 Shaoming Chen
Shaoming Chen Minghui Yang
Minghui Yang Yuheng Lin
Yuheng Lin- 1International Business School, Guangzhou City University of Technology, Guangzhou, China
- 2Department of Mathematics, Hong Kong Baptist University, Kowloon, Hong Kong SAR, China
The main purpose of this paper is to investigate the happiness factors and assess the performance of machine learning techniques on predicting the happiness levels of European immigrants and natives. Two types of machine learning methods, Ordinal Logistic Regression (OLR) and Artificial Neural Network (ANN), are employed for analytical modeling. Our results with a total sample size of 196,724 respondents from nine rounds of the European Social Survey (ESS) indicate that the determinants of happiness for immigrants and natives are significantly inconsistent. Therefore, variables should be specifically selected to predict the happiness levels of these two different groups. The sensitivity analysis shows that satisfaction with life, subjective general health, and the highest level of education are the three most prominent determinants that contribute to the happiness of immigrants and natives. The overall accuracies of OLR and ANN baseline models are >80%. This can be further improved by building models for each individual country. The application of OLR and ANN implies that machine learning algorithms can be a useful tool for predicting happiness levels. The greater knowledge of migration and happiness will allow us to better understand the decision-making processes and construct more effective policies.
Introduction
People have long been eager to find the key to open the door to happiness. For most people, happiness is the main, if not the only, goal of life. The term “happiness” is frequently used interchangeably with the scientific term “Subjective well-being” (SWB), which was first introduced by Diener (1984) and has been defined as the cognitive and affective self-assessment of an individual’s life (Diener et al., 2002). As researchers seek to understand the nature of subjective well-being, there are more and more studies on SWB and a wealth of meaningful academic achievements.
The number of immigrants in the European Union (EU) who are driven by a desire for a happier life is not negligible (Hendriks, 2015). According to Eurostat data, 23 million people migrated from non-EU countries to EU countries in 2020, accounting for 5.1% of the EU population (Eurostat, 2020). The proportion of immigrants from the EU Member States or non-EU countries is shown in Figure 1.
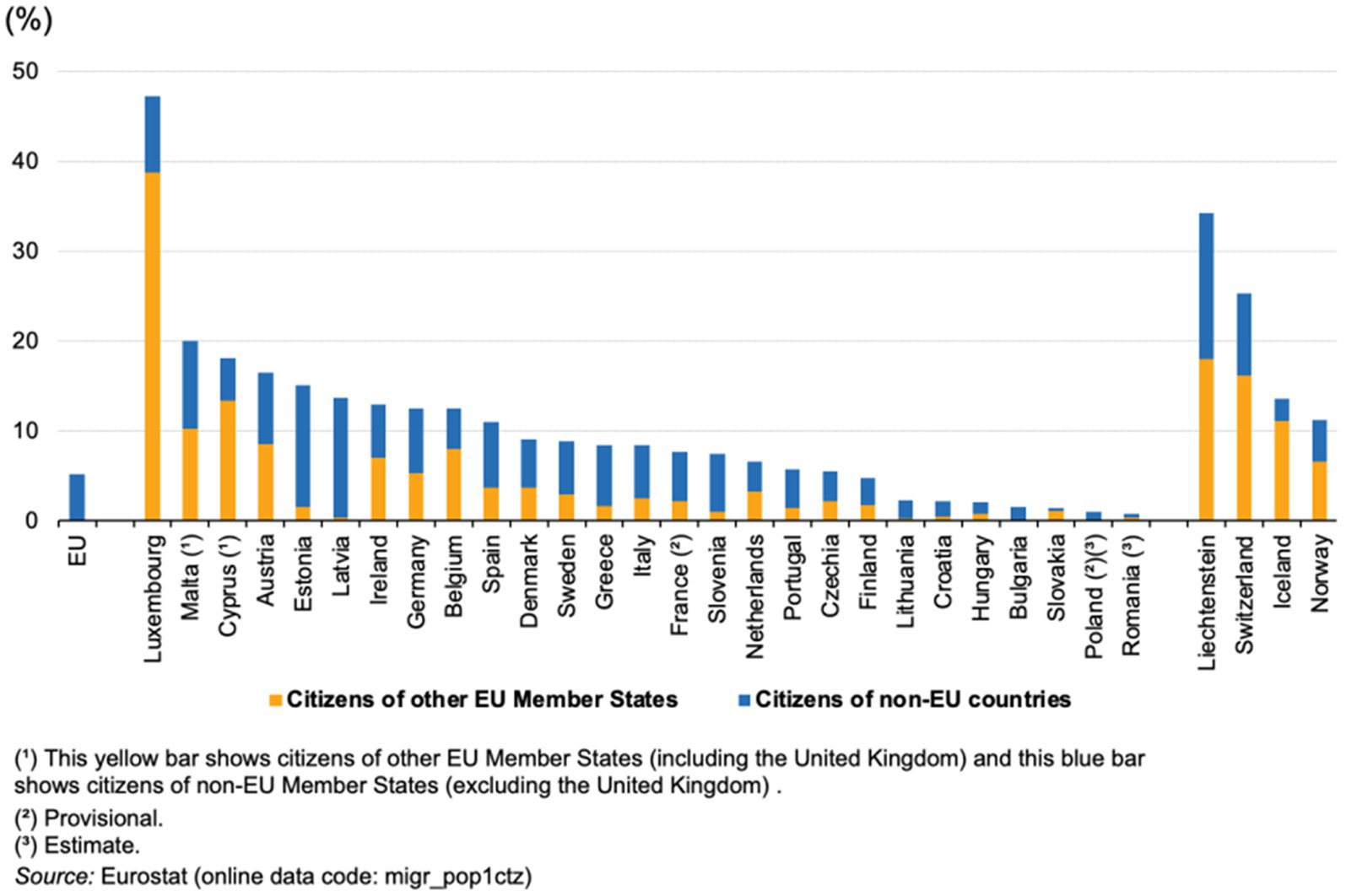
Figure 1. Percentage of immigrant composition in EU countries.
Caring for human life and well-being is the first and only legitimate goal of good governance, and a growing number of policymakers around the world are moving toward this goal. In 2019, the EU Council of Ministers asked all its member states to put people and their well-being at the center of policy design.1 Policymakers would benefit from understanding whether outcomes are consistent with their goals and expectations, while it can be challenging for them to forecast the happiness levels of immigrants and natives.
Most of the existing research on the question is hampered by the absence of panel data on migrants, and the approach of these studies is also limited to simple linear regression models. Hence, their findings are likely to be vulnerable to selection bias and unobserved heterogeneity. To address this gap, this article explores the factors of happiness and the accuracy of classification predictive modeling via analysis of data from the European Social Survey (ESS) by using the Ordinal Logistic Regression (OLR) model and the Artificial Neural Network (ANN) model. The OLR method is the most appropriate and practical technique to analyze the effect of independent variables on a rank order dependent variable, and the ANN as an alternative approach to linear regression has gained popularity in different fields (Larasati et al., 2011). Some researchers have pointed out the advantages of a supervised learning ANN against either linear or logistic regression (Dreiseitl and Ohno-Machado, 2002; Grnholdt and Martensen, 2005).
This study contributes to the literature in several ways. First, this paper enriches the understanding of happiness factors by taking more variables into consideration, which can also help to boost prediction accuracy. Second, our study extends the extant literature by providing a new perspective on happiness research via applying machine learning algorithms to social survey data. Third, this article sheds light on how to optimize the prediction accuracy of people’s happiness for the future studies.
The remainder of this paper is organized as follows. Section “Literature review” explains recent studies in literature parallel to the focus of the current study. Section “Methodology and data” introduces methodology and data processing, and Section “Results” reports the results and evaluation of the two algorithms. Finally, conclusions and limitations are provided in Section “Discussion”.
Literature review
The factors of happiness
The research about happiness or subjective well-being has been performed in different academic disciplines such as economics, psychology, and sociology. As the EAF (Ecological Acculturation Framework) suggests, immigrants’ successful adaptation to a new country is a function of the fit between the characteristics of individuals and the requirements of the settings in which they function (Salo and Birman, 2015). According to Lu and Wang (2010), the research on happiness can be summarized as the following happiness function: , where H is the dependent variable, is the determining equation of happiness. The independent variables are mainly composed of D, which are the demographic factors (e.g., age, gender, health, levels of education, religious beliefs, etc.). E represents the economic factors (e.g., income, unemployment, inflation, government expenditure, urbanization, etc.). S represents the social institution factors (e.g., democratic rights, the level of local autonomy, etc.).
The relationship between income and happiness is an eternal topic in the economics of happiness. The pioneering research of Easterlin (1974) on income and happiness arouse economists’ interest in happiness research. The now-familiar finding is that people with higher incomes are typically happier than people with less, which has been confirmed in studies of developed countries and developing countries (Easterlin and Sawangfa, 2010). In addition, cross-national studies have shown that residents of rich nations are happier than that of poor nations (Sacks et al., 2012).
Unemployment has a significant negative impact on happiness (Štreimikienė and Grundey, 2009; Krause, 2014). First, unemployment can lead to a decrease in income, thereby reducing the quality of life. Second, unemployment can cause psychological stress. Unemployed people have negative feelings of depression, anxiety, and even shame, leading to a loss of self-esteem and social isolation. The analysis of the national unemployment rate shows that when the unemployment rate of the country is low, people tend to be happier (Stanca, 2010).
Some studies on the happiness of people living in different areas find that living in a large city has a negative effect on happiness. On the contrary, living in rural or suburban regions has a positive effect (Lenzi and Perucca, 2020). The main explanations for this conclusion are: (1) people in cities are full of uncertainty about the future, and fear of unemployment; (2) The cost of living in urban areas is higher; (3) social and environmental issues, such as crime rates, traffic congestion, and population density.
