 Makiko Chiba
Makiko Chiba- College of Foreign Languages, Zhejiang University of Technology, Hangzhou, China
Since the popularity of the Internet, it is now customary for people to browse the news on the Internet. In the process of browsing news, there are often comments to express and spread personal emotions. This has become a very popular way of spreading news sentiment. This research is based on information fusion technology to realize the research on the identification algorithm of news sentiment communication tendency. Based on the research results of many scholars, this article first elaborates the definition, method, and framework of information fusion technology. In this paper, the corresponding technology is selected, and then in the research of the tendency recognition algorithm, an emotion tendency recognition algorithm based on the integrated probabilistic reasoning model is proposed. The algorithm proved its effectiveness and robustness through experiments. Finally, the experimental results show that in all the parameter combination conditions, the algorithm can not only reduce the feature dimension but also ensure the accuracy of recognition under the probability of 89%.
Introduction
As information explodes in the new era, it has become an indispensable technology for information convergence in all fields. Simultaneously, as people pay more and more attention to online news, which has led to an increasing informativeness of news commentary. And people’s comments are often mixed with many personal emotions, so the recognition of news sentiment tendencies has become an inevitable result. The work of this article can not only analyze the changing trend of emotional orientation, but also provide an indispensable reference for the future news industry.
Many scholars at home and abroad have provided a large number of references for the research on multi-mode, information fusion, news sentiment communication, and tendency recognition algorithms. Peng et al. (2017) proposed a semi-supervised learning method based on the collaborative filtering theory using labeled and unlabeled interactive information, called NormMulInf. The method he proposed initially determined the similarity measure by integrating biological information. For example, the similarity between samples and the local correlation between sample labels. He then integrated the similarity information into a robust principal component analysis model, which was solved using augmented Lagrangian multipliers. Experimental results show that the method he proposed can accurately classify and predict drug–target interactions. Hong et al. (2017) proposed a new framework called Multi-scale Spatial Information Fusion (MSIF). The MSIF he proposed captures the inherent spatial information contained in homogeneous regions of different sizes through a multi-scale strategy. In MSIF, local one-dimensional embedding (L1-DE) and information fusion are used iteratively, and the iterative process is terminated within a finite number of steps. Algorithm analysis proves the effectiveness of the proposed method. Experimental results on four widely used HSI data sets show that compared with other state-of-the-art spectral spatial classification methods, his proposed method achieves higher classification accuracy. Li et al. (2018) proposed a Bayesian information fusion method for determining the probabilistic health index of power transformers. The method he proposed integrates various data obtained from transformer measurements, maintenance records, and fault statistics. By using these data, he used Bayesian Belief Network (BBN) to build an inference model. In the inference model, the significance of each individual measurement to the corresponding component in the BBN is jointly determined by principal component analysis and expert experience, and then quantified by score probability transformation. Finally, the reasoning model is used to derive the probabilistic health index, and he provides a case study to prove the applicability of the proposed method for assessing the condition of the transformer. Qi et al. (2017) proposed a laser beam welding (LBW) process parameter optimization method based on multi-fidelity (MF) meta-model. The results show that the MF meta-model is superior to the single-fidelity meta-model in terms of global and local accuracy. Finally, the fast elite non-dominated sorting genetic algorithm (NSGA-II) is used to facilitate the exploration of the parameter space of the LBW process and the multi-objective pareto optimal search. Lei et al. (2021) proposed a novel graph convolution model to learn and fuse multi-hop neighbor information relations. Lei et al. (2021) uses a weight sharing mechanism to design graph convolutions of different orders to avoid potential overfitting problems. In addition, Lei et al. (2021) designed a new multi-hop neighbor information fusion (MIF) operator that mixes different neighbor characteristics from 1 hop to k hops. Lei et al. (2021) theoretically analyzed the computational complexity of the model and the number of trainable parameters. Experiments on the text network show that his proposed model achieves the most advanced performance than text GCN. Ouyang et al. (2021) proposed an information fusion FMEA method based on binary language information and interval probability. He uses the theory of binary language sets to convert heterogeneous information into interval numbers, and at the same time uses interval probability comparison to analyze failure modes. Finally, he verified the reliability and effectiveness of the proposed method by comparing different FMEA methods. The data of these studies are not comprehensive, and the experimental results are still open for discussion and are not recognized by the public, so they cannot be popularized.
This paper’s innovation was in reducing the data storage space by PCA dimensionality decrease, which resulted in accelerating the algorithm. While this paper employs an approach, model, and architecture for data fusion technique, which are most appropriate for this study are chosen. This provides the most effective technical support for research. Finally, this paper proposes an emotional orientation recognition algorithm based on an integrated probabilistic inference model, which significantly improves the efficiency of emotional orientation recognition.
Information Fusion and the Tendency of News Sentiment Communication
Information Fusion
Analysis and processing over a large amount of accessed information is the process of information fusion to achieve the target result. From the perspective of mathematics, information fusion is to find the relationship between multiple functions and solve them in parallel to obtain the output (Huang, 2017).
The functional model of multi-modal information fusion includes a variety of functional modules (Prasath, 2017). According to the level of information in the transmission process, it is divided into low-level processing and high-level processing. In the early stage of the low-level processing process, a numerical result is formed by mining the characteristics of the information data. It is possible for these results to reflect the underlying signal signatures in multi-modal information which enables correlation and identification between data. That data can be used as a basis for the analysis of information. Additionally, since the advanced processing is also analyzed at a later stage of information fusion, on a semantic level, it reflects the features of the semantic level. It mainly extracts information features from symbolic logic and can realize functional modules, such as logical reasoning and situation estimation (Chahine et al., 2018; Yu et al., 2019).
The signal information processing process is information data processing, feature extraction, state recognition, and decision-making judgment (Groen et al., 2017). Regarding the information involved in each stage of the information processing process, there are three different stages of information processing. This first stage is data, which is processed by smoothing and filtering the collected data; at the second stage is features, which extract the characteristics of the information; from the third stage is decision-making. The three levels of information fusion have their own characteristics and will not conflict with each other in the process. It can perform fusion processing on information at any level, but it will increase the load of the system while increasing the depth of information fusion processing. Therefore, it should be judged according to the task’s information fusion requirements, hardware processing capabilities, etc., and decide at which level the fusion processing should be performed (Chandra et al., 2019).
In the first layer of fusion, data layer fusion is the first layer of fusion. It performs data fusion immediately after collecting the original data. The characteristic is less amount with information loss and better accuracy of fusion results. However, due to the complexity and noise of the collected data, the amount of fusion calculation is large, and the requirements for information synchronization are relatively high; the feature layer is merged into the second level. After data processing, the information expressed by the data has become more pure. Therefore, feature extraction can be performed on the information, and the obtained feature vectors can be processed uniformly for judgment. The calculation amount of this fusion method is relatively small, but the fusion result is greatly affected by the characteristic information, and it is susceptible to interference; the fusion processing time of the decision-making layer is the preliminary detection result that the system has formed on the target. At this time, the decision-level fusion processing can allow the system to merge the single-source detection results to form a more complete and accurate judgment. This method has the least amount of calculation and the strongest anti-interference ability. However, due to problems, such as the difficulty of obtaining prior knowledge and the difficulty of constructing huge knowledge bases, related theories need to be further improved (Song et al., 2017).
Commonly used multi-mode information fusion methods can be roughly divided into three categories: probability and statistics methods, logical reasoning methods, and neural network methods (Gupta and Banerjee, 2019). A probabilistic and statistical approach to the problem includes the weighted average method, the Bayesian estimation method, or the Kalman filtering method. There are specific mathematical models for all of them, which are traced for the process from fusion information manipulation. But they are not good at handling massive data, and the difficulty of solving will increase with the increase of the amount of data, and it is necessary to adopt coefficients suitable for the system according to the requirements of different systems or prior knowledge. When the model does not conform, the fusion result will be far from the actual value. Logical reasoning methods are usually D-S evidence theory and fuzzy logic methods, which are closer to human thinking than probability and statistics methods. It is usually used for information fusion at the decision-making level, but evidence theory requires evidence to be independent of each other. However, in complex systems, there are many coupling relationships between various evidence, and there may be exponential explosion problems under the premise of large amount of data. The fuzzy logic method needs to determine the fuzzy language set and the membership function corresponding to the actual input distribution space, and the adaptive ability is too poor. The neural network method has strong fault tolerance and self-learning ability. Through its powerful generalization ability and non-linear processing ability, it can theoretically fit arbitrarily complex functions. It obtains the hidden knowledge in the information through different learning algorithms, and obtains the uncertainty reasoning mechanism. However, the neural network method also needs to rely on human prior knowledge to adjust the network architecture. Each of these multi-mode information fusion methods has its own characteristics and shortcomings. Due to the complementarity of various methods, each method is often combined to construct a new information fusion method (Kelly and Ahmad, 2018).
