 Yanyan Sheng
Yanyan Sheng- Department of Counseling, Quantitative Methods and Special Education, Southern Illinois University, Carbondale, IL, USA
The half-t family has been suggested for the scale hyperparameter in Bayesian hierarchical modeling. Two parameters define a half-t distribution: the scale s and the degree-of-freedom ν. When s is set at a finite value that is slightly larger than the actual standard deviation of the parameters, the half-t prior density can be vaguely informative. This paper focused on such densities, and applied them to the hierarchical three-parameter item response theory (IRT) model. Monte Carlo simulations were carried out to investigate the performance of such specifications in parameter recovery and model comparisons under situations where the actual variability of item parameters varied, and results suggest that the half-t family does offer advantages over the commonly adopted uniform or inverse-gamma prior density by allowing the variability for item parameters to be either very small or large. A real data example is also provided to further illustrate this.
1. Introduction
With current enhanced computational technology and the emergence of Markov chain Monte Carlo (MCMC) simulation techniques (e.g., Chib and Greenberg, 1995), the methodology for parameter estimation with item response theory (IRT) models has rapidly moved to a fully Bayesian approach. One of the many advantages that this approach offers in the simultaneous estimation of both item and person parameters is the flexibility of setting prior distributions for model parameters or hyperparameters. The existing literature in Bayesian statistics (Gelman et al., 2003) offers two general options in specifying prior distributions by choosing between fully informative priors using application-specific information and non-informative priors. Each of these is adopted depending on the availability of prior information. However, when prior information is desired but not readily available, neither would provide a common solution for various actual situations. The problem with the former, in particular, is that misspecification tends to result in biased estimates and hence incorrect inferences (e.g., Mislevy, 1986). This paper focuses on something in the middle, namely, a somewhat informative prior distribution that can be used in a wide range of applications.
The fully Bayesian estimation procedure has been developed for the three-parameter normal ogive (3PNO; Lord, 1980) model by Sahu (2002; see also Johnson and Albert, 1999) generalizing the approach for the two-parameter model by Albert (1992). The procedure has been further implemented in some applications, e.g., Béguin and Glas (2001) and Glas and Meijer (2003). However, this specification where the hyperparameters take specific values causes problems when prior distributions for the item slope and intercept parameters are not strongly informative. Specifically, studies have shown that improper non-informative prior densities for the item slope and intercept parameters result in an undefined posterior distribution, which gives rise to unstable parameter estimates (Sheng, 2008, 2010). Even with proper non-informative prior densities, the procedure either fails to converge or requires an enormous number of iterations for the Markov chain to reach convergence (Sheng, 2010). Sheng (2013) shows that if one specifies prior distributions for the hyperparameters of the item parameters, instead of setting values for them, the problem can be resolved. This type of hierarchical modeling allows a more objective approach to inference by estimating the parameters of prior distributions from data rather than specifying them using subjective information.
Research on the effect of prior distributions for hyperparameters in Bayesian hierarchical models advises caution in choosing a prior distribution for the scale hyperparameter, as certain specifications of the hyperpriors may cause problems in inference (Brown and Draper, 2006; Gelman, 2006). In the Bayesian literature and software, various non-informative prior distributions have been suggested for the variance parameter in hierarchical linear models, including an improper uniform prior on σ (Gelman et al., 2003), an improper uniform prior on log(σ), and a conjugate inverse-gamma (0.001, 0.001) prior (Spiegelhalter et al., 1994, 2003). Gelman (2006), however, in an attempt to illustrate the performance of these prior distributions for σ near zero, which is where classical and Bayesian inferences differ the most (see Brown and Draper, 2006), pointed out problems with the latter two, especially with the inverse-gamma family of non-informative prior distributions. As Gelman (2006) stated, the problem with the uniform prior distribution on log(σ) is that it results in an improper posterior distribution (p. 521), and the problem with the inverse-gamma family is that inferences are sensitive to the choice of the hyperparameters when low values of σ are possible (p. 522). With respect to the proper non-informative prior, he recommended the use of a half-t family, which is inherently conjugate (see Gelman, 2006, for a detailed illustration) and is preferred over other parametric family for the hyperprior distributions because flat-tailed distributions allow for robust inference (Berger and Berliner, 1986). When the scale of the half-t distribution is set to a finite value that is slightly larger than the actual variability of the parameters, the resulting prior density can be vaguely informative.
In view of the above, the purpose of this study is to develop Bayesian hierarchical 3PNO IRT models with such half-t densities being the item scale hyperpriors and further investigate their performance in estimating model parameters as well as in providing model-data fit under different test situations where the actual variability of item parameter varies.
The remainder of the paper is organized as follows. Section 2 describes the hierarchical 3PNO IRT model and the Gibbs sampling procedure where half-t hyperpriors are assumed for the scale parameters for item slopes and intercepts. Then, two simulation studies were carried out to evaluate the performance of this model specification in parameter recovery as well as to compare it with other model specifications with uniform or inverse-gamma prior densities. The methodology and results of these simulation studies are presented in Sections 3 and 4, respectively. Section 5 gives an example where the model specification under investigation is implemented on a subset of College Basic Academic Subjects Examination (CBASE; Osterlind, 1997) English data. Finally, a few summary remarks are provided in Section 6.
2. Model and the Gibbs Sampling Procedure
Before the study is further described, the hierarchical 3PNO model is briefly illustrated. Suppose a test consists of k binary response items (e.g., multiple-choice items), each measuring a single unified latent trait, θ. Let y = [yij]n × k denote a matrix of n responses to the k items where yij = 1 (yij = 0) if the i-th person answers the j-th item correctly (incorrectly) for i = 1, …, n and j = 1, …, k.
The probability of person i obtaining a correct response to item j can be defined as
for the 3PNO IRT model, where Φ denotes the normal CDF, θi is a scalar latent trait parameter, αj is a scalar slope parameter describing the item discrimination, βj is the intercept parameter associated with item difficulty, and γj is a pseudo-chance-level parameter indicating that the probability of correct response is < zero even for those with very low trait levels. This model is applicable for objective items, such as multiple-choice or true-or-false items where an item is too difficult for some examinees.
