 Jing Lu1
Jing Lu1 Jiwei Zhang
Jiwei Zhang Zhaoyuan Zhang
Zhaoyuan Zhang Bao Xu
Bao Xu- 1Key Laboratory of Applied Statistics of MOE, School of Mathematics and Statistics, Northeast Normal University, Changchun, China
- 2Key Lab of Statistical Modeling and Data Analysis of Yunnan Province, School of Mathematics and Statistics, Yunnan University, Kunming, China
- 3Department of Statistics, School of Mathematics and Statistics, Northeast Normal University, Changchun, China
- 4Institute of Mathematics, Jilin Normal University, Siping, China
In this paper, a new two-parameter logistic testlet response theory model for dichotomous items is proposed by introducing testlet discrimination parameters to model the local dependence among items within a common testlet. In addition, a highly effective Bayesian sampling algorithm based on auxiliary variables is proposed to estimate the testlet effect models. The new algorithm not only avoids the Metropolis-Hastings algorithm boring adjustment the turning parameters to achieve an appropriate acceptance probability, but also overcomes the dependence of the Gibbs sampling algorithm on the conjugate prior distribution. Compared with the traditional Bayesian estimation methods, the advantages of the new algorithm are analyzed from the various types of prior distributions. Based on the Markov chain Monte Carlo (MCMC) output, two Bayesian model assessment methods are investigated concerning the goodness of fit between models. Finally, three simulation studies and an empirical example analysis are given to further illustrate the advantages of the new testlet effect model and Bayesian sampling algorithm.
1. Introduction
In education and psychological tests, a testlet is defined as that a bundle of items share a common stimulus (a reading comprehension passage or a figure) (Wainer and Kiely, 1987). For example, in a reading comprehension test, a series of questions may be based on a common reading passage. The advantages of the testlet design are not only to allow for more complicated and interrelated set of items, but also to improve the testing efficiency (Thissen et al., 1989). Namely, with several items embedded in a testlet, test takers need not waste a considerable amount of time and energy in processing a long passage just to answer a single item. Despite their appealing features, this testing format poses a threat to item analysis because items within a testlet often violate the local independence assumption of item response theory (IRT). The traditional item response analysis tends to overestimate the precision of person ability obtained from testlets, and overestimate test reliability\information, and yields biased estimation for item difficulty and discrimination parameters (Sireci et al., 1991; Yen, 1993; Wang and Wilson, 2005a; Wainer et al., 2007; Eckes, 2014; Eckes and Baghaei, 2015).
In the face of these problems, two methods have been proposed to cope with the local item dependence. One method is to estimate a unidimensional model but treat items within a testlet as a single polytomous item (Sireci et al., 1991; Yen, 1993; Wainer, 1995; Cook et al., 1999) and then apply polytomous item response models such as the generalized partial-credit model (Muraki, 1992), the graded response models (Samejima, 1969), or the nominal response model (Bock, 1972). This method is appropriate when the local dependence between items within a testlet is moderate and the test contains a large proportion of independent items (Wainer, 1995), but it becomes impractical as the number of possible response patterns increases geometrically with the number of items in a testlet and thus is not frequently used (Thissen et al., 1989). An alternative method is testlet effects can be taken into account by incorporating specific dimensions in addition to the general dimension into the IRT models. Two such multidimensional IRT models are often used by researchers. That is, the bi-factor models (Gibbons and Hedeker, 1992) and the random-effects testlet models (Bradlow et al., 1999; Wainer et al., 2007). However, Li et al. (2006), Rijmen (2010), and Min and He (2014) find that the random-effects testlet models can be used as a special case of the bi-factor models. It is obtained by constraining the loadings on the specific dimension to be proportional to the loading on the general dimension within each testlet. In practice, researchers prefer to use simple random-effects testlet models if the two models are available and the model fit is not too much damage. Next, we discuss the specific forms of some commonly used testlet effect models.
Several literatures on testlet structure modeling have been proposed to capture the local item dependence from different perspectives for the past two decades. Bradlow et al. (1999) and Wainer et al. (2000) extend the traditional IRT models including a random effect parameter to explain the interaction between testlets and persons. The probit link function of the above model is formulated as Φ[aj(θi − bj + ηid(j))], where Φ is the normal cumulative distribution function, θi denotes the the ability for the ith examinee, aj and bj, respectively denote the discrimination parameter and difficulty parameter for the jth item, and ηid(j) is a random effect that represents the interaction of examinee i with testlet d(j) [d(j) denotes the testlet d contains item j]. Further, Li et al. (2006) propose a general two parameter normal ogive testlet response theory (2PNOTRT) model from the perspective of multidimensionality. Each item response in the multidimensional model depends on both the primary dimension and the secondary testlet dimensions. Under the 2PNOTRT model, the basic form of probit link function is expressed as Φ[aj1θi − tj + aj2ηid(j)], where tj is a threshold parameter related to the item difficulty. The latent traits underlying examinees' responses to items in testlets consist of general ability θ and several secondary dimensions, one for each testlet. Item parameters aj1 and aj2 indicate the discriminating power of an item with respect to the primary ability θ and the secondary dimension ηd, respectively. Because the secondary dimension ηid(j) is a random effect that represents the interaction of examinee i with testlet d(j), it is believed that the loading of the secondary dimensions ηd should be the discriminating power of the testlet with respect to it, and it should be related to the discrimination parameters of the items in the testlet with respect to the intended ability, θ. The above two testlet effect models are constructed in the framework of probit link function. On this basis, Zhan et al. (2014) propose the concept of within-item multidimensional testlet effect. In this paper, we introduce a new item parameter as a testlet discrimination parameter and propose a new two parameter logistic testlet model in the framework of logit link function for dichotomously scored items, as detailed in the next section. Moreover, testlet response theory modeling has also been extended to the other field of educational and psychological measurement such as large-scale language assessments (Rijmen, 2010; Zhang, 2010; Eckes, 2014), hierarchical data analysis (Jiao et al., 2005, 2013), cognitive diagnostic assessments (Zhan et al., 2015, 2018).
One of the most commonly used estimation methods for the above-mentioned testlet effect models is the marginal maximum likelihood method via the expectation-maximization (EM; Dempster et al., 1977) algorithm (Bock and Aitkin, 1981; Mislevy, 1986; Glas et al., 2000; Wang and Wilson, 2005b). The ability parameters and testlet effects are viewed as unobserved data (latent variables), and then we can find the maximum of a complete data likelihood (the responses and unobserved data) marginalized over unobserved data. However, the marginal maximum likelihood estimation of testlet models has been hampered by the fact that the computations often involve analytically intractable high dimensional integral and hence it is hard to find the maximum likelihood estimate of the parameters. More specifically, when the integrals over latent variable distributions are evaluated using Gaussian quadrature (Bock and Aitkin, 1981), the number of calculations involved increases exponentially with the number of latent variable dimensions. Even though the number of quadrature points per dimension can be reduced when using adaptive Gaussian quadrature (Pinheiro and Bates, 1995), the total number of points again increases exponentially with the number of dimensions. In addition, when the EM algorithm is employed to compute marginal maximum likelihood estimates with unobserved data, the convergence of EM algorithm can be very slow whenever there is a large fraction of unobserved data, and the estimated information matrix is not a direct by product of maximization.
An alternative method is to use a fully Bayesian formulation, coupled with a Markov Chain Monte Carlo (MCMC) procedure to estimate the testlet model parameters (e.g., Wainer et al., 2000, 2007). The Bayesian method, including Metropolis-Hastings algorithm (Metropolis et al., 1953; Hastings, 1970; Tierney, 1994; Chib and Greenberg, 1995; Chen et al., 2000) and Gibbs algorithm (Geman and Geman, 1984; Tanner and Wong, 1987; Albert, 1992), has some significant advantages over classical statistical analysis. It allows meaningful assessments in confidence regions, incorporates prior knowledge into the analysis, yields more precise estimators (provided the prior knowledge is accurate), and follows the likelihood and sufficiency principles. In this current study, an effective slice-Gibbs sampling algorithm (Lu et al., 2018) in the framework of Bayesian is used to estimate the model parameters. The slice-Gibbs sampling, as the name suggests, can be conceived of an extension of Gibbs algorithm. The sampling process consists of two parts. One part is the slice algorithm (Damien et al., 1999; Neal, 2003; Bishop, 2006; Lu et al., 2018), which samples the two parameter logistic testlet effect models from the truncated full conditional posterior distribution by introducing the auxiliary variables. The other part is Gibbs algorithm which updates variance parameters based on the sampled values from the two parameter logistic testlet effect models. The motivation for this sampling algorithm is manifold. First, the slice-Gibbs sampling algorithm is a fully Bayesian method, which averts to calculate multidimensional numerical integration compared with the marginal maximum likelihood method. Second, the slice algorithm has the advantage of a flexible prior distribution being introduced to obtain samples from the full conditional posterior distributions rather than being restricted to using the conjugate distributions, which is required in Gibbs sampling algorithm and limited using the normal ogive framework (Tanner and Wong, 1987; Albert, 1992; Bradlow et al., 1999; Wainer et al., 2000; Fox and Glas, 2001; Fox, 2010; Tao et al., 2013). The detailed discussions about the informative priors and non-informative priors of item parameters are shown in the simulation 2. Third, it is known that the Metropolis-Hasting algorithm (Metropolis et al., 1953; Hastings, 1970; Tierney, 1994; Chib and Greenberg, 1995; Chen et al., 2000) severely depends on the standard deviation (tuning parameter) of the proposal distributions, and it is sensitive to step size. More specifically, if the step size is too small random walk, the chain will take longer to traverse the support of the target density; If the step size is too large there is great inefficiency due to a high rejection rate. However, the slice algorithm automatically tunes the step size to match the local shape of the target density and draws the samples with acceptance probability equal to one. Thus, it is easier and more efficient to implement.
