
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol. , 14 April 2022
Sec. Quantitative Psychology and Measurement
Volume 13 - 2022 | https://doi.org/10.3389/fpsyg.2022.855379
 Endris Assen Ebrahim1,2*
Endris Assen Ebrahim1,2* Mehmet Ali Cengiz1
Mehmet Ali Cengiz1Verbal learning and memory summaries of older adults have usually been used to describe neuropsychiatric complaints. Bayesian hierarchical models are modern and appropriate approaches for predicting repeated measures data where information exchangeability is considered and a violation of the independence assumption in classical statistics. Such models are complex models for clustered data that account for distributions of hyper-parameters for fixed-term parameters in Bayesian computations. Repeated measures are inherently clustered and typically occur in clinical trials, education, cognitive psychology, and treatment follow-up. The Hopkins Verbal Learning Test (HVLT) is a general verbal knowledge and memory assessment administered repeatedly as part of a neurophysiological experiment to examine an individual’s performance outcomes at different time points. Multiple trial-based scores of verbal learning and memory tests were considered as an outcome measurement. In this article, we attempted to evaluate the predicting effect of individual characteristics in considering within and between-group variations by fitting various Bayesian hierarchical models via the hybrid Hamiltonian Monte Carlo (HMC) under the Bayesian Regression Models using ‘Stan’ (BRMS) package of R. Comparisons of the fitted models were done using leave-one-out information criteria (LOO-CV), Widely applicable information criterion (WAIC), and K-fold cross-validation methods. The full hierarchical model with varying intercepts and slopes had the best predictive performance for verbal learning tests [from the Advanced Cognitive Training for Independent and Vital Elderly (ACTIVE) study dataset] using the hybrid Hamiltonian-Markov Chain Monte Carlo approach.
Verbal learning and memory tests are highly varied among older-aged adults due to various influences. Early cognitive intervention in older adults is a critical program to reduce the future risk of dementia (Thomas et al., 2019). The efficacy of the Chinese form Hopkins Verbal Learning Test (HVLT) for screening dementia and mild cognitive impairment in a Chinese population showed that HVLT scores were affected by age, education, and sex (Shi et al., 2012). The dataset of Advanced Cognitive Training for Independent and Vital Elderly (ACTIVE) study consists of two hierarchies in which four different repeated measures are nested within each participant (Luo and Wang, 2014). The outcome measures of the cognitive training interventions were the total HVLT from three learning trials and the baseline measure (Gross, 2011).
Bayesian logistic and hierarchical probit models of accuracy data that allow two levels of mixed-effects in repeated-measures designs have been implemented. The Bayes factor through the Bayesian information criterion estimate and the Widely applicable information criterion (WAIC) model selection techniques were used (Song et al., 2017). Duff (2016) used stepwise regression model to scrutinize the effect of age, education, and gender on HVLT scores in 290 cognitively intact older adults. The study revealed that age was negatively correlated with the HVLT score, while education status was positively correlated. Moreover, there were fewer gender differences among four repeatedly measured verbal learning tests (Lekeu et al., 2009).
Another study showed that besides capabilities through training, personal characteristics like age, unmarried status, and lower occupational cognitive requirements increased the likelihood of cognitive risk (Silva et al., 2012). Higher educational levels and active engagement in exercise may contribute to cognitive reserve and have a protective effect on cognitive decline in late life (Shen et al., 2021).
Gender effects on neuropsychological performance were negligible when the age and educational status of elderly people were controlled (Welsh-Bohmer et al., 2009). Recently, the Markov chain Monte Carlo (MCMC) methods have been widely used to generate samples from complicated and high-dimensional distributions (Hadfield, 2017). Among all Bayesian computational methods, the Hamiltonian Monte Carlo (HMC) (Almond, 2014) approach is the most efficient for approximating complex data structure models and converges faster than the traditional Metropolis-Hastings and Gibbs methods (Kruschke and Vanpaemel, 2015). The common MCMC approaches show poor performance and tremendously slow convergence in complex parameter structures (Yao and Stephan, 2021).
The HVLT is the ultimate in situations calling for multiple neuropsychological assessments (Benedict et al., 1998). Classical statistical inferences and single-level models have limitations for predicting naturally nest data. Bayesian hierarchical models (Congdon, 2020) were able to predict verbal learning test and memory scores from baseline personal characteristics, such as age, gender, cognitive status [mini-mental state exam (MMSE) score], years of education, and participants’ booster training and reasoning ability measured by training progress (Kuslansky et al., 2004).
In Bayesian inference, the WAIC, the leave one out information criterion (LOO-IC), and K-fold cross-validation (K-fold-CV) are recently developed measures of complexity penalized fitting models (Almond, 2014; Sivula et al., 2020). In this article, model comparisons and model selections were performed using these three methods under the Bayesian Regression Models using ‘Stan’ (BRMS) package of R (Bürkner, 2018). In most cases, WAIC and LOO-IC showed a slight preference for the random slope model over other models (Bürkner, 2018). However, the general model selection principle shows to choose the null model when diffuse priors are used in the parameters to be included or rejected by the algorithms (Liu, 2000). Therefore, in this article, we used the HMC approach to fit the three different Bayesian hierarchical models and select the best predictive model.
The ACTIVE study was a randomized controlled trial conducted in 1999–2001 at six diverse research centers in the United States and organized by the New England Research Institutes (NERI). A total of 1,575 purposively selected older adults were included in this study (Willis et al., 2015), in which 26% of the participants were African American. The ACTIVE dataset accessed from the study of Willis et al. (2015) has 13 variables. However, this modeling paper used six explanatory variables, and the dependent variable HVLT is used as repeated measures of learning tests and memory ability. In this dataset, HVLT has four different repeated measurement scores doi: 10.3886/ICPSR04248.v3.
Suppose X is the matrix of explanatory variables, and Y is the outcome variable that is the Total Hopkins Verbal Learning Test Score (THVLTS). Besides the classical statistics, a more flexible Bayesian model is required that can accommodate the varying correlation between covariates and independent variables that occur in repeated measures-type longitudinal data. The general form of the Bayesian hierarchical model for repeated measures data can be expressed as:
Where Y denotes the vector of outcome variable; β denotes a vector of fixed effects parameters; U denotes a vector of associated random effects (specifictoeachsubject); X is a matrix of covariates (explanatory variables); Z denotes a block diagonal matrix of covariates for the random effects as a complement of X embraced of m blocks that each block has ni × q dimension matrix and ε denote a column vector of residuals. We assumed that the random effects U∼N(0d, Ω) and the residuals . Where U and ε are independently distributed. Based on the unknown vector of φΩ and φR, the unknown random effects in Ω and R can be written as Σ = (φΩ, φR) (Laird and Ware, 1982).
Where X is divided into two columns corresponding to fixed effects and a corresponding random effects design matrix denoted as and , respectively. And the parameters are divided into fixed effects β(F) and random effects β(R) = U. Cov(ui,ui) = Var(ui) = Ω and
It can be assumed that the hyperparameters of both the intercept and the coefficient/slope model have uniform hyper-prior distributions with appropriate assumptions for the parameters μu, μβ, σu, σβ ve ρ. Then, the mathematical form of the three possible Bayesian hierarchical models (Nalborczyk and Vilain, 2019) for predicting the verbal learning and memory test with two (group/subject and time) random effects (Hilbe, 2009) can be written as follows:
Here, the model is fitted by varying the intercept without including any predictor variable. Thus, this model shows the overall within and between-subject variations of the outcome variable (Goldstein et al., 2009).
Here, the BRMS command is fitted in R with varying intercepts for both clusters (i.e., participating subjects) and repeated measures (i.e., measurement time point) by including all predictor variables in the model. Thus, this model can be called a random intercept and fixed slope model (McGlothlin and Viele, 2018).
