
- Department of Linguistics, University of Southern California, Los Angeles, CA, USA
Segmenting stimuli into events and understanding the relations between those events is crucial for understanding the world. For example, on the linguistic level, successful language use requires the ability to recognize semantic coherence relations between events (e.g., causality, similarity). However, relatively little is known about the mental representation of discourse structure. We report two experiments that used a cross-modal priming paradigm to investigate how humans represent the relations between events. Participants repeated a motor action modeled by the experimenter (e.g., rolled a ball toward mini bowling pins to knock them over), and then completed an unrelated sentence-continuation task (e.g., provided a continuation for “Peter scratched John.…”). In two experiments, we tested whether and how the coherence relations represented by the motor actions (e.g., causal events vs. non-causal events) influence participants’ performance in the linguistic task. (A production study was also conducted to explore potential syntactic priming effects.) Our analyses focused on the coherence relations between the prompt sentences and participants’ continuations, as well as the referential shifts in the continuations. As a whole, the results suggest that the mental representations activated by motor actions overlap with the mental representations used during linguistic discourse-level processing, but nevertheless contain fine-grained information about sub-types of causality (reaction vs. consequence). In addition, the findings point to parallels between shifting one’s attention from one-event to another and shifting one’s attention from one referent to another, and indicate that the event structure of causal sequences is conceptualized more like single events than like two distinct events. As a whole, the results point toward common representations activated by motor sequences and discourse-semantic relations, and further our understanding of the mental representation of discourse structure, an area that is still not yet well-understood.
Introduction
Our ability to segment stimuli into events and to understand the relations between those events is a key aspect of human cognition, and crucial for understanding and interacting with the world (e.g., Zacks and Swallow, 2007). Within the domain of cognitive psychology, there exists a large body of work investigating what cues humans use to recognize relations such as causality (e.g., Michotte, 1946/1963; Kanizsa and Vicario, 1968; Schlottmann et al., 2006) and similarity (e.g., Gati and Tversky, 1984; Gentner and Markman, 1997; Simmons and Estes, 2008). Many of these studies have focused on visual stimuli, such as the collision events used by Michotte and colleagues. However, as humans we also process information about events in other modalities, including language. In the linguistic domain, successful comprehension relies on listeners being able to recognize and understand the different kinds of relations that can hold between clauses (e.g., Hobbs, 1979; Mann and Thompson, 1986; Sanders et al., 1992; Kehler, 2002; Asher and Lascarides, 2003). For example, if someone says to a listener that “Tom yelled at Peter” and then continues with “Peter kicked Tom’s car,” the listener’s understanding of what the speaker is trying to convey will be very different depending on whether she construes Tom’s yelling to be what resulted in Peter kicking Tom’s car (a causal relation), or whether she thinks Tom yelled at Peter because Peter had kicked his car (an explanation relation). In other words, the listener’s inferences about the coherence relation between these two clauses (and correspondingly, the events they describe) have a fundamental effect on how she understands the situation. As noted by Webber et al. (2003), “a text means more than the sum of its component sentences. One source of additional meaning are relations taken to hold between adjacent sentences” (see also Sanders et al., 1993, p. 545). Thus, for successful communication, comprehenders need to be able to figure out the intended coherence relations between clauses1.
However, existing work in the linguistic domain has not reached a consensus about (i) what coherence relations there are, or (ii) how they are represented (see e.g., Sanders et al., 1993; Webber et al., 2003 for discussion). Some researchers argue that all coherence relations can be derived from a small set of primitives (e.g., Sanders et al., 1992; Kehler, 2002) whereas others work with a large, relatively unconstrained set of relations (e.g., Mann and Thompson, 1988). Furthermore, researchers differ in how they represent coherence relations, e.g., as hierarchical structures or as logical rules, and in what role they attribute to explicit connectives such as “because” and “as a result.”
This paper aims to further our understanding of coherence relations – in particular, which relations are “psychologically real” and how they might be represented – by exploring the interface between the linguistic and non-linguistic domains. The experiments reported here used a cross-modal priming paradigm where participants carried out sequences of motor actions involving small objects, and then completed a seemingly unrelated linguistic sentence-continuation task. For example, a participant might roll a ball toward toy bowling pins in order to knock them over (cause-effect sequence), and then be asked to provide a continuation for a sentence such as “Peter tickled John.” Two experiments tested whether and how the coherence relations represented by the motor actions (e.g., causal events vs. events that do not involve causality) influence participants’ performance in the linguistic task.
Existing work has found evidence for action-language congruity effects in a range of areas, including the semantics of space and motion (e.g., Glenberg and Kaschak, 2002; Zwaan and Taylor, 2006; Glenberg et al., 2008) as well as emotional valence and motion (e.g., Casasanto and Dijkstra, 2010). For example, Zwaan and Taylor found that the physical act of rotating a knob interacts with the comprehension of sentences involving manual rotation, such as “Liza opened the pickle jar.” These findings also receive support from neurolinguistic investigations showing that the cortical areas activated during the processing of action verbs such as “kick” overlap with the areas that are activated when people physically perform the same action (e.g., Buccino et al., 2005; Pulvermüller et al., 2005; Tettamanti et al., 2005). However, the question of whether discourse-level aspects of language production may also involve domain-general representations is not yet well-understood. For some early evidence, see Kaiser (2009), summarized in the General Discussion.
Both of the experiments reported here make use of priming – i.e., the observation that prior exposure to a stimulus influences (often facilitates) subsequent processing of a similar stimulus. Prior work has shown that priming occurs in a range of linguistic domains, including syntax, semantics, and phonology. For example, in the domain of syntax, producing a particular syntactic structure boosts the likelihood of the speaker producing the same structure again (e.g., Bock, 1986; Pickering and Branigan, 1998). The two experiments reported here use priming to see if two processes – the observation and execution of motor actions on the one hand, and language production on the other hand – make use of the same (or overlapping) underlying representations. Priming provides us with a tool to identify and diagnose properties of the representations utilized during the observation and execution of actions and during language production, which can further our understanding of the abstract mental representations involved in the production and conceptualization of coherence relations.
The experiments reported here have two common goals. The first goal is to learn more about how people represent coherence relations in the linguistic domain. As mentioned above, this is an area that is not yet well-understood, and many central questions remain open. The second goal is to learn about the relation between the linguistic domain and the non-linguistic domain, especially in terms of how humans represent relations between events in these two domains.
Experiment 1 tested whether (i) performing a motor action involving a cause-effect relation can bias participants to produce causal relations in a subsequent, unrelated linguistic task, and whether (ii) our mental representations distinguish between different sub-types of causality. If carrying out causal motor actions influences participants’ linguistic choices in the production task, this provides evidence that the representations activated by the motor actions and discourse-level coherence representations overlap with each other. Furthermore, by taking a closer look at different kinds of causal relations – in particular the relation between causal sequences where the second action is an intentional reaction vs. causal sequences where the second action is an involuntary consequence – we can start to gain insights into what kind of information is encoded in these representations, i.e., how fine-grained they are.
