 Yee-Hui Oh
Yee-Hui Oh John See
John See Anh Cat Le Ngo
Anh Cat Le Ngo Raphael C. -W. Phan
Raphael C. -W. Phan Vishnu M. Baskaran
Vishnu M. Baskaran
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Psychol. , 10 July 2018
Sec. Emotion Science
Volume 9 - 2018 | https://doi.org/10.3389/fpsyg.2018.01128
This article is part of the Research Topic Recognizing Microexpression: An Interdisciplinary Perspective View all 11 articles
Over the last few years, automatic facial micro-expression analysis has garnered increasing attention from experts across different disciplines because of its potential applications in various fields such as clinical diagnosis, forensic investigation and security systems. Advances in computer algorithms and video acquisition technology have rendered machine analysis of facial micro-expressions possible today, in contrast to decades ago when it was primarily the domain of psychiatrists where analysis was largely manual. Indeed, although the study of facial micro-expressions is a well-established field in psychology, it is still relatively new from the computational perspective with many interesting problems. In this survey, we present a comprehensive review of state-of-the-art databases and methods for micro-expressions spotting and recognition. Individual stages involved in the automation of these tasks are also described and reviewed at length. In addition, we also deliberate on the challenges and future directions in this growing field of automatic facial micro-expression analysis.
In 1969, Ekman and Friesen (1969) spotted a quick full-face emotional expression in a filmed interview which revealed a strong negative feeling a psychiatric patient was trying to hide from her psychiatrist in order to convince that she was no longer suicidal. When the interview video was played in slow motion, it was found that the patient was showing a very brief sad face that lasted only for two frames (1/12s) followed by a longer-duration false smile. This type of facial expressions is called micro-expressions (MEs) and they were actually first discovered by Haggard and Isaacs (1966) 3 years before the event happened. In their study, Haggard and Isaacs discovered these micromomentary expressions while scanning motion picture films of psychotherapy hours, searching for indications of non-verbal communication between patient and therapist.
MEs are very brief, subtle, and involuntary facial expressions which normally occur when a person either deliberately or unconsciously conceals his or her genuine emotions (Ekman and Friesen, 1969; Ekman, 2009b). Compared to ordinary facial expressions or macro-expressions, MEs usually last for a very short duration which is between 1/25 and 1/5 of a second (Ekman, 2009b). Recent research by Yan et al. (2013a) suggest that the generally accepted upper limit duration of a micro-expression is within 0.5s. Besides short duration, MEs also have other significant characteristics such as low intensity and fragmental facial action units where only part of the action units of full-stretched facial expressions are presented (Porter and Ten Brinke, 2008; Yan et al., 2013a). Due to these three characteristics of the MEs, it is difficult for human beings to perceive micro-expressions with the naked eye.
In spite of these challenges, new psychological studies of MEs and computational methods to spot and recognize MEs have been gaining more attention lately because of its potential applications in many fields, i.e., clinical diagnosis, business negotiation, forensic investigation, and security systems (Ekman, 2009a; Frank et al., 2009a; Weinberger, 2010). One of the very first efforts to improve the human ability at recognizing MEs was conducted by Ekman where he developed the Micro-Expression Training Tool (METT) to train people to recognize seven categories of MEs (Ekman, 2002). However, it was found in Frank et al. (2009b) that the performance of detecting MEs by undergraduate students only reached at most 40% with the help of METT while unaided U.S. coast guards performed not more than 50% at best. Thus, an automatic ME recognition system is in great need in order to help detect MEs such as those exhibited in lies and dangerous behaviors, especially with the modern advancements in computational power and parallel multi-core functionalities. These have enabled researchers to perform video processing operations that used to be infeasible decades ago, increasing the capability of computer-based understanding of videos in solving different real-life vision problems. Correspondingly, in recent years researchers have moved beyond psychology to using computer vision and video processing techniques to automate the task of recognizing MEs.
Although normal facial expression recognition is now considered a well-established and popular research topic with many good algorithms developed (Zeng et al., 2009; Bettadapura, 2012; Sariyanidi et al., 2015) with accuracies exceeding 90%, in contrast the automatic recognition of MEs from videos is still a relatively new research field with many challenges. One of the challenges faced by this field is spotting the ME of a person accurately from a video sequence. As a ME is subtle and short, spotting of MEs is not an easy task. Furthermore, spotting of MEs becomes harder if the video clip consists of spontaneous facial expressions and unrelated facial movements, i.e., eye-blinking, opening and closing of mouth, etc. On the other hand, other challenges of ME recognition include inadequate features for recognizing MEs due to its low change in intensity and lack of complete, spontaneous and dynamic ME databases.
In the past few years, there have been some noteworthy advances in the field of automatic ME spotting and recognition. However, there is currently no comprehensive review to chart the emergence of this field and summarize the development of techniques introduced to solve these tasks. In this survey paper, we first discuss the existing ME corpora. In our perspective, automatic ME analysis involves two major tasks, namely, ME spotting and ME recognition. ME spotting focuses on finding the occurrence of MEs in a video sequence while ME recognition involves assigning an emotion class label to an ME sequence. For both tasks, we look into the range of methods that have been proposed and applied to various stages of these tasks. Lastly, we discuss the challenges in ME recognition and suggest some potential future directions.
The prerequisite of developing any automatic ME recognition system is having enough labeled affective data. As ME research in computer vision has only gained attention in the past few years, the number of publicly available spontaneous ME databases is still relatively low. Table 1 gives the summary of all available ME databases to date, including both posed and spontaneous ME databases. The key difference between posed and spontaneous MEs is in the relevance between expressed facial movement and underlying emotional state. For posed MEs, facial expressions are deliberately shown and irrelevant to the present emotion of senders, therefore not really helpful for the recognition of real subtle emotions. Meanwhile, spontaneous MEs are the unmodulated facial expressions that are congruent with an underlying emotional state (Hess and Kleck, 1990). Due to the nature of the posed and spontaneous MEs, the techniques for inducing facial expressions (for purpose of constructing a database) are contrasting. For the case of posed MEs, subjects are usually asked to relive an emotional experience (or even watching example videos containing MEs prior to the recording session) and perform the expression as well as possible. However, eliciting spontaneous MEs is more challenging as the subjects have to be involved emotionally. Usually, emotionally evocative video episodes are used to induce the genuine emotional state of subjects, and the subjects have to attempt to suppress their true emotions or risk getting penalized.
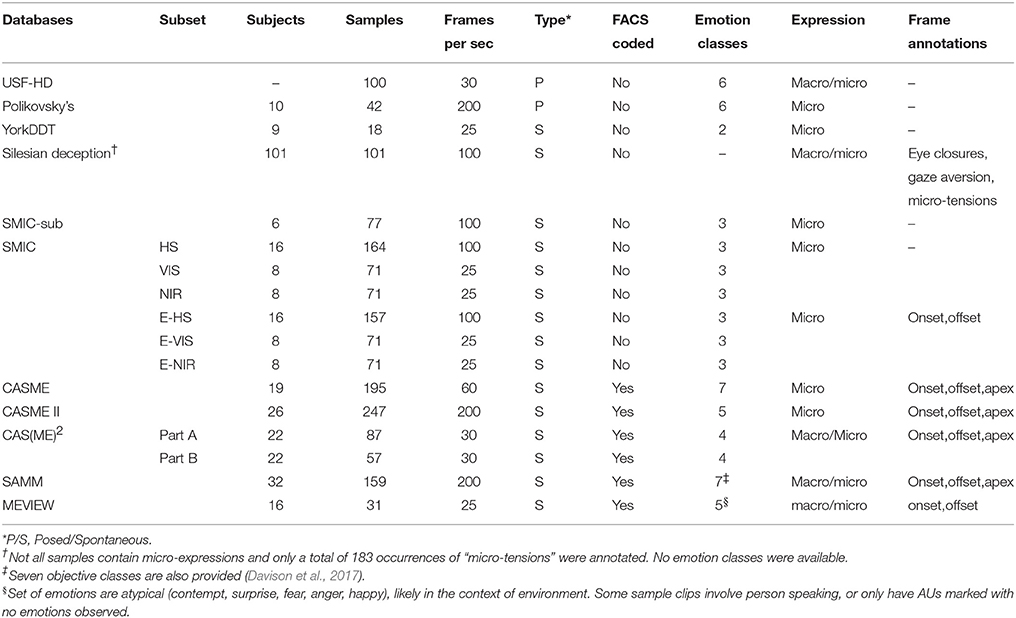
Table 1. Micro-expression databases.
According to Ekman and Friesen (1969) and Ekman (2009a), MEs are involuntary which could not be created intentionally. Thus, posed MEs usually do not exhibit the characteristics (i.e., the appearance and timing) of spontaneously occurring MEs (Porter and Ten Brinke, 2008; Yan et al., 2013a). The early USD-HD (Shreve et al., 2011) and Polikovsky's (Polikovsky et al., 2009) databases consist of posed MEs rather than spontaneous ones; hence they do not present likely scenarios encountered in real life. In addition, the occurrence duration of their micro-expressions (i.e., 2/3 s) exceeds the generally acceptable duration of MEs (i.e., 1/2 s). To have a more ecological validity, research interest then shifted to spontaneous ME databases. Several groups have developed a few spontaneous MEs databases to aid researchers in the development of automatic ME spotting and recognition algorithms. To elicit MEs spontaneously, participants are induced by watching emotional video clips to experience a high arousal, aided by an incentive (or penalty) to motivate the disguise of emotions. However, due to the challenging process of eliciting these spontaneous MEs, the number of samples collected for these ME databases is still limited.
Table 1 summarizes the known ME databases in the literature, which were elicited through both posed and spontaneous means. The YorkDDT (Warren et al., 2009) is the smallest and oldest database, with spontaneous MEs that also include other irrelevant head and face movements. The Silesian Deception database (Radlak et al., 2015) was created for the purpose of recognizing deception through facial cues. This database is annotated with eye closures, gaze aversion, and micro-expression, or “micro-tensions,” a phrase used by the authors to indicate the occurrence of rapid facial muscle contraction as opposed to having an emotion category. This dataset is not commonly used in spotting and recognition literature as it does not involve expressions per se; its inception primarily for the purpose of automatic deception recognition.
The SMIC-sub (Pfister et al., 2011) database presents a better set of spontaneous ME samples in terms of frame rate and database size. Nevertheless, it was further extended to the SMIC database (Li et al., 2013) with the inclusion of more ME samples and multiple recordings using different cameras types: high speed (HS), normal visual (VIS), and near-infrared (NIS). However, the SMIC-sub and SMIC databases do not provide Action Unit (AU) (i.e., facial components that are defined by FACS to taxonomize facial expressions) labels and the emotion classes were only based on participants' self-reports. Sample frames from SMIC are shown in Figure 1.

Figure 1. Sample frames from a “Surprise” sequence (Subject 1) in SMIC. Images reproduced from the database with permission from Li et al. (2013).
The CASME dataset (Yan et al., 2013b) provides a more comprehensive spontaneous ME database with a larger amount of MEs as compared to SMIC. However, some videos are extremely short, i.e., < 0.2 s, hence poses some difficulty for ME spotting. Besides, CASME samples were captured only at 60 fps. An improved version of it, known as CASME II was established to address these inadequacies. The CASME II database (Yan et al., 2014a) is the largest and most widely used database to date (247 videos, sample frames in Figure 2) with samples recorded using high frame-rate cameras (200 fps).

Figure 2. Sample frames from a “Happiness” sequence (Subject 6) in CASME II. Images reproduced from the database with permission from Yan et al. (2014a).
To facilitate the development of algorithms for ME spotting, extended versions of SMIC (SMIC-E-HS, SMIC-E-VIS, SMIC-E-NIR), CAS(ME)2 (Qu et al., 2017), and SAMM (Davison et al., 2016a) databases were developed. In SMIC-E databases, long video clips that contain some additional non-micro frames before and after the labeled micro frames were included as well. The CAS(ME)2 database (with samples given in Figure 3) is separated into two parts: Part A contains both spontaneous macro-expressions and MEs in long videos; and Part B includes cropped expression samples with frame from onset to offset. However, CAS(ME)2 is recorded using a low frame-rate (25 fps) camera due to the need to capture both macro- and micro-expressions.

Figure 3. Sample frames from a “Disgust” sequence (Subject 15) in CAS(ME)2. Images reproduced from the database (©Xiaolan Fu) with permission from Qu et al. (2017).
In the SAMM database (with samples shown in Figure 4), all micro-movements are treated objectively, without inferring the emotional context after each experimental stimulus. Emotion classes are then labeled by trained experts later. In addition, about 200 neutral frames are included before and after the occurrence of the micro-movement, which makes spotting feasible. The SAMM is arguably the most culturally diverse database among all of them. In short, the SMIC, CASME II, CAS(ME)2, and SAMM are considered the state-of-the-art databases for ME spotting and recognition that should be widely adopted for research.

Figure 4. Sample frames from a sequence (Subject 6) in SAMM that contains micro-movements. Images reproduced from the database with permission from Davison et al. (2016a).
The need for data acquired from more unconstrained “in-the-wild” situations have compelled further efforts to provide more naturalistic high-stake scenarios. The MEVIEW dataset (Husak et al., 2017) was constructed by collecting mostly poker game videos downloaded from YouTube with a close-up of the player's face (samples frames in Figure 5). Poker games are highly competitive with players often try to conceal or fake their true emotions, which facilitates likely occurrences of MEs. With the camera view switching often, the entire shot with a single face in video (averaging 3s in duration) was taken. An METT-trained annotator labeled the onset and offset frames of the ME with FACS coding and emotion types. A total of 31 videos with 16 individuals were collected.

