 Nabil Anan Orka
Nabil Anan Orka M. Nazim Uddin2
M. Nazim Uddin2
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
DATA REPORT article
Front. Plant Sci., 12 September 2023
Sec. Sustainable and Intelligent Phytoprotection
Volume 14 - 2023 | https://doi.org/10.3389/fpls.2023.1251888
Plants undergo stress whenever they are subjected to adverse conditions or an element that inhibits metabolism and growth (Lichtenthaler, 1996). Plants incur irreversible harm, even death, when overtaxed under unfavorable circumstances for an extended period (Pahlich, 1993). Plant stress is caused by two types of environmental conditions: biotic stressors, or living creatures such as fungus, bacteria, and insects, and abiotic stressors, or non-living elements such as drought, salinity, and a dearth of minerals (Mosa et al., 2017). Plant stressors drastically impair agricultural productivity. Crop-wise yield losses aggravated by these detrimental organisms can be severe, ranging from 26.3% to 40.3% (Oerke, 2006). Based on a study (Gatehouse et al., 1992), an estimated 37% of global agricultural yield is lost due to pests and pathogens, while 13% is lost due to insects. In addition, crop nutritional deficiencies endanger over two billion people’s food security (Gaikwad et al., 2020), reducing crop yield by up to 70% (Francini and Sebastiani, 2019). Precision agriculture strives to address these issues by facilitating the use of better resources and continuously enhancing the food supply’s sustainability. It has been extensively demonstrated that precision agriculture is an indispensable ingredient of streamlined pest management and nutrition monitoring systems (Mavridou et al., 2019; Nugroho et al., 2020; Presti et al., 2022).
Artificial intelligence (AI) continues to strengthen its influence in various fields because of its constant innovations and utilization of robust applications to solve complex problems that conventional computer systems and human beings cannot successfully handle. The growing acceptance of AI is not an exception to precision agriculture. In fact, data-driven AI applications contribute significantly to the discipline (Linaza et al., 2021). Machine vision systems, for example, have a widespread application in the control of herbicides, livestock, and crops (Dhanya et al., 2022). For AI to learn and enhance accuracy over time, an abundance of readily accessible data is imperative. However, in precision agriculture, the effort and costs associated with data collection and annotation, as well as laboratory analysis, make dataset preparation painstaking (Lu and Young, 2020). On the contrary, open access data alleviates such complications. As a result, it stimulates new projects and ensures reproducible outcomes.
The PlantVillage dataset (Hughes et al., 2015) continues to be the mainstay of computer vision tasks associated with plant stress identification since its debut. By far, the largest public dataset of leaf images is the PlantVillage dataset, which consists of 54,309 healthy and unhealthy leaf images divided into 38 categories by species and diseases. The efforts linked with tomatoes (Solanum lycopersicum) can help comprehend the scope of PlantVillage. Because the collection contains the most tomato pictures, a plethora of research is devoted to the identification of tomato pests and pathogens (Nandhini and Ashokkumar, 2021; Tan et al., 2021; Al-gaashani et al., 2022; Bhujel et al., 2022). TensorFlow, Python’s open-source machine learning framework, features two plant disease datasets, PlantaeK (Kour and Arora, 2022) and PlantLeaves (Chouhan et al., 2019). The PlantDoc dataset contains internet-curated images of 17 diseases across 13 plant species (Singh et al., 2020). There are also some crop-specific open access archives for dealing with rice (Oryza sativa) (Raksarikon, 2021) and sugar beet (Beta vulgaris) (Yi et al., 2020) nutritional deficiencies. However, notable research gaps continue to persist.