The remainder of this article is organized as follows. Section 2 describes the two parameter logistic testlet effect model, the prior assumptions and model identifications. A detailed description of the slice-Gibbs sampling algorithm and Bayesian model assessment criteria are presented in section 2. In section 3, three simulation studies are given, the first of which considers the performances of parameter recovery using the slice-Gibbs algorithm under different design conditions. In the second simulation, the prior sensitivity of the the slice-Gibbs sampling algorithm is assessed using the simulated data. In the third simulation, based on the Markov chain Monte Carlo (MCMC) output, two Bayesian model assessment methods are used to evaluate the model fit. In section 5, an empirical example is analyzed in detail to further demonstrate the applicability of the testlet structure models and the validity of the slice-Gibbs sampling algorithm. At last, we conclude with a few summary remarks in section 6.
2. The New Two Parameter Logistic Testlet Model and Prior Assumptions
The new two parameter logistic testlet model (N2PLTM):
In Equation (1), i = 1, …, n. indicates persons. Suppose a text contains J items, items in such tests are grouped into K(1 ≤ K ≤ J) mutually exclusive and exhaustive testlets. Denote testlet d containing item by d(j) and the size of each testlet by nk(1 ≤ k ≤ K) which can be written as with d(1) and d(J) = K. yij represents the response of the ith examinee answering the jth item, and the correct response probability is expressed as pij. And θi denotes ability parameter for the ith examinee. aj is the discrimination parameter of the item j. bj denotes the difficulty parameter of the item j, and is the testlet discrimination parameter where nd(j) is the numbers of items in testlet (testlet d contains item j) and Sd(j) is the set of the serial numbers of item in the testlet. The purpose of using the testlet discrimination parameter is to consider the interaction between the discrimination parameters for all Sd(j) items in the same testlet and the testlet effect, rather than just examining the influence of the jth item discrimination parameter on the testlet effect for the traditional testlet models. The random effect ηid(j) represents the interaction of individual i with testlet d(j). It can be interpreted as a random shift in individuals' ability or another ability dimension (Li et al., 2006). The following priors and hyper-priors are used to estimate the parameters of N2PLTM. The latent ability θ and the testlet effect η are assumed to be independently and normally distributed under the testlet model. That is, has a multivariate normal distribution N(μ, Σ), where μ is mean vector, Σ is a diagonal matrix, . The variances of ηik (k = 1, 2, …, K), which can be allowed to vary across testlets, indicate the amount of local dependence in each testlet. If the variance of ηik is zero, the items within the testlet can be considered conditionally independent. As the variance increases, the amount of local dependence increases. The priors to the discrimination parameters are set from truncated normal priors, , where I(0, +∞) denotes the indicator function that the values range from zero to infinity, and the difficulty parameters are assumed to follow the normal distribution, . In addition, the hyper-priors for , and are assumed to follow inverse Gamma distribution with shape parameter v and scale parameter τ. Let Ω = (θ, a, b, η) represents the collection of the unknown parameters in model (1), where , , and The joint posterior distribution of Ω given the data is represented by
2.1. Model Identifications
In Equation 1, the linear part of the testlet effect model, aj(θi − bj) + αd(j)ηid(j), can be rewritten as follows
where the testlet discrimination αd(j) consists of the discrimination parameters aj. That is, , and k ∈ Sd(j) − {j} means that k belongs to the set Sd(j) excluding the index j. To eliminate the trade offs among the ability θ, difficulty parameter b and testlet effect ηid(j) in location, we fix the mean population level of ability to zero and restrict a item difficulty parameter to zero. Meanwhile, to eliminate the trade off between the ability θ and the discrimination parameter a in scale, we need restrict the variance population level of ability to one. However, ajbj, and still have the trade offs in scale. In fact, we only need fix a item discrimination parameter to one. In summary, the required identification conditions are as follows:
Several identification restriction methods of two parameter IRT models have been widely used. The identification restrictions of our model are based on the following methods.
(1) To fix the mean population level of ability to zero and the variance population level of ability to one (Lord and Novick, 1968; Bock and Aitkin, 1981; Fox and Glas, 2001; Fox, 2010). That is, θ ~ N(0, 1);
(2) To fix the item difficulty parameter to a specific value, most often zero, and restrict the discrimination parameter to a specific value, most often one (Fox and Glas, 2001; Fox, 2010). That is, b1 = 0 and a1 = 1.
3. Bayesian Inferences
3.1. Slice-Gibbs Algorithm to Estimate Model Parameters
The motivation for the slice-Gibbs sampling algorithm is that the inferred samples can easily be drawn from the full conditional distribution by introducing the auxiliary variables. Before giving the specific Bayesian sampling process, we give the definition of auxiliary and its role in the sampling process. Auxiliary variables are variables that can help to make estimates on incomplete data, while they are not part of the main analysis. Basically, the auxiliary variables are latent unknown parameters without any direct interpretation which are introduced for technical/simulation reasons or for the reason of making an analytically intractable distribution tractable. Within the Bayesian framework, in the method of auxiliary variables, realizations from a complicated distribution can be obtained by augmenting the variables of interest by one or more additional variables such that the full conditionals are tractable and easy to simulate from. The construction of sampling algorithms via the introduction of auxiliary variable received much attention since it resulted in both simple and fast algorithms (Tanner and Wong, 1987; Higdon, 1998; Meng and van Dyk, 1999; Fox, 2010).
For each of the response variable yij, we introduce two mutually independent random auxiliary variables λij and φij. The random variables λij and φij are assumed to follow a Uniform (0,1). The following two cases must be satisfied.
Case 1: When yij = 1, an equivalent condition for yij = 1 is the indicator function I(0 < λij ≤ pij) must be equal to 1, as opposed to I(0 < φij ≤ qij) is set to 0, where qij = 1 − pij. In addition, if the joint distribution (λij and pij) integrate out the auxiliary variables λij, the obtained marginal distribution is just equal to the correct response probability of the ith individual answering the jth item.
Case 2: Similarly, when yij = 0, an equivalent condition for yij = 0, that is, the indicator function I(0 < φij ≤ qij) must be equal to 1, as opposed to is I(0 < λij ≤ pij) set to 0.
