 Caroline Keck
Caroline Keck Axel Mayer
Axel Mayer Yves Rosseel1
Yves Rosseel1- 1Department of Data Analysis, Ghent University, Ghent, Belgium
- 2Psychological Methods and Evaluation, Bielefeld University, Bielefeld, Germany
Within the framework of constrained statistical inference, we can test informative hypotheses, in which, for example, regression coefficients are constrained to have a certain direction or be in a specific order. A large amount of frequentist informative test statistics exist that each come with different versions, strengths and weaknesses. This paper gives an overview about these statistics, including the Wald, the LRT, the Score, the - and the D-statistic. Simulation studies are presented that clarify their performance in terms of type I and type II error rates under different conditions. Based on the results, it is recommended to use the Wald and -test rather than the LRT and Score test as the former need less computing time. Furthermore, it is favorable to use the degrees of freedom corrected rather than the naive mean squared error when calculating the test statistics as well as using the - rather than the -distribution when calculating the p-values.
Introduction
Imagine a researcher wants to examine a novel psychotherapy program. A randomized experiment is set up with three treatment groups. One is a control group (X = 0), one participates in an established, standard psychotherapy program (X = 1) and one participates in the novel psychotherapy program (X = 2). No covariates are considered. The researcher is interested in the group means of the dependent variable Y, which denotes the score on a mental health questionnaire. Studies like this are usually conducted to show the superiority of the novel treatment over the standard treatment, as well as the superiority of the standard treatment over the control group. Thus, the researcher assumes that μ2 > μ1 > μ0. However, following classical null hypothesis testing procedures, we usually first test a hypothesis like H0 : μ2 = μ1 = μ0 against Ha: not H0, that is, not all three means are equal. If we can reject H0 in favor of Ha, a second step often follows, in which we execute pairwise comparisons to determine which means are equal and which means are not equal. This implies multiple testing, which brings along the risk of an inflated type I error rate. The framework of constrained statistical inference (Silvapulle and Sen, 2005; Hoijtink, 2012) allows us to test so-called informative hypotheses, meaning that we can test the null hypothesis H0 : μ2 = μ1 = μ0 against the ordered hypothesis Ha : μ2 > μ1 > μ0 in a single step. Thus, in contrast to classical null hypothesis testing, researchers have the advantages that they can formulate their hypotheses of interest directly, instead of making a detour via another hypothesis, while additionally avoiding to increase the risk for inflated type I error rates.
Informative hypothesis testing can be conducted by means of the Bayesian (see, e.g., Hoijtink et al., 2008; Hoijtink, 2012) as well as the frequentist (see, e.g., Barlow et al., 1972; Robertson et al., 1988; Silvapulle and Sen, 2005) approach, where the latter is the focus of this paper. The Bayesian approach is implemented in the R (R Core Team, 2020) package bain (Gu et al., 2020). The frequentist approach is implemented in SAS/STAT® by means of the PLM procedure (for instructions, see Chapter 87 of SAS Institute Inc., 2015) as well as in several R packages including restriktor (Vanbrabant, 2020) and ic.infer (Grömping, 2010). Recent work of Keck et al. (2021) also demonstrated how to integrate informative hypothesis testing into the EffectLiteR (Mayer and Dietzfelbinger, 2019) package.
Restriktor and ic.infer use a broad range of test statistics, which are presented in Silvapulle and Sen (2005). However, research in the field of constrained statistical inference often uses the famous -statistic (see, e.g., Kuiper and Hoijtink, 2010; Vanbrabant et al., 2015) and neglects the distance statistic (D-statistic). Furthermore, each test statistic comes in various versions, for example depending on which estimate is used for the mean squared error or the variance-covariance matrix, and oftentimes, it is not obvious which software program uses which test statistic. There are also different options regarding the distributions that can be used to compute the p-values (). At the same time, small sample properties of informative test statistics are mostly unknown. Finally, simulation studies that examine the performance of informative test statistics are lacking in the constrained statistical inference literature.
The aim of this paper is twofold. First, we want to give an overview of a broad range of different informative test statistics, including the Wald test, the likelihood-ratio test (LRT), the Score test, the - and the D-statistic as well as their different versions. Second, we want to clarify how those test statistics perform when sample and effect sizes, hypotheses and the distribution used for calculating the p-values vary. Note that we only consider the regression setting, where all variables are observed. The paper is structured as follows: We start by presenting the univariate linear regression model to explain all necessary terminology that is used in the following section, where we define the test statistics. These test statistics include “regular” as well as informative test statistics to illustrate the link between them. We also discuss different versions of these test statistics. Subsequently, we report about simulation studies that we conducted. We introduce the design of the studies, that included a broad range of sample sizes as well as effect sizes, and we outline type I and type II error rates. We conclude with a short discussion. Supplementary materials are provided and will be referenced throughout the paper.
Univariate linear regression model
The univariate linear regression model for an observation i can be defined as:
where yi is the value of the response variable for observation i = 1, 2, …, n, xi0 is 1 and xi1, …, xip are the values of the p regressors for observation i, which are assumed to be fixed (in terms of repeated sampling). β0, …, βp are the regression coefficients and εi is a residual for observation i. In matrix notation, the model can be written as y = Xβ + ε, where X is called the design matrix.
This regression model relies on several assumptions. First, we assume that the expected value of εi is zero. That is, E(εi) = 0 for all i. In matrix notation, this is expressed as E(ε) = 0, which implies that E(y) = Xβ, meaning that there is a linear relationship between E(y) and the columns of X. Second, we assume that xi is non-stochastic and X is of full column rank. Third, we assume that the error term has a constant variance: for all i. This implies that for all i. Fourth, we assume that the covariance of any two error terms is zero, that is Cov(εi, εj) = 0 for all (i, j), where i ≠ j.
