 Céline Pozniak
Céline Pozniak Barbara Hemforth1
Barbara Hemforth1 Christoph Scheepers
Christoph Scheepers- 1Laboratoire de Linguistique Formelle, CNRS, Paris Diderot University, Paris, France
- 2Institute of Neuroscience & Psychology, University of Glasgow, Glasgow, United Kingdom
Human language processing must rely on a certain degree of abstraction, as we can produce and understand sentences that we have never produced or heard before. One way to establish syntactic abstraction is by investigating structural priming. Structural priming has been shown to be effective within a cognitive domain, in the present case, the linguistic domain. But does priming also work across different domains? In line with previous experiments, we investigated cross-domain structural priming from mathematical expressions to linguistic structures with respect to relative clause attachment in French (e.g., la fille du professeur qui habitait à Paris/the daughter of the teacher who lived in Paris). Testing priming in French is particularly interesting because it will extend earlier results established for English to a language where the baseline for relative clause attachment preferences is different form English: in English, relative clauses (RCs) tend to be attached to the local noun phrase (low attachment) while in French there is a preference for high attachment of relative clauses to the first noun phrase (NP). Moreover, in contrast to earlier studies, we applied an online-technique (visual world eye-tracking). Our results confirm cross-domain priming from mathematics to linguistic structures in French. Most interestingly, different from less mathematically adept participants, we found that in mathematically skilled participants, the effect emerged very early on (at the beginning of the relative clause in the speech stream) and is also present later (at the end of the relative clause). In line with previous findings, our experiment suggests that mathematics and language share aspects of syntactic structure at a very high-level of abstraction.
Introduction
Abstract syntactic structures enable us to produce and understand sentences that we have never heard or produced before. Beyond these syntactic representations, human sentence processing requires cognitive resources in varying amounts depending on complexity of the sentences. A question that is still debated is how specific these abstract syntactic structures and the required cognitive capacities are to language processing (Koelsch et al., 2004; Fedorenko et al., 2007; Fedorenko et al., 2009; Scheepers et al., 2011; Amalric and Dehaene, 2016; see also Patel, 2003; Scheepers, 2003; Scheepers and Sturt, 2014; Van de Cavey and Hartsuiker, 2016). To answer this, two main classes of questions for resource sharing between cognitive domains have been discussed in the literature:
(1) Sharing of structure building resources: Are abstract representations and/or procedures in language different from other domains, such as mathematics or music? Or do the domains share representations and/or operations for processing? If there are shared representations and/or procedures, which level of representation do they concern? Do they concern syntactic (structural) representations of linguistic, mathematical, or musical representations or do they concern their meaning, i.e., semantic or conceptual representations?
(2) Sharing of processing capacity: Independent of linguistic representations, does the linguistic domain share cognitive resources with other domains like music or mathematics, meaning that domains require the same additional cognitive resources in cases of cognitive load (e.g., to process complex linguistic, mathematical, or musical structures)?
Much of the literature in psycholinguistics and cognitive psychology focused on the second research question (shared cognitive capacity) or some combination of the two questions. The experiment presented in this paper focused on the sharing of structure building resources. It showed that linguistic and mathematical expressions shared abstract structural representations or structure building procedures leading to mathematical priming effects on sentence processing. Priming studies within (Bock, 1986; Pickering and Branigan, 1998) or even across languages (Hartsuiker et al., 2004) have been proposed to find out more about the nature of linguistic abstractions. In particular, crosslinguistic priming effects are considered a major argument for shared representations between the first and second language of a bilingual speaker. We applied a very similar approach to cross-domain sharing of structure building resources. Before presenting our experiments, we discuss diverging approaches to the status of linguistic representations in relation to other cognitive domains.
A very strict separation between the linguistic domain and others claiming the absence of any shared resources has been suggested by Amalric and Dehaene (2016) for the relationship between language and mathematics. In their study, they aimed to find out whether mathematical capacities are active in similar brain areas as language competence (for instance, the language semantics network) or rather in separate brain circuits. They ran fMRI experiments in which they scanned the brains of mathematicians and non-mathematicians while they had to evaluate the truth of meaningful and meaningless mathematical and non-mathematical statements such as (1a,b) and (2a,b).
[1] a. A finite left-invariant measure over a compact group is bi-invariant.
b. In finite measure, the series expansion of the roots of a holomorphic map is reflexive.
[2] a. In ancient Greece, a citizen who could not pay his debts was made a slave.
b. The Greek mythology is the smallest alcohol derived from the VAT.
The results showed that left-hemispheric brain regions generally associated with language competence were not activated for meaningful mathematical statements in professional mathematicians. Conversely, regions associated with mathematical capacities were not activated during meaningful non-mathematical statements. Amalric and Dehaene (2016) concluded from their studies that high-level mathematical thinking and language do not activate the same regions in the brain and thus do not draw on the same resources. However, when looking at their experimental design, the authors’ conclusions appear to concern mainly the representation and storage of mathematical knowledge compared to general knowledge. Thus, with respect to the two research questions proposed above, this study was mostly related to possible shared relations on the semantic level and possibly with respect to general cognitive resources. The experiments did not concern possible overlap with respect to the syntactic processing of mathematical and linguistic expressions. This means, high-level mathematical knowledge seemed to activate brain regions typically involved with space and number and not the semantic network which is typically activated by encyclopedic knowledge. However, these facts do not rule out that some of the rules and processes for the two domains are shared at the syntactic level. The experiment presented in this paper is mainly about this latter aspect.
In favor of shared structure building resources, Patel (2003) suggested the shared syntactic resource hypothesis. This hypothesis implies that domains like music and language demand syntactic rules for processing (linguistic or musical elements need rules to integrate them into larger units such as sentences or musical phrases). Even though these rules themselves are probably specific to their domains, they might employ shared basic structure building resources, e.g., common operations to be executed in the same neural areas. An example for this may be operations to reactivate preceding elements in order to integrate new ones. With respect to shared cognitive capacities, Kljajević, 2010 suggested that some domains like language and music share the same syntactic working memory resources (see also Fedorenko et al., 2007, 2009). However, sharing some cognitive resources for processing does not imply shared structure building resources, i.e., that a connection can be established via abstract representations across domains (and thus, priming across domains; see Koelsch et al., 2004). Domains could just refer to the same domain general cognitive resources to process complex structures (shared capacities). Cross-domain priming studies allow for a more direct test of the connection between the linguistic domain and non-linguistic domains with respect to abstract representations.
Some of the clearest evidence established so far can be found in Scheepers et al. (2011) (see also Scheepers, 2003; Scheepers and Sturt, 2014; Van de Cavey and Hartsuiker, 2016), who found a connection between the linguistic domain and mathematics by looking at relative clause attachment (e.g., he met the daughter of the teacher who lived in Paris) in English. Before presenting our experiment, we describe these findings, and the rationale behind them, in more detail.
Previous Evidence
Scheepers et al. (2011) studied in how far mathematical expressions influence relative clause attachment. Relative clause attachment has the interesting property that it presents a syntactic ambiguity with a close correspondence in certain mathematical expressions (as explained further below). Taking an example from Spanish, in sentences like [3], the relative clause can either attach “high” to the first noun phrase (la criada) or “low” to the second noun phrase (la actriz). Interestingly, different languages have different basic attachment preferences: the relative clause in French (or Spanish, Portuguese, German) will more often attach to the first noun phrase (high attachment), whereas the relative clause in other languages like in English will more frequently attach to the second noun phrase (low attachment).
[3] Algúien disparó contra la criada de la actriz [que estava en el balcón].
Someone shot the maid of the actress [that was standing on the balcony]. (Cuetos and Mitchell, 1988).
Attachment preferences for relative clauses can be quite different across and within languages depending on the particular construction, showing that they can be influenced by a variety of factors: the anaphoric status of the relative pronoun (Hemforth et al., 2000), length and information structure (Hemforth et al., 2015), prosody (Fodor, 2002), syntactic (Gibson et al., 1996) or pragmatic properties (Gilboy et al., 1995), or presence or absence of pseudo-relatives in the grammar of the respective language (Grillo and Costa, 2014).
In this paper, we aimed to find out whether these preferences can be changed via structural priming, particularly via priming from non-linguistic structures. The hierarchical structure ambiguity involved in relative clause attachment, i.e., integrating some structural element locally (low-attachment) or non-locally (high-attachment) is not specific to linguistic processing and can be found in other domains like mathematics, music, and possibly in a variety of other cognitive domains (see also Van de Cavey and Hartsuiker, 2016). Therefore, relative clause attachment constitutes a key phenomenon to study whether different domains like mathematics and linguistics have shared representations and whether a connection between the domains can be found in terms of cross-domain structural priming.
Scheepers et al. (2011) noticed a certain resemblance between the structural alternatives for sentences like [3] on the one hand and mathematical expressions like 90-(9 + 1)∗5 versus 90-9 + 1∗5 on the other hand. Apart from giving different results, these two mathematical expressions have hierarchical structures comparable to, respectively, high versus low attachment of a relative clause in a sentence like [3], and can actually be represented in similar ways. For example, in Figure 1, the expression 90-(9 + 1)∗5 [where the final multiplication operator takes scope over a complex expression (9 + 1) on its left] is analogous to high attachment of a relative clause (where the relative clause, or “CP,” takes scope over the entire preceding complex noun phrase), while in Figure 2, the expression 90-9 + 1∗5 (where the final operator takes scope over the most recent number on the left) corresponds to low attachment of a relative clause (where the CP takes scope over the most recent noun phrase, or “DP,” on its left).
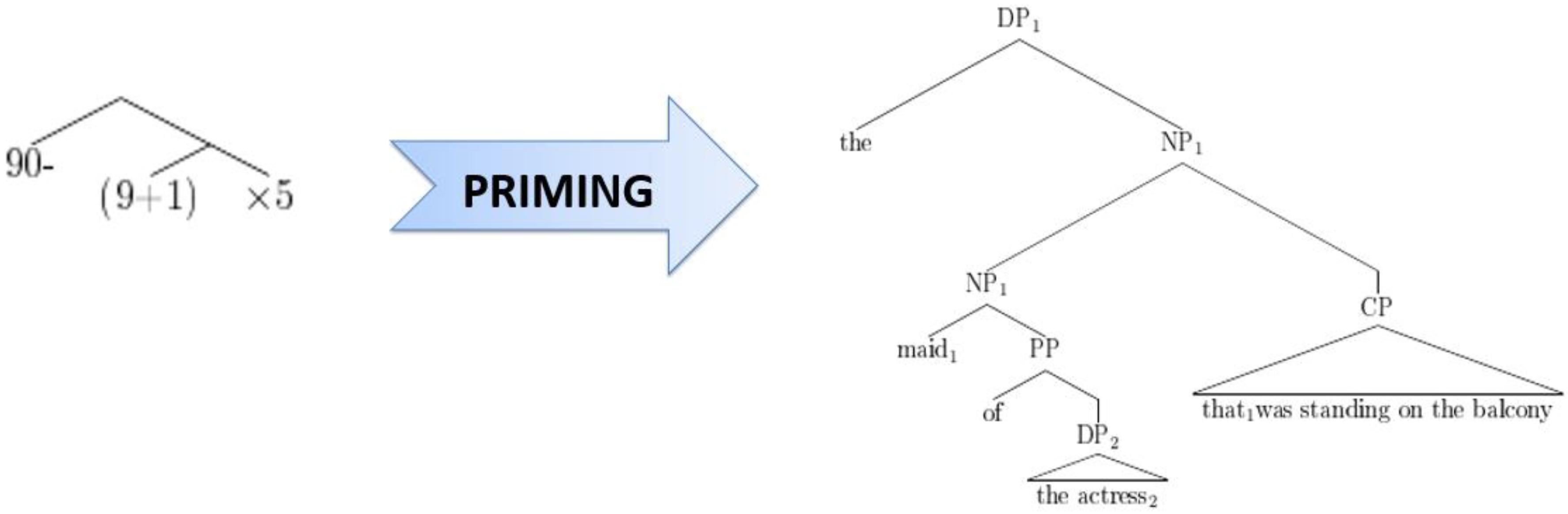
FIGURE 1. Correspondence between 90–(9 + 1)∗5 and high attachment of a relative clause.
