 Qingqing Feng†
Qingqing Feng† Qiongya Song
Qiongya Song Lijin Zhang
Lijin Zhang Shufang Zheng
Shufang Zheng Junhao Pan
Junhao Pan
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol. , 10 September 2020
Sec. Quantitative Psychology and Measurement
Volume 11 - 2020 | https://doi.org/10.3389/fpsyg.2020.02167
An increasing number of studies have focused on models that integrate moderation and mediation. Four approaches can be used to test integrated mediation and moderation models: path analysis (PA), product indicator analysis (PI, constrained approach and unconstrained approach), and latent moderated structural equations (LMS). To the best of our knowledge, few studies have compared the performances of PA, PI, and LMS in evaluating integrated mediation and moderation models. As a result, it is difficult for applied researchers to choose an appropriate method in their data analysis. This study investigates the performance of different approaches in analyzing the models, using the second-stage moderated mediation model as a representative model to be evaluated. Four approaches with bootstrapped standard errors are compared under different conditions. Moreover, LMS with robust standard errors and Bayesian estimation of LMS and PA were also considered. Results indicated that LMS with robust standard errors is the superior evaluation method in all study settings. And PA estimates could be severely underestimated as they ignore measurement errors. Furthermore, it is found that the constrained PI and unconstrained PI only provide acceptable estimates when the multivariate normal distribution assumption is satisfied. The practical guidelines were also provided to illustrate the implementation of LMS. This study could help to extend the application of LMS in psychology and social science research.
Within education and psychology research, mediation and moderation effects are usually applied to gain a better understanding of the relationships between the predictors and outcomes. Mediation models can help in understanding the mechanisms of observed phenomena. In the mediated mechanism, an indirect effect is an effect of an independent variable on a dependent variable via a mediator variable; a direct effect is an effect of an independent variable on a dependent variable without a mediator variable (Baron and Kenny, 1986). Moderation models demonstrate that the effects of predictors on outcomes are dependent on the moderators (James and Brett, 1984; Baron and Kenny, 1986). The integrated model of mediation and moderation incorporates the properties of mediation and moderation simultaneously in a single study to explain the complexity of real world (e.g., Liao et al., 2010; Teper et al., 2013).
There are two main types of integrated models for mediation and moderation, as delineated by statisticians: moderated mediation and mediated moderation (Baron and Kenny, 1986; Edwards and Lambert, 2007). The differentiation between these two main types depends on the importance of the moderated and mediated effects within an experiment (Baron and Kenny, 1986; Edwards and Lambert, 2007). In recent years, there have been many practical studies applying an integrated moderation and mediation approach. For example, this study identified 203 original articles with the keywords “moderated mediation” and 44 articles with the keywords “mediated moderation” published in the PsychArticle database between January 2000 and January 2020. Given that the majority of articles applied the moderated mediation model, this became the focus of this study. This model has a latent interaction effect between moderator and mediator variables, thus qualifying it as a representation of the integrated model. The method for testing a mediated effect in the integrated model is similar to that in the simple mediation model, which is easy for researchers to master. However, the moderated effect is much more difficult to calculate in this complex model than in the simple moderated model. Therefore, this study concentrates on the estimation of the path coefficient of the interaction effect under the second-stage moderated mediation model.
Throughout the study, variables correspond to the following basic equations:
This study uses X to represent the independent variable; Y to represent the dependent variable; M to represent the mediator, which mediates the relationship between X and Y; and Z to represent the moderator, which moderates the process of M predicting Y. According to the equations, the path coefficient from X to M is a and the path coefficient from X to Y is c. These two effects are classified as direct effects. The path coefficient from M to Y is b1, and from Z to Y it is b2. The parameter of the relationship from the interaction effect MZ to the dependent variable Y is b3.
Many researchers have discussed and applied the integrated moderation and mediation model in their studies, based on the manifest variable framework (e.g., Edwards and Lambert, 2007; Hayes, 2013; Fang et al., 2014). However, there has been less discussion and application of the approaches within the latent variable framework (Cheung and Lau, 2017). Within the latent variable framework, a measurement model is built to relate each latent variable to its corresponding indicators (Figure 1). We assume that the independent variable X and the moderator variable Z each have three indicators, and that the dependent variable Y and the mediator variable M each have four indicators. This assumption is only required to approximate an actual study. In reality, a study may not have three indicators with a just-identified model for every latent variable. Furthermore, different indicators for the variables M and Z, which would be used to form an interaction MZ, could increase the complexity in some approaches when forming the latent interaction term MZ. Taking the latent variable X as an example, its measurement model can be represented as:
where x1 to x3 are the indicators of latent variable X, τs are the intercepts, and λs are the factor loadings. The error variance is represented as Var(δxs) and the variance of latent variable X is Var(X). Similarly, the measurement models for Y, M, and Z can be defined in the same way.
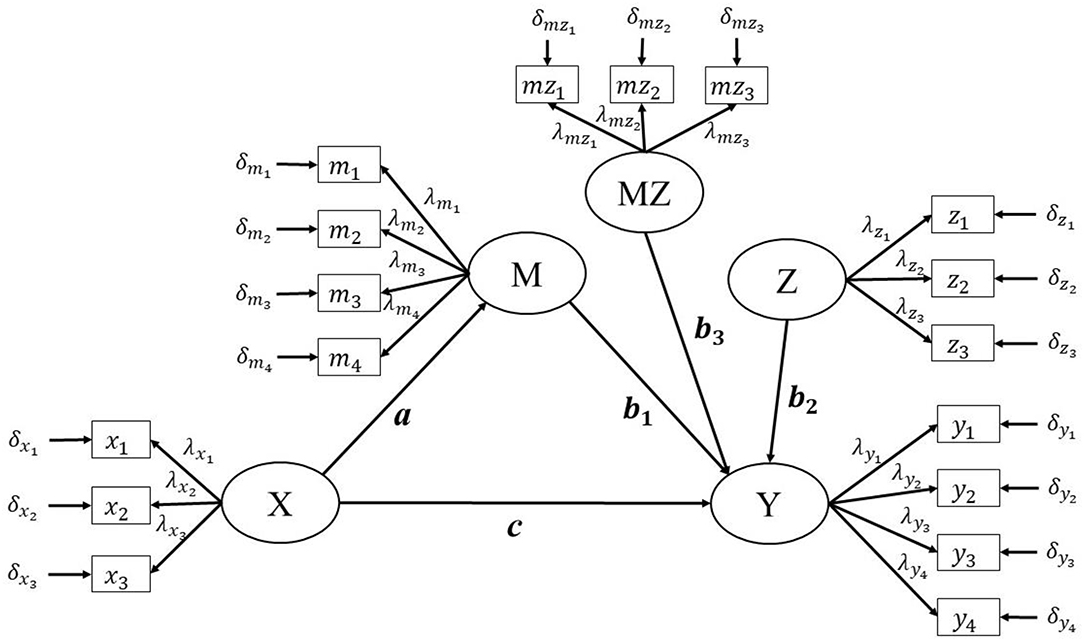
Figure 1. The population model of the Product Indicator approach's paring strategy of indicators.
It is inherently difficult to estimate the interaction effect in the integrated moderation and mediation model due to the complicated non-linear constraints in the latent framework (Jöreskog and Yang, 1996). Although many approaches have been developed and shown to work quite well in estimating the latent interaction effect (e.g., Klein and Moosbrugger, 2000; Algina and Moulder, 2001; Wall and Amemiya, 2001), a complete comparison of the approaches to clarify the optimal choice has not been conducted. This study addresses this research gap. Two simulation studies with different conditions are developed to evaluate the various methods for estimating the second-stage moderated mediation model. The approaches examined here were path analysis (PA), constrained product indicator analysis (CPI), unconstrained product indicator analysis (UPI), and latent moderated structural modeling (LMS).
Many previous researchers have provided procedures to use traditional regression methods to analyze moderated mediation (e.g., Muller et al., 2005; Edwards and Lambert, 2007; Preacher et al., 2007; Hayes, 2013). In contrast to traditional regression analysis, PA can simultaneously estimate all effects and integrate them into a single complete model framework. Based on this framework, PA uses the means of indictors to represent the value of the corresponding latent variables. For example:
Thus, the interaction term could be computed as:
PA has been employed extensively in practical research because it is easy to grasp and convenient to apply (Cheung and Lau, 2017). However, the use of PA has also been opposed due to its lack of consideration of measurement errors. Cheung and Lau (2008) have previously found that simple regression analysis for a mediation model underestimates the coefficients and the extent of underestimation increases as measurement errors increase. Statisticians have recommended methods within a latent framework to reduce such inaccuracy resulting from measurement errors (e.g., Marsh et al., 2004; Klein and Muthén, 2007; Wen et al., 2010). Considering the complicated latent interaction effect, measurement errors may lead to more bias in the integration model (Ree and Carretta, 2006; Cheung and Lau, 2008; Antonakis et al., 2010; Ledgerwood and Shrout, 2011).
Within the latent variable framework, Kenny and Judd (1984) proposed the idea of measuring a latent interaction effect by multiplying the indicators of two latent variables. On the basis of this concept, many statisticians have proposed and developed various approaches to estimate interaction effects using PI (e.g., Jöreskog and Yang, 1996; Klein and Moosbrugger, 2000; and Wall and Amemiya, 2001, 2003; Marsh et al., 2004). PI has proven to be more accurate than the traditional regression method and PA, as it considers the measurement errors of the product indicators (Jöreskog and Yang, 1996).
However, in practical research, PI has not been used as often as PA. There are two main reasons that the application of PI has been limited. One is that PI is quite difficult to grasp and carry out. The use of PI requires many extra constraints to identify the model. Although previous researchers have already developed the UPI approach (Marsh et al., 2004), many applied researchers still find it difficult to implement. The other reason that the application of PI has been limited is that it is difficult to choose and execute the most appropriate method to form the product indicators for the latent interaction effect (Marsh et al., 2004).
In this study, it is assumed that the three indicators of M and first three of the four indicators of Z were multiplied to form the indicators for the latent interaction factor, as detailed in the following equation:
Here, τmzss represent the intercepts of the product indicators, λmzss represent the factor loadings of the latent interaction, MZ represents the latent interaction factor, and Var(δmzs) represents the error variances.
