 Hailu Yang
Hailu Yang Qian Liu
Qian Liu Xiaoyu Ding
Xiaoyu Ding Chen Chen
Chen Chen Lili Wang
Lili Wang- 1School of Computer Science and Technology, Harbin University of Science and Technology, Harbin, China
- 2School of Computer Science and Technology, Chongqing University of Posts and Telecommunications, Chongqing, China
Online social networks have been incorporated into people’s work and daily lives as social media and services continue to develop. Opinion leaders are social media activists who forward and filter messages in mass communication. Therefore, competent monitoring of opinion leaders may, to some extent, influence the spread and growth of public opinion. Most traditional opinion leader mining approaches focus solely on the user’s network structure, neglecting the significance and role of semantic information in the generation of opinion leaders. Furthermore, these methods rank the influence of users globally and lack effectiveness in detecting local opinion leaders with low influence. This paper presents a community-based opinion leader mining approach in semantic social networks to address these issues. Firstly, we present a new node semantic feature representation method and community detection algorithm to generate the local public opinion circle. Then, a novel influence calculation method is proposed to find local opinion leaders by combining the global structure of the network and local structure of the public opinion circle. Finally, nodes with high comprehensive influence are identified as opinion leaders. Experiments on real social networks indicate that the proposed method can accurately measure global and local influence in social networks, as well as increase the accuracy of local opinion leader mining.
1 Introduction
The social network is a complex structure made up of people or entities who are linked together by some kind of relationship or shared interest (friendship, professional relationship, kinship, etc.) [1]. As tens of thousands of people around the world utilize social networks to interact, the Internet can continue to share an enormous quantity of data, resulting in the exponential expansion of social media and online social networks (e.g., Facebook, Twitter, Weibo) in recent years. Simultaneously, online social networks have grown in popularity as a result of their convenience, openness, anonymity, and virtual character, and have steadily evolved into a major carrier of online opinion and information distribution [2–5]. Texts, emojis, hashtags, and gif videos all contribute to the propagation of public opinion on social media [6]. As a result, online public opinion has evolved into a distinct form of public opinion with increasing social clout.
Most studies on online public opinion, including online opinion mining, dissemination patterns, and data mining, currently focus on the spread of online public opinion on social media [7–9]. The status of users in social networks is unequal, those in the center play a leading and driving role in the development of online public opinion, while those in the periphery are easily influenced by other factors (Aleahmad et al., 2016). Internet opinion leaders are often at the center, and their communication can easily push certain events to the forefront of the public opinion wave (Walter and Brüggemann, 2020). Public opinion leadership has the potential to not only actively guide public life, but also to trigger a wide range of negative emotions [12]. As a result, mining public opinion leaders is an important factor of guiding correct public opinion and sustaining network order.
Community detection is the process of dividing social users into tightly connected and highly relevant groups so that each group can be well separated from the others (Chunaev, 2020). Community detection has important applications in the fields of social network analysis, data mining, spatial database technology, statistics, biology, and smart grids [14–18]. This paper uses community detection to build a public opinion circle of users with the same ideas and opinions in social networks. Different from directly detecting opinion communities by leveraging connections between nodes [19], we use the semantic cohesiveness [20] and structural compactness of the community to further enhance the impact and effect of opinion leaders in the local environment.
Thanks to the development of online web technology, we can easily extract semantic information released by any individual from popular semantic social networks such as Facebook, Twitter, and Sina Weibo. At present, online opinion leaders detection mostly uses user behavior analysis [21,22], text semantic or sentiment analysis [23,24], node centrality analysis [25,26]. These methods, however, do not adequately account for the complexity of individuals in the local environment, and there is a lack of effective identification of opinion leaders with strong local influence.
To improve the performance of online opinion leader mining, we propose using the individual’s local structure to weight the influence score when mining opinion leaders. Firstly, an LDA topic model is introduced to obtain the topic distribution of semantic information of users and complete the construction of social networks; then a community detection algorithm based on σ-norm is proposed to obtain the community structure of social networks and form multiple opinion circles; Finally, using the graph structure of the community, we propose an influence calculation method based on the global and local structure of the graph to detect the opinion leaders of social networks. Experiments on real social networks show that the method proposed in this paper can extract online opinion leaders accurately and effectively.
