresponding to the rule. represents the weight of the rule. and represent attribute weights.
3.3.2.2. Reasoning process
First, the data are input into the designed belief rule base, and then the activated rules are combined by the ER analytic algorithm. Finally, the assessment results are output. The reasoning process is shown in Figure 5. The detailed process is as follows:
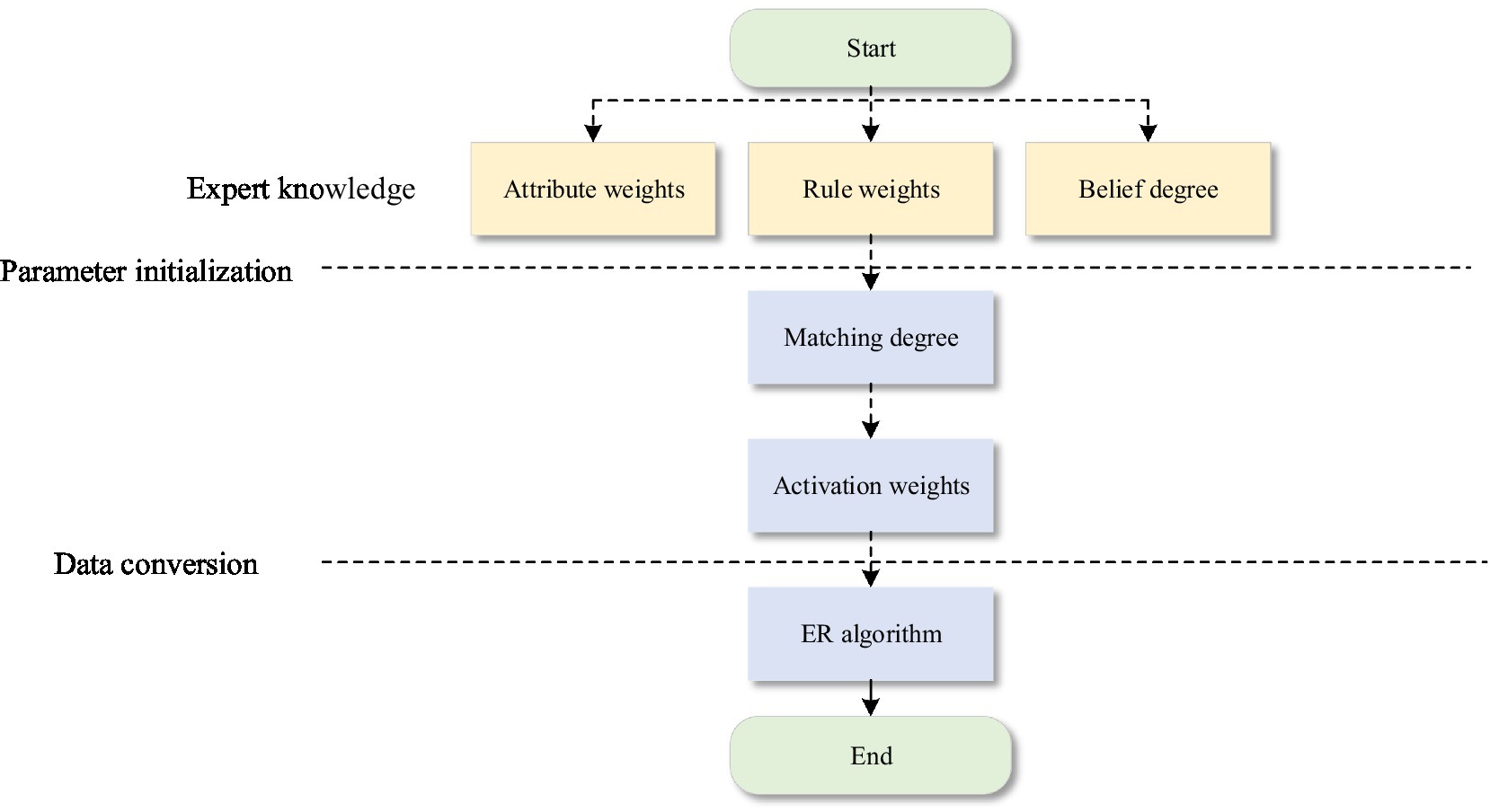
Figure 5. BRB model reasoning process.
Step 1: In the BRB model, the input information needs to be transformed into a unified measurement framework, and the following formula is used to calculate the matching degree between the input and the reference value.
where denotes the matching degree of the attribute of the rule.
Step 2: After the matching degree is calculated, the calculated degree of activation of the input information to the rule is needed to calculate the rule activation weight. The formula is as follows:
is the activation weight of the rule, is the rule weight of the rule, and is the attribute weight.
Step 3: After the evidence is activated and the activation weight of each rule is calculated, the belief distribution of the activated rule is combined using the ER analysis algorithm. The formulas are as follows:
Step 4: The final output of the stock forecast is .
is the actual output of the model, and is the belief of the estimated result .
3.3.3. Model optimization
Trading analysts make recommendations on trading behavior based on historical data, which can be verified by stock price movements and volume. These investment recommendations are used as actual values for the training of the model. The model constructed in this paper is an alternative to the process of investor analysis. To improve the accuracy of the model, it is necessary to train the model continuously. The goal of training is to find a set of parameters to minimize the difference between the predicted and actual values. The optimization model is described as follows:
where is the set of parameters to be optimized. The set includes the belief degree, rule weight, and attribute weight. represents the actual investment recommendations of the stock market. denotes the investment recommendation output by the model. represents the number of test data, and represents the number of correct evaluation results.
In this paper, projection covariance matrix adaption evolution strategy (P-CMA-ES), which is an extension of CMA-ES algorithm is used for optimization. Compared with CMA-ES algorithm, P-CMA-ES algorithm reduces the complexity and improves the effectiveness of the optimization process (Yin et al., 2017). As an intelligent optimization algorithm for global optimization, P-CMA-ES can quickly converge to the global optimum without large sample set (Hu et al., 2020). It has significant advantages in small sample size and nonlinear optimization. The working process of the P-CMA-ES is shown in Figure 5. The optimization process is as follows:
Step 1: The dimension of the problem is defined, and the parameter set is initialized.
Step 2: Perform sampling operations and define the expected value. The covariance matrix of the corresponding population is generated by using the normal distribution. The formula is shown below.
represents the descendant of the generation. represents the expected value of the g-th generation. is the step size of the generation. is the orthogonal distribution, and represents the covariance matrix of the population.
Step 3: Based on the projection algorithm, the solution is mapped to the hyperplane, and the parameters are constrained. The formula is shown below.
represents the parameter vector. is the number of constraint variables. is the number of constraints.
Step 4: The subpopulations that meet the constraints are selected. The formula is described as follows.
denotes the weight of the optimal solution, and all weights add up to 1.
