 Dustin Kai-Yan Lau
Dustin Kai-Yan Lau Yuan Liang
Yuan Liang Hoang-Anh Nguyen3
Hoang-Anh Nguyen3
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol., 16 February 2022
Sec. Psychology of Language
Volume 13 - 2022 | https://doi.org/10.3389/fpsyg.2022.784019
This article is part of the Research TopicReading Acquisition of Chinese as a Second/Foreign LanguageView all 20 articles
In the current study, the orthographic knowledge required for writing Chinese characters was assessed among participants with L1 Vietnamese background who learn Chinese as a foreign language. A total of 42 undergraduates were recruited. They were invited to participate in a delayed Chinese character copying task consisting of 32 characters. Their Chinese character reading abilities were also obtained using a character naming task. All the tests were conducted online during the pandemic in 2021. Results indicated that the participants’ accuracy in the copying task was affected by the familiarity of the characters and the number of strokes of the characters. These effects minimized as reading performance increased. In the inter-stroke interval (ISI) analysis, results indicated a significant boundary effect where ISIs between orthographic units were longer than ISIs within orthographic units, showing the participants’ tendency to chunk Chinese characters into functional units when they write. Only high achievers in the reading task demonstrated the use of both large and small grain-size units in writing (i.e., radical-boundary ISI > logographeme-boundary ISI > non-boundary ISI), while the low achievers only used small grain-size units in their writing. We suggest that the delayed copying task incorporated with handwriting measures is an effective method to assess orthographic knowledge of L2 Chinese learners.
The rapid economic development of China has driven a growth in the learning of Chinese language worldwide. However, due to the unique properties of Chinese, learning to communicate using Chinese as a second language is not an easy task.
For example, Chinese phonologically is a tonal language, where lexical tones associate with syllables contribute to meaning differences. Besides, Chinese is usually described as morphosyllabic in which each basic orthographic unit, or character, is mapped onto one syllable and one morpheme (Chao, 1970; Hoosain, 1992). There are about 1,100 syllables and over 3,000 common characters in modern Chinese. That means on average, each syllable corresponds to more than three different morphemes and characters. For example, the syllable [chang2] corresponds to 长<long>, 尝<taste>, and 常<frequent>. Being able to tell that the common syllable [chang2] in [chang2du4] <length> and [chang2jian4]<common> corresponds to different morphemes is important. Otherwise, it will cause confusion when one tries to parse the meaning of multimorphemic words. One of the useful strategies to differentiate homophonic heteronyms is to refer to their orthographic forms. It is, therefore, commonly believed that the learning of the orthographic forms of Chinese will promote the proficiency of using the language (Zhao, 2009).
Orthographically, each Chinese character is a compilation of strokes organized in a square construction. For example, the character 大 [da4]<big> is constructed by putting the three strokes 一, 丿, and ㇏ in a specific pattern. The number of strokes within a character range from 1 to 24 (Shu et al., 2003). The more strokes in the characters, the higher will be the visual complexity. On the other hand, there exists a major group of characters in Chinese called phonetic compounds, which are composed by putting together semantic radicals that give clues to meanings and phonetic radicals that give clues to sound of the host character. For example, the character 筷 [kuai4]<chopsticks> contains the semantic radical ⺮<bamboo>, which gives a clue to the character’s meaning, and the phonetic radical 快[kuai4]<quick>, which is pronounced identically as the host character. Semantic and phonetic radicals are organized in different configurations. The most common configurations are left-right (e.g., 快) and top-bottom (e.g., 筷).
Apart from phonetic and semantic radicals, there is another group of sub-character orthographic units frequently occurring in Chinese characters documented in the literature. In their study reporting the writing errors produced by a Chinese patient with dysgraphia, Law and Leung (2000) reported the observations of errors involving substitutions of logographemes (i.e., stroke patterns in radicals that are spatially separated, such as “土” and “口” in the radical “吉’’)1. Similar errors of logographeme deletions, substitutions, and transpositions during Chinese character copying was also reported in Han et al. (2007). The significant role of logographemes in Chinese character writing was observed not only among neurogenic patients but also neurotypical individuals (e.g., Lui et al., 2010; Lui, 2012; Wong and Lau, 2019). For example, using a delayed copying task, Lui (2012) observed that L1 Chinese primary school children demonstrated better performance on copying stimuli with less number of logographemes, after controlling for number of strokes. The “word length” effect was taken as evidence to suggest that logographemes are used by L1 Chinese learners in their writing process.
When individuals start learning a second language, intensive instructions are usually needed. Later on, they are expected to learn new items without instructions by applying their metalinguistic knowledge regarding the second language. With sufficient knowledge of the Chinese orthography, individuals learning Chinese as second language are expected to be able to learn to read and write new Chinese characters independently.
The knowledge of the Chinese orthographic system required for writing Chinese characters include the configuration of the Chinese characters (e.g., Yeh and Li, 2002), a repertoire of the orthographic units of different grain sizes (e.g., Lau, 2019), and the positional consistency of the components (Taft et al., 1999; Lui et al., 2010). Previous studies have documented the significance of each of these areas of orthographic knowledge in learning to read Chinese (e.g., Loh et al., 2018; Chan et al., 2021; Chang et al., 2021; Loh et al., 2021).
The significance of knowledge of configuration of Chinese characters in learning to read Chinese is that it helps to distinguish visually complex characters (e.g., Yeh and Li, 2002). Evidence of the significance of awareness of character configuration in Chinese character learning among CSL learners were reported in previous studies (e.g., Loh et al., 2018, Loh et al., 2021). For example, Loh et al. (2018) conducted a structure identification task on CSL children attending Grade 5–11 in mainstream education in Hong Kong and observed that the children were able to choose the most matched structures (represented in line-drawing figures) of the target characters in over 60% of the time across all grade levels. Similar results were reported in Loh et al. (2021).
The importance of a repertoire of the orthographic units of different grain sizes in learning to write Chinese concerns its role in allowing the decomposition of characters into components so as to reduce the workload of learners’ working memory in the processing. This allows the individuals to more efficiently and effectively recall and retain the orthographic forms of characters than perceiving the characters as a pile of interwoven strokes (Loh et al., 2021). The repertoire was usually tested by asking L2 learners to decompose Chinese characters into components. For example, Shen and Ke (2007) reported that American CSL college students were able to improve from just above 50% scoring rate to over 70% scoring rate after 1 year of study. In another study, Nguyen et al. (2016) also found that a group of Vietnamese students who had studied Chinese for 3 months were able to use components as processing units when learning unfamiliar Chinese characters.
Finally, the significance of positional consistency of the components in learning Chinese characters has been reported among L1 Chinese (e.g., Tong et al., 2017) and L2 Chinese (e.g., Chang et al., 2021; Loh et al., 2021). By using radicals with high positional consistency to create pseudo-characters and radicals with low positional consistency to create non-characters, Chang et al. (2021) observed that L2 Chinese learners showed tendency to choose the pseudo-characters as “more like real characters” and such tendency was observed among those with higher Chinese reading proficiency but not among those with lower Chinese reading proficiency.
