 François G. Meyer
François G. Meyer- Applied Mathematics, University of Colorado at Boulder, Boulder, CO, United States
The notion of Fréchet mean (also known as “barycenter”) network is the workhorse of most machine learning algorithms that require the estimation of a “location” parameter to analyse network-valued data. In this context, it is critical that the network barycenter inherits the topological structure of the networks in the training dataset. The metric–which measures the proximity between networks–controls the structural properties of the barycenter. This work is significant because it provides for the first time analytical estimates of the sample Fréchet mean for the stochastic blockmodel, which is at the cutting edge of rigorous probabilistic analysis of random networks. We show that the mean network computed with the Hamming distance is unable to capture the topology of the networks in the training sample, whereas the mean network computed using the effective resistance distance recovers the correct partitions and associated edge density. From a practical standpoint, our work informs the choice of metrics in the context where the sample Fréchet mean network is used to characterize the topology of networks for network-valued machine learning.
1 Introduction
There has been recently a flurry of activity around the design of machine learning algorithms that can analyze “network-valued random variables” (e.g. [1–8], and references therein). A prominent question that is central to many such algorithms is the estimation of the mean of a set of networks. To characterize the mean network we borrow the notion of barycenter from physics, and define the Fréchet mean as the network that minimizes the sum of the squared distances to all the networks in the ensemble. This notion of centrality is well adapted to metric spaces (e.g., [4, 9, 10]), and the Fréchet mean network has become a standard tool for the statistical analysis of network-valued data.
In practice, given a training set of networks, it is important that the topology of the sample Fréchet mean captures the mean topology of the training set. To provide a theoretical answer to this question, we estimate the mean network when the networks are sampled from a stochastic block model. The stochastic block models [11, 12] have great practical importance since they provide tractable models that capture the topology of real networks that exhibit community structure. In addition, the theoretical properties (e.g., degree distribution, eigenvalues distributions, etc.) of this ensemble are well understood. Finally, stochastic block models provide universal approximants to networks and can be used as building blocks to analyse more complex networks [13–15].
In this work, we derive the expression of the sample Fréchet mean of a stochastic block model for two very different distances: the Hamming distance [16] and the effective resistance perturbation distance [17]. The Hamming distance, which counts the number of edges that need to be added or subtracted to align two networks defined on the same vertex set, is very sensitive to fine scale fluctuations of the network connectivity. To detect larger scale changes in connectivity, we use the resistance perturbation distance [17]. This network distance can be tuned to quantify configurational changes that occur on a network at different scales: from the local scale formed by the neighbors of each vertex, to the largest scale that quantifies the connections between clusters, or communities [17]. See ([18–20], and references therein) for recent surveys on network distances.
Our analysis shows that the sample Fréchet mean network computed with the Hamming distance is unable to capture the topology of networks in the sample. In the case of a sparse stochastic block model, the Fréchet mean network is always the empty network. Conversely, the Fréchet mean computed using the effective resistance distance recovers the underlying network topology associated with the generating process: the Fréchet mean discovers the correct partitions and associated edge densities.
1.1 Relation to existing work
To the best of our knowledge, we are not aware of any theoretical derivation of the sample Fréchet mean for any of the classic ensemble of random networks. Nevertheless, our work share some strong connections with related research questions.
1.1.1 The Fréchet mean network as a location parameter
Several authors have proposed simple models of probability measures defined on spaces of networks, which are parameterized by a location and a scale parameter [5, 21]. These probability measures can be used to assign a likelihood to an observed network by measuring the distance of that network to a central network, which characterizes the location of the distribution. The authors in [5] explore two choices for the distance: the Hamming distance, and a diffusion distance. Our choice of distances is similar to that of [5].
1.1.2 Existing metrics for the Fréchet mean network
The concept of Fréchet mean necessitates a choice of metric (or distance) on the probability space of networks. The metric will influence the characteristics that the mean will inherit from the network ensemble. For instance, if the distance is primarily sensitive to large scale features (e.g., community structure or the existence of highly connected “hubs”), then the mean will capture these large scale features, but may not faithfully reproduce the fine scale connectivity (e.g., the degree of a vertex, or the presence of triangles).
One sometimes needs to compare networks of different sizes; the edit distance, which allows for creation and removal of vertices, provides an elegant solution to this problem. When the networks are defined on the same vertex set, the edit distance becomes the Hamming distance [22], which can also be interpreted as the entrywise
1.2 Content of the paper: our main contributions
Our contributions consists of two results.
