 Ze Wang
Ze Wang
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol. , 30 September 2020
Sec. Educational Psychology
Volume 11 - 2020 | https://doi.org/10.3389/fpsyg.2020.579545
This article is part of the Research Topic What Big Data Can Tell Us About the Psychology of Learning and Teaching View all 12 articles
The programming language of R has useful data science tools that can automate analysis of large-scale educational assessment data such as those available from the United States Department of Education’s National Center for Education Statistics (NCES). This study used three R packages: EdSurvey, MplusAutomation, and tidyverse to examine the big-fish-little-pond effect (BFLPE) in 56 countries in fourth grade and 46 countries in eighth grade for the subject of mathematics with data from the Trends in International Mathematics and Science Study (TIMSS) 2015. The BFLPE refers to the phenomenon that students in higher-achieving contexts tend to have lower self-concept than similarly able students in lower-achieving contexts due to social comparison. In this study, it is used as a substantive theory to illustrate the implementation of data science tools to carry out large-scale cross-national analysis. For each country and grade, two statistical models were applied for cross-level measurement invariance testing, and for testing the BFLPE, respectively. The first model was a multilevel confirmatory factor analysis for the measurement of mathematics self-concept using three items. The second model was multilevel latent variable modeling that decomposed the effect of achievement on self-concept into between and within components; the difference between them was the contextual effect of the BFLPE. The BFLPE was found in 51 of the 56 countries in fourth grade and 44 of the 46 countries in eighth grade. The study provides syntax and discusses problems encountered while using the tools for modeling and processing of modeling results.
Data science tools, particularly those developed with the statistical language of R (R Core Team, 2020), have been increasingly used in educational and social sciences. For scholarly articles, R is the second most frequently used data science software following SPSS (Muenchen, n.d.). Given its integrated system of data wrangling, statistical modeling, visualization, and communication (Grolemund and Wickham, 2018), R is appealing to those conducting empirical analysis (i.e., using real data) as well as those interested in simulation studies. Currently, there are over 16,000 R packages available on the Comprehensive R Archive Network (CRAN) – R’s main repository of packages – and more packages in other repositories (such as GitHub). Packages are developed for various topics (for example, see “Task Views” at the CRAN). They, together with R’s core packages, provide tools for researchers to work with different aspects of using data. There are also search engines (e.g., RSeek, Nabble), online communities (e.g., Stack Overflow, Cross Validated, RStudio Community), and mailing lists (e.g., R-help, R-devel) that are available for additional help for using R. At the same time, the sheer amount of R resources seems daunting to beginner users, let alone its sometimes unfamiliar or non-user-friendly ways of “doing” things.
Large-scale assessments (LSAs) are great data sources (Rutkowski et al., 2014). An LSA typically involves complex design frameworks for the development of items, sampling participants, data collection, and variable creation. The United States Department of Education’s National Center for Education Statistics (NCES) houses multiple international LSA studies across the lifespan from early childhood to adults (National Center for Education Statistics, n.d.). These studies are sponsored by two organizations: The International Association for the Evaluation of Educational Achievement (IEA) and the Organization for Economic Cooperation and Development (OECD), although the work is typically directed by testing firms and research institutes in cooperation with national research institutions and governmental agencies. In the United States, the National Assessment of Educational Progress (NAEP) is an LSA that was first conducted in 1969 (National Center for Education Statistics, 2020). LSAs allow researchers to use nationally and internationally representative data to answer research questions and even for policymaking (Wagemaker, 2014).
Despite its rich data, LSAs have been used only to the extent that is far from its potential (Wang, 2017). It takes quite some time for one to get familiar with an LSA. Substantive researchers may be unaware of the relevant content in LSAs that can be used for their research. Or, they may lack the expertise to go through the database which may contain hundreds of datasets, or to run large-scale analysis. At the same time, when a researcher does use an LSA, many times only data from a single or a few countries/regions are used for analysis (e.g., Wang et al., 2012; Smith et al., 2020).
In this article, I illustrate how to use a few R packages that I have found particularly useful for conducting large-scale cross-national analysis using NCES data. Those packages are EdSurvey (Bailey et al., 2020), MplusAutomation (Hallquist and Wiley, 2018), and tidyverse (Wickham et al., 2019). Several other packages were used for this study but the main functions are from these three packages.
The goal of this study is twofold. First, it examines and continues to document the big-fish-little-pond effect (BFLPE) using the Trends in International Mathematics and Science Study (TIMSS), an international LSA by IEA. Second, it demonstrates the implementation of data science tools to carry out large-scale cross-national analysis. I provide syntax so that interested readers can replicate the analysis. The syntax can also be modified for similar analyses.
Traditional tools tend to treat different aspects of the whole data manipulation and statistical analysis in compartments. Each tool is for a special purpose and the user has to piece all the different elements together to use multiple tools for a more complex problem. To illustrate my point, think about the different statistics courses a doctoral student in educational psychology typically takes. The student may take courses that cover regression, analysis of variance, factor analysis, structural equation modeling, etc. For those courses, the professor may provide data for homework problems and/or projects, or the student may be encouraged to work on projects with their “own” data. In the latter case, the data may be from the student’s advisor or another fellow graduate student. Most likely, the data are already cleaned/managed in the sense that the variables are ready to be used to apply the learned statistical techniques. The student may be unappreciative of the data management steps that lead to the cleaned data until they are involved in a bigger grant project or at the dissertation/thesis stage. However, data wrangling is time-consuming. Data scientists spend from 50 to 80% of their time collecting and preparing unruly digital data (Lohr, 2014). With the amount of data available in every field, the toolbox of quantitative researchers, especially those working with empirical data, needs to include tools that allow them to handle various types and quantities of data.
The programming language R has increasingly become a popular statistical analysis software. It is open source meaning that everyone can access and contribute to its development. Despite its relatively long history (The first publicly available version of R was released in 2000), R has only gained more acceptance among social science researchers in the past decade or so. R was born out of S, which was intended to be a programming language focused on data analysis, and has evolved into a system used not only by computer programmers and data analysts but also by physical scientists, psychologists, journalists, etc. Researchers use R because (a) it is free and open-source; (b) it has many packages built to meet various needs of statistical analysis; (c) there are freely provided useful resources among the R community; (d) collaboration using R is easy; (e) analysis with R can be highly reproducible; and (f) data wrangling using R can be fast, dependable, and highly replicable (Barrett, 2019).
RStudio is an integrated development environment (IDE) for R. It uses R to develop codes and analysis that can be executed and has greater usability than R. Essentially RStudio can be thought of as the interface between the user and R. It depends on and adds onto R, which means that the R program has to be installed before RStudio for RStudio to implement R. Any R package or function can be used in RStudio. RStudio has many features for good usability. One basic feature I particularly like is auto-completion. When the user types the first few characters of an R command, function, or the name of a data object that has been created, RStudio will show a list of complete names from which the user can choose to insert. This saves a lot of time typing and finding typos. For more experienced users who would like to develop their own packages, RStudio provides tools that automatically organize the structure necessary for package development. Interested readers can check out the “Advanced R” book (Wickham, 2019).
One particular challenge of using LSAs is to access and browse the data. A researcher may have some idea about the LSA after reading its description online or the user’s guide, but getting hands-on with the data usually means downloading big zipped files, unzipping them, and making them viewable using statistical software such as SPSS or SAS. Sometimes, there are hundreds of datasets that can be explored. The R EdSurvey package, recently developed by Bailey et al. (2020), makes accessing and transforming LSAs data to be R-ready a breeze.
EdSurvey was developed for data downloading, processing, manipulation, and analysis of LSAs by NCES and incorporates special survey methodologies (complex sampling, sampling weights, replicate weights, etc.) in a single package. In addition to data procuration, EdSurvey has methods developed for statistical analysis. However, these methods are for analysis of observed variables. Researchers interested in using latent variable modeling techniques such as factor analysis has to rely on other packages. The R package lavaan (Rosseel, 2012) is widely used for latent variable modeling but its capabilities are still limited for analysis using LSAs. For example, sampling weights in lavaan can only be used for non-clustered data. Although it is possible to use lavaan for multilevel structural equation modeling, only listwise deletion can be used for handling missing data.
Mplus (Muthén and Muthén, 1998-2017) is a comprehensive program for structural equation modeling (SEM) including latent variable modeling. Mplus is especially popular among applied researchers. It is syntax-based but relatively easy to use. It has many capabilities for advanced analysis (e.g., multilevel latent variable modeling, intensive longitudinal data analysis, Bayesian analysis) and can handle many data issues (e.g., missing data, non-normality, clustered data, complex survey designs); new methodologies are routinely added for its development. The most recent version is Version 8. Unlike R, it is not open source, and the user purchases licenses for the software and technical support services.