Thus far, previous studies that investigated orthographic knowledge of CSL learners mostly relied on tasks that involved close-end questions, i.e., either binary choice (e.g., Chang et al., 2021) or multiple choice questions were given (e.g., Loh et al., 2018; Chan et al., 2021). One of the potential issues associated with close-end questions concern the possible ceiling effect in the data obtained, particularly if the participants have relatively good orthographic knowledge. In the current study, we explored the possibility of using a handwriting task to measure CSL learners’ orthographic knowledge, which potentially can avoid the ceiling effect issues described.
Using tablets installed with a homebrew Android application that recorded the written responses of the participants using the open-sourced MotionEvent package, Lau (2020b) invited a group of undergraduate students with L1 Chinese background to participate in an immediate character copying task. In the experiment, the inter-stroke intervals (ISIs), measured as the time difference between the end point of a stroke and the start point of the subsequent stroke, in the handwriting production were collected. The results indicated that after controlling for the inter-stroke distance (ISD) (i.e., the linear distance between the end point of a stroke and the start point of the subsequent stroke), the radical-boundary ISIs, i.e., ISIs located at the boundary between the semantic and phonetic radicals, were longer than the logographeme-boundary ISIs, i.e., ISIs located at the boundary between consecutive logographemes, which, in turn, were longer than the non-boundary ISIs, i.e., ISIs located within logographemes. Examples of radical-boundary ISIs, logographeme-boundary ISIs and non-boundary ISIs were given in Figure 1. The significant orthographic boundary effect was taken as evidence to support that radicals and logographemes are functional writing units when people write Chinese characters. Apart from the significant boundary effect observed, it was further found that radical-boundary ISIs of high-frequency characters were shorter than radical-boundary ISIs of low-frequency characters, which is consistent with previous studies that have reported the radical boundary effect in peripheral processing of writing (e.g., Zhang and Feng, 2017).
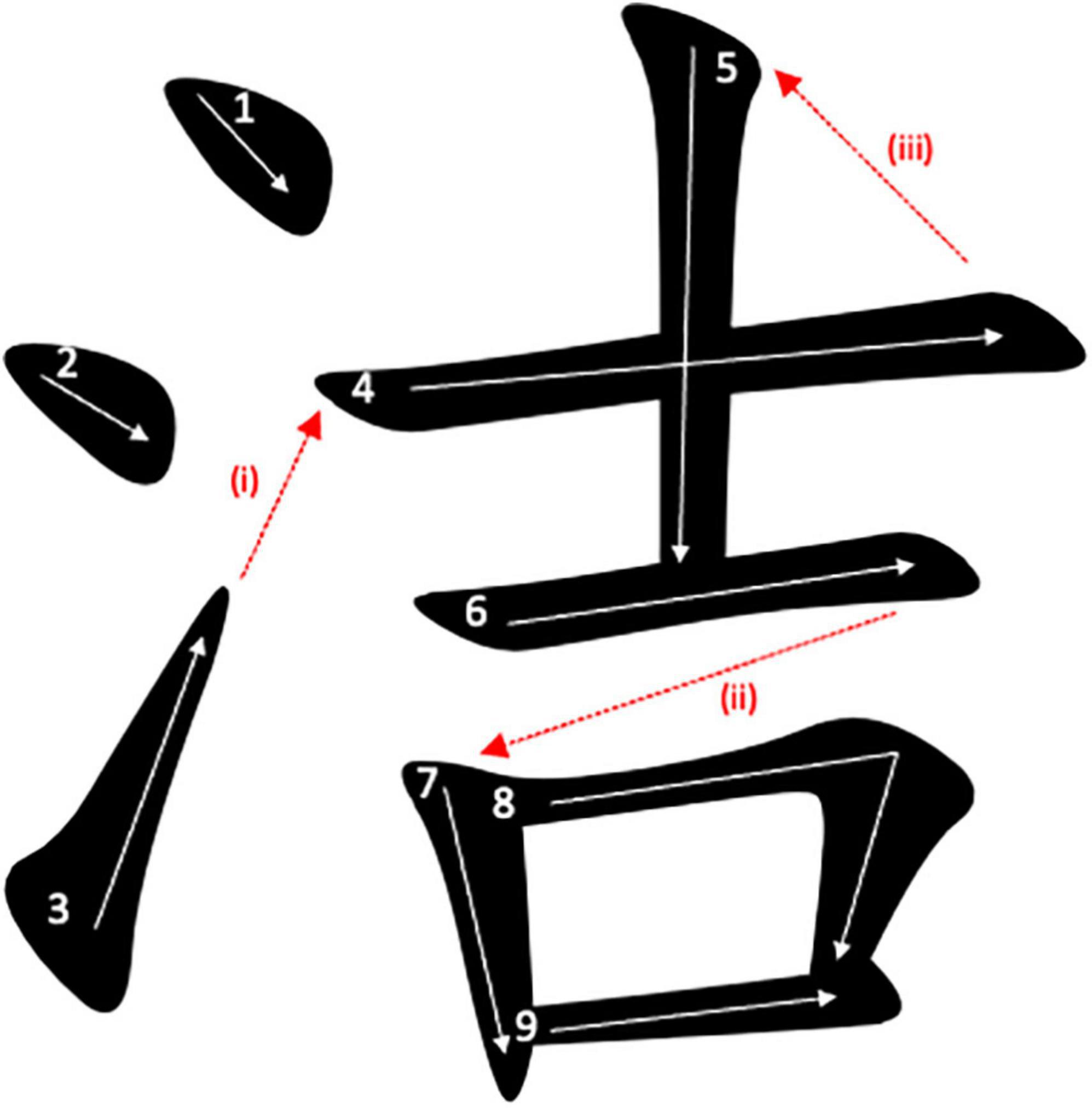
Figure 1. Examples of (i) radical-boundary ISI, (ii) logographeme-boundary ISI, and (iii) non-boundary ISI. The white arrows denote the stroke sequence to write the character.
Similar orthographic boundary effect was observed not only among mature L1 Chinese users but also beginning L1 Chinese learners. Lau (2019) applied a similar immediate character copying task, but with fewer stimuli, on a group of primary school Chinese children. A similar significant orthographic boundary effect (i.e., radical-boundary ISI > logographeme-boundary ISI > non-boundary ISI) was observed, suggesting the unique roles of radicals and logographemes as orthographic units essential for individuals learning to write Chinese character. Finally, it was also reported that children with higher proficiency demonstrated greater flexibility in choosing between radicals and logographemes as the writing units, whereas younger children tend to heavily use logographemes as the writing units. The difference was attributed to the exposures needed for the acquisition of the graphic motor patterns associated with (high-frequency) radicals by concatenating the graphic motor patterns associated with the corresponding constituent logographemes which are unique in Chinese writing (Lau and Yuen, 2019).
Overall, results of previous studies indicated that handwriting measures allowed the observations of orthographic knowledge, particularly the flexibility of using orthographic units of different grain sizes, applied by L1 Chinese users in writing Chinese characters. In the current study, we attempted to examine the orthographic knowledge required for writing Chinese characters among individuals with L1 Vietnamese background who learn Chinese as a foreign language by applying similar handwriting measures. Vietnamese students are unique since they have a demand for understanding Chinese scripts to preserve their culture, which had for a long time previously been documented in Chinese characters. The Vietnamese even invented the chñ’ Nôm scripts by modifying Chinese characters to represent native Vietnamese words in the 13th century (Nguyễn Đình Hoà, 1959). In 1910, the French colonial administration required that all public documents be written by the Vietnamese alphabet (Vietnamese: chũ’ Quếc ngñ’; literally meaning “national language script”), a romanization of Vietnamese based on the alphabets of Romance languages. As a result, Chinese characters gradually fell out of use in Vietnam (Zhang, 2009), until recently learning Chinese as a foreign language gradually became more popular because learning the language possibly improve the vocational competitiveness of the learners.