The model can be estimated by means of different approaches such as ordinary least squares (OLS) or maximum likelihood (ML). It can be shown that under the presented assumptions, the OLS estimates of β are BLUE (best linear unbiased estimators, see, e.g., Seber and Lee, 2012). Using an example including four predictors, the following model is fitted:
and , and are obtained via OLS estimation. We may be interested in hypotheses concerning a single parameter like H0 : β1 = 0 vs. Ha : β1 ≠ 0 or we might be interested in hypotheses about nested model comparisons like H0 : β1 = 0 ∧ β2 = 0 vs. Ha : β1 ≠ 0 ∨ β2 ≠ 0 ∨ β3 ≠ 0 ∨ β4 ≠ 0. We can compute various important quantities that are used in hypothesis testing and that are characterized by a hat on top of it. Note that the hat indicates that estimation of the model parameters takes place in an unrestricted way, which will change once we test informative hypotheses. First, an unbiased estimator for the mean squared error is:
where k is the column rank of X and is the estimated residual sum of squares , where êi = yi − ŷi and ŷi are the model predicted values of the response variable. Note that by considering k, we yield a small-sample correction for the mean squared error, as opposed to simply using:
which corresponds to the maximum likelihood estimator of .
The variance-covariance matrix of the estimated regression coefficients is usually computed as:
where 1 is the unit information matrix:
Note that if certain model assumptions are violated, for example if the error term does not have a constant variance, robust versions of the standard errors (Huber, 1967; White, 1980) and the variance-covariance matrix (Zeileis, 2006) can be used.
We can also test hypotheses about linear or non-linear combinations of regression parameters, like H0 : β1 + β2 = 0 ∧ β3 + β4 = 0 vs. Ha : β1 + β2 ≠ 0 ∨ β3 + β4 ≠ 0. Note that in this paper, we will focus only on hypotheses containing linear combinations of regression coefficients. These combinations are specified by means of the R-matrix and each part of the hypothesis can be expressed as a row in R:
leading to the full constraint matrix:
Then the hypothesis of interest can be expressed as H0 : Rβ = 0 vs. Ha : Rβ ≠ 0. Note that all kinds of hypotheses, including the single parameter case and comparisons of nested models, as discussed before, can be expressed by means of the R-matrix.
In case our hypothesis of interest contains inequality constraints, like Ha : β1 + β2 > 0∨ β3 + β4 > 0, R still looks the same, but we need to fit a model where we enforce the inequality constraints on the regression coefficients. This can be done by means of quadratic programming, for example using the subroutine solve.QP() of the R package quadprog (Turlach and Weingessel, 2019). It implements the dual method of Goldfarb and Idnani (1982, 1983). If we apply this method in the linear regression context, it has the following form (see “Data Sheet 1” in the Supplementary materials for further explanations):
Note that all quantities based on an inequality constrained model are denoted by a tilde on top of them. Assume that the unconstrained estimates are (0.100 −0.1300.100 −0.2400.250), but the inequality constrained estimates may be (0.110 −0.1100.120 −0.2300.240), where the estimates of β0, β3 and β4 may also change slightly, even though they already satisfied the constraints in the unrestricted estimation. The restricted estimation will also lead to different residuals than the unrestricted estimation.
If our hypothesis of interest contains equality constraints, for example Ha : β1 + β2 = 0 ∨ β3 + β4 = 0, the equality constrained estimates can also be found via quadratic programming. Note that here, Ha from informative hypothesis testing equals H0 from classical null hypothesis testing. Similarly, all estimated quantities with a bar on top are both the quantities from the equality constrained fit in informative hypothesis testing and the quantities obtained based on H0 in classical null hypothesis testing, which are in fact equality constrained estimates as well. The corresponding mean squared error terms for the inequality and equality constrained case are defined as follows:
where is the residual sum of squares of the inequality constrained fit , where ẽi = yi − ỹi and ỹi are the model predicted values of the response variable. Furthermore, is the residual sum of squares under the equality constrained fit , where ēi = yi − ȳi and ȳi are the model predicted values of the response variable. Finally, h is the row rank of R.
Similarly, we can define the unit information matrices of the inequality and equality constrained fits:
Note that X from the inequality constrained fit equals X from the unconstrained fit. The estimates and as well as the corresponding mean squared error terms and unit information matrices are used in the test statistics that are presented in the subsequent section.
Hypothesis testing
In order to give a broad overview about different test statistics, we present regular test statistics used in classical null hypothesis testing, as well as informative test statistics used in informative hypothesis testing. Note that an overview table containing all test statistics is provided at the end of each section. All test statistics can be applied in the setting of linear regression. “Data Sheet 2” in the Supplementary materials shows how these test statistics are implemented in R code.
Classical null hypothesis testing
The test statistics from classical null hypothesis testing that we will explain include the Wald test, the LRT, the Score test, the F-test as well as the t-test. The large sample test statistics, that is the Wald test, the LRT and the Score test, can be defined as follows Buse (1982):
where is the log-likelihood evaluated at , is the log-likelihood evaluated at and is the score function evaluated at . All three test statistics follow asymptotically a χ2-distribution under the null hypothesis with df = h, if the model is correct.
Note that all three test statistics implicitly depend on S2 in the information matrices (see Equation 6) and in the log-likelihoods. In the regression setting, since we always know what the residual degrees of freedom are, we can use instead of to obtain the corrected instead of naive test statistic versions. That way, we can use the F-distribution with df1 = h, df2 = n − p to obtain the p-values, which is more precise in small samples compared to the χ2-distribution.