In practice, a single leaf could exhibit several irregularities (McCauley et al., 2009). However, no agricultural dataset encompasses multiple labels or categories in a single shot. Aside from tomatoes, the PlantVillage dataset contains two other vegetables, but all of the documented crops and plants are widely cultivated in the United States. According to an FAO assessment, around 6000 plant species are produced for food, with 200 species offering considerable food quantities worldwide (Bélanger et al., 2019). As a result, there remains innumerable crop anomalies that must be addressed. In the PlantaeK and PlantLeaves datasets, the complete set of pictures is divided into only two broad categories: healthy and diseased. The issue with the PlantDoc dataset is that plants can be stressed without displaying visible indications (McCauley et al., 2009). As such, it raises some questions about the reliability of the labeling. Finally, there is no public dataset containing images of both abiotic and biotic stresses over an extensive spectrum of crops.
With the purpose of a freely accessible, expert annotated collection of healthy, nutritiously depleted and pest-impaired leaf photos, we propose a dataset encompassing the principal crops in Bangladesh, namely tomato (Solanum lycopersicum), eggplant (Solanum melongena), cucumber (Cucumis sativus), bitter gourd (Momordica charantia), snake gourd (Trichosanthes cucumerina), ridge gourd (Luffa acutangula), ash gourd (Benincasa hispida), and bottle gourd (Lagenaria siceraria). The dataset comprises 4,749 high-resolution (3024 x 3024) images organized into 57 distinct categories. In addition to strengthening insect and disease management for the aforementioned crops, the collection aims to fill the data shortage in the field of crop nutrition deficiency.
The main contributions of our dataset include:
● The largest number of classes featured in an agro-domain dataset.
● The first multi-label classification challenge in agriculture.
● The inaugural open-access dataset to cover symptoms of both biotic and abiotic stressors across multiple crops at the same time, establishing a benchmark in plant stress recognition.
From March 17, 2022 to May 5, 2023, we used an iPhone 13 Pro Max to capture 5000 leaf samples from observational fields in Bangladesh Agricultural Research Institute (BARI), Gazipur. We solely employed the primary 12 MP wide camera with an f/1.5-aperture lens. Apart from the exposure setting, which was set at -1, we did not modify any default parameters when capturing the photos. This was determined because when the images were overexposed to sunshine, the computational software system altered the shots in such a way that the leaves differed radically from what they seemed to naked eyes. The images were captured directly overhead with a 1:1 aspect ratio, leading to a resolution of 3024 x 3024. The flash was switched off.
We opted to collect samples in natural lighting environments rather than controlled ones to ensure generalizability of the algorithms trained on the dataset. We set up our data collecting equipment — a table and a camera mounted on a tripod — right adjacent to fields with plenty of natural light. During the course of a day’s data collection, we monitored illuminances with a Digital LX1330B Illuminance Meter. We avoided bias by, first, sampling at random with no specific plant stress in mind, and second, maintaining identical heights from the table’s base to the phone camera for each crop. The exact spacing between the camera and the leaf/table are listed below:
● Ash gourd - 22.5 cm
● Bitter gourd - 14 cm
● Bottle gourd - 27.5 cm
● Cucumber - 24 cm
● Eggplant - 23 cm
● Ridge gourd - 23 cm
● Snake gourd - 22 cm
● Tomato - 15 cm
Instead of photographing leaves in plants with a complex background that included several leaves, soil, and other plant elements, we sampled one leaf at a time and placed it on top of a satin fabric with a homogeneous black tone. In our dataset, we encountered the early stages of crop anomalies, when the differentiating traits are difficult to spot visually. Such complexities mandated a consistent background with just one leaf in succession, rendering the distinct features more obvious. In addition, the PlantVillage dataset (Hughes et al., 2015), widely regarded as the gold standard in automated plant disease identification, relied on a grey or black paper sheet as a background. As a result, we used an analogous method whilst employing the same black satin cloth for each snapshot. Furthermore, we observed that the black backdrop accentuated the colors of the symptoms while ensuring that no shadows were formed to introduce scene complexity. Finally, researchers frequently implement segmentation to extract the leaves from complicated surroundings (Luo et al., 2023). Fortunately, because of the uniform black backdrop, segmentation is not necessary; hence, we ensured ease of use.