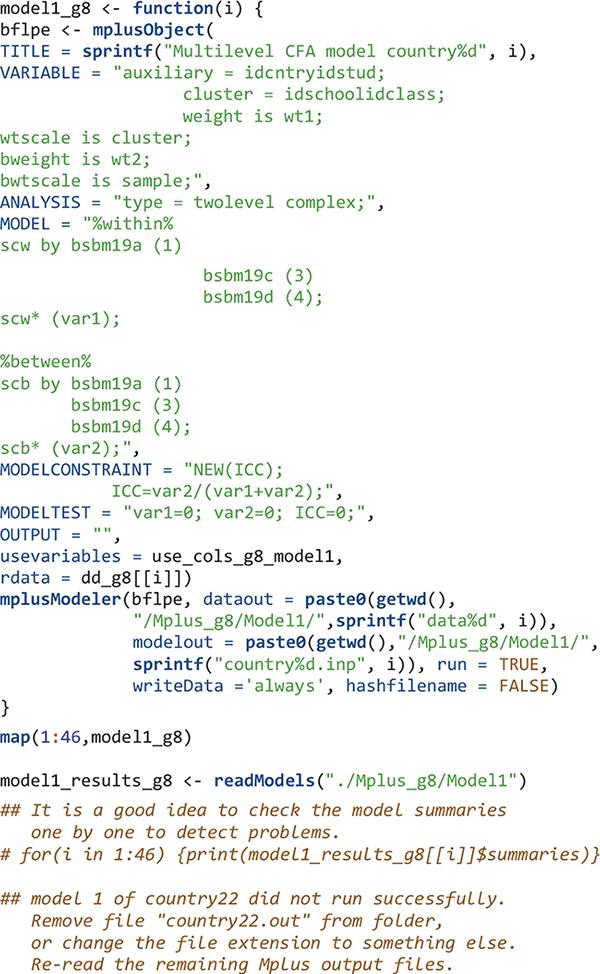
One drawback of Mplus is that the input or output of every model is stored as a separate file (.inp for input files and .out for output files). If one is to run many models, extracting information from the many output files can be a problem. The process can be tedious and error-prone. In addition, while Mplus is great for modeling, it has very limited capability for data management either to prepare data for the model or to further process data contained in the output files. To address these problems, Hallquist developed the R MplusAutomation package that can create, batch run, and extract results from many models (Hallquist and Wiley, 2018). Data to be analyzed can be managed in R like other R objects; sections of the Mplus input syntax are embedded in the object created by calling the mplusObject function; the mplusModeler function creates Mplus input files as well as dataset files if requested; the runModels function runs a group of Mplus models; and the Mplus output files (i.e., those with.out extension) can be extracted using the readModels. In addition, the MplusAutomation package provides functions to tabulate summary statistics, compare models, and extract parameters.
Another useful R package for programming large-scale analysis with LSAs is tidyverse (Wickham et al., 2019). Technically, tidyverse is not a single R package; rather, it is a collection of R packages that share an underlying design philosophy, grammar, and data structures, which makes data wrangling, analysis, and visualization relatively easy.
For cross-national analysis using data from LSAs, it is necessary to process data before and after modeling them. While it is possible to use other packages (e.g., the “data.table” package; Dowle and Srinivasan, 2019) or the R base package to get the same results, I chose tidyverse because of its comprehensiveness and because it is relatively easy to use. The functions used in the present study are a tiny part of all the capacity of tidyverse. Here I would like to particularly point out the pipe operator (%>%) and the map function. The pipe operator comes from the magrittr (Bache and Wickham, 2014) package but is loaded automatically with tidyverse. It chains sequential operations to avoid creating intermediate objects and nested function calls and to make the syntax more readable. The map function is from the purr package (Henry and Wickham, 2020a) which is also loaded automatically with tidyverse. It takes a vector and a function as function inputs (i.e., arguments), applies the function to each element of the vector, and returns the results in a list of the same length. It is an efficient way of eliminating “for” loops so that the code is easier to write and read. If the output is more desired in a vector format, there are four variants which return a specific type of results: map_lgl (for a logical vector), map_int (for an integer vector), map_dbl (for a double vector), and map_chr (for a character vector).
When students compare their ability in an academic subject, they tend to compare themselves in their immediate context. As a result, students in higher-achieving contexts have lower self-concept than similarly able students in lower-achieving contexts. This phenomenon is called the big-fish-little-pond effect (BFLPE; Marsh, 1990). The BFLPE can be explained by the social comparison theory. According to this theory, individuals evaluate themselves by comparing themselves to others (Festinger, 1954; Suls et al., 2002). For such comparisons, those in an individual’s immediate social group often serve as the comparison target (Rogers et al., 1978). To evaluate one’s academic ability, the student may compare his/her academic position with their classmates when they form their academic self-concept. As a result, students from different classes may have different self-evaluations even when their academic abilities are the same.
Due to its social comparison nature, the BFLPE is a contextual effect, which occurs when the aggregate of a person-level characteristic (e.g., mathematics ability) is related to the outcome (e.g., mathematics self-concept) even after controlling for the effect of the individual characteristic; in other words, the “context” has an additional effect on the individual. Contextual effects can be examined using multilevel modeling statistical techniques (Raudenbush and Bryk, 2002). In a two-level modeling framework (e.g., students nested within classes), if the predictor variable is grand-mean centered, the between-level effect is the contextual effect; if the predictor is group-mean centered, the difference between the between-level effect and the within-level effect is the contextual effect.
TIMSS is an international assessment of student achievement in mathematics and science in fourth and eighth grades. It is sponsored by IEA and directed by the TIMSS & PIRLS International Study Center at Boston College. The first TIMSS was administered in 1995 and has been administered every 4 years since then. TIMSS 2015 was the sixth cycle and is the most recent administration with data released to the public (TIMSS 2019 results are expected to be released in December 2020). In addition to tests measuring achievement, background and non-cognitive information is collected from students, teachers, and school principals, allowing researchers to examine relationships between achievement and personal and contextual factors across countries/regions.
Large-scale assessments have been used to study the BFLPE across countries. Marsh and Hau (2003) used the Program of Student Assessment (PISA) 2000 data collected in 26 countries; Seaton et al. (2009) used PISA 2003 data collected in 41 countries; Nagengast and Marsh (2011) used PISA 2006 data and examined the BFLPE with a total international sample from 57 countries, a total United Kingdom sample, and four samples from United Kingdom counties. Using TIMSS 2007, Wang (2015) examined the BFLPE in 49 countries in eighth-grade mathematics. Wang and Bergin (2017) further examined the BFLPE in 59 countries using TIMSS 2011 in eighth-grade mathematics. However, no study has investigated the BFLPE across many countries using TIMSS 2015.
The present study used TIMSS 2015 data from 56 countries at the fourth-grade level and 46 countries at the eighth-grade level (Foy, 2017). The total sample consisted of 330,204 students from 15,740 classes in 10,964 schools in fourth grade and 285,190 students from 11,856 classes in 8,500 schools in eighth grade (see Tables 1, 2).
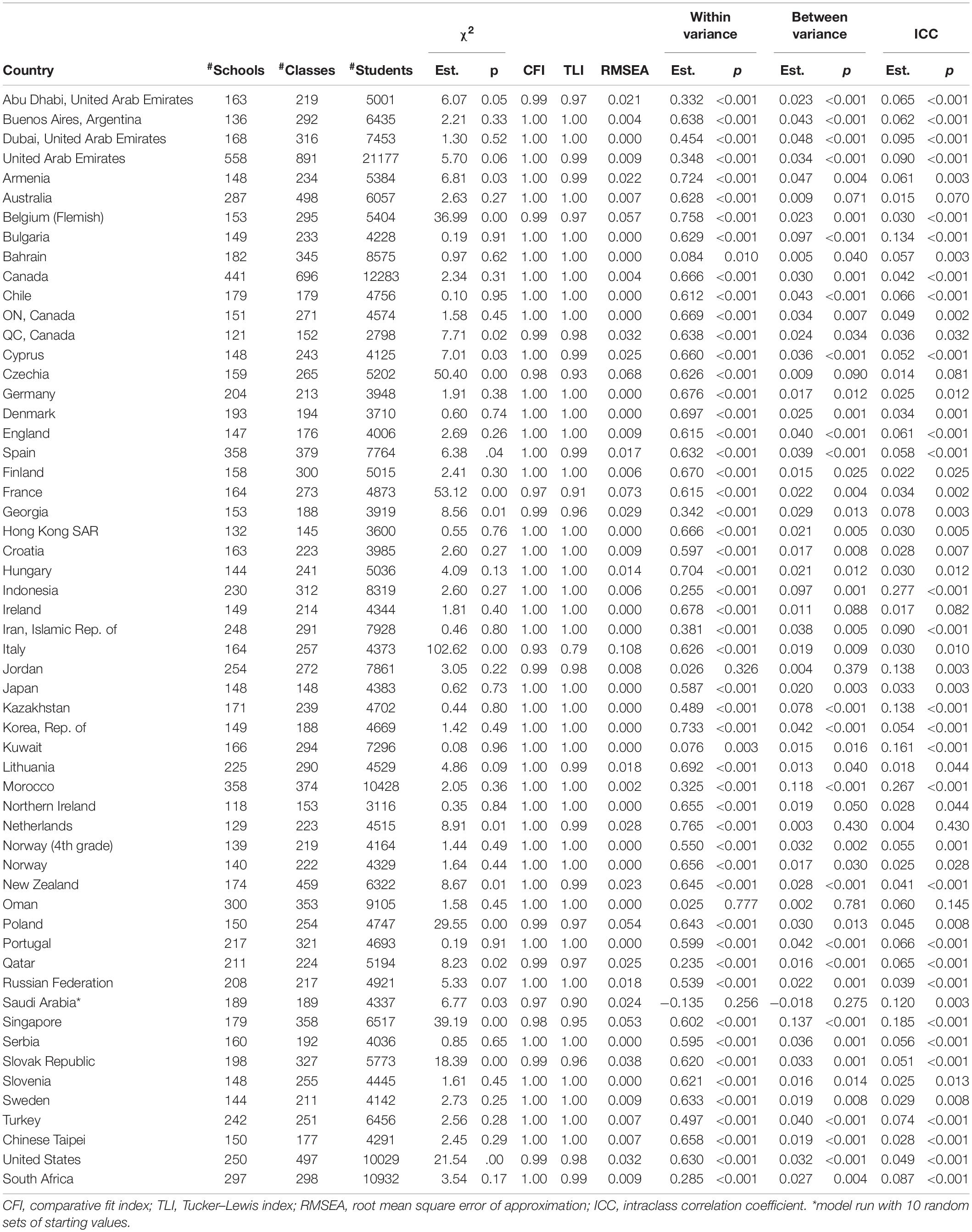
Table 1. Results of Model 1 in Fourth Grade.
