 Ali Ünlü
Ali Ünlü
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
HYPOTHESIS AND THEORY article
Front. Psychol. , 25 January 2023
Sec. Quantitative Psychology and Measurement
Volume 13 - 2022 | https://doi.org/10.3389/fpsyg.2022.993660
This article is part of the Research Topic Towards a Basic Standard Methodology for International Research in Psychology View all 15 articles
In self-determination theory (SDT), multiple conceptual regulations of motivation are posited. These forms of motivation are especially qualitatively viewed by SDT researchers, and there are situations in which combinations of these regulations occur. In this article, instead of the commonly used numerical approach, this is modeled more versatilely by sets and relations. We discuss discrete mathematical models from the theory of knowledge spaces for the combinatorial conceptualization of motivation. Thereby, we constructively add insight into a dispute of opinions on the unidimensionality vs. multidimensionality of motivation in SDT literature. The motivation order derived in our example, albeit doubly branched, was approximately a chain, and we could quantify the combinatorial details of that approximation. Essentially, two combinatorial dimensions reducible to one were observed, which could be studied in other more popular scales as well. This approach allows us to define the distinct, including even equally informative, gradations of any regulation type. Thus, we may identify specific forms of motivation that may otherwise be difficult to measure or not be separable empirically. This could help to dissolve possible inconsistencies that may arise in applications of the theory in distinguishing the different regulation types. How to obtain the motivation structures in practice is demonstrated by relational data mining. The technique applied is an inductive item tree analysis, an established method of Boolean analysis of questionnaires. For a data set on learning motivation, the motivation spaces and co-occurrence relations for the gradations of the basic regulation types are extracted, thus, enumerating their potential subforms. In that empirical application, the underlying models were computed within each of the intrinsic, identified, introjected, and external regulations, in autonomous and controlled motivations, and the entire motivation domain. In future studies, the approach of this article could be employed to develop adaptive assessment and training procedures in SDT contexts and for dynamical extensions of the theory, if motivational behavior can go in time.
Knowledge space theory (KST) was introduced by Doignon and Falmagne (1985, 1999), refer also Falmagne and Doignon (2011), which is a relatively recent psychometric theory. Initially, that theory was developed for the assessment and training of knowledge, but has evolved into a broader range of applications (e.g., Albert and Lukas, 1999; Falmagne et al., 2013). KST, as compared with the statistical item response theory (e.g., Van der Linden and Hambleton, 1997), for example, is inherently combinatorial; it did not develop from classical numerical scales in the first place (for a conceptual comparison of these theories, see Ünlü, 2007). The behavioral orientation of KST is good for qualitative modeling. Since numerical values (e.g., person ability or item difficulty) are more strongly aggregated numbers, in particular, restricted by their own natural ordering, the use of more fine-grained combinatorial structures (e.g., persons represented by their sets of skills they possess) allows for greater flexibility in more diagnostic modeling, as we will describe in this article. In a numerical approach, two persons are typically reduced to their aggregate motivation degrees, say 1.27 < 2.35, which are always comparable (real numbers). This is in contrast to representing persons by the sets of motivations they possess, which are not necessarily comparable, for example, if represented by {a, c, e} and {b, c, d}, where neither is a subset of the other. To avoid misconception at this point, obviously, there may be situations where the former perspective is desirable or sufficient for a use case, but if the aim is to have a qualitative assessment or conceptualization, the latter approach may be better suited. It depends on what the research aims are. For example, if ordering motivational behavior along the relative autonomy continuum is preferred, if continuously unidimensional, a quantitative single-valued scoring rule can suffice. However, if the goal is to see which motivations more strongly interrelate to what substantive outcomes, a qualitative model can be more useful. This article assumes that the latter perspective is desired for the problem of interest.
We describe an application of KST to self-determination theory (SDT). SDT was proposed by Deci and Ryan (1985, 2000), refer also Ryan and Deci (2000, 2002). The need for qualitative treatment of motivation was raised by researchers in SDT, in particular by Chemolli and Gagné (2014), with further pertinent SDT references therein, describing empirical problems that required a qualitative conceptualization of motivation (e.g., Koestner et al., 1996; Vansteenkiste et al., 2009). KST can contribute to this endeavor, as this article aims at demonstrating sets and relations among motivations (for advantages and a limitation, refer to section “Usefulness of this approach for motivation research and limitation”).
Why do we treat the dichotomous data case first with this article? We are aware that SDT instruments use Likert scales and that dichotomization of polytomous or continuous data or variables can be controversial, but we have the following reasons. The theory of knowledge spaces is far more advanced in the dichotomous formulation, with a plethora of easier-to-grasp and better-accessible results that can readily be applied in motivation research. For example, if you take Birkhoff’s theorem, an important mathematical as well as methodological result, this theorem is way easier to formulate and understand than its polytomous counterparts. In KST, the polytomous case is an ongoing research, still, many powerful dichotomous concepts of KST have to be generalized and developed for polytomous items, if possible. In addition, dichotomous indicators can provide useful information about binary classification problems, for example, whether a person is intrinsically motivated or not, or more generally, which motivations may or may not be present in the total motivational profile of a person. That is, dichotomous indicators can still be informative enough for such use cases involving binary decisions. Dichotomous results may also be viewed as necessary conditions for a polytomous model, for example, when violated, they may give evidence against the model. In general, results obtained by dichotomous analyses are, albeit rougher, easier to interpret. In particular, what we will see in this article is that the approach based on sets and relations in dichotomous formulation allows us to quantify, combinatorially and qualitatively, how far multidimensionality may be away from unidimensionality, thus contributing to the debated issue of dimensionality in SDT (Chemolli and Gagné, 2014; Sheldon et al., 2017). Anyhow, we have to see the merits of this approach after SDT researchers have given this method a try by testing it across their motivation scales or empirical studies.
How to derive KST relations among motivations from empirical data? We discuss one possibility based on the data-analytic approach of the inductive item tree analysis (IITA). There are other methods as well (e.g., Albert and Lukas, 1999), for example, by querying experts; theory-driven, based on skills or competencies; or by data mining (which is nearest to what we present). Publications to learn more about IITA are Schrepp (1999a,b, 2003, 2006), Sargin and Ünlü (2009), Ünlü and Sargin (2010), and Ünlü and Schrepp (2021). As a well-established method of Boolean analysis of questionnaires, IITA takes as input a data set (e.g., of motivation scores), and in this article, it is treated for the dichotomous case and derives the set of implications deemed to be plausible for the data set according to some faithful criteria. That is, detailed later, the IITA algorithm can be used to extract motivation co-occurrence relations, and thus, by application of Birkhoff’s theorem, quasi-ordinal motivation spaces, from data motivation variables.
In addition to data analysis, rather theoretically, we believe that the application of KST to SDT can in particular be useful for the representation of the logical structure of motivations. Based on mathematical considerations, we may obtain principled definitions of such pertinent concepts as self-determination and derive from these more abstract definitions, results about their universal (mathematical or axiomatic) properties in population instead of sample quantities (Ünlü, 2022).
This article has the following structure. In section “Self-determination theory,” the theory of self-determination is reviewed, and in section “Knowledge space theory, Birkhoff’s theorem, and inductive item tree analysis,” the knowledge space theory. In particular, section “Knowledge space theory, Birkhoff’s theorem, and inductive item tree analysis” also includes a short introduction to IITA and Birkhoff’s theorem. In section “Sets and relations among motivations,” the application of KST sets and relations to motivation is described. The SDT analogs of the basic concepts of KST are the motivation domain, motivation structure, motivation state, motivation co-occurrence relation, and quasi-ordinal motivation space. In section “An empirical application,” an empirical example is provided, which concerns learning motivation. In section “Usefulness of this approach for motivation research and limitation,” we outline why this approach to the modeling and analysis of motivation is useful and a limitation of this study. This article ends with a conclusion in section “Conclusion,” and with Appendices A, B containing the scale and binary data sets used for the empirical application, respectively.
Self-determination theory maintains a comprehensive website at https://selfdeterminationtheory.org. As a theory of motivation, SDT investigates what drives people to act (Ryan(ed.), 2019; Conesa et al., 2022; Gagné et al., 2022). The basic concepts of SDT are best represented by Table 1, a table very often reported in SDT publications, and here, we present a slightly modified interpretation of it.
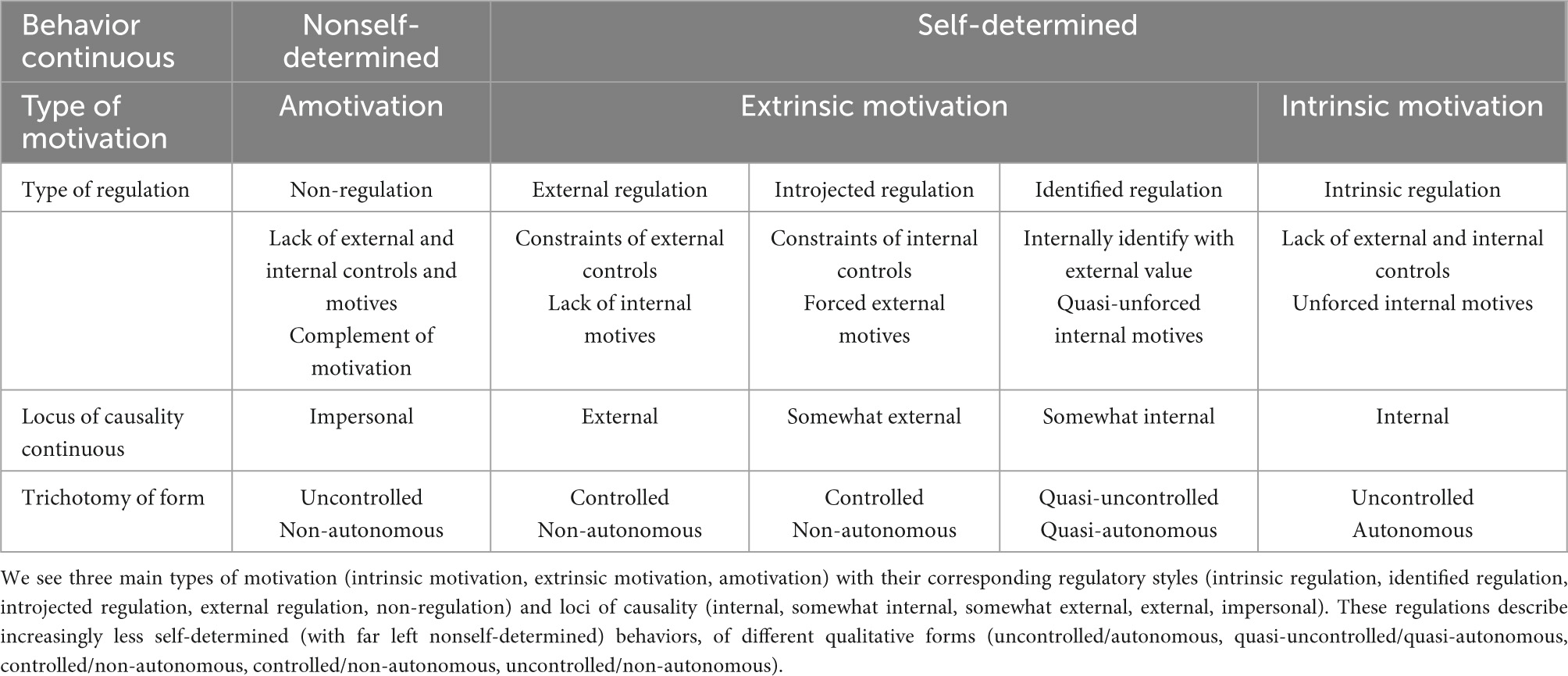
Table 1. Self-determination continuum also called SDT’s taxonomy of motivation (cf., Deci and Ryan, 2000).
Briefly, intrinsic motivation represents behavior enjoyed doing it for its own sake, extrinsic motivation is instrumental behavior, and amotivation is the lack of motivation. SDT does not further differentiate intrinsic motivation and amotivation, thus their single regulations are interpreted accordingly. But extrinsic motivation, which is assumed, can have varying internalization. Extrinsic motivation is differentiated into three (or four) gradually internalized regulation types, in increasing order of internalities, namely, external regulation, introjected regulation, identified regulation, and integrated regulation. Again briefly, external regulation is behavior dictated by purely external factors such as reward or punishment. Introjected regulation is more internalized than external regulation and includes proving oneself worthy or avoiding guilt. Identified regulation is even more internalized than introjected regulation and is described as acting to express rational values without being accompanied by unforced interval motives such as fun or inherent satisfaction. Integrated regulation, although extrinsic motivation, is assumed to be only internal motivation (different from intrinsic regulation), located on the internalization continuum of SDT between identified regulation and intrinsic regulation. With integrated regulation, a person’s identified values are even further internalized and integrated with each other. Integrated regulation seems to be difficult to measure (e.g., Roth et al., 2009; Gagné et al., 2014). In literature, additional forms of motivation have also been proposed, for example, negative introjection (left) and positive introjection (right) in Sheldon et al. (2017) or avoidance introjection (left) and approach introjection (right) in Assor et al. (2009). In each of these cases, both forms of introjection are between external regulation and identified regulation. Probably other forms of motivation may be possible here and there. Why do we list them? In the approach based on sets and relations, which provides a general framework, all of these motivations can be easily included in the formulation of the models. These motivations define what will be called the motivation domain, the set of all motivations of interest. The set and relation representations defined are built upon the specified domain of motivations.
In this article, we show how KST can be applied to qualitatively model these motivations or regulations of SDT’s (extended) taxonomy. Instead of, typically by confirmatory factor analysis, introducing one or more latent continuous dimensions and factors, to represent each of the regulation types, we use sets and relations among those motivations or regulations. A strength of the latter approach is that it allows for very general combinatorial structures and, thus, offers more flexibility in modeling motivation qualitatively (section “Usefulness of this approach for motivation research and limitation”).
We give a short introduction to KST (Doignon and Falmagne, 1985), including the theorem by Birkhoff (1937), and IITA (Schrepp, 1999b; Sargin and Ünlü, 2009). These three components are the building blocks of the methodology used in this article. The core contributions of our study are to apply KST models to represent motivation in SDT, with equivalent mathematical representations at the levels of persons and motivations by Birkhoff’s theorem as a byproduct, and the concrete implementation of those models in data through the use of IITA.
An application with examples of the concepts in motivation presented here can be found in section “Sets and relations among motivations.”
The starting point for a theory of knowledge assessment is to assume that in a knowledge domain of interest, the pieces of knowledge may imply each other. For example, in the knowledge domain of natural numbers, the mastery of the arithmetic problem b “3 ⋅ 2 = ” may imply the mastery of the arithmetic problem a “2 + 2 = ”. That is, the mastery of problem a is assumed to be a prerequisite for the mastery of problem b. Mathematically, this is represented by the ordered pair a ⊑ b of a binary relation ⊑ on the knowledge domain. In accordance with the interpretation of mastery, that relation is assumed to be reflexive and transitive, a quasi-order, or as it is also called in KST, a surmise relation.
Definition 1. Let Q be a non-empty and finite set of dichotomous items, the (knowledge) domain. Let ⊑ be a binary relation on Q, that is, a subset of Q × Q. We call ⊑ a quasi-order or surmise relation (on Q) if and only if it is reflexive and transitive, that is, if and only if, respectively, x ⊑ x for all x ∈ Q, and x ⊑ y, y ⊑ z implies x ⊑ z for all x, y, z ∈ Q.
Typically, Q can be a psychological or educational test consisting of dichotomous questions or problems that can either be solved (coded 1) or failed (coded 0) by examinees, and a surmise relation on that test then captures the mastery dependencies among the test items.
The implications of the surmise relation entail that only certain mastery patterns, represented by subsets of the domain, are admissible, which are called the knowledge states. For example, the subset of items is mastered by a student’s, her or his, knowledge state. If it contains the multiplication item b, then it must also contain the addition item a, since a ⊑ b. The collection of all so compatible knowledge states is called the knowledge structure. In ideal conditions, if no response errors occur, the only response patterns possible would be the knowledge states.
Definition 2. Let Q be a domain. A knowledge structure ℋ on Q is a set of subsets of Q, which contains at least the empty set ∅ and Q itself. The elements of ℋ are called knowledge states.
Knowledge states are subsets of Q. Thus, we can take their union ∪ and intersection ∩, which yield the important special case of a knowledge structure, a quasi-ordinal knowledge space.
Definition 3. Let ℋ be a knowledge structure on the domain Q. We call ℋ a knowledge space (on Q) if and only if G ∪ H ∈ ℋ for all G, H ∈ ℋ. The knowledge structure ℋ is a closure space (on Q) if and only if G ∩ H ∈ ℋ for all G, H ∈ ℋ. A quasi-ordinal knowledge space is a knowledge structure that is both a knowledge space and a closure space.
The quasi-ordinal knowledge space model is the set representation at the level of persons and the surmise relation model is the order representation at the level of items. They correspond to a person’s ability and item difficulty of numerical item response theory. In contrast to the numerical approach, in KST, the two representations are connected by a central mathematical theorem, which is Birkhoff’s theorem. The details of this theorem can be found in Falmagne and Doignon (2011, section 3.8, pp. 56–58).
Theorem 1 (Birkhoff, 1937). There exists a one-to-one correspondence between the collection of all quasi-ordinal knowledge spaces ℋ on a domain Q and the collection of all surmise relations ⊑ on Q, defined by the two equivalences, for p, q ∈ Q, H ⊆ Q,
This theorem mathematically links two different levels of empirical interpretations. It will be applied to SDT and exemplified in section “Sets and relations among motivations.”
Validation procedures were proposed in the literature based on probabilistic extensions of knowledge structures. The most prominent one is the basic local independence model, a latent class scaling model (Doignon and Falmagne, 1999, chapter 7). For logistic and generalized normal ogive statistical validation procedures in KST, refer to Stefanutti (2006) and Ünlü (2006), respectively. Latent class analysis exploratory, estimation, and testing procedures were also studied for knowledge structures (Schrepp, 2005; Ünlü, 2011). For recent developments in performance- and competence-based knowledge space theory, including further, also more qualitative, validation procedures, refer to Falmagne et al. (2013).
In IITA, competing relations are generated and a fit measure is computed for each of these relations in order to find that relation which most adequately describes the data. Since traditional inference-based methods, such as (asymptotic) chi-squared goodness-of-fit tests (available as well), do almost always reject the wished model (placed in the null hypothesis), this class of IITA relational mining techniques is generally effective and more useful. The R (The R Core Team, 2022) package DAKS (Ünlü and Sargin, 2010) freely available at https://CRAN.R-project.org/package=DAKS implements the IITA procedures, in addition to software by Schrepp (2006).
What is the general problem addressed by IITA? Assume that you have noisy indicators for latent variables of interest and that among those latent variables there exist latent logical, that is, deterministic, implications. The goal of IITA is to detect these implications from the information on the indicators. A typical KST example of an implication, refer section “Knowledge space theory and Birkhoff’s theorem,” is that the mastery of a math problem may imply the mastery of another math problem, where the questions of a math test are the indicators. In section “Sets and relations among motivations,” we apply this idea to motivation in SDT. There, the indicators are the test items of a motivation questionnaire (https://selfdeterminationtheory.org/questionnaires), which measure their underlying, for example, intrinsic and external regulations. Then, a logical implication between motivations assumes that the latent possession or occurrence of a motivation implies the possession or occurrence of another motivation. If in a study such motivational implications are deemed to be realistic or of interest, IITA is a technique that can be used to uncover those implications from the motivation questionnaire data.