Step 5: The covariance matrix of the subpopulation is updated and gradually approaches the optimal solution, which process is described as follows:
where and represents the learning rate, is the evolutionary path of the generation, and is the damping coefficient. represents the expected value of a normal distribution , where is the identity matrix.
Remark 3: The hierarchical BRB is easy to extend. When the model needs to add new indicators, it can be achieved by increasing the level of the model. Each layer of the model contains two indicators, which facilitates the analysis of the relationship between the indicators. The analysis process is more organized.
Remark 4: The BRB uses the ER algorithm as the inference engine, and expert knowledge is introduced. Therefore, the validity of the decision-making results is guaranteed. In addition, a BRB is established based on IF-THEN rules to make the reasoning process interpretable.
4. Case study
The Shanghai Composite Index is a comprehensive index of all stocks, which can reflect the situation of the entire securities market, thereby providing investors with different investment references. Therefore, in this section, the Shanghai Composite Index is used as the research object to analyze stock market sentiment. The stock data are a time series, and a continuous data set of stock market opening days in 2010–2019 is used in this paper. The data contain four variables: opening price, closing price, high price and low price. Although there are many data in this range, there are few data with decision-making significance and buying and selling signals. Additionally, when calculating indicators such as MA and MACD and actually analyzing stocks, investors need to refer to multiple days of data to arrive at an investment strategy. Therefore, this experiment analyzes 390 days of stock market trading with a time interval of 5–9 days.
The stock market evaluation model is introduced in Section 4.1. Based on the results of different types of assessments, comprehensive decisions about the stock market are conducted in Section 4.2. The experimental results are analyzed in Section 4.3, and the effectiveness of the model is demonstrated. The experimental results are analyzed in Section 4.3. The effectiveness of the model is proved.
4.1. The stock market evaluation model
First, we build a primary stock market model. According to the classification of technical indicators, models are established to fuse data. Then, based on this model, the utility obtained quantifies the state of the stock market. In the actual analysis of stocks, it is impossible to judge trading behavior only by relying on quantitative data. Therefore, the relationship between the data are compared at this time. In addition, the stock data are a time series, and the golden cross needs to be judged with reference to the previous day’s data. Therefore, it is necessary to convert part of the quantitative data into qualitative data as input to the model. The influence of technical indicators on the state of the stock market can be divided into three levels, namely, positive signal, intermediate signal and negative signal. Based on Section 3 analysis, 5-day deviation, MACD deviation and K-D were quantitative data, combined with expert knowledge to set reference values such as Table 4.
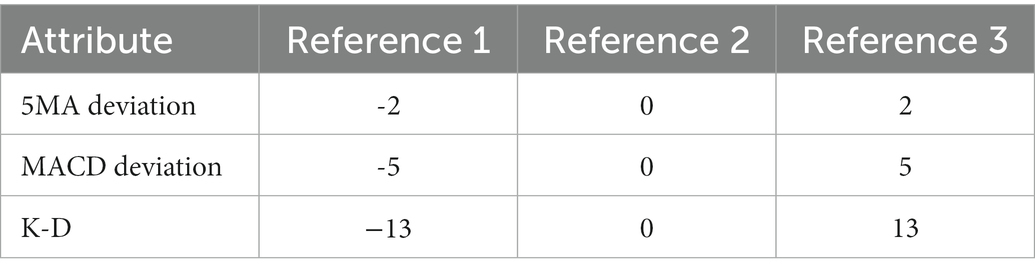
Table 4. Reference value of quantitative data.
4.2. Stock market comprehensive decision-making model
The stock market comprehensive decision-making model is defined in Section 3.2 of this paper. In BRB1, premise attributes and are the output utility of the ER_MACD and ER_KDJ models, respectively, and the reference points of premise attributes are shown in Table 5 and Table 6. The reference point of the output of the BRB1 model is displayed in Table 7. In BRB2, the BRB1 model output is the premise attribute input, and the attribute is the ER_MA model output utility. The model outputs , and the reference value is displayed in Table 8, 9. The initial belief rules for BRB1 and BRB2 are shown in Tables 10, 11.

Table 5. The reference point of .

Table 6. The reference points of .

Table 7. The reference point of .

Table 8. The reference point of .

Table 9. The reference point of .
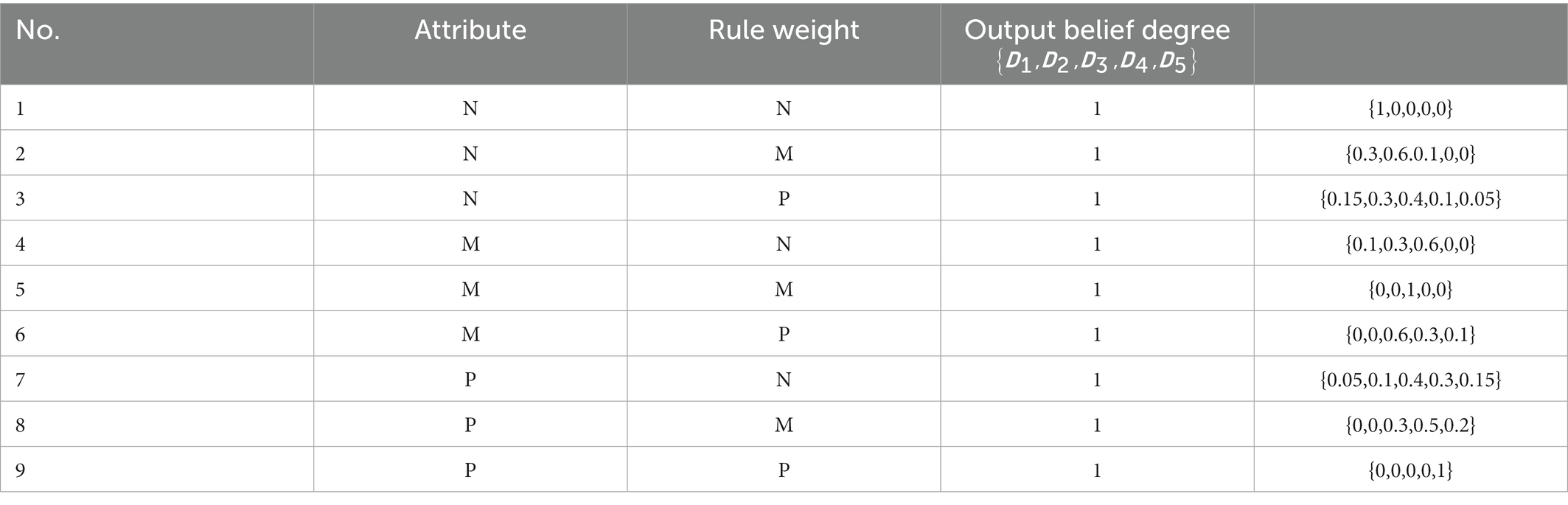
Table 10. BRB1 initial belief rule base.

Table 11. BRB2 initial belief rule base.