To implement Gibbs sampling to the 3PNO model defined in (1), two latent variables, Z and W, are introduced such that Zij ~ N(ηij, 1) (Albert, 1992; Tanner and Wong, 1987), where ηij = αjθi − βj, and Wij = 1 (Wij = 0) if person i knows (does not know) the correct answer to item j with a probability density function
Prior densities p(θ), p(ξ) and p(γ) can be assumed for θi, ξj and γj, respectively, where . Here we focus on the normal conjugate priors for ξj so that , . Further, with hyperpriors assumed for the hyperparameters μα, μβ, , , the joint posterior distribution of (θ, ξ, γ, W, Z, μξ, Σξ) is hence
where is the likelihood function, with pij being the model probability function as defined in (1). Assume a normal prior for θi, a conjugate Beta prior for γj so that , γj ~ Beta(d, t), and conditionally conjugate half-t prior distributions for σα and σβ with mean 0, degrees-of-freedom ν and scale s, where ν and s are chosen to provide minimal prior information to constrain the scale hyperparameters to lie in a reasonable range. Hence, with the prior distributions specified this way, the full conditional distributions of all the parameters can be derived in closed forms through a multiplicative reparameterization following Knape et al. (2008) and updated iteratively using the Gibbs sampler (see the Appendix in Supplementary Material).
The half-t distribution considered for σα and σβ takes the form
(Gelman, 2006). Setting ν = 1 results in a special case of half-Cauchy, which has a broad peak at zero and can be weakly informative if s takes large but finite values. On the other hand, setting the scale s to infinity corresponds to a flat prior distribution, setting the degrees of freedom ν to 100 corresponds to a half-normal distribution, which can be non-informative but proper if the scale s is set to a high value, such as 100. Here, in the study, we considered a half-normal, a half-Cauchy, and a half-t distribution with 4 degrees of freedom (ν = 4).
3. Methodology of Monte Carlo Simulations
In order to evaluate the performance of the hierarchical 3PNO model as described in Section 2, two simulation studies were conducted where it was compared with other model specifications in parameter recovery and/or model comparisons.
3.1. Simulation Study 1
In the IRT literature, it is well accepted that when prior information is not readily available, large data sizes are needed to estimate IRT parameters (e.g., Swaminathan and Gifford, 1983), as Bayesian estimation with a flat prior is equivalent to a maximum likelihood estimation, and that the accuracy of item (person) parameter estimates is related to the number of subjects (items) (e.g., Natesan et al., 2016; Sheng, 2010). Hence, in this simulation study, we evaluated the effect of sample size, test length, actual variability of item slope and intercept parameters on the accuracy with which model parameters are estimated considering a half-normal, a non-informative uniform or an inverse gamma prior.
Item responses for k items (k = 10, 20, and 40) and n individuals (n = 100, 300, 500, and 1000) were generated according to the 3PNO model, as defined in (1). Ability parameters were generated as samples from a standard normal distribution, pseudo-chance-level parameters were generated from a uniform distribution, γj ~ U(0.05, 0.4), and item slope and intercept parameters were generated as samples from uniform distributions so that
• Sim1: αj ~ U(0, 2), βj ~ U(−1, 1);
• Sim2: αj ~ U(0, 2), βj ~ U(−0.5, 0.5); and
• Sim3: αj ~ U(0.5, 1.5), βj ~ U(−1, 1).
When implementing the MCMC procedure, a diffuse prior were assumed for γj, μα and μβ so that γj ~ Beta(1, 1), p(μα)∝1 and p(μβ)∝1. In addition, three ways of setting the prior distributions for αj and βj were considered such that both had
1. non-informative prior distributions that are uniform on σ, i.e., and ;
2. inverse-gamma (0.001, 0.001) prior distributions;
3. half-t prior distributions with 100 degrees of freedom, which are in practice equivalent to a half-normal.
It is noted that although the inverse-gamma (0.001, 0.001) prior density was not suggested by Gelman (2006), it was considered in this study because of its popularity (see e.g., Xu et al., 2009; O'Brien et al., 2015). With each of the prior specifications considered, the Gibbs sampling procedure was implemented where 10,000–50,000 iterations were obtained with the first half set as burn-in.
3.2. Simulation Study 2
In the first simulation study, only two levels of variability (i.e., and ), and three different hyperpriors (one uniform, one inverse-gamma and one half-normal) were considered. Given that the range for item intercept parameters (βj) is generally wider than [−1, 1] in practice, it would be interesting to see how the weakly informative half-t family performs when the variance for β goes beyond 1. Hence, a second simulation study was conducted where two factors were manipulated, namely, actual variability of the item intercept parameters and specifications of prior distributions for the item scale hyperparameters.
Item responses for 20 items and 1000 individuals were generated according to the 3PNO model, as defined in (1). Ability parameters were generated as samples from a standard normal distribution, item slope and pseudo-chance-level parameters were generated from uniform distributions, αj ~ U(0, 2) and γj ~ U(0.05, 0.4), and item intercept parameters were generated as samples from uniform distributions so that
• Sim1: β ~ U(−0.5, 0.5);
• Sim2: β ~ U(−1, 1);
• Sim3: β ~ U(−2, 2); and
• Sim4: β ~ U(−4, 4).
It is noted that in the four simulations, the uniform distributions from which the intercept parameters were sampled from have an increasingly large σβ ranging from 0.29−2.31 (with the corresponding variance ranging from 0.083−5.333).
In addition, six ways of setting the prior distributions for and were considered such that both had
1. non-informative prior distributions that are uniform on σ, i.e., and ;
2. non-informative inverse-gamma (0.001, 0.001) prior distributions for σ2;
3. informative inverse-gamma (3, 2) prior distributions for σ2;
4. weakly informative half-Cauchy prior distributions for σ;
5. weakly informative half-t prior distributions for σ with ν = 100, which in practice are equivalent to half-normal distributions;
6. weakly informative half-t prior distributions for σ with ν = 4.
The Gibbs sampling procedure was implemented where 20,000 iterations were obtained with the first 10,000 as burn-in.