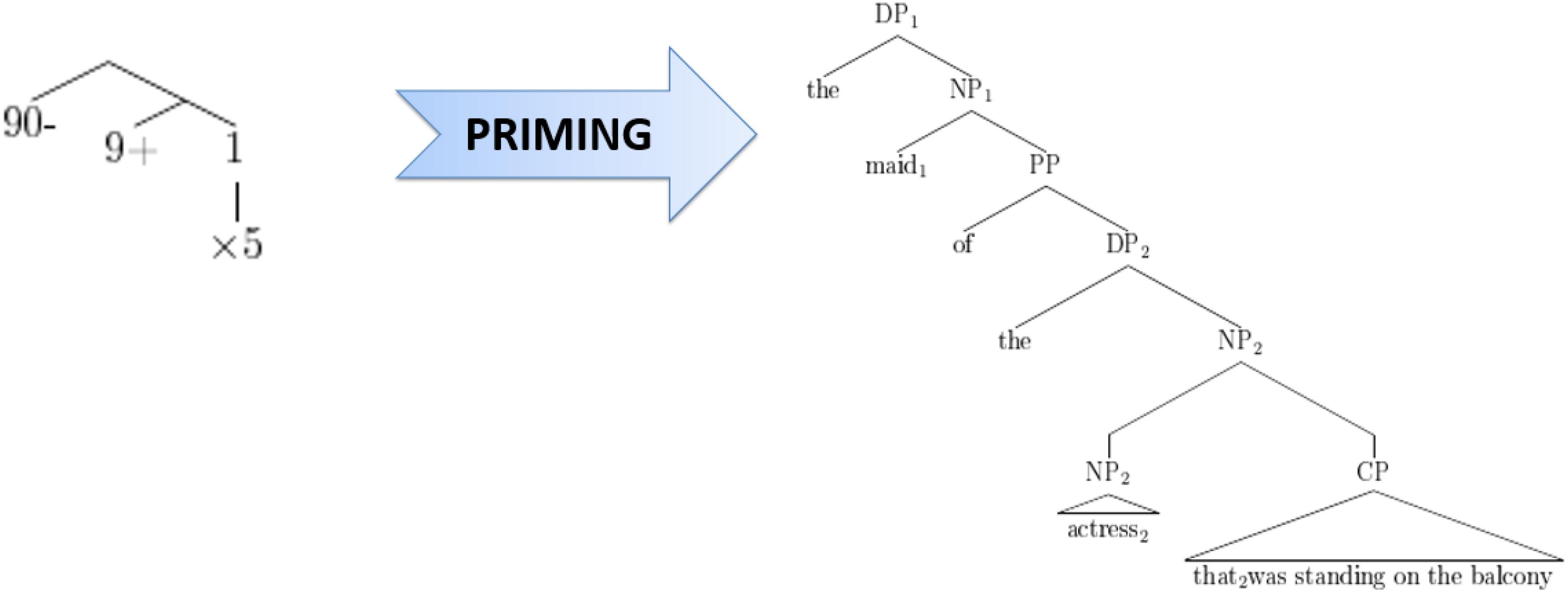
FIGURE 2. Correspondence between 90–(9 + 1)∗5 and low attachment of a relative clause.
Figures 1, 2 illustrate that at an abstract level, the hierarchical structure of mathematical expressions can be analogous to that of linguistic expressions. However, there is an important difference between mathematical expressions and relative clause sentences with respect to their ambiguity. Indeed, when considering mathematical operator-precedence rules, mathematical expressions like 90-(9 + 1)∗5 and 90-9 + 1∗5 are not ambiguous at all. By contrast, sentences with relative clause attachment like Someone shot the maid of the actress that was standing on the balcony remain ambiguous on the surface. The main research question of Scheepers et al. (2011) was whether unambiguous mathematical expressions (like the ones discussed above) influence relative clause attachment via structural priming, which would suggest shared (abstract) structural representations between mathematics and language, or shared procedures to process them, i.e., shared structure building resources.
To answer this question, they set up off-line sentence completion experiments in English. Participants were presented with a questionnaire composed of equations to solve and sentence preambles to complete (starting with the relative pronoun, see Table 1). Critical relative clause items were preceded by mathematical expressions to solve (equations analogous to the high-attachment or low-attachment option for relative clause sentences, and “control” equations that did not entail hierarchical structuring).

TABLE 1. Example of an item in the experiment from Scheepers et al. (2011).
Their results showed a priming effect with more high attachment completions after “high” attaching mathematical expressions and more low attachment completions after “low” attaching mathematical expressions, but interestingly, only in subgroups of participants who were adept in solving the mathematical equations correctly (i.e., business and math students). Another subsample of participants (psychology students) did not show reliable cross-domain structural priming effects, presumably due to a lack of knowledge of the arithmetic operator-precedence rules, as suggested by a high number of mathematical errors in that group (see also Scheepers and Sturt, 2014).
To address this problem, Scheepers et al. (2011) ran another experiment where they added redundant brackets to the critical mathematical equations [e.g., 90-((5 + 15)/15) or 90-5 + (15/15), respectively]. This time, psychology students made far fewer mathematical mistakes and showed clear cross-domain structural priming effects.
Thus, the experiments from Scheepers et al. (2011) (see also Scheepers and Sturt, 2014; Van de Cavey and Hartsuiker, 2016) suggest that linguistic structural processing (more specifically, sentence completion) can be influenced by structural processing in a non-linguistic domain, in this case the mathematical domain.
The Present Study
While being fairly conclusive in terms of shared structural representations across different cognitive domains, the previous research leaves many questions unanswered. The one we are interested in is whether this cross-structural priming effect can also be generalized to on-line language comprehension, which is less prone to metalinguistic or strategic effects.
To address this question, we conducted an experiment using an on-line comprehension paradigm, namely visual-world eye-tracking (e.g., Cooper, 1974; Tanenhaus et al., 1995). This technique combines spoken language with a simultaneously presented visual scene, measuring how auditory language comprehension affects scene perception (more specifically, attention-allocation to syntactic interpretation-relevant referents in the scene) in real time. We chose this paradigm because it has previously been successfully used to investigate language-internal structural priming (from reading to listening) of constituent order in German (Scheepers and Crocker, 2004), or of priming of ditransitive structures in English, for example (Arai et al., 2007).
Another question addressed by our study is whether cross-structural priming from mathematical equations to relative-clause attachment can also be observed in French where relative clause attachment preferences differ from those in English. As discussed earlier, English exhibits a general low-attachment preference for relative clauses, whereas French (the language used in the present study) shows a general high-attachment preference. Indeed, for the notion of cross-domain structural priming to bear substance, it is important to demonstrate that it is independent from language-specific structural biases.
For the current experiment, we expected early as well as late effects of priming from mathematical expressions to relative clause attachment, particularly for participants with good mathematical knowledge and less so for mathematically less adept participants. Similar to Patel (2003), we assumed that basic processing operations for building hierarchical structures are shared between mathematical and linguistic expressions. Thus, participants with good knowledge of the relevant mathematical operations should show fixations corresponding to a stronger tendency to attach the relative clause high after “high attachment” equations than after “low attachment” equations at the beginning of the relative clause, and also (potentially) toward the end of the sentence. No clear predictions could be made at this point for participants with low mathematical knowledge.
Experiment
Scheepers et al. (2011) found an influence from mathematical expressions on relative clause attachment in English. Still, they (and others) only focused on language production and used off-line questionnaires, which only provided indirect access to linguistic processing. Our study extended this work by setting up an on-line paradigm (visual-world eye-tracking) in another language, i.e., French, a high-attachment preference language. Moreover, we studied priming in comprehension where priming effects have been shown somewhat less consistently (see Traxler et al., 2014, for a discussion).
An important fact about French is that it has different types of relative clauses depending on the verb in the main clause, and this peculiarity (which does not exist in English) can have a modulating influence on relative clause attachment preferences (Grillo and Costa, 2014). Therefore, it was imperative to pre-test our French materials in order to confirm the general high attachment preference for relative clauses.
Norming Study
According to Grillo and Costa (2014), relative clauses introduced by a perceptual verb are called pseudo-relatives, which are structurally different from traditional relative clauses because they refer to events and will modify the verb and not any of the nouns. As an illustration, the relative clause in [5a] only denotes a property of the lawyer while in [4a] it can also denote an event. It is also possible to pronominalize the head noun of a pseudo-relative clause like in [4b] contrary to [5b]. In that case, [4] has two readings: a pseudo-relative reading and a traditional relative reading, and according to Grillo and Costa (2014), the pseudo-relative reading is preferred, meaning that the relative clause takes the first noun as its subject (here, the son), an interpretation that superficially resembles high attachment (and this relative clause attaches to the verb). This type of relative clause exists in French but not in English.
[4] a. Le médecin voit le fils de l’avocat qui court.
The doctor sees the son of the lawyer that runs.
b. Le médecin le voit qui court.
The doctor sees him that runs.
[5] a. Le médecin déteste le fils de l’avocat qui court.
The doctor hates the son of the lawyer that runs.
b. ∗Le médecin le déteste qui court.
∗The doctor hates him that runs.
Thus, in order to avoid having different structures of relatives which could add noise to our experimental results, we decided to have the same main clause for every item: Voici …. Indeed, Grillo and Costa (2014) attribute the high attachment preference for relative clauses in French mainly to the existence of pseudo-relative clauses. By excluding pseudo-relative readings in French, the high attachment preference for sentences like [5] is therefore less certain1. This is why we decided to run a forced choice task with our items to test attachment preferences.
Participants
Fifty native speakers of French participated in the experiment (mean age: 35 years old, σ = 17). They were recruited via the RISC2 platform. Three participants were excluded because their first language was not French.
Materials
The items consisted of 30 sentences containing an ambiguous relative clause, followed by two possible interpretations of the relative clause (see [6]). The interpretations were either about the first noun (NP1, [6a]) or the second noun (NP2, [6b]).
[6] Voici le cuisinier de l’ingénieur qui va finir ce sur quoi il travaillait.
Here we have the cook of the engineer who will finish what he was working on.
a. Le cuisinier va finir ce sur quoi il travaillait.
The cook finished what he was working on.
b. L’ingénieur va finir ce sur quoi il travaillait.
The engineer finished what he was working on.
Orders of interpretation-paraphrases (NP1-related first or NP2-related first) were counterbalanced across the 30 items per presentation list. Two lists were created with order of paraphrases swapped across lists. Thirty filler sentences of an independent experiment were added to the lists. The order of presentation was randomized individually for each participant.
Procedure
The experiment was run online via the Internet-based platform IbexFarm (Drummond, 2010). For each trial, participants read a sentence with an ambiguous relative clause and they had to choose which of the two interpretations was more natural and acceptable. The experiment lasted about 20 min.
Results
No significant difference was found concerning the order of the interpretation paraphrases. Participants chose NP1-attachment paraphrases 71% of the time and NP2-attachment paraphrases 29% of the time. A logistic regression model with simple intercept showed a significant difference between NP1-and NP2-attachment: β = 1.44, z = 4.85, p < 0.001. Thus, we found that the NP1-modifying high-attachment interpretation was strongly preferred, contrasting with English which is more biased toward low attachment.
Eye-Tracking Experiment
We ran an Eye-Tracking experiment using the Visual World paradigm in French. We manipulated mathematical equations in order to investigate directly their priming effect on ambiguous relative clause comprehension.
Participants
Thirty six native speakers of French participated in the eyetracking experiment, all living in Paris at the time of the experiment (mean age: 30 years old, σ = 11). All participants gave written informed consent before taking part and the study was approved by the College of Science and Engineering Committee at the University of Glasgow (Application Number: 300150090) as well as by the Comiteì d’Ethique pour les Recherches en Santeì at the University Paris Sorbonne Cité (CERES; Application Number: 2018-34).
Participants were divided into two groups3 (more information in the procedure section): a mathematical knowledge group and a no mathematical knowledge group, see also Scheepers and Sturt (2014).
Materials
For this experiment, we used the SR Research Experiment Builder 2.1.140 [Computer software] (2017) for the setup. Thirty experimental items (see Appendix) were constructed, each comprising two types of prime equations (see below), plus a picture and a spoken sentence as target visual-world materials. Each of the 30 target pictures (Figure 3) comprised cartoon-like depictions of several objects and characters in an arbitrary layout (with changing positions across items): two human protagonists (e.g., a chef and an engineer, serving as referents for NP1 and NP2 in the spoken sentences, respectively), two objects associated with those protagonists (e.g., a roast chicken and a tall building), and two unrelated distractor objects (e.g., a broom and a coat). The association between nouns and their related objects was based on semantic and pragmatic associations as estimated by the authors of this paper4.

FIGURE 3. Example of a picture used as target visual-world materials.
Audio stimuli were spoken French sentences like [6], which ended in an attachment-ambiguous relative clause (e.g., English translation: “Here we have the cook of the engineer who will finish what he was working on”). Relative clauses were constructed to be “semantically neutral,” i.e., they were constructed to be equally plausible modifiers of NP1 or NP2. The sentences were spoken by a female native French speaker using neutral intonation and digitized for later presentation using Audacity and checked in PRAAT (Boersma and Weenink, 2018).
Each item included two types of priming equations – high-attachment (e.g., 4 + (6-2)/2) and low-attachment (e.g., 4 + 6-2/2) – which were paired with one of the pictures (composed of four objects and two human characters) plus a spoken sentence as target for visual-world trials. See Table 2 for example equations in the two conditions (high attachment and low attachment). The equations were structurally equivalent to the high- and low-attachment equations used in Scheepers et al. (2011). They were easily solvable without using a calculator and always resulted in a non-negative whole number. In high-attachment equations, a multiplication or division operation at the end was preceded by a bracketed term (either an addition or a subtraction) on its left, whereas in low-attachment equations, the brackets were omitted so that the final multiplication or division took scope over the most recently encountered number. Participants were thus presented with 30 experimental items, 15 items per condition.

TABLE 2. Example equations in the two conditions.
Fifty six fillers were also added. These comprised 26 equations (structurally different from the critical prime equations, Table 3) and 30 pictures combined with auditory French sentences that ended in unambiguous relative clauses (e.g., English translation: “Here we have the gardeners who will offer a necklace to the sculptor,” Figure 4)5.

TABLE 3. Example equations for the fillers.

FIGURE 4. Example of a picture used as filler visual-world materials.
The two experimental conditions (high attachment equation/low attachment equation) were presented to participants following a Latin square design: Two counterbalanced presentation lists were generated such that (a) half of the experimental picture-sentence combinations (serving as targets) were preceded by high-attachment prime equations and the other half by low-attachment prime equations and (b) item-condition combinations were swapped across the two lists. As our dependent variable, we looked at fixations on the NP1 object vs. the NP2 object, meaning fixations on the NP1 object out of fixations on both objects.
The materials per list were pseudo-randomized, ensuring that each experimental pair of prime equation and picture-sentence combination was separated from the others by at least one filler trial, randomly chosen from the pool of filler equations and filler visual-world trials. Because of the latter, there was no regular sequencing of mathematical versus visual-world trials (i.e., it was not the case that a mathematical trial was always followed by a visual-world trial or vice versa). To ensure that participants paid attention to the pictures and sentences, comprehension questions were included after 16 of the (filler or experimental) visual-world trials. Eight concerned the spoken sentence (e.g., “was a cowboy mentioned?”), and eight referred to the picture itself (e.g., “was there a broom in the picture?”).
