



94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol. , 20 December 2011
Sec. Cognition
volume 2 - 2011 | https://doi.org/10.3389/fpsyg.2011.00348
This article is part of the Research Topic Cognitive and Affective Control View all 22 articles
In humans, there is a trade-off between the need to respond optimally to the salient environmental stimuli and the need to meet our long-term goals. This implies that a system of salience sensitive control exists, which trades task-directed processing off against monitoring and responding to potentially high salience stimuli that are irrelevant to the current task. Much cognitive control research has attempted to understand these mechanisms using non-affective stimuli. However, recent research has emphasized the importance of emotions, which are a major factor in the prioritization of competing stimuli and in directing attention. While relatively mature theories of cognitive control exist for non-affective settings, exactly how emotions modulate cognitive processes is less well understood. The attentional blink (AB) task is a useful experimental paradigm to reveal the dynamics of both cognitive and affective control in humans. Hence, we have developed the glance–look model, which has replicated a broad profile of data on the semantic AB task and characterized how attentional deployment is modulated by emotion. Taking inspiration from Barnard’s Interacting Cognitive Subsystems, the model relies on a distinction between two levels of meaning: implicational and propositional, which are supported by two corresponding mental subsystems: the glance and the look respectively. In our model, these two subsystems reflect the central engine of cognitive control and executive function. In particular, the interaction within the central engine dynamically establishes a task filter for salient stimuli using a neurobiologically inspired learning mechanism. In addition, the somatic contribution of emotional effects is modeled by a body-state subsystem. We argue that stimulus-driven interaction among these three subsystems governs the movement of control between them. The model also predicts attenuation effects and fringe awareness during the AB.
Cognitive control is typically defined as the biasing of cognitive functions, perhaps especially perception and response, to promote “task-appropriate” behavior, and particularly to override pre-potent responses. While a valuable working hypothesis, such a definition poses several questions: what constitutes task-appropriate, indeed, what constitutes a task and, ultimately, what constitutes an organism’s goals? Due partially to the constraints imposed by experimental method, the notions of task, goal and, thus, cognitive control, have tended to be narrowly prescribed. For example, the concept of task has, if only tacitly, been directly associated with the set of task instructions that can be easily and unambiguously imposed in well-controlled laboratory experiments; e.g., a participant might be instructed to report a letter in the color red.
This definition of cognitive control is, of course, limiting, artificial, and not fully reflective of the diversity of goal-driven control processes to be found beyond the sphere of traditional experimental work. For example, many psycholinguistic phenomena, such as, the Moses illusion (Erickson and Mattson, 1981), suggest that task set does not enforce strict categorical boundaries. In particular, the trajectory of task-focused processing seems unperturbed by small semantic inconsistencies; that is, when processing demands are high, the central executive seems content with a broad schematic consistency of meaning. In addition, although only relatively recently considered in the laboratory, it would seem clear that affect and body-state feedback in general, has a major role in guiding perception and action over and above its immediate goals. To take a very obvious example, “flight or fight” responses to threatening stimuli are surely prioritized, and accordingly bias attentional and response processes. In the extreme case, Ohman and Soares (1994) have shown that, compared to healthy controls, phobics have larger skin conductance responses to masked fear related pictures, such as snakes, even when they were unaware of their presentation. In addition, it has been reported that anxiety can modulate attentional control (Koster et al., 2006), or delay the disengagement of visual attention away from threatening stimuli (Fox et al., 2001; Yiend and Mathews, 2001; Georgiou et al., 2005). Bishop et al. (2004) have also shown an interaction between anxiety state and attentional focus on threatening stimuli. Moreover, Leyman et al. (2007) have reported that patients with major depressive disorders show enhanced attention to angry faces compared to controls.
The literature’s restricted perspective on cognitive control is particularly apparent in neural modeling of task set. Neural network models that address the issue at all, typically realize cognitive control as a statically configured task-demand system (Cohen et al., 1990; Houghton and Tipper, 1994; Bowman and Wyble, 2007; Zylberberg et al., 2010), which simply foregrounds task relevant pathways and backgrounds others. In particular, in such models, there is little consideration for how such a task-demand system knows what to foreground and what to background; how it might, indeed, configure such biasing; how these configurations may change according to performance; and the interaction between such configurations and affective/body-state influences. Modeling work focused on notions of conflict and entropy (Botvinick et al., 2001; Davelaar, 2008; Wyble et al., 2008), have brought a richer perspective on cognitive control, but the interrelationship between representation of meaning, affect, body-state, and dynamic reconfiguration of task set, remains only superficially explored.
Our central tenet is, then, that cognitive control does not provide a perfectly delineated task filter, which enforces absolute, affect-immune, categorical boundaries between target and non-target. In addition, we argue that this “imprecision” ought, in fact, to be adaptive and, thus, of functional value for the organism. There are a number of ways in which this imprecision may manifest itself.
1. Enforcement of task set may, to a significant degree, be reliant upon schematic (categorically loose) representations; what might be called gist meaning.
2. Affect and body-state in general may play a major role in guiding task-focus; and they interfere with goal-directed processing via two different pathways, i.e., by a body-state route or by a fast and direct route that bypasses body-state. In addition, as often demonstrated, anxiety impacts the reconfiguration of task set.
3. The benefit of (more schematic) gist-based filtering may be observed when the attentional system is challenged to the point of near-overload, as exemplified by phenomena such as fringe awareness (Mangan, 2001; May, 2004) and improved attentional blink (AB) performance in the presence of distraction (Olivers and Nieuwenhuis, 2005, 2006; Taatgen et al., 2007).
Our glance–look model realizes this broader notion of cognitive control by partitioning central executive mediated salience detection into two stages. The first of these, the glance, undertakes a schematic glimpse at meaning and is, also, the site at which affective and bodily evaluations guide attentional focus. In contrast, the second stage, the look, operates in a fashion more consistent with classic perspectives on salience detection and task-focus. That is, it performs a more detailed (referentially specific) analysis of meaning. These two stages map directly onto the propositional and implicational central executive subsystems in Barnard’s (1985) interacting cognitive subsystems (ICS).
We will present the glance–look model and its interpretation of cognitive control as follows. Firstly, we will provide background on the experimental paradigm, i.e., the AB task (Raymond et al., 1992), which is well suited to revealing the dynamics of both cognitive and affective control in humans. In particular, it has been observed with ERP (Flaisch et al., 2007) and psychophysiologically (Phelps et al., 2006) that emotion does not only affect the processing of the affective stimulus itself, but also following stimuli, emphasizing the importance of the temporal profile of affective salience. We will argue that the AB task provides a suitable platform to study the complicated temporal structure when cognition and emotion interact. And then, we will review and highlight the structure and principles of the model’s realization of salience detection and attentional control. The theory of the glance–look model is inherited from ICS; however, this particular computational implementation and its parameter setting are systematically justified here. In particular, a unique modeling approach with mathematical formalization of the model parameters is detailed in Appendix.
Secondly, we will model several experimental results from the literature covering semantic and affective influences on attentional control and AB attenuation effects due to distraction. In Experiment 1, we will describe how the glance–look model explains the semantic key-distractor AB phenomenon (Barnard et al., 2004). This will demonstrate the model’s two levels of meaning: implicational (when glancing) and propositional (when looking). In particular, we will explain the finding of a classic AB in the semantic key-distractor task in terms of the glance subsystem’s focus on (implicational) gist meaning. Furthermore, this meaning is represented in a self-organizing statistical learning framework: latent semantic analysis (LSA, Landauer and Dumais, 1997; Landauer et al., 1998, 2007). In Experiment 2, and again in a key-distractor AB setting, we consider the role of affective salience in guiding attentional focus. This involves adding a body-state subsystem to the glance–look model. In this way, we model the capacity for affectively charged key-distractors to generate a variety of AB profiles (Barnard et al., 2005; Arnell et al., 2007), dependent upon intrinsic salience of the affective key-distractor and participant group (anxious vs. non-anxious). In Experiment 3, we consider how guide of cognitive control by gist meaning can be functionally beneficial. We do this by exploring how the glance–look model exhibits a relatively graceful degradation in perception at high sensory loads, generating fringe awareness. In addition, we argue that, somewhat counter-intuitively, an increased reliance on implicational (gist) meaning can improve behavioral performance, consistent with overinvestment theories of temporal attention and the beneficial effect of distraction upon AB performance (Olivers and Nieuwenhuis, 2005, 2006; Taatgen et al., 2007).
Finally, we will draw general conclusions on the glance–look model’s contributions in broadening the notion of cognitive and affective control. We will also suggest some possible neural correlates of our model, in particular, relating it to several cognitive neuroscience models of cognitive and affective interaction (Pessoa, 2008).
Humans have an exceptional capacity for assessing the salience of the stimuli that arise in their environment and for adjusting processing accordingly. For example, when standing on a street corner we are subject to a plethora of stimuli: cars passing, conversations amongst pedestrians, and street vendors plying their trade. When placed in such environments, humans are very good at prioritizing these competing stimuli: directing attention toward the highest priority events and ignoring the rest. Furthermore, when we perceive a significant event, such as a car careening off the road, the current task is interrupted and attention is redirected to reacting to the new event. It is also clear that there is a trade-off between the need to meet (potentially long-term) goals and the need to respond optimally according to the salience level of environmental stimuli. This suggests that a system of salience sensitive control exists, which trades goal-directed processing off against monitoring and responding to (potentially high salience) stimuli that are irrelevant to the current task. In previous work, we have proposed the glance–look model, which formally specifies mental representations and processes that support salience detection and attentional control in the context of temporal attention (Su et al., 2009; Bowman et al., 2011).
A classic experimental paradigm that explores the temporal deployment of attention is the AB task. Following on from earlier work by Broadbent and Broadbent (1987), Raymond et al. (1992) were the first to use the term AB. The task they used involved letters being presented using rapid serial visual presentation (RSVP) at around 10 items a second at the same spatial location. One letter (T1) was presented in a distinct color and was the target whose identity was to be reported. A second target (T2) followed after a number of intervening items, presence or absence of T2 was to be reported. Typically, participants had to report whether the letter “X” was among the items that followed T1. The key finding was that report of T2 was impaired as a function of serial position. That is, T2s occurring immediately after T1 were accurately detected – a phenomenon typically described as lag-1 sparing (Wyble et al., 2009). Detection then declined across serial-positions 2, and also 3, and then recovered to baseline around lags 5 or 6 (corresponding to a target onset asynchrony in the order of 500–600 ms).
As research on the blink and RSVP in general has progressed, it has become evident that the allocation of attention over time is affected by the meaning of items (Maki et al., 1997) and their personal salience (Shapiro et al., 1997b). There is also evidence from electrophysiological recording that the meaning of a target is processed even when it is not reported (Shapiro and Luck, 1999).
In order to examine semantic effects, Barnard et al. (2004) used a variant of the AB paradigm in which no perceptual features were present to distinguish targets from background items. In this task, words were presented at fixation in RSVP format. Targets were only distinguishable from background items in terms of their meaning. This variant of the paradigm did not rely on dual target report. Rather, participants were simply asked to report a word if it refers to a job or profession for which people get paid, such as “waitress,” and these targets were embedded in a list of background words that all belonged to the same category. In this case, they were inanimate things or phenomena encountered in natural environments; see Figure 1. However, streams also contained a key-distractor item, which, although not in the target category, was semantically related to that category. The serial position that the target appeared after the key-distractor was varied. We call this the key-distractor AB task, which, importantly, enables us to observe and quantify the semantic imprecision of the task filter. That is, the key-distractor is not in the target category. However, it is semantically related to that category. The critical question, then, is can key-distractors capture attention, even though strictly, they are task irrelevant.
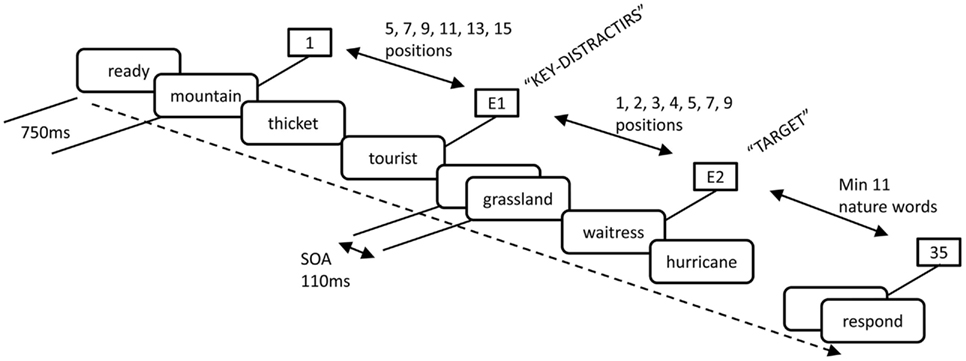
Figure 1. Task schema for the key-distractor AB task; adapted from Barnard et al. (2004).
Participants could report the target word (accurate report), say “Yes” if they were confident a job word had been there, but could not say exactly what it was (to capture some degree of awareness of meaning), or say “No” if they did not see a target, and there were, of course, trials on which no target was presented. When key-distractors were household items, a different category from both background and target words, there was little influence on target report. However, key-distractors that referenced a property of a human agent, but not one for which they were paid, like “tourist” or “husband,” gave rise to a classic and deep blink, see Figure 5. We call household items low salient (LS) key-distractors and human items high salient (HS) key-distractors. Thus, the task filter during an AB task can, at least partially, be “tricked” when facing semantically salient, but, in fact task irrelevant, stimuli.