Following the acquisition, the samples were handed over to a laboratory, where an experienced team meticulously analyzed and labeled each image. The team performed both perceptual labeling and laboratory analytical labeling. Here, each leaf was visually identified first, followed by rigorous laboratory examination. Nevertheless, we did not impose any specific criterion in order to allow the team to carry out the annotation procedure to the best of their scientific knowledge while minimizing bias. We adopted this dual approach for two reasons. First of all, plants are susceptible to stress irrespective of whether they exhibit any clear visual cues (McCauley et al., 2009). Second of all, sun rays reaching the leaves might occasionally mimic the appearance of several symptoms, even when the plants were not truly affected (Barbedo, 2019). The chemical analysis, for these reasons, was indispensable for dealing with the challenges.
The annotation was overseen by two researchers (M.N.U. and M.S.H.) with over 15 years of expertise in the subject. In the event of a disagreement amongst team members, the supervisors (M.N.U. and M.S.H.) served as mediators, using their professional judgments.
Despite acquiring 5000 photos categorized into 110 classes, we opted not to include some of the classes due to a significant imbalance in class representation. For example, powdery mildew on bottle gourd and eggplant aphid had just one sample apiece. The number of phosphorus deficiency representatives of different crops was insufficient as well. As such, we omitted classes with fewer than 10 samples to avoid skewed predictive accuracies towards the majority classes. The final dataset comprises 4,749 images grouped into 57 distinct classes. Table 1 describes a thorough overview of the dataset. It should be emphasized that the dataset is labeled and designed for the classification of the secondary classes listed in Table 1. We provided broad abiotic and biotic categories as primary classes so that researchers could easily comprehend the dataset and, if required, customize it for their specific goals and applications. In addition, we incorporated both the dorsal and ventral surfaces since symptoms are frequently found on either side. Figure 1 depicts example representatives of a few of the 57 classes. In our dataset, most insect categories, such as beetles and mites, show the signs or symptoms of pest-infestation. However, in several instances, the insects themselves were noticeable.