The incorrect answer option for the mathematical equations always corresponded to the result of linear processing of the equation without taking operator-precedence rules into account (i.e., the result according to an incorrect structuring of the equation). Positioning of correct/incorrect answer options was counterbalanced across items.
Hypothesis
Based on our experimental design, upon hearing “qui va finir ce sur quoi il travaillait” (“who will finish what he was working on”) in the sentence, we expected participants to look more at the NP1-related object (roast chicken) in Figure 3 if they had been primed toward assuming a high-attachment structure, and to look more at the NP2-related object (building) if they had been primed toward assuming a low-attachment structure. In principle, such priming effects could manifest themselves as early as during encountering the relative pronoun (“qui”) in the sentence if participants expect references to NP1- and NP2-related objects in the relative clauses. Alternatively, such effects could take more time to emerge (e.g., toward the end of the relative clause, when all interpretation-relevant information is available). We expected that mathematical priming would affect attachment preferences particularly for mathematically adept participants, who solved equations correctly while no clear predictions were made for mathematically less adept participants.
Procedure
Before the experiment started, participants had to solve the following equation: 1 + 2∗3 = ? Depending on the answer (7 or 9), they were either in the mathematical knowledge group (7) or the no mathematical knowledge group (9).
The eye-tracking experiment was run with an SR Research Eyelink 2 system in a sound attenuated booth. We recorded eye fixations from the dominant eye based on the Test Miles (1930). Each experiment started with a nine-point calibration.
Participants were instructed that there were two types of trials: (i) mathematical trials and (ii) picture-sentence trials6. Each picture-sentence trial was preceded by the presentation of a fixation dot for drift-correction. On mathematical trials, participants saw an equation on the screen with two possible answer options below it (see Figure 5). They had to choose the correct answer by pressing the left button on a gamepad for the answer on the left, and the right button for the answer on the right.
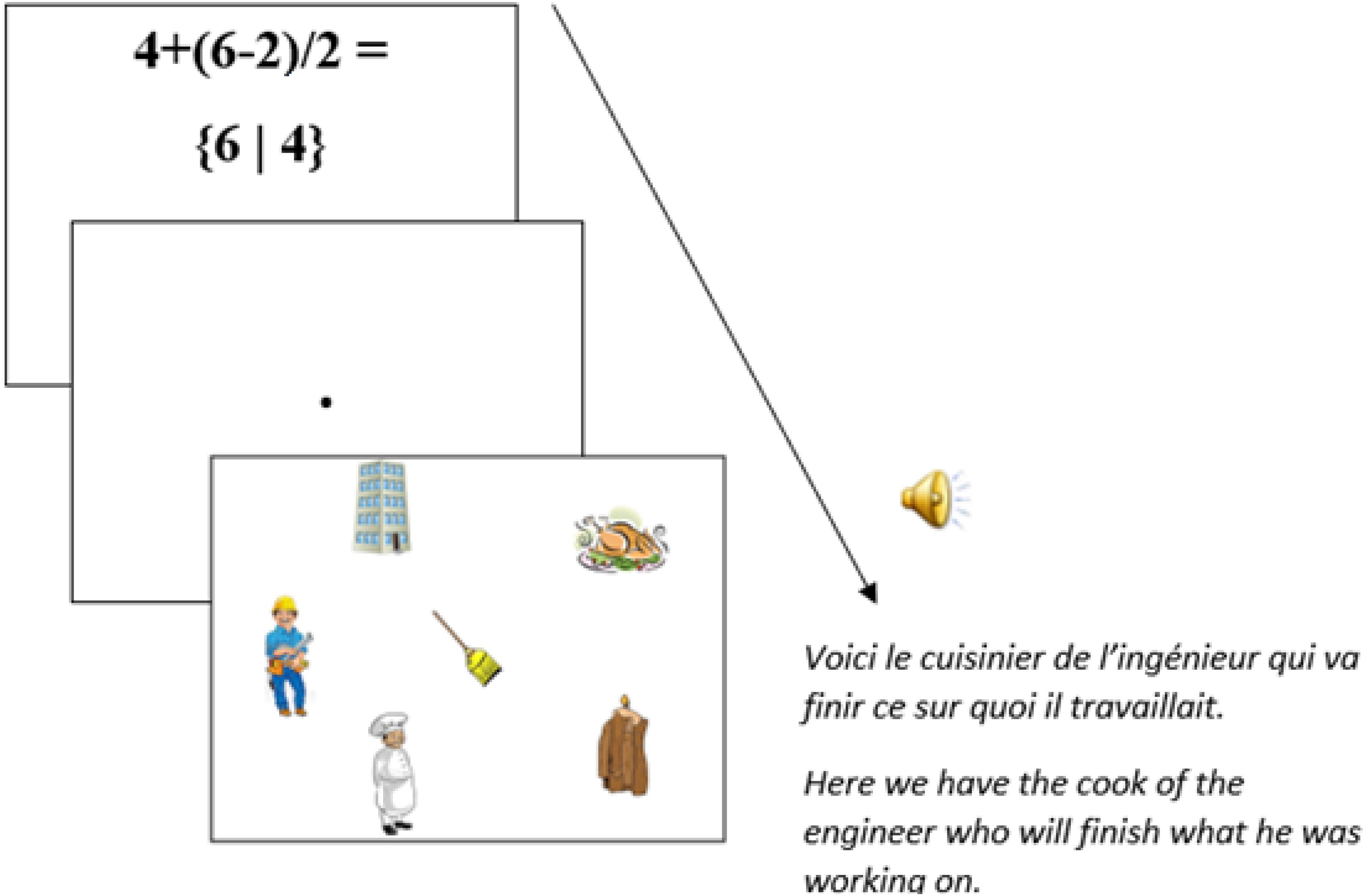
FIGURE 5. Presentation sequence for a critical prime (equation) – target (visual-world trial) pair of stimuli.
In picture-sentence trials, they had to look at pictures while listening to related spoken sentences. Participants were informed that after some of the picture-sentence trials, a question related to either the picture or the sentence would appear, which they were to answer with either the right-hand button (for “yes”) or the left-hand button (for “no”) on the gamepad. Eye movements were recorded throughout the presentation of each picture, which stayed on screen for 5000 ms. The speech recordings for the sentences started playing right after the onset of each picture presentation. Figure 5 illustrates the presentation sequence for a critical prime-target pair of trials and Figure 6 for a non-critical prime-target pair of trials. There was a practice session before the actual experiment (four trials) to familiarize participants with the task.
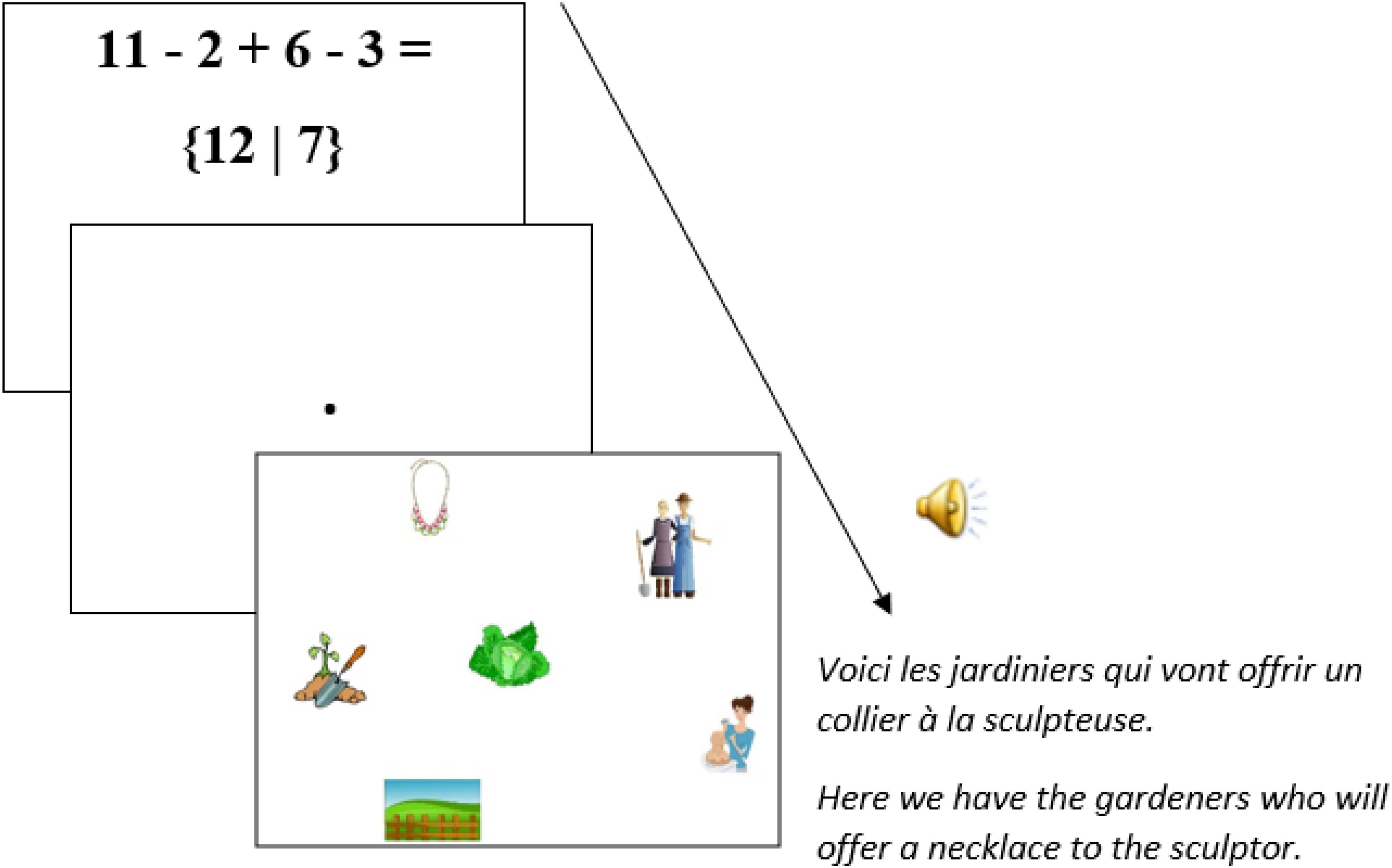
FIGURE 6. Presentation sequence for a non-critical prime (equation) – target (visual-world trial) pair of stimuli.
Importantly, participants remained unaware about the pairing of critical prime-target trials until debriefing at the end of the experimental session.
Analysis Methods
We used the R package EyetrackingR (Dink and Ferguson, 2015) to analyze the Eye-Tracking data. We then analyzed them by running growth curve analyses (Mirman et al., 2008). Independent variables (predictors) were Prime Condition (high attachment vs. low attachment), Time and Group (mathematical knowledge and no mathematical knowledge). Dependent variables (outcome variables) were fixations on the NP1-related object or on the NP2-related object. For the results presented in this paper, we focused on the NP1- and NP2-related objects because they were the relevant objects for the interpretation of the ambiguous relative clause, rather than the protagonists. Fixations on NP1 and NP2 can be found in supplementary materials7). Random variables were participants and items.
We chose growth curves due to the fact that eye fixations on the target objects should change depending on what part of the sentence participants are listening to at a certain moment. Thus, time is a very strong predictor that needs to be taken into account. Growth-curve analyses included time as a continuous predictor with the dependent variable being categorical (binary).
Growth-curves for the visual world data were analyzed with Bayesian generalized linear mixed models (Sorensen et al., 2016, among others) using the R package Rstan. Our main motivation behind choosing a Bayesian modeling framework was that previous frequentist analyses (using the lme4 package) often failed to converge when a maximal random effects structure justified by the design was used (cf. Barr et al., 2013). Bayesian models are much less prone to convergence failure, even with relatively small data sets. Another advantage of Bayesian analysis is that it directly tests the likelihood of the hypothesis of interest, contrasting with indirect null-hypothesis testing as in frequentist frameworks. Moreover, we express the uncertainty of the effects by the means of credible intervals.
Our hypothesis was that a priming effect would show up especially for the mathematical knowledge group. In other words, looks to the NP1-related object would be more frequent in the high attachment condition for the mathematical knowledge group. The opposite pattern was expected for the NP2-targeted object.
Fixed effects were Time, Group, and Prime Condition as well as their interactions. Random effects were participants and items, and we also included random slopes for the effects of Prime Condition and Group for items, as well as their interactions. For participants, we only included random slopes for Prime Condition.
As for the coding, the group factor was coded 1 for the mathematical knowledge group and -1 for the no mathematical knowledge group. The Prime Condition factor was coded 1 for high attachment and -1 for low attachment. Normal distributions with μ = 0, SD = 10 on a logit scale were used as weakly informative priors.
To determine the shape of the fixed effect of time, we ran three linear mixed models with simple intercepts to test which polynomial function corresponds best to our data (see Appendix C)8. Then, we ran Bayesian models with 4 chains and 6000 iterations each. Model convergence was verified graphically and by inspecting model coefficients in R.
According to our hypothesis, potential priming effects may show up either at the beginning of the relative clause or toward the end of the sentence (when all the information is available). We therefore analyzed the data per participant group in two separate time-windows: (i) 200 ms before the beginning of the relative clause until 200 ms after the beginning of the relative clause, and (ii) 500 ms before the end of the sentence until the end of the sentence.