Self-assessed health, have a strong positive correlation with SWB (MacKerron, 2012). The relationship between health status and SWB is bidirectional, with physical health being a determinant of happiness. Older people with illnesses such as coronary heart disease, arthritis, and chronic lung disease show an increase in depression, a decrease in hedonism, and an impaired sense of well-being; psychological well-being also has a protective effect on health, reducing some psychological illnesses to a certain extent and leading to a longer life (Steptoe et al., 2015).
MacKerron (2012) found that the levels of positive emotions and happiness of women are higher than that of men. The reasons for this difference are mainly: (1) Women’s income levels have increased significantly and income is an important factor in happiness; (2) Discrimination against women’s work, abilities are decreasing and social recognition has a positive impact on enhancing SWB; (3) Women are better at controlling the negative impact of emotions than men (Chong and Yue, 2020); (4) The increasing educational attainment of women (Triandafyllidou and Isaakyan, 2016) and (5) The improved social-labor situation (Elgorriaga et al., 2020). It is worth noting that women aged above 50 tend to have a lower level of happiness because of the transition to menopause (Beutel et al., 2009). Accumulating resources in personal (e.g., self-esteem) and social (e.g., income, employment, and partnership) and away from anxiety and depression play crucial roles in maintaining the happiness of aging women (Smith-DiJulio et al., 2008; Beutel et al., 2009).
There is a “U-shaped” relationship between age and SWB, meaning that happiness decreases and then increases as age increases (Steptoe et al., 2015; Clark, 2018). The socioemotional selectivity theory explains that as people age, they accumulate emotional wisdom that makes them choose to retain more emotionally satisfying events, friendships, and experiences. A moderate increase in positive emotional experiences may offset the increase in physical pain. Thus, despite the fact that older people face reduced income, lower social status, and increased mortality, their happiness does not necessarily decline (Steptoe et al., 2015).
The effect of migration on happiness
The motivation for migration is to pursue a better life, while the outcomes of the choice are difficult to predict. Researchers from various disciplines have long been interested in the role that migration play in people’s happiness. There are two main questions that are being investigated: (1) Do immigrants become happier after migration? and (2) Are immigrants as happy as natives?
A number of studies show that immigrants are likely to be happier after migration (Cuellar et al., 2004; Erlinghagen, 2012), but the specific migration flows can make a difference. According to the report of the International Organization for Migration (IOM) (2013), migration has a negative effect on the immigrants’ happiness when they flow to developing countries. In addition, Western Europeans who move to undeveloped areas such as Southern Europe suffer from a decline in the happiness level (Bartram, 2015). In contrast, Eastern Europeans tend to be happier when they migrate to Western Europe (Bartram, 2013).
From the aspect of migration timing, Guedes Auditor and Erlinghagen (2021) found some evidence for an increase in individual SWB in the course of migration and a significant decrease in SWB 1–2 years before migration (Erlinghagen, 2016). Lower life satisfaction and higher perceived isolation reported from those couples which men immigrate in advance of their female partners (Erlinghagen, 2021). However, this trailing-wife-hypothesis on international migration couples not only relies on small immigrant samples (KIing-O’Riain and Chiyoko, 2015) and specific immigrant group (e.g., high-skilled immigrants; Cangia et al., 2018), but also is restricted by specific migration flows (Kõu et al., 2015; Mayes and Koshy, 2018).
Concurrently, a few studies show that immigrants occasionally reach the happiness levels of natives (Cuellar et al., 2004; Rasmi et al., 2012). The possible causes of this phenomenon are that (1) the sample sizes of immigrants are too limited to detect significant differences (Hendriks, 2015) and (2) the included time-variant controls (e.g., income and health) offset the potential gaps (Obućina, 2013). Whether migration decisions bring happiness or not depends on several aspects, and typically, immigrants might not reach the same happiness levels as natives. To address this situation, scholars and policymakers need to help immigrants make optimal decisions to develop a society that incorporates thriving immigrants.
When formulating policies related to improving public happiness, it can be more precise with a prediction system. The government will be able to predict the happiness levels of people by inputting their characteristics into the prediction system. This makes policies vary from person to person, thereby saving public resources and improving efficiency. For both immigrants and natives to benefit from the policy and improve their happiness, machine learning algorithms can be employed to predict their happiness levels.
In our study, we establish the OLR model and the ANN model via using the ESS data to assess the performance of machine learning techniques on predicting the happiness levels of European immigrants and natives. Furthermore, the differences in happiness factors between these two groups are investigated through single-country and cross-country modeling, and the degree of the relative importance of happiness factors is assessed with sensitivity analysis.
Methodology and data
Methodology
Most of the machine learning algorithms applied in happiness research use unstructured data in computer science, such as predicting the happiness levels through facial features in pictures (Li et al., 2016) and the textual data on Twitter (Islam and Goldwasser, 2020). Some studies used machine learning techniques on survey data. A cross-sectional survey in Spain with 823 samples shows that the performance of Deep Neural Network (DNN) in predicting the level of happiness is better than that of the traditional method (Pérez-Benito et al., 2019). In addition, a study using two rounds of ESS data to investigate the German national vote also proved that neural network is superior to other methods (Weber et al., 2018).
In this study, the response variable Y is ordinal, representing three levels of happiness (unhappy, neutral, happy). Since the ordinality of the response variable, we use OLR for the first analysis. This is one of the variations of logistic regression used for predicting an ordinal response variable Y. The advantage of OLR is that it does not assume a spacing between levels of Y. In other words, even if the levels of Y are recorded as 1, 5, 10, it can have the same regression coefficients and p-values from a response variable at levels of 0, 1, 2. Therefore, only the values of rank-ordering of Y are used in the ordinal model.
The most commonly used OLR model is called the proportional odds (PO) model. The PO model for a response variable Y with levels is stated as follows:
where ; is the intercepts with the number of , and is the regression coefficients. For fixed , the model is an ordinary logistic model for the event . Using a common vector of to correlate the probability for varying , the PO model can perform parsimonious modeling of the distribution of (Harrell, 2015).
The ANN model is one of the most popular machine learning algorithms applied in social science studies. Furthermore, the ANN model is also an isomorph with binary classification logistic regression when it has zero hidden nodes (also known as “neurons”; Boulle et al., 2001). Therefore, it is possible to compare the performance of the ANN model with the OLR model. Some studies pointed out that the ANN model appeared to be more powerful in predicting the level of happiness versus the LR models (Dreiseitl and Ohno-Machado, 2002; Grnholdt and Martensen, 2005).
The simplest and the most widely used structure in the ANN model consists of three layers: input, hidden and output layers, as shown in Figure 2. When the ANN model has a single hidden layer, this structure is also known as a “vanilla” neural network.
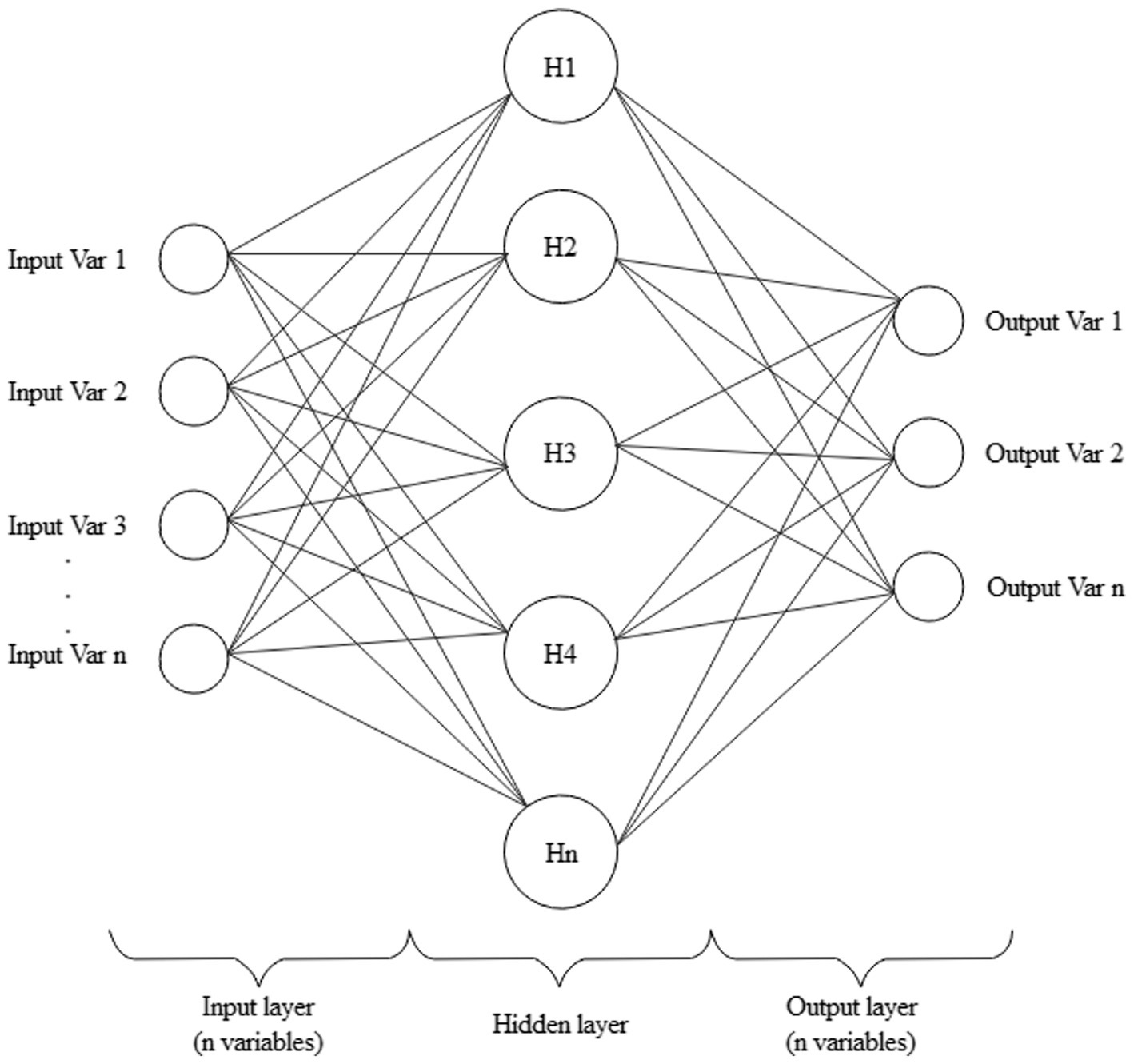
Figure 2. The “vanilla” neural network.