Figure 5. Sample frames from a “Contempt” sequence in MEVIEW that contains micro-movements marked with AU L12. Images reproduced from the database (Husak et al., 2017) under Fair Use.
Automatic ME analysis involves two tasks: ME spotting and ME recognition. Facial ME spotting refers to the problem of automatically detecting the temporal interval of a micro-movement in a sequence of video frames; and ME recognition is the classification task to identify the ME involved in the video samples. In a complete facial ME recognition system, accurately and precisely identifying frames containing facial micro-movements (which contribute to facial MEs) in a video is a prerequisite for high-level facial analysis (i.e., facial ME recognition). Thus, the automatic facial expression spotting frameworks are developed to automatically search the temporal dynamics of MEs in streaming videos. Temporal dynamics refer to the motions of facial MEs that involve onset(start), apex(peak), offset(end), and neutral phases. Figure 6 shows a sample sequence depicting these phases. According to the work by Valstar and Pantic (2012), the onset phase is the moment where muscles are contracting and appearance of facial changes grows stronger; the apex phase is the moment where the expression peaks (the most obvious); and the offset phase is the instance where the muscles are relaxing and the face returns to its neutral appearance (little or no activation of facial muscles). Typically a facial motion shifts through the sequence of neutral-onset-apex-offset-neutral, but other combinations such as multiple apices are also possible.

Figure 6. A video sequence depicting the order in which onset, apex and offset frames occur. Sample frames are from a “Happiness” sequence (Subject 2) in CASME II. Images reproduced from the database with permission from Yan et al. (2014a).
In general, a facial ME spotting framework consists of a few stages: the pre-processing, feature description, and lastly the detection of the facial micro-expressions. The details of each of the stages will be further discussed in the following sections.
In facial ME spotting, the general pre-processing steps include facial landmark detection, facial landmark tracking, face registration, face masking, and face region retrieval. Table 2 shows a summary of existing pre-processing techniques that are applied in facial ME spotting.
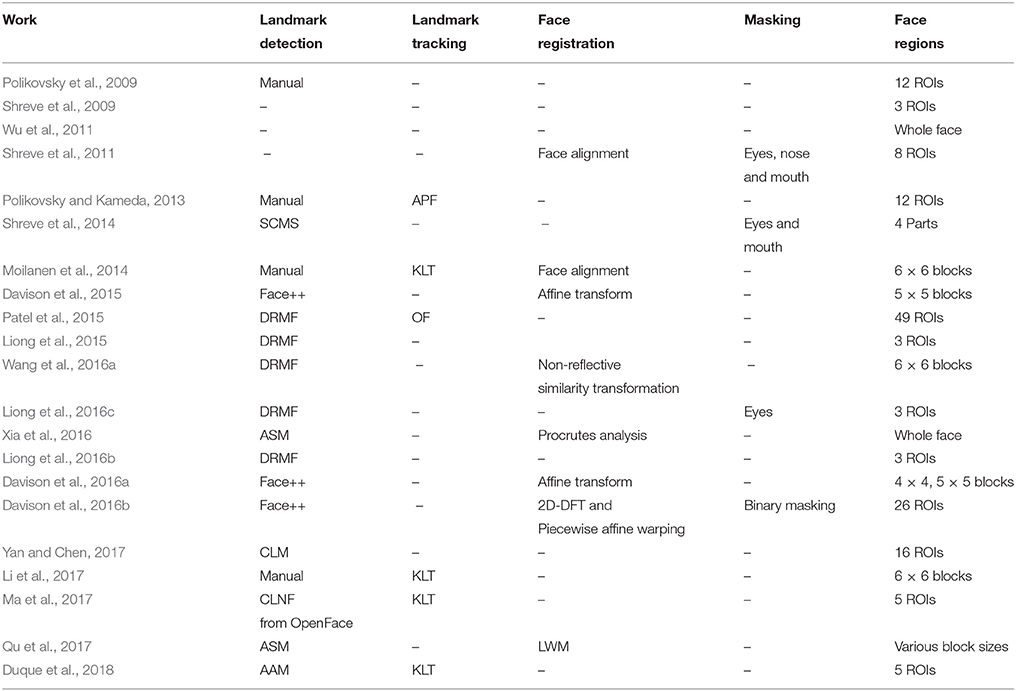
Table 2. A survey of pre-processing techniques applied in facial micro-expression spotting.
Facial landmark detection is the first most important step in the spotting framework to locate the facial points on the facial images. In the field of MEs, two ways of locating the facial points are applied: the manual method and automatic facial landmark detection method. In an early work on facial micro-movement spotting (Polikovsky et al., 2009), facial landmarks are manually selected only at the first frame, and fixed in the consecutive frames as they assumed that the examined frontal faces are located relatively in the same location. In their later work (Polikovsky and Kameda, 2013), a tracking algorithm is applied to track the facial points that had been manually detected at the first frame throughout the whole sequence. To prevent the hassle of manually detecting the facial points, majority of the recent works (Davison et al., 2015, 2016a,b; Liong et al., 2015, 2016b,c; Wang et al., 2016a; Xia et al., 2016) opt to apply automatic facial landmark detection. Instead of running the detection for the whole sequence of facial images, the facial points are only detected at the first frame and fixed in the consecutive frames with the assumption that these points will only change minimally due to the subtleness of MEs.
To the best of our knowledge, the facial landmark detection techniques that are commonly employed for facial ME spotting are promoted Active Shape Model (ASM) (Milborrow and Nicolls, 2014), Discriminative Response Maps Fitting (DRMF) (Asthana et al., 2013), Subspace Constrained Mean-Shifts (SCMS) (Saragih et al., 2009), Face++ automatic facial point detector (Megvii, 2013), and Constraint Local Model (CLM) (Cristinacce and Cootes, 2006). In fact, the promoted ASM, DRMF, and CLM are the notable examples of part based facial deformable models. Facial deformable models can be roughly separated into two main categories: holistic (generative) models and part based (discriminative) models. The former applies holistic texture-based facial representation for the generic face fitting scenario; and the latter uses the local image patches around the landmark points for the face fitting scenario. Although the holistic-based approaches are able to achieve impressive registration quality, these representations unfaithfully locate facial landmarks in unseen images, when target individuals are not included in the training set. As a result, part based models which circumvent several drawbacks of holistic-based methods, are more frequently employed in locating facial landmarks in recent years (Asthana et al., 2013). The promoted ASM, DRMF, and CLM are from part based deformable models, however their mechanisms are different. The ASM applies shape constraints and searches locally for each feature point's best location; whereas DRMF learns the variation in appearance on a set of template regions surrounding individual features and updates the shape model accordingly; as for CLM, it learns a model of shape and texture variation from a template (similar to active appearance models), but the texture is sampled in patches around individual feature points. In short, the DRMF is computationally lighter than its counterparts.
Part based approaches mainly rely on optimization strategies to approximate the responses map through simple parametric representations. However, some ambiguities still result due to the landmark's small support region and imperfect detectors. In order to address these ambiguities, SCMS which employs Kernel Density Estimator (KDE) to form a non-parametric representation of response maps was proposed. To maximize over the KDE, the mean-shift algorithm was applied. Despite the progress in automatic facial landmark detection, these approaches are still not considerably robust toward “in-the-wild” scenarios, where large out-of-plane tilting and occlusion might exist. The Face++ automatic facial point detector was developed by Megvii (2013) to address such challenges. It employs a coarse-to-fine pipeline with neural network and sequential regression, and it claims to be robust against influences such as partial occlusions and improper head pose up to 90° tilt angle. The efficacy of the method (Zhang et al., 2014) has been tested on the 300-W dataset (Sagonas et al., 2013) (which focuses on facial landmark detection in real-world facial images captured in-the-wild), yielding the highest accuracy among the several recent state-of-the-arts including DRMF.
In ME spotting research, very few works applied tracking to the landmark points. This could be due to the sufficiency of landmark detection algorithms used (since MEs movements are very minute) or that general assumptions have been made to fix the location of the detected landmarks points. The two tracking algorithms that were reportedly used in a few facial ME spotting works (Polikovsky and Kameda, 2013; Moilanen et al., 2014; Li et al., 2017) are Auxiliary Particle Filtering (APF) (Pitt and Shephard, 1999) and Kanade-Lucas-Tomasi (KTL) algorithm (Tomasi and Kanade, 1991).
Image registration is the process of aligning two images—the reference and sensed images, geometrically. In the facial ME spotting pipeline, registration techniques are applied onto the faces to remove large head translations and rotations that might affect the spotting task. Generally, registration techniques can be separated into two major categories: area-based and feature-based approaches. In each of the approaches, either global mapping functions or local mapping functions are applied to transform the the sensed image to be as close as the reference image.
For area-based (a.k.a. template matching or correlation-like) methods, windows of predefined size or even entire images are utilized for the correspondence estimation during the registration. This approach bypasses the need for landmark points, albeit some restriction to only shift and small rotations between the images (Zitova and Flusser, 2003). In the work by Davison et al. (2016b), a 2D-Discrete Fourier Transform (2D-DFT) was used to achieve face registration. This method calculates the cross-correlation of the sensed and reference images before finding the peak, which in turn is used to find the translation between the sensed and reference images. Then, the process of warping to a new image is performed by piece-wise affine (PWA) warping.
For feature-based approach to face registration, salient structures which include region features, line features and point features are exploited to find the pairwise correspondence between the sensed and reference images. Thus, feature-based approach are usually applied when the local structures are more significant than the information carried by the image intensities. In some ME works (Shreve et al., 2011; Moilanen et al., 2014; Li et al., 2017), the centroid of the two detected eyes are selected as the distinctive point (also called control points) and exploited for face registration by using affine transform or non-reflective similarity transform. The consequence of such simplicity entails their inability to handle deformations locally. A number of works (Li et al., 2017; Xu et al., 2017) employed Local Weighted Mean (LWM) (Goshtasby, 1988) which seeks to find a 2-D transformation matrix using 68 facial landmark points of a model face (typically from the first frame). In another work by Xia et al. (2016), Procrustes analysis is applied to align the detected landmark points in frames. It determines a linear transformation (such as translation, reflection, orthogonal rotation, and scaling) of the points in sensed images to best conform them to points in the reference image. Procrustes analysis has several advantages: low complexity for easy implementation and it is practical for similar object alignment (Ross, 2004). However, it requires a one-to-one landmark correspondence and the convergence of means is not guaranteed.
Instead of using mapping functions to map the sensed images to the reference images, a few studies (Shreve et al., 2011; Moilanen et al., 2014; Li et al., 2017) correct the mis-alignment by rotating the faces according to the angle between the pair of lines that join the centroids of the two detected eyes to the horizontal line. In this mechanism, errors can creep in if the face contours of the sensed and reference face images are not consistent with one another, or that the subject's face is not entirely symmetrical to begin with.
Due to the diversity of face images with various types of degradations to be registered, it is challenging to fix a standard method that is applicable to all conditions. Thus, the choice of registration method should correspond to the assumed geometric deformation of the sensed face image.
In the facial ME spotting task, a masking step can be applied onto the face images to remove noise caused by undesired facial motions that might affect the performance of the spotting task. In the work by Shreve et al. (2011), a static mask (“T”-shaped) was applied on the face images to remove the middle part of the face that includes the eyes, nose, and mouth regions. Eye regions were removed to avoid the noise caused by eye cascades and blinking (which is not considered a facial micro-expression); the nose region is masked as it is typically rigid, which might not reveal much significant information even with it; and mouth region is excluded since opening and closing of the mouth introduces undesired large motion. It is arguable if too much meaningful information may have been removed from the face area in the masking steps introduced in Shreve et al. (2011) and Shreve et al. (2014), as the two most expressive facial parts (in the context of MEs) are actually located near the corner of the eyebrow and mouth areas. Hence, some control is required to prevent excluding too much meaningful information. Typically, specific landmark points around these two areas are used as reference or boundary points in the masking process.
In the work by Liong et al. (2016c), the eye regions are masked to reduce false spotting of the apex frame from long videos. They observed that eye blinking motion is significantly more intense than that of micro-expression motion, thus masking is necessary. To overcome potential inaccurate landmark detection, a 15-pixel margin was added to extend the masked region. Meanwhile, Davison et al. (2016b) applied a binary mask to obtain 26 FACS-based facial regions that include the eyebrows, forehead, cheeks, corners around eyes, mouth, regions around mouth, and etc. The regions are useful for the spotting task as each of these regions contain a single or a group of AUs, which will be triggered when the ME occurs. It is also worth mentioning that a majority of works in the literature still do not include a masking pre-processing step.
From psychological findings on concealed emotions (Porter and Ten Brinke, 2008), it was revealed that facial micro-expression analysis should be done on the upper and lower halves of the face separately instead of considering the entire face. This finding substantiated an earlier work (Rothwell et al., 2006), whereby ME recognition was also performed on the segmented upper and lower parts of the face. Duan et al. (2016) later showed that the eye region is much more salient than the whole face or mouth region for recognizing micro-expressions, in particular happy and disgust expressions. Prior knowledge from these works encourage splitting of the face into important regions for automatic facial micro-expression spotting.
In the pioneering work of spotting facial MEs (Shreve et al., 2009), the face was segmented into three regions: the upper part (which includes the forehead), middle part (which includes the nose and cheeks), and the lower part (which include the mouth); and each was analyzed as individual temporal sequences. In their later work (Shreve et al., 2011), the face image is further segmented into eight regions: forehead, left and right of the eye, left and right of cheek, left and right of mouth and chin. Each of the segments is analyzed separately in sequence. With the more localized segments, tiny changes in certain temporal segments could be observed. However, unrelated edged features such as hair, neck, and edge of the face that are present in the localized segments might induce noise and thus affect the extracted features. Instead of splitting the face images into few segments, Shreve et al. (2014) suggested to separate the face images into four quadrants, and each of the quadrant is analyzed individually in the temporal domain. The reason behind this is because of the constraint on locality as facial micro-expressions are restricted to appear in at most two bordering regions (i.e., first and second quadrant, second and third quadrant, third and forth quadrant, and the first and fourth quadrant) of the face (Shreve et al., 2014).