Concerning the pre-test (1 + 2∗3 = ?), 20 participants were initially attributed to the mathematical knowledge group and 16 participants to the no mathematical group. However, after inspecting the results more closely, we found that the accuracy rate for the condition equations within the experiment was lower than 70% for two participants from the mathematical knowledge group. We decided to put them in the no mathematical knowledge group, leading to two balanced groups with 18 participants each. We present the analysis with this change in the results section9.
Results
Comprehension accuracy
To be sure that participants were engaged to the task, we included comprehension questions on the pictures (Did you see an umbrella on the picture? / Was the little girl sick?). Participants from the mathematical knowledge group answered 87% of the comprehension questions correctly, while participants from the no mathematical knowledge group answered 85% of the comprehension questions correctly. This difference was not significant.
Mathematical performance
When looking at the percentage of correct answers to the equations, we found that participants from the mathematical knowledge group answered 84% of the high-attachment equations and 97% of the low-attachment equations correctly. By contrast, participants in the no mathematical knowledge group answered 12% high-attachment equations and 19% low-attachment equations correctly. As for the structurally simpler filler equations, participants in the mathematical knowledge group answered them correctly 96% of the time, and participants of the no mathematical knowledge group 90% of the time.
These results suggest that participants in the mathematical knowledge group generally “understood” the structure of the prime equations, whereas participants in the no mathematical knowledge group had difficulty particularly with identifying the correct operator-precedence relations in the equations (as already suggested by the initial classification).
Eye fixations on the NP1 (vs. NP2)-related object
As explained before, we focus on fixations on the NP1- and the NP2-object in the results section. Fixations to other objects can be found in supplementary materials10. Probabilities of looks in this section are looks to the NP1-object out of NP1- and NP2-object fixations. We only show looks to the NP1-related object because looks to the NP2-object would be their mirror image.
Figures 7, 8 show raw proportions of looks to the NP1-related object (out of fixations to NP1-related object + fixations to NP2-related object) in relation to Prime Condition (high attachment vs. low attachment) every 50 ms, from the first noun to the end of the sentence (3023 ms). Results from the mathematical knowledge group (upper part of the Figure), and from the no mathematical knowledge group (lower part of the Figure) are presented. The blue line refers to fixations to the NP1-related object under the low attachment condition while the red line concerns fixations to the NP1-related object under the high attachment condition.
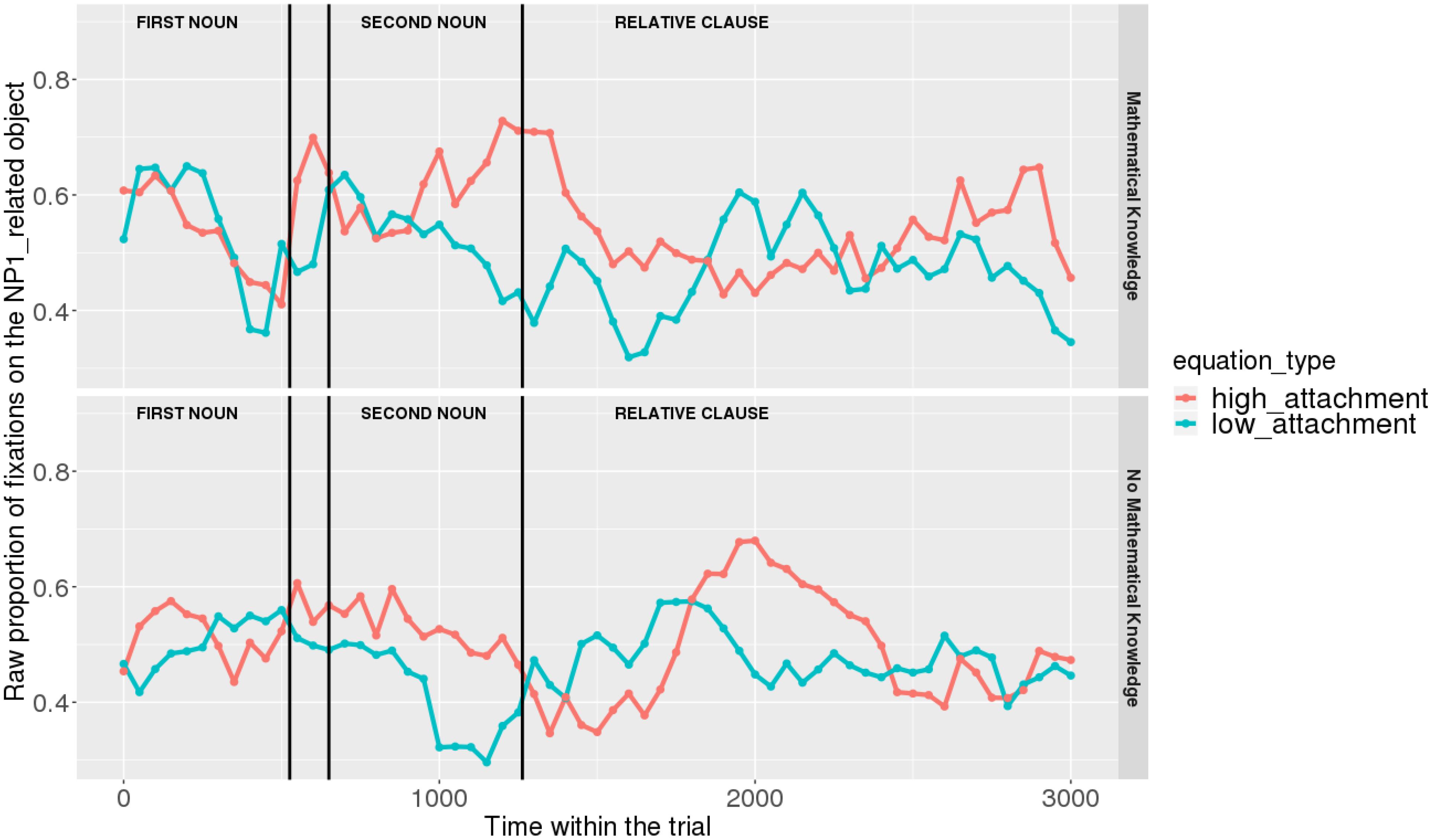
FIGURE 7. Raw proportion of fixations on the NP1-related object (roasted chicken) in relation to Prime Condition for both groups (Participants variable, t1).
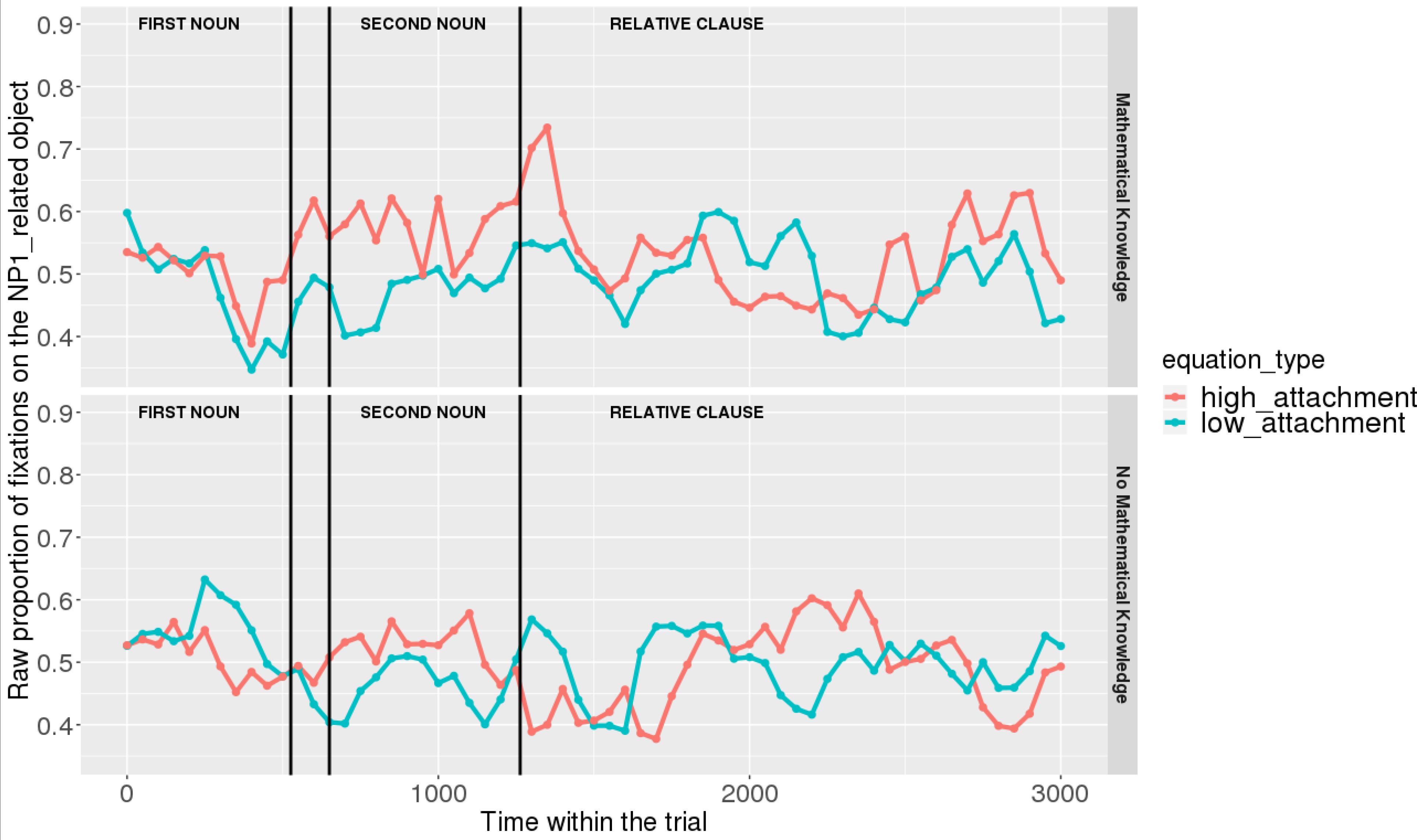
FIGURE 8. Raw proportion of fixations on the NP1-related object (roasted chicken) in relation to Prime Condition for both groups (Items variable, t2).
As shown, respectively, in Figures 9, 10, an interaction of Time, Group, and Prime Condition was observed around the beginning of the relative clause, more precisely in the region 200 ms before and 200 ms after the beginning of the relative clause (poly1,  = 8.20, 95% CrI = [1.95, 14.34], P() < 0 < 0.006) and (less so) 500 ms before the end of the sentence until the end of the sentence (poly1, = 3.69, 95% CrI=[-1.17 8.67], P() < 0 <0.07). This means that there was an effect of mathematical attachment over time and that the difference between high attachment and low attachment differs across mathematical knowledge groups over time.
= 8.20, 95% CrI = [1.95, 14.34], P() < 0 < 0.006) and (less so) 500 ms before the end of the sentence until the end of the sentence (poly1, = 3.69, 95% CrI=[-1.17 8.67], P() < 0 <0.07). This means that there was an effect of mathematical attachment over time and that the difference between high attachment and low attachment differs across mathematical knowledge groups over time.
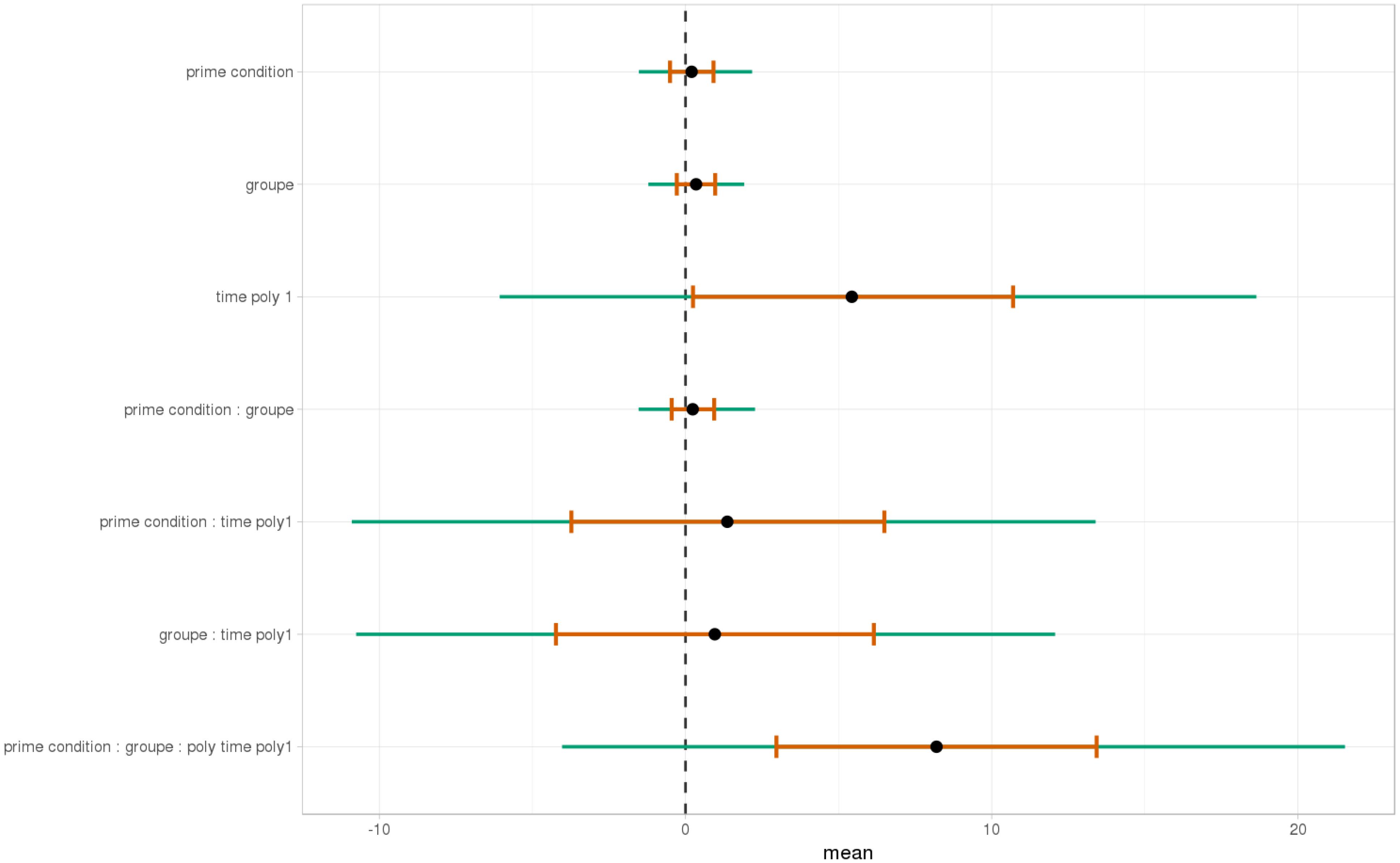
FIGURE 9. Posterior distribution of independent variables for the first part: during the beginning of the relative clause (1063–1463 ms).