The first layer includes inputs that represent the feature (independent) variables, and the last layer includes outputs that are the response (dependent) variables. The number of nodes in the output layer is equal to the number of the classification categories of the model. The nodes of the hidden layer connect the input and output layers, where the network takes in weighted inputs and produces the outputs through an activation function. When the ANN contains one or more hidden layers, it is a multilayer perceptron.
The ANN model is a combination of function composition and matrix multiplication. The expression is
where is the input. L is the number of layers. is the activation function at layer . are the weights between k-th node in layer and j-th node in a layer.
Data processing and descriptive statistic
The data for this study are from the European Social Survey (ESS, 2020). This is a cross-national survey conducted every 2 years since its establishment in 2001. To achieve a large sample size, the data in this study is pooled across all ESS from round 1 in 2001 to the latest round 9 in 2018. For the cross-national comparison, we select 15 countries into account because the data of other countries are absent in at least one round of the survey. After the selection of the ESS database, the total sample size is 255,824 from nine rounds of surveys in 15 countries.
Since most variables in survey data are categorical variables and represent answers to survey questions. Some samples should be identified as invalid by values as 6/66 (i.e., not applicable), 7/77 (i.e., refusal), 8/88 (i.e., do not know), and 9/99 (i.e., no answer). The immigrants and natives are identified by the answer to the question that “Are you born in this country?” (Bartram, 2013). After defining and deleting these invalid values, the dataset remains 76.8982% of the original case. There are 196,724 samples in total, of which 179,324 are natives and 17,400 are immigrants.
The response variable of this study is happiness. The question C1 “How happy are you” in all survey rounds has answers ranging from 0 to 10. The measurement of happiness is a hot topic with many methods that contain multi-item scales, such as the Subjective Fluctuating Happiness Scale (SFHS) and the Subjective Authentic–Durable Happiness Scale (SA–DHS) have gained popularity, with which some studies provide insights into the general construct of happiness (Dambrun et al., 2012; Monacis et al., 2021). For our study that includes the analysis of different countries, using a single measure can minimize the potential for various interpretations of specific dimensions. Thus, we use a single-item scale for comparisons across different countries and cultures (Abdel-Khalek, 2006; Graham, 2012). It is meaningless to use 11 answer values to classify the happiness levels directly. Therefore, this study defines happiness into three levels: Unhappy (values ranging from 0 to 3), Neutral (values ranging from 4 to 6), and Happy (values ranging from 7 to 10).
The feature variables are selected by the forward stepwise regression method, where the baseline models are ordinal logistic regression (OLR) models of total native group and total immigrant group. Finally, 13 selected feature variables in the models below represent the determinants that are significantly associated with happiness (Bartram, 2012).
The mean and standard deviation of variables are listed in Table 1, which shows that immigrants are happier than natives. On top of that, immigrants have more faith in the politics and economy of countries. However, the unemployment rate of immigrants is higher than the natives, and their income is lower than natives.
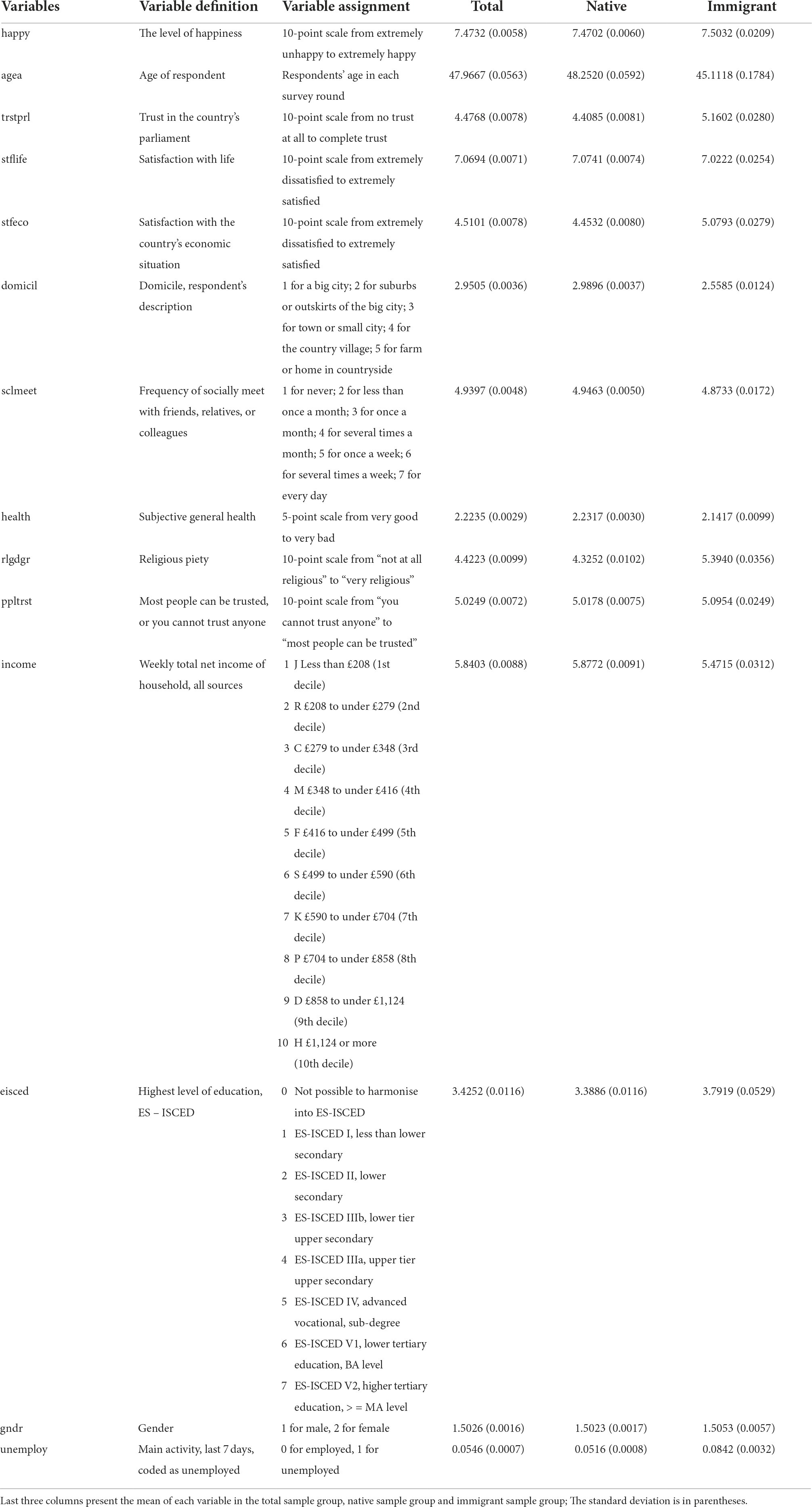
Table 1. Variable definition and descriptive statistics.
Results
Ordinal logistic regression
On the basis of the data pre-processing, the feature variables are determined. Two OLR models with the total samples of native group and immigrant group are selected as the baseline models of this study. The data in each model is divided into a training dataset (70%) and a test dataset (30%) to train the models. Then, the performance of trained models is tested.
A more comprehensive setting of OLR models should be considered. The OLR models are only valid when the assumptions are satisfied. The Variance Inflation Factor (VIF) tests should be performed to confirm there is no multi-collinearity. Since all the VIF for each independent variable in the OLR models is <10, there are no multi-collinearity problems. The mean values of VIF for each model are shown in Tables 2, 3. Moreover, the Brant test should be conducted to test the proportional odds assumption. We conclude that the assumption holds since the probability for all variables in the models is >0.05. Therefore, the proportional odds assumption is not violated, and the models are valid.