Jöreskog and Yang (1996) introduced a strong constrained model, called the constrained product indicator (CPI) approach, of the latent interaction effect in order to identify the model. This approach assumes that indicators are centralized and multivariate normally distributed (Algina and Moulder, 2001). For example, the first (product) indicator for the latent interaction MZ could be represented as:
where the factor loadings and error variances of the indicator mz1 could be considered as functions of the factor loadings and error variances of the indicators of M and Z. The constraints of CPI consist of the variance and mean of the latent interaction of MZ, as well as the factor loadings and error variances of the indicators for MZ (Moulder and Algina, 2002; Marsh et al., 2004).
The constraint of the factor loading of indicator mz1 for MZ is:
Based on Equation 6, the error variances of the product indicators are not freely estimated.
The constraint of the error variances of indicators mz1 for MZ could be expressed as:
The constraint of the variance of MZ is as follows:
The constraint of the mean of latent variable MZ could also be expressed as:
However, Jöreskog and Yang's (1996) strong constrained model was too complex, given the increasing number of indicators. Therefore, it is difficult for most researchers to apply the model in real studies. Another limitation of the CPI approach is the assumption of the multivariate-normal distributed indicators. Although every indicator of the variable is normally distributed, the indicator for the latent interaction based on multiplication may not obey the normal distribution (Aroian, 1947; Moosbrugger et al., 1997). It is not clear how the non-normally distributed indicators of interaction would bias the estimation of the CPI approach.
Statisticians have considered various ways to relax the constraints and simplify the PI model, such as the partial constrained approach (Wall and Amemiya, 2001), the unconstrained approach (Marsh et al., 2004), and the expanded unconstrained approach (Kelava and Brandt, 2009). The unconstrained approach proposed by Marsh et al. (2004, 2013), which only requires the constraints of the latent mean (Equation 10), is commonly utilized. This is what is referred to as the UPI approach in this paper.
An advantage of the UPI approach is that it only requires the mean of the latent interaction to be fixed, which makes the approach easy to apply, even for complicated models. Additionally, simulation studies have identified that the UPI approach provides a more precise estimation than the CPI approach when data violate the multivariate normality assumption. However, compared to the Algina and Moulder (2001) revised strict constrained model, the UPI approach showed less power in the estimation, even under the multivariate normality assumption (Marsh et al., 2004).
In sum, there are four types of constraints involved in the PI approach: (1) the constraints of the factor loadings of the product indicators; (2) the constraints of the error variances of the product indicators; (3) the constraint of the variance of the latent interaction factor; and (4) the constraint of the mean of the latent interaction factor. Jöreskog and Yang (1996) CPI approach requires all four constraints, whereas Marsh et al. (2004) UPI approach requires a minimum of only one constraint, that is, the mean of the latent interaction should to be fixed. This study aims to compare these two approaches to evaluate the performance for the constrained form of the PI approach.
Another limitation of the PI approach is the difficulty researchers face in choosing among multiple indicators to construct the product indicators for the latent interaction factor (Marsh et al., 2004). Different strategies to construct the product indicators in the same model may perform differently (e.g., Marsh et al., 2004; Saris et al., 2007; Aytürk et al., 2019). Researchers need to choose suitable strategies to get a reasonable result, which makes the application of the PI approach a challenge.
There are many strategies to construct product indicators. The most widely applied strategies are Matching and Parceling (e.g., Marsh et al., 2004; Aytürk et al., 2019).
Indicators are paired according to factor loadings. This means that the indicators with larger factor loadings for M need to be multiplied with the indicators with larger factor loadings for Z. In this study, we could produce three product indicators for the latent interaction factor.
A parcel means an aggregation (e.g., average) of the indicators for the latent factors. The parceling strategy could help reduce the number of indicators by using the parcels to replace the original indicators. However, there are also many strategies to form the parcels, such as putting the indicators of the highest and the lowest factor loadings in one parcel or randomly setting the indicators.
Since the comparison between matching and parceling is not the focus of the current study, applied researchers are suggested to refer to previous studies for guidelines. Aytürk et al. (2019) pointed out that parceling has advantages of considering all the indicators while matching ignoring the remaining indicators which are not used for generating interaction terms. Since the number of indicators per factor is small in the current study, a matching strategy with multiple indicators, using indicators for M and Z with the highest factor loading, will be used (Marsh et al., 2004). The matching approach would be repeated until all indicators of one variable are matched (Figure 1).
Klein and Moosbrugger (2000) proposed the LMS equation modeling to address the estimation of the latent interaction model. The LMS approach constructs the latent interaction effect as a conditioned linear effect on another variable. It simply utilizes the original data to estimate the interaction, without introducing product indicators (Kelava et al., 2011; Aytürk et al., 2019).
LMS not only takes measurement errors into account, but also solves the two issues affecting the PI approach. LMS could prevent researcher frustration in terms of having to choose which strategy to use in constructing the product indicators. Furthermore, LMS does not require any extra non-linear constraints to identify the model and does not need the interaction indicators to obey the strict multivariate normally distributed assumption (Klein and Moosbrugger, 2000; Kelava et al., 2011). Many previous simulation studies have already proven that LMS can provide precise parameter and standard error estimates with smaller biases (Schermelleh-Engel et al., 1998; Klein and Moosbrugger, 2000). However, most mainstream analysis software cannot apply LMS with real study data. Issues are experienced in forming the conclusion for LMS, even with Mplus. For example, Mplus cannot export model fit indices that can be used to directly evaluate the model fitting of moderated mediation models (e.g., comparative fit index, CFI). These issues decrease the attractiveness of LMS for applied researchers.
Apart from the traditional maximum likelihood (ML) estimation, Bayesian estimation has also been demonstrated efficient in structural equation modeling and has recently become increasingly popular (van de Schoot et al., 2017). Compared with the ML estimator, Bayesian estimation is based on a sampling method rather than on asymptotic theory (large-sample theory), and thus performs better with small sample size (Muthén and Asparouhov, 2012). Moreover, without a strict assumption of normal distribution, the Bayesian method is also expected to have better performance with non-normally distributed data. In this research, to simply compare the Bayesian estimation with the ML estimator, we used both of them in LMS and PA since the CPI and UPI models cannot be conducted using Bayesian method in Mplus 8.41. Default settings of Mplus with non-informative priors were used except for the minimum number of iterations (which was set at 10,000) in Bayesian estimation. The default non-informative prior for the intercepts of items, factor loadings and path coefficients are N(0, infinity). For the variance-covariance matrix of latent variables, the default prior is inverse-Wishart(0, -p-1) where p is the dimension of the multivariate block of latent variables (Muthén and Muthén, 1998-2017). We obtained the point estimates using the median of posterior distribution and calculated the 95% credible interval based on the percentile method.
For the present research, two simulation studies with different conditions were conducted. In the first study, the data were generated to follow a normal distribution and have high/low reliability. Additionally, our definition called for no correlation between the moderator variable, Z, and the independent variable, X. In the second study, non-normally distributed data were taken into consideration. This study explored the tendency of estimates to be biased for non-normal distributions with different skews and kurtoses. The correlation of the independent variable, X, and the moderator variable, Z, was also considered in the second study.
The four approaches: PA, CPI, UPI, and LMS in these studies were compared. Since the bootstrap method is often required in mediation analysis, we obtained the bootstrapped standard errors and confidence intervals in four approaches using 100 bootstrap draws2, which is suggested as the least number of draws in the bootstrap method (Rutter, 2000). Since the bootstrap method is not available for the MLR estimator (Maximum Likelihood estimation with Robust standard errors), which is the default estimation method in LMS with Mplus, we also calculated the robust standard errors in LMS and compared this with the bootstrap method. As mentioned above, the LMS and PA approaches with Bayesian estimation were also taken into consideration.
As per the research design of Marsh et al. (2004), data are generated with a normal distribution. The settings for this are as follows: The population model in simulation studies is the same as that in Figure 1 except MZ does not have its indicator.
The factor loadings of the independent variable, X (λx1, λx2, and λx3), are 1.0, 0.65, and 0.72, respectively. The error variance of the indicators (Var(δxs)) are all set to 0.36/1.5. The intercepts (τxs) are 0.5 and the variance of X (Var(X)) is 1.0.
For the mediator variable M, the factor loadings of the four indicators (λm1, λm2, λm3, and λm4) are 1.0, 0.81, 0.53, and 0.66, respectively. The error variances (Var(δms)) are all 0.36/1.5. The intercepts (τms) are set to 0.5 and the residual variance of M (Var(δM)) is 0.36.
The indicators of the moderator variable, Z, have factor loadings (λz1, λz2, and λz3) of 1.0, 0.83, and 0.79, respectively. The error variances of the indicators (Var(δzs)) are all 0.36/1.5. The intercepts (τzs) are set to 0.5 and the variance of Z (Var(Z)) is 1.0.
The dependent variable, Y, has four indicators with factor loadings (λy1, λy2, λy3, and λy4) set as 1.0, 0.68, 0.75, and 0.83, respectively. The error variances (Var(δys)) are all 0.36. The intercepts of the four indicators (τys) are set to 0.5, and the residual variance of Y (Var(δY)) is 0.36/1.5.
Finally, the path coefficients in Equation 1 are set as follows: a = 0.75, c = 0.3, b1 = 0.56, and b2 = 0.48.
This study has a 4*3*2 design with a manipulation of the sample sizes, the effect of the interaction term, and the reliability of latent variable. The four levels of sample sizes are: (a) N = 100, (b) N = 200, (c) N = 500, and (d) N = 1,000. These sample sizes are typical in psychological research. N = 100 is considered the minimum sample size for SEM, N = 200 is a common, medium sample size (Boomsma, 1982), and a sample of 500 is considered large enough to provide unbiased estimates for most applied research (Kyriazos, 2018). Moreover, Cham et al. (2012) suggested that the sample size for latent moderation modeling should be relatively large, so the sample size of 1,000 was also considered in the current study.
There are also three levels of path coefficients of b3: (a) b3 = 0, (b) b3 = 0.2, and (c) b3 = 0.4. Among these settings, b3 = 0 is intended to test for the Type I error, and b3 = 0.2 and 0.4 are intended to test the power of the four approaches (Klein and Moosbrugger, 2000).