Over the last 20 years, the AB task has been the subject of very extensive empirical research, coupled with the development of a substantial body of theory (e.g., see Chun and Potter, 1995; Shapiro et al., 1997a; Visser et al., 1999; Bowman and Wyble, 2007). A specific focus for the glance–look model has been the key-distractor AB (Barnard et al., 2004), which it models using parallel distributed executive function. In this section, we will explain three principles that underlie the model and govern its perspective on cognitive control: sequential processing, two stages, and serial allocation of attention. Although the basic structure of the model has been proposed previously (Su et al., 2009; Bowman et al., 2011), parameter setting is only systematically justified here, and a unique modeling approach with mathematical formalization of the model is provided in Appendix. Importantly, in subsequent sections, where the model’s scope is extended to other AB phenomena, e.g., the affective blink and the attenuation effect, the model parameters are unchanged.
With any RSVP task, items arrive in sequence and need to be correspondingly processed. Thus, we require a basic method for representing this sequential arrival and processing of items. At one level, we can view our approach as implementing a pipeline. New items enter the front of the pipeline (in this case, from the visual system); they are then fed through until they reach the back of the pipeline (where they enter the response system). The key data structure that implements this pipeline metaphor is a delay-line. This is a simple mechanism for representing time constrained serial order. One can think of a delay-line as an abstraction for items passing (in turn) through a series of processing levels. In this sense, it could be viewed as a symbolic analog of a sequence of layers in a neural network; a particularly strong analog being with synfire chains (Abeles et al., 1993).
Every cycle, a new item enters the pipeline and all items currently in transit are pushed along one place. We shall refer to this as the delay-line update cycle, and assume that one cycle corresponds to 20 ms. This assumption is justified by the observation that underlying neural mechanisms can represent updates on a time scale of tens of milliseconds (Bond, 1999; Panzeri et al., 2001). Thus, in each delay-line update cycle, all delay-lines increment by one slot every 20 ms. Note, the update rate of the model is every 5 ms. This assumption is not constrained by neurobiology, but by the requirement of simulation, i.e., the sampling rate has to be faster than the update rate of constituent representations. This fine grain of time course allows us to be more discriminating with regard to the temporal properties of the AB. However, a high sampling rate would have implementation costs, in terms of how long simulations would take to run.
A delay-line is a very natural mechanism to use in order to capture the temporal properties of a blink experiment, which is inherently a time constrained order task. To illustrate the data structure, consider a delay-line of 10 elements, as shown in Figure 2, where indices indicate the position of the constituent representations of the corresponding RSVP item/word. We shall use this terminology throughout, i.e., a single RSVP item will be modeled by a number of constituents in a delay-line representation. We assume six constituent representations comprise one RSVP item/word, which approximates the 110-ms presentation used in most AB experiments (e.g., Barnard et al., 2004).
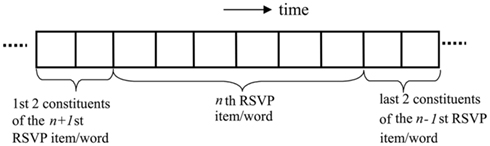
Figure 2. A 10-slot delay-line with three RSVP items in progress through it.
A constituent representation in the model contains three variables. The first one is the identity of the item. The second and the third elements are an implicational and a propositional salience assessment respectively. The origins of these terms are outlined in later sections. The salience assessments are initially set to un-interpreted.
As noted earlier, a number of theoretical explanations and indeed computational models of the AB have been proposed; see Bowman and Wyble (2007) for a review. However, apart from the model discussed in Barnard and Bowman (2003), all these proposals seek to explain “basic” blink tasks, in which items in the RSVP stream are semantically primitive, e.g., letters or digits. Consequently, none of these “mainstream” theories or models is directly applicable to semantic and affective influences on the shape of the blink curves. However, of these previous theories, that introduced by Chun and Potter (1995) has some similarities to this model. Their theory assumes two stages of processing. The first stage performs an initial evaluation to determine featural properties of items, including “categorical” features. This stage is not capacity limited and is subject to rapid forgetting. The second stage builds upon and consolidates the results of the first in order to develop a representation of the target sufficient for subsequent report. This stage is capacity limited, invokes central conceptual representations and storage, and is only initiated by detection of the potential target on the first stage.
Like Chun and Potter (1995), we have argued elsewhere for a two-stage model (Barnard and Bowman, 2003; Barnard et al., 2004), but recast to focus exclusively on semantic analysis and executive processing. In particular, Barnard and Bowman (2003) modeled the key-distractor blink task using a two-stage model. In the context of modeling distributed control, we implemented the two-stage model as a dialog between two levels of meaning. In the first stage, a generic level of semantic representation is monitored and initially used to determine if an incoming item is salient. If it is found to be so, then, in the second stage, the specific referential meaning of the word is subjected to detailed semantic scrutiny in order to access its salience in the context of the specific task set. In this stage, a word’s meaning is actively evaluated in relation to the required referential properties of the target category. If this reveals a match, then the target is encoded for later report. The first of these stages is somewhat akin to first taking a “glance” at generic meaning, with the second akin to taking a closer “look” at the relationship between the meaning of the incoming item and the target category. These two stages are implemented in two distinct semantic subsystems proposed within our model for cognitive and affective control: the implicational subsystem or Implic (which supports the first stage) and the propositional subsystem or Prop (which supports the second; Barnard, 1999). Except for these two subsystems (Implic and Prop), the model, in its most basic form, also includes Source and Sink, which reflect the perceptual processing and response systems respectively, see Figure 3.
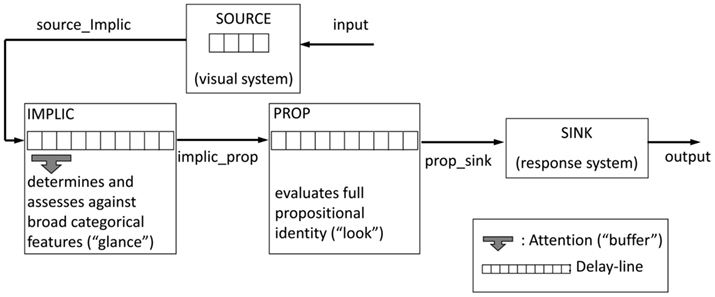
Figure 3. Top-level structure of the glance–look model with Implic attended (buffered).
Implic and Prop process qualitatively distinct types of meaning. Implicational meaning, is holistic, abstract and schematic, and is where affect is represented and experienced (Barnard, 1999). Propositional meaning is classically “rational,” being based upon propositional representation and captures referentially specific semantic properties and relationships. The exchanges between two levels of meaning reflect distributed executive functions, rather than a centralized executive control system, which might suffer from a homunculus problem.
There is significant evidence that a good deal of human semantic processing relies upon propositionally impoverished representations. It is this evidence that gives the clearest justification for the existence of a distinct implicational level of meaning. In particular, semantic errors make clear that sometimes we only have (referentially non-specific) semantic gist information available to us, e.g., false memories (Roediger and McDermott, 1995) and the Moses illusion (Erickson and Mattson, 1981). With respect to the latter, when comprehending sentences, participants often miss a semantic inconsistency if it does not dramatically conflict with the gist of the sentence, e.g., in a Noah specific sentence, such as “How many animals of each kind did Moses take into the Ark?” most people respond “two” even though, when questioned, they know that the relevant biblical character was really Noah rather than Moses. Substitution of Moses for Noah often fails to be noticed, while substitution with Nixon, or even Adam, is noticed. This is presumably because both Moses and Noah fit the generic (implicational) schema “aged male biblical figure,” but Nixon and Adam do not.
In addition, Gaillard et al. (2006) reported that in a subliminal priming study, semantic gist information was available even when participants failed to correctly name masked emotional words. Specifically, in error, words semantically related to target words were often reported (e.g., target “war,” response “danger”; target “bomb,” response “death”). This suggests the availability of implicational meaning and the absence of veridical propositional meaning. In addition, deep dyslexia (Coltheart et al., 1987), in which sufferers generate incorrect referents (e.g., reading “lion” as “tiger”), can be regarded as a marker of broadly intact extraction of implicational meaning and significantly impaired attribution of referentially more stringent propositional meaning.
To tie this into the previous section, the implicational and propositional subsystems perform their corresponding salience assessments as items pass through them in the pipeline. We will talk in terms of the overall delay-line and subsystem delay-lines. The former of which describes the complete end-to-end pipeline, from the visual to the response subsystem, while the latter is used to describe the portion of the overall pipeline passing through a component subsystem, e.g., the propositional delay-line.
Our third principle is a mechanism of attentional engagement and cognitive control. It is only when attention is engaged at a subsystem that it can assess the salience of items passing through it. Furthermore, attention can only be engaged at one subsystem at a time. Consequently, semantic processes cannot glance at an incoming item, while looking at and scrutinizing another. This constraint will play an important role in generating a blink in our models.
When attention is engaged at a subsystem, we say that it is buffered (Barnard, 1999). In the context of this paper, the term buffer refers to a moving focus of attention. Thus, salience assignment can only be performed if the subsystem is buffered and only one subsystem can be buffered at a time. The buffer mechanism ensures that the central attentional resources are allocated serially, while data representations pass concurrently, in the sense that all data representations throughout the overall delay-line are moved on one place every 20 ms.
Each subsystem assigns salience on the basis of the constituent representations entering it. Salience assignment is performed at the delay-line of the subsystem when it is buffered. As explained previously, an item (i.e., a word) in RSVP is composed of several constituent representations, six in the current simulation. Thus, the semantic meaning of a word builds up gradually through time. A subsystem accesses the meaning of a word by looking across several of its constituent representations. We assume the meaning of a word emerges from the first few representations. It is important to point out that we are not talking about letter by letter reading here, but the whole word forming an image that builds up gradually through time.
In relation to the time course associated with the extraction of meaning, we assume that three constituent time slots, amounting to 60 ms of presentation, are required for the extraction of useful meaning. Such an estimate is consistent with early research showing that the number of items reportable from a visual array rises rapidly with exposures up to 50 ms, and plateaus thereafter (Mackworth, 1963). A 60-ms integration time also equates closely with a finding recently reported by Grill-Spector and Kanwisher (2005). They show not only that detection increases with exposure durations up to 68 ms, but also that at exactly the time point that the simple detection of an object approximates maximum performance, the ability to report its category also approximates its maximal level, indicating that accurate generic semantic information can indeed be available on the same time scale as simple detection. Thus, the glance–look model specifies not just how attention relates to meaning and salience, but also the time course of meaning formation.
The general idea that attention deployment is governed by an initial glance at generic meaning and then optionally pursued by more detailed scrutiny of referentially specific propositional meaning, is captured here by two stages of buffering with distributed control. The subsystem that is buffered decides when the buffer moves and where it moves to. In real life situations, stimuli do not arrive as rapidly as in AB experiments, so Implic and Prop will normally interpret the representation of the same item or event for an extended period. However, in laboratory situations, such as RSVP, items may fail to be implicationally processed as the buffer moves between subsystems. The buffer movement dynamic provides the underlying mechanism for the blink as follows.
• When in response to the key-distractor being found to be implicationally salient the buffer moves from Implic to Prop, salience assessment cannot be performed on a set of words (i.e., a portion of the RSVP stream) entering Implic following the key-distractor. Hence, when these implicationally un-interpreted words are passed to Prop, propositional meaning, which builds upon coherent detection of implicational meaning, cannot be accessed. If a target word falls within this window, it will not be detected as implicationally salient and thus will not be reported.
• There is normally lag-1 sparing in key-distractor AB experiments, i.e., a target word immediately following the key-distractor is likely to be reported. This arises in our model because buffer movement takes time, hence, the word immediately following the key-distractor may be implicationally interpreted before the buffer moves to Prop.
• When faced with an implicationally un-interpreted item, Prop is no longer able to assign salience and the buffer has to return to Implic to assess implicational meaning. Then, Implic assigns salience to its constituent representations again. After this, targets entering the system will be detected as implicationally and propositionally salient and thus will be reported. Hence, the blink recovers.
In this section, we will demonstrate how key-distractors can capture attention through time, causing semantically prescribed targets to be missed. In addition, our model interfaces with statistical learning theories of meaning to demonstrate how attentional capture is modulated by the semantic salience of the eliciting key-distractor. In the course of this illustration, we will provide a concrete account of performance in the key-distractor AB paradigm where, as just discussed, attention is captured by meaning. The key principles that underlie this account are the division of the processing across two types of meaning, derived from the previously highlighted distinction made in the ICS architecture, between a generic form of meaning referred to as implicational meaning, and propositional meaning, which is referentially specific (Teasdale and Barnard, 1993).
Barnard et al. (2004) used LSA (Landauer and Dumais, 1997; Landauer et al., 1998, 2007) to assess similarities between key-distractors and job targets. LSA is a statistical learning method, which inductively uses the co-occurrence of words in texts and principal component analysis to build a (compact) multidimensional representation of word meaning. In particular, an “objective” measure of the semantic distance between a pair of words or between a word and a pool of words can be extracted from LSA. The critical finding of Barnard et al. was an informal observation that the depth of the blink induced by a key-distractor was modulated by its proximity to the target category, i.e., its semantic salience. We seek here to build from this informal understanding to reproduce in a formal model the key effect of modulation of attentional capture by semantic salience and to explain that effect, again formally, using LSA.