3.3. Evaluation Criteria
For both simulation studies, convergence was evaluated using the Gelman-Rubin R (Gelman and Rubin, 1992) statistic. The usual practice is using multiple Markov chains from different starting points. Alternatively, a single chain can be divided into sub-chains so that convergence is assessed by comparing the between and within sub-chain variance (Fox, 2007). Since a single chain is less wasteful in the number of iterations needed, the latter approach was adopted. For each Markov chain, the initial values were set to be αj = 1, βj = 0, and γj = 0.2 for all items j and θi = 0 for all persons i. After discarding the burn-in samples, the chain was then separated into five sub-chains of equal length and the R statistic was calculated following the procedure by Gelman and Rubin (1992). Convergence can also be monitored visually using time series graphs of the simulated sequence, such as the trace plot, the running mean plot, and the autocorrelation plot shown in Figure 1 for one item. It is observed that for this item, the autocorrelations between successive parameter draws became negligible at lags > 600, suggesting burn-in for a single chain should not take longer than that (Geyer, 1992). Indeed, the trace plot and the running mean plot both suggest possible convergence within 10,000 iterations. Inspection of such plots has, however, been criticized for being unreliable and unwieldy in the presence of a large number of model parameters (Gelman et al., 2003; Nylander et al., 2008). The R statistic obtained from using a single chain was hence the major approach for assessing convergence in this study.
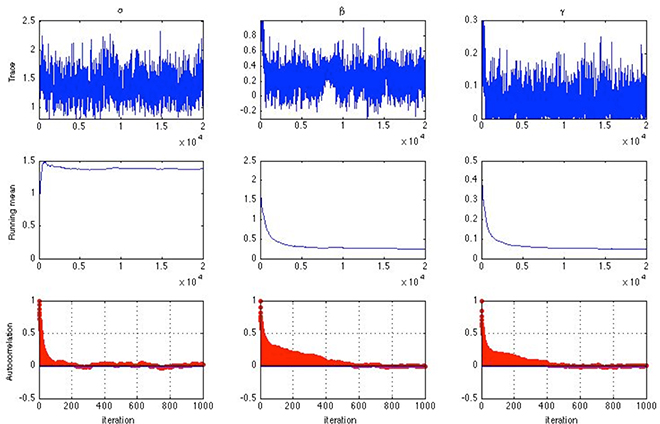
Figure 1. Trace plots (top), running mean plots (middle) and autocorrelation plots (bottom) of α, β and γ for one item assuming a half-normal prior distribution for σα and σβ [n = 1000, k = 10, chain-length = 20, 000, item slopes and intercepts were generated from αj ~ U(0, 2) and βj ~ U(−1, 1)].
For each simulated scenario, 25 replications, as recommended by Harwell et al. (1996), were conducted to avoid erroneous results in estimation due to sampling error. The accuracy of item/person parameter estimates was evaluated using the root mean square error (RMSE) and bias. Let τ denote the true value of a parameter (e.g., αj, βj, γj, or θi) and tr its estimate in the rth replication (r = 1, …, R). The RMSE is defined as
and the bias is defined as
These quantities were averaged over items/persons to provide summary indices.
In simulation study 2 where six model specifications were compared, the adequacy of the fit of the hierarchical 3PNO model with a given prior density on the simulated data was evaluated using Bayesian deviance. It should be noted that this measure provides a model comparison criterion. Hence, it evaluates the fit of a model in a relative, not absolute, sense. The Bayesian deviance information criterion (DIC) was introduced by Spiegelhalter et al. (2002) who generalized the classical information criteria (e.g., AIC, BIC) to one that is based on the posterior distribution of the deviance. This criterion is defined as , where is the posterior expectation of the deviance (with L being the likelihood function), and is the effective number of parameters (Carlin and Louis, 2000). In addition, let , where is the posterior mean. To compute Bayesian DIC, MCMC samples of the parameters, ϑ(1), …, ϑ(G), can be drawn from the Gibbs sampler, then is approximated as . Generally more complicated models tend to provide better fit. Hence, penalizing for the number of parameters makes DIC a more reasonable measure to use. In this study, the Bayesian deviance estimate was obtained after each implementation and averaged across the 25 replications for each model specification.
4. Simulation Results
The results of the two simulation studies are presented in this section and described as follows.
4.1. Simulation Study 1
Each implementation of the Gibbs sampler gave rise to Gelman-Rubin R statistics close to 1, indicating possible convergence of the Markov chains within the simulated number of iterations. Hence, the posterior estimates were obtained as the posterior expectations of the Gibbs samples and the average RMSE and bias values for αj, βj, γj, and θi are summarized in Tables 1–4. A close examination of these values leads to the following observations:
1. In Sim1 where the actual variances for α and β were both 0.333, the half-normal distribution performed relatively less well in recovering item and person parameters than the uniform or inverse-gamma distributions when data sizes (n × k) were < 10,000, although it has to be noted that this distribution consistently resulted in smaller bias in estimating α regardless of sample size or test length. The uniform prior density performed similarly as the inverse-gamma prior density, with a slight advantage for data with small sample sizes (i.e., n = 100) especially where k = 10.
2. Sim2 differed from Sim1 in that the actual variance for β decreased to 0.083, a value closer to zero. Hence, we focus on the results in recovering β here. From Table 2, it is obvious that the half-normal distribution consistently performed better in recovering β than the uniform or inverse-gamma distribution when k < 40 or with large sample sizes (n > 300) when k = 40. Between the two non-informative priors, the uniform prior density performed less well than the inverse-gamma (0.001, 0.001) prior density.
3. Similar to Sim2, Sim3 differed from Sim1 in the actual variance for α being reduced to 0.083, and consequently, the results in recovering α are discussed here. It is noted from Table 1 that the half-normal distribution consistently resulted in smaller RMSE and bias and hence performed better than the non-informative uniform or inverse-gamma family of prior distributions (except for the situations where n < 500 and k = 40). The uniform prior density tended to result in larger RMSE or bias than the inverse-gamma (0.001, 0.001) prior when k < 40.
4. It is interesting to note that the half-normal prior density consistently resulted in smaller bias in estimating α in all the simulated conditions.
5. Further, it is noted that the benefit of using a half-normal prior in Sim2 or Sim3 where it resulted in smaller RMSE and bias in estimating β or α was not reflected in estimating θ unless the data size was over 12, 000 in Sim2 or unless k ≥ 20 in Sim3.