Therefore, the joint posterior distribution based on the auxiliary variables is given by
We find that the Equation (2) can be obtained by taking expectations about the auxiliary variables for the Equation (3). Each step of the algorithm needs to satisfy the Equation (3). The detailed slice-Gibbs sampling algorithm is given by
Step 1: Sample the auxiliary variables λij and φij given the response variable Y and the parameters Ω. The full conditional posterior distributions can be written as
Step 2: Sample the discrimination parameter aj. The prior of the discrimination parameters is . According to the Equation (3), for all i, if 0 < λij ≤ pij, or 0 < φij ≤ qij, . The following inequalities are established
Or equivalently,
And,
Or equivalently,
Similarly, for all i, if 0 < λij ≤ pij, or 0 < φij ≤ qij, . The following inequalities are established
Or equivalently,
And,
Or equivalently,
Let
When given the response variable Y, the auxiliary variable λ, φ and other parameters Ω1 (all of the parameters except aj), the full conditional distribution is represented by
In Equation (5),
And
Step 3: Sample the difficulty parameter bj. The prior of the difficulty parameters is . According to the Equation (3), for ∀i, if we have 0 < λij ≤ pij, the following inequalities are established,
Or equivalently,
Similarly, for all i, if 0 < φij ≤ qij, the following inequalities are established
Or equivalently,
Let Dj = {i|yij = 1, 0 < λij ≤ pij}, Ej = {i|yij = 0, 0 < φij ≤ qij}. Thus, given the response variable Y, the auxiliary variable λ, φ and other parameters Ω2 (all of the parameters except bj). The full conditional posterior distribution is given by
In Equation (6),
And
Step 4: Sample the latent ability θi, the prior of the latent ability is assumed to follow a normal distribution with mean μθ and variance . Given the response variable Y, the auxiliary variable λ, φ and other parameters Ω3 (all of the parameters except θi). The full conditional posterior distribution of θi is
In Equation (7),
Step 5: Sample the testlet random effect ηid(j). Assuming that the jth term comes from the kth testlet [i.e., d(j) = k] and the order of the terms in the kth testlet is form jk to nk + jk − 1. Then, the joint posterior distribution can be rewritten as
where The prior of the testlet random effect ηik is assumed to follow a normal distribution with mean μη and variance . Given the response variable Y, the auxiliary variable λ, φ and other parameters Ω4 (all of the parameters except ηik). The full conditional distribution of ηik is given by
In Equation (8),
Step 6: Sample the variance parameter , the variance is assumed to follow a Inverse-Gamma(v1, τ1) hyper prior. Given the discrimination parameters a, the hyper parameters v1 and τ1. The full conditional posterior distribution of is given by
Thus,
Step 7: Sample the variance parameter , the variance is assumed to follow a Inverse-Gamma(v2, τ2) hyper prior. Given the difficulty parameters b, the hyper parameters v2 and τ2. The full conditional posterior distribution of is given by
Thus,
Step 8: Sample the random effect variance parameter , the variance is assumed to follow a Inverse-Gamma (v3, τ3) hyper prior. Given the random effect parameters η, the hyper parameters v3 and τ3. The full conditional posterior distribution of is given by
Thus,
3.2. Bayesian Model Assessment
Within the framework of Bayesian, Bayes factor has played a major role in assessing the goodness of fit of competing models (Kass and Wasserman, 1995; Gelfand, 1996). It is defined as the ratio of the posterior odds of model 1 to model 2 divided by the prior odds of model 1 to model 2
In Equation (11), y denotes the observation data, p(Mh) denotes the model prior likelihood, and p(Mh|y) are the marginal likelihoods of the data matrix y for model h, h = 1, 2. The Bayes factor (BF) provide a summary of evidence for M1 compared to M2. M1 is supported when BF > 1, and M2 is supported otherwise. A value of BF between 1 and 3 is considered as minimal evidence for M1, a value between 3 and 12 as positive evidence for M1, a value between 12 and 150 as strong evidence for M1, and a value >150 as very strong evidence (Raftery, 1996). However, one of the obstacles to use of the Bayes factors is the difficulty associated with calculating them. As we known, while the candidate model with high-dimensional parameters are used to fit the data, it is not possible integrate out the all parameters of models to obtain the closed-form expression of marginal distribution. In addition, it are acutely sensitive to the choice of prior distributions. If the use of improper priors for the parameters in alternative models results in Bayes factors that are not well defined. However, numerous approaches have been proposed for model comparison with improper priors (Aitkin, 1991; Gelfand et al., 1992; Berger and Pericchi, 1996; Ando, 2011). In our article, Based on the noninformative priors, a “pseudo-Bayes factor” approach is implemented, which provides a type of approximation to the BF.
3.2.1. Pseudo-Bayes Factor
The pseudo-Bayes factor (PsBF) method (Geisser and Eddy, 1979) overcome BF sensitive to the choice of prior distributions. It can be obtained by calculating the cross-validation predictive densities. Considering i = 1, …, n individuals response to items. Let y−(ij) be the observed data without the ijth observation and let Ξ denote all the parameters under the assumed model. The cross-validation predictive density (CVPD) can be defined by
In Equation (12), the density p(yij|y − (ij)) denotes supporting the possibility of values of yij when the model is fitted to observations except yij. According to conditional independence hypothesis, the equation p(yij|y−(ij), Ξ) = p(yij|Ξ) can be established, the responses on the different items are independent given ability and the responses of the individuals are independent of one another. The Pseudo Bayes factor (PsBF) for comparing two models (M1 and M2) is expressed in terms of the product of cross-validation predictive densities and can be written as
In practice, we can calculate the logarithm of the numerator and denominator of the PsBF and it can be used for comparing different models. The model with a larger PsBF has a better fit of the data. Gelfand and Dey (1994) and Newton and Raftery (1994) proposed an importance sampling to evaluate the marginal likelihood (CVPD) of the data. Given the sample size R, r = 1, …, R, the samples Ξ(m) from the posterior distribution p(Ξ|y−(ij)) often easily obtained via an MCMC sampler. The estimated likelihood function is
3.2.2. The Deviance Information Criteria (DIC)
A model comparison method is often based on a measure of fit and some penalty function based on the number of free parameters for the complexity of the model. Two well-known criteria of model selection based on a deviance fit measure are the Bayesian information criterion (BIC; Schwarz, 1978) and Akaike's information criterion (AIC; Akaike, 1973). These criteria depend on the effective number of parameters in the model as a measure of model complexity. However, in Bayesian hierarchical models, it is not clear how to define the number of parameters due to the prior distribution imposes additional restrictions on the parameter space and reduces its effective dimension. Therefore, Spiegelhalter et al. (2002) proposed the deviance information criterion (DIC) for model comparison when the number of parameters is not clearly defined in hierarchical models. The DIC is defined as the sum of a deviance measure and a penalty term for the effective number of parameters based on a measure of model complexity. This term estimates the number of effective model parameters and equals
The DIC can be defined as
In Equation (15), Ξ is the parameter of interest in the model. The complexity is measured by the effective number of parameters, PD. is the posterior expectation of the deviance. It is calculated from the MCMC output by taking the sample mean of the simulated values of the deviance, . That is defined as the deviance of the posterior estimation mean. Here denotes the posterior means of the parameters. The model with a smaller DIC has a better fit of the data.
4. Simulation Study
4.1. Simulation 1
This simulation study is conducted to evaluate the recovery performance of the slice-Gibbs sampling algorithm under different simulation conditions.
The following design conditions are considered: (a) testlet type: 20 dichotomous items in 2 or 4 testlets (J = 20, each testlet has 10 or 5 dichotomous items); (b) number of examinees, N = 500 and 1,000; and (c) testlet effect: the variances of the testlet random effect are 0.25 and 1.00. That is, or 1.00, where i = 1, …, N, k = 1, 2, or k = 1, 2, 3, 4. The true values of item discrimination parameters ajs are generated from a truncated normal distribution, that is, aj ~ N(0, 1)I(0, +∞), and the item difficulty parameters bjs are generated from N(0, 1). Ability parameters θis for N = 500 or 1,000 examinees are drawn from a standard normal distribution. The testlets random effect parameters ηiks are also generated from a normal distribution. That is, . Response data are simulated using the N2PLTM in Equation (1). The non-informative priors and hyper priors of parameters are considered as follows:
The non-informative priors and hyper priors are often used in many educational measurement studies (e.g., van der Linden, 2007; Wang et al., 2018). In this paper, the prior specification will be uninformative enough for the data to dominate the priors, so that the influence of the priors on the results will be minimal.
4.1.1. Convergence Diagnostic for Slice-Gibbs Algorithm
As an illustration, we only consider the convergence in the case of 20 dichotomous items in 4 testlets, the number of individuals is 500, and the variance of the random testlet variables is 0.25. Two methods are used to check the convergence of our algorithm. One is the “eyeball” method to monitor the convergence by visually inspecting the history plots of the generated sequences (Zhang et al., 2007), and another method is to use the Gelman-Rubin method (Gelman and Rubin, 1992; Brooks and Gelman, 1998) to check the convergence of the parameters. Bayesian computation procedure is implemented by R software. The convergence of slice-Gibbs algorithm algorithm is checked by monitoring the trace plots of the parameters for consecutive sequences of 20,000 iterations. We set the first 10,000 iterations as the burn-in period. Four chains started at overdispersed starting values are run for each replication. The trace plots of item parameters randomly selected are shown in Figure 1. In addition, we find the potential scale reduction factor (PSRF; Brooks and Gelman, 1998) values of all parameters are <1.1, which ensures that all chains converge as expected. As an illustration, the PSRF values of all item parameters are shown in Figure 2. On a desktop computer [AMD EPYC 7542 32-Core Processor] with 2.90 GHz dual core processor and 1TB of RAM memory, the average convergence times for our new algorithm and the traditional Metropolis-Hastings algorithm based on 50 replications, are shown in Table 1.