Experiment 2 continues to explore the relation between linguistic and non-linguistic domains. Whereas Experiment 1 focuses on the question of whether fine-grained information about the relations between events can be represented in a domain-general way, Experiment 2 looks at a high-level, general property of events, namely event boundaries. This study has two main aims: first, to test whether the presence/absence of event boundaries in motor actions influences how participants complete the linguistic sentence-continuation task. In particular, it tests whether performing two distinct motor actions results in participants producing more continuations with two distinct subjects (i.e., continuations which shift attention to a new character), compared to a situation where only one motor action is performed. In other words, does shifting from one action to the next in one domain boost the likelihood of shifting from one referent to the next in another domain? We chose to analyze the subjects of participants’ continuation sentences because of the well-known connection between subject hood and topicality (Reinhart, 1982; Chafe, 1994; Lambrecht, 1994). In other words, analyzing the subjects of the continuation sentences can provide a measure of topic-shifting, allowing us to assess whether shifting from one action to the next (in the domain of motor actions) has consequences on the linguistic level in terms of topic-shifts. Second, in order to gain insights into how causality is represented, Experiment 2 tests whether a causal action sequence patterns more like a sequence of two distinct actions or like a single action. Because causal sequences often consist of multiple sub-events (e.g., event 1: I roll the ball, event 2: the bowling pins fall over), it is not a priori clear whether they are conceptualized as a single event (possibly with complex internal structure) or as two separate events.
Broadly speaking, the research presented in this paper has implications for our understanding of the mental representation of coherence relations, an area that is not yet well-understood. The results suggest that motor actions activate richly encoded representations that can overlap, on an abstract level, with discourse-level aspects of language. Investigating effects of motor actions on language further contributes to our understanding of causality sub-types and how causal sequences are conceptualized.
Experiment 1
Experiment 1 focuses on two related issues, namely (i) the domain-generality of coherence representations and (ii) the level of detail present in these representations. In exploring the domain-generality of how people represent relations between events, this study focuses on the notion of causality. Causal connections have been argued to be fundamental to how humans conceptualize events (e.g., Sanders, 2005; see also Trabasso and van den Broek, 1985; Wolfe et al., 2005 on the facilitative effects of causal connections on memory and processing), and Experiment 1 tests whether causal relations between physical events involve the same kinds of mental representations as causal relations between linguistically encoded events. Specifically, Experiment 1 tests whether execution of motor actions that represent causal relations influences the rate of causal relations produced in a language task.
In addition, this study also asks how detailed such causality representation are. Do comprehenders merely activate a rudimentary notion of causality that is shared across domains, or does this domain-general representation include fine-grained information about sub-types of causality? In particular, this study focuses on the distinction between two sub-types of causality: (i) situations where the result is involuntary consequence and (ii) continuations where the result consists of a volitional, intentional reaction. In the subsequent discussion, these two causal sub-types are referred to as the consequence-type and the reaction-type. Examples are shown in (1). In (1a), the result of falling over is an involuntary consequence of being kicked, whereas in (1b), the act of kicking back is a deliberate, intentional reaction to the original kicking event.
JasonkickedMatt. Mattfellover. ⇒ consequencetype (1a)
JasonkickedMatt. Mattkickedhimback. ⇒ reactiontype (1b)
Although most linguistic approaches to coherence relations do not distinguish these two sub-types of causality, this distinction is made in Rhetorical Structure Theory (RST, Mann and Thompson, 1988), a theory which aims to provide a descriptive characterization of how text is organized. Mann and Thompson propose a large number of different discourse relations, including “Volitional result” and “Non-volitional result.” The former is (i) a situation where the initial action/situation causes another action that is volitional, whereas the latter is (ii) a situation where the initial action/situation causes another action that is not volitional (see Mann and Thompson, 1988, p. 275 for further details and examples). Thus, this corresponds to the distinction between consequence-type and reaction-type causal relations. Recent research on Dutch by Stukker et al. (2008) also makes a number of important, fine-grained distinctions regarding sub-types of causality, including intentional vs. non-intentional causation (see e.g., Stukker et al., 2008, p. 1305 regarding the use of the two connectives daardoor “because of that” and daroom “that’s why,” which are associated with non-intentional and intentional causality, respectively).
However, as Knott (1993) notes, it is important to ask whether this distinction is psychologically real: “How do we decide whether to subdivide or not to subdivide result into volitional result and non-volitional result? Again, different cuts through the space of relations are possible: why distinguish between volitional and non-volitional result, and not between, say, immediate and delayed result?” (Knott, 1993, p. 48). Shedding light on this question is the second main aim of Experiment 1. Thus, in addition to investigating the domain-generality of causality representations, this experiment also tests whether the distinction into reaction-type causality and consequence-type causality is justifiable, and in doing so, aims to gain new insights into how detailed our representations of causality are.
Materials and Methods
Participants
Thirty adult native English speakers from the University of Southern California community participated. All studies reported in this paper were approved by the University of Southern California University Park Institutional Review Board, which is fully accredited by the Association for the Accreditation of Human Research Protection Programs (AAHRPP).
Materials
Motor action trials (Priming trials). This study used 12 critical prime actions and 24 filler actions. The actions involved manipulating small toys or other objects. The critical actions were of three types: (i) Causal actions, (ii) Two-Event actions, and (iii) One-Event actions. In causal actions, one action causes something to happen (e.g., rolling a ball into dominos to make them fall over). Because the prime actions all involved inanimate objects/toys, the Causal actions all exemplify consequence-type causality. Two-event actions involved two distinct actions that are not causally connected (e.g., open and close a folding ruler, tie a bendy pencil into a knot). One-event actions involved events that could be construed as a single action (e.g., building part of a jigsaw puzzle). Examples are provided in Table 1 and Figure 1.

Figure 1. (A) Example of a Causal action. (B) Example of a One-Event action. (C) Example of a Two-Event action.

Table 1. Examples of prime actions.
Norming study. An initial norming study was conducted to ensure that the three action types were indeed conceptualized as intended. The norming study included a large set of different actions, including Causal actions, Two-Event, and One-Event actions, actions that involved sorting objects into categories, and other kinds of actions. Eighteen native English speakers (who did not participate in any of the other studies) watched the experimenter perform each action, repeated the action themselves and were then asked to indicate whether the action is best described as “two unrelated things happening,” “one thing causing another thing to happen,” “two similar things happening,” “objects being sorted into different categories or groups,” or “none of the above.” Based on the outcomes of this norming study, four action sequences that were consistently judged to be causal were identified and chosen as the Causal primes for the main experiment. Furthermore, four action sequences that were consistently judged to involve two unrelated things happening were chosen to be the Two-Event actions in the main experiment, and four One-Event action sequences were chosen from actions that in the priming study were not judged to involve causation, similarity, sorting, or multiple actions.
It is worth noting that the One-Event actions involve smaller sub-actions (e.g., combining the different jigsaw pieces into a bigger piece of the puzzle). Thus, the term “One-Event” refers to the cumulative event that is composed of the smaller sub-actions. These kinds of One-Event actions were used in order to keep the duration and intuitive “complexity” of the actions as comparable as possible. Crucially, people’s norming responses suggest that they did not perceive the One-Event actions as involving causality, similarity or two distinct events.
Generally speaking, any action or event can be viewed on different levels of granularity and decomposed into smaller and smaller sub-parts (e.g., the act of picking up a puzzle piece could be further decomposed into various sub-components involving visual perception, programming of a reaching motion, carrying out the reaching motion, and so on). What is most relevant here is that, relatively speaking, the sub-components of the One-Event trials are conceptualized as contributing toward a single goal-driven action (e.g., assembling a puzzle or building a sandwich). Thus, in this regard they contrast with the Two-Event actions, which do not form a single, coherent, goal-driven action.
The 24 filler actions used in the main study were also chosen on the basis of the norming study, to ensure that they were not perceived as involving causation, similarity, sorting or multiple actions. This was done to minimize any danger of the filler actions priming the target trials.