In summary, the contributions of this paper are as follows:
(1) We propose a new opinion leader mining method that considers both semantic information and network structure of users.
(2) We construct a new node semantic feature representation method by computing the similarity between user documents and global topics to map user semantic to topology spaces.
(3) A community detection algorithm based on σ-norm is proposed, which can accurately output high-quality community partition results by exploiting the robustness of l21-norm and F-norm.
(4) We present a new influence calculation method that combines the global and local structure of the graph, successfully avoiding the impact of global high-influence nodes in local influence calculation.
2 Semantic Information Discovery of Social Network
In social networks, users express their views or opinions in response to various message. We define the social network as
2.1 LDA Representation of Semantic Information
LDA (Latent Dirichlet Allocation) is a three-level Bayesian model for document generation, which considers an article as having multiple topics, and each topic corresponds to a different word. Figure 1 shows the semantic information published by users in the social network, which contains three documents with the words marked with different colors. For example, words related to the biological environment are “coronavirus” and “vaccines,” which are marked with green; words related to political life are “government” and “official,” which are marked with yellow; words related to economy are “economy” and “opening,” which are marked with blue. If all the words in the document are marked, it can be found that each post mixes different topics in different proportions. For example, the first post mixes bioenvironmental and political themes, and the bioenvironmental theme has a higher proportion. With this idea, the topic distribution of semantic information in social networks can be extracted and the exploration of semantic information can be realized.
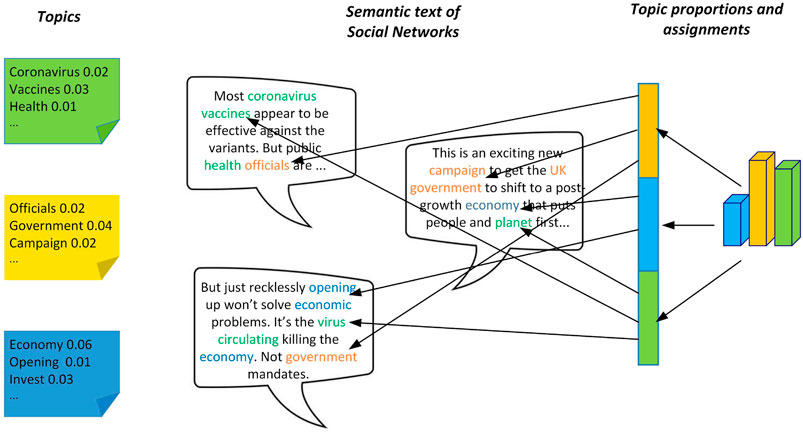
FIGURE 1. LDA model for document generation process of semantic information published by users in social networks.
The mathematical notation involved in the LDA topic model is shown in Table 1, and it is generated for each node as follows:
(1) θd ∼ Dirichlet(α): The topic distribution θd of document d follows the Dirichlet distribution with hyperparameter α, where α determines the proportion of the distribution of topics in document d.
(2) βz ∼ Dirichlet(η): The word distribution βz of topic z follows the Dirichlet distribution with hyperparameter η, where η determines the proportion of words distributed in the topic.
(3)
(4)

TABLE 1. Description of notations.
In summary, n documents will correspond to n independent Dirichlet-Multinomial conjugate structures, and K topics will correspond to K independent Dirichlet-Multinomial conjugate structures. Use α to generate topic distribution θ, and topic distribution θ determines the specific topic. Use η to generate word distribution β, which determines the specific keyword, i.e
2.2 Gibbs Sampling Process
Gibbs sampling is a Markov-Chain-Monte-Carlo (MCMC) method and is widely used in probability inference (Su et al., 2018). Gibbs sampling approximately samples a group of random variables from a complex joint distribution to obtain the conditional probability distribution of each characteristic dimension. Specifically for the LDA model, our goal is to obtain the overall probability distribution
Using the relationship existing in Eq. 1, the joint probability distribution
Where
When zi = o, wi = y, the probability
Thus, Eq. 3 can be reduced to:
Where αo(αt) is the hyperparameter α of the topic distribution corresponding to the topic of o(t). ηy(ηh) is the hyperparameter η of the word distribution corresponding to the keyword of y(h).