Here, we can focus on examining the dependence between the random intercepts and the random coefficients (Bafumi and Gelman, 2011). In this case, we are interested in whether the effects of age and reasoning skill have correlations with variations in verbal and memory test skills measured by trail scores.
Where S is the covariance matrix, is the corresponding correlation matrix, and ρ is the association between intercepts and coefficients used in the calculation of S. The prior matrix R is the LKJ-correlation (Lewandowski et al., 2009) with a parameter ζ(zeta) which regulates the strength of the association.
As shown in Figure 1 above, each component of the mixed effect model appears in the graph as a node. The dotted arrows represent deterministic (fixed) dependencies between the parameters (e.g., from β to μij), whereas the solid arrows represent probabilistic (random) dependencies (e.g., from to Yij) (Bürkner, 2018). The hyper-parameters of the varying both intercept and slope model (μα, μβ, σα, σβ, and ρ) can be assumed to have hyper-prior distributions with appropriate assumptions for the parameters (Liu, 2016; Congdon, 2020).

Figure 1. A varying intercept and slope model (Bayesian Framework).
WAIC (Watanabe, 2010) could be achieved as an improvement over the divergence-based information criterion (DIC) for Bayesian models. The deviation term used in the calculation of the WAIC is Log-Point Based -Requires Predictive-Density (LNTTY). LNTTY is calculated as:
The whole ppost(θ) is the posterior distribution used in the calculation of LNTTY. Similar to LNTTY, WAIC’s penalty term is purely Bayesian and is computed as:
Where pWAIC is the penalty term which is the variance of the log-predictive-density terms aggregated over N data points. Thus, the WAIC can be calculated as:
Bayesian leave-one-out cross-validation (LOO-CV) is different from the WAIC. Because there is no penalty term in its calculation. LOO-CV can be computed as:
Where ppost(−i)(θ) is the posterior distribution based on a sub-set of the data at point i from the dataset. LNTTY used ith data points to calculate both the posterior distribution and the parameter estimation. Here, in contrast, the log-pointwise predictive density (LPPDloo) is used the same for prediction only. Therefore, there is no need for a penalty term to correct potential bias by using the data twice (Vehtari et al., 2017).
Sometimes, multiple Pareto Corrected Significance Sampling (PSIS-LOO) fails, and it takes too long to remodel in the iteration. Therefore, we can estimate LOO-CV using K-fold-CV by separating the data into completely random multiples, which leads to looking at each cross-validation estimate distinctly (Vehtari et al., 2018).
The Bayesian K-fold-CV partitions the dataset into k subsets yk(k = 1, 2, …, K). The Bayesian hierarchical model (BHM) generates each training dataset yke separately, which returns a ppost(e)(θ) = p(θ|y(ke)) posterior distribution (Vehtari and Gelman, 2014). To preserve reliability with WAIC and LOO-IC, defining the predictive accuracy of every point in the dataset is essential. Therefore, the log-predictive distribution function is
Using “S” simulations corresponding to a subset of k (usually K = 10) containing the ith data point and the posterior distribution P(θ|y(ke)). The overall estimate of the expected log point predictive density for a new dataset is determined as follows:
Therefore, a point estimate of the k-fold value is the sum of the iterative folds from the data points.
Similar to Gibbs sampling, HMC practices a proposal distribution that changes subject to the recent location in the parameter space (Liu, 2000). However, unlike the Gibbs algorithm, HMC does not rely on computing the conditional posterior distribution of parameters and sampling from it (Mai and Zhang, 2018). HMC has two advantages over other MCMC methods: little or no autocorrelation of the samples and fast mixing, i.e., the chain converges to the distribution immediately (Nalborczyk and Vilain, 2019). Therefore, it is the best approach for continuous distributions with low (auto) correlation and low rejection of samples.
When the model parameters are continuous rather than discrete, HMC, also known as Hybrid Monte Carlo, can overpower such random walk behavior using a clever scheme of supplementary variables that converts the tricky of sampling from the targeted function into the simulating Hamiltonian dynamics (Britten et al., 2021). HMC is an MCMC algorithm that avoids the random walk behavior and sensitivity to correlated parameters that outbreak other MCMC approaches by performing a series of steps informed by first-order gradient information (Hilbe, 2009).
The HMC algorithm is based on the Hamiltonian (total energy) calculating the trajectory for a time t = 0, …, T and then taking the final position X(T) = Xn+1.
The steps of the algorithm are as follows:
HMC algorithm
1. Choose a starting point and a velocity distribution θ0 = X0q(v)
2. for n = 0, …
3. Set the initial position as X(t = 0) = Xn
4. Draw a random initial velocity, v(t = 0)∼q(v);
5. Integrate the orbit numerically with the total energy for some time (use the Leapfrog method):
6. Calculate the probability of acceptance:
7. Set Xn+1 = X(t = T)
8. Increment
In practice, the three basic Bayesian hierarchical models have been fitted in BRMS default settings, and population-level (fixed) effects and subject-level (random) effects were obtained (Luo et al., 2021). All three models (Models 1, 2, and 3) had both fixed and random (mixed) parts but with different estimated parameter types. In the result, the estimate shows the posterior mean and Est. Error is the SD for each parameter. Model convergence was achieved well enough both the bulk effective sample size (Bulk_ESS) and the tail effective sample size (Tail_ESS) for the 95% CIs were adequate (Vehtari et al., 2017). In general, every parameter is summarized using the posterior distribution’s mean (“Estimate”) and SD (“Est. Error”), as well as two-sided 95% credible intervals as lower and upper bounds based on quintiles.
Table 1 of the fixed effects shows that the posterior mean verbal testing score was estimated to be 26.33 with an SD of 0.73. The 95% credible interval shows that the posterior distribution mean (intercept) was significant. On the other hand, the random effect showed significant verbal score test variation between groups (participant subjects) and within-subjects (between different measurements of different time points). Thus, according to the null model, the HVLT score showed more between-group/subject variation than within-group (between repeated measurements) variation.

Table 1. Results from the fitted null model: Model 1.
Table 2 showed that the coefficient of booster training was positive with a zero overlapping 95% CI. This indicates that, on average, there is little evidence that taking booster training increases elderly adults’ verbal learning and memory test scores by 0.1865, but the evidence-based on the data and random intercept model. On the other hand, adults’ years of education (edu) estimate was negative with a zero overlapping 95% CI. This negative estimate indicates that, on average, in the random intercept model, there is little evidence that increasing the years of education decreases elderly adults’ verbal learning and memory test scores by 0.0034 units.