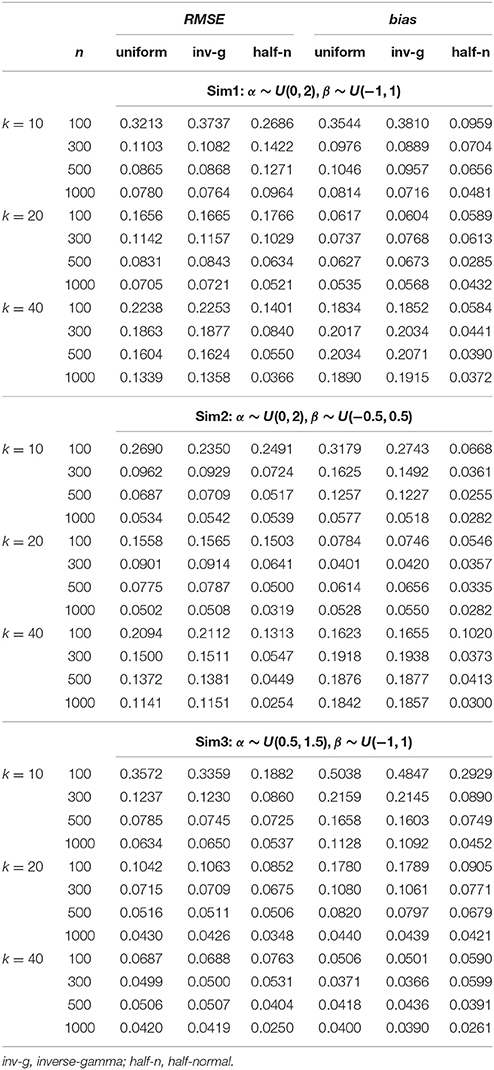
Table 1. Average RMSE and bias for recovering slope (α) parameters in the hierarchical 3PNO model with the three prior specifications under the three test length, four sample size and three actual variance conditions.
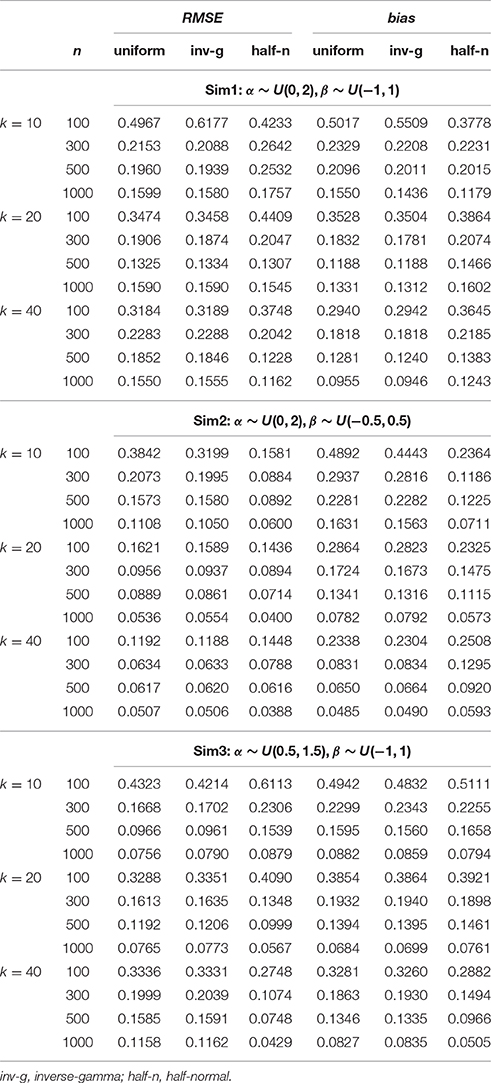
Table 2. Average RMSE and bias for recovering intercept (β) parameters in the hierarchical 3PNO model with the three prior specifications under the three test length, four sample size and three actual variance conditions.
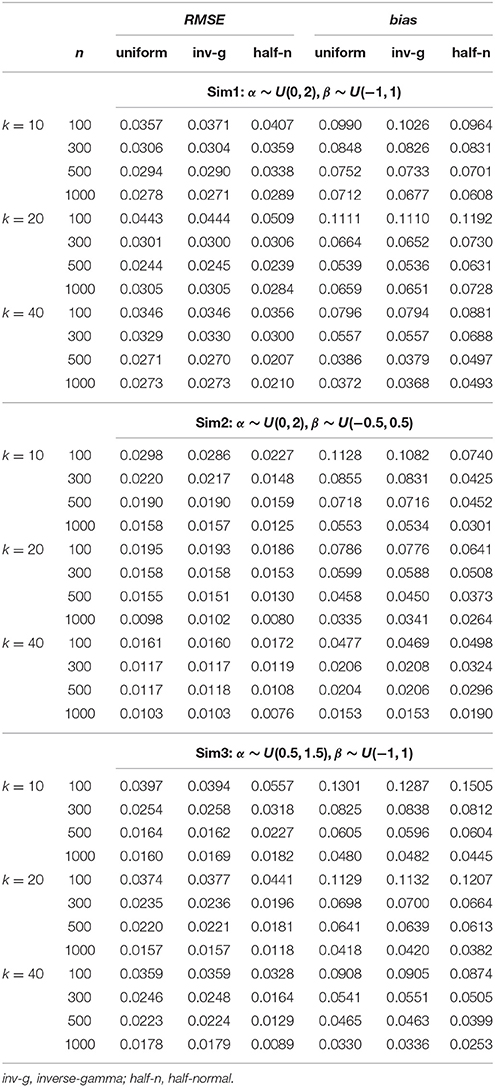
Table 3. Average RMSE and bias for recovering guessing (γ) parameters in the hierarchical 3PNO model with the three prior specifications under the three test length, four sample size and three actual variance conditions.