Sentence-continuation trials (Target trials). In the main experiment, the motor action prime trials were intermixed with semantically unrelated sentence-continuation trials, where participants provided a continuation sentence to a transitive prompt sentence (ex.2). The study contained 9 critical sentence-continuation trials and 24 filler sentence-continuation trials. The critical prompt sentences were transitive sentences with two male or two female names. The verbs were all agent-patient verbs involving physical interaction (kick, pinch, tickle, scratch, slap, punch, poke, push, hit)2. Agent-patient verbs were used in order to keep the semantic class of the verbs consistent. We chose to use verbs involving physical interactions because the prime actions were also physical (see e.g., Schlottmann et al., 2006; on differences between physical and non-physical causation, see also Kanizsa and Vicario, 1968).
Critical trials consisted of pairs of action primes and sentence-continuation prompts. Because there were three conditions (Causal prime action, Two-Event prime action, and One-Event prime action), we created three lists using a Latin-Square design. Reverse versions of each list were also created to control for effects of presentation order. In both forward and reverse lists, the prime action trial immediately preceded the sentence-continuation trial (i.e., there were no intervening trials between primes and targets). However, the filler actions and filler sentence-continuation trials were not presented in pairs, but rather pseudorandomly intermixed. This was done to ensure that participants would not perceive the actions and the sentences as being connected to each other.
Jason kicked Matt. Matt hit him in retaliation.
Jason kicked Matt. He was a rather violent person. (2)
Procedure
Participants sat in front of a computer screen at a wide table. On action trials, the screen showed the word “ACTION.” Upon seeing this, the participant turned away from the computer screen, watched the experimenter perform the intended action, and then repeated it. (The actions were not described in words at any point.) After completing the action, the participant would press a key on the keyboard. The screen would then move on to the next trial, and show the word ACTION (if the next trial was also an action trial), or it would show a sentence that the participant had to type a continuation for (if the next trial was a sentence-completion trial). On sentence-continuation trials, participants were instructed to write a natural-sounding continuation sentence for the sentence shown on the screen. They were encouraged to avoid overthinking, and to write what first came to mind. After completing the sentence-continuation, the participant would press a key, and the screen would either show the word ACTION or another sentence that the participant was asked to continue. This set-up was used to create the impression that the ordering of sentence-completion trials and action trials was random.
Coding
Continuations were double-coded by two blind coders, who analyzed the semantic coherence relation between the prompt sentence and the continuation sentence provided by the participant. For example, coders marked whether the event in the continuation sentence was a consequence of the event described in the prompt sentence, or perhaps an explanation why the prompt sentence event happened. The coding schema used the coherence relations from Kehler (2002) and Kehler et al. (2008). The relations that are most relevant to the current discussion are shown in Table 2, with examples. Building on Rohde (2008), training and detailed coding guidelines were used to ensure consistency among coders. Each coder went through the data independently. Coders were instructed to be conservative and to avoid over-interpretation, i.e., to err on the side of choosing “unclear” if there was not enough information available to determine the intended coherence relation. Subsequently, any discrepancies between the coders were resolved through discussion. If the two coders did not agree on a coherence relation or agreed that not enough information was available to determine intended coherence relation, the trial was coded as “unclear.” In the end, 4.8% of the critical trials were coded as having unclear/ambiguous relations.

Table 2. Some of the most important coherence relation labels used in coding, and examples from participants’ continuations.
In addition to the coherence relations from Kehler’s work, we also distinguished two sub-types of cause-effect relations, as mentioned above: (i) continuations where the result is involuntary/automatic consequence (consequence-type) and (ii) continuations where the result consists of a volitional, intentional reaction (reaction-type). There were also some continuations that were judged to be causal but it was unclear which of these two groups they belonged to. These were coded as a third sub-type, “unclear causal” (e.g., Joe punched Tom. Tom resented Joe for the result of his life. Here, Tom’s resenting Joe is caused by the punch, but it is not clear whether should be regarded as an involuntary, automatic response or – especially in light of the long duration of the resentment – as a more volitional reaction.) In the end, 5.6% of causal continuations were coded as “unclear causal.”
Predictions
This experiments tests two main predictions. The more general prediction has to do whether causal actions will boost the rate of causal continuations in the sentence-completion task. If causal action primes result in more causal continuations, this indicates that these two processes make use of the same (or overlapping) underlying representations.
The second main prediction has to do with the level of detail that is encoded in the relevant representations. Importantly, the causal motor action primes used in Experiment 1 only involve involuntary consequences (e.g., the bowling pins fall over). There are no causal primes with results that were volitional reactions. Thus, by looking at which sub-type participants’ causal continuations fall into, we can see whether the motor primes’ consequence-type nature is mirrored in the linguistic continuations. If yes, this suggests that the representations that overlap are more detailed than a simple causal/non-causal division might suggest, i.e., that the domain-general representation of causality is nevertheless sophisticated enough to include the distinction between consequence-type and reaction-type causal relations.
Both One-Event and Two-Event prime actions were included in order to check whether the simple number of events could play a role. In particular, it could be that what is being primed is the number of distinct events or predicates or the fact that there is a temporal sequence such that the second event occurs after the first event. According to this view, if someone carried out a two-event action – regardless of whether it’s causal or non-causal – this might prime them to produce a causal continuation rather than an explanation or an elaboration, for example. Thus, in order to be able to probe whether causal actions in particular are priming causal continuations in the sentence-completion task, Experiment 1 included both One-Event actions and non-causally related Two-Event actions (in addition to the Causal actions).
Results
To test whether the prime actions influenced participants’ continuations, mixed-effects logistic regression models were used (e.g., Baayen et al., 2008) to analyze (i) the overall proportion of causal continuations as a function of condition (Causal, One-Event, Two-Event), (ii) the proportion of consequence-type causal continuations as a function of condition, and (iii) the proportion of reaction-type causal continuations as a function of condition. In the initial general analyses, the three sub-types of causal continuations – reaction-type causal continuations, consequence-type causal continuations and unclear causal continuations – were all grouped together. In each analysis, participant, and item were included as random effects3. Mixed-effects regression models were used because the data is categorical and thus not well-suited for ANOVAs (see e.g., Jaeger, 2008). At the end of the results section, we also consider a production study that addresses the question of whether the results of Experiment 1 could be attributed to syntactic priming. As will become clear, we argue that this is not the case.
General Causality
Starting with the overall proportion of causal vs. non-causal continuations, we see in Figure 2A (which includes all three sub-types of causal continuations; consequence causal, reaction causal and unclear causal) that participants’ continuations do indeed show significant effects of prime type: after performing Causal actions, participants produced significantly more Causal continuations than after performing One-Event actions (80 vs. 66%, β = −1.115, Wald Z = −2.599, p < 0.01). The rate of Causal continuations after Causal actions was also marginally higher than the rate of Causal continuations after Two-Event actions (80 vs. 71%, β = −0.774, Wald Z = −1.811, p = 0.07). In contrast, there is no significant difference between the rate of Cause continuations occurring after One-Event and Two-Event actions (β = 0.227, Wald Z = 0.621, p = 0.53). In sum, the results indicate that performing a Causal action makes participants more likely to produce a causally connected continuation in the sentence-continuation task, as compared to non-Causal actions.