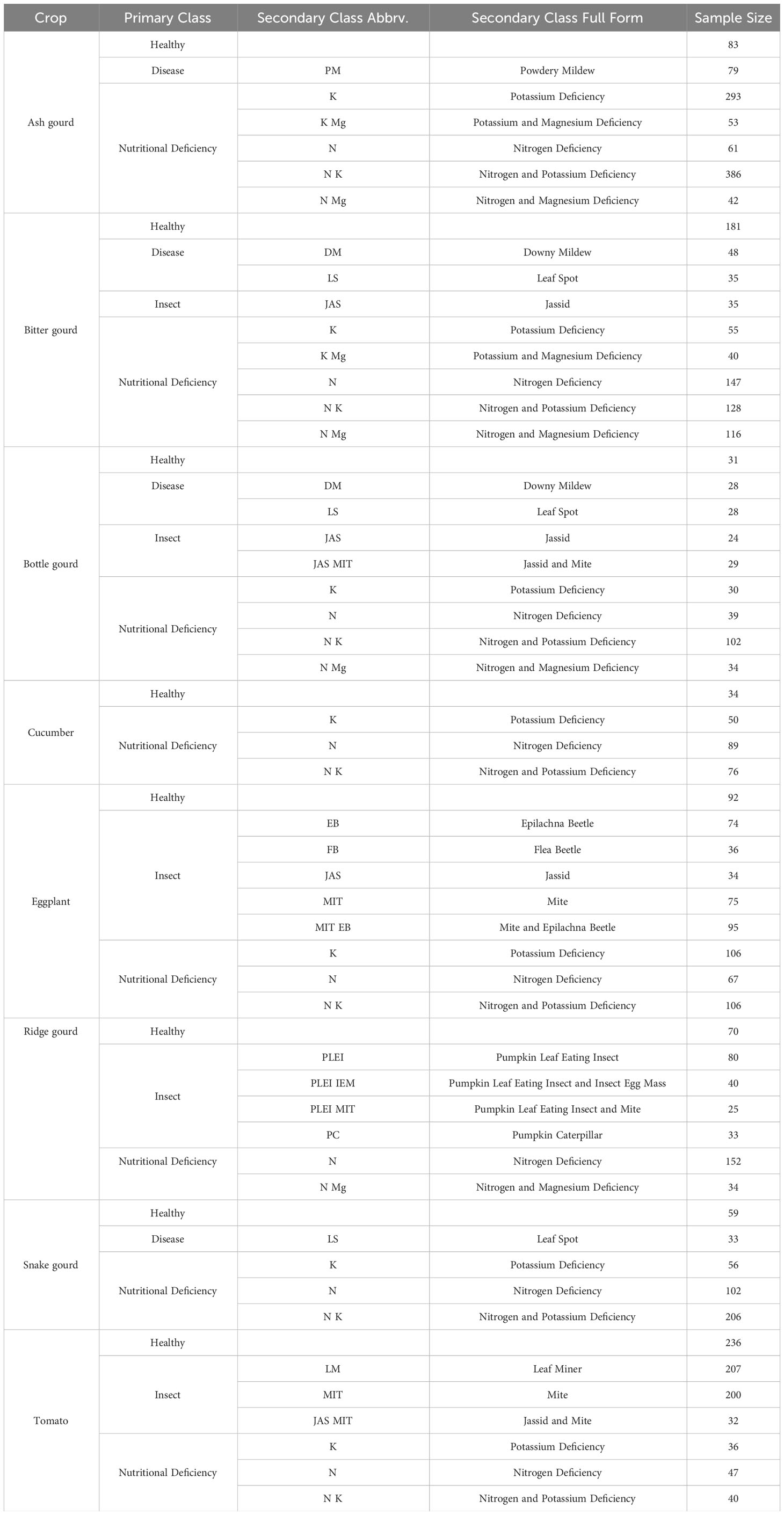
Table 1 Class distribution of the OLID I dataset.

Figure 1 Example members of the OLID I dataset.
In the agri-sector, our dataset is a pioneer in multi-label classification, where multiple categories appear in a single snapshot. We provided two leaves with multiple stress symptoms to demonstrate. Figure 1 exhibits a cucumber leaf with a pale green tint in the center and yellow tips, indicating nitrogen and potassium shortages, respectively. Similarly, the eggplant leaf, which includes numerous pits of varied sizes as well as yellow and brown speckles cluttered all over, demonstrates both beetle and mite infestations. Table 1 intends to assist researchers in identifying leaves that have multiple labels or classes. For example, ‘N Mg’ denotes an absence of nitrogen and magnesium, while ‘JAS MIT’ represents leaves afflicted with both jassids and mites. The underscore refers to the existence of multiple categories in an image, which were diligently grouped and organized within the dataset in adequately named folders.
The primary objective of our dataset is to be utilized for plant stress recognition. The PlantVillage dataset has consistently served as the benchmark in this context. Nevertheless, researchers recently achieved 100% accuracy on it (Bruno et al., 2022). We aspired to offer a successor to PlantVillage with additional stressor categories encompassing hitherto unexplored crops and high-resolution photographs.
The presence of multiple labels in individual photos, which the PlantVillage collection lacks, is perhaps the most valuable aspect of OLID I. Another aspect that separates our dataset from PlantVillage is that our dataset encompasses 57 classes to PlantVillage’s 38, including 16 multi-label classes. Finally, despite the gourd family’s impact in our global nutritional needs (Rolnik and Olas, 2020), there is still a significant lack in research on cucurbits stress detection, which we seek to fulfill.
OLID I is available on Kaggle (Orka et al., 2023a) and Zenodo (Orka et al., 2023b). In Zenodo, we uploaded the dataset in sections so that individuals with limited network access can view it more easily. In addition, we supplied an excel file with complete breakdown of the classes in both databases.
