 Holger Brandt
Holger Brandt Nora Umbach
Nora Umbach Augustin Kelava
Augustin Kelava
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Psychol. , 30 November 2015
Sec. Quantitative Psychology and Measurement
Volume 6 - 2015 | https://doi.org/10.3389/fpsyg.2015.01813
The application of mixture models to flexibly estimate linear and nonlinear effects in the SEM framework has received increasing attention (e.g., Jedidi et al., 1997b; Bauer, 2005; Muthén and Asparouhov, 2009; Wall et al., 2012; Kelava and Brandt, 2014; Muthén and Asparouhov, 2014). The advantage of mixture models is that unobserved subgroups with class-specific relationships can be extracted (direct application), or that the mixtures can be used as a statistical tool to approximate nonnormal (latent) distributions (indirect application). Here, we provide a general standardization procedure for linear and nonlinear interaction and quadratic effects in mixture models. The procedure can also be applied to multiple group models or to single class models with nonlinear effects like LMS (Klein and Moosbrugger, 2000). We show that it is necessary to take nonnormality of the data into account for a correct standardization. We present an empirical example from education science applying the proposed procedure.
The estimation of nonlinear latent effects in the structural equation modeling (SEM) framework has received increasing attention over the last three decades. Several approaches for the analysis of nonlinear SEM have been published, which include among others the product indicator approaches (e.g., Kenny and Judd, 1984; Bollen, 1995; Jaccard and Wan, 1995; Jöreskog and Yang, 1996; Ping, 1995, 1996; Wall and Amemiya, 2001; Marsh et al., 2004; Little et al., 2006; Marsh et al., 2006; Kelava and Brandt, 2009), distribution analytic approaches (Klein and Moosbrugger, 2000; Klein and Muthén, 2007), moment based approaches (Wall and Amemiya, 2000, 2003; Mooijaart and Bentler, 2010), and Bayesian approaches (Arminger and Muthén, 1998; Lee, 2007; Kelava and Nagengast, 2012; Kelava and Brandt, 2014).
A typical structural model for a latent criterion η and two latent predictor variables (ξ1, ξ2) that includes one interaction effect and two quadratic effects is given by
where α is the latent intercept, the γs are the latent regression coefficients, and ζ is the latent residual.
In recent years, researchers have performed simulation studies to investigate the performance of several approaches to estimate latent nonlinear effects with structural equation models (e.g., Moulder and Algina, 2002; Wall and Amemiya, 2003; Marsh et al., 2004; Klein and Muthén, 2007; Cham et al., 2012; Brandt et al., 2014; Kelava et al., 2014). One of the main concerns in these studies was that nonlinear effects may be confounded with nonnormal distributions of the variables, which may lead to biased parameter or standard error estimates. For example, with the latent moderated structural equation modeling approach (LMS; Klein and Moosbrugger, 2000), it has been shown that it provides most efficient estimates under the condition of normally distributed predictors, but that this method produces spurious effects when data are nonnormally distributed (Kelava and Nagengast, 2012). Within the widely used class of the product indicator approaches, the unconstrained approach (Marsh et al., 2004, 2006; Kelava and Brandt, 2009) has become most popular, because it provides fairly robust parameter estimates (Marsh et al., 2004; Kelava and Nagengast, 2012) and in contrast to constrained approaches (Kenny and Judd, 1984; Jöreskog and Yang, 1996) it is comparatively easy to implement. Nevertheless, standard errors tend to be underestimated even in situations with normally distributed data, which leads to inflated Type I error rates (Kelava et al., 2011).
One conceptually different approach to modeling nonlinear effects is the use of semiparametric mixture models (SEMM; Arminger and Stein, 1997; Jedidi et al., 1997a,b; Dolan and van der Maas, 1998; Arminger et al., 1999; Muthén, 2001; Bauer and Curran, 2004; Bauer, 2005; Pek et al., 2009, 2011). Finite mixtures of linear SEM are used to approximate the unknown nonlinear relationship of the latent variables. While parametric approaches specify the functional form of their relationship a priori, the SEMM approach does not require assumptions about the functional form. In addition, the SEMM approach does not require the assumption of normally distributed latent variables and disturbances inherent in conventional SEM, but allows for flexible approximations of nonnormal distributions. Hence, the SEMM approach is a flexible tool for predicting the latent dependent variable if there is nonnormality and if obtaining a strict parametric representation of the functional relation does not have the highest priority (for a discussion see Bauer, 2005).
In general, mixture models can be applied with two different objectives. First, they can be used to identify unobserved groups within a heterogeneous population with linear and/or nonlinear group-specific relationships between the variables. In this kind of direct application, the mixture distributions are interpreted as representing distinct subpopulations. Second, mixture models can be used to approximate nonnormal distributions or nonlinear relationships per se, without assuming meaningful distinct subgroups in a population (McLachlan and Peel, 2000). These applications are then called indirect (see Bauer, 2005, for an application) and can be classified as a semiparametric approach to SEM. They have the advantage that they can be applied even when assumptions for traditional SEM are violated.
When a parametric representation of the nonlinear functional relation is of interest and nonnormality is given, an alternative is a recently proposed nonlinear structural equation mixture modeling approach (NSEMM; Kelava et al., 2014). With the NSEMM approach, nonnormality of the latent predictors can be approximated by applying a mixture of normal distributions (as an indirect application). Alternatively, the NSEMM approach can be used in a direct application, where heterogeneous subpopulations show different linear or nonlinear relations (e.g., interaction or quadratic effects) between latent variables.
In general, as in manifest regression, it is common to use standardized regression coefficients in SEM in order to make effects comparable in their size and facilitate interpretation of results. For linear SEM, Bollen (1989, p. 165) defines a standardized coefficient for a coefficient γi of a given predictor ξi (cp. Equation 1) as
where ϕii = Var(ξi) and ϕ00 = Var(η). Standardized coefficients allow researchers to compare the effect sizes of predictors independent of the scaling of the predictor and the dependent variable. This argument also applies to interaction and quadratic effects. First, effect sizes are comparable across different studies. Second, simple slopes (see Aiken and West, 1991) based on standardized effects may give additional information about the importance of such nonlinear effects compared to simple slopes for unstandardized coefficients because they are also independent of the variables' scaling. Third, the size of linear effects depends on the means of the predictor variables when nonlinearity is present in the data. In order to make linear effects comparable in nonlinear models, researchers often center predictors before analyzing data; however, in some situations (e.g., in multiple group or latent class models; see below) this a priori centering is not possible. In these cases, an appropriate post-hoc standardization procedure is necessary that allows to compare linear effects in a meaningful way.
For mixture SEM and nonlinear SEM as introduced above, the standardization of parameter estimates needs some special considerations. For example, product terms of latent variables (e. g., ξ1ξ2 or ) have means and variances, which are not zero and one, respectively, even if the original variables were standard normally distributed (Bohrnstedt and Goldberger, 1969; Friedrich, 1982). Therefore, standardization procedures for linear SEM as produced by currently available software packages are not suitable for nonliner SEM.