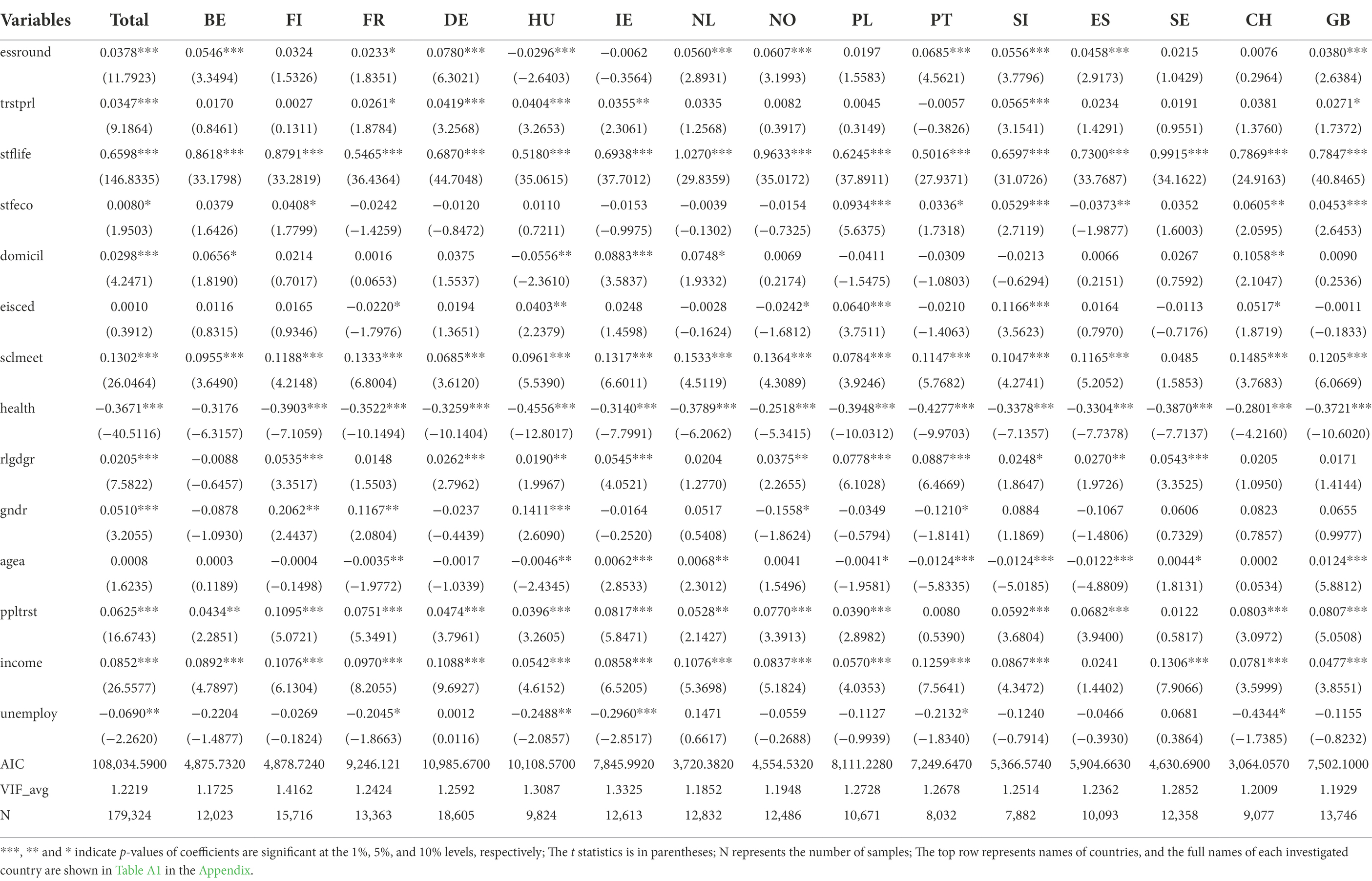
Table 2. The comparison of happiness determinants across nations in native group.
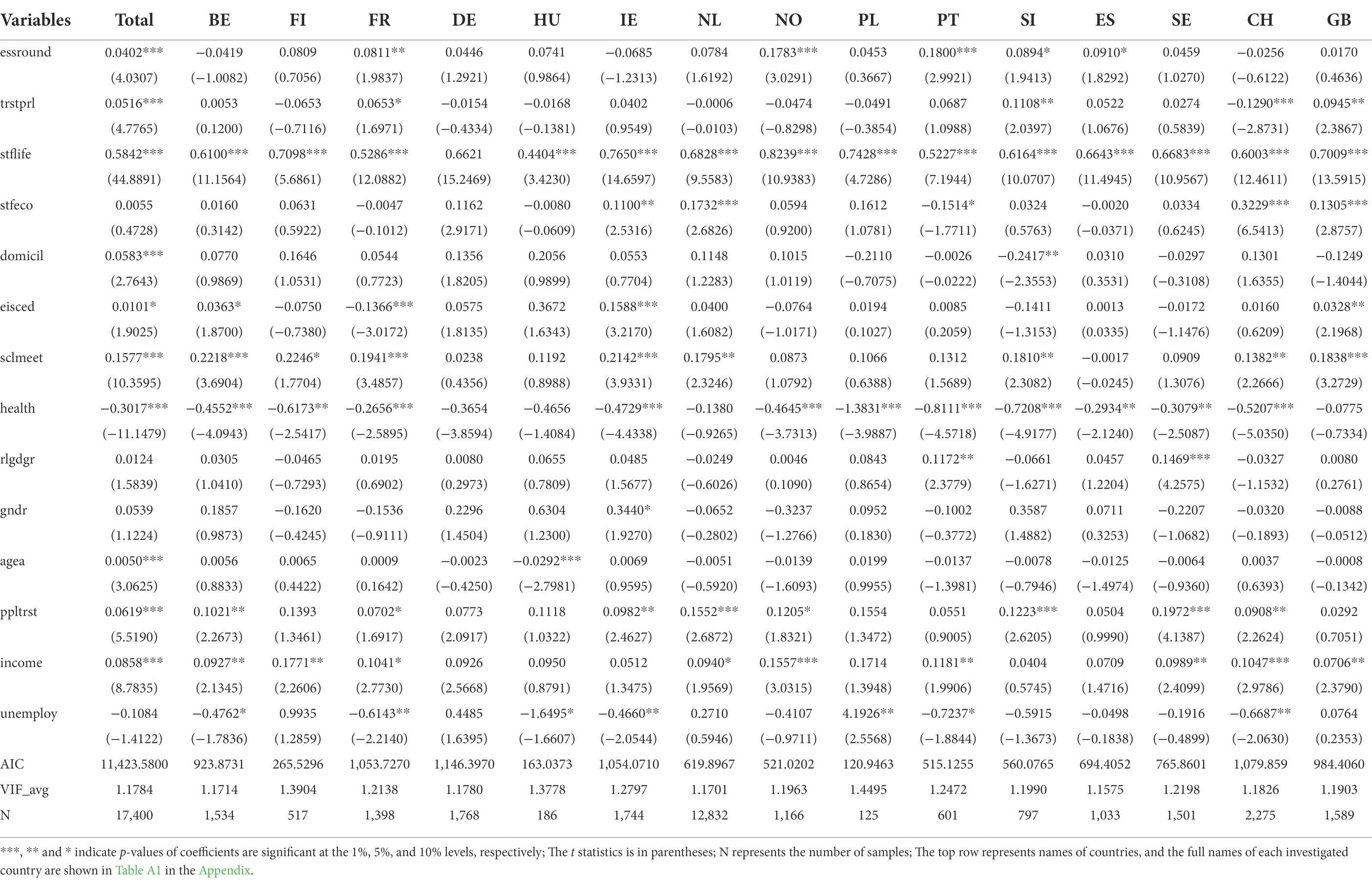
Table 3. The comparison of happiness determinants across nations in immigrant group.
When analyzing the ESS data, survey weights should be taken into account. If there are no weights, the estimation may be biased and over-fitted (Kaminska, 2020). Therefore, population weights and design weights are employed for the regressions of multiple countries. However, only design weight is employed for the regressions of a single country (Bartram, 2019). The survey package is used to specify sample design in R software and construct the ordinal logistic regression. In addition, we use the survey round as a variable in all models to mitigate the influence of time and events, because the investigated period encompasses significant events, such as the economic crisis. We use the same set of feature variables and other settings in the analysis of all models and change only the sample size from total samples to the sample of the individual country. This can validate the consistency in the determinants of happiness.
Tables 2, 3 demonstrate that there are diverged in the happiness factors between the total native and immigrant groups. Stfeco, rlgdgr, gndr, and unemploy significantly influence the happiness of the total native group. However, agea and eisced are determinants of happiness for the total immigrant group. The results of the two baseline models show a difference between immigrants and natives in determinants of happiness.
We compare the native group with the immigrant group of their total samples in the two baseline models. The comparison at the level of individual countries can be investigated with separate ordinal logistic regression. The results of separate regressions show that stflife, sclmeet, ppltrst, income and health are the determinants of happiness of the native groups in most countries. Comparing the results of total samples with that of the individual countries’ samples, the differences in the determinants of happiness in the native groups are relatively small. However, the determinants of the immigrant group fluctuate drastically between different countries. Only stflife and health are significant to happiness in immigrant groups of most countries. Therefore, the determinants of happiness are inconsistent because they vary from the total samples to the samples of individual countries. In other words, the factor may be not significant to happiness when changing the samples in the model. The values of the Akaike Information Criterion (AIC) in each OLR model show that it is better to set up the model for each individual country. In addition, the AIC values of both native and immigrant groups in the model of individual countries are less than that of the total samples in the baseline models.
One of the main purposes of our research is to predict the happiness levels of immigrants and natives. Therefore, the performance metrics of accuracy, F1-score, precision, and recall are employed to assess the models. Considering the macro metrics can treat the importance of each sample equally, we adopt the macro average of F1-score, precision, and recall to evaluate the multi-class classification. In other words, it assigns equal weight to all data points. The mltest package is employed to calculate the performance metrics of multiclass classification based on the confusion matrix. The calculation of the macro F1-score, precision and recall are as follows:
where the happiness is Y in 3 levels. represents the class. The confusion matrix of class against other classes is used to calculate the , , and . These indicate the True Positive Rate of class, the False Positive Rate of class, and the False Negative Rate of class, respectively.
The performance assessments of the native group are shown in Table 4. For the OLR models in the native group, macro metrics of most models are above 50%. The accuracy rates of OLR models for Belgium (i.e., BE), Finland (i.e., FI), Netherlands (i.e., NL), Norway (i.e., NO), Sweden (i.e., SE), and Switzerland (i.e., CH) are nearly 90%. This indicates that the selected feature variables in the OLR model fit these countries better than the baseline model of the native group. The performances of the models in countries, such as France (i.e., FR), Hungary (i.e., HU), Poland (i.e., PL), and Portugal (i.e., PT), are lower than the average. This indicates that the selected feature variables are not ideal.