We set the error variances of the indicators to control for the reliability of the latent variable, and under high reliability conditions, the error variances of the indicators are all set to 0.36. The mean reliability of the four latent variables X, M, Z, and Y were 0.822 (SD = 0.013), 0.836 (SD = 0.012), 0.859 (SD = 0.010), and 0.896 (SD = 0.008) in the condition of N = 500 and b3 = 0.2. All variables are identified to have high reliability. Under low reliability conditions, the error variances (δs) were changed to 1.5 in accordance with previous research by Cheung and Lau (2017). The mean reliability of the latent variables, X, M, Z, and Y, were set as 0.542 (SD = 0.037), 0.569 (SD = 0.033), 0.601 (SD = 0.030), and 0.684 (SD = 0.024), respectively, in the same condition. The mean reliability of X, M, Z, and Y barely changed across the same (high or low) reliability conditions, demonstrating that the manipulation of reliability was successful.
This study aims to test the four approaches with the bootstrap method in the 24 conditions with the generated data. The simulation data are generated by the statistical program R (version 3.5.3). The 24 conditions each have 1,000 replications. The Monte Carlo experiments were conducted using Mplus 8.4 (Muthén and Muthén, 1998-2017).
In the simulation study, the performance of the approaches is evaluated using five different measures: relative bias of parameter estimates, standard error (SE) ratio, coverage rate, power and type I error, and completion rate. These are all common assessment metrics for the accuracy of parameter estimates.
The relative bias measure is the relative bias between the estimated value and the true value of a parameter. The equation for relative bias, represented by RB, is:
where is the estimated value and θ is the parameter's true value. |RB| ≤ 10 % is a threshold typically accepted by researchers (Flora and Curran, 2004).
The SE ratio is the ratio between the mean of the standard error of in 1,000 replications and the standard deviation of across 1,000 replications, which is defined as:
A ratio between 0.9 and 1.1 is usually accepted as representing a relatively precise estimation (Hoogland and Boomsma, 1998).
The coverage rate is the probability that the estimate values will fall in the 95% (bootstrapped) confidence interval/Bayesian credible interval. Usually, the coverage rate needs to be over 90% to ensure the likelihood that the parameter estimation results are included (Collins et al., 2001). The coverage rate relates to the estimation's relative bias and its SE.
Power is the probability of correctly rejecting the false null hypothesis; that is, when parameters are non-zero. On the contrary, if the null hypothesis is true, then the probability of the false rejection of the null hypothesis is the type I error when the true values of parameters are zero.
The acceptable level of power is above 80%. The Type I error rate should be within the 95% confidence interval of a binomial variable [0.0365, 0.0635] (; Cham et al., 2012).
The completion rate is the proportion of replications with fully proper solutions in the 1,000 replications for each condition.
Marsh et al. (2004) found that the change of the interaction term does not heavily influence the estimation of the main effect. Results in the current study also demonstrated the same conclusion except for the PA method. Thus, to save space, we focus on the estimates of the path coefficient b3 and the moderated mediation index (a * b3, Hayes, 2015), and the estimates of indirect effects at different values of the moderator (a * (b1 + b3*Z), when Z = 0, 1 SD, − 1 SD) in the four analysis approaches. The comparison applies the five evaluation measures. The detailed results of the main effects are available in the Supplemental Materials. All the simulation materials including data generation, analysis, evaluation measurements and so on are also uploaded as the Supplemental Materials.
As detailed in Tables 1–3, PA with bootstrap method / Bayesian estimation underestimated the parameters which are not zero (e.g., b3= 0.2 and 0.4, the average indirect effects), and the relative biases are unacceptable when reliability is low. The average estimates of indirect effects and moderated mediation index were also seriously biased using path analysis even when the reliability was high. This result aligns with previous researchers' conclusions about PA regarding parameter underestimation (Cheung and Lau, 2017).
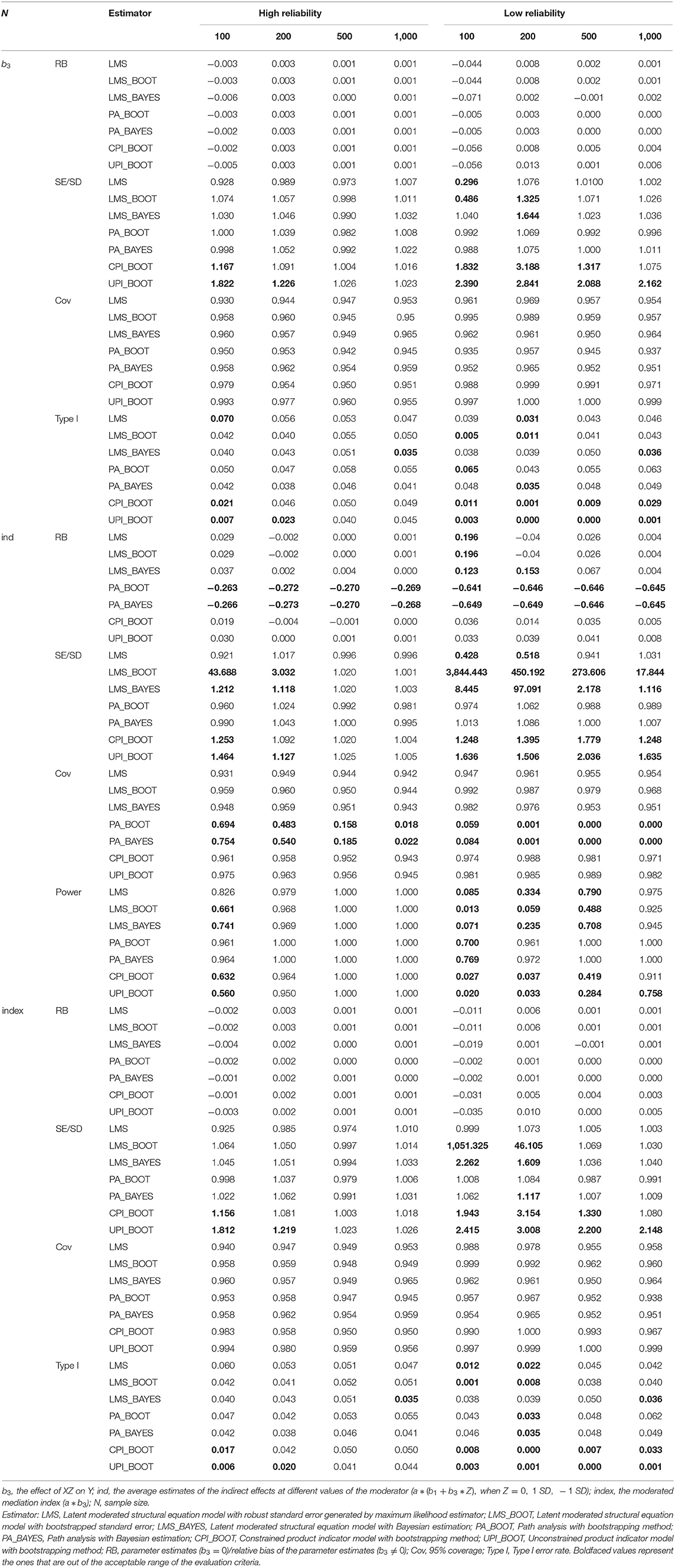
Table 1. Results of Simulation Study 1 when b3 = 0.
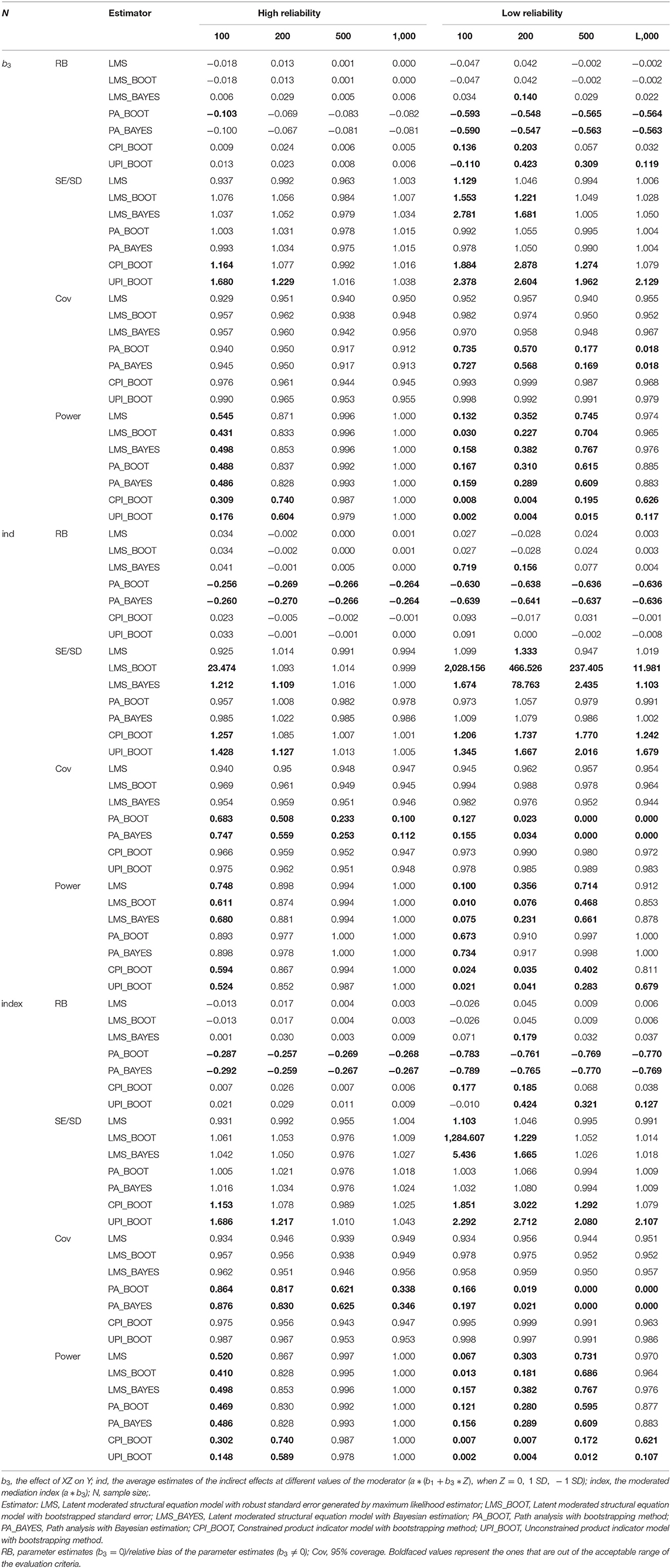
Table 2. Results of Simulation Study 1 when b3 = 0.2.