For nonlinear SEM, Wen et al. (2010) addressed the problem of a correct standardization of the parameter estimates for SEM with single latent interaction effects. They showed that the standardized results (as given for linear SEM) provided by software programs are incorrect, because they refer to falsely standardized product variables. They provided formulas that allow one to transform an incorrectly standardized solution or an unstandardized solution to a correctly standardized solution. Following Wen et al.'s (2010) notation, the correctly standardized coefficients refer to an equation with correctly standardized variables (Friedrich, 1982; Wen et al., 2010), which is given as
Note, that η•, , and are standardized variables with zero means and unit variances. The product variables , , and are products of standardized variables, but they are not standardized variables themselves (i.e., their means are not equal to zero and their variances are not equal to one, in general). A regression equation with standardized product variables of the form , which have zero mean and unit variance would lead to an incorrectly standardized solution (as shown by Wen et al., 2010). As a consequence, , , and in Equation (3) refer to the correctly standardized coefficients for the nonlinear model and , , and refer to the standardized coefficients provided by standard statistic software that need additional corrections for interaction and quadratic effects.
The applicability of the formulas presented by Wen et al. (2010) suffers from three limitations. First, their standardization is limited to approaches that explicitly estimate (co-)variances of the latent product terms (e.g., the variance of ξ1ξ2 or the covariance between ξ1ξ2 and ). These (co-)variances can be retrieved from product indicator approaches or moment based approaches (e.g., Wall and Amemiya, 2003). They cannot be retrieved from distribution analytic approaches as LMS (Klein and Moosbrugger, 2000)—which is implemented as a standard estimator for nonlinear effects in Mplus (Muthén and Muthén, 1998–2012)—or QML (Klein and Muthén, 2007), because no (co-)variances of the latent product terms are estimated. As a consequence, neither a transformation from an incorrectly standardized solution provided by software programs (see Equation 12 in Wen et al., 2010) nor from an unstandardized solution (see Equation 11 and Supplementary Material (A.1) in Wen et al., 2010) is possible based on the formulas provided by Wen et al. (2010).
Second, the same is true for semiparametric approaches using mixtures of normal distributions to account for nonlinearity or nonnormality of the latent predictors (Jedidi et al., 1997b; Kelava and Nagengast, 2012; Kelava et al., 2014). In these approaches, the latent predictors' (nonnormal) distribution is approximated by a mixture of normal distributions with class-specific means and covariances. They have been shown to produce robust parameter estimates and are based on a latent class framework. The approaches do not provide estimates for the (co-)variances of the overall marginal distribution of the product terms and can be classified as distribution analytic approaches. Hence, the standardization procedure provided by Wen et al. (2010) can also not be used for this class of approaches.
Third, the procedure is restricted to models with centered latent predictor variables (see Wen et al., 2010, p. 4). This is problematic in situations where the means of the latent predictor variables have a substantive meaning. This can be the case in situations where multiple group models are estimated with known groups (Jöreskog, 1971; Sörbom, 1974) or latent classes where class membership is unknown a priori (Jedidi et al., 1997b). Then, typically the means are not restricted to be zero, but are estimated freely because they may contain information about the dissimilarities between the (a priori known or unknown) groups. If in fact nonlinearity is present in the data, the size of the linear effects depends on the means of the variables (e.g., Echambadi and Hess, 2007). Hence, the interpretation and the standardization of the linear effects need to be conducted with regard to the means of the variables involved in these situations.
In this article, we will provide the following extensions to previous work on the standardization of linear and nonlinear effects in SEM including latent mixtures: In the next section, we generalize the standardization procedure for nonlinear effects in SEM for (latent) class models with uncentered latent predictor variables. In situations with normally distributed data, this generalization allows for standardized parameter estimates of distribution analytic approaches, for example, LMS in Mplus, which do not provide explicit estimates of the (co-)variances of the latent product terms as compared to product indicator approaches. Furthermore, this generalization allows one to standardize (linear and nonlinear) group-specific regression coefficients for multiple group and latent class models in a direct application of mixture models.
Then, we derive formulas for the indirect application of semiparametric latent mixture SEM, which may or may not include nonlinear effects (Jedidi et al., 1997b; Bauer, 2005; Kelava and Nagengast, 2012; Kelava et al., 2014). The formulas we present are general in the sense that they can be applied to all mixture models including nonlinear effects, (e.g., to Growth Curve Mixture Models with interaction effects; Wen et al., 2014), or to multiple sample analyses with nonlinear effects when class membership is known a priori. The formulas provided can be used to standardize (non-)linear effects in situations with nonnormally distributed data (e.g., when applying the NSEMM approach). After the formal presentation, the proposed procedures are illustrated using data from education science.
For multiple class models with known or unknown class membership, the structural model specified in Equation (1) extends to
with g = 1, …, G (latent) classes. In this model, each regression coefficient may be class-specific. The latent residual is distributed as ζg ~ N(0, ψg) and the latent predictors are distributed as with class-specific parameters.
If the estimated parameters in the measurement model are allowed to differ across classes in addition to the proposed relaxation of the parameters in the structural model, the interpretation of the latent constructs is class-specific. To ensure that the latent constructs have the same meaning across classes, it is necessary to set the parameters of the measurement model equal across classes (intercepts, factor loadings and residual variances for strict measurement invariance, or intercepts and factor loadings for strong invariance, Meredith, 1993).
The standardization of the model given in Equation (4) is conducted within each class, such that the effect sizes can be calculated for each latent class separately. It is based on the correct within class standardization of ηg, which is given by
with the class-specific (conditional) expectation κ0, g and variance ϕ00, g of ηg. For the structural model given in Equation (4), the class-specific (conditional) expectation κ0, g is given by
with class-specific means κ1, g, κ2, g of the latent predictors ξ1, g, ξ2, g. We assume that the latent residual term ζg has an expected value of zero within each class g. The expected values of the latent product terms are
with class-specific variances ϕ11, g, ϕ22, g of the predictors ξ1, g, ξ2, g, and covariance ϕ12, g. Note that these equations do not depend on any distributional assumption. The model implied variance ϕ00, g of ηg is given in Supplementary Material A. Extending Equation (5) results in
Replacing the predictor variables by their standardized versions and results in
Standard algebra, some rearrangements, and substituting Equation (7) into Equation (9) leads to
From this, the correctly standardized regression coefficients (see Equation 3) can be defined as:
An extension to more than two predictor variables and more than one dependent variable is straightforward.
Note that the formulations for the class-specific nonlinear effects in Equations (13–15) are similar to those given in Equation (10) and the discussion section by Wen et al. (2010). In contrast to the procedure suggested by Wen et al. (2010), we do not need an estimate for the (co-)variances of the product terms, but provide a formula for the model implied variance of ηg in Supplementary Material A. The procedure suggested here only requires information about the means and (co-)variances of the latent predictors , and the assumption of normally distributed predictors within each class. Setting G = 1 allows one to use the formulas for the LMS approach as well as all other approaches for the estimation of latent interaction and quadratic effects under the assumption of normally distributed predictors (for nonnormally distributed predictors, see the next section). The formulas are presented here for the transformation of the unstandardized coefficients because software programs (e.g., Mplus; Muthén and Muthén, 1998–2012) typically only provide unstandardized results for nonlinear models, especially when latent classes are extracted.