Note that the LRT, the Wald and the Score test are asymptotically equivalent. However, it has been shown that the values of the Wald test are always slightly larger than the values of the LRT, which in turn are always slightly larger than the values of the Score test (Buse, 1982, p. 157). Thus, using the same critical χ2 value, the tests may have different power properties, which can be one aspect guiding the choice between them. Another aspect may be the time it takes to compute the three tests. For the Wald test, we need to fit the unconstrained model, whereas for the Score test, we need to fit the equality constrained model and for the LRT, we need to fit both the unconstrained and equality constrained model. In many cases, fitting the unconstrained model takes the least amount of time, which is why the Wald test is chosen often. However, in some cases, for example if the equality constrained model has a lot less parameters than the unconstrained model, it may be faster to fit the equality constrained model compared to the unconstrained model.
The F-test can be calculated as Seber and Lee (2012, p. 100):
Another test statistic version results from using instead of , which we denote as Fnaive. Seber and Lee (2012, p. 100) show that Fcorrected can be re-written to contain the unit information matrix:
where the superscript “info” refers to the information matrix. When instead of is used in constructing the unit information matrix, we call this test statistic . If the model is specified correctly, Fcorrected follows an F-distribution with df1 = h, df2 = n − k under the null hypothesis.
The one-sample t-test is defined as Allen(1997, p. 67):
where is the value of β under the null hypothesis and is the standard error of . Under the null hypothesis, t is t-distributed with df = n − k, if the model is correct. Note that if h = 1 the t- and F-statistic are related in a certain way, which is t2 = F.
It is widely known that the one-sample t-test can be used for testing both two-sided hypotheses like H0 : β = 0 against Ha : β ≠ 0 as well as one-sided hypotheses like H0 : β = 0 against Ha : β > 0 or Ha : β < 0. The test statistic stays the same in both cases, but the p-value is computed differently. That is, when testing a two-sided hypothesis, half of the significance level is allocated to each side of the t-distribution, whereas when testing a one-sided hypothesis, all of it is allocated to one side of the t-distribution. That means that the cut-off levels, denoting from which point on the t-statistic can be considered to be significant, change. The two-sided p-value, which is the default output of most statistical software, simply adds up the probabilities of the negative and positive version of the observed t-value (tobs), independently of whether it was in fact positive or negative:
Since the t-distribution is symmetric, P(t > tobs) is the same as P(t < −tobs). When we are interested in the one-sided p-value and Ha : β > 0, the p-value is obtained as:
whereas if Ha : β < 0, the p-value is obtained as:
Note that in case the obtained t-value is a positive number and we are interested in Ha : β > 0 or in case t is a negative number and we are interested in Ha : β < 0, the one-sided p-value can be obtained by dividing the two-sided p-value by 2.
In summary, the t-statistic is a special case, since this statistic from the classical null hypothesis testing framework can be used for testing an informative hypothesis, as long as the hypothesis only contains one parameter. If we are interested in more than one parameter, we can no longer use the t-statistic, but have to use an informative test statistic. Table 1 shows an overview about all presented regular test statistics.

Table 1. Overview of all presented regular test statistics.
Informative hypothesis testing
Informative test statistics are often a modified version of the regular test statistics. In case the model is correct, the large sample informative test statistics, including the LRT, the Wald test, the Score test and the D-statistic, asymptotically follow a -distribution under the null hypothesis, which is a mixture of χ2-distributions. The small sample informative test statistic, that is the -statistic, follows an -distribution under the null hypothesis, if the model is correctly specified. The -distribution is a mixture of F-distributions. Note that similar to classical null hypothesis testing, we can use the corrected instead of naive mean squared error to obtain the large sample test statistics. In that way, we can calculate the p-values by means of the -distribution instead of the -distribution to obtain more precise results in small sample sizes.
The LRTcorrected test statistic can be calculated as follows Silvapulle and Sen (2005, p. 157):
where is the log-likelihood evaluated at and is the log-likelihood evaluated at . has been calculated using and has been calculated using . If and were used instead, we would obtain LRTnaive.
The Wald statistic can be found in Silvapulle and Sen (2005, p. 154):
where . The Wald version where we use instead of is called . Both versions implicitly contain 1 (see Equation 6), which can also be replaced by 1. Note that will give different results, especially in small sample sizes, due to the missing correction. Assuming is defined as in Equation 5, we can re-write the Wald statistic as:
which is identical to . Note that we can also replace by a more robust sandwich-estimator, which is not commonly done in the applied literature.
The D-statistic is calculated as follows (Silvapulle and Sen, 2005, p. 159):
where and are the values of the following two functions at their solutions (see “Data Sheet 3” in the Supplementary materials for further information):
When minimizing these functions, we treat and W as known constants. Note that in the regression case, Dcorrected is identical to and WaldVCOV, as long as is used. In contrast, if we switch to using , we obtain Dnaive, in which case .
The -statistic can be found in (Silvapulle and Sen, 2005, p. 29):
According to Silvapulle and Sen (2005, p. 29), including the constant from the regular F-statistic in the -statistic is not necessary, as it does not affect the results. Again, when using instead of , we obtain . We can re-write the -statistic similarly to how we re-wrote the F-statistic. Assuming that we use to compute the unit information matrix, we obtain:
Again, 1 can be replaced by 1.
There are various versions of the Score statistic. can be found in Silvapulle and Sen (2005, p. 159):
where . When using as compared to , we obtain . Another version of the Score statistic, , is defined as follows Silvapulle and Silvapulle (1995, p. 342):
where 1 has been calculated by means of (see Equation 13). In contrast, if we use , we obtain .