The IITA algorithm consists of three computational components. First, it constructs a selection set of competing quasi-orders on the domain of latent (e.g., motivation) variables. That construction is inductive. For varying numbers of observed counterexamples of an (e.g., motivational) implication (premises true but conclusions false), anchored with the simplest quasi-order consisting of all implications that are not violated in the data, in successive steps, quasi-orders (e.g., motivation co-occurrence relations) are constructed. This is realized by adding specific implications that have no more than the predefined numbers of counterexamples in the data set and that do not violate transitivity. In this way, a maximum of sample size plus one, typically a much smaller number than this, of increasingly more complex quasi-orders are derived. Second, the fit of each constructed quasi-order to the data set is quantified by a measure of the average squared differences between the observed and under the model expected numbers of counterexamples for the implications. Third, a best-fitting (e.g., motivation co-occurrence) relation of the selection set with the computed minimum discrepancy is chosen as the final solution. Subsequently, we outline these components of the technique, and more details can be found in Ünlü and Schrepp (2021, section 2).
We start with notation. Let Q = {i1, …, im} be the domain of m ≥ 2 dichotomous items. Let D = {d1, …, dN} be the data set (with repetitions) of observed response patterns (mappings) dn : Q → {0, 1}, where dn (i) = 0 or 1 stands for the response of the subject n = 1, …, N to the item i ∈ Q. For i, j ∈ Q, let bij = |{d ∈ D : d(i) = 1 ∧ d(j) = 0}| be the number of subjects of the sample who solved item i but failed item j. If we postulate the implication i ⟶ j (Definition 5), bij is the number of observed counterexamples for that implication. We can define the binary relation ⊑0 of all implications that are not violated in data D by j⊑0i :⟺ bij = 0 for all i, j ∈ Q. This relation ⊑0 is a quasi-order on Q (Van Leeuwe, 1974). However, this is not the final quasi-order that IITA returns. To accept ⊑0 is generally not satisfactory since this is data fitting, which does not account for response errors. Thus, IITA allows for varying numbers of observed counterexamples L = 0, 1, …, N.
The construction of the quasi-orders is as follows. The IITA algorithm starts with ⊑0, but inductively constructs bigger quasi-orders. The procedure to construct the L + 1 step quasi-order ⊑L+1 from the L step quasi-order ⊑L, anchoring with ⊑0, for L = 0, 1, …, N − 1, consists of the following steps 1, 2, and 3:
1. To determine the set AL+1 of all item pairs that are not already contained in ⊑L and have no more than L + 1 observed counterexamples in D.
2. To iteratively repeat the following two operations a and b:
a. For each element of AL+1, check if it violates transitivity in ⊑L ∪ AL+1. If so, mark that element.
b. If no element is marked in operation a, stop step 2. Otherwise, delete all marked elements from AL+1 and restart the process in operation a with this reduced new set AL+1.
3. When the process in step 2 stops, the remaining implications in AL+1 do not violate transitivity in ⊑L ∪ AL+1. By construction, ⊑L+1 := ⊑L ∪ AL+1 is the L + 1 step quasi-order.
Thus, by IITA, the increasingly bigger quasi-orders ⊑0 ⊆ ⊑1 ⊆ … ⊆ ⊑N are inductively constructed.
Among these relations, IITA proposes the following method to determine the best-fitting quasi-order. We quantify the fit of any of the IITA quasi-orders ⊑L, L = 0, 1, …, N to the data set D by the measure:
where the sum is taken over all item pairs (j, i) ∈ Q × Q, i ≠ j, and m is the number of items. In addition, bij is the observed number of subjects who solved item i but failed item j, and tij is the corresponding theoretical value expected and derived under the assumption that ⊑L is the correct quasi-order underlying the data set D.
The derivation of the tij estimators is intricate and necessitate a few considerations.
1. Assume that ⊑L, for a given L, is the quasi-order of true logical implications between the items. How many violations for a true implication i⟶Lj, i, j ∈ Q can we expect? If we assume a single response error probability by which a true implication may be violated, that rate can be estimated by:
where 𝒢 = {j⊑Li : i ≠ j ∧ pi ≠ 0}, and , i ∈ Q is the relative frequency of subjects of the sample who solved item i. Thus, γL is an estimated average amount of random response errors in the data, under the assumption that ⊑L is the underlying true quasi-order. For further motivation for this choice of estimator, refer to Ünlü and Schrepp (2021).
2. Under the assumption that ⊑L is the correct quasi-order, thus based on the corresponding estimated error probability γL, for any item pair (j, i) ∈ Q × Q, i≠j, the, under ⊑L derived, theoretical values tij used in the definition of the diff measure can be estimated as follows: three cases are distinguished (for more details, refer to Ünlü and Schrepp, 2021). First, if j⊑Li, i≠j, use the estimation equation tij = γLpiN. Second, if j⋢Li and i⋢Lj, assume that the items are stochastically independent, and set tij = (1 − pj)piN. Third, if j⋢Li but i⊑Lj, the estimator is tij = max(0, (pi − pj + pjγL)N).
A validation procedure is obtained that gives information about which model to pick. With the above ingredients, in data D, the fit measure diff is computed for each quasi-order obtained by inductive construction. Thus, a non-negative real value is associated with any of the competing quasi-orders. Since diff quantifies an average squared difference between observed and expected variables, smaller values of the measure are interpreted to indicate a better fit. In particular, the decision rule is to select that quasi-order among ⊑0, ⊑1, …, ⊑N, which has the minimum diff value. This is the final solution returned by the IITA algorithm.
We apply the basic concepts of KST to SDT and describe them in motivation.
Before presenting the definitions, a general remark is in order. The program of this article has far-reaching consequences (section “Usefulness of this approach for motivation research and limitation”). The KST models applied to motivation can be used to develop routines in motivation research for the adaptive assessment and training of motivation using computers. Adaptive testing is the major strength and point of origin of KST (Falmagne et al., 2013, with references therein). Noteworthy, there is an essential difference between the educational vs. motivational applications of the models. The number of conceivable states of motivation in SDT may not be that large as compared with the states of knowledge studied in KST, with several million feasible knowledge states in large-scale empirical studies. This is clearly an advantage of the SDT application, in particular, for combinatorial as well as statistical reasons.
We want to motivate the basic concepts by an example, and then give the definitions for motivation. Consider the regulations, for ease of presentation with no gradations of the regulations (generalized below), external regulation a, introjected regulation b, identified regulation c, and intrinsic regulation d. These motivations make up the motivation domain of interest, that is, the set of all considered motivations M = {a, b, c, d} (other choices for the domain are discussed later). The central assumption is that these motivations can only occur in certain combinations in the population of reference, called the motivation states, which are subsets of the motivation domain. For example, a student could be externally and introjectedly motivated at the same time, represented by the state or subset {a, b} of the motivation domain. Or, this is an assumption that can change depending on the model used; for a student to be intrinsically motivated, the student necessarily needs to have the other three motivations. In this case, M = {a, b, c, d} is the only possible motivation state containing intrinsic regulation, and other combinations containing intrinsic regulation such as {a, d} (externally and intrinsically motivated) or {d} (only intrinsically motivated) are excluded according to the posited model. Since amotivation is understood to be the state of no motivation, this could be modeled by a specific subset, the empty set ∅. We can collect together all feasible combinations of motivations, the motivation states, into a set on its own, called the motivation structure. In this example, the combinations {a, b} and M belong to the motivation structure, but not {a, d} and {d}. As mentioned, if this model is deemed to be empirically inadequate, it can be replaced by another model; the mathematical definition allows us to flexibly define the states, that is, the combinations of motivations considered to be feasible or occurring in an empirical study. The practical derivation of the motivation structure can be (inclusive “or”) theory-driven, derived from querying experts, or obtained by statistics and data analysis, where the latter is the approach pursued with this article. Let us assume that a researcher has identified the following motivation structure in the motivation domain of her study,
This motivation structure captures the logical organization of the motivations of interest in the population of reference. Only those combinations of the motivations are feasible, in the sense that they have shares of the population. Mathematically though, the motivation structure is defined to always include the empty set and the motivation domain, for technical reasons. Leaving out these extreme states from the definition of a motivation structure, in principle you could, will complicate, or probably invalidate, mathematical results, at least in their common formulations. We will stay with the definition used in KST and include as stated always the empty set and the motivation domain itself. So, amotivation, if modeled as the empty set, in contrast to the element(s) of the domain, and the possibility of possessing all regulations jointly are assumed to be motivation states under any deterministic model. Thus, if these extreme motivation states do not occur, any specified deterministic model will be wrong in those states. Otherwise, the deterministic model can always be chosen to be correct in all other states. However, this “methodological artifact” is not restrictive from an empirical viewpoint. In practice, if any of these two states is deemed to be empirically implausible, its probability of occurrence in the population of reference will (virtually) be zero, thus it will be discarded in the probabilistic formulation and extension of the deterministic model. However, as seen below, at the level of motivations viewed as “items” composing the states, this subtle issue is resolved and does not appear.
The motivation structure ℳ in Eq. 1 induces the two directed graphs shown in Figure 1, which suggests a process of how motivation may progress from state to state, for example, over time. Figure 1 helps to indicate the general idea, and in particular, the flexibility that comes with such a discrete mathematical structure. Depending on the empirical situation, a proper model could be specified (e.g., quantitatively by exploratory data analysis, below), allowing for the qualitative, or even dynamic over time, analysis of motivation.

Figure 1. The directed graphs, in black and red, respectively, of the motivation structure ℳ = {∅, {a}, {b}, {a, b}, {b, c}, {a, b, c}, M}, with M = {a, b, c, d}. A black arc (directed edge) A ⟶ B linking the motivation state A (left) to the motivation state B (right) means A ⊂ B (A subset of B) and there is no other motivation state between the two. A red arc B ⟶ A linking the motivation state B (right) to the motivation state A (left) stands for B ⊃ A (B superset of A) and there is no other state in between. A trajectory describing the transition from the state of pure external motivation {a} to the state of pure introjected motivation {b}, along directed edges (of both colors) in only states of the motivation structure, is shown in green, {a} ⟶ {a, b} (black arc) and {a, b} → {b} (red arc). Another trajectory, now from state {b} to state {a}, posited under this model, probably critical empirically, is to become amotivated first, purging the existent introjected motivation, before the other external motivation can be gained, shown in blue. In particular, there is no direct arc linking the two motivation states, thus, according to this model, external motivation cannot be directly converted into introjected motivation and vice versa, but instead, for example, under the green trajectory, must be attained jointly first before the initial one is forfeited to end up with the other. In these graphs, motivations are gained or lost one by one in progressions from state to state. Restrictions of this sort imply serviceable mathematical properties.
With motivation progression, things can get mathematically more tractable, if only “learning” is possible. That is, if only additional, new motivations are attained, one by one, and no motivations are lost during progression, moving from left to right in the graph of Figure 1, along the black arcs only. In such a more restrictive model, in this example, a student cannot reach the states of pure external motivation or pure introjected motivation if she or he is initially only introjectedly or externally motivated, respectively. This would be prohibited by model assumption. This case of only “learning,” that is, merely moving from left to right along black arcs, cumulative in the “items” or motivations “learned,” one at a time, is the case that has been extensively studied in dichotomous KST. It is especially interesting, if justifiable in a study on motivation, since it entails a rich mathematical theory, implying strong mathematical measurement properties (Falmagne and Doignon, 2011).
Here is the definition in terms of motivation.
Definition 4. Let M be a non-empty set of motivations or regulations (examples below). Let ℳ be a collection of subsets of M, which contains at least ∅ and M. Then, ℳ is called a motivation structure on (or in) the motivation domain M. The elements of ℳ are the motivation states.
Example 1. We consider the general case. The motivation domain M could consist of k forms (gradations) of non-regulation a1, …, ak; l forms of external regulation e1, …, el; m forms of introjected regulation j1, …, jm; n forms of identified regulation d1, …, dn; u forms of integrated regulation g1, …, gu; and o forms of intrinsic regulation i1, …, io. In this case, the extreme motivation state M describes hypothetical behavior that is regulated by all types jointly. The other extreme state ∅ may represent a sort of totally unregulated behavior, unexplainable by any of the types (regarding the extreme states, refer to the aforementioned text). The motivation structure in this domain can contain arbitrary combinations of these regulations, such as the state consisting of the last form of external regulation and the first two (if o ≥ 2) of intrinsic regulation {el, i1, i2}, which represents a student extrinsically and intrinsically motivated in respective gradations of the regulations.
Example 2. Let the notation be as in Example 1. Assume that the motivations are not further graded, k = l = m = n = o = 1, where integrated regulation is not of interest (in the sequel). If non-regulation a, external regulation e, introjected regulation j, identified regulation d, and intrinsic regulation i can only occur separately,
If, in this representation, the intermediate introjected and identified regulations have cumulative gradations j1≼j…≼jjm and d1≼d…≼ddn, indexed in the increasing rankings of their linear orderings ≼j and ≼d (orders are treated later),
We present the corresponding directed graphs of Example 2 in Figure 2.
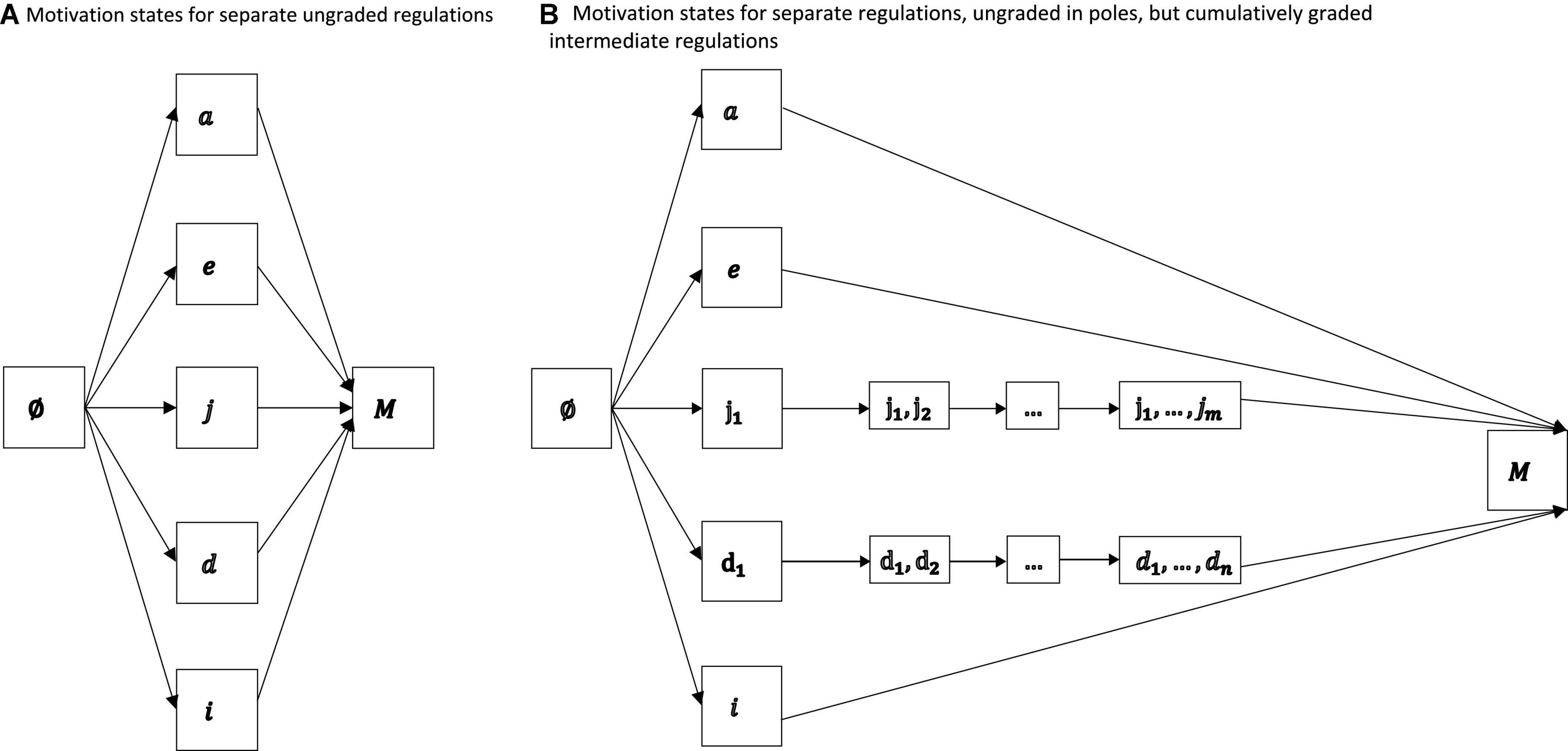
Figure 2. Motivation states for separate ungraded regulations (A) and separate but cumulatively graded intermediate regulations (B). In both representations, non-regulation, external regulation, and intrinsic regulation are singletons. The linear orders imposed on the gradations of introjected regulation and identified regulation could be associated with the varying cumulative internalities that the gradations may have along an internalization continuum.
Besides motivation structures, the set representation, there is the other representation based on relations. We can adumbrate how the two representations are connected by reconsidering the example with ℳ = {∅, {a}, {b}, {a, b}, {b, c}, {a, b, c}, M} in Eq. 1. These states are the combinations of motivations that people can have. Under this model, if a person possesses motivation c, that is, if she or he is in one of the states {b, c}, {a, b, c}, or {a, b, c, d}, then this person must also possess motivation b, since b is in all motivation states that contain c. That is, (for any person) if motivation c occurs/is possessed, then motivation b occurs/is possessed. We also express this by saying that motivation c implies motivation b (always in the interpretation of occurrence or possession), denoted by c ⟶ b or b ⊑ c. Similarly, we see that if motivation d is possessed, then necessarily all other motivations must also be possessed, that is, d implies a, b, and c; for, the only state containing d is M, which contains all other motivations. Thus, a, b, c ⊑ d. In addition, the motivations a and b do not imply each other, since the motivation states {a} and {b} contain the motivations a and b, but not b and a, respectively. Note that this does not exclude that both motivations can occur jointly, for example, with state {a, b}. In this way, we inspect all pairs of motivations to determine whether these motivations are in relation or not, thereby yielding the following motivational implications or relation pairs a ⊑ d and b ⊑ c ⊑ d (including b ⊑ d). Thus, this construction, which is one part of Birkhoff’s theorem, the direction from set to relation, is concrete. The other direction from relation to set is also comprehensible and accordingly obtained. We define those subsets of the motivation domain to be motivation states that are consistent with all implications or pairs of the relation. For example, given the above relation ⊑, since d implies a, b, and c, we cannot take {a, d} to be a motivation state since it is not consistent with the relation ⊑, which requires that if d is possessed, then all of the other motivations must also be possessed. This subset {a, d} of the motivation domain contains d, but not the required, implied, motivations b and c. Since motivation a has no prerequisite motivation in the relation ⊑, that is, since it does not imply any other motivation, it can occur as the only motivation. That is, {a} is consistent with ⊑, and thus, a derived motivation state. In this way, we can check for any subset of the motivation domain whether this subset contains with any of its motivations also all of the motivations implied by this motivation in the underlying relation. This constitutes the other part of Birkhoff’s theorem. In accordance with the interpretation of motivation in possession or occurrence, we call this relation ⊑ corresponding to ℳ, which is the collection of all these derived pairs of motivations, a motivation co-occurrence relation (formally defined below).