1.2.1 The network distance is the Hamming distance
We prove that when the probability space is equipped with the Hamming distance, then the sample Fréchet mean network converges in probability to the sample median network (computed using the majority rule), in the limit of large sample size. This result has significant practical consequences. Consider the case where one needs to estimate a “central network” that captures the connectivity structure of a training set of sparse networks. Our work implies that if one uses the Hamming distance, then the sample Fréchet mean will be the empty network.
1.2.2 The network distance is the resistance perturbation distance
We prove that when the probability space is equipped with the resistance perturbation distance, then the adjacency matrix of the sample Fréchet mean converges to the sample mean adjacency matrix with high probability, in the limit of large network size. Our theoretical analysis is based on the stochastic block model [12], a model of random networks that exhibit community structure. In practical applications, our work suggests that one should use the effective resistance distance to learn the mean topology of a sample of networks.
1.3 Outline of the paper
In Section 2, we describe the stochastic block model, the Hamming and resistance distances that are defined on this probability space. The reader who is already familiar with the network models and distances can skip to Section 3 wherein we detail the main results, along with the proofs of the key results. In Section 4, we discuss the implications of our work. The proofs of some technical lemmata are left aside in Section 5.
2 Network ensemble and distances
2.1 The network ensemble
Let
Because there is a unique correspondence between a network
We define the matrix
where
2.2 The Hamming distance between networks
Let
Definition 1. The Hamming distance between
where the elementwise
Because the distance
2.3 The resistance (perturbation) distance between networks
For the sake of completeness, we review the concept of effective resistance (e.g., [26, 27]). Let
We denote by
Intuitively,
where
The resistance-perturbation distance (or resistance distance for short) is based on comparing the effective resistances matrices
Definition 2. Let
3 Main results
We first review the concept of sample Fréchet mean, and then present the main results. We consider the probability space
3.1 The sample Fréchet mean
The sample Fréchet function evaluated at
The minimization of the Fréchet function
Definition 3. The sample Fréchet mean network is the set of adjacency matrices
Solutions to the minimization problem in Equation 10 always exist, but need not be unique. In Theorem 1 and Theorem 2, we prove that the sample Fréchet mean network of
A word on notations is in order here. It is customary to denote by
3.2 The sample Fréchet mean of
The following theorem shows that the sample Fréchet mean network converges in probability to the sample Fréchet median network, computed using the majority rule, in the limit of large sample size,
Theorem 1. Let
where
Remark 1. The matrix
where
Remark 2. The network size
One could envision a scenario where the network size
Before deriving the proof of theorem 1, we present an extension of the Hamming distance to weighted networks. We remember that the sample Fréchet mean network computed using the Hamming distance has to be an unweighted network, since the Hamming distance is only defined for unweighted networks. This theoretical observation notwithstanding, the proof of theorem 1 becomes much simpler if we introduce an extension of the Hamming distance to weighted networks; in truth, we extend a slightly different formulation of the Hamming distance.
Let
Now, assume that
The function
We now present the sample probability matrix
and
We can combine the definitions of
The proof of this simple identity is very similar to the proof of lemma 1, and is omitted for brevity. We are now ready to present the proof of theorem 1.
Proof of Theorem 1. The proof relies on the observation (formalized in lemma 1) that the Fréchet function
Lemma 1. Let
where
Proof. The proof of lemma 1 is provided in Section 5.
To call attention to the distinct roles played by the terms in Equation 20, we define the dominant term of
and the residual
so that
The next step of the proof of theorem 1 involves showing that the sample median network,
Lemma 2.
Proof of lemma 2. We have
Because
We now turn our attention to the residual and we confirm in the next lemma that
Lemma 3.
Proof. The proof of lemma 3 is provided in Section 5.2.
The last technical lemma that is needed to complete the proof of theorem 1 is a variance inequality [31] for
Lemma 4. We assume that there exists
with high probability.
Proof. The proof of lemma 4 is provided in Section 5.3.
We are now in position to combine the lemmata and complete the proof of theorem 1.
Let
Now, by definition of
and therefore,
This last inequality, combined with Equation 24 proves that
Let
The term
Combining Equations 28–30 we get
We conclude that
which completes the proof of the theorem.