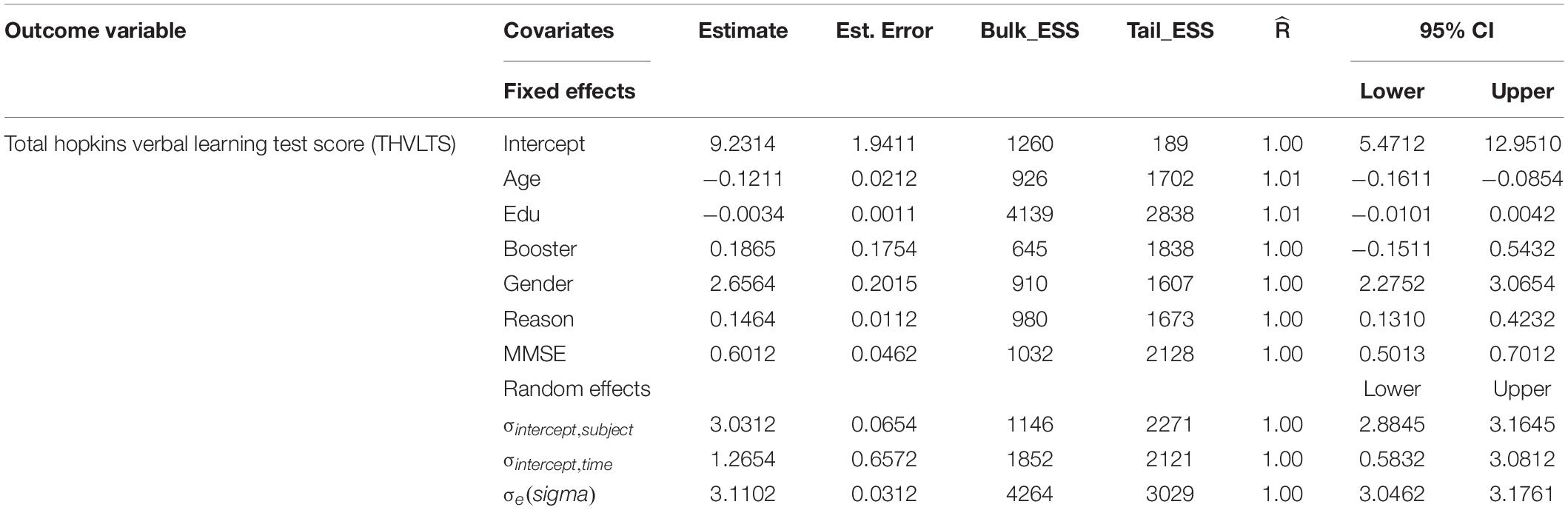
Table 2. Results from the fitted varying intercept model: Model 2.
According to the predictive effects of each explanatory variable shown in Figure 2 and Table 3, taking booster training, age, and gender were the most influential factors affecting participants’ cognitive verbal test and memory ability. Table 3 reveals that there is also an adverse association between the intercepts and coefficients for reasoning ability, which implies reasoning ability has a large average score value showing additional variability by poor reasoning ability than by good reasoning ability. Nevertheless, it can be seen that the slope estimate of such a model is even further unreliable than that of the preceding models, as it can be clearly understood from the associated standard error and the size of the 95% CIs. Table 3 also showed that booster training had a significant positive predictive effect on elderly adults’ verbal learning and memory test scores. In contracts, adults’ years of education had a significant negative impact on elderly adults’ verbal learning and memory test scores.
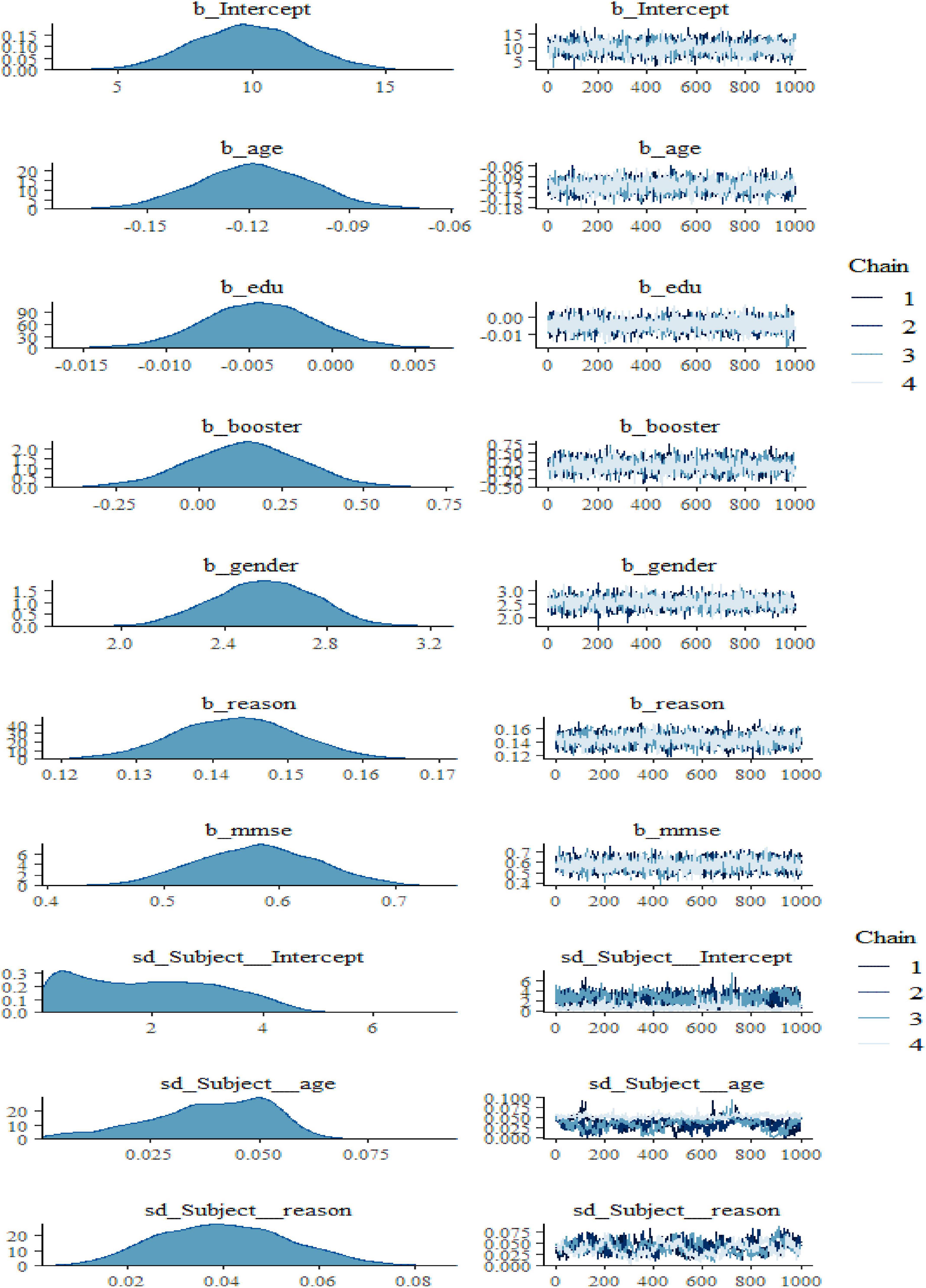
Figure 2. Bayesian hierarchical varying slope convergence diagnosis.