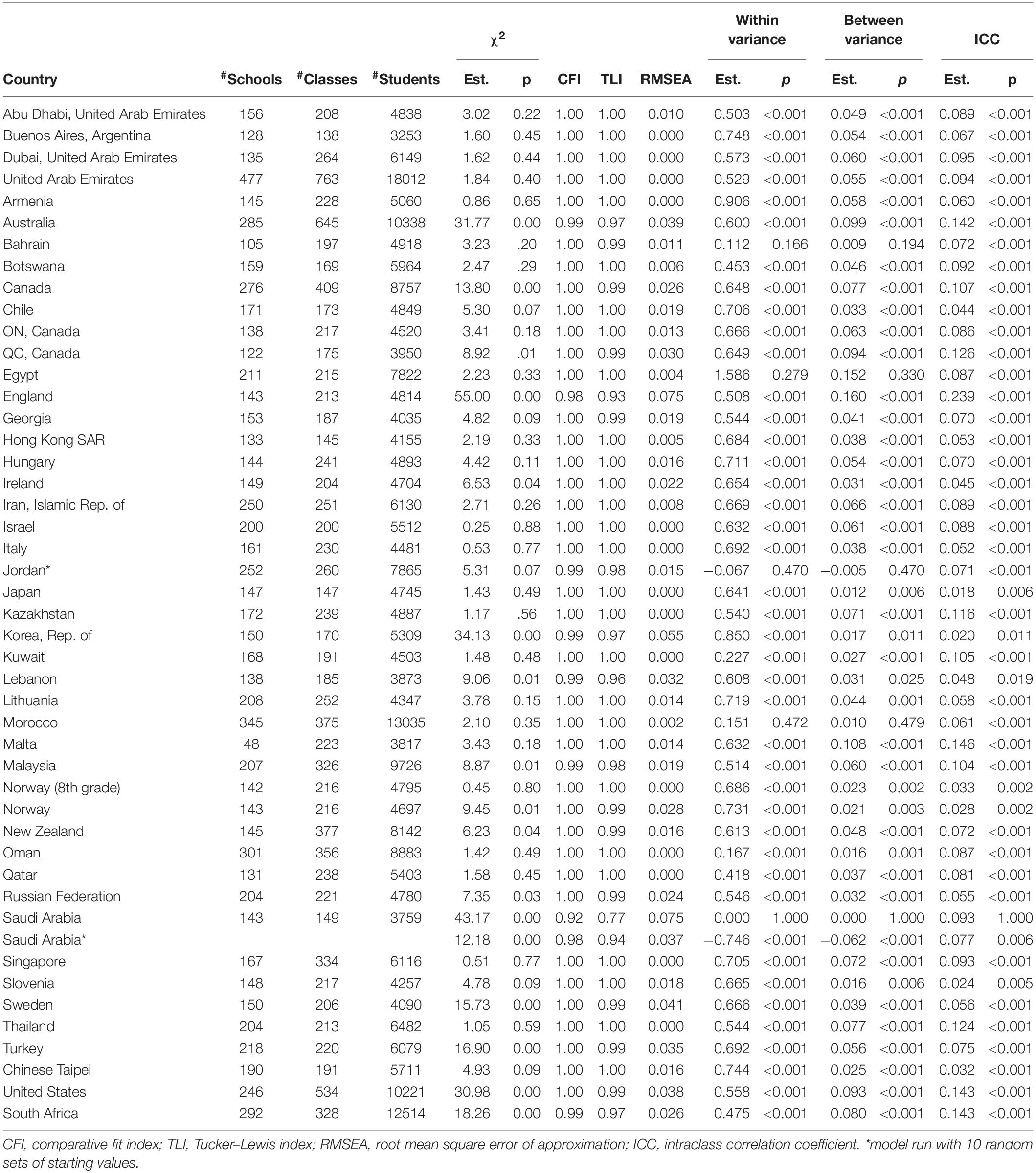
Table 2. Results of Model 1 in Eighth Grade.
Mathematics self-concept was measured by three items in each grade: (a) I usually do well in mathematics; (b) I am just not good at mathematics (for fourth-graders)/Mathematics is not one of my strengths (for eighth-graders); and (c) I learn things quickly in mathematics. This conceptualization of mathematics self-concept is consistent with Wang (2015); Wang and Bergin (2017) but differs from other articles using TIMSS data such as Marsh et al. (2014, 2015), which included a perceived relative standing item, Mathematics is more difficult for me than for many of my classmates for eighth-grade. A similar item in fourth grade is Mathematics is harder for me than for many of my classmates. Wang and Bergin (2017) argued that the perceived relative standing item should be separated from the self-concept items.
The three mathematics self-concept items were rated on a 1 to 4 Likert-scale (1 = Agree a lot, 2 = Agree a little, 3 = Disagree a little, 4 = Disagree a lot) and positively worded items were reverse coded so that a higher value corresponded to a higher level of self-concept. Mathematics self-concept was modeled as a latent variable with the three items as indicators and decomposed as having a within and between components during statistical modeling.
TIMSS databases use matrix sampling for the design of test administration where each student answered some but not all items on the test. Student achievement was estimated using item response theory together with a multiple imputation technique. Each student’s mathematics achievement was measured by five plausible values. Those plausible values are not appropriate for reporting individual achievement and are suitable for estimating group characteristics (Wu, 2005). When used for statistical analysis, the five plausible values are treated as multiply imputed values: the analysis is run five times, each time using a single plausible value, and the five sets of results are then combined for point estimates and statistical inference (Enders, 2010).
Data collected in each country are hierarchical because schools were selected first and then classes were selected within schools and either all or sampled students responded to the student survey and the achievement test. For the three-sampling-stage process, TIMSS used probability proportional to size (PPS) sampling to select schools, classes, and students so that schools with more students had a higher probability of being selected and each individual student in the population had roughly the same probability of being selected. Probability weights and adjustment variables for non-responses were calculated for each sampling stage. For analysis using data from each country, a two-level modeling technique was adopted: the within-level was the student level and the between-level was the class level, further clustering at the school-level was accommodated at the between-level by incorporating the probability weights and adjustment factors of selecting schools.
Two statistical models are used corresponding to the first two models in Wang and Bergin (2017). The first statistical model is the multilevel confirmatory factor analysis (CFA) model, which was applied for cross-level measurement invariance testing and separately for each country and grade (see Figure 1). The second statistical model is the multilevel SEM model where there are within and between effects of mathematics achievement on mathematics self-concept (see Figure 2). The rescaled difference between the between and within effects is the BFLPE.