Another popular facial segmentation method is splitting the face into a specific number (m×n) of blocks (Moilanen et al., 2014; Davison et al., 2015, 2016a; Wang et al., 2016a; Li et al., 2017). In the blocking representation, the motion changes in each block could by observed and analysis independently. However, with the increasing in the number of blocks (i.e., m×n), the computation load increases accordingly. Besides, features such as hairs and edges of face that appear in the blocks will affect the final feature vectors as these elements are not related to the facial motions.
A unique approach to facial segmentation for ME spotting is to split the face by Delaunay triangulation (Davison et al., 2016b). It gives more freedom to the shape that defines the regions of the face. Unfortunately, areas of the face that are not useful for ME analysis such as the cheek area may still be captured within the triangular regions. To address this problem, more recent methods partition the face into a few region-of-interests (ROIs) (Polikovsky et al., 2009; Polikovsky and Kameda, 2013; Liong et al., 2015, 2016b,c, 2018; Davison et al., 2016b; Li et al., 2018). The ROIs are regions that correspond to one or more FACS action units (AUs). As such, these regions contain rigid facial motions when the muscles (AUs) are activated. Some studies (Liong et al., 2015, 2016b,c; Davison et al., 2016b) show that ROIs are more effective compared to the use of the entire face in constraining the salient locations for spotting.
Facial micro-expression spotting, or “micro-movement” spotting [a term coined by Davison et al. (2016a)] refers to the problem of automatically detecting the temporal interval of a micro-movement in a sequence of video frames. Current approaches for spotting facial micro-movement can be broadly categorized into two groups: classifier-based methods (supervised/unsupervised) and rule-based (use of thresholds or heuristics) methods. There are many possible dichotomies; this survey discusses some early ideas, followed by two distinct groups of works – one on spotting ME movement or window of occurrence, another on spotting the ME apex. A summary of the existing techniques for spotting facial micro-expressions (or micro-movements) are depicted in Table 3.
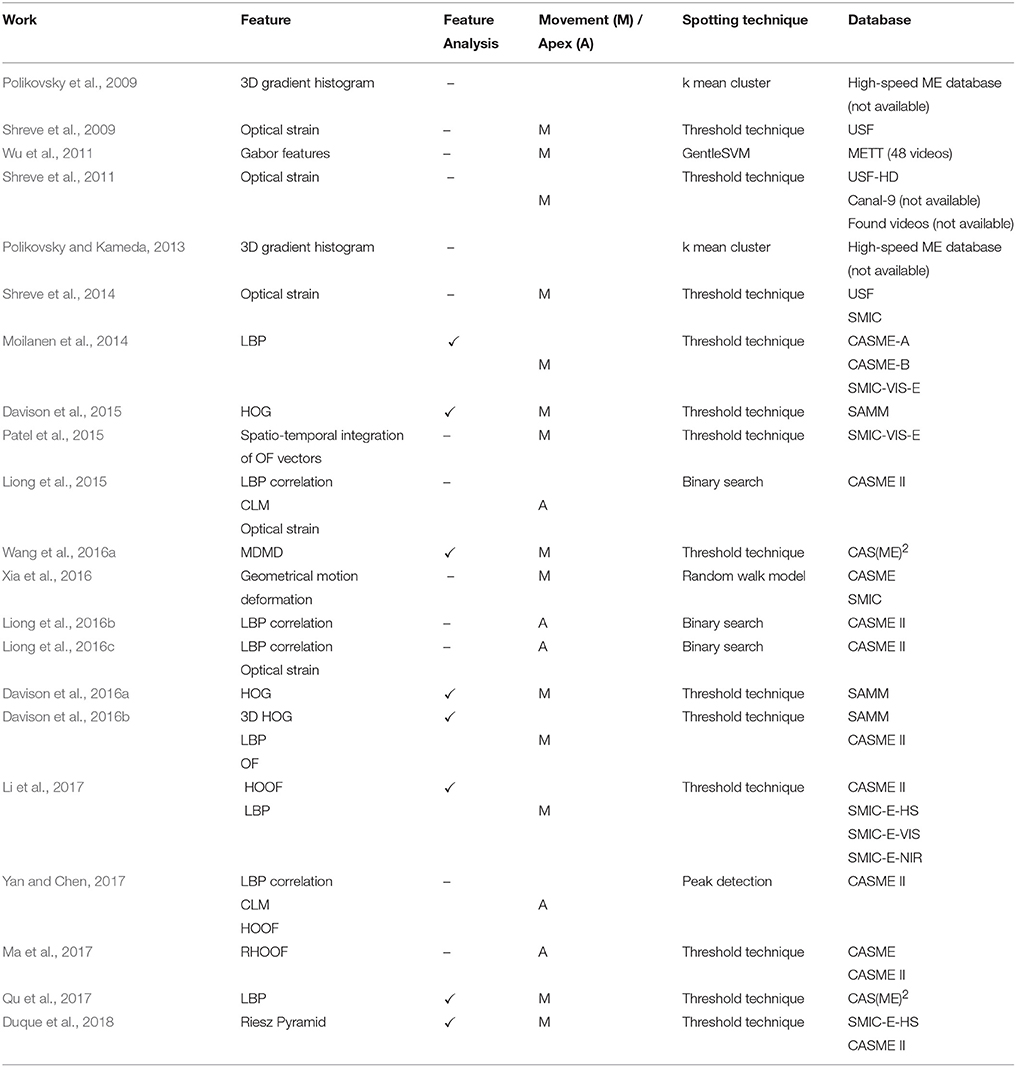
Table 3. Facial micro-expression (or micro-movement) spotting works in literature.
In the early works by Polikovsky et al. (2009) and Polikovsky and Kameda (2013), 3D-HOG was adopted to extract the features from each of the regions in the ME videos. Then, k-means clustering was used to cluster the features to particular AUs within predefined facial cubes. “Spotting” was approached as a classification task: each frame is classified to neutral, onset, apex or offset, and compared with ground truth labels. The classification rates achieved were satisfactory, in the range of 68–80%. Although their method could potentially contribute to facial micro-movement spotting by locating the four standard phases described by FACS, there are two glaring drawbacks. First, their method was only tested on posed facial ME videos, which are not a good representation of spontaneous (naturally induced) facial MEs. Secondly, the experiment was run as a classification task in which the frames were clustered into one of the four phases; this is highly unsuitable for real-time spotting. The work of Wu et al. (2011) also treats the spotting task as a classification process. Their work uses Gabor filters and the GentleSVM classifier to evaluate the frames. From the resulting label of each frame, the duration of facial micro-expressions were measured according to the transition points and the video frame-rate. Subsequently, they are only considered as ME when their durations last for 1/25–1/5s. They achieved very high spotting performance on the METT training database (Ekman, 2003). However, this was not convincing on two counts; first, only 48 videos were used in the experiments, and second, the videos were synthesized by inserting a flash of micro-expression in the middle of a sequence of neutral face images. In real-world conditions, frame transitions would be much more dynamic compared to the abrupt changes that were artificially added.
Instead of treating the spotting task as frame-by-frame classification, the works of Shreve et al. (2009, 2011) are the first to consider the temporal relation from frame-to-frame and employ a threshold technique to locate spontaneous facial MEs. This follows a more objective method that does not require machine learning. Their works are also the first in the literature to attempt spotting both macro- (i.e., ordinary facial expressions) and micro-expressions from videos. In their work, optical strain, which represents the amount of deformation incurred during motion, was computed from selected facial regions. Then, the facial MEs are spotted by tracking the strain magnitudes across frames following these heuristics: (1) strain magnitude exceeds the threshold (calculated from the mean of each video) and is significantly larger than that of the surrounding frames, and (2) the duration of the detected peak can only last at most 1/5th of a second. A 74% true positive rate and 44% false positive rate was achieved in the spotting task. However, a portion of data used in their experiments were posed, while some of them (Canal-9 and Found Videos databases) were not published or are currently defunct. In their later work (Shreve et al., 2014), a peak detector was applied to locate sequences containing MEs based on strain maps. However, the details of the peak detector and threshold value were not disclosed.
Micro-expression movements can be located by identifying a "window" of occurrence, typically marked by a starting or onset frame, and an ending or offset frame. In the work by Moilanen et al. (2014), the facial motion changes were modeled by feature difference (FD) analysis of appearance-based features (i.e., LBP) that incorporates the Chi-Square (χ2) distance to form the FD magnitudes. Only the top 1/3 of total blocks (per frame) with the greatest FD values were chosen and averaged to an initial feature value representing the frame. The contrasting difference vector is then computed to find relevant peaks from across the sequence. Spotted peak frames (i.e., the peaks that exceed the threshold) are compared with the provided ground truth frames; and considered true positive if they fall within the span of k/2 frames (where k is half of the interval frames in the window) before the onset and after the offset. The proposed technique was tested on CASME-A, CASME-B, and SMIC-VIS-E, achieving a true positive rate of 52, 66, and 71%, respectively.
The same spotting approach was adopted by Li et al. (2017) and tested on various spontaneous facial ME databases: CASME II, SMIC-E-HS, SMIC-E-VIS, and SMIC-E-NIR. This work also indicated that LBP consistently outperforms HOOF in all the datasets with higher AUC (area-under-the-ROC-curve) values and lower false positive rates. To spot facial micro-expressions on the new CAS(ME)2 database, the same spotting approach (Moilanen et al., 2014) is adopted by Wang et al. (2016a). Using their proposed main directional optical flow (MDMD) approach, ME spotting performance on the CAS(ME)2 is 0.32, 0.35, and 0.33 for recall, precision and F1-score, respectively. For all these works (Moilanen et al., 2014; Wang et al., 2016a; Li et al., 2017; Qu et al., 2017), the threshold value for peak detection is set by taking the difference between the mean and max value of the contrasting difference vector and multiplying it by a fraction in the range of [0,1]. Finally, this value is added with the mean value of the contrasting difference vector to denote the threshold. By these calculations, at least one peak will always be detected as the threshold value will never exceed the maximum value of the contrasting difference vector. This could potentially result in misclassification of non-ME movements since it will always detect a peak. Besides, pre-defining the ME window intervals (which obtains the FD values) may not augur well with videos captured at different frame rates. To address the potentiality of a false peak, these works (Moilanen et al., 2014; Davison et al., 2015; Wang et al., 2016a; Li et al., 2017; Qu et al., 2017) proposed to compute the baseline threshold based on a neutral video sequence from each individual subject in the datasets.
In the work of Davison et al. (2015), all detected sequences which are less than 100 frames are denoted as true positives, in which eye blinks and eye gaze are included; while peaks that are detected but not coded as a movement are classed to false positives. The approach achieved scores of 0.84, 0.70, and 0.76 for recall, precision, and F1-measure, respectively on the SAMM database. In their later works, Davison et al. (2016a) and Davison et al. (2016b) introduced “individualized baselines,” which are computed by taking a neutral video sequence for the participants and using the χ2 distance to get an initial feature for the baseline sequence. The maximum value of this baseline feature is identified as the threshold. This improved their previous attempt by a good margin.
A number of innovative approaches were proposed. Patel et al. (2015) computed optical flow vectors over small local regions and integrated them into spatiotemporal regions to find the onset and offset times. In another approach, Xia et al. (2016) applied random walk model to compute the probability of frames containing MEs by considering the geometrical deformation correlation between frames in a temporal window. Duque et al. (2018) designed a system that is able to differentiate between MEs and eye movements by analyzing the phase variations between frames based on the Riesz Pyramid.
Besides spotting facial micro-movements, a few other works focused on spotting a specific type of ME phase, particularly the apex frame (Liong et al., 2015, 2016b,c; Yan and Chen, 2017). The apex frame, which is the instant indicating the most expressive emotional state in an ME sequence, is believed to be able to effectively reveal the true expression for the particular video. In the work by Yan and Chen (2017), the frame that has the largest feature magnitude was selected as the apex frame. A few interesting findings were revealed: CLM (which provides geometric features) is especially sensitive to contour-based changes such as eyebrow movement, and LBP (which produces appearance features) is more suitable for detecting changes in appearance such as pressing of lips; however, OF is the most all-rounded feature as it is able to spot the apex based on the resultant direction and movement of facial motions. A binary search method was proposed by Liong et al. (2015) to automatically locate the apex frame in a video sequence. By observing that the apex frames are more likely to appear in areas concentrated with peaks, the proposed binary search method iteratively partitions the sequence into two halves, by selecting the half that contains a higher sum of feature difference values. This is repeated until a single peak is left. The proposed method reported a mean absolute error (MAE) of 13.55 frames and standard error (SE) of 0.79 on CASME II using LBP difference features. A recent work by Ma et al. (2017) used Region HOOF (RHOOF) based on 5 regions of interests (ROIs) for apex detection, which resulted in more robust results.