Our model also reflects gradations in semantic salience. We assume that the human cognitive system has a space of semantic similarity available to it comparable to that derived from LSA. The link between principal component analysis (which is at the heart of LSA) and Hebbian learning (O’Reilly and Munakata, 2000), which remains the most biologically plausible learning algorithm, provides support for this hypothesis. Accordingly, we have characterized the assessment of semantic salience in terms of LSA.
To encapsulate the target category in LSA space, we identified five pools of words, for respectively, human relatedness, occupation relatedness, payment relatedness, household relatedness, and nature relatedness. Then, we calculated the center of each pool in LSA space. We reasoned that the target category could be identified relative to these five semantic meanings (i.e., pool centers); see Appendix. This process can be seen as part of a more general categorization mechanism that works on all LSA dimensions. In the context of this experiment, it focuses on the five most strongly related components, as discussed above.
Next, we needed to determine the significance that the human system placed on proximity to each of these five meanings when making target category judgments. To do this, we trained a two-layer neural network to make what amounts to a “targetness” judgment from LSA distances (i.e., cosines) to each of the five meanings, cf. Figure 4. Specifically, we trained a single response node using the Delta rule (O’Reilly and Munakata, 2000) to classify targets from non-targets. The words used in Barnard et al.’s (2004) experiment were used as the training patterns. During training, for each target word, the five corresponding LSA distances were paired with an output (i.e., response node activation) of one, while the LSA distances for non-target words were paired with an output of zero. This analysis generated five weights: one for each LSA distance. These weights effectively characterize the significance that the target salience check ascribes to each of the five constituent meanings; thereby, skewing LSA space as required by implicational salience assessment, cf. Appendix.
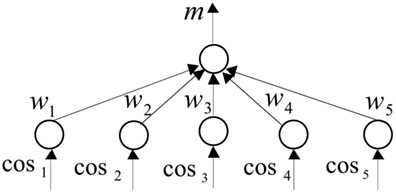
Figure 4. A neural network that integrates five LSA cosines to classify targets from non-targets.
Activation of our neural network response unit (denoted m in Figure 4) becomes the Implic salience assessment decision axis in our model. Thus, words that generate response unit activation above a prescribed threshold were interpreted as implicationally salient, while words generating activation below the threshold were interpreted as unsalient.
Some parameters in our model are justified by neurophysiology, but others need to be set according to the human data observed in AB experiments. There are three sets of such parameters that are fitted using the behavioral curves: (1) salient assignment threshold at Implic; (2) the delay of buffer movement between Implic and Prop; and (3) the length of delay-lines in all subsystems. We fit these parameters using a multi-level approach (Su et al., 2007), which takes inspiration from the computer science notion of refinement. In the computational modeling of a particular cognitive phenomenon, the model development process can start with an abstract black-box analysis of the observable behavior arising from the phenomenon. For example, with the modeling of psychological phenomena, this may amount to a characterization of the pattern of stimulus–response data using a minimum of assumptions. Then, from this solid foundation, one could develop increasingly refined and concrete models, in a progression toward white-box models. Importantly though, this approach enables cross abstraction level validation, showing, for example, that the white-box model is correctly related to the black-box model, i.e., in computer science terms, is related by refinement (Bowman and Gomez, 2006).
A central, and as yet largely unresolved, research question is how to gain the benefit of contained well-founded modeling in the context of structurally detailed descriptions on the one hand, and on the other hand, avoid the “irrelevant specification problem” (Newell, 1990). This problem is classically viewed as arising when a large number of assumptions are made during model implementation, such that it is unclear what assumptions correspond to known cognitive behavior. We provide an initial step in the direction of developing a progressive multi-level approach to cognitive modeling. In particular, all levels of our models occupy just part of the full trajectory of cognitive models (in particular, we regard the glance–look model as the white-box model, and will not consider the neural level). In addition, the relationships between levels that we highlight will be rather specific and will not be supported by formal reasoning. More complete instantiations of our methodological proposal awaits further computational theoretic work on how to relate the sorts of models developed in the cognitive modeling setting. The actual parameter setting and descriptions of black- to gray- and then to white-box modeling we explained in Appendix in order to make the main body more accessible for readers.
Simulation of the glance–look model has shown that high salience key-distractors were much more likely to generate above-threshold response unit activation than low salience items. This in turn ensured that HS items were more often judged to be implicationally salient, which ensured that the buffer moved from Implic to Prop more often for HS items. Since the blink deficit is caused by such buffer movement, targets following HS items were more likely to be missed, cf. Figure 5.
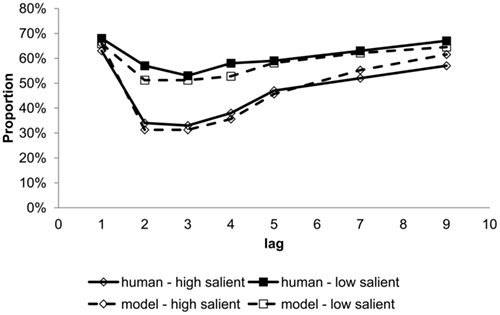
Figure 5. Target report accuracy by serial position comparing human data (Barnard et al., 2004) and model simulation for both high and low salient key-distractors. Lag indicates the number of items intervening between the key-distractor and the target.
We have shown that in the context of Barnard et al.’s (2004) key-distractor blink task, attention is captured when a key-distractor is interpreted as implicationally salient and thus, in error, task relevant. This then causes attention (i.e., the buffer) to be redeployed to the propositional subsystem, in order to enable a more detailed (propositional) assessment of the salience of the key-distractor. Critically, this redeployment of attention leaves a temporal window in which implicational salience is not assessed. During this redeployment, the system is vulnerable to missing even highly salient items. It is through this mechanism that the model blinks. This instantiates the idea (Barnard and Bowman, 2003; Barnard et al., 2004) that semantic blink effects are mediated by first glancing at a form of meaning that supports a sense of relevance in the task context and then moving to a more stringent evaluation of the extent to which word meaning matches the referentially specific properties required by the task.
In addition, we have provided a further case study for the utility of LSA as a means of modeling word meanings. Although the LSA space did not furnish a direct route to distinguishing high and low salience key-distractors, a weighted sum of five attributes did model generic meaning and we established empirically that this could form a basis for discriminating our key-distractors. The effectiveness of LSA depends on the appropriateness of the corpora used to derive the semantic space employed (Landauer et al., 1998). Nevertheless, we have shown that measures of semantic distance derived from LSA, which we take as a useful approximation of implicational salience assessment, can reproduce the key-distractor blink and semantic modulations of blink depth.
This model has its origins in work on emotional disorders (e.g., see Teasdale, 1999 for an extended discussion). In this respect, the broader mode of processing meaning bears some resemblance to recent suggestions from the experimental literature that emotion, body-state, and task manipulations can modulate blink effects (Barnard et al., 2005; Olivers and Nieuwenhuis, 2005, 2006; Arend et al., 2006; Arnell et al., 2007). We next move to model these effects.
There are now several reports of specific effects of affective variables during the AB (e.g., Arnell et al., 2007 and Barnard et al., 2005). In particular, (Anderson, 2005) has shown that the blink is markedly attenuated when the second target is an aversive word. These findings are consistent with the perspective that emotions have a major influence on salience sensitive control. Accordingly, the interaction between emotional salience and temporal attention is being actively investigated in the AB literature. Consequently, we have incorporated emotional salience into the glance–look model. We have particularly focused on modeling the effect of emotional stimuli in two data sets collected using Barnard’s key-distractor AB tasks. Similarly to the previous section, in these tasks, participants search an RSVP stream of words for an item in a target category. Again, performance on the target identification task is investigated as a function of the lag that the target item appears relative to a key-distractor. However, rather than being semantically salient, in these tasks, the key-distractor is emotionally charged.
Arnell et al. (2007) have reported a characteristic blink effect when the key-distractors are emotionally charged words. Specifically, sexual words captured attention more significantly than mildly threatening, anxiety-related, or other emotional words. A deeper blink occurs in the sexual key-distractor condition than control conditions, see Figure 7. In addition, sexual words were better encoded as reflected by heightened performance in a subsequent memory test. This effect suggests that stimulus emotionality is a cue of intrinsic salience used by cognitive control. In particular, perception of high priority emotionally salient stimuli can override the task filter, in this case a specific set of target words defined by semantic category. There is also neurobiological evidence that supports the modulation of cognitive control by affect. For instance, patients with damage to specific emotional centers in the brain (unilateral damage to the left Amygdala) show no differential effect to aversive compared to emotionally neutral words (Anderson and Phelps, 2001). The implication is that this region plays a central role in the pathway by which affect-driven salience is assessed.
Arnell et al. (2007) has argued that it is the arousal, rather than valence, of these key-distractors that correlates with the reduced accuracy in target identification. In particular, the participants’ accuracy of reporting the targets reduced significantly when key-distractors were taboo words. In order, then, to model attentional capture by emotional words, in particular “tabooness,” in the context of LSA, we have identified 10 reference words that we view as representing a schema of a taboo–sexual condition; see Appendix. The choice of these 10 reference words is inspired by Jay (2009), which has addressed the utility and ubiquity of taboo words in the context of how they carry emotional information and what makes these words taboo. Our reference words do not occur as key-distractors in Arnell’s experiments, but most of them (or their synonyms) are used in Jay’s article for defining what taboo words are.
We calculated the semantic distance in LSA space between each of Arnell et al.’s (2007) key-distractors (from both the arousal and control conditions) and the pool of (reference) taboo defining words. The high arousal key-distractors had the largest similarity to these reference words, while control condition words showed minimal similarity to the reference pool; see Appendix. Our glance–look model can thus be extended to describe both semantic and emotional salience by computing the semantic similarity of each word to the target set as well as the taboo defining references. We assume that if any of these dimensions has reached a certain threshold, the implicational subsystem will regard the item as salient, and trigger the buffer to move to the propositional subsystem. As a result of this, both task relevant and intrinsic emotionally salient key-distractors can cause the system to blink.
Barnard et al. (2005) has shown another way in which emotion could interfere with cognitive control. The main finding in this study was that although the threatening key-distractors do not capture attention of unselected participants as they did in Arnell et al. (2007), they can capture attention with participants that were both high state and high trait anxious. In addition, consistent with the notion that this phenomenon is not identical to that identified by Arnell et al. (2007) the blink exhibited in Barnard et al. (2005) was specifically late and short, cf. Figure 8 solid lines (where it is only at lag-4 that the high state and high trait anxious group differs significantly from the low sate anxious group). State anxiety is defined as transitory anxiety experienced at a particular time (often in the recent past or during the experiment). On the other hand, trait anxiety refers to a more general and long-term experience of anxiety; and it often reflects individual differences in reaction to threat (Spielberger, 1972, 1983).
Consistent with the ICS framework, this attentional capture by threat was modeled through the addition of a body-state subsystem, cf. Figure 6. It is assumed that the body-state subsystem responds to the glance at meaning, i.e., to implicational meaning. A bodily evaluation of salience is then fed-back to Implic; thereby, enriching the representation. In effect, the body-state feeds back information in the form of a “somatic marker” (Damasio, 1994; Bechara et al., 2000), which, in the context of the task being considered here, would be a threat marker. Another assumption is that the body-state representation is built upon the implicational meaning with a delay, so the blink onset is positively shifted as shown in Figure 8. Huang et al. (2008) have demonstrated in a series of AB experiments with different task instructions, that emotional key-distractors only generate an AB if the task involves semantic judgments rather than more surface tasks, such as those based on visual features, rhyming patterns, or phonological cues. This evidence also suggests that emotional and body-state representations are activated in the processing of (implicational) meaning.
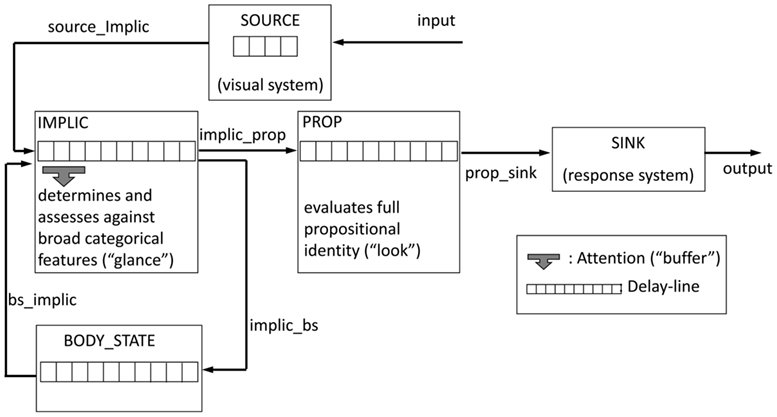
Figure 6. The glance–look model extended with body-state subsystem.