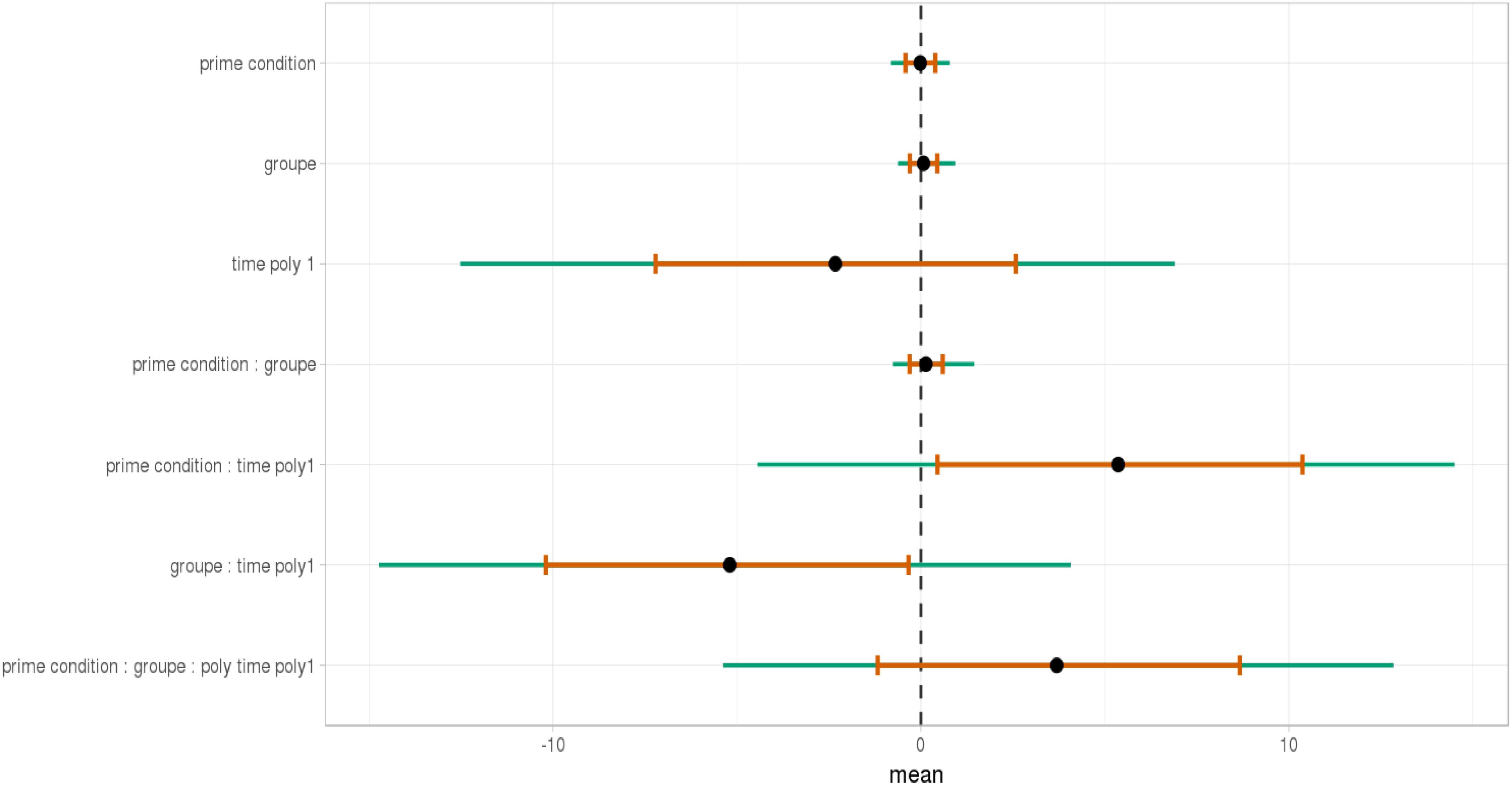
FIGURE 10. Posterior distribution of independent variables for the second part: from the relative to the end of the sentence (2523–3023 ms).
When sub-setting the data by group, we found different patterns for the mathematical knowledge group and the no mathematical knowledge group in the two time-windows.
At the beginning of the relative clause in Figures 11, 12, we found an interaction between Prime Condition and Time (Figure 13, poly1: = 6.43, 95% CrI = [0.58, 12.36], P() < 0 < 0.02)11 for the mathematical knowledge group. We also found an interaction for the no mathematical knowledge group but with a different pattern over time: the initial difference between high attachment and low attachment disappears over time (see the results for this group on the right in Figure 10), which explains why there is an inverse pattern for the interaction between time and Prime Condition in Figure 14 for this group (poly 1: = 6.43, 95% CrI = [-11.54, 1.03, P() < 0 = 0.95.
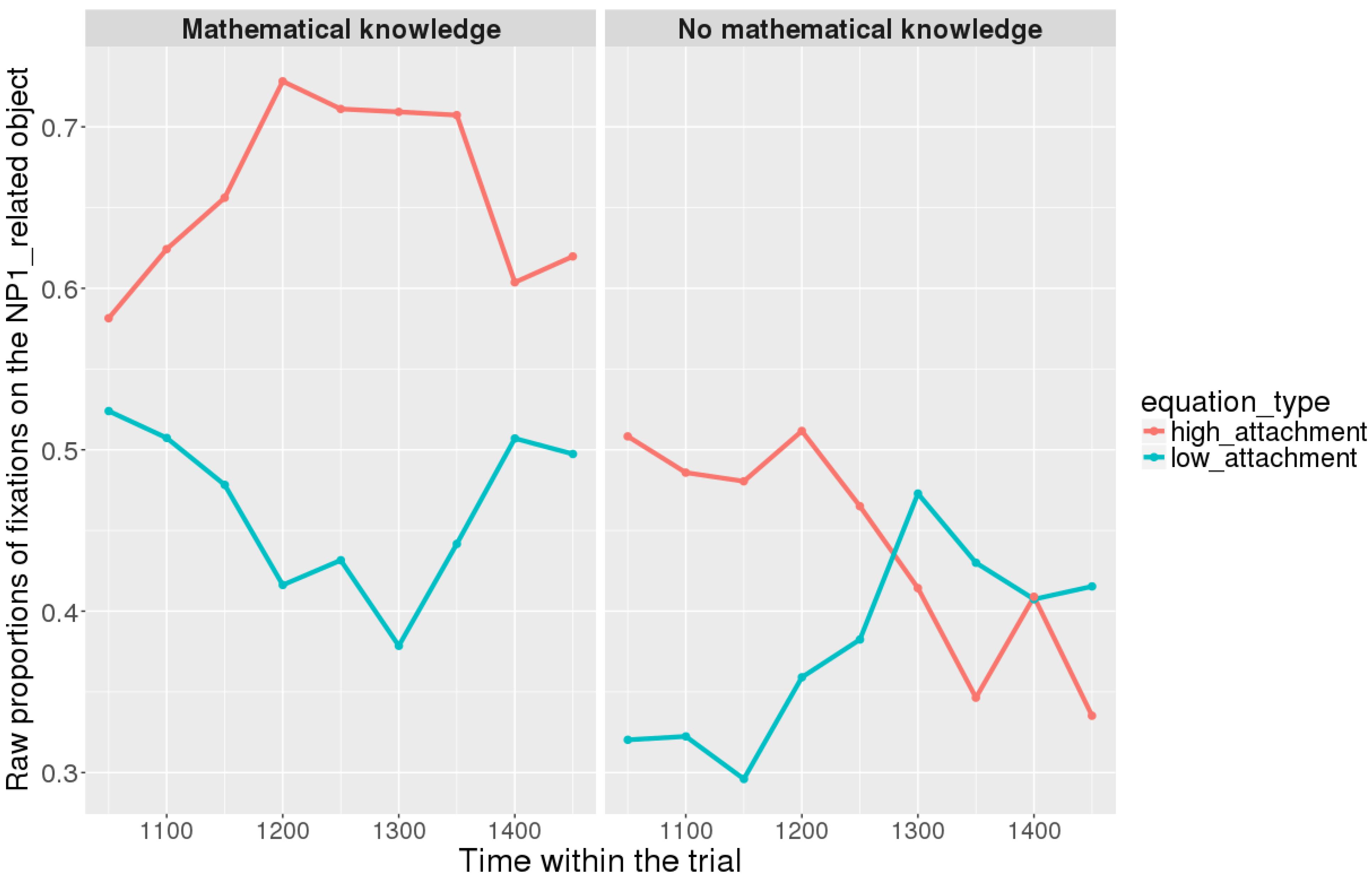
FIGURE 11. Proportions of looks toward the NP1-related object in each of the two groups at the beginning of the relative clause (1063–1463 ms). Red curves: high-attachment prime condition; blue curves: low-attachment prime condition (Participants variable).
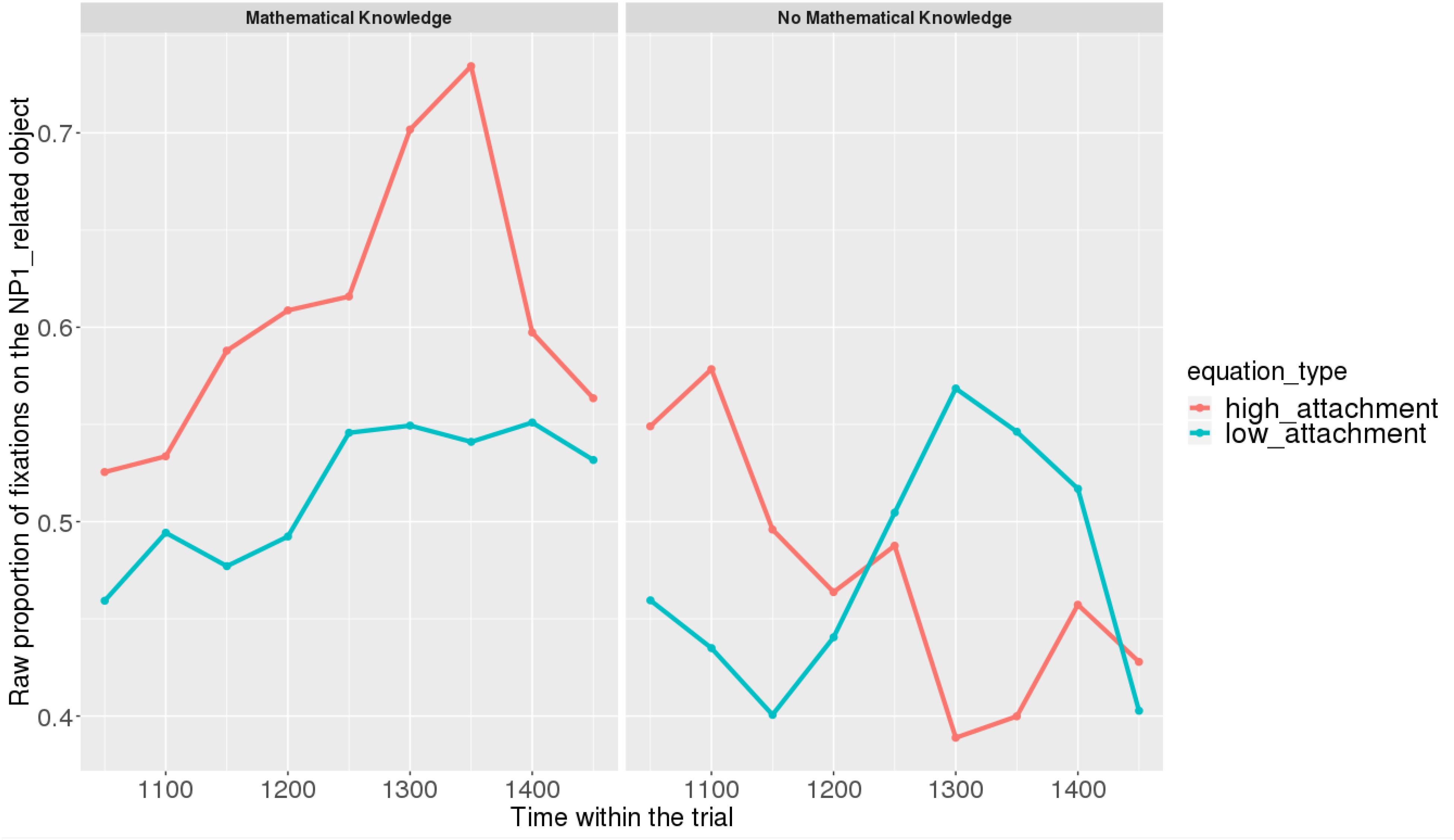
FIGURE 12. Proportions of looks toward the NP1-related object in each of the two groups at the beginning of the relative clause (1063–1463 ms). Red curves: high-attachment prime condition; blue curves: low-attachment prime condition (Items variable).