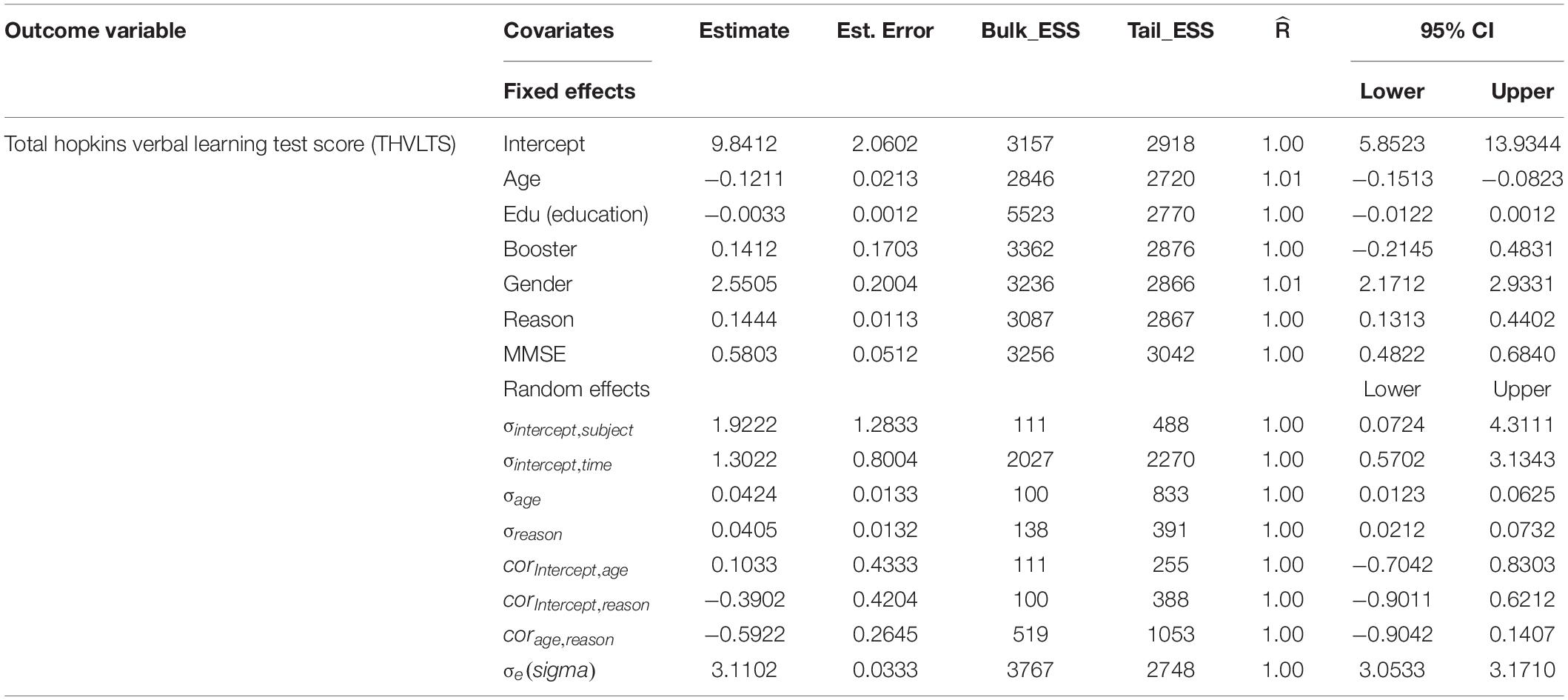
Table 3. Results from the fitted varying slope mode: Model 3.
We also noticed in Figure 2 and Figure 3 below that adding any term to the early model showed predictive performance improvements on the fitted models are ordered from Models 1 to 3 (full model). However, such a result may not be interpreted as a universal rule, subsequent adding extra terms to a unique model may also result in overfitting, which corresponds to a condition in which the fitted model is over-specified about the data, making the model good at clarifying the sample dataset but poor at predicting no observed data. The model convergence diagnosis plots are hairy caterpillars which showed the model converged. On the other hand, the models have well converged based on the estimated statistical values. This means that the R-hat statistics were close to 1 and the (bulk and tail) ESSs values were sufficiently high when ESS > 100 was chosen as the cutoff (Vehtari et al., 2021). The majority of parameters still showed sufficiently high ESS values when more conservative cutoffs were chosen (i.e., ESS > 400 or even 1,000, see Zitzmann and Hecht, 2019).
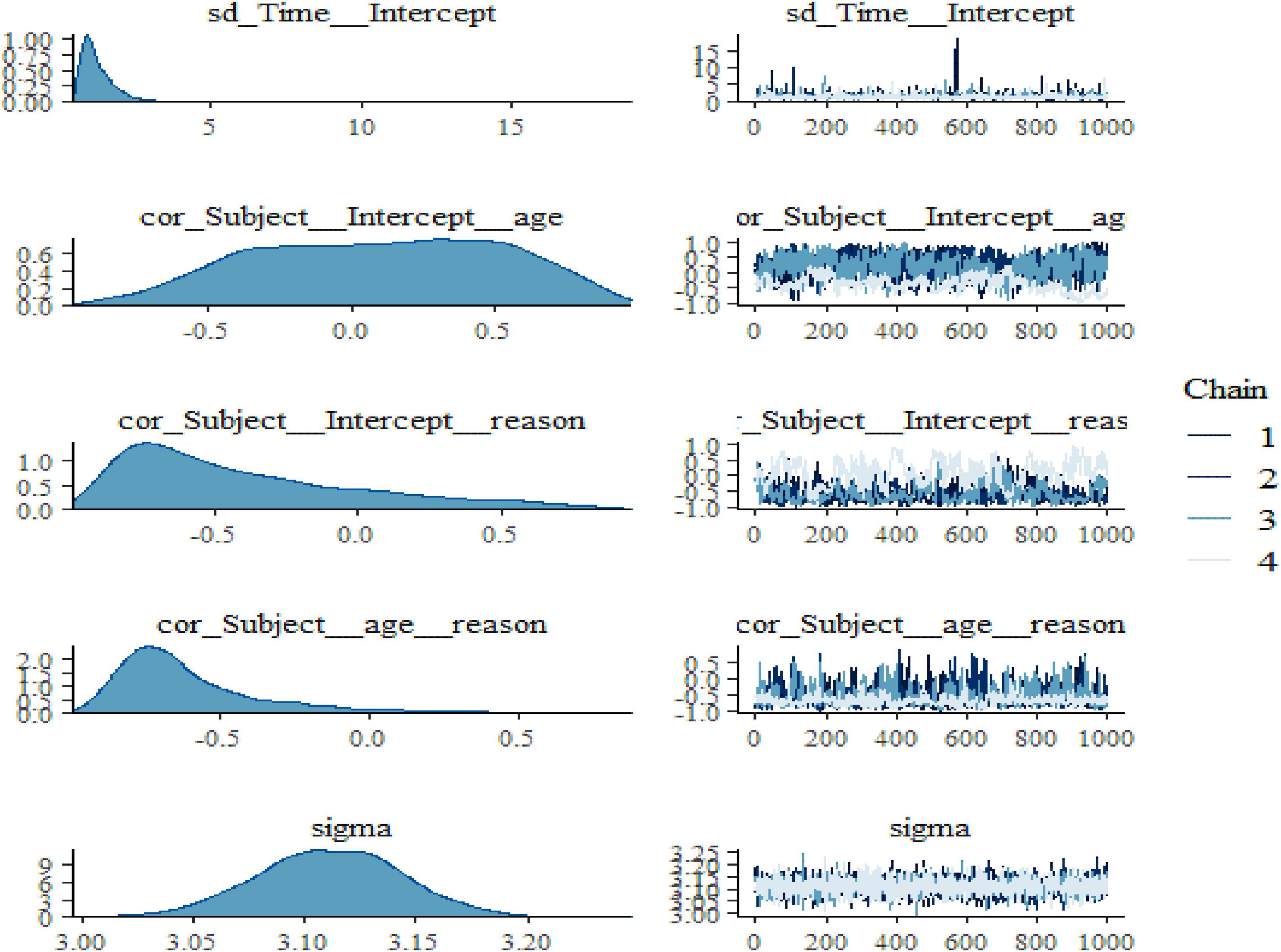
Figure 3. Bayesian hierarchical varying slope convergence diagnosis (Continuous).
Based on the fitted varying slope model, which accounted for six predictors from the data, fixed effects showed that age, gender, reasoning ability, and booster training were significant predictors of verbal learning and memory test scores, whereas random-effect showed that much of the variation in test scores occurred within-subjects (between measurement time points) than between subjects.
After we have built the three different models, it is necessary to identify relatively the best model that can be used to predict the outcome variable and make inferences. However, choosing the model that has the best predictive and a better fit on the actual data is complicated with diverse information criteria since all selected models on the actual data might not essentially achieve as fit on a different dataset. In its place, it is necessary to decide on a model that fits best in terms of predicting new data which had not been practiced.
In case of the non-existence of extra information, cross-validation methods such as WAIC and LOO-CV can be used. According to Table 4, the varying slope model has the lowest WAIC, LOO-IC, and 10-fold estimates. However, the difference is relatively small when we compare the difference in estimates of criteria for each model and the corresponding standard errors (in the column SE).