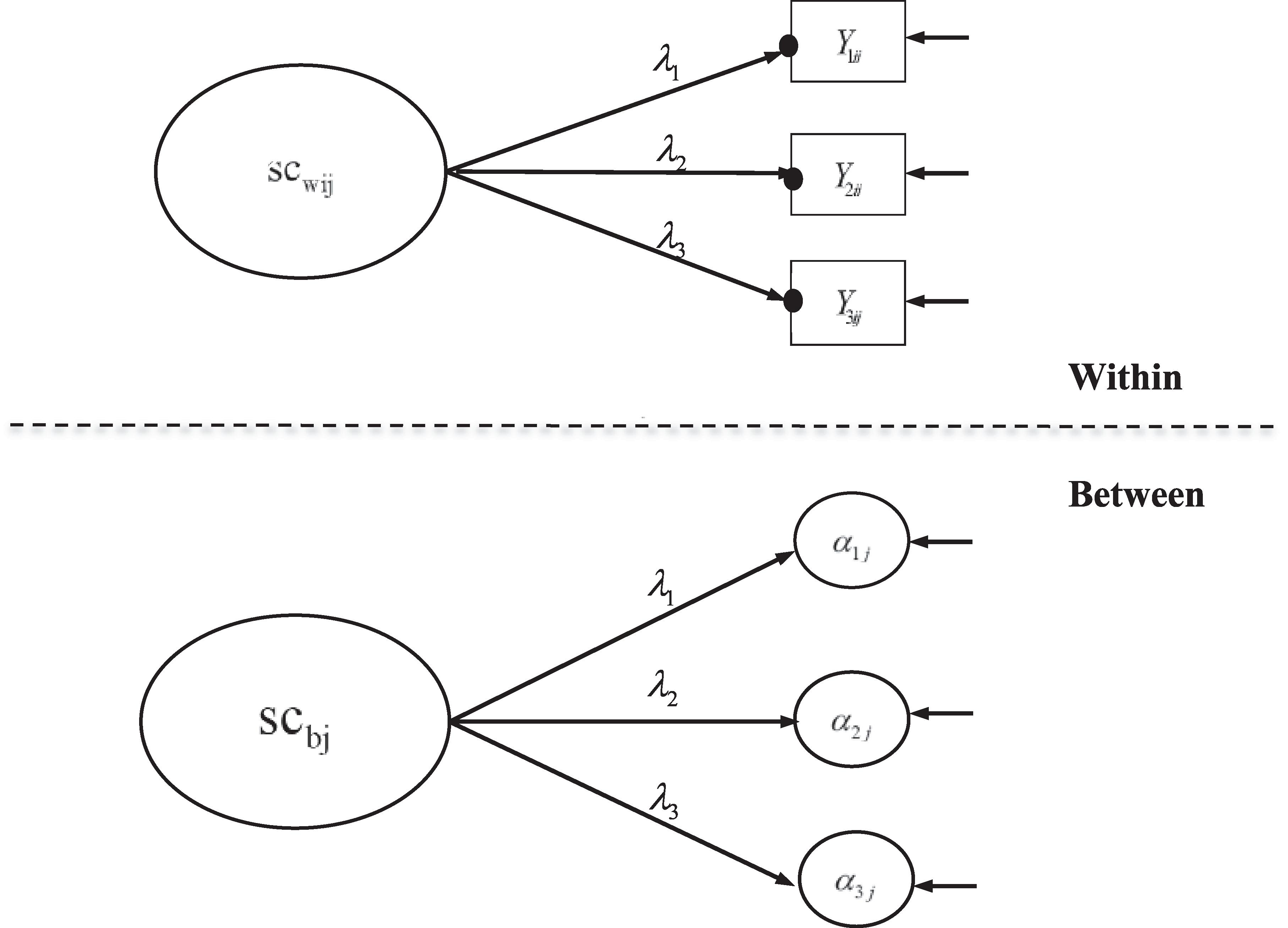
Figure 1. Statistical Model 1 – two-level confirmatory factor analysis model with multilevel measurement invariance of mathematics self-concept. The solid dots indicate random intercepts for different classes. Reprinted with permission from Wang and Bergin (2017); Copyright 2017 by Elsevier.
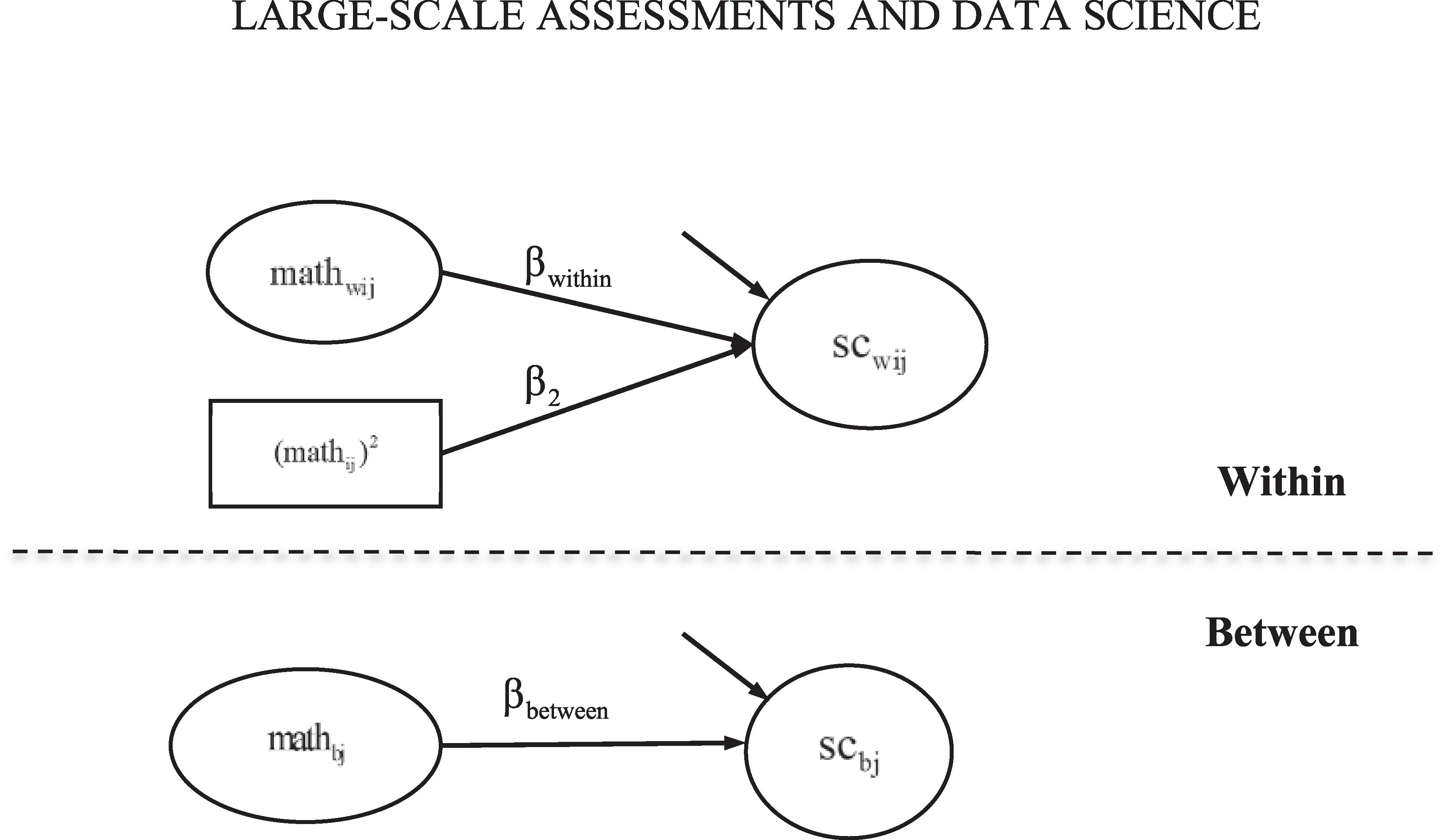
Figure 2. Statistical Model 2 – Model to test the big-fish-little-pond effect. Indicators of the within- and between-level mathematics self-concept are not shown in figure. Reprinted with permission from Wang and Bergin (2017); Copyright 2017 by Elsevier.
To illustrate the models, let Yij be a vector with three elements, representing values of the three mathematics self-concept items and let scij be the latent mathematics self-concept for student i in class j. In a single-level CFA model, Yij is the vector of indicators of scij. In the two-level model, scij is decomposed into a within and a between component.
where scwij is the within component and scbjis the between component. scwij and scbj each is measured by three indicators as shown in equations (2) and (3), respectively.
αj represents class-specific indicator intercepts at the within level that function as indicators of the latent factor scbj at the between level; γ is a vector of constants representing the grand mean indicator intercepts at the between level. λ is a vector of factor loadings that are invariant across levels. The invariance of cross-level factor loadings ensures that the interpretation of mathematics self-concept at the within and between levels is the same.
The predictor, mathematics achievement, is also decomposed into a within and a between components.
mathij is the mathematics achievement of student i in class j; μmath is a constant representing the grand mean of mathematics achievement for all students in all classes; mathwij is student i’s mathematics achievement around the class-average mathematics achievement; and mathbj is the average mathematics achievement for class j, around the grand mean.
Further, the relationship between mathematics self-concept and mathematics achievement is modeled at the two levels in equations (5) and (6), respectively.
In equation (5), the quadratic component of student mathematics achievement is included following previous BFLPE research (e.g., Marsh and Hau, 2003). The standardized effect size of the BFLPE can be calculated as:
Var(mathbj), Var(scwij), and Var(scbj) are the variances of the between-level mathematics achievement, the within-level self-concept, and the between-level self-concept, respectively. The detailed calculations of those variances are illustrated in Wang and Bergin (2017).
Here I explain the R syntax to examine the BFLPE using TIMSS 2015 data. First, Mplus and R are installed. I also recommend RStudio be installed. All syntax is written using RStudio as an R script (R scripts are like text files). Next, start R or RStudio and install the packages EdSurvey, MplusAutomation, and tidyverse. I also install the rlang package (Henry and Wickham, 2020b) for two functions related to expressions that are used in extracting model fit indices. After the packages are installed, load them using the library function. Packages only need to be installed once on the computer. However, they have to be loaded every time R or RStudio is started.

For large-scale analysis with many files, it is important to have a good file system. All related files for the present study are stored in the folder called “BFLPE study.” This folder is created manually in the C: drive and set as the working directory. Alternatively, one can create an R project using RStudio and associate the R project with this working directory. Except for this main folder, all other folders and their contents are created by running syntax in RStudio.
Under this “BFLPE study” folder, there are three subfolders called, “TIMSS,” “Mplus_g4,” and “Mplus_g8,” respectively. The “TIMSS” folder has a subfolder named “2015” inside which are TIMSS 2015 datasets downloaded via an internet connection, as well as META files and text files to be created to facilitate fast reading of data using the EdSurvey package. The “Mplus_g4” folder has two subfolders: “Model1” and “Model2,” corresponding to the two statistical models. “Model 1” includes all Mplus input, output, and data files used for the first statistical model (i.e., multilevel CFA) for all countries at the fourth-grade level and “Model 2” has all Mplus input, output, and data files for the second statistical model (i.e., the BFLPE model) for all countries at the fourth-grade level. The “Mplus_g8” folder also has two subfolders “Model1” and “Model2” with similar information but for eighth grade.

