 K. Richard Ridderinkhof1,2*
K. Richard Ridderinkhof1,2* Nelleke C. van Wouwe3
Nelleke C. van Wouwe3 Guido P. H. Band3,4
Guido P. H. Band3,4 Scott A. Wylie5
Scott A. Wylie5 Stefan Van der Stigchel6
Stefan Van der Stigchel6 Pieter van Hees1
Pieter van Hees1 Jessika Buitenweg1 Irene van de Vijver1
Jessika Buitenweg1 Irene van de Vijver1 Wery P. M. van den Wildenberg1
Wery P. M. van den Wildenberg1
- 1 Department of Psychology, Amsterdam center for the study of adaptive control in brain and behavior (Acacia), University of Amsterdam, Amsterdam, Netherlands
- 2 Cognitive Science Center Amsterdam, University of Amsterdam, Amsterdam, Netherlands
- 3 Institute of Psychology, Leiden University, Leiden, Netherlands
- 4 Leiden Institute for Brain and Cognition, Leiden, Netherlands
- 5 Department of Neurology, Vanderbilt University Medical Center, Nashville, TN, USA
- 6 Helmholtz Institute, Utrecht University, Utrecht, Netherlands
Reward-based decision-learning refers to the process of learning to select those actions that lead to rewards while avoiding actions that lead to punishments. This process, known to rely on dopaminergic activity in striatal brain regions, is compromised in Parkinson’s disease (PD). We hypothesized that such decision-learning deficits are alleviated by induced positive affect, which is thought to incur transient boosts in midbrain and striatal dopaminergic activity. Computational measures of probabilistic reward-based decision-learning were determined for 51 patients diagnosed with PD. Previous work has shown these measures to rely on the nucleus caudatus (outcome evaluation during the early phases of learning) and the putamen (reward prediction during later phases of learning). We observed that induced positive affect facilitated learning, through its effects on reward prediction rather than outcome evaluation. Viewing a few minutes of comedy clips served to remedy dopamine-related problems associated with frontostriatal circuitry and, consequently, learning to predict which actions will yield reward.
Introduction
Parkinson’s disease (PD) is a neurodegenerative process commencing in the midbrain, in particular affecting dopaminergic neurons of the substantia nigra projecting into the dorsolateral striatum (mostly the putamen; Bjorklund and Dunnett, 2007), resulting in motor deficits, such as tremor, bradykinesia, and rigidity (McAuley, 2003). As the disease progresses, dopamine (DA) depletion affecting cognitive circuits of the basal ganglia contribute to impairments in a range of cognitive domains, including reinforcement learning, reversal learning, risky decision-making, working memory, response inhibition, and speed/accuracy balancing (e.g., Cooper et al., 1992; Swainson et al., 2000; Cools et al., 2001; Frank, 2005; Moustafa et al., 2008; Wylie et al., 2009, 2010; Claassen et al., 2011). The purpose of the present investigation was to determine whether reward-based learning deficits in patients with PD might be remedied non-invasively by factors that induce positive affect.
Induced positive affect yields improved performance in a variety of tasks that rely on frontostriatal dopaminergic interactions, including antisaccade tasks, task switching, and varieties of Go/NoGo tasks such as the AX-CPT (Dreisbach and Goschke, 2004; Dreisbach et al., 2005; Dreisbach, 2006; Van der Stigchel et al., 2011; van Wouwe et al., 2011a). Interestingly, patients with PD show performance impairments in each of these tasks (e.g., Kitagawa et al., 1994), suggesting that performance improvements after positive affect might result from changes in dopaminergic levels in the brain. Before discussing how induced positive affect might remedy PD-related deficits in reward-based decision-learning, we first turn to a brief exposition of the neurocognitive bases of such reinforcement learning.
Neurocognitive Mechanisms Underlying Reward-Based Decision-Learning
Decisions about how best to respond in a situation are often guided by past learning of the relations between events, actions, and their outcomes. Probabilistic reward-based decision-learning paradigms enable us to measure the process of learning (through trial-and-error) associations between stimuli, actions, and their related rewards. Several brain areas have been linked to key aspects of reward-based decision-learning, including prefrontal regions (e.g., the dorsolateral and orbitofrontal cortices) and the basal ganglia. Additionally, the neurotransmitter DA plays a modulatory role in these functions through projections from midbrain DA nuclei to the striatum and cortical areas (Schultz, 2006).
Lesion and human imaging studies support a functional dissociation between the contributions of various regions within the striatum to reward-based decision-learning (for an overview, see Balleine et al., 2007). In addition to the role of dorsal versus ventral striatum in different aspects of reward-based learning (Knutson et al., 2001; McClure et al., 2003; O’Doherty et al., 2004; Seger and Cincotta, 2005; Seymour et al., 2007), recent fMRI work suggest that distinct regions within dorsal striatum may contribute to different phases of learning (Haruno and Kawato, 2006a).
A Q-learning model can be used to generate individual parameters that reflect two important aspects of learning. First, the mismatch between anticipated rewards and actual rewards is computed as a reward prediction error (RPE), which learners use for adjusting decision-making on future trials, in particular in the early stages of learning when they rely on feedback to determine which actions maximize rewards. Haruno and Kawato (2006a) observed that higher RPE values were associated with activation of the caudate nucleus and ventral striatum and their associated frontal circuitry (orbitofrontal, dorsolateral prefrontal, and anterior cingulate cortex), involved in generating and testing hypotheses regarding reward optimization (c.f. Alexander et al., 1990; Oyama et al., 2010). Second, as learning progresses, participants attempt to forecast which actions will likely yield reward (or avoid punishment); this is computed as the stimulus-action-dependent reward prediction (SADRP). Higher SADRP values reflect more effective learning of stimulus-action-reward associations, and hence, are maximal at the later stages of the task. Haruno and Kawato (2006a) reported higher SADRP values to be associated with activation of the anterior putamen and its associated motor circuitry (supplementary motor area, premotor and primary motor cortex), involved in integrating information on the expectation of reward with processes that mediate the actions leading to the reward (c.f. Alexander et al., 1990; Gerardin et al., 2003).
To explain these patterns, the authors proposed that the caudate (embedded in the cortical striatal loop which includes the orbitofrontal cortex and dorsolateral prefrontal cortex) is involved in generating and testing hypotheses regarding reward optimization. Global reward-related features of the stimulus-action-reward associations are propagated from the caudate to motor loops (which include the putamen and premotor areas) by means of a dopamine signal that is subserved by reciprocal projections between the striatum and the substantia nigra (Haruno and Kawato, 2006b). During later stages of learning, putamen activity increases with reward predictions (i.e., with learning SADRPs). Activity in the putamen increases to incorporate more specific motor information with the associated stimuli and the expected reward; that is, the reward associated with a specific stimulus and a specific action becomes more predictable and learning is gradually fine-tuned (Haruno and Kawato, 2006b). As these SADRP values increase, the RPE is reduced as subjects more accurately anticipate the rewards associated with their actions. Note that the change in emphasis from RPE during early phases of learning to SADRP during later stages bears resemblance to the dynamics of phasic DA-activity as a function of learning. The phasic DA bursts displayed by striatal neurons in response to reward have been reported to shift in time from the presentation of unexpected reward during early phases of learning to the presentation of conditioned reward-predicting stimuli during later stages (Schultz et al., 2003; Balleine et al., 2007).