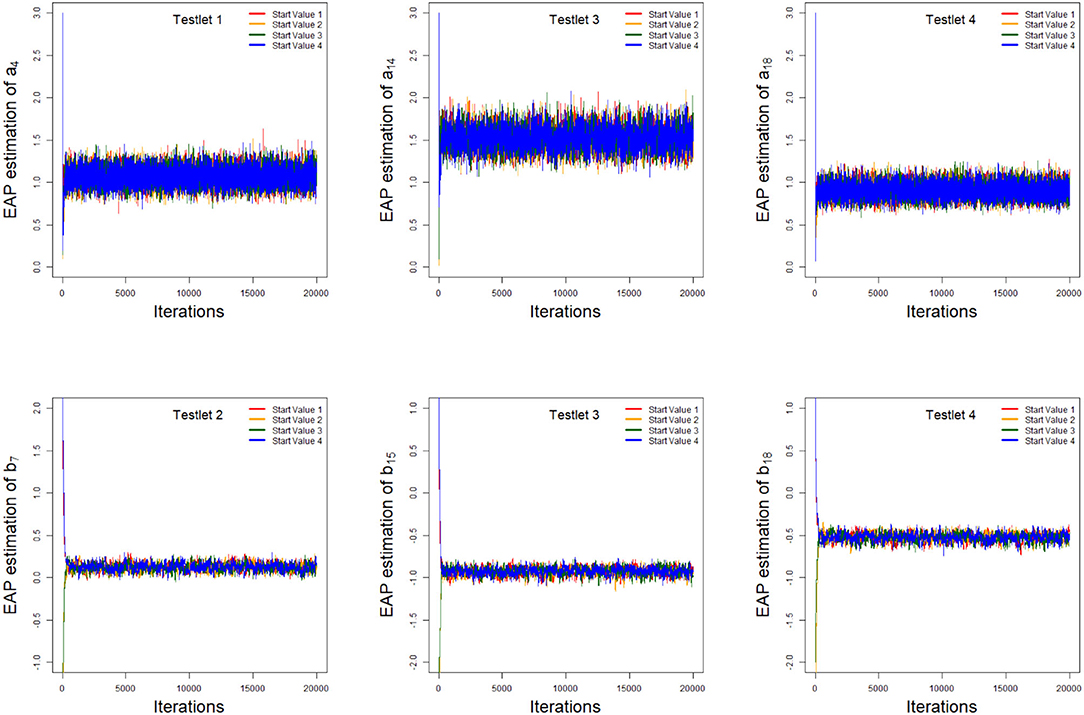
Figure 1. The trace plots of the arbitrarily selected item parameters.
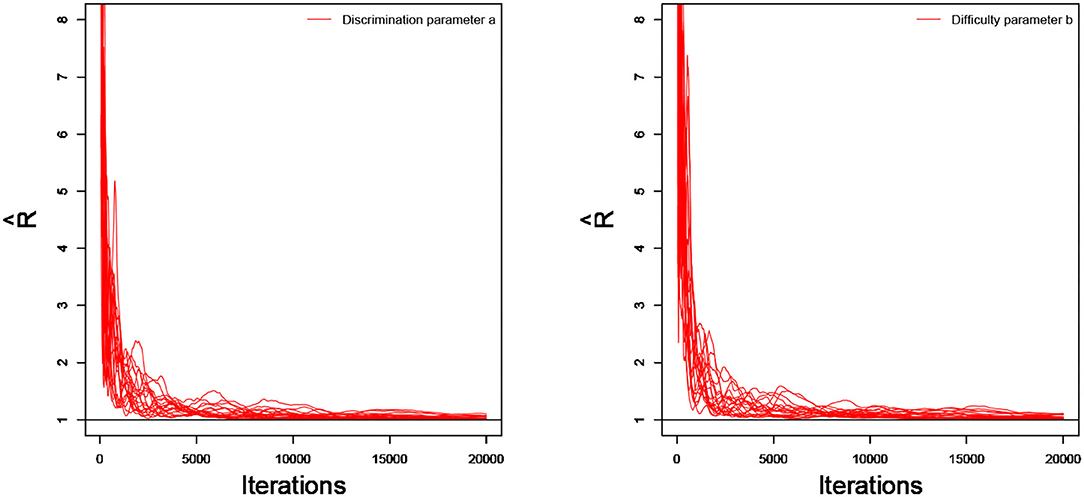
Figure 2. The trace plots of for the simulation study 1.

Table 1. Convergence times for all 8 simulation conditions in simulation study 1.
4.1.2. The Accuracy Evaluation of Parameter Estimation
The accuracy of the parameter estimates is measured by two evaluation methods, namely, Bias and mean squared error (MSE). The recovery results are based on the 50 replications in each simulation condition. The number of replication we choose is based on the previous research in educational psychological assessments. For example, Wang et al. (2013) proposed a semi-parametric approach, specifically, the Cox proportional hazards model with a latent speed covariate to analyze the response time data. In their simulation study, 10 replications (Page 15, section 4.1) are used for each simulation condition. Zhan et al. (2017) proposed joint modeling of attributes and response speed using item responses and response times simultaneously for cognitive diagnosis to provide more refined diagnostic feedback with collateral information in item response times. In their simulation study, they used 30 replications (Page 276) in each condition to reduce the random error. Lu et al. (2020) proposed a new mixture model for responses and response times with a hierarchical ability structure, which incorporates auxiliary information from other subtests and the correlation structure of the abilities to detect examinees' rapid guessing behavior. The recovery of the estimates was based on 20 replications (Page 14, section 5). Lu and Wang (2020) proposed to use an innovative item response time model as a cohesive missing data model to account for the two most common item nonresponses: not-reached items and omitted items. They considered 20 replications (Page 21) for each simulation condition. Therefore, based on the previous empirical conclusions, we adopt 50 replications in our simulation studies. If we consider a large number of replications, it is impossible to check the values (potential scale reduction factor; PSRF, Brooks and Gelman, 1998) calculated from each simulated dataset (replication) to ensure the parameter convergence. It will be a huge work when the simulated conditions increase. Let ϑ be the parameter of interest. S = 50 data sets are generated. Also, let denotes the posterior mean obtained from the sth simulated data set for s = 1, …, S.
The Bias for parameter ϑ is defined as
and the mean squared error (MSE) for parameter ϑ is defined as
From Tables 2–4, the Bias is between −0.3267 and 0.2769 for the discrimination parameters, between –0.2259 and 0.2071 for the difficulty parameters, between −0.0132 and 0.0161 for the variance parameters of a, between −0.0219 and 0.1303 for the variance parameters of b, between −0.2932 and 0.0332 for the variance parameter of testlet effect η. the MSE is between 0.0000 and 0.1162 for the discrimination parameters, between 0.0000 and 0.0552 for the difficulty parameters, between 0.0002 and 0.0005 for the variance parameters of a, between 0.0002 and 0.0449 for the variance parameters of b, between 0.0000 and 0.1848 for the variance parameter of testlet effect η. In summary, the slice-Gibbs algorithm provides accurate estimates of the parameters in term of various numbers of examinees and items.
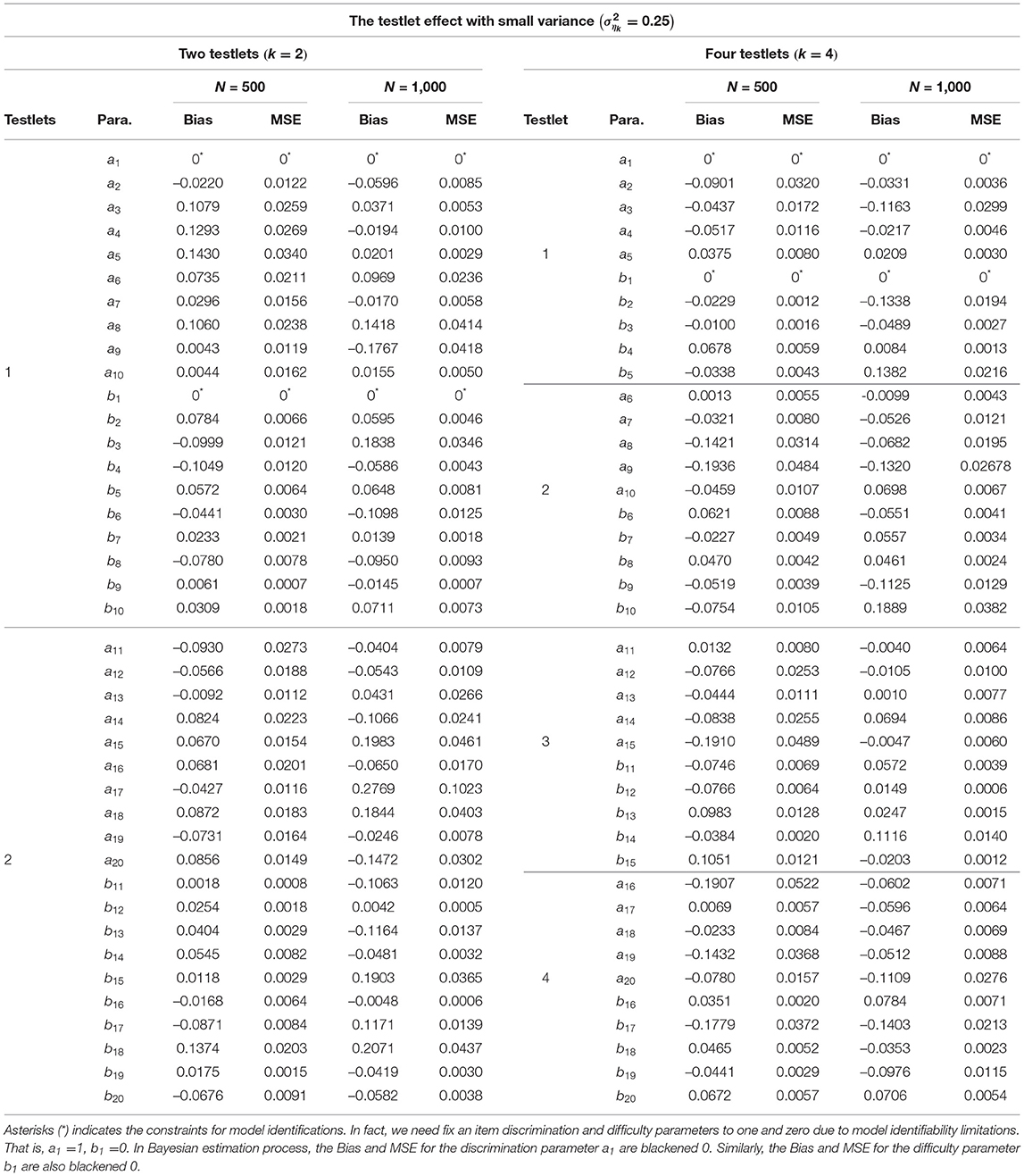
Table 2. Evaluating accuracy of the item parameter estimates based on different simulation conditions in the simulation study 1.