Commonly used models for information fusion include JDL model, Dasarathy model, waterfall model, etc. This article briefly introduces two representative models of JDL and Dasarathy (Minchae and Kyung-Shik, 2017; Boguslaw et al., 2018).
JDL Model
The JDL model is a fusion model constructed as a clue to the information processing process. With a general sense, the JDL fusion model is a functional model by which the basic concepts and processes of information fusion are explained and provides that framework for further discussion. Although the original intention of this model is based on the needs of military applications, it has been developed and perfected and is also used in civil applications (Yadav et al., 2019). The JDL model is shown in Figure 1.
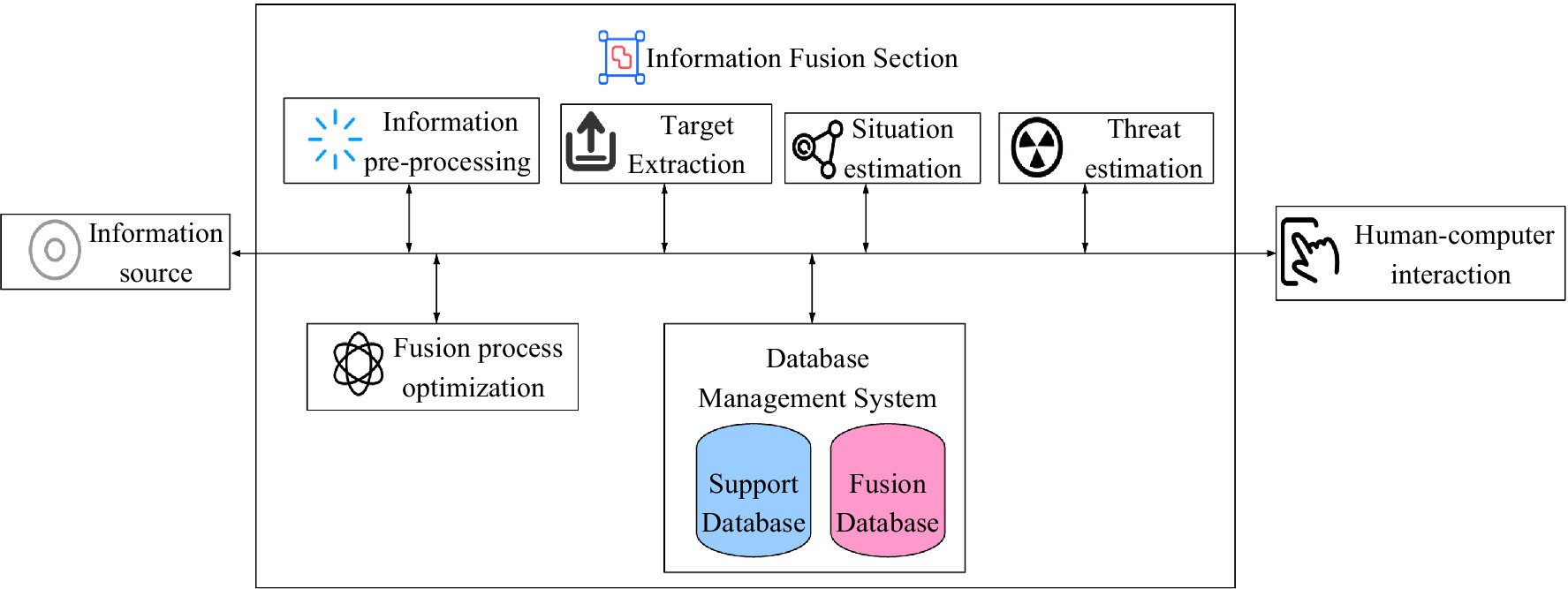
Figure 1. JDL data fusion model.
Dasarathy Model
With the Dasarathy model, it is built based on the perspective of information representation. It can demonstrate clearly and effectively the levels of fusion behavior (Yang and Seng, 2017). The Dasarathy model is shown in Figure 2.
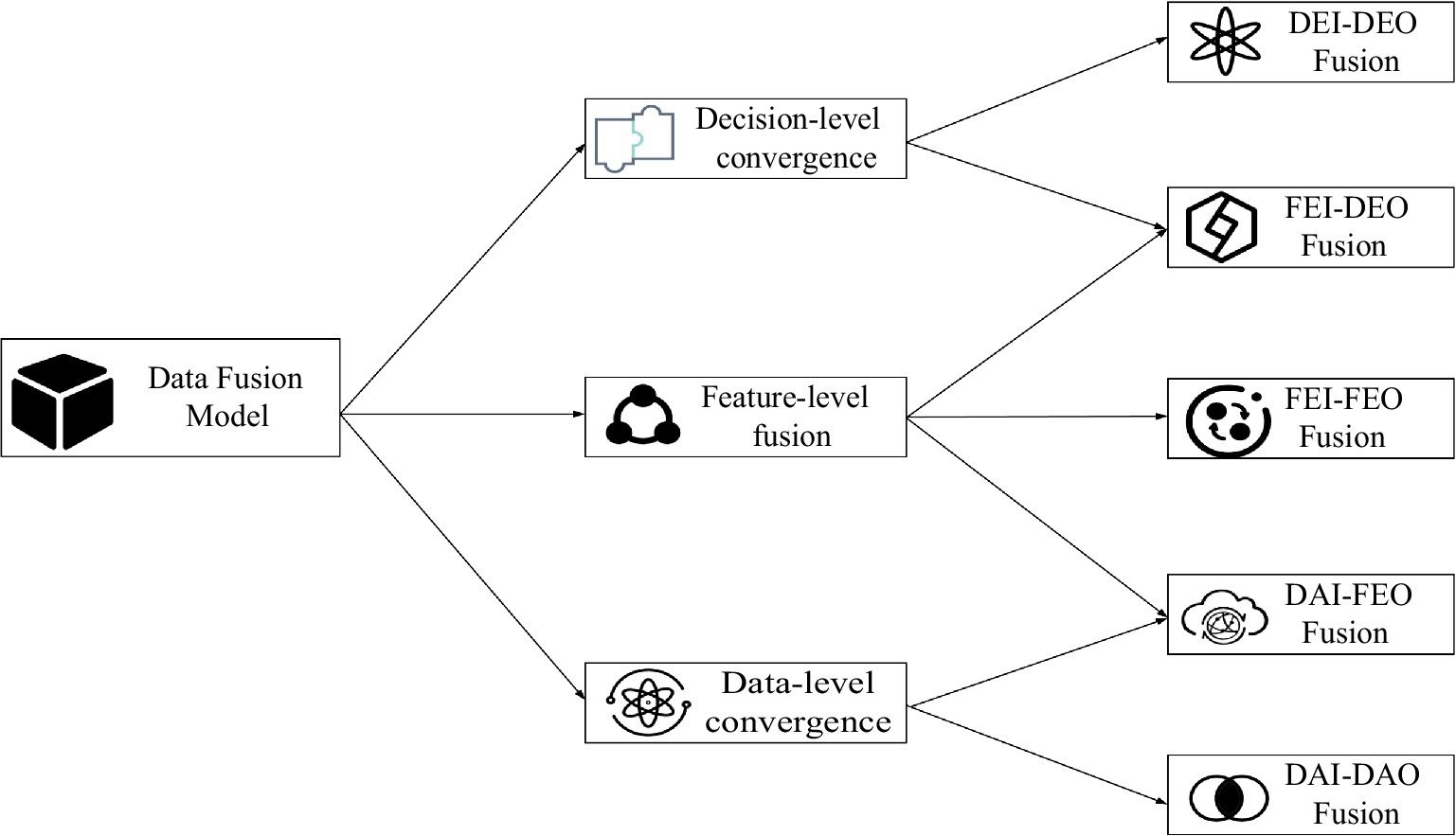
Figure 2. Dasarathy data fusion model.
The information fusion system architecture has not yet reached a unified classification form. But as a whole, it can be divided into three categories: centralized structure, distributed structure, and hierarchical structure (Allen et al., 2019). The so-called centralized structure means that all fusion processes are completed by a fusion center. The centralized system structure is shown in Figure 3.