The ME spotting task is akin to a binary detection task (ME is present/not present), hence typical performance metrics can be used. Moilanen et al. (2014) encouraged the use of a Receiver Operating Characteristic (ROC) curve, which was adopted in most subsequent works (Patel et al., 2015; Xia et al., 2016; Li et al., 2017). In essence, the spotted peaks, which are obtained based on a threshold level, will be compared against ground truth labels to determine whether they are true or false spots. If one spotted peak is located within the frame range of [onset - , offset + ] of a labeled ME clip, the spotted sequence (N frames centered at the peak) will be considered as a true positive ME; otherwise the N frames of spotted sequence will be counted as false positive frames. The specified range considers a tolerance interval of 0.5 s, which corresponds to the presumed maximum duration of MEs. To obtain the ROC curve, true positive rate (TPR), and false positive rate (FPR) are computed as follows:
Recently, Tran et al. (2017) proposed a micro-expression spotting benchmark (MESB) to standardize the performance evaluation of the spotting task. Using a sliding window based multi-scale evaluation and a series of protocols, they recognize the need for a fairer and more comprehensive method of assessment. Taking a leaf out of object detection, the Intersection over Union (IoU) of the detection set and ground truth set was proposed to determine if a sampled sub-sequence window is positive or negative for ME (threshold set at 0.5).
Several works that focused on the spotting of the apex frame (Yan et al., 2014b; Liong et al., 2015, 2016b,c) used Mean Absolute Error (MAE) to compute how close are the estimated apex frames to the ground-truth apex frames:
When spotting is performed on the raw long videos, Liong et al. (2016c) introduced another measure called Apex Spotting Rate (ASR), which calculates the success rate in spotting apex frames within the given onset and offset range of a long video. An apex frame is scored 1 if it is located between the onset and offset frames, and 0 otherwise:
ME recognition is a task that classifies an ME video into one of the universal emotion classes (e.g., Happiness, Sadness, Surprise, Anger, Contempt, Fear, and Disgust). However, due to difficulties in the elicitation of micro-expressions, not all classes are available in the existing datasets. Typically, the emotion classes of the collected samples are unevenly distributed; some are easier to elicit hence they have more samples collected.
Technically, a recognition task involves feature extraction and classification. However, a pre-processing stage could be involved prior to the feature extraction to enhance the availability of descriptive information to be captured by descriptors. In this section, all the aforementioned steps are discussed.
A number of fundamental pre-processes such as face landmark detection and tracking, face registration and face region retrieval, have all been discussed in section 3 for the spotting task. Most recognition works employ similar techniques as those used for spotting, i.e., ASM (Milborrow and Nicolls, 2014), DRMF (Asthana et al., 2013), Face++ (Megvii, 2013) for landmark detection; LWM (Goshtasby, 1988) for face registration. Meanwhile, division of the facial area into regions is a step often found within various feature representation techniques (discussed in section 4.2) to further localize features that change subtly. Aside from these known pre-processes, two essential pre-processing techniques have been instrumental in conditioning ME data for the purpose of recognition. We discuss these two steps which involve magnification and interpolation of ME data.
The uniqueness of facial micro-expressions is in its subtleness, which is one of reasons why recognizing them automatically is very challenging. As the intensity levels of facial ME movements are very low, it is extremely difficult to discriminate ME types among themselves. One solution to this problem is to exaggerate or magnify these facial micro-movements. In recent works (Park et al., 2015; Zarezadeh and Rezaeian, 2016; Li et al., 2017; Wang et al., 2017), the Eulerian Motion Magnification (EMM) (Wu et al., 2012) method was employed to magnify the subtle motions in the ME videos. The EMM method extracts the frequency bands of interest from the different spatial frequency bands obtained from the decomposition of an input video, by using band-pass filters; these extracted bandpass signals at different spatial level are amplified by a magnification factor α to magnify the motions. Li et al. (2017) demonstrated that the EMM method helps to enlarge the difference between different categories of micro-expressions (i.e., inter-class difference); thus the recognition rate is increased. However, larger amplification factors may cause undesirable amplified noise (i.e., motions that are not induced by MEs), which may degrade recognition performance. To prevent over-magnifying ME samples, Le Ngo et al. (2016a) theoretically estimated the upper bounds of effective magnification factors. Besides, the authors also compared the performance of the amplitude-based Eulerian motion magnification (A-EMM) and phase-based Eulerian motion magnification (P-EMM); with the To deal with the distinctive temporal characteristic of different ME classes, a magnification scheme was proposed by Park et al. (2015) to adaptively select the most discriminative frequency band needed for EMM to magnify subtle facial motions. A recent work by Le Ngo et al. (2018) showed that Global Lagrangian Motion Magnification (GLMM) can contribute toward better recognition capability compared to local Eulerian based approaches, particularly at higher magnification factors.
Another concern for ME recognition is with the uneven length (or duration) of ME video samples. In fact, it can contribute to two contrasting scenarios: (a) the case of short duration videos, which restricts the application of the feature extraction techniques which require varied temporal window size (e.g., LBP-based methods that can form binary patterns from varied radius); and (b) the case of long duration videos, whereby redundant or replicated frames (due to high frame rate capture) could deteriorate the recognition performance. To solve the problem, the temporal interpolation method (TIM) is applied to either up-sample (clips that are too short) or down-sample (clips that are too long) clips to produce clips of similar frame lengths.
Briefly, TIM takes original frames as input data to construct a manifold of facial expressions; then it samples on the manifolds for a particular number of output frames (refer to Zhou et al., 2011 for detailed explanation). It is shown by Li et al. (2017) that modifying the frame length of ME videos can improve the recognition performance if the number of interpolated frames are small. However, when the interpolated frames are increased, the recognition performance is somewhat hampered due to over-interpolation. Therefore, the appropriate interpolation of the ME sequence is vital in preparation for recognition. An alternative technique Sparsity-Promoting Dynamic Mode Decomposition (DMDSP) (Jovanović et al., 2014) was adopted by Le Ngo et al. (2015) and Le Ngo et al. (2016b) to select only significant dynamics in MEs to form sparse structures. From the comprehensive experimental results shown in Le Ngo et al. (2016b), DMDSP achieved better recognition performance compared to TIM (on similar features and classifiers) due to its ability to keep only the significant temporal structures while eliminating irrelevant facial dynamics.
While the aforementioned pre-processing techniques showed positive results in improving ME recognition, yet these methods will notably lengthen the computation time of the overall recognition process. For a real-time system to be feasible, this cost has to be taken into consideration.
In the past few years, research in automatic ME analysis have been much focused on the problem of ME recognition: given an ME video sequence/clip, the purpose of recognition is to estimate its emotion label (or class). Table 4 summarizes the existing ME methods in the literature. From the perspective of feature representations, they can be roughly divided into two main categories: single-level approaches and multi-level approaches. Single-level approaches refer to frameworks that directly extract feature representations from the video sequences; while for multi-layer approaches, the image sequences are first transformed into another domain or subspace prior to feature representation to exploit other kinds of information to describe MEs.
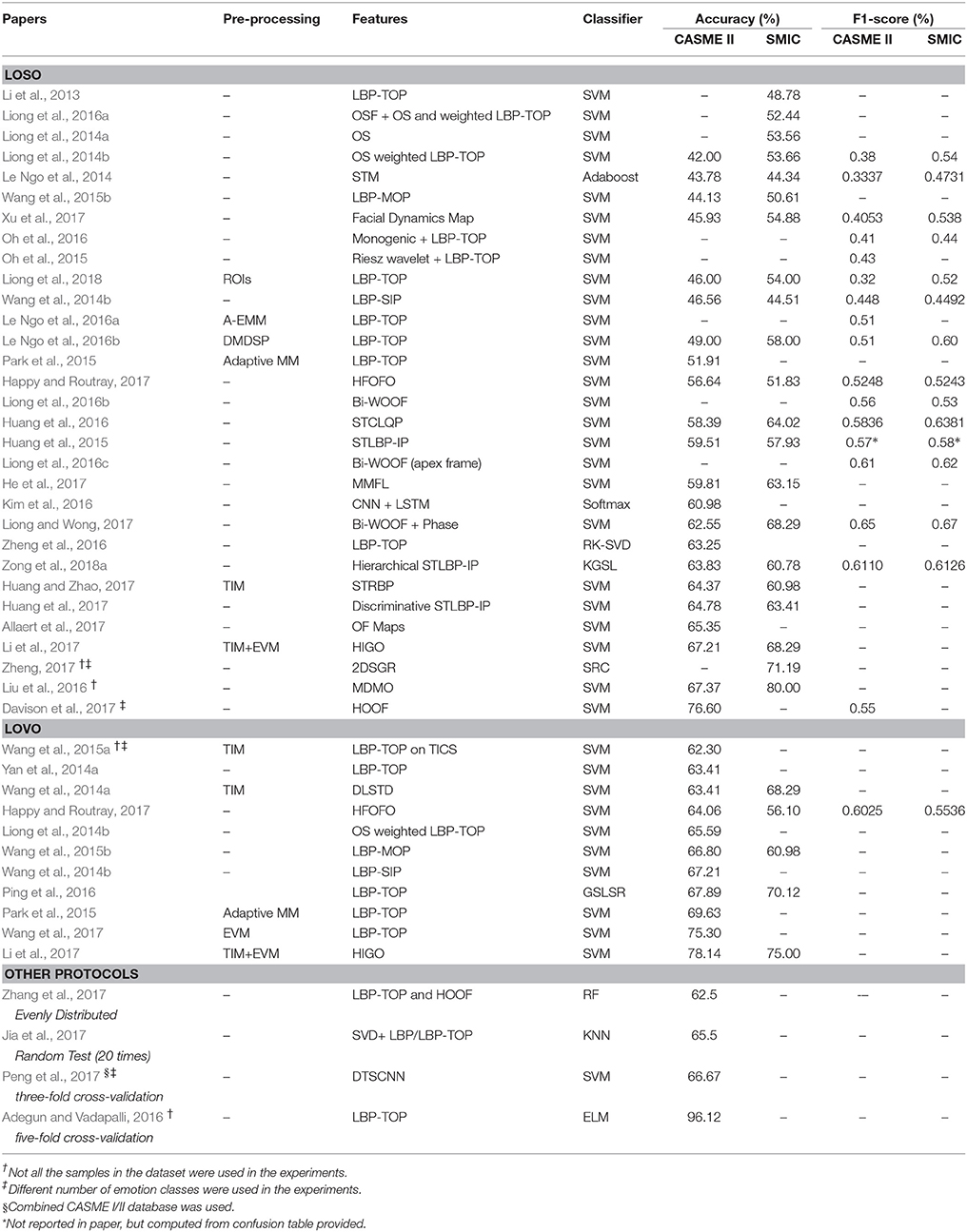
Table 4. Benchmarking facial micro-expression recognition works in literature.
Feature representation is a transformation of raw input data to a succinct form; typically in face processing, representations can be from two distinct categories: geometric-based or appearance-based (Zeng et al., 2009). Specifically, geometric-based features describe the face geometry such as the shapes and locations of facial landmarks; whereas appearance-based features describe intensity and textural information such as wrinkles, furrows, and other patterns that are caused by emotion. However from previous studies in facial expression recognition (Fasel and Luettin, 2003; Zeng et al., 2009), it is observed that appearance-based features are better than geometric-based features in coping with illumination changes and mis-alignment error. Geometric-based features might not be as stable as appearance-based features as they need precise landmark detection and alignment procedures. For these similar reasons, appearance-based feature representations have become more popular in the literature on ME recognition
Among appearance-based feature extraction methods, local binary pattern on three orthogonal planes (LBP-TOP) is widely applied in many works (Li et al., 2013; Guo et al., 2014; Le Ngo et al., 2014, 2015, 2016a,b; Yan et al., 2014a; Adegun and Vadapalli, 2016; Zheng et al., 2016; Wang et al., 2017). Most existing datasets (SMIC, CASME II, SAMM) have all reported the LBP-TOP as their baseline evaluation method. LBP-TOP is an extension of its low-level representation, local binary pattern (LBP) (Ojala et al., 2002), which describes local texture variation along a circular region with binary codes which are then encoded into a histogram. LBP-TOP extracts features from local spatio-temporal neighborhoods over three planes: the spatial (XY) plane similarly to the regular LBP, the vertical spatio-temporal (YT) plane and the horizontal spatio-temporal (XT) plane; this enables LBP-TOP to dynamically encode temporal variations.
Subsequently, several variants of LBP-TOP were proposed for the ME recognition task. Wang et al. (2014b) derived Local Binary Pattern— Six Interception Points (LBP-SIP) from LBP-TOP by considering only the 6 unique points lying on three intersecting lines of the three orthogonal planes as neighbor points for constructing the binary patterns. By reducing redundant information from LBP-TOP, LBP-SIP reported better performance than LBP-TOP in this task. A more compact variant, LBP-MOP (Wang et al., 2015b) was constructed by concatenating the LBP features from only three mean images, which are the temporal pooling result of the image stacks along the three orthogonal planes. The performance of LBP-MOP was comparable to LBP-SIP, but with its computation time dramatically reduced. While LBP considers only pixel intensities, spatio-temporal completed local quantized patterns (STCLQP) (Huang et al., 2016) exploited more information containing sign, magnitude, and orientation components. To address the sparseness problem (in most LBP variants), specific codebooks were designed to reduce the number of possible codes to achieve better compactness.
Recent works have yielded some interesting advances. Huang and Zhao (2017) proposed a new binary pattern variant called spatio-temporal local Radon binary pattern (STRBP) that uses Radon transform to obtain robust shape features. Ben et al. (2017) proposed an alternative binary descriptor called Hot Wheel Patterns (HWP) (and its spatio-temporal extension HWP-TOP) to encode the discriminative features of both macro- and micro-expressions images. A coupled metric learning algorithm is then used to model the shared features between micro- and macro-expression information.
As suggested in several studies (e.g., Li et al., 2017), the temporal dynamics that reside along the video sequences are found to be essential in improving the performance of ME recognition. As such, optical flow (OF) (Horn and Schunck, 1981) based techniques, which measure the spatio-temporal changes in intensity, came into contention as well.