To assess the orthographic knowledge of our participants, they were given a delayed character copying task, which requires better usage of orthographic knowledge to be temporarily stored in the short term memory compared with immediate copying tasks (e.g., Han et al., 2007; Bonin et al., 2015). Given that better orthographic knowledge has been reported to be associated with better reading performances (e.g., Leong et al., 2011; Tong et al., 2017), participants’ performance in a reading test was included in the data analyses. It was expected that individuals with better reading scores, hence better orthographic knowledge, would achieve higher accuracy in the task. Besides, it was expected that similar effect of number of strokes (Lau, 2020b) and character frequency (Lau, 2019, 2020b) observed in L1 Chinese users’ handwriting would also be observed among our participants. Most importantly, it was anticipated that for those who have a better repertoire of the orthographic units of different grain sizes should be better in mastering both radicals and logographemes as writing units. Hence, it was expected that they would demonstrate the significant orthographic boundary effect (i.e., radical-boundary ISI > logographeme-boundary ISI > non-boundary ISI) in their writing.
A total of 42 undergraduate students (2 Male and 40 Female, age range from 18 to 22, year of university education range from 1 to 4) majoring in Chinese were recruited in the University of Languages and International Studies, Vietnam National University, Hanoi. Only individuals with no reports of sensory, intellectual and learning problems and no prior training of linguistics and psychology were recruited. All participants reported to have completed at least grade 1–4 of HSK.
Data collection was conducted during the pandemic in 2021. Therefore, each participant was tested individually via a Zoom meeting. The Zoom meeting was video-recorded for later accuracy judgment.
A total of 190 characters (40 non-phonetic compounds and 150 phonetic compounds) were selected from the HSK word list. In each trial, a randomly ordered selected character was shown on the screen. The participant was required to read aloud the character. No feedback of accuracy was given. Each correctly named item was given one mark.
A total of 32 Chinese characters, half of them organized in left-right and half of them organized in top-bottom configurations, were selected from the HSK word list. Table 1 shows the demographic information of the stimuli. The participants were invited to use their own smartphones to perform the writing task. A weblink designed for collecting handwriting data using the open-sourced MotionEvent package was given. In each randomly ordered trial, a target character was displayed on the screen for 5 s. Upon the disappearing of the target character, the participant was required to write, using their index fingers2, the target character they just saw on his/her smartphone using the browser-based handwriting data collection app. Upon completion of the task, the participant was instructed to submit the handwriting data to the research team via email. Accuracy of each copied item was obtained. Besides, the elapsed time and coordinates each time the fingertip touched or left the device screen were recorded accordingly. The ISIs and the corresponding ISDs were calculated accordingly.

Table 1. Demographic information of the stimuli of the left-right and top-bottom configurations.
Separate linear mixed effects models with maximal model structure (Barr et al., 2013) were computed using the lme4 package (version 1.1–18.1; Bates et al., 2015) in R (version 3.5.1; R Core Team, 2018) for the accuracy and the ISIs obtained. In the accuracy analysis, character frequency, number of strokes, Configuration, Gender and reading scores were entered as fixed factors to investigate their significance in predicting the copying accuracy. In the ISI model, the ISD, number of strokes, Configuration, Gender, character frequency, radical frequency, logographeme frequency, and regularity of the corresponding ISIs were entered as fixed factors to investigate their significance in predicting the ISIs. By-subject and by-item random intercepts and random slopes were included for each fixed main effect based on recommendations by Barr et al. (2013). Significance was determined using a cut-off point of t > 2. The results of the statistical models of accuracy and ISI analyses are summarized in Tables 2, 3 correspondingly.
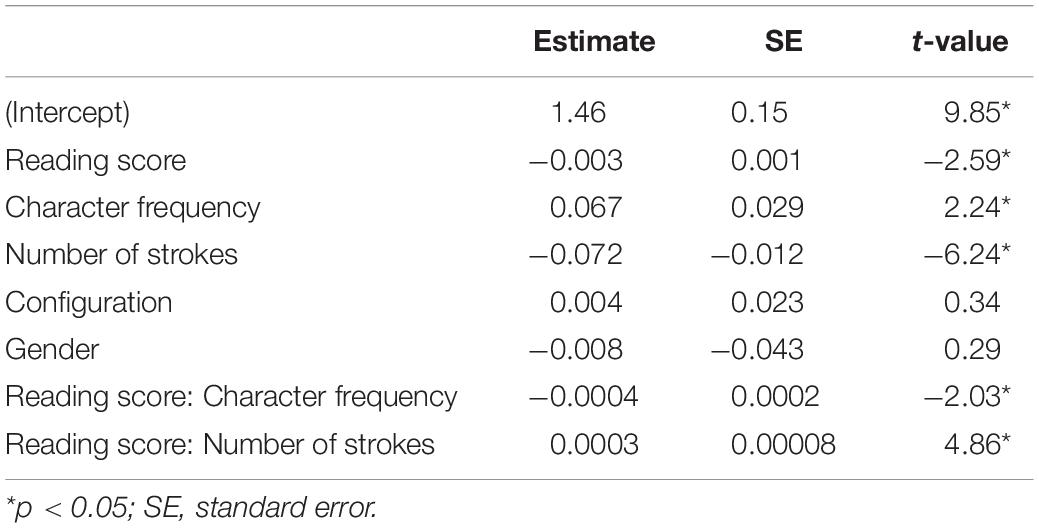
Table 2. Results of the model examining the predictors of accuracy of delayed copying.
