 André Beauducel
André Beauducel Norbert Hilger
Norbert Hilger- Institute of Psychology, University of Bonn, Bonn, Germany
The non-diagonal elements of the observed covariances are more exactly reproduced by the factor loadings than by the model implied by the corresponding factor score predictors. This is a limitation to the validity of factor score predictors. It is therefore investigated whether it is possible to estimate factor loadings for which the model implied by the factor score predictors optimally reproduces the non-diagonal elements of the observed covariance matrix. Accordingly, loading estimates are proposed for which the model implied by the factor score predictors allows for a least-squares approximation of the non-diagonal elements of the observed covariance matrix. This estimation method is termed score predictor factor analysis and algebraically compared with Minres factor analysis as well as principal component analysis. A population-based and a sample-based simulation study was performed in order to compare score predictor factor analysis, Minres factor analysis, and principal component analysis. It turns out that the non-diagonal elements of the observed covariance matrix can more exactly be reproduced from the factor score predictors computed from score predictor factor analysis than from the factor score predictors computed from Minres factor analysis and from principal components.
Introduction
The factor model reproduces the observed covariances from the loadings and inter-correlations of the common factors as well as from the loadings of the unique factors. The factor loadings and factor inter-correlations are typically identified by means of rotational criteria in exploratory factor analysis or by means of model specification in the context of confirmatory factor analysis. However, the individual scores on the factors are indeterminate (Wilson, 1929; Guttman, 1955; Grice, 2001) even when all parameters (loadings, inter-factor correlations, loadings of unique factors) of the factor model are identified. It has been argued that acknowledging and quantifying factor indeterminacy is important for validity (Rigdon et al., 2019). Since the individual scores on the factors themselves are indeterminate, individual scores on so-called “factor score estimators” (McDonald, 1981), sometimes called “factor score predictors” (Krijnen, 2006), are computed when individual scores on the common factors are needed. The need for individual scores can occur in different areas, for example, in the context of psychological assessment, when individuals are selected for a job or when an optimal treatment has to be assigned to an individual.
Since “estimating” scores that are not uniquely defined may be regarded as unconventional (Schönemann and Steiger, 1976), Krijnen's (2006) term “factor score predictor” will be used in the following. However, even this term does not describe that, in fact, scores are only constructed (McDonald and Burr, 1967) in a way that they reflect some aspects of the original, but indeterminate factors. Since the factor score predictors are not identical with the factors themselves, three criteria for the evaluation of factor score predictors are typically considered (Grice, 2001): The maximal correlation of the factor score predictor with the factor (validity), that factor score predictors do not correlate with non-corresponding factors (univocality), and the similarity of the inter-correlations of the factor score predictors with the inter-correlations of the factors (correlational accuracy). The importance of an evaluation of the quality of factor score predictors has been acknowledged repeatedly (Ferrando and Lorenzo-Seva, 2019; Rigdon et al., 2019).
Although the aim of the factor model is to reproduce the observed covariances, the covariances that are reproduced from factor score predictors are not the same as the covariances that are reproduced from the factors themselves (Beauducel, 2007). Even when the factor model reproduces the observed covariances quite well, the factor score predictors typically will not reproduce the observed covariances as well. Nevertheless, factor score predictors that optimally represent the factors should reproduce the covariances as well as the factors themselves. Rigdon et al. (2019, p. 10) recommend that researchers who need factor score predictors “…use all available information in their calculation to minimize the influence of the factors' arbitrary components.” One information that is available—beyond the determinacy coefficient—is how well factor score predictors reproduce the observed covariances (Beauducel and Hilger, 2015). Especially the reproduction of the non-diagonal elements of the observed covariance matrix by means of the common factors, as performed with Minres factor analysis (MFA, Comrey, 1962; Harman and Jones, 1966; Harman, 1976), represents a core aspect of the factor model because the non-diagonal elements represent the associations between the observed variables. Moreover, Beauducel and Hilger (2015) found that an optimal reproduction of the non-diagonal elements of the observed covariance matrix by the factor score predictors is possible when there is a single variable with a perfect loading on each factor. However, perfect factor loadings rarely occur in empirical research. In fact, the weighting of observed variables resulting in factor score predictors that optimally reproduce the non-diagonal elements of the observed covariance matrix is widely unknown. In order to close this gap it is proposed to estimate factor loadings in a way that not the loadings but the factor score predictors computed from the loadings optimally reproduce the non-diagonal elements of the observed covariance matrix. The idea behind this approach is that the indeterminacy of factors threatens the validity of factor score predictors less systematically, when the loadings and the factor score predictors computed from the loadings reproduce the same non-diagonal elements of the observed covariance matrix.
In sum, (1) factor score predictors do not reproduce the non-diagonal elements of the observed covariance matrix as well as the common factors do. (2) The reproduction of the non-diagonal elements of the observed covariance can be considerably improved when a single variable with a perfect loading occurs on each common factor. This leads to the question whether it is possible to find factor loadings for which the corresponding factor score predictors optimally reproduce the non-diagonal elements of the observed covariance matrix, in cases where none of the variables has a perfect loading. After some definitions, an estimation method of factor loadings is proposed for which the non-diagonal elements of the covariance matrix reproduced from the model implied by the corresponding factor score predictors are a least-squares approximation of the non-diagonal elements of the observed covariance matrix. This is a specific estimation method in the context of the factor model because loadings are estimated for which the factor score predictors that are computed from the loadings optimally reproduce the non-diagonal elements of the observed covariance matrix. Therefore, the method is termed Score-predictor factor analysis and compared with MFA as well as principal components analysis (PCA) by means of algebraic considerations, a small population-based simulation, and a sample-based simulation study.
Definitions
Let x be a random vector of order p representing a population of observed scores with E(x) = 0. According to the factor model x can be decomposed by
where Λ is a p × q loading matrix, f is a random vector of order q representing the common factors with E(f) = 0, E(ff′) = Φ, and diag(Φ) = I, and u is a random vector of order p representing the unique variance of each variable, with E(u) = 0 and E(uu′) = diag(E(uu′)) = Ψ2. Accordingly, the covariance matrix of observed variables that is reproduced from the factor model can be written as
Factor score predictors are linear combinations of measured variables that can be described in the framework of regression component analysis (Schönemann and Steiger, 1976). Consider regression components ξ of order q, resulting from linear combination of p measured variables x, with ξ = B′x, where B is a p × q weights matrix. The covariance of ξ is
According to Schönemann and Steiger (1976), the pattern of regression weights for predicting x from ξ is
so that the prediction of x by ξ is
The covariances reproduced from the regression components are therefore
Entering the weights of the regression factor score predictor, (Thurstone, 1935), into the right hand side of Equation (5) yields
Beauducel (2007) has shown that Equation (6) holds for the regression factor score predictor, the Bartlett factor score predictor (Bartlett, 1937), and the McDonald factor score predictor (McDonald, 1981). Thus, Σr are the covariances that are reproduced from the model that is implied by the abovementioned factor score predictors. Since the model implied by the factor score predictors depends on Λ, it is proposed to find loading estimates, for which the non-diagonal elements of Σr are a least squares approximation of the non-diagonal elements of Σ.