Table 4. Model comparisons based on predictive performance.
Among the fitted models above, it looks like the final model (Model 3) in the HMC algorithm is the best model. Therefore, as a function of the six explanatory variables and the random coefficient for age and reasoning ability, Model 3 has the best predictive performance for the cognitive HVLT.
According to Figure 4, the varying slope and intercept model fit well and produced nearly identical posterior observed density and posterior predictive distribution plots of the outcome variable of THVLTS from the ACTIVE study.
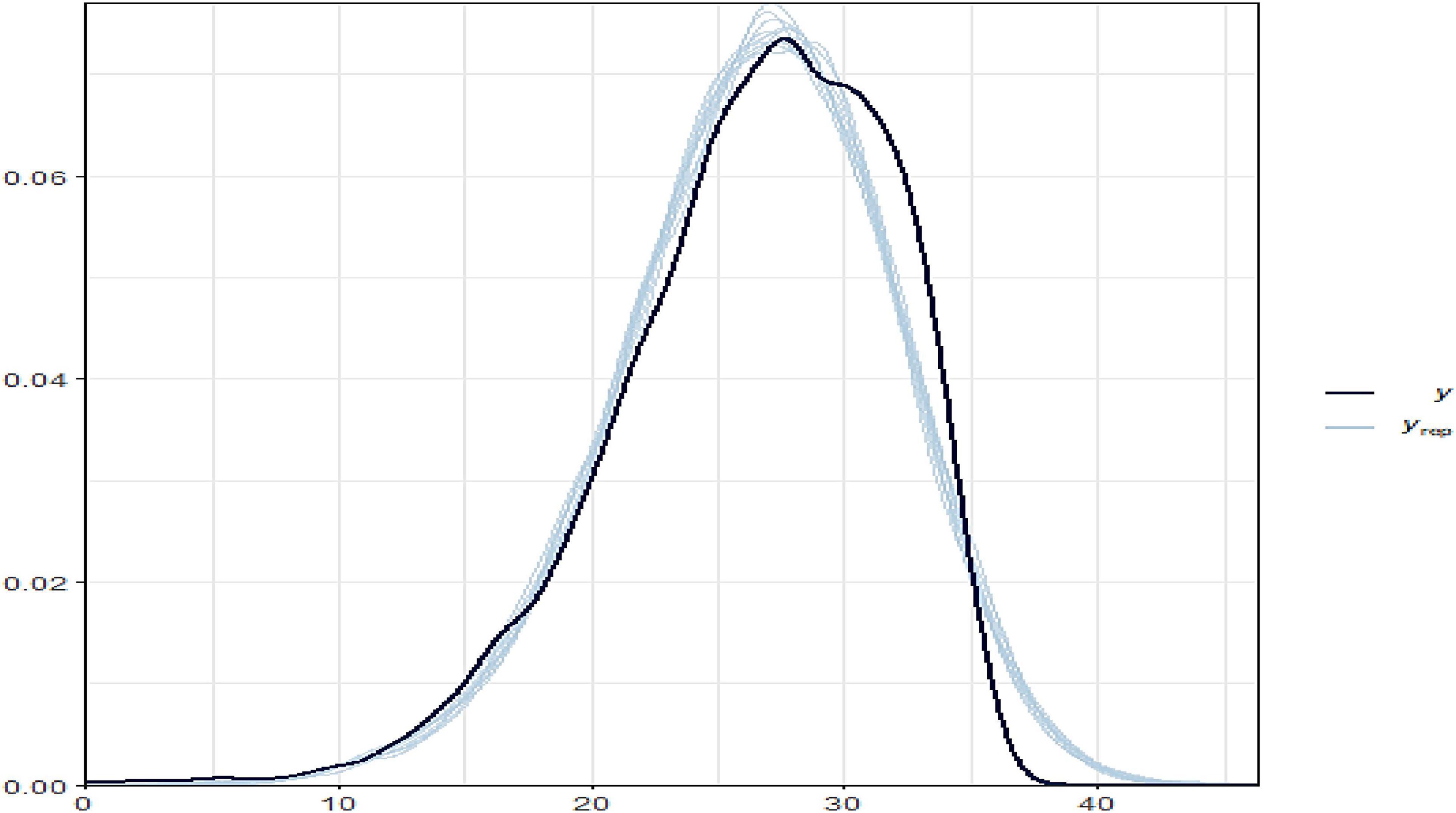
Figure 4. Bayesian hierarchical varying slope fitted model on the observed and predicted outcomes.
Furthermore, the marginal effect of each predictor variable revealed (Figure 5) that age and reasoning skills are the most significant explanatory variables that predict the THVLTS of the ACTIVE study.
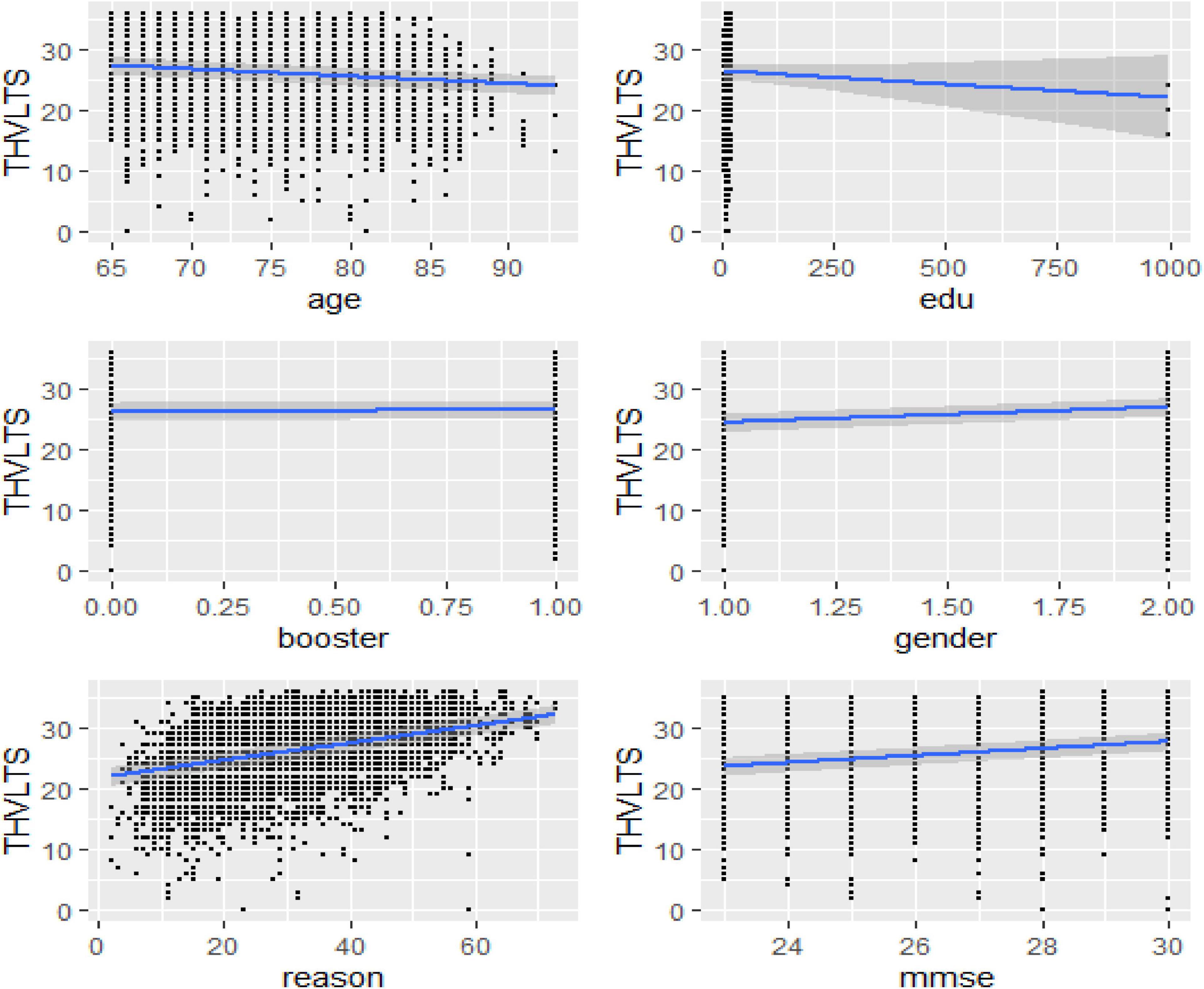
Figure 5. Bayesian hierarchical varying slope model marginal prediction effects.