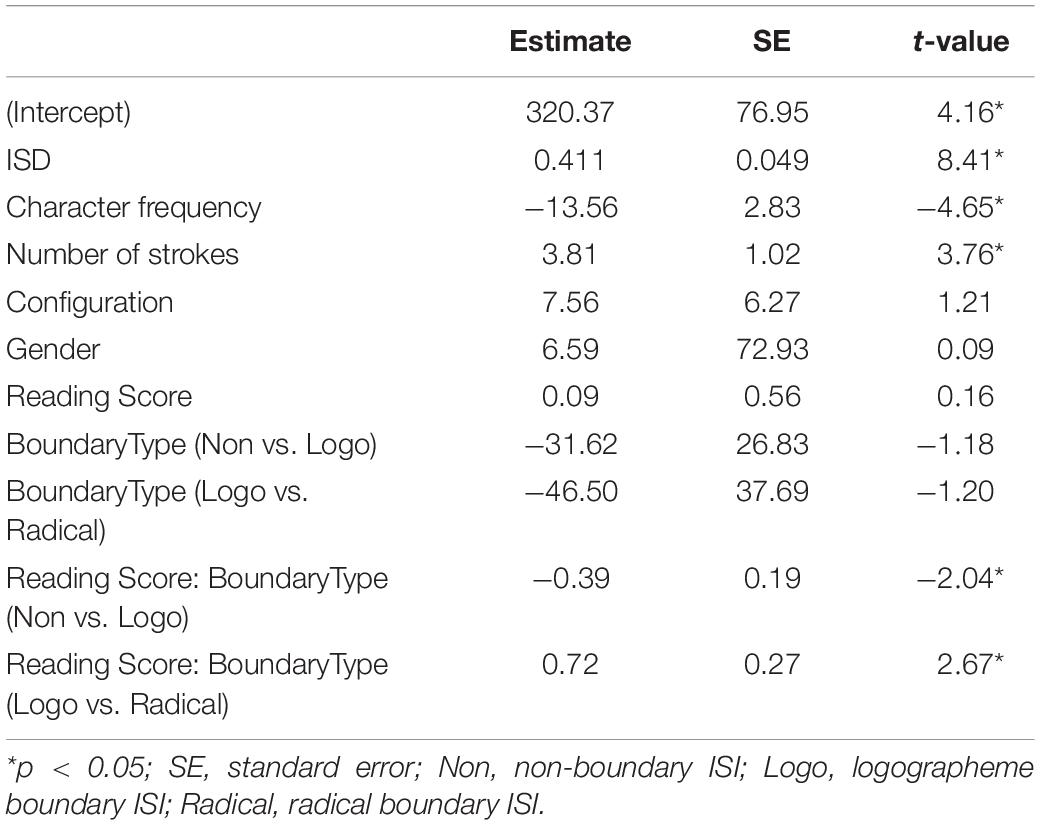
Table 3. Results of the model examining the predictors of ISI of delayed copying.
The average reading scores obtained was 131.88 with a standard deviation of 29.97. The average accuracy of the delayed copying task was 92.08% with a standard deviation of 7.09. Results of correlation test using Pearson’s r indicated strong association between reading scores and accuracy in delayed copying (r = 0.55, p < 0.01).
Results of LMEM showed that accuracy increased as character frequency increased (0.07 ± 0.03, average count), particularly among those with lower readings scores (interaction of Reading Score/Character Frequency: −0.0004 ± 0.0002). Results also showed that accuracy decreased as number of strokes increased (−0.07 ± 0.01, average count), particularly among those with lower reading scores (interaction of Reading Score/Character Frequency: 0.0004 ± 0.00008). Effect of Configuration and Gender were not significant in predicting Accuracy.
Only accurate trials were included in the data analysis. Data from the items with ISIs beyond three standard deviations from the mean (a total of 0.3%) were excluded from the analysis. The results showed that the ISI increased with ISD (0.41 ± 0.05). The longer the ISD, the longer were the ISI. Besides, ISI also increased with stroke number (3.83 ± 1.02), meaning that longer ISIs were associated with characters with more strokes. On the other hand, ISI was observed to decrease with character frequency (−13.02 ± 2.79), meaning that shorter ISIs were associated with characters with higher frequencies.
Figure 2 shows the ISI as a function of BoundaryType and Reading Score. The results showed that the ISI increased with Reading Score at the Radical Boundary (interaction of Character Frequency/Between-Radicals: 0.72 ± 0.27) and decreased with Reading Score within logographemes (interaction of Character Frequency/Within-Logographeme: −0.39 ± 0.19). As indicated in the figure, Between-Radicals ISIs increased as Reading Score increased while Within-Logographeme ISIs decreased as Reading Score increased.
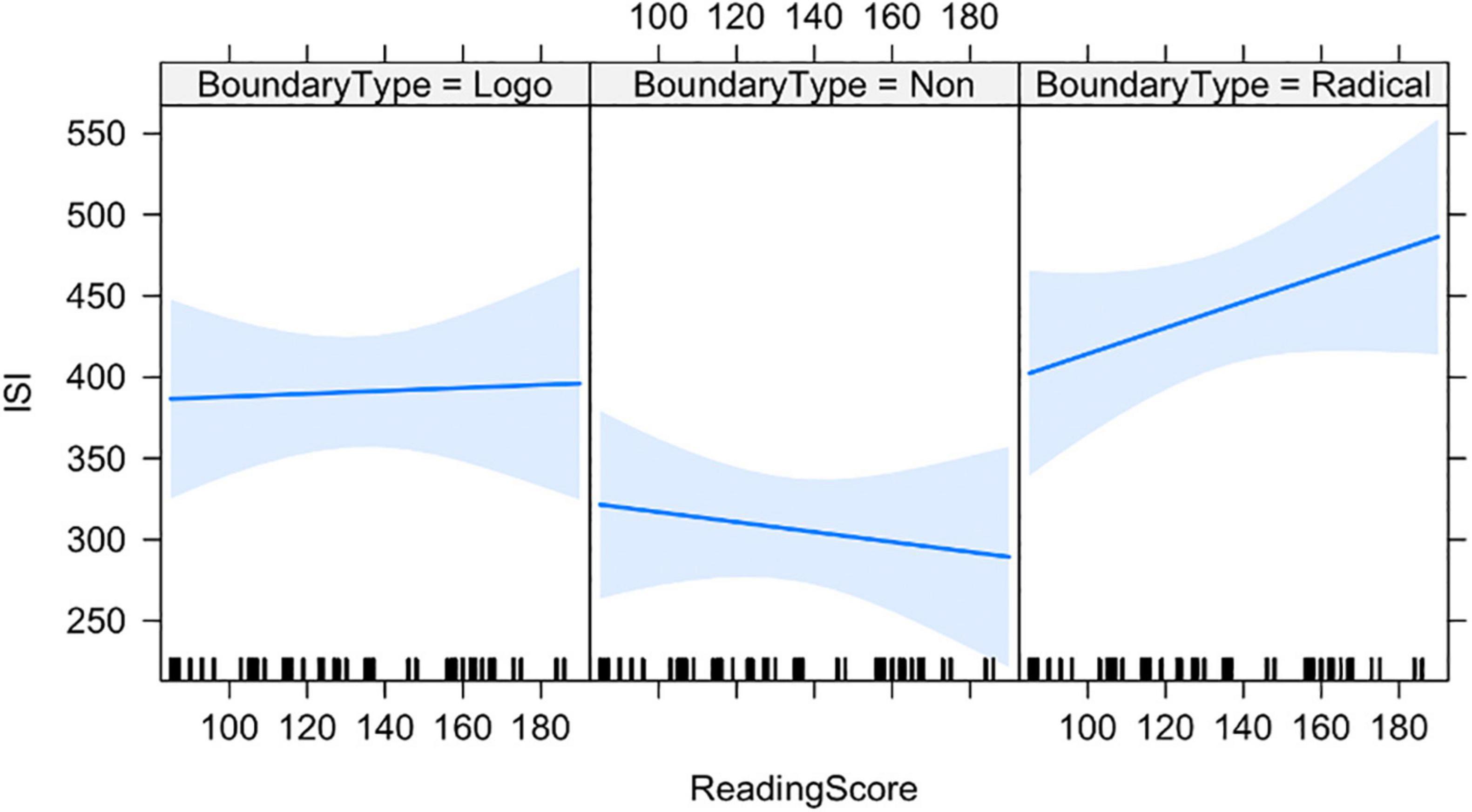
Figure 2. ISI as a function of BoundaryType and Reading Score. Non, non-boundary ISI; Logo, logographeme-boundary ISI; Radical, radical-boundary ISI.