Proposed Method
Approximation of the Non-diagonal Elements of the Observed Sample Covariance Matrix
As factor model parameters will typically be estimated on the basis of covariance matrices observed in the sample, the estimation procedures are given for the samples. For the sample, Equation (2) can be written as
and Equation (6) can be written as
where S is the sample covariance matrix. The condition for MFA can be expressed as
where is the loading matrix of MFA. According to Harman and Jones (1966), the following classical principal factor procedure allows for finding :
1) Start with an arbitrary p × p diagonal matrix H and compute S − diag(S) + H.
2) Perform the eigen-decomposition S − diag(S) + H = KΓK′, with eigenvectors K and with Γ containing the eigenvalues in descending order.
3) Determine the q common factors and compute , where Kq is a p × q submatrix of K and is the q × q submatrix of Γ.
4) Determine the reproduced communalities by means of .
5) Insert into Equation (7) and check whether a convergence criterion is met. The convergence criterion is defined by the difference between the previous value resulting from Equation (9) and the current values resulting from Equation (7).
6) Repeat step 2–5 until the convergence criterion is met.
By means of these steps MFA estimates the loadings of orthogonal factors that are conform to the condition expressed in Equation (9). The present approach is to replace in Equation (9) by the covariances reproduced from the factor score predictor (Equation 6). This leads to
where is a loading pattern resulting from the estimation method proposed here, which is called Score predictor factor analysis (SPFA). The covariance of the SPFA factors is . According to this condition, loadings are estimated for which the non-diagonal elements of the covariance matrix reproduced from the abovementioned factor score predictors (regression, Bartlett, McDonald) are a least squares approximation of the non-diagonal elements of the observed covariance matrix. The corresponding orthogonal loading pattern is
where “−1/2” denotes the inverse of the symmetric square-root. The corresponding unique variance is . The estimation of SPFA loadings can be performed by means of the same algorithm as for MFA. The only difference is that
is inserted instead of in step 3 and the following steps of the abovementioned algorithm. An R-script for SPFA estimation is given in the Supplementary Material (section 1).
Reproducing Covariances From Loadings and From the Corresponding Factor Score Predictor Models
The MFA and SPFA estimation procedures were described for the sample observed covariance matrix because these procedures will typically be calculated for sample matrices. However, in the following, the population observed covariance matrices will be used in order to describe further properties of SPFA and MFA.
Equations (2) and (6) of the factor model imply Σ − diag(Σ) ≠ Σr − diag(Σr) for Λ′ Σ−1 Λ ≠ I. It follows from Krijnen et al. (2015, Equation 7) that
so that Λ(Λ′ Σ−1 Λ)−1 Λ′ = ΛΛ′ if (Λ′ Ψ−2 Λ)−1 = 0. If one loading per column of Ψ approaches one, the corresponding element in Ψ approaches zero, so that (Λ′ Ψ−2 Λ)−1 also approaches zero (Beauducel and Hilger, 2015). Accordingly, Σ − diag(Σ) will become similar to Σr − diag(Σr) under this condition. This implies that the corresponding elements of the covariance matrices reproduced from MFA will also become similar when one loading per column of Λ approaches one.
For SPFA, the non-diagonal elements of covariance matrices reproduced from the loadings are given by . The non-diagonal elements of the covariance matrix reproduced from the factor score predictors are given by . Theorem 1 describes that Σs − diag(Σs) = Σrs − diag(Σrs) always holds for SPFA.
Theorem 1. Σs − diag(Σs) = Σrs − diag(Σrs).
Proof. Writing Equation (11) for the population yields , which implies
This completes the proof.
Theorem 1 implies that the non-diagonal elements of the covariance matrix reproduced from the orthogonal common factor loadings Λs are identical to the non-diagonal elements of the covariances reproduced from the regression-, Bartlett-, and McDonald factor score predictors computed from Λs and . Thus, the fit of the SPFA model to the non-diagonal elements of the observed covariance matrix is equal to the model fit implied by the SPFA factor score predictors.
The non-diagonal elements of ΣA, the covariance matrix reproduced from the loadings A of PCA, are identical to the non-diagonal elements of Σrc, the covariance matrix reproduced from the orthogonal principal component scores c. This follows from ΣA = Σrc which is shown in Theorem 2.
Theorem 2. If x = Ac, E(cc′) = I, and ΣA = AA′ then ΣA = Σrc.
Proof. The component scores are (A′ A)−1 A′ x = c so that the corresponding weights BA = A(A′ A)−1 can be entered into Equation (6). This yields
It follows from and from xc′ = Acc′ = A that Equation (15) can be written as
The covariance matrix reproduced from the component loadings is
It follows from that
This completes the proof.
To summarize, the PCA loadings and -scores as well as the SPFA loadings and score predictors reproduce the non-diagonal elements of the observed covariance matrix equally well. In contrast, the factor model and MFA has this property only when one element of each column has a perfect communality.
Model Error and the SPFA Model
Even in a population without model error of MFA, i.e., for , the error of the model implied by the MFA factor score predictors could be substantial, i.e., with . In contrast, SPFA finds a least squares approximation of the factor score predictor model to the non-diagonal elements of the observed covariance matrix (Equation 10). For the model of MFA and SPFA one might therefore expect
Thus, one would expect that the model error of MFA loadings is smaller or equal to the model error of SPFA factor score predictors which is smaller or equal to the model error of the MFA factor score predictors. Dividing the traces in Equation (19) by p(p-1) and taking the square root yields the standardized root mean squared residual for non-diagonal elements (SRMRND) as an index of model error that has been used elsewhere (Beauducel and Hilger, in press). In the following, the relationship between the SRMRND of the factor score predictor model derived from MFA will be compared with the SRMRND of SPFA and PCA for population data that fit perfectly to the factor model. PCA will be included as a frame of reference because PCA has the same property as SPFA in that the model fit computed from the loadings equals the model fit that is computed from the scores (Theorem 2).
Results
Population Simulation for MFA, SPFA, and PCA for Data Without Factor Model Error
The simulations were performed with IBM SPSS Version 24. For MFA and SPFA should have an identical model fit in terms of Equation (19). According to Equation (13), this condition holds when one variable on each common factor has a perfect loading. Therefore, a population-based simulation study starting with a loading matrix containing one perfect loading per factor and a set of constant non-zero loadings on each factor was performed. In the next step, the perfect loadings were reduced by a decrement of 0.01 until all non-zero loadings were nearly equal. In the following example, the initial loading matrix and the final loading matrix is given for q = 3 factors, p = 9 variables, and p/q = 3.
For q = 3, p = 15, and p/q = 5 similar matrices were generated. Figures 1A,B illustrates the fit of the model implied by the factor/component scores of MFA, SPFA, and PCA in terms of SRMRND for these loading matrices. The size of the largest loading on each factor is given on the x-axis and the SRMRND is given on the y-axis. The models implied by PCA scores have consistently the largest SRMRND, i.e., the lowest fit, whereas the models implied by SPFA factor score predictors have the lowest SRMRND. The SRMRND of the model implied by the MFA factor score predictors is in between. This shows that the relationship between the MFA loading based SRMRND, the SPFA factor score predictor based SRMRND, and the MFA factor score predictor based SRMRND in Figure 1 is as predicted in Equation (19). With increasing largest loadings, the SRMRND of the model implied by MFA factor score predictors becomes more similar to the SRMRND of the SPFA factor score predictors. For p/q = 5 (Figure 1B) the differences between the SRMRND of MFA, SPFA, and PCA are smaller than for p/q = 3 (Figure 1A). It should be noted that the SRMRND based on SPFA loadings is identical to the SRMRND based on the SPFA factor score predictor (Theorem 1) and that the SRMRND based on PCA loadings is identical to the SRMRND based on component scores (Theorem 2). Since no model error according to the factor model was introduced, the SRMRND based on MFA loadings was always zero.