Remedies for Cognitive Impairments in Parkinson’s Disease
DA medication in Parkinson’s patients, serving to increase dopaminergic influx into the striatum, improves the efficacy of using incoming response-relevant stimulus information to control behavior (Cools et al., 2001, 2007). Reward-based learning benefits from DA medication, specifically for learning that certain actions are likely to yield reward (Frank, 2005; Shohamy et al., 2005; Bodi et al., 2009). Because regions of the striatum are differentially affected by PD, DA medication may differentially affect these structures and their related functions. Using the Q-learning approach sketched above, van Wouwe et al. (2012) observed that DA medication improved SADRP (i.e., reward prediction, presumably supported by the anterior putamen and associated motor circuitry), but did not affect RPE (i.e., outcome evaluation, presumably supported by the caudate and ventral striatum and associated frontal circuitries). Similar effects were observed for the effects of deep brain stimulation of the subthalamic nucleus (van Wouwe et al., 2011b).
To the extent that impaired decision-learning in patients with PD follows from the decline in their striatal DA-system, one might suppose that any intervention that enhances dopaminergic functionality may serve to remedy the learning deficit. In fact, mild increases in DA-activity in the reward-processing system can be triggered by a broad spectrum of positive reinforcers (Burgdorf and Panksepp, 2006). One simple, non-invasive, and even agreeable means to trigger mild increases in DA levels is the induction of positive affect (a mood state characterized by subjective well-being and happiness; Ashby et al., 1999, 2002). Recent neuroimaging studies in humans have demonstrated that funny cartoons, implicit laughter, affectively positive music, and positive (as opposed to negative) emotional pictures can activate reward-related areas. According to a neurobiological theory on the influence of positive affect (Ashby et al., 1999; Ashby et al., 2002), induced positive affect leads to temporary increase of dopamine release in midbrain DA-generation centers. This dopamine release is subsequently propagated to dopaminergic projection sites in the prefrontal cortex and the striatum. Only a limited amount of DA transporters is available to remove DA from the synaptic cleft; hence, once boosted, DA levels will remain elevated for some period of time after affect induction. Together, these findings suggest a neurobiological link between positive affect and a transient but functional boost in DA.
Positive affect can be induced by commonplace methods, including watching comedy movie clips, experiencing success on an ambiguous task, self-recall of positive emotional states, and administering small unexpected rewards. These positive feelings last for approximately 30 min, a time course similar to that of DA-release in the ventral striatum induced by brief electrical stimulation (Floresco et al., 1998). Behavioral influences of positive affect are thought to be mediated by the same tonic dopaminergic neural mechanisms that mediate reward. We predict that PD-related impairments in reward-based decision-learning will be remedied by watching brief feel-good movie clips.
The Present Study
The present study investigates the effect of induced positive affect on reward-based decision-learning. PD patients performed the previously mentioned probabilistic learning task (Haruno and Kawato, 2006a) after watching either Charlie Chaplin slapstick movie clips (between-subjects) or affect-neutral documentary clips. We determined the effect of induced affect on RPEs, in particular during the early phase of learning, and on formation of stimulus-action-reward associations (SADRP), in particular during more progressed phases of learning. Based on recent findings on the effects of DA medication on reward-based learning in this task (van Wouwe et al., 2012), we expect that positive affect will help improve the putamen-based process of predicting which action will yield reward (reflected by SADRP in late stages of learning) more than the caudate-based process of outcome evaluation (expressed in RPE early during learning).
Materials and Methods
Participants
A total of 51 PD patients participated in the experiment after giving written informed consent. They were recruited through Dutch national websites dedicated to PD, and received a small present in return for their participation. All patients had normal or corrected-to normal vision, and no Parkinson-unrelated neurological or psychiatric history according to self-report. Patients were tested individually at their homes. They were asked to abstain from drinking coffee during the hour before testing, and to continue taking their medication at the required time on the day of testing. Tests were planned 60–90 min after regular medication intake. In addition to monoamine oxidase (MAO-B)/catechol-O-methyl transferase (COMT) inhibitors (N = 29), patients received either dopamine precursors only (levodopa; N = 10), agonists only (pramipexole, ropinirole, pergolide, amantadine, or apomorphine; N = 9), levodopa plus agonists (N = 32), or neither (N = 1). Explorative analyses indicated that there was no difference between the neutral and positive affect groups in terms of daily levodopa dosage [t(49) = 0.129, p = 0.898], agonists dosage [above- versus below-average versus no agonist, χ2(1, 51) = 0.644, p = 0.725], or years since formal diagnosis [t(49) = 0.259, p = 0.797].
Each of the patients was assigned randomly to one of two affect induction groups. The two groups (N = 24/27 for neutral and positive affect groups, respectively) did not differ in terms of age [M = 62/59, st.dev = 9.7/10.5, t(49) = 0.914, p = 0.365], years of disease since diagnosis [M = 7.0/6.7, st.dev = 4.8/4.5, t(49) = 0. 259, p = 0.797], daily dosage (mg/day) of levodopa [M = 404/393, st.dev = 311/327, t(49) = 0.129, p = 0.898], level of education [t(49) = 0. 658, p = 0.514], and male/female composition [χ2(1, 51) = 1.663, p = 0.197].
Procedures
The experiment consisted of a training session (two practice blocks, see Task), a mood measurement, a film clip for affect induction, another mood measurement, an experimental session (two test blocks, see Task), a third mood measurement, and an exit session (consisting of general health questionnaires, a brief exit interview, and debriefing), all frequently interrupted with short breaks. The whole session lasted 60 min maximum. All experimental procedures were approved by a local ethics committee and by the board of the Dutch Parkinson Patiënten Vereniging, and were conducted in accordance with the Helsinki Declaration, international laws, and institutional guidelines.
Affect Induction
Affect induction was operationalized by showing the patients film clips that lasted 8–9 min. One group of patients (referred to as the Positive Affect group) watched a slapstick clip from the Charlie Chaplin movie City Lights (the famous boxing scene, ending just prior to the part where Chaplin loses the fight). The other patients (referred to as the Neutral Affect group) watched a clip from a Dutch documentary on toll for heavy-traffic on the German Autobahn. The clips were played on a 17″-widescreen laptop computer. Mood was measured three times: immediately before and after affect induction, and immediately after the experimental session. We used a short Manekin test in which mood (valence, from negative to positive) and arousal (from not aroused to highly aroused) were scored on a 5-point Likert scale ranging from −2 to +2 (Hutchison et al., 1996).
Task and Apparatus
A probabilistic learning task, adapted from Haruno and Kawato (2006a), was implemented on a 17″-widescreen laptop computer, placed at a distance of ∼60 cm in front of the participant. Stimuli consisted of colored fractal pictures against a white background. Responses to stimuli were right or left button presses registered by comfortable response keys (see Figure 1; the computer keyboard was shielded with a perspex plate such that hands and wrists could rest on the plate, which minimized tremor and prevented unintentional depressing of other keys).

Figure 1. Laptop computer with adjusted response buttons. The computer keyboard was shielded with a perspex plate such that hands and wrists could rest comfortably on the plate, which minimized tremor and prevented unintentional depressing of other keys.