Finally, based on the above model, five kinds of labels can be output to represent the investment recommendations. The meaning of the labels is displayed in Table 12, and the definition formula for the five labels is shown as:

Table 12. The meaning of labels.
4.3. Simulation experiment
This experiment is based on three ER stock market evaluation models, which are used for data fusion, processing semi-quantitative information and quantifying the state of the stock market. Figures 6, 7, 8 show the evaluation results of the ER_MA, ER_MACD, and ER_KDJ models, respectively. In this section, two sample data are selected as examples to analyze the evaluation process of the stock market.
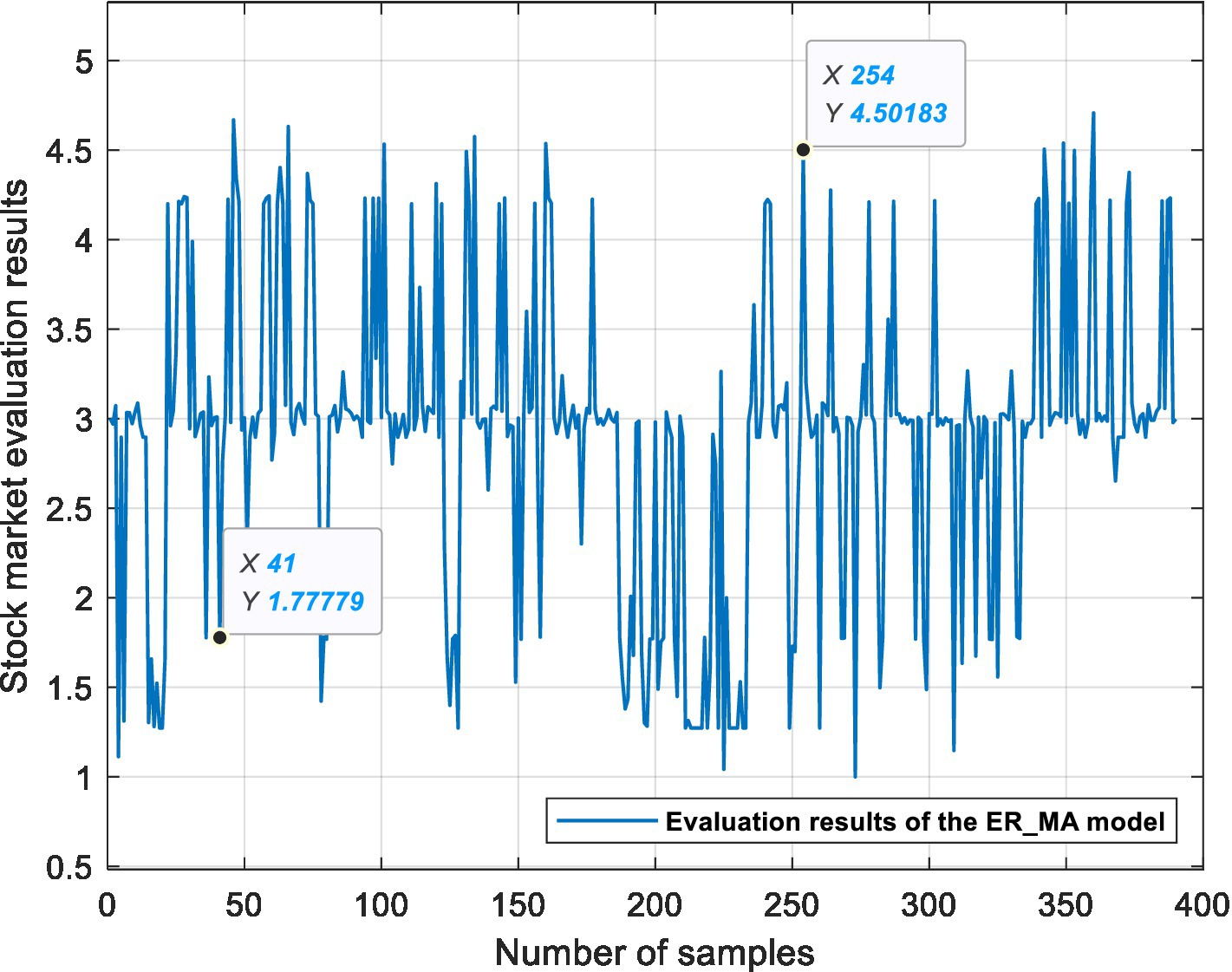
Figure 6. ER_MA model stock market evaluation results.
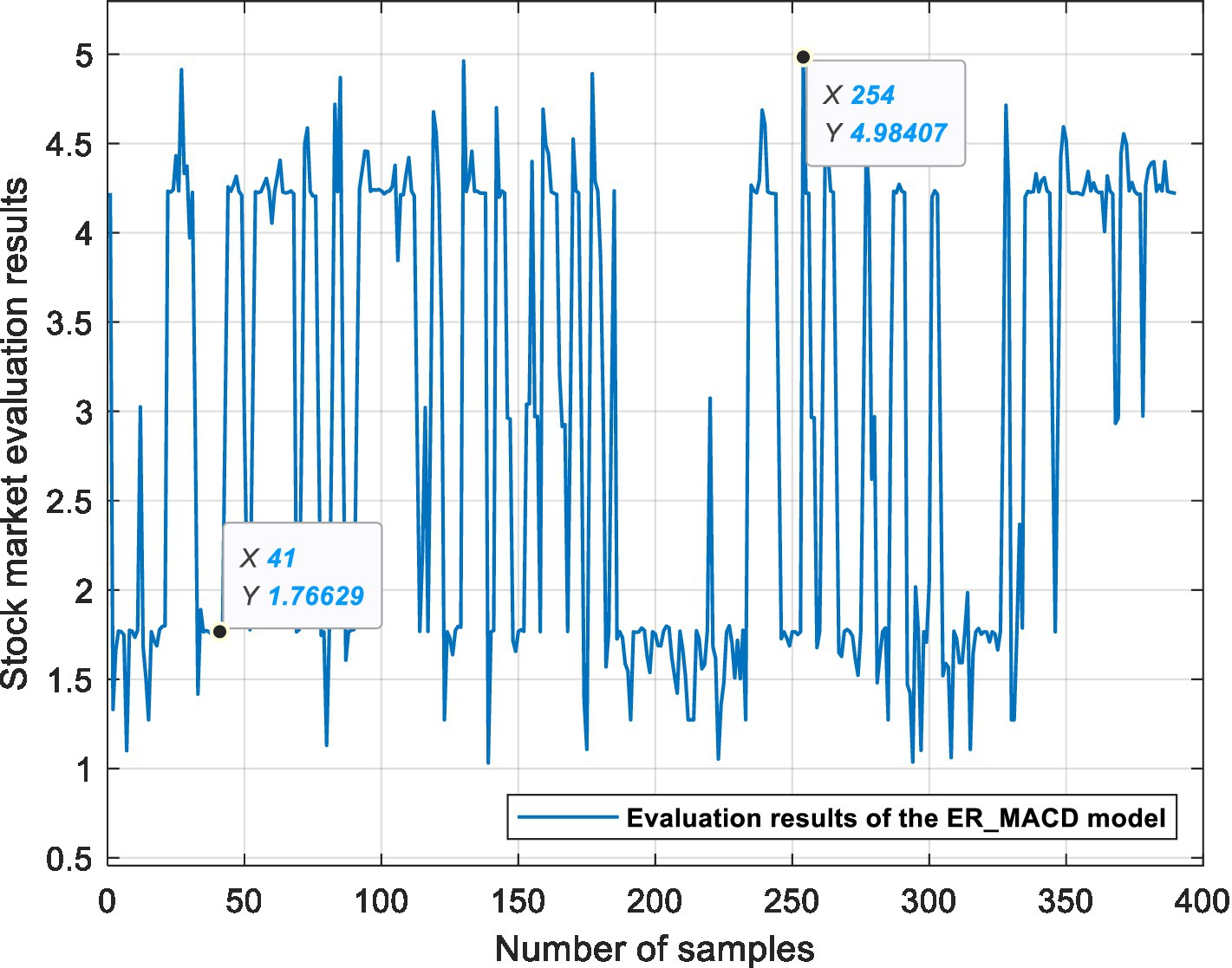
Figure 7. ER_MACD model stock market evaluation results.