The dataset is fairly straightforward for setting up because we put photographs in folders that correspond to the proper annotations. Segmentation will not be required since we settled on persistent background. However, as the dataset is imbalanced, we advocate any form of augmentation before training different algorithms. For example, the Augmentor package (Bloice et al., 2017) in Python has horizontal flip, 90-degree rotation, vertical flip, random rotation, random shear, random skew, and random zoom functions that can be used to increase sample sizes for particular classes and balance the dataset without compromising variance. In addition, generative AI could potentially be utilized to create highly lifelike samples (Lu et al., 2022). We acknowledge that, due to the scarcity of high-performance equipment, many researchers will be unable to fully use the high-resolution photographs; nevertheless, cloud-based solutions, such as Google Colab, can effortlessly overcome this limitation. Moreover, the images can be readily scaled to accommodate resource restrictions. Finally, while our dataset comprises Red-Green-Blue (RGB) photographs, color transformation is an alternative that has previously shown promising results (Krishnaswamy Rangarajan and Purushothaman, 2020; Schuler et al., 2021).
We believe our dataset will encourage researchers to embark on novel endeavors that will stretch their abilities. In particular, the dataset will inspire more realistic detection algorithms that can recognize many stressors in a single picture. With a plethora of plant species and stress categories, OLID I offers a dataset that embraces scientific rigor and aims to eliminate oversights in data labeling, reducing the likelihood of feeding erroneous data to the algorithm and creating misinterpretation. The effective use of our dataset will result in considerable improvements in plant stress recognition, while simultaneously building trust in AI.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: Zenodo (https://zenodo.org/record/8105154) and Kaggle (https://www.kaggle.com/datasets/raiaone/olid-i).
NO: Conceptualization, Methodology, Investigation, Visualization, Writing - Original Draft; MU: Methodology, Validation, Resources, Data Curation, Supervision; FT: Investigation, Resources, Writing - Review and Editing; MH: Validation, Data Curation, Supervision. All authors contributed to the article and approved the submitted version.
We wish to express our deepest appreciation to the Principal Investigator of the UAPAR Project, ID – TF 94/21, BARI-KGF, Ministry of Agriculture, Bangladesh, for his invaluable support. The project's provision of facilities and logistical assistance enabled the successful execution of our experiments, and their financial support greatly contributed to our ability to publish this research. We are also immensely grateful to Mr. Bakhtiar and Mr. Helal for their steadfast dedication in assisting us with data collection.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Al-gaashani, M. S., Shang, F., Muthanna, M. S., Khayyat, M., Abd El-Latif, A. A. (2022). Tomato leaf disease classification by exploiting transfer learning and feature concatenation. IET Image Process. 16, 913–925. doi: 10.1049/ipr2.12397
Barbedo, J. G. A. (2019). Detection of nutrition deficiencies in plants using proximal images and machine learning: A review. Comput. Electron. Agric. 162, 482–492. doi: 10.1016/j.compag.2019.04.035
Bélanger, J., Pilling, D., et al. (2019). The state of the world’s biodiversity for food and agriculture (Rome, Italy: Food and Agriculture Organization of the United Nations).
Bhujel, A., Kim, N.-E., Arulmozhi, E., Basak, J. K., Kim, H.-T. (2022). A lightweight attention-based convolutional neural networks for tomato leaf disease classification. Agriculture 12, 228. doi: 10.3390/agriculture12020228
Bloice, M. D., Stocker, C., Holzinger, A. (2017). Augmentor: an image augmentation library for machine learning. arXiv preprint arXiv:1708.04680. doi: 10.48550/arXiv.1708.04680
Bruno, A., Moroni, D., Dainelli, R., Rocchi, L., Morelli, S., Ferrari, E., et al. (2022). Improving plant disease classification by adaptive minimal ensembling. Front. Artif. Intell. 5, 868926. doi: 10.3389/frai.2022.868926
Chouhan, S. S., Singh, U. P., Kaul, A., Jain, S. (2019). “A data repository of leaf images: Practice towards plant conservation with plant pathology,” in 2019 4th International Conference on Information Systems and Computer Networks (ISCON). 700–707 (Mathura, India: IEEE).