Basically, the two representations are mathematically equivalent, but empirically they are interpreted at two different levels. From a practical viewpoint, the representation based on motivation structures is at the level of persons, whereas the co-occurrence relation is at the level of motivations “viewed as items.” What do we mean by this? A motivation structure describes the feasible combinations of the motivations people can have. An element of the structure is the motivation state of a person, a collection of regulations that jointly characterize a person. In contrast, the representation based on relations asks for valid hierarchical dependencies, a relation ⊑, among the regulations, similar to ordering items, for example, by item difficulty. For a pair of motivations x and y, we set x ⊑ y, if possessing motivation y entails possessing motivation x. This could result from or include, for example, when temporally one motivation (x) is attained before or at the same time as the other motivation (y). This implicational interpretation of motivation is general. In fact, if the concept of motivation structure is deemed to be empirically plausible, this entails the plausibility of implications between the motivations as the two formulations are connected mathematically as well as by interpretation. In addition, a special case of co-occurrence relation is the trivial relation, the diagonal, according to which no implications between the regulations are assumed, except for the reflexive implications, which are tautologies. Thus, mathematically also this case of completely unrelated regulations is contained in the definition of motivation co-occurrence relation.
Definition 5. Let M be the motivation domain. Assume that we can form pairs (x, y) of the regulations of the domain (e.g., if possession of y implies the possession of x). Let the set of all these pairs of regulations be denoted as ⊑. For a pair (x, y) in ⊑, we can also write x ⊑ y. We call this set ⊑ a motivation co-occurrence relation if and only if it has the following additional properties, for any choice of regulations x, y, z of the domain:
1. x ⊑ x (reflexivity)
2. if x ⊑ y and y ⊑ z, then x ⊑ z (transitivity).
That is, a motivation co-occurrence relation is a quasi-order (e.g., Davey and Priestley, 2002) on the motivation domain. If x ⊑ y, we say that y implies x, and write y ⟶ x.
The axioms of reflexivity and transitivity are empirically necessary. It is obvious that under the motivation possession interpretation, the properties of reflexivity and transitivity necessarily hold. Reflexivity is logically trivial. Possession of x implies the possession of x. We must also have transitivity. If possession of z implies the possession of y, and possession of y, in turn, implies the possession of x, then possession of z must also imply the possession of x. Thus, if we derive implications between motivations consistently in this interpretation, the resulting relationship will be reflexive and transitive, a motivation co-occurrence relation.
The two representations based on motivation structure and motivation co-occurrence relation are basically equivalent. You have to additionally assume that the motivation structure is closed under (set) union and intersection.
Definition 6. Let ℳ be a motivation structure. A motivation structure is closed under union or intersection if the unions or intersections of motivation states are again motivation states, respectively. We call the motivation structure ℳ a motivation space if ℳ is closed under union. The motivation structure ℳ is called a motivation closure space if ℳ is closed under intersection. If the motivation structure ℳ is closed under union and intersection, ℳ is called a quasi-ordinal motivation space. That is, quasi-ordinal motivation spaces are motivation spaces and motivation closure spaces.
In this article, because of Birkhoff’s theorem, we are mainly concerned with quasi-ordinal motivation spaces.
Example 3. The motivation structures ℳ1 and ℳ2 in Example 2 are motivation closure spaces, but not motivation spaces, and thus, not quasi-ordinal motivation spaces. The motivation structure ℳ in Eq. 1 is a quasi-ordinal motivation space.
We recap the old, but important theorem by Birkhoff (1937) informally, which allows us to switch between the two representations of motivation, on the one hand as a motivation structure and on the other as a motivation co-occurrence relation. In applications, you could choose between the two representations depending on the focus of the study. For example, if progressions in motivation states of persons during dynamic motivation assessment are tracked (Figure 1), the representation by sets can be adequate. Or, if dependencies between motivations regarding their occurrences are of interest (Figure 3), the representation by relations is more useful. We loosely present Theorem 1 in its interpretation in motivation as a corollary, but the corresponding constructions were discussed in the example before.
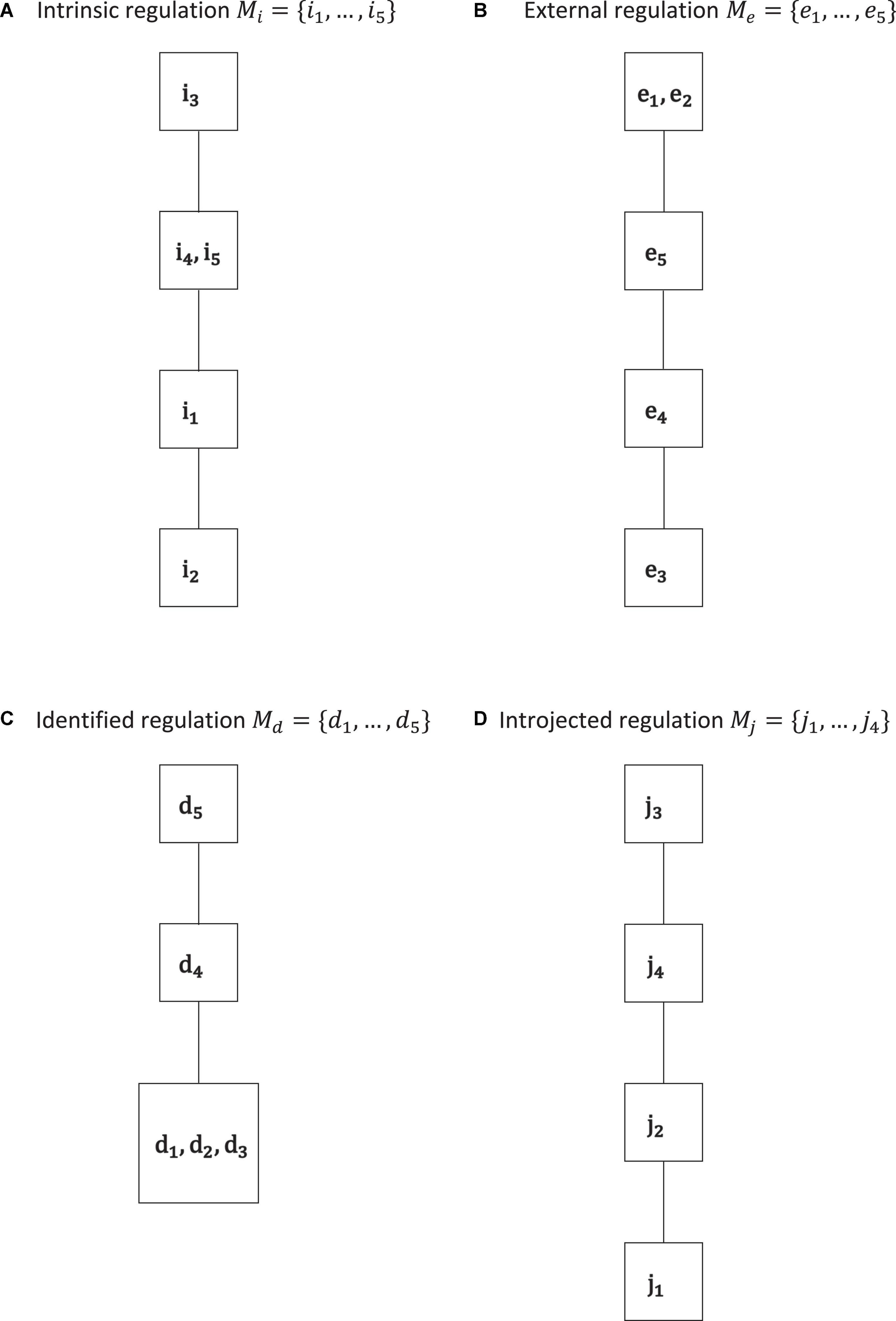
Figure 3. Motivation co-occurrence relations obtained by IITA of the empirical data set for the types of intrinsic regulation (A), external regulation (B), identified regulation (C), and introjected regulation (D). In each type, we see gradations that are cumulative, in the sense that they form linear orders or chains. Except for introjected regulation, there are equally informative gradations.
Corollary 1. Let M be any motivation domain. For each motivation structure on M, which is a quasi-ordinal motivation space, you can construct a unique motivation co-occurrence relation on M, which is, in the above coherent sense, consonant with this space. Vice versa, for each motivation co-occurrence relation on M, a corresponding unique and consonant quasi-ordinal motivation space on M can be constructed. Since this is bijectively possible, meaning the two constructions define inverse transformations to each other, respecting the particular discrete properties, there is no loss of combinatorial information when changing from one representation to the other.
In this section, we discuss an illustrative example of the approach based on sets, relations, and IITA. We used data kindly provided by Müller et al. (2007). The data comprise the learning motivation subscale scores of Austrian pupils in different school class subject areas. Investigated were five items each for the intrinsic regulation and external regulation subscales, and five and four items for the intermediate identified regulation and introjected regulation subscales, respectively. For further information about the scale and for the data sets of the empirical application, see Appendices A, B. Free software to run IITA analyses can be found in Schrepp (2006) and Ünlü and Sargin (2010).
In the original data, the scores ranged from (integer) 1 − 5, including missing values, with a higher score indicating a higher level of endorsement of a regulation. The data were dichotomized relative to the center at the mid-value 3 (balanced score) of the scale. The scores x ≤ 2 (non-affirmative scores) were set to 0 and scores x ≥ 4 (affirmative scores) were set to 1. Thus, the dichotomous score 0 encoded the negative manifest response (not endorsed regulation) and negative latent response (not possessed regulation), and 1 the positive manifest response (endorsed regulation) and positive latent response (possessed regulation). Response patterns containing at least one balanced score of 3 or missing values were discarded. The sample sizes for the used subsets of motivations ranged from N = 180 up to 1, 168 cases for all motivation variables altogether or only the introjected subscale, respectively (Table 2). For all resulting data sets, refer to Appendix B.
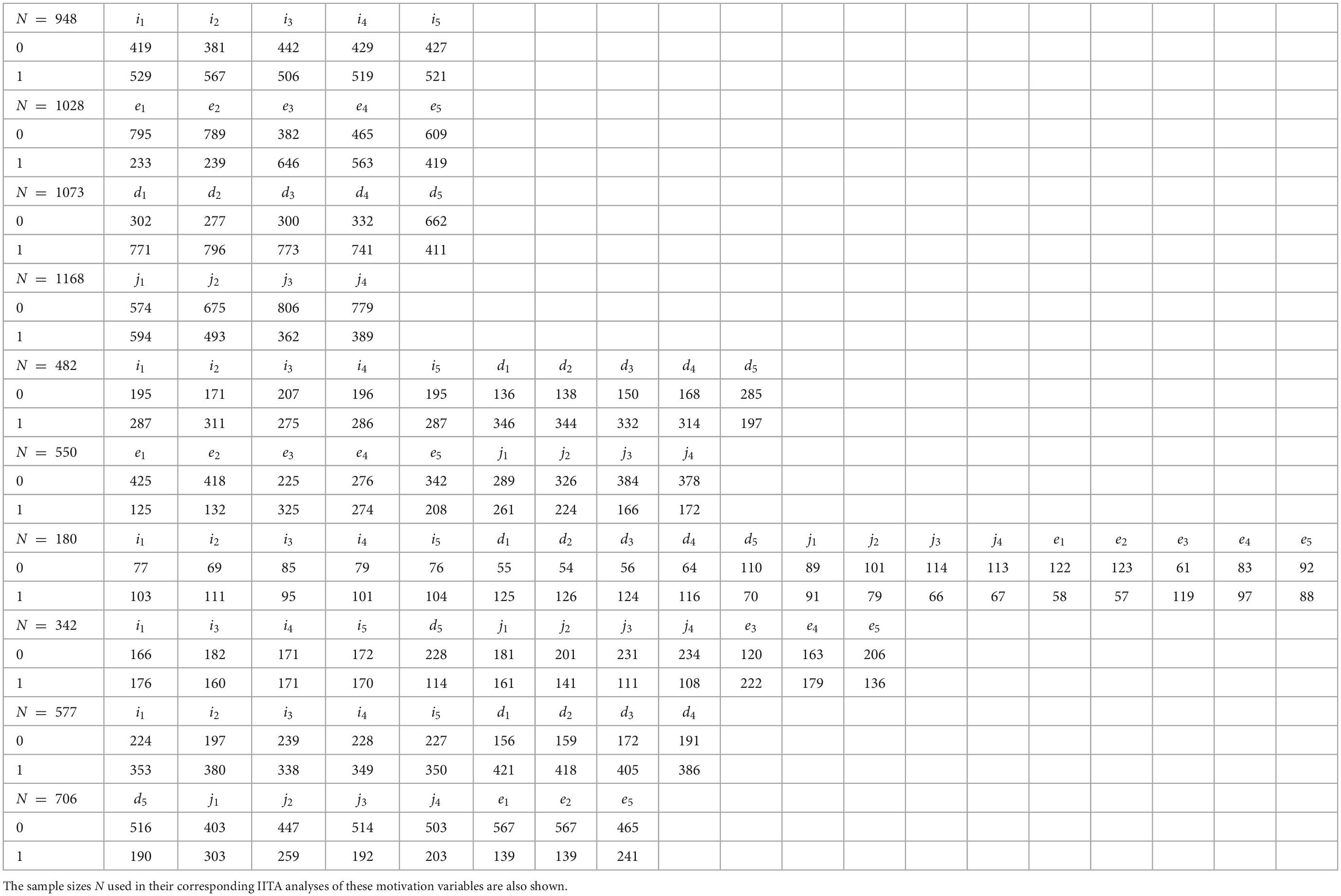
Table 2. Frequency distributions of the dichotomous scores across motivation variables of, from top to bottom, the individual regulation types, of autonomous motivation and controlled motivation, of the entire motivation domain, and the subsets A, B, and C of the data set, respectively.
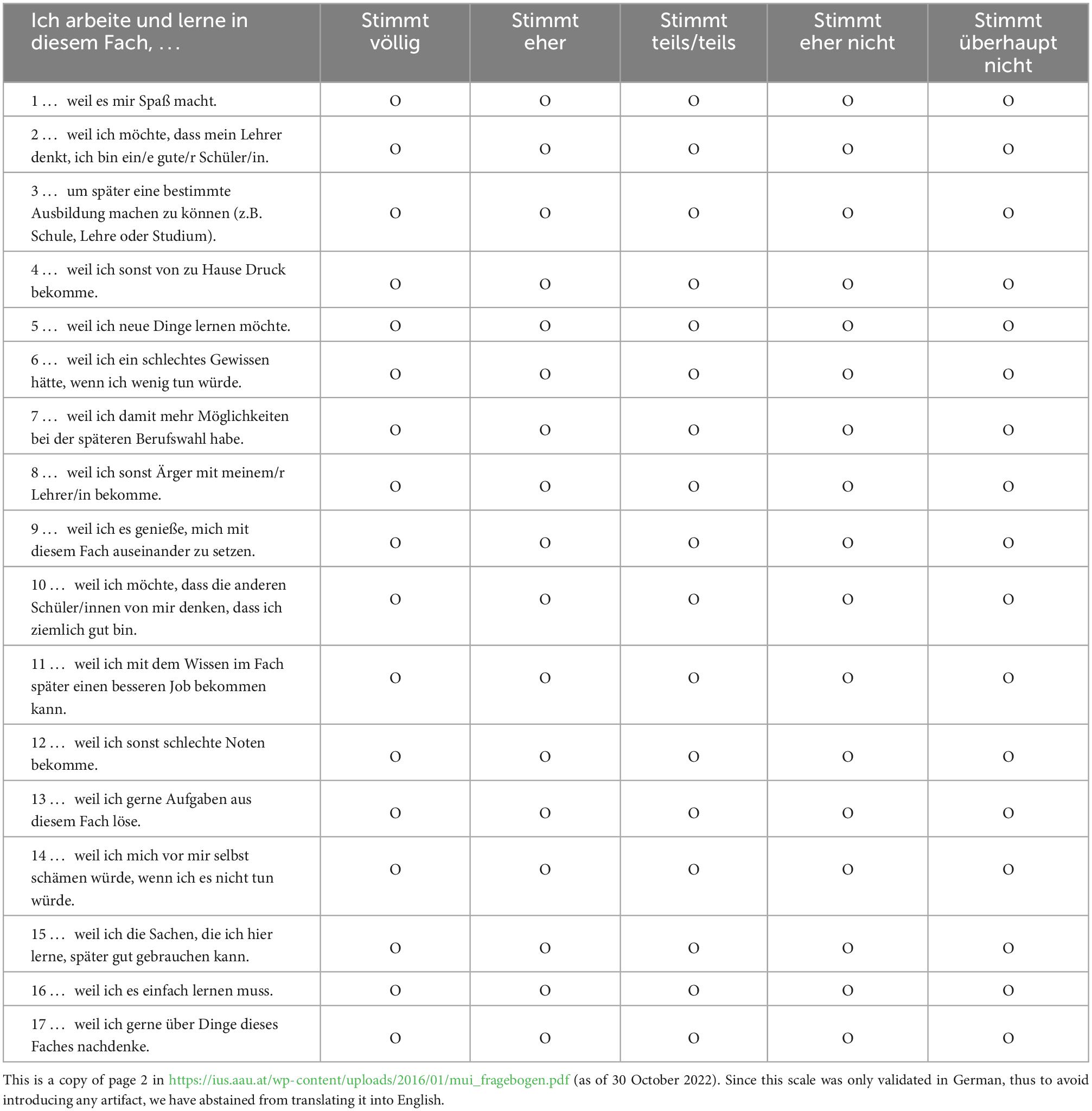
Table 3. The scale (Müller et al., 2007) used for the empirical application (Appendix A).