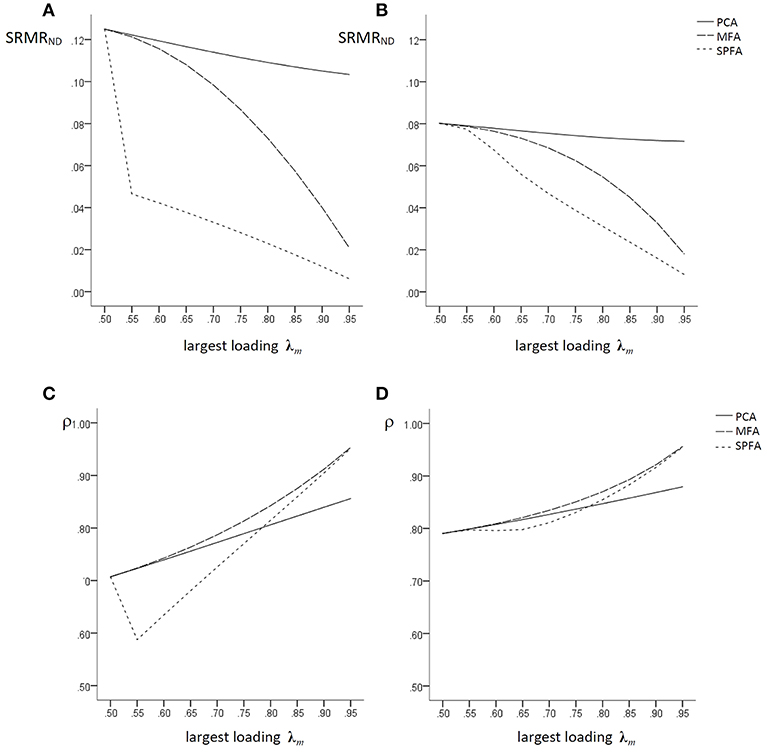
Figure 1. Population factor models without model error: SRMRND based on PCA-, MFA-, and SPFA-scores with (A) q = 3, p = 9, p/q = 3 and (B) q = 3, p = 15, p/q = 5; ρ for PCA-, MFA-, and SPFA-scores with (C) q = 3, p = 9, p/q = 3 and (D) q = 3, p = 15, and p/q = 5.
The determinacy coefficient, i.e., the correlation of the regression (best linear) factor score predictor (Krijnen et al., 1996) based on MFA (Grice, 2001) and on SPFA and of the PCA scores with the factors (see below) for the corresponding models are given in Figures 1C,D. The coefficient of determinacy should regularly be computed in the context of factor analysis (e.g., Grice, 2001; Lorenzo-Seva and Ferrando, 2013). Moreover, the correlation of the PCA scores with the common factors as well as the correlation of the SPFA factor score predictors with the common factors were computed in order to as certain how well these scores can be used in order to represent the common factors. Since the correlation of the factor score predictors with the common factor is typically not perfect, it might be possible that PCA scores correlate in a similar magnitude with the common factors as the factor score predictors. Similarly, the SPFA factor score predictor might also correlate with the common factors in a similar magnitude as the factor score predictor. Since the scores of the wanted components are given by with E(cc′) = I, their correlation with the common factors is
The best linear SPFA factor score predictor is given by and the standard deviation of this factor score predictor is so that its correlation with the factor is given by
The results in Figures 1C,D are based on covariance matrices without error of the factor model. Accordingly, the correlation of the MFA factor score predictors with the factors is always larger than the correlation of the SPFA factor score predictors and the PCA scores with the factors. For largest loadings below 0.70, the PCA scores have larger correlations with the factors than the SPFA factor score predictor, for largest loadings greater 0.75 the SPFA factor score predictor has larger correlations with the factor than the PCA scores.
Population Simulation for MFA, SPFA, and PCA for Data With Factor Model Error
When model error was introduced according to Tucker, the population correlation matrices were generated from the loadings of major factors and from the loadings of 50 “minor factors” as well as from the corresponding uniqueness. Minor factors have been introduced by Tucker et al. (1969) in order to represent small parts of the common variance, which are not part of a given population model. These minor factors therefore represent the “many minor influences” (Tucker et al., 1969), which are not part of the model but that affect the observed scores in the real world (MacCallum, 2003). According to MacCallum and Tucker (1991), the loading matrices of 50 minor factors were generated from z-standardized normally distributed random numbers. In the population with large model error, the relative contribution of minor factors was successively reduced by the factor 0.95, and the amount of variance explained by the minor factors was set to 30% of the observed total variance. The random numbers were generated by means of the Mersenne Twister random number generator in IBM SPSS 24. All loadings of minor factors were between −1 and +1. Since minor factors were introduced into the population data and since they represent 30% of the total variance, a factor model that is only based on the population loadings of the major factors contains necessarily a substantial amount of model error. In the population with moderate model error, the relative contribution of minor factors was successively reduced by the factor 0.85, and the amount of variance explained by the minor factors was set to 20% of the observed total variance.
Orthogonal Procrustes-rotation (Schönemann, 1966) of MFA-, SPFA-, and PCA loadings toward the initial loadings of the major factors was performed in the following in order to assure that different similarities of the loadings of MFA, SPFA, and PCA to the initial loadings of the major factors are not due to different rotational positions of the factors/components. However, even when the loadings of the three major MFA and SPFA factors were rotated by means of orthogonal Procrustes-rotation toward the initial loading matrix containing only non-zero loadings of 0.50, the resulting MFA and SPFA loadings are quite different from the initial loadings of the major factors. As an example, Table 1 contains the loadings for the population with large model error. It is remarkable that the maximal loadings of the MFA factors are considerably smaller than the initial maximal loading of 0.95, even when the MFA loadings are rotated toward the initial loading matrix by means of orthogonal Procrustes-rotation. In contrast, the maximal loadings of the Procrustes-rotated major SPFA factors are close to 0.95.