3.3 The sample Fréchet mean of
Here we equip the probability space
In the following, we need to ensure that the effective resistances are always well defined for networks sampled from
The next theorem proves that the sample Fréchet mean converges toward the expected adjacency matrix
Theorem 2. Let
in the limit of large network size
Proof of theorem 2. The proof combines three elements. We first observe that the effective resistance of the sample Fréchet mean is the sample mean effective resistance.
Lemma 5. Let
Proof of lemma 5. The proof relies on the observation that the Fréchet function in Equation 10, is a quadratic function of
where we have used the definition of the effective resistance distance given by Equation 8. The minimum of Equation 35 is given by Equation 34.
The second element of the proof of theorem 2 is a concentration result for the effective resistance
In contrast, the proof of theorem 2 follows a different line of attack, where we replace the law of large number with a concentration result for the effective resistance
In the next lemma, we prove that
Lemma 6. Let
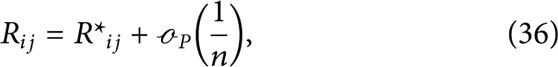
where
Before deriving the proof of lemma 6 we make a few remarks to help guide the reader’s intuition.
Remark 3. We justify Equation 37 with a simple circuit argument. We first analyse the case where
On the other hand, when the vertices
where
Our proof of lemma 6, requires that we introduce another operator on the graph, the normalized Laplacian matrix (e.g., [28]). Let
where
where
Proof of lemma 6. The lemma relies on the characterization of
where
where
where
Substituting Equation 43 into Equation 41, we get
The first (and dominant) term of Equation 45 is
Let us examine the second term of Equation 45. Löwe and Terveer [39] provide the following estimate for
The corresponding eigenvector
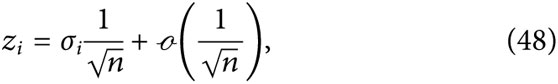
where the “sign” vector
We derive from Equation 48 the following approximation to
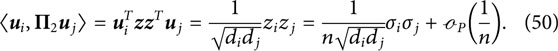
We therefore have
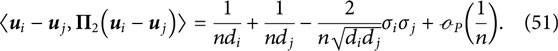
The degree
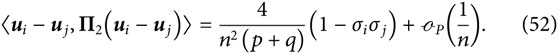
Combining Equations 47, 52 yields

We note that
which confirms that
This concludes the proof the lemma.
Remark 4. Lemma 6 can be extended to a stochastic block model of any geometry for which we can derive the analytic expression of the dominant eigenvalues; see (see e.g., [39, 41]) for equal size communities, and (see e.g., [42]) for the more general case of inhomogeneous random networks.
We can apply Lemma 6 to derive an approximation to the sample mean effective resistance.
Corollary 1. Let
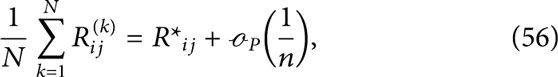
where
Lastly, the final ingredient of the proof of theorem 2 is Lemma 7 that shows that matrix
Lemma 7. Let
where
Then
Proof of lemma 7. The proof is elementary and relies on the following three identities. First, we recover
We can then recover
Finally,
This concludes the proof of theorem 2.
4 Discussion of our results
This paper provides analytical estimates of the sample Fréchet mean network when the sample is generated from a stochastic block model. We derived the expression of the sample Fréchet mean when the probability space
We show that the sample mean network is an unweighted network whose topology is usually very different from the average topology of the sample. Specifically, in the regime of networks where
This work is significant because it provides for the first time analytical estimates of the sample Fréchet mean for the stochastic blockmodel, which is at the cutting edge of rigorous probabilistic analysis of random networks [12]. The technique of proof that is used to compute the sample Fréchet mean for the Hamming distance can be extended to the large class of inhomogeneous random networks [43]. It should also be possible to extend our computation of the Fréchet mean with the resistance distance to stochastic block models with
From a practical standpoint, our work informs the choice of distance in the context where the sample Fréchet mean network has been used to characterize the topology of networks for network-valued machine learning (e.g., detecting change points in sequences of networks [2, 8], computing Fréchet regression [6], or cluster network datasets [7]). Future work includes the analysis of the sample Fréchet mean when the distance is based on the eigenvalues of the normalized Laplacian Wills and Meyer [20].
5 Additional proofs
5.1 Proof of lemma 1
We start with a simple result that provides an expression for the Hamming distance squared. Let
The proof of Equation 61 is elementary, and is omitted for brevity. We now provide the proof of lemma 1.