Subjects were instructed that the goal of the task was to make as much money as possible by pressing a left or a right button to each picture stimulus that appeared on the computer screen. Each response provided the chance to either win or lose €0.25 in game money (note: participants were not remunerated for their participation). Figure 2 depicts the sequence of a trial from the task. Each trial began with the presentation of one of three picture stimuli (colored fractals) in the center of the screen. The picture stimulus subtended visual angles of 5.67° × 4.41° (9 cm × 7 cm) and remained on the screen for 1000 ms. Participants were instructed to view the picture stimulus, but not to respond until the picture stimulus disappeared and was replaced by a response screen. The response screen consisted of the fixation cross and two blue boxes displayed at the bottom left and bottom right portions of the screen, respectively (see Figure 2). Upon the presentation of the response screen, the participant was instructed to make a left or a right button press, which would then be indicated on the screen by a change in color (from blue to green) of the box that corresponded to the response side that was chosen (left button press = left box turns green). The participant was given 2 s to issue a response. After the button press was indicated on the screen for 500 ms, a large box with feedback appeared in the center of the screen for 2000 ms. If the participant chose the correct response, the large box appeared in green, indicating that €0.25 had been won. If the incorrect response was chosen, the box appeared in red, indicating that the participant had lost €0.25. Throughout the entire trial, and throughout the entire block, a running tab of the total amount of money won by the participant was depicted in the upper center portion of the screen. Thus, if the participant won or lost €0.25 on a particular trial, the running total was immediately updated.
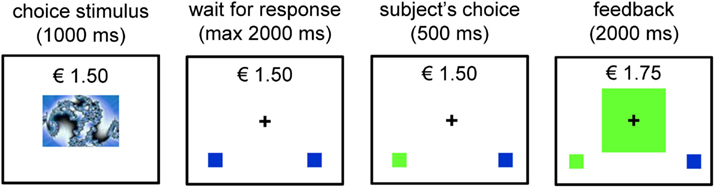
Figure 2. Trial example of the probabilistic learning task adapted from Haruno and Kawato (2006a). In the example, the subject receives a reward by pressing the left button with this specific stimulus.
Participants completed a practice block in which they learned for each of the three picture stimuli which response led to reward, until they selected the correct button five subsequent times for all stimuli (max 60 trials). This practice block was non-probabilistic, so as to acquaint the patients with the general task and set-up. Next, participants completed a practice block of 21 trials in which the reward outcome of each response to a picture stimulus was determined. For each picture, one response hand was assigned as the optimal choice and the other response hand was designated as the non-optimal choice; selecting the optimal response hand resulted in a 90% probability of winning €0.25 and a 10% probability of losing €0.25; the probabilities of winning versus losing were reversed for the non-optimal response hand. As an example, a left response to fractal stimulus X yielded a €0.25 reward with a probability of 0.9 (90%) and a €0.25 loss with a probability of 0.1 (10%). A right response to the same stimulus yielded a €0.25 loss with a probability of 0.9 and a €0.25 with a probability of 0.1. Therefore, the optimal behavior for fractal stimulus X was to press the left button, which participants had to learn by trial-and-error. The dominant probabilities for optimal behavior regarding the other fractal stimuli were also 0.9; the optimal response for each fractal was pseudo-randomized over left and right hands, such that the left response was optimal for one or two stimuli whereas the right response was optimal for the remaining stimuli.
Next, after the affect induction session, participants completed two experimental blocks of 60 trials each. In the first block, the probabilities were 90:10 as described above; in the second block, the probabilities were 80:20. For each training and experimental block, a novel set of three picture stimuli was used, and the specific response options were randomly mapped onto each of the fractals. Across blocks and across participants, left and right hand dominant response patterns occurred equally often. Additionally, the fractal stimuli were presented pseudo-randomly (with equal frequency) within a block.
Data Analysis
Computational model to calculate SADRP and RPE
A reinforcement model (Q-learning; Sutton and Barto, 1998) was used to compute each participant’s SADRP and RPE during learning. Q-learning is an implementation of a temporal difference model which assumes that stimulus-action-reward associations are acquired as a single representation during learning. The SADRP value (Q) consists of the predicted amount of reward for a certain decision (left or right response, r) made for a specific stimulus (one of three fractal stimuli, FS). Thus, the value of SADRP on trial t is the value of Q associated with the particular stimulus and response on that trial. This value thus relates reward to sensory input and actions. Individual predicted reward values (SADRPs) for each action (two possible responses) and each fractal stimulus (three different fractal stimuli) are calculated at time t, Qt (FS, r) which adds up to six SADRP values per block. The RPE represents the actual reward received (Rt) minus the expected reward, RPE = Rt − Qt (FS, r). For the next occurrence of the same stimulus and action, SADRP and RPE values are updated according to the “Q-learning algorithm” to maximize reward (Sutton and Barto, 1998)
The learning rate is updated separately for each FS according to the following rule:
The formula of this learning rate is often used in reinforcement learning studies or studies on adaptive control (Young, 1984; Bertsekas and Tsitsiklis, 1996; Dayan et al., 2000; Haruno and Kawato, 2006a,b). It provides an estimation of a learning parameter which is updated recurrently with the presentation of a stimulus. In the current study, reduces with the presentation of each fractal stimulus, but remains equal if a specific FS is not presented. The initial value of the learning rate was set to 1, and was previously observed not to affect the estimation of SADRP and RPE (Haruno and Kawato, 2006a).
The learning rate decreases toward the end of the learning stage (when SADRP becomes reliable). This is an important feature of because it means that, at the end of learning, the SADRP is less affected by an unexpected RPE (due to the probabilistic nature of the task).
Reward prediction errors are expected to be large early on during learning (i.e., first 20 trials), and small later on (i.e., the last 20 trials). By contrast, the SADRP value is expected to be small during initial phases of learning, but to increase and converge to an asymptotic value as learning progresses.
Statistical analyses
To test for the efficacy of affect induction, a Mann–Whitney U test was used to compare mood and arousal between groups across the three measurements.
For the probabilistic learning task, average reward per trial, average SADRP value per trial, and average RPE value per trial in each block were analyzed by a repeated-measures analysis of variance (RM-ANOVA) including the within-subject variables Stage (first, second, and third part of the block, comprising 20 trials each) and Probability (90/10, 80/20) and the between-subjects variable Affect Group (Positive, Neutral). Where appropriate, the effects of Stage were examined further using linear and quadratic contrast analyses.
Results
Affect Induction
Before the film clips, mood (as indexed by the Manekin score on the valence question) was comparable across Affect groups (MPOS = 0.88, MNEU = 0.83; Mann–Whitney U = 323.500, p = 0.992). Immediately after the film clips, mood was elevated in the Positive compared to Neutral group (MPOS = 1.16, MNEU = 0.54; Mann–Whitney U = 174.000, p = 0.003), and within the Positive group after compare to before affect induction [F(1, 26) = 4.24, p = 0.05]. After the experimental blocks, mood levels were equal again (MPOS = 1.00, MNEU = 1.04; Mann–Whitney U = 304.000, p = 0.672). Thus, the positive affect induction was successful, albeit short-lived. Arousal was not different between groups at any stage (all F < 1.8).