The object TIMSS_15_g8 is a survey data frame (SDF) which stores all TIMSS 2015 information from the student survey, teacher survey, school survey, as well as achievement information in eighth grade for all participating countries. For the remainder of this section, only syntax relevant to eighth-grade analysis is presented. Interested readers can easily modify the syntax to suit for fourth grade.
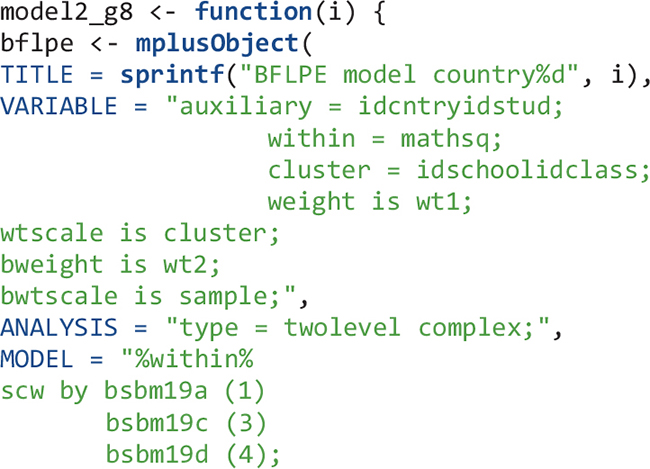
For this study, students’ mathematics achievement, the three items measuring their mathematics self-concept, and weight variables and adjustment factors accounting for the PPS sampling are used for analysis. Clustering within classes and schools are considered; country id and student id variables are specified as auxiliary variables just for quality control purposes (i.e., to make sure the data are created and used correctly).
The mathematics self-concept items in the SDF are stored as factors and need to be converted to numeric variables. Missing values are specified. All observed variables are standardized within each country. Weight variables and the square term of mathematics achievement used in the Mplus input files are created. For statistical model 1 (i.e., the multilevel CFA model), mathematics achievement data are not used so there is a single dataset for each country. For statistical model 2 (the BFLPE model), each plausible value of mathematics achievement is stored in a different dataset for a total of five datasets for each country. These five datasets are used as imputed datasets in the Mplus syntax.
For analysis, two mathematics self-concept items have to be reverse coded.

For each of the 46 countries, an object is created – using the mplusObject function – that contains all syntax sections needed to create a Mplus input file for Model 1 for that country. Next, the Mplus input file is created and run using the mplusModeler function. Iterations on countries are done using the map function. Datasets are exported and Mplus output files are created when the model is run. The readModels function extracts information in all Mplus output files in the folder.
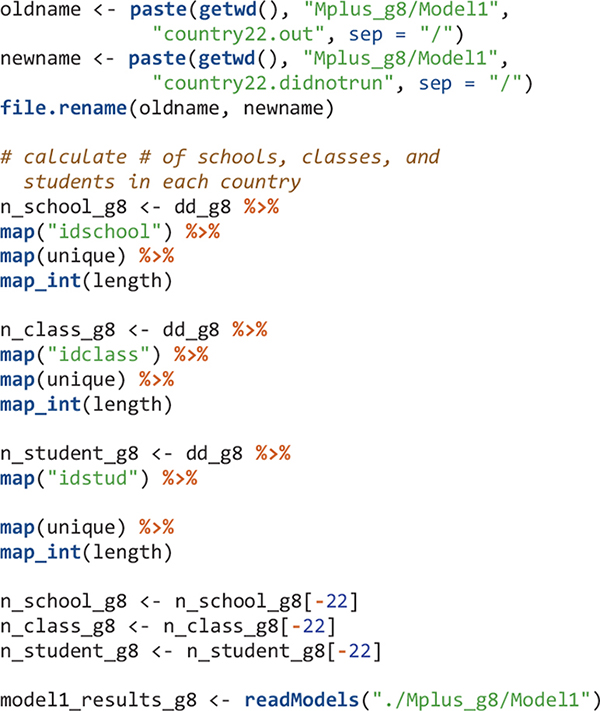
The next step after reading Mplus output files is usually to get some type of summary tables. However, for large-scale analysis using LSAs, oftentimes, the model for a few countries may not run properly. In that case, functions such as Summary Table and paramExtract of the MplusAutomation package will not work well and will give errors. Country 22 was the problematic one. Here I simply skip the Mplus output for this country and will manually revise the Mplus input file for this country later. To skip country 22’s Mplus output, I change its Mplus output file extension to.didnotrun so that this file would not be read using the readModels function. I also calculate the number of schools, classes, and students in each country.
The readModels function imports results into R as mplus.model objects with a predictable structure. This structure, shown in Table 3 of Hallquist and Wiley (2018), serves as a guide to what can be extracted from Mplus outputs.
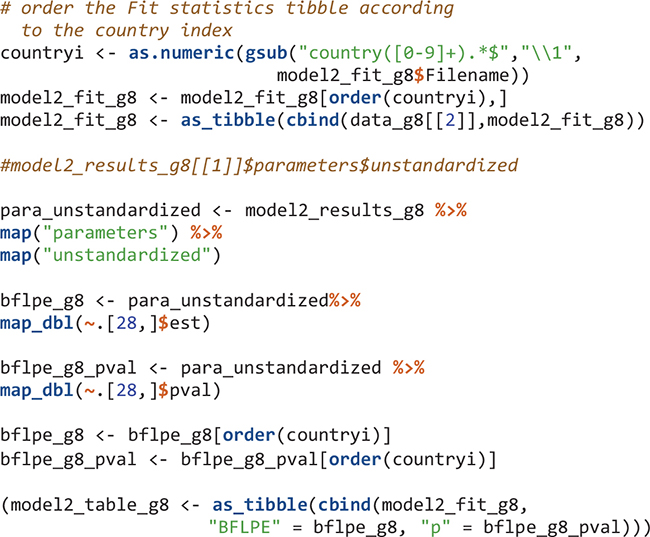
There are multiple summary and fit indices for the modeling results in each country. Extract such information can be easily done by applying the map function and its variants. To extract parameters, we need to know the position of the parameters in the results. For example, after viewing the model1_results_g8[[1]]$parameters$unstandardized object, the within-level variance of mathematics self-concept is in the fourth row. Its estimate and the p value of the estimate are extracted. All results for Model 1 are in the model1_table_g8 object.
The order of elements in R objects is important to match results for countries. The elements in edsurvey.data.frame.list objects in this study (e.g., TIMSS_15_g8 and data_g8) are in ascending order using three-letter country codes. Therefore, the first element is for Abu Dhabi, United Arab Emirates with country code “aad” and the second element is for Buenos Aires, Argentina using country code “aba.” When the Mplus input and output files are created, I simply name them by their country number; therefore the Mplus input and output for Abu Dhabi, United Arab Emirates are country1.inp and country1.out, respectively; and the Mplus input and output for Buenos Aires, Argentina are country2.inp and country2.out, respectively. When reading Mplus outputs using the readModels function, the order in the resulted mplus.model object (the “model1_results_g8”) is ascending alphabetically. Therefore, the first element in “model1_results_g8” has information for country1 and the second element has information for country10 (Chile) instead of country2. We reordered the elements in the mplus.model objects to be ascending according to country numbers (1, 2, 3, etc.).


For eighth-grade Model 2, the flow is similar: create an object that contains Mplus input syntax sections, create Mplus input files, run the model in Mplus, output the data and Mplus output files, read the Mplus output files, and extract summary and parameter information from the Mplus output files.

As explained in the Syntax section, Model 1 did not run successfully for Saudi Arabia (country47) in fourth grade and Jordan (country22) in eighth grade. In both cases, Mplus output messages that the Fisher information matrix is non-positive definite and this could be due to issues with starting values for the model parameters. Non-positive definite matrices cause problems in parameter estimation of latent variable modeling (i.e., Heywood cases; see Kolenikov and Bollen, 2012), indicate lack of model fit, and could be the result of model misspecification, empirical under-identification, sampling fluctuations, or even outliers (Bollen, 1987). For parameter estimation of multilevel CFA modeling with the maximum likelihood estimation with robust standard errors (MLR), by default, Mplus uses fixed starting values. These fixed starting values could lead to non-convergence of parameter estimation. For the two problematic cases (Saudi Arabia in fourth grade and Jordan in eighth grade) of Model 1, I manually modified the Mplus input files to use 10 random sets of starting values to address the issue of non-convergence of the fixed starting value run. After the modifications, the model estimation terminated normally, although there was a warning messaging of a non-positive definite covariance matrix for the latent variables.
In addition, after examining the summary results, I decided that the model for Saudi Arabia in eighth grade needed further attention because the estimates for the within-level variance and the between-level variance were both zero. This could suggest a problem with parameter estimation and changing starting values may solve the problem. I manually modified the Mplus input file to use 10 random sets of starting values. After the modification, the results were more trustworthy (see Table 1, row “Saudi Arabia*”).