In addition, it is assumed that high anxiety levels (both state and trait) are required before this body-state feedback has sufficient strength to have a major effect on implicational salience. Such difference in sensitivity to affect between high and low anxious individuals is supported by neurophysiological findings (fMRI, Bishop et al., 2004). In their experiment, both high and low anxious people showed increased amygdala activation for fearful faces vs. neutral faces when the faces were attended. However, when the faces were unattended, only high anxious participants showed increased amygdala activation for fearful faces vs. neutral faces. This suggests that for high state and high trait anxious individuals, threatening key-distractors are implicationally interpreted as highly salient when body-state feedback enhances their implicational representation. This enhanced representation precipitates a detailed “look” at the meaning of these items by initiating a buffer move to Prop. Any new items, in particular targets, that arrive at Implic while the buffer is at Prop will be missed. However, since threatening key-distractors are not semantically salient, the buffer will move swiftly back to Implic and the blink is restricted in its length and depth. (In Arnell et al.’s (2007) experiment, although taboo words are not semantically salient, they are emotionally exceptionally salient, so the buffer does not move back to Implic faster than normal).
Without changing the model parameters set in Experiment 1, but by simply introducing the additional dimension of emotion salience, simulations of the glance–look model indeed reproduced the emotional AB phenomena in Experiment 2. For example, as shown in Figure 7 dashed lines, the model reproduced a deeper blink for arousal (sexual-related) but not neutral key-distractors. In addition, as shown in Figure 8 dashed lines, the model generated a characteristic late and short blink at around lag-4, which is uniquely observed in Barnard et al. (2005). In summary, the glance–look model has effectively broadened classical notions of task filtering that, in a wider sense, should embrace affect and body-state.
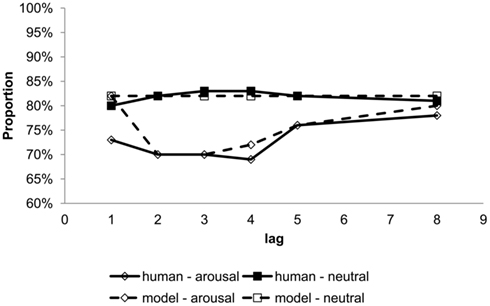
Figure 7. Target report accuracy by serial position comparing human data (Arnell et al., 2007) and model simulation for arousal sexual-related and neutral key-distractors.
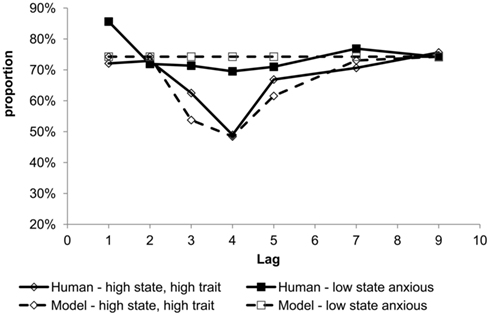
Figure 8. Target report accuracy by serial position comparing human data (Barnard et al., 2005) and model simulations for high state and high trait anxious and low state anxious.
In this section, we have modeled emotional effects on the AB using the glance–look model. By reproducing two key experimental findings, we have proposed two distinct mechanisms by which affect may play a critical role in guiding temporal attention. The first mechanism takes a direct path, by which affect directly increases the salience of the stimuli to such a degree that control is redeployed from monitoring generic meaning to the more specific referential meaning. Hence, we see a somewhat classic blink curve as observed by Arnell et al. (2007). The second mechanism is via the body-state feedback loop, by which affect can influence cognitive control as seen in Barnard et al. (2005). These two mechanisms may occur simultaneously, but body-state feedback often has a delay of several hundred milliseconds. Hence, we argue that in Arnell et al. (2007), the body-state feedback arrives too late to affect the shifting of attention because the buffer has already committed to move from Implic to Prop. Thus, the effect of body-state feedback on cognitive control may only become important when the salience of emotional stimuli is not sufficient to trigger the buffer to move from Implic to Prop. We argue that this is the case in Barnard et al. (2005). Indeed, in high anxious individuals with hyperactive body-state subsystems, body-state feedback (although arriving with a delay) may still enhance the salience of the item sufficiently to trigger the buffer to move. Indeed, the glance–look model has reproduced the delayed blink curve in Barnard et al. (2005).
Although the focus of our modeling is the time course of blink onset, which is the key to distinguishing these two mechanisms of affective control, i.e., via the direct path (Arnell et al., 2007) or body-state feedback loop (Barnard et al., 2005), we have also noticed other differences between these two types of emotional effects in the AB. First, lag-1 sparing is markedly weaker in the taboo key-distractor condition compared to its control conditions, cf. Arnell et al. (2007) and classic semantic AB blink curves. Although not formally modeled in this paper, we argue that this may result from a faster reconfiguration when stimuli are exceptionally salient. In particular, the very presence of extreme taboo words and knowledge that they have a high likelihood of recurring in this task context may bias a rapid shift of attention toward them. The glance–look model predicts such reduced lag-1 sparing when the buffer movement delay from Implic to Prop is sampled from a negatively shifted distribution, i.e., the buffer moves faster from Implic to Prop. Such a shortened delay when switching attentional focus may leave a shorter window of time for the lag-1 item to be implicationally processed. This would lower the probability of reporting targets that immediately follow the key-distractor. There are plausible neurobiological mechanisms that may support such rapid orientation toward threatening stimuli. One of the most prominent theories is the fast sub-cortical route for emotion, proposed by LeDoux et al. (1986), LeDoux (1996). They showed, in a fear conditioning paradigm, that there exists a direct route between thalamus and amygdale, bypassing the cortex.
Second, the blink is shorter in Barnard et al. (2005) than in Arnell et al. (2007). As previously discussed, this is modeled by a reduced buffer movement delay from Prop to Implic when Prop is processing mildly threatening words. However, it is unlikely to be the case when participants are processing extremely salient taboo words. They not only rapidly capture our attention, but also engage extensively before releasing the control and allowing the buffer to return to Implic. Thus, the glance–look model naturally mimics our subjective experience of taboo words.
In summary, the glance–look model supports a broader perspective on cognitive and affective control. In particular, it has moved toward a schematic and embodied account by introducing a gist-based implicational subsystem, which is sensitive to body-state feedback. In this sense, it broadens classical theories of cognitive control. When moving to such a perspective of cognitive control, some commonly considered distinctions become somewhat undermined. For example, the difference between endogenous (top-down) salience and exogenous (bottom-up) salience is not as clear-cut as commonly considered. That is, the distinction between a stimulus that is viewed as salient on the basis of top-down influences (e.g., the ink color red when color-naming in a Stroop task) and on the basis of bottom-up influences (e.g., a threatening word when color-naming during an emotional Stroop task) is really a distinction between salience prescribed by the experimenter (endogenous) and salience prescribed by the participant’s longer-term goals (exogenous). Thus, both endogenous and exogenous reflect biases on stimulus processing due to organism goals, and, in that sense, are both top-down, it is simply that in the endogenous case, goals are short-term and artificially enforced, while in the exogenous case, goals are long-term and intrinsic to the organism.
Recent findings also suggest beneficial effects of focusing on schematic and gist-based implicational meaning when the attentional system is under high cognitive load. Two important findings support this view. One is the fringe awareness phenomenon shown in the key-distractor AB, cf. (Barnard et al., 2004), where some level of awareness is preserved during the AB while full referential identity is apparently absent. There is also evidence for a counterintuitive pattern, in which distracting participants can in fact reduce blink depth (Olivers and Nieuwenhuis, 2005, 2006; Arend et al., 2006). Thus, in this context, reducing attentional focus seems to improve awareness. It has been argue that such distraction may counteract an overinvestment of attention. To elaborate further, in a typical laboratory setting, participants are encouraged to recall as accurately as possible. As previously argued by several authors (Olivers and Nieuwenhuis, 2005, 2006; Arend et al., 2006), this could well, in a very broad informal sense, result in more “investment of attention” than is strictly necessary to accomplish item report. Hence, task manipulations and emotional states (e.g., by using music, positive affect, or dynamic visual patterns) can attenuate blink effects (i.e., enhance awareness of the second target) by, it is argued, encouraging a more distributed state of attention. This section shows how the glance–look model can provide a more formal information processing account for the fringe awareness and overinvestment findings in the AB. In addition, we argue for a re-evaluation of conventional theories of cognitive function based on interactions between attention, emotion, and consciousness.
As previously discussed, Barnard et al. (2004) used three types of response in their AB experiments: (1) report of the target identity, (2) “No job seen,” and (3) “Yes, I saw a job, but could not report its identity.” These responses reflect different degrees of awareness of target presence. The glance–look model suggests that the salience assignment of a target word can also be processed to three different degrees, cf. Table 1. We argue that different degrees of processing can potentially result in different types of response.

Table 1. Different degrees of processing and their corresponding responses from the model.
As shown in the first row of Table 1, targets that are found salient both at Prop and Implic can be reported correctly with their identity at the end of the sequence. As previously discussed, a subsystem needs to evaluate at least three constituent representations in order to access the salience of a word. In the second situation in Table 1, some items may be implicationally un-interpreted because Implic is not buffered when they are passed through the implicational delay-line. The model assumes that implicationally unprocessed items will not be evaluated for meaning at the propositional level. Our model predicts that this will result in a situation where subjects are completely unaware of the presence of an incoming item, and will respond “no” at the end of the trial. Finally, as shown by the third situation in Table 1, some targets can be partially processed by Implic, but only for less than three constituent representations. Hence, we argue that when executive processes are reconfiguring, participants could be only fringe aware of salient stimuli. Although lacking the full referential identity, they are capable of reacting to at least some categorical information. This further suggests that gist-based implicational meaning may contribute to awareness of stimuli without extended propositional processing.
Given the existence of fringe awareness based on semantic “gist,” the next question is whether schematic (implicational) representations alone are sufficient to identify items in RSVP streams when the capacity of the system is being pushed toward its limit, i.e., when there are distractions. Here, we model attenuation effects using the glance–look model and, thereby, provide a computational account of the overinvestment theory. In particular, overinvestment may reflect (functionally unnecessary) extended processing in our second propositional stage, delaying attention’s return to a state in which implicational representations are evaluated. The implicational mode of attending to meaning has a broader focus on generic meaning, which we argue incorporates affect, and derivatives of multimodal or lower order inputs, such as music. When participants are exposed to dynamic patterns, being visual, musical, or internally generated, while performing the central AB task, there would be more changes in input to Implic. With our model of distributed control, these may well encourage the implicational mode of attending to meaning, perhaps “calling” the buffer back from Prop to Implic, and, thus, supporting more distributed awareness of this type of generic meaning.
The degree of, distraction-induced, attenuation reported in Arend et al. (2006), Olivers and Nieuwenhuis(2005, 2006) should, though, reflect two factors: the degree to which the ancillary task has direct consequences for the representation of generic (implicational) meaning and the extent to which the reporting of an item requires extended evaluation of propositional meanings. Crucially, when attenuation effects are observed, the paradigm often involves reporting letters in a background stream of digits (Olivers and Nieuwenhuis, 2005, 2006; Arend et al., 2006). Letters are drawn from a small and highly familiar set, and hence, in the limit, may require only the briefest “look” at a propositional representation, or in most cases, only a “glance” at the implicational representation, to support correct report. So, we assume in the model that the buffer moves from Implic to Prop with a reduced probability when participants are distracted. And, we also assume that the majority of items can be reported when they have only been implicational processed.
As seen in Figure 9A, the glance–look model has reproduced the “No” response, which often occurs at serial position 3 and 4. And, these lags are the deepest points of the blink. Using the same parameter setting, our model generated partial processing at serial position 2, because it is the moment when the buffer is shifting from Implic to Prop. At this serial position, human participants often respond with “yes,” confirming that they are aware of the presence of the target but unable to identify it, cf. Figure 9B. Hence, the glance–look model naturally captures the fringe awareness. Finally, the glance–look model also reproduced the attenuation effects, cf. Figure 10. Due to limitation of space, we only show the simulation result for Experiment 1 of Olivers and Nieuwenhuis (2005), in which the blink depth reduced when participants had additional tasks.
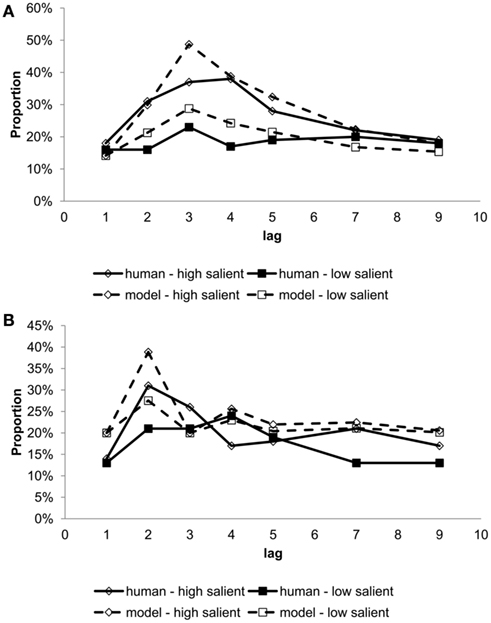
Figure 9. Proportion of (A) “No” response and (B) “Yes” response (i.e., reflecting partial awareness) by serial position comparing human data (Barnard et al., 2004) and model simulation for high and low salient key-distractors.