Probabilistic Learning: Reward
Not surprisingly, average reward per trial (in €) increased as a function of learning Stage [Mfirst = 0.059, Msecond = 0.099, Mthird = 0.110; F(2, 98) = 18.49, p < 0.001; linear contrast: p < 0.001, quadratic contrast: p = 0.023]. Probability also produced a main effect on reward, such that better performance was seen in the 90:10 compared to 80:20 blocks [M90:10 = 0.120, M80:20 = 0.058; F(1, 49) = 44.93, p < 0.001]. This effect of Probability remained constant across Stages [F(2, 98) = 0.69].
Positive affect induction exerted a beneficial effect on reward per trial [MPOS = 0.096, MNEU = 0.082; F(1, 49) = 5.12, p < 0.028]. This influence of Affect was seen for early, middle, and late Stages of learning alike [F(2, 98) = 1.55], remained constant across 90:10 and 80:20 Probabilities [F(1, 49) = 2.11], and did not engage in a three-way interaction with Stage and Probability [F(2, 98) = 0.55].
Probabilistic Learning: RPE
As expected, the average RPE per trial (in €) was observed to diminish from early to later Stages of learning [Mfirst = 0.191, Msecond = 0.152, Mthird = 0.148; F(2, 89) = 65.29, p < 0.001; linear contrast: p < 0.001, quadratic contrast: p < 0.001]. Probability also affected RPE, such that smaller RPEs were observed in the 90:10 compared to 80:20 blocks [M90:10 = 0.138, M80:20 = 0.192; F(1, 49) = 79.59, p < 0.001]. The effect of Stage varied across Probabilities [F(2, 98) = 4.14, p = 0.019]; as can be seen in Figure 3A, the diminution of RPE as a function of learning was steeper in the 90:10 than 80:20 probability condition. Thus, patients learned to reduce their prediction errors over time, especially in the easier condition.
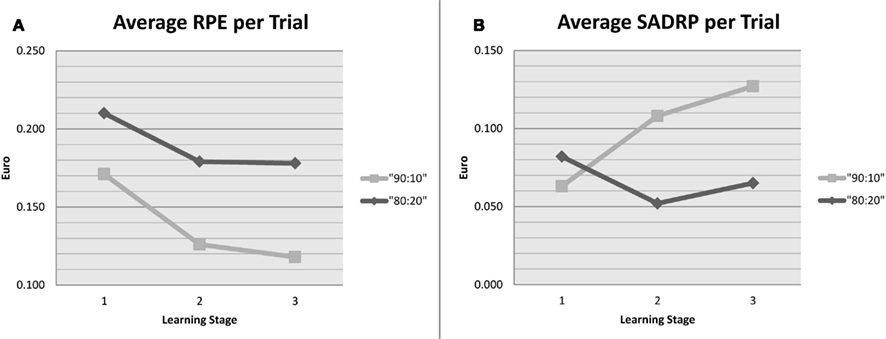
Figure 3. Q-model parameters values during stages 1 (trial 1–20), 2 (trial 21–40), and 3 (trial 41–60) of learning, separately for each probability condition. (A) Average RPE values per trial. (B) Average SADRP values per trial.
Positive affect induction failed to exert any effect on RPE [main effect of Affect: F(1, 49) = 2.32; Affect × Stage: F(2, 98) = 0.65; Affect × Probability: F(1, 49) = 0.002; Affect × Stage × Probability: F(2, 98) = 0.66].
Probabilistic Learning: SADRP
In line with expectations, the average SADRP per trial (in €) was observed to increase from early to later Stages of learning [Mfirst = 0.046, Msecond = 0.081, Mthird = 0.097; F(2, 89) = 64.29, p < 0.001; linear contrast: p < 0.001, quadratic contrast: p < 0.008]. Probability also affected SADRP, such that smaller SADRPs were observed in the 80:20 compared to 90:10 blocks [M90:10 = 0.099, M80:20 = 0.048; F(1, 49) = 30.53, p < 0.001]. The effect of Stage varied across Probabilities [F(2, 98) = 4.32, p = 0.016]; as can be seen in Figure 3B, the 90:10 probability condition showed a steep increase of SADRP as a function of learning, whereas no such increase was seen in the 80:20 condition. Thus, patients learned to predict which stimulus-action combinations yielded reward, but only in the easier Probability condition.
Positive affect induction exerted a beneficial effect on SADRP [MPOS = 0.096, MNEU = 0.082; F(1, 49) = 4.48, p < 0.039]. This influence of Affect differed across learning Stages [F(2, 98) = 3.19, p = 0.045]. As can be seen in Figure 4, SADRP was low in the early stage of learning for positive and neutral Affect groups alike, but the increase during later stages was steeper for the positive Affect group, suggesting that positive affect facilitates learning that response X to stimulus Y is likely to yield reward. The influence of Affect was similar for the 90:10 and 80:20 Probabilities [F(1, 49) = 0.79], and did not engage in a three-way interaction with Stage and Probability [F(2, 98) = 0.13].
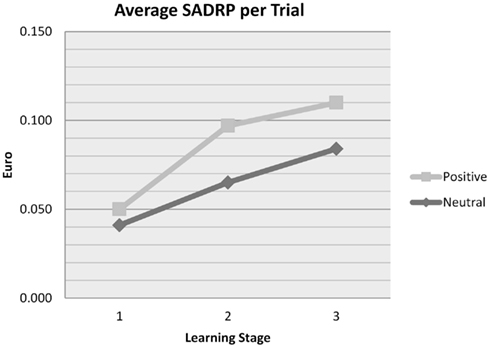
Figure 4. Average SADRP values per trial, separately for each Affect group, during stages 1 (trial 1–20), 2 (trial 21–40), and 3 (trial 41–60) of learning, collapsed across the 90:10 and 80:20 conditions.
Discussion
Induced positive affect was expected to influence distinct components of reward-based learning in patients with PD. We investigated the effects of positive affect induction (i.e., watching Charlie Chaplin slapstick movie clips) on outcome evaluation (the processing of RPEs to update hypotheses) and reward anticipation (the formation of SADRP) that have been tied to distinct regions in the striatum and their associated circuitries. For learning to be successful, subjects must evaluate discrepancies between expected (or predicted) reward associated with a particular decision and the actual outcome of that decision. When an error occurs (i.e., predicted reward does not match the actual outcome), expectancies about possible outcomes associated with a decision can be updated to increase the likelihood of selecting a more optimal (i.e., reward-yielding) response in the future. As expectancies about the outcomes of particular decisions become more accurate, subjects are less swayed by the occasional violation of these reward expectancies and learn to optimize their selection of the most advantageous response to a stimulus. Behavioral findings typically reported for the probabilistic reward-based decision-learning task adopted here (e.g., Haruno and Kawato, 2006a; van Wouwe et al., 2012) were successfully reproduced in the current study. Participants’ learning improved from the beginning to the end of the task: the formation of predictive stimulus-action-reward associations increased over time while prediction errors diminished.