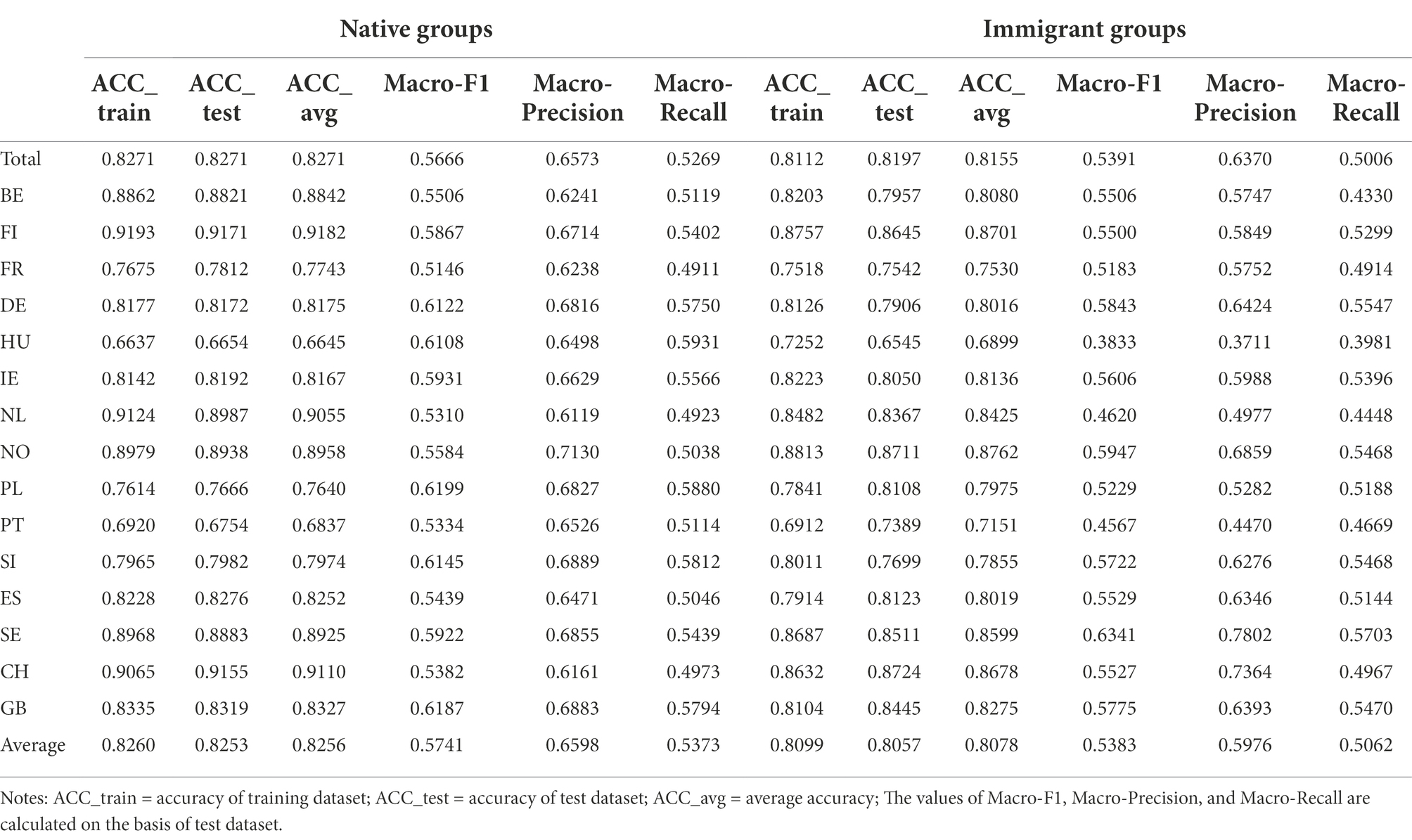
Table 4. The performance metrics of OLR models.
A geographical feature is that the countries with good performance of models are located in Western Europe (Belgium, Netherlands, Switzerland) and Northern Europe (Finland, Norway, Sweden). Hungary and Poland are two Eastern European countries with poor performance models. This phenomenon indicates that determinants of happiness for individual countries may need to be reconsidered with specific conditions of countries, such as the geographic location and the economic development.
In Table 4, the average performance of native groups’ models is better than that of immigrant groups’ models. Only the models of Finland and Norway maintain a high accuracy of nearly 90%. The model of the immigrant group in Belgium has a declining performance with a 6.69% accuracy loss.
From the results of OLR models in the native group, immigrant group, and subgroup of individual countries, it can be concluded that the selected feature variables should be further considered. The reason is that the determinants of happiness may be inconsistent among the native group, immigrant group, and subgroup of individual countries.
Artificial neural network
The ANN model is introduced to make a comparison with the OLR model. Before training the ANN model, it is recommended to normalize all variables (i.e., make the minimum value to 0 and the maximum value to 1). Since the weight parameters of the neural network will be affected by the values of a wide range of variables, it is not conducive to the training and prediction of the neural network. This paper uses the most common structure of the neural network with a single hidden layer.
The nnet package is selected to construct the neural network. This is because it can accept response variables as factor variables that have been set in the OLR model. Furthermore, it is of great significance to select the appropriate number of nodes in the hidden layer based on the background knowledge and experiments. A for-loop is created to run each model in the neuron number from 1 to 14. The optimal number of neurons can minimize the test error of the model. The number of iterations (i.e., maxit in the nnet package) is set to 2,000, which is a large enough number that ensures all models converge in the for-loop.
The ANN model is trained based on the above configurations. The illustration of the models with total native and immigrant samples are shown in Figures 3, 4, respectively. The black lines represent positive weights and the gray lines represent negative weights. The strength of weights is represented by the thickness of the line. The B1 and B2 are bias layers that apply constant values to the nodes, similar to the intercept terms of the regression model. Although the learning pattern of ANN can be visualized, the study of its structure cannot give usable conclusions about the function approximation. In other words, the relationship between the response variable and feature variables cannot be directly defined.
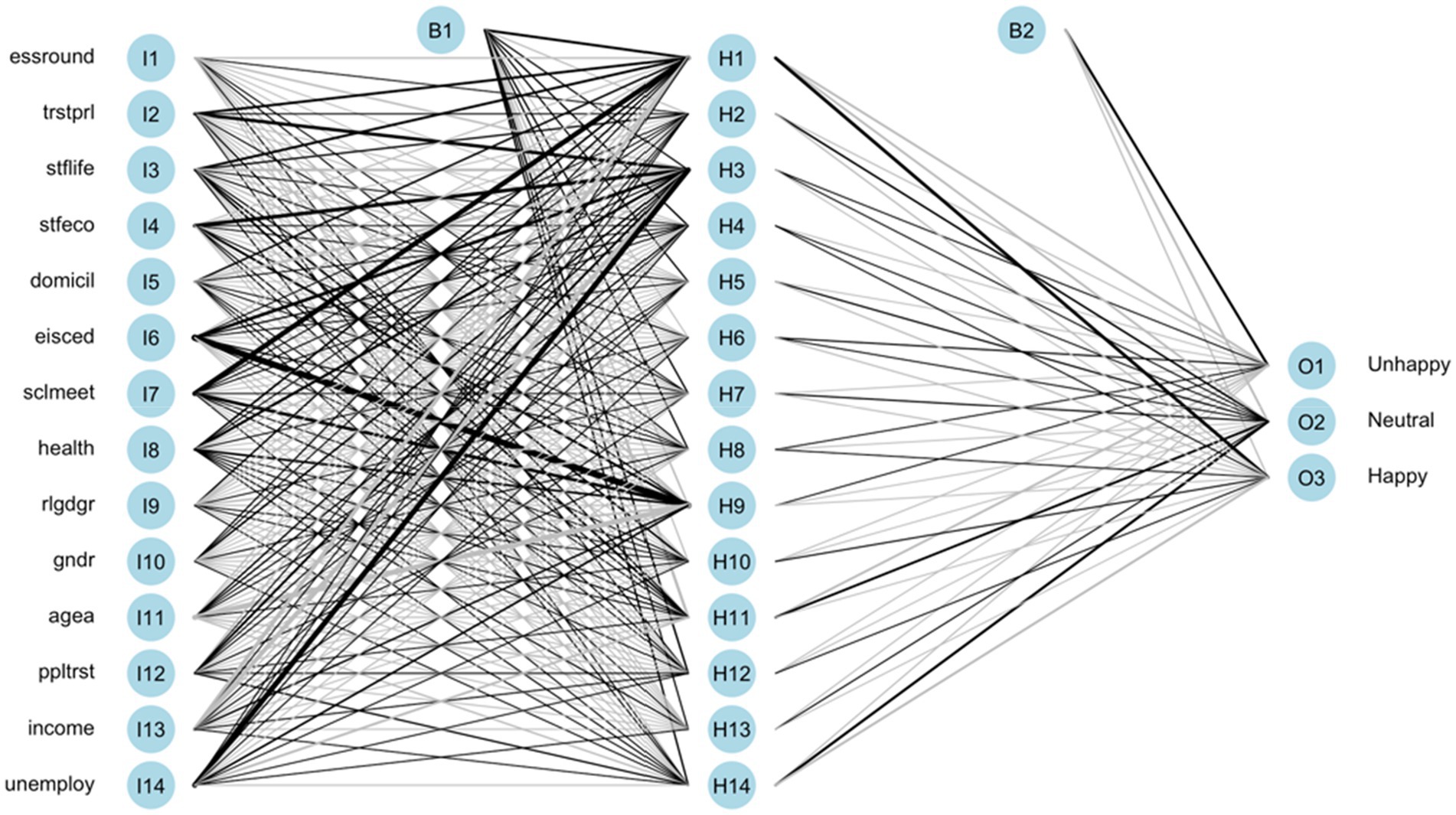
Figure 3. Trained ANN of the total native group.