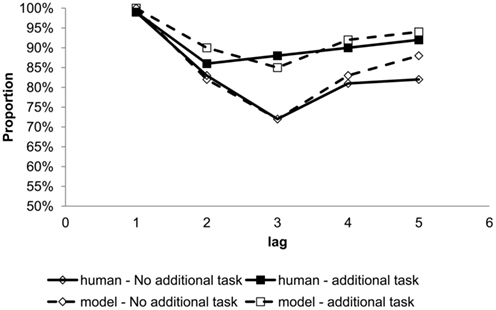
Figure 10. Target report accuracy by serial position comparing human data (Olivers and Nieuwenhuis, 2006) and model simulation for with and without distraction, i.e., an additional task.
The glance–look model has shown that lack of awareness can be accounted for by the allocation of attention to different levels of meaning in a system where there is only distributed control of processing activity. Just as the focus of our attention may shift among entities in our visual and auditory scenery under the guidance of salient change, shifts in attention to different entities in our semantic scenery can lead to RSVP targets being either, (1) correctly identified; (2) “noticed” with fringe awareness of presence; or (3) overlooked. Salience states at each of two levels of meaning allow these three response patterns to be captured. Although the proposal, like that of Chun and Potter (1995), relies on two stages, both of our stages are semantic in nature and the temporal dynamic involves controlled changes in the focus of attention, rather than classic capacity or resource limitations. The idea of monitoring a generic form of meaning for implicational salience, the level at which affect is represented in the model, and switching only when required to evaluate propositional meaning, represent two “modes” of attending to meaning. The former mode has a broader focus on generic meaning (i.e., the “gist”) and the latter a more evaluative focus on specific meanings, which can be verbally reported. This is similar to the distinction in the literature between “phenomenal” and “access” awareness (Lamme, 2003). Furthermore, the broader mode of processing meaning bears some resemblance to recent suggestions that task manipulations can attenuate blink effects, by encouraging a more distributed state of awareness, which would arise at our implicational level. In particular, music, positive affect, and dynamic visual patterns may counteract on overinvestment of attention (Olivers and Nieuwenhuis, 2005, 2006; Arend et al., 2006) and produce a fleeting conscious percept (Crick and Koch, 2003).
In summary, consciousness is modeled as an emergent property from the interaction among three subsystems: implicational, propositional, and body-state. In particular, we differentiate two types of consciousness. One is akin to full “access” awareness, i.e., conscious content can be verbally reported, and is supported by both implicational and propositional processing. In other words, it is a result of a detailed “look” and more extensive mental processing. The other is akin to “phenomenal” (or fringe) awareness. We argue that the latter is a result of attending to the implicational level or “glance.” It is also notable that the implicational level is holistic, abstract and schematic, and is where multimodal inputs are integrated, and affect is represented and experienced (Barnard, 1999).
In addition, the glance–look model makes several predictions on the relationship between these two modes of consciousness. First, fringe awareness provides a basis for a more complete state of consciousness. Second, comparing to full access awareness, phenomenal, or fringe awareness is directly affected by emotional, multimodal, body-state, and lower order inputs. However, once propositional level information has been attended, a conscious percept is much less likely to be interrupted. The validation of these predictions awaits further experimental work.
The model however also predicts that attenuation should be less pronounced either with secondary tasks whose content does not directly influence the level of generic (implicational) meaning or, as with semantic blink effects, where a fuller evaluation of propositional meanings is required. Should such effects be found, it would provide an encouraging convergence between basic laboratory tasks and the literature on attention to meaning and affect in emotional disorders, using a non-computationally specified version of our current proposal (Teasdale, 1999).
We started this paper with the observation that, as classically formulated and empirically studied, cognitive control has been rather narrowly delineated. In particular, studies have typically focused exclusively on the cognitive and on experimental materials that afford a precise discrete demarcation into task relevant and non-task relevant. One might, indeed, describe this as an all-or-none circumscription of task-focus: stimuli are either completely goal relevant or completely goal irrelevant. This problem is being partially addressed by a body of emerging cognitive control research that incorporates the affect dimension, the journal special topic that this paper is presented under being a case in point. Indeed, there is now a good deal of evidence that, even when task irrelevant, affect laden stimuli bias attentional focus and are prioritized (Anderson, 2005; Barnard et al., 2005; Arnell et al., 2007).
The other pillar of our argument to broaden the notion of goal-relevance, and which certainly remains underexplored, is the role of meaning representations (in their broadest sense) in cognitive control. Firstly, the space of meaning representations that the brain carries is likely to be inherently continuous and graded. This certainly is, for example, the perspective arising from statistical learning techniques, both in their supervised (O’Reilly and Munakata, 2000) and unsupervised (Landauer and Dumais, 1997; Landauer et al., 1998, 2007) formulations. Thus, it is just difficult for our brains to perfectly delineate one meaning category from another. The goal specifications, that we employ, and which are surely substantially driven by meaning, are likely to be graded in nature, rather than discrete.
In this context, we have proposed a model of central executive function based upon two levels of meaning and, correspondingly, two levels of filtering. The first of these, the glance, extracts a schematic, implicational, representation of meaning; and it is at this level that affect is encompassed. The second, the look, assesses a referentially bound propositional perspective on meaning. Using this framework, we were able to integrate graded representations of meaning, based upon LSA, with emotional and body-state influences. We illustrated this model in the context of the key-distractor AB task. We were able to model a spectrum of key-distractor AB phenomena, including, modulation of blink depth by key-distractor semantic salience, deep blink profiles with taboo key-distractors, smaller, and later concern associated blinks with milder affective key-distractors, fringe awareness patterns, and blink attenuation in the presence of distraction.
In the current trend of cognitive neuroscience, functional MRI is the primary method that maps cognitive functions to underlying neurobiology. However, in the context of AB, the poor temporal resolution of BOLD functional imaging is not sensitive to the very rapid switch between Implic and Prop in our glance–look model. Hence, one must be speculative when relating subsystems in our model to brain areas. Nonetheless, we argue that mechanisms implemented in our model fit within existing neuroscientific findings of cognitive and affective networks in human brain. For example, it is argued that neurons in the dorsolateral prefrontal cortex (DLPFC) encode task set (Miller and Cohen, 2001). DLPFC and parts of the multiple-demand (MD) system (Duncan, 2010) could be correlated with Prop, where the task filter derived from experimental instruction is implemented. It is also argued that animals have the ability to extract threatening information from the environment, and such ability is hard-wired through evolution. Threatening stimuli act as cues of potential danger and may trigger “flight or fight” responses, so it is important for all animals, including humans. Hence, threatening information needs to be rapidly extracted directly from sensory inputs, likely via the neural pathway from the sensory thalamus to the amygdala (LeDoux, 1996). This is consistent with our glance–look model that emotion induced representations are extracted directly from sensory inputs at Implic, cf. modeling intrinsic salience due to emotion in Section “Experiment 2.” In addition, the body representations encoded in our body-state subsystem are likely to correlate with somatosensory cortex, insula, and hypothalamus (Bechara et al., 2005).
Implic as the central subsystem for the integration of cognition and emotion plays a critical role in the glance–look model account of cognitive and affective control theory. We believe a number of candidate regions in the brain are well situated to perform this function. Firstly, the amygdala is not only highly connected to both cortical and sub-cortical systems, but also participates in both cognitive processing, such as attention orientation, and emotional processing (Heller and Nitschke, 1997). Secondly, it has been shown that the orbitofrontal cortex (OFC), the ventromedial prefrontal cortex (VMPFC), and the anterior cingulated cortex (ACC) are also likely to be part of this integration network (Pessoa, 2008). (Also, see Taylor and Fragopanagos, 2005 for a review of neural correlates of attention and emotion systems, and for an alternative computational account for the time course of attentional control network. It is likely that the glance–look model also draws on resource in other areas of the brain that are sensitive to functional MRI. However, to get temporal information in the time frame of RSVP, time resolved techniques, such as Magnetoencephalography is highly desirable).
With respect to the interaction between emotion and cognition, the general effect of emotion in cognitive control has been experimentally studied, but related computational theories are not fully spelled out in the literature. Some successful computational models of emotion rely on statistical learning algorithms, e.g., reinforcement learning (Montague et al., 1996; Schultz et al., 1997). Others argue for competition between emotion and cognitive processing (Mathews et al., 1997; Mathews and Mackintosh, 1998; Taylor and Fragopanagos, 2005; Wyble et al., 2008). Our glance–look model fits within the latter bracket and arguing for competitive interaction between cognition and emotion, i.e., emotional salience can attract attention and impair (cognitive) task oriented processing. However, our model specifies how they compete in time, and predicts the complex temporal dynamics of cognitive and affective control. In addition, our model addresses the importance of processing at the implicational level.
From an evolutionary perspective, implicational meaning has its origins in the multimodal control of action (Barnard et al., 2007). The implicational subsystem, across the human line of decent, is where overt responses are selected on the basis of a blending and assessment of external (visual and auditory) and internal (body-state) stimuli. This is augmented by a propositional subsystem only in Homo sapiens and hence gives rise to a unique form of “cognitive” control. In some sense, most current theories of cognitive control lack a coherent behavioral grounding that goes beyond the fact that we are good at attending to stimuli that are relevant to what we are doing in intellectual tasks. However, the idea of implicational salience is that it can deal either with affective or non-affective salience. We argue that emotional blinks reflect “incidental” salience, which is partly due to processing of implicational meaning and partly due to a later body-state intervention. For emotional stimuli (specifically in the context of AB) there are only minimal requirements to do a propositional evaluation. So, in some sense, the essence of “cognitive” control is how much involvement of the propositional subsystem there is in evaluating representations in relation to task filters. Although task demands require a propositional representation, the glance–look model evolving here has the basic elements that enable affect, goals, body-state, and meaning to be addressed.
The glance–look model’s simulation of blink attenuation with distraction does prompt an intriguing prediction. The model explains such attenuation in terms of an over emphasis on propositional level processing and, in that sense, fits with over investment theories of the AB (Taatgen et al., 2007). Importantly, this explanation is highly stimulus and task type dependent. That is, we are proposing that, in the context of the experimental laboratory, the cognitive system applies an extensive propositional analysis when it is, in some cases, not strictly necessary. This level of analysis is particularly redundant in the context of highly over learnt stimulus sets that are easily classified on the basis of surface features at the implicational system. However, this, at least partial, redundancy of propositional processing, would not obtain so significantly when semantic salience judgments are being made. Such salience would particularly obtain in the semantic key-distractor AB tasks considered in Section “Experiment 1” of this paper. Thus, we predict that addition of distraction manipulations, such as, background starfield (Arend et al., 2006), inducing positive affect (Olivers and Nieuwenhuis, 2005, 2006), and a peripheral task (Taatgen et al., 2007), would not attenuate the semantic key-distractor blink without, at the least, a cost to baseline target report performance. In other words, in semantic key-distractor tasks, emphasis on propositional processing is necessary and cannot be subverted without performance cost.
In addition to testing this pivotal prediction, it would clearly be beneficial to broaden the application of the glance–look model beyond the AB domain. In particular, it will be important to test the model in the context of Stroop and emotional Stroop experiments, particularly those focused on strategic, typically conflict-based, patterns of behavior (Botvinick et al., 2001; Wyble et al., 2008).
It is also important to note that the glance–look model is formulated within a broader architectural framework: the ICS architecture (Barnard, 1985). Such broader theories are not now very common in cognitive neuroscience theory, which has become focused on rather small scale neural network models of particular cognitive phenomena. Integration within architectural frameworks, though, enables higher level macro theoretic constraints to be brought to bear, such as the macroscopic information flows between component subsystems (Barnard, 2004). Such broader perspectives should enable the undoubtedly extensive and diverse constraints that impinge on central executive function, and the role affect and meaning play in that system, to be coherently brought to bear.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The UK Engineering and Physical Sciences Research Council supported this research (grant number GR/S15075/01). The participation of Philip Barnard in this project was supported by the Medical Research Council under project code A060_0022.
Abeles, M., Bergman, H., Margalis, E., and Vaadia, E. (1993). Spatiotemporal firing patterns in the frontal cortex of behaving monkeys. J. Neurophysiol. 70, 1629–1638.
Anderson, A. K. (2005). Affective influences on the attentional dynamics supporting awareness. J. Exp. Psychol. Gen. 134, 258–281.
Anderson, A. K., and Phelps, E. A. (2001). Lesions of the human amygdala impair enhanced perception of emotionally salient events. Nature 411, 305–309.
Arend, I., Johnston, S., and Shapiro, K. (2006). Task irrelevant visual motion and flicker attenuate the attentional blink. Psychon. Bull. Rev. 13, 600–607.
Arnell, K. M., Killman, K. V., and Fijavz, D. (2007). Blinded by emotion: target misses follow attention capture by arousing distractors in RSVP. Emotion 7, 465–477.
Barnard, P. J. (1985). “Interacting cognitive subsystems: a psycholinguistic approach to short-term memory,” in Progress in the Psychology of Language, Vol. 2, ed. A. Ellis (Hove: Lawrence Erlbaum Associates Ltd.), 197–258.
Barnard, P. J. (1999). “Interacting cognitive subsystems: modelling working memory phenomena with a multi-processor architecture,” in Models of Working Memory, eds A. Miyake, and P. Shah (Cambridge: Cambridge University Press), 298–339.