In the work by Xu et al. (2017), a proposal to extract only principal directions of the OF maps was purportedly to eliminate abnormal OF vectors that resulted from noise or illumination changes. A similar concept of exploiting OF in the main direction was employed by Liu et al. (2016) to design main directional mean optical flow (MDMO) features. MDMO is a ROI-based OF feature, which considers both local statistic (i.e., the mean of OF vectors in the bin with the maximum count in each ROI) and its spatial location (i.e., the ROI to which it belongs). Unlike the aforementioned works which exploited only the single dominant direction of OF in each facial region, Allaert et al. (2017) determined the consistent facial motion, which could be in multiple directions from a single facial region. The assumption was made based on the fact that facial motions spread progressively due to skin elasticity, hence only the directions that are coherent in the neighboring facial regions are extracted to construct a consistent OF map representation.
Motivated by the use of optical strain (OS) for ME spotting (Shreve et al., 2009, 2014), Liong et al. (2014a) proposed to leverage on its strengths for ME recognition. OS is derived from OF by computing the normal and shear strain tensor components of the OF. This enables the capture of small and subtle facial deformation. In their work, the OS magnitude images are temporally pooled to form a single pooled OS map; then the resulting map is max-normalized and resized to a fixed smaller resolution before transforming into a feature vector that represent the video. To emphasize the importance of active regions, the authors (Liong et al., 2014b) proposed to weight local LBP-TOP features with different weights which were generated from the temporal mean-pooled OS map. This allows regions that actively exhibit MEs to be given more significance, hence increasing the discrimination between emotion types. In a more recent attempt, Liong et al. (2016b) proposed a Bi-Weighted Oriented Optical Flow (BI-WOOF) descriptor which applies two schemes to weight the HOOF descriptor locally and globally. Locally, the magnitude components were used to weight the orientation bins within each ROI; the resultant locally weighted histograms are then weighted again (globally) by multiplying with the mean optical strain (OS) magnitude of each ROI. Intuitively, a larger change in the pixel's movement or deformation will contribute toward a more discriminative histogram. Instead of considering the whole image sequences, the authors also demonstrated promising recognition performance using only two frames (i.e., the onset frame and the apex frame) instead of using whole sequences. This was able to reduce the processing time by a large margin.
Zhang et al. (2017) proposed to aggregate the histogram of the oriented optical flow (HOOF) (Chaudhry et al., 2009) with LBP-TOP features region-by-region to generate local statistical features. In their work, they revealed that fusing of local features within each ROI can capture more detailed and representative information than globally done. In the work by Happy and Routray (2017), fuzzy histogram of optical flow orientation (FHOFO) was proposed for ME recognition. In HFOFO, the histograms are only the collection of orientations without being weighted by the optical flow magnitudes; the assumption was made that MEs are so subtle that the induced magnitudes should be ignored. They also introduced a fuzzification process that considers the contribution of an orientation angle to its surrounding bins based on fuzzy membership functions; as such smooth histograms for motion vector are created.
Aside from methods based on low-level features, there are also numerous techniques proposed to extract other types of feature representations. Lu et al. (2014) proposed a Delaunay-based temporal coding model (DTCM) to encode the local temporal variation (in grayscale values) in each subregion obtained by Delaunay triangulation and preserve the ones with high saliency as features. In the work of Li et al. (2017), the histogram of image gradient orientation (HIGO), which is a degenerate variant of HOG, was employed in the recognition task. It uses simple vote rather than weighted vote when counting the responses of the gradient orientations. As such, it could depress the influence of illumination contrast by ignoring the magnitude. The use of color space was also experimented in the work of Wang et al. (2015a), where LBP-TOP features were extracted from Tensor Independent Color Space (TICS). In TICS, the three color components (R, G, and B) were transformed into three uncorrelated components which are as independent as possible to avoid redundancy and thus increase the recognition performance. The Sparse Tensor Canonical Correlation Analysis (STCCA) representation proposed by Wang et al. (2016b) offers a solution to mitigate the sparsity of spatial and temporal information in a ME sequence.
Signal components such as magnitude, phase and orientation can be exploited as features for ME recognition. Oh et al. (2015) proposed a monogenic Riesz wavelet framework, where the decomposed magnitude, phase, and orientation components (which represent energy, structural and geometric information respectively) are concatenated to describe MEs. In their extended work (Oh et al., 2016), higher-order Riesz transform was adopted to exploit the intrinsic two-dimensional (i2D) local structures such as corners, junctions, and other complex contours. They demonstrated that i2D structures are better representative parts than i1D structures (i.e., simple structures such as lines and straight edges) in describing MEs. By supplementing the robust Bi-WOOF descriptor (Liong et al., 2016b) with Riesz monogenic phase information derived from the onset-apex difference image (Liong and Wong, 2017), recognition performance can be further boosted.
Integral projections are an easy way of simplifying spatial data to obtain shape information along different directions. The LBP-Integral Projection (IP) technique proposed by Huang et al. (2015) applies the LBP operator on these projections. A difference image is first computed from successive frames (to remove face identity) before it is projected into two parts: vertical projection and horizontal projection. This method was found to be more effective than directly using features derived from the original appearance information. In their extended work (Huang et al., 2017), original pixel information is replaced by extracted subtle emotion information as input for generating spatio-temporal local binary pattern with revisited integral projection (STLBP-RIP) features. To further enhance the discriminative power of these features, only features with the smallest Laplacian scores are selected as the final feature representation.
A few works increase the significance of features by means of excluding irrelevant information such as pose and subject identity, which may obstruct salient emotion information. Robust principal component analysis (RPCA) (Wright et al., 2009) was adopted in Wang et al. (2014a) and Huang et al. (2016) to extract subtle emotion information for feature extraction. In Wang et al. (2014a), the extracted subtle emotion information was encoded by local spatio-temporal directional (LSTD) to extract more detailed spatio-temporal directional changes on the x, y, and t directions from each plane (XY, XT, and YT). Lee et al. (2017) proposed an interesting use of Multimodal Discriminant Analysis (MMDA) to orthogonally decompose a sample into three modes or “identity traits” (emotion, gender and race) in a simultaneous manner. Only the essential emotion components are magnified before the samples are synthesized and reconstructed.
Recently, numerous new works have begun exploring other forms of representation and mechanisms. He et al. (2017) proposed a strategy to extract low-level features from small regions (or cubes) of a video by learning a set of class-specific feature mappings. Jia et al. (2017) devised a macro-to-micro transformation model based on singular value decomposition (SVD) to recognize MEs by utilizing macro-expressions as part of the training data. This overcomes the lack of labeled data in MEs databases. There were various recent attempts at casting the recognition task as one arising from a different problem. Zheng (2017) formulated it as a sparse approximation problem and presented the 2D Gabor filter and sparse representation (2DSGR) technique for feature extraction. Zhu et al. (2018) drew inspiration from similarities between MEs and speech to propose a transfer learning method that projects both domain signals to a common subspace. In a radical move, Davison et al. (2017) proposed to re-group MEs based on Action Units (AUs) instead of by emotion categories, which are arguably susceptible to bias in self-reports used during the construction of dataset. Their experimental results on CASME II and SAMM showed that recognition performance should be higher than what is currently expected from other works that used emotion labels.
The last stage in an ME recognition task involves the classification of the emotion type. Various types of classifiers have been used for the task of ME recognition such as k-Nearest Neighbor (k-NN), support vector machine (SVM), random forest (RF), sparse representation classifier (SRC), Relaxed K-SVD, group sparse learning (GSL) and extreme learning machine (ELM). From the literature, the most widely used classifier is the SVM. SVMs are computational algorithms that construct a hyperplane or a set of hyperplanes in a high or infinite dimensional space (Cortes and Vapnik, 1995). During the training of SVM, the margins between the borders of different classes are sought to be maximal. Compared to other classifiers, SVMs are robust, accurate, and very effective even in cases where the number of training samples is small. On the contrary, two other notable classifiers—RF and k-NN are seldom used in the ME recognition task. Although the RF is generally quicker than SVM, it is prone to overfit when dealing with noisy data. The k-NN uses an instance-based learning process which may not be suitable for sparse high-dimensional data such as face data.
To deal with the sparseness of MEs, several works tried using relaxed K-SVD, SRC, and GSL techniques for classification. However, each of these methods tackle the sparseness of MEs differently. The relaxed K-SVD (Zheng et al., 2016) learns a sparse dictionary to distinguish different MEs by minimizing the variance of sparse coefficients. The SRC (Yang et al., 2012) used in Zheng (2017) represents a given test sample as a sparse linear combination of all training samples; hence the sparse nonzero representation coefficients are likely to concentrate on training samples that are of the same class as the test sample. A Kernelized GSL (Zong et al., 2018a) is proposed to facilitate the process of learning a set of importance weights from hierarchical spatiotemporal descriptors that can aid the selection of the important blocks from various facial blocks. Neural networks can offer a one-shot process (feature extraction and classification), with a remarkable ability to extract complex patterns from data. However, a substantial amount of labeled data is required to properly train a neutral network without overfitting it, resulting in it being less favorable for ME recognition since labeled data is limited. The ELM (Huang et al., 2006), which is naturally just feed-forward network with a single hidden layer was used by Adegun and Vadapalli (2016) to classify MEs.
The original dataset papers (Li et al., 2013; Yan et al., 2014a; Davison et al., 2016a) all propose the adoption of the Leave-One-Subject-Out (also known as “LOSO”) cross-validation as the default experimental protocol. This is done with consideration that the samples were collected by eliciting the emotions from a number of different participants (i.e., S number of subjects). As such, cross validation should be carried out by withholding a particular subject s while the other S−1 subjects are used in the training step. This removes the potential identity bias that may arise during the learning process; a subject that is being evaluated could have been seen and learned in the training step. A number of other works used the Leave-One-Video-Out (“LOVO”) cross-validation protocol instead, which exhaustively divides all samples into S number of possible train-test partitions. This protocol is deemed to avoid irregular partitioning but is often likely to overestimate the performance of the classifier. A few works opted to report their results using their own choice of evaluation protocol, such as an evenly distributed sets (Zhang et al., 2017), random sampling of test partition (Jia et al., 2017), and five-fold cross validation (Adegun and Vadapalli, 2016). Generally, the works in literature can be categorized into these three groups, as shown in Table 4.
The ME recognition task reports the typical performance metric of Accuracy, which is commonly used in other image/video recognition problems. A majority of works in the literature report the Accuracy metric, which is simply the number of correctly classified video sequences over the total number of video sequences in the dataset. However, due to the imbalanced nature of the ME datasets which was first discussed by Le Ngo et al. (2014), Accuracy scores can be highly skewed toward classes that are larger as classifiers tend to learn poorly from classes that are less represented. Consequently, it makes more sense to report the F1-Score (or F-measure), which is the harmonic mean of the Precision and Recall:
where tp, fp, and fn are the number of true positives, false positives, false negatives, respectively. The overall performance of a method can be reported by macro-averaging across all classes (i.e., compute scores for each class, then average them), or by micro-averaging across all classes (i.e., summing up the individual tp, fp, and fn in the entire set before computing scores).
The studies reviewed in sections 2, 3, and 4 show the progress in the research work in ME analysis. However, there is still considerable room for improvement in the performance of ME spotting and recognition. In this section, some recognized problems in existing databases and challenging issues in both tasks are discussed in detail.
Acquiring valuable spontaneous ME data and their ground truth is far from being solved. Among the various affective states, certain emotions (such as happiness) are relatively easier to be elicited compared to others (e.g., fear, sadness, anger) (Coan and Allen, 2007). Consequently, there is an imbalanced distribution of samples per emotion and number of samples per subject. This could be biased toward particular emotions that constitute a larger portion of the training set. To address this issue, a more effective way of eliciting affective MEs (especially to those are relatively difficult) should be discovered. Social psychology has suggested creative strategies for inducing affective expressions that are difficult to elicit (Coan and Allen, 2007). Some works have underlined the possibility of using other complementary information from the body region (Song et al., 2013) or instantaneous heart rate from skin variations (Gupta et al., 2018) to better analyze micro-expressions.
Almost all the existing datasets contain a majority of subjects from one particular country or ethnicity. Though it is common knowledge that basic facial expressions are universal across the cultural background, nevertheless subjects from different backgrounds may express differently toward the same elicitation, or at least with different intensity level as they may have different ways of expressing an emotion. Thus, a well-established database should comprise a diverse range of ethnic groups to provide better generalization for experiments.
Although much effort has been paid toward the collection of databases of spontaneous MEs, some databases (e.g., SMIC) lack important metadata such as FACS. It is generally accepted that human facial expression data need to be FACS coded. The main reason being that FACS AUs are objective descriptors and independent of subjective interpretation. Moreover, it is also essential to report the reliability measure of the inter-observers (or inter-coders) involved in the labeling of data.
Considering the implementation of real-life applications of ME recognition in the near future, existing databases that are constructed under studio environments, may not best represent MEs exhibited in real-life situations. Thus, developing and introducing real-world ME databases could bring about a leap of progress in this domain.
Recent work on the spotting of MEs have achieved promising results on successfully locating the temporal dynamics of micro-movements; however, there is room for improvement as the problem of spotting MEs remains a challenging task to date.
Even though the facial landmark detection algorithms have made remarkable progress over the past decade, the available landmark detectors are not always accurate or steady. The unsteadiness of face alignment based on imprecise facial landmarks may result in significant noise (i.e., rigid head movements and eye gaze) associated with dynamic facial expressions. This in turn increases the difficulty in detecting the correct MEs. Thus, a more advanced robust facial landmark detection is required to correctly and precisely locate the landmark points on the face.