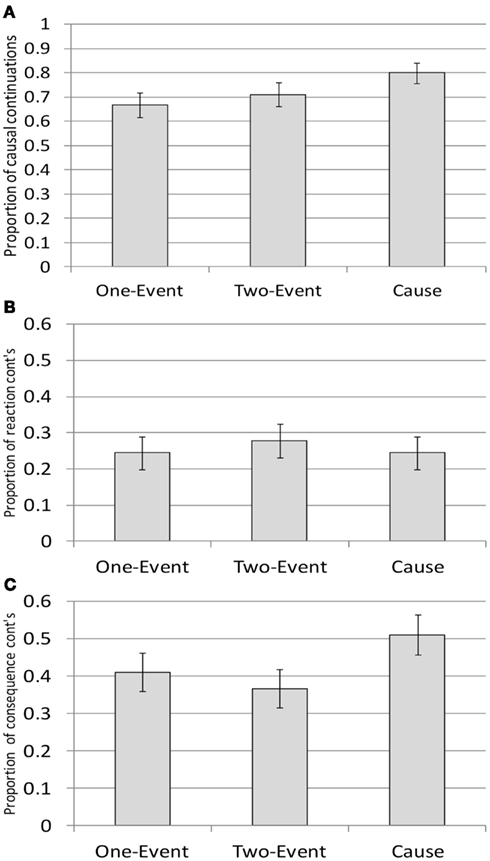
Figure 2. (A) Proportion of causal continuations as a function of the three different kinds of prime actions. (Error bars show ± 1 SE). (B) Proportion of reaction-type continuations as a function of the three different kinds of prime actions. (Error bars show ± 1 SE). (C) Proportion of consequence-type continuations as a function of the three different kinds of prime actions. (Error bars show ± 1 SE.).
Causality Sub-Types
When we take a more detailed look at the two kinds of causal sub-types, consequence-type causality and reaction-type causality, a striking asymmetry emerges in terms of whether their frequencies are affected by the action primes. First, when one considers the proportion of reaction-type causal continuations, shown in Figure 2B, there are no effects of priming (ps > 0.5). In general, the rate of reaction-type continuations is relatively low (below 30%).
In contrast, the rate of consequence-type causal continuations – as shown in Figure 2C – is clearly affected by the kind of motor action that participants performed during the priming trials: there are significantly more consequence-type continuations after Causal actions than after Two-Event actions (51 vs. 36.7% consequence continuations, β = −0.83, Wald Z = −2.466, p < 0.02). Similarly, the rate of consequence continuations was numerically higher after Causal actions than after One-Event actions (51 vs. 41%, β = −0.486, Wald Z = −1.542, p = 0.123). The rate of consequence-type continuations after One-Event actions and Two-Event actions did not differ significantly (β = −0.269, Wald Z = −0.84, p = 0.4).
Could These Effects be Due to Syntactic Priming? Production Study
A potential question that comes up is whether the effects observed here could be due to syntactic priming. It is well-known that hearing or producing a particular kind of syntactic structure makes people more likely to produce that structure again (Bock, 1986; Pickering and Branigan, 1998; Bock and Griffin, 2000; Arai et al., 2007). In Experiment 1, the primes were presented in a non-linguistic modality, but participants were not prevented from encoding them linguistically (e.g., silently describing the action in words). Thus, one might wonder whether the results reported in the preceding sections could be due to priming of syntactic representations.
To address this question, a production study was conducted: 24 new participants watched the experimenter carry out the action, repeated the action themselves, and were then asked to describe the action in words. More specifically, participants received the following instructions: “What did you do/what happened? You should write down whatever you feel best describes what happened, using whatever words seem most appropriate to you.” Afterward, the syntactic properties of participants’ descriptions were analyzed. As will become clear below, the results of the production study show that it is very unlikely that the results described above are due to syntactic priming.
For One-Event actions, 92.7% of people’s descriptions were monoclausal structures (e.g., “I arranged the sticks in a hexagon,” “I arranged puzzle pieces for the bottom left corner of a puzzle”). The rest were also one-clause descriptions but contained an additional fronted clause (e.g., “Using 6 puzzle pieces, I completed a portion of a puzzle of a red car”). In contrast, participants’ descriptions of Two-Event actions always included two verbs/two predicates, due to the semantics of these primes involving two distinct actions (e.g., “I made a cross out of two yellow sticks and then rolled a red die,” “I put two sticks on top of each other and then rolled a die,” “I opened and closed an orange folding ruler before tying a knot into a piece of green sparkly plastic tube.”)
However, the descriptions of the Causal actions are the ones that are most relevant for the question of whether the results of Experiment 1 could be due to syntactic priming. For the Causal actions, 97.9% of descriptions were highly transitive (i.e., include a subject, a verb, and a direct object), for example “I positioned five dominoes in a line and knocked them over with a rubber ball,” “I stacked the dominoes in a row, and knocked them down with the ball,” “I placed two green and red toy cars facing right and pushed the red one to hit the green and move it4.” All but three of these descriptions included two or more transitive clauses (like the examples above), and the three remaining descriptions consisted of a single transitive clause (e.g., “I pushed the red car into the green car.”) In sum, in the vast majority of cases people produced multiple transitive clauses when describing the causal actions.
The high rate of transitive sentences is noteworthy when coupled with the observation that consequence-type continuations are less transitive than reaction-type continuations. Consequence-type continuations (where the result is an involuntary consequence) are often intransitive and lack a direct object (e.g., “She felt hurt”, “He fell over”), whereas reaction-type continuations (where the result is a volitional, intentional reaction) are often highly transitive and mention an object to whom some action is done (e.g., “He punched him back”, “Melissa told on Angela”). If the causal actions were syntactically priming participants’ continuations in the sentence-completion task, Experiment 1 should have resulted in the exactly opposite pattern of what was actually found, namely Causal actions boosting the rate of consequence-type continuations but having no effect on the rate of reaction-type continuations.
In sum, we take the results of this production study as an indication that the results of Experiment 1 cannot be attributed to syntactic priming: if anything is being primed by the causal actions, it is a transitive structure, which could not generate the results that were obtained. (It is important to note that the aim of the production study was simply to address potential concerns regarding syntactic priming. The finding that the actions used in Experiment 1 were almost always described with transitive sentences should not be interpreted as a claim that all causal event sequences must be described with transitives; the relation between transitivity and event structure is a complex topic that is beyond the scope of this paper. The modest aim of the production study was simply to assess the potential impact (or lack thereof) of syntactic priming.) In sum, it seems reasonable to conclude that the results of Experiment 1 cannot be attributed to priming on the level of syntactic representations. Rather, it seems that priming is taking place on the level of more abstract conceptual representations that are shared both by motor actions and linguistic representations.
Discussion
Experiment 1, which used a priming paradigm involving motor actions that preceded target trials in a sentence-completion task, showed that Causal action primes resulted in more causally connected sentence-completions than One-Event or Two-Event action primes. As a whole, this finding points toward a shared abstract level of representation being activated/used by motor sequences and discourse-level coherence relations.
More specifically, the results show that the priming effect is carried by an increase in the rate of consequence-type causal continuations, and not the rate of reaction-type continuations: participants were equally likely to produce reaction-type continuations in all three prime conditions. In contrast, after carrying out a causal action sequence involving a consequence-type relation, participants produced a higher rate of consequence-type continuations in the sentence-completion task, compared to non-causal action primes. Overall, causal primes resulted in significantly more consequence-type continuations than Two-Event primes and in numerically more consequence-type continuations than One-Event primes. As predicted, One-Event primes and Two-Event primes do not differ in the proportion of subsequent consequence-type continuations. (It is not clear why the difference between Causal primes and One-Event primes does not quite reach significance.)
Given that the causal motor actions involved consequence-type relations rather than reaction-type relations, the results of Experiment 1 suggest that a shared abstract level of representation is activated by motor sequences and discourse-level coherence relations, and that this level of representation is sufficiently detailed to encode the distinction between consequence and reaction. However, it is important to keep in mind that participants were not prevented from encoding the prime actions linguistically (i.e., were not prevented from putting them in words). Thus, the motor action information could have been converted into some kind of linguistic information by the participants, which in turn could be what overlaps with the representations that participants use in the sentence-continuation task. Importantly, the production study described above provides evidence that the results of Experiment 1 cannot be derived from syntactic priming. This indicates that the relevant level of representation is not syntactic. Instead, it seems more plausible to assume that the motor actions, whether they are encoded linguistically or not, are activating semantic representations that also involve information about the relations between events, and that this is what overlaps with the representations used in the sentence-continuation task.