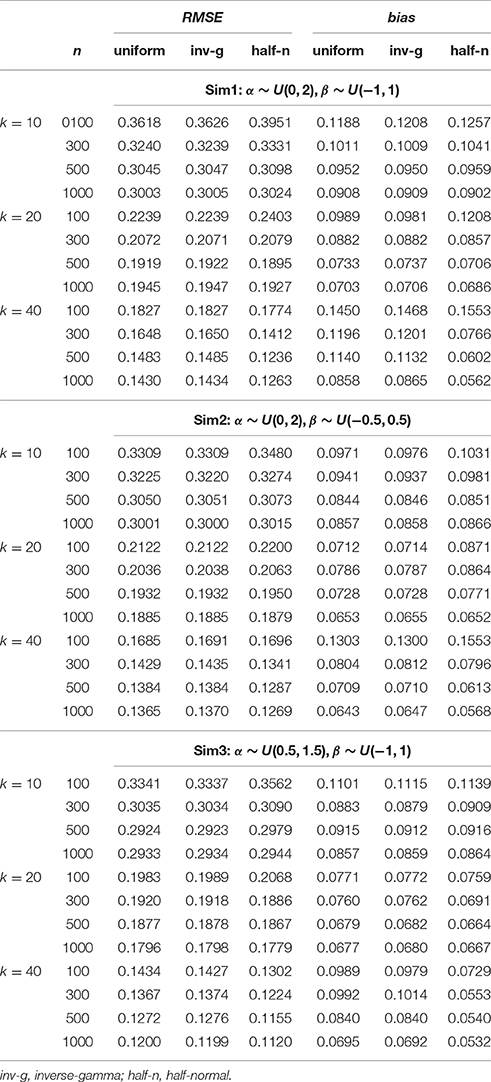
Table 4. Average RMSE and bias for recovering person parameters (θ) in the hierarchical 3PNO model with the three prior specifications under the three test length, four sample size and three actual variance conditions.
From these observations, it is hence noted that the half-normal prior outperforms the uniform or inverse-gamma family of prior distributions in estimating the corresponding parameters in the hierarchical 3PNO model when the variability for item slope or intercept parameters is close to zero. Further, the inverse-gamma (0.001, 0.001) prior tends to perform better in parameter recovery than the uniform prior when the respective item parameters have a small variance. This can be explained by the fact that the non-informative uniform prior density is flat and hence does not restrict σ away from large values, whereas inverse-gamma (0.001, 0.001) and half-normal distributions have a peak around zero and do perform such shrinkage for variances near zero. It is further noted that the estimation error and bias in estimating item parameters (α, β, or γ) reduce with the increase of sample sizes, and that the error and bias in estimating person parameters (θ) reduce with the increase of test lengths. This is consistent with findings from other studies (e.g., Swaminathan and Gifford, 1983; Sheng, 2010; Natesan et al., 2016).
4.2. Simulation Study 2
Each implementation of the Gibbs sampler gave rise to Gelman-Rubin R statistics close to 1, indicating possible convergence within 20,000 iterations. Hence, the posterior estimates were obtained as the posterior expectations of the Gibbs samples and the average RMSE and bias values for αj, βj, and γj are summarized in Table 5. A close examination of these values leads to the following observations:
1. In all four simulations where the actual variability for the intercept parameters (σβ) ranged between 0.29−2.31, the three weakly informative half-t prior densities, namely, the half-Cauchy, the half-normal and the half-t with 4 degrees of freedom had consistently smaller RMSE if not bias in recovering item and person parameters, and in particular in recovering βj, compared with the other three prior distributions.
2. It is noted that in Sim2 where σβ was about 0.5, the three weakly informative half-t densities had more bias in estimating β and γ than the two non-informative prior densities. When σβ moved further away from 0.5 (i.e., toward 0 in Sim1 or toward 2.5 in Sim4), their advantages over other model specifications became more obvious in that they resulted in much smaller average RMSE and bias values.
3. Among the three weakly informative half-t densities, the half-normal resulted in relatively smaller RMSE and bias in recovering item and person parameters in Sim1, but larger RMSE and bias in Sim2, Sim3, and Sim4.
4. Between the two non-informative priors, the inverse-gamma (0.001, 0.001) prior distribution performed slightly better in estimating β and γ in Sim1, but worse in estimating other parameters or in other situations. This is consistent with findings from the first simulation study.
5. In Sim1 where σβ was close to 0, the informative inverse-gamma (3, 2) prior distribution was correctly specified with little bias and hence had small RMSE in recovering βj. However, when σβ moved further away from 0, it became less appropriate, and consequently resulted in an obviously larger bias and RMSE in recovering especially item parameters.
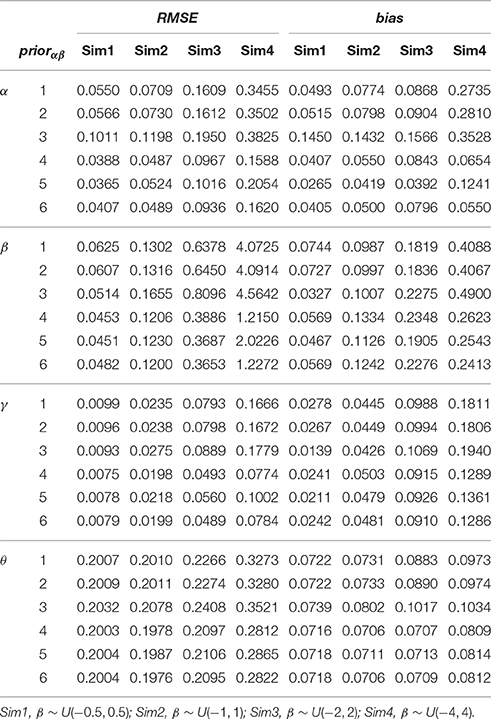
Table 5. Average RMSE and bias for recovering item and person parameters in the hierarchical 3PNO model with the six prior specifications (n = 1000, k = 20).
From these observations, it is noted that the weakly informative half-t family works well in a wider range of situations than the non-informative or the informative prior densities in recovering the 3PNO model item parameters. Specifically, when the actual scale hyperparameter is close to 0, the non-informative prior density does not work well compared with informative or weakly informative prior densities, as prior information helps to restrict σβ away from large values. Even with prior information, the informative inverse-gamma (3,2) prior density does not outperform the weakly informative half-t distribution because the latter has a better behavior near 0. Figure 2 graphically illustrates this point. The non-informative inverse-gamma prior distribution, in general, is not recommended for large σ values because it is not non-informative for these values (see Figure 2). On the other hand, prior information has to be correctly specified, as misspecification leads to large bias and hence large estimation error, e.g., the actual σβ in Sim4 was clearly not in the range of the inverse-gamma (3, 2) distribution (see Figure 2). When comparing among the three half-t distributions, the half-Cauchy is more likely to allow for occasionally large values than the half-t density with 4 degrees of freedom, or the half-normal, which has the smallest tail (see Figure 2). Hence, if it is known a priori that the scale hyperparameter might be far away from 0, a half-Cauchy or a half-t distribution with a small degrees of freedom is suggested. Otherwise, a half-normal may be considered.