Proof of lemma 1. Applying Equation 61 for each network
Using the expressions for the sample mean Equation 17 and correlation Equation 18, and observing that
we get
Also, we have
Whence
Completing the square yields
We can then substitute Equations 63, 65 into Equation 64, and we get the result advertised in the lemma,
where we recognize the first term as
5.2 Proof of lemma 3
Proof of lemma 3. We recall that the residual
The sample mean
Let
The sample correlation,
Let
Combining Equations 69, 70 yields
with probability
5.3 Proof of lemma 4
We first provide some inequalities (the proof of which are omitted) that relate
Lemma 8. Let
Proof of lemma 4. Let
Because of Lemma 8, we have
Also,
The entries of
Let
We recall that we assume that
Because
Substituting the expression of
Inserting the inequalities given by Equation 81 into Equation 77 gives the following lower bound that happens with probability
We bring the proof to an end by observing that
whence we conclude that
with probability
with probability
5.4 Proof of Equation 55
We show that
Proof. Let
Now
because the
we conclude that
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
FM: Conceptualization, Data curation, Formal Analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing–original draft, Writing–review and editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. FM was supported by the National Science Foundation (CCF/CIF 1815971).
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Dubey P, Müller H-G. Fréchet change-point detection. The Ann Stat (2020) 48:3312–35. doi:10.1214/19-aos1930
2. Ghoshdastidar D, Gutzeit M, Carpentier A, Von Luxburg U. Two-sample hypothesis testing for inhomogeneous random graphs. The Ann Stat (2020) 48:2208–29. doi:10.1214/19-aos1884
3. Ginestet CE, Li J, Balachandran P, Rosenberg S, Kolaczyk ED. Hypothesis testing for network data in functional neuroimaging. The Ann Appl Stat (2017) 11:725–50. doi:10.1214/16-aoas1015
4. Kolaczyk ED, Lin L, Rosenberg S, Walters J, Xu J. Averages of unlabeled networks: geometric characterization and asymptotic behavior. The Ann Stat (2020) 48:514–38. doi:10.1214/19-aos1820
5. Lunagómez S, Olhede SC, Wolfe PJ. Modeling network populations via graph distances. J Am Stat Assoc (2021) 116:2023–40. doi:10.1080/01621459.2020.1763803
6. Petersen A, Müller H-G. Fréchet regression for random objects with euclidean predictors. The Ann Stat (2019) 47:691–719. doi:10.1214/17-aos1624
7. Xu H. Gromov-Wasserstein factorization models for graph clustering. Proc AAAI Conf Artif intelligence (2020) 34(04):6478–85. doi:10.1609/aaai.v34i04.6120
8. Zambon D, Alippi C, Livi L. Change-point methods on a sequence of graphs. IEEE Trans Signal Process (2019) 67:6327–41. doi:10.1109/tsp.2019.2953596
10. Jain BJ. Statistical graph space analysis. Pattern Recognition (2016) 60:802–12. doi:10.1016/j.patcog.2016.06.023
11. Snijders TA. Statistical models for social networks. Annu Rev Sociol (2011) 37:131–53. doi:10.1146/annurev.soc.012809.102709
12. Abbe E. Community detection and stochastic block models: recent developments. J Machine Learn Res (2018) 18:1–86.
13. Airoldi EM, Costa TB, Chan SH. Stochastic blockmodel approximation of a graphon: theory and consistent estimation. In: Advances in neural information processing Systems (2013). p. 692–700.
14. Ferguson D, Meyer FG. Theoretical analysis and computation of the sample Fréchet mean of sets of large graphs for various metrics. Inf Inference (2023) 12:1347–404. doi:10.1093/imaiai/iaad002
15. Olhede SC, Wolfe PJ. Network histograms and universality of blockmodel approximation. Proc Natl Acad Sci (2014) 111:14722–7. doi:10.1073/pnas.1400374111
16. Mitzenmacher M, Upfal E. Probability and computing: randomization and probabilistic techniques in algorithms and data analysis. Cambridge, United Kingdom: Cambridge University Press (2017).