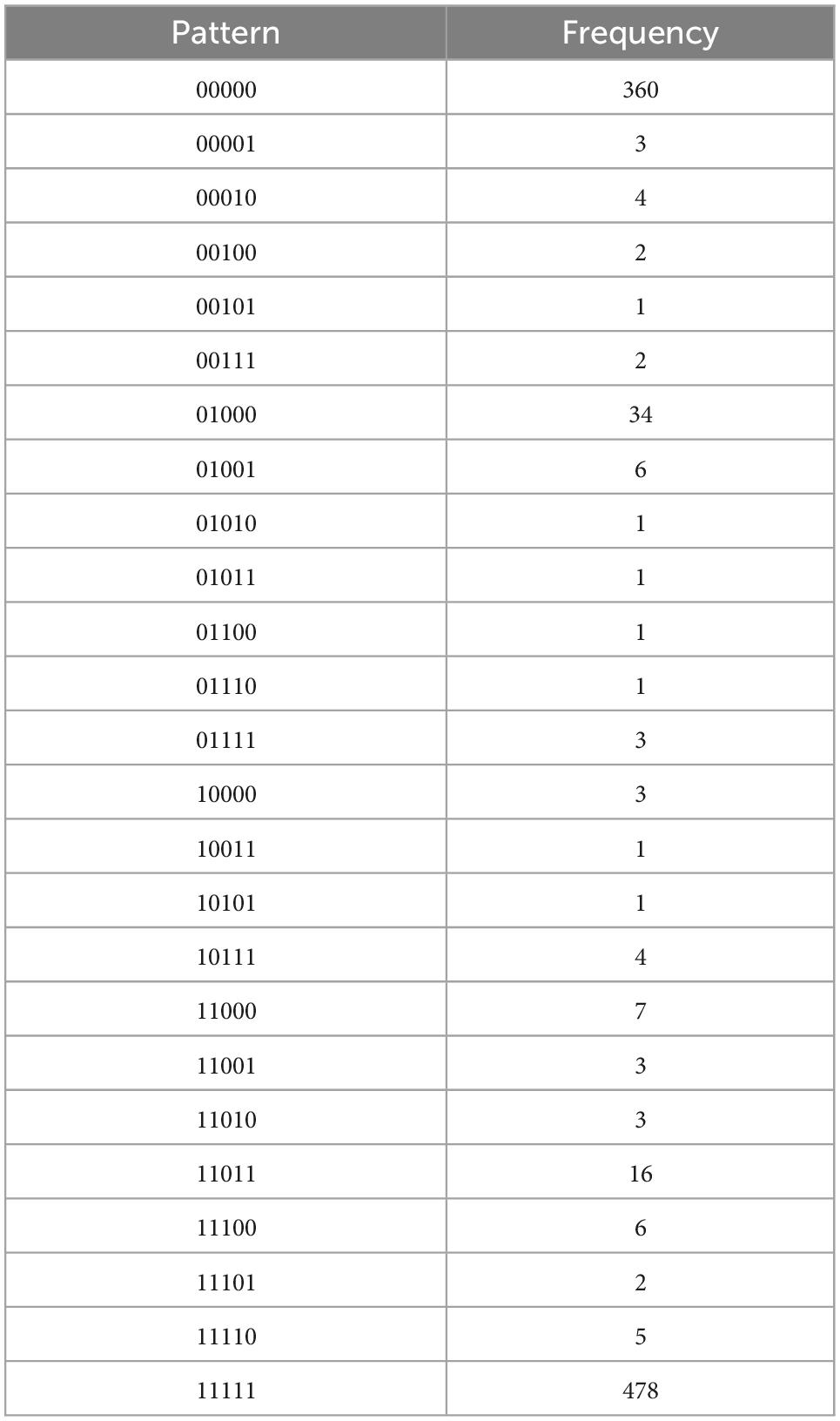
Table 4A. Intrinsic regulation, with N = 948, k = 5 items, and u = 25 unique response patterns (Appendix B).
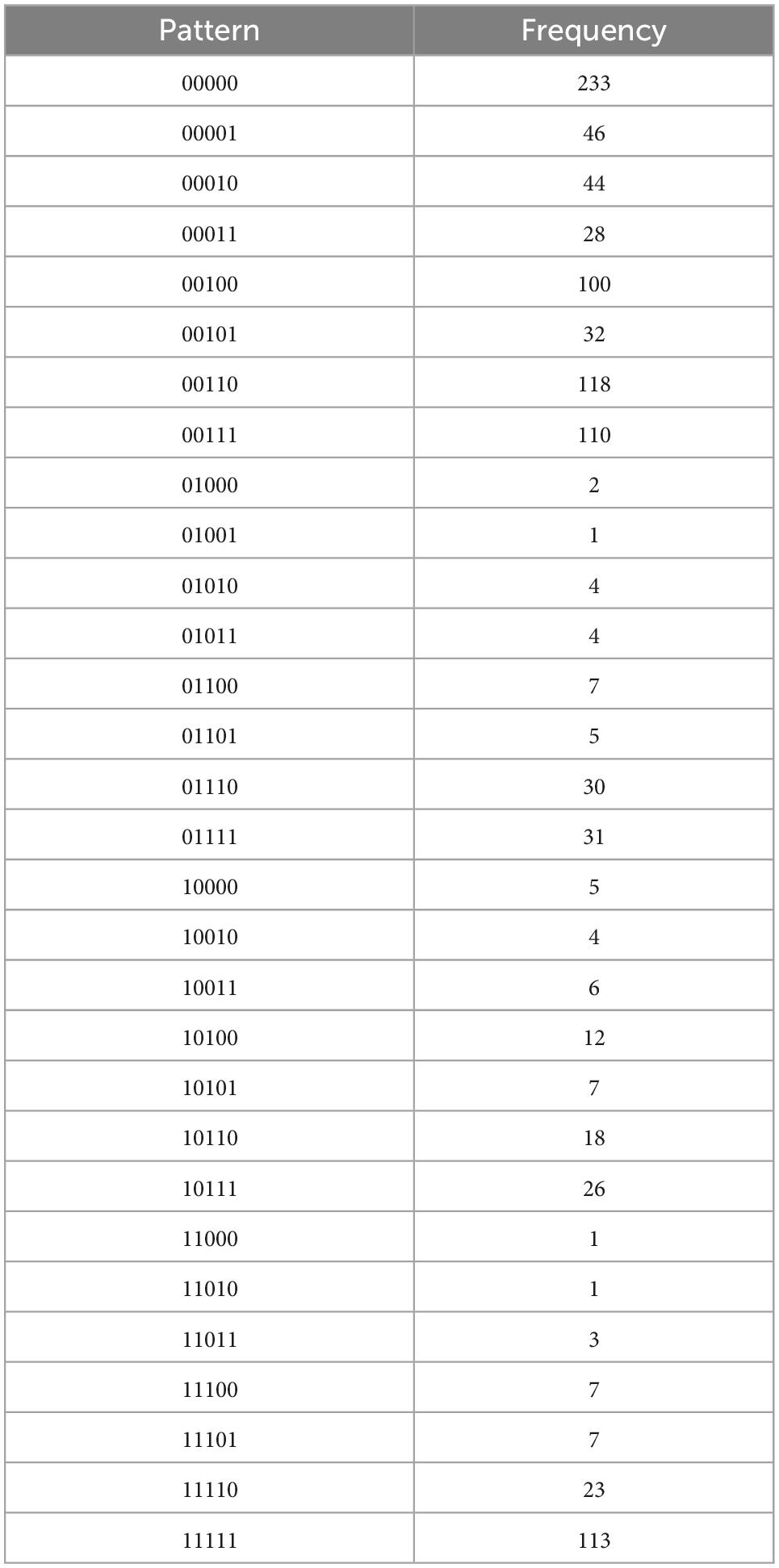
Table 4B. External regulation, with N = 1028, k = 5 items, and u = 30 unique response patterns (Appendix B).
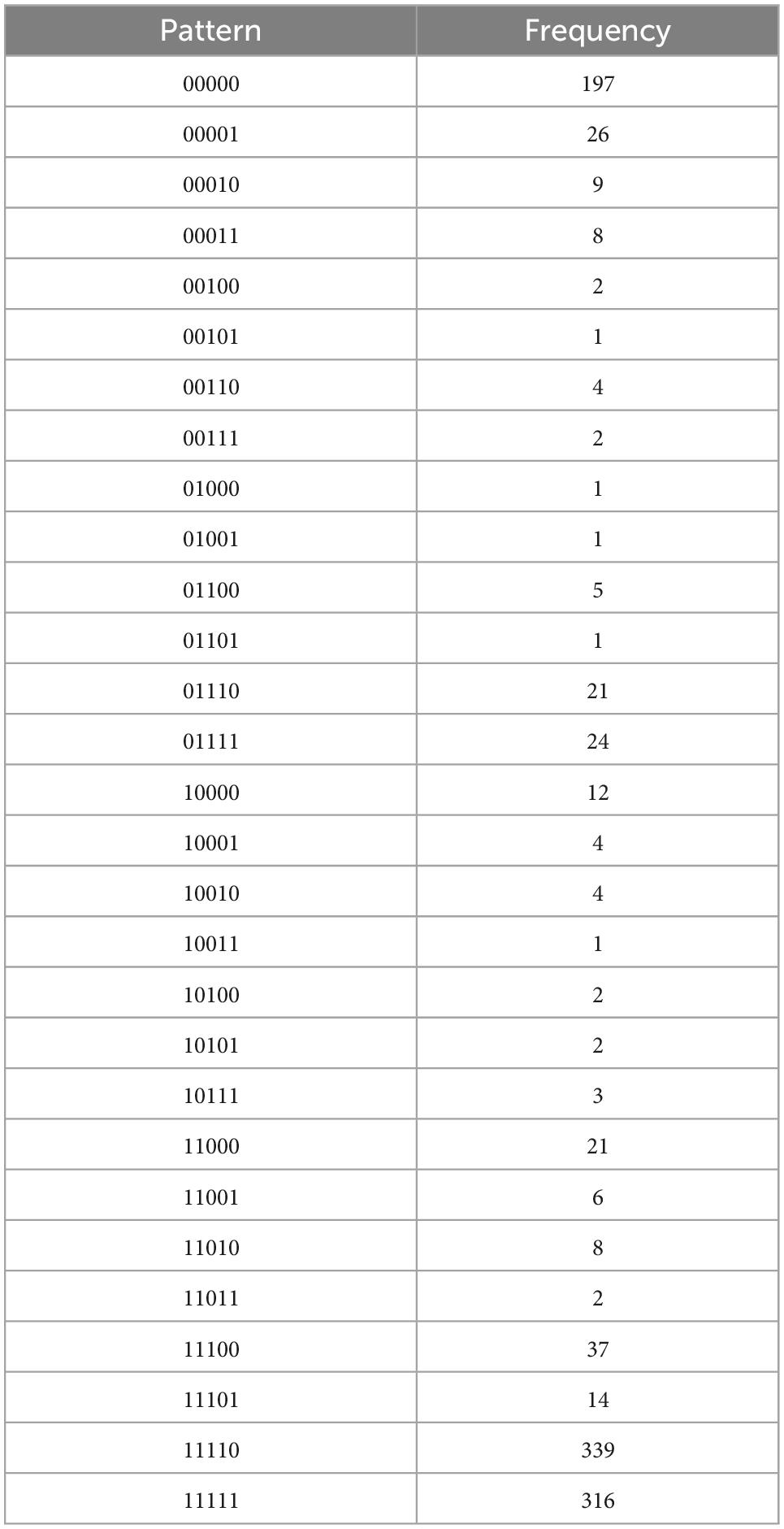
Table 4C. Identified regulation, with N = 1073, k = 5 items, and u = 29 unique response patterns (Appendix B).
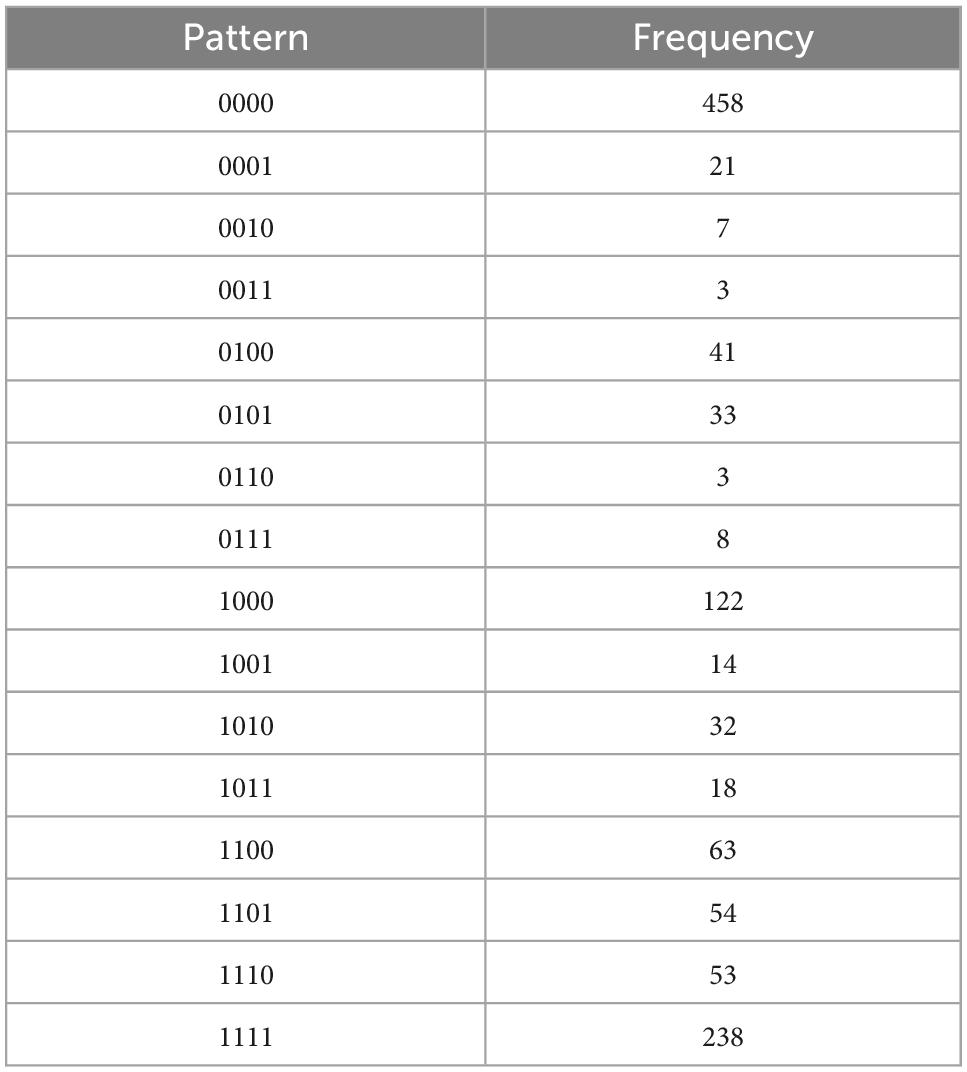
Table 4D. Introjected regulation, with N = 1168, k = 4 items, and u = 16 unique response patterns (Appendix B).
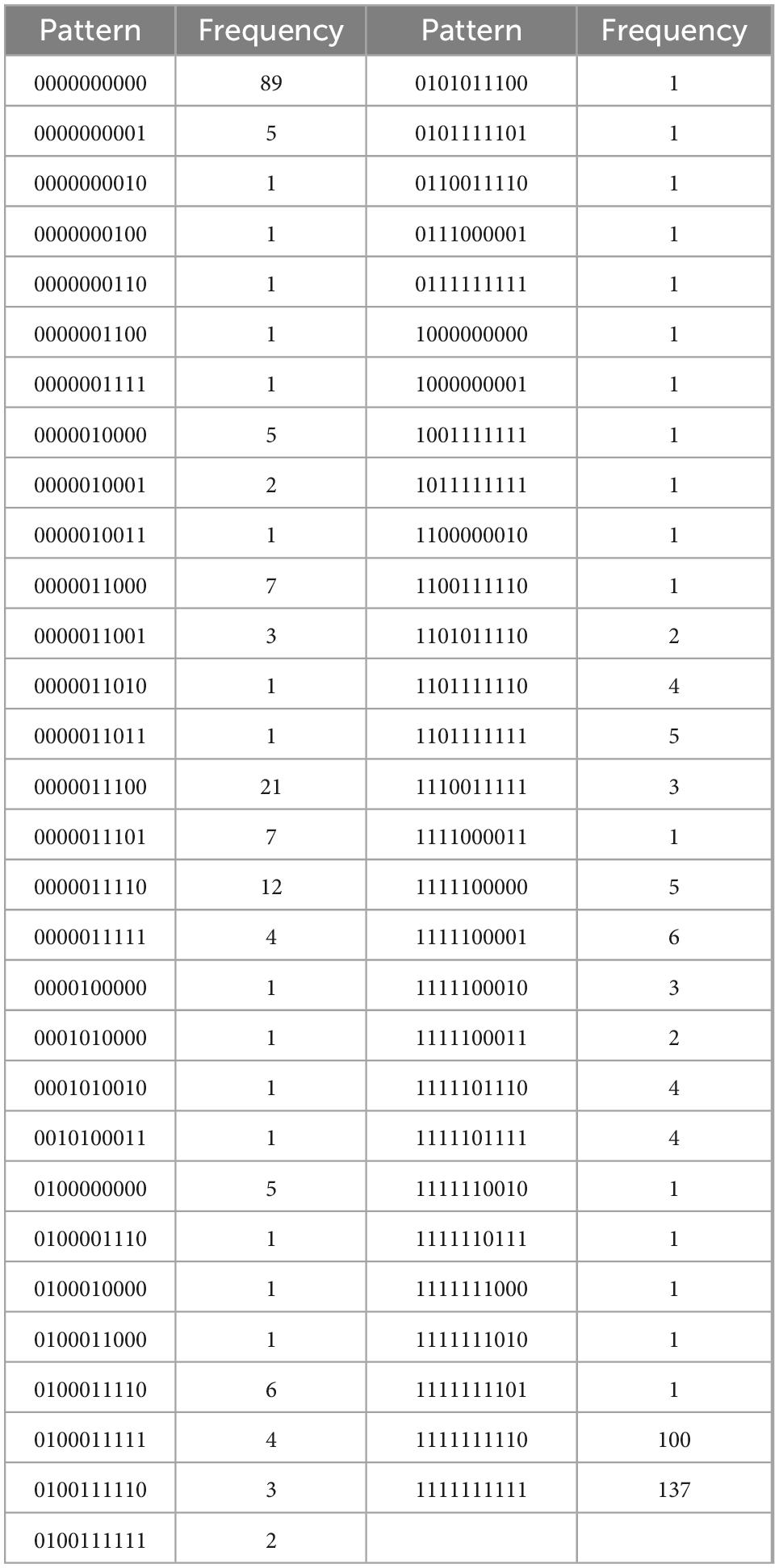
Table 4E. Autonomous motivation, with N = 482, k = 10 items, and u = 59 unique response patterns (Appendix B).