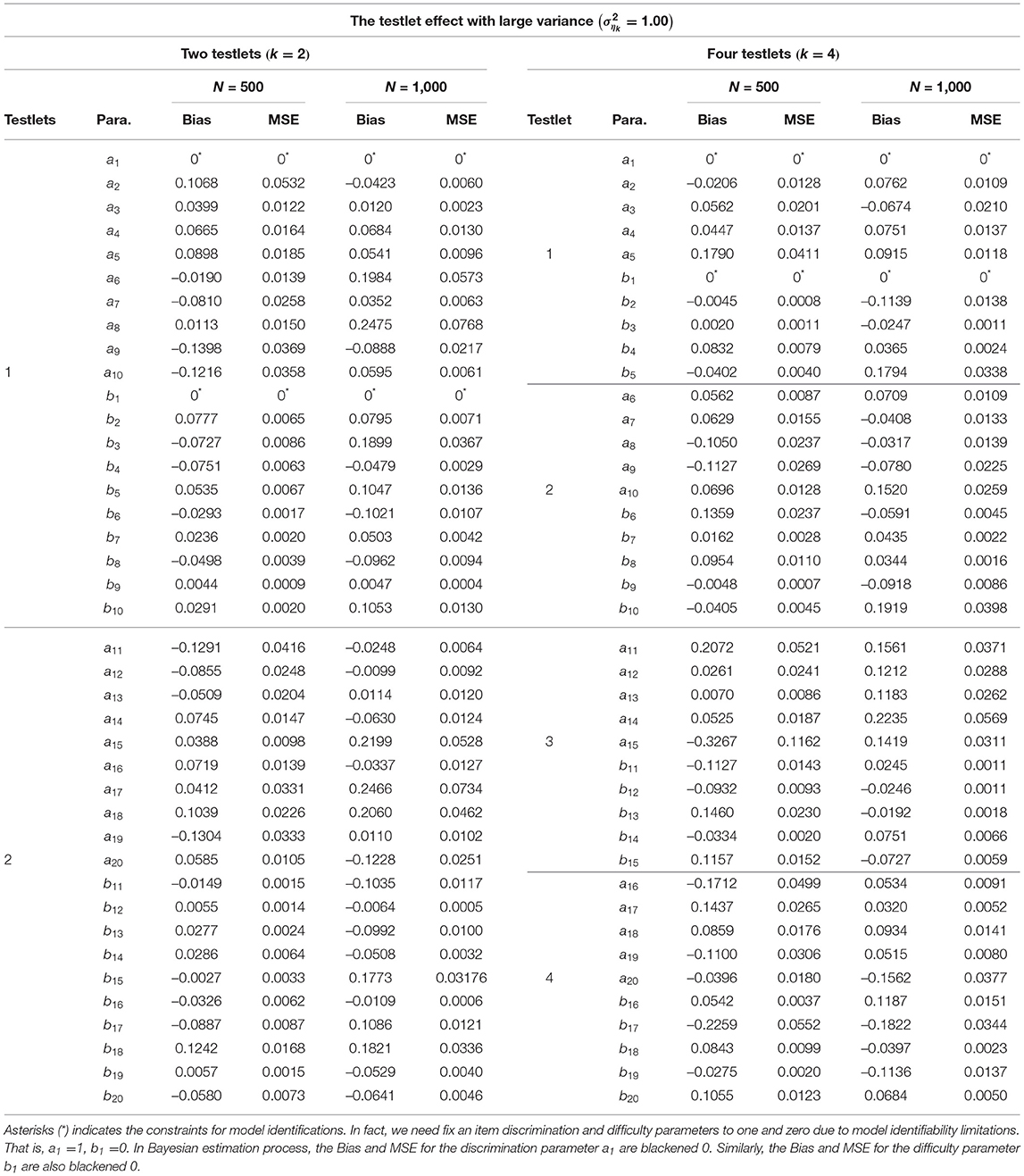
Table 3. Evaluating accuracy of the item parameter estimates based on different simulation conditions in the simulation study 1.
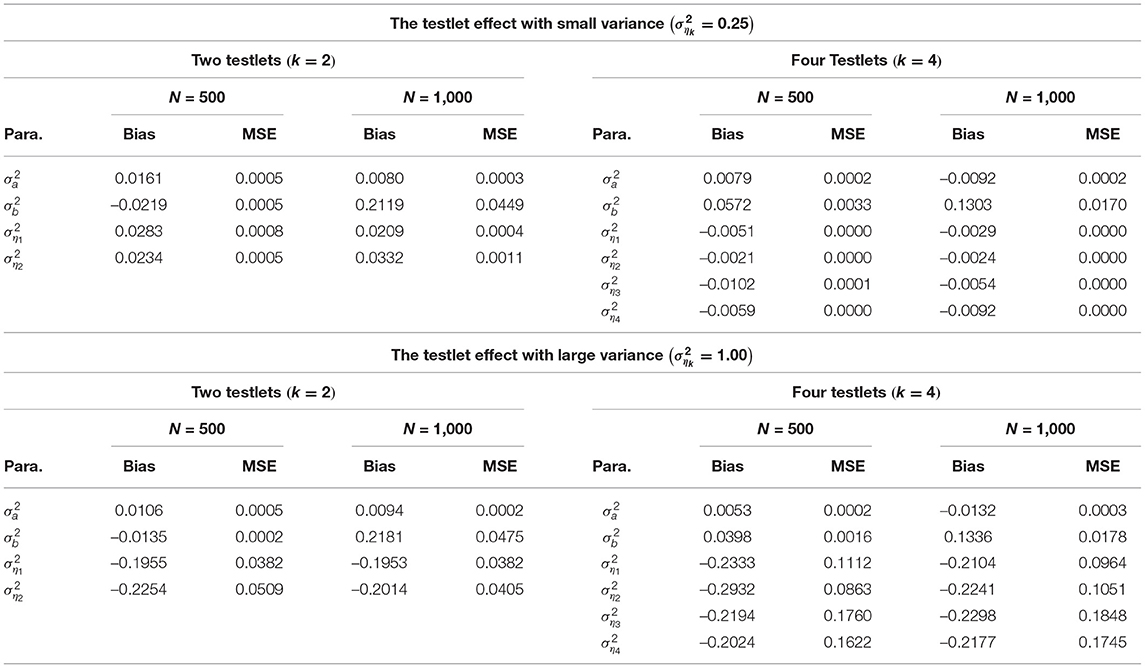
Table 4. Evaluating accuracy of the variance parameter estimates.
4.2. Simulation 2
This simulation study is designed to show that the slice-Gibbs sampling algorithm is sufficiently flexible to recover various prior distributions of the item parameters and address the sensitivity of our slice-Gibbs algorithm with different priors.
Response pattern with 500 examinees and 4 testlets (5 items per testlet) is generated by N2PLTM as given by Equation (1). The true values of item parameters and ability parameters are generated same as in simulation 1. The true value of the testlet effect variance is set equal to 0.25. The specified types of item parameter priors are given by the following:
Type I: Informative priors, aj ~ N(0, 1)I(0, +∞) and bj ~ N(0, 1);
Type II: Noninformative priors, aj ~ N(0, 100)I(0, +∞) and bj ~ N(0, 100);
Type III: Noninformative priors, aj ~ Uniform(0, 100) and bj ~ Uniform(0, 100).