Gibbs sampling is performed on the topics of all words by Eq. 5, and when the sampling converges, the topics corresponding to all words are obtained; then, according to the correspondence between the sampled words and topics, we can get the topic distribution θd of each document and the distribution βk of keywords in each topic.
3 Community Detection Based on Topic Distribution
3.1 Node Representation
In this paper, the semantic information corresponding to the user nodes vi in the social network is used as the document di to generate the topic distribution
In Eq. 6, xi,j denotes the value of the ith row and jth column of the data matrix X, and
3.2 Establishing Associations
Calculating the similarity between node vectors can establish association for nodes. Two users with high correlation in a social network will correspond to a large similarity value, low correlation users will correspond to a low similarity value, and uncorrelated users will have zero similarity value. Commonly used similarity calculation methods include cosine similarity, Pearson correlation coefficient, and Gaussian kernel similarity calculation methods. These methods are sensitive to noise and outliers and are easy to ignore the local structure of data and the size of the vector itself. Therefore, this paper chooses a data similarity matrix learning method based on sparse representation [28] that is robust to noise kernel outliers in the data [29] and fits the requirement of connecting social network users. We can obtain the similarity matrix between users in a social network by solving the following equation:
Where ai,j is the value of the ith row and jth column of the similarity matrix A, A ∈ Rn×n. n is the number of users in the social network.
After calculation and derivation, the following results can be obtained:
Where
3.3 Constructing Community Detection Algorithm
Loss function is usually constructed using the l1-norm and the l2-norm. The loss function constructed using the l1-norm has the disadvantage of being insensitive to larger outliers but sensitive to smaller ones; the l2-norm does the opposite. σ-norm [30] neutralizes the above two problems and is defined as follows:
Where σ is the adaptive parameter. The generalization of the vector
After constructing the similarity matrix A of the social network by Eq. 8, we introduce the rank constraint and propose the following objective function:
In Eq. 11, U is the target matrix obtained from learning, due to the introduction of rank constraint, the target matrix U will have k connected components, so it can directly output the k community structures of the social network; L is the Laplace matrix of U; L = R − S, where R is diagonal matrix,
However, the dependence of L on the variable S and the nonlinearity of the rank constraint leads to the difficulty in solving Eq. 11. To solve this puzzle, we define
Where ρ is a balancing factor that can increase or decrease its value to cope with the cases that the connected components of the target matrix U are greater or less than k until k connected components of U exist. According to Fan’s study [32], there is the following theorem:
Where
Eq. 14 is the final objective function, where the objective matrix U has k connected components, so that the final community detection results can be obtained directly using this algorithm.
3.4 Algorithm Optimization
We introduce an iterative optimization algorithm for solving Eq. 14 and the target variable U therein. Since the target variable U and other variables F are coupled in one equation, solving Eq. 14 and deriving all variables at once is a challenging problem. In addition, the constraints in the objective function are not smooth. Assuming that A, F has been obtained, the target variable U can be computed using ALM (Augmented Lagrange Multiplier). ALM performs superiorly on matrix analysis problems [33]. Similarly, when the variable U is fixed, F can be computed. The detailed computational strategy is as follows:
(1) Keep F fixed, update U.
When F is fixed, using the Laplace matrix nature
Define the matrix Q ∈ Rn×n, where
Where
The simplification of Eq. 16 yields:
Let
Suppose the optimal solution to Eq. 18 is
Equation 19 written in vector form has
We further denote
According to Eqs 19, 21, we know that the optimal solution
As denoted above
(2) Keep U fixed, update F.
When U is fixed, it is equivalent to solving the following problem:
The study in [31] indicates that the optimal solution to F is formed by the k eigenvectors of L corresponding to the k smallest eigenvalues.