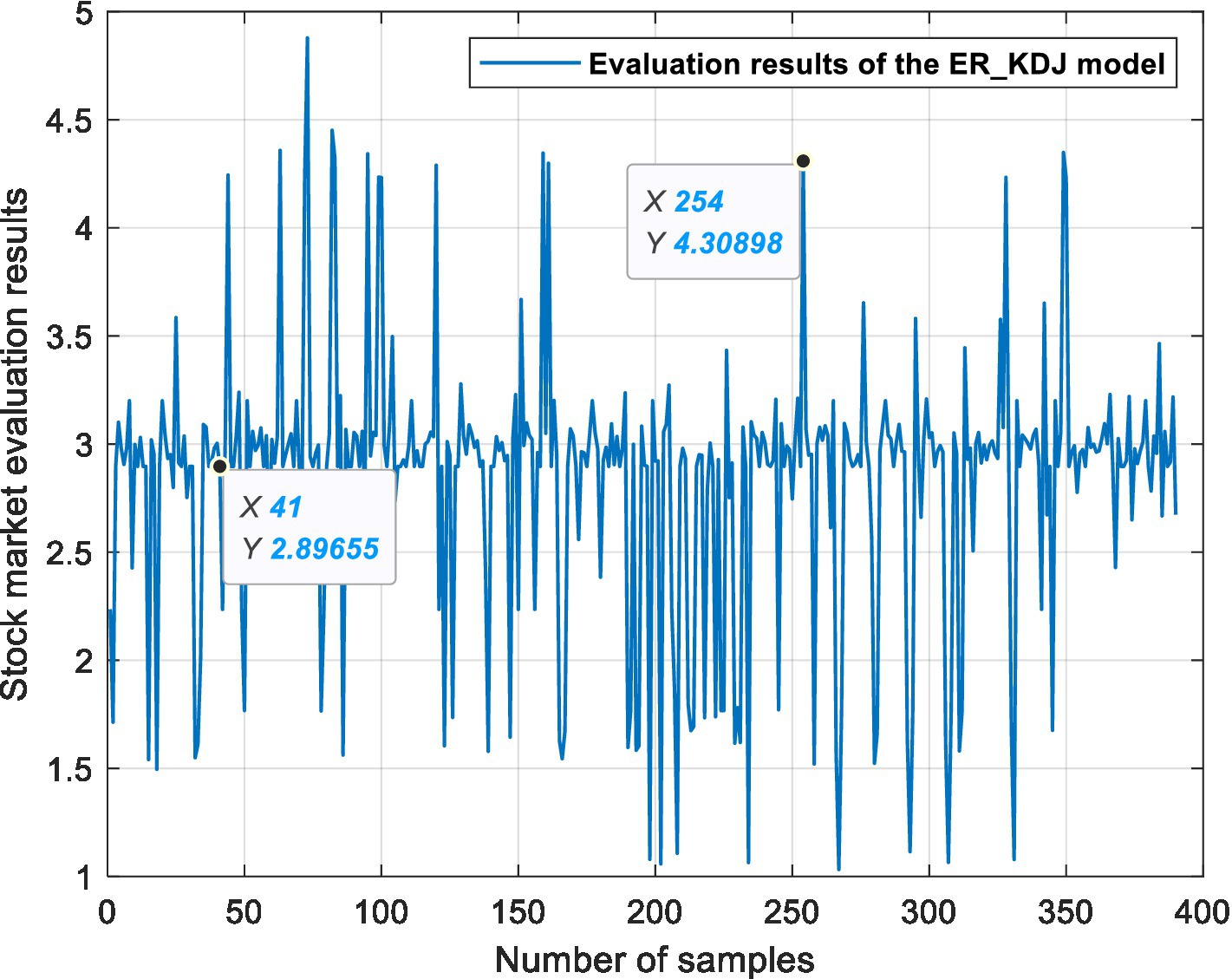
Figure 8. ER_KDJ model stock market evaluation results.
Example 1: Take the 41st sample data, that is, the Shanghai Stock Exchange Index on April 20, 2011, as an example. After calculation, the data of this day are shown in Table 13. The data show 10 MA >20 MA > 60 MA, which is rated as a positive signal. There is no crossing between 5 MA and 10 MA, and the 5MA_ deviation is divided into intermediate signals. Therefore, according to the influence of these three attributes on the stock market, the ER_MA model evaluates that the current market is in a positive state. Investors can consider buying half a position. The ER_MACD model is analyzed in the same way. In the ER_KDJ model, the K-D value attribute is divided into negative signals, and there is no crossing between the K value and D value. Therefore, the model evaluates that the current market is in an intermediate state, and investors can consider taking a position and waiting.

Table 13. Data from 2011/4/20.
Example 2: Take the 254th sample data, that is, the Shanghai Stock Exchange Index on January 14, 2016, as an example. After calculation, the data of this day are shown in Table 14. The data show that 10 MA < 20 MA <60 MA. There is no crossing between 5 MA and 10 MA, and the 5 MA_ deviation is divided into intermediate signals. At this time, based on the ER_MA model, the current market is in a negative state, and investors need to consider reducing their positions. For the ER_MACD model, the data show that DIF < 0, and DEA < 0. DIF and DEA have formed a dead cross, and the deviation degree of MACD shows a negative signal. Therefore, this model evaluates that the current stock market is in a negative state, and investors can consider selling stocks. By the same token, the ER_KDJ model can evaluate that the current market is in a negative state at this time.