Based on the selected sample participants in the ACTIVE study dataset (Willis et al., 2015), the Bayesian hierarchical linear models of three types were fitted by considering only six explanatory variables as predictors of the cognitive verbal learning test. The null model without any predictor effect but with only the intercept term was fitted, and it shows a mass of cognitive verbal learning ability variability across subjects. The varying intercept model with the addition of all predictor variables was fitted; and getting booster training, age, and reasoning ability were significant predictor of verbal test scores (Duff, 2016). The varying coefficient/slope model (i.e., Model 3) is the best-fitted model than the other fitted models since it had the lowest WAIC, LOO-IC, and 10-fold estimates (Bafumi and Gelman, 2011). A bulk of participants’ cognitive verbal test scores variations were observed between subjects (Ryoo, 2011). The full hierarchical model with varying intercepts and slopes has the best performance for predicting verbal learning tests (from ACTIVE study dataset) using the hybrid Hamiltonian Markov Chain Monte Carlo approach.
Socio-demographic and training-related characteristics influence elderly verbal learning tests that can be measured in multiple occupations (Welsh-Bohmer et al., 2009).
Total Hopkins Verbal Learning Test Score from the ACTIVE study can be used as a measure of elderly adults’ cognitive verbal learning ability. Four demographic characteristics of adults, such as age, gender, educational status, and cognitive status (MMSE score), were measured at the baseline, and characteristics measured after cognitive training such as reasoning ability and booster training were considered. THVLTS from the ACTIVE study can be used as a measure of elderly adults’ cognitive verbal learning ability. According to the findings, the varying intercept and slope model fit best, and age, gender, booster, and reasoning ability are the main significant predictors for THVLTS, which measures cognitive verbal learning. Taking booster training had a positive significant predictive effect, while years of education (edu) had a negative significant predictive effect on THVLTS.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in the article/supplementary material.
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements. Written informed consent was not obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article. This is because this quantitative analysis and modeling paper used open-access secondary data on repeated measurements.
EE participated in all aspects of the study: designing the study, performing data management, conducting the data analysis, writing the first draft of the manuscript, and discussing with MC to improve the manuscript, as it is a part of the first author’s Ph.D. dissertation. MC participated in revising the manuscript, commenting, and proofreading. Both authors listed have made a substantial, direct, and intellectual contribution to the manuscript and approved it for publication.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Our great appreciation and thanks are forwarded to NACDA members for the helpful repeated measured data collected and accessibility.
Almond, R. G. (2014). A comparison of two MCMC algorithms for hierarchical mixture models. CEUR Workshop Proc. 1218, 1–19. doi: 10.1016/j.neuroimage.2008.02.017
Bafumi, J., and Gelman, A. (2011). Fitting multilevel models when predictors and group effects correlate. SSRN Electron. J. 2, 8–14. doi: 10.2139/ssrn.1010095
Benedict, R. H. B., Schretlen, D., Groninger, L., and Brandt, J. (1998). Hopkins verbal learning test – revised: normative data and analysis of inter-form and test-retest reliability. Clin. Neuropsychol. 12, 43–55. doi: 10.1076/clin.12.1.43.1726
Britten, G. L., Mohajerani, Y., Primeau, L., Aydin, M., Garcia, C., Wang, W.-L., et al. (2021). Evaluating the benefits of Bayesian hierarchical methods for analyzing heterogeneous environmental datasets: a case study of marine organic carbon fluxes. Front. Environ. Sci. 9:491636. doi: 10.3389/FENVS.2021.491636
Bürkner, P. C. (2018). Advanced Bayesian multilevel modeling with the R package brms. R J. 10, 395–411. doi: 10.32614/rj-2018-017
Bürkner, P. C. (2019). thurstonianIRT: Thurstonian IRT models in R. J. Open Sour. Softw. 4:1662. doi: 10.21105/joss.01662
Congdon, P. D. (2020). Book Bayesian Hierarchical Models: With Applications Using R Second Edition. London: Chapman & Hall.
Depaoli, S., and van de Schoot, R. (2017). Improving transparency and replication in Bayesian statistics: the WAMBS-checklist. Psychol. Methods 22, 240–261. doi: 10.1037/met0000065
Depaoli, S., Winter, S. D., and Visser, M. (2020). The importance of prior sensitivity analysis in bayesian statistics: demonstrations using an interactive shiny app. Front. Psychol. 11:608045. doi: 10.3389/FPSYG.2020.608045/FULL
Dominique, A. (2015). “Doing Bayesian data analysis,” in Doing Bayesian Data Analysis, ed. J. K. Kruschke (Bloomington, IN: Dept. of Psychological and Brain Sciences, Indiana University). doi: 10.1016/c2012-0-00477-2
Duff, K. (2016). Demographically corrected normative data for the hopkins verbal learning test-revised and brief visuospatial memory test-revised in an elderly sample. Appl. Neuropsychol Adult. 23, 179–185. doi: 10.1080/23279095.2015.1030019
Gelman, A. (2006). Prior distributions for variance parameters in hierarchical models (Comment on Article by Browne and Draper). Bayesian Anal. 1, 515–534. doi: 10.1214/06-BA117A
Goldstein, H., Carpenter, J., Kenward, M. G., and Levin, K. A. (2009). Multilevel models with multivariate mixed response types. Stat. Model. 9, 173–197. doi: 10.1177/1471082X0800900301
Gross, A. L. (2011). Memory Strategy use Among Older Adults: Predictors and Health Correlates in the Advanced Cognitive Training for Independent and Vital Elderly (Active) Study. Ph.D. Dissertation. Available online at: https://www.zhangqiaokeyan.com/academic-degree-foreign_mphd_thesis/02061282945.html (accessed August 19, 2021).
Hadfield, J. (2017). MCMCglmm Course Notes. Available online at: http://cran.nexr.com/web/packages/MCMCglmm/vignettes/CourseNotes.pdf (accessed September 9, 2021).
Hilbe, J. M. (2009). Data analysis using regression and multilevel/hierarchical models. J. Stat. Softw. 30, 530–548. doi: 10.18637/jss.v030.b03
Kruschke, J. K., and Vanpaemel, W. (2015). “Bayesian estimation in hierarchical models,” in The Oxford Handbook of Computational and Mathematical Psychology, eds J. R. Busemeyer, Z. Wang, J. T. Townsend, and A. Eidels (Oxford: Oxford University Press), 279–299.