Prior specifications for the other parameters are identical to the simulation study 1. To implement the MCMC sampling algorithm, chains of length 20,000 with an initial burn-in period 10,000 are chosen, and the PSRF values of all parameters are <1.1. Based on 25 replications, the average times for all parameters to converge in Type I, Type II and Type III are 0.4597, 0.4428, and 0.4506 h, respectively.
The average Bias and MSE for item parameters based on 50 replication are shown in Table 5. We find that the average Bias and MSE for item parameters are relatively unchanged under the three different prior distributions. The slice-Gibbs sampling algorithm allows for informative (Type I) or non-informative (Type II, Type III) priors of the item parameters and is not sensitive to the specification of priors. Moreover, a wider range of prior distributions is also appealing.

Table 5. Average Bias and MSE for the item parameter estimates using three prior distributions in the simulation study 2.
4.3. Simulation 3
In this simulation study, we will investigate the power of the model assessment methods. Namely, whether the Bayesian model comparison criteria based on the MCMC output could identify the true model from which the data are generated. The simulation design is as follows.
A data set with 500 examinees from standard normal distribution and four testlets (five items per testlet) is generated from the N2PLTM model. For the true values of parameters, the discrimination parameters ajs are generated from the truncated normal distribution, that is, aj ~ N(0, 1)I(0, +∞). The difficulty parameters bjs are generated from normal distribution, that is, bj ~ N(0, 1). The independent-items model as Model 1 is used to model assessment in which the random effects are set to zero. Model 1 is known as two parameter logistic model (2PLM; Birnbaum, 1957). In addition, the testlets random effect parameters ηiks are generated from a normal distribution. That is, ηik ~ N(0, 0.25), k = 1, 2, 3, 4. Model 2 is the traditional two parameter logistic testlet model (T2PLTM; Bradlow et al., 1999), which is give by
Model 3 is the N2PLTM in Equation (1). The parameter priors are identical to the simulation study 1. The parameters are estimated based on 20,000 iterations after a 10,000 burn-in period, and the PSRF values of all parameters are <1.1. Two Bayesian model assessment methods are used to model fitting. That is, DIC and log-PsBF. The results of Bayesian model assessment based on 50 replications are shown in Table 6.
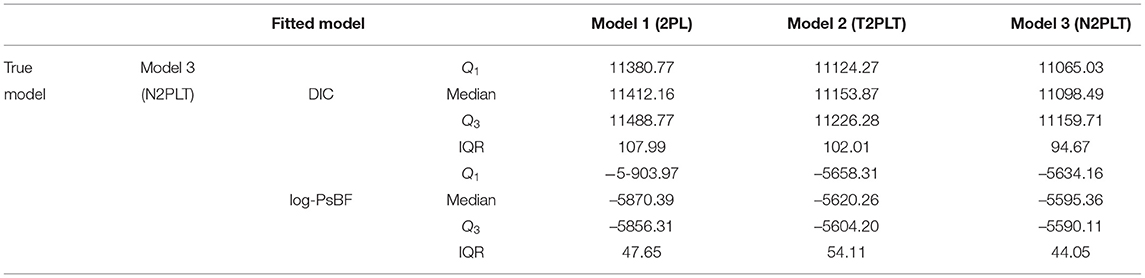
Table 6. The results of Bayesian model assessment in the simulation 3.
From Table 6, we find that when the Model 3 (N2PLTM model) is the true model, the Model 3 is chosen as the best-fitting model according to the results of the DIC and log-PsBF, which is what we expect to see. The medians of DIC and log-PsBF are respectively 11098.49 and −5595.36. The Model 2 (T2PLTM model) is the second best fitting model, which is attributed to the fact that the Model 2 with testlet random effect as well as the Model 3 also can capture the dependency structure between items. The differences between Model 3 and Model 2 in the median of DIC and log-PsBF are −55.38 and 24.9, respectively. However, compared the T2PLTM model, the N2PLTM model with the testlet discrimination parameter α is more flexible and the fitting is more sufficient. The Model 1 (2PL model) is worst-fitting model. The medians of DIC and log-PsBF are respectively 11412.16 and −5870.39. The differences between Model 3 model and Model 1 in the median of DIC and log-PsBF are −313.67 and 275.03, respectively. This is because the Model 1 do not consider the complicated and interrelated sets of items, thus it can not improve the model fitting for the testlet item response data. In summary, the Bayesian assessment criteria is effective for identifying the true models and it can be used in the subsequent empirical example analysis.
5. Empirical Example
To illustrate the applicability of the testlet IRT modeling method to large-scale test assessments, we consider a data set of students' English reading comprehension test for Maryland university (Tao et al., 2013). A total of 1,289 students take part in the test and answer 28 items. The 28 items consist of 4 testlets. Testlet 1 is formed by Items 1 to 8, that is, d(1) = ⋯ = d(8) = 1; Testlet 2 by Items 9 to 15, that is, d(9) = ⋯ = d(15) = 2; Testlet 3 by Items 16 to 23, that is, d(16) = ⋯ = d(23) = 3; and Testlet 4 by Items 24–28, that is, d(24) = ⋯ = d(28) = 4. The following prior distributions are used to analyze the data. That is,
We consider three models to fit the real data. The three models are 2PLM, T2PLTM and N2PLTM, respectively. The slice-Gibbs algorithm is applied to estimate the parameters of the three models. The slice-Gibbs sampling is iterated 20,000 iterations, with a burn-in period of 10,000 iterations. The convergence of the chains is checked by PSRF, which are <1.1. The item parameters of the N2PLTM are estimated and the item parameter estimators and the corresponding standard deviations are provided in Table 7. In the Bayesian frame work, the 95% highest posterior density intervals (HPDI) are calculated as confidence regions for the item parameters and are given in the columns labeled HPDIa and HPDIb in Table 8.

Table 7. The results of Bayesian model assessment in the real data.
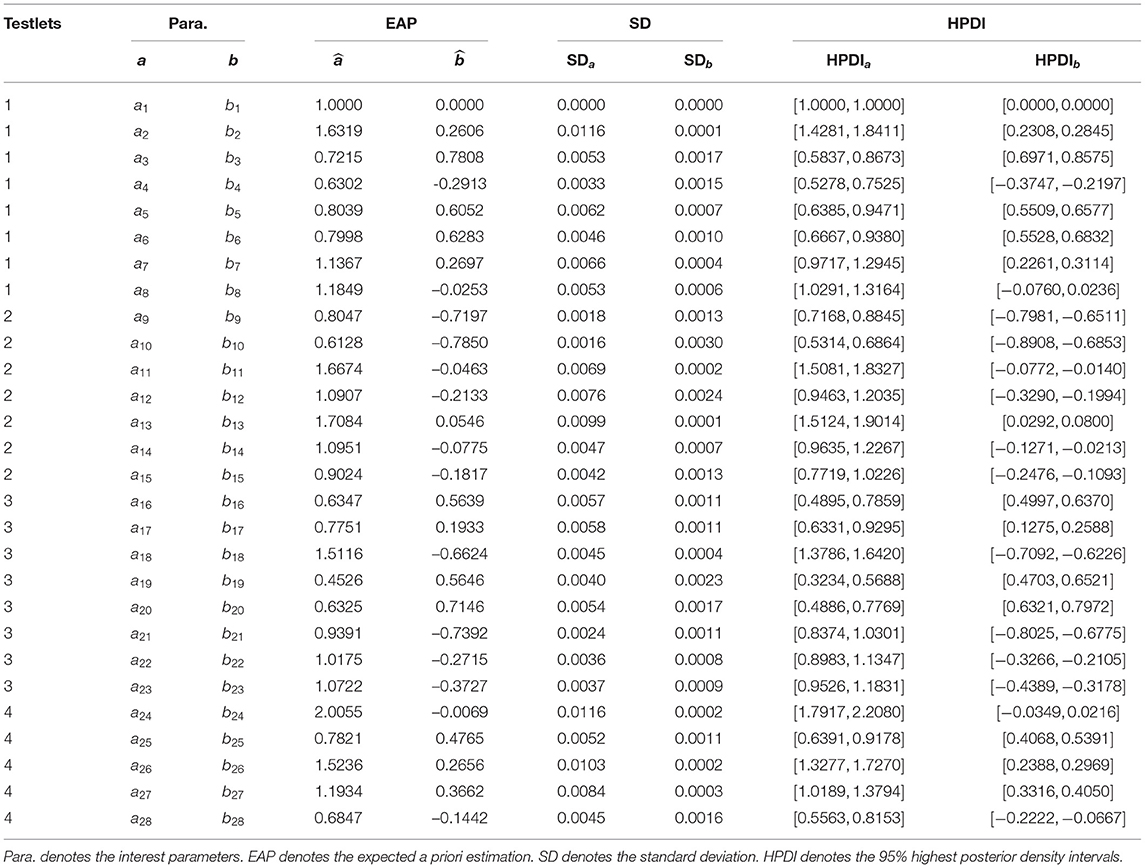
Table 8. The estimation results of item parameter for the real data.