Model 1 has two degrees of freedom. The model fit indices are in Table 1 for fourth grade and in Table 2 for eighth grade. Based on the regular model fit cutoffs (root mean square error of approximation, or RMSEA < 0.08; comparative fit index, or CFI > 0.95, Tucker–Lewis index, or TLI > 0.95) (Browne and Cudeck, 1993; Hu and Bentler, 1999; Kline, 2016), the model did not fit data from four (Czechia, France, Italy, and Saudi Arabia) of the 56 countries in fourth grade. However, only Italy had relatively poor model fit (CFI = 0.93, TLI = 0.79, RMSEA = 0.108). Czechia, France, and Saudi Arabia had relatively low TLI (0.93, 0.91, and 0.90, respectively) but their CFI values are greater than 0.95 and RMSEA values less than 0.08. In eighth grade, two (England and Saudi Arabia) out of the 46 countries did not have good model fit. Nevertheless, although both countries had relatively low TLI values (0.93 and 0.94, respectively), their CFI (0.98 for both countries) and RMSEA values (0.075 and 0.037, respectively) indicated adequate model fit.
Tables 1, 2 also include the within-level variance, the between-level variance, and the intraclass correlation coefficient (ICC) of mathematics self-concept for each country. For the three datasets (fourth grade Saudi Arabia, eighth grade Saudi Arabia, and eighth grade Jordan) that needed random sets of starting values, the estimates of the within-level variance and the between-level variance were negative. For the other datasets, in fourth grade, the within-level variance was statistically significant at the 0.05 level for all countries except Jordan (p = 0.326) and Oman (p = 0.777); the between-level variance was statistically significant at the 0.05 level for all countries except Australia (p = 0.071), Czechia (p = 0.090), Ireland (p = 0.088), and Netherlands (p = 0.430), as well as for Jordan (p = 0.379), and Oman (p = 0.781); the ICC ranged from 0.4% (Netherlands) to 27.7% (Indonesia). In eighth grade, the within-level variance was statistically significant at the 0.05 level for all countries except Bahrain (p = 0.166), Egypt (p = 0.279), and Morocco (p = 0.472); the same three countries had statistically non-significant between-level variance (p-Values were 0.194, 0.330, and 0.479 for Bahrain, Egypt, and Morocco, respectively); the ICC ranged from 1.8% (Japan) to 23.9% (England). A small ICC means that there is little between class variation compared to within class. However, a small ICC of mathematics self-concept can also be viewed as resulting from social comparison largely within the class.
Model 2 has nine degrees of freedom. Tables 3, 4 show modeling results for fourth grade and eighth grade, respectively. For each model fit index, there is a mean and a standard deviation. This is because the model for each country in each grade was actually run five times using the five plausible values of mathematics achievement in the TIMSS 2015 database and therefore there were five values for each model fit index. The mean and standard deviation of the five values were reported in the Mplus output. For example, the mean of CFI values for Abu Dhabi, United Arab Emirates in eighth grade was 0.93 with a standard deviation of 0.005. Using regular model fit cutoffs of CFI > 0.95 and TLI > 0.95 for the mean, most countries did not have adequate model fit. Using RMSEA < 0.08 for the mean, 52 out of 56 countries had good model fit in fourth grade and 43 out of 46 countries had good model fit in eighth grade.
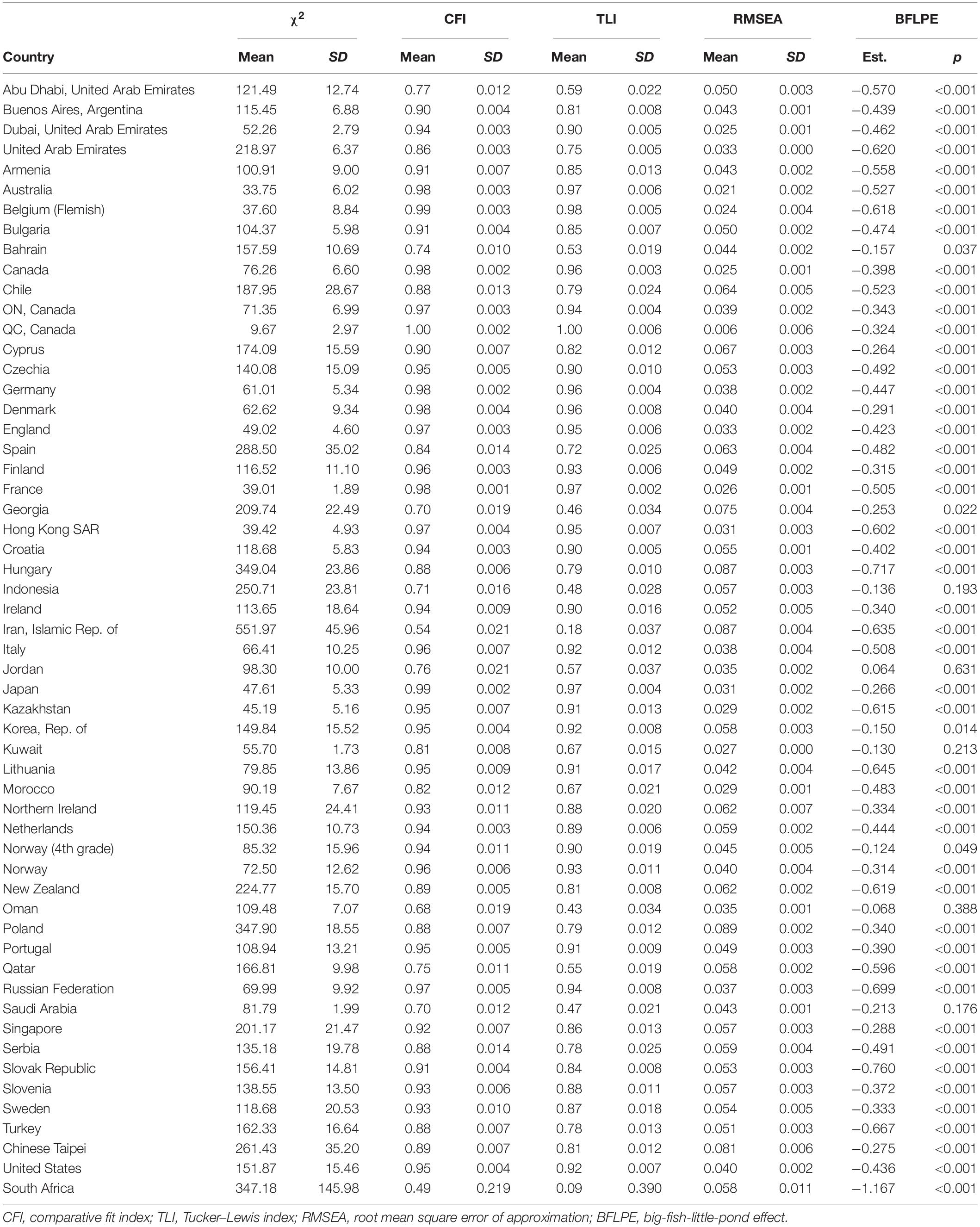
Table 3. Results of Model 2 in Fourth Grade.
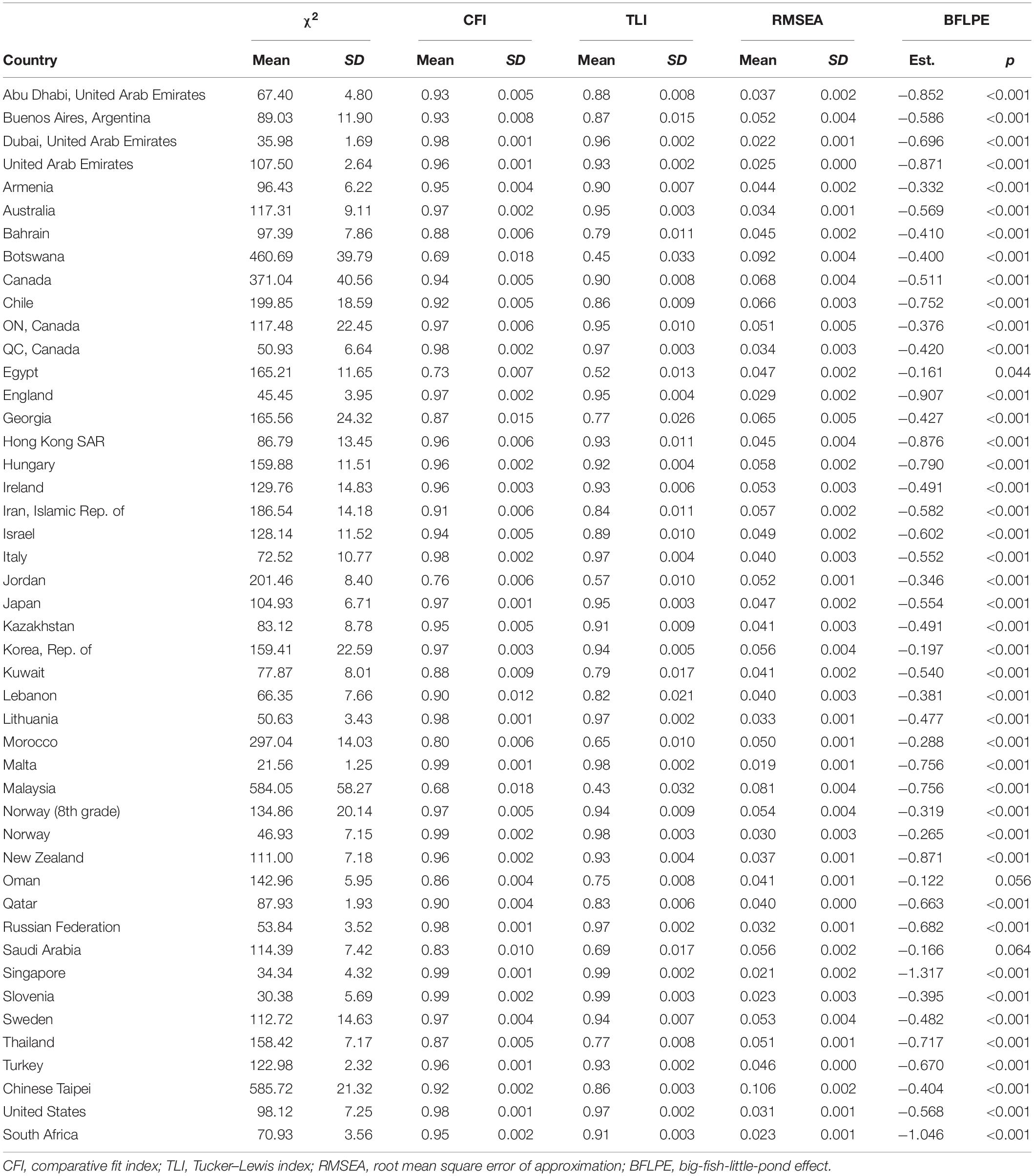
Table 4. Results of Model 2 in Eighth Grade.