The stopping condition for algorithm optimization is that the relative change in U is less than 10–3 or the number of iterations is greater than 150. Compared with other traditional community detection algorithms, our proposed community detection algorithm based on σ-norm requires the computation of Eq. 14. The time complexity of Eq. 14 is O(itn2), where it is the number of iterations; it ≪ n. Therefore, the time complexity of the proposed community detection algorithm is O(n2). The process of community detection for semantic social networks has been given above, and the whole framework is shown in Algorithm 1.
Algorithm 1. A community analysis approach to semantic social networks

4 Opinion Leaders Mining in Social Network
4.1 Definitions
Before explaining the opinion leader mining approach, we formalize some definitions that will be used subsequently. In Section 2 we define the social network as
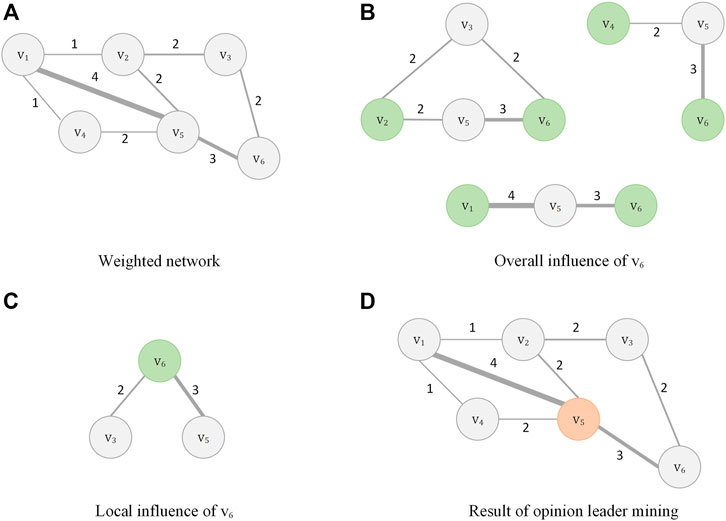
FIGURE 2. An example of online opinion leader mining method based on global and local influence, (A) is weighted network. (B) is overall influence of v6, (C) is local influence of v6, (D) is result of opinion leader mining.
Definition 1 (Node neighborhood). The neighborhood of node vi is a node set composed of the neighbors of vi. The neighborhood of node vi denoted as M(vi) is defined as follows:
In Figure 2A, nodes v2, v4 and v5 are neighbors of node v1. Thus, M(v1) = {v2, v4, v5}.
Definition 2 (public neighbor). The nodes vi, vj represent two different nodes in the network G. The public neighbor nodes between these two nodes are represented by PN(vi, vj), which is defined as follows:
In Figure 2A, the neighbors of node v1 and v5 are M(v1) = {v2, v4} and M(v3) = {v2, v6}, respectively. Thus, PN(v1, v5) = {v2}.
Definition 3 (Sum of Weights). The sum of weights is an extension of the degree and is usually used when analyzing weighted networks [35]. The sum of weights of v1 denoted as ω(vi) is defined as follows:
In Figure 2A, The sum of weights for the set of nodes {v1, v2, v3, v4, v5, v6} are {6, 5, 4, 3, 11, 5}.
Definition 4 (Degree Centrality). Degree centrality is the most direct metric for portraying node centrality in network analysis and the simplest measure of node influence, denoted by CD(vi) and defined as follows:
Where n is the total number of nodes and d(vi) is the degree of the node vi.In Figure 2A, the degree centrality of node v2 is 0.6 and the degree centrality of node v5 is 0.8. Therefore, the influence of node v2 is higher than v5 analyzed from the perspective of degree centrality.
Definition 5 (Comprehensive Node Centrality). Comprehensive node centrality is an extension of degree centrality that considers not only the number of connections between nodes but also the degree of participation of nodes in the network, i.e., a node centrality measure that combines degrees and weights [36]. Denoted by
Where d(vi) is the degree of node vi; ω(vi) is the sum of the weights of node vi; τ is the positive tuning parameter (default τ = 1.1), which can be set on a situational basis. If τ is between 0 and 1, then it is favorable for nodes with high degree, while if τ is set above 1, then it is favorable for nodes with low degree.In Figure 2A, the comprehensive node centrality of node v3 is 2.83 and the degree centrality of node v6 is 3.16. Therefore, the influence of node v6 is higher than v3 analyzed from the perspective of comprehensive node centrality.