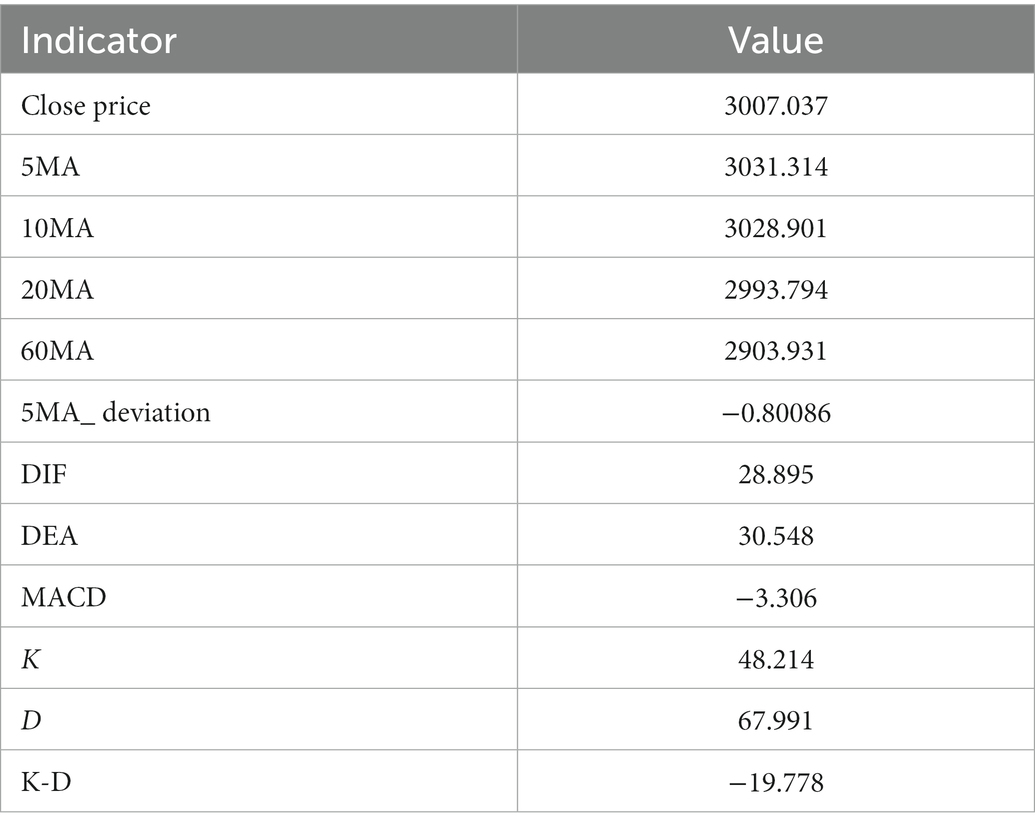
Table 14. Data from 2016/1/14.
In the BRB1 model, the full set is used for testing. In the BRB2 model, 290 pieces of data are trained, and 100 pieces of data are test sets. To prove the effectiveness of the model, 10 rounds of experiments were carried out. For the hierarchical BRB model, the maximum number of iterations was 300. Figure 9 shows the results of the comprehensive analysis of stocks. The average value of 10 rounds of experiments represents the accuracy of the model. To further verify the effectiveness of the methods used in this paper, this model is compared with the BP neural network, ELM, RF and RBF. To facilitate the comparison of the experiment, 200 pieces of data are also selected as the training set, and 190 pieces of data are selected as the test set. Ten rounds of experiments were carried out, and the accuracy of the model was the average of 10 rounds of experiments. The accuracy of 10 rounds of experiments with 5 methods is shown in Figure 10. The accuracy of each method is shown in Table 15. The optimized belief rule base is shown in Tables 16, 17.
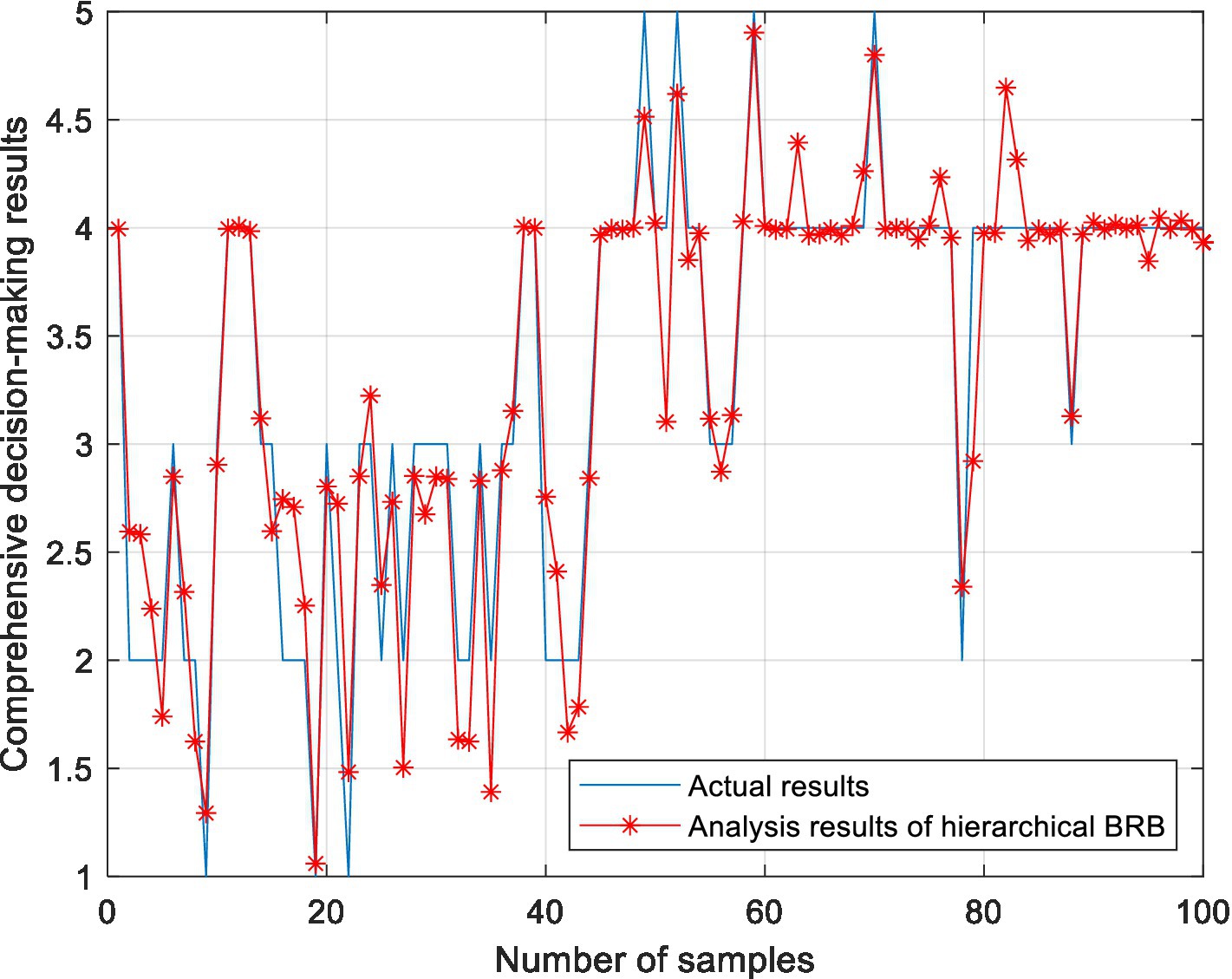
Figure 9. Analysis results of the hierarchical BRB model.