In fourth grade, the BFLPE was negative and statistically significant at the 0.05 level in all but five countries (Indonesia, Jordan, Kuwait, Oman, and Saudi Arabia), ranging from −0.124 (Norway) to −1.167 (South Africa) with a mean of −0.461 and a median of −0.447 measured as the Cohen’s d. In eighth grade, the BFLPE was negative and statistically significant at the 0.05 level in all but two countries (Oman and Saudi Arabia), ranging from −0.161 (Egypt) to −1.317 (Singapore) with a mean of −0.576 and a median of −0.553. The model fit indices in general were not as good as those for Model 1. It is interesting to see that the countries where the BFLPE did not manifest tended to have some of the worst model fit.
Large-scale assessments such as those available from NCES are rich data sources for researchers to study substantive research questions. One particular challenge for using such data is due to their sizes. The researcher needs to navigate various documents and datasets to identify variables and information that are useful and has to be good at data wrangling. When the analysis has to be scaled up for many groups (e.g., states, countries, regions), manually running analysis for individual groups is tedious and should be avoided. Data science tools can be particularly useful because they can automate repeated actions.
In this study, I showed how to use three R packages, EdSurvey, MplusAutomation, and tidyverse to conduct a large-scale analysis of the BFLPE across countries. Mainly, the EdSurvey was used to obtain data, MplusAutomation was used to run complex multilevel latent variable models and to extract results from Mplus outputs, and tidyverse was used for data management. Although each of the three packages is quite useful in its own way, the combination of them is a powerful toolkit for applied quantitative researchers interested in using NCES data. With these few packages learned, a researcher can do most data wrangling and analysis of LSAs.
Other R packages have been developed that may also be useful for researchers interested in analysis of LSAs. The lavaan.survey package (Oberski, 2014) combines special features of the lavaan and survey packages to allow for SEM analysis of complex survey data. However, it also has some of the same limitations as lavaan and survey. For example, missing data cannot be handled with full information maximum likelihood together with survey weights. The MplusAutomation package, because it calls and therefore has the same capacity of modeling as Mplus, can apply more advanced methods to deal with missing data, complex survey designs, and other analysis issues. It is possible to only use existing R packages without having to rely on the external Mplus software to address the missing data and other issues. For example, the semTools package (Jorgensen et al., 2020) has the runMI function that can fit a lavaan model to multiply imputed datasets or fit the lavaan model while imputing the missing values using the Amelia (Honaker et al., 2011) or the mice (van Buuren and Groothuis-Oudshoorn, 2011) package. For more experienced R users, exploring various packages for specific data and analysis issues may be a joyful learning journey. However, for less experienced users who are interested in applying latent variable modeling to large-scale educational assessment data, I recommend spending time to get familiar with the three packages discussed in this study: EdSurvey, MplusAutomation, and tidyverse.
The BFLPE was found in 51 of the 56 countries in fourth grade and 44 of the 46 countries in eighth grade for the subject of mathematics, suggesting generalizability of the effect. Earlier work using TIMSS (Wang, 2015; Wang and Bergin, 2017) and PISA (Marsh and Hau, 2003; Seaton et al., 2009) also showed the existence of the BFLPE in many countries. While the theoretical explanation of the BFLPE is social comparison, it is not clear how students compare. Huguet et al. (2009) argued that forced upward social comparison with the entire class underlies the BFLPE and found that controlling for perceived relative standing would eliminate the BFLPE; however, Wang (2015); Wang and Bergin (2017) found that students’ perceived relative standing in the class did not eliminate but instead may decrease the BFLPE. All of these studies used cross-sectional data. In fact, the majority of existing BFLPE research has used cross-sectional, self-reported data. There is a need for future research based on alternative data types and formats of data collection.
Interestingly, Oman and Saudi Arabia did not have statistically significant BFLPE in both grades. Four (Cyprus, Algeria, Morocco, and Slovenia) of the 49 countries in Wang (2015) and one (Syrian Arab Republic) of the 59 countries in Wang and Bergin (2017) did not show statistically significant BFLPE for eighth-grade mathematics. It is not clear why these countries differed from other countries. It could be due to their education or social systems but a closer look at these countries may shed light on BFLPE research.
While the research on model fit of SEM is still quite active, there is little research on how these fit indices behave in large-scale analysis of complex survey data. In this project, I used traditional cutoffs for model fit indices that were developed based on single-level analysis and with the maximum likelihood estimator. The multilevel CFA model seemed to fit the data well in most of the countries, but the BFLPE model fit rather poorly in the majority of the countries. For the BFLPE model, the measurement model at both levels is saturated and constrained to have cross-level measurement invariance as in the multilevel CFA model. If the model fit indices are to be trusted, the poor fitting of the BFLPE model could be due to: (a) unmodeled relationships between the residuals of the self-concept indicator items and mathematics achievement, (b) the orthogonality assumption across levels, or (c) both (a) and (b). In SEM, it is typically not advised to include covariances between a predictor and the residuals of indicators of an outcome variable. The orthogonality assumption across levels is not a testable assumption for latent variables (mathematics self-concept in this project). Another possibility is that the relationship between mathematics achievement and mathematics self-concept could be reciprocal. While the BFLPE research uses achievement as the predictor and self-concept as the outcome, one’s self-concept could likely affect achievement.
Despite the large sample sizes, the structure of data used in this project is “simple” and data collection was through surveys only. The data are well organized and the unit of analysis is students. Data management is necessary for statistical modeling but could be done using techniques that are designed for traditional data analysis. A related concept is “big data,” which is a broader concept and the massive amount of data may be unstructured and in different formats such as texts, speeches, and photographs. From the “big data” standpoint, the data used for this study are “small data” – data that can be represented in spreadsheets on a single computer (Chen and Wojcik, 2016). In this study, I used many “small data” files, therefore, the term “large-scale.”
The use of technology allows the collection of behavior data that were not possible before. For example, the 2017 NAEP was administered for the first time as a digitally based assessment. Response process data were collected that could provide insights into students’ test-taking behaviors, how such behaviors relate to achievement, and even diagnostics of learning strategies. Other types of data such as videos, texts, online social network data (e.g., Twitter and Facebook) are additional examples. Researchers in psychology and other social sciences can take advantage of these more “novel” data types with the use of data science and big data tools (Chen and Wojcik, 2016).
This study shows that the analysis of many similarly structured datasets can be automated using data science tools. However, the researcher still needs to scrutinize modeling results to identify possible problems. Any result that looks suspicious should be examined more closely. For this project, I found that the initial results for Saudi Arabia in eighth grade could be problematic due to the estimates of variances of latent variables. Because the model did run and fit information could be extracted, I might have trusted the initial results. However, a closer look rendered that the initial model had a problem with starting values. The convenience of data science tools should not be substituted for content expertise.
This study has a didactic nature and focuses on analysis of LSAs. The field of data science and big data has begun to attract more researchers in social sciences (Gilmore, 2016); there is a high demand of tutorials showing “how to” use various data tools. Some tools are more general for writing purposes. For example, R Markdown is a powerful tool to create fully reproducible documents, combining code, results, explanatory texts, tables, references, etc. Other tools, such as those used in this study, are for more specific purposes. Teaching researchers how to use these tools can be a particularly useful area in its own right. We need “twofers” who can help bridge data engineering and domain knowledge to move both worlds forward.
Publicly available datasets were analyzed in this study. This data can be found here: https://timssandpirls.bc.edu/timss2015/international-database.
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. Written informed consent from the participants’ legal guardian/next of kin was not required to participate in this study in accordance with the national legislation and the institutional requirements.
ZW conceived the study, performed the statistical analysis, and wrote the manuscript.
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Bache, S. M., and Wickham, H. (2014). magrittr: A Forward-Pipe Operator for R. R package version 1.5.
Bailey, P., Emad, A., Huo, H., Lee, M., Liao, Y., Lishinski, A., et al. (2020). EdSurvey: Analysis of NCES Education Survey and Assessment Data. R package version 2.5.0.