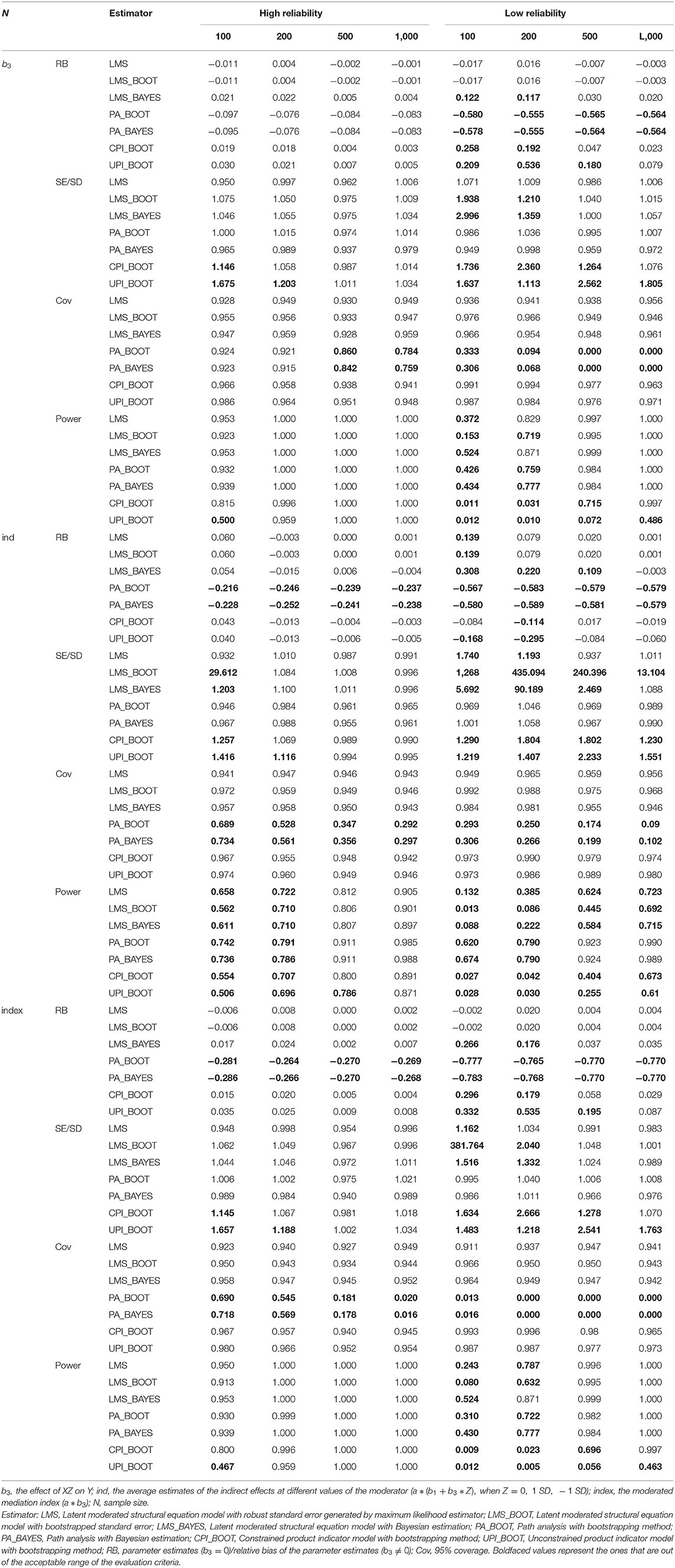
Table 3. Results of Simulation Study 1 when b3 = 0.4.
Moreover, when reliability is high, LMS, CPI, and UPI provide smaller estimate biases than PA, and the estimated values using these three approaches are expected to become more precise as the sample size increases. Under the condition of low reliability, although CPI and UPI presented biased estimates in many situations, CPI was more suitable than UPI overall. However, as demonstrated by previous research (Marsh et al., 2004), when sample size was small (N = 100), UPI was less biased than CPI when reliability was low.
Compared with the other three approaches, LMS always resulted in a lower relative bias of the estimates, especially with low reliability. LMS with ML estimation provided more accurate estimates than the Bayesian estimation under most conditions. However, LMS with Bayesian estimation performed best among all the approaches in many conditions when the sample size was 100 and b3 ≠ 0.
The SE ratios of LMS with robust standard errors and PA were all within the acceptable interval of [0.9, 1.1] when the reliability is high, which demonstrates a relatively accurate estimate. This result is superior to the results for CPI and UPI, which both could not provide a relatively precise estimate of the SE. With low reliability, these two approaches can also provide an acceptable SE ratio under most conditions. Both CPI and UPI had SE ratios that fell outside of the standard interval of [0.9, 1.1].
Moreover, LMS with the bootstrap method seriously overestimated the standard errors of indirect effects when the sample size was 100 or reliability was low, which can be circumvented by the robust standard error. LMS with Bayesian estimation performed better than the bootstrap method in these conditions; however, it still overestimated standard errors.
The coverage rates of the PA decreased as the sample size grew. When the sample size is no less than 500 or the parameters of interest are the moderated mediation index and the indirect effects, PA cannot achieve acceptable coverage rates in most conditions. LMS, CPI and UPI could fit the 90% coverage rate when reliability is high. Under low reliability conditions, PI and LMS had acceptable coverage rates in most conditions, but PI performed better than LMS because PI produced overestimates of SE.
Results show that all four approaches would have a higher power with an increased sample size (N), path coefficient of interaction (b3), and reliability. The statistical power of LMS and PA was found to be higher than that of CPI, and the statistical power of CPI was higher than that of UPI across all conditions. When reliability is low, all the approaches would all be less capable of providing an acceptable power of b3 and moderation effect when the sample size is low (N = 100 and N = 200). Considering indirect effects, PA performed best and still provided acceptable power even with low reliability while other approaches failed.
When b3 = 0, the four approaches can be compared with regards to the type I error. Table 1 shows that the type I error of the four approaches is between [0.006, 0.070] and [0, 0.063] when the reliability is high or low, respectively. Of the four approaches, PA and LMS had a relatively larger type I error, and UPI resulted in the lowest type I error. In three LMS modeling conditions, LMS with the bootstrap method performed best when the reliability was low since it often overestimated the standard error.
Table 4 shows the completion rate of these approaches under different conditions. PA had a 100% completion rate across all conditions. Additionally, LMS and CPI had acceptable completion rates, whereas UPI had the lowest completion rate when the conditions involved low reliability and relatively small sample size (N = 100 and 200).
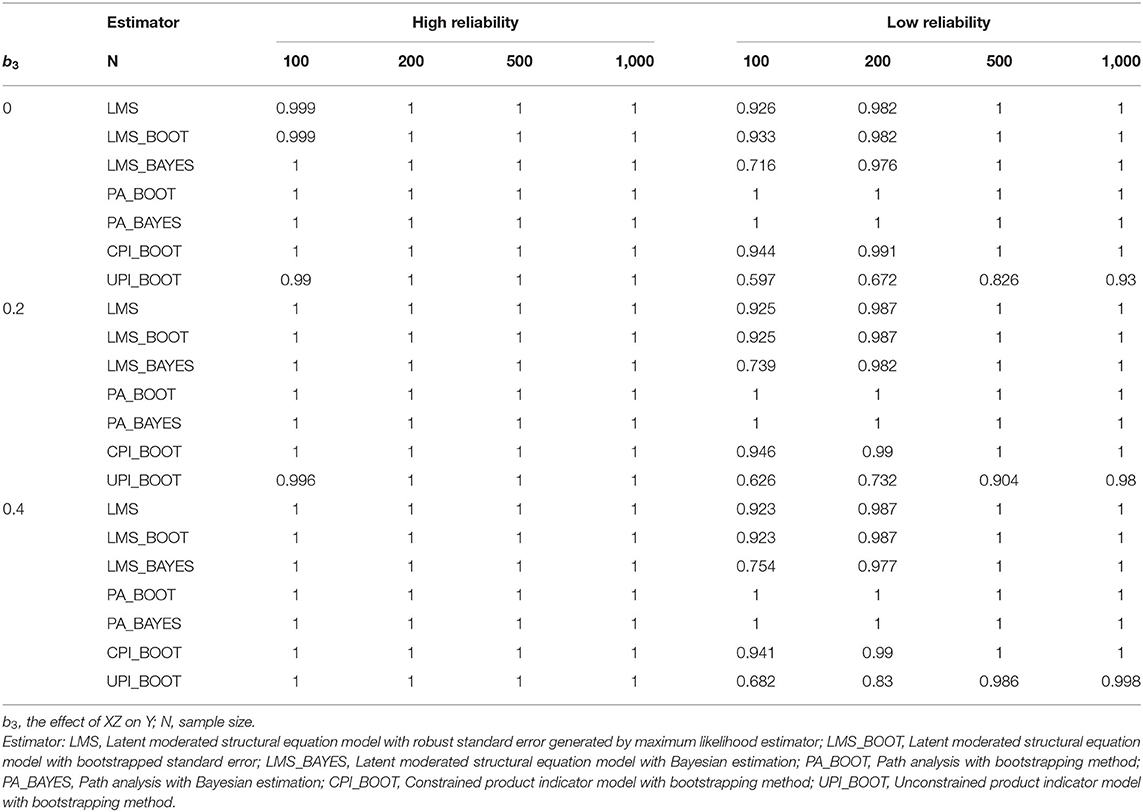
Table 4. Completion rate of the four approaches in study 1.