Furthermore, can be calculated as Silvapulle and Sen (2005, p. 166):
where and 1 is calculated using and can be replaced by either 1 or 1. If we use to calculate 1, we obtain . Silvapulle and Sen (2005, p. 166) mention another way to express :
where the superscript “Robertson” indicates that this is the version defined by Robertson et al. (1988), 1 is calculated using and can be replaced by either 1 or 1. Assuming that is defined as in Equation 5, can be re-written as:
where , again allowing for a more robust sandwich-estimator of to be inserted. Table 2 gives an overview about all the informative test statistics that were presented.

Table 2. Overview of all presented informative test statistics.
P-values
There are two approaches for calculating the p-value of informative test statistics (Silvapulle and Sen, 2005). In this paper, we use the approach where we first calculate the weights of the respective mixture distribution (). Note that the sum of the weights from 0 to q is one, where q is the rank of X under the null hypothesis.
If the residuals of our data are normally distributed, we can use the multivariate normal probability function as well as the ic.weight() function of the R package ic.infer (Grömping, 2010) to compute the weights. These calculations are also implemented in the R package restriktor (Vanbrabant, 2020). Once we have computed the weights, the p-values of the observed -value () and of the observed -value () are obtained as follows Silvapulle and Sen (2005, pp. 86 and 99):
It can be expected that the p-values are very similar, irrespective of whether they are calculated based on the - or -distribution, as long as sample sizes are large. However, for small sample sizes, the -distribution should yield more accurate results.
Simulation studies
We conducted several simulation studies to examine the impact of different conditions on the performance of the presented test statistics in terms of type I and type II error rates. We were interested in the effects of sample and effect sizes, the number of regression parameters considered in Ha as well as the distribution used for calculating the p-values. Our main motivation was to provide a reference framework for applied researchers who wish to test informative hypotheses, helping them to chose the optimal test statistic(s) in the present situation.
Design
We generated a design matrix X, including data for five regression coefficients and considered effect sizes of f2 = 0.02 (small), f2 = 0.10 (medium) and f2 = 0.35 (large) and sample sizes of 10, 25, 50, 100, 500, 1000, 2000, and 10000. For examining the type I error rate, we generated a random outcome Y, whereas for examining the type II error rate, we fixed all βs to 0.1 and generated y with a random error term that was specific for the effect size used. Since , where R2 is the determination coefficient, we can calculate the error terms of y by plugging in the f2-specific value of R2 in
where Cor(X) is the correlation matrix of the design matrix X. The number of replications was 1000.
We considered two different kinds of R matrices, where the first one was defined as follows:
This represents the hypothesis that only β1 is greater than zero: Ha : β1 > 0. The second R matrix was defined as:
stating that at least one of the regression coefficients, except the intercept, are greater than zero: Ha : β1 > 0 ∨ β2 > 0 ∨ β3 > 0 ∨ β4 > 0 ∨ β5 > 0.
To compute the test statistics, we used and as well as and and to compute the p-values, we used the - as well as the -distribution. In addition to the manual calculation of the test statistics, we also included the test statistics as reported by the R package restriktor.
Type I results
Test statistics were first applied the way they are presented in the referenced literature. That is, makes use of , whereas all other test statistics make use of (or ). For calculating the p-values, the -distribution is used for LRTcorrected, , , WaldVCOV, Dcorrected, , , and ScoreVCOV. The -distribution is used for calculating the p-values for the -statistic, the F-distribution is used for calculating the p-values for the F-statistic and the t-distribution is used for calculating the p-values for the t-statistic. Note that restriktor always uses (or ) for all available test statistics and always calculates the p-value based on the -distribution. Tables 3, 4 show the results.
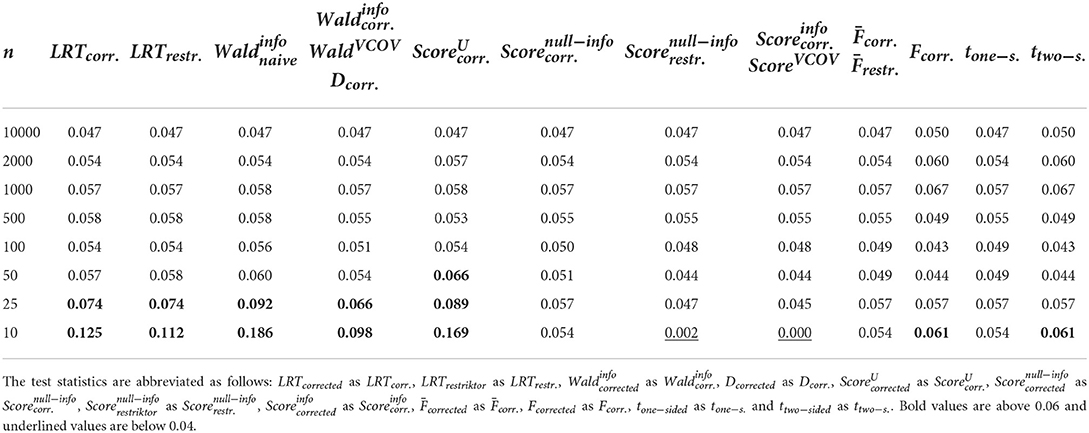
Table 3. Type I error rates when using R1 and applying the test statistics as outlined in the referenced books.