The standardized coefficients for the linear effects and depend on the class-specific means of the latent predictor variables (see also Moosbrugger et al., 1997). In general, linear effects are not independent of data transformations if nonlinear effects are present in the data. Hence, an interpretation of the linear effects as substantive effects should only be conducted when the predictors have a physically meaningful scale. Typically, these effects can only be interpreted meaningfully in combination with the nonlinear effects, in the sense of simple slopes (see Aiken and West, 1991). With the standardization proposed here, the linear effects are interpreted as the standardized linear relationship for subjects with an average value in the respective predictor variable. As a consequence, these effects can be interpreted in the same way as if the predictor variables had been centered prior to analysis. For the special case with zero means of the predictor variables, that is for κ1, g = κ2, g = 0, and G = 1, the formulas simplify to those provided by Wen et al. (2010), but note that centering the predictor variables is arbitrary and hence, the size of the (un-)standardized linear effects is arbitrary too.
If data are nonnormally distributed, it needs to be taken into account for the standardization because the variances and covariances between the latent product variables (and consequently the explained variance of the dependent variable) depend on the predictor variables' distribution. In the next section, we consider this by using a mixture model to approximate nonnormal distributions.
For the indirect application of the mixture model, the standardization is carried out across the mixture components. The restrictions imposed on the parameters constrain some or all parameters to be the same across classes except for the means and (co-)variances of the latent predictors. More specifically, for the NSEMM approach, all parameters except for the means and (co-)variances of the latent predictors are constrained across classes. This allows for a straightforward interpretation of the regression coefficients while the latent predictors' distribution can be approximated by the mixture model. In other indirect applications of SEMM approaches (e.g., Bauer, 2005) linear class-specific regression coefficients are used to approximate curvilinear relationships with unknown functional form. For such applications, a standardization cannot be conducted from a conceptual point because a standardized effect necessarily refers to a specific parametric effect with an a priori defined functional relationship between the variables.
In the NSEMM approach, the measurement model is restricted to be equal across classes and the structural model from Equation (4) is constrained such that
with the latent residual distributed as ζg ~ N(0, ψ). The latent predictors are distributed as within each class. The overall distribution of ξg is a nonnormal mixture distribution (see Haas et al., 2009) with mean vector
and covariance matrix
The standardized coefficients are defined analogously to Equations (11–15) without the class-specificity:
The means and the (co-)variances of the latent predictors are the elements of the mean vector and the covariance matrix in Equations (17) and (18) (see Supplementary Material A for the general formulas for the moments of mixture variables). An extension to more than two predictor variables and more than one dependent variable again is straightforward.
The model implied variance ϕ00 of ηg again is given in Supplementary Material A. Note that for the derivation of this variance we do not assume that the predictor variables are normally distributed. As a consequence, third and fourth moments of the variables need to be taken into account for the calculation of the model implied variance of ηg. Here, we suggest to use the moments of the mixture distributions that approximate the nonnormality of the latent predictors as an estimate for these higher order moments. The derivation of the model implied variance of the latent dependent variable shows that it is essential to take nonnormality of the predictor variables into account when standardizing linear and nonlinear effects.
In applications of multiple group models, class-specific regression coefficients are not always standardized using the within-class means and variances. However, they can be standardized using the pooled means and variances across groups, or they can be standardized using those of a reference group. If researchers want to use pooled parameters in order to have a common reference system for different subgroups, the means and variances of an indirect application of a mixture model (given in Equations (19–23)) can be used instead of those for a within group standardization based on the formulas given in Equations (11–15).
The decision whether a standardization should be conducted using the within variances or the pooled variances should be based on the comparisons that the user wants to make. If different groups within a study are compared to each other (e.g., female and male students) then a pooled variance is meaningful because differences across groups (e.g., means) are maintained and represented in the standardized results. The frame of reference is defined by the pooled means and variances. As a consequence, standardized coefficients refer to a common metric in the study.
If estimates are compared across studies for specific subgroups (e.g., female students across different studies in a meta analysis) then a within standardization is meaningful because the frame of reference is then defined by group-specific parameters. The pooled variances could lead to wrong interpretations because they are influenced by the group proportions in each study; if these proportions are different across studies (e.g., 10% females in one study and 80% in another study) a comparison of standardized effects based on the pooled variance can be misleading (this will be the case when, e.g., the variances of male and female students are clearly different because the weighted sums of the means and variances depend on the group proportions).
In Supplementary Material B, we illustrate the two standardization procedures with a fictitious data set on shoe size and body height.
In this section, we illustrate the standardization procedure for direct and indirect applications of nonlinear structural equation mixture models with an example based on data from the Program for International Student Assessment 2009 (PISA; Organisation for Economic Co-Operation and Development, 2010), which is publicly available under http://pisa2009.acer.edu.au/downloads.php. The sample was an Australian subsample of N = 1092 students who took part in a reading test. Students' attitude toward reading (Att) and their reported online activities (Online; i.e., read emails or chat online) were selected as predictors of reading skills (Read). For simplicity, we neglected the clustered data structure due to the schools that had only a minor impact on the reading skills outcome (ICC = 0.15)1.
In addition to the linear effects, we also tested the nonlinear structure between the variables and included one interaction and two quadratic effects in each model to increase the predictive power of the model. We assumed that students with a positive attitude toward reading (i.e., students with high values in Att) benefit more in terms of their reading skills from engaging in online reading activities. We operationalized this hypothesis with an interaction between Att and Online. Furthermore, we formulated quadratic effects for both latent predictor variables based on recommendations by Ganzach (1997) and Klein et al. (2009) because quadratic effects should be included into an interaction model in order to avoid spurious interaction effects. We also based this decision on the assumption that a positive reading attitude and online activities do not linearly increase reading skills; instead, we assumed that there may be a saturation effect which was operationalized by a negative quadratic effect.
In addition to the structural model, we included different assumptions with regard to observed or unobserved groups. First, we were interested if different latent classes with distinct linear and nonlinear effects could be extracted from the data. This may offer insights about how reading skills may be class-specific and therefore if different subpopulations need to be assumed. This model is a direct application of a mixture model [Model (a)]. Second, in Model (b), we tested whether the latent predictors were nonnormally distributed, while we assumed a global relationship between the variables for all students. This model is an indirect application of a mixture model and allows for an unbiased estimation of the latent nonlinear effects if nonnormality is present in the data. Third, we tested whether gender effects could be identified in the data [Model (c)]. Previous research has indicated that attitudes toward reading as well as reading skills differ for girls and for boys (Schiefele, 2009; Wigfield and Cambria, 2010). Here, we also tested whether the relationships between these variables differ across girls and boys (for the gender specific relationship between interest and achievement, see Schiefele et al., 1992).