Previous research has taken the violation of the normality assumption, and the influence this has on the estimations of the path coefficient of the interaction effect, into account (e.g., Marsh et al., 2004). Although the indicators of M and Z are normally distributed, the product indicators of MZ and the latent interaction of MZ may not obey the assumption of multivariate normality (Klein and Moosbrugger, 2000). This condition would result in a biased estimation of the SE, significance testing, and confidence interval, which are all based on the multivariate normally distributed assumption. Study 1 and previous research (Marsh et al., 2004) have proven that PIs can provide unbiased estimates when using normally distributed data. However, if the indicators of M and Z are non-normally distributed, CPI is found to result in more biased estimates than UPI (Marsh et al., 2004). For indicators that are slightly non-normal (e.g., skewness = 0.5 and kurtosis = 1.1), LMS's estimates are still within the acceptable interval (Klein and Moosbrugger, 2000; Klein and Muthén, 2007), and have stronger testing power (Cham et al., 2012). Nevertheless, for the indicators that are strongly non-normal (e.g., skewness = 0.9 and kurtosis = 1.5), researchers have found that both LMS and CPI would be biased in estimating the path coefficient of the interaction effect (Coenders et al., 2008). In study 2, we explore the effects on the estimates of the four approaches with varying non-normally distributed data.
In study 1, we neglected the possibility that X and Z were correlated. However, this is likely in practical situations, particularly in the moderated mediation model. Therefore, in study 2, we also compared the estimates based on the four approaches when X and Z were related. In other words, the correlation of X and Z was set at 0 / 0.3.
The data settings in study 2 are similar to those in study 1 regarding the factor loadings, error variances of indicators, variances of latent variables, and path coefficients of a, b1, b2, and c. To simplify, only high reliability conditions will be considered in study 2. Moreover, we will only consider b3 = 0 and 0.2 for the path coefficient of the interaction effect with N = 200 (which represents a common, medium sample size in psychology research, Boomsma, 1982).
This study controlled the distribution of errors (δ) for the indicators of M and Z to create non-normally distributed data. There were five types of distributions for the data:
Type 1: Normal distribution: δms, δzs ~ N(0, 0.36).
Type 2: Uniform distribution: δms, δzs ~ U[0, 1].
Type 3: Symmetrical moderated kurtosis distribution: δms, δzs ~ (Hu and Bentler, 1998).
Type 4: Symmetrical high kurtosis distribution: δms, δzs ~ (Cham et al., 2012).
Type 5: Slightly skewed distribution: δms, δzs ~ .
The distribution of errors (δ) for the indicators of X and Y were still normally distributed as in study 1.
Based on the five distributions of data, the estimates of different effects are shown in Tables 5, 6.
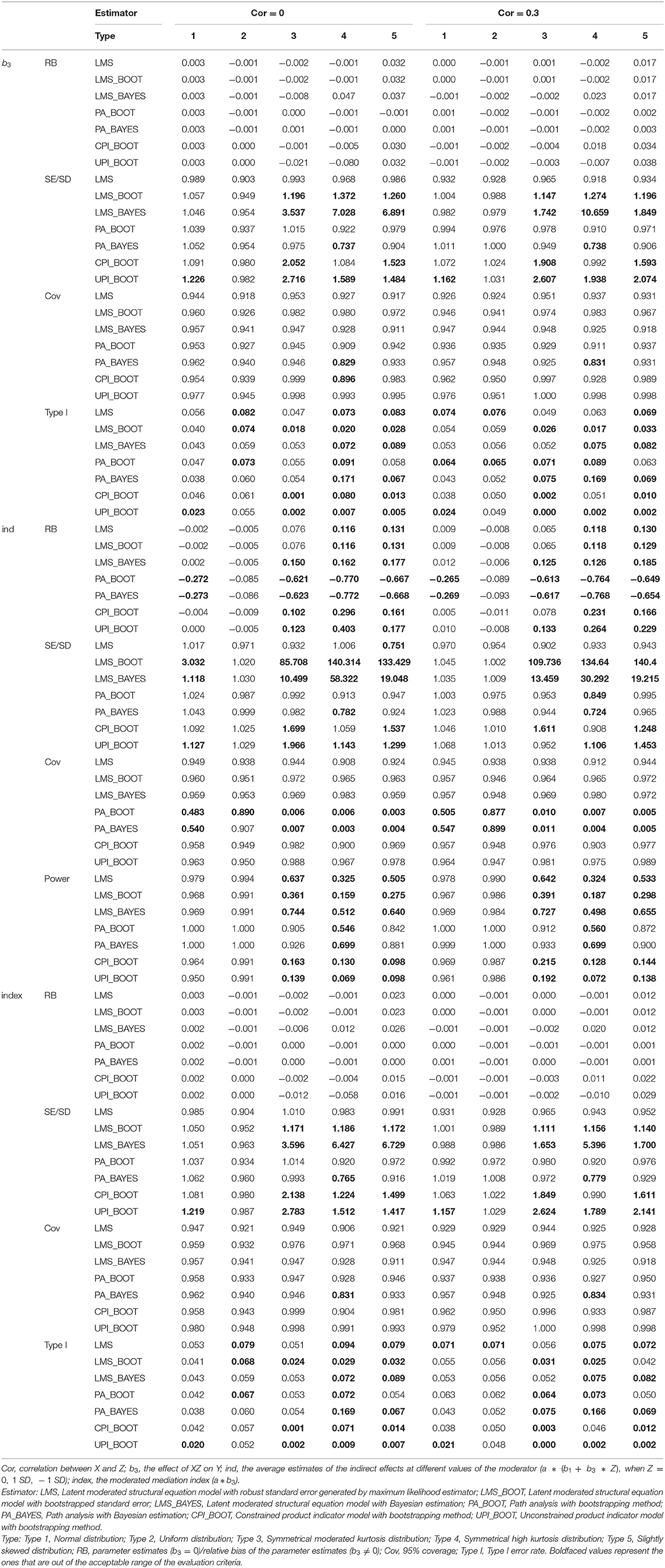
Table 5. Results of Simulation Study 2 when b3 = 0.
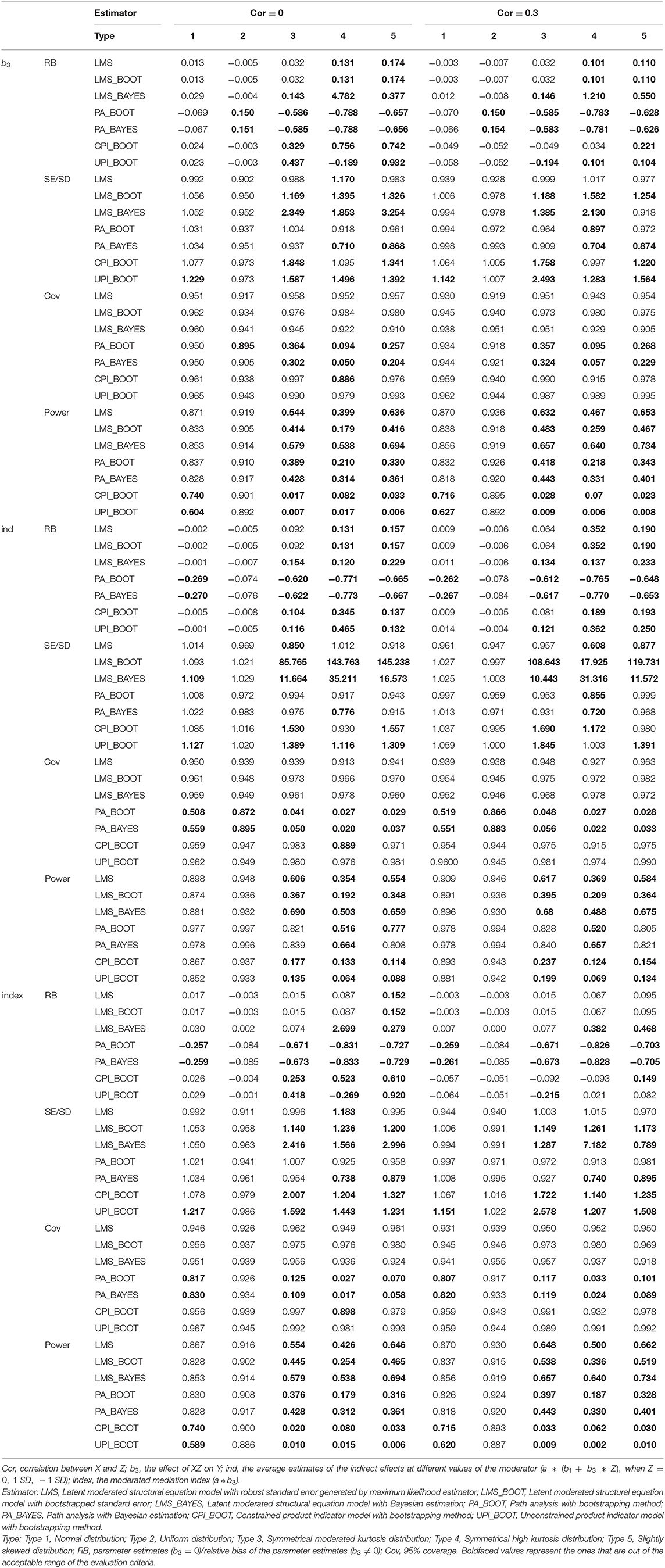
Table 6. Results of Simulation Study 2 when b3 = 0.2.
Similar to study 1, this study focuses on comparing the estimates of the path coefficient (b3) of the interaction MZ, the moderated mediation index (a * b3), and the average estimates of indirect effects at different values of the moderator (a * (b1 + b3*Z), when Z = 0, 1 SD, − 1 SD) through the four approaches.
According to Tables 5, 6, results were similar when the correlation between X and Z is 0 or 0.3. Specifically, when the correlation is not zero, the estimates of four approaches were generally better, compared to zero-correlation conditions. Within the conditions of normal distribution and uniform distribution (Types 1 and 2), CPI, UPI and LMS can provide unbiased estimates, LMS had the smallest relative bias when b3 ≠ 0. When b3 = 0, the results of LMS and PI were similar. The accuracy of estimates with PA was relatively lower than that of the other three approaches when the parameters of interests were not zero. PA estimation was even less suitable when the data had a symmetrical moderated kurtosis distribution, a symmetrical high kurtosis distribution, or a slightly skewed distribution (Types 3–5). For the Type 3 data, only estimates by LMS with maximum likelihood estimator met the criteria when b3 ≠ 0.