Definition 6 (Average Degrees). The average degree of node vi is the sum of the degrees of all neighboring nodes of vi over the degree of vi, denoted by
Where d(vi) and d(vj) are the degrees of nodes vi and vj; M(vi) is the set of neighboring nodes of vi.
Definition 7 (Average Weights). The Average Weight of node vi is the sum of the weights of all neighboring nodes of vi over the weight of vi, denoted by
Where ω(vi) and ω(vj) are the weights of nodes vi and vj; M(vi) is the set of neighboring nodes of vi.
Definition 8 (Contribution Probability). The influence of the node vi itself is measured by its location in the network. In the unweighted network, we take the inverse of the average degree as the probability that neighbor nodes contribute to the influence of node vi, which is defined as follows:
In the weighted network, we take the inverse of the average weight as the probability that neighbor nodes contribute to the influence of node vi, which is defined as follows:
In Eqs 32, 33,
4.2 Influence Calculation
After completing community discovery, it is necessary to perform opinion leader mining on different community structures. We propose a social network opinion leader mining method based on the overall and local structure of graphs by using the information interaction ability between nodes and the local characteristics of nodes.
(1) Users of overall influence.
Social network is a relatively stable social relationship system formed by the information interaction among users. Strong information interaction ability indicates that users are in the hub position in social networks and can promote network information sharing. Therefore, opinion leaders, as key nodes in social networks, will have high intensity information interaction ability.
The information interaction ability between nodes vi and vj in social network G can be measured by counting the number of common nodes between them. A higher number of common nodes for vi and vj indicates a higher closeness between them, which means a higher information interaction capability between vi and vj [37]. The metric of information interaction ability of node v is formulated as follows:
Where PN(vi, vj) is public neighbors of vi and vj;
Since the social network constructed in Section 3 is a weighted undirected graph, considering only the degrees of the nodes will bias the results. Therefore, we extend the sum of degrees to the sum of weights when analyzing the weighted network. The information interaction capacity of nodes in the weighted network is calculated as follows:
Where ω(vi) is the sum of the weights of node vi. Equations 34, 35 utilize the information interaction ability of vi with other nodes as a measure of the overall structural influence, i.e., the sum of the information interaction ability for users in the social network. This is a relationship between the user and other users in the social network, that is, from the overall structure of the graph.
(2) Users of local influence.
The local influence of a user is the influence of the user itself and the surrounding users on it. The local influence of node vi is defined as follows:
Where CD(vj) is the degree centrality of the neighbor nodes vj for vi and p(vj) is the node contribution probability. For the weighted network, it is obviously not possible to consider only the node degree. For example, in Figure 2A, d(v4) = d(v6) = 2, but ω(v6) > ω(v4), so v6 has a higher degree of participation in the network. Therefore, the local influence calculation of users for the weighted network will consider both degree and weight, which are defined as follows:
Where
(3) Influence Ranking.
The user’s influence will be evaluated by taking into account the user’s ability to interact with information, as well as the influence of the user itself and the surrounding users on it, i.e., by integrating the overall and local structure of the graph. Its calculation formula is as follows:
Equation 38 is applied to the unweighted network and Eq. 39 is applied to the weighted network. These two equations enable the node influence assessment of all users in the social network. The higher influence of a node means that it is more important in the network, and the most important node is the opinion leader in the social network.
4.3 An Illustrative Example
Figure 2A is a weighted network, containing six nodes {v1, v2, …, v6}. Figure 2B shows the information interaction of v6 with other nodes, and the number of common neighbor nodes between v6 and other nodes is used to measure the information interaction ability between two nodes. The stronger information interaction ability of v6 means the higher overall influence of v6 in G. With Eq. 35, the overall influence of each node in G can be obtained, and the results are shown in Table 2.

TABLE 2. Overall influence results for weighted network G.