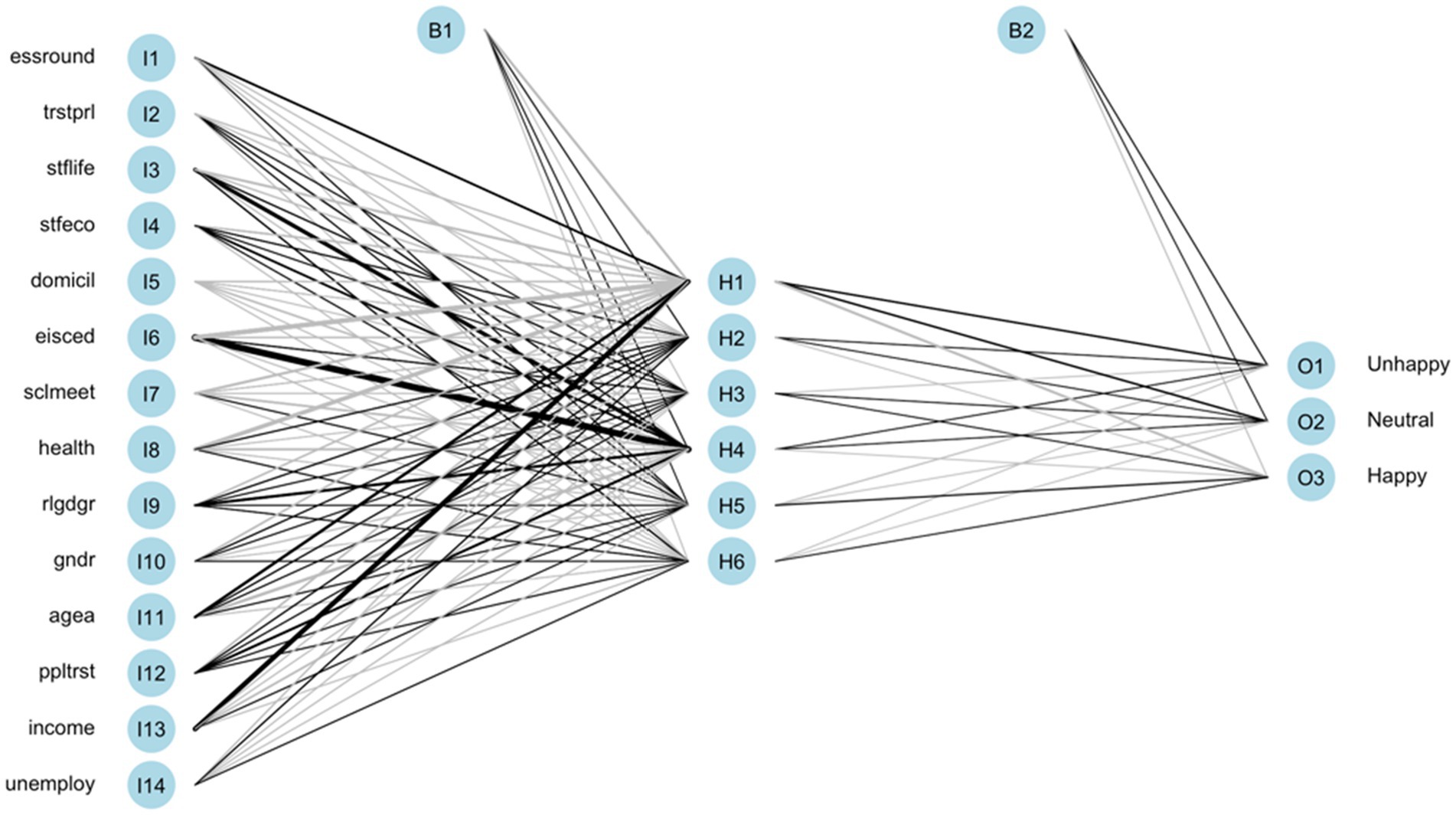
Figure 4. Trained ANN of the total immigrant group.
Although neural network models are described as “black boxes,” a sensitivity analysis can be used to rank the variable importance of the ANN model. Among a few methods that are capable of evaluating sensitivity in neural networks, the NeuralNetTools package is employed to compute the variable importance, which is based on the Lek profile method (Beck, 2018) that uses combinations of the absolute values of the weights. As shown in Table 5, the importance ranking order is different in each model of native groups. Notwithstanding, the top four important variables are similar among models. Stflife, eisced, and health are three of the most crucial factors that occupy the importance ranking of the native groups’ ANN models. Among these three factors, stflife is the most influential to natives’ happiness given that it appears in the importance rankings of all native groups. In addition, health can only stay in the rankings for half of the native groups, while eisced only fails to enter the rankings for native groups in GB and SE. The sensitivity analysis from the ANN model sheds more light on this matter that cannot be found in OLR models.
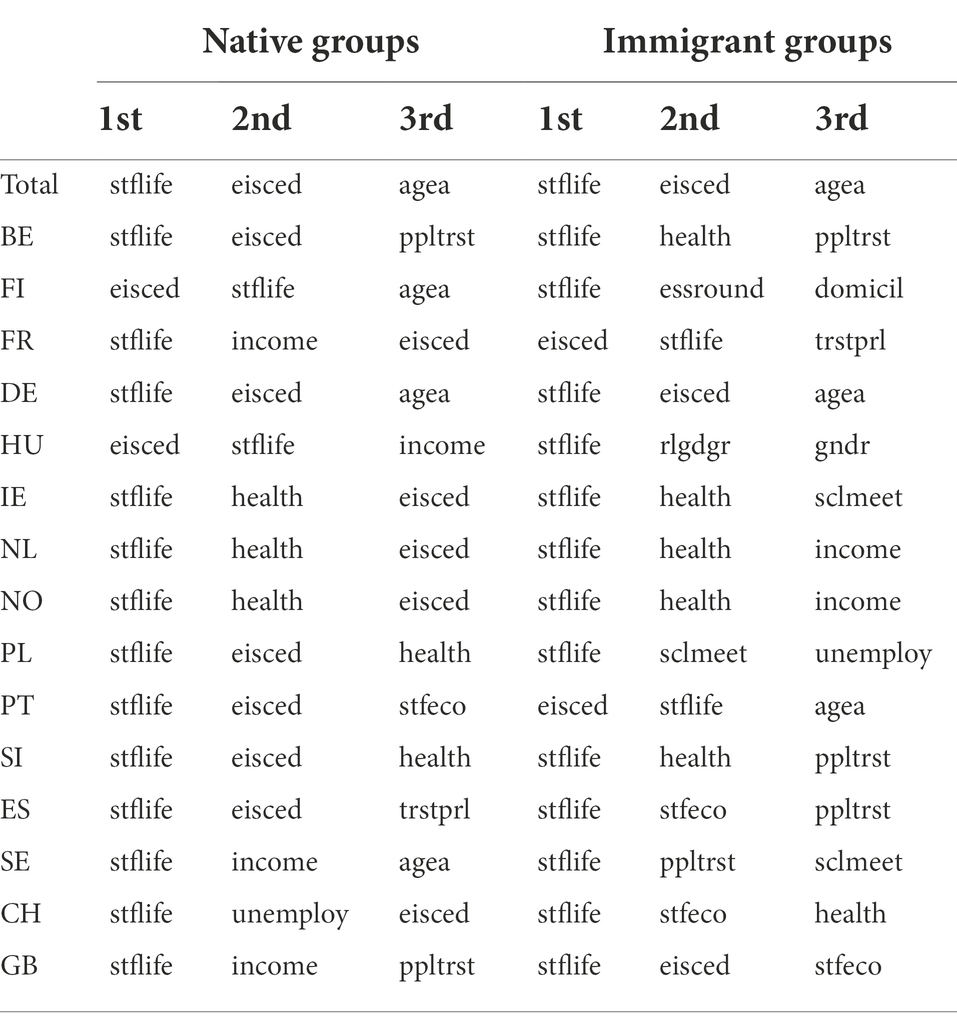
Table 5. Variable importance from native groups’ ANN models.
The situation of immigrant groups is different from that of native groups. In Table 5, the top four important happiness determinants of the immigrant groups are diverse. Although stflife, eisced, and health are still three of the most important variables for immigrant groups, there are fewer models with the same factors in the importance ranking. Only stflife remains in the importance rankings among all immigrant groups. For immigrant groups, health appears more frequently in the importance ranking than eisced, which is contrary to the native groups.
Compared with the OLR model, the overall performance of the ANN model in the native group is better. The individual countries that have good performance with OLR are still outstanding and even better when using the ANN. However, the countries with the poor performance of the OLR models have been improved with the ANN. In particular, the average accuracy of ANN for Portugal has increased most by 4.2281%. In addition, the moderate macro F1 and recall of ANN are 2.8240% and 4.3635% greater than that of OLR. This indicates that the ANN performs better than the OLR in classifying each happiness level (Table 6).
Although the overall performance of the model for native groups has improved, the model for immigrant groups of individual countries, such as FI, HU and PL, is overfitted. Neural networks with a small sample size can easily memorize the data and cause overfitting. Therefore, large sample size is needed in most cases to train the ANN model. The immigrant sample sizes of FI, HU and PL are the smallest among all countries, with 517, 186, and 125, respectively. The accuracy gaps between their training and test datasets are the largest, 18.9538%, 23.4341%, and 30.4295%, respectively. The accuracy gaps between their training and test datasets increase as the sample size decreases (Table 6).