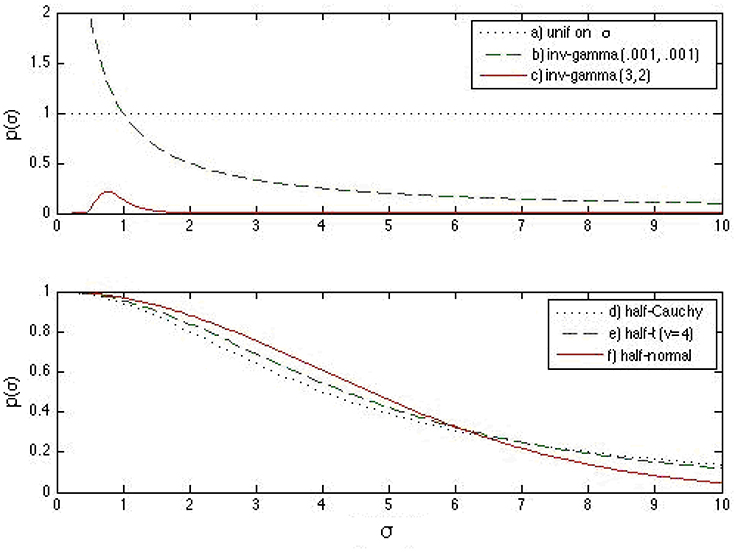
Figure 2. Prior density functions for the slope and intercept standard deviation parameters: (a) uniform prior distribution on σα (or σβ), (b) inverse-gamma (0.001, 0.001) prior distribution on (or ), (c) inverse-gamma (3, 2) prior distribution on (or ), (d) half-Cauchy prior distribution for σα (or σβ), (e) half-t prior distribution for σα (or σβ) with 4 degrees of freedom, and (f) half-normal prior distribution for σα (or σβ). It is noted that the half-t distributions are on a different scale compared to the previous three densities.
In addition to parameter recovery, the model comparison results in each simulation were averaged over the 25 replications and are summarized in Table 6, which shows the averaged estimates for the posterior expectation of the deviance (), the deviance of the posterior expectation [] values, the effective number of parameters (pD), and the Bayesian DIC, respectively. The model with the half-Cauchy or half-t prior density shows consistently smaller , , and DIC than those with other prior specifications. Since small deviance values indicate better model fit, models with such prior distributions for the scale hyperparameters are shown to provide a better description of the simulated data when the actual σβ was especially larger than 0.29, even after penalizing for model complexities, i.e., the effective number of parameters.
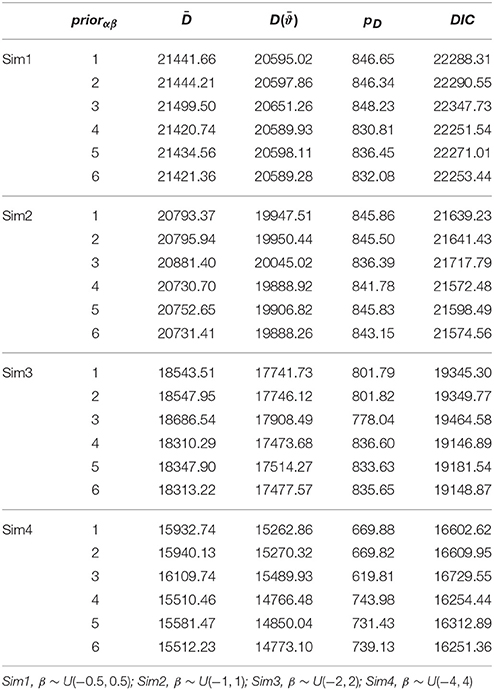
Table 6. Average Bayesian deviance estimates for the hierarchical 3PNO model with the six prior specifications under four simulated scenarios (n = 1000, k = 20).
After a close examination and comparison of the values shown in the table, a few remarks can be drawn from these results:
• In all four simulations where σβ ranged between 0.29−2.31, Bayesian deviances consistently preferred the models with half-t prior densities, whose deviance values were increasingly smaller compared with other model specifications when σβ became larger.
• The two non-informative priors performed similarly in describing the simulated data according to Bayesian DIC, which was slightly larger for the model with the inverse-gamma (0.001, 0.001) prior.
• In all the simulated scenarios, the model with the informative inverse-gamma (3,2) prior distribution had consistently the largest average deviance values and hence is not preferred. One may further note that as σβ moved further away from 0, the difference in deviances between this model specification and others was increasingly larger.
• Among the three half-t distributions considered, the Bayesian deviance measures did not favor the half-normal prior density.
• It is interesting to note that when σβ was small with values of e.g., 0−0.6, models with half-t prior densities tended to have smaller effective number of parameters (pD) than those with non-informative prior densities. The opposite is true for situations where σβ was over 1.
In summary, the results in parameter recovery and model comparisons using Bayesian deviances suggest that the hierarchical 3PNO model with weakly informative half-t densities for the item scale hyperparameters does show advantages compared with those with non-informative or informative prior distributions in various test situations where the actual variability ranges from small to large values. When the actual variability of item parameters is not close to 0, the half-Cauchy or the half-t with small degrees of freedom is preferred over the half-normal distribution because of its flexibility in allowing for occasional large variability.
5. An Example With CBASE Data
As an illustration, the hierarchical 3PNO model with the weakly informative half-t hyperpior was implemented to a subset of CBASE English subject data, and further compared with the other model specifications in describing the data.