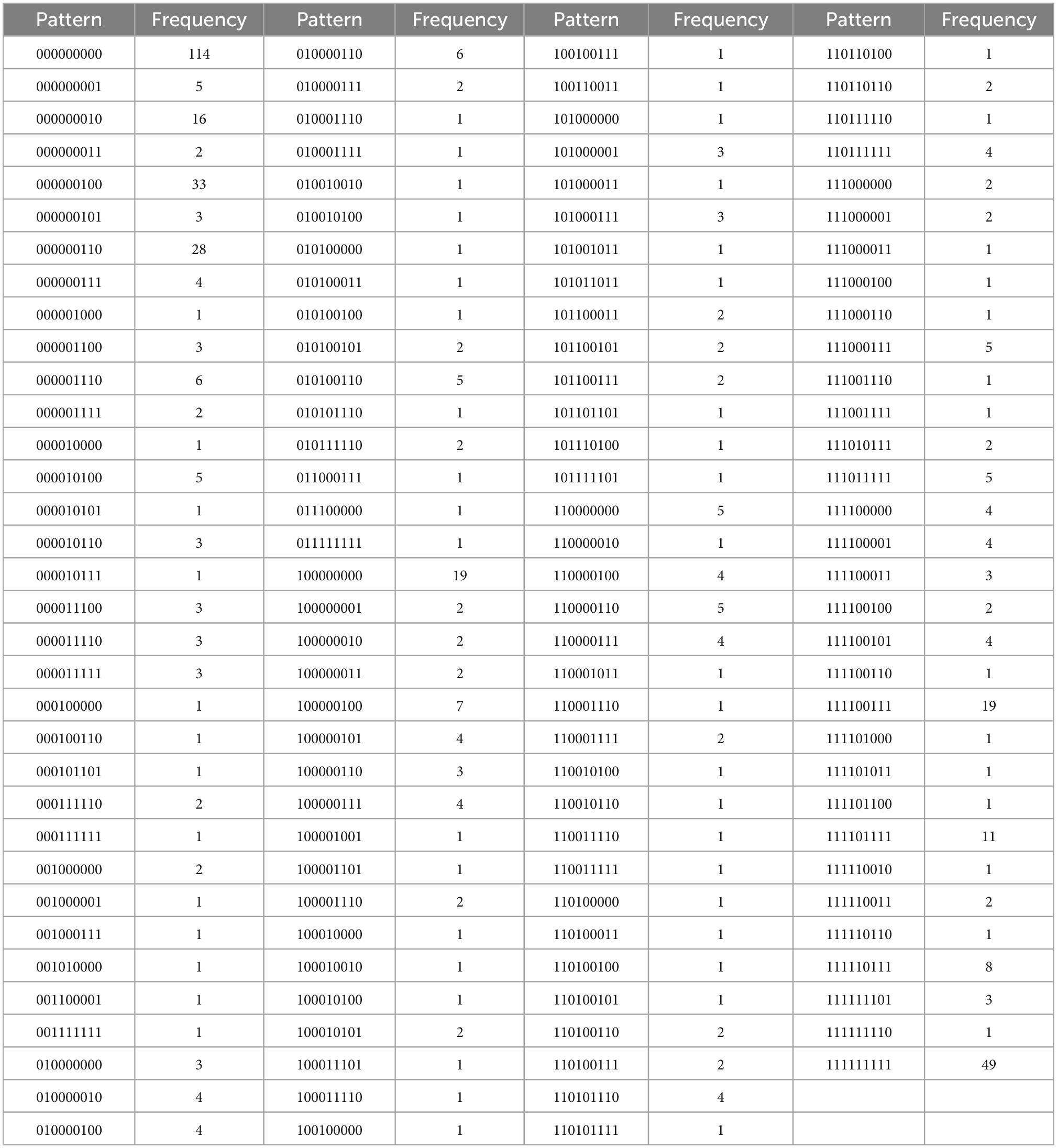
Table 4F. Controlled motivation, with N = 550, k = 9 items, and u = 134 unique response patterns (Appendix B).
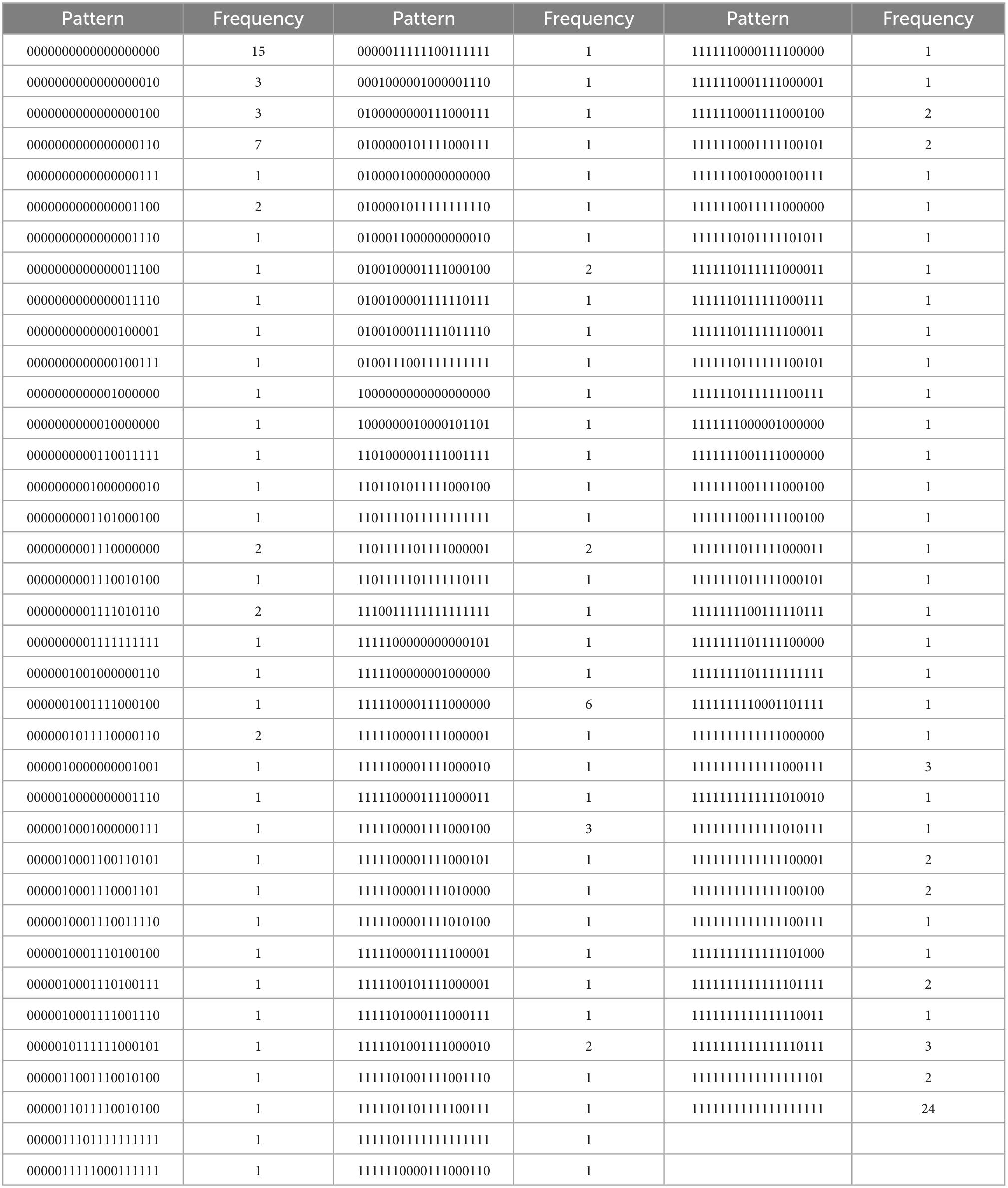
Table 4G. All regulations, with N = 180, k = 19 items, and u = 109 unique response patterns (Appendix B).
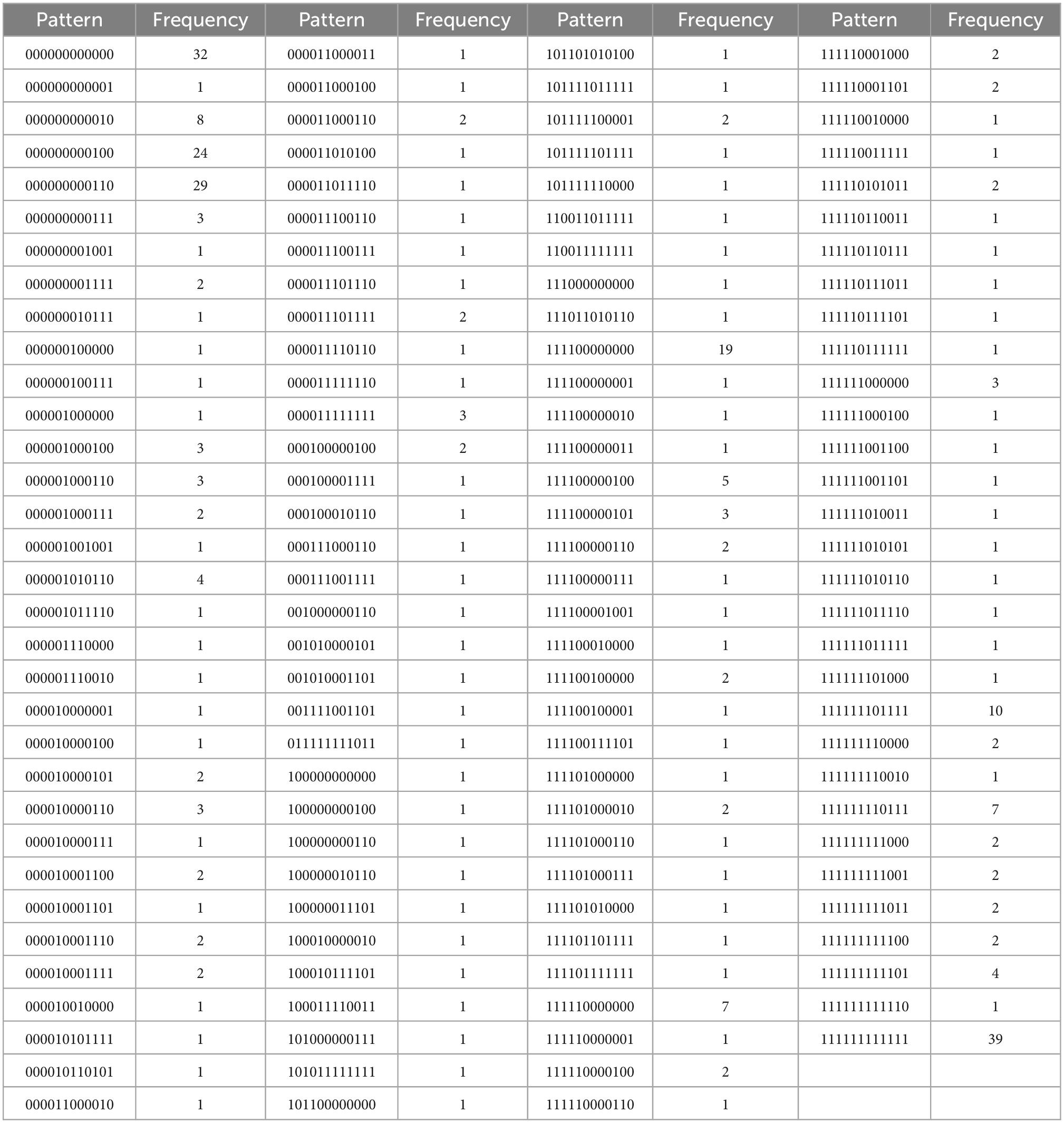
Table 4H. For A = {i1, i3, …, i5, d5, j1, …, j4, e3, e4, e5}, with N = 342, k = 12 items, and u = 130 unique response patterns (Appendix B).
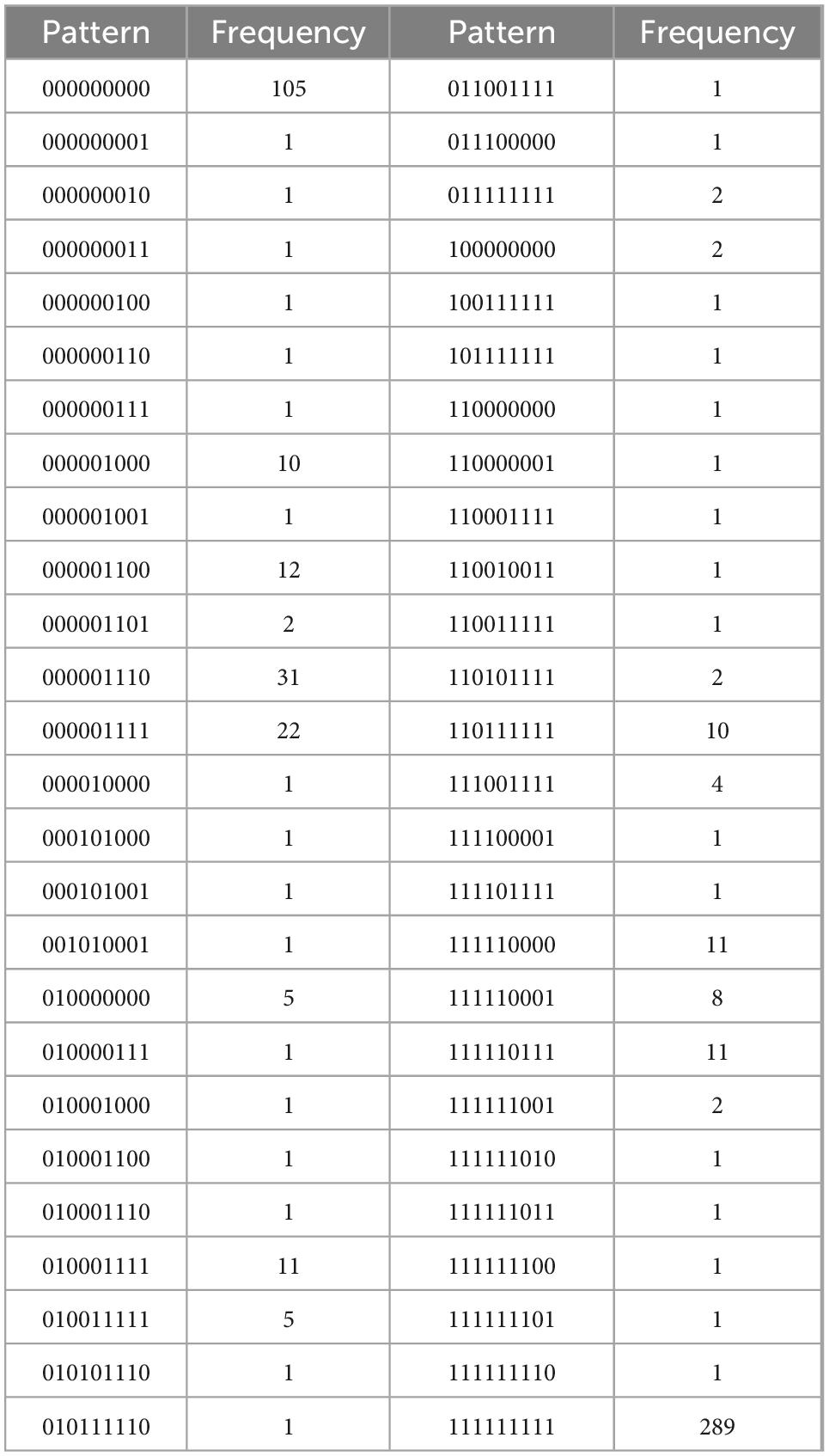
Table 4I. For B = {i1, …, i5, d1, …, d4}, with N = 577, k = 9 items, and u = 52 unique response patterns (Appendix B).
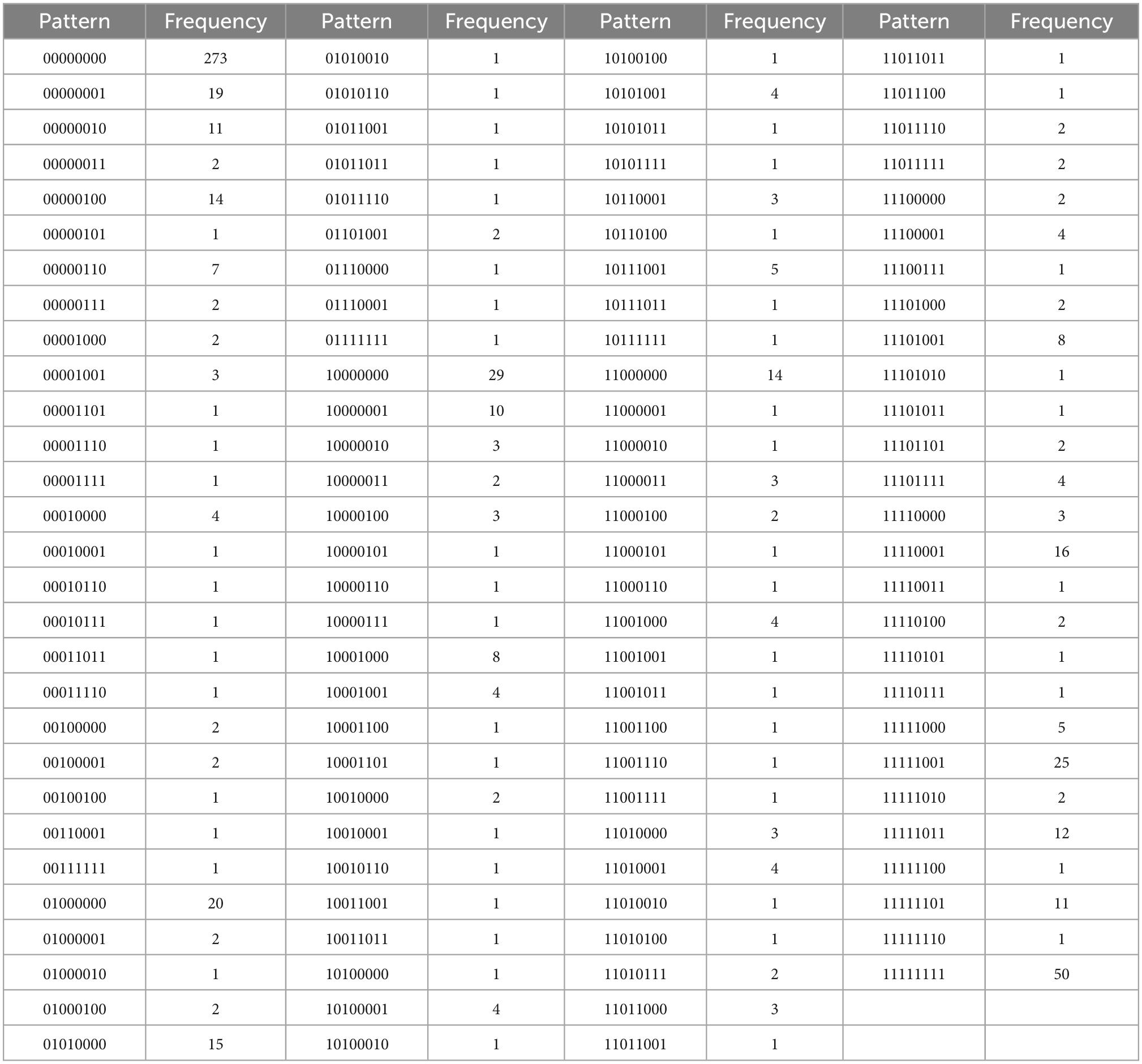
Table 4J. For C = {d5, j1, …, j4, e1, e2, e5}, with N = 706, k = 8 items, and u = 114 unique response patterns (Appendix B).
In general, IITA is supposed to provide more reliable results with larger sample sizes. In practice, however, a solution computed for a smaller sample size can still be an empirically useful model. This may be the case if the derived IITA hierarchy yields an acceptable and also simple description of a higher number of motivation variables, scaled altogether in one go. This may be especially so, if no other alternative model is available or difficult to get, or if an exploratory first model is needed that covers a larger number of variables to inspect for their multivariate relationships. Such a preliminary model may be further adjusted in subsequent analyses. A strategy for how to perform sequential exploratory IITA analyses with more and more refined subsets of motivation variables is outlined, actually for the first time in the literature on IITA, with the example of this section. Thus, we also contribute to the methodology of IITA. The results obtained are illuminating as they constructively add insight into a dispute in SDT literature (Chemolli and Gagné, 2014; Sheldon et al., 2017).