Between 7 and 11 items were aggregated into three indicators for each latent variable (i.e., item parcels) for didactic purposes2. The measurement models were given by
with an intercept vector τ, a factor loading matrix Λ and a residual vector ϵ. The factor loading matrix Λ was formulated with a simple structure (i.e., each item loaded only on one latent variable). The residual variables ϵ were assumed to be mutually uncorrelated and normally distributed with zero mean vector and (diagonal) covariance matrix Θ. For the identification of the model, the intercept and the factor loading of the first indicator of each latent variable were fixed to zero and one, respectively.
We specified three different types of structural models: (a) a direct application of a mixture model with varying regression coefficients across classes and (b) an indirect application with fixed regression coefficients across classes. Each of these models (a) and (b) were specified with two or three latent classes. Finally, Model (c) was a multiple group model with gender as a grouping variable and varying regression coefficients across groups. For comparison, a single class model was analyzed, too.
More specifically, Model (a) was specified as
with a normally distributed residual ζg ~ N(0, ψg) and predictors within each latent class g.
Model (b) was specified for the indirect application as
with a normally distributed residual ζg ~ N(0, ψ) and predictors within each latent class g. The latent classes in this model were used to approximate the potentially nonnormal distribution of the latent variables Att and Online.
Model (c) was specified as a multiple group model with gender as a grouping variable, such that reading skills were predicted separately for male and female students, whereby the measurement model was invariant across groups. The structural model was formulated according to Equation (25).
All models were estimated in Mplus (Muthén and Muthén, 1998–2012).
The model fit indices for the three models with different class solutions are presented in Table 1. For the direct application, the two class solution was selected as the final model because the BIC value was smaller compared to the three class solution. For the indirect application, the two class solution provided the best fit. The larger fit indices for the single class solution indicated the necessity to account for nonnormality in the data when analyzing nonlinear effects (for details see Kelava et al., 2014).
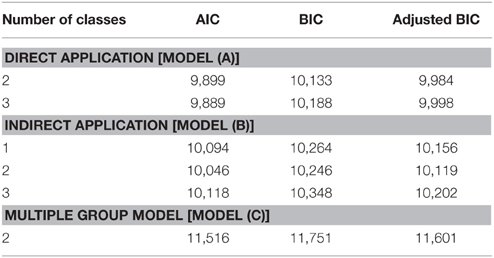
Table 1. Model fit indices for the three models.
In this analysis, we did not evaluate whether the direct or the indirect application [Model (a) or Model (b)] was more appropriate because the application of either model should be based on theory. While Model (a) aims to extract subgroups with homogeneous patterns, Model (b) fits a model for all subjects and only accounts for nonnormality by the latent class model. Thus, the latent classes are not interpreted as subgroups. Figure 1 illustrates the differences between Model (a) and (b). The subgroups in Model (a) were distinguished especially by their reading skills and attitudes. The second class consisted of a very homogeneous group of subjects with high reading skills and attitudes (see estimates in Table 3, C = 2). In Model (b) differences in the subgroups were related only to high or low reading attitudes. This implies that the better model fit for the two class solution compared to the single class solution was caused by the nonnormality of the reading attitudes in this example.
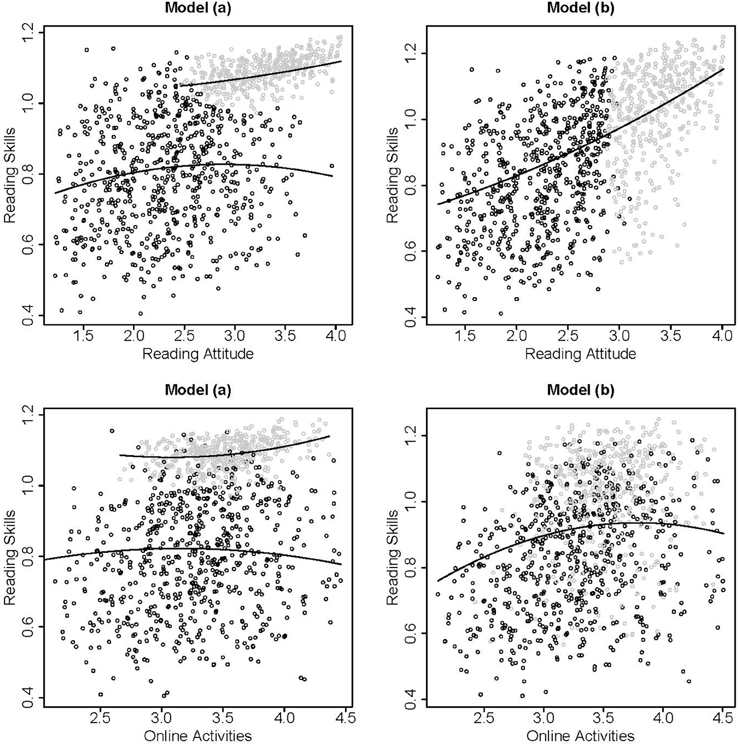
Figure 1. Scatter plots of the estimated factor scores based on the two class solutions of Model (a) (left panels) and Model (b) (right panels) for reading attitude and reading skills (upper panels) and online activities and reading skills (lower panels). The model based relationships between the variables are indicated with solid lines, class membership is indicated by black or gray dots.
The results of the two class solution of Model (a), which is the direct application of a mixture model with class-specific (non)-linear effects, are presented in Table 2. None of the nonlinear effects were significant, each of these effects were close to zero and had a standardized absolute effect size between 0.029 and 0.104. The only significant linear effects were γ1, 1 and γ2, 1 in class 1; however, the effect sizes of the linear effects in the two groups were different with and in class 1, and and in class 2 (although this difference was not significant with p = 0.202 and p = 0.768, respectively). This indicated nonlinearity in the data, which was accounted for by the two classes (see details for modeling semiparametric curvilinear relationships with class-specific linear effects in Bauer, 2005). The explained variance was smaller in class 1 with 6% compared to class 2 with 24% (1−0.942 = 0.058 in class 1 and 1−0.756 = 0.244 in class 2).
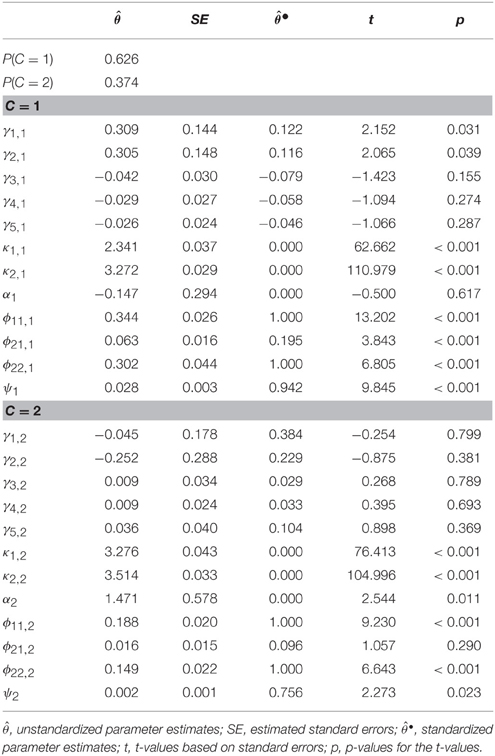
Table 2. Unstandardized and standardized parameter estimates, standard errors, t- and p-values for the direct application of a nonlinear model with two latent classes.