5.1. Method
The overall CBASE exam contains 25 multiple-choice items on English reading/literature. The data used in this study were from college students who took the LP form of CBASE in years 2001 and 2002. After removing those who attempted the exam multiple times and removing missing responses, a sample of 1,200 examinees was randomly selected. To assess the model goodness-of-fit, hierarchical 3PNO models with the three half-t prior distributions were compared with each other and further compared with those with uniform and inverse-gamma prior densities described in Section 4.
5.2. Results
Each of the six model specifications was implemented to the CBASE English data using the Gibbs sampling procedure, where 20,000 iterations were obtained with the first 10,000 set as burn-in. The Gelman-Rubin R statistics were used to assess convergence and they were found to be around or close to 1, suggesting that stationarity had been reached within the simulated Markov chains for the model. The Bayesian deviance estimates were subsequently obtained for each model specification and the results are summarized in Table 7. Among the six model specifications considered, the ones with half-t and half-Cauchy prior densities had the smallest DIC and/or expected posterior deviance () values. Therefore, the 3PNO model with a half-t or half-Cauchy hyperprior provided the best description of the data compared with other model specifications, even after penalizing for a large effective number of parameters (e.g., pD = 987.24 for the half-t, and pD = 993.80 for the half-Cauchy). On the other hand, with slightly larger deviances, the model with an informative inverse-gamma (3, 2) hyperprior described the data less adequately than those with other prior specifications. The relatively small differences in deviances suggested the actual variability might be close to 0. Furthermore, the model with a half-normal or half-t hyperprior had a larger pD than that with a non-informative prior density. Given the findings from the second simulation study in Section 4, this indicated that the actual standard deviation for the item slope and/or intercept parameters with the data was not larger than 1.
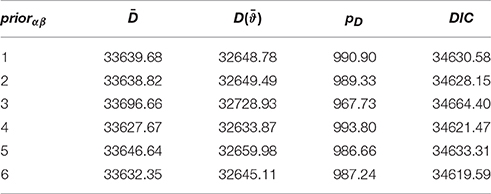
Table 7. Bayesian deviance estimates for the six prior specifications with the CBASE data.
6. Concluding Remarks
The half-t family offers a good alternative parametric family for the prior distribution of scale hyperparameters in Bayesian hierarchical modeling. This paper adopts it as the hyperprior for item scale parameters in the hierarchical 3PNO IRT model, with the focus being on the weakly informative half-t distributions. Their utility in parameter estimation and model comparison has been explored and the results show that they do offer advantages over the commonly adopted uniform or inverse-gamma prior density by allowing the variability for item slope and/or intercept parameters to be either very small or large. The weakly informative half-t, and especially the weakly informative half-Cauchy density provides certain level of prior information while it still allows occasional large values. Hence, it overcomes problems resulting from using either a non-informative or an informative prior density when prior information is desired but not readily available. Consequently, the flat-tailed half-t distributions are applicable in a wide range of applications and are recommended. In particular, when prior information is not readily available but non-informative priors are not desired, the use of a half-Cauchy distribution is recommended with the scale set to a finite value that is higher than the actual standard deviation. It has to be noted that this paper only focuses on weakly informative half-t distributions. One may set the scale of the distribution to be large, e.g., s = 100, to make it non-informative. For a non-informative but proper prior distribution, a half-normal with the scale s set to a high value, such as 100 should be considered.
The use of the half-t prior density for the slope/intercept scale hyperparameter has also an effect on estimating person parameters in 3PNO models. Based on results from the first simulation study, we can see that it tends to result in smaller bias and error in estimating them for data sizes > 10,000. For small data sizes, the use of half-normal prior for item scale hyperparameters may not be suggested over the uniform or inverse-gamma (0.001, 0.001) prior if the focus is primarily on estimating person ability parameters. One may need to further explore the use of other half-t prior densities, such as the half-Cauchy, under these conditions. It would also be interesting to find out the reason why manipulating the hyperpriors for item parameters has such an effect on estimating person parameters in the hierarchical 3PNO model, and/or investigate the effect of different (hyper)priors for person parameters in estimating the model.
Further, results and hence conclusion of the second simulation study are based on tests with k = 20 and n = 1000. Although it is believed that similar results can be obtained with other test lengths (e.g., k = 10 or k > 20) and/or larger sample sizes (n > 1000), additional studies are needed to confirm this and to further investigate the use of half-Cauchy or other half-t prior densities for item scale hyperparameters in smaller sample size conditions (e.g., n < 500).
In this study, due to the computational expense of MCMC procedures, only 25 replications were adopted and hence the simulation results are based on a limited number of replications. Future studies shall follow the procedure illustrated by Koehler et al. (2009) to ensure the adequacy of the number of replications. Alternatively, one may consider using variational Bayes as suggested by Natesan et al. (2016) given its improved computational efficiency and equivalent estimation accuracy when compared with MCMC. In addition, only certain prior or hyperprior densities for item slope and intercept scale hyperparameters were investigated in this paper. Future research may include more prior specifications or adopt non-conjugate priors for them. Finally, in this study, only Bayesian deviance was used to evaluate individual models. Given that DIC may be limited in that it is not invariant to parameterization and sometimes can produce unrealistic results, further studies can adopt other methods for model comparisons, such as Bayes factors (Kass and Raftery, 1995) or posterior predictive model checking (Rubin, 1984).
Author Contributions
YS designed the study, carried out all the analyses and wrote the manuscript.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Albert, J. H. (1992). Bayesian estimation of normal ogive item response curves using Gibbs sampling. J. Educ. Stat. 17, 251–269. doi: 10.2307/1165149
Béguin, A. A., and Glas, C. A. W. (2001). MCMC estimation and some model-fit analysis of multidimensional IRT models. Psychometrika 66, 541–562. doi: 10.1007/BF02296195
Berger, J. O., and Berliner, L. M. (1986). Robust Bayes and empirical Bayes analysis with epsilon-contaminated priors. Ann. Stat. 14, 461–486. doi: 10.1214/aos/1176349933
Browne, W. J., and Draper, D. (2006). A comparison of Bayesian and likelihood-based methods for fitting multilevel models. Bayesian Anal. 1, 473–514. doi: 10.1214/06-BA117
Carlin, B. P., and Louis, T. A. (2000). Bayes and Empirical Bayes Methods for Data Analysis 2nd Edn. London: Chapman & Hall.