Results also showed that ISIs located at the Logographeme Boundaries were significantly longer than ISIs within logographemes (98.22 ± 16.76). Effect of Configuration and Gender were not significant in predicting ISI.
The current study aimed at examining the orthographic knowledge required for writing Chinese characters among individuals with Vietnamese L1 and Chinese L2 by observing their performances in a delayed copying task.
Results showed that participants with lower reading scores were more prone to making errors in the delayed copying task. This strong association between reading and writing performance is consistent with previous studies conducted among L1 Chinese learners (e.g., Tan et al., 2005; Yeung et al., 2011) as well as L2 Chinese learners (e.g., Cao and Perfetti, 2016; Wong, 2018). In general, a strong reading-writing connection was reported among learners of Chinese.
In this current study, to understand the association between accuracy of delayed copying and reading score, the processes involved to achieve the requirement of the delayed copying task. Using the logogen model (Ellis and Young, 1996), Bonin et al. (2015) explained the processes involved in delayed copying task and Han et al. (2007) also highlighted the orthographic components involved in Chinese character delayed copying. During each trial of the delayed copying task, a Chinese character was presented. The participants were required to copy the character upon the disappearance of the Chinese character. To achieve this, if the character was a familiar item, it would be visually recognized and the corresponding stored item in the orthographic output lexicon would be activated. Subsequently, the sub-character units, such as phonetic and semantic radicals and logographemes, would be temporarily stored in the orthographic output buffer, waiting for the motor execution of writing. During the handwriting phase, the corresponding graphic motor patterns of the sub-character units would be retrieved for the motor execution of writing. In the case that the character was an unfamiliar item, the visual recognition stage would not be possible. Instead, the character would be directly broken down into its sub-character components and temporarily stored in the orthographic output buffer for the motor execution of the writing. Similarly, in the handwriting phase, the corresponding graphic motor patterns of the sub-character units would be retrieved for the motor execution of writing. To facilitate our discussion, the former, which involves familiar characters, is referred as the lexical approach, while the latter, which involves unfamiliar characters, is referred as the non-lexical approach.
It is important to note that the use of non-lexical approach should be more prone to making errors in the delayed copying task. It is because it involves only short term memory and lacks the support from long term lexical memory. The significant effects of character frequency and number of strokes in predicting the accuracy of the task observed in the current study provided support to this notion. High frequency characters should have higher familiarity than low frequency characters, hence are less prone to errors in the delayed copying. Similarly, the more number of strokes in the characters, the higher demand in the short term memory, particularly when unfamiliar characters were encountered, and, therefore, are more prone to errors in the delayed copying as well.
Finally, the significant interaction effect between reading scores and character frequency as well as the significant interaction effect between reading scores and number of strokes indicated that those with better reading scores were less affected by frequency and number of strokes of the stimuli in the delayed copying task comparatively. Among participants with better reading performance, it is likely that they have better lexical knowledge, which allows better usage of the lexical approach in the delayed coping task, as well as better orthographic knowledge, which allows better usage of the non-lexical approach when unfamiliar items were encountered. On the other hand, among participants with weaker reading performance, the insufficient lexical knowledge means they probably have to heavily rely on the non-lexical approach, which has heavy demand of orthographic knowledge, to achieve the task requirements. Therefore, the lower accuracies achieved indicated that they have insufficient orthographic knowledge too. The insufficient orthographic knowledge may be exhibited in the delayed copying task as (1) having fewer familiar orthographic units with various grain sizes stored, and/or (2) being not flexible enough in using orthographic units with various grain sizes in the processing. The results obtained in the ISI analysis further supported this claim.
In the ISI analysis, the results showed that longer ISIs are associated with longer ISDs. This is consistent with previous observations among L1 Chinese users (e.g., Lau, 2019, 2020b). Such observation should not be surprising, since the longer the physical distance that the fingertip travels during the writing process, the longer time should it take to achieve the travel.
Besides, the results showed that longer ISIs are associated with characters with more strokes. Again, this is consistent with previous observations among L1 Chinese users (e.g., Lau, 2020a,b). Lau (2020b) suggested that the positive correlation between number of strokes and ISIs may be due to more processing units being temporarily stored in the orthographic output buffer, which induced heavier processing demand during the writing process. This is particularly applicable when the non-lexical approach was used to achieve the requirement of the delayed copying task in the current study.
Moreover, results also showed that shorter ISIs are associated with characters with higher frequency. Once again, this is consistent with previous observations among L1 Chinese users (Lau, 2019, 2020a). Lau (2020a) suggested that the character frequency effect may reflect that the time needed to retrieve and/or plan for the writing of high frequency writing units are shorter than that of low frequency writing units. Alternatively, it is also possible that the delayed copying of low frequency characters relies heavily on the non-lexical approach, which induces heavier demands in short term memory given the lack of support from long term lexical memory. Hence, the handwriting process would also be affected accordingly, given the nature of cascaded relationship between central processing and peripheral processing of writing (e.g., Qu et al., 2011; Roux et al., 2013).
Finally, the results showed longer ISIs at radical boundaries and logographeme boundaries in general. Such significant boundary effect was reported in previous reports among L1 Chinese users (Lau, 2019, 2020a,b). Lau (2020b) suggested that the longer ISIs located at the orthographic unit boundaries were attributed to longer time required to retrieve the writing units. The significant orthographic unit boundary effects observed in the current study, therefore, indicated that all the participants chunk the target characters into smaller units when they write the characters. However, unlike typical mature L1 Chinese users, the radical boundaries are comparable instead of longer than logographeme boundary (i.e., radical-boundary ISI = logographeme-boundary ISI), except among the better readers. Only the better readers demonstrated the boundary effect that indicated a better mastery of orthographic units of different grain sizes in their writing (i.e., radical-boundary ISI > logographeme-boundary ISI > non-boundary ISI). It is important to note that a better mastery of orthographic units of different grain sizes does not necessarily mean an overall faster writing speed, hence shorter ISIs in general. Instead, the better mastery of orthographic units of different grain sizes should avoid the heavy reliance of orthographic buffer and/or short term visual memory to fulfill the task requirements. Therefore, individuals who can use both big and small units flexibly in the delayed copying task should demonstrate both higher accuracy in the task as well as the specific orthographic boundary pattern (i.e., radical-boundary ISI > logographeme-boundary ISI > non-boundary ISI) in their handwriting performance.
Our results indicated that among those scored low in the reading task, they showed tendency to use smaller units, i.e., logographemes, as the writing units, while among those score high in the reading task, they demonstrated higher tendency to use both large units, i.e., radicals, and small units, i.e., logographemes, as the writing units. In fact, this mastery sequence from small to larger orthographic units is consistent with previous observations among L1 Chinese learners. For example, Lau (2019) tested a group of grade 1 and a group of grade 5 L1 Chinese children using an immediate copying task. It was observed that only the grade 5 children showed tendency to use both logographemes and radicals as writing units, while the grade 1 children showed tendency to use only logographemes as writing units. It was suggested that the early L1 Chinese learners tend to use smaller writing units, because the smaller units consist of fewer strokes, such that the associated graphic motor patterns are less complex. Besides, it was also suggested that the tendency is related to the fact that there are more units to be learnt when the orthographic units are bigger (e.g., Ziegler and Goswami, 2005; Lui, 2012). Similar explanations should also be applicable to beginning L2 Chinese learners.