To avoid the intrusion of eye blinks, majority of works in the literature simply mask out the eye regions. However, according to some findings (Zhao et al., 2011; Vaidya et al., 2014; Lu et al., 2015; Duan et al., 2016), the eye region is one of the most discriminative regions for affect recognition. As many spontaneous MEs involving muscles around eye regions, there is a need to differentiate between the eye blinks corresponding to certain expressions and those that are merely irrelevant facial motions. In addition, the onsets of the many MEs also temporally overlap with eye blinks (Li et al., 2017). Thus, this warrants a more robust approach at dealing with overlapping occurrences of facial motions.
The few studies (Liong et al., 2015; Yan and Chen, 2017) investigated the effectiveness of individual feature descriptors in capturing the micro-movements for the ME spotting task. They have showed that micro-movements that are induced from different facial components actually resulted in motion changes from different perspectives such as appearance, geometric, and etc. For example, lifting up or down the eyebrows results in a clear contour change (geometrical), which could be effectively captured by geometric-based feature descriptors; pressing of lips could cause the variation in appearance but not the position, and thus appearance-based feature descriptors can capture these changes. Interestingly, they reported that motion-based features such as optical flow based features outperformed appearance-based and geometric-based features in the ME spotting. The problem remains that the assumptions made by optical flow methods are likely to be violated in unconstrained environments, rendering real-time implementation challenging.
Majority of existing efforts toward the spotting of MEs employ rule-based approaches that rely on thresholds. Frames with magnitude exceeding the pre-defined threshold value are the frames (i.e., the temporal dynamics) where ME appears. However, prior knowledge is required to set the appropriate threshold for distinguishing the relevant peaks from local magnitude variation and background noise. This is not really practical in the real-time domain. Instead, Liong et al. (2015) designed a simple divide-and-conquer strategy, which does not require a threshold to locate the temporal dynamics of MEs. Their method finds the apex frame based on a high concentration of peaks.
Further steps should also be considered to locate the onset and offset frames of these ME occurrences. While it is relatively easier to identify the peaks and valleys of facial movements, the onset and offset frames are much more difficult to determine. The task of locating the onset and offset frames will be even tougher when dealing with real-life situations where facial movements are continuously changing. Thus, the indicators and criteria for determining the onset and offset frames need to be properly defined and further studied. Spotting the ME onset and offset frames is a crucial step which can lead to automatic ME analysis.
In the past few years, much effort has been done toward ME recognition, including developing new features to better describe MEs. However, due to the short elapsed duration and low intensity of MEs, there is still room for improvement toward achieving satisfactory accuracy rates. This could be due to several possible reasons.
In most works, block-based segmentation of a face to extract local information is a common practice. Existing efforts employed block-based segmentation of a face without considering the contribution from each of the blocks. Ideally, the contribution from all blocks should be varied, whereby the blocks containing the key facial components such as eyebrows, eyes, mouth, and cheek should be highlighted as the motion changes at these regions convey meaningful information from differentiating different MEs. Higher weights can be assigned to those regions that contain key facial components to enhance the discriminative power. Alternatively, the discriminative features from the facial blocks can be selected through a learning process; the recent work of Zong et al. (2018a) offers a solution to this issue.
Since the emergence of the ME recognition works, many different feature descriptors have been proposed for MEs. Due to the characteristic of the feature descriptors, the extracted features might carry different information (e.g., appearance, geometric, motion, etc). For macro-expressions, it has been shown in (Fasel and Luettin, 2003) and Zeng et al. (2009) that geometric-based features performed poorer than appearance- and motion-based features as they are highly dependent on the precision of facial landmark points. However, recent ME works (Huang et al., 2015, 2017) show that shape information is arguably more discriminative for identifying certain MEs. Perhaps different features may carry meaningful information for different expression types. This should be carefully exploited and taken into consideration during feature extraction process.
The advancement of Deep Learning has prompted the community to look for new ways of extracting better features. However, a crucial ingredient to this remains as to the feasible amount of data necessary to train a model that does not over-fit easily; the small scale of data (lack of ME samples per category) and the imbalanced distribution of samples are the primary obstacles. Recently an approach by Patel et al. (2016) made an attempt to utilize deep features transferred from pretrained ImageNet models. The authors deemed that fine-tuning the network to the ME datasets is not plausible (insufficient data) and opted for a feature selection scheme. Some other works (Kim et al., 2016; Peng et al., 2017) have also begun exploring the use of deep neural networks by encoding spatial and temporal features learned from network architectures that are relatively “shallower” than those used in the ImageNet challenge (Russakovsky et al., 2015). This may be a promising research direction in terms of advancing the features used for this task.
Another on-going development that challenges existing experimental presuppositions is cross-database recognition. This setup mimics a realistic setting where training and test samples may come from different environments. Current recognition performance based on single databases, is expected to plunge under such circumstances. Zong et al. (2017, 2018b) proposed a domain regeneration (DR) framework, which aims to regenerate micro-expression samples from source and target databases. The authors aptly point out that much is still to be done to discover more robust algorithms that work well across varying domains. The first ever Micro-Expression Grand Challenge (Yap et al., 2018) was held with special attention given to the importance of cross-database recognition settings. Two protocols – Hold-out Database Evaluation (HDE) and Composite Database Evaluation (CDE), were proposed in the challenge, using the CASME II and SAMM databases. The reported performances (Khor et al., 2018; Merghani et al., 2018; Peng et al., 2018) were poorer than most other works that apply only to single databases, indicating that future methods need to be more robust across domains.
An important issue that should be addressed in ME recognition is how the data is evaluated. Due to the different evaluation protocols used in existing works, a fair comparison among these works could not be adequately established. Currently, the two popular evaluation protocols that are widely applied in ME recognition are: leave-one-video-out cross-validation (LOVOCV) and leave-one subject-out cross validation (LOSOCV). The common k-fold cross-validation is not suitable as the current publicly available spontaneous ME datasets are highly imbalanced (Le Ngo et al., 2014). The number of samples per subject and the number of samples per emotion class in these datasets vary quite considerably. For instance, in the CASME II dataset, the number of samples that belong to the “Surprise” class is 25 compared to the 102 samples of the “Others” class; while the difference in the number of samples for “Subject 08” and “Subject 17” are 8 and 34, respectively. As such, with k-fold cross-validation, the fairness in evaluation is likely to be questionable. The same goes with employing LOVOCV, where only one video sample is left out as the test sample while the remaining samples are used for training; subsequently, the average accuracy across all folds is taken as the final result. This can possibly introduce additional biases on certain subjects that have more representation during the evaluation process. Moreover, the performance of such a protocol typically over-estimates the actual classifier performance due to a substantially large training set. It is paramount to stress that the LOSOCV protocol is a more convincing evaluation protocol as it separates the samples of the test set based on the subject identity. As such, the training model is not biased toward the identity of the subject (akin to face recognition instead). Naturally, this protocol also limits the ability of methods to learn the intrinsic micro-expression dynamics of each subject. The intensity and manner of which micro-expressions are shown may differ from person to person, hence compartmentalizing a subject altogether may inhibit the modeling process.
Besides the usage of evaluation protocol, the choice of performance metrics is also crucial to understanding the actual performance of automatic ME analysis. Currently, two performance metrics are used most widely: the Accuracy rate and F1-score. While the Accuracy rate is straightforward in calculation, it does not give an adequate reflection of the effectiveness of a classifier as it is susceptible to heavily skewed data (uneven distribution of samples per emotion class), a characteristic found in most current datasets. Also, the Accuracy rate merely shows the average “hit rate” across all classes; thus the performance of the classifier that deals with each emotion class is not revealed. It is a much preferred practice to report confusion matrices for better understanding of its per-class performances. From thereafter, performance metrics such as F1-score, Precision and Recall provide a better measure of a classifier's performance when dealing with imbalanced datasets (Sokolova and Lapalme, 2009; Le Ngo et al., 2014). The overall F1-score, Precision and Recall scores should be micro-averaged based on the total number of true positives, false positives, and false negatives.
There are several existing works considering different number of emotion classes instead of using the emotion classes provided by the databases. For instance, in the works by Wang et al. (2015a) and Zheng (2017), the authors considered only three or four emotion labels (i.e., Positive, Negative, Surprise, and/or Others) instead of the original emotion labels of the CASME II (i.e., Happiness, Surprise, Disgust, Repression, and Others). Due to the reduction in the number of emotion classes considered, the classification task could be relatively simpler compared to those that have more emotion classes. As a result, higher performances were reported but this also inhibits these works from fair benchmarking against other works on the merit of their methods. It is important to note also that the grouping of classes may be biased toward negative categories since there is only one positive category (Happiness).
Recently, Davison et al. (2017) challenged the current use of emotion classes by proposing the use of objective classes, which are determined by restructuring these new categories around the Action Units (AUs) that have been FACS coded. Samples from the two most recent FACS coded datasets, CASME II and SAMM, were re-grouped into these objective classes for their use. The authors argued that emotion classification requires the context of the situation for an interpreter to make a meaningful interpretation, while relying on self-reports (Yan et al., 2014a) can also cause further unpredictability and bias. Although FACS coding can objectively assign AUs to specific muscle movements of the face but the emotion type becomes less obvious. Lim and Goh (2017), through their fuzzy modeling, provided some insights as to why the emotional content in ME samples are non-mutually exclusive as they may contain traces of more than one emotion type.
Research on the machine analysis of facial MEs has witnessed substantial progress in the last few years as several new spontaneous facial MEs databases were made available to aid automatic analysis of MEs. This has spiked the interest of the affective and visual computing community with a good number of promising methods making headways in both automatic ME spotting and recognition tasks. This necessitates a comprehensive review of recent advances to better taxonomize the increasing number of existing works. In addition, this paper also summarizes the issues that have not received sufficient attention, but are crucial for feasible machine interpretation of MEs. Among the important issues that are yet to be addressed in the field of ME spotting:
• Handling macro movements: Differentiating between larger, macro facial movements such as eye blinks and twitches, for better spotting of the onset of MEs,
• Developing more precise spotting techniques that can cope with various head poses and camera views: Extension of current constrained environments toward more real-time “in-the-wild” settings will provide a major leap in practicality.
• Establishing a firm criteria for defining the onset and offset frames for MEs: This allows ME short sequences to be extracted from long videos, which in turn, can be classified into emotion classes.
For the ME recognition task, there are a few issues that deserve the community's attention:
• Excluding irrelevant facial information: As MEs are very subtle, it is a great challenge to remove other image perturbations caused by face alignment and slight head rotations which may interfere with the MEs.
• Improving feature representations: Encoding subtle movements are difficult even when feature representations are rich. This is due to limitations in the amount of data that is currently available.
• Encouraging cross-database evaluation: Evaluating within single databases often gives a false impression of a method's performance, especially when existing databases lack diversity.
Y-HO and JS compiled and analyzed the works reviewed in this article, ACLN organized the structure of the review, and RCWP provided the critical analysis and necessary proof reading. All authors took part in the writing of the article.
This work is supported in part by Telekom Malaysia Research & Development (TM R&D) Fund-UbeAware, 2beAware and ParaDigm projects, Ministry of Higher Education Grant (FRGS/1/2016/ICT02/MMU/02/2) Malaysia, The Belt and Road Young Scholar Exchange Grant (17510740100), China and Multimedia University, Malaysia.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The reviewer XL and handling Editor declared their shared affiliation.
Adegun, I. P., and Vadapalli, H. B. (2016). “Automatic recognition of micro-expressions using local binary patterns on three orthogonal planes and extreme learning machine,” in Pattern Recognition Association of South Africa and Robotics and Mechatronics International Conference (PRASA-RobMech) (Stellenbosch), 2016, 1–5.
Allaert, B., Bilasco, I. M., Djeraba, C., Allaert, B., Mennesson, J., Bilasco, I. M., et al. (2017). “Consistent optical flow maps for full and micro facial expression recognition,” in VISAPP, Proc. of the 12th Int. Joint Conf. on Computer Vision, Imaging and Computer Graphics Theory and Applications (Porto), 235–242.
Asthana, A., Zafeiriou, S., Cheng, S., and Pantic, M. (2013). “Robust discriminative response map fitting with constrained local models,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Portland), 3444–3451.
Ben, X., Jia, X., Yan, R., Zhang, X., and Meng, W. (2017). Learning effective binary descriptors for micro-expression recognition transferred by macro-information. Pattern Recogn. Lett. 107, 50–58. doi: 10.1016/j.patrec.2017.07.010
Bettadapura, V. (2012). Face expression recognition and analysis: the state of the art. arXiv preprint arXiv:1203.6722.
Chaudhry, R., Ravichandran, A., Hager, G., and Vidal, R. (2009). “Histograms of oriented optical flow and binet-cauchy kernels on nonlinear dynamical systems for the recognition of human actions,” in IEEE Conference on Computer Vision and Pattern Recognition, 2009 (Miami), 1932–1939.
Coan, J. A., and Allen, J. J. (2007). Handbook of Emotion Elicitation and Assessment. Oxford University Press.
Cristinacce, D., and Cootes, T. F. (2006). “Feature detection and tracking with constrained local models,” in BMVC (Edinburgh).
Davison, A., Lansley, C., Costen, N., Tan, K., and Yap, M. H. (2016a). SAMM: a spontaneous micro-facial movement dataset. IEEE Trans. Affect. Comput. 9, 116–129. doi: 10.1109/TAFFC.2016.2573832
Davison, A. K., Lansley, C., Ng, C. C., Tan, K., and Yap, M. H. (2016b). Objective micro-facial movement detection using facs-based regions and baseline evaluation. arXiv preprint arXiv:1612.05038.
Davison, A. K., Merghani, W., and Yap, M. H. (2017). Objective classes for micro-facial expression recognition. arXiv preprint arXiv:1708.07549.