Chib, S., and Greenberg, E. (1995). Understanding the Metropolis-Hastings algorithm. Am. Stat. 49, 327–335. doi: 10.1080/00031305.1995.10476177
Fox, J.-P. (2007). Multilevel IRT modeling in practice with the package mlirt. J. Stat. Softw. 20, 1–16. doi: 10.18637/jss.v020.i05
Gelman, A. (2006). Prior distributions for variance parameters in hierarchical models. Bayesian Anal. 1, 515–534. doi: 10.1214/06-BA117A
Gelman, A., Carlin, J. B., Stern, H. S., and Rubin, D. B. (2003). Bayesian Data Analysis. 2nd Edn. London: Chapman & Hall.
Gelman, A., and Rubin, D. B. (1992). Inference from iterative simulation using multiple sequences (with discussion). Stat. Sci. 7, 457–511. doi: 10.1214/ss/1177011136
Geyer, G. J. (1992). Practical markov chain monte carlo. Stat. Sci. 7, 473–483. doi: 10.1214/ss/1177011137
Glas, C. W., and Meijer, R. R. (2003). A Bayesian approach to person fit analysis in item response theory models. Appl. Psychol. Meas. 27, 217–233. doi: 10.1177/0146621603027003003
Harwell, M., Stone, C. A., Hsu, T.-C., and Kirisci, L. (1996). Monte Carlo studies in item response theory. Appl. Psychol. Meas. 20, 101–125. doi: 10.1177/014662169602000201
Kass, R. E., and Raftery, A. E. (1995). Bayes factors. J. Am. Stat. Assoc. 90, 773–795. doi: 10.1080/01621459.1995.10476572
Knape, J., Sköld, M., Jonzén, N., Åkesson, M., Bensch, S., Hansson, B., and Hasselquist, D. (2008). An analysis of hatching success in the great reed warbler Acrocehalus arundinaceus. Oikos 117, 430–438. doi: 10.1111/j.2007.0030-1299.16266.x
Koehler, E., Brown, E., and Haneuse, S. J. (2009). On the assessment of Monte Carlo error in simulation-based statistical analyses. Am. Stat. 63, 155–162. doi: 10.1198/tast.2009.0030
Lord, F. M. (1980). Applications of Item Response Theory to Practical Testing Problems. Hillsdale, NJ: Lawrence Erlbaum Associates.
Mislevy, R. J. (1986). Bayes modal estimation in item response models. Psychometrika 51, 177–195. doi: 10.1007/bf02293979
Nateson, P., Nandakumar, R., Minka, T., and Rubright, J. D. (2016). Bayesian prior choice in IRT estimation using MCMC and variational Bayes. Front. Psychol. 7:1422. doi: 10.3389/fpsyg.2016.01422
Nylander, J. A., Wilgenbusch, J. C., Warren, D. L., and Swofford, D. L. (2008). AWTY (Are we there yet?): A system for graphical exploration of MCMC convergence in Bayesian phylogenetics. Bioinformatics 24, 581–583. doi: 10.1093/bioinformatics/btm388
O'Brien, J., Gunawardena, H., Chen, X., Ibrahim, J., and Qaqish, B. (2015). The Midpoint Mixed Model with a Missingness Mechanism (M5): A Likelihood-Based Framework for Quantification of Mass Spectrometry Proteomics Data (Preprint). arXiv preprint arXiv:1507.06907.
Osterlind, S. (1997). A national review of scholastic achievement in general education: How are we doing and why should we care?, ASHE-ERIC Higher Education Report, vol. 25, Washington, DC: George Washington University Graduate School of Education and Human Development.
Rubin, D. B. (1984). Bayesianly justifiable and relevant frequency calculations for the applied statistician. Ann. Stat. 12, 1151–1172. doi: 10.1214/aos/1176346785
Sahu, S. K. (2002). Bayesian estimation and model choice in item response models. J. Stat. Comput. Simul. 72, 217–232. doi: 10.1080/00949650212387
Sheng, Y. (2008). Markov chain Monte Carlo estimation of normal ogive IRT models in MATLAB. J. Stat. Softw. 25, 1–15. doi: 10.18637/jss.v025.i08
Sheng, Y. (2010). A sensitivity analysis of Gibbs sampling for 3PNO IRT models: Effect of priors on parameter estimates. Behaviormetrika 37, 87–110. doi: 10.2333/bhmk.37.87
Sheng, Y. (2013). An empirical investigation of Bayesian hierarchical modeling with unidimensional IRT models. Behaviormetrika 40, 19–40. doi: 10.2333/bhmk.40.19
Spiegelhalter, D. J., Best, N., Carlin, B., and van der Linde, A. (2002). Bayesian measures of model complexity and fit (with discussion). J. R. Stat. Soc. B 64, 583–640. doi: 10.1111/1467-9868.00353
Spiegelhalter, D. J., Thomas, A., Best, N. G., Gilks, W. R., and Lunn, D. (1994, 2003). BUGS: Bayesian Inference Using Gibbs Sampling. Cambridge, England: MRC Biostatistic Unit.
Swaminathan, H., and Gifford, J. A. (1983). “Estimation of parameters in the three-parameter latent trait model,” in New Horizons in Testing, ed D. Weiss (New York, NY: Academic Press), 13–30.
Tanner, M. A., and Wong, W. H. (1987). The calculation of posterior distribution by data augmentation (with discussion). J. Am. Stat. Assoc. 82, 528–550. doi: 10.1080/01621459.1987.10478458
Keywords: item response theory, Gibbs sampling, three-parameter models, hyperprior, scale hyperparameter, half-t, half-Cauchy, half-normal
Citation: Sheng Y (2017) Investigating a Weakly Informative Prior for Item Scale Hyperparameters in Hierarchical 3PNO IRT Models. Front. Psychol. 8:123. doi: 10.3389/fpsyg.2017.00123
Received: 12 October 2016; Accepted: 17 January 2017;
Published: 06 February 2017.
Edited by:
Prathiba Natesan, University of North Texas, USAReviewed by:
Dylan Molenaar, University of Amsterdam, NetherlandsLihua Yao, Defense Manpower Data Center, USA
Copyright © 2017 Sheng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yanyan Sheng, eXNoZW5nQHNpdS5lZHU=