A remark regarding notation is in order. The manifest items or indicators of the instruments and their measured or underlying motivations are denoted with the same symbols. For example, we use e to stand for a manifest test item of the external regulation subscale and the corresponding latent external regulation. In particular, the variable names of the IITA solutions, for example, presented in the plots, are understood to be denoting the underlying motivations, not indicator variables. In the sequel, the five indicator variables and their corresponding (possibly equal) gradations of intrinsic regulation are i1, …, i5 (o = 5); for external regulation the manifest and latent variable names are e1, …, e5 (l = 5); and for identified regulation d1, …, d5 (n = 5) and introjected regulation j1, …, j4 (m = 4). Thus, the motivation domains for the poles of the internalization continuum are Mi = {i1, i2, i3, i4, i5} and Me = {e1, e2, e3, e4, e5}, and for the intermediate regulations Md = {d1, d2, d3, d4, d5} and Mj = {j1, j2, j3, j4}. We performed IITA analyses and derived sets and relations for the individual subscales (Figure 3). We also distinguished and ran the analyses separately in autonomous and controlled motivations Ma = Mi ∪ Md and Mc = Me ∪ Mj, respectively (Figure 4). In addition, all motivations were jointly analyzed M = Mi ∪ Me ∪ Md ∪ Mj (Figure 5). Motivation models for further subsets of the domain were also derived (Figure 6).
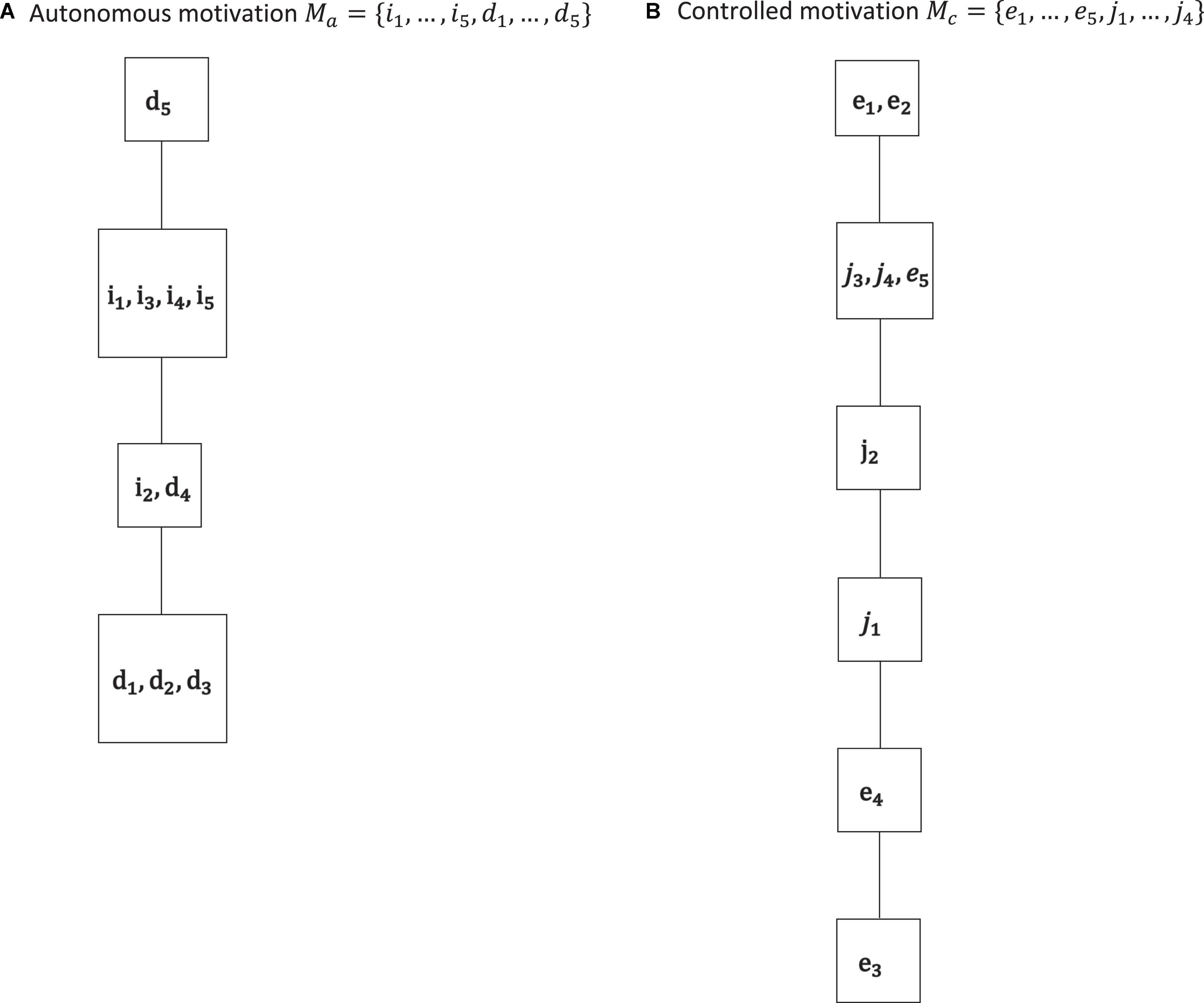
Figure 4. The IITA quasi-order solutions for autonomous motivation (A) and controlled motivation (B) of the empirical data set. By Birkhoff’s theorem, the corresponding quasi-ordinal motivation spaces are ℳa = {∅, {d1, …, d3}, {i2, d1, …, d4}, {i1, …, i5, d1, …, d4}, Ma}, and ℳc = {∅, {e3}, {e3, e4}, {e3, e4, j1}, {e3, e4, j1, j2}, {e3, …, e5, j1, …, j4}, Mc}, respectively. We see cumulative gradations of autonomous motivation and controlled motivation. This corroborates the higher-order interpretation of the basic motivations in these two non-basic autonomous and controlled motivations, which is also advocated in SDT literature.
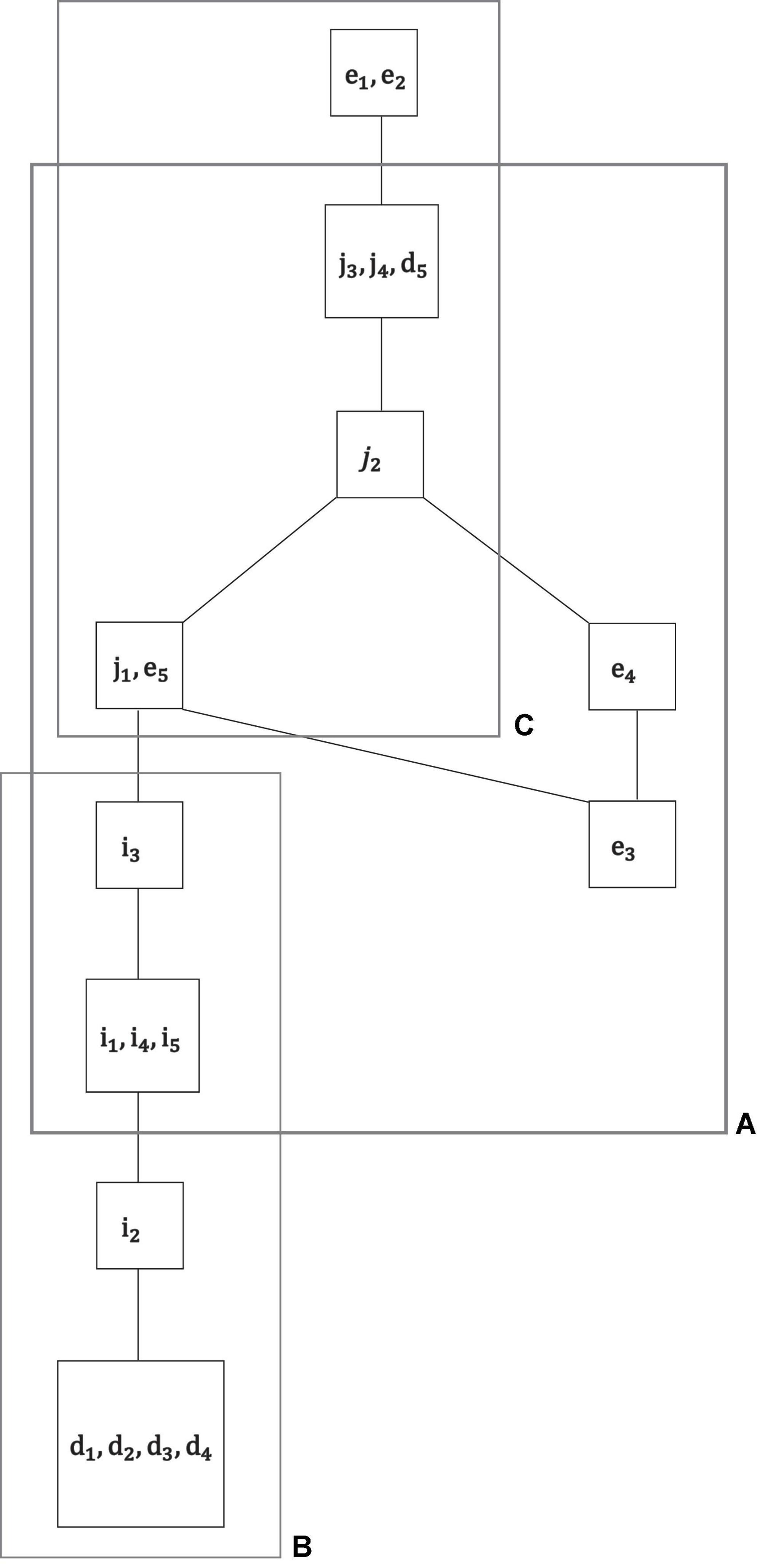
Figure 5. For exploratory analysis, all motivations of the empirical data set were jointly analyzed M = Mi ∪ Me ∪ Md ∪ Mj. The sample size of N = 180 students for a total of k = 19 motivations was small for an overall IITA computation. Thus, based on the exploratory global solution (this figure), collections of motivations were delineated that were further analyzed more reliably, in lower numbers of jointly scaled motivations with larger sample sizes. In this example, the three subsets of motivations A, B, and C were regarded to be adequately sized and located within the overall graph for subsequent, more refined IITA analyses (Figures 6A–C).
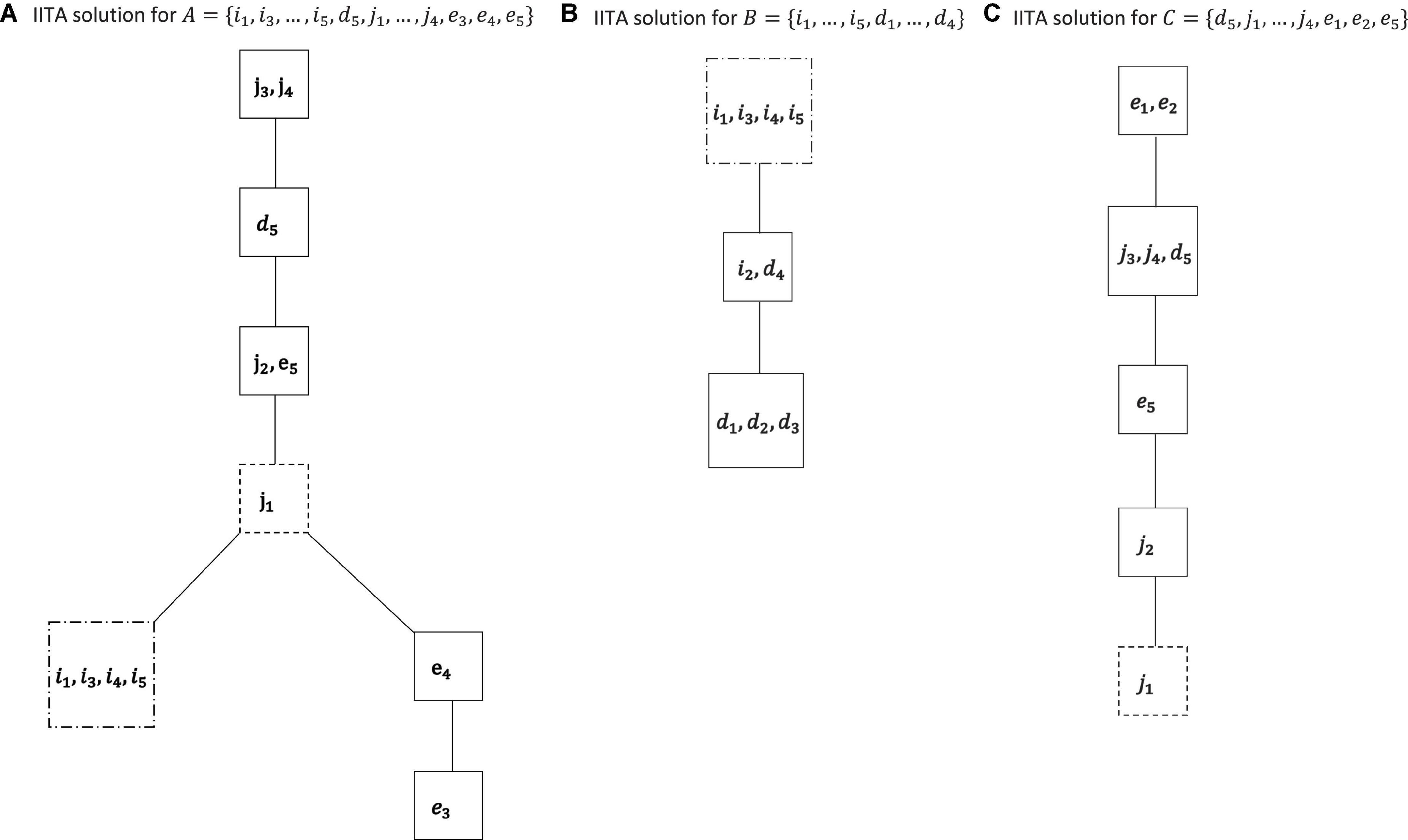
Figure 6. IITA computations for the motivations A = {i1, i3, …, i5, d5, j1, …, j4, e3, e4, e5} (A), B = {i1, …, i5, d1, …, d4} (B), and C = {d5, j1, …, j4, e1, e2, e5} (C) of the empirical data set. The dashed boxes indicate the respective linkage knots for the three graphs (Figure 7).
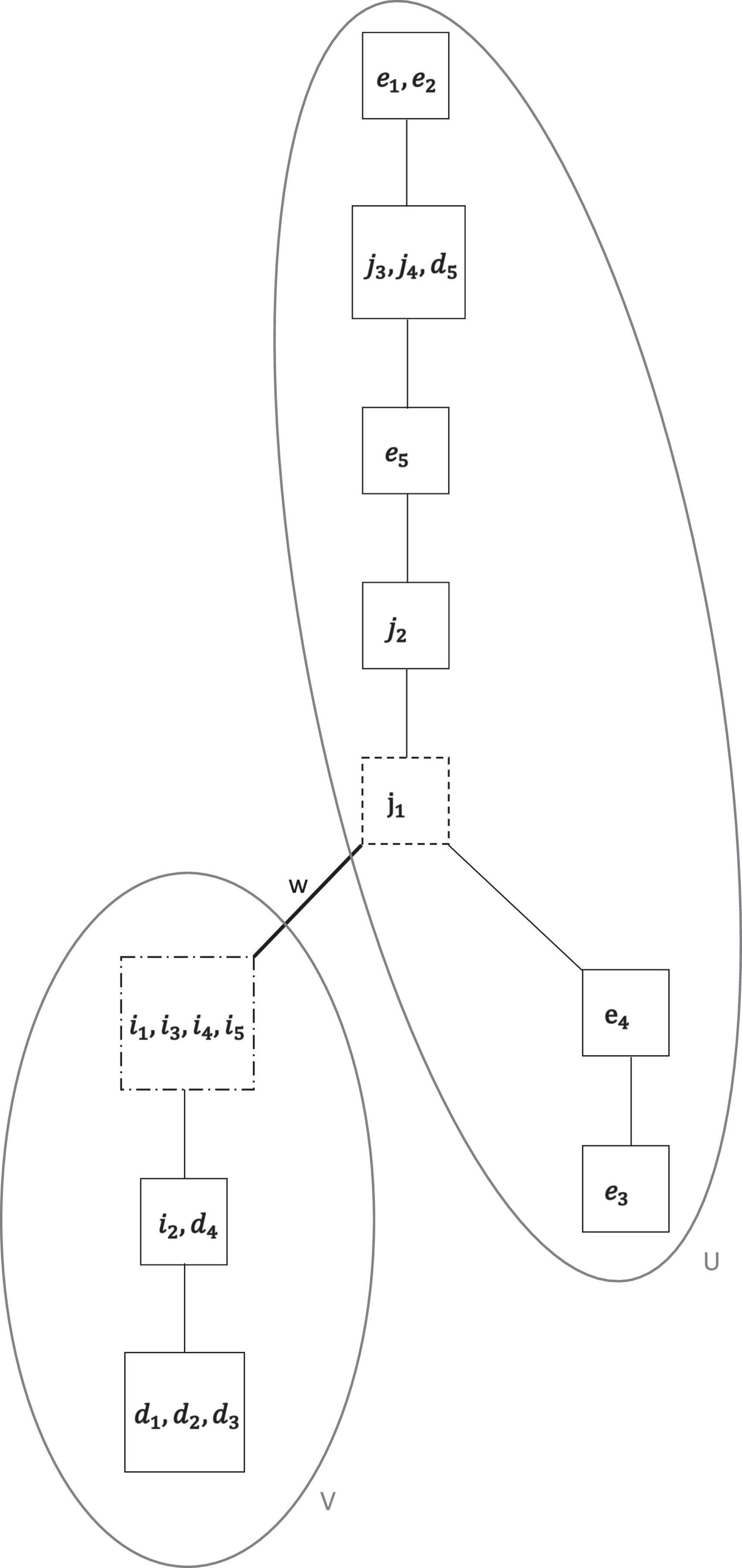
Figure 7. The concatenated final motivation co-occurrence relation ⊑f on the motivation domain of all regulations M = {i1, …, i5, d1, …, d5, j1, …, j4, e1, …, e5}, obtained by sequential exploratory IITA analyses of the data set. The graph is composed of two, connected by w, chains U (of essentially controlled motivation) and V (of autonomous motivation).
Those motivations are interpreted as the gradations of the types of intrinsic regulation, external regulation, identified regulation, and introjected regulation, or of autonomous motivation and controlled motivation, which may or may not be a same gradation, depending on the solution obtained by IITA, in the following sense. Whether two motivations denominate the same gradation will be judged on the basis of parallel or equally informative motivations. Given the data-analytically derived motivation co-occurrence relation by IITA on M or Mx, where x = i, e, d, j, a, c, we can obtain the corresponding quasi-ordinal motivation space. Any (two or more) regulations in M or Mx, which are then contained in the same motivation states of this space, are called parallel or equally informative. In a sense, they carry the same information regarding the distribution of motivation in the population. Equivalently, in the other representation, parallel or equally informative regulations imply each other in the motivation co-occurrence relation. That is, for any two equally informative gradations, each one is a possessed motivation if and only if the other is. Equally informative gradations occur always jointly. We take this to mathematically define those parallel gradations or regulations of the solution that are “equal.”