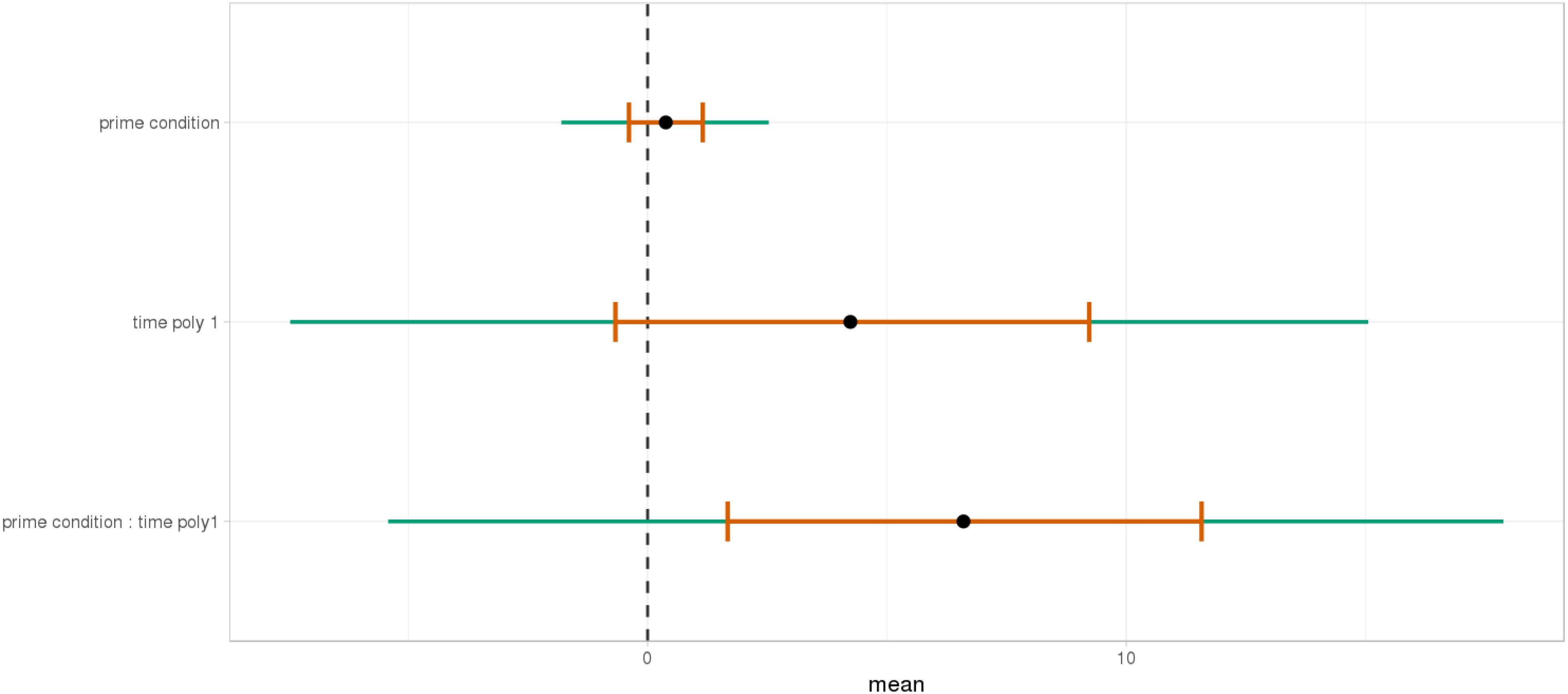
FIGURE 13. Posterior distribution of independent variables for the first part (1062–1462 ms) in the mathematical knowledge group.
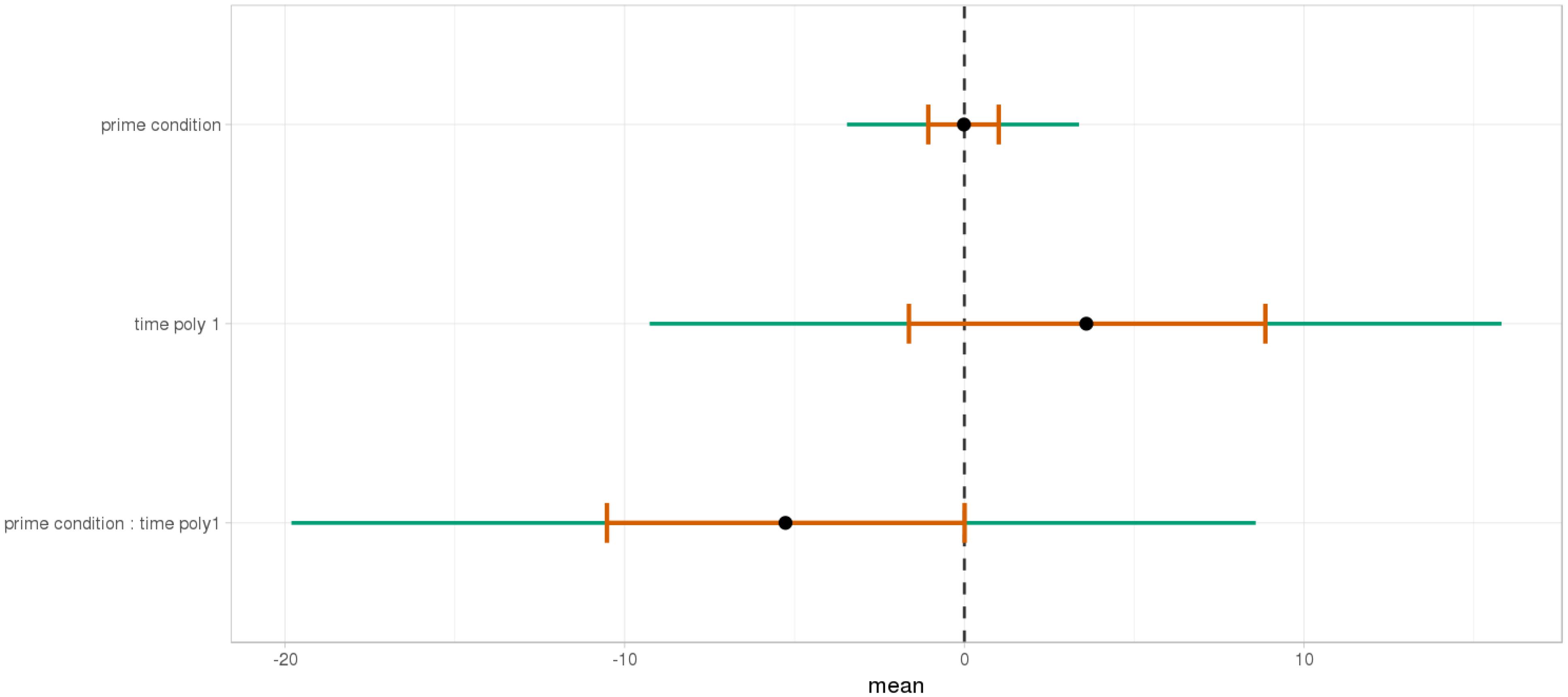
FIGURE 14. Posterior distribution of independent variables for the first part (1064–1464 ms) in the no mathematical knowledge group.
At the end of the sentence (Figures 15, 16), the interaction of time and Prime Condition is still there for the mathematical knowledge group (Figure 17 poly 1: = 6.91, 95% CrI=[1.99, 11.82], P() < 0< 0.003 but not for the no mathematical knowledge group (Figure 18, poly 1: = 1.42, 95% CrI=[-3.79, 6.60], P() < 0< 0.30).
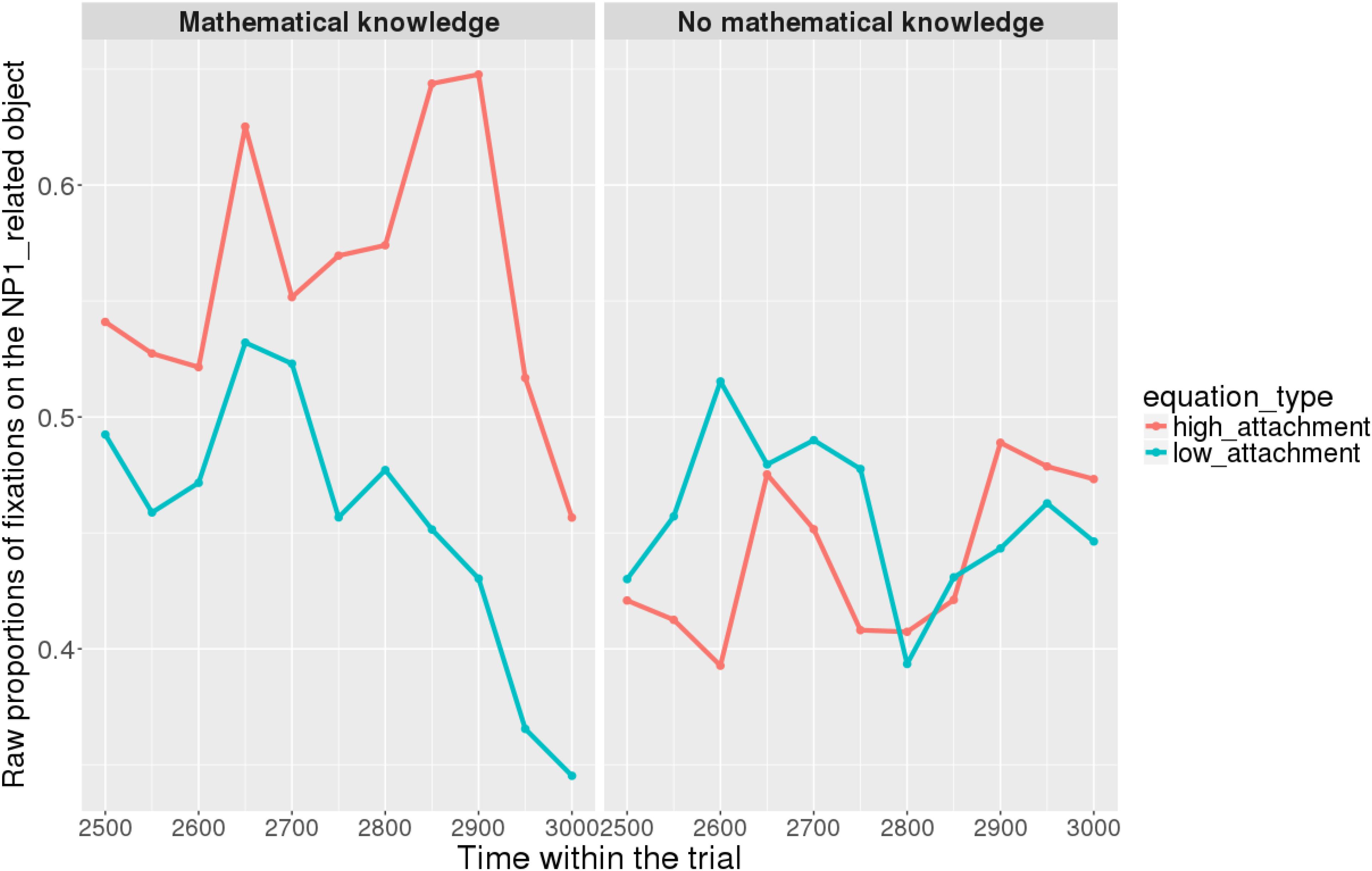
FIGURE 15. Proportions of looks toward the NP1-related object in each of the two groups at the end of the sentence (2523–3023 ms). Red curves: high-attachment prime condition; blue curves: low-attachment prime condition (Participants variable).