17. Monnig ND, Meyer FG. The resistance perturbation distance: a metric for the analysis of dynamic networks. Discrete Appl Mathematics (2018) 236:347–86. doi:10.1016/j.dam.2017.10.007
18. Akoglu L, Tong H, Koutra D. Graph based anomaly detection and description: a survey. Data Mining Knowledge Discov (2015) 29:626–88. doi:10.1007/s10618-014-0365-y
19. Donnat C, Holmes S. Tracking network dynamics: a survey using graph distances. The Ann Appl Stat (2018) 12:971–1012. doi:10.1214/18-aoas1176
20. Wills P, Meyer FG. Metrics for graph comparison: a practitioner’s guide. PLoS ONE (2020) 15(2):e0228728–54. doi:10.1371/journal.pone.0228728
21. Banks D, Carley K. Metric inference for social networks. J classification (1994) 11:121–49. doi:10.1007/bf01201026
22. Han F, Han X, Liu H, Caffo B. Sparse median graphs estimation in a high-dimensional semiparametric model. The Ann Appl Stat (2016) 10:1397–426. doi:10.1214/16-aoas940
23. Chen J, Hermelin D, Sorge M. On computing centroids according to the p-norms of hamming distance vectors. In: 27th annual European symposium on algorithms, 144 (2019). p. 1–28.28
24. Ferrer M, Serratosa F, Sanfeliu A. Synthesis of median spectral graph. In: Pattern recognition and image analysis: second iberian conference (2005). p. 139–46.
25. White D, Wilson RC. Spectral generative models for graphs. In: 14th international conference on image analysis and processing (ICIAP 2007). IEEE (2007). p. 35–42.
29. Von Luxburg U, Radl A, Hein M. Hitting and commute times in large random neighborhood graphs. The J Machine Learn Res (2014) 15:1751–98.
30. Fréchet M. Les espaces abstraits et leur utilité en statistique théorique et même en statistique appliquée. J de la Société Française de Statistique (1947) 88:410–21.
31. Sturm K-T. Probability measures on metric spaces of nonpositive. Heat Kernels Analysis Manifolds, Graphs, Metric Spaces (2003) 338:357.
32. Jiang X, Munger A, Bunke H. On median graphs: properties, algorithms, and applications. IEEE Trans Pattern Anal Machine Intelligence (2001) 23:1144–51. doi:10.1109/34.954604
33. Löwe M, Terveer S. A central limit theorem for the mean starting hitting time for a random walk on a random graph. J Theor Probab (2023) 36:779–810. doi:10.1007/s10959-022-01195-9
34. Sylvester J. Random walk hitting times and effective resistance in sparsely connected Erdős-Rényi random graphs. J Graph Theor (2021) 96:44–84. doi:10.1002/jgt.22551
35. Ottolini A, Steinerberger S. Concentration of hitting times in erdős-rényi graphs. J Graph Theor (2023) 107:245–62. doi:10.1002/jgt.23119
36. Wills P, Meyer FG. Change point detection in a dynamic stochastic blockmodel. In: Complex networks and their applications VIII (2020). p. 211–22.
37. Levin DA, Peres Y, Wilmer EL. Markov chains and mixing times. American Mathematical Soc. (2009).
38. Rempała G. Asymptotic factorial powers expansions for binomial and negative binomial reciprocals. Proc Am Math Soc (2004) 132:261–72. doi:10.1090/s0002-9939-03-07254-x
39. Löwe M, Terveer S. Hitting times for random walks on the stochastic block model (2024). arXiv preprint arXiv:2401.07896.
40. Deng S, Ling S, Strohmer T. Strong consistency, graph laplacians, and the stochastic block model. J Machine Learn Res (2021) 22:1–44.
41. Avrachenkov K, Cottatellucci L, Kadavankandy A. Spectral properties of random matrices for stochastic block model. In: International symposium on modeling and optimization in mobile, ad hoc, and wireless networks (2015). p. 537–44.
42. Chakrabarty A, Chakraborty S, Hazra RS. Eigenvalues outside the bulk of inhomogeneous Erdős–Rényi random graphs. J Stat Phys (2020) 181:1746–80. doi:10.1007/s10955-020-02644-7
Keywords: network-valued data, network barycenter, network topology, statistical network analysis, Fréchet mean, network distance
Citation: Meyer FG (2024) When does the mean network capture the topology of a sample of networks?. Front. Phys. 12:1455988. doi: 10.3389/fphy.2024.1455988
Received: 27 June 2024; Accepted: 21 August 2024;
Published: 08 October 2024.
Edited by:
Víctor M. Eguíluz, Spanish National Research Council (CSIC), SpainReviewed by:
Renaud Lambiotte, University of Oxford, United KingdomMingao Yuan, North Dakota State University, United States
Copyright © 2024 Meyer. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: François G. Meyer, Zm1leWVyQGNvbG9yYWRvLmVkdQ==