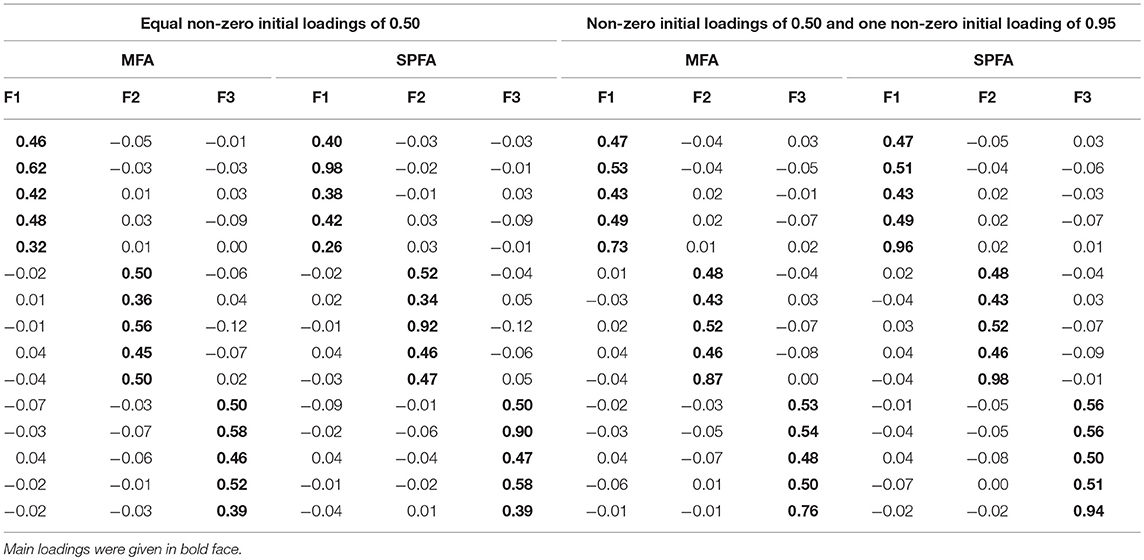
Table 1. Major MFA- and SPFA-factor loadings based on model error and Procrustes-rotation toward the initial (model error free) loadings of the major factors.
The SRMRND of MFA, SPFA, and PCA that were based on three major factors with initial maximal non-zero loadings of 0.50 to 0.95 is given in Figures 2A,C. Even in data that were based on the model error of the factor model, the fit of the MFA loadings was the best. However, the SRMRND of the models implied by the scores was smaller for SPFA than for MFA and PCA.
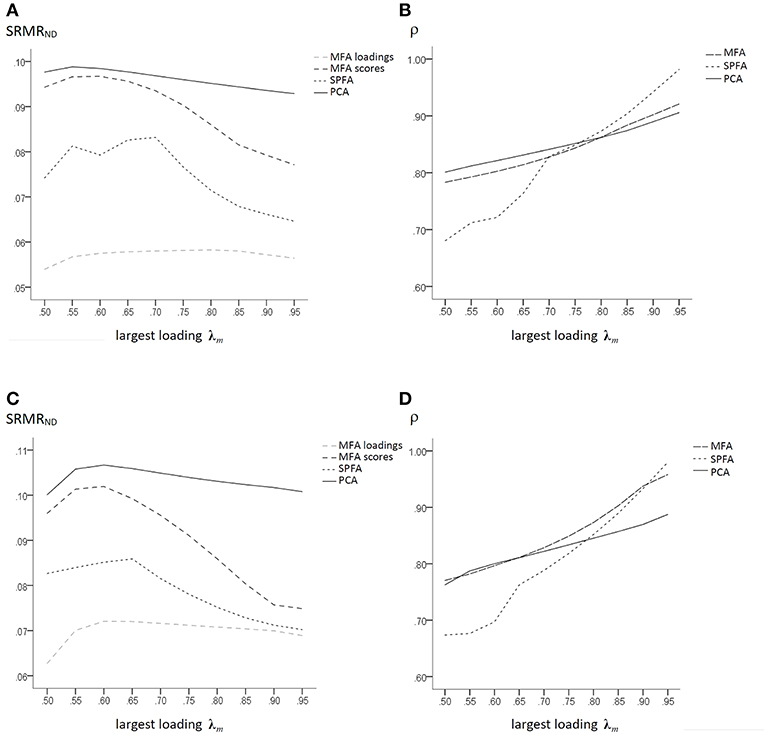
Figure 2. Population factor models with q = 3, p = 15, p/q = 5; large model error: (A) SRMRND for MFA loadings, MFA-scores, PCA, and SPFA; (B) ρ for PCA-, MFA-, and SPFA-scores; moderate model error; (C) SRMRND for MFA loadings, MFA-scores, PCA, and SPFA; (D) ρ for PCA-, MFA-, and SPFA-scores.
The correlation ρ of the regression (best linear) factor score predictor based on MFA and on SPFA and of the PCA scores with the major factors for the corresponding models based on large model error are given in Figure 2B. For largest initial major factor loadings below 0.75, the PCA scores have larger correlations with the factors than the MFA and SPFA factor score predictors. For largest initial factor loadings greater 0.75 the SPFA factor score predictor has larger correlations with the factor than the MFA factor score predictor and the PCA scores. Thus, in presence of large model error of the factor model, the SPFA factor score predictor can be a more valid measure of the original major factor than the corresponding MFA factor score predictor. This occurs probably in presence of a model error leading to underestimation of the initial maximal loadings on the major factors by means of MFA (Table 1). Under such conditions, SPFA may result in a more accurate estimation of the initial maximal loadings and thereby in a more valid factor score predictor. It should also be noted that the mean determinacy coefficient was slightly larger for PCA scores than for MFA factor score predictor when the size and variability of the main loadings were small (see Figure 2B). Thus, for the respective population data, the maximum determinacy coefficient was obtained for PCA for small variability of main loadings and for SPFA for a larger variability of main loadings. When model error was moderate, the determinacy coefficient of the MFA factor score predictor was mostly larger than the determinacy coefficient of the SPFA factor score predictor (Figure 2D).
Sample-Based Simulation for MFA, SPFA, and PCA
A sample-based simulation was performed in order to investigate the size of the SRMRND and the determinacy coefficient (ρ) for MFA, SPFA, and PCA when sampling error occurs across a number of different conditions. Again, the Mersenne Twister random number generator was used for the generation of random numbers. The simulation was performed for q = 3 factors with p = 15 variables and for q = 6 with p = 30, for n = 150 and 600 cases, for p/q = 5 variables with non-zero population loadings per factor, and for non-zero initial population loadings λi = 0.35, 0.40, 0.45, and 0.50. At each λi-level, one of the non-zero population loadings per factor was increased to a maximum loading of the model λm by 0.00, 0.15, 0.30, and 0.45. For example, for the λi = 0.40 solutions, there was one simulation where all non-zero loadings were λi = 0.40, one simulation with one loading λm = 0.55 per factor, one simulation with λm = 0.70 per factor, and one simulation with λm = 0.95 per factor. The simulations were performed with model error and without model error. Model error was based on 50 minor factors, which were generated from z-standardized normally distributed random numbers. A moderate amount of model error was introduced, where the relative contribution of minor factors was successively reduced by the factor 0.85, and the amount of variance explained by the minor factors was set to 20% of the observed total variance. For each level of λi and λm the same set of minor factors was used in order to introduce the same population model error across conditions. With a constant set of minor factors, changes in the SRMRND and ρ can clearly be attributed to λi and λm and not to a changing set of minor factors. Overall, there were 128 conditions, i.e., 16 (= 4 λi-levels × 4 λm-levels) loading patterns × 2 numbers of factors × 2 sample sizes × 2 levels of model error. For each of the 128 population conditions 1,000 samples were drawn and analyzed by means of MFA, SPFA, and PCA. As for the population simulation, orthogonal Procrustes-rotation (Schönemann, 1966) toward the initial population loadings of the major factors was performed in order to assure that different similarities of the MFA, SPFA, and PCA loadings to the initial loadings of the major factors are due to the method of variance extraction and not to different rotational positions of the factors/components. For a subset of the sample-based simulation conditions (q = 6, λi = 0.35 and 0.50, all λm-levels, n = 150 and 600, without and with model error), Varimax-rotation was performed by means of the gradient-projection algorithm provided by Jennrich (2001) and Bernaards and Jennrich (2005) in order to compare effects of factor rotation on ρ for MFA, SPFA, and PCA.