A remark on this definition of “equality” is in order. Obviously, if two regulations as true constructs are equal objects, they necessarily, by identity, must be parallel. However, the converse may not be the case. One could imagine equally informative gradations being different constructs. But this is only hypothetical. In reality, by definition, parallel gradations can only be observed jointly. They cannot be separated empirically if the model holds true. In this sense, experimentally, we can only know their summative effect on another substantive variable of a study, but we have no information about what effect an individual part or gradation may have. This is reminiscent of entanglement in quantum mechanics in physics (e.g., Jaeger, 2009; Duarte, 2019), where we may know everything about a system, but nothing about its parts. If we cannot separate the parallel gradations, but only observe their “summative motivation,” which may be an aggregate “motivation” different from the postulated basic motivations, we can take any of those gradations to represent their same “summative motivation.” If this “summative motivation” is composed of only genuine gradations of the same basic regulation type, we assume or say that this “summative motivation” and its constituting parallel gradations are a same “gradation” of that regulation type.
To sum up, for practical purposes, if by data analysis, we detect two parallel regulations, letting aside variability of the solution, they may or may not be truly equal gradations (objects), which does not matter empirically, as a result of their unidentifiability, but in any case, they can be considered to be “equal” or equivalent in that more general sense. That is, if we term the latter notion of “equality” the parallel equality, in contrast to true (object) equality, the true equality cases entail parallel equality, but parallel equality encompasses additional cases that are not true equality. It is this generalized notion of equality that we use in the sequel.
In Figure 3, we can see the motivation co-occurrence relations, with their spaces below, that were detected for the separate subscales. We may expect a linear order since the items of each subscale should be measuring the same latent regulation type, in cumulative and possibly equal gradations.
The corresponding quasi-ordinal motivation spaces are, by application of Birkhoff’s theorem, ℳi = {∅, {i2}, {i1, i2}, {i1, i2, i4, i5}, Mi}, ℳe = {∅, {e3}, {e3, e4}, {e3, e4, e5}, Me}, ℳd = {∅, {d1, d2, d3}, {d1, d2, d3, d4}, Md}, and ℳj = {∅, {j1}, {j1, j2}, {j1, j2, j4}, Mj}. Except for introjected regulation, in each solution, we have equally informative regulations, namely, {i4, i5}, {e1, e2}, and {d1, d2, d3}. Thus, by definition (of parallel equality), we assume that these regulations denote equal gradations for each type of intrinsic regulation, external regulation, and identified regulation, respectively, and that the other gradations are distinct.
In SDT, researchers distinguish between autonomous (intrinsic and identified) motivations and controlled (external and introjected) motivations. This higher-order interpretation of the basic regulations is shown to be substantively important for the study of motivation and empirically adequate in motivation data (e.g., Deci and Ryan, 2008; Gagné et al., 2010, 2014). For example, evidence is reported by Gagné et al. (2010) that a second-order two-factor confirmatory factor analysis model can yield adequate fit, where the two higher-order factors group together the autonomous vs. controlled regulations as first-order factors. Consequently, in Figure 4, the relations and sets obtained by IITA in the autonomous and controlled motivations of the data set are reported.
Autonomous motivation and controlled motivation may be viewed as higher-order, aggregate types of motivation, different from SDT’s postulated basic motivations. The cumulative (i.e., linearly ordered) gradations of autonomous motivation and controlled motivation obtained in the solutions corroborate that interpretation. In particular, the results indicate that the intermediate regulations are interweaved with their respective polar regulations in their common aggregate types, fairly arbitrary. The former can imply the latter and vice versa. They can be equally informative gradations of their underlying higher-order regulation types, even if they are different basic motivations. For example, intrinsic motivation i2 and identified motivation d4, basic motivations of different subscales, are equally informative, and by definition, they may be viewed as the same gradation of autonomous motivation. Or, the parallel regulations j3, j4, and e5, if the model is true, can be viewed to be an equal gradation of the controlled motivation type. It is important to note, however, that the interpretation of the relations and their derivation from data are based on motivation possession or occurrence. Thus, possession of intrinsic motivation i2 implies the possession of one, and thus all, of the identified motivations d1, d2, and d3. External regulation e1 occurs if and only if external regulation e2 occurs, and in this case, all other regulations, external and introjected, must necessarily be also possessed motivations. Thus, if a person attains specific polar or intermediate regulations, we may infer that this person also possesses the motivations implied by those regulations.
In Figure 5, we ran the IITA algorithm on all motivations available in the data set for exploration, first and foremost. The sample size of N = 180 is small, relative to a large number of k = 19 motivation variables. That is okay since the aim was to look for possible interrelationships among the variables and to gain guidance on what motivation combinations to further investigate in narrow analyses.
In this example, we carved out the three subsets of motivations A, B, and C in Figure 5, which basically give a covering of the whole graph with overlapping motivations that will be used to mesh together the separate IITA solutions in those subsets. The choice of subsets made in Figure 5 was also motivated by the following observations. Motivation e5 seemed to be critical in the overall solution compared with what we obtained in Figures 3B, 4B. Also, motivations d5 and i1, i3, i4, i5 constituted linkages of autonomous motivation with controlled motivation, which is important information not contained in Figures 3, 4. In addition, subsets B and C are chains, indicating that each of their motivations is more strongly interrelated, where B is a proper subset of the autonomous motivation scale and deviates from the relation obtained in Figure 4A. The binding subset between B and C is A, where the external motivations are not in accordance with the solution computed in controlled motivation in Figure 4B. Thus, these subsets with their extra or deviating structures may require further consideration.
The refined analyses in those subsets A, B, and C are reported in Figure 6.
The dashed boxes of two types indicate the knots where the three graphs are lumped together, respectively. For solutions A and B of Figure 6, there is only one option, to append solution B to solution A. For solutions A and C of Figure 6, the more refined solution C replaces the corresponding part of solution A. This also turned out to be the more preferential meshed solution in accompanying data analyses in even smaller subsets of the involved variables. Thus, the combined and final motivation co-occurrence relation in Figure 7 was obtained.
The corresponding space of motivation states for this overall solution, as a graph, is shown in Figure 8.
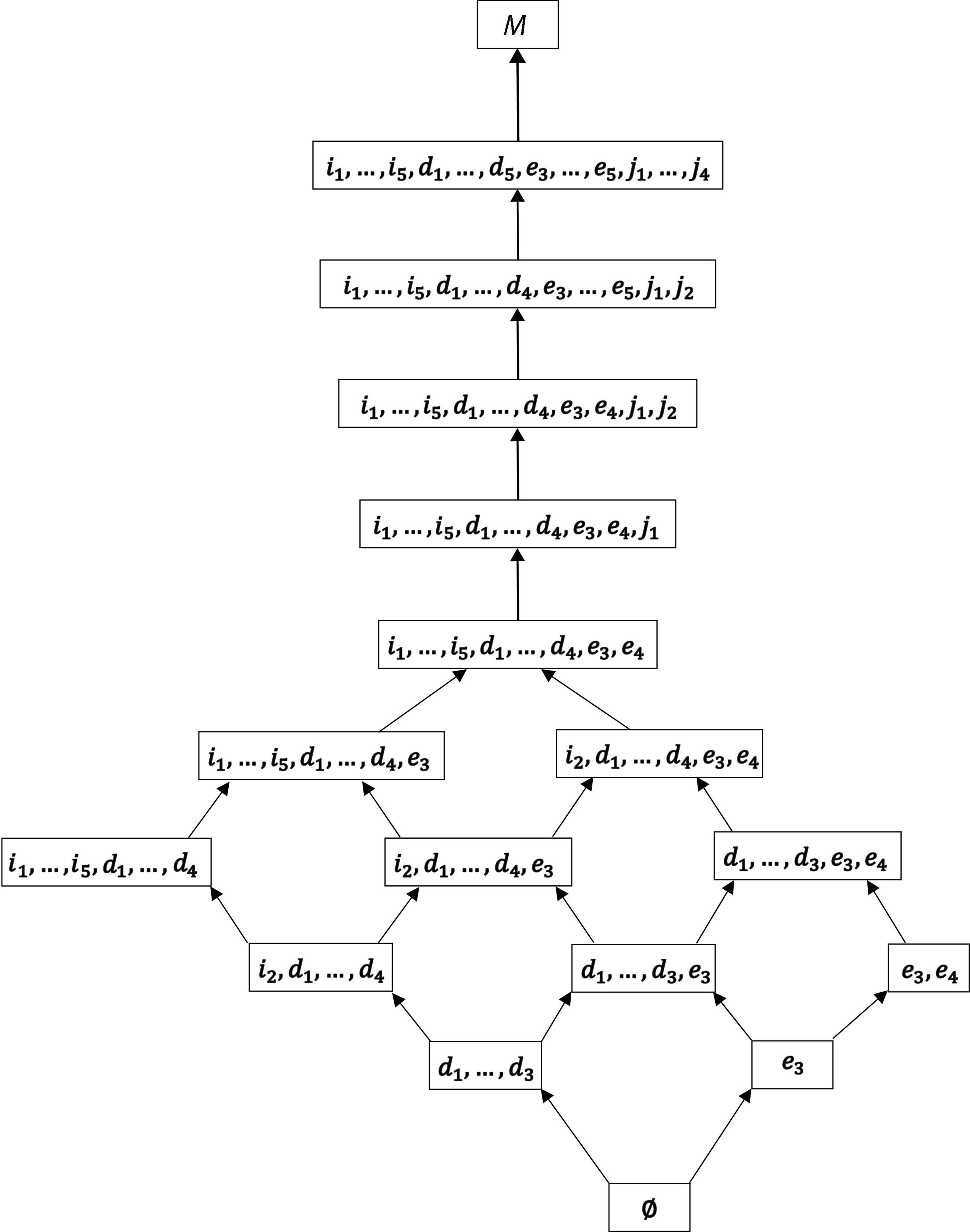
Figure 8. The quasi-ordinal motivation space ℳf corresponding to the final IITA solution ⊑f. The graphical representation is read from bottom to top, where a sequence of arcs linking a motivation state to a state located top of it means that the former is a subset of the latter. The bottom part of the graph indicates a branched multidimensional structure, the top part a linear unidimensional (“mixed” dimensionality).
From Figures 7, 8, we can see how the different motivations are interrelated with each other in the interpretation of motivation possession. Deviations from a perfect chain structure are due to incomparability between (all) intrinsic regulations (i1, …, i5) and (four) identified regulations (d1, d2, d3, d4) on the one hand and (two) external regulations (e3, e4) on the other, located in the bottom parts of these figures. Except for (one) identified motivation (d5), which is intermingled with (two) introjected motivation (j3, j4), the hierarchy depicted in Figure 7 can essentially be partitioned into the two chains of autonomous motivation (V) and controlled motivation (U). These parts are connected by an edge (w) between intrinsic motivation (i1, i3, i4, i5) and introjected motivation (j1).
We have the following interpretation, in our example, regarding the discrimination or separability of controlled motivation and autonomous motivation. According to the hierarchical structure of their defining regulations, in Figure 8, controlled motivation and autonomous motivation cannot always be mutually exclusive, and thus separable. There are the motivation states, which only entail either controlled motivation or autonomous motivation, {e3} and {e3, e4} or {d1, d2, d3}, {i2, d1, d2, d3, d4}, and {i1, i2, i3, i4, i5, d1, d2, d3, d4}, respectively. However, the majority of the states imply autonomous as well as controlled motivations jointly. For example, the state {i2, d1, d2, d3, d4, e3} is autonomous motivations i2 and d1, d2, d3, and d4 as well as controlled motivation e3. Thus, in a population of reference, depending on the distribution of the motivation states, we may end up sampling students either autonomously or controlled motivated (three or two states, respectively), autonomously as well as controlled motivated (eleven states), or none of them (∅).
Importantly, the final solution can be utilized for the qualitative assessment of combinatorial dimensionality, in the following sense. We see that the derived multidimensional structure, that is, genuine quasi-order, is close to a unidimensional structure, meaning a chain. In particular, note that this is not the common definition of numerical dimensionality of the parameter or factor space of a statistical (e.g., item response or structural equation) model. Compared to the latter, the combinatorial view of dimensionality is more qualitative. In the solution, in Figure 7, omitting the external gradations e3 and e4, on M\{e3, e4}, the restricted motivation co-occurrence relation is a single chain. Thus, the two-dimensional structure (i.e., linked two chains) of autonomous motivation V and controlled motivation U on the entire motivation domain becomes a unidimensional structure, if slightly pruned. That is, with the approach of this article, based on relations, we may see how close a multidimensional structure is to unidimensionality. In the empirical example it is very close, and where discrepancies in the structure may occur combinatorially. This may especially be so in relatively structured motivation data of validated SDT questionnaires.
In particular, this could dissolve a dispute of opinions put forth by Chemolli and Gagné (2014) and Sheldon et al. (2017). These authors advocated mutually exclusive views of a multidimensional vs. a unidimensional structure of motivation, respectively. In the empirical application of this article, at least, the two opinions only differ slightly, so both views basically seem to be justified in this example. In other applications, in the same manner, researchers could investigate the dimensionality of motivation. Presumably, if the theory holds true empirically, there should not be greater discrepancies between the unidimensional vs. multidimensional views of motivation, and this could be combinatorially quantified, similar to the example. However, this is only a conjecture, which needs to be tested critically in more popular scales; for example, in the Multidimensional Work Motivation Scale (MWMS), refer Gagné et al. (2010, 2014) and Trépanier et al. (2022).
To conclude, in Table 2, we summarize the frequency distributions of the dichotomous scores across motivation variables and the sample sizes underlying any of the IITA analyses of the empirical data sets. All analyzed data sets with individual binary entries can be found in Appendix B.
We summarize the main conclusions from the results and the application of KST to SDT.
1. First and foremost, the problem of unidimensionality vs. multidimensionality of motivation, which has been disputed among SDT researchers (in particular, Chemolli and Gagné, 2014; Sheldon et al., 2017), can be more informatively assessed and resolved based on discrete KST combinatorial structures, as compared to numerical dimensionality of parametric psychometric models. Take as an example, Figure 7. It is by no means obvious, or unique, how to derive this figure’s hierarchy among the motivations by covariance structure models. You have too many fit and model selection indices (Tables 13.1 and 13.2 in West et al., 2012), and even if some of these indices may be indicative (but others generally are not) and you order motivations by their real unidimensional factor loadings, for instance, you may not be able to distinguish parallel or equally informative gradations nor account for the incomparable motivations (branching) located at the bottom part of the hierarchy. There may be workarounds though, more or less ad hoc and arbitrary solutions, which, however, may not be as straightforward and principled anymore as the natural combinatorial approach directly operating with orders.
2. In particular, we have contributed to the issue of the number of essential dimensions underlying the theory’s posited motivations. We could only try one data set. Thus, we conjecture that in other empirical data sets of validated SDT instruments, if occurring, multidimensionality, essentially, is two dimensions only, which are also qualitatively close to unidimensional. The findings of this article corroborated the higher-order classification into autonomous motivation and controlled motivation, which is also advocated by other SDT researchers, the two branches of the hierarchy, but altogether the motivations were also close to a single chain structure. Whether the close proximity of one vs. two combinatorial dimensions may entail significant differences in real use cases is an interesting question. If necessary, based on the hierarchy of dependencies among the regulations, combinatorially, we could exploit the full information in the graph and differentiate between “mixed” dimensionalities, in the sense that certain motivations are chained, thus combinatorially unidimensional, whereas others are branched, thus combinatorially two (or more) dimensional.
3. In addition, this article adds insight into possible inconsistencies that may arise in applications of the theory in the way the different regulation types can be empirically distinguishable (e.g., integrated regulation seems to be difficult to identify). In particular, we conjecture that there may be equally informative or parallel gradations of the basic regulation types that may not be separable empirically, and thus remain unidentifiable or indistinguishable by experiments, most likely. Therefore, the generalized notion of equality, parallel equality, of the regulations of motivation can be adequate.
4. A key requirement for any statistical or mathematical model used to represent motivation qualitatively should be the flexibility that comes with representing structures. This is more the case with discrete structures than with numerical values. Numerical values such as factor loadings, factor scores, person abilities, or item difficulties, typical parameters of the structural equation or item response models, are more strongly aggregated numbers, implying their more restrictive natural linear orderings. The use of more general combinatorial structures such as surmise relations or even surmises functions (Doignon and Falmagne, 1999) allows for greater flexibility in the representing structures, for a more qualitative, thus diagnostic, conceptualization of motivation. Even a multidimensional numerical approach, which generally may be ambiguous and more difficult to interpret compared with a unidimensional model, can only yield partially ordered structures, by component-wise comparisons. In particular, partial orders do not differentiate parallel or equally informative motivations. Due to the use of more general KST structures, you can in principle describe more data sets in practice.
5. On top of that, in contrast to the commonly used psychometric approaches, the representing structures in KST are mathematically linked by theorems such as Birkhoff’s, offering additional flexibility in the choices of equivalent representations, depending on the targeted use cases. For example, in the Rasch model (Van der Linden and Hambleton, 1997; Chemolli and Gagné, 2014), ability and difficulty estimates provide essentially separate representations, at the levels of persons and items, respectively. There is no direct and interpretable connection between these real-valued point estimates. In contrast, the more differentiated set representation (motivation structure) used for the persons is mathematically connected, by Birkhoff’s theorem (Theorem 1), to the fine-grained order representation (co-occurrence relation) used for the motivations. The two levels, people and regulations, are combinatorially interrelated, which offers more ways for qualitatively representing and interpreting motivation-related results.
6. A cornerstone of KST is adaptive testing (for applications in education, see Falmagne et al., 2013). Originally, KST was developed and is predestinated for this purpose. Thus, the KST approach to SDT, as advocated by us, can provide the necessary framework to develop adaptive assessment procedures for motivation testing in SDT. To our knowledge, adaptive testing has not been addressed at all in the SDT literature. To motivate, consider Figure 7. Under this co-occurrence relation, for example, if we test that a student is intrinsically motivated, possessing motivation i2, we do not need to further test that student for the identified regulations d1, d2, d3, and d4, as possessing the latter is necessary, implied by possession of the former. Or, if a student is tested not to be externally motivated, not possessing regulation e5, we can infer that this student must also not possess the motivations j3, j4, d5, e1, and e2. Thus, the assessment can skip testing for those motivations. These are only simple illustrative examples. Dependency hierarchies accompanied by adaptivity of this sort can build the basis for efficient computerized adaptive assessment procedures for testing and also training motivation in various SDT application domains (e.g., to automate and efficiently test, or train, work motivation among employees of a bigger company).
7. Related to the preceding point, the KST approach to SDT also has the advantage that it can allow for dynamical motivation systems for the study of motivational behavior in time, particularly how motivation can progress in an orderly fashion, or perhaps become altogether unpredictable or even chaotic. The provision of a dynamical (including longitudinal) self-determination theory could be accomplished based on stochastic (learning) paths (Falmagne, 1993). The general idea underlying such an extension of SDT has been conceptually exemplified in section “Sets and relations among motivations,” with Figure 1.