When the L2 Chinese learners achieve more advanced levels, they demonstrated higher tendency to use bigger processing units in writing. There are at least three benefits of using radicals as writing units. First, fewer units will be needed to be temporarily stored in the orthographic output buffer, which makes it less error prone in the writing task, independent of the usage of the lexical or non-lexical approach to achieve the requirements of the delayed copying task. It is because the orthographic output buffer is in the common pathway shared by the two approaches. Second, the use of bigger units, i.e., radicals, potentially allows the usage of the phonological information associated with phonetic radicals (e.g., Lau and Ma, 2018; Lau, 2020a) and semantic information associated with semantic radicals (e.g., Law et al., 2005) in supporting the writing process. Finally, the use of bigger units appears to have the advantage of achieving more efficient writing, as indicated in the significant decrease in the non-boundary ISIs observed among those who performed better in the reading task. This may be a result of reducing demands in the orthographic output buffer and/or having support from the phonological and semantic information associated with the radicals. Future studies will be needed to warrant this claim.
In the current study, we attempted to use a handwriting task to measure orthographic knowledge of Chinese L2 learners. In the following, we discussed how the knowledge of the Chinese orthographic system required for writing Chinese characters, including the configuration of the Chinese characters, a repertoire of the orthographic units of different grain sizes, and the positional consistency of the components, can be observed in the handwriting task.
In the delayed copying task conducted, characters of either left-right or top-bottom constructions were selected as stimuli to observe the participants’ awareness of left-right and top-bottom configurations of Chinese characters. Given that the results of both accuracy analysis and ISI analysis indicated no significant effect of configuration in predicting the participants’ performance, it is suggested that the majority of our participants have mastered the awareness of the configurations of Chinese character. Results of error analysis further supported this notion.
One possible way to detect the confusion of configurations of characters concerns the observations of stroke sequence used by the participants in copying the target characters. One such example was given in Figure 3. As observed in the sequence of writing, indicated by the number next to the onset position of each stroke written, the top-bottom configured character “获”[huo4]<obtain> was written as left-right configured. Nevertheless, such kind of errors was observed to be really exceptional in the current study. Among all the errors produced by the participants, only one involves such confusion of the configuration of the target character. The error was produced by a participant whose reading score ranked second lowest among all participants. Hence, it is suggested that the awareness of common configurations of characters should be relatively easy that even beginning L2 Chinese learners who have completed grade 1–4 of HSK are able to master. It is further suggested that future studies should include other less common configurations of characters, such as enclosed and semi-enclosed configurations (Yeh and Li, 2002; Chang et al., 2021), to obtain a more comprehensive picture of how L2 Chinese learners master the awareness of different character configurations.
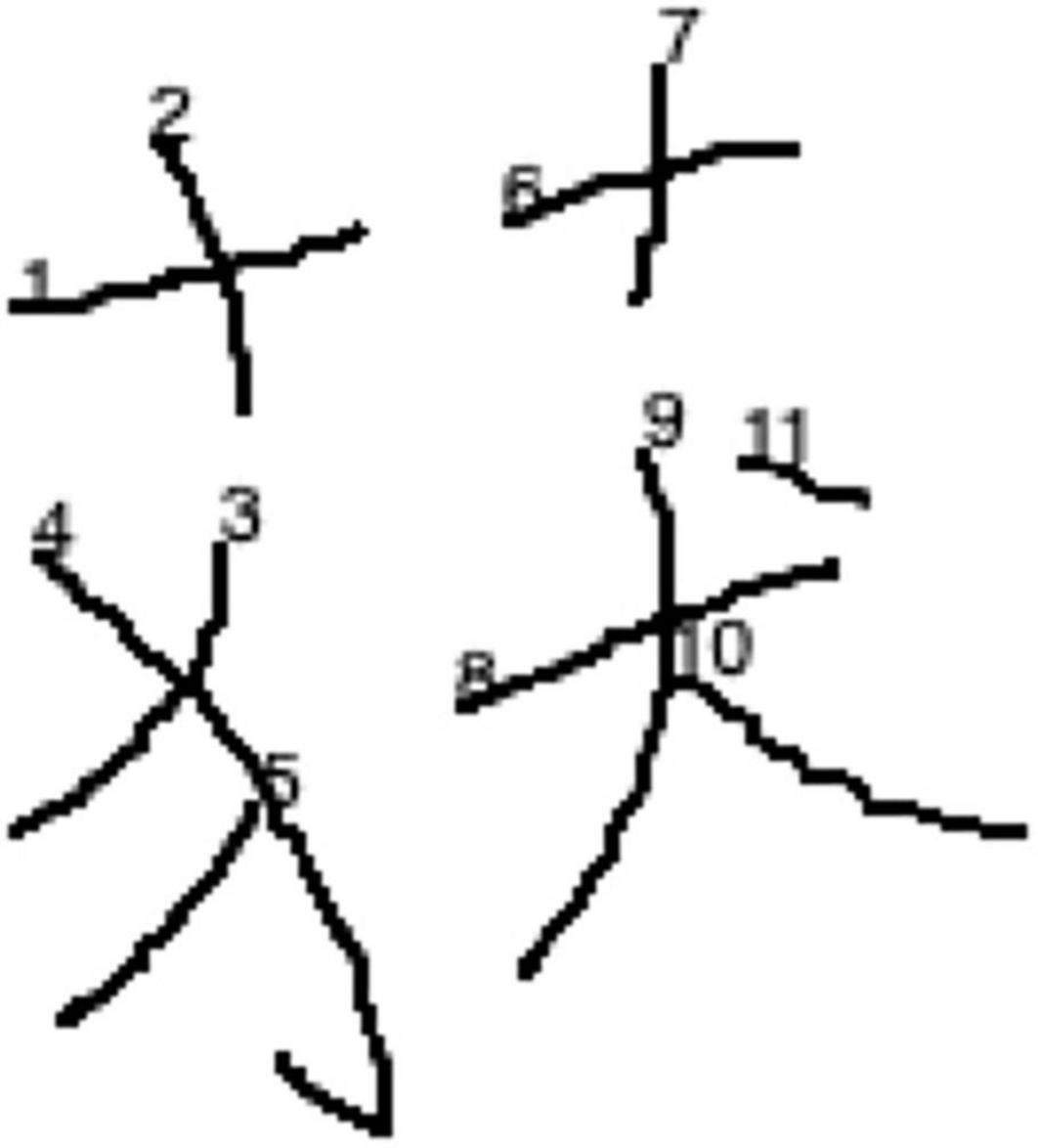
Figure 3. An example of error indicating confusion of character configuration. The order of stroke sequence was indicated next to the onset position of each stroke.
Regarding the repertoire of orthographic units of different grain sizes, as indicated in the ISI analysis, the low achievers in the reading test demonstrated the abilities to use logographemes but not radicals in their writing. On the contrary, those with higher reading scores managed to use both logographemes and radicals in their writing. It is suggested that the better readers possess larger repertoires of orthographic units of different grain sizes, which allowed them to perform better in the delayed copying task. Nevertheless, it is noteworthy that the majority (72.3%) of the errors observed in the task involve substitutions or omission of logographemes, which were observed among both weak and good readers. This suggested that despite having relatively larger repertoire of orthographic units, the better readers in the current study still have not master all the orthographic units required for the delayed copying task. This is, in fact, within expectation, as building the repertoire of orthographic units probably requires sufficient exposures and practice.