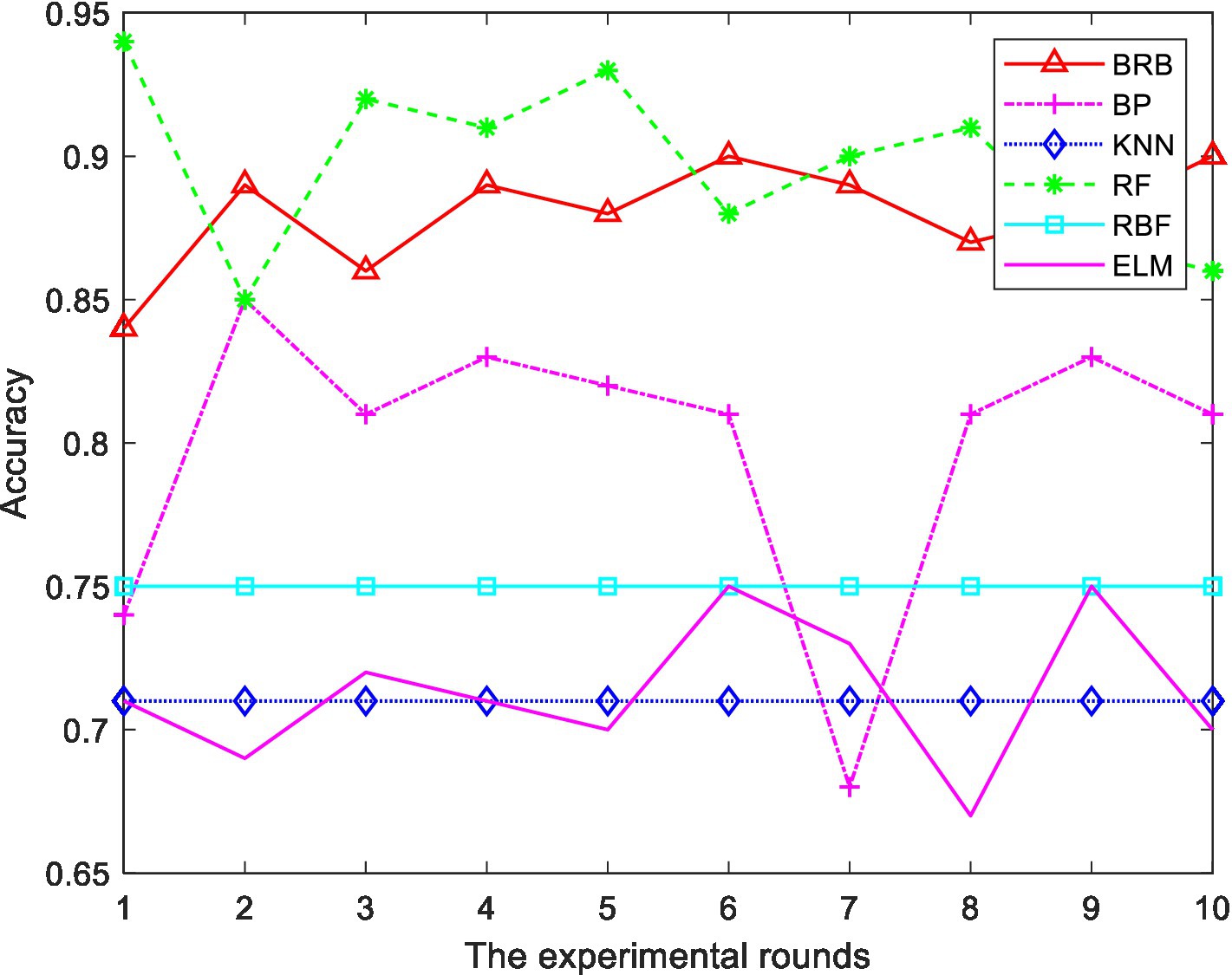
Figure 10. Comparison of different methods.

Table 15. Accuracy of different methods.

Table 16. BRB1 optimized belief rule base.
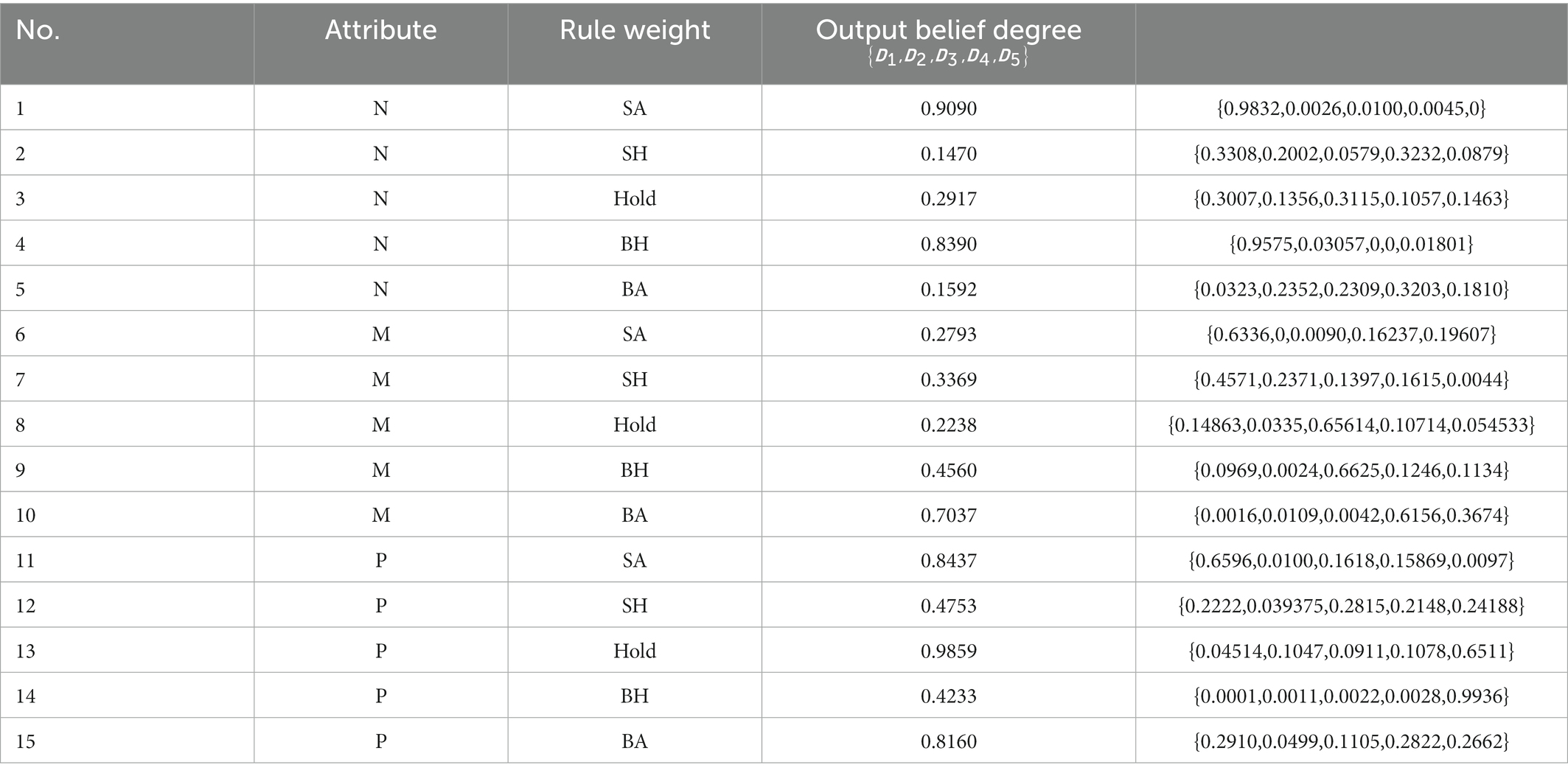
Table 17. BRB2 optimized belief rule base.