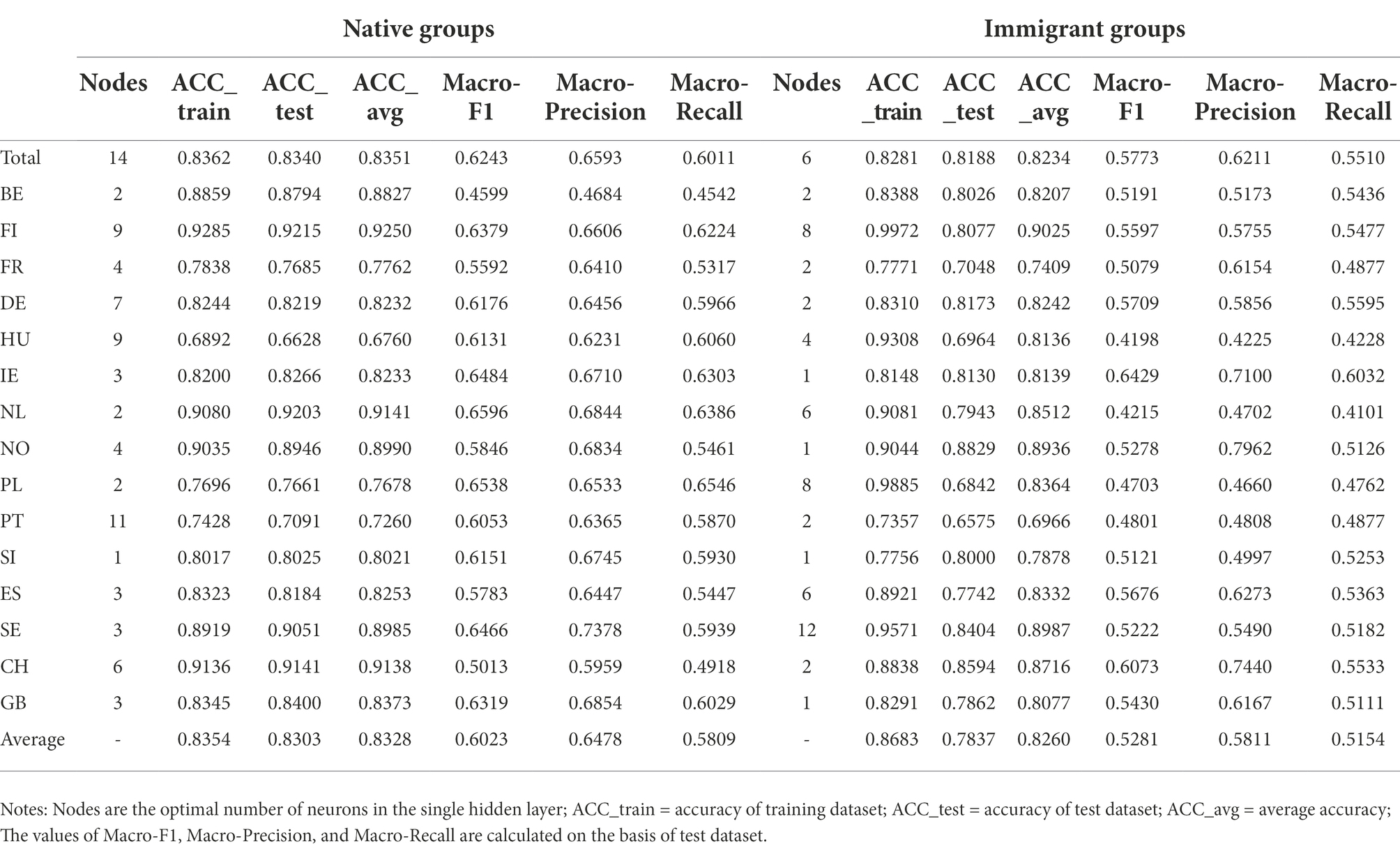
Table 6. The performance metrics of ANN models.
Discussion
People have migrated in pursuit of happiness for thousands of years. Migration to another country has a significant psychological impact on the individual, however, it is not solely a personal issue because it also has an influence on the sociocultural, civic-political and economic development of both the origin and destination countries. EU countries host a large number of international migrants, and their policymakers are becoming increasingly aware that the happiness level of immigrants can have a ripple effect on individuals, households, communities and, ultimately, countries.
The purpose of the current study is twofold: (i) to study the differences in happiness factors between immigrants and natives through single-country and cross-country modeling; (ii) to evaluate the performance of machine learning techniques on predicting the happiness levels of immigrant groups and native groups. To this end, we employ a total sample size of 196,724 respondents to establish the OLR model and the ANN model via using the ESS data of 15 countries in nine survey rounds.
The results show that the determinants of happiness are different among the immigrant groups, native groups, and even in each country surveyed. Consistent with previous studies (MacKerron, 2012; Hendriks, 2015; Steptoe et al., 2015), the sensitivity analysis shows that satisfaction with life, subjective general health, and the highest level of education are the three most prominent determinants that contribute to one’s happiness. With the advantages of the ANN method, we further find that subjective general health is more important than education for immigrants, and education is more important than subjective general health for natives. Therefore, it is necessary to build different models for immigrants and natives in each country.
As regards the performance of prediction models, the overall accuracies of OLR and ANN baseline models in both immigrant groups and native groups are >80%. A lower error can be achieved through a case-by-case analysis. In addition, the evaluation results of each model indicate that the prediction performance of ANN is better than OLR. This is congruent with the results of Weber et al. (2018). However, ANN may lead to overfitting for a small sample of immigrant groups, which partially supports prior research (Dreiseitl and Ohno-Machado, 2002) stating that artificial neural networks are subject to the pervasive trade-offs between flexibility and overfitting.
Some theoretical and practical implications should be noted. First, this paper has demonstrated that the research of migration and happiness can benefit from the knowledge acquired using cutting-edge machine learning methods with social survey data. Although a number of quantitative research have been performed to advance the understanding of the happiness-gap between immigrants and natives (Hendriks, 2015), this is the first time that machine learning algorithms are applied to the study of this field. The application of machine learning methods, especially artificial neural network, can provide quantitative insights into the relative importance of happiness factors. Therefore, researchers and policymakers need to understand that the machine learning approach is capable of revealing previously unknown relationships and thereby allows us to better understand the decision-making processes and construct better policies. Second, the study of happiness has remained exceptionally data-driven, while prior studies tend to use self-collected samples (Li et al., 2016; Pérez-Benito et al., 2019; Islam and Goldwasser, 2020), resulting in a dispersed field in which few scholars build on each other’s work. One of our insights is that the combination of the machine learning approach with a huge amount of microdata coming from the same dataset enables scholars to replicate results and make attempts to boost prediction accuracy based on others’ research.
While the findings reported here represent a contribution to the literature, the present study bears certain limitations. Therefore, further theoretical and empirical work is needed to improve the performance of machine learning methods in the research of migration and happiness.
First, due to the lack of immigrant samples in particular countries, such as Hungary and Poland, the machine learning algorithms may be overfitted. Future research should concentrate on the sampling of immigrants to avoid overfitting. Second, the factor gender is included as one of the determinants in our study that has not been examined as a mutual determinant in both native and immigrant groups across countries. The gender difference is an intriguing point worth further investigation, but due to the limitations of ESS data, whose samples are newly selected in each round and do not provide time-varying information like longitudinal data, we were unable to investigate it in depth. It could be a promising venue for future research to employ longitudinal data from a specific country (e.g., the UK’s Understanding Society data) that would allow us to examine the gender difference and the generations of immigrants. Third, factors like cultural distance, cultural diversity, and discrimination can be taken into account to improve the happiness level prediction model for immigrants. Bobowik et al. (2022) examined the linkage of global identification and ethnocultural diversity with the social network data of immigrants, where they found that the ethnocultural diversity among strong contacts was associated with global identification. Though there is a negative relationship between discrimination and SWB in immigrant groups, the relationship weakens when comparison strategies are considered, implying that how immigrants cope with discrimination under comparison processes may affect their SWB accordingly (Madi et al., 2022).
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found at: https://doi.org/10.21338/NSD-ESS-CUMULATIVE.
Author contributions
YL, SC, and MY: conceptualization and writing—review and editing. YL and SC: methodology and formal analysis. YL: software, data curation, and writing—original draft preparation. SC: supervision and funding acquisition. All authors contributed to the article and approved the submitted version.
Funding
This research was supported by Foundation for Distinguished Young Talents in Higher Education of Guangdong, China (Grant No. 2019WQNCX15).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^https://www.consilium.europa.eu/en/press/press-releases/2019/10/24/economy-of-wellbeing-the-council-adopts-conclusions/
References
Abdel-Khalek, A. M. (2006). Measuring happiness with a single-item scale. Soc. Behav. Pers. 34, 139–150. doi: 10.2224/sbp.2006.34.2.139
Bartram, D. (2012). Elements of a sociological contribution to happiness studies. Sociol. Compass 6, 644–656. doi: 10.1111/j.1751-9020.2012.00483.x
Bartram, D. (2013). Happiness and ‘economic migration’: a comparison of eastern European migrants and stayers. Migr. Stud. 1, 156–175. doi: 10.1093/migration/mnt006
Bartram, D. (2015). Inverting the logic of economic migration: happiness among migrants moving from wealthier to poorer countries in Europe. J. Happiness Stud. 16, 1211–1230. doi: 10.1007/s10902-014-9554-z
Bartram, D. (2019). Sociability among European migrants. Sociol. Res. Online 24, 557–574. doi: 10.1177/1360780418823213
Beck, M. W. (2018). NeuralNetTools: visualization and analysis tools for neural networks. J. Stat. Softw. 85, 1–20. doi: 10.18637/jss.v085.i11
Beutel, M. E., Glaesmer, H., Decker, O., Fischbeck, S., and Brähler, E. (2009). Life satisfaction, distress, and resiliency across the life span of women. Menopause 16, 1132–1138. doi: 10.1097/gme.0b013e3181a857f8
Bobowik, M., Benet-Martínez, V., and Repke, L. (2022). Ethnocultural diversity of immigrants' personal social networks, bicultural identity integration and global identification. Int. J. Psychol. 57, 491–500. doi: 10.1002/ijop.12814
Boulle, A., Chandramohan, D., and Weller, P. (2001). A case study of using artificial neural networks for classifying cause of death from verbal autopsy. Int. J. Epidemiol. 30, 515–520. doi: 10.1093/ije/30.3.515
Cangia, F., Levitan, D., and Zittoun, T. (2018). Family, boundaries and transformation. The international mobility of professionals and their families. Migrat. Lett. 15, 17–31. doi: 10.33182/ml.v15i1.343
Chong, C., and Yue, X. (2020). Does economic growth improve human happiness? A review of the influencing factors of SWB. Nankai Econ. Stud. 4, 24–45. doi: 10.14116/j.nkes.2020.04.002
Clark, A. E. (2018). Four decades of the economics of happiness: where next? Rev. Income Wealth 64, 245–269. doi: 10.1111/roiw.12369
Cuellar, I., Bastida, E., and Braccio, S. M. (2004). Residency in the United States, subjective well-being, and depression in an older Mexican-origin sample. J. Aging Health 16, 447–466. doi: 10.1177/0898264304265764
Dambrun, M., Desprès, G., and Lac, G. (2012). Measuring happiness: from fluctuating happiness to authentic–durable happiness. Front. Psychol. 3:16. doi: 10.3389/fpsyg.2012.00016
Diener, E. (1984). Subjective well-being. Psychol. Bull. 95, 542–575. doi: 10.1037/0033-2909.95.3.542
Diener, E., Lucas, R. E., and Oishi, S. (2002). “Sujective well-being: the science of happiness and life satisfaction” in Handbook of Positive Psychology. eds. C. R. Snyder and S. J. Lopez (New York, NY: Oxford University Press), 463–473.