Parkinson’s disease patients were shown affectively neutral or positive film clips before participating in the learning task. We predicted that induced positive affect would improve the formation of stimulus-action-reward associations (as reflected in higher SADRP values), especially toward the end of the task, with less pronounced effects on outcome evaluation (expressed in RPE). Evidence that positive affect was induced was provided by pre- and post-test Likert scales in which participants in the positive affect condition confirmed that they felt more positive and amused after compared to before viewing the positive movie clip, whereas participants in the neutral condition reported no change in affect after the clip. Indeed, learning (as measured by earned rewards) benefited from induced positive affect. Consistent with our predictions, SADRP at the late stages of learning was larger in the positive compared to neutral affect group. Positive affect did not influence RPE values, not even when zooming in on the initial learning phase.
These findings present a striking parallel with recent findings on the effects of DA medication on reward-based learning in the same task. Using a within-subjects design, van Wouwe et al. (2012) observed that PD patients who were on compared to off their regular DA medication showed higher SADRP values, especially toward the later stages of learning, while RPEs remained unaltered, even in early stages of learning. Although by no means conclusive, the present data are suggestive of the notion that induced positive affect incurs an increase in tonic DA which then modulates learning in much the same way as DA medication does.
Neuroimaging and computational studies (Haruno and Kawato, 2006a,b) have suggested that SADRP values are linked to activity in the anterior putamen (and its associated sensorimotor circuitry involved in action selection), whereas RPE values are linked to activity in the caudate and ventral striatum (and their associated circuitry involved in hypothesis generation and value updating). The present findings therefore provide consistent, albeit indirectly, with the idea that induced positive affect may benefit the action-oriented learning functions of the severely dopamine-depleted putamen in PD patients, while leaving the processing of RPEs in the less affected caudate and ventral striatum unaltered. During initial stages of mild PD, the disease is characterized by DA depletions in the striatum that produce motor deficits, involving the motor loop (including putamen and supplementary motor areas). During later stages of more progressed PD, these effects extend to the dorsolateral loop (including the dorsolateral prefrontal cortex and the dorsolateral head of the caudate) and still later to the orbitofrontal loop (lateral orbitofrontal cortex, ventromedial head of caudate) and the anterior cingulate loop (involving the anterior cingulate cortex and the ventral striatum, in particular the nucleus accumbens). Based on these differential effects of PD progression on striatal subregions and associated circuitries (Kaasinen and Rinne, 2002), it can be argued that SADRP should indeed benefit more from DA medication and positive affect than RPE, as the putamen is usually more depleted from DA than caudate and ventral striatum early in the disease. However, since the present data do not speak directly to the issue of striatal subcomponents, future work should confirm these speculations.
Relation to Other Studies: Reinforcement Learning in Parkinson’s Disease
Studies of PD patients are important from a clinical perspective, but also provide a complementary approach to investigate the role of the basal ganglia and DA function in reward-based learning. The primary treatment to reduce PD motor symptoms such as tremor, bradykinesia, and rigidity, aims to increase DA availability and activity, including, most prominently, medication functioning as a DA precursor (typically levodopa) or as a DA agonist (Hornykiewicz, 1974). Because regions of the striatum are differentially affected by the disease, DA medication differentially affects these structures and their related functions. Although DA pharmacotherapy successfully improves motor deficits in PD, its effects on cognitive processes are more ambivalent. For example, DA medication can have positive and negative consequences on cognitive performance among PD patients (Cools, 2006). Specific cognitive functions that rely on the heavily DA-depleted dorsolateral and motor loops improve with DA pharmacotherapy, whereas other aspects of cognition that depend on ventral circuitries of the basal ganglia and remain relatively spared in early PD are impaired by DA medication (Gotham et al., 1988; Swainson et al., 2000; Cools et al., 2001; Czernecki et al., 2002).
However, not all aspects of reward-based decision-learning are compromised by DA medication. For example, Shohamy et al. (2005) found that feedback-based learning improved when PD patients were ON DA medication compared to when they were OFF medication. Frank et al. (2004) showed that this benefit obtained specifically for learning that certain actions are likely to yield reward, whereas learning that certain other actions are likely to yield punishment was negatively affected by DA medication. This pattern of levodopa-induced improved incentive learning but impaired avoidance learning, replicated by Bodi et al. (2009), is taken to reflect strengthened disinhibition along the direct route and weakened inhibition along the indirect route within the basal ganglia.
Although studies converge on the notion that striatal regions play a key role in reward-based decision-learning (Knutson et al., 2001; McClure et al., 2003; Frank et al., 2004; O’Doherty et al., 2004; Tricomi et al., 2004; Seger and Cincotta, 2005; Haruno and Kawato, 2006a,b; Bodi et al., 2009; Cools et al., 2009), the modulatory role of DA in different structures within the striatum is not yet well established. DA might have dissociable effects on different component processes of reward-based decision-learning (vis. outcome evaluation, supported by caudate and ventral striatum, versus reward prediction, supported by anterior putamen).
While reinforcement learning appears to depend on phasic DA dynamics, the modulation of dopamine levels by medication (L-dopa) or, allegedly, by positive affect, is of more tonic nature, begging the question why and how tonic alterations of DA levels should influence reinforcement learning. First, there is evidence that administration of L-dopa yields an increase in presynaptic dopamine synthesis increases (Tedroff et al., 1996; Pavese et al., 2006) and in phasic (spike-dependent) DA bursts (Keller et al., 1988; Harden and Grace, 1995). Second, in a probabilistic reinforcement learning paradigm, Parkinson’s patients learned better from positive feedback when they were ON compared to OFF their dopaminergic medication (Frank et al., 2004). It should be noted that in the latter study, learning from NEGATIVE feedback was impaired when PD patients learned were ON compared to OFF their dopaminergic medication; presumably, the continuous medication-induced stimulation of D2 receptors effectively precludes the detection of phasic dips in DA firing (Frank, 2005). Thus, Frank’s patient and modeling work showed that PD patients OFF medication more effectively process negative feedback in comparison to positive feedback whereas PD patients ON medication show the opposite pattern. In the current task though, a RPE results from either unexpected positive or negative feedback, thus a preference for positive or negative feedback cannot be distinguished based on SADRP and RPE values.
Relation to Other Studies: Positive Affect
Induced positive affect has been shown to yield improved performance in a variety of tasks that rely on frontostriatal dopaminergic interactions (e.g., Dreisbach and Goschke, 2004; Dreisbach, 2006; Van der Stigchel et al., 2011; van Wouwe et al., 2011a; for a recent review see Chiew and Braver, 2011). Findings that patients with PD show performance impairments in these tasks (e.g., Kitagawa et al., 1994) lend some suggestive credit to the notion that performance improvements after positive affect might result from changes in dopaminergic levels in the brain. Circumstantial evidence in support of this notion derives from similarities between the effects of induced positive affect and those of genetic variations in DA polymorphisms as well as individual differences in spontaneous eye-blink rate. Compared to individuals with low blink rates, greater cognitive flexibility was observed in individuals with high blink rates (allegedly associated with high tonic DA levels), especially if they were carriers of the DRD4 exon III 4/7 genotype (associated with high levels of prefrontal DA; Dreisbach et al., 2005).