The results for the two class solution of Model (b), which is the indirect application of a mixture model with (non)-linear effects, are presented in Table 3. In this model, the online activities had a significant negative quadratic effect on reading skills with an effect size of . The standardized linear effect for reading attitude was strong with . This effect can be interpreted as the effect for subjects with an average level of reading attitude. The standardized multivariate relationship between reading attitude, online activities, and reading skills are illustrated in Figure 2. The nonlinear relationship between online activities and reading skills modeled a saturation effect; that is, for subjects with standardized online activities between –3 and 0, a positive relation with reading skills was observed. For subjects with standardized online activities between 0 and 3, the reading skills only changed marginally. The explained variance in the model was 35% (1 − 0.647).
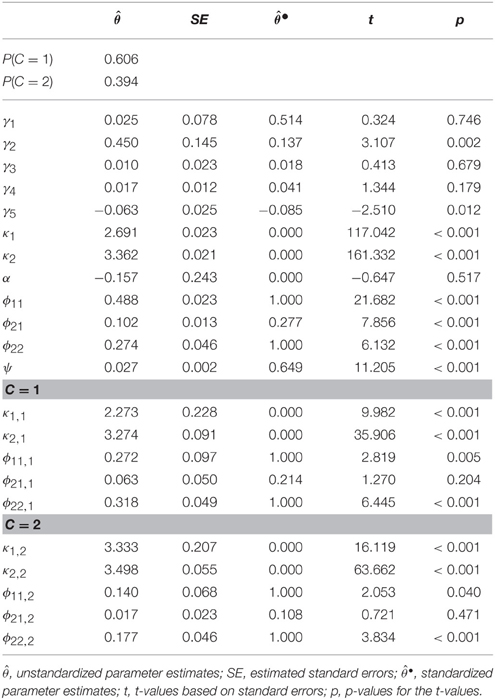
Table 3. Unstandardized and standardized parameter estimates, standard errors, t- and p-values for the indirect application of a nonlinear model with two latent classes.
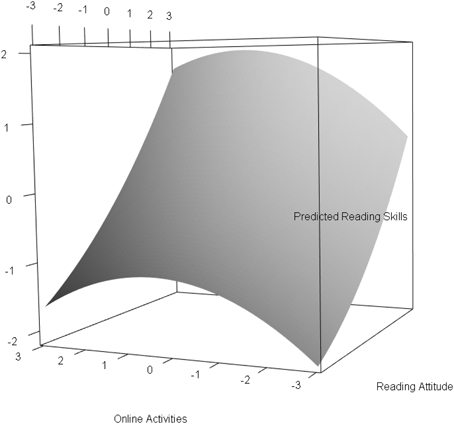
Figure 2. Standardized multivariate relationship between reading attitude, online activities and reading skills.
The nonnormal distribution of the latent predictor variables is illustrated in Figure 3. The nonnormality was mostly caused by reading attitudes (see class-specific means in Table 3).
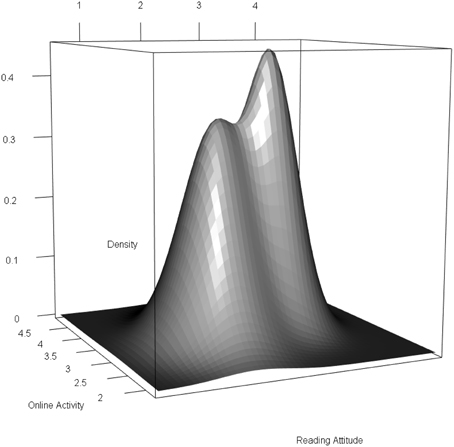
Figure 3. Nonnormal bivariate distribution of the latent predictors.
The results for Model (c), the multiple group model with (non)-linear effects, are presented in Table 4. We calculated two versions of standardized effects. The first version () refers to a within class standardization with class-specific means and variances3. The second version () refers to pooled means and variances across groups (based on Equations 17 and 18). The results for female and male students were fairly similar for most parameters. The standardized regression coefficients were also fairly similar to those in Model (b) presented above. In both groups, the online activities had a negative quadratic effect on reading skills with standardized effect sizes of = −0.141 and for female and male students, respectively, using the within class variances. The standardized quadratic effects of online activities based on the pooled variances only differed marginally from them with and . The explained variances (based on the pooled variances) were fairly similar for female and male students with 42% (1−0.582) and 39% (1−0.606), respectively.
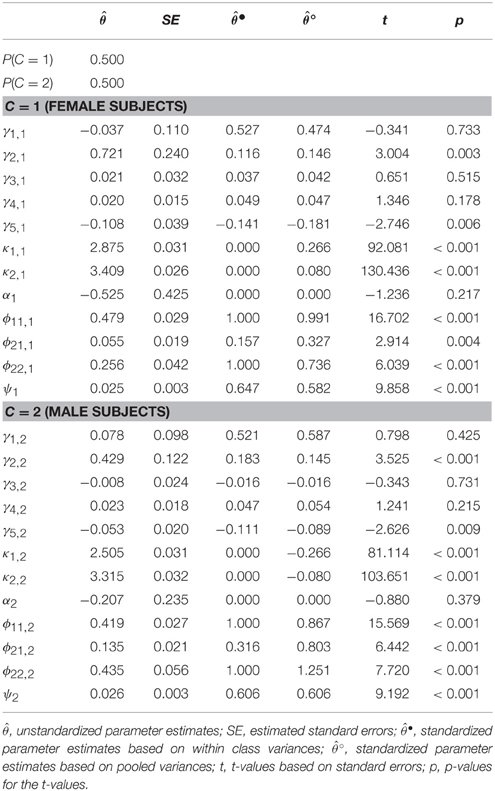
Table 4. Unstandardized and standardized parameter estimates, standard errors, t- and p-values for the direct application of a nonlinear model with two observed classes (Gender).
The two groups differed mainly in the dispersion of online activities, where male students had a larger variability in their activities compared to female students (with ϕ22, 1 = 0.256 and ϕ22, 2 = 0.435) and in the average reading attitudes which were higher for females than for males (κ1, 1 = 2.875 vs. κ1, 2 = 2.505) with a standardized difference of based on the pooled means and variances. The standardization of the linear effects further showed that the standardized relationships were fairly similar across groups, despite the rather different unstandardized effects. By comparing the standardized effects, more meaningful differences can be seen because standardized effects refer to the effects of an average member of the respective group. In contrast, the unstandardized effects are complicated to compare, because the predictors' means in the two subgroups were different.