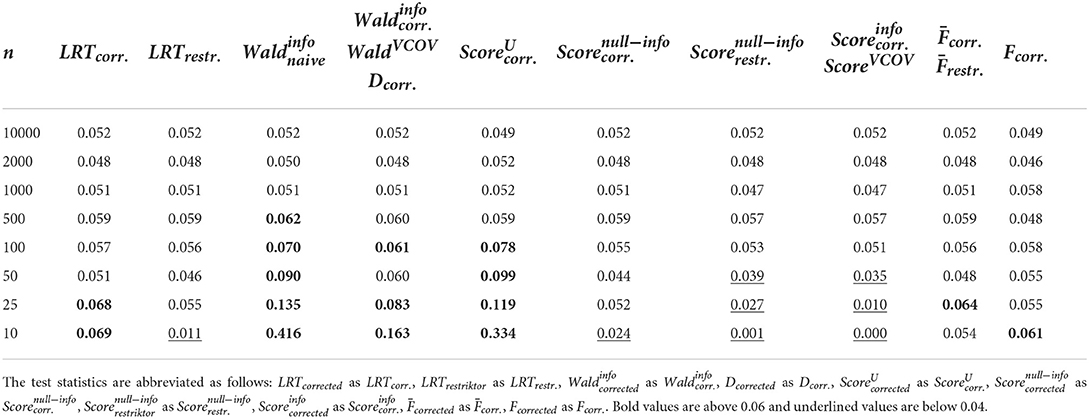
Table 4. Type I error rates when using R2 and applying the test statistics as outlined in the referenced books.
We can observe that when using R1 (see Table 3), that is when testing a hypothesis concerning only one regression parameter, type I error rates are identical between F and ttwo−sided as well as between and tone−sided, showing the link between classical null hypothesis testing and informative hypothesis testing. When using R2 (see Table 4), that is when testing a hypothesis concerning multiple regression parameters, problems with type I error rates seem to occur earlier as compared to when using R1. More specifically, problematic type I error rates occur as early as with n = 500 or n = 100 when using R2, but only start occurring with n = 50 or n = 25 when using R1. Apart from that, and show the highest type I error rates for both R matrices, whereas and show the most appropriate type I error rates for both R matrices. This is because the -distribution is more precise in small sample sizes as compared to the -distribution.
When using the -distribution instead of the -distribution when calculating the p-value for all test statistics, type I error rates are closer to the nominal level when sample sizes get smaller. This can be seen in Tables 5, 6 where a selection of test statistics are shown.
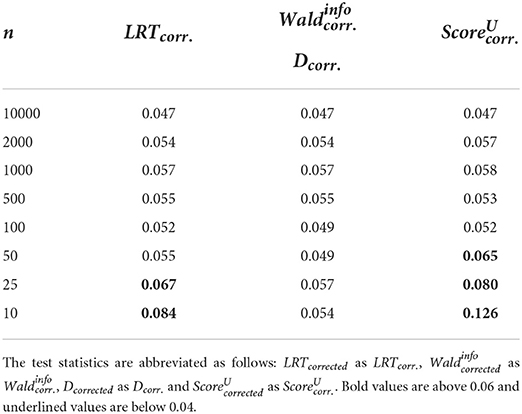
Table 5. Type I error rates when using R1, (or ) and the -distribution for calculating the p-value.
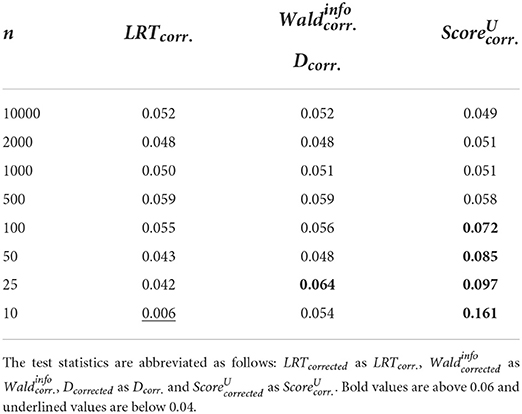
Table 6. Type I error rates when using R2, (or ) and the -distribution for calculating the p-value.
Furthermore, it can be observed that when using R1, type I error rates increase when using LRTcorrected and and n = 10 in contrast to n = 25. The same can only be observed for when using R2, but not for LRTcorrected, where the type I error rate decreases quite substantially instead. More results can be found in “Data Sheet 4” in the Supplementary materials.
Type II results
Figures 1, 2 show the type II error rates when applying the test statistics as in the referenced books.
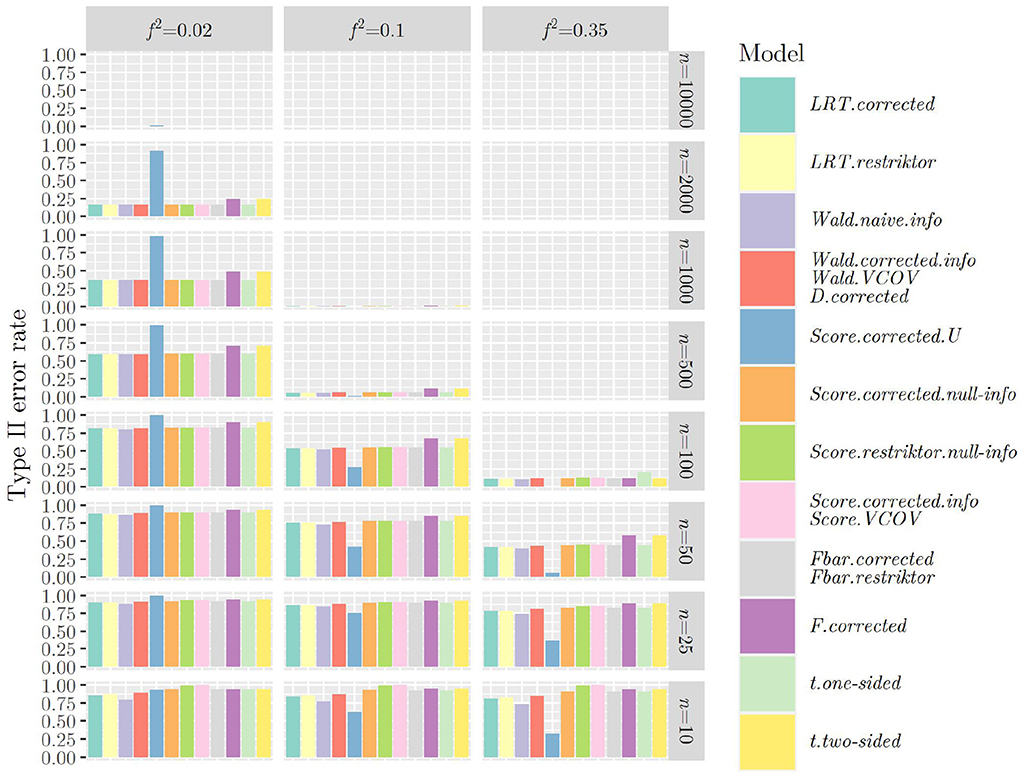
Figure 1. Type II error rates when using R1 and applying the test statistics as outlined in the referenced books.