In sum, the results of Experiment 1 indicate that causality representations, even when originating from non-linguistic, motor action input, seem to be sufficiently richly encoded to have subtle effects on language production.
It is interesting to note that the distinction between reaction and consequence is also relevant in the domain of cognitive psychology for the difference between physical causation and social causation (e.g., Kanizsa and Vicario, 1968; Schlottmann et al., 2006). A situation where one billiard ball hits another involves physical causation, whereas a situation where one animal runs away from another involves social causation. Although not normally described in terms of reaction vs. consequence, it seems that the distinction between physical and social causation could be interpreted as mapping onto the distinction between consequence-type causal relations and reaction-type causal relations respectively. Work in cognitive psychology suggests that there are some differences in the perception of social and physical causality by adults (Schlottmann et al., 2006), and this seems to align well with the results of Experiment 1, which point to a cognitively meaningful distinction between reaction-type causal relations and consequence-type causal relations.
Experiment 2
The results of Experiment 1 indicate that detailed information about coherence relations – causality in particular – can be represented in a domain-general way. This suggests that our mental representations of coherence relations contain fine-grained, specific information. However, if our aim is to learn more about the mental representations of coherence relations, we also want to gain an understanding of the more general properties of coherence representations. Thus, Experiment 2 shifts away from the specifics to a more abstract level, and explores a very general property of event sequences, namely the representation of event boundaries. The human ability to segment stimuli into distinct events is a crucial aspect of cognition. In the visual domain, the boundaries between events have been shown to have effects on attention and memory (e.g., Swallow et al., 2009), suggesting that the cognitive process of shifting from one event to another has far-reaching effects on humans’ mental representations.
Experiment 2 addresses two main questions. First, it tests whether the presence/absence of event boundaries in the domain of motor actions influences how participants complete the linguistic sentence-continuation task. In particular, does performing two distinct actions (Two-Event primes) make participants more likely to produce continuations with two distinct subjects – i.e., continuations which shift attention to a new character? Conversely, does performing one action (One-Event primes) make participants more likely to maintain focus on the subject of the prompt sentence? As will be discussed in more detail in the “predictions” section, referent shifts were used as the dependent variable because of the well-known association between subjects and topics. The second main aim of this experiment is to gain insights into how causality is represented, and so it tests whether Causal primes pattern like Two-Event or like One-Event primes, in terms of the referential shift patterns that they induce. In other words, how are two causally connected events conceptualized – more like a one-event situation or a two-event sequence? A better understanding of this issue can help to clarify whether the event structure of causal sequences is best grouped with one-event representations or two-event representations.
Material and Methods
Participants
Twenty-four adult native English speakers from the University of Southern California community participated. None of the participants had participated in the other studies reported in this paper.
Materials
Motor action trials (prime trials). The same actions were used as in Experiment 1.
Sentence-completion trials (target trials). Instead of the agent-patient verbs used in Experiment 1, this experiment uses a class of so-called implicit-causality verbs (IC; Garvey and Caramazza, 1974; Stewart et al., 2000; Koornneef and Van Berkum, 2006), namely so-called Noun1 IC verbs, e.g., frighten, annoy, and amuse:
Angela frightened Melissa.
She was wearing a scary mask. (3)
Noun1 IC verbs were chosen for Experiment 2 because they allow for a situation where no overwhelming subject or object bias is expected, and thus they are well-suited for the purpose of testing whether the prime motor actions can induce referential shifts. The agent-patient verbs used in Experiment 1 would not have been suitable for this purpose, because they have a strong preference to shift to talking about the object (e.g., Stevenson et al., 1994), which could mask weak shifts toward the subject or lead to potential ceiling effects in the case of the object.
Let us consider in more depth why Noun1 IC verbs are well-suited for Experiment 2: prior work has shown that, when followed by the connective because, this particular class of IC verb tends to elicit continuations that start with reference to the preceding subject. For example, with a sentence like “Angela frightened Melissa because …” or “Angela amused Melissa because …,” the presence of the connective “because” signals that an explanation must be provided, and so participants tend to continue by saying something about the subject Angela (Noun1). Given this robust preference, this class of IC verbs is called Noun1 IC verbs. However, Rohde (2008, see also Kehler et al., 2008; for summary of these results) showed that when no overt connective is provided and participants’ continuations constitute a new sentence (as in ex.3), Noun1 IC verbs show a very different pattern: now, continuations after Noun1 IC verbs are almost equally likely to refer to the preceding subject or the preceding object (about 60% subject continuations, 40% object continuations) – this differs strikingly from the pattern that is observed with a “because” connective (85% subject continuations, see Rohde, 2008). The absence of a clear subject preference in the absence of an explicit connective presumably stems from the resulting absence of any explicit coherence relation constraints: when given a sentence with an IC verb that is not followed by an explicit because, participants still produce a fairly high rate of explanation continuations (over 55% in Rohde’s study), but they also produce other coherence relations, many of which tend to start with the non-subject. This shifts the overall reference pattern to one where the preceding subject and object are (near)equal candidates for subsequent reference. Thus, thanks to this balanced situation, Noun1 IC verbs with no overt connective are well-suited for Experiment 2, where we are interested in seeing whether priming with motor actions influences the likelihood of maintaining vs. shifting reference.
It is worth noting that although explanation relations resemble causal (cause-effect) relations in that both refer to causes and consequences – albeit in a different linear order –, existing research suggests that these relations differ in fundamental ways. Causal relations are often regarded as more iconic, since they reflect the natural chronological order of events, unlike explanation relations (see van den Broek, 1990; see also Zwaan and Radvansky, 1998). This fundamental distinction is supported by recent psycholinguistic research by Briner et al. (2012) who found that explanation relations are processed more slowly than causal relations (see also Noordman, 2001 for related work and Johnston and Welsh, 2000 for data from language acquisition). In light of these differences, this paper treats causal relations and explanation relations as distinct.
Coding. Continuations were analyzed for which character is mentioned at the start of the continuation, the preceding subject or object (or both or neither). As in Experiment 1, two coders blind to the experimental conditions worked independently. Afterward, disagreements were resolved through discussion. If the coders could not agree, the item was marked as “unclear” (13.5% of the trials).
Predictions
When continuing the prompt sentence, e.g., “Jason frightened Matt”, participants may opt to continue by talking about Jason, as shown in ex(4a). Here, the prompt sentence and the continuation sentence have the same subject, Jason. In other words, we are maintaining focus on the initial subject. This referent maintenance pattern can also be thought of as topic maintenance, given that the topic of a sentence is normally realized in subject position in English (Reinhart, 1982; Chafe, 1994; Lambrecht, 1994).
Alternatively, participants may choose to shift to talking about the other character, namely the preceding object [ex (4b)]. Here, the prompt sentence and the continuation sentence have different subjects, in a pattern that we can characterize as shifting to a new character or topic-shift.
Jason frightened Matt.
He was wearing a scary mask. (4a)
Jason frightened Matt.
He ran away screaming. (4b)
Experiment 2 aims to test whether the presence/absence of event boundaries in motor actions influences the likelihood of topic-shifts in the sentence-completion task. If the mental representations activated by shifting from one motor action to another (Two-Event primes) overlap with the representations activated when shifting from one referent to another [topic-shift, ex.(4a)], then there should be more topic-shifts (object-referring continuations) after Two-Event primes than after One-Event primes. In other words, we should find a higher rate of object-referring continuations (and a lower rate of subject-referring continuations) after Two-Event primes than after One-Event primes.