The interpretation of the two standardizations based on either within class parameters or pooled parameters refer to two different frames of reference. For example, the linear effect of reading attitude on reading skills, , based on the within class means and variances is the standardized effect for female students with average reading attitude in this group (i.e., κ1, 1 = 2.875). This standardized parameter can be used to compare the effect to other studies in which effects for female students are examined. The standardized effect, , based on the pooled means and variances refers to female subjects with average reading skills referring to the complete sample (i.e., κ1 = 0.5κ1, 1+0.5κ1, 2 = 2.690). This effect can be used to meaningfully compare the groups within this study: for subjects with the same average reading skills (of κ1 = 2.690) the standardized effect is 0.474 for female and 0.587 for male students.
Figure 4 illustrates the relationships between the variables using simple slopes based on standardized effects using the pooled means and variances.
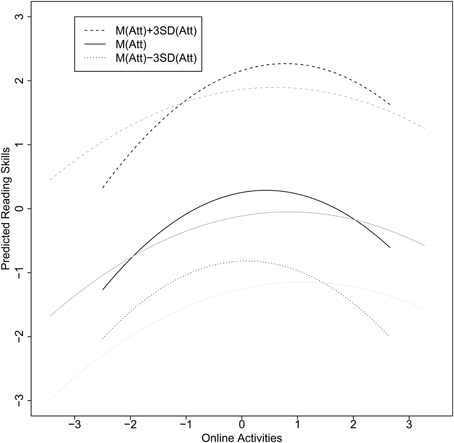
Figure 4. Simple slopes for female (black lines) and male students (gray lines) based on a standardization using the pooled variances. The relationship for online activities and reading skills were estimated for low, average, and high reading attitudes.
The standardization of the linear and nonlinear regression coefficients in this example allows us to compare the effect sizes between different models and subgroups. Furthermore, it allows researchers to compare the results here to other samples where, for example, the means of the latent variables are different and therefore the unstandardized coefficients could not be meaningfully compared. In addition, the percentage of variance explained for the latent criterion could be calculated (), which could not have been done in a straightforward manner without the derivation of the model implied variance of ηg.
In this article, we provided a standardization procedure for linear and nonlinear SEM including traditional parametric nonlinear SEM (e.g., LMS; Klein and Moosbrugger, 2000), semiparametric SEMM (e.g., Jedidi et al., 1997b), and recently proposed mixture approaches for nonnormal variables (e.g., NSEMM; Kelava and Nagengast, 2012; Kelava et al., 2014).
The formulas provided are more general than those provided by Wen et al. (2010) because they do not need the strong assumption of centered and normally distributed latent predictor variables. Although the formulas provided here refer to Equations (4) and (16) with a single dependent variable and two predictor variables, an extension to more variables is straightforward and can be inferred directly from the formulas. These formulas are useful in at least three situations.
First, they are useful when the product indicator approaches are not used and a standardization of a nonlinear model is needed. For example, this is the case when popular commercial latent variable modeling software like Mplus (Muthén and Muthén, 1998–2012) is applied to examine nonlinear interaction or quadratic effects (with the XWITH command). Since estimates for the variances of the latent product terms (e.g., ξ1ξ2) are not needed, the proposed standardization procedure can be applied to all approaches for the estimation of nonlinear interaction and quadratic effects (e.g., the LMS approach Klein and Moosbrugger, 2000, the QML approach; Klein and Muthén, 2007, or the NSEMM approach Kelava et al., 2014).
Second, the formulas are also useful when standardizing linear as well as nonlinear effects in cases when centering the observed variables does not imply centered latent variables (e.g., in latent mixture models or in multiple group SEM). In these situations, the class- or group-specific means contain information about the dissimilarity of the latent subpopulations that are extracted or are specified in the case of observed groups. This aspect needs to be taken into account during the standardization procedure. In the presence of nonlinearity, the linear effects are not invariant against a transformation of data (Moosbrugger et al., 1997). The standardization as proposed here allows researchers to interpret the effect size of a linear effect for subjects with an average value in the respective predictor variable. Researchers have previously proposed centering variables in interaction models so that an interpretation of the linear effects is meaningful (i.e., the sample mean in the respective predictor variable). In the case of latent mixture models or in multiple group SEM, centering the observed variables does not lead to centered predictor variables within each group and hence, centering is not meaningful in these scenarios. The standardization procedure presented in this paper allows researchers to refer to effects of centered variables. Thus, results from multiple group/class models can be compared to results from single group models with centered variables.
Third, the formulas are additionally useful for standardization in cases when the variables are nonnormally distributed. Several simulation studies have shown that nonnormality of the variables may introduce a bias in the parameter estimation of the nonlinear effects (Marsh et al., 2004; Cham et al., 2012; Kelava and Nagengast, 2012; Brandt et al., 2014; Kelava et al., 2014) particularly for distribution analytic approaches (e.g., LMS or QML). This bias is due to a misspecified mean and covariance structure when data are nonnormal because the estimates are derived under the assumption of normality of the latent predictor variables and measurement error variables. Hence, considering nonnormal latent distributions (e.g., by using mixture distributions) is essential for an unbiased estimation of nonlinear effects. In this article, we showed that it is again necessary to take the nonnormality of the variables into account for a correct standardization.
In practical applications of multiple group models, it is sometimes desirable to standardize effects with a pooled variance estimate or the variance of a reference group instead of within class variances. The procedure proposed here allows for all of these cases by using the respective variances derived for the direct and the indirect application of mixture models. We illustrated this with an empirical example from education science. It is obvious that the standardization depends on a reliable estimate for the class-specific variances and therefore classes (or observed groups) should not be too small.
From a substantive user's perspective, the formulas can be applied by simple algebra after parameter estimates were obtained. The standardization procedure is implemented in the package nlsem for the R system for statistical computing (R Core Team, 2015), which is freely available at http://CRAN.r-project.org/package=nlsem. The package can also be used to standardize effects estimated with Mplus.
Besides the desirable properties of the proposed standardization procedure, it is important to note that there are still situations of nonlinear SEM that are not covered by this procedure. For example, semiparametric spline models for latent variables (Yang and Dunson, 2010; Kelava and Brandt, 2014) require separate procedures that account for the specific structure of these regression functions. Furthermore, the proposed procedure can be extended for multilevel data structures. In cases where multilevel nonlinear structural equation models are given (e.g., Leite and Zuo, 2011; Nagengast et al., 2013; Kelava and Brandt, 2014), adapted procedures are needed that still offer interpretable results. Future work is needed to address these remaining issues.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
This work was supported by the Deutsche Forschungsgemeinschaft (DFG; Grants No. KE 1664/1-1, KE 1664/1-2, BR 5175/1-2) and Open Access Publishing Fund of University of Tübingen.
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fpsyg.2015.01813
1 ^A latent multilevel model that included a latent random intercept variable for reading skills did not substantively change the parameter estimates presented here.