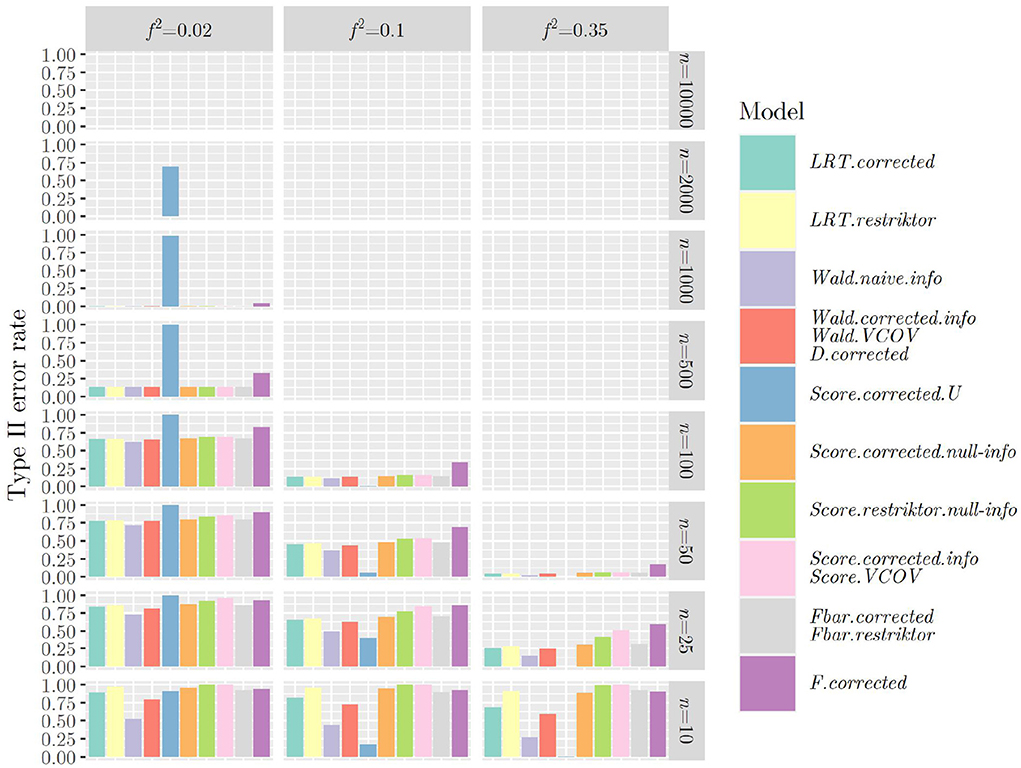
Figure 2. Type II error rates when using R2 and applying the test statistics as outlined in the referenced books.
Once more, we can observe that when using R1 (see Figure 1), that is when testing a hypothesis concerning only one regression parameter, type II error rates are identical between F and ttwo−sided as well as between and tone−sided, showing the link between classical null hypothesis testing and informative hypothesis testing. When using R2 (see Figure 2), that is when testing a hypothesis concerning multiple regression parameters, problems with type II error rates seem to occur later (in terms of sample size) as compared to when using R1. This was the other way around regarding the type I error rate and it demonstrates the nature of the relationship between type I and type II error rates: If one goes down, the other one goes up and vice versa.
The same mechanism can be observed when using the -distribution instead of the -distribution when calculating the p-value for all test statistics (Figures 3, 4): Type II error rates are increased in small sample sizes, since type I error rates had improved, that is, decreased. Again, further results can be found in “Data Sheet 5” in the Supplementary materials.
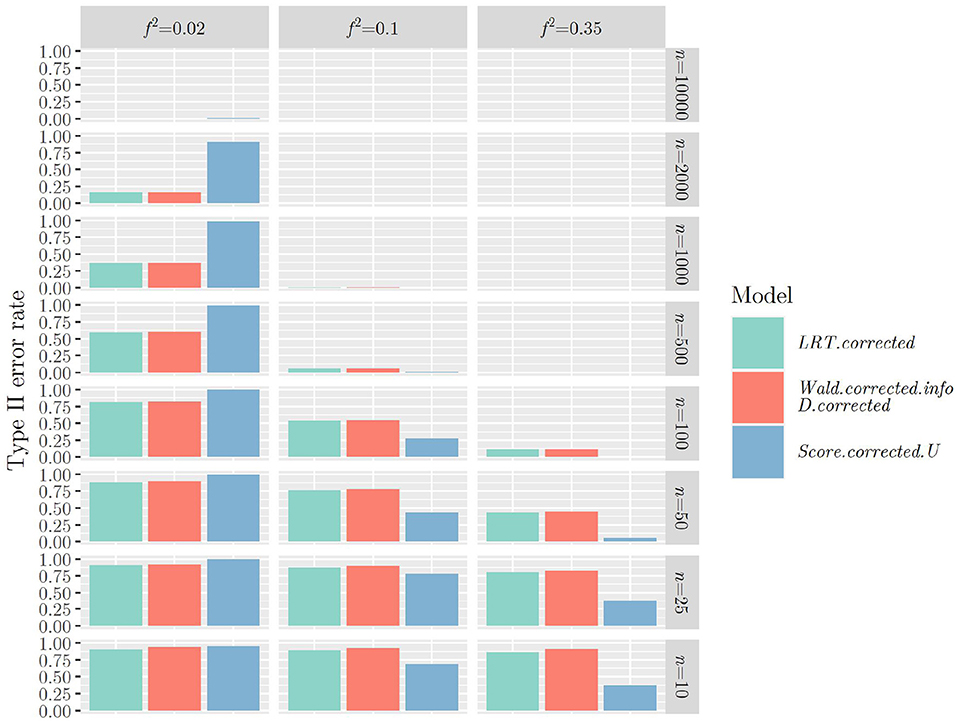
Figure 3. Type II error rates when using R1, (or ) and the -distribution for calculating the p-value.