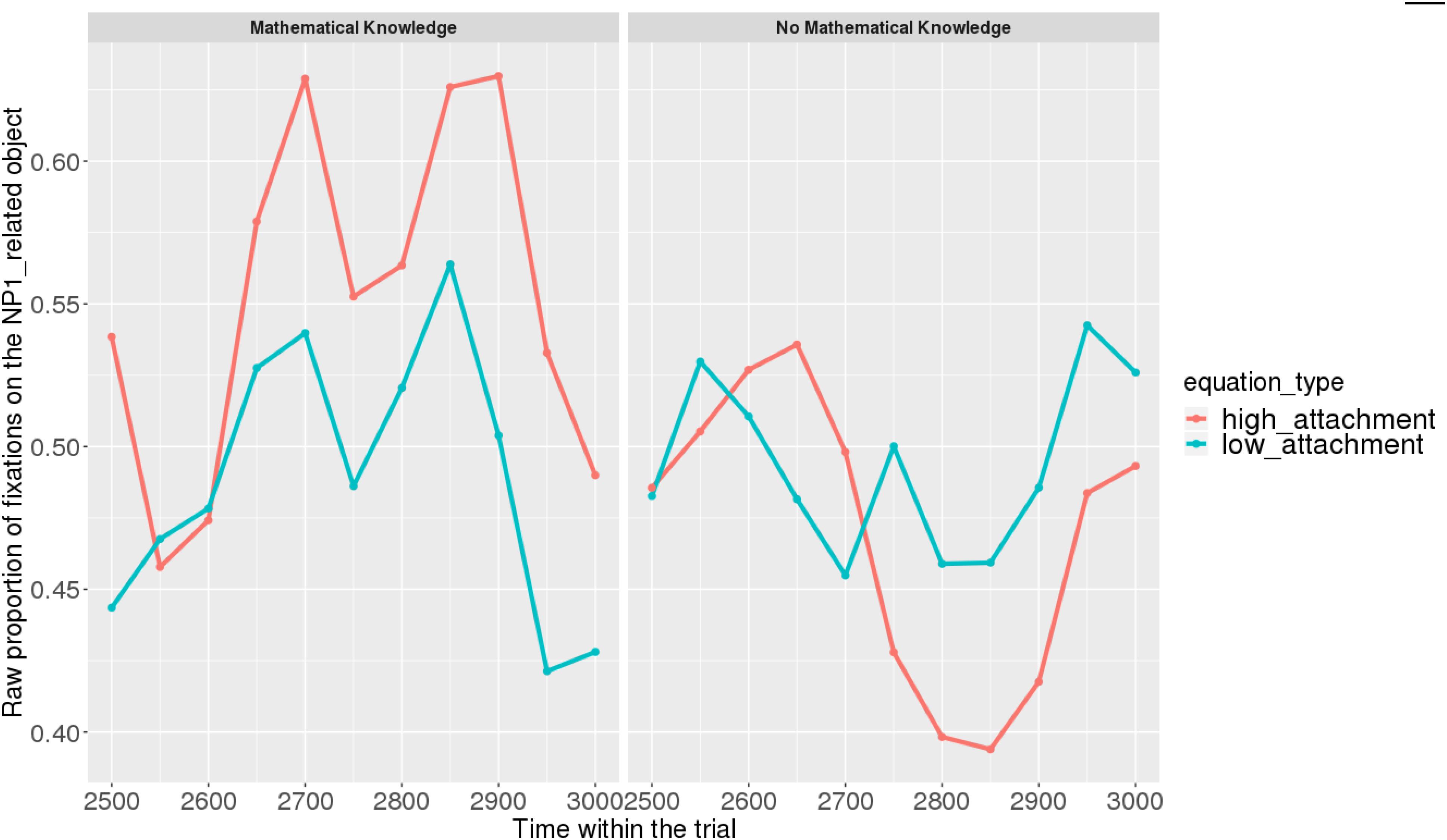
FIGURE 16. Proportions of looks toward the NP1-related object in each of the two groups at the end of the sentence (2523–3023 ms). Red curves: high-attachment prime condition; blue curves: low-attachment prime condition (Items variable).
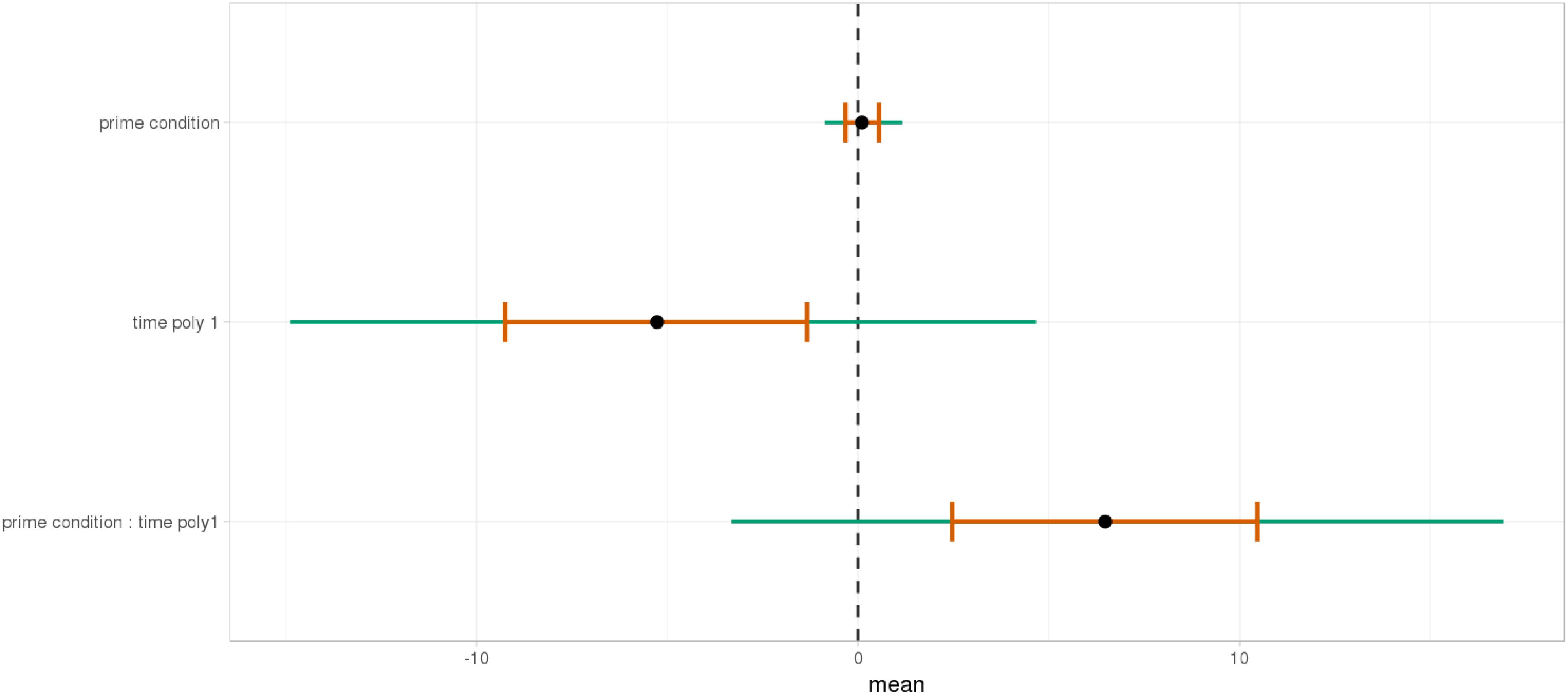
FIGURE 17. Posterior distribution of independent variables for the second part (2515–3015 ms) in the mathematical knowledge group.
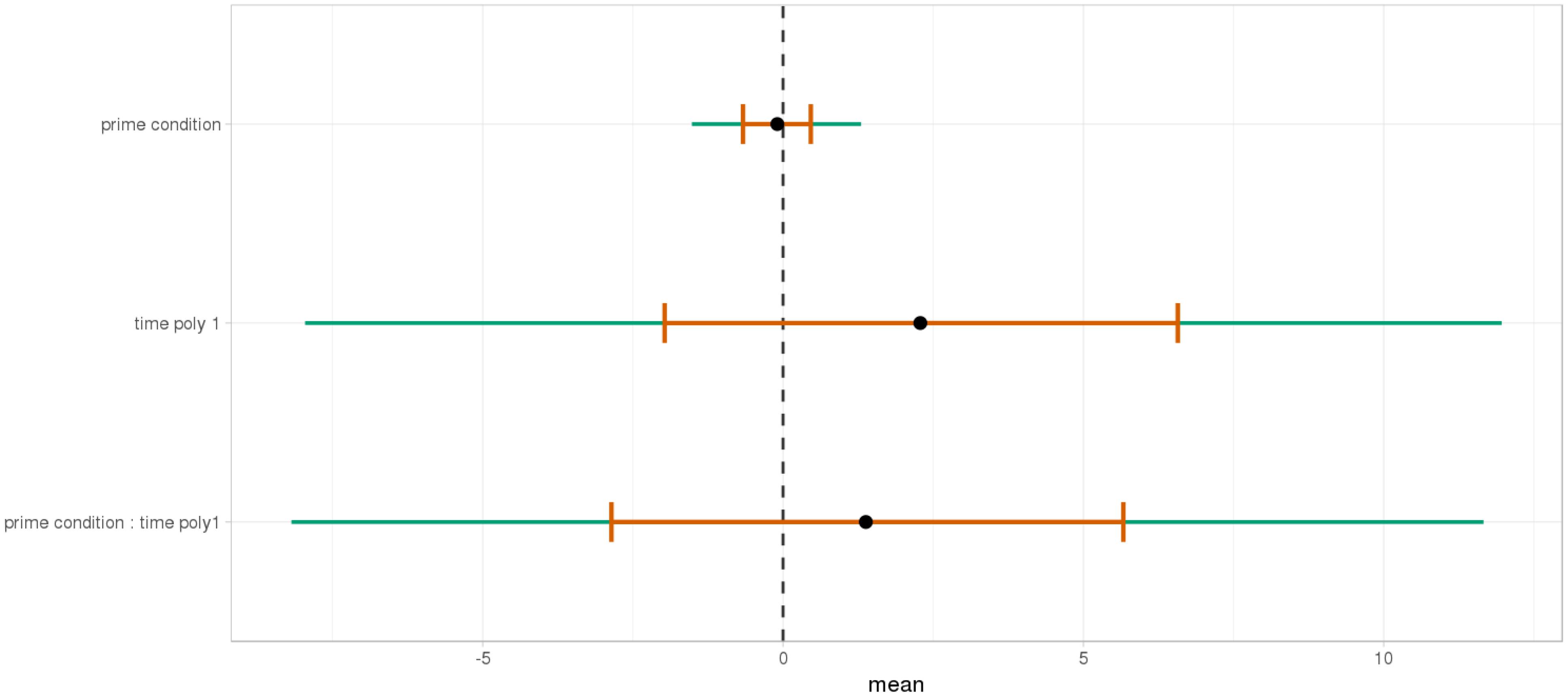
FIGURE 18. Posterior distribution of independent variables for the second part (2530–3030 ms) in the no mathematical knowledge group.
Overall, it can be concluded that cross-domain structural priming effects emerged very early on (even before the onset of the relative pronoun itself) and were especially robust and persistent in the mathematical knowledge group of participants compared to the no mathematical knowledge group.
General Discussion
The present study replicates and extends aspects of earlier off-line results by Scheepers et al. (2011) and others (e.g., Scheepers and Sturt, 2014; Van de Cavey and Hartsuiker, 2016) in interesting and important ways. Specifically, we investigated structural priming across cognitive domains – from mathematical equations to relative-clause attachments in spoken sentences – in French, a language known to contrast with English in terms of general relative clause attachment preferences: whereas English speakers/listeners usually prefer to attach relative clauses low to the most recent NP in a sentence, French speakers typically prefer high attachment of relative clauses, as was also confirmed in the pre-test of our materials. More importantly, the present study is the first to investigate cross-domain structural priming effects within the context of on-line sentence comprehension: indeed, the visual-world eye-tracking paradigm allowed us to pin down more precisely than previous studies at which point during processing of an attachment-ambiguous relative clause potential cross-domain syntactic priming effects would emerge. Another potentially important aspect of the present study is that the visual world paradigm is arguably less prone to strategic effects, as it requires no metalinguistic judgment or explicit syntactic attachment decisions by the participants (i.e., they just “look and listen” and are unlikely to become aware of their syntactically driven visual biases). It may be argued that participants leave interpretations underspecified when no explicit interpretation is required as Swets et al. (2008) have suggested for relative clause attachment ambiguities in reading. This may, however, be different for ambiguity resolution in the visual world paradigm where interpretations are done in a reduced universe. Recent studies on pronoun resolution using the “look and listen” paradigm showed that participants’ fixations reflect their interpretational preferences about as much as when questions about the interpretation are asked (Colonna et al., 2015).
Given that structural priming relies on the accurate processing of the structural primes (mathematical equations in this case), clear structural priming effects were in fact only expected for mathematically adept participants – in line with Scheepers et al. (2011) who found that without additional help in solving the mathematical primes (such as additional redundant brackets in the prime equations) mathematically less skilled participants would not only struggle to solve the priming equations correctly, but also show a generally less robust priming effect from mathematical equations to linguistic expressions. The latter was also evident in the no mathematical knowledge group of participants in our study: although there was evidence of cross-domain structural priming in this group as well, effects were less pronounced and more distributed over time than in the mathematical knowledge group who were much more likely to solve the prime equations correctly, and who showed cross-domain structural priming effects during the earliest stages of integrating the ambiguous relative clause into the preceding sentence context (specifically, around the onset of the relative pronoun in the spoken target sentence).
The early effect is interesting in terms of when exactly during sentence processing cross-domain structural priming effects would emerge. Scheepers et al. (2011) actually speculated about potential processing mechanisms that could underlie their off-line results. In what they called the incremental-procedural account they proposed that, just as the processing of linguistic materials, processing of mathematical equations structured like A + (B + C)∗D, respectively, A + B + C∗D would proceed in an incremental “left-to-right” fashion. This would trigger a form of mild (monotonic) revision as soon as the final multiplication or division operator is encountered at the end of the equation, because the operator-precedence rules require that this operation is applied before the preceding term [(B + C), respectively, C] is added; in “high-attachment” equations like A + (B + C)∗D, the final operator would combine with a complex expression on its left (B + C), whereas in “low-attachment” equations like A + B + C∗D it would combine with the most recent number (C) on its left. In analogy to this, a form of mild revision is also likely to take place when encountering a relative pronoun after incrementally processing a partial sentence such as The tourist guide mentioned the bells of the church… (that) because (i) the sentence is obviously not complete at this point and (ii) the relative pronoun needs to be integrated with a preceding noun phrase. In analogy to the mathematical primes, this relative pronoun can either combine with a complex noun phrase on its left (e.g., the bells of the church, yielding high attachment) or with the most recent noun phrase on its left (e.g., the church, yielding low attachment). Scheepers et al. (2011) proposed that it is this combinatorial choice that is affected by cross-domain structural priming, and the present findings (particularly for the mathematically adept group of participants) seem to support this incremental-procedural view: Evidence for structural priming became manifest as soon as the relative pronoun (qui) was encountered in the speech stream, i.e., in a time window from 200 ms before to 200 ms after the onset of the relative pronoun. This early onset of effects is in line with the hypothesis that cross-domain structural priming influences the immediate (incremental) syntactic integration of relative pronouns during sentence processing. However, one probably needs to be cautious with this interpretation, as a different treatment of the response proportions in a supplemental analysis (using NP1-related object fixations in proportion to fixations on all the other objects available12) suggested more delayed effect onsets relative to the relative pronoun, while still showing clear support for cross-domain structural priming.