If this holds, it would show that in a situation where the prime clearly involves two distinct events, this can induce referent shifts. With this finding, we can then turn to the Causal primes, to see whether they pattern more like Two-Event primes or like One-Event primes. In other words, will they trigger shifts to another character, or will we see a pattern of topic maintenance? The former result would suggest that Causal sequences are conceptualized as two events, whereas the latter would indicate that Causal sequences are conceptualized as single events.
More broadly, if Experiment 2 reveals an effect of the prime actions’ event structure on the referent-shift/referent maintenance patterns in participants’ continuations, this would provide evidence that the representations activated by the event structure of the motor actions overlap with the representations that are activated during referential processing in discourse.
Results and Discussion
Mixed-effects logistic regression was used to test whether the rate of object-referring continuations differs as a function of the prime action. In other words, are people more likely to shift to talking about the object of the preceding sentence after some prime types than others? Only those continuations that started with reference to either the preceding subject or object were included; continuations that were coded as “unclear” or that began with reference to another entity were excluded from subsequent analyses (13.5%). In each analysis, participant, and item as were included as random effects5.
As can be seen in Figure 3, the proportion of continuations that started with the prompt sentence object is significantly higher after Two-Event primes than after One-Event primes (65.9 vs. 45.24%, β = 1.121, Wald Z = 3.181, p < 0.005). This suggests that the rate of referential shifts does indeed correlate to the One-Event vs. Two-Event distinction in the predicted way: when the prime action shifts from one event to another, this is reflected in participants’ continuations. Crucially, a comparison of Two-Event primes and Causal primes reveals significantly more shifting to the prompt sentence object after Two-Event primes than after Causal primes (65.9 vs. 48.75%, β = −1.098, Wald Z = −2.796, p < 0.01). Causal primes and One-Event primes did not differ (β = 0.303, Wald Z = 0.844, p = 0.4). In sum, Causal prime actions pattern like One-Event prime actions, and both of these differ from Two-Event primes.
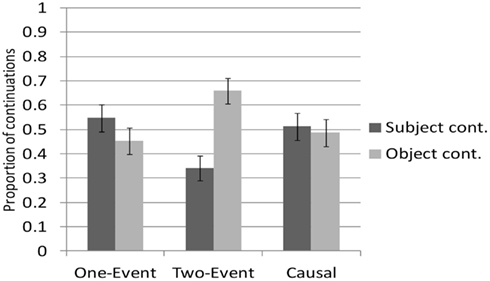
Figure 3. Proportion of continuations that start by referring to the preceding subject or the preceding object, as a function of prime type. (Error bars show ± 1 SE.)
We interpret the finding that Two-Event primes result in more object-referring continuations than One-Event primes as evidence that the mental representations activated by shifting from one-event to another event overlap with the mental representations activated by shifting one’s attention from one referent to another (topic-shift). The finding that Causal primes pattern like One-Event primes in failing to create a bias for topic-shifting suggests that Causal prime actions are conceptualized – at least at some level – in the same way as One-Event actions. Thus, even though the Causal sequences do involve two sub-events (e.g., event 1: I roll the ball, event 2: the bowling pins fall over), our findings suggest that these sub-events are conceptualized as one (potentially complex) event.
In addition to computing the proportion of continuations with topic-shift vs. topic maintenance, the coherence relations in participants’ continuations were also analyzed. They were coded the same way as in Experiment 1. (However, this was not the main aim of Experiment 2: no causal priming was expected in Experiment 2, given that the IC verbs used in this study tend to exhibit a strong bias for explanation relations, which is expected to mask any potential causal priming.) As expected, the most frequent coherence relation in all three conditions was the explanation/because relation (e.g., Angela frightened Melissa. She was not wearing any makeup.)6 All three conditions showed 45–48% explanation continuations (a high proportion, given the large number of different coherence relations that are available), and there were no significant differences between conditions. The overall rates of causal continuations (around 35%), as well as the rate of the consequence and reaction sub-types, also did not differ significantly across conditions. In our opinion, the lack of significant priming for causal (cause + effect) relations is not surprising, given that IC verbs have a strong inherent bias for another kind of continuation (explanation). More generally, when combined with Experiment 1, these patterns suggest that causal priming can be masked in the presence of a stronger discourse-level bias – a finding which fits with the general observation that priming effects (syntactic, semantic, etc.) are often relatively small but nevertheless real.
As a whole, the key finding from Experiment 2 – that referent shifts can be induced by priming with two discrete motor actions – suggests that shifting one’s attention from one event to another resembles the act of shifting one’s attention from one referent to another. This points to intriguing similarities between our mental representations of events and entities, something which is also reflected in the fact that they can both be referred to with the same kinds of anaphoric expressions, as illustrated in (5a–b; e.g., Webber, 1991; Kehler and Ward, 2004).
General Discussion
The two experiments presented in this paper used a cross-modal priming paradigm to investigate how people represent coherence relations in linguistic and non-linguistic domains. Although the coherence relations between sentences play a central role in language comprehension, researchers have come to divergent conclusions about how humans represent and process coherence relations, as well as what the proper taxonomy of coherence relations is. The two experiments in this paper aim to shed some light on these issues, although many questions still remain open for future work.
Experiment 1 explored the domain-generality of coherence relations and the level of detail present in these representations, with a focus on causal relations. Participants carried out different kinds of motor actions (Causal actions, Two-Event actions, and One-Event actions), and provided continuations for agent-patient sentences (e.g., “Mary pinched Kate.”) The coherence relations in participants’ continuations were analyzed. The results showed that carrying out causal actions – as compared to non-causal actions – made participants more likely to provide causal continuations in the sentence-continuation task. We interpret this as an indication that the mental representations activated by the motor actions overlap, at least in part, with the mental representations used during linguistic discourse-level processing. Furthermore, a detailed analysis of the results shows that the boost in causal continuations is carried by a particular sub-type of causal relations, namely consequence relations (rather than reaction relations). This shows that the mental representations activated by the motor actions contain fine-grained information about the difference between reactions and consequences, and that this is also reflected in the linguistic domain. Although existing models of coherence relations differ in whether they represent coherence relations as logical rules or hierarchical structures (see e.g., Sanders et al., 1993; Webber et al., 2003 for discussion), both of these approaches are in theory compatible with the findings of Experiment 1, as long as they are able to distinguish sub-types of causal relations and allow for some level of representational overlap between discourse-level processing and more domain-general knowledge systems related to causality and event structure.
Because participants were not prevented from encoding the motor actions in linguistic form (e.g., silently describe them), one might wonder about the actual source of the priming effects. To shed light on this, a production study was conducted, and the results indicate that the priming effects observed in Experiment 1 cannot be attributed to syntactic priming. Instead, it seems that the connection is on the level of semantic/conceptual representations: it seems reasonable to conclude that causality representations that were originally triggered by the presentation of non-linguistic, visuo-motor stimuli are tapping into the same (or overlapping) level of representation that is used during the comprehension and production of linguistic stimuli.
To better understand how humans represent coherence relations, we need to gain insights not only into the fine-grained details but also the more general properties of these representations. Experiment 2 explored a truly fundamental property of event sequences, namely the presence of event boundaries. Using the same kind of priming paradigm as in Experiment 1, Experiment 2 looked at the cognitive consequences of shifting one’s attention from one event to another, separate event. The results point to parallels between shifting one’s attention from one event to another and shifting one’s attention from one referent to another. More specifically, Two-Event primes were more likely to result in referential shifts in participants’ linguistic continuations than One-Event primes. This study also found that Causal primes trigger the same patterns as One-Event primes, suggesting that the two sub-events comprising the Causal sequences are conceptualized as one event (potentially with some kind of internal structure). However, although the outcomes of Experiment 2 shed new light on the nature of discourse-level representations, more work is needed before we can attain a deep understanding of the similarities between shifting between events and shifting between referents, and whether other factors – in addition to event boundaries – may also be influencing the likelihood of topic-shift in these kinds of contexts. Because the research methodology used in this paper (using motor actions as primes for potential discourse-level effects) is still very new, future work will play an important role in helping us to gain a more in-depth understanding of this area.