The results of the sample-based simulation study are as follows: For the simulation without model error, the mean SRMRND was smallest when based on the loadings of MFA model, was larger when based on the SPFA scores, again larger when based on the MFA scores, and largest when based on PCA scores (see Figure 3). This result corresponds to Equation (19). It was not necessary to show the SRMRND for the loadings based on the SPFA and PCA because it is equal to the SRMRND based on the respective scores (Theorem 1 and 2). The SRMRND decreases with increasing λm so that the SRMRND become more similar for the loadings of the MFA model, the SPFA scores, and the MFA scores. The effect of sample size on mean SRMRND is not very important, given that the larger sample was four times larger than the smaller sample. However, the standard deviation of the SRMRND decreased with increasing sample size and with a larger number of factors. Moreover, a larger number of factors resulted in smaller SRMRND differences between MFA model, SPFA scores, MFA scores, and PCA scores (see Figure 3). Results were rather similar for the condition with model error (see Figure 4). The only substantial difference of this condition is that the effect of λm on the SRMRND was less pronounced. This implies that the differences between the SRMRND of MFA and SPFA do not decrease substantially when λm increases.
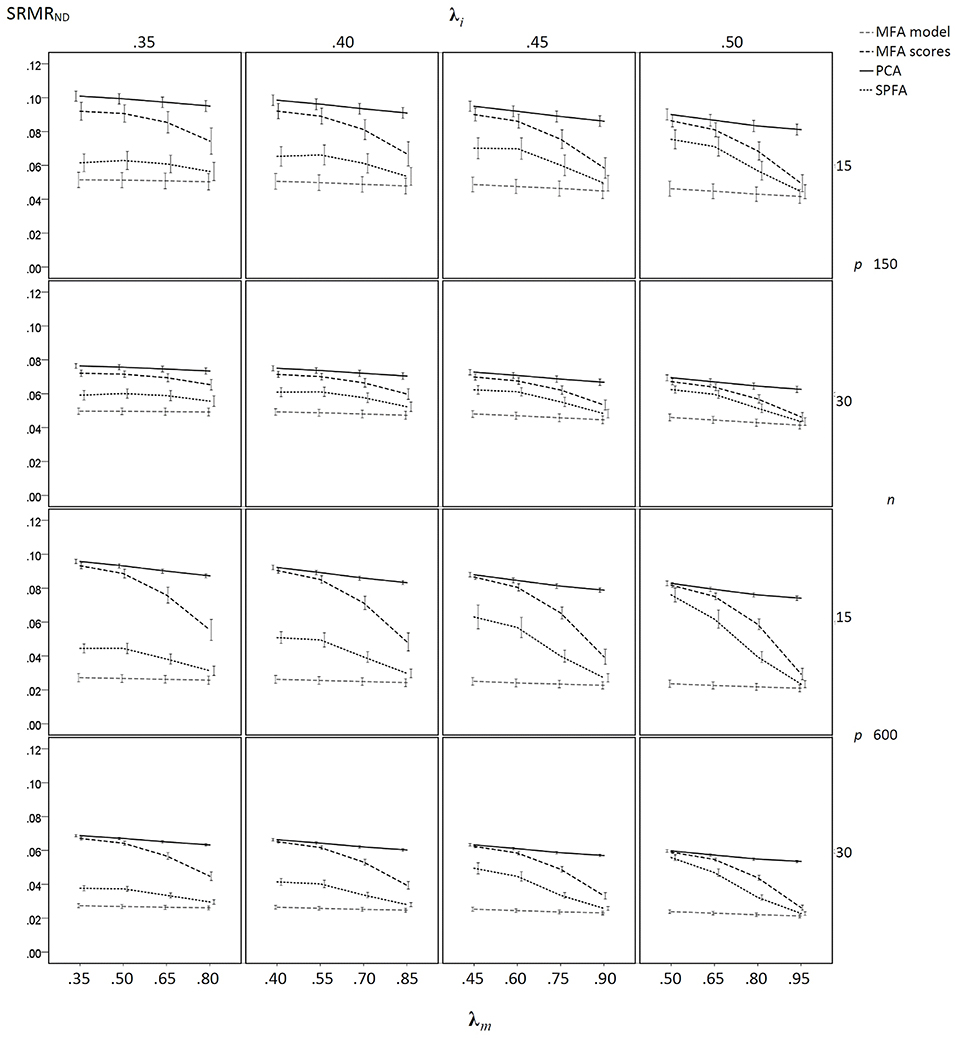
Figure 3. Mean SRMRND based on samples drawn from population factor models without model error for q = 3 with p = 15 and q = 6 with p = 30 for the MFA-model, MFA-scores, PCA-scores, and SPFA-scores; λi = initial population loadings; λm = maximal population loadings; the error bars represent standard deviations.
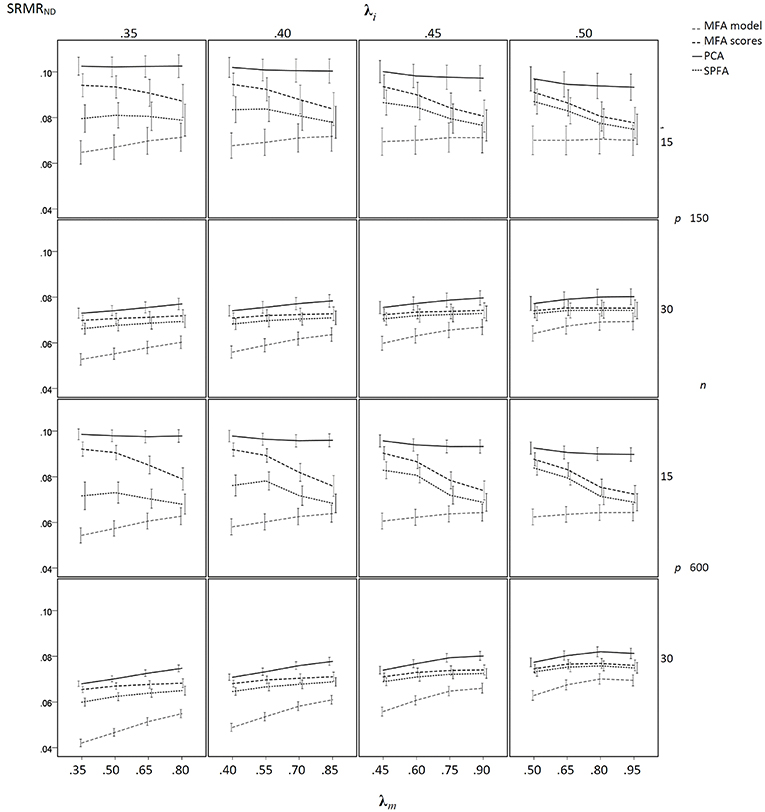
Figure 4. Mean SRMRND based on samples drawn from population factor models with model error for q = 3 with p = 15 and q = 6 with p = 30 for the MFA-model, MFA-scores, PCA-scores, and SPFA-scores; λi = initial population loadings; λm = maximal population loadings; the error bars represent standard deviations.