Dhanya, V., Subeesh, A., Kushwaha, N., Vishwakarma, D., Kumar, T. N., Ritika, G., et al. (2022). Deep learning based computer vision approaches for smart agricultural applications. Artif. Intell. Agric. 6, 211–229. doi: 10.1016/j.aiia.2022.09.007
Francini, A., Sebastiani, L. (2019). Abiotic stress effects on performance of horticultural crops. Horticulturae 5 (4), 67.
Gaikwad, K. B., Rani, S., Kumar, M., Gupta, V., Babu, P. H., Bainsla, N. K., et al. (2020). Enhancing the nutritional quality of major food crops through conventional and genomics-assisted breeding. Front. Nutr. 7, 533453. doi: 10.3389/fnut.2020.533453
Gatehouse, A. M., Hilder, V. A., Powell, K., Boulter, D., Gatehouse, J. A. (1992). “Potential of plant-derived genes in the genetic manipulation of crops for insect resistance,” in Proceedings of the 8th International Symposium on Insect-Plant Relationships. 221–234 (Dordrecht, Netherlands: Springer).
Hughes, D., Salathé, M., et al. (2015). An open access repository of images on plant health to enable the development of mobile disease diagnostics. arXiv preprint arXiv:1511.08060. doi: 10.48550/arXiv.1511.08060
Kour, V. P., Arora, S. (2022). “Plantaek: A leaf database of native plants of jammu and kashmir,” in Recent Innovations in Computing. 359–368 (Singapore: Springer).
Krishnaswamy Rangarajan, A., Purushothaman, R. (2020). Disease classification in eggplant using pre-trained vgg16 and msvm. Sci. Rep. 102322. doi: 10.1038/s41598-020-59108-x
Lichtenthaler, H. K. (1996). Vegetation stress: an introduction to the stress concept in plants. J. Plant Physiol. 148, 4–14. doi: 10.1016/S0176-1617(96)80287-2
Linaza, M. T., Posada, J., Bund, J., Eisert, P., Quartulli, M., Dollner,¨, J., et al. (2021). Data-driven artificial intelligence applications for sustainable precision agriculture. Agronomy 11, 1227. doi: 10.3390/agronomy11061227
Lu, Y., Chen, D., Olaniyi, E., Huang, Y. (2022). Generative adversarial networks (gans) for image augmentation in agriculture: A systematic review. Comput. Electron. Agric. 200, 107208. doi: 10.1016/j.compag.2022.107208
Lu, Y., Young, S. (2020). A survey of public datasets for computer vision tasks in precision agriculture. Comput. Electron. Agric. 178, 105760. doi: 10.1016/j.compag.2020.105760
Luo, Z., Yang, W., Yuan, Y., Gou, R., Li, X. (2023). Semantic segmentation of agricultural images: a survey. Inf. Process. Agric. doi: 10.1016/j.inpa.2023.02.001
Mavridou, E., Vrochidou, E., Papakostas, G. A., Pachidis, T., Kaburlasos, V. G. (2019). Machine vision systems in precision agriculture for crop farming. J. Imaging 5, 89. doi: 10.3390/jimaging5120089
McCauley, A., Jones, C., Jacobsen, J. (2009). Plant nutrient functions and deficiency and toxicity symptoms. Nutrient Manage. module 9, 1–16.