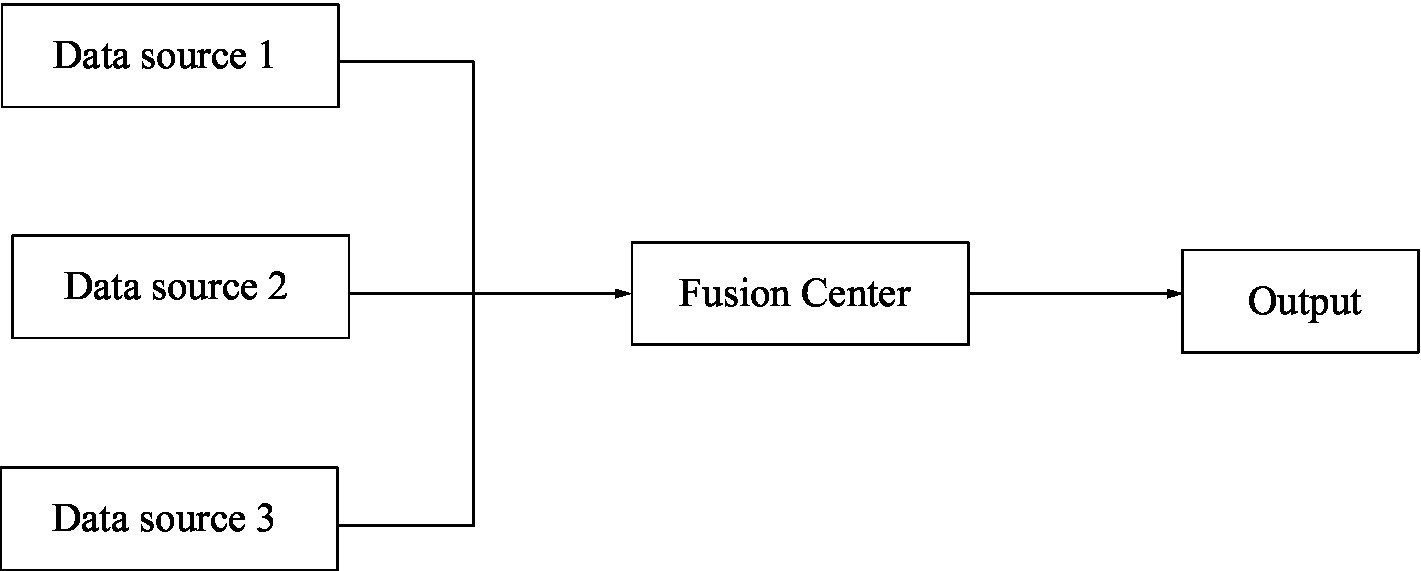
Figure 3. Centralized structure of information convergence.
Compared with the centralized structure, the distributed structure requires almost no original information and data, so the requirements for channel capacity are greatly reduced (Chen and Chen, 2019). Its structure is shown in Figure 4.
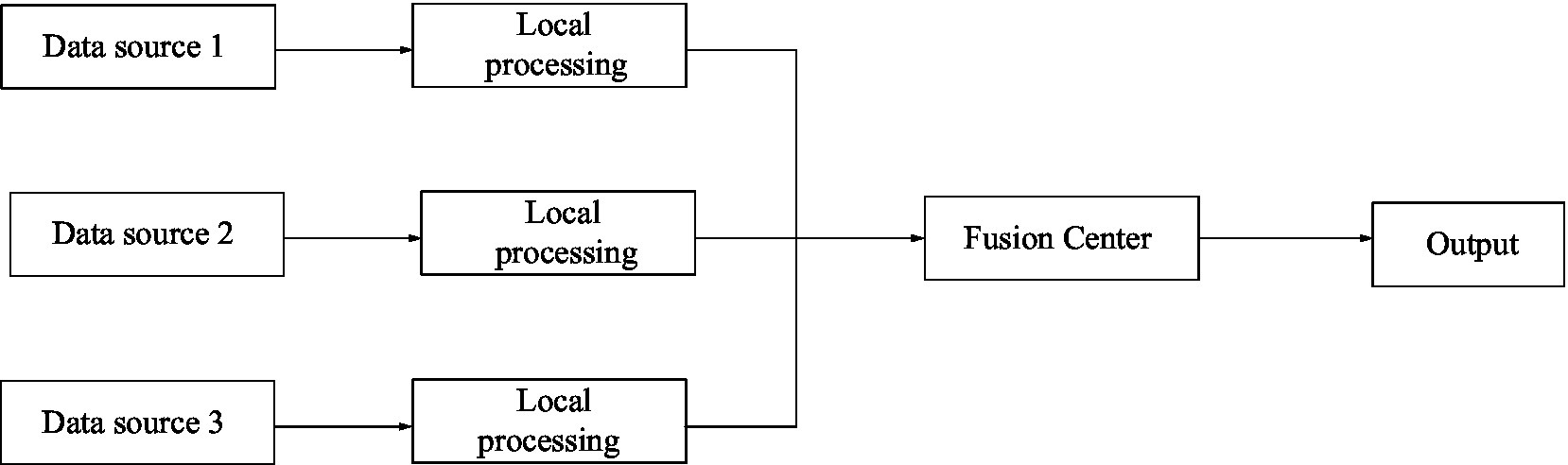
Figure 4. Distributed architecture of information fusion.
Hierarchical structure is a combination of centralized structure and distributed structure. The hierarchical structure is divided into two types, one is without feedback and the other is with feedback (Yang et al., 2017; Kamel et al., 2019). Figure 5 shows a hierarchical structure without feedback, and Figure 6 shows a hierarchical structure with feedback.
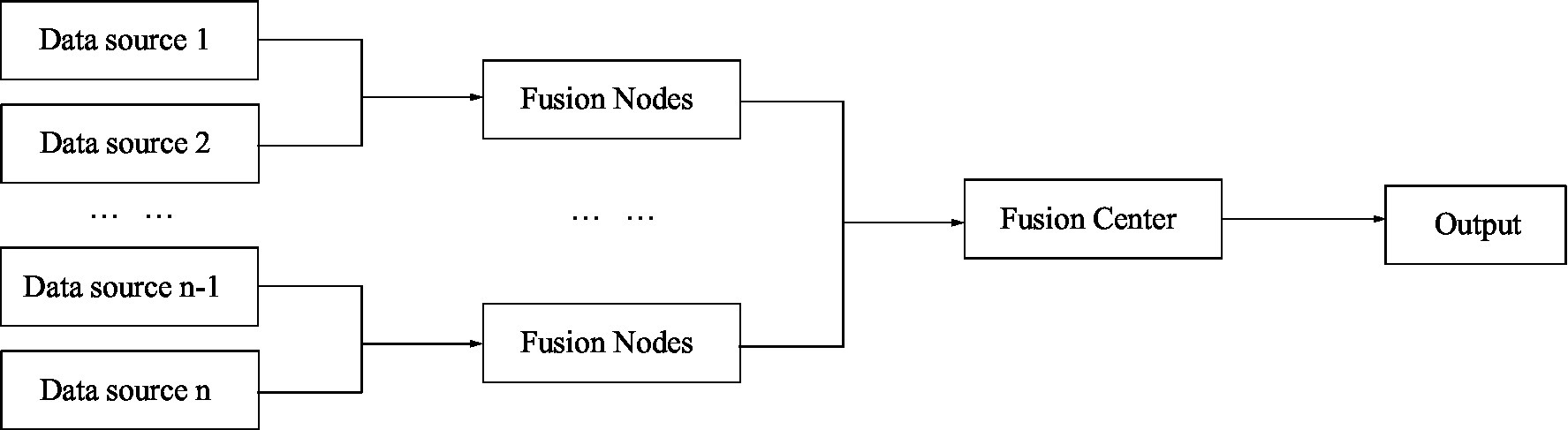
Figure 5. Information fusion without feedback hierarchical structure.
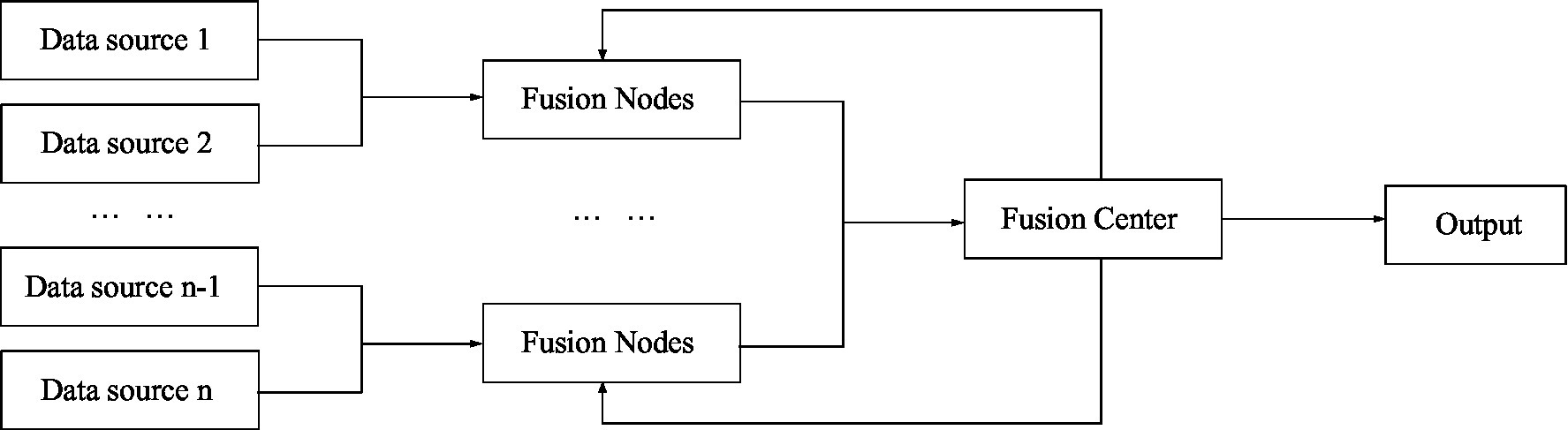
Figure 6. Information fusion with feedback hierarchical structure.