Figure 2C shows all neighboring nodes of node v6 in G. Each neighbor node has an inconsistent impact on v6. The higher Eq. 37 contribution probability of neighbor nodes, the higher influence on node v6. The local influence of each node can be obtained using (τ = 1.1), and the results are shown in Table 3.
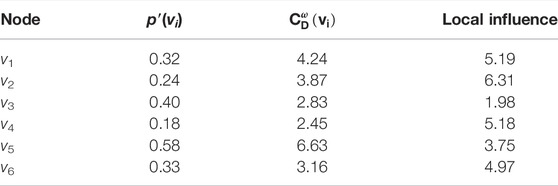
TABLE 3. Local influence results for weighted network G.
The influence scores of all nodes can be obtained using Eq. 39, as shown in the Table 4. According to Table 4, it is known that v5 has the highest influence. Therefore v5 has the highest importance in the weighted network G, which is the opinion leader. Figure 2D shows the result of opinion leader mining, and the opinion leaders have been marked with different colors.

TABLE 4. The influence score for each node.
5 Experience and Analysis
5.1 Dataset Analysis
Microblogging has now become an important social platform for most people to get information and communicate. Opinion leaders at the center of social networks are essential communication media for providing information to others. Analysis of online opinion leaders through microblog data can effectively identify the source of negative information and control it. Therefore, to validate the method proposed in this paper, we collected 37,590 posts by 1,879 users from three domains of Sina Weibo: fashion, technology and education as the experimental dataset, among which fashion, technology and education contain 11,260, 12,262 and 14,068 posts, respectively, and all posts made by a single user represent his semantic information.
According to some current studies, there is no precise evaluation system for opinion leaders. Therefore, we tag users with community labels by the domain they belong to and use the number of user followers and the activity indexes provided by Sina Weibo platform (number of users reading, number of interactions, number of super topics) as the basis for evaluating online opinion leaders. Opinion leaders were determined according to the ratio of 40 and 60%, expressed as OPE, which was calculated as follows:
In Eq. 40, OPEi represents the opinion leader evaluation indexes of user i, and a larger value indicates that the user i is more likely to become opinion leader; Fansi, Readi, Interi, and STopi denote the number of fans, readers, interactions, and super topics of user i, respectively; max(Fans), min(Fans) indicate the maximum and minimum values of the number of fans among all users, and other similar variables have similar meanings.
Figure 3 shows the distribution of the number of followers and OPE values in the Weibo dataset, where different colors represent different domains. It can be seen that the number of users with fans greater than 1000 W and OPE greater than eight is extremely small, and the influence of these users will also be at the top of the dataset, so we define the top 10% of users with OPE values in each domain as online opinion leaders for subsequent verification of the effectiveness and performance of the opinion leader mining method proposed in this paper.
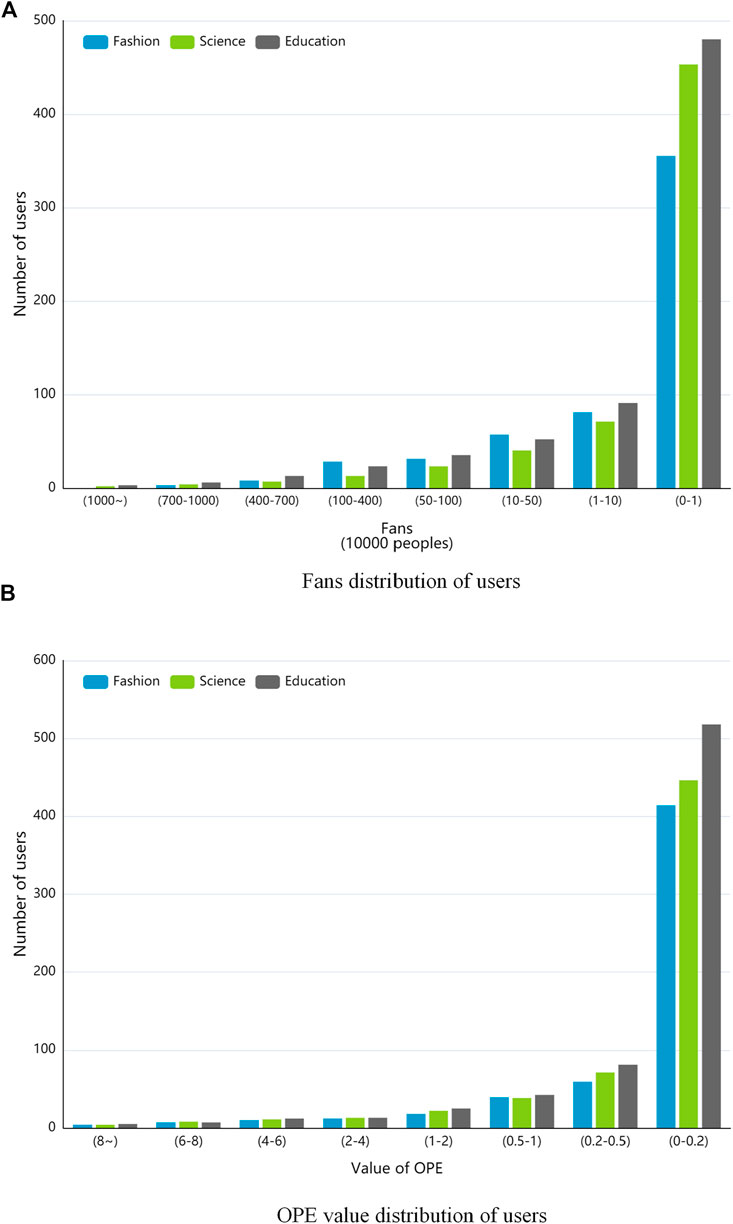
FIGURE 3. Distribution of fans and OPE in micro-blog dataset, (A) is fans distribution of users. (B) is OPE value distribution of users.