2 ^Reading skills: average of items R06, R102, R219, R220, R414, R447, R452, and R458. Attitude toward reading: items ST24Q01–ST24Q11. Online activities: items ST26Q01–ST26Q07.
3 ^For a visualization of standardized group differences in an empirical data set see Figure 4.
Aiken, L. S., and West, S. G. (1991). Multiple Regression: Testing and Interpreting Interactions. Newbury Park, CA: Sage.
Arminger, G., and Muthén, B. O. (1998). A Bayesian approach to nonlinear latent variable models using the gibbs sampler and the metropolis-hastings algorithm. Psychometrika 63, 271–300. doi: 10.1007/BF02294856
Arminger, G., and Stein, P. (1997). Finite mixtures of covariance structure models with regressors. Soc. Methods Res. 26, 148–182. doi: 10.1177/0049124197026002002
Arminger, G., Stein, P., and Wittenberg, J. (1999). Mixtures of conditional mean- and covariance-structure models. Psychometrika 64, 475–494. doi: 10.1007/BF02294568
Bauer, D. J. (2005). A semiparametric approach to modeling nonlinear relations among latent variables. Struct. Equ. Model. 12, 513–535. doi: 10.1207/s15328007sem1204/1
Bauer, D. J., and Curran, P. J. (2004). The integration of continous and discrete latent variable models: potential problems and promising opportunities. Psychol. Methods 9, 3–29. doi: 10.1037/1082-989X.9.1.3
Bohrnstedt, G. W., and Goldberger, A. S. (1969). On the exact covariance of products of random variables. Am. Stat. Assoc. J. 64, 1439–1442. doi: 10.1080/01621459.1969.10501069
Bollen, K. A. (1995). “Structural equation models that are nonlinear in latent variables: a least squares estimator,” in Sociological methodology 1995, ed P. V. Marsden (Oxford: Blackwell), 223–251.
Brandt, H., Kelava, A., and Klein, A. G. (2014). A simulation study comparing recent approaches for the estimation of nonlinear effects in SEM under the condition of non-normality. Struct. Equ. Model. 21, 181–195. doi: 10.1080/10705511.2014.882660
Cham, H., West, S. G., Ma, Y., and Aiken, L. S. (2012). Estimating latent variable interactions with nonnormal observed data: a comparison of four approaches. Multivariate Behav. Res. 47, 840–876. doi: 10.1080/00273171.2012.732901
Dolan, C. V., and van der Maas, H. L. J. (1998). Fitting multivariate normal finite mixtures subject to structural equation modeling. Psychometrika 63, 227–253. doi: 10.1007/BF02294853
Echambadi, R., and Hess, J. D. (2007). Mean-centering does not alleviate collinearity problems in moderated multiple regression models. Mar. Sci. 26, 438–445. doi: 10.1287/mksc.1060.0263
Friedrich, R. J. (1982). In defense of multiplicative terms in multiple regression equations. Am. J. Polit. Sci. 26, 797–833. doi: 10.2307/2110973
Ganzach, Y. (1997). Misleading interaction and curvilinear terms. Psychol. Methods 3, 235–247. doi: 10.1037/1082-989X.2.3.235
Haas, M., Mittnik, S., and Paolella, M. (2009). Asymmetric multivariate normal mixture garch. Comput. Stat. Data Anal. 53, 2129–2154. doi: 10.1016/j.csda.2007.12.018
Jaccard, J., and Wan, C. K. (1995). Measurement error in the analysis of interaction effects between continuous predictors using multiple regression: multiple indicator and structural equation approaches. Psychol. Bull. 117, 348–357. doi: 10.1037/0033-2909.117.2.348
Jedidi, K., Jagpal, H. S., and DeSarbo, W. S. (1997a). Finite-mixture structural equation models for response based segmentation and unobserved heterogeneity. Mark. Sci. 16, 39–59. doi: 10.1287/mksc.16.1.39
Jedidi, K., Jagpal, H. S., and DeSarbo, W. S. (1997b). STEMM: a general finite mixture structural equation model. J. Classif. 14, 23–50. doi: 10.1007/s003579900002
Jöreskog, K. G. (1971). Simultaneous factor analysis in several populations. Psychometrika 36, 409–426. doi: 10.1007/BF02291366
Jöreskog, K. G., and Yang, F. (1996). “Nonlinear structural equation models: the kenny-judd model with interaction effects,” in Advanced Structural Equation Modeling: Issues and Techniques, eds G. A. Marcoulides and R. E. Schumacker (Mahwah, NJ: Erlbaum), 57–87.
Kelava, A., and Brandt, H. (2009). Estimation of nonlinear latent structural equation models using the extended unconstrained approach. Rev. Psychol. 16, 123–131. Available online at http://hrcak.srce.hr/70644
Kelava, A., and Brandt, H. (2014). A general nonlinear multilevel structural equation mixture model. Front. Quant. Psychol. Meas. 5:748. doi: 10.3389/fpsyg.2014.00748
Kelava, A., and Nagengast, B. (2012). A Bayesian model for the estimation of latent interaction and quadratic effects when latent variables are non-normally distributed. Multivariate Behav. Res. 47, 717–742. doi: 10.1080/00273171.2012.715560
Kelava, A., Nagengast, B., and Brandt, H. (2014). A nonlinear structural equation mixture modeling approach for non-normally distributed latent predictor variables. Struct. Equ. Model. 21, 468–481. doi: 10.1080/10705511.2014.915379
Kelava, A., Werner, C., Schermelleh-Engel, K., Moosbrugger, H., Zapf, D., Ma, Y., et al. (2011). Advanced nonlinear structural equation modeling: theoretical properties and empirical application of the distribution-analytic LMS and QML estimators. Struct. Equ. Model. 18, 465–491. doi: 10.1080/10705511.2011.582408
Kenny, D., and Judd, C. M. (1984). Estimating the nonlinear and interactive effects of latent variables. Psychol. Bull. 96, 201–210. doi: 10.1037/0033-2909.96.1.201
Klein, A. G., and Moosbrugger, H. (2000). Maximum likelihood estimation of latent interaction effects with the LMS method. Psychometrika 65, 457–474. doi: 10.1007/BF02296338
Klein, A. G., and Muthén, B. O. (2007). Quasi maximum likelihood estimation of structural equation models with multiple interaction and quadratic effects. Multivariate Behav. Res. 42, 647–674. doi: 10.1080/00273170701710205
Klein, A. G., Schermelleh-Engel, K., Moosbrugger, H., and Kelava, A. (2009). “Assessing spurious interaction effects,” in Structural Equation Modeling in Educational Research: Concepts and Applications, eds T. Teo and M. Khine (Rotterdam, NL: Sense Publishers), 13–28.