Kuslansky, G., Katz, M., Verghese, J., Hall, C. B., Lapuerta, P., LaRuffa, G., et al. (2004). Detecting dementia with the Hopkins verbal learning test and the mini-mental state examination. Arch. Clin. Neuropsychol. 19, 89–104. doi: 10.1016/S0887-6177(02)00217-2
Laird, N. M., and Ware, J. H. (1982). Random-effects models for longitudinal data. Biometrics 38:963. doi: 10.2307/2529876
Lekeu, F., Magis, D., Marique, P., Delbeuck, X., Bechet, S., Guillaume, B., et al. (2009). Journal of clinical and experimental neuropsychology the California verbal learning test and other standard clinical neuropsychological tests to predict conversion from mild memory impairment to dementia. Exp. Neuropsychol. 32, 164–173. doi: 10.1080/13803390902889606
Lewandowski, D., Kurowicka, D., and Joe, H. (2009). Generating random correlation matrices based on vines and extended onion method. J. Multivar. Anal. 100, 1989–2001. doi: 10.1016/j.jmva.2009.04.008
Liu, H. (2000). Efficiency of Markov Chain Monte Carlo Algorithms for Bayesian Inference in Random Regression Models. Ph.D. Dissertation. 12347. Available online at: https://lib.dr.iastate.edu/rtd/12347 (accessed October 20, 2021).
Liu, X. (2016). Methods and Applications of Longitudinal Data Analysis. Bethesda, MD: Uniformed Services University of the Health Sciences.
Luo, S., and Wang, J. (2014). Bayesian hierarchical model for multiple repeated measures and survival data: an application to Parkinson’s disease. Stat. Med. 33, 4279–4291. doi: 10.1002/sim.6228
Luo, W., Li, H., Baek, E., Chen, S., Lam, K. H., and Semma, B. (2021). Reporting practice in multilevel modeling: a revisit after 10 years. Rev. Educ. Res. 91, 311–355. doi: 10.3102/0034654321991229
Mai, Y., and Zhang, Z. (2018). Software packages for Bayesian multilevel modeling. Struct. Equ. Model. 25, 650–658. doi: 10.1080/10705511.2018.1431545
McElreath, R. (2020). Statistical Rethinking: A Bayesian Course with Examples in R and STAN, 2nd Edn. London: Chapman and Hall/CRC.
McGlothlin, A. E., and Viele, K. (2018). Bayesian hierarchical models. JAMA 320, 2365–2366. doi: 10.1001/jama.2018.17977
Nalborczyk, L., and Vilain, A. (2019). An introduction to Bayesian multilevel models using brms: a case study of gender effects on vowel variability in standard Indonesian. J. Speech Lang. Hear. Res. 62, 1225–1242. doi: 10.1044/2018_JSLHR-S-18-0006
Piironen, J., and Vehtari, A. (2016). “On the hyperprior choice for the global shrinkage parameter in the horseshoe prior,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, Lauderdale, FL. doi: 10.48550/arxiv.1610.05559
Polson, N. G., and Scott, J. G. (2012). On the half-Cauchy prior for a global scale parameter. Bayesian Anal. 7, 887–902. doi: 10.1214/12-BA730
Ryoo, J. H. (2011). Model selection with the linear mixed model for longitudinal data. Multivar. Behav. Res. 46, 598–624. doi: 10.1080/00273171.2011.589264
Shen, L., Tang, X., Li, C., Qian, Z., Wang, J., and Liu, W. (2021). Status and factors of cognitive function among older adults in urban China. Front. Psychol. 12:728165. doi: 10.3389/FPSYG.2021.728165
Shi, J., Tian, J., Wei, M., Miao, Y., and Wang, Y. (2012). The utility of the hopkins verbal learning test (Chinese version) for screening dementia and mild cognitive impairment in a Chinese population. BMC Neurol. 12:136. doi: 10.1186/1471-2377-12-136
Silva, D., Guerreiro, M., Maroco, J., Santana, I., Rodrigues, A., Marques, J. B., et al. (2012). Comparison of four verbal memory tests for the diagnosis and predictive value of mild cognitive impairment. Dement. Geriatr. Cogn. Disord. Extra 2:120. doi: 10.1159/000336224
Sivula, T., Magnusson, M., and Vehtari, A. (2020). Uncertainty in Bayesian Leave-One-Out Cross-Validation Based Model Comparison. Available online at: https://arxiv.org/abs/2008.10296v2 (accessed October 11, 2021).
Song, Y., Nathoo, F. S., and Masson, M. E. J. (2017). A Bayesian approach to the mixed-effects analysis of accuracy data in repeated-measures designs. J. Mem. Lang. 96, 78–92. doi: 10.1016/j.jml.2017.05.002
Thomas, K. R., Rebok, G. W., and Willis, S. L. (2019). Advanced cognitive training for independent and vital elderly (ACTIVE). Encycloped. Gerontol. Popul. Aging 1–7. doi: 10.1007/978-3-319-69892-2_1075-1
Vehtari, A., Gelman, A., Simpson, D., Carpenter, B., and Burkner, P. C. (2021). Rank-normalization, folding, and localization: an improved (formula presented) for assessing convergence of MCMC (with discussion). Bayesian Anal. 16, 667–718. doi: 10.1214/20-BA1221
Vehtari, A., and Gelman, A. (2014). WAIC and cross-validation in Stan. ArXiv [Preprint]. Available online at: https://statmodeling.stat.columbia.edu/2014/05/26/waic-cross-validation-stan/ (accessed December 5, 2021).
Vehtari, A., Gelman, A., and Gabry, J. (2017). Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Stat. Comput. 27, 1413–1432. doi: 10.1007/s11222-016-9696-4
Vehtari, A., Simpson, D. P., Yao, Y., and Gelman, A. (2018). Limitations of “limitations of Bayesian leave-one-out cross-validation for model selection”. Comput. Brain Behav. 2, 22–27. doi: 10.1007/S42113-018-0020-6
Watanabe, S. (2010). Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory. J. Mach. Learn. Res. 11, 3571–3594.
Welsh-Bohmer, K. A., Østbye, T., Sanders, L., Pieper, C. F., Hayden, K. M., Tschanz, J. A. T., et al. (2009). Neuropsychological performance in advanced age: influences of demographic factors and apolipoprotein E: findings from the Cache County memory study. Clin. Neuropsychol. 23, 77–99. doi: 10.1080/13854040801894730
Willis, S. L., Jones, R., Ball, K., Morris, J., Marsiske, M., Tennstedt, S., et al. (2015). Advanced Cognitive Training for Independent and Vital Elderly (ACTIVE), United States, 1999–2008. Ann Arbor, MICH: Inter-University Consortium for Political and Social Research [Distributor].
Yao, Y., and Stephan, K. E. (2021). Markov chain monte carlo methods for hierarchical clustering of dynamic causal models. Hum. Brain Mapp. 42:2973. doi: 10.1002/HBM.25431
Zitzmann, S., and Hecht, M. (2019). Going beyond convergence in Bayesian estimation: why precision matters too and how to assess it. Struct. Equ. Model. 26, 646–661. doi: 10.1080/10705511.2018.1545232
Different scholars suggested various priors for a component in a hierarchical model of variability parameters depending on the fitted Bayesian model structure and MCMC method. Some researchers proposed non-informative prior distributions, including uniform and inverse-gamma families in Gibbs sampling. Other researchers suggested a half-t family for the hierarchical model and demonstrate relatively weakly informative prior distribution. Half-student-t prior, a default prior in BRMS for SD parameters leads to better convergence. Still, the local shrinkage parameters lead to an increased number of divergent transitions in the BRMS of Stan (Piironen and Vehtari, 2016). The robust options for group-level standard deviations in Bayesian hierarchical models are half-normal (0,100), half-Student t with 3 degrees of freedom, or half-Cauchy prior distributions (Congdon, 2020).
Bürkner (2019) and McElreath (2020) proposed a half-normal distribution for SD priors in BRMS. Choosing a truncated normal distribution considers a good idea that the standard deviation cannot be less than 0. However, a prior on the random effect parameter with a long right tail has been revealed as “conservative” because it allows for bulky value estimates of the SD parameters.