Broadly speaking, these studies contribute to our understanding of how coherence relations are represented in the mind. The finding that non-linguistic stimuli can influence coherence-related processes in the linguistic domain also fits well with results obtained in earlier work (Kaiser, 2009). In two eye-tracking studies using a priming paradigm, Kaiser (2009) explored how coherence relations presented by means of visuo-spatial/non-linguistic primes or by means of linguistic primes influence pronoun interpretation. Recent research has shown that pronoun interpretation is sensitive to the coherence relations between sentences, as exemplified in ex.(6) where interpretation of “him” is influenced by the coherence relation between the clauses (causal vs. parallel).
Kaiser (2009) conducted two experiments using a paradigm that combines visual-world eye-tracking and priming. In one experiment, participants were presented with visuo-spatial primes, silent video clips that encoded causal relations, similarity relations or other/neutral relations (e.g., Causal = Triangle knocks into circle which falls off a ledge). In another experiment, the coherence relation primes were linguistic (e.g., participants read “The patient pressed the red emergency button near the bed and a nurse quickly ran into the room” for Causal). Participants were then shown a target scene with three characters and heard a sentence like “Phil linded Stanley and Kate hepped him.” (Nonce words were used to eliminate verb semantics). Participants’ eye-movements were used to assess which entities were considered as referents for “him.” The results show that pronoun interpretation can indeed be primed by coherence relations in preceding linguistic and visual input, even when primes and targets are connected only on the level of abstract coherence relations, and even when primes are presented in a non-linguistic modality.
These earlier findings, like the two productions studies presented in the current paper, highlight the important role that coherence relations play in language processing, and suggest that coherence relations make reference to domain-general representations. Broadly speaking, this line of research has the potential to offer new insights into the nature of the interface between linguistic and non-linguistic representations. It taps into one of the central questions in psycholinguistics, namely the extent to which language is distinct from other cognitive processes vs. supported by domain-general processes.
This research was partially supported by funding from the University of Southern California Undergraduate Research Associates Program and NIH grant 1R01HD061457 to Elsi Kaiser. We wish to thank Noelle Garza, Alexandra Ruelas, and Boutaina Cherqaoui for assistance with the experiments and data analysis. Thanks are also due to the two reviewers who provided extremely useful and insightful comments.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
- ^The research reported in this paper explores not only the relations that people construct between clauses (and the events they describe) but also the relations between events that are presented in a non-linguistic way. For the sake of brevity, when talking about people’s interpretation of linguistic input, this paper will often simply refer to the coherence relations between events, rather than “the coherence relations between the events that are described by the two clauses” or “the coherence relations between the events that comprehenders assume the speaker intends their linguistic output to describe.” However, despite this simplification, we assume that to fully understand linguistic input, comprehenders construct a propositional representation of the events that a particular linguistic form describes and also engage in real-world reasoning about the current state of affairs (e.g., that kicking someone’s car might result in the car owner reacting negatively.)
- ^The study also included three verbs of social interaction (embrace, greet, and hug). However, these verbs were excluded from further analysis because their semantic properties differ from the agent-patient verbs. In particular, these social interaction verbs are (by default) construed as involving reciprocal actions – for example, when someone greets another person, the default assumption is that the other person reciprocates. Crucially, these verbs do not involve a clear agent-patient asymmetry, in contrast to verbs like “hit” or “scratch” where one person is clearly the agent and other is the “undergoer” who is affected by the agent’s actions (see also Levin, 1993 for more on verb classes).
- ^When specifying the structure of random effects, we started with fully crossed and fully specified random effects, tested whether the model converges, and reduced random effects (starting with item effects) until the model converged (see Jaeger at http://hlplab.wordpress.com, May 14, 2009). Then, we used model comparison to test each random effect; only those that were found to contribute significantly to the model were included in the final analyses. However, all models contained random intercepts for subjects and items.
- ^Could the highly transitive nature of the causal descriptions be an artifact caused by the instructions and not a true reflection of how the participants in Experiment 1 might have verbalized the events? Specifically, could it be that the production instructions caused an artificially high rate of responses like “I knocked over the dominoes with a ball” instead of “The ball knocked over the dominoes”? In our opinion, the high rate of first-person sentences is unlikely to be due to the wording of the instructions: First, in both Experiment 1 and the production study, each trial involved two occurrences of the action being conducted by a human agent (the experimenter and then the participant), and so it seems unlikely that participants would verbalize the actions without encoding the human agent. The second (related) reason why we expect people’s descriptions to have human agents regardless of the instructions is based on prior work showing that animate entities (in this case “I,” the participant) are highly accessible and usually realized in subject position (e.g., Branigan et al., 2008). Thus, it seems that the high rate of transitive sentences with first-person subjects is unlikely to be due to the instructions. We feel that the production study can be used to test whether syntactic priming might be responsible for the results of Experiment 1 (and to argue, as we do, that the results cannot be attributed to syntactic priming). Further evidence for the claim that the results discussed in this paper cannot be reduced to syntactic priming comes from Experiment 2, where participants produced an increased proportion of sentences with two distinct subjects following Two-Event primes – which, if described linguistically, would yield two sentences with the same subject (e.g., “I opened the ruler and I tied the pencil in a knot.”).
- ^Random effect structure was determined as in Experiment 1.
- ^When thinking about the subject/object biases and coherence relation biases of IC verbs, it is important to keep in mind that although coherence relations and referential patterns are often related (e.g., with Noun1 IC verbs, explanation continuations tend to start by talking about the preceding subject, Noun1), this is not an absolute relationship (see also Pickering and Majid, 2007, p. 784 for related discussion). For example, it is perfectly possible to generate explanation continuations after Noun1 IC verbs that do not start by referring to Noun1 (e.g., Jason frightened Matt. Matt was very easily startled by the smallest thing.)
References
Arai, M., Van Gompel, R. P. G., and Scheepers, C. (2007). Priming ditransitive structures in comprehension. Cogn. Psychol. 54, 218–250.
Asher, N., and Lascarides, A. (2003). Logics of Conversation. Cambridge: Cambridge University Press.
Baayen, H. R., Davidson, D. J., and Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 59, 390–412.
Bock, K., and Griffin, Z. (2000). The persistence of structural priming: transient activation or implicit learning? J. Exp. Psychol. Gen. 129, 177–192.
Branigan, H. P., Pickering, M. J., and Tanaka, M. (2008). Contributions of animacy to grammatical function assignment and word order during production. Lingua 118, 172–189.
Briner, S., Virtue, S., and Kurby, C. (2012). Processing causality in narrative events: temporal order matters. Discourse Process. 49, 61–77.
Buccino, G., Riggio, L., Melli, G., Binkofski, F., Gallese, V., and Rizzolatti, G. (2005). Listening to action-related sentences modulates the activity of the motor system: a combined TMS and behavioral study. Brain Res. Cogn. Brain Res. 24, 355–363.
Chafe, W. L. (1994). Discourse, Consciousness, and Time: The Flow and Displacement of Conscious Experience in Speaking and Writing. Chicago: University of Chicago Press.
Gati, I., and Tversky, A. (1984). Weighting common and distinctive features in conceptual and perceptual judgments. Cogn. Psychol. 16, 341–370.