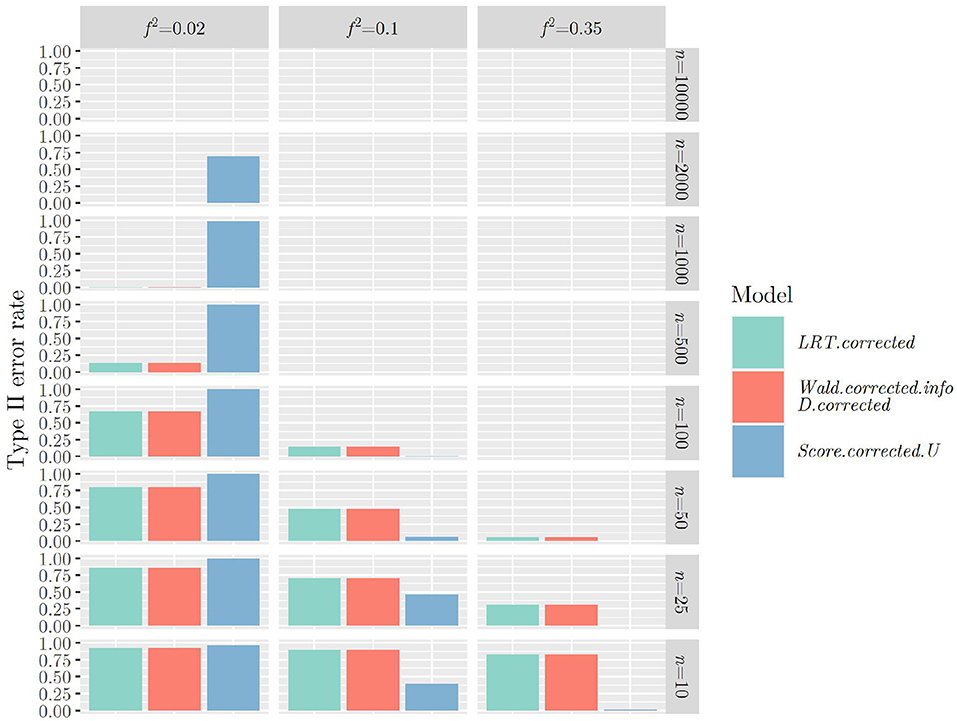
Figure 4. Type II error rates when using R2, (or ) and the -distribution for calculating the p-value.
Discussion
In this paper, we gave an overview of a large number of different informative test statistics, including their different versions. Furthermore, we clarified how those test statistics perform in terms of type I and type II error rates under different conditions by means of simulation studies in the context of linear regression. We considered varying sample and effect sizes as well as two different constraint matrices, where one specified a hypothesis about one parameter and the other one specified a hypothesis about multiple parameters. Moreover, we considered the naive and corrected mean squared errors of the unconstrained, inequality and equality constrained models as part of the test statistics as well as the - and -distribution to calculate the p-values.
Based on our findings, the following recommendations can be made. Considering the time it takes to compute the informative test statistics, both the Wald and the -test versions are favorable, since they only need fitting of the inequality constrained model to obtain and 1. Even if we do not use 1 but use 1 instead, the increase in time is small in the context of linear regression. The Score test and the LRT versions are less favorable, since they require fitting both the inequality constrained as well as the equality constrained model to obtain and , as well as the respective unit information matrices or log-likelihoods.
The D-statistic versions only require fitting the unconstrained model to obtain . However, we then additionally need to compute the two functions and , which is as time-consuming as fitting the inequality constrained model. Thus, there is no advantage of using the D-statistic versions over the Wald and the -test versions in the context of linear regression. However, if the regression model was non-linear, computing the two functions would be significantly less computationally expensive than fitting the inequality constrained model.
Moreover, we recommend using the corrected mean squared error versions in the test statistics as well as using the -distribution for calculating the p-values, if sample sizes are small. This seems to keep type I error rates closer to the nominal level compared to using the naive mean squared error versions and using the -distribution for calculating the p-value. An additional interesting finding was that the relationship between LRT, Wald and Score test values that has been found in the unconstrained context also holds in the constrained context. That is, Wald test values are always slightly larger than LRT values, which in turn are always slightly larger than Score test values.
The limitations of our simulation studies include the following aspects. We treated all variables as manifest, even though variables of interest in the social and behavioral sciences are often latent in nature. Furthermore, we solely generated normal data despite the fact that violations against the normality assumption occur regularly. Moreover, we used orthogonal predictors without interactions albeit this is rarely the case in the social and behavioral sciences. And lastly, we only included the regular versions of the standard errors and the variance-covariance matrix. Future research should thus repeat the simulation studies in the context of Structural Equation Modeling (SEM) to take into account latent variables. Furthermore, the impact of non-normal data as well as correlated predictors with interactions and using the robust versions of the standard errors and the variance-covariance matrix should be examined. It may be that under these conditions, type I and type II error rates deviate from the results presented in this paper. Moreover, the properties of informative test statistics, especially concerning the D-statistic, should also be investigated in the context of non-linear models.