Davison, A. K., Yap, M. H., and Lansley, C. (2015). “Micro-facial movement detection using individualised baselines and histogram-based descriptors,” in 2015 IEEE International Conference on Systems, Man, and Cybernetics (SMC) (Kowloon), 1864–1869.
Duan, X., Dai, Q., Wang, X., Wang, Y., and Hua, Z. (2016). Recognizing spontaneous micro-expression from eye region. Neurocomputing 217, 27–36.
Duque, C., Alata, O., Emonet, R., Legrand, A.-C., and Konik, H. (2018). “Micro-expression spotting using the Riesz pyramid,” in WACV 2018 (Lake Tahoe).
Ekman, P. (2002). Microexpression Training Tool (METT). University of California, San Francisco, CA.
Ekman, P. (2003). Micro Expression Training Tool (METT) and Subtle Expression Training Tool (SETT). San Francisco, CA: Paul Ekman Company.
Ekman, P. (2009a). “Lie catching and microexpressions,” in The Philosophy of Deception, ed C. Martin (Oxford University Press), 118–133.
Ekman, P. (2009b). Telling Lies: Clues to Deceit in the Marketplace, Politics, and Marriage (revised edition). WW Norton & Company.
Ekman, P., and Friesen, W. V. (1969). Nonverbal leakage and clues to deception. Psychiatry 32, 88–106.
Fasel, B., and Luettin, J. (2003). Automatic facial expression analysis: a survey. Pattern Recogn. 36, 259–275. doi: 10.1016/S0031-3203(02)00052-3
Frank, M., Herbasz, M., Sinuk, K., Keller, A., and Nolan, C. (2009a). “I see how you feel: training laypeople and professionals to recognize fleeting emotions,” in The Annual Meeting of the International Communication Association (New York City, NY: Sheraton New York.
Frank, M. G., Maccario, C. J., and Govindaraju, V. (2009b). “Behavior and security,” in Protecting Airline Passengers in the Age of Terrorism, eds P. Seidenstat, X. Francis, and F. X. Splane (Santa Barbara, CA: Greenwood Pub Group), 86–106.
Goshtasby, A. (1988). Image registration by local approximation methods. Image Vis. Comput. 6, 255–261.
Guo, Y., Tian, Y., Gao, X., and Zhang, X. (2014). “Micro-expression recognition based on local binary patterns from three orthogonal planes and nearest neighbor method,” in International Joint Conference on Neural Networks (IJCNN), 2014 (Beijing), 3473–3479.
Gupta, P., Bhowmick, B., and Pal, A. (2018). “Exploring the feasibility of face video based instantaneous heart-rate for micro-expression spotting,” in Proceeding of IEEE CVPR Workshops (Salt Lake City), 1316–1323.
Haggard, E. A., and Isaacs, K. S. (1966). “Micromomentary facial expressions as indicators of ego mechanisms in psychotherapy,” in Methods of Research in Psychotherapy, eds L. A. Gottschalk and H. Auerbach (Boston, MA: Springer), 154–165.
Happy, S., and Routray, A. (2017). Fuzzy histogram of optical flow orientations for micro-expression recognition. IEEE Trans. Affect. Comput. doi: 10.1109/TAFFC.2017.2723386
He, J., Hu, J.-F., Lu, X., and Zheng, W.-S. (2017). Multi-task mid-level feature learning for micro-expression recognition. Pattern Recogn. 66, 44–52. doi: 10.1016/j.patcog.2016.11.029
Hess, U., and Kleck, R. E. (1990). Differentiating emotion elicited and deliberate emotional facial expressions. Eur. J. Soc. Psychol. 20, 369–385.
Huang, G.-B., Zhu, Q.-Y., and Siew, C.-K. (2006). Extreme learning machine: theory and applications. Neurocomputing 70, 489–501. doi: 10.1016/j.neucom.2005.12.126
Huang, X., Wang, S.-J., Liu, X., Zhao, G., Feng, X., and Pietikainen, M. (2017). Discriminative spatiotemporal local binary pattern with revisited integral projection for spontaneous facial micro-expression recognition. IEEE Trans. Affect. Comput. doi: 10.1109/TAFFC.2017.2713359
Huang, X., Wang, S.-J., Zhao, G., and Piteikainen, M. (2015). “Facial micro-expression recognition using spatiotemporal local binary pattern with integral projection,” in Proceedings of the IEEE International Conference on Computer Vision Workshops (Santiago), 1–9.
Huang, X., and Zhao, G. (2017). “Spontaneous facial micro-expression analysis using spatiotemporal local radon-based binary pattern,” in 2017 International Conference on The Frontiers and Advances in Data Science (FADS) (Xi'an), 159–164.
Huang, X., Zhao, G., Hong, X., Zheng, W., and Pietikäinen, M. (2016). Spontaneous facial micro-expression analysis using spatiotemporal completed local quantized patterns. Neurocomputing 175, 564–578. doi: 10.1016/j.neucom.2015.10.096
Husak, P., Cech, J., and Matas, J. (2017). Spotting facial micro-expressions “in the wild”. In 22nd Computer Vision Winter Workshop (Retz).
Jia, X., Ben, X., Yuan, H., Kpalma, K., and Meng, W. (2017). Macro-to-micro transformation model for micro-expression recognition. J. Comput. Sci. 25, 289–297. doi: 10.1016/j.jocs.2017.03.016
Jovanović, M. R., Schmid, P. J., and Nichols, J. W. (2014). Sparsity-promoting dynamic mode decomposition. Phys. Fluids 26:024103. doi: 10.1063/1.4863670
Khor, H.-Q., See, J., Phan, R. C. W., and Lin, W. (2018). “Enriched long-term recurrent convolutional network for facial micro-expression recognition,” in Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE International Conference on (Xi′an: IEEE), 667–674.
Kim, D. H., Baddar, W. J., and Ro, Y. M. (2016). “Micro-expression recognition with expression-state constrained spatio-temporal feature representations,” in Proceedings of the 2016 ACM on Multimedia Conference (Amsterdam), 382–386.
Lee, Z.-C., Phan, R. C.-W., Tan, S.-W., and Lee, K.-H. (2017). “Multimodal decomposition for enhanced subtle emotion recognition,” in Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2017 (Kuala Lumpur: IEEE), 665–671.
Le Ngo, A. C., Liong, S.-T., See, J., and Phan, R. C.-W. (2015). “Are subtle expressions too sparse to recognize?” in 2015 IEEE International Conference on Digital Signal Processing (DSP) (Singapore), 1246–1250.
Le Ngo, A. C., Oh, Y.-H., Phan, R. C.-W., and See, J. (2016a). “Eulerian emotion magnification for subtle expression recognition,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Shanghai), 1243–1247.
Le Ngo, A. C., Johnston, A., Phan, R. C.-W., and See, J. (2018). “Micro-expression motion magnification: Global Lagrangian vs. Local Eulerian Approaches,” in Automatic Face & Gesture Recognition (FG 2018) Workshops, 2018 13th IEEE International Conference on (Xi'an: IEEE), 650–656.
Le Ngo, A. C., Phan, R. C.-W., and See, J. (2014). “Spontaneous subtle expression recognition: imbalanced databases and solutions,” in Asian Conference on Computer Vision (Singapore: Springer), 33–48.
Le Ngo, A. C., See, J., and Phan, C.-W. R. (2016b). Sparsity in dynamics of spontaneous subtle emotion: analysis & application. IEEE Trans. Affect. Comput. doi: 10.1109/TAFFC.2016.2523996
Li, J., Soladie, C., and Seguier, R. (2018). “LTP-ML: micro-expression detection by recognition of local temporal pattern of facial movements,” in Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE International Conference on (Xi'an: IEEE).
Li, X., Pfister, T., Huang, X., Zhao, G., and Pietikainen, M. (2013). “A spontaneous micro-expression database: inducement, collection and baseline,” in 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), 1–6.
Li, X., Xiaopeng, H., Moilanen, A., Huang, X., Pfister, T., Zhao, G., et al. (2017). Towards reading hidden emotions: a comparative study of spontaneous micro-expression spotting and recognition methods. IEEE Trans. Affect. Comput. doi: 10.1109/TAFFC.2017.2667642
Lim, C. H., and Goh, K. M. (2017). “Fuzzy qualitative approach for micro-expression recognition,” in Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2017 (Kuala Lumpur: IEEE), 1669–1674.
Liong, S.-T., Phan, R. C.-W., See, J., Oh, Y.-H., and Wong, K. (2014a). “Optical strain based recognition of subtle emotions,” in 2014 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS) (Kuching), 180–184.
Liong, S.-T., See, J., Phan, R. C.-W., Le Ngo, A. C., Oh, Y.-H., and Wong, K. (2014b). “Subtle expression recognition using optical strain weighted features,” in Computer Vision-ACCV 2014 Workshops (Singapore: Springer), 644–657.
Liong, S.-T., See, J., Phan, R. C.-W., Oh, Y.-H., Le Ngo, A. C., Wong, K., et al. (2016a). Spontaneous subtle expression detection and recognition based on facial strain. Signal Process. Image Commun. 47, 170–182. doi: 10.1016/j.image.2016.06.004
Liong, S.-T., See, J., Phan, R. C.-W., and Wong, K. (2016b). Less is more: micro-expression recognition from video using apex frame. arXiv preprint arXiv:1606.01721.
Liong, S.-T., See, J., Phan, R. C.-W., Wong, K., and Tan, S.-W. (2018). Hybrid facial regions extraction for micro-expression recognition system. J. Signal Process. Syst. 90, 601–617. doi: 10.1007/s11265-017-1276-0
Liong, S.-T., See, J., Wong, K., Le Ngo, A. C., Oh, Y.-H., and Phan, R. (2015). “Automatic apex frame spotting in micro-expression database,” in 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR) (Kuala Lumpur), 665–669.
Liong, S.-T., See, J., Wong, K., and Phan, R. C.-W. (2016c). “Automatic micro-expression recognition from long video using a single spotted apex,” in Asian Conference on Computer Vision (ACCV) Workshops (Taipei: Springer), 345–360.
Liong, S.-T., and Wong, K. (2017). “Micro-expression recognition using apex frame with phase information,” in Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2017 (Kuala Lumpur: IEEE), 534–537.
Liu, Y.-J., Zhang, J.-K., Yan, W.-J., Wang, S.-J., Zhao, G., and Fu, X. (2016). A main directional mean optical flow feature for spontaneous micro-expression recognition. IEEE Trans. Affect. Comput. 7, 299–310. doi: 10.1109/TAFFC.2015.2485205
Lu, Y., Zheng, W.-L., Li, B., and Lu, B.-L. (2015). “Combining eye movements and EEG to enhance emotion recognition,” in IJCAI (Buenos Aires), 1170–1176.
Lu, Z., Luo, Z., Zheng, H., Chen, J., and Li, W. (2014). “A delaunay-based temporal coding model for micro-expression recognition,” in Asian Conference on Computer Vision (ACCV) Workshops (Singapore: Springer), 698–711.
Ma, H., An, G., Wu, S., and Yang, F. (2017). “A region histogram of oriented optical flow (RHOOF) feature for apex frame spotting in micro-expression,” in 2017 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS) (Xiamen), 281–286.
Megvii, I. (2013). Face++ Research Toolkit. Available online at: www.faceplusplus.com
Merghani, W., Davison, A., and Yap, M. (2018). “Facial Micro-expressions Grand Challenge 2018: evaluating spatio-temporal features for classification of objective classes,” in Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE International Conference on (Xi'an: IEEE), 662–666.
Milborrow, S., and Nicolls, F. (2014). “Active shape models with SIFT descriptors and MARS,” in VISAPP (2) (Lisbon), 380–387.
Moilanen, A., Zhao, G., and Pietikainen, M. (2014). “Spotting rapid facial movements from videos using appearance-based feature difference analysis,” in 2014 22nd International Conference on Pattern Recognition (ICPR) (Stockholm), 1722–1727.
Oh, Y.-H., Le Ngo, A. C., Phan, R. C.-W., See, J., and Ling, H.-C. (2016). “Intrinsic two-dimensional local structures for micro-expression recognition,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Shanghai), 1851–1855.
Oh, Y.-H., Le Ngo, A. C., See, J., Liong, S.-T., Phan, R. C.-W., and Ling, H.-C. (2015). “Monogenic riesz wavelet representation for micro-expression recognition,” in 2015 IEEE International Conference on Digital Signal Processing (DSP) (Singapore), 1237–1241.
Ojala, T., Pietikainen, M., and Maenpaa, T. (2002). Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 24, 971–987. doi: 10.1109/TPAMI.2002.1017623
Park, S. Y., Lee, S. H., and Ro, Y. M. (2015). “Subtle facial expression recognition using adaptive magnification of discriminative facial motion,” in Proceedings of the 23rd Annual ACM Conference on Multimedia Conference (Brisbane), 911–914.
Patel, D., Hong, X., and Zhao, G. (2016). “Selective deep features for micro-expression recognition,” in 23rd International Conference on Pattern Recognition (ICPR), 2016 (Cancun), 2258–2263.
Patel, D., Zhao, G., and Pietikäinen, M. (2015). “Spatiotemporal integration of optical flow vectors for micro-expression detection,” in International Conference on Advanced Concepts for Intelligent Vision Systems (Catania: Springer), 369–380.
Peng, M., Wang, C., Chen, T., Liu, G., and Fu, X. (2017). Dual temporal scale convolutional neural network for micro-expression recognition. Front. Psychol. 8:1745. doi: 10.3389/fpsyg.2017.01745
Peng, M., Wu, Z., Zhang, Z., and Chen, T. (2018). “From macro to micro expression recognition: deep learning on small datasets using transfer learning,” in Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE International Conference on (Xi′an: IEEE), 657–661.