When cor (X, Z) = 0, for Type 4 data, no approach could provide an acceptable biased estimate of the latent interaction effect when it is not zero. Of the four approaches, LMS's estimates with maximum likelihood estimation had a relatively smaller bias than did the others. When cor (X, Z) = 0.3, CPI could estimate the path coefficient of the interaction effect more accurately than did LMS with a symmetrical high kurtosis distribution (Type 4). For the slightly skewed distributed data (Type 5), all approaches had a relative bias higher than the required standard of 10% when the parameter is not zero. Nevertheless, LMS still presented the smallest relative bias. In general, LMS performed best in terms of the coefficient estimates for all five distributions.
Compared with the maximum likelihood estimation, results did not show any obvious advantages of the Bayesian method in non-normality conditions.
Based on the SE ratio criterion, only the results of LMS with robust standard errors were acceptable under all conditions except for Type 4 data and b3 = 0.2.
To make a preliminary comparison between the bootstrapped SE and the default SE generated by the ML estimator, we also compared the bootstrapped SE with 100 draws and the default SE in this study. Moreover, to explore whether the SE overestimates were caused by the low number of draws, we also considered bootstrapped SE with 1,000 draws. To save space, we only reported the SE results of this extra investigation. Results showed that PI without the bootstrap method underestimated the standard errors. In comparison, PI with the bootstrap method overestimated the standard errors, thus performing better in coverage rate and worse in power (Table 7). Additionally, the bootstrap method with 1,000 draws still overestimated the SE and could not provide the acceptable SE when data was seriously non-normally distributed. The results were similar to the bootstrap method with 100 draws in most conditions.
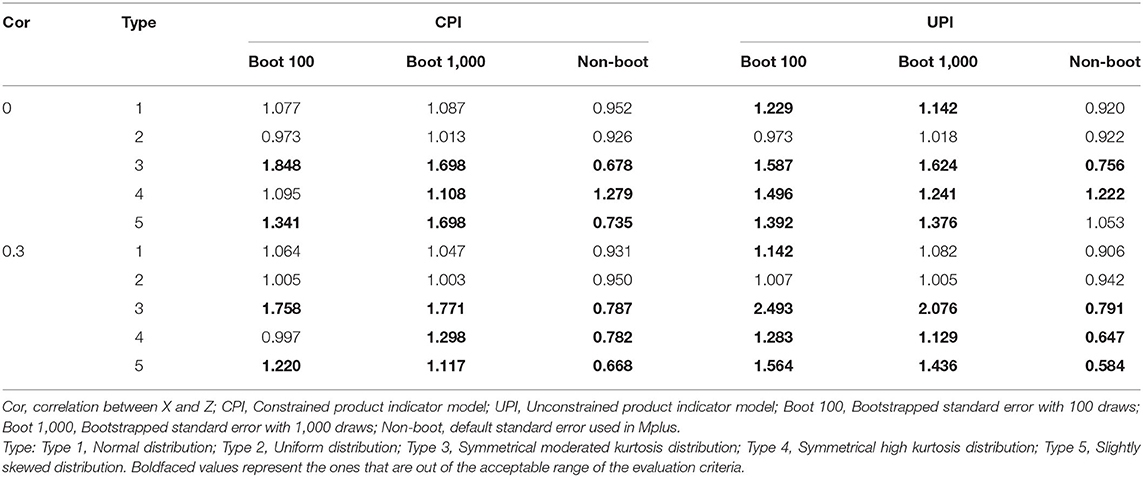
Table 7. Standard error ratio of b3 using PI with/without bootstrapped standard errors in study 2 (b3 = 0.2).
All of the approaches resulted in a coverage rate of approximately 90% in all five conditions except PA. For PA, coverage rates were <90% with non-normally distributed data (Types 2–5) and non-zero parameters.
As shown in Table 6, we found that LMS had the highest statistical power for detecting b3 and the moderated mediation effect (a * b3) among the four approaches under both normal and non-normal conditions. In comparison, PA performed better in detecting indirect effects.
The type I error rates of b3 and a * b3 for the four approaches in the five conditions were between 0 and 0.16. CPI and UPI resulted in a smaller type I error, while PA resulted in a larger type I error especially when the data is symmetrically high kurtosis distributed (see Table 5 for details).
All approaches could reach 100% completion rate for Type 1 and Type 2 data (Table 8). For non-normally distributed data, PA could reach the 100% completion rate for all the conditions except for the Type 4 data when b3 ≠ 0 and X was not correlated with Z (completion rate = 99.9%). Additionally, LMS also demonstrated a higher completion rate than did PI with non-normally distributed data.
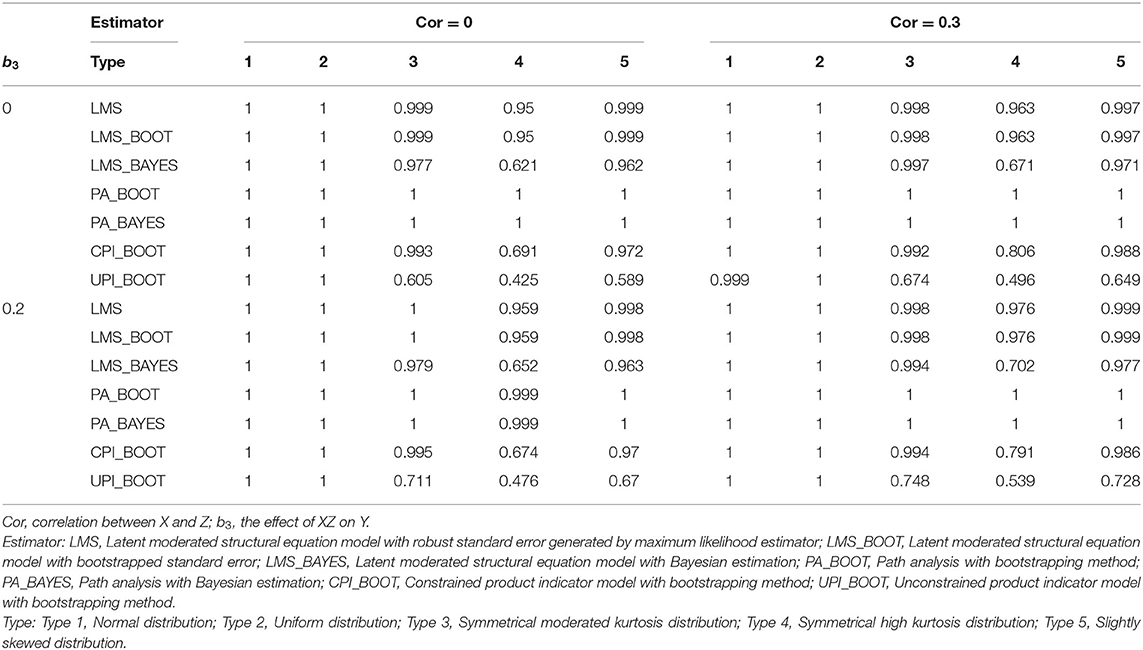
Table 8. Completion rate of the four approaches in study 2.
The results of the above two simulation studies demonstrated the advantages of LMS over the other three approaches. However, some limitations still hinder the application of LMS. For example, the model fitting cannot be evaluated directly in Mplus. To promote the use of LMS, we provided the practical guidelines which illustrated how to evaluate the model fitting, and how to adopt the Johnson-Neyman procedure (Johnson and Neyman, 1936) with LMS results. The corresponding Mplus codes are available in the Supplementary Materials.
Maslowsky et al. (2015) have provided a detailed tutorial for applying the LMS method with the ML estimator. In this section, we simply summarized the guidelines in their paper and illustrated some points that were not covered in it.
LMS can be easily implemented in Mplus using the XWITH command. However, standardized coefficients are not available using Mplus. Applied researchers can obtain standardized coefficients by standardizing the data.
Considering the model fitting in LMS, although it is difficult to evaluate the model fitting directly, there is still an alternative choice based on model comparison. Maslowsky et al. (2015) proposed a two-step method to evaluate model fitting: (1) Conduct the model without interaction term (Model 0) and evaluate the model based on CFI, Tucker-Lewis index (TLI), chi-square value, and so on; (2) add the interaction term (Model 1) and compare the model fitting with Model 0 based on the log-likelihood ratio test. The model fitting of Model 1 is acceptable only when the Model 0 fits data well and the log-likelihood test indicates that Model 1 is better than Model 0. For more details about Mplus codes of this two-step method, please refer to Maslowsky et al. (2015).
Both the bootstrapped SE or the robust SE can be obtained in LMS, and the corresponding Mplus codes were available in the Supplementary Materials when the simulation studies were mentioned. However, the current studies showed that LMS with the bootstrap method is time-consuming and overestimates the SE when the reliability is low or when data are non-normally distributed. To obtain robust results, we suggest that applied researchers draw the conclusion based on both the bootstrapped confidence interval and the significance test.
The Johnson-Neyman technique is used to obtain the continuously plotted confidence intervals around simple slopes for all values of the moderator. This technique can facilitate the interpretation of results in moderation analysis (Preacher et al., 2007). It can also be implemented in LMS using Mplus. Its code is available in the Supplementary Materials.
Based on the two simulation studies, we recommend the LMS approach as the optimal choice for the analysis of second-stage moderated mediation models. It can provide relatively unbiased and robust estimates of the latent interaction effect b3, moderated mediation index a * b3, and indirect effects. This conclusion was proven not only in the condition of low reliability, but also in the case of the violation of the multivariate-normally-distributed assumption.
Of all the simulation studies conducted, the low reliability study produced results with higher relative bias and a larger SE ratio, plus a lower statistical power and completion rate. Although PA is a simple approach for researchers to grasp and implement, measurement errors cause issues for its application. When the reliabilities were approximately 0.8 (the accepted reliability level for a social science scale), PA with ML estimator showed an 8.45% underestimation of the interaction effect when b3 ≠ 0. The bias of this estimate rose to 56.68% when reliability decreased to 0.6. It seems that PA suffers from an increasing bias of its estimate with the decreasing reliability of the data. This issue has also been identified by previous research (Cheung and Lau, 2017). Although PA performed worst in the estimates, a PA approach (Ng and Chan, 2020) based on the factor scores was shown to efficiently estimate latent moderation models. Ng and Chan (2020) also found that this factor score method provided unbiased estimates of the moderation effect when the composite reliability was just acceptable. Further studies are suggested to investigate the performance of this factor score approach in moderated mediation models, and to test whether PA's good performance in detecting mediation effects remains.