Leite, W., and Zuo, Y. (2011). Modeling latent interactions at level 2 in multilevel structural equation models: an evaluation of mean-centered and residual-centered approaches. Struct. Equ. Model. 18, 449–464. doi: 10.1080/10705511.2011.582400
Little, T. D., Bovaird, J. A., and Widaman, K. F. (2006). On the merits of orthogonalizing powered and interaction terms: implications for modeling interactions among latent variables. Struct. Equ. Model. 13, 497–519. doi: 10.1207/s15328007sem1304/1
Marsh, H. W., Wen, Z., and Hau, K.-T. (2004). Structural equation models of latent interactions: evaluation of alternative estimation strategies and indicator construction. Psychol. Methods 9, 275–300. doi: 10.1037/1082-989X.9.3.275
Marsh, H. W., Wen, Z., and Hau, K.-T. (2006). “Structural equation models of latent interaction and quadratic effects,” in Structural Equation Modeling: A Second Course, eds G. R. Hancock and R. O. Müller (Greenwich, CT: Information Age Publishing), 225–265.
Meredith, W. (1993). Measurement invariance, factor analysis and factorial invariance. Psychometrika 58, 525–543. doi: 10.1007/bf02294825
Mooijaart, A., and Bentler, P. M. (2010). An alternative approach for nonlinear latent variable models. Struct. Equ. Model. 17, 357–573. doi: 10.1080/10705511.2010.488997
Moosbrugger, H., Schermelleh-Engel, K., and Klein, A. G. (1997). Methodological problems of estimating latent interaction effects. Methods Psychol. Res. Online 2, 95–111.
Moulder, B. C., and Algina, J. (2002). Comparison of methods for estimating and testing latent variable interactions. Struct. Equ. Model. 9, 1–19. doi: 10.1207/S15328007SEM0901/1
Muthén, B. O. (2001). “Second-generation structural equation modeling with a combination of categorical and continuous latent variables: new opportunities for latent-class growth modeling,” in New Methods for the Nalysis of Change, eds L. M. Collins and A. Sayer (Washington, DC: American Psychological Association), 291–322.
Muthén, B. O., and Asparouhov, T. (2009). “Growth mixture modeling: analysis with non-Gaussian random effects,” in Longitudinal Data Analysis, eds G. Fitzmaurice, M. Davidian, G. Verbeke, and G. Molenberghs (Boca Raton, FL: Hapman & Hall/CRC), 143–165.
Muthén, B., and Asparouhov, T. (2014). Growth mixture modeling with non-normal distributions. Stat. Med. 34, 1041–1058. doi: 10.1002/sim.6388
Muthén, L. K., and Muthén, B. O. (1998–2012). Mplus User's Guide, 7th Edn. Los Angeles, CA: Muthén & Muthén.
Nagengast, B., Trautwein, U., Kelava, A., and Lüdtke, O. (2013). Synergistic effects of expectancy and value on homework engagement: the case for a within-person perspective. Multivariate Behav. Res. 48, 428–460. doi: 10.1080/00273171.2013.775060
Organisation for Economic Co-Operation Development (2010). PISA 2009 Results: What Students Know and Can do – Student Performance in Reading, Mathematics and Science, Vol. 1. Paris: OECD.
Pek, J., Losardo, D., and Bauer, D. J. (2011). Confidence intervals for a semiparametric approach to modeling nonlinear relations among latent variables. Struct. Equ. Model. 18, 537–553. doi: 10.1080/10705511.2011.607072
Pek, J., Sterba, S. K., Kok, B. E., and Bauer, D. J. (2009). Estimating and visualizing nonlinear relations among latent variables: a semiparametric approach. Multivariate Behav. Res. 44, 407–436. doi: 10.1080/00273170903103290
Ping, R. A. (1995). A parsimonious estimating technique for interaction and quadratic latent variables. J. Mark. Res. 32, 336–347. doi: 10.2307/3151985
Ping, R. A. (1996). Latent variable interaction and quadratic effect estimation: a two-step technique using structural equation analysis. Psychol. Bull. 119, 166–175. doi: 10.1037/0033-2909.119.1.166
R Core Team (2015). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Schiefele, U. (2009). “Situational and individual interest,” in Handbook of Motivation in School, eds K. R. Wentzel and A. Wigfield (New York, NY: Taylor Francis), 197–223.
Schiefele, U., Krapp, A., and Winteler, A. (1992). “Interest as a predictor of academic achievement: a meta-analysis of research,” in The Role of Interest in Learning and Development, eds K. A. Renninger, S. Hidi, and A. Krapp (Hillsdale: Erlbaum), 183–212.
Sörbom, D. (1974). A general method for studying differences in factor means and factor structures between groups. Br. J. Math. Stat. Psychol. 28, 138–151.
Wall, M. M., and Amemiya, Y. (2000). Estimation for polynomial structural equation models. J. Stat. Am. Assoc. 95, 929–940. doi: 10.1080/01621459.2000.10474283
Wall, M. M., and Amemiya, Y. (2001). Generalized appended product indicator procedure for nonlinear structural equation analysis. J. Educ. Behav. Stat. 26, 1–29. doi: 10.3102/10769986026001001
Wall, M. M., and Amemiya, Y. (2003). A method of moments technique for fitting interaction effects in structural equation models. Br. J. Math. Stat. Psychol. 56, 47–63. doi: 10.1348/000711003321645331
Wall, M. M., Guo, J., and Amemiya, Y. (2012). Mixture factor analysis for approximating a nonnormally distributed continuous latent factor with continuous and dichotomous observed variables. Multivariate Behav. Res. 47, 276–313. doi: 10.1080/00273171.2012.658339
Wen, Z., Marsh, H. W., and Hau, K.-T. (2010). Structural equation models of latent interactions: An appropriate standardized solution and its scale-free properties. Struct. Equ. Model. 17, 1–22. doi: 10.1080/10705510903438872
Wen, Z., Marsh, H. W., Hau, K.-T., Liu, H., and Morin, A. J. S. (2014). Interaction effects in latent growth models: evaluation of alternative estimation approaches. Struct. Equ. Model. 21, 361–374. doi: 10.1080/10705511.2014.915205
Wigfield, A., and Cambria, J. (2010). Students' achievement values, goal orientations, and interest: definitions, development, and relations to achievement outcomes. Dev. Rev. 30, 1–35. doi: 10.1016/j.dr.2009.12.001
Keywords: interaction effect, quadratic effect, nonlinear effect, mixture model, nonnormality, standardization
Citation: Brandt H, Umbach N and Kelava A (2015) The Standardization of Linear and Nonlinear Effects in Direct and Indirect Applications of Structural Equation Mixture Models for Normal and Nonnormal Data. Front. Psychol. 6:1813. doi: 10.3389/fpsyg.2015.01813
Received: 04 June 2015; Accepted: 10 November 2015;
Published: 30 November 2015.
Edited by:
Holmes Finch, Ball State University, USAReviewed by:
Christian Geiser, Utah State University, USACopyright © 2015 Brandt, Umbach and Kelava. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Holger Brandt, aG9sZ2VyLmJyYW5kdEB1bmktdHVlYmluZ2VuLmRl
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.