Based on the results of Bayesian model selection form Table 7, we find that the N2PLTM is the best fitting model compared to the other two models. The DIC and log-PsBF are respectively 40632.52 and −20708.47. The second best fitting model is T2PLTM. The differences between N2PLTM and T2PLTM in the DIC and log-PsBF are −163.83 and 85.76, respectively. The 2PL model is worst-fitting model. The DIC and log-PsBF are respectively 44179.93 and –22021.39.
From Table 8, we find that for each testlet, the four items with highest discrimination are 2, 13, 18, and item 24, respectively. The expected a posteriori (EAP) estimations for the four item discrimination parameters are 1.6319, 1.7084, 1.5116, and 2.0055. The four most difficult items in each testlet are 3, 13, 20, and item 25 in turn. The EAP estimations for the four item difficulty parameters are 0.7808, 0.0546, 0.7146, and 0.4765. Compared to the items in the other three testlets, the items in the testlet 2 are relatively easy because the EAP estimates of the difficulty parameters (b9, b10, b11, b12, b14, and b15) are <0. In addition, the SD is between 0.0000 and 0.0116 for the discrimination parameters, between 0.0000 and 0.0030 for the difficulty parameters.
6. Concluding Remarks
To explore the relations between items with dependent structure, this current study proposes a N2PLTM and presents a effective Bayesian sampling algorithm. More specifically, an improved Gibbs sampling algorithm based on auxiliary variables is developed for estimating N2PLTM. The slice-Gibbs sampling algorithm overcomes the traditional Gibbs sampling algorithm's dependence on the conjugate prior for complex IRT model, and avoids some shortcomings of the Metropolis algorithm (such as sensitivity to step size, severe dependency on the candidate function or tuning parameter). Based on different simulation conditions, we find that the slice-Gibbs sampling algorithm can provide accurate parameter estimates in the sense of having small Bias and MSE values. In addition, the average Bias and MSE for item parameters are relatively unchanged under the three different prior distributions. The slice-Gibbs sampling algorithm allows for informative or non-informative priors of the item parameters and is not sensitive to the specification of priors. In summary, the algorithm is effective and can be used to analyze the empirical example.
However, the computational burden of the slice-Gibbs sampling algorithm becomes intensive especially when a large number of examinees or the items is considered, or a large number of the MCMC sample size is used. Therefore, it is desirable to develop a standing-alone R package associated with C++ or Fortran software for more extensive large-scale assessment program.
In addition, the new algorithm based on auxiliary variables can be extended to estimate some more complex item response and response time models, e.g., graded response model, Weibull response time model and so on.
Data Availability Statement
The datasets analyzed in this manuscript are not publicly available. Requests to access the datasets should be directed to Bao Xu, eHViYW85N0AxNjMuY29t.
Author Contributions
JL and JZ completed the writing of the article, original thoughts, and provided key technical support. JL and ZZ provided key technical support. BX provided the data. JT and JL completed the article revisions. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Natural Science Foundation of China (grant no. 12001091) and China Postdoctoral Science Foundations (grant nos. 2021M690587 and 2021T140108). In addition, this work was also supported by the Fundamental Research Funds for the Central Universities of China (grant no. 2412020QD025).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Aitkin, M. (1991). Posterior bayes factor (with discussion). J. R. Stat. Soc. B 53, 111–142. doi: 10.1111/j.2517-6161.1991.tb01812.x
Akaike, H. (1973). “Information theory and an extension of the maximum likelihood principle,” in Second International Symposium on Information Theory, eds B. N. Petrov and F. Csaki (Budapest: Academiai Kiado), 267–281.
Albert, J. H. (1992). Bayesian estimation of normal ogive item response curves using Gibbs sampling. J. Educ. Stat. 17, 251–269. doi: 10.3102/10769986017003251
Ando, T. (2011). Predictive bayesian model selection. Am. J. Math. Manag. Sci. 31, 13–38. doi: 10.1080/01966324.2011.10737798
Berger, J. O., and Pericchi, L. R. (1996). The intrinsic Bayes factor for linear models. in Bayesian Statistics 5, eds J. M. Bernardo, J. O. Berger, A. P. Dawid, and A. F. M. Smith (Oxford: Oxford University Press), 25–44.
Birnbaum, A. (1957). Efficient Design and Use of Tests of a Mental Ability For Various Decision Making Problems. Series Report No. 58-16. Randolph Air Force Base, TX: USAF School of Aviation Medicine.
Bishop, C. (2006). Slice Sampling. Pattern Recognition and Machine Learning. New York, NY: Springer.
Bock, R. D. (1972). Estimating item parameters and latent ability when responses are scored in two or more nominal categories. Psychometrika 37, 29–51.
Bock, R. D., and Aitkin, M. (1981). Marginal maximum likelihood estimation of item parameters: an application of an EM algorithm. Psychometrika 46, 443–459.
Bradlow, E. T., Wainer, H., and Wang, X. (1999). A Bayesian random effects model for testlets. Psychometrika 64, 153–168.
Brooks, S. P., and Gelman, A. (1998). Alternative methods for monitoring convergence of iterative simulations. J. Comput. Graphical Stat. 7, 434–455.
Chen, M.-H., Shao, Q.-M., and Ibrahim, J. G. (2000). Monte Carlo Methods in Bayesian Computation. New York, NY: Springer.
Chib, S., and Greenberg, E. (1995). Understanding the metropolis-hastings algorithm. Am. Stat. 49, 327–335.
Cook, K. F., Dodd, B. G., and Fitzpatrick, S. J. (1999). A comparison of three polytomous item response theory models in the context of testlet scoring. J. Outcome Meas. 3, 1–20.
Damien, P., Wakefield, J., and Walker, S. (1999). Gibbs sampling for Bayesian non-conjugate and hierarchical models by auxiliary variables, J. R. Stat. Soc. B 61, 331–344.
Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. 39, 1–38.
Eckes, T. (2014). Examining testlets effects in the TestDaF listening section: a testlet response theory modeling approach. Lang. Test. 31, 39–61. doi: 10.1177/0265532213492969
Eckes, T., and Baghaei, P. (2015). Using testlet response theory to examine local dependence in C-Testes. Appl. Meas. Educ. 28, 1–14. doi: 10.1080/08957347.2014.1002919
Fox, J.-P. (2010). Bayesian Item Response Modeling: Theory and Applications. New York, NY: Springer.
Fox, J.-P., and Glas, C. A. W. (2001). Bayesian estimation of a multilevel IRT model using Gibbs sampling. Psychometrika 66, 269–286. doi: 10.1007/BF02294839
Geisser, S., and Eddy, W. (1979). A predictive approach to model selection. J. Am. Stat. Assoc. 74, 153–160.
Gelfand, A. E. (1996). “Model determination using sampling-based methods,” in W. R. Gilks, S. Richardson, and D. J. Spiegelhalter Markov Chain Monte Carlo in Practice (London: Chapman-Hall), 145–161.
Gelfand, A. E., and Dey, D. K. (1994). Bayesian model choice: asymptotics and exact calculations. J. R. Stat. Soc. Ser. B 56, 501–514.
Gelfand, A. E., Dey, D. K., and Chang, H. (1992). “Model determination using predictive distributions with implementation via sampling-based methods (with discussion),” in Bayesian Statistics 4, eds J. M. Bernardo, J. O. Berger, A. P. Dawid and A. F. M. Smith (Oxford: Oxford University Press), 147–167.
Gelman, A., and Rubin, D. B. (1992). Inference from iterative simulation using multiple sequences. Stat. Sci. 7, 457–472.
Geman, S., and Geman, D. (1984). Stochastic relaxation, Gibbs distributions and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 6, 721–741.
Gibbons, R. D., and Hedeker, D. R. (1992). Full-information bi-factor analysis. Psychometrika 57, 423–436.
Glas, C. A. W., Wainer, H., and Bradlow, E. T. (2000). “Maximum marginal likelihood and expected a posteriori estimation in testlet-based adaptive testing,” in Computerized Adaptive Testing, Theory and Practice, eds W. J. van der Linden, and C. A. W. Glas (Boston, MA: Kluwer-Nijhoff), 271–288.
Hastings, W. K. (1970). Monte Carlo sampling methods using Markov chains and their applications. Biometrika 57, 97–109.
Higdon, D. M. (1998). Auxiliary variable methods for Markov Chain Monte Carlo with applications. J. Am. Stat. Soc. 93, 585–595.