Barrett, T. S. (2019). Six Reasons to Consider Using R in Psychological Research. Available online at: https://psyarxiv.com/8mb6d/ (accessed August 14, 2020).
Bollen, K. A. (1987). Outliers and improper solutions: a confirmatory factor analysis example. Sociol. Methods Res. 15, 375–384. doi: 10.1177/0049124187015004002
Browne, M. W., and Cudeck, R. (1993). “Alternative ways of assessing model fit,” in Testing Structural Equation Models, eds K. A. Bollen and J. S. Long (Thousand Oaks, CA: Sage), 136–162.
Chen, E. E., and Wojcik, S. P. (2016). A practical guide to big data research in psychology. Psychol. Methods 21, 458–474. doi: 10.1037/met0000111
Dowle, M., and Srinivasan, A. (2019). Data.Table: Extension of ‘Data.Frame‘. R Package Version 1.12.8.
Festinger, L. (1954). A theory of social comparison processes. Hum. Relat. 7, 117–140. doi: 10.1177/001872675400700202
Foy, P. (2017). TIMSS 2015 User Guide for the International Database. Boston, MA: TIMSS & PIRLS International Study Center, Lynch School of Education.
Gilmore, R. O. (2016). From big data to deep insight in developmental science. WIREs Cogn. Sci. 7, 112–126. doi: 10.1002/wcs.1379
Hallquist, M. N., and Wiley, J. F. (2018). mplusautomation: an R package for facilitating large-scale latent variable analyses in Mplus. Struct. Equ. Model. 25, 621–638. doi: 10.1080/10705511.2017.1402334
Henry, L., and Wickham, H. (2020b). rlang: Functions for Base Types and Core R and ‘Tidyverse’ Features. R package version 0.4.6.
Honaker, J., King, G., and Blackwell, M. (2011). Amelia II: a program for missing data. J. Stat. Softw. 45:47. doi: 10.18637/jss.v045.i07
Hu, L.-T., and Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: conventional criteria versus new alternatives. Struct. Equ. Model. 6, 1–55. doi: 10.1080/10705519909540118
Huguet, P., Dumas, F., Marsh, H., Régner, I., Wheeler, L., Suls, J., et al. (2009). Clarifying the role of social comparison in the big-fish–little-pond effect (BFLPE): an integrative study. J. Pers. Soc. Psychol. 97, 156–170. doi: 10.1037/a0015558
Jorgensen, T. D., Pornprasertmanit, S., Schoemann, A. M., and Rosseel, Y. (2020). semTools: Useful Tools for Structural Equation Modeling. R package version 0.5-3.
Kline, R. B. (2016). Principles and Practice of Structural Equation Modeling, 4th Edn. Los Angeles, CA: Guilford.
Kolenikov, S., and Bollen, K. A. (2012). Testing negative error variances: is a Heywood case a symptom of misspecification? Sociol. Methods Res. 41, 124–167. doi: 10.1177/0049124112442138
Lohr, S. (2014). For Big-Data Scientists, ‘Janitor Work’ is Key Hurdle to Insights. New York, NY: The New York Times.
Marsh, H. W. (1990). A multidimensional, hierarchical model of self-concept: theoretical and empirical justification. Educ. Psychol. Rev. 2, 77–172. doi: 10.1007/bf01322177
Marsh, H. W., Abduljabbar, A. S., Morin, A. J. S., Parker, P., Abdelfattah, F., Nagengast, B., et al. (2015). The big-fish-little-pond effect: generalizability of social comparison processes over two age cohorts from Western, Asian, and Middle Eastern Islamic countries. J. Educ. Psychol. 107, 258–271. doi: 10.1037/a0037485
Marsh, H. W., Abduljabbar, A. S., Parker, P. D., Morin, A. J. S., Abdelfattah, F., and Nagengast, B. (2014). The Big-Fish-Little-Pond Effect in mathematics: a Cross-cultural comparison of U.S. and Saudi Arabian TIMSS responses. J. Cross Cult. Psychol. 45, 777–804. doi: 10.1177/0022022113519858
Marsh, H. W., and Hau, K.-T. (2003). Big-Fish–Little-Pond effect on academic self-concept: a cross-cultural (26-country) test of the negative effects of academically selective schools. Am. Psychol. 58, 364–376. doi: 10.1037/0003-066x.58.5.364
Muenchen, R. A. (n.d.). The Popularity of Data Science Software. Vienna: R Language Training & Data Science Market Share Analysis.
Muthén, L. K., and Muthén, B. O. (1998-2017). Mplus User’s Guide, 8th Edn. North Yorkshire: Muthén & Muthén.
Nagengast, B., and Marsh, H. W. (2011). The negative effect of school-average ability on science self-concept in the UK, the UK countries and the world: the Big-Fish-Little-Pond-Effect for PISA 2006. Educ. Psychol. 31, 629–656. doi: 10.1080/01443410.2011.586416
National Center for Education Statistics (2020). History and Innovation. Available online at: https://nces.ed.gov/nationsreportcard/about/timeline.aspx (accessed August 14, 2020).
National Center for Education Statistics (n.d.). International Activities Program. Available online at: https://nces.ed.gov/surveys/international/index.asp (accessed August 14, 2020).
Oberski, D. (2014). lavaan.survey: an r package for complex survey analysis of structural equation models. J. Stat. Softw. 57:27. doi: 10.18637/jss.v057.i01
R Core Team (2020). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Raudenbush, S. W., and Bryk, A. S. (2002). Hierarchical Linear Models: Applications and Data Analysis Methods, 2nd Edn. Thousand Oaks, CA: Sage.
Rogers, C. M., Smith, M. D., and Coleman, J. M. (1978). Social comparison in the classroom: the relationship between academic achievement and self-concept. J. Educ. Psychol. 70, 50–57. doi: 10.1037/0022-0663.70.1.50
Rosseel, Y. (2012). lavaan: an R Package for structural equation modeling. J. Stat. Softw. 48:36. doi: 10.18637/jss.v048.i02
Rutkowski, L., von Davier, M., and Rutkowski, D. (eds) (2014). Handbook of International Large-Scale Assessment: Background, Technical Issues, and Methods of Data Analysis. Boca Raton, FL: Chapman & Hall/CRC Press.
Seaton, M., Marsh, H. W., and Craven, R. G. (2009). Earning its place as a pan-human theory: Universality of the big-fish-little-pond effect across 41 culturally and economically diverse countries. J. Educ. Psychol. 101, 403–419. doi: 10.1037/a0013838
Smith, T. J., Walker, D. A., Chen, H.-T., and Hong, Z.-R. (2020). Students’ sense of school belonging and attitude towards science: a cross-cultural examination. Int. J. Sci. Math. Educ. 18, 855–867. doi: 10.1007/s10763-019-10002-7
Suls, J., Martin, R., and Wheeler, L. (2002). Social comparison: why, with whom, and with what effect? Curr. Direct. Psychol. Sci. 11, 159–163. doi: 10.1111/1467-8721.00191
van Buuren, S., and Groothuis-Oudshoorn, K. (2011). mice: multivariate imputation by chained equations in R. J. Stat. Softw. 45:67. doi: 10.18637/jss.v045.i03
Wagemaker, H. (2014). “International large-scale assessments: from research to policy,” in Handbook of International Large-Scale Assessment: Background, Technical Issues, and Methods of Data Analysis, eds L. Rutkowski, M. von Davier, and D. Rutkowski (Milton Park: Taylor & Francis), 11–36.
Wang, Z. (2015). Examining big-fish-little-pond-effects across 49 countries: a multilevel latent variable modelling approach. Educ. Psychol. 35, 228–251. doi: 10.1080/01443410.2013.827155
Wang, Z. (2017). Editorial: large-scale educational assessments. Int. J. Quant. Res. Educ. 4, 1–2. doi: 10.1007/978-94-007-4629-9_1
Wang, Z., and Bergin, D. A. (2017). Perceived relative standing and the big-fish-little-pond effect in 59 countries and regions: analysis of TIMSS 2011 data. Learn. Individ. Diff. 57, 141–156. doi: 10.1016/j.lindif.2017.04.003
Wang, Z., Osterlind, S. J., and Bergin, D. A. (2012). Building mathematics achievement models in four countries using TIMSS 2003. Int. J. Sci. Math. Educ. 10, 1215–1242. doi: 10.1007/s10763-011-9328-6
Wickham, H., Averick, M., Bryan, J., Chang, W., McGowan, L. D. A., François, R., et al. (2019). Welcome to the tidyverse. J. Open Source Softw. 4:1686. doi: 10.21105/joss.01686
Keywords: big-fish-little-pond effect, data science, latent variable modeling, large-scale assessment, R, TIMSS
Citation: Wang Z (2020) When Large-Scale Assessments Meet Data Science: The Big-Fish-Little-Pond Effect in Fourth- and Eighth-Grade Mathematics Across Nations. Front. Psychol. 11:579545. doi: 10.3389/fpsyg.2020.579545
Received: 02 July 2020; Accepted: 25 August 2020;
Published: 30 September 2020.
Edited by:
Ronnel B. King, University of Macau, ChinaReviewed by:
Lu Wang, Ball State University, United StatesCopyright © 2020 Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ze Wang, d2FuZ3plQG1pc3NvdXJpLmVkdQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.