In a recent study (van Wouwe et al., 2011a), we provided indirect evidence for a modulatory effect of induced positive affect on the dynamics of subcortical dopamine. In accordance with the logic explicated in Frank’s model (outlined above), if positive affect serves to increase striatal DA levels, then the increased availability of DA molecules in the synaptic cleft should limit the effects of phasic dips as triggered by negative feedback and errors. As a result, a less pronounced dopaminergic error signal should be carried to the dorsal medial frontal cortex, which should in turn give rise to a less pronounced error-related negativity as measured using scalp-EEG immediately after a performance error. Consistent with Ashby’s notion that induced positive affect produced a transient boost in DA, van Wouwe et al. (2011a) observed reduced amplitudes for the error-related negativity after watching comedy clips compared to neutral film fragments.
The current study contributed insights beyond those reported above by focusing on component processes of reward-based decision-learning that rely on different striatal circuits, and by examining the effects of induced positive affect on model parameters representing these component processes. The evidence reported here likens the effects of induced positive effect directly to the effects of DA agonists in PD patients. Our results allow us to articulate with greater precision the effect of positive affect on the caudate and ventral striatum on the one hand and on the putamen on the other. While positive affect leaves outcome evaluation processes (supported by caudate and ventral striatum) unaffected, learning to predict which actions yield reward (supported by the anterior putamen and associated motor circuitry) is improved, at least transiently, after viewing movie clips containing positive and amusing content, such as Charlie Chaplin slapstick.
The present observations touch also on recent findings on the effect of motivational incentives on the efficiency of cognitive performance in patients with PD (Harsay et al., 2010). DA neurons in the striatal reward system respond with a phasic increase in firing to stimuli that cue the prospect of upcoming reward (Schultz et al., 1992; Kawagoe et al., 2004). Evidence from non-human primates suggests direct striatal dopaminergic modulation of reward-dependent improvements of performance (Nakamura and Hikosaka, 2006). Neural decrements in reward-processing among patients with PD presumably reflect degeneration of dopaminergic neurotransmission (Backman et al., 2006; Kaasinen et al., 2000), and may be remedied by increasing reward (Goerendt et al., 2004). Due perhaps to deterioration in dopaminergic striatal circuitry, antisaccade performance is subject to decline in individuals with PD; the prospect of future reward, however, provides a motivational incentive for optimizing oculomotor preparation (Harsay et al., 2010).
Limitations
Some limitations apply to the experimental paradigm adopted here. First, in our version of the reward-based learning task, the patients always received the 90:10 block before the 80:20 block. The finding that probability did not influence any of the effects of interest may therefore have been confounded by an order effect (e.g., the increased difficulty associated with lower probabilities might have been countered by increases in learning efficiency due to practice). We used a fixed easy-to-more-difficult order to ascertain successful learning and comfortable participation in all of our patients. We readily acknowledge that, had we not used such a fixed order, we might have been able to show that, for instance, positive affect benefits learning in difficult situations more than in easier conditions.
The between-subjects design used in the present study has some obvious disadvantages. However, as confirmed in an informal pilot, when we combined the two affect conditions into one within-subjects design, the experiment lasted too long, such that (1) some patients experienced substantial fatigue during the second subsession, and (2) the wear-out of dopamine medication started to play a role (with either decreased performance toward the end of the session, or the need to take medication during the second half of the session). Hence, we decided to opt for a between-subjects design; despite the increase in variance, the effects of induced effect turned out to be robust enough to counter this disadvantage. Yet, future studies should aim at replicating such findings in a within-subjects setting.
The addition of age-matched control groups might have supplemented the conclusions of this study in interesting ways. In particular, such an addition could confirm that the patients were more impaired than healthy controls in reinforcement learning (as documented in the literature), and could specify how much positive affect ameliorated deficits relative to performance in healthy controls. Yet, the key rationale of studying PD patients was that the nature of their specific impairment is such that, if the dopamine hypothesis were correct, their deficient reinforcement learning performance should benefit from induced positive affect. Such a finding (as we obtained) is in and of itself important and informative: DA-related deficits in PD can be remedied (at least transiently) by such a simple (and pleasant) measure as induced positive affect. The importance of that finding should in itself not depend on comparing this effect to age-matched controls, even though we recognize the potential supplemental value of such a comparison, and recommend such comparisons for future studies.
Stimulus-action-dependent reward prediction and RPE have been linked to the role of DA bursts at different time points and in different stages of learning. These distinctions notwithstanding, SADRP and RPE are not entirely independent at the behavioral level. By and large, increases in SADRP values are associated with decreases in RPE values. Thus, while our findings suggest that induced positive affect impacts putamen-based processes more than processes supported by caudate and ventral striatum, and that induced positive affect impacts late stages of learning more than early stages, these findings do not entirely exclude the possibility that the caudate and ventral striatum are modulated by positive affect altogether.
Finally, we did not obtain clinical measures of disease severity or progression, such as UPDRS scores or Hoehn–Yahr assessments, nor did we pursue formal diagnostic interviews by specialists. Thus, we cannot exclude that our positive and neutral affect groups differed in terms of relevant clinical variables. Yet, since the groups did not differ in years since disease onset, medication dosage, or other background variables, and since our samples included only patients who could ambulate independently (rendering it unlikely that they met criteria for Hoehn–Yahr stages IV or V), and since the sample sizes in our groups were rather considerable in comparison to typical studies in the field (for evidence on individual differences among PD patients revealed only in larger samples, see Wylie et al., 2009), we are confident that the results reported here are representative and robust. The finding that the SADRP values, previously associated with putamen function, benefit more from induced positive affect than the RPE values, previously associated with the function of the caudate and accumbens nuclei, appears to underline the suggestion that our patient groups were on average in relatively early stages of their disease, affecting the putamen more than other striatal areas. We acknowledge the lack of UPDRS scores or Hoehn–Yahr assessments limits the conclusiveness of our inferences (even though such measures do not provide direct measures of putamen versus caudate/accumbens involvement; in fact, identical UPDRS scores may actually reflect very different underlying patterns of striatal circuit dysfunction). However, we view the potential of our approach to differentiate these possible patterns (by incorporating the Q-model and the documented correspondence of the Q-learning model’s key parameters to striatal substructures) as a major strength of our study approach. This approach allows us to articulate with greater precision which aspects of the striatal circuitry benefits from induced positive affect.
Conclusion
In conclusion, induced positive affect modulates computational measures of probabilistic reward-based decision-learning in patients diagnosed with PD. Previous work has shown these measures to rely on the nucleus caudatus and nucleus accumbens (outcome evaluation during the early phases of learning) and the anterior putamen (reward prediction during later phases of learning). We observed that positive affect facilitated learning, through its effects on reward prediction rather than outcome evaluation; these effects show a striking similarity to the effects of dopaminergic medication. Among PD patients who were on their regular medication regime, watching a few minutes of comedy clips apparently served to remedy dopamine-related problems associated with frontostriatal circuitry and, consequently, in learning to predict which actions will yield reward.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Alexander, G. E., Crutcher, M. F., and DeLong, M. R. (1990). Basal ganglia-thalamocortical circuits: parallel substrates for motor, oculomotor, ‘prefrontal’ and ‘limbic’ functions. Prog. Brain Res. 85, 119–147.
Ashby, F. G., Isen, A. M., and Turken, A. U. (1999). A neuropsychological theory of positive affect and its influence on cognition. Psychol. Rev. 106, 529–550.