Emotional Orientation Recognition Algorithm Based on Integrated Probabilistic Reasoning Model
PCA Dimensionality Reduction
Proportional component analysis (PCA) was a popular dimensionality reduction algorithm that was widely being used in the field of image recognition (e.g., face recognition). That kind of algorithm has been developed to solve the problem of temporal complexity and spatial complexities which caused by the high-level dimensionality in the feature space. The principle of PCA is to linearly transform the high-dimensional feature space to generate a low-dimensional feature space to achieve the purpose of reducing the feature dimension. For example, if there is “I” in each sample, or almost all texts have “I,” then “I” is not very distinguishable. The contribution to classification is small and can be removed. Therefore, the purpose of PCA dimensionality reduction is to find those elements with large changes, that is, those dimensions with large variance. The removal of those dimensions that have not changed much reduces the amount of calculation and improves the efficiency and accuracy of classification (Mostafa and Nebot, 2017).
The linear transformation of PCA is not arbitrary. The low-dimensional feature space obtained after linear transformation must be able to represent the main information of the original high-dimensional feature space, so that the transformation is not distorted. So during dimensionality reduction in PCA, noise and redundant features are removed such that the correlation across dimensions in the generated low-dimensional feature space to be as small as possible. Each dimension is highly representative and contains richer classification and identification information. After dimensionality reduction, the dimensional correlation in the feature space should be as small as possible, and the covariance matrix between the dimensions of the original feature space needs to be calculated in the linear transformation. The elements in the covariance matrix are composed of the covariance between each vector element. After obtaining the covariance matrix, the eigenvalues and eigenvectors are further calculated to obtain the principal components.
Emotional Orientation Recognition Algorithm Based on Integrated Probabilistic Reasoning Model
Dictionary-Based Emotion Recognition Algorithm
The research on the recognition method of review text sentiment orientation mainly starts from the three levels of vocabulary, sentence and text. In the study of vocabulary-level emotional orientation recognition, the recognition method based on dictionary is an important research point. An algorithm for dictionary-based sentiment recognition is constructed in this paper using a simple “numerical” approach. They are namely to determine the emotional orientation of a review text with a comparison of the number of its positive and negative emotional comments.
Dictionary Selection
This article reviews the text sentiment orientation recognition dictionary and chooses Hownet sentiment dictionary. According to the research needs of this article, four vocabularies of positive evaluation words, positive emotion words, negative evaluation words, and negative emotion words in the Chinese dictionary are selected. Because the dictionary does not contain some Internet terms that frequently appear in common comments, such as V5, ding, liangle, and garbage. This article artificially adds these commonly used network emotion words when establishing positive sentiment evaluation vocabulary and negative sentiment evaluation vocabulary to improve the sentiment vocabulary.
Emotional Orientation Recognition Algorithm Based on Emotional Words
The sentiment orientation recognition algorithm based on sentiment words in this paper is a simple method of comparing the number of positive sentiment comments and negative sentiment comments contained in the review text, named SWM (Sentiment-word method). Since the algorithm is based on a dictionary, the first step in the algorithm is word segmentation, which uses the Jiyi Chinese word segmentation component. After word segmentation, the comment text is compared with the words in the positive sentimental vocabulary. It counts the number of words in the text that appear in the positive sentiment evaluation lexicon, denoted as S; after word segmentation, the comment text is compared with the words in the negative sentiment review lexicon, and the number of words in the text in the negative sentiment review lexicon is counted and recorded as T. Comparing the sizes of S and T, if S ≥ T, the text is determined to be a positive sentiment review text with a positive attitude; if it is determined to be a negative sentiment review text with a negative attitude.
Emotional Orientation Recognition Algorithm Based on Polynomial Bayesian Model
Overview of Bayes’ Theorem
In text classification, a certain text needs to be classified into a certain category, and several categories are often given during classification. Each text will have multiple characteristics, which can be described by the characteristics of the text.
It assumes that a certain text has n features, and each feature is represented by a vector. Then the text feature set can be represented by an n-dimensional vector , where is the n features in the text, and the set of x constitutes the training set feature set X. At the same time, it is assumed that there are m categories given in the classification, then category set , each text x can correspond to one or more categories in set Y.
Bayes’ theorem is based on probability statistics, and its main idea is based on samples and related data information. It calculates the posterior probability, and the attribution category of the test sample can be determined through the posterior probability.
Polynomial Bayesian Model
Bayes’ theorem is based on the assumption that text features are mutually exclusive, and this assumption is often not true in reality. If the text features are not independent of each other, it will lead to a high dimensionality of the text feature space and increase the time complexity and space complexity of the algorithm. According to the related knowledge of probability statistics, by observing the results of multiple experiments, it can be found that the probability of an event often obeys the normal distribution, Poisson distribution, binomial distribution, and other forms. Therefore, a polynomial model can be introduced on the basis of Bayesian theory to reduce the complexity of training.
Emotional Orientation Recognition Algorithm Based on Integrated Probabilistic Reasoning Model
Integrated Probabilistic Reasoning Model Classification Algorithm Framework
Online comments are the main form of emotional expression for the public to comment on news on the Internet and are an important data source for identifying the emotional tendencies of short online texts. Based on the short length of the short text, it contains less information. The classification algorithm framework of the integrated probabilistic reasoning model presented in this article contains the following parts:
1. It uses N-gram to extract the features in the training set and normalize it;
2. It uses principal component analysis to reduce the dimensionality of the feature space of the training set;
3. It uses the Ens-PRM method to build an ensemble classifier model;
4. It analyzes the classification results of each sub-classifier and makes the final classification judgment.
Probabilistic Reasoning Model
Probabilistic Reasoning Model (PRM) is a combination of PCA and Bayesian algorithm. PRM first uses PCA to compress the feature space to extract more discriminating features, and then evaluates the intra-class density under the random division of the feature space. The algorithm runs fast and is easy to implement.
The Bayesian classifier is one of the classic classifiers, which includes the conditional probability density evaluation function for each category, and requires a larger number of training sets to achieve better results. Use the likelihood rate to test the decision rules to obtain the minimum probability of error, is referred to as Bayesian error rate, bayes error rate is used to measure the discriminative capability of the features. The PRM algorithm uses the maximum posterior probability (MAP) as the classification criterion, and the optimal classification of the MAP decision rule is based on the minimum Bayesian error rate.
Integrated Probabilistic Reasoning Model
The integrated probabilistic reasoning model includes two parts: random feature subspace division and base classifier integration.
1. Feature subspace division
In order to reduce the redundancy of the feature space and make full use of the discriminative information in the feature space, the sentiment orientation recognition algorithm based on the integrated probabilistic reasoning model uses a random subspace division method to divide the original feature space. This makes the subspace a series of N-Gram sequences containing emotion identification information. Ens-PRM uses a dynamic random partition method to divide subspaces, and then integrates corresponding PRM-based classifiers. The heuristic integrated classifier has a higher classification accuracy rate.
Using the ensemble method, different base classifiers have complementary capabilities with each other. The classification error of a base classifier can be compensated by the classification result of another base classifier that is correctly classified, and the final ensemble classifier can obtain higher robustness than a single classifier. The random feature space division method is used to divide the feature space into several subspaces and form the corresponding base classifier. Among them, the number of base classifiers in the ensemble classifier and the dimension of each random subspace feature must be preset. For simplicity, we assume that the number of features in each subspace is the same, set the sampling rate to α, and the total number of features as Nf. Then the feature number Nfs in each feature subspace is floor (α*Nf), where floor is rounded down.
This article assumes that the feature space division is based on the division of feature subsets, and the weight distribution of sample features DD is based on the uniform distribution of Nf. It is assumed that M times are randomly divided, and M feature subsets are obtained.
2. Ens-PRM algorithm
Ens-PRM algorithm and integrated probabilistic inference model algorithm, the algorithm is described as follows:
Enter:
Sample of n labeled categories, where , category label , N is the total number of categories, and Y is the sample space;
And the number of base classifiers: M.
Output:
Integrated separator: H.
Ens-PRM algorithm steps are as follows:
a. Its initialized feature weight distribution DDi;
b. According to the feature space division method mentioned above, the sample space is divided based on feature subsets, and the data set is reduced to , where r is the dimension of the feature subspace;
c. It returns as input to the learning algorithm mentioned above, trains the feature subspace, and outputs the base classifier hi;
d. It repeats steps (b–c) M times to construct an integrated classifier .