The reduction in reliability also had a negative impact on the PI analysis of the interaction effect. It is reasonable to expect that the process of PI, which requires the multiplication of indicators, would widen the effect of measurement errors. This was evident in our investigation; decreasing the reliability of the data resulted in increasing bias of the respective estimates. By contrast, LMS simply conducts the interaction with the original data in the latent-variable framework. It not only considers the effect of measurement errors, but also limits the influence of the errors on the estimation. Therefore, the estimates of the LMS approach were still acceptable under conditions of varying reliabilities (Cham et al., 2012).
Study 2 compared the four approaches with four different types of non-normally distributed data: uniform distribution, symmetrical moderated kurtosis distribution, symmetrical high kurtosis distribution, and moderated skewed distribution. We took this approach because the dependent variable, X, may be correlated with the moderator, Z, in real data analysis. We also considered the possibility of these variables being correlated simultaneously with the condition of non-normally distributed indicators. The estimates were similar to the conditions when X was not correlated with Z. The results indicated that the LMS approach was the optimal choice for all of these situations. For the normally distributed and uniformly distributed data, the PI and LMS approaches both demonstrated only a minor level of bias in their estimates (Wall and Amemiya, 2001; Marsh et al., 2004; Cheung and Lau, 2017). When the data follow the symmetrical moderated kurtosis distribution, LMS provides the estimates with the least biases (Klein and Moosbrugger, 2000; Cheung and Lau, 2017). For the symmetrical high kurtosis distributed and slightly skewed distributed data, estimates could not meet the criteria with any approach. However, compared with the other three approaches, LMS was the most suitable in estimating moderation effects. Although it also failed to fall in the ideal interval, it still maintained an acceptable balance between the accuracy and standard errors for the estimation. A possible explanation for this may be that LMS conducts the interaction directly, without product indicators, whereas these indicators are required and need to follow the multivariate-normally distributed assumption for other methods. When the data are non-normally distributed, the violation of the assumption would create biased estimates for standard errors, significance tests, and intervals of the parameters under the PI analysis (Klein and Moosbrugger, 2000).
The violation of the assumption of normally distributed data would more severely influence the estimation of indirect effects than would the interaction effects among all the approaches. All four approaches provided unacceptably biased estimates of indirect effects. These results were consistent with previous studies (Cham et al., 2012; Aytürk et al., 2019). A recent study showed that the application of instrumental variables in latent moderation models can reduce the influence of non-normality (Brandt et al., 2020). However, since this method cannot be easily applied in Mplus, we suggest that applied researchers use this method with R software when facing data that seriously violates the normality assumption. Moreover, the performance of the instrumental variables has not been investigated thoroughly in moderated mediation models, and therefore more simulation studies are needed in the future.
Compared with the ML estimation, the advantages of Bayesian analysis in small sample size conditions were demonstrated in study 1. However, while providing the best estimates among all the approaches, Bayesian estimation also tends to overestimate the standard errors of indirect effects, thus reducing the power. Moreover, the Bayesian method did not perform better than the ML estimator with non-normally distributed data in study 2. This research just made a preliminary exploration of the different performances between the traditional ML method and the Bayesian method in moderated mediation models. More studies are needed to compare these two methods in other settings, and to investigate whether the disadvantages of Bayesian LMS in estimating standard errors can be circumvented by informative priors. Moreover, since the posterior predictive p-values are not available in latent moderated mediation models, the model fitting of Bayesian analysis suggest these models also need to be further explored.
Considering the standard error estimates, LMS with robust standard errors performed better than bootstrapped standard errors in estimating indirect effects, especially with low reliability and small sample size. The overestimates of standard errors made the bootstrap method fail to provide acceptable power in these conditions. PI with bootstrapped standard errors also demonstrated the overestimates similar to LMS with the bootstrap method with non-normally distributed data. However, the number of bootstrap draws used in this study is small, so future studies should investigate whether the problem of overestimating can be circumvented by increasing the number of bootstrap draws.
Model fitting is also a problem existing in all the latent approaches applied for moderated mediation models. While LMS with Mplus cannot provide indices for evaluation of the model fitting directly, there are still alternative methods. In addition to the two-step method proposed by Maslowsky et al. (2015), Gerhard et al. (2017) also proposed a new index for detecting omitted non-linear terms (quadratic and interaction terms) in latent moderation analysis. Moreover, although PI can provide the commonly used indices in SEM, Mooijaart and Satorra (2009) also showed that the chi-square test is insensitive when detecting the interaction effect using the PI method.
For this research, we still have much more to do with the integrated model. Although this study has already discussed the moderated mediation model under the conditions of low reliability, non-normal distribution, and the correlation between independent and moderator variables, it could not cover all situations for actual studies. Future studies may focus more on other types of the integrated model, such as the first-stage moderated mediation model, to investigate whether the performances of the four estimation approaches are similar. Since these are all complex models, the appropriate approaches for different conditions may vary. The conditions in this study were also limited; conclusions could be enriched with datasets with categorical and/or missing data, more complex manipulation of the moderated mediation index, and the consideration of correlation with measurement errors, and so on. Future studies are also suggested to include more indicators per factor to compare the performance of matching and parceling strategies in moderated mediation models. Moreover, the advantages of LMS in handling the missing values compared to PI were also demonstrated in the previous study (Cham et al., 2017). Since Bayesian estimation has advantages in dealing with missing values (Pan et al., 2017), future research should further investigate the performance of these methods in such conditions.
In sum, although PA is the most widely applied approach for the moderated mediation model in practical studies, it is strongly biased by the ignorance of measurement errors. CPI and UPI could both provide acceptable estimates when the multivariate normal distribution assumption holds. It is strongly suggested to apply LMS in practical research, as it could provide precise estimates for parameters, and powerful conclusions under conditions such as low reliability, non-normal distributions of data, and correlations between variables. However, when facing seriously non-normally distributed data, no approach in this paper can provide accurate estimates, and thus no method is appropriate for application in these conditions. The practical guidelines also illustrated the implementation of LMS in detail, especially on how to obtain the bootstrapped confidence interval, how to implement the Johnson-Neyman technique, and how to evaluate model fitting. This research could help to broaden the application of LMS in psychology and social science research, and to provide researchers with an emerging tool to generalize their conclusions.
Simulation datasets were analyzed in this study. All the simulation materials including data generation, analysis, and evaluation measures can be found in the Supplementary Materials.
QF, QS, LZ, and JP designed and executed the study, conducted the data analyses, and wrote the manuscript. LZ and JP made substantial contributions in conducting additional simulation studies and revising the manuscript critically. QS, LZ, SZ, and JP critically reviewed and revised the manuscript. QF, QS, and LZ are the co-first authors and contributed equally to this work. All authors approved the final version of the manuscript for submission.
This work was supported by the National Natural Science Foundation of China (NSFC 31871128) and the MOE (Ministry of Education) Project of Humanities and Social Science of China (18YJA190013).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2020.02167/full#supplementary-material
1. ^The model constraints used in PI are not available with Bayesian estimation in Mplus.
2. ^Because it is very time-consuming to use the bootstrap method in latent moderated structural equation modeling, bootstrapped standard errors are computed just using 100 draws. Under conditions of low reliability and 1000 samples with 100 bootstrap draws, it took more than a month to complete one simulation condition on a tower server with Intel Xeon E5-2620 CPU and 32-Gbit memory.
Algina, J., and Moulder, B. C. (2001). A note on estimating the Jöreskog-Yang model for latent variable interaction using lisrel 8.3. Struct. Eqn. Model. A Multidisc. J. 8, 40–52. doi: 10.1207/S15328007SEM0801_3
Antonakis, J., Bendahan, S., Jacquart, P., and Lalive, R. (2010). On making causal claims: areview and recommendations. Leadership Quart. 21, 1086–1120. doi: 10.1016/j.leaqua.2010.10.010
Aroian, L. A. (1947). The probability function of the product of two normally distributed variables. Ann. Mathe. Statist. 18, 265–271. doi: 10.1214/aoms/1177730442
Aytürk, E., Cham, H., Jennings, P. A., and Brown, J. L. (2019). Latent variable interactions with ordered-categorical indicators: comparisons of unconstrained product indicator and latent moderated structural equations approaches. Educ. Psychol. Measure. 80, 262–292. doi: 10.1177/0013164419865017
Baron, R. M., and Kenny, D. A. (1986). The moderator–mediator variable distinction in social psychological research: conceptual, strategic, and statistical considerations. J. Personal. Soc. Psychol. 51, 1173–1182. doi: 10.1037/0022-3514.51.6.1173
Boomsma, A. (1982). “The robustness of LISREL against small sample sizes in factor analysis models,” in Systems Under Indirect Observation: Causality, Structure, Prediction (Part 1), eds K. G. Jöreskog and H. Wold (Amsterdam: North-Holland), p. 149–173.