Jiao, H., Wang, S., and He, W. (2013). Estimation methods for one-parameter testlet models. J. Educ. Meas. 50, 186–203. doi: 10.1111/jedm.12010
Jiao, H., Wang, S., and Kamata, A. (2005). Modeling local item dependence with the hierarchical generalized linear model. J. Appl. Meas. 6, 311–321.
Kass, R. E., and Wasserman, L. (1995). A reference Bayesian test for nested hypotheses and its relationship to the Schwarz criterion. J. Am. Stat. Assoc. 90, 928–934.
Li, Y., Bolt, D. M., and Fu, J. (2006). A comparison of alternative models for testlets. Appl. Psychol. Meas. 30, 3–21. doi: 10.1177/0146621605275414
Lord, F. M., and Novick, M. R. (1968). Statistical Theories of Mental Test Scores. Reading, MA: Addison-Wesley.
Lu, J., and Wang, C. (2020). A response time process model for not reached and omitted items. J. Educ. Meas. 57, 584–620. doi: 10.1111/jedm.12270
Lu, J., Wang, C., Zhang, J., and Tao, J. (2020). A mixture model for responses and response times with a higher-order ability structure to detect rapid guessing behaviour. Br. J. Math. Stat. Psychol. 73, 262–288. doi: 10.1111/bmsp.12175
Lu, J., Zhang, J. W., and Tao, J. (2018). Slice-Gibbs sampling algorithm for estimating the parameters of a multilevel item response model. J. Math. Psychol. 82, 12–25. doi: 10.1016/j.jmp.2017.10.005
Meng, X.-L., and van Dyk, D. A. (1999). Seeking efficient data augmentation schemes via conditional and marginal augmentation. Biometrika 86, 301–320. doi: 10.1093/biomet/86.2.301
Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., and Teller, E. (1953). Equations of state calculations by fast computing machines. J. Chem. Phys. 21, 1087–1092. doi: 10.1063/1.1699114
Min, S. C., and He, L. Z. (2014). Applying unidimensional and multidimensional item response theory models in testlet-based reading assessment. Lang. Test. 31, 453–477. doi: 10.1177/0265532214527277
Mislevy, R. J. (1986). Bayes modal estimation in item response models. Psychometrika 51, 177–195. doi: 10.1007/BF02293979
Muraki, E. (1992). A generalized partial credit model: application of an EM algorithm. Appl. Psychol. Meas. 16, 159–176. doi: 10.1177/014662169201600206
Newton, M. A., and Raftery, A. E. (1994). Approximate Bayesian inference with the weighted likelihood bootstrap. J. R. Stat. Soc. Ser. B 56, 3–48.
Pinheiro, P. C., and Bates, D. M. (1995). Approximations to the log-likelihood function in the nonlinear mixed-effects model. J. Comput. Graphical Stat. 4, 12–35.
Raftery, A. E. (1996). “Hypothesis testing and model selection,” in Markov Chain Monte Carlo in Practice, eds W. R. Gilks, S. Richardson, and D. J. Spiegelhalter (Washington, DC: Chapman & Hall), 163–187.
Rijmen, F. (2010). Formal relations and an empirical comparison among the bi-factor, the testlet, and a second-order multidimensional IRT model. J. Educ. Meas. 47, 361–372. doi: 10.1111/j.1745-3984.2010.00118.x
Samejima, F. (1969). Estimation of latent ability using a response pattern of graded scores. Psychometrika Monogr. Suppl. 17, 1–100.
Sireci, S. G., Thissen, D., and Wainer, H. (1991). On the reliability of testlet-based tests. J. Educ. Meas. 28, 237–247.
Spiegelhalter, D. J., Best, N. G., Carlin, B. P., and van der Linde, A. (2002). Bayesian measures of model complexity and fit (with discussion). J. R. Stat. Soc. Ser. B 64, 583–639. doi: 10.1111/1467-9868.00353
Tanner, M. A., and Wong, W. H. (1987). The calculation of posterior distributions by data augmentation. J. Am. Stat. Assoc. 82, 528–550.
Tao, J., Xu, B., Shi, N.-Z., and Jiao, H. (2013). Refining the two-parameter testlet response model by introducing testlet discrimination sparameters. Jpn. Psychol. Res. 55, 284–291. doi: 10.1111/jpr.12002
Thissen, D., Steinberg, L., and Mooney, J. A. (1989). Trace lines for testlets: A use of multiple categorical response models. J. Educ. Meas. 26, 247–260.
Tierney, L. (1994). Markov chains for exploring posterior distributions (with discussions). Ann. Stat. 22, 1701–1762.
van der Linden, W. J. (2007). A hierarchical framework for modeling speed and accuracy. Psychometrika 72, 287–308. doi: 10.1007/s11336-006-1478-z
Wainer, H. (1995). Precision and differential item functioning on a testlet-based test: the 1991 law school admissions test as an example. Appl. Meas. Educ. 8, 157–186.
Wainer, H., Bradlow, E. T., and Du, Z. (2000). “Testlet response theory: an analog for the 3PL model useful in testlet-based adaptive testing. in Computerized Adaptive Testing: Theory and Practice, eds W. J. van der Linden and C. A. W. Glas (Dordrecht; Boston; London: Kluwer Academic), 245–269.
Wainer, H., Bradlow, E. T., and Wang, X. (2007). Testlet Response Theory and Its Applications. Cambridge: Cambridge University Press.
Wainer, H., and Kiely, G. L. (1987). Item clusters and computerized adaptive testing: a case for testlet. J. Educ. Meas. 24, 185–201.
Wang, C., Fan, Z., Chang, H.-H., and Douglas, J. (2013). A semiparametric model for jointly analyzing response times and accuracy in computerized testing. J. Educ. Behav. Stat. 38, 381–417. doi: 10.3102/1076998612461831
Wang, C., Xu, G., and Shang, Z. (2018). A two-stage approach to differentiating normal and aberrant behavior in computer based testing. Psychometrika 83, 223–254. doi: 10.1007/s11336-016-9525-x
Wang, W.-C., and Wilson, M. (2005a). Exploring local item dependence using a random-effects facet model. Appl. Psychol. Meas. 29, 296–318. doi: 10.1177/0146621605276281
Wang, W.-C., and Wilson, M. (2005b). The Rasch testlet model. Appl. Psychol. Meas. 29, 126–149. doi: 10.1177/0146621604271053
Yen, W. M. (1993). Scaling performance assessments: strategies for managing local item dependence. J. Educ. Meas. 30, 187–213.
Zhan, P., Jiao, H., and Liao, D. (2017). Cognitive diagnosis modelling incorporating item response times. Br. J. Math. Stat. Psychol. 71, 262–286. doi: 10.1111/bmsp.12114
Zhan, P., Li, X., Wang, W.-C., Bian, Y., and Wang, L. (2015). The multidimensional testlet effect cognitive diagnostic models. Acta Psychol. Sin. 47, 689–701. doi: 10.3724/SP.J.1041.2015.00689
Zhan, P., Liao, M., and Bian, Y. (2018). Joint testlet cognitive diagnosis modeling for paired local item dependence in response times and response accuracy. Front. Psychol. 9:607. doi: 10.3389/fpsyg.2018.00607
Zhan, P., Wang, W.-C., Wang, L., and Li, X. (2014). The multidimensional testlet-effect Rasch model. Acta Psychol. Sin. 46, 1208–1222. doi: 10.3724/SP.J.1041.2014.01208
Zhang, B. (2010). Assessing the accuracy and consistency of language proficiency classification under competing measurement models. Lang. Test. 27, 119–140. doi: 10.1177/0265532209347363
Keywords: bayesian inference, deviance information criterion, logarithm of the pseudomarignal likelihood, item response theory, testlet effect models, slice-Gibbs sampling algorithm, Markov chain Monte Carlo
Citation: Lu J, Zhang J, Zhang Z, Xu B and Tao J (2021) A Novel and Highly Effective Bayesian Sampling Algorithm Based on the Auxiliary Variables to Estimate the Testlet Effect Models. Front. Psychol. 12:509575. doi: 10.3389/fpsyg.2021.509575
Received: 02 November 2019; Accepted: 06 July 2021;
Published: 11 August 2021.
Edited by:
Pietro Cipresso, University of Turin, ItalyReviewed by:
Holmes Finch, Ball State University, United StatesPeida Zhan, Zhejiang Normal University, China
Copyright © 2021 Lu, Zhang, Zhang, Xu and Tao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jiwei Zhang, emhhbmdqdzcxM0BuZW51LmVkdS5jbg==; Zhaoyuan Zhang, emhhbmd6eTMyOEBuZW51LmVkdS5jbg==
†Present address: Zhaoyuan Zhang, School of Mathematics and Statistics, Yili Normal University, Yili, China