The above experiments show that, compared with other methods, the model constructed in this paper has certain advantages. The description is as follows:
1. In 10 rounds of experiments, the accuracy of the ER and hierarchical BRB model constructed in this paper is between 88 and 91%, indicating the feasibility of the model.
2. As can be seen from Figure 10, RF also performs well in terms of prediction accuracy. However, RF is regarded as a black box, and the intermediate process of decision making is difficult to explain. Although the accuracy is high, it does not explain the reason for the decision. Moreover, when the number of decision trees in a random forest is large, the space and time required for training is relatively large. However, the reasoning process of BRB is transparent and the model can be interpreted. The process of model construction is based on expert knowledge. The results are more interpretable and reliable. Therefore, it is more suitable for analyzing the field of stock investment with risks.
3. Compared to other methods, this model can comprehensively handle quantitative and qualitative information.
5. Conclusion
This paper proposed a stock analysis model based on ER and hierarchical BRB, which can not only analyze the stock market from both quantitative and qualitative perspectives, but also solve the problem of rule explosion caused by multiple attribute inputs in traditional BRB models. In addition, the whole reasoning process of the model is relatively transparent, and the decision results can be interpreted. The experimental results show that the proposed model is suitable for analyzing this kind of investment decision making problems under uncertain and risky environment. In the future, the following areas of work need to be enhanced:
1. In the in-depth study of the stock market, the impact of uncertain factors is considered, such as national policies, market supply and demand. In the future, a standard stock market buying and selling decision-making system needs to be constructed.
2. The optimization model in this paper is based on the P-CMA-ES algorithm, which is a global optimization algorithm. The optimization process does not consider the meaning of the optimization parameters, and the optimization process lacks interpretability. Therefore, ensuring the interpretability of the optimization process is a problem that needs to be solved.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Author contributions
YC and JL participated in the conceptualization. YG, WH and HL were in charge of the methodology and software. GZ and HW performed validation, formal analysis. First draft writing, review, and editing were handled by YC, JL, and WH. All authors contributed to the article and approved the submitted version.
Funding
This work was supported in part by the Natural Science Foundation of China under Grant 62203461 and Grant 62203365, in part by the Postdoctoral Science Foundation of China under Grant No. 2020 M683736, in part by the Teaching reform project of higher education in Heilongjiang Province under Grant Nos. SJGY20210456 and SJGY20210457, in part by the Natural Science Foundation of Heilongjiang Province of China under Grant No. LH2021F038, in part by the graduate academic innovation project of Harbin Normal University under Grant No. HSDSSCX2022-18, in part by the Foreign Expert Projects in Heilongjiang under Grant No. GZ20220131.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Aguirre, A. A. A., Medina, R. A. R., and Méndez, N. D. D. (2020). Machine learning applied in the stock market through the moving average convergence divergence (MACD) indicator. Invest. Manag. Financ. Innov. 17, 44–60. doi: 10.21511/imfi.17(4).2020.05
Al-Ani, Y. A. A., and Zubaidi, F. N. M. (2021). Statistical analysis of the anticipated risks of the Iraqi stock market. Ind. Eng. Manag. Syst. 20, 702–711. doi: 10.7232/iems.2021.20.4.702
Ananthi, M., and Vijayakumar, K. (2021). Stock market analysis using candlestick regression and market trend prediction (CKRM). J. Ambient Intell. Hum. Comput. 12, 4819–4826. doi: 10.1007/s12652-020-01892-5
Anghel, G. D. I. (2015). Stock market efficiency and the MACD. Evidence from countries around the world. Proc. Econ. Finance 32, 1414–1431. doi: 10.1016/S2212-5671(15)01518-X
Arashim, R. M. M. (2022). Analysis of market efficiency and fractal feature of NASDAQ stock exchange: time series modeling and forecasting of stock index using ARMA-GARCH model. Future Bus. J. 8, 1–12. doi: 10.1186/s43093-022-00125-9
Barra, S., Carta, S. M., Corriga, A., Podda, A. S., and Recupero, D. R. (2020). Deep learning and time series-to-image encoding for financial forecasting. IEEE CAA J. Automat. Sin. 7, 683–692. doi: 10.1109/JAS.2020.1003132
Cao, Y., Zhou, Z. J., Hu, C. H., He, W., and Tang, S. W. (2021). On the interpretability of belief rule based expert systems. IEEE Trans. Fuzzy Syst. 29, 3489–3503. doi: 10.1109/TFUZZ.2020.3024024
Chen, Y. J., Chen, Y. M., Tsao, S. T., and Hsieh, S. F. (2018). A novel technical analysis-based method for stock market forecasting. Soft. Comput. 22, 1295–1312. doi: 10.1007/s00500-016-2417-2
Chen, W., Zhang, H., Mehlawat, M. K., and Jia, L. (2021). Mean–variance portfolio optimization using machine learning-based stock price prediction. Appl. Soft Comput. 100:106943. doi: 10.1016/j.asoc.2020.106943
Cheng, C. H., and Chen, C. H. (2018). Fuzzy time series model based on weighted association rule for financial market forecasting. Expert. Syst. 35:e12271. doi: 10.1111/exsy.12271
Cheng, C., Wang, J., Zhou, Z., Teng, W., Sun, Z., and Zhang, B. (2022). A BRB-based effective fault diagnosis model for high-speed trains running gear systems. IEEE Trans. Intell. Transp. Syst. 23, 110–121. doi: 10.1109/TITS.2020.3008266
de Oliveira, F. A., Zárate, L. E., de Azevedo Reis, M., and Nobre, C. N.. (2011). The Use of Artificial Neural Networks in the Analysis and Prediction of Stock Prices. IEEE International Conference on Systems, Man, and Cybernetics, pp. 2151–2155.