Barnard, P. J. (2004). Bridging between basic theory and clinical practice. Behav. Res. Ther. 42, 977–1000.
Barnard, P. J., and Bowman, H. (2003). Rendering information processing models of cognition and affect computationally explicit: distributed executive control and the deployment of attention. Cogn. Sci. Q. 3, 297–328.
Barnard, P. J., Duke, D. J., Byrne, R. W., and Davidson, I. (2007). Differentiation in cognitive and emotional meanings: an evolutionary analysis. Cogn. Emot. 21, 1155–1183.
Barnard, P. J., Ramponi, C., Battye, G., and Mackintosh, B. (2005). Anxiety and the deployment of visual attention over time. Vis. Cogn. 12, 181–211.
Barnard, P. J., Scott, S., Taylor, J., May, J., and Knightley, W. (2004). Paying attention to meaning. Psychol. Sci. 15, 179–186.
Bechara, A., Damasio, H., and Damasio, A. R. (2000). Emotion, decision making and the orbitofrontal cortex. Cereb. Cortex 10, 295–307.
Bechara, A., Damasio, H., Tranel, D., and Damasio, A. R. (2005). The Iowa gambling task and the somatic marker hypothesis: some questions and answers. Trends Cogn. Sci. (Regul. Ed.) 9, 159–162.
Bishop, S. J., Duncan, J., and Lawrence, A. D. (2004). State anxiety modulation of the amygdala response to unattended threat-related stimuli. J. Neurosci. 24, 10364–10368.
Bond, A. H. (1999). Describing behavioural states using a system model of the primate brain. Am. J. Primatol. 49, 315–338.
Botvinick, M., Braver, T., Barch, D., Carter, C., and Cohen, J. (2001). Conflict monitoring and cognitive control. Psychol. Rev. 108, 624–652.
Bowman, H., and Gomez, R. S. (2006). Concurrency Theory, Calculi and Automata for Modelling Untimed and Timed Concurrent Systems. London: Springer.
Bowman, H., Su, L., Wyble, B., and Barnard, P. J. (2011). Salience Sensitive Control, Temporal Attention and Stimulus-Rich Reactive Interfaces, Human Attention in Digital Environments. Cambridge: University Press.
Bowman, H., and Wyble, B. (2007). The simultaneous type, serial token model of temporal attention and working memory. Psychol. Rev. 114, 38–70.
Broadbent, D. E., and Broadbent, M. H. P. (1987). From detection to identification: response to multiple targets in rapid serial visual presentation. Percept. Psychophys. 42, 105–113.
Chun, M. M., and Potter, M. C. (1995). A two-stage model for multiple target detection in rapid serial visual presentation. J. Exp. Psychol. Hum. Percept. Perform. 21, 109–127.
Cohen, J. D., Dunbar, K., and McClelland, J. L. (1990). On the control of automatic processes: a parallel distributed processing account of the Stroop effect. Psychol. Rev. 97, 332–361.
Coltheart, M., Patterson, K., and Marshall, J. C. (eds). (1987). Deep Dyslexia. London: Routledge, 23–43.
Cousineau, D., Brown, S., and Heathcote, A. (2004). Fitting distributions using maximum likelihood: methods and packages. Behav. Res. Methods Instrum. Comput. 36, 277–290.
Cousineau, D., Charbonneau, D., and Jolicoeur, P. (2006). Parameterizing the attentional blink effect. Can. J. Exp. Psychol. 60, 175–189.
Davelaar, E. J. (2008). A computational study of conflict-monitoring at two levels of processing: reaction time distributional analyses and hemodynamic responses. Brain Res. 1202, 109–119.
Duncan, J. (2010). The multiple-demand (MD) system of the primate brain: mental programs for intelligent behaviour. Trends Cogn. Sci. (Regul. Ed.) 14, 172–179.
Erickson, T. D., and Mattson, M. E. (1981). From words to meaning: a semantic illusion. J. Verb. Learn. Verb. Behav. 20, 540–551.
Flaisch, T., Junghofer, M., Bradley, M. M., Schupp, H. T., and Lang, P. J. (2007). Rapid picture processing: affective primes and targets. Psychophysiology 45, 1–10.
Fox, E., Russo, R., Bowles, R. J., and Dutton, K. (2001). Do threatening stimuli draw or hold visual attention in sub-clinical anxiety? J. Exp. Psychol. Gen. 130, 681–700.
Gaillard, R., del Cul, A., Naccache, L., Vinckier, F., Cohen, L., and Dehaene, S. (2006). Nonconscious semantic processing of emotional words modulates conscious access. Proc. Natl. Acad. Sci. U.S.A. 103, 7524–7529.
Georgiou, G. A., Bleakly, C., Hayward, J., Russo, R., Dutton, K., Eltiti, S., and Fox, E. (2005). Focusing on fear: attentional disengagement from emotional faces. Vis. Cogn. 12, 145–158.
Grill-Spector, K., and Kanwisher, N. (2005). Visual recognition: as soon as you know it is there, you know what it is. Psychol. Sci. 16, 152–160.
Heller, W., and Nitschke, J. B. (1997). Regional brain activity in emotion: a framework for understanding cognition in depression. Cogn. Emot. 11, 637–661.
Houghton, G., and Tipper, S. P. (1994). “A model of inhibitory mechanisms in selective attention,” in Inhibitory Processes in Attention, Memory, and Language, eds D. Dagenbach, and T. H. Carr (San Diego, CA: Academic Press), 53–112.
Huang, Y. M., Baddeley, A., and Young, A. W. (2008). Attentional capture by emotional stimuli is modulated by semantic processing. J. Exp. Psychol. Hum. Percept. Perform. 34, 328–339.
Koster, E. H. W., Crombez, G., Verschuere, B., and De Houwer, J. (2006). Attention to threat in anxiety-prone individuals: mechanisms underlying attentional bias. Behav. Res. Ther. 30, 635–643.
Lamme, V. A. (2003). Why visual attention and awareness are different. Trends Cogn. Sci. (Regul. Ed.) 7, 12–18.
Landauer, T. K., and Dumais, S. T. (1997). A solution to Plato’s problem: the latent semantic analysis theory of the acquisition, induction and representation of knowledge. Psychol. Rev. 104, 211–240.
Landauer, T. K., Foltz, P. W., and Laham, D. (1998). Introduction to latent semantic analysis. Discourse Process. 25, 259–284.
Landauer, T. K., McNamara, D. S., and Dennis, S. (eds). (2007). Handbook of Latent Semantic Analysis. Mahwah, NJ: Lawrence Erlbaum Associates.
LeDoux, J. E., Sakaguchi, A., Iwata, J., and Reis, D. J. (1986). Interruption of projections from the medial geniculate body to an archi-neostriatal field disrupts the classical conditioning of emotional responses to acoustic stimuli. Neuroscience 17, 615–627.
Leyman, L., De Raedt, R., Schacht, R., and Koster, E. H. W. (2007). Attentional biases for angry faces in unipolar depression. Psychol. Med. 37, 393–402.
Maki, W. S., Frigen, K., and Paulsen, K. (1997). Associative priming by targets and distractors during rapid serial presentation. J. Exp. Psychol. Hum. Percept. Perform. 23, 1014–1034.
Marr, D. (2000). “Vision,” in Minds, Brains and Computers, The Foundation of Cognitive Science (An Anthology), eds R. Cummins, and D. D. Cummins (Malden, MA: Blackwell), 69–83.
Mathews, A., and Mackintosh, B. (1998). A cognitive model of selective processing in anxiety. Cognit. Ther. Res. 22, 539–560.
Mathews, A., Mackintosh, B., and Fulcher, E. P. (1997). Cognitive biases in anxiety and attention to threat. Trends Cogn. Sci. (Regul. Ed.) 1, 340–345.
Miller, E. K., and Cohen, J. D. (2001). An integrative theory of prefrontal cortex function. Annu. Rev. Neurosci. 24, 167–202.
Montague, P. R., Dayan, P., and Sejnowski, T. J. (1996). A framework for mesencephalic dopamine systems based on predictive Hebbian learning. J. Neurosci. 16, 1936–1947.
Ohman, A., and Soares, J. J. F. (1994). Unconscious anxiety: phobic responses to masked stimuli. J. Abnorm. Psychol. 103, 231–240.
Olivers, C. N. L., and Nieuwenhuis, S. (2005). The beneficial effects of concurrent task – irrelevant mental activity on temporal attention. Psychol. Sci. 16, 265–269.
Olivers, C. N. L., and Nieuwenhuis, S. (2006). The beneficial effects of additional task load, positive affect, and instruction on the attentional blink. J. Exp. Psychol. 32, 364–379.
O’Reilly, R. C., and Munakata, Y. (2000). Computational Explorations in Cognitive Neuroscience: Understanding the Mind by Simulating the Brain. Cambridge, MA: MIT Press.
Panzeri, S., Rolls, E. T., Battaglia, F., and Lavis, R. (2001). Speed of feedforward and recurrent processing in multilayer networks of integrate-and-fire neurons. Network 12, 423–440.
Pessoa, L. (2008). On the relationship between emotion and cognition. Nat. Rev. Neurosci. 9, 148–158.
Phelps, E. A., Ling, S., and Carrasco, M. (2006). Emotion facilitates perception and potentiates the perceptual benefits of attention. Psychol. Sci. 17, 292–299.
Raymond, J. E., Shapiro, K. L., and Arnell, K. M. (1992). Temporary suppression of visual processing in an RSVP task: an attentional blink. J. Exp. Psychol. Hum. Percept. Perform. 18, 849–860.
Roediger, H. L., and McDermott, K. B. (1995). Creating false memories: remembering words not presented in lists. J. Exp. Psychol. Learn. Mem. Cogn. 21, 803–814.
Schultz, W., Dayan, P., and Montague, P. R. (1997). A neural substrate of prediction and reward. Science 275, 1593–1598.
Shapiro, K. L., Arnell, K. M., and Raymond, J. E. (1997a). The attentional blink. Trends Cogn. Sci. (Regul. Ed.) 1, 291–296.
Shapiro, K. L., Caldwell, J. I., and Sorensen, R. E. (1997b). Personal names and the attentional blink: the cocktail party revisited. J. Exp. Psychol. Hum. Percept. Perform. 23, 504–514.
Shapiro, K. L., and Luck, S. J. (1999). “The attentional blink: a front-end mechanism for fleeting memories,” in Fleeting Memories, Cognition of Brief Visual Stimuli, ed. V. Coltheart (Boston, MA: A Bradford Book, MIT Press), 95–118.
Spielberger, C. D. (1972). Anxiety: Current trends in theory and research: I. New York, NY: Academic Press.
Spielberger, C. D. (1983). Manual for the State-Trait Anxiety Inventory (STAI), PaloAlto, CA: Consulting Psychologists Press.
Su, L., Bowman, H., Barnard, P. J., and Wyble, B. (2009). Process algebraic modelling of attentional capture and human electrophysiology in interactive systems. Formal Aspect. Comput. 21, 513–539.
Su, L., Bowman, H., and Barnard, P. J. (2007). Attentional capture by meaning, a multi-level modelling study. 29th Annual Meeting of the Congitive Science Society, Nashville, TN, 1521–1526.
Taatgen, N. A., Juvina, I., Herd, S., Jilk, D., and Martens, S. (2007). “Attentional blink: an internal traffic jam?” in Proceedings of the 8th International Conference on Cognitive Modelling. Ann Arbor, MI.
Taylor, J. G., and Fragopanagos, N. (2005). The interaction of attention and emotion. Neural Networks 18, 353–369.
Teasdale, J. D. (1999). Emotional processing, three modes of mind, and the prevention of relapse in depression. Behav. Res. Ther. 37, S53–S77.
Teasdale, J. D., and Barnard, P. J. (1993). Affect, Cognition and Change: Re-modelling Depressive Thought. Hove: Lawrence Erlbaum Associates.
Visser, T. A. W., Bischof, W. F., and Di Lollo, V. (1999). Attentional switching in spatial and non-spatial domains: evidence from the attentional blink. Psychol. Bull. 125, 458–469.
Wyble, B., Bowman, H., and Nieuwenstein, M. (2009). The attentional blink provides episodic distinctiveness: sparing at a cost. J. Exp. Psychol. Hum. Percept. Perform. 35, 787–807.
Wyble, B., Sharma, D., and Bowman, H. (2008). Strategic regulation of cognitive control by emotional salience: a neural network model. Cogn. Emot. 22, 1019–1051.
Yiend, J., and Mathews, A. (2001). Anxiety and attention to threatening pictures. Q. J. Exp. Psychol. 54, 665–681.
Zylberberg, A., Slezak, D. F., Roelfsema, P. R., Dehaene, S., and Sigman, M. (2010). The brain’s router: a cortical network model of serial processing in the primate brain. PLoS Comput. Biol. 6, e1000765. doi: 10.1371/journal.pcbi.1000765
Human reference words: human people mankind womankind someone mortal fellow sentient folk soul.
Occupation reference words: occupation profession job trade employment work business career livelihood vocation.
Payment reference words: payment fee remuneration recompense bribe salary honorarium income earnings wages.
Household reference words: ornament device utensil gadget tool possession decoration fitting fixture furnishing.