Finally, research in the social and behavioral sciences is often not only interested in inference concerning regression coefficients, but also regarding effects of interest. These effects may be average or conditional treatment effects, which are defined as a linear or non-linear combination of regression coefficients. The EffectLiteR approach (Mayer et al., 2016) provides a framework and R package for the estimation of average and conditional effects of a discrete treatment variable on a continuous outcome variable, conditioning on categorical and continuous covariates. Keck et al. (2021) already demonstrated how to integrate informative hypothesis testing into the EffectLiteR framework in the context of linear regression. The present paper provides interested readers who want to apply informative hypothesis testing concerning regression coefficients or effects of interest with practical information regarding test statistics as well as type I and type II error rates.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
CK and YR contributed to conception and design of the study. CK performed the statistical analysis and wrote the first draft of the manuscript. CK, YR, and AM wrote sections of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
Funding
This work has been supported by the Research Foundation Flanders (FWO, Grant No. G002819N to YR and AM).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2022.899165/full#supplementary-material
References
Barlow, R. E., Bartholomew, D. J., Bremner, J. M., and Brunk, H. D. (1972). Statistical Inference under Order Restrictions. New York, NY: Wiley.
Buse, A. (1982). The likelihood ratio, Wald and Lagrange multiplier tests: An expository note. Am. Stat. 36, 153–157. doi: 10.1080/00031305.1982.10482817
Goldfarb, D., and Idnani, A. (1982). Dual and Primal-Dual Methods for Solving Strictly Convex Quadratic Programs, Berlin: Springer.
Goldfarb, D., and Idnani, A. (1983). A numerically stable dual method for solving strictly convex quadratic programs. Math. Program. 27, 1–33. doi: 10.1007/BF02591962
Grömping, U. (2010). Inference with linear equality and inequality constraints using R: The package ic.infer. J. Stat. Softw. 33, 1–31. doi: 10.18637/jss.v033.i10
Gu, X., Hoijtink, H., Mulder, J., Van Lissa, C. J., Van Zundert, C., Jones, J., et al. (2020). Bain: Bayes factors for informative hypotheses. R package version 0.2.4.
Hoijtink, H. (2012). Informative Hypotheses: Theory and Practice for Behavioral and Social Scientists. Boca Raton, FL: Chapman & Hall/CRC.
Hoijtink, H., Klugkist, I., and Boelen, P. A. (2008). Bayesian Evaluation of Informative Hypotheses. New York, NY: Springer.
Huber, P. (1967). “The behavior of maximum likelihood estimates under nonstandard conditions,” in Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Vol. 1, Statistics (Berkeley, CA: University of California Press), 221–233.
Keck, C., Mayer, A., and Rosseel, Y. (2021). Integrating informative hypotheses into the EffectLiteR framework. Methodology 17, 307–325. doi: 10.5964/meth.7379
Kuiper, R. M., and Hoijtink, H. (2010). Comparisons of means using exploratory and confirmatory approaches. Psychol. Methods 15, 69–86. doi: 10.1037/a0018720
Mayer, A., and Dietzfelbinger, L. (2019). EffectLiteR: Average and conditional effects. R package version 0.4–4.
Mayer, A., Dietzfelbinger, L., Rosseel, Y., and Steyer, R. (2016). The EffectLiteR approach for analyzing average and conditional effects. Multivariate Behav. Res. 5, 374–391. doi: 10.1080/00273171.2016.1151334
R Core Team (2020). R: A Language and Environment for Statistical Computing. Vienna: R foundation for statistical computing.
Robertson, T., Wright, F. T., and Dykstra, R. L. (1988). Order Restricted Statistical Inference. New York, NY: Wiley.
Silvapulle, M. J., and Sen, P. K. (2005). Constrained Statistical Inference: Order, Inequality, and Shape Restrictions. Hoboken, NJ: Wiley.
Silvapulle, M. J., and Silvapulle, P. (1995). A Score test against one-sided alternatives. J. Am. Stat. Assoc. 90, 342–349. doi: 10.1080/01621459.1995.10476518
Turlach, B. A., and Weingessel, A. (2019). Quadprog: Functions to solve quadratic programming problems. R package version 1.5–8.
Vanbrabant, L., Van de Schoot, R., and Rosseel, Y. (2015). Constrained statistical inference: Sample-size tables for ANOVA and regression. Front. Psychol. 5, 1565. doi: 10.3389/fpsyg.2014.01565
White, H. (1980). A heteroskedasticity-consistent covariance matrix and a direct test for heteroskedasticity. Econometrica 48, 817–838. doi: 10.2307/1912934
Keywords: informative hypothesis testing, constrained statistical inference, informative test statistics, type I error rates, naive mean squared error, corrected mean squared error, -distribution, -distribution
Citation: Keck C, Mayer A and Rosseel Y (2022) Overview and evaluation of various frequentist test statistics using constrained statistical inference in the context of linear regression. Front. Psychol. 13:899165. doi: 10.3389/fpsyg.2022.899165
Received: 18 March 2022; Accepted: 31 August 2022;
Published: 14 October 2022.
Edited by:
Begoa Espejo, University of Valencia, SpainReviewed by:
Joshua Ray Tanzer, Lifespan, United StatesKaterina M. Marcoulides, University of Minnesota Twin Cities, United States
Copyright © 2022 Keck, Mayer and Rosseel. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Caroline Keck, Y2Fyb2xpbmUua2Vja0BVR2VudC5iZQ==