Ashby, F. G., Valentin, V. V., and Turken, A. U. (2002). “The effects of positive affect and arousal on working memory and executive attention: neurobiology and computational models,” in Emotional Cognition: From Brain to Behavior, eds S. Moore and M. Oaksford (Amsterdam: John Benjamins), 245–287.
Backman, L., Nyberg, L., Lindenberger, U., Li, S. C., and Farde, L. (2006). The correlative triad among aging, dopamine, and cognition: current status and future prospects. Neurosci. Biobehav. Rev. 30, 791–807.
Balleine, B. W., Delgado, M. R., and Hikosaka, O. (2007). The role of the dorsal striatum in reward and decision-making. J. Neurosci. 27, 8161–8165.
Bertsekas, D. P., and Tsitsiklis, J. N. (1996). Neuro-Dynamic Programming. Belmont: Athena Scientific.
Bjorklund, A., and Dunnett, S. B. (2007). Dopamine neuron systems in the brain: an update. Trends Neurosci. 30, 194–202.
Bodi, N., Keri, S., Nagy, H., Moustafa, A., Myers, C. E., Daw, N., Dibo, G., Takats, A., Bereczki, D., and Gluck, M. A. (2009). Reward-learning and the novelty-seeking personality: a between- and within-subjects study of the effects of dopamine agonists on young Parkinson’s patients. Brain 132, 2385–2395.
Burgdorf, J., and Panksepp, J. (2006). The neurobiology of positive emotions. Neurosci. Biobehav. Rev. 30, 173–187.
Chiew, K. S., and Braver, T. S. (2011). Positive affects versus reward: emotional and motivational influences on cognitive control. Front. Psychol. 2:279. doi:10.3389/fpsyg.2011.00279
Claassen, D. O., van den Wildenberg, W. P. M., Ridderinkhof, K. R., Jessup, C. K., Harrison, M. B., Wooten, G. F., and Wylie, S. A. (2011). The risky business of dopamine agonists in Parkinson disease and impulse control disorders. Behav. Neurosci. 125, 492–500.
Cools, R. (2006). Dopaminergic modulation of cognitive function-implications for L-DOPA treatment in Parkinson’s disease. Neurosci. Biobehav. Rev. 30, 1–23.
Cools, R., Barker, R. A., Sahakian, B. J., and Robbins, T. W. (2001). Enhanced or impaired cognitive function in Parkinson’s disease as a function of dopaminergic medication and task demands. Cereb. Cortex 11, 1136–1143.
Cools, R., Frank, M. J., Gibbs, S. E., Miyakawa, A., Jagust, W., and D’Esposito, M. (2009). Striatal dopamine predicts outcome-specific reversal learning and its sensitivity to dopaminergic drug administration. J. Neurosci. 29, 1538–1543.
Cools, R., Sheridan, M. A., Jacobs, E., and D’Esposito, M. (2007). Impulsive personality predicts dopamine-dependent changes in fronto-striatal activity during component processes of working memory. J. Neurosci. 27, 5506–5514.
Cooper, J. A., Sagar, H. J., Doherty, S. M., Jordan, N., Ridswell, P., and Sullivan, E. V. (1992). Different effects of dopaminergic and anticholinergic therapies on cognitive and motor function in Parkinson’s disease. Brain 115, 1701–1725.
Czernecki, V., Pillon, B., Houeto, J., Pochon, J., Levy, R., and Dubois, B. (2002). Motivation, reward, and Parkinson’s disease: influence of dopatherapy. Neuropsychologia 40, 2257–2267.
Dayan, P., Kakade, S., and Montague, P. (2000). Learning and selective attention. Nat. Neurosci. 3, S1218–S1223.
Dreisbach, G. (2006). How positive affect modulates cognitive control: the costs and benefits of reduced maintenance capability. Brain Cogn. 60, 11–19.
Dreisbach, G., and Goschke, T. (2004). How positive affect modulates cognitive control: reduced perseveration at the cost of increased distractibility. J. Exp. Psychol. Learn. Mem. Cogn. 30, 343–353.
Dreisbach, G., Müller, J., Goschke, T., Strobel, A., Schulze, K., Lesch, K. P., and Brocke, B. (2005). Dopamine and cognitive control: the influence of spontaneous eye-blink rate and dopamine gene polymorphisms on perseveration and distractibility. Behav. Neurosci. 119, 483–490.
Floresco, B. S., Yang, C. R., Phillips, A. G., and Blaha, C. D. (1998). Basolateral amygdala stimulation evokes glutamate receptor-dependent dopamine efflux in the nucleus accumbens of the anaesthesized rat. Eur. J. Neurosci. 10, 1241–1251.
Frank, M. J. (2005). Dynamic dopamine modulation in the basal ganglia: a neurocomputational account of cognitive deficits in medicated and nonmedicated parkinsonism. J. Cogn. Neurosci. 17, 51–72.
Frank, M. J., Seeberger, L. C., and O’Reilly, R. C. (2004). By carrot or by stick: cognitive reinforcement learning in parkinsonism. Science 306, 940–943.
Gerardin, E., Lehericy, S., Pochon, J. B., Tezenas du Montcel, S., Mangin, J. F., Poupon, F., Agid, Y., Le Bihan, D., and Marsault, C. (2003). Foot, hand, face, and eye representation in the human striatum. Cereb. Cortex 13, 162–169.
Goerendt, I. K., Lawrence, A. D., and Brooks, D. J. (2004). Reward processing in health and Parkinson’s disease: neural organization and reorganization. Cereb. Cortex 14, 73–80.
Gotham, A., Brown, R., and Marsden, C. (1988). ‘Frontal’ cognitive function in patients with Parkinson’s disease ‘on’ and ‘off’ levodopa. Brain 111, 299–321.
Harden, D. G., and Grace, A. A. (1995). Activation of dopamine cell firing by repeated l-DOPA administration to dopamine-depleted rats: its potential role in mediating the therapeutic response to l-DOPA treatment. J. Neurosci. 15, 6157–6166.
Harsay, H. A., Buitenweg, J. I. V., Wijnen, J. G., Guerreiro, M. J. S., and Ridderinkhof, K. R. (2010). Remedial effects of motivational incentive on declining cognitive control in healthy aging and Parkinson’s disease. Front. Aging Neurosci. 2:144. doi:10.3389/fnagi.2010.00144
Haruno, M., and Kawato, M. (2006a). Different neural correlates of reward expectation and reward expectation error in the putamen and caudate nucleus during stimulus-action reward association learning. J. Neurophysiol. 95, 948–959.
Haruno, M., and Kawato, M. (2006b). Heterarchical reinforcement-learning model for integration of multiple cortico-striatal loops: fMRI examination in stimulus-action-reward association learning. Neural Netw. 19, 1242–1254.
Hornykiewicz, O. (1974). Mechanisms of action of L-DOPA in Parkinsons-disease. Life Sci. 15, 1249–1259.
Hutchison, K. E., Trombley, R. P., Collins, F. L., McNeil, D. W., Turk, C. L., Carter, L. E., and Leftwich, M. J. T. (1996). A comparison of two models of emotion: can measurement of emotion based on one model be used to make inferences about the other? Pers. Indiv. Differ. 21, 785–789.