Gentner, D., and Markman, A. B. (1997). Structure mapping in analogy and similarity. Am. Psychol. 52, 45–56.
Glenberg, A., Sato, M., Cattaneo, L., Riggio, L., Palumbo, D., and Buccino, G. (2008). Processing abstract language modulates motor system activity. Q. J. Exp. Psychol. 61, 905–919.
Glenberg, A. M., and Kaschak, M. P. (2002). Grounding language in action. Psychon. Bull. Rev. 9, 558–565.
Jaeger, T. F. (2008). Categorical data analysis: away from ANOVAs (transformation or not) and towards logit mixed models. J. Mem. Lang. 59, 434–446.
Johnston, J., and Welsh, E. (2000). Comprehension of “because” and “so”: the role of prior event representation. First Lang. 20, 291–304.
Kaiser, E. (2009). “Effects of anaphoric dependencies and semantic representations on pronoun interpretation,” in Anaphora Processing and Applications, eds S. L. Devi, A. Branco, and R. Mitkov (Heidelberg: Springer), 121–130.
Kanizsa, G., and Vicario, G. (1968). “The perception of intentional reaction,” in Experimental Research on Perception, eds G. Kanizsa and G. Vicario (Trieste: University of Trieste), 71–126.
Kehler, A., Kertz, L., Rohde, H., and Elman, J. (2008). Coherence and coreference revisited. J. Semant. 25, 1–44.
Kehler, A., and Ward, G. (2004). “Constraints on ellipsis and event reference,” in Handbook of Pragmatics, eds L. R. Horn and G. Ward (Oxford: Blackwell), 383–403.
Knott, A. (1993). “Using cue phrases to determine a set of rhetorical relations,” in Intentionality and Structure in Discourse Relations: Proceedings of the ACL SIGGEN Workshop, ed. O. Rambow Columbus: Ohio State University.
Koornneef, A. W., and Van Berkum, J. J. A. (2006). On the use of verb-based implicit causality in sentence comprehension: evidence from self-paced reading and eye tracking. J. Mem. Lang. 54, 445–465.
Lambrecht, K. (1994). Information Structure and Sentence form: TOPIC, Focus, and the Mental Representation of Discourse Referents. Cambridge: Cambridge University Press.
Levin, B. (1993). English Verb Classes and Alternations: A Preliminary Investigation. Chicago, IL: University of Chicago Press.
Mann, W. C., and Thompson, S. A. (1986). Relational propositions in discourse. Discourse Process. 9, 57–90.
Mann, W. C., and Thompson, S. A. (1988). Rhetorical structure theory: toward a functional theory of text organization. Text 8, 243–281.
Michotte, A. (1946/1963). The Perception of Causality, trans. T. R. Miles and E. Miles (New York: Basic Books).
Noordman, L. G. M. (2001). On the production of causal-contrastive “although” sentences in context,” in Text Representation: Linguistic and Psycholinguistic Aspects, eds T. Sanders, J. Schilperoord, and W. Spooren (Amsterdam: John Benjamins), 153–180.
Pickering, M. J., and Branigan, H. P. (1998). The representation of verbs: evidence from syntactic persistence in written language production. J. Mem. Lang. 39, 633–651.
Pickering, M. J., and Majid, A. (2007). What are implicit causality and consequentiality? Lang. Cogn. Process. 22, 780–788.
Pulvermüller, F., Shtyrov, Y., and Ilmoniemi, R. (2005). Brain signatures of meaning access in action word recognition: an MEG study using the mismatch negativity. J. Cogn. Neurosci. 17, 884–892.
Reinhart, T. (1982). Pragmatics and linguistics: an analysis of sentence topics. Philosphica 27, 53–94.
Rohde, H. (2008) Coherence-Driven Effects in Sentence and Discourse Processing. Ph.D. Dissertation, University of California, San Diego.
Sanders, T. J. M. (2005). “Coherence, causality and cognitive complexity in discourse,” in Proceedings of the First International Symposium on the Exploration and Modelling of Meaning, eds M. Aurnague, and M. Bras (Toulouse: Universite de Toulouse-le-Mirail), 31–46.
Sanders, T., Spooren, W., and Noordman, L. (1992). Toward a taxonomy of coherence relations. Discourse Process. 15, 1–35.
Sanders, T., Spooren, W., and Noordman, L. (1993). Coherence relations in a cognitive theory of discourse representation. Cogn. Linguist. 4, 93–133.
Schlottmann, A., Ray, E., Mitchell, A., and Demetriou, N. (2006). Perceived physical and social causality in animated motions: spontaneous reports and ratings. Acta Psychol. (Amst.) 123, 112–143.
Simmons, S., and Estes, Z. (2008). Individual differences in the perception of similarity and difference. Cognition 108, 781–795.
Stevenson, R. J., Crawley, R. A., and Kleinman, D. (1994). Thematic roles, focus and the representation of events. Lang. Cogn. Process. 9, 519–548.
Stewart, A. J., Pickering, M. J., and Sanford, A. J. (2000). The time course of the influence of implicit causality information: focusing versus integration accounts. J. Mem. Lang. 42, 423–443.
Stukker, N., Sanders, T., and Verhagen, A. (2008). Causality in verbs and in discourse connectives. Converging evidence of cross-level parallels in Dutch linguistic categorization. J. Pragmat. 40, 1296–1322.
Swallow, K. M., Zacks, J. M., and Abrams, R. A. (2009). Event boundaries in perception affect memory encoding and updating. J. Exp. Psychol. Gen. 138, 236–257.
Tettamanti, M., Buccino, G., Saccuman, M. C., Gallese, V., Danna, M., Scifo, P., Fazio, F., Rizzolatti, G., Cappa, S. F., and Perani, D. (2005). Listening to action-related sentences activates fronto-parietal motor circuits. J. Cogn. Neurosci. 17, 273–281.
Trabasso, T., and van den Broek, P. (1985). Causal thinking and the representation of narrative events. J. Mem. Lang. 24, 912–630.
van den Broek, P. W. (1990). “Causal inferences in the comprehension of narrative texts,” in Psychology of Learning and Motivation: Inferences and Text Comprehension, eds A. C. Graesser and G. H. Bower (New York, NY: Academic Press), 175–196.
Webber, B. L. (1991). Structure and ostension in the interpretation of discourse deixis. Lang. Cogn. Process. 6, 107–135.
Webber, B. L., Stone, M., Joshi, A. K., and Knott, A. (2003). Anaphora and discourse structure. Comput. Linguist. 29, 545–587.
Wolfe, M. B. W., Magliano, J. P., and Larsen, B. (2005). Causal and semantic relatedness in discourse understanding and representation. Discourse Process. 39, 165–187.
Zwaan, R. A., and Radvansky, G. A. (1998). Situation models in language comprehension and memory. Psychol. Bull. 123, 162–185.
Keywords: psycholinguistics, discourse, causality, priming, coherence relations
Citation: Kaiser E (2012) Taking action: a cross-modal investigation of discourse-level representations. Front. Psychology 3:156. doi: 10.3389/fpsyg.2012.00156
Received: 04 October 2011; Accepted: 30 April 2012;
Published online: 11 June 2012.
Edited by:
Andriy Myachykov, University of Glasgow, UKReviewed by:
Hannah Rohde, University of Edinburgh, UKTed J. M. Sanders, Universiteit Utrecht, Netherlands
Copyright: © 2012 Kaiser. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Elsi Kaiser, Department of Linguistics, University of Southern California, 3601 Watt Way, GFS 301, Los Angeles, CA 90089-1693, USA. e-mail:ZW1rYWlzZXJAdXNjLmVkdQ==