Brandt, H., Umbach, N., Kelava, A., and Bollen, K. A. (2020). Comparing estimators for latent interaction models under structural and distributional misspecifications. Psychol. Methods, 25, 321–345. doi: 10.1037/met0000231
Cham, H., Reshetnyak, E., Rosenfeld, B., and Breitbart, W. (2017). Full information maximum likelihood estimation for latent variable interactions with incomplete indicators. Multivar. Behav. Res. 52, 12–30. doi: 10.1080/00273171.2016.1245600
Cham, H., West, S. G., Ma, Y., and Aiken, L. S. (2012). Estimating latent variable interactions with nonnormal observed data: a comparison of four approaches. Multivar. Behav. Res. 47, 840–876. doi: 10.1080/00273171.2012.732901
Cheung, G. W., and Lau, R. S. (2008). Testing mediation and suppression effects of latent variables: Bootstrapping with structural equation models. Organ. Res. Methods 11, 296–325. doi: 10.1177/1094428107300343
Cheung, G. W., and Lau, R. S. (2017). Accuracy of parameter estimates and confidence intervals in moderated mediation models: acomparison of regression and latent moderated structural equations. Organ. Res. Methods 20, 746–769. doi: 10.1177/1094428115595869
Coenders, G., Batista-Foguet, J. M., and Saris, W. E. (2008). Simple, efficient and distribution-free approach to interaction effects in complex structural equation models. Q. Quant. 42, 369–396. doi: 10.1007/s11135-006-9050-6
Collins, L. M., Schafer, J. L., and Kam, C. M. (2001). A comparison of inclusive and restrictive strategies in modern missing data procedures. Psychol. Methods 6, 330–351. doi: 10.1037/1082-989X.6.4.330
Edwards, J. R., and Lambert, L. S. (2007). Methods for integrating moderation and mediation: a general analytical framework using moderated path analysis. Psychol. Methods 12, 1–22. doi: 10.1037/1082-989X.12.1.1
Fang, J., Zhang, M., Gu, H., and Liang, D. (2014). Moderated mediation model analysis based on asymmetric interval. Adv. Psychol. Sci. 22, 1660–1668. doi: 10.3724/SP.J.1042.2014.01660
Flora, D. B., and Curran, P. J. (2004). An empirical evaluation of alternative methods of estimation for confirmatory factor analysis with ordinal data. Psychol. Methods 9, 466–491. doi: 10.1037/1082-989X.9.4.466
Gerhard, C., Buechner, R. D., Klein, A. G., and Schermelleh-Engel, K. (2017). A fit index to assess model fit and detect omitted terms in nonlinear sem. Struct. Eqn. Model. 24, 414–427. doi: 10.1080/10705511.2016.1268923
Hayes, A. F. (2013). Introduction to Mediation, Moderation, and Conditional Process Analysis: A Regression-Based Approach. New York, NY: Guilford Press.
Hayes, A. F. (2015). An index and test of linear moderated mediation. Multivari. Behav. Res. 50, 1–22. doi: 10.1080/00273171.2014.962683
Hoogland, J. J., and Boomsma, A. (1998). Robustness studies in covariance structure modeling: an overview and a meta-analysis. Sociol. Methods Res. 26, 329–367. doi: 10.1177/0049124198026003003
Hu, L. T., and Bentler, P. M. (1998). Fit indices in covariance structure modeling: Sensitivity to underparameterized model misspecification. Psychological Methods, 3, 424–453. doi: 10.1037/1082-989X.3.4.424
James, L. R., and Brett, J. M. (1984). Mediators, moderators, and tests for mediation. J. Appl. Psychol. 69, 307–321. doi: 10.1037/0021-9010.69.2.307
Johnson, P. O., and Neyman, J. (1936). Tests of certain linear hypotheses and their applications to some educational problems. Statist. Res. Memoirs, 1, 57–93.
Jöreskog, K. G., and Yang, F. (1996). Nonlinear structural equation models: the Kenny-Judd model with interaction effects. Adv. Struct. Eqn. Model. 36, 57–88.
Kelava, A., and Brandt, H. (2009). Estimation of nonlinear latent structural equation models using the extended unconstrained approach. Rev. Psychol. 16, 123–132.
Kelava, A., Werner, C. S., Schermelleh-Engel, K., Moosbrugger, H., Zapf, D., Ma, Y., et al. (2011). Advanced nonlinear latent variable modeling: distribution analytic LMS and QML estimators of interaction and quadratic effects. Struct. Eqn. Model. 18, 465–491. doi: 10.1080/10705511.2011.582408
Kenny, D. A., and Judd, C. M. (1984). Estimating the nonlinear and interactive effects of latent variables. Psychol. Bull. 96, 201–210. doi: 10.1037/0033-2909.96.1.201
Klein, A. G., and Moosbrugger, H. (2000). Maximum likelihood estimation of latent interaction effects with the LMS method. Psychometrika 65, 457–474. doi: 10.1007/BF02296338
Klein, A. G., and Muthén, B. O. (2007). Quasi-maximum likelihood estimation of structural equation models with multiple interaction and quadratic effects. Multivar. Behav. Res. 42, 647–673. doi: 10.1080/00273170701710205
Kyriazos, T. (2018). Applied psychometrics: sample size and sample power considerations in factor analysis (EFA, CFA) and SEM in general. Psychology 9, 2207–2230. doi: 10.4236/psych.2018.98126
Ledgerwood, A., and Shrout, P. E. (2011). The trade-off between accuracy and precision in latent variable models of mediation processes. J. Personal. Soc. Psychol. 101, 1174–1188. doi: 10.1037/a0024776
Liao, H., Liu, D., and Loi, R. (2010). Looking at both sides of the social exchange coin: a social cognitive perspective on the joint effects of relationship quality and differentiation on creativity. Acad. Manage. J. 53, 1090–1109. doi: 10.5465/amj.2010.54533207
Marsh, H. W., Wen, Z., Hau, K.-T., and Nagengast, B. (2013). “Structural equation models of latent interaction and quadratic effects,” in Quantitative Methods in Education and the Behavioral Sciences: Issues, Research, and Teaching. Structural Equation Modeling: A Second Course, eds G. R. Hancock and R. O. Mueller. p. 267–308.
Marsh, H. W., Wen, Z., and Hau, K. T. (2004). Structural equation models of latent interactions: evaluation of alternative estimation strategies and indicator construction. Psychol. Methods 9, 275–300. doi: 10.1037/1082-989X.9.3.275
Maslowsky, J., Jager, J., and Hemken, D. (2015). Estimating and interpreting latent variable interactions: a tutorial for applying the latent moderated structural equations method. Int. J. Behav. Dev. 39, 87–96. doi: 10.1177/0165025414552301
Mooijaart, A., and Satorra, A. (2009). On insensitivity of the chi-square model test to nonlinear misspecification in structural equation models. Psychometrika 74, 443–455. doi: 10.1007/s11336-009-9112-5
Moosbrugger, H., Schermelleh-Engel, K., and Klein, A. G. (1997). Methodological problems of estimating latent interaction effects. Methods Psychol. Res. Online, 2, 95–111.
Moulder, B. C., and Algina, J. (2002). Comparison of methods for estimating and testing latent variable interactions. Struct. Eqn. Model. 9, 1–19. doi: 10.1207/S15328007SEM0901_1
Muller, D., Judd, C. M., and Yzerbyt, V. Y. (2005). When moderation is mediated and mediation is moderated. J. Personal. Soc. Psychol. 89, 852–863. doi: 10.1037/0022-3514.89.6.852
Muthén, B., and Asparouhov, T. (2012). Bayesian structural equation modeling: a more flexible representation of substantive theory. Psychol. Methods 17, 313–335. doi: 10.1037/a0026802
Muthén, L. K., and Muthén, B. O. (1998-2017). Mplus User's Guide. 8th edition. Los Angeles, CA: Author.
Ng, J. C. K., and Chan, W. (2020). Latent moderation analysis: a factor score approach. Struct. Eqn. Model. 27, 629–648. doi: 10.1080/10705511.2019.1664304
Pan, J., Ip, E. H., and Dubé, L. (2017). An alternative to post hoc model modification in confirmatory factor analysis: the bayesian lasso. Psychol. Methods 22, 687–704. doi: 10.1037/met0000112
Preacher, K. J., Rucker, D. D., and Hayes, A. F. (2007). Addressing moderated mediation hypotheses: theory, methods, and prescriptions. Multivar. Behav. Res. 42, 185–227. doi: 10.1080/00273170701341316
Ree, M. J., and Carretta, T. R. (2006). The role of measurement error in familiar statistics. Organ. Res. Methods 9, 99–112. doi: 10.1177/1094428105283192
Rutter, C. M. (2000). Bootstrap estimation of diagnostic accuracy with patient-clustered data. Acad. Radiol. 7, 413–419. doi: 10.1016/S1076-6332(00)80381-5
Saris, W. E., Batista-Foguet, J. M., and Coenders, G. (2007). Selection of indicators for the interaction term in structural equation models with interaction. Q. Quan. 41, 55–72. doi: 10.1007/s11135-005-3956-2
Schermelleh-Engel, K., Klein, A., and Moosbrugger, H. (1998). “Estimating nonlinear effects using a latent moderated structural equations approach,” in Interaction and Nonlinear Effects in Structural Equation Modeling. eds Schumacker, R. E. and Marcoulides G. A (Mahwah, NJ: Lawrence Erlbaum Associates, Inc).
Teper, R., Segal, Z. V., and Inzlicht, M. (2013). Inside the mindful mind: how mindfulness enhances emotion regulation through improvements in executive control. Curr. Direct. Psychol. Sci. 22, 449–454. doi: 10.1177/0963721413495869
van de Schoot, R., Winter, S. D., Ryan, O., Zondervan-Zwijnenburg, M., and Depaoli, S. (2017). A systematic review of Bayesian articles in psychology: the last 25 years. Psychol. Methods 22, 217–239. doi: 10.1037/met0000100
Wall, M. M., and Amemiya, Y. (2001). Generalized appended product indicator procedure for nonlinear structural equation analysis. J. Educ. Behav. Statist. 26, 1–29. doi: 10.3102/10769986026001001
Wall, M. M., and Amemiya, Y. (2003). A method of moment's technique for fitting interaction effects in structural equation models. Br. J. Mathe. Statist. Psychol. 56, 47–63. doi: 10.1348/000711003321645331
Keywords: latent moderated structural equations, product indicator, path analysis, moderated mediation model, approach comparison
Citation: Feng Q, Song Q, Zhang L, Zheng S and Pan J (2020) Integration of Moderation and Mediation in a Latent Variable Framework: A Comparison of Estimation Approaches for the Second-Stage Moderated Mediation Model. Front. Psychol. 11:2167. doi: 10.3389/fpsyg.2020.02167
Received: 09 March 2020; Accepted: 03 August 2020;
Published: 10 September 2020.
Edited by:
Kwanghee Jung, Texas Tech University, United StatesReviewed by:
Joyce Lok Yin Kwan, The Education University of Hong Kong, Hong KongCopyright © 2020 Feng, Song, Zhang, Zheng and Pan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Junhao Pan, cGFuanVuaEBtYWlsLnN5c3UuZWR1LmNu
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.