8. Mathematical, not statistical, modeling is possible. Mathematical models of motivation, such as discrete combinatorial structures (not only of KST), may help to understand, from a purely theoretical viewpoint, the logical foundations of the theory. In particular, the order-theoretic and algebraic properties of self-determination may be derived and studied mathematically (Ünlü, 2022), thus providing principled definitions of the central concept of self-determination. This may improve on the theory since in SDT, self-determination is commonly “defined” in a more or less ad hoc manner, based on such descriptive scoring protocols as the relative autonomy index (Grolnick and Ryan, 1987), an index that was criticized (Chemolli and Gagné, 2014; Ünlü, 2016). Or, the important internalization continuum of SDT can be mathematically defined by orders (Figure 2B).
9. Sets and relations derived for different motivations, for example, in the domains of work, sport, or learning, could be combinatorially compared, at a qualitative level. This could aim at finding structural invariants of motivation across different application contexts of the theory of self-determination.
The KST approach is relatively universal. It is generally applicable in any context in which implications between, even abstract, information units are of interest. For example, information units can be the geometry questions of a mathematical literacy test, where we are interested in whether the mastery of a geometry question implies the mastery of other questions of the test. In our context, the information units are regulations, among which the implications in their interpretation of motivation possession are considered. In principle, the application presented in this article is generalizable to other (psychological) theories (with appropriate operationalizations), if the system of interest, its defining units of information, the implications among those units, and their interpretation are delineated as the objects of the study. Not-so-obvious applications of this approach to other fields include system failure analysis (e.g., of a nuclear plant), where the failure of a component of the system may imply the failure of other components. Or, in medical diagnosis, the system is the patient, the information units are represented by the symptoms, and a physician examines whether the presence of certain symptoms in the patient imply that of others.
The present article has an obvious limitation, in that only one scale and data set were analyzed, which can be found in Appendices A, B, respectively. In future studies, more popular scales such as the MWMS (Trépanier et al., 2022), Sport Motivation Scale (SMS; Pelletier et al., 2013), and Academic Motivation Scale (AMS; Vallerand et al., 1992) with corresponding data sets could be examined using the KST and IITA approaches. This is an important direction for subsequent work. On the one hand, it remains to be seen if in those application domains with their questionnaires and data sets similar results can be obtained. On the other hand, it would be interesting to see how domain-specific motivation spaces and co-occurrence relations obtained in different application contexts of SDT structurally compare with each other. This could give (qualitative) information about the properties, similarities, and differences, of work motivation, sport motivation, and academic motivation, for example. To accomplish such a program, at this point, we have a personal recommendation addressed to the field of SDT. In the future, SDT researchers could consider providing their most pertinent data sets in a publicly accessible database. That would greatly facilitate research of the sort reported in this article.
Chemolli and Gagné (2014) advocated the use of qualitative motivation in self-determination theory (SDT). The approach presented here to motivation, an application of knowledge space theory (KST), is inherently qualitative, based on sets and relations in motivation regulations. In particular, this methodology allows us to treat each regulation as a separate variable of the motivation domain (cf., Koestner et al., 1996), and to represent every person by her or his total motivational profile, the motivation state, of all regulations within the person (cf., Vansteenkiste et al., 2009). This approach is flexible and general. It incorporates combinatorial unidimensionality as well as multidimensionality of the possible motivation structures in a unified and natural manner by the use of linear orders (chains) and genuine quasi-orders, respectively. In the empirical application, we have seen that there are unidimensional substructures, such as that of autonomous motivation (Figure 4A) and controlled motivation (Figure 4B). We have also seen that the overall motivation structure was basically branched into autonomous motivation and controlled motivation and was two-dimensional in that sense (Figure 7). However, that motivation structure could be slightly pruned to become a chain, and thus unidimensional. Basically, two combinatorial dimensions reducible to one were observed.
In essence, these results are in accordance with, both, the seemingly contrary and exclusionary opinions expressed in the articles by Chemolli and Gagné (2014) and Sheldon et al. (2017), thereby bringing together and uniting their views. The conjecture is that in empirical data sets of reliable and valid SDT instruments if occurring, multidimensionality is essentially two dimensions that are qualitatively close to unidimensional. In future applications of this approach to other scales (e.g., Trépanier et al., 2022), one could check if this may be generally so. But in any case, one could study how close a multidimensional relational structure is to unidimensionality, and how to prune the structure accordingly, if possible.
The presented qualitative conceptualization of motivation based on KST can contribute to SDT in novel ways, practically and theoretically (cf. also section “Usefulness of this approach for motivation research and limitation”). Especially, adaptive assessment and training of motivation, ideally computerized, or the dynamical or longitudinal analysis of motivation progression in time, could be accomplished based on stochastic paths in empirically valid motivation spaces of the feasible motivation states (Figures 1, 8). This article paves the way for these and other fruitful and interdisciplinary contributions to the study of motivation from the viewpoint of knowledge axiomatization and assessment in education. We have only considered the basic, yet powerful, concepts and their interpretations in motivation. More work in this direction is needed, especially by applied SDT researchers, to relate the combinatorial structures of motivation to behaviors and experimental outcomes.
In the end, we would like to describe this contribution as a cross-disciplinary methodology, an application of knowledge modeling in education and mathematical psychology, KST, to the study of motivation in, amongst others, social and personality psychology, SDT. As such, the KST approach is, most probably, not familiar to applied researchers in SDT, but we think it is worth the effort. To our knowledge, the qualitative representation and the analysis of motivation based on discrete combinatorial structures, as proposed in this article, are interesting new views on the quantitative treatment of motivation in the theory of self-determination.
The original contributions presented in this study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. Written informed consent from the participants’ legal guardian/next of kin was not required to participate in this study in accordance with the national legislation and the institutional requirements. Written informed consent was not obtained from the individual(s), nor the minor(s)’ legal guardian/next of kin, for the publication of any potentially identifiable images or data included in this article.
The author confirms being the sole contributor of this work and has approved it for publication.
The author thanks Dr. Erol Koçdemir for his invaluable, always competent support.
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Albert, D., and Lukas, J. (eds). (1999). Knowledge spaces: theories, empirical research, and applications. Mahwah, NJ: Lawrence Erlbaum.
Assor, A., Vansteenkiste, M., and Kaplan, A. (2009). Identified versus introjected approach and introjected avoidance motivations in school and in sports: the limited benefits of self-worth strivings. J. Educ. Psychol. 101, 482–497. doi: 10.1037/a0014236
Chemolli, E., and Gagné, M. (2014). Evidence against the continuum structure underlying motivation measures derived from self-determination theory. Psychol. Assess. 26, 575–585. doi: 10.1037/a0036212
Conesa, P. J., Onandia-Hinchado, I., Duñabeitia, J. A., and Moreno, M. Á. (2022). Basic psychological needs in the classroom: a literature review in elementary and middle school students. Learn. Motiv. 79:101819. doi: 10.1016/j.lmot.2022.101819
Davey, B. A., and Priestley, H. A. (2002). Introduction to lattices and order. Cambridge: Cambridge University Press. doi: 10.1017/CBO9780511809088
Deci, E. L., Hodges, R., Pierson, L., and Tomassone, J. (1992). Autonomy and competence as motivational factors in students with learning disabilities and emotional handicaps. J. Learn. Disabil. 25, 457–471. doi: 10.1177/002221949202500706
Deci, E. L., and Ryan, R. M. (1985). Intrinsic motivation and self-determination in human behavior. New York, NY. Plenum. doi: 10.1007/978-1-4899-2271-7
Deci, E. L., and Ryan, R. M. (2000). The “what” and “why” of goal pursuits: human needs and the self-determination of behavior. Psychol. Inq. 11, 227–268. doi: 10.1207/S15327965PLI1104_01
Deci, E. L., and Ryan, R. M. (2008). Facilitating optimal motivation and psychological well-being across life’s domains. Can. Psychol. 49, 14–23. doi: 10.1037/0708-5591.49.1.14
Doignon, J.-P., and Falmagne, J.-Cl. (1985). Spaces for the assessment of knowledge. Int. J. Man-Mach. Stud. 23, 175–196. doi: 10.1016/S0020-7373(85)80031-6
Doignon, J.-P., and Falmagne, J.-Cl. (1999). Knowledge spaces. Berlin: Springer. doi: 10.1007/978-3-642-58625-5
Duarte, F. J. (2019). Fundamentals of quantum entanglement. Bristol: IOP Publishing. doi: 10.1088/2053-2563/ab2b33
Falmagne, J.-Cl. (1993). Stochastic learning paths in a knowledge structure. J. Math. Psychol. 37, 489–512. doi: 10.1006/jmps.1993.1031
Falmagne, J.-Cl., Albert, D., Doble, C., Eppstein, D., and Hu, X. (eds). (2013). Knowledge spaces: applications in education. Heidelberg: Springer. doi: 10.1007/978-3-642-35329-1
Falmagne, J.-Cl., and Doignon, J.-P. (2011). Learning spaces. Berlin: Springer. doi: 10.1007/978-3-642-01039-2
Gagné, M., Forest, J., Gilbert, M.-H., Aube, C., Morin, E., and Malorni, A. (2010). The Motivation at Work Scale: validation evidence in two languages. Educ. Psychol. Meas. 70, 628–646. doi: 10.1186/s13054-016-1208-6
Gagné, M., Forest, J., Vansteenkiste, M., Crevier-Braud, L., Van den Broeck, A., Aspeli, A. K., et al. (2014). The Multidimensional Work Motivation Scale: validation evidence in seven languages and nine countries. Eur. J. Work Organ. Psychol. 24, 178–196. doi: 10.1080/1359432X.2013.877892
Gagné, M., Parker, S. K., Griffin, M. A., Dunlop, P. D., Knight, C., Klonek, F. E., et al. (2022). Understanding and shaping the future of work with self-determination theory. Nat. Rev. Psychol. 1, 378–392. doi: 10.1038/s44159-022-00056-w
Grolnick, W. S., and Ryan, R. M. (1987). Autonomy in children’s learning: an experimental and individual difference investigation. J. Pers. Soc. Psychol. 52, 890–898. doi: 10.1037//0022-3514.52.5.890
Jaeger, G. (2009). Entanglement, information, and the interpretation of quantum mechanics. Berlin: Springer. doi: 10.1007/978-3-540-92128-8
Koestner, R., Losier, G. F., Vallerand, R. J., and Carducci, D. (1996). Identified and introjected forms of political internalization: extending self-determination theory. J. Pers. Soc. Psychol. 70, 1025–1036. doi: 10.1037//0022-3514.70.5.1025
Müller, F. H., Hanfstingl, B., and Andreitz, I. (2007). Skalen zur motivationalen Regulation beim Lernen von Schülerinnen und Schülern: adaptierte und ergänzte Version des Academic Self-Regulation Questionnaire (SRQ-A) nach Ryan & Connell [Scales of motivational regulation for student learning: adapted and supplemented version of the Academic Self-Regulation Questionnaire (SRQ-A) by Ryan & Connell] (Transl. A. Ünlü). In Institut für Unterrichts- und Schulentwicklung (ed.), Wissenschaftliche Beiträge [Scientific contributions] (Transl. A. Ünlü). Klagenfurt: Alpen-Adria-Universität, 1–17.
Pelletier, L. G., Rocchi, M. A., Vallerand, R. J., Deci, E. L., and Ryan, R. M. (2013). Validation of the revised Sport Motivation Scale (SMS-II). Psychol. Sport Exerc. 14, 329–341. doi: 10.1016/j.psychsport.2012.12.002
Roth, G., Assor, A., Niemiec, C. P., Ryan, R. M., and Deci, E. L. (2009). The emotional and academic consequences of parental conditional regard: comparing conditional positive regard, conditional negative regard, and autonomy support as parenting practices. Dev. Psychol. 45, 1119–1142. doi: 10.1037/a0015272
Ryan, R. M. (ed.) (2019). The Oxford handbook of human motivation. New York, NY: Oxford University Press. doi: 10.1093/oxfordhb/9780190666453.001.0001
Ryan, R. M., and Connell, J. P. (1989). Perceived locus of causality and internalization: examining reasons for acting in two domains. J. Pers. Soc. Psychol. 57, 749–761. doi: 10.1037//0022-3514.57.5.749
Ryan, R. M., and Deci, E. L. (2000). Self-determination theory and the facilitation of intrinsic motivation, social development, and well-being. Am. Psychol. 55, 68–78. doi: 10.1037/0003-066X.55.1.68
Ryan, R. M., and Deci, E. L. (2002). “Overview of self-determination theory: an organismic dialectical perspective,” in Handbook of self-determination research, eds E. L. Deci and R. M. Ryan (Rochester, NY: University of Rochester Press), 3–33. doi: 10.1111/bjhp.12054
Sargin, A., and Ünlü, A. (2009). Inductive item tree analysis: corrections, improvements, and comparisons. Math. Soc. Sci. 58, 376–392. doi: 10.1016/j.mathsocsci.2009.06.001
Schrepp, M. (1999a). Extracting knowledge structures from observed data. Br. J. Math. Stat. Psychol. 52, 213–224. doi: 10.1348/000711099159071
Schrepp, M. (1999b). On the empirical construction of implications between bi-valued test items. Math. Soc. Sci. 38, 361–375. doi: 10.1016/S0165-4896(99)00025-6
Schrepp, M. (2003). A method for the analysis of hierarchical dependencies between items of a questionnaire. Methods Psychol. Res. Online 19, 43–79.
Schrepp, M. (2005). About the connection between knowledge structures and latent class models. Methodology 1, 93–103. doi: 10.1027/1614-2241.1.3.93
Schrepp, M. (2006). ITA 2.0: a program for classical and inductive item tree analysis. J. Stat. Softw. 16:10. doi: 10.18637/jss.v016.i10
Sheldon, K. M., Osin, E. N., Gordeeva, T. O., Suchkov, D. D., and Sychev, O. A. (2017). Evaluating the dimensionality of self-determination theory’s relative autonomy continuum. Pers. Soc. Psychol. Bull. 43, 1215–1238. doi: 10.1177/0146167217711915
Stefanutti, L. (2006). A logistic approach to knowledge structures. J. Math. Psychol. 50, 545–561. doi: 10.1016/j.jmp.2006.07.003
The R Core Team (2022). R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing.
Trépanier, S.-G., Peterson, C., Gagné, M., Fernet, C., Levesque-Côté, J., and Howard, J. L. (2022). Revisiting the Multidimensional Work Motivation Scale (MWMS). Eur. J. Work Organ. Psychol. doi: 10.1080/1359432X.2022.2116315
Ünlü, A. (2006). Estimation of careless error and lucky guess probabilities for dichotomous test items: a psychometric application of a biometric latent class model with random effects. J. Math. Psychol. 50, 309–328. doi: 10.1016/j.jmp.2005.10.002
Ünlü, A. (2007). Nonparametric item response theory axioms and properties under nonlinearity and their exemplification with knowledge space theory. J. Math. Psychol. 51, 383–400. doi: 10.1016/j.jmp.2007.07.002
Ünlü, A. (2011). A note on the connection between knowledge structures and latent class models. Methodology 7, 63–67. doi: 10.1027/1614-2241/a000023
Ünlü, A. (2016). Adjusting potentially confounded scoring protocols for motivation aggregation in organismic integration theory: an exemplification with the relative autonomy or self-determination index. Front. Educ. Psychol. 7:272. doi: 10.3389/fpsyg.2016.00272
Ünlü, A., and Sargin, A. (2010). DAKS: an R package for data analysis methods in knowledge space theory. J. Stat. Softw. 37:2. doi: 10.18637/jss.v037.i02
Ünlü, A., and Schrepp, M. (2021). Generalized inductive item tree analysis. J. Math. Psychol. 103:102547. doi: 10.1016/j.jmp.2021.102547
Vallerand, R. J., Pelletier, L. G., Blais, M. R., Brière, N. M., Senécal, C., and Vallières, E. F. (1992). The Academic Motivation Scale: a measure of intrinsic, extrinsic, and amotivation in education. Educ. Psychol. Meas. 52, 1003–1017. doi: 10.1177/0013164492052004025
Van der Linden, W. J., and Hambleton, R. K. (eds). (1997). Handbook of modern item response theory. New York, NY: Springer. doi: 10.1007/978-1-4757-2691-6
Vansteenkiste, M., Sierens, E., Soenens, B., Luyckx, K., and Lens, W. (2009). Motivational profiles from a self-determination perspective: the quality of motivation matters. J. Educ. Psychol. 101, 671–688. doi: 10.1037/a0015083
West, S. G., Taylor, A. B., and Wu, W. (2012). “Model fit and model selection in structural equation modeling,” in Handbook of structural equation modeling, ed. R. H. Hoyle (New York, NY: Guilford Press), 209–231.
The SRQ-A questionnaire, in its original two versions, can be retrieved from https://selfdeterminationtheory.org/self-regulation-questionnaires/ (as of 30 October 2022). Validations of this scale were presented by Ryan and Connell (1989) and Deci et al. (1992). The adapted and supplemented version of the SRQ-A in German by Müller et al. (2007), which is used for the empirical application, can be retrieved from https://ius.aau.at/wp-content/uploads/2016/01/mui_fragebogen.pdf (as of 30 October 2022). We have decided not to translate this scale into English, for the following reason. The German modification seems to be more than a mere translation of the original SRQ-A. According to the authors, only nine of the seventeen items are reused, just translated, items of the original SRQ-A. Understandably, it has only been validated in the German language (Müller et al., 2007). Thus, to avoid the risk of any distortion of its validated properties by an unverified translation (e.g., from German to English), we reproduce this scale in its original form in Table 3. Other works could study possible translations of this German modification of the SRQ-A into different languages (such as English), to validate or invalidate it in further settings.
The binary data sets used for the empirical application are available in Tables 4A–4J, as frequency tables containing the observed response patterns with their respective absolute frequencies, for intrinsic regulation (Table 4A), external regulation (Table 4B), identified regulation (Table 4C), introjected regulation (Table 4D), autonomous motivation (Table 4E), controlled motivation (Table 4F), all regulations (Table 4G), and for the subsets of motivations A = {i1, i3, …, i5, d5, j1, …, j4, e3, e4, e5} (Table 4H), B = {i1, …, i5, d1, …, d4} (Table 4I), and C = {d5, j1, …, j4, e1, e2, e5} (Table 4J). Note that the sequence of how the response patterns are laid out in a data set according to their absolute frequencies is irrelevant for computations. The data sets made available in this appendix were analyzed by IITA with free software (Schrepp, 2006; Ünlü and Sargin, 2010).
Keywords: self-determination theory, motivation, knowledge space theory, set, relation, inductive item tree analysis, motivational implication, dimensionality
Citation: Ünlü A (2023) Qualitative motivation with sets and relations. Front. Psychol. 13:993660. doi: 10.3389/fpsyg.2022.993660
Received: 22 July 2022; Accepted: 12 December 2022;
Published: 25 January 2023.
Edited by:
Miguel Ángel Carrasco, National University of Distance Education (UNED), SpainReviewed by:
Barbara Hanfstingl, University of Klagenfurt, AustriaCopyright © 2023 Ünlü. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ali Ünlü,  YWxpZ2FsaWJ1ZW5sdWVAZ21haWwuY29t
YWxpZ2FsaWJ1ZW5sdWVAZ21haWwuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.