The third area of orthographic knowledge concerns the positional consistency of orthographic units. Although there was no observation of errors produced by the participants that involved substitutions using logographemes in illegal positions, this may not be sufficient to argue that the participants demonstrated the awareness of positional consistency of orthographic units. Instead, given that the positional consistency of orthographic units should be item-specific, hence the corresponding knowledge should also be exposure-dependent, it is expected that even the better readers in the current study may not have fully mastered the awareness. It is suggested that future studies that include stimuli containing orthographic units of varying degree of positional consistency will be needed to further the investigations.
One obvious limitation of the current study concerns the gender-imbalance of the participants. While this may have potentially created a gender biased issue regarding the results obtained, the female-dominance in the participants actually reflected the common gender-imbalance of L2 Chinese learners in Vietnam. Despite the fact that the insignificant effect of gender observed in both the accuracy and ISI analyses in the current study appeared to support that gender is not a critical factor that affects orthographic knowledge, it is suggested that future studies should try to include more male participants to avoid similar gender-imbalance issue.
Another potential source of limitations concerns the remoteness of the data collection which was conducted through online Zoom sessions. Despite generally good audio and video quality of all the recordings was revealed, it is unclear whether the precision across different smart devices used by the participants may vary, hence potentially affecting the data obtained. The fact that recent studies (e.g., Anwyl-Irvine et al., 2021; Bignardi et al., 2021) reported high accuracy, reliability and validity of data obtained from browser-based and tablet-based experiments, which are independent from the operating systems of the smart devices used, may provide some support to the use of remote data collection via smart devices. It is suggested that a more ideal way is to at least obtain information of smart devices used by the participants and include that as a control variable in the statistical analysis in the future. This is considered particularly important, as remote data collection is getting more popular these days, especially under the city-wide lockdown policies announced by many governments due to the COVID-19 pandemic. The use of browser-based experiments, such as the delayed copying task used in the current study, may help to reduce the difficulties of collecting data face-to-face. In fact, we have further identified other advantages of using browser-based experiments. For example, it allows efficient data collection, which is welcomed by most participants, particularly during the pandemic, as they do not have to physically attend the experiment sessions. It is further suggested that future studies should explore the use of automatized browser-based copying experiments, while at the same time statistically controlled for the potential variability due to precisions of different smart devices, to achieve mass data collection through crowd-sourcing (e.g., Huang et al., 2016). Data obtained from such big-data experiments should yield invaluable results.
Finally, given the success of the current study in using the delayed copying task to measure orthographic awareness of L2 Chinese learners, it is suggested that future studies should make better use of similar handwriting experiments to investigate other areas of orthographic awareness, required for writing Chinese characters, such as positional consistency of orthographic units. Besides, previous experiments also reported significant phonetic regularity effect among L1 Chinese users’ handwriting performance (e.g., Lau, 2020a). Future studies involving experiments of similar construct are recommended to investigate L2 Chinese learners’ knowledge of the functions of phonetic and semantic radicals of Chinese characters. Such experiments should allow the investigation of how L2 Chinese learners master not only the orthographic system but also its interactions with the phonological and semantic systems of Chinese.
The current study attempted to use a delayed-copying task to measure the orthographic awareness required for writing Chinese characters among L2 Chinese learners in Vietnam. The results of accuracy analysis and ISI analysis indicated that the awareness of character configurations is mastered by most L2 Chinese learners who have completed at least grade 1–4 of HSK. Besides, the results of the ISI analysis further indicated that the weaker readers tend to use only small grain size orthographic units while the better readers tend to use both small and big grain size orthographic units in the delayed copying task. We propose that the use of stimuli with different orthographic properties together with handwriting measures is effective in measuring the orthographic awareness of L2 Chinese learners.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author/s.
The studies involving human participants were reviewed and approved by the Human Subjects Ethics Sub-Committee of The Hong Kong Polytechnic University (HSEARS20210529002). The patients/participants provided their written informed consent to participate in this study.
DL and YL contributed to the conception and design of the study. YL and H-AN organized the data collection and data analyses. DL performed the statistical analysis and wrote the first draft of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
This study was funded by the Departmental Publication Subsidy Scheme of the Department of Chinese Language Studies of The Education University of Hong Kong, and the Departmental General Research Fund of the Department of Chinese and Bilingual Studies of The Hong Kong Polytechnic University (ZZKG).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2022.784019/full#supplementary-material
Anwyl-Irvine, A. L., Dalmaijer, E. S., Hodges, N., and Evershed, J. K. (2021). Realistic precision and accuracy of online experiment platforms, web browsers, and devices. Behav. Res. Methods 53, 1407–1425. doi: 10.3758/s13428-020-01501-5
Barr, D. J., Levy, R., Scheepers, C., and Tily, H. J. (2013). Random effects structure for confirmatory hypoth- esis testing: keep it maximal. J. Mem. Lang. 68, 255–278. doi: 10.1016/j.jml.2012.11.001
Bates, D., Mächler, M., Bolker, B., and Walker, S. (2015). Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48. doi: 10.18637/jss.v067.i01
Bignardi, G., Dalmaijer, E., Anwyl-Irvine, A., and Astle, D. (2021). Collecting Big Data with Small Screens: Group-Tests of Children’s Cognition with Touchscreen Tablets Are Reliable and Valid. Behav. Res. Methods 53, 1515–1529. doi: 10.31219/osf.io/aw6c5
Bonin, P., Méot, A., Lagarrigue, A., and Roux, S. (2015). Written object naming, spelling to dictation, and immediate copying: different tasks, different pathways? Q. J. Exp. Psychol. 68, 1268–1294. doi: 10.1080/17470218.2014.978877
Cao, F., and Perfetti, C. (2016). Neural Signatures of the Reading-Writing Connection: Greater Involvement of Writing in Chinese Reading than English Reading. PLoS One 11:e0168414. doi: 10.1371/journal.pone.0168414
Chan, T. S., Loh, E. K., and Hung, C. O. (2021). A longitudinal study of Chinese as a second language kindergarteners’ orthographic awareness and its association with their lexical learning performance. Curr. Psychol. 2021, 1–12. doi: 10.1007/s12144-021-01797-2
Chang, L.-Y., Tseng, C.-C., Perfetti, C. A., and Chen, H.-C. (2021). Development and validation of a Chinese pseudo-character/non-character producing system. Behav. Res. Methods 2021:8. doi: 10.3758/s13428-021-01611-8
Ellis, A. W., and Young, A. W. (1996). Human cognitive neuropsychology: A textbook with readings. Hove: Psychology Press.
Han, Z., Zhang, Y., Shu, H., and Bi, Y. (2007). The orthographic buffer in writing Chinese characters: Evidence from a dysgraphic patient. Cogn. Neuropsychol. 24, 431–450. doi: 10.1080/02643290701381853
Hoosain, R. (1992). “Psychological reality of the word in Chinese,” in Language processing in Chinese, eds H.-C. Chen and O. J. L. Tzeng (Amsterdam: Elsevier), 111–130.