In short, the method of randomly dividing feature subspaces can set the number of divided spaces. For example, 30 and 50 are divided into 30 or 50 expert subsystems. The number of features in each subsystem is evenly distributed, and each subsystem recognizes the text to be tested. It calculates the average probability p1 for all subsystems to judge a certain text as a positive sample, and the average probability p2 for judgment as a negative sample. If p1 > p2, the text is a positive sample; if p1 < p2, the text is a negative sample.
It uses Bayesian formula to get the most possible target value:
The observed joint probability is equal to the product of the probabilities of a single attribute:
Then the target value of the naive Bayes algorithm is expressed as follows:
The information gain Gain(T,E) of a relative sample set T of an attribute E is defined as:
If the target attribute has a different values, then the entropy Entropy(T) of T relative to the category of a state is defined as follows, where wr is the proportion of r in T that belongs to the category:
When an output neuron k is iterating at t, its output error signal is defined as follows:
The instantaneous value of the entire error energy:
Mean square error energy:
The instantaneous value of the cost function degenerates to:
In:
The formula of the simple linear classifier algorithm:
The hypothesis to be learned is a function of the following form:
Bell-shaped Gaussian kernel function:
The linear discriminant function is:
The classification is required to correctly classify all samples in the face of:
The problem of seeking the optimal classification surface is transformed into a constrained optimization problem:
It uses the Lagrangian multiplier method:
The optimal classification function solution of the problem is:
Adding a relaxation term to condition , becomes:
The corresponding classification function also becomes:
News Sentiment Communication
This article crawled relevant news comment texts from Sina News and Sohu News and collected a total of 200 news comment sets (including 108 Sina News and 92 Sohu News). As a result, the sentiment recognition process was applied to the set of comments in this paper, where duplicate comments and sentiment-irrelevant comments have been filtered out in the recognition process. The relevant statistical information of the data set used in the news sentiment communication experiment is shown in Table 1.
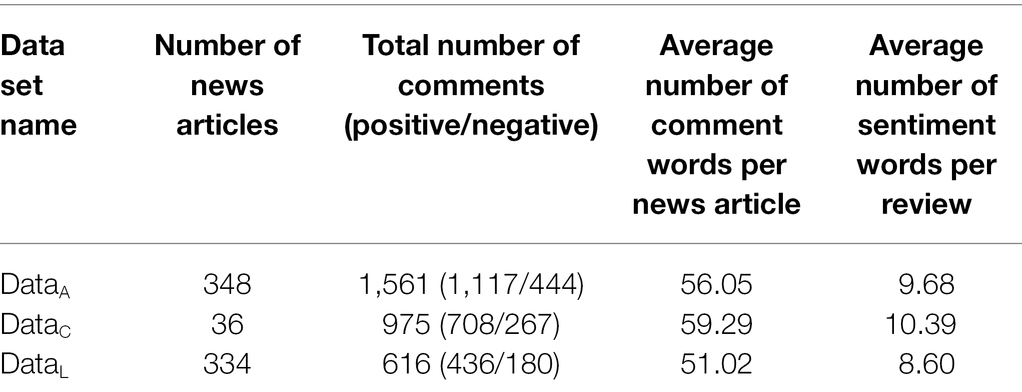
Table 1. Statistical information related to the dataset used in the news emotion communication experiment.
The specific information of the final comment set is shown in Figure 7.
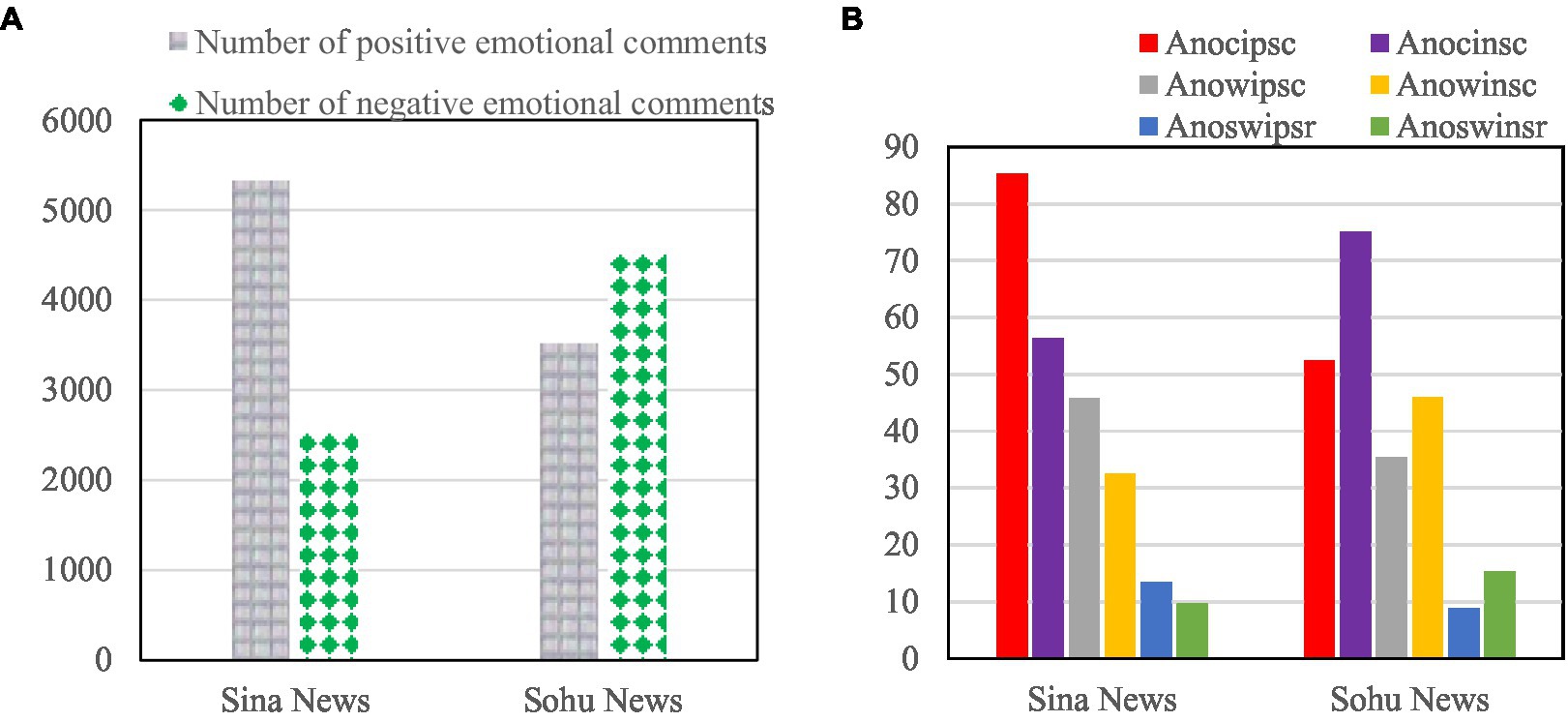
Figure 7. Information on the experimental dataset of news sentiment commentary. (A) Shows the number of positive/negative sentiment comments on Sina News and Sohu News. (B) Shows the average number of positive/negative.
Figure 7A shows the number of positive/negative sentiment comments on Sina News and Sohu News. Figure 7B shows the average number of positive/negative sentiment characters (Anocipsc/Anocinsc), the average number of positive/negative sentiment words (Anowipsc/Anowinsc), and the average number of positive/negative sentiment words (Anoswipsr/Anoswinsr) of Sina News and Sohu News.
It constructs an emotional word vocabulary, as shown in Table 2.