Pfister, T., Li, X., Zhao, G., and Pietikäinen, M. (2011). “Recognising spontaneous facial micro-expressions,” in 2011 IEEE International Conference on Computer Vision (ICCV) (Barcelona), 1449–1456.
Ping, L., Zheng, W., Ziyan, W., Qiang, L., Yuan, Z., Minghai, X., et al. (2016). Micro-expression recognition by regression model and group sparse spatio-temporal feature learning. IEICE Trans. Inform. Syst. 99, 1694–1697. doi: 10.1587/transinf.2015EDL8221
Pitt, M. K., and Shephard, N. (1999). Filtering via simulation: auxiliary particle filters. J. Am. Stat. Assoc. 94, 590–599.
Polikovsky, S., and Kameda, Y. (2013). Facial micro-expression detection in hi-speed video based on facial action coding system (facs). IEICE Trans. Inform. Syst. 96, 81–92. doi: 10.1587/transinf.E96.D.81
Polikovsky, S., Kameda, Y., and Ohta, Y. (2009). “Facial micro-expressions recognition using high speed camera and 3d-gradient descriptor,” in 3rd International Conference on Crime Detection and Prevention (ICDP 2009) (London, UK), 1–6.
Porter, S., and Ten Brinke, L. (2008). Reading between the lies identifying concealed and falsified emotions in universal facial expressions. Psychol. Sci. 19, 508–514. doi: 10.1111/j.1467-9280.2008.02116.x
Qu, F., Wang, S.-J., Yan, W.-J., Li, H., Wu, S., and Fu, X. (2017). CAS(ME)2: a database for spontaneous macro-expression and micro-expression spotting and recognition. IEEE Trans. Affect. Comput. doi: 10.1109/TAFFC.2017.2654440
Radlak, K., Bozek, M., and Smolka, B. (2015). “Silesian Deception Database: presentation and analysis,” in Proceedings of the 2015 ACM on Workshop on Multimodal Deception Detection (Seattle, DC), 29–35.
Ross, A. (2004). Procrustes Analysis. Course report, Department of Computer Science and Engineering, University of South Carolina.
Rothwell, J., Bandar, Z., O'Shea, J., and McLean, D. (2006). Silent talker: a new computer-based system for the analysis of facial cues to deception. Appl. Cogn. Psychol. 20, 757–777. doi: 10.1002/acp.1204
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). ImageNET Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 115, 211–252. doi: 10.1007/s11263-015-0816-y
Sagonas, C., Tzimiropoulos, G., Zafeiriou, S., and Pantic, M. (2013). “300 faces in-the-wild challenge: the first facial landmark localization challenge,” in Proceedings of the IEEE International Conference on Computer Vision Workshops (Sydney), 397–403.
Saragih, J. M., Lucey, S., and Cohn, J. F. (2009). “Face alignment through subspace constrained mean-shifts,” in 2009 IEEE 12th International Conference on Computer Vision (Kyoto), 1034–1041.
Sariyanidi, E., Gunes, H., and Cavallaro, A. (2015). Automatic analysis of facial affect: a survey of registration, representation, and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37, 1113–1133. doi: 10.1109/TPAMI.2014.2366127
Shreve, M., Brizzi, J., Fefilatyev, S., Luguev, T., Goldgof, D., and Sarkar, S. (2014). Automatic expression spotting in videos. Image Vis. Comput. 32, 476–486. doi: 10.1016/j.imavis.2014.04.010
Shreve, M., Godavarthy, S., Goldgof, D., and Sarkar, S. (2011). “Macro-and micro-expression spotting in long videos using spatio-temporal strain,” in 2011 IEEE International Conference on Automatic Face & Gesture Recognition and Workshops (FG 2011) (Santa Barbara), 51–56.
Shreve, M., Godavarthy, S., Manohar, V., Goldgof, D., and Sarkar, S. (2009). “Towards macro-and micro-expression spotting in video using strain patterns,” in 2009 Workshop on Applications of Computer Vision (WACV) (Snowbird), 1–6.
Sokolova, M., and Lapalme, G. (2009). A systematic analysis of performance measures for classification tasks. Inform. Process. Manage. 45, 427–437. doi: 10.1016/j.ipm.2009.03.002
Song, Y., Morency, L.-P., and Davis, R. (2013). “Learning a sparse codebook of facial and body microexpressions for emotion recognition,” in Proceedings of the 15th ACM on International Conference on Multimodal Interaction (Sydney: ACM), 237–244.
Tomasi, C., and Kanade, T. (1991). Detection and tracking of point features. Int. J. Comput. Vis. 9, 137–154.
Tran, T.-K., Hong, X., and Zhao, G. (2017). “Sliding window based micro-expression spotting: a benchmark,” in Advanced Concepts for Intelligent Vision Systems (ACIVS), 18th International Conference on (Antwerp: Springer), 542–553.
Vaidya, A. R., Jin, C., and Fellows, L. K. (2014). Eye spy: the predictive value of fixation patterns in detecting subtle and extreme emotions from faces. Cognition 133, 443–456. doi: 10.1016/j.cognition.2014.07.004
Valstar, M. F., and Pantic, M. (2012). Fully automatic recognition of the temporal phases of facial actions. IEEE Trans. Syst. Man Cybern. Part B 42, 28–43. doi: 10.1109/TSMCB.2011.2163710
Wang, S.-J., Wu, S., Qian, X., Li, J., and Fu, X. (2016a). A main directional maximal difference analysis for spotting facial movements from long-term videos. Neurocomputing 230, 382–389. doi: 10.1016/j.neucom.2016.12.034
Wang, S.-J., Yan, W.-J., Sun, T., Zhao, G., and Fu, X. (2016b). Sparse tensor canonical correlation analysis for micro-expression recognition. Neurocomputing 214, 218–232.
Wang, S. J., Yan, W. J., Li, X., Zhao, G., Zhou, C.-G., Fu, X., et al. (2015a). Micro-expression recognition using color spaces. IEEE Trans. Image Process. 24, 6034–6047. doi: 10.1109/TIP.2015.2496314
Wang, S.-J., Yan, W.-J., Zhao, G., Fu, X., and Zhou, C.-G. (2014a). “Micro-expression recognition using robust principal component analysis and local spatiotemporal directional features,” in Workshop at the European Conference on Computer Vision (Zurich: Springer), 325–338.
Wang, Y., See, J., Oh, Y.-H., Phan, R. C., Rahulamathavan, Y., Ling, H. C., et al. (2017). “Effective recognition of facial micro-expressions with video motion magnification,” in Multimedia Tools and Applications. 76, 21665–21690. doi: 10.1007/s11042-016-4079-6
Wang, Y., See, J., Phan, R. C. W., and Oh, Y. H. (2014b). “LBP with Six Intersection Points: reducing redundant information in LBP-TOP for micro-expression recognition,” in Computer Vision–ACCV 2014 (Singapore: Springer), 525–537.
Wang, Y., See, J., Phan, R., and Oh, Y. H. (2015b). Efficient spatio-temporal local binary patterns for spontaneous facial micro-expression recognition. PLoS ONE 10:e0124674. doi: 10.1371/journal.pone.0124674
Warren, G., Schertler, E., and Bull, P. (2009). Detecting deception from emotional and unemotional cues. J. Nonverb. Behav. 33, 59–69. doi: 10.1007/s10919-008-0057-7
Weinberger, S. (2010). Airport security: intent to deceive? Nature 465, 412–415. doi: 10.1038/465412a
Wright, J., Ganesh, A., Rao, S., Peng, Y., and Ma, Y. (2009). “Robust principal component analysis: exact recovery of corrupted low-rank matrices via convex optimization,” in Advances in Neural Information Processing Systems (Vancouver), 2080–2088.
Wu, H.-Y., Rubinstein, M., Shih, E., Guttag, J. V., Durand, F., and Freeman, W. T. (2012). Eulerian video magnification for revealing subtle changes in the world. ACM Trans. Graph. 31, 1–8. doi: 10.1145/2185520.2185561
Wu, Q., Shen, X., and Fu, X. (2011). “The machine knows what you are hiding: an automatic micro-expression recognition system,” in Affective Computing and Intelligent Interaction ACII 2011 (Memphis), 152–162.
Xia, Z., Feng, X., Peng, J., Peng, X., and Zhao, G. (2016). Spontaneous micro-expression spotting via geometric deformation modeling. Comput. Vis. Image Understand. 147, 87–94. doi: 10.1016/j.cviu.2015.12.006
Xu, F., Zhang, J., and Wang, J. (2017). Microexpression identification and categorization using a facial dynamics map. IEEE Trans. Affect. Comput. 8, 254–267. doi: 10.1109/TAFFC.2016.2518162
Yan, W.-J., Wang, S.-J., Chen, Y.-H., Zhao, G., and Fu, X. (2014b). “Quantifying micro-expressions with constraint local model and local binary pattern,” in Workshop at the European Conference on Computer Vision (Zurich: Springer), 296–305.
Yan, W.-J., and Chen, Y.-H. (2017). Measuring dynamic micro-expressions via feature extraction methods. J. Comput. Sci. 25, 318–326. doi: 10.1016/j.jocs.2017.02.012
Yan, W.-J., Li, X., Wang, S.-J., Zhao, G., Liu, Y.-J., Chen, Y.-H., et al. (2014a). CASME II: an improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE 9:e86041. doi: 10.1371/journal.pone.0086041
Yan, W.-J., Wu, Q., Liang, J., Chen, Y.-H., and Fu, X. (2013a). How fast are the leaked facial expressions: the duration of micro-expressions. J. Nonverb. Behav. 37, 217–230. doi: 10.1007/s10919-013-0159-8
Yan, W.-J., Wu, Q., Liu, Y.-J., Wang, S.-J., and Fu, X. (2013b). “Casme database: a dataset of spontaneous micro-expressions collected from neutralized faces,” in 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG) (Shanghai), 1–7.
Yang, J., Zhang, L., Xu, Y., and Yang, J.-Y. (2012). Beyond sparsity: the role of l 1-optimizer in pattern classification. Pattern Recogn. 45, 1104–1118.
Yap, M. H., See, J., Hong, X., and Wang, S.-J. (2018). “Facial Micro-Expressions Grand Challenge 2018 Summary,” in Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE International Conference on (Xi'an: IEEE), 675–678.
Zarezadeh, E., and Rezaeian, M. (2016). Micro expression recognition using the eulerian video magnification method. Brain 7, 43–54. Available online at: http://www.brain.edusoft.ro/index.php/brain/article/view/623
Zeng, Z., Pantic, M., Roisman, G. I., and Huang, T. S. (2009). A survey of affect recognition methods: audio, visual, and spontaneous expressions. IEEE Trans. Pattern Anal. Mach. Intell. 31, 39–58. doi: 10.1109/TPAMI.2008.52
Zhang, J., Shan, S., Kan, M., and Chen, X. (2014). “Coarse-to-fine auto-encoder networks (cfan) for real-time face alignment,” in European Conference on Computer Vision (Zurich: Springer), 1–16.
Zhang, S., Feng, B., Chen, Z., and Huang, X. (2017). “Micro-expression recognition by aggregating local spatio-temporal patterns,” in International Conference on Multimedia Modeling (Reykjavik: Springer), 638–648.
Zhao, Y., Wang, X., and Petriu, E. M. (2011). “Facial expression anlysis using eye gaze information,” in 2011 IEEE International Conference on Computational Intelligence for Measurement Systems and Applications (CIMSA), 1–4. IEEE.
Zheng, H. (2017). “Micro-expression recognition based on 2d gabor filter and sparse representation,” in Journal of Physics: Conference Series Vol. 787 (IOP Publishing).
Zheng, H., Geng, X., and Yang, Z. (2016). “A relaxed K-SVD algorithm for spontaneous micro-expression recognition,” in Pacific Rim International Conference on Artificial Intelligence (Phuket: Springer), 692–699.
Zhou, Z., Zhao, G., and Pietikäinen, M. (2011). “Towards a practical lipreading system,” in 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Colorado Springs), 137–144.
Zhu, X., Ben, X., Liu, S., Yan, R., and Meng, W. (2018). Coupled source domain targetized with updating tag vectors for micro-expression recognition. Multimedia Tools Appl. 77, 3105–3124. doi: 10.1007/s11042-017-4943-z
Zitova, B., and Flusser, J. (2003). Image registration methods: a survey. Image Vis. Comput. 21, 977–1000. doi: 10.1016/S0262-8856(03)00137-9
Zong, Y., Huang, X., Zheng, W., Cui, Z., and Zhao, G. (2017). “Learning a target sample re-generator for cross-database micro-expression recognition,” in Proceedings of the 2017 ACM on Multimedia Conference (Mountain View, CA), 872–880.
Zong, Y., Huang, X., Zheng, W., Cui, Z., and Zhao, G. (2018a). Learning from hierarchical spatiotemporal descriptors for micro-expression recognition. IEEE Trans. Multimed. doi: 10.1109/TMM.2018.2820321
Keywords: facial micro-expressions, subtle emotions, survey, spotting, recognition, databases, spontaneous, expressions
Citation: Oh Y-H, See J, Le Ngo AC, Phan RC-W and Baskaran VM (2018) A Survey of Automatic Facial Micro-Expression Analysis: Databases, Methods, and Challenges. Front. Psychol. 9:1128. doi: 10.3389/fpsyg.2018.01128
Received: 02 December 2017; Accepted: 12 June 2018;
Published: 10 July 2018.
Edited by:
Wenfeng Chen, Renmin University of China, ChinaReviewed by:
Xunbing Shen, Jiangxi University of Traditional Chinese Medicine, ChinaCopyright © 2018 Oh, See, Le Ngo, Phan and Baskaran. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: John See, am9obnNlZUBtbXUuZWR1Lm15
† These authors have contributed equally to this work.
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.