Nature reference words: archipelago backwoods beach biosphere brook channel cliff cloud cloudburst coastline crevasse crevice cyclone desert diamond drought sediment earthquake eruption estuary everglades fissure fjord floodplain frost geyser gorge grassland habitat hailstone headwind hillside hoarfrost iceberg icecap inlet island landscape lightning limestone meadow monsoon moonlight moraine mudflats outback outcrop pampas plains plateau puddle quartz rainbow raindrop rapids reef riverbank riverbed salt marsh sandstorm savannah seashore shoreline skyline snowflake straits stream sunshine swamp tempest tornado breeze tributary causeway waterfall wetlands whirlpool woodland.
Taboo reference words: vulgar offensive feces sex slang slur disgusting taboo blasphemous insulting.
In the first step of the refinement trajectory, we regard the system as a black-box. That is, no assumptions are made about the internal structure of the system and there is no decomposition, at all, of the black-box into its constituent components. Thus, the point of reference for the modeler is the externally visible behavior, i.e., the semantic blink curves (Barnard et al., 2004). Such models are extensionalist in nature, and they simply characterize the data. A critical benefit of black-box cognitive modeling is that there are less degrees of freedom and fewer hidden assumptions, making data fitting and parameter setting both well-founded and, typically, computationally tractable. For example, if the system can be described in closed form, key parameters can be determined by solving a set of equations, if not, computational search methods can be applied.
An extensionalist model simply provides a systematic characterization of how data in a domain varies. This technique has been widely used in modeling response time distributions (Van Zandt, 2000; Cousineau et al., 2004) and, more recently, in modeling serial position curves of basic attentional blink tasks (Cousineau et al., 2006). In our context of exploring the key-distractor attentional blink task, the behavior curves have sharp blink onsets and shallow recoveries as shown in Figure 5. This shape matches an inverted Gamma distribution. Hence, we use the following equation to model blink curves.
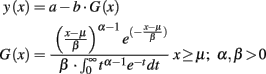
where G is a Gamma distribution, x is the serial position, a sets the baseline performance, and b describes the difference between the deepest point of the blink and the baseline. If b is set to 0, the function models the complete absence of the blink and baseline performance at all lags. So, we call b the depth parameter or the capture constant. In particular, b is related to key-distractor salience and thus characterizes the attentional capture by salience effect we are interested in. After fitting y to the human blink curves show in Figure 5, a is set to 0.67 for both high and low salient cases, but b is 1.8 for high salient key-distractors and 0.8 for low salient ones. It will become clear later that the capture constant b is related to implicational salience assignment threshold. Other parameters in the model (α = 2.2, β = 1.6, μ = 0) were fixed during data fitting, so, they do not affect the depth of the blink.
In the black-box model, we used a Gamma distribution to describe the shape of blink curves. However, it does not describe the underlying mechanism of the cognitive system and what mental processes are likely to produce the AB phenomenon. In addition, the black-box model does not set all parameters in the glance–look model. We have introduced an intermediate step between black- and white-box models in order to incrementally add complexity. In particular, we set as many parameters as we can, at this stage, without defining the complex semantic space, which will be left to the final refinement. Hence, the intermediate gray-box model refines the black-box model, and reflects the three assumptions about internal structure explained in Section “Theory of the Glance-look Model” (i.e., sequential processing, two stages, and serial allocation of attention).
Salience assignment. In the gray-box model, the salience assignment threshold is indirectly modeled using a parameter called the intrinsic probability of identification (denoted P), which refers to the probability that an item will be seen if it is presented as a single target in an RSVP stream. Note, P(X, Y) is not the probability that both items X and Y are seen in an AB setting, but rather the probability that both would individually be seen in two separate single target events.
The intrinsic probability of detecting a target P(T) = 0.67 is set by the baseline performance of humans (Barnard et al., 2004). The intrinsic probability of a background word being implicationally salient is assumed to be zero, since this sort of error is so rare as to be effectively zero. The intrinsic probability of detecting a high and low salient key-distractor is P(HS) and P(LS) respectively. According to the gray-box model, if the key-distractor is implicational salient and the buffer shifts to Prop, the lag-3 item (i.e., the deepest point in AB) will always be missed. So, the deepest point in the blink curve reflects the joint probability of missing the key-distractor and detecting the target, i.e., P(¬HS, T) and P(¬LS, T) in the high and low salient conditions respectively. According to the behavior curves (Barnard et al., 2004), we set P(¬HS, T) = 0.34 and P(¬LS, T) = 0.54, cf. Figure A1. Assuming Implic assesses targets and key-distractors independently, we have the following.
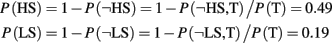
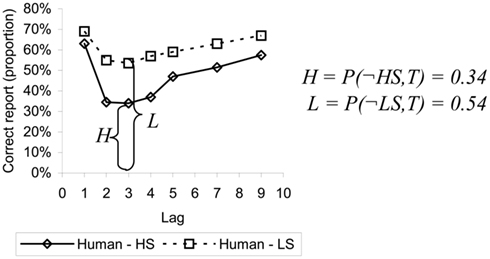
Figure A1. Target report accuracy by lag in humans for high and low salient key-distractors with intrinsic identifications.
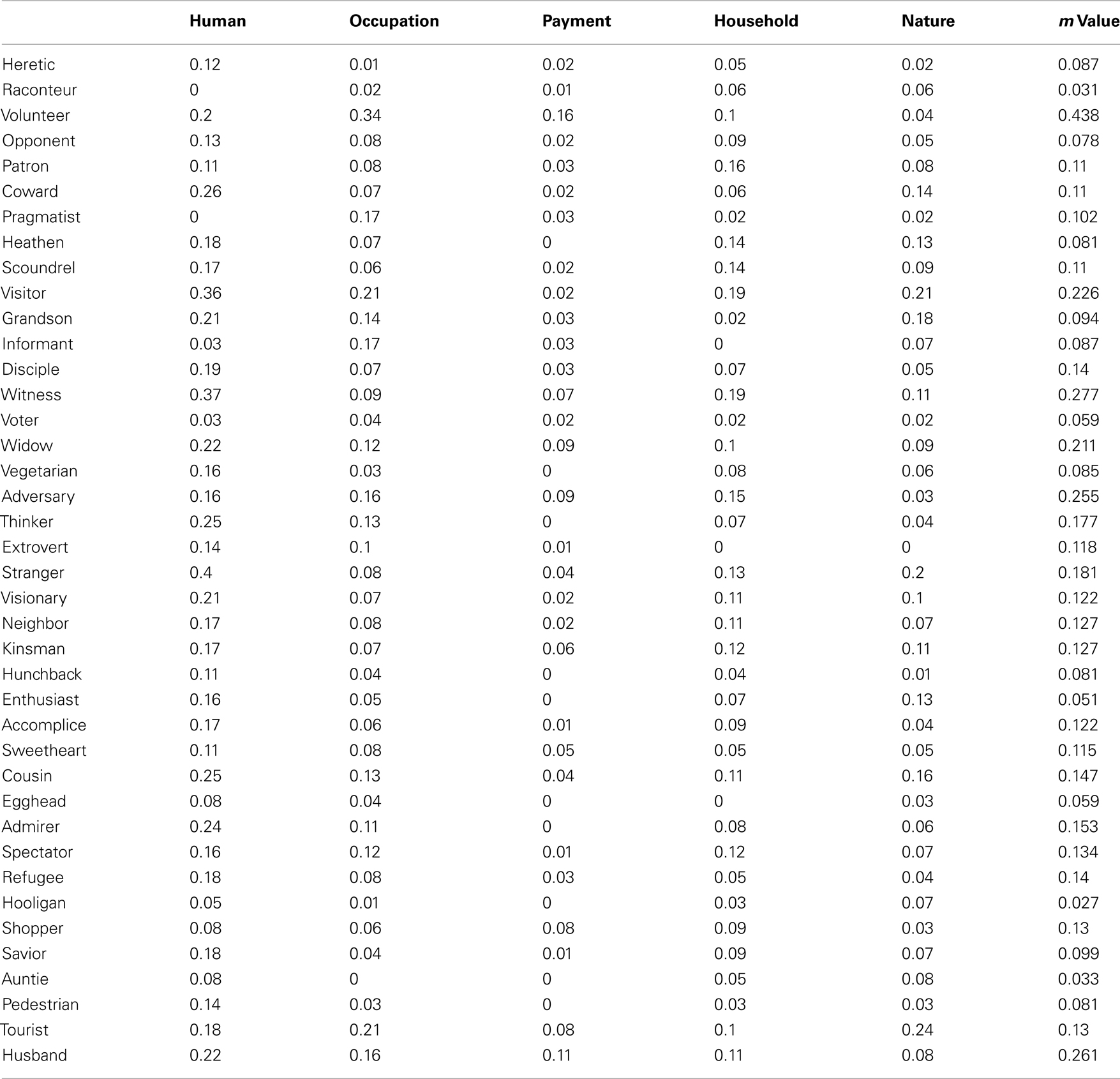
Latent semantic analysis cosines for high salient key-distractors of Barnard et al. (2004).
Hence, the intrinsic probability of identification sets the likelihood of an item passing the salient assignment threshold at Implic. Although humans perceive information in a noisy environment, so salient items may be missed, in the current model, to limit degrees of freedom and obtain a model that is as simple as possible, we assume that Prop is perfectly accurate in classifying targets from non-targets.
Buffer movement delay. In the glance–look model, the buffer can move in two directions, i.e., from Implic to Prop and vice versa. So, there are two buffer movement parameters D1 and D2, which denote the delay of buffer movement from Implic to Prop and vice versa respectively. We also assume that salience assignment only takes place at the first three constituents in a subsystem’s delay-line. When fitting the delay parameters, lag-1 sparing sets the lower bound of D1. That is, Implic determines that the buffer needs to move if the first three constituent representations is implicationally salient, as shown in Figure A2A. In order to report targets that immediately follow the key-distractor (i.e., the lag-1 case), Implic should process at least three constituent representations of the lag-1 item, as shown in Figure A2B. Hence, D1 should be no less than 120 ms.
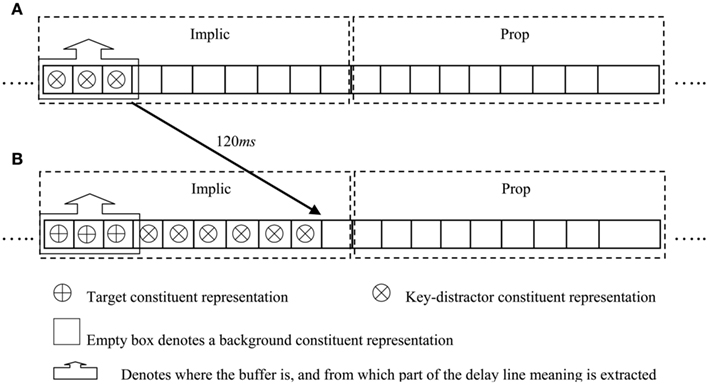
Figure A2. Snapshots of the delay-line in the lag-1 case when (A) Implic decides to move the buffer to Prop after it has processed the first three constituent representations of the key-distractor; (B) the buffer actually moves just after Implic has processed the first three constituent representations of the target.
Furthermore, the onset of the blink sets the upper bound of D1. In order to miss lag-2 targets, D1 must be larger than 220 ms. This is the time when the first two constituent representations of the lag-2 item have just entered Implic, as shown in Figure A3. The phenomenon of fringe awareness indicates that lag-2 targets can be processed to some extent. So, some of the lag-2 constituent representations are likely to be implicationally processed before the buffer moves away. As a result of these constraints, D1 is sampled from a narrow Gamma distribution peaks at 200 ms and bounded between 120 and 220 ms. The AB curves generally have a sharp onset and slow recovery, so D2, which is related to blink recovery, is more variable than D1, and is sampled from a wider Gamma distribution.
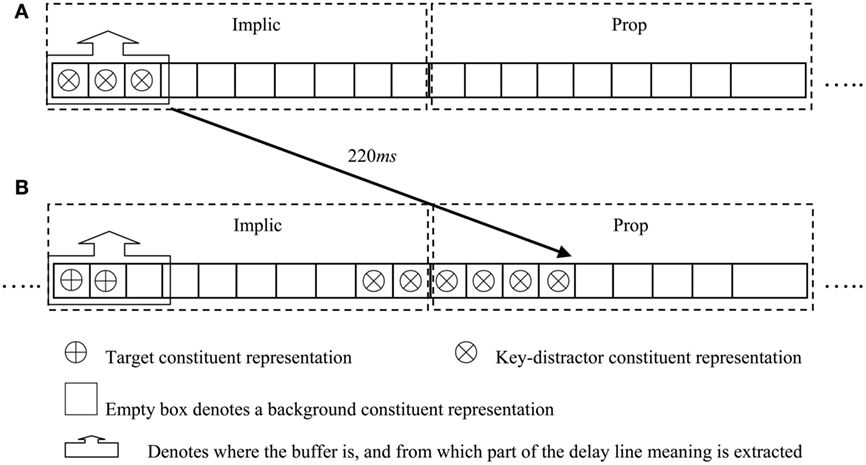
Figure A3. Snapshots of the delay-line when (A) Implic decides to move the buffer to Prop after it has processed the first three constituent representations of the key-distractor; (B) the first two constituent representations of the lag-2 item (target) have entered Implic.