Kaasinen, V., Nagren, K., Hietala, J., Oikonen, V., Vilkman, H., Farde, L., Halldin, C., and Rinne, J. O. (2000). Extrastriatal dopamine D2 and D3 receptors in early and advanced Parkinson’s disease. Neurology 54, 1482–1487.
Kaasinen, V., and Rinne, J. O. (2002). Functional imaging studies of dopamine system and cognition in normal aging and Parkinson’s disease. Neurosci. Biobehav. Rev. 26, 785–793.
Kawagoe, R., Takikawa, Y., and Hikosaka, O. (2004). Reward-predicting activity of dopamine and caudate neurons – a possible mechanism of motivational control of saccadic eye movement. J. Neurophysiol. 91, 1013–1024.
Keller, R. W., Kuhr, W. G., Wightman, R. M., and Zigmond, M. J. (1988). The effect of l-dopa on in vivo dopamine release from nigrostriatal bundle neurons. Brain Res. 447, 191–194.
Kitagawa, M., Fukushima, J., and Tashiro, K. (1994). Relationship between antisaccades and the clinical symptoms in Parkinson’s disease. Neurology 44, 2285–2289.
Knutson, B., Adams, C., Fong, G., and Hommer, D. (2001). Anticipation of increasing monetary reward selectively recruits nucleus accumbens. J. Neurosci. 21, 1–5.
McAuley, J. H. (2003). The physiological basis of clinical deficits in Parkinson’s disease. Prog. Neurobiol. 69, 27–48.
McClure, S., Berns, G., and Montague, P. (2003). Temporal prediction errors in a passive learning task activate human striatum. Neuron 38, 339–346.
Moustafa, A. A., Sherman, S. J., and Frank, M. J. (2008). A dopaminergic basis for working memory, learning and attentional shifting in parkinsonism. Neuropsyqschologia 46, 3144–3156.
Nakamura, K., and Hikosaka, O. (2006). Role of dopamine in the primate caudate nucleus in reward modulation of saccades. J. Neurosci. 26, 5360–5369.
O’Doherty, J., Dayan, P., Schultz, J., Deichmann, R., Friston, K., and Dolan, R. J. (2004). Dissociable roles of ventral and dorsal striatum in instrumental conditioning. Science 304, 452–454.
Oyama, K., Hernadi, I., Iijima, T., and Tsutsui, K.-I. (2010). Reward prediction erro coding in dorsal striatal neurons. J. Neurosci. 30, 11447–11457.
Pavese, N., Evans, A. H., Tai, Y. F., Hotton, G., Brooks, D. J., Lees, A. J., and Piccini, P. (2006). Clinical correlates of levodopa-induced dopamine release in Parkinson disease: a pet study. Neurology 67, 1612–1617.
Schultz, W. (2006). Behavioral theories and the neurophysiology of reward. Annu. Rev. Psychol. 57, 87–115.
Schultz, W., Apicella, P., Scarnati, E., and Ljungberg, T. (1992). Neuronal activity in monkey ventral striatum related to the expectation of reward. J. Neurosci. 12, 4595–4610.
Schultz, W., Tremblay, L., and Hollerman, J. R. (2003). Changes in behavior-related neuronal activity in the striatum during learning. Trends Neurosci. 26, 321–328.
Seger, C. A., and Cincotta, C. M. (2005). The roles of the caudate nucleus in human classification learning. J. Neurosci. 25, 2941–2951.
Seymour, B., Daw, N., Dayan, P., Singer, T., and Dolan, R. (2007). Differential encoding of losses and gains in the human striatum. J. Neurosci. 27, 4826–4831.
Shohamy, D., Myers, C. E., Grossman, S., Sage, J., and Gluck, M. A. (2005). The role of dopamine in cognitive sequence learning: evidence from Parkinson’s disease. Behav. Brain Res. 156, 191–199.
Swainson, R., Rogers, R. D., Sahakian, B. J., Summers, B. A., Polkey, C. E., and Robbins, T. W. (2000). Probabilistic learning and reversal deficits in patients with Parkinson’s disease or frontal or temporal lobe lesions: possible adverse effects of dopaminergic medication. Neuropsychologia 38, 596–612.
Sutton, R. S., and Barto, A. G. (1998). Reinforcement Learning: An Introduction. Cambridge: MIT Press.
Tedroff, J., Pedersen, M., Aquilonius, S. M., Hartvig, P., Jacobsson, G., and Långström, B. (1996). Levodopa-induced changes in synaptic dopamine in patients with Parkinson’s disease as measured by [11c] raclopride displacement and PET. Neurology 46, 1430–1436.
Tricomi, E., Delgado, M., and Fiez, J. (2004). Modulation of caudate activity by action contingency. Neuron 41, 281–292.
Van der Stigchel, S., Imants, P., and Ridderinkhof, K. R. (2011). Positive affect increases cognitive control in the antisaccade task. Brain Cogn. 75, 177–181.
van Wouwe, N. C., Band, G. P. H., and Ridderinkhof, K. R. (2011a). Positive affect modulates flexibility and evaluative control: evidence from the N2 and ERN. J. Cogn. Neurosci. 23, 425–539.
van Wouwe, N. C., Ridderinkhof, K. R., van den Wildenberg, W. P. M., Band, G. P. H., Abisogun, A. A., Elias, W. J., Frysinger, R. C., and Wylie, S. A. (2011b). Deep brain stimulation of the subthalamic nucleus improves reward-based decision-learning in Parkinson’s disease. Front. Neurosci. 5:30. doi:10.3389/fnhum.2011.00030
van Wouwe, N. C., Ridderinkhof, K. R., Band, G. P., van den Wildenberg, W. P. M., and Wylie, S. A. (2012). Dose dependent dopaminergic modulation of reward-based learning in Parkinson’s disease. Neuropsychologia 50, 583–591.
Wylie, S. A., Ridderinkhof, K. R., Elias, W. J., Frysinger, R. C., Bashore, T. R., Downs, K. E., van Wouwe, N. C., and van den Wildenberg, W. P. M. (2010). Subthalamic nucleus stimulation influences expression and suppression of impulsive behavior in Parkinson’s disease. Brain 133, 3611–3624.
Keywords: Parkinson’s disease, positive affect, frontostriatal circuitry, probabilistic learning
Citation: Ridderinkhof KR, van Wouwe NC, Band GPH, Wylie SA, Van der Stigchel S, van Hees P, Buitenweg J, van de Vijver I and van den Wildenberg WPM (2012) A tribute to Charlie Chaplin: induced positive affect improves reward-based decision-learning in Parkinson’s disease. Front. Psychology 3:185. doi: 10.3389/fpsyg.2012.00185
Received: 05 July 2011; Accepted: 21 May 2012;
Published online: 13 June 2012.
Edited by:
Wim Notebaert, Ghent University, BelgiumReviewed by:
Rachael D. Seidler, University of Michigan, USAMaarten A. S. Boksem, Erasmus University Rotterdam, Netherlands
Copyright: © 2012 Ridderinkhof, van Wouwe, Band, Wylie, Van der Stigchel, van Hees, Buitenwegs, van de Vijver and van den Wildenberg. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: K. Richard Ridderinkhof, Department of Psychology, University of Amsterdam, Weesperplein 4, 1018 XA Amsterdam, Netherlands. e-mail:ay5yLnJpZGRlcmlua2hvZkB1dmEubmw=