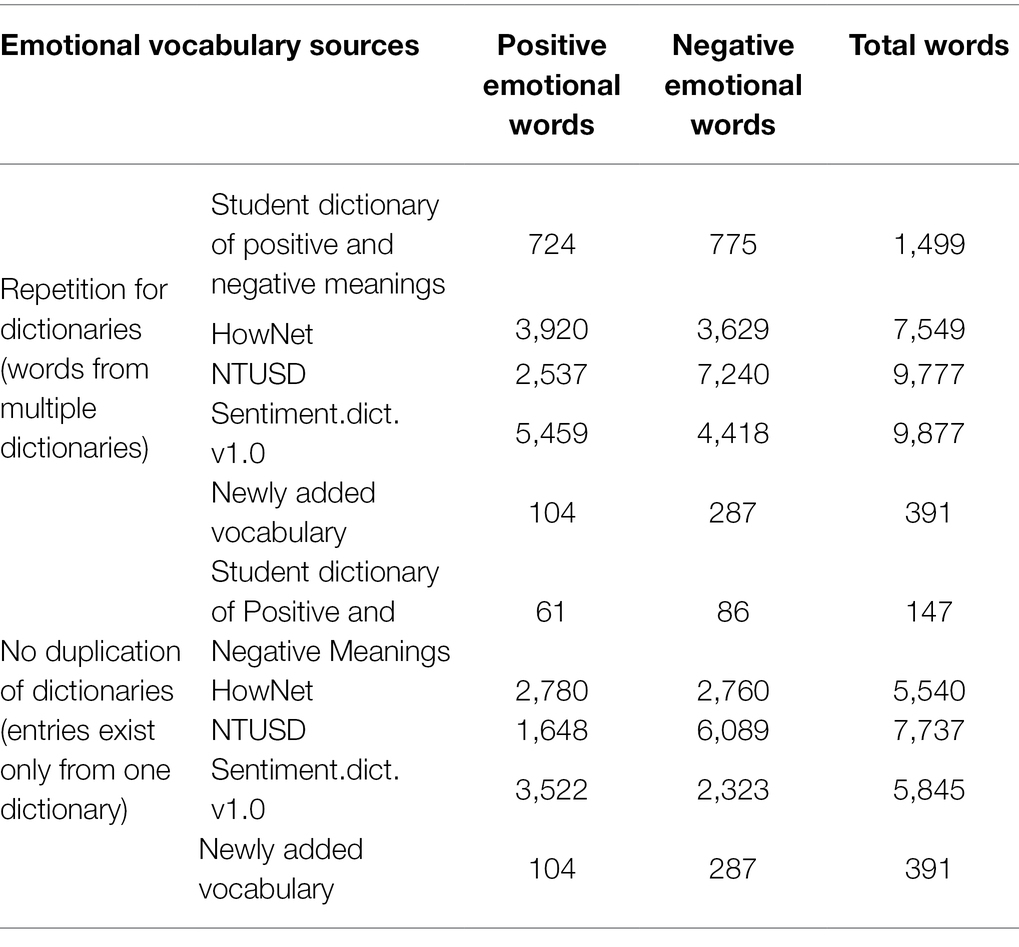
Table 2. Distribution of words in the emotion word list among the four emotion resources.
When the unmarked rate is 0.5, the comparison results of the recognition algorithms are shown in Tables 3 and 4.
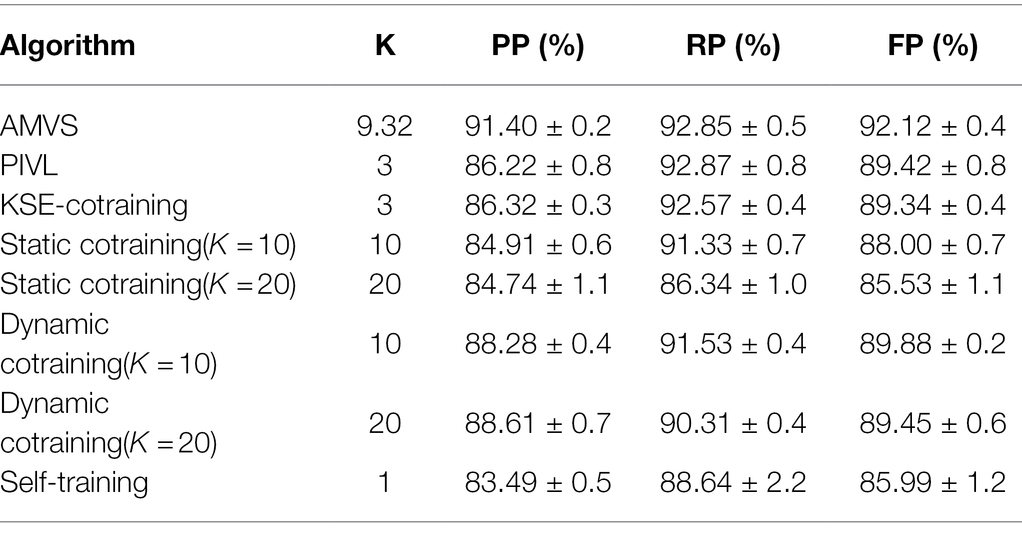
Table 3. Comparison results of recognition algorithms when the label-free rate is taken as 0.5 (base classifier is MNB).
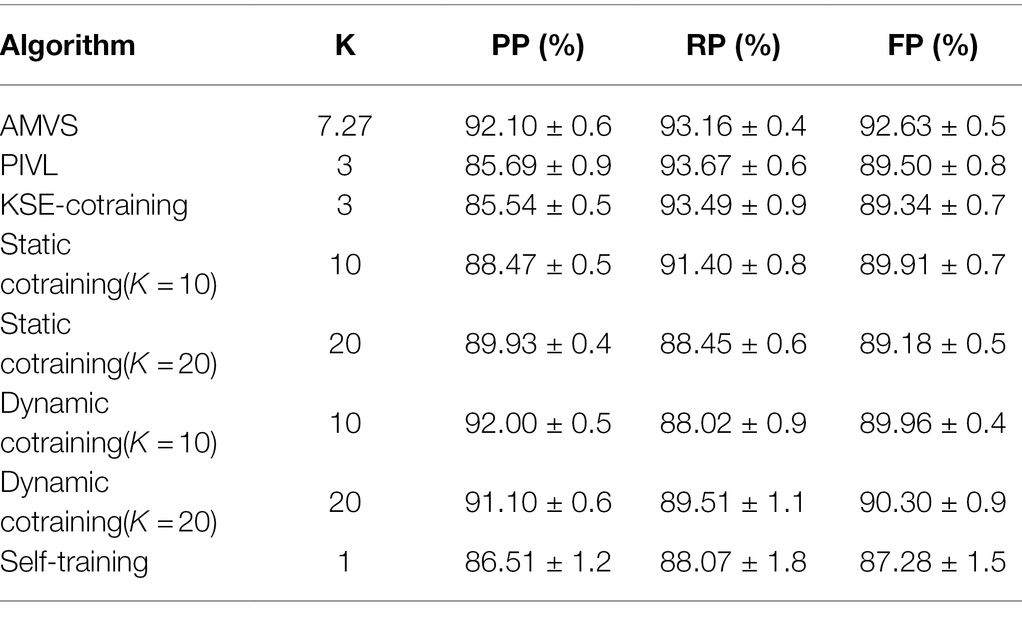
Table 4. Comparison results of recognition algorithms when the label-free rate is taken as 0.5 (base classifier is SVM).
Tables 3 and 4 record the recognition results of all algorithms. Compared with other recognition algorithms, the algorithm in this paper shows higher accuracy.
According to the parameter settings when the best effect is achieved, the number of base classifiers K in the algorithm are, respectively, selected as 10 and 20 for experiment. The results are shown in Figures 8, 9.
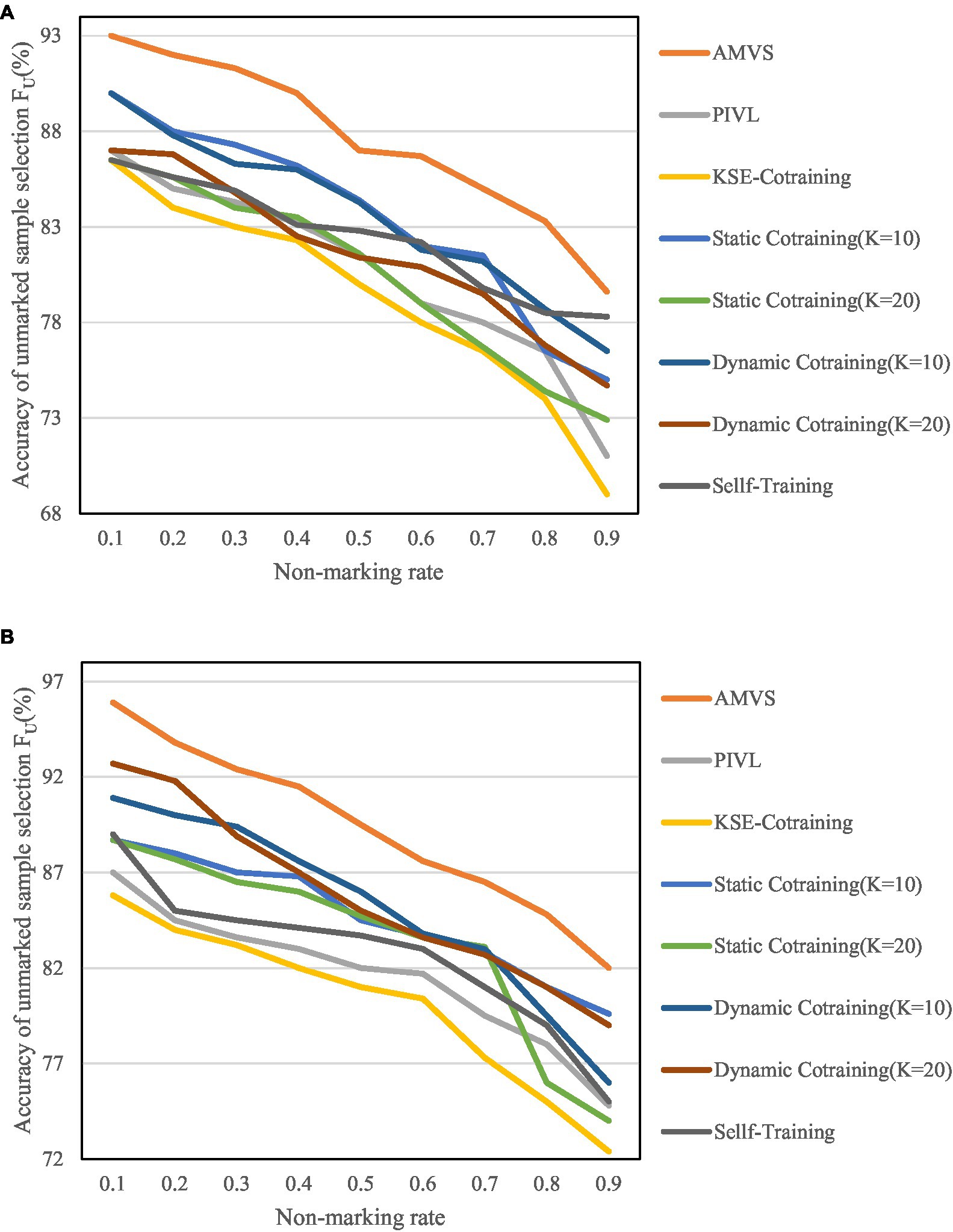
Figure 8. Variation of unmarked sample selection accuracy FU at different unmarked rates. (A) Variation of FU when the base classifier is MNB. (B) Variation of FU when the base classifier is SVM.