Mosa, K. A., Ismail, A., Helmy, M., Mosa, K. A., Ismail, A., Helmy, M. (2017). Introduction to plant stresses. Plant Stress Tolerance: Integrated Omics Approach 1–19. doi: 10.1007/978-3-319-59379-1_1
Nandhini, S., Ashokkumar, K. (2021). Improved crossover based monarch butterfly optimization for tomato leaf disease classification using convolutional neural network. Multimedia Tools Appl. 80, 18583–18610. doi: 10.1007/s11042-021-10599-4
Nugroho, A. P., Purba, S., Pratomo, Y. B., Hadi, S., Utami, S. S. (2020). “Development of cloud-based bioacoustics monitoring system for supporting integrated pest management in agriculture production,” in IOP Conference Series: Earth and Environmental Science, Vol. 1. 012032 (Yogyakarta, Indonesia: IOP Publishing).
Oerke, E.-C. (2006). Crop losses to pests. J. Agric. Sci. 144, 31–43. doi: 10.1017/S0021859605005708
Orka, N. A., Uddin, M. N., Toushique, F. M., Hossain, M. S. (2023a). “Olid i,” in An open leaf image dataset of Bangladesh’s major crops (Kaggle). doi: 10.34740/KAGGLE/DS/3472313
Orka, N. A., Uddin, M. N., Toushique, F. M., Hossain, M. S. (2023b). “Olid i,” in An open leaf image dataset of Bangladesh’s major crops (Zenodo). doi: 10.5281/zenodo.8105154
Pahlich, E. (1993). Larchers definition of plant stress: A valuable principle for metabolic adaptibility research. Rev. Bras. Fisiologia Vegetal 5, 209–216.
Presti, D. L., Di Tocco, J., Massaroni, C., Cimini, S., De Gara, L., Singh, S., et al. (2022). Current understanding, challenges and perspective on portable systems applied to plant monitoring and precision agriculture. Biosensors Bioelectronics 222, 115005. doi: 10.1016/j.bios.2022.115005
Raksarikon, W. (2021). Nutrient deficiency symptoms in rice (Kaggle). Available at: https://www.kaggle.com/datasets/guy007/nutrientdeficiencysymptomsinrice.
Rolnik, A., Olas, B. (2020). Vegetables from the cucurbitaceae family and their products: Positive effect on human health. Nutrition 78, 110788. doi: 10.1016/j.nut.2020.110788
Schuler, J. P. S., Romani, S., Abdel-Nasser, M., Rashwan, H., Puig, D. (2021). “Reliable deep learning plant leaf disease classification based on light-chroma separated branches,” in Artificial Intelligence Research and Development: Proceedings of the 23rd International Conference of the Catalan Association for Artificial Intelligence, Vol. 339. 375 (Leida, Spain: IOS Press).
Singh, D., Jain, N., Jain, P., Kayal, P., Kumawat, S., Batra, N. (2020). “Plantdoc: A dataset for visual plant disease detection,” in roceedings of the 7th ACM IKDD cods and 25th COMAD, vol. 2020. (New York, NY, USA: Association for Computing Machinery), 249–253. doi: 10.1145/3371158.3371196
Tan, L., Lu, J., Jiang, H. (2021). Tomato leaf diseases classification based on leaf images: a comparison between classical machine learning and deep learning methods. AgriEngineering 3, 542–558. doi: 10.3390/agriengineering3030035
Keywords: plant stress recognition, multi-label classification, crop nutritional deficiency, automated pest management, precision agriculture, computer vision, machine vision
Citation: Orka NA, Uddin MN, Toushique FM and Hossain MS (2023) OLID I: an open leaf image dataset for plant stress recognition. Front. Plant Sci. 14:1251888. doi: 10.3389/fpls.2023.1251888
Received: 02 July 2023; Accepted: 23 August 2023;
Published: 12 September 2023.
Edited by:
Nieves Goicoechea, University of Navarra, SpainReviewed by:
Serosh Karim Noon, NFC Institute of Engineering and Technology (NFCIET), PakistanCopyright © 2023 Orka, Uddin, Toushique and Hossain. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Nabil Anan Orka, bmFiaWxhbmFuQGl1dC1kaGFrYS5lZHU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.