Gelman (2006) suggested half-Cauchy prior with a mode at 0 and scale set to a considerable value by reasonably explaining the restrictive nature of half-Cauchy prior in providing enough information for the small numbers of groupings in the hierarchical nature of the data. Bayesian hierarchical model, to reduce the occurrence of unrealistically large SD estimates, BRMS-Stan documentation suggested half-Cauchy is the prior that automatically bound at 0. R-Stan renormalizes the distribution used so that the sum of the area between the bounds is 1.
The half-Cauchy (0, 1) prior is a case of the half-Student t-distribution with v1 degrees of freedom parameterized in the SD metric. It occupies a reasonable middle ground of different prior classes that performs well near the origin. It does not lead to drastic compromises estimates of the population-level (location) and group-level effect of the parameter space (Polson and Scott, 2012).
Sensitivity analysis of priors Appendix Table 1 shows the robustness of a Bayesian analysis when choosing different prior distributions in the fitted models. According to Bürkner (2019), for each SD component of the random parameters in hierarchical models, any prior distribution is practically well-defined on the non-negative real numbers only. In this study, we used the default in BRMS, the truncated Student’s t distribution with 3 degrees of freedom considered a reference prior. Then, because negative values are incredible for a standard deviation, we practiced a very strong informative truncated normal prior with a mean of 5 and a standard deviation of 0.01, and a half Cauchy prior for the sensitivity analysis of the impact of the prior on the Bayesian hierarchical models for the applied dataset.
Models with an effective sample size greater than 1000 and R-hat closest to 1.00 but not greater than 1.10 showed the consistency of an ensemble of Markov chains (Dominique, 2015). Moreover, both Bulk-ESS and Tail-ESS should be at least 100 (approximately) per Markov chain to be reliable and indicate that estimates of the respective posterior quantiles are reliable (Vehtari et al., 2021). In this paper, the R-hat, Bulk-ESS, and Tail-ESS results of the null, varying intercept, and varying coefficient models fulfilled these convergence diagnosis metrics. Therefore, the effective sample sizes (ESS) and potential scale reduction (R-hat) convergence diagnostic metrics are sufficient for stable estimates in each fitted model.
We used the sensitivity analysis for priors to scrutinize the final fully hierarchical specified model (Model 3) results, based on the default (or reference) prior, with the results obtained using different prior distributions. The posterior distributions and 95% posterior density (HPD) intervals by the median for the fixed effects and random effects, including SD of the verbal learning test score, did not change much depending on the priors specified, which indicates a practically identical interpretation of the estimates depending on the priors. Thus, because of no significant percentage deviation among models depending on the alternative prior specification, we reported the model results with the half-Cauchy prior that yielded good model convergence and sufficient ESS values (i.e., greater than or equal to 100). Besides, a good-looking posterior density plot of the predicted versus the observed data in Figure 4 was considered.
As it can be explained by Depaoli and van de Schoot (2017), and Depaoli et al. (2020), sensitivity analysis results could be provided through visuals, akin to the Shiny app plots or it may be in a table format indicating the degree of discrepancy in estimates or HPD intervals across parameters as we presented in the Appendix table below.
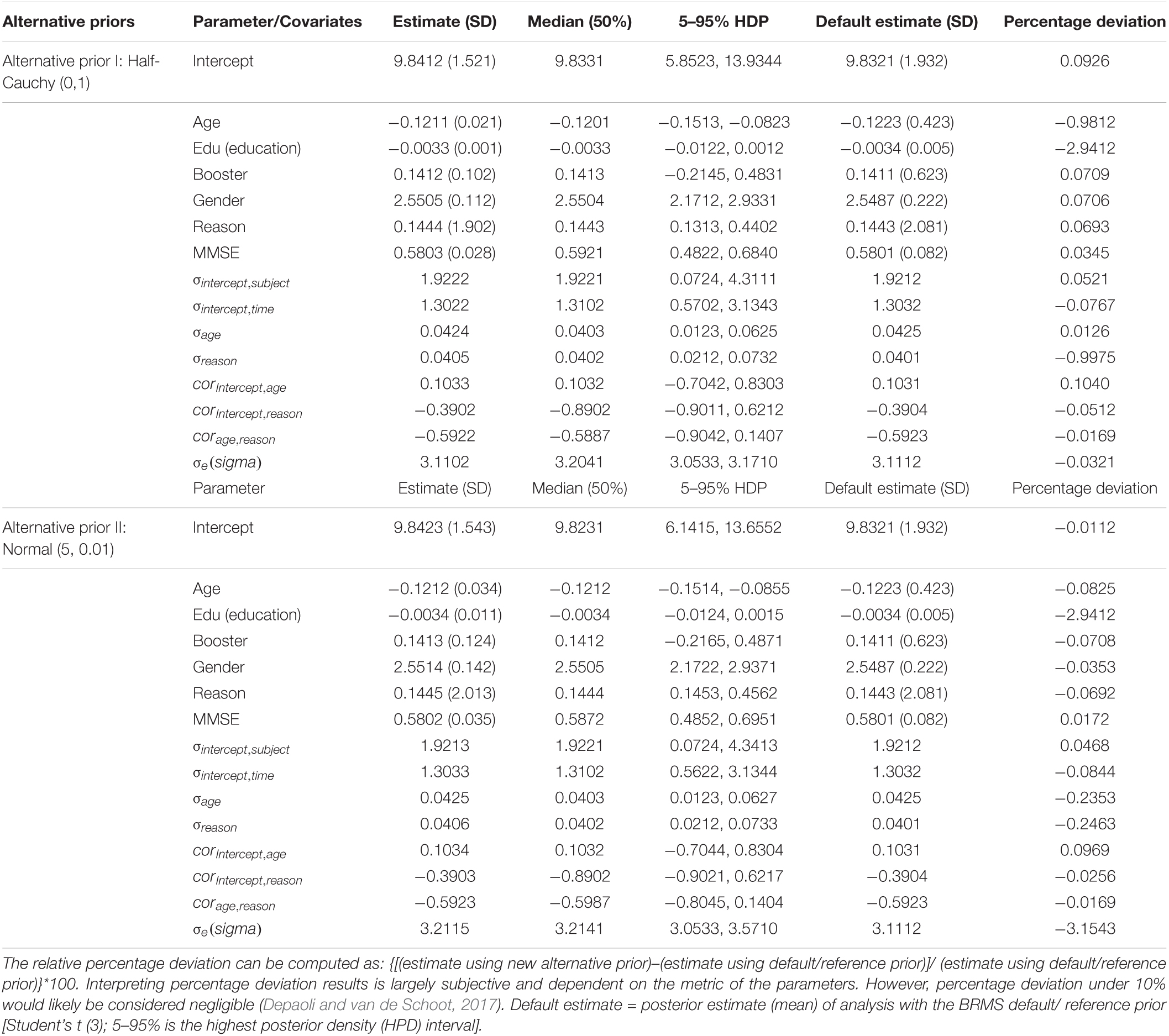
Appendix Table 1. Posterior estimates with the verity of priors: Sensitivity analysis results.
Keywords: predicting, Hamiltonian Monte Carlo, Verbal Learning Test, hierarchical, model
Citation: Ebrahim EA and Cengiz MA (2022) Predicting Verbal Learning and Memory Assessments of Older Adults Using Bayesian Hierarchical Models. Front. Psychol. 13:855379. doi: 10.3389/fpsyg.2022.855379
Received: 15 January 2022; Accepted: 14 March 2022;
Published: 14 April 2022.
Edited by:
Holmes Finch, Ball State University, United StatesReviewed by:
Steffen Zitzmann, University of Tübingen, GermanyCopyright © 2022 Ebrahim and Cengiz. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Endris Assen Ebrahim, ZW5kMzg0QGdtYWlsLmNvbQ==, orcid.org/0000-0002-8959-6052
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.