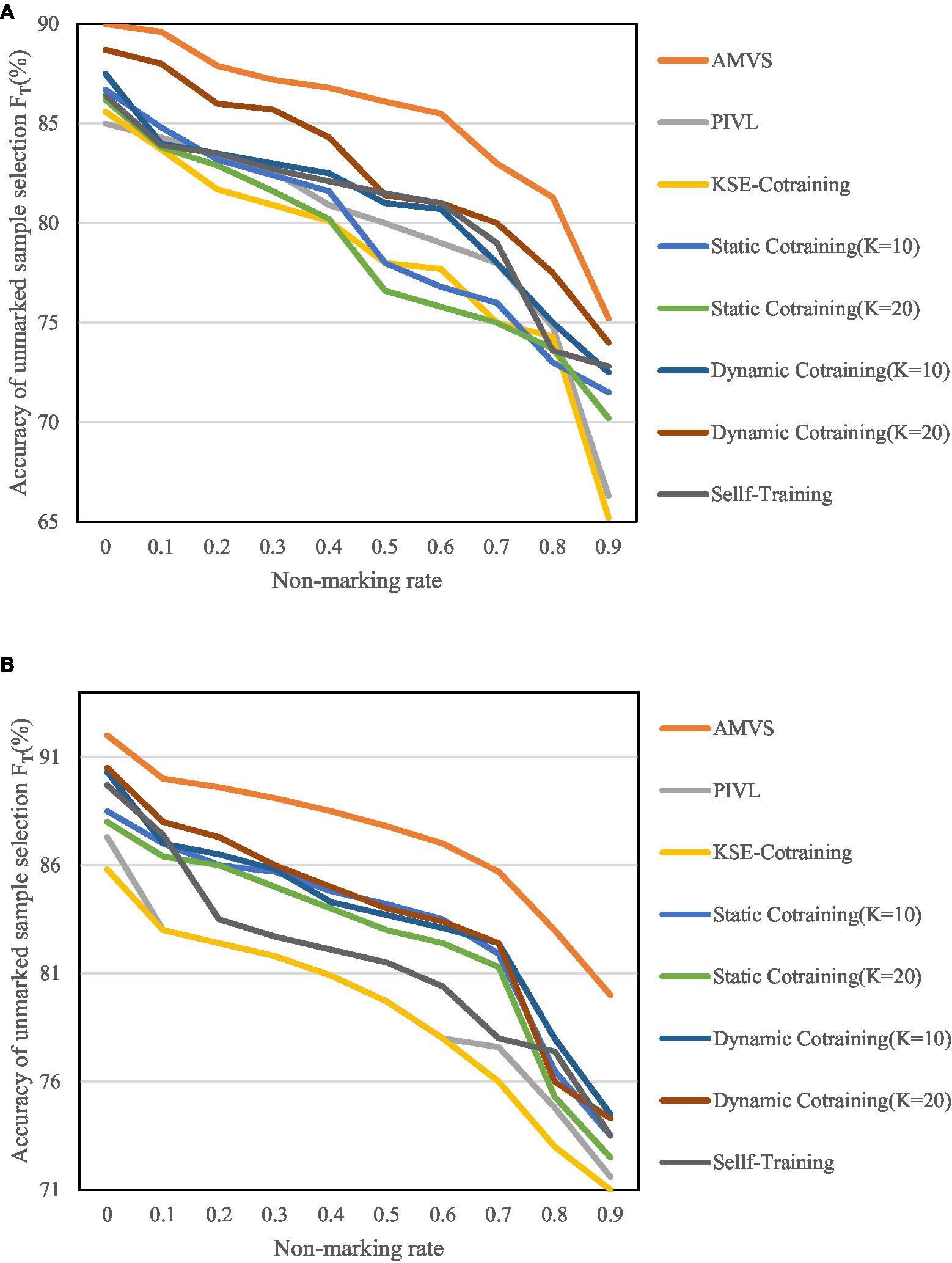
Figure 9. Variation of unmarked sample selection accuracy FT at different unmarked rates. (A) Variation of FT when the base classifier is MNB. (B) Variation of FT when the base classifier is SVM.
Figures 8, 9 show that as the unlabeled rate continues to increase, the algorithm has shown high scalability and robustness in the screening of unlabeled samples, even when the unlabeled rate reaches 0.9. That is, when there are very few labeled samples in the training set, the above recognition accuracy can also be achieved.
The parameter settings of different recognition algorithms are shown in Table 5.

Table 5. Parameter settings of different recognition algorithms.
It tests the effect of the number S of cross-divided check subsets on the performance of the algorithm, and the specific results are shown in Figure 10.
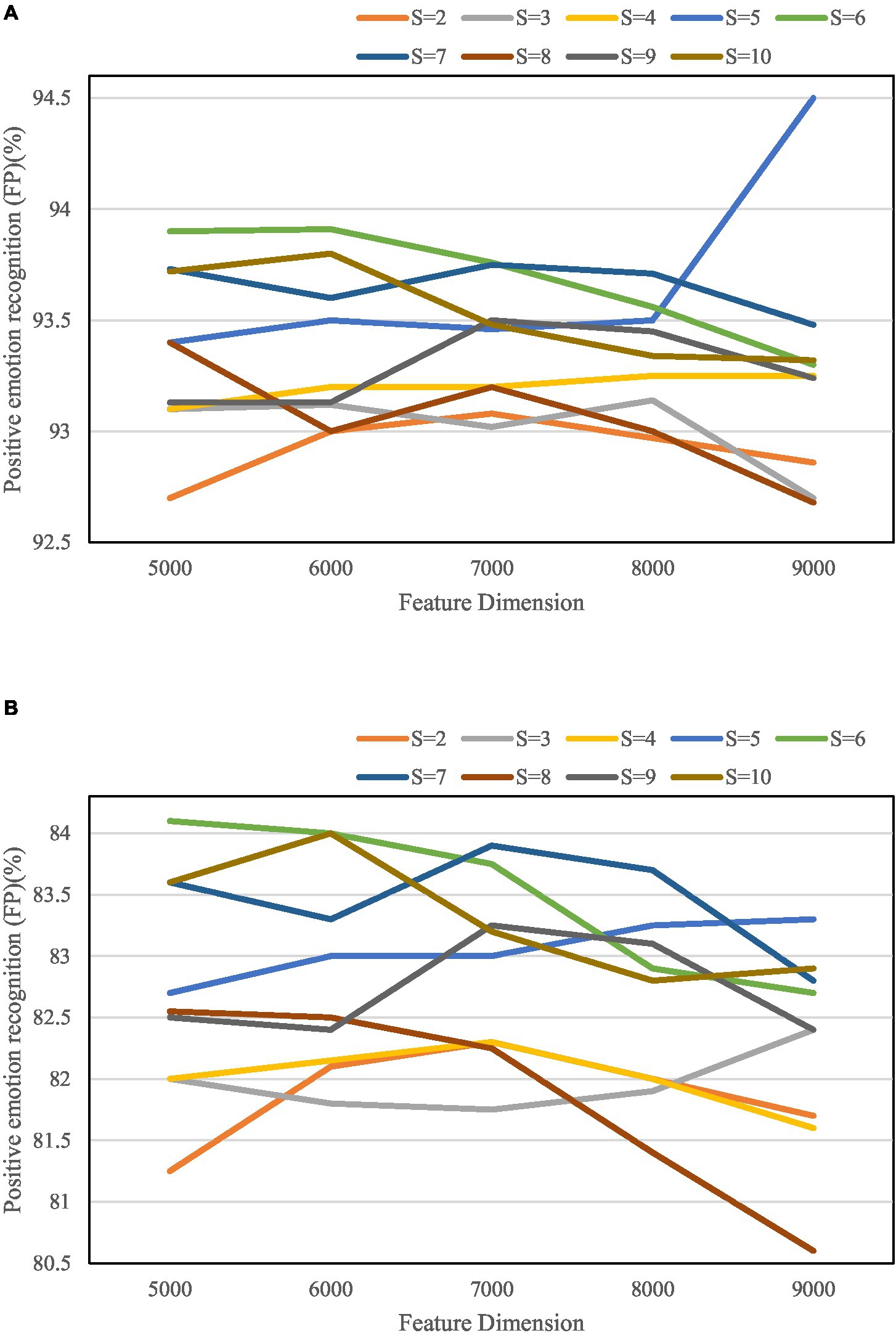
Figure 10. Micro-averaged F-value results for positive/negative sentiment sample identification. (A) Micro-averaged F-value results for positive sentiment sample identification. (B) Micro-averaged F-value results for negative sentiment sample identification.