In the condition without model error, the mean determinacy coefficient (ρ) was largest for PCA when λm was small, it was largest for MFA when λm was large, and it was smallest for SPFA when λm was small (see Figure 5). When λm > 0.75 mean ρ was larger for SPFA than for PCA and comes close to MFA. For increasing overall level of salient loadings (λi), the mean ρ becomes more similar for MFA, SPFA, and PCA. Moreover, the standard deviation of ρ was considerably smaller for the larger sample size. In the condition with model error, the mean ρ was smallest for SPFA only for models with the smaller number of factors, small λi, and small λm. For the larger number of factors, small λi, and large λm, the mean ρ was slightly larger for SPFA than for MFA and PCA (see Figure 6). Again, for larger λi the mean ρ becomes more similar for MFA, SPFA, and PCA. The effect of sample size on the standard deviations was less pronounced in the condition with model error than in the condition without model error. For the conditions with q = 6, for n = 150 and n = 600, with and without model error, the mean ρ after Varimax-rotation was also computed for MFA, SPFA, and PCA (Figure 7). Overall, the differences were small and the mean ρ for SPFA reached the level of MFA. No substantial advantages occurred for PCA when Varimax-rotation was performed.
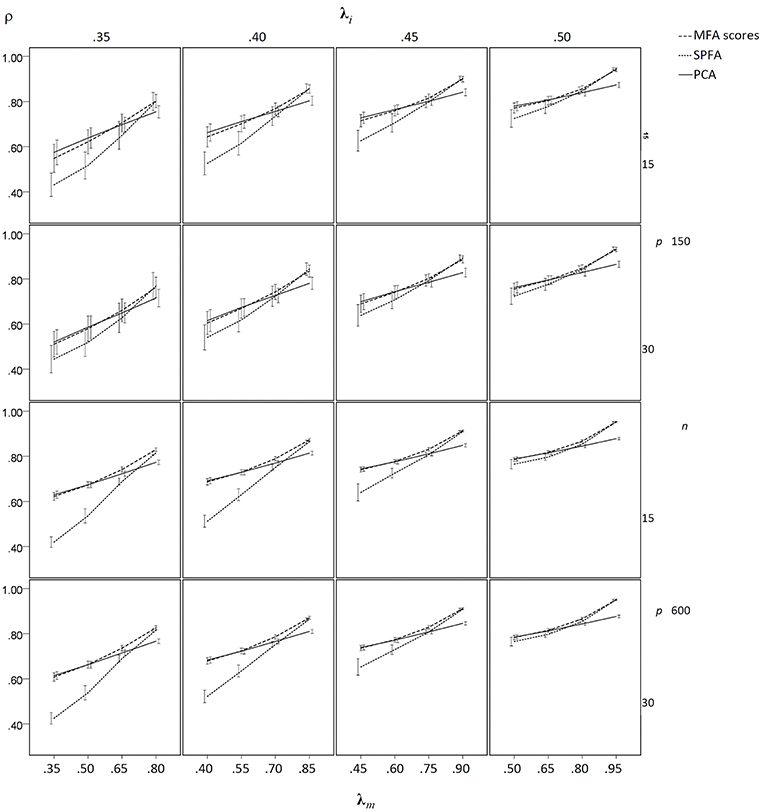
Figure 5. Mean determinacy coefficient (ρ) based on samples drawn from population factor models without model error for q = 3 with p = 15 and q = 6 with p = 30 for the MFA-scores, PCA-scores, and SPFA-scores; λi = initial population loadings; λm = maximal population loadings; the error bars represent standard deviations.
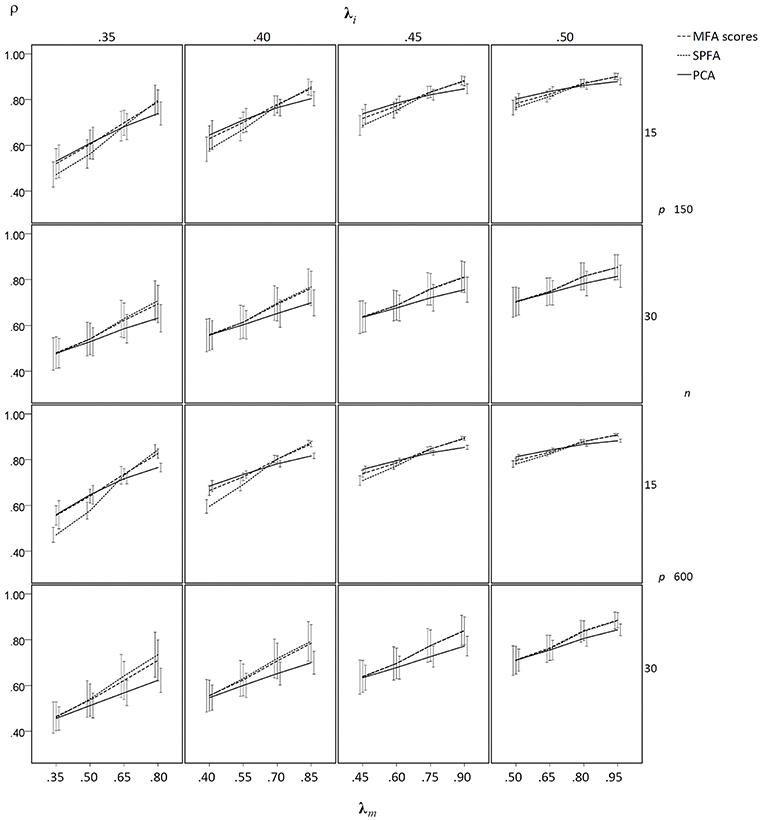
Figure 6. Mean determinacy coefficient (ρ) based on samples drawn from population factor models with model error for q = 3 with p = 15 and q = 6 with p = 30 for the MFA-scores, PCA-scores, and SPFA-scores; λi = initial population loadings; λm = maximal population loadings; the error bars represent standard deviations.
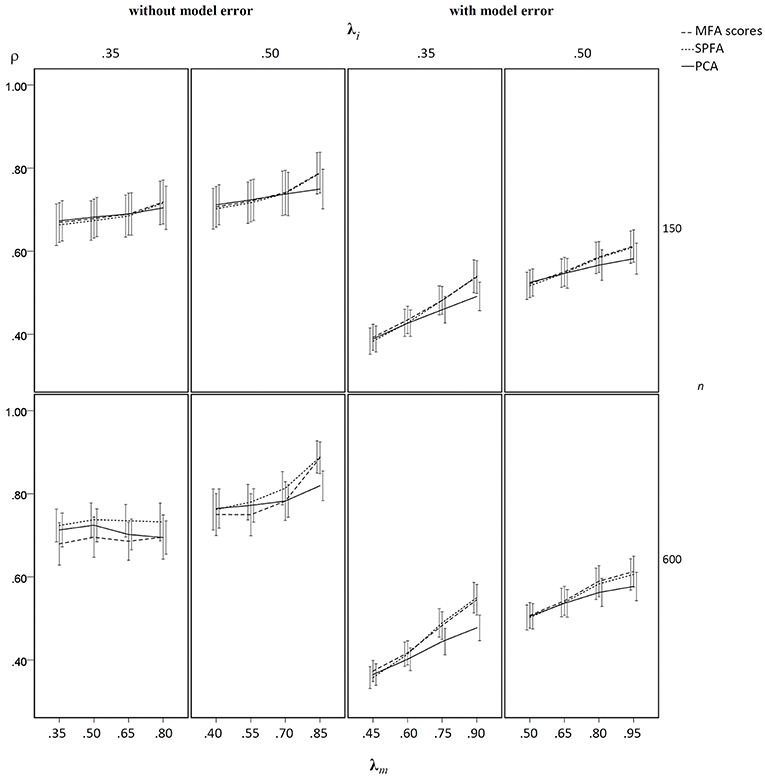
Figure 7. Mean determinacy coefficient (ρ) based on samples drawn from population factor models with model error for q = 6 with p = 30 for the MFA-scores, PCA-scores, and SPFA-scores; λi = initial population loadings; λm = maximal population loadings; the error bars represent standard deviations.