Huang, C.-R., Wang, S.-C., Yao, Y., and Chan, A. (2016). “Crowdsourcing, word segmentation, and semantic transparency: A new empirical approach to Chinese linguistics,” in Paper presented at the 15th International Symposium on Chinese Languages and Linguistics (IsCLL-15), (Taiwan).
Lau, D. K. Y. (2019). Grain size units of Chinese handwriting: development and disorder. Clin. Ling. Phonet. 33, 869–884. doi: 10.1080/02699206.2019.1584723
Lau, D. K. Y. (2020a). Orthographic and phonological processing in Chinese character copying – a preliminary report. Front. Psychol. 11:2122. doi: 10.3389/fpsyg.2020.02122
Lau, D. K. Y. (2020b). Validation of constituent logographemes and radicals in Chinese characters using handwriting data. Behav. Res. Methods 52, 305–316. doi: 10.3758/s13428-019-01227-z
Lau, D. K. Y., and Ma, K. H. W. (2018). A Phonetic Radical Account of the Phonology-to-Orthography Consistency Effect on Writing Chinese Characters: Evidence from a Chinese Dysgraphic Patient. Cogn. Neuropsychol. 35, 403–414. doi: 10.1080/02643294.2018.1510387
Lau, D. K. Y., and Yuen, C. T. (2019). Representations of grapho-motor patterns unique to Chinese character writing: evidence from a patient with mirror writing. Clin. Ling. Phonet. 33, 1031–1049. doi: 10.1080/02699206.2019.1602788
Law, S. P., and Leung, M. T. (2000). Structural representations of characters in Chinese writing: evidence from a case of acquired dysgraphia. Psychologia 43, 67–83.
Law, S. P., Yeung, O., Wong, W., and Chiu, K. M. (2005). Processing of semantic radicals in writing Chinese characters: Data from a Chinese dysgraphic patient. Cogn. Neuropsychol. 22, 885–903. doi: 10.1080/02643290442000392
Leong, C. K., Tse, S. K., Loh, K. E., and Ki, W. W. (2011). Orthographic Knowledge Important in Comprehending Elementary Chinese Text by Users of Alphasyllabaries. Read. Psychol. 32, 237–271. doi: 10.1080/02702711.2010.495605
Loh, E. K. Y., Liao, X., and Leung, S. O. (2018). Acquisition of orthographic knowledge: developmental difference among learners with Chinese as a second language (CSL). System 74, 206–216. doi: 10.1016/j.system.2018.03.018
Loh, E. K. Y., Liao, X., Leung, S. O., and Tam, L. C. W. (2021). How do Chinese as a second language (CSL) learners acquire orthographic knowledge: component, structure and position regularity. Lang. Awareness 30, 297–316.
Lui, H. M. (2012). The processing units of writing Chinese characters: A developmental perspective. Unpublished M.Phil Thesis. Hong Kong: University of Hong Kong.
Lui, H.-M., Leung, M.-T., Law, S.-P., and Fung, R. S.-Y. (2010). A database for investigating the logographeme as a basic unit of writing Chinese. Internat. J. Speech-Lang. Pathol. 12, 8–18. doi: 10.3109/17549500903203082
Nguyễn Đình Hoà (1959). Chũ′ Nôm the Demotic System of Writing in Vietnam. J. Am. Orient. Soc. 79, 270–274. doi: 10.2307/595134
Nguyen, T. P., Li, H., Wu, X., and Sun, P. (2016). [The development of Chinese component awareness in Vietnamese students learning Chinese as a foreign language]. Stud. Psychol. Behav. 14, 20–26.
Prattichizzo, D., Meli, L., and Malvezzi, M. (2015). Digital Handwriting with a Finger or a Stylus: A Biomechanical Comparison. IEEE Transact. Hapt. 8, 356–370. doi: 10.1109/TOH.2015.2434812
Qu, Q., Damian, M. F., Zhang, Q., and Zhu, X. (2011). Phonology contributes to writing: evidence from written word production in a nonalphabetic script. Psychol. Sci. 22, 1107–1112. doi: 10.1177/0956797611417001
R Core Team (2018). R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing.
Roux, S., McKeeff, T. J., Grosjacques, G., Afonso, O., and Kandel, S. (2013). The interaction between central and peripheral processes in handwriting production. Cognition 127, 235–241. doi: 10.1016/j.cognition.2012.12.009
Shen, H. H., and Ke, C. (2007). Radical awareness and word acquisition among nonnative learners of Chinese. Mod. Lang. J. 91, 97–111. doi: 10.1111/j.1540-4781.2007.00511.x
Shu, H., Chen, X., Anderson, R. C., Wu, N., and Xuan, Y. (2003). Properties of school Chinese: implications for learning to read. Child Dev. 74, 27–47. doi: 10.1111/1467-8624.00519
Taft, M., Zhu, X., and Peng, D. (1999). Positional specificity of radicals in Chinese character recognition. J. Mem. Lang. 40, 498–519. doi: 10.1006/jmla.1998.2625
Tan, L. H., Spinks, J. A., Eden, G., Perfetti, C. A., and Siok, W. T. (2005). Reading depends on writing, in Chinese. Proc. Natl. Acad. Sci. U S A 102, 8781–8785.
Tong, X., Tong, X., and McBride, C. (2017). Radical sensitivity is the key to understanding Chinese character acquisition in children. Read. Writ. 30, 1251–1265. doi: 10.1007/s11145-017-9722-8
Wong, P. T.-Y., and Lau, D. K.-Y. (2019). “Phonology is accessed during Chinese character copying,” in Proceedings of the Conference Abstract: Academy of Aphasia 57th Annual Meeting, Macau - Macau. doi: 10.3389/conf.fnhum.2019.01.00005
Wong, Y. K. (2018). Exploring the reading-writing relationship in young Chinese language learners’ sentence writing. Read. Writ. 31, 945–964.
Yeh, S.-L., and Li, J.-L. (2002). Role of Structure and Component in Judgments of Visual Similarity of Chinese Characters. J. Exp. Psychol 28, 933–947. doi: 10.1037/0096-1523.28.4.933
Yeung, P., Ho, C., Chik, P., Lo, L., Luan, H., Chan, D., et al. (2011). Reading and spelling Chinese among beginning readers: What skills make a difference? Sci. Stud. Read. 15, 285–313. doi: 10.1080/10888438.2010.482149
Zhang, Q., and Feng, C. (2017). The interaction between central and peripheral processing in Chinese handwritten production: evidence from the effect of lexicality and radical complexity. Front. Psychol. 8:334. doi: 10.3389/fpsyg.2017.02220
Keywords: handwriting, copying, orthographic knowledge, L2 Chinese, Vietnam
Citation: Lau DK-Y, Liang Y and Nguyen H-A (2022) Measuring Orthographic Knowledge of L2 Chinese Learners in Vietnam Using a Handwriting Task – A Preliminary Report. Front. Psychol. 13:784019. doi: 10.3389/fpsyg.2022.784019
Received: 27 September 2021; Accepted: 03 January 2022;
Published: 16 February 2022.
Edited by:
Linjun Zhang, Peking University, ChinaReviewed by:
Qingfang Zhang, Renmin University of China, ChinaCopyright © 2022 Lau, Liang and Nguyen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dustin Kai-Yan Lau, ZHVzdGluLmxhdUBwb2x5dS5lZHUuaGs=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.