It can be seen from Figure 10 that in all the parameter combination conditions, the algorithm can not only reduce the feature dimensionality but also ensure the accuracy of recognition with a probability of 89%.
Discussion
In order to solve the problem of manual labeling of training examples, this article provides a polygon-based adjustable emotion recognition algorithm. The algorithm introduces emotional vocabulary to calculate the emotional weight of N-gram attributes. It selects the corresponding attributes according to the emotional weight distribution data and adjusts the saliency distribution of the attributes in the repeated selection process. For each visual sample, after completing the training process multiple times during the inspection process, the sample with the highest label reliability is selected to refine the training. It is demonstrated that the angle by which the features are selected by the algorithm in this paper is more versatile by comparison with many traditional algorithms. A more reliable and accurate labeling of its unlabeled samples.
Conclusion
This paper designs and implements an emotional orientation recognition algorithm (Ens-PRM) based on an integrated probabilistic inference model. In the experimental comparison between Ens-PRM and a simple dictionary-based algorithm, we have demonstrated that the recognition accuracy of the dictionary-based algorithm is not high, but also it is susceptible to the interference of objective emotions and has poor generality. It can be seen from the experimental results that Ens-PRM has achieved better classification results. But Ens-PRM is more time-consuming, when the data set is huge, Ens-PRM takes longer. Therefore, research is needed to improve the operation speed of Ens-PRM in the future.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author Contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Conflict of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Allen, D. E., Mcaleer, M., and Singh, A. K. (2019). Daily market news sentiment and stock prices. Appl. Econ. 51, 3212–3235. doi: 10.1080/00036846.2018.1564115
Boguslaw, B., Alojzy, Z. N., Yochanan, S., and Tadeusz, W-D. (2018). Forecasting company default using news sentiment analytics. Inter. J. Econ. Bus. Law 7, 8–49.
Chahine, C., Vachier-Lagorre, C., Chenoune, Y., el Berbari, R., el Fawal, Z., and Petit, E. (2018). Information fusion for unsupervised image segmentation using stochastic watershed and hessian matrix. IET Image Process. 12, 525–531. doi: 10.1049/iet-ipr.2017.0798
Chandra, B. S., Sastry, C. S., and Jana, S. (2019). Robust heartbeat detection from multimodal data via CNN-based generalizable information fusion. IEEE Trans. Biomed. Eng. 66, 710–717. doi: 10.1109/TBME.2018.2854899
Chen, M. Y., and Chen, T. H. (2019). Modeling public mood and emotion: blog and news sentiment and socio-economic phenomena. Futur. Gener. Comput. Syst. 96, 692–699. doi: 10.1016/j.future.2017.10.028
Groen, F. C. A., Pavlin, G., Winterboer, A., and Evers, V. (2017). A hybrid approach to decision making and information fusion: combining humans and artificial agents. Robot. Auton. Syst. 90, 71–85. doi: 10.1016/j.robot.2016.08.009
Gupta, K., and Banerjee, R. (2019). Does OPEC news sentiment influence stock returns of energy firms in the United States? Energy Econ. 77, 34–45. doi: 10.1016/j.eneco.2018.03.017
Hong, L., Song, Y., and Chen, C. (2017). Hyperspectral image classification based on multiscale spatial information fusion. IEEE Trans. Geosci. Remote Sens. 55, 5302–5312. doi: 10.1109/TGRS.2017.2705176
Huang, H. C. (2017). An evolutionary optimal fuzzy system with information fusion of heterogeneous distributed computing and polar-space dynamic model for online motion control of Swedish redundant robots. IEEE Trans. Ind. Electron. 64, 1743–1750. doi: 10.1109/TIE.2016.2562613
Kamel, M., Siuky, F. N., and Yazdi, H. S. (2019). Robust sentiment fusion on distribution of news. Multimed. Tools Appl. 78, 21917–21942. doi: 10.1007/s11042-019-7505-8
Kelly, S., and Ahmad, K. (2018). Estimating the impact of domain-specific news sentiment on financial assets. Knowl.-Based Syst. 150, 116–126. doi: 10.1016/j.knosys.2018.03.004
Lei, F., Liu, X., Li, Z., Dai, Q., and Wang, S. (2021). Multihop neighbor information fusion graph convolutional network for text classification. Math. Probl. Eng. 2021, 1–9. doi: 10.1155/2021/6665588
Li, S., Ma, H., Saha, T., and Wu, G. (2018). Bayesian information fusion for probabilistic health index of power transformer. IET Gener. Transm. Distrib. 12, 279–287. doi: 10.1049/iet-gtd.2017.0582
Minchae, S., and Kyung-Shik, S. (2017). Construction of consumer confidence index based on sentiment analysis using news articles. J. Intell. Inf. Syst. 23, 1–27. doi: 10.13088/jiis.2017.23.3.001
Mostafa, M. M., and Nebot, N. R. (2017). Sentiment analysis of Arabic language influence on Spanish vocabulary: an El Paí s newspaper and Twitter case study. J. Inf. Technol. Case Appl. 19, 145–157. doi: 10.1080/15228053.2017.1394143
Ouyang, L., Zhu, Y., Zheng, W., and Yan, L. (2021). An information fusion FMEA method to assess the risk of healthcare waste. J. Manag. Sci. Eng. 6, 111–124. doi: 10.1016/j.jmse.2021.01.001
Peng, L., Liao, B., Zhu, W., Li, Z., and Li, K. (2017). Predicting drug–target interactions with multi-information fusion. IEEE J. Biomed. Health Inform. 21, 561–572. doi: 10.1109/JBHI.2015.2513200
Prasath, V. B. (2017). Image denoising by anisotropic diffusion with inter-scale information fusion. Pattern Recognit. Image Anal. 27, 748–753. doi: 10.1134/S1054661817040174
Qi, Z., Yang, Y., Ping, J., Xinyu, S., Longchao, C., Jiexiang, H., et al. (2017). A multi-fidelity information fusion metamodeling assisted laser beam welding process parameter optimization approach. Adv. Eng. Softw. 110, 85–97. doi: 10.1016/j.advengsoft.2017.04.001
Song, Q., Liu, A., and Yang, S. Y. (2017). Stock portfolio selection using learning-to-rank algorithms with news sentiment. Neurocomputing 264, 20–28. doi: 10.1016/j.neucom.2017.02.097
Yadav, R., Kumar, A. V., and Kumar, A. (2019). News-based supervised sentiment analysis for prediction of futures buying behaviour. IIMB Manag. Rev. 31, 157–166. doi: 10.1016/j.iimb.2019.03.006
Yang, S. Y., Mo, S. Y. K., Liu, A., and Kirilenko, A. A. (2017). Genetic programming optimization for a sentiment feedback strength based trading strategy. Neurocomputing 29–41. doi: 10.1016/j.neucom.2016.10.103
Yang, H.-F., and Seng, J.-L. (2017). The association between stock price volatility and financial news: a sentiment analysis approach. Kybernetes 46, 1341–1365. doi: 10.1016/j.neucom.2016.10.103
Keywords: multi-modal, information fusion technology, news sentiment communication, tendency recognition algorithm, news sentiment dissemination
Citation: Chiba M (2022) Application of the Recognition Algorithm of News Sentiment Dissemination Tendency Based on Multi-Mode Information Fusion. Front. Psychol. 13:853899. doi: 10.3389/fpsyg.2022.853899
Edited by:
Deepak Kumar Jain, Chongqing University of Posts and Telecommunications, ChinaReviewed by:
Wenqian Shang, Communication University of China, ChinaShuai Li, Anyang Normal University, China
Gabriel Gomes, State University of Campinas, Brazil
Copyright © 2022 Chiba. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Makiko Chiba, bWFraWtvX2NoaWJhQHpqdXQuZWR1LmNu