Dreiseitl, S., and Ohno-Machado, L. (2002). Logistic regression and artificial neural network classification models: a methodology review. J. Biomed. Inform. 35, 352–359. doi: 10.1016/S1532-0464(03)00034-0
Easterlin, R. A. (1974). “Does economic growth improve the human lot? Some empirical evidence” in Nations and Households in Economic Growth: Essays in Honor of Moses Abramovitz. eds. P. A. David and M. W. Reder (New York, NY: Elsevier), 89–125.
Easterlin, R. A., and Sawangfa, O. (2010). “Happiness and economic growth: does the cross section predict time trends? Evidence from developing countries” in International Differences in Well-being. eds. E. Diener, D. Kahneman, and J. Helliwell (New York, NY: Oxford University Press), 166–216
Elgorriaga, E., Ibabe, I., and Arnoso, A. (2020). Intention to return of Spanish emigrant population and associated psychosocial factors (Intención de retorno de la población emigrante española y factores psicosociales asociados). Int. J. Soc. Psychol. 35, 413–440. doi: 10.1080/02134748.2020.1732104
Erlinghagen, M. (2012). Nowhere better than here? The subjective well-being of German emigrants and Remigrants. Comp. Popul. Stud. 36. doi: 10.12765/CPoS-2011-15
Erlinghagen, M. (2016). “Anticipation of life satisfaction before emigration: evidence from German panel data” in Advances in Happiness Research: A Comparative Perspective. ed. T. Tachibanaki (Tokyo: Springer Japan), 229–244.
Erlinghagen, M. (2021). “Migration motives, timing, and outcomes of internationally Mobile couples” in The Global Lives of German Migrants: Consequences of International Migration Across the Life Course. eds. M. Erlinghagen, A. Ette, N. F. Schneider, and N. Witte (Cham: Springer International Publishing), 157–171.
ESS (2020). European social survey Cumulative file, ESS 1–9. Data file edition 1.0. NSD-Norwegian Centre for Research Data, Norway-data archive and distributor of ESS data for ESS ERIC. [Dataset] doi: 10.21338/NSD-ESS-CUMULATIVE
Eurostat (2020). Migration and migrant population statistics. [Dataset]. Available at: https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Migration_and_migrant_population_statistics.
Graham, C. (2012). Happiness Around the World: The Paradox of Happy Peasants and Miserable Millionaires. Oxford University Press.
Grnholdt, L., and Martensen, A. (2005). Analysing customer satisfaction data: a comparison of regression and artificial neural networks. Int. J. Mark. Res. 47, 121–130. doi: 10.1177/147078530504700201
Guedes Auditor, J., and Erlinghagen, M. (2021). “The happy migrant? Emigration and its impact on subjective well-being,” in The Global Lives of German Migrants: Consequences of International Migration Across the Life Course. eds. M. Erlinghagen, A. Ette, N. F. Schneider, and N. Witte (Cham: Springer International Publishing), 189–204.
Harrell, F.E. Jr. (2015). Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis. Springer, Cham.
Hendriks, M. (2015). The happiness of international migrants: a review of research findings. Migr. Stud. 3, 343–369. doi: 10.1093/migration/mnu053
International Organization for Migration (IOM) (2013). World Migration Report 2013: Migrant Well-being and Development. Geneva: United Nations Publications.
Islam, T., and Goldwasser, D. (2020). “Does yoga make you happy? Analyzing twitter user happiness using textual and temporal information,” in: 2020 IEEE International Conference on Big Data (Big Data). (Atlanta, GA: IEEE).
Kaminska, O. (2020). “Guide to using weights and sample design indicators with ESS data,” in European Social Survey.
KIing-O’Riain,, and Chiyoko, R. (2015). Emotional streaming and transconnectivity: skype and emotion practices in transnational families in Ireland. Glob. Netw. (Oxf.) 15, 256–273. doi: 10.1111/glob.12072
Kõu, A., van Wissen, L., van Dijk, J., and Bailey, A. (2015). A life course approach to high-skilled migration: lived experiences of Indians in the Netherlands. J. Ethn. Migr. Stud. 41, 1644–1663. doi: 10.1080/1369183X.2015.1019843
Krause, A. (2014). “Happiness and work,” IZA Discussion Papers. doi: 10.1016/B978-0-08-097086-8.94047-9
Larasati, A., DeYong, C., and Slevitch, L. (2011). Comparing neural network and ordinal logistic regression to analyze attitude responses. Serv. Sci. 3, 304–312. doi: 10.1287/serv.3.4.304
Lenzi, C., and Perucca, G. (2020). “Urbanization and subjective well-being” in Regeneration of the Built Environment from a Circular Economy Perspective. eds. S. D. Torre, S. Cattaneo, C. Lenzi, and A. Zanelli (Cham: Springer International Publishing), 21–28. doi: 10.1007/978-3-030-33256-3_3
Li, J., Roy, S., Feng, J., and Sim, T. (2016). “Happiness level prediction with sequential inputs via multiple regressions,” in: Proceedings of the 18th ACM International Conference on Multimodal Interaction. (Tokyo, Japan: Association for Computing Machinery).
Lu, Y., and Wang, T. (2010). A review of research on factors influencing subjective well-being. Econ. Perspect. 5, 125–130.
MacKerron, G. (2012). Happiness economics from 35 000 feet. J. Econ. Surv. 26, 705–735. doi: 10.1111/j.1467-6419.2010.00672.x
Madi, D., Bobowik, M., Verkuyten, M., and Basabe, N. (2022). Social intergroup and temporal intrapersonal comparisons: responses to perceived discrimination and protective mechanisms of eudaimonic well-being. Int. J. Intercult. Relat. 86, 74–84. doi: 10.1016/j.ijintrel.2021.10.007
Mayes, R., and Koshy, P. (2018). Transnational labour migration and the place of reproductive labour: trailing wives and community support in Boddington. Work Employ. Soc. 32, 670–686. doi: 10.1177/0950017017702602
Monacis, L., Limone, P., Dambrun, M., Delle Fave, A., and Sinatra, M. (2021). Measuring and assessing fluctuating and authentic–durable happiness in Italian samples. Int. J. Environ. Res. Public Health 18:1602. doi: 10.3390/ijerph18041602
Obućina, O. (2013). The patterns of satisfaction among immigrants in Germany. Soc. Indic. Res. 113, 1105–1127. doi: 10.1007/s11205-012-0130-9
Pérez-Benito, F. J., Villacampa-Fernández, P., Conejero, J. A., García-Gómez, J. M., and Navarro-Pardo, E. (2019). A happiness degree predictor using the conceptual data structure for deep learning architectures. Comput. Methods Prog. Biomed. 168, 59–68. doi: 10.1016/j.cmpb.2017.11.004
Rasmi, S., Chuang, S. S., and Safdar, S. (2012). The relationship between perceived parental rejection and adjustment for Arab, Canadian, and Arab Canadian youth. J. Cross-Cult. Psychol. 43, 84–90. doi: 10.1177/0022022111428172
Sacks, D. W., Stevenson, B., and Wolfers, J. (2012). The new stylized facts about income and subjective well-being. Emotion 12, 1181–1187. doi: 10.1037/a0029873
Salo, C. D., and Birman, D. (2015). Acculturation and psychological adjustment of Vietnamese refugees: an ecological acculturation framework. Am. J. Community Psychol. 56, 395–407. doi: 10.1007/s10464-015-9760-9
Smith-DiJulio, K., Woods, N. F., and Mitchell, E. S. (2008). Well-being during the menopausal transition and early postmenopause: a longitudinal analysis. Menopause 15, 1095–1102. doi: 10.1097/gme.0b013e3181728451
Stanca, L. (2010). The geography of economics and happiness: spatial patterns in the effects of economic conditions on well-being. Soc. Indic. Res. 99, 115–133. doi: 10.1007/s11205-009-9571-1
Steptoe, A., Deaton, A., and Stone, A. A. (2015). Subjective wellbeing, health, and ageing. Lancet 385, 640–648. doi: 10.1016/S0140-6736(13)61489-0
Štreimikienė, D., and Grundey, D. (2009). Life satisfaction and happiness-the factors in work performance. Econ. Soc. 2, 9–26. doi: 10.14254/2071-789X.2009/2-1/2
Triandafyllidou, A., and Isaakyan, I. (2016). “Re-thinking the gender dimension of high-skill migration” in High-skill Migration and Recession: Gendered Perspectives. eds. A. Triandafyllidou and I. Isaakyan (London: Palgrave Macmillan UK), 293–305.
Weber, P., Weber, N., Goesele, M., and Kabst, R. (2018). Prospect for knowledge in survey data: an artificial neural network sensitivity analysis. Soc. Sci. Comput. Rev. 36, 575–590. doi: 10.1177/0894439317725836
Appendix

Table A1. Full names of investigated countries
Keywords: happiness levels, European, classification predictive modeling, immigrant, native
Citation: Chen S, Yang M and Lin Y (2022) Predicting happiness levels of European immigrants and natives: An application of Artificial Neural Network and Ordinal Logistic Regression. Front. Psychol. 13:1012796. doi: 10.3389/fpsyg.2022.1012796
Edited by:
Seth Oppong, University of Botswana, BotswanaReviewed by:
Edurne Elgorriaga, University of the Basque Country, SpainLidia Scifo, Libera Università Maria SS. Assunta, Italy
Jeff Bolles, University of North Carolina at Pembroke, United States
Copyright © 2022 Chen, Yang and Lin. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yuheng Lin, MjA0MjE4NDJAbGlmZS5oa2J1LmVkdS5oaw==