Empirical Example
In order to illustrate SPFA, we analyzed real data based on a sample of 474 German participants (306 females, age/years: M = 21.34, SD = 4.50), who answered 12 items from a short knowledge test. Six items were from the knowledge domain mathematics and six items were from the knowledge domain of economics. Two PCA components, two MFA factors, and two SPFA factors were Varimax-rotated by means of the gradient projection method provided by Bernaards and Jennrich (2005) based on the R-script of Weide and Beauducel (2019). The empirical correlations and the script of PCA, MFA, and SPFA combined with GPR-Varimax rotation are available in the Supplementary Material (section 2). The Varimax-loadings of PCA, MFA, and SPFA clearly show the difference between the two knowledge domains (see Table 2). Overall, the PCA loadings are larger (see also Widaman, 2018) than the MFA loadings. However, the largest SPFA loading is larger than the largest PCA loading, but the size of the remaining SPFA loadings is more similar to the MFA loadings. Thus, SPFA gives more emphasis on the variables with the largest loadings. Researchers expecting large differences in the quality of their measured variables or with a few high-quality variables in a set of moderate variables might therefore be interested in SPFA. The SRMRND for the scores computed from the solutions is 0.008 for PCA, 0.007 for MFA, and 0.004 for SPFA. Thus, the model implied by the SPFA factor score predictor has an optimal fit to the non-diagonal elements of the covariance matrix.
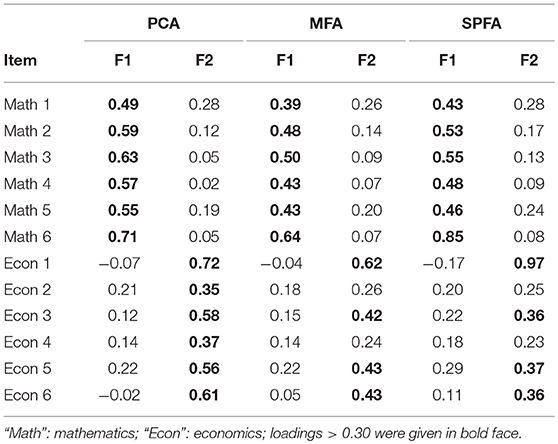
Table 2. Varimax-rotated PCA-, MFA-, and SPFA- factor loadings of the 12 item knowledge test.
Discussion
The starting point of the present study was that the model implied by the factor score predictors of the common factor model does not reproduce the non-diagonal elements of the observed covariance matrix as well as the common factors do (Beauducel and Hilger, 2015). To address this discrepancy, it was proposed to estimate factor loadings in a way that not the loadings but the factor score predictors computed from the loadings optimally reproduce the non-diagonal elements of the observed covariance matrix. This estimation method is termed “Score Predictor Factor Analysis” (SPFA) and based on a similar estimation procedure as MFA, where the loadings are estimated so that the reproduced matrix of the score predictors is as similar as possible to the observed covariance matrix. It is shown that the covariance matrix reproduced by the SPFA loadings is identical to the matrix reproduced by the SPFA score predictors (Theorem 1). It was also shown that the SPFA loadings will reproduce the non-diagonal elements of the observed covariances less or equally well than the MFA loadings and that the model implied by the SPFA score predictor will reproduce the non-diagonal elements of the observed covariances equally or better than the model implied by the MFA factor score predictor. Therefore, when the focus is on the loadings, there are reasons for preferring MFA and when the focus is on the factor score predictor, there are reasons for preferring SPFA. Moreover, it is an empirical question whether the error of MFA or the error of SPFA is more substantial.
The evaluation of SPFA was based on a comparison with MFA and PCA by means of a population-based simulation study and a sample-based simulation study. One dependent variable of the simulation studies was the standardized root mean square residual based on the non-diagonal elements of the observed covariance matrix (SRMRND). This fit index allows to investigate how well the intended goal of SPFA to reproduce the non-diagonal elements of the observed covariance matrix by means of the model implied by the SPFA factor score predictors can be achieved. Moreover, the mean coefficient of determinacy (ρ) was computed in order to investigate the correlation of the MFA-, SPFA-best linear factor score predictors, and PCA-components with the population factors.
It was found in the simulations based on populations and samples that the SRMRND based on the SPFA factor score predictor was consistently smaller than the SRMRND based on the MFA factor score predictor and PCA scores. The SRMRND based on PCA scores was consistently larger than the SRMRND based on the MFA- and SPFA-factor score predictor. These results were also found when the simulations were based on population data that do not fit perfectly to the factor model (i.e., when model error occurs). Thus, the model implied by the SPFA-factor score predictor allows for an optimal score-based reproduction of the non-diagonal elements of the observed covariance matrix. Therefore, SPFA estimation of factor loadings may be of interest when factor score predictors are to be computed.
Finally, when there was some population error of the factor model and when there were a few large main loadings, the SPFA factor score predictor had a larger coefficient of determinacy than the MFA factor score predictor. Thus, in case of bad model fit and when a few large main loadings occur, the SPFA factor predictor can be chosen to best represent the population factors in terms of validity as well. Moreover, when there were rather small and nearly equal main loadings, the PCA score had a larger coefficient of determinacy than the MFA factor score predictor and than the SPFA factor score predictor, so that the PCA score may represent the original factors most appropriately under these conditions. Although the differences between PCA and the factor model have often been regarded as negligible (Velicer and Jackson, 1990; Fava and Velicer, 1992), differences between these models could occur from several perspectives (Widaman, 2018) and also from the perspective of individual scores. However, the differences between PCA and the factor model indicate a low validity of a factor model when the component scores have a larger correlation with a common factor than the respective best linear factor score predictor. This may indicate problems with the uncertainty of the factor that have been addressed in Rigdon et al. (2019).
One strategy to decide whether the MFA factor score predictor, the SPFA factor score predictor, or PCA scores should be computed, could be to chose the score with the largest coefficient of determinacy. The Equations (21) and (22) that were given for the computation of determinacy coefficients for PCA scores and SPFA factor score predictors can be used for this purpose. If the SPFA factor score predictor or the PCA score outperforms the MFA factor score predictor in terms of the correlation with the MFA factor, this could be a good reason to chose one of these scores.