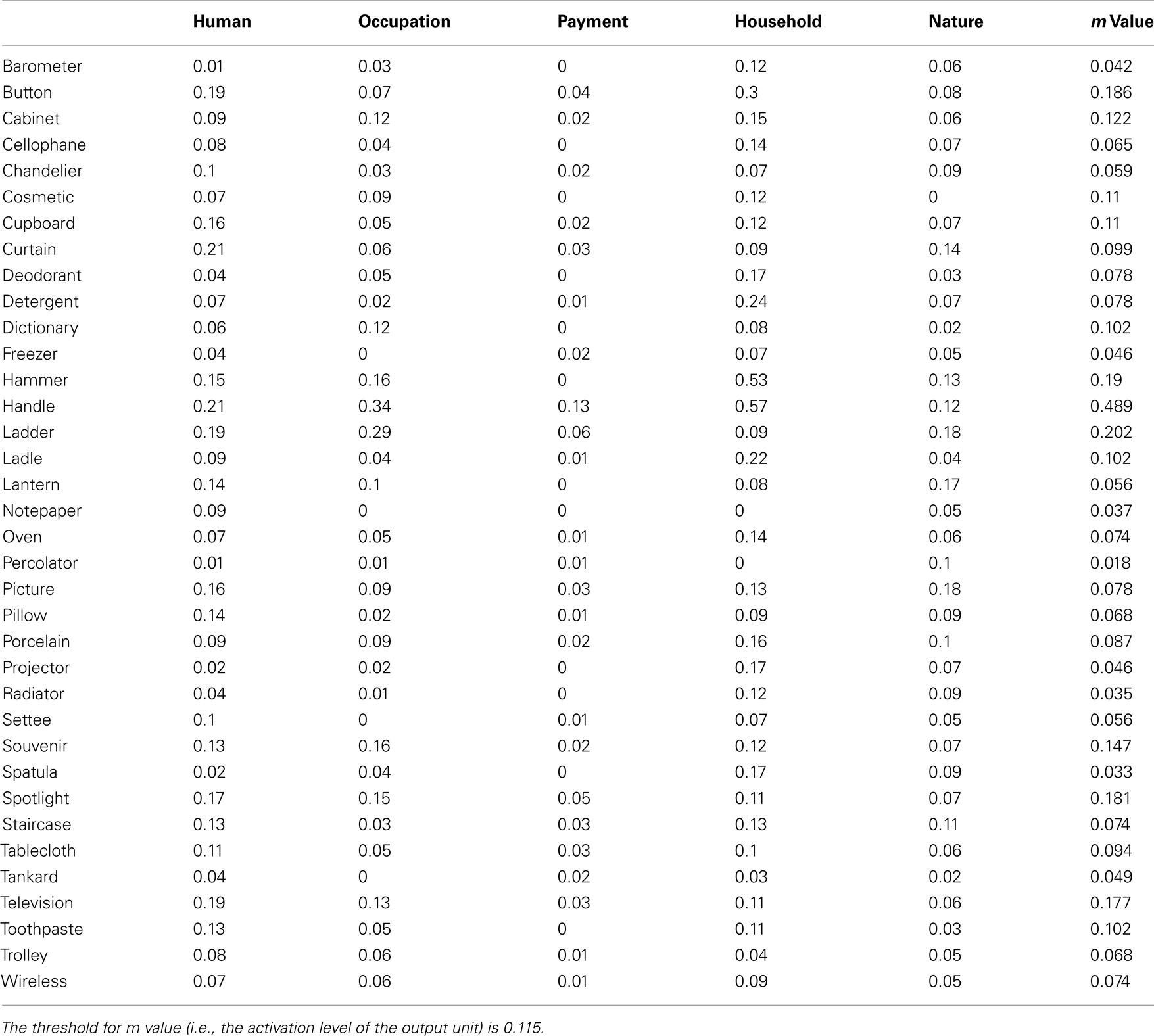
Latent semantic analysis cosines for low salient key-distractors of Barnard et al. (2004).
Delay-line length. Each subsystem has a local memory, which holds its representations before they are sent to other subsystems. We denote the length of the implicational and propositional delay-lines by L1 and L2 respectively, which are measured by the number of constituent representations they hold. We argue that the lower bound of L1 is set by the fact that the buffer must move to Prop in time to process the item. Items cannot enter Prop immediately after being processed at Implic. (If this were the case, the buffer would have to move immediately to Prop in order to process it, but this would rule out lag-1 sparing as previously explained.) Rather, constituent representations progress along an intermediate portion of delay-line that functionally sits between the point of implicational salience assessment and the point of exit from Implic, and buffers (using the standard computer science meaning here) Implic to Prop communication. In other words, targets that are presented alone in an RSVP stream can be potentially processed by both Implic and Prop, given the buffer moves with a delay. This is ensured by the following inequation:
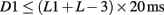
where L = 6 denotes the number of constituent representations in an RSVP item. The right hand side of the inequation is the delay between an item being detected as implicational salient and all its constituents entering Prop, as shown in Figure A4. (Note, the figure and its caption explain the above inequation in detail.) Given the values of D1 calculated previously, we found the lower bound of L1 is around 7.
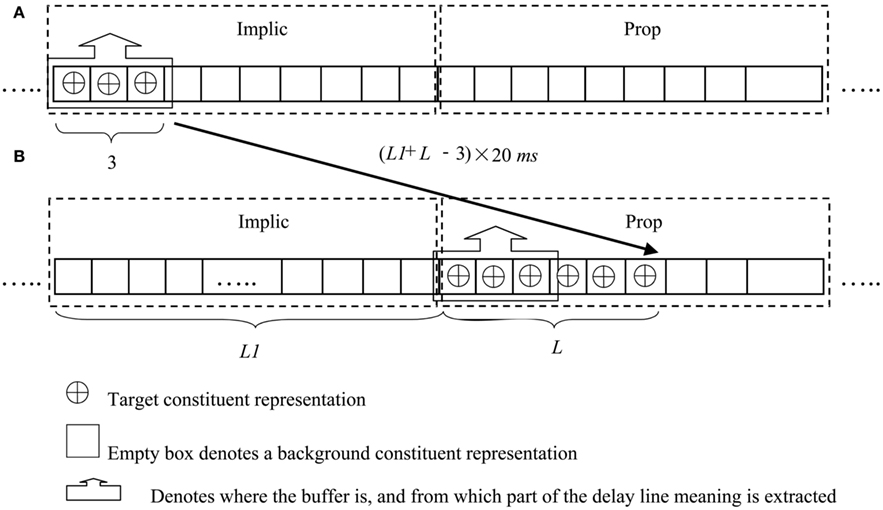
Figure A4. Snapshots of the delay-line when (A) Implic decides to move the buffer to Prop after it has processed the first three constituent representations of the target; (B) the buffer actually moves just after the last three constituent representations of the target have entered Prop.
Latent semantic analysis cosines to taboo reference words for key-distractors of Arnell et al. (2007).
The recovery of the blink sets the upper bound of L1. That is, Implic can only process the beginning of the lag-2 item as shown in Figure A5A,B. The decision is made for the buffer to move back from Prop to Implic, when Prop has detected three implicationally unprocessed constituent representations, which is the back end of the lag-2 item, as shown in Figure A5C. In general, the blink recovers after lag-5. Thus, the buffer should potentially return to Implic when the lag-5 item enters Implic or soon after that point in time, as shown in Figure A5D. (Note, the figure and its caption explain the above inequation in detail.) Hence, L1 is constrained by the following inequation.
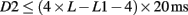
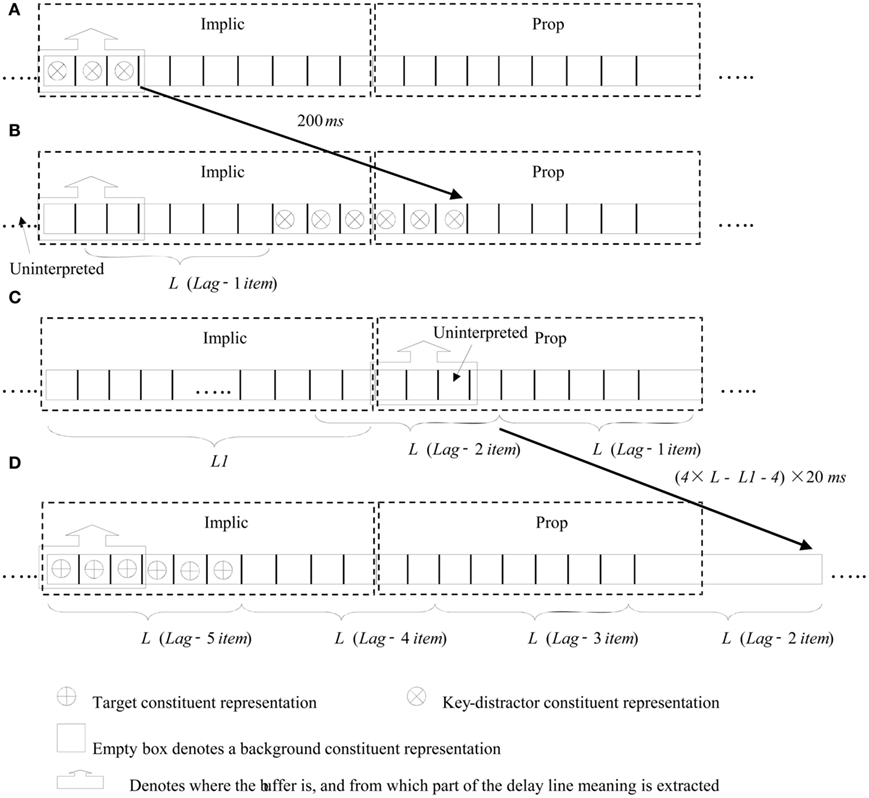
Figure A5. Snapshots of the delay-line when (A) Implic decides to move the buffer to Prop after it has processed the first three constituent representations of the key-distractor; (B) buffer actually moves after a delay of 200 ms; (C) Prop decides to move the buffer back to Implic after it has seen three implicationally un-interpreted constituent representations; (D) the buffer actually arrives at Implic when the last three constituent representations of the lag-5 item (target) have entered Implic.
Given the distribution of D2, we set the length of the Implic delay-line to 10, which is around the mean of the L1 distribution. The length of the Prop delay-line L2 is unconstrained in this model because it does not affect the shape of the blink. Thus, for simplicity, we assume that delay-line lengths are the same for all subsystems.
The glance–look model is an intensionalist account (i.e., it is structurally detailed). Importantly, it uses the delay-line length and buffer movement delay distributions inferred for the gray-box model. However, in the white-box model, the salience assignment threshold is explicitly modeled from word meaning represented in LSA space. The choice of the threshold for the response unit (as previously introduced) was directly constrained by the two higher level models, ensuring analogous parameter manipulations in all models. In particularly, the threshold value makes 52.5% of high salient and 22.2% of low salient key-distractors implicationally salient. In the glance–look model, the ratio between high and low salient key-distractors based on the response unit activation is 52.5/22.2 = 2.36. In the gray-box model, the ratio between high and low salient key-distractors in the intrinsic probability of identification is 0.49/0.19 = 2.58. In the extensionalist model, the ratio between high and low salient key-distractors in the capture constant is 1.8/0.8 = 2.25. This similarity suggests that the activation of the response unit, the intrinsic probability of identification and the capture constant model the same underlying cognitive mechanism consistently.
In the general domain of theory development in cognitive psychology, there has always been something of a tension between theorists who operate at the level of box-and-arrow models and those that rely on complete, fully specified, simulations. Here we have provided evidence that classic box-and-arrow models can be implemented at a level appropriate to the constraints built into the model, and reproduce a dataset in a manner consistent with a purely extensionalist account of the data. We then showed how the addition of a more detailed account of a key component, the processing of word meanings, could be added to refine the model, again maintaining consistency in model parameters.
Computer science, which has often been used as a metaphor in the cognitive modeling domain, gives a clear precedent for analyzing and thinking about modeling a single system in terms of multiple views. Cognitive science has, of course, developed similar and parallel conceptualizations to those of computer science; indeed, Marr famously elaborated a version of this position in his three levels of cognitive description (Marr, 2000). However, despite Marr’s observations, concrete modeling endeavors in cognitive science typically seek to model data accurately and to compete for adequacy. Rarely, if ever, are multiple abstraction levels explicitly modeled for the same data while maintaining formal relationships between models at different levels.
Keywords: computational modeling, attentional blink, emotion, cognitive control, body-state
Citation: Su L, Bowman H and Barnard P (2011) Glancing and then looking: on the role of body, affect, and meaning in cognitive control. Front. Psychology 2:348. doi: 10.3389/fpsyg.2011.00348
Received: 01 August 2011; Accepted: 04 November 2011;
Published online: 20 December 2011.
Edited by:
Tom Verguts, Ghent University, BelgiumReviewed by:
Kimberly Sarah Chiew, Washington University in St. Louis, USACopyright: © 2011 Su, Bowman and Barnard. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Li Su, Department of Experimental Psychology, University of Cambridge, Downing Street, Cambridge CB2 3EB, UK. e-mail:bHM1MTRAY2FtLmFjLnVr
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.