Feng, F., He, X., Wang, X., Luo, C., Liu, Y., and Chua, T. S. (2019). Temporal relational ranking for stock prediction. ACM Trans. Inf. Syst. 37, 1–30. doi: 10.1145/3309547
Feng, Z. C., He, W., Zhou, Z. J., Ban, X. J., Hu, C. H., and Han, X. X. (2021). A new safety assessment method based on belief rule base with attribute reliability. IEEE CAA J. Automat. SINICA 8, 1774–1785. doi: 10.1109/JAS.2020.1003399
Feng, Z. C., Zhou, Z. J., Hu, C. H., Chang, L. L., Hu, G. Y., and Zhao, F. J. (2019). A new belief rule base model with attribute reliability. IEEE Trans. Fuzzy Syst. 27, 903–916. doi: 10.1109/TFUZZ.2018.2878196
He, G., Zhu, S., and Gu, H. (2020). The nonlinear relationship between investor sentiment, stock return, and volatility. Discrete Dyn. Nat. Soc. 2020:5454625. doi: 10.1155/2020/5454625
Hossain, M. S., Rahaman, S., Mustafa, R., and Andersson, K. (2018). A belief rule-based expert system to assess suspicion of acute coronary syndrome (ACS) under uncertainty. Soft. Comput. 22, 7571–7586. doi: 10.1007/s00500-017-2732-2
Hu, G. Y., Zhou, Z. J., Hu, C., Zhang, B. C., Zhou, Z. G., Zhang, Y., et al. (2020). Hidden behavior prediction of complex system based on time-delay belief rule base forecasting model. Knowl.-Based Syst. 203:106147. doi: 10.1016/j.knosys.2020.106147
Jin, Z., and Guo, K. (2021). The dynamic relationship between stock market and macroeconomy at Sectoral level: evidence from Chinese and US stock market. Complexity 2021:6645570. doi: 10.1155/2021/6645570
Kara, Y., Boyacioglu, M. A., and Baykan, Ö. K. (2011). Predicting direction of stock price index movement using artificial neural networks and support vector machines: the sample of the Istanbul stock exchange. Expert Syst. Appl. 38, 5311–5319. doi: 10.1016/j.eswa.2010.10.027
Kong, G., Xu, D. L., Body, R., Yang, J. B., Jones, K. M., and Carley, S. (2012). A belief rule-based decision support system for clinical risk assessment of cardiac chest pain. Eur. J. Oper. Res. 219, 564–573. doi: 10.1016/j.ejor.2011.10.044
Kong, G., Xu, D. L., Yang, J. B., and Ma, X. (2015). Combined medical quality assessment using the evidential reasoning approach. Expert Syst. Appl. 42, 5522–5530. doi: 10.1016/j.eswa.2015.03.009
Malagrino, L. S., Roman, N. T., and Monteiro, A. M. (2018). Forecasting stock market index daily direction: a Bayesian network approach. Expert Syst. Appl. 105, 11–22. doi: 10.1016/j.eswa.2018.03.039
Salman, A., and Ali, Q. (2021). Covid-19 and its impact on the stock market in GCC. J. Sustain. Finance Invest. 2021:1944036. doi: 10.1080/20430795.2021.1944036
Tanaka-Yamawaki, M., and Tokuoka, S. (2007). Adaptive use of technical indicators for the prediction of intra-day stock prices. Physica A 383, 125–133. doi: 10.1016/j.physa.2007.04.126
Wang, J., and Kim, J. (2018). Predicting stock Price trend using MACD optimized by historical volatility. Math. Probl. Eng. 2018:9280590:12. doi: 10.1155/2018/9280590
Wu, M., and Diao, X.. (2015). Technical Analysis of Three Stock Oscillators Testing MACD, RSI and KDJJ Rules in SH & SZ Stock Markets. In: 4th International Conference on Computer Science and Network Technology (ICCSNT). IEEE, pp. 320–323.
Xiao, C., Xia, W., and Jiang, J. (2020). Stock price forecast based on combined model of ARI-MA-LS-SVM. Neural Comput. Applic. 32, 5379–5388. doi: 10.1007/s00521-019-04698-5
Yang, J. B., Liu, J., Wang, J., Sii, H. S., and Wang, H. W. (2006). Belief rule-base inference methodology using the evidential reasoning approach-RIMER. IEEE Trans. Syst. Man Cybern. A Syst. Hum. 36, 266–285. doi: 10.1109/TSMCA.2005.851270
Yang, J. B., and Xu, D. L. (2013). Evidential reasoning rule for evidence combination. Artif. Intell. 205, 1–29. doi: 10.1016/j.artint.2013.09.003
Yin, X., Wang, Z. L., Zhang, B. C., Zhou, Z. J., Feng, Z. C., Hu, G. Y., et al. (2017). A double layer BRB model for health prognostics in complex electromechanical system. IEEE Access 5, 23833–23847. doi: 10.1109/ACCESS.2017.2766086
Yuan, X., Yuan, J., Jiang, T., and Ain, Q. U. (2020). Integrated long-term stock selection models based on feature selection and machine learning algorithms for China stock market. IEEE Access 8, 22672–22685. doi: 10.1109/ACCESS.2020.2969293
Zheng, L., and He, H. (2021). Share price prediction of aerospace relevant companies with recurrent neural networks based on PCA. Expert Syst. Appl. 183:115384. doi: 10.1016/j.eswa.2021.115384
Zhou, Z. J., Chang, L. L., Hu, C. H., Han, X. X., and Zhou, Z. G. (2016). A new BRB-ER-based model for assessing the lives of products using both failure data and expert knowledge. IEEE Trans. Syst. Man Cybern. Syst. 46, 1529–1543. doi: 10.1109/TSMC.2015.2504047
Keywords: stock market analysis, evidential reasoning, belief rule base, stock market evaluation, decision making
Citation: Chen Y, Liu J, Gao Y, He W, Li H, Zhang G and Wei H (2023) A new stock market analysis method based on evidential reasoning and hierarchical belief rule base to support investment decision making. Front. Psychol. 14:1123578. doi: 10.3389/fpsyg.2023.1123578
Edited by:
Yu-Wang Chen, The University of Manchester, United KingdomCopyright © 2023 Chen, Liu, Gao, He, Li, Zhang and Wei. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wei He, ✉ aGV3ZWlAaHJibnUuZWR1LmNu; Hongyu Li, ✉ aHNkbGloeUAxNjMuY29t
†These authors have contributed equally to this work and share first authorship