What are the more general implications of cross-domain structural priming between mathematics and language processing? In the introduction, we discussed seemingly conflicting evidence suggesting a strict separation between language and mathematics in the brain (e.g., Amalric and Dehaene, 2016). We would argue that this conclusion is too narrowly focused on the semantics of linguistic vs. mathematical expressions and does not apply to the processing of abstract hierarchical structure as investigated here and in previous studies. It is also important to keep in mind that shared processing resources for mathematical and linguistic expressions must not necessarily rely on networks that are specialized for linguistic and/or mathematical processing. Indeed, it is conceivable that potentially shared representations may be processed at some separate, domain-general level that is independently accessible by brain networks that are more specialized for mathematics and language. Such a view also concurs with findings from Varley et al. (2005) showing that patients with severe agrammatic aphasia can nevertheless perform well at various mathematical tasks.
To conclude, in line with previous findings (e.g., Scheepers et al., 2011), the present visual-world eye-tracking experiment suggests that mathematics and language share aspects of syntactic structure at a very high level of abstraction. These effects appear to be largely independent of baseline RC-attachment preferences (low attachment in English, high attachment in French). More importantly, for mathematically skilled participants at least, the present study appears to indicate that cross-domain priming from mathematics to language influences the very earliest stages of integrating a relative clause into the prior sentence context, in line with an incremental-procedural account of hierarchical structure priming.
Author Contributions
CP and CS conceived the idea and designed the experiments. CP and BH designed the pretest. CP analyzed the data. CP, BH, and CS interpreted the results and revised the content. CP wrote the initial draft.
Funding
Travel grant (Bourse de mobilité sortante) from the Labex-EFL Laboratoire d’Excellence “Fondements Empiriques de la Linguistique” France.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was partly funded by the Laboratoire d’Excellence Empirical Foundations of Linguistics (ANR-10-LABX-0083). We thank Yair Haendler for his helpful advice for the Bayesian analysis and Olaf Mikkelsen for his contribution in running the experiments. We also thank Eunice Fernandes, Holly Branigan, and Moreno Coco for kindly letting us use their visual materials for the eye-tracking experiment.
Footnotes
- ^Still, it can be argued that the voici construction resembles a pseudo-relative construction (Lahousse and Karssenberg, 2016). Nevertheless, since the construction was systematically the same for all items, the preference should be the same, and it cannot explain differences in attachment preferences due to priming.
- ^http://www.risc.cnrs.fr
- ^Participants were unaware of this classification, and none of them produced a result other than 9 or 7 (except one participant, whose data was thus excluded from analysis).
- ^Although we did not run a norming study to confirm the association between the nouns and their related objects as judged by the authors of this paper, looks at the targeted object during the ambiguous relative clause to be discussed in the results section showed the associations were relevant for the task.
- ^See https://www.dropbox.com/sh/qq7ujz55dgfzgtp/AAAOsJK4aXmjRY1o_mo3J_-Wa?dl==0 for more details (Appendix A).
- ^The instructions can be found in Appendix B https://www.dropbox.com/sh/qq7ujz55dgfzgtp/AAAOsJK4aXmjRY1o_mo3J_-Wa?dl==0.
- ^Available at www.dropbox.com/sh/qq7ujz55dgfzgtp/AAAOsJK4aXmjRY1o_mo3J_-Wa?dl==0.
- ^This is available on https://www.dropbox.com/sh/qq7ujz55dgfzgtp/AAAOsJK4aXmjRY1o_mo3J_-Wa?dl==0.
- ^The former analysis is available in Appendix D on https://www.dropbox.com/sh/qq7ujz55dgfzgtp/AAAOsJK4aXmjRY1o_mo3J_-Wa?dl==0.
- ^Available at https://www.dropbox.com/sh/qq7ujz55dgfzgtp/AAAOsJK4aXmjRY1o_mo3J_-Wa?dl==0.
- ^The fact that P() < 0 < <0.02 means that the probability of the hypothesis “<0” is very low, meaning that participants from the mathematical knowledge group look more to NP1-targeted object across the relevant time period when the Prime Condition is high attachment. This is not the case for the participants from the no mathematical knowledge group with P() < 0 = 0.95, where the priming effect disappears over time.
- ^This is available on https://www.dropbox.com/sh/qq7ujz55dgfzgtp/AAAOsJK4aXmjRY1o_mo3J_-Wa?dl==0.
References
Amalric, M., and Dehaene, S. (2016). Origins of the brain networks for advanced mathematics in expert mathematicians. Proc. Natl. Acad. Sci. U.S.A. 113, 4909–4917. doi: 10.1073/pnas.1603205113
Arai, M., Van Gompel, R. P., and Scheepers, C. (2007). Priming ditransitive structures in comprehension. Cognit. Psychol. 54, 218–250. doi: 10.1016/j.cogpsych.2006.07.001
Barr, D. J., Levy, R., Scheepers, C., and Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: keep it maximal. J. Mem. Lang. 68, 255–278. doi: 10.1016/j.jml.2012.11.001
Bock, J. K. (1986). Syntactic persistence in language production. Cognit. Psychol. 18, 355–387. doi: 10.1016/0010-0285(86)90004-6
Boersma, P., and Weenink, D. (2018). Praat: doing phonetics by computer [Computer program]. Version 6.0. Available at: http://www.praat.org/
Colonna, S., Schimke, S., and Hemforth, B. (2015). Different effects of focus in intra and inter sentential pronoun resolution in German. Lang. Cogn. Neurosci. 30, 1306–1325. doi: 10.1080/23273798.2015.1066510
Cooper, R. M. (1974). The control of eye fixation by the meaning of spoken language: a new methodology for the real-time investigation of speech perception, memory, and language processing. Cogn. Psychol. 6, 8–107. doi: 10.1016/0010-0285(74)90005-X
Cuetos, F., and Mitchell, D. C. (1988). Cross-linguistic differences in parsing: restrictions on the use of the late closure strategy in Spanish. Cognition 30, 73–105. doi: 10.1016/0010-0277(88)90004-2
Dink, J. W., and Ferguson, B. (2015). Eyetrackingr: An R Library for Eye-Tracking Data Analysis. Available at: www.eyetracking-r.com
Drummond, A. (2010). Internet Based EXperiments (IBEX) (version 0.3). Available at: http://spellout.net/ibexfarm
Fedorenko, E., Gibson, E., and Rohde, D. (2007). The nature of working memory in linguistic, arithmetic and spatial integration processes. J. Mem. Lang. 56, 246–269. doi: 10.1016/j.jml.2006.06.007
Fedorenko, E., Patel, A., Casasanto, D., Winawer, J., and Gibson, E. (2009). Structural integration in language and music: evidence for a shared system. Mem. Cogn. 37, 1–9. doi: 10.3758/MC.37.1.1
Fodor, J. D. (2002). “Prosodic disambiguation in silent reading,” in Proceedings of the North East, ed. M. Hirotani (Amherst: GSLA).
Gibson, E., Pearlmutter, N., Canseco-González, E., and Hickok, G. (1996). Cross-linguistic attachment preferences: evidence from English and Spanish. Cognition 59, 23–59. doi: 10.1016/0010-0277(95)00687-7
Gilboy, E., Sopena, J. M., Clifton, C. Jr., and Frazier, L. (1995). Argument structure and association preferences in Spanish and English complex NPs. Cognition 54, 131–167. doi: 10.1016/0010-0277(94)00636-Y
Grillo, N., and Costa, J. (2014). A novel argument for the universality of parsing principles. Cognition 133, 156–187. doi: 10.1016/j.cognition.2014.05.019
Hartsuiker, R. J., Pickering, M. J., and Veltkamp, E. (2004). Is syntax separate or shared between languages? Cross-linguistic syntactic priming in Spanish- English bilinguals. Psychol. Sci. 15, 409–414. doi: 10.1111/j.0956-7976.2004.00693.x
Hemforth, B., Fernandez, S., Clifton, C. Jr., Frazier, L., Konieczny, L., and Walter, M. (2015). Relative clause attachment in German, English, Spanish and French: effects of position and length. Lingua 166, 43–64. doi: 10.1016/j.lingua.2015.08.010
Hemforth, B., Konieczny, L., and Scheepers, C. (2000). “Syntactic attachment and anaphor resolution: The two sides of relative clause attachment,” in Architectures and Mechanisms for Language Processing, eds M. Crocker, M. Pickering, and C. Clifton (Cambridge: Cambridge University Press),259–281.
Kljajević, V. (2010). Is syntactic working memory language specific? Psihologija 43, 85–101. doi: 10.2298/PSI1001085K
Koelsch, S., Kasper, E., Sammler, D., Schulze, K., Gunter, T., and Friederici, A. D. (2004). Music, language and meaning: brain signatures of semantic processing. Nat. Neurosci. 7, 302–307. doi: 10.1038/nn1197
Lahousse, K., and Karssenberg, L. (2016). Les «pseudo-relatives» dans les structures clivées en il ya … qui …. Available at: https://www.arts.kuleuven.be/ling/presentationalclefts/Lahousse_2016_les_pseudos-relatives
Miles, W. R. (1930). Ocular dominance in human adults. J. Gen. Psychol. 3, 412–430. doi: 10.1080/00221309.1930.9918218
Mirman, D., Dixon, J. A., and Magnuson, J. S. (2008). Statistical and computational models of the visual world paradigm: Growth curves and individual differences. J. Mem. Lang. 59, 475–494. doi: 10.1016/j.jml.2007.11.006
Patel, A. D. (2003). Language, music, syntax and the brain. Nat. Neurosci. 6, 674. doi: 10.1038/nn1082
Pickering, M. J., and Branigan, H. P. (1998). The representation of verbs: evidence from syntactic priming in language production. J. Mem. Lang. 39, 633–651. doi: 10.1111/cogs.12687
Scheepers, C. (2003). Syntactic priming of relative clause attachments: persistence of structural configuration in sentence production. Cognition 89, 179–205. doi: 10.1016/S0010-0277(03)00119-7
Scheepers, C., and Crocker, M. W. (2004). “Constituent order priming from reading to listening: a visual-world study,” in The On-Line Study of Sentence Comprehension: Eyetracking, Erps, and Beyond, eds M. Carrerias and C. Clifon (New York, NY: Psychology Press), 167–185.
Scheepers, C., and Sturt, P. (2014). Bidirectional syntactic priming across cognitive domains: From arithmetic to language and back. Q. J. Exp. Psychol. 67, 1643–1654. doi: 10.1080/17470218.2013.873815
Scheepers, C., Sturt, P., Martin, C. J., Myachykov, A., Teevan, K., and Viskupova, I. (2011). Structural priming across cognitive domains: from simple arithmetic to relative-clause attachment. Psychol. Sci. 22, 1319–1326. doi: 10.1177/0956797611416997
Sorensen, T., Hohenstein, S., and Vasishth, S. (2016). Bayesian linear mixed models using Stan: a tutorial for psychologists, linguists, and cognitive scientists. Quant. Methods Psychol. 12, 175–200. doi: 10.20982/tqmp.12.3.p175
SR Research Experiment Builder 2.1.140 [Computer software] (2017). SR Research Experiment Builder 2.1.140 [Computer software]. Mississauga, ON: SR Research Ltd.
Swets, B., Desmet, T., Clifton, C. Jr., and Ferreira, F. (2008). Underspecification of syntactic ambiguities: evidence from self-paced reading. Mem. Cognit. 36, 201–216. doi: 10.3758/MC.36.1.201
Tanenhaus, M. K., Spivey-Knowlton, M. J., Eberhard, K. M., and Sedivy, J. C. (1995). Integration of visual and linguistic information in spoken language comprehension. Science 268, 1632–1634. doi: 10.1126/science.7777863
Traxler, M. J., Tooley, K. M., and Pickering, M. J. (2014). Syntactic priming during sentence comprehension: evidence for the lexical boost. J. Exp. Psychol. Learn. Mem. Cogn. 40:905. doi: 10.1037/a0036377
Van de Cavey, J., and Hartsuiker, R. J. (2016). Is there a domain-general cognitive structuring system? Evidence from structural priming across music, math, action descriptions, and language. Cognition 146, 172–184. doi: 10.1016/j.cognition.2015.09.013
Varley, R. A., Klessinger, N. J. C., Romanowski, C. A. J., and Siegal, M. (2005). Agrammatic but numerate. Proc. Natl Acad. Sci. U.S.A. 102, 3519–3524. doi: 10.1073/pnas.0407470102
Appendix: Materials Used for the Spoken Sentences and the Equations (Items)
Spoken Sentences
Equations

Keywords: priming, arithmetic, psycholinguistics, eyetracking, visual world paradigm, relative clause attachment, language, French
Citation: Pozniak C, Hemforth B and Scheepers C (2018) Cross-Domain Priming From Mathematics to Relative-Clause Attachment: A Visual-World Study in French. Front. Psychol. 9:2056. doi: 10.3389/fpsyg.2018.02056
Received: 15 January 2018; Accepted: 05 October 2018;
Published: 05 November 2018.
Edited by:
Andriy Myachykov, Northumbria University, United KingdomReviewed by:
Martin Lachmair, Leibniz-Institut für Wissensmedien (IWM), GermanyPaul Edward Engelhardt, University of East Anglia, United Kingdom
Copyright © 2018 Pozniak, Hemforth and Scheepers. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Céline Pozniak, Y2VsaW5lLnBvem5pYWtAZ21haWwuY29t