However, whereas the results on the SRMRND are not affected by factor rotation, the results for the determinacy coefficient depend on factor rotation. The effects of factor rotation on determinacy coefficients were therefore eliminated in the first simulation study by means of orthogonal Procrustes rotation in order to compare MFA, SPFA, and PCA as methods for the extraction of variance. In a sample-based simulation, determinacy coefficients for MFA, SPFA, and PCA were compared for Varimax-rotated factors. It turns out that the differences between the methods were less marked when Varimax-rotation was performed. There was no substantial decrease of the determinacy coefficients when SPFA was combined with Varimax-rotation. Thus, SPFA-factor score predictors optimally reproduce the non-diagonal elements of the observed covariance matrix and provide similar determinacy coefficients as MFA. Therefore, SPFA estimation of factor loadings might be of interest when the factor score predictors are important.
An empirical example based on a short knowledge test demonstrates that SPFA gives more emphasis to the measured variables with the largest absolute loadings than PCA and MFA. Thus, when researchers expect that they have a few high-quality variables in a set of variables with moderate quality, they might be interested into SPFA. Moreover, the development and investigation of methods of factor rotation that might further enhance the focus on the variables with the largest loadings could be of interest.
Further research should be performed in order to investigate SPFA estimation of loadings in different methods of factor rotation, in the context of larger numbers of factors and variables. The precision of methods that allow to determine the number of factors to extract should also be investigated in the context of SPFA.
Data Availability
The datasets generated for this study are available on request to the corresponding author.
Author Contributions
All authors listed have made substantial, direct, and intellectual contribution to the work, and approved it for publication.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2019.01895/full#supplementary-material
References
Bartlett, M. S. (1937). The statistical conception of mental factors. Br. J. Psychol. 28, 97–104. doi: 10.1111/j.2044-8295.1937.tb00863.x
Beauducel, A. (2007). In spite of indeterminacy many common factor score estimates yield an identical reproduced covariance matrix. Psychometrika 72, 437–441. doi: 10.1007/s11336-005-1467-5
Beauducel, A., and Hilger, N. (2015). Extending the debate between Spearman and Wilson 1929: when do single variables optimally reproduce the common part of the observed covariances? Multivariate Behav. Res. 50, 555–567. doi: 10.1080/00273171.2015.1059311
Beauducel, A., and Hilger, N. (in press). On the fit of models implied by unit-weighted scales. Commun. Stat. Simul. Comp. doi: 10.1080/03610918.2018.1532517
Bernaards, C. A., and Jennrich, R. I. (2005). Gradient projection algorithms and software for arbitrary rotation criteria in factor analysis. Educ. Psychol. Meas. 65, 676–696. doi: 10.1177/0013164404272507
Comrey, A. L. (1962). The minimum residual method of FA. Psychol. Rep. 11, 15–18. doi: 10.2466/pr0.1962.11.1.15
Fava, J. L., and Velicer, W. F. (1992). An empirical comparison of factor, image, component, and scale scores. Multivariate Behav. Res. 27, 301–322. doi: 10.1207/s15327906mbr2703_1
Ferrando, P. J., and Lorenzo-Seva, U. (2019). Assessing the quality and appropriateness of factor solutions and factor score estimates in exploratory item factor analysis. Educ. Psychol. Meas. 78, 762–780. doi: 10.1177/0013164417719308
Grice, J. W. (2001). Computing and evaluating factor scores. Psychol. Methods 6, 430–450. doi: 10.1037/1082-989X.6.4.430
Guttman, L. (1955). The determinacy of factor score matrices with applications for five other problems of common factor theory. Br. J. Stat. Psychol. 8, 65–82. doi: 10.1111/j.2044-8317.1955.tb00321.x
Harman, H. H., and Jones, W. H. (1966). FA by minimizing residuals (minres). Psychometrika 31, 351–368. doi: 10.1007/BF02289468
Jennrich, R. I. (2001). A simple general procedure for orthogonal rotation. Psychometrika 66, 289–306. doi: 10.1007/BF02294840
Krijnen, W. P. (2006). Some results on mean square error for factor score prediction. Psychometrika 71, 395–409. doi: 10.1007/s11336-004-1220-7
Krijnen, W. P., Wansbeek, T. J., and Ten Berge, J. M. F. (1996). Best linear predictors for factor scores. Commun. Stat. Theory Methods 25, 3013–3025. doi: 10.1080/03610929608831883
Lorenzo-Seva, U., and Ferrando, P. J. (2013). FACTOR 9.2 A comprehensive program for fitting exploratory and semiconfirmatory factor analysis and IRT models. Appl. Psychol. Meas. 37, 497–498. doi: 10.1177/0146621613487794
MacCallum, R. C. (2003). Working with imperfect models. Multivariate Behav. Res. 38, 113–139. doi: 10.1207/S15327906MBR3801_5
MacCallum, R. C., and Tucker, L. R. (1991). Representing sources of error in the common-factor model: implications for theory and practice. Psychol. Bull. 109, 502–511. doi: 10.1037/0033-2909.109.3.502
McDonald, R. P. (1981). Constrained least squares estimators of oblique common factors. Psychometrika 46, 337–341. doi: 10.1007/BF02293740
McDonald, R. P., and Burr, E. J. (1967). A comparison of four methods of constructing factor scores. Psychometrika 32, 381–401. doi: 10.1007/BF02289653
Rigdon, E. E., Becker, J.-M., and Sarstedt, M. (2019). Factor indeterminacy as metrological uncertainty: implications for advancing psychological measurement. Multivariate Behav. Res. 54, 429–443. doi: 10.1080/00273171.2018
Schönemann, P. H. (1966). A generalized solution of the orthogonal Procrustes problem. Psychometrika 31, 1–10. doi: 10.1007/BF02289451
Schönemann, P. H., and Steiger, J. H. (1976). Regression component analysis. Br. J. Math. Stat. Psychol. 29, 175–189. doi: 10.1111/j.2044-8317.1976.tb00713.x
Tucker, L. R., Koopman, R. F., and Linn, R. L. (1969). Evaluation of factor analytic research procedures by means of simulated correlation matrices. Psychometrika 34, 421–459. doi: 10.1007/BF02290601
Velicer, W. F., and Jackson, D. N. (1990). Component analysis versus common factor analysis: some issues in selecting an appropriate procedure. Multivariate Behav. Res. 25, 1–28. doi: 10.1207/s15327906mbr2501_1
Weide, A. C., and Beauducel, A. (2019). Varimax rotation based on gradient projection is a feasible alternative to SPSS. Front. Psychol. 10:645. doi: 10.3389/fpsyg.2019.00645
Widaman, K. F. (2018). On common factor and principal component representations of data: implications for theory and for confirmatory replications. Struct. Equat. Model. 25, 829–847. doi: 10.1080/10705511.2018.1478730
Keywords: factor analysis, Minres, factor score predictors, principal component analysis, indeterminacy
Citation: Beauducel A and Hilger N (2019) Score Predictor Factor Analysis: Reproducing Observed Covariances by Means of Factor Score Predictors. Front. Psychol. 10:1895. doi: 10.3389/fpsyg.2019.01895
Received: 22 March 2019; Accepted: 31 July 2019;
Published: 16 August 2019.
Edited by:
Alessandro Giuliani, Istituto Superiore di Sanità (ISS), ItalyReviewed by:
Xiaoxiao Sun, University of Arizona, United StatesDiana Martella, Universidad Autónoma de Chile, Chile
Copyright © 2019 Beauducel and Hilger. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: André Beauducel, YmVhdWR1Y2VsJiN4MDAwNDA7dW5pLWJvbm4uZGU=