5.2 Evaluation Metrics
To compare the performance of the community discovery method and online opinion leader mining method proposed in this paper with other methods, we use several widely used evaluation metrics.
Accuracy (AC) [38] is used to evaluate the correctness of the results for community detection algorithms and the correctness of the results for online opinion leader mining, which is defined as follows:
Where n is the total number of nodes; pci denotes the predicted consequence; cci denotes the practical consequence; and δ(pci, cci) is the Kronecker function, indicating that it is equal to 1 if pci and cci are the same and 0 otherwise.
Normalized mutual information (NMI) [39] is used to compare the similarity between ground-truth and detected communities and to evaluate the quality of community segmentation in social networks. It is defined as follows:
Where H(X) and H(Y) are the information entropy of the random variables X and Y; H(X|Y) and H(Y|X) are the conditional entropy of the random variables X and Y.
F1-score [40] is a composite metric that balances accuracy and recall which is defined as follows:
Where
The modularity(Q) [41] is used to assess the quality of the community structure and is defined as follows:
Where
5.3 Results of Community Detection
After cleaning the dataset (advertisement, duplicate, brief), all semantic information published by each user is used as one document, and all semantic information of all users is used as corpus. After that, the topic distribution of each document is obtained using the LDA topic model, and node representation and data matrix construction are performed. Then the similarity matrix is calculated using Eq. 8 to achieve the construction of social networks, where the parameter m is set to 30 by default.
However, in the node representation process, the number of topics is an important parameter to determine the combined similarity of two users and to identify the community structure. In order to obtain the optimal value of the number of topics, the relationship between the number of different topics and the constructed similarity matrix is discussed. To obtain the optimal value of the number of topics, the relationship between the number of different topics and the constructed similarity matrix is discussed.
Figure 4 shows the relationship network diagrams constructed by the similarity matrix corresponding to different topic numbers. It can be clearly seen that regardless of the number of topics three main community structures are presented, corresponding exactly to users from three different domains, so it is reasonable to use the semantic information of individual users for the construction of the network. Regarding the choice of topic number, it is obvious from Figure 4 that the community structure boundaries will not be obvious when the topic number is smaller and larger, and when the topic number is equal to 25 and 35, the community structure is of higher quality with clear contours, which is obviously better than the relationship network graph presented by other topic numbers. Therefore, we set the number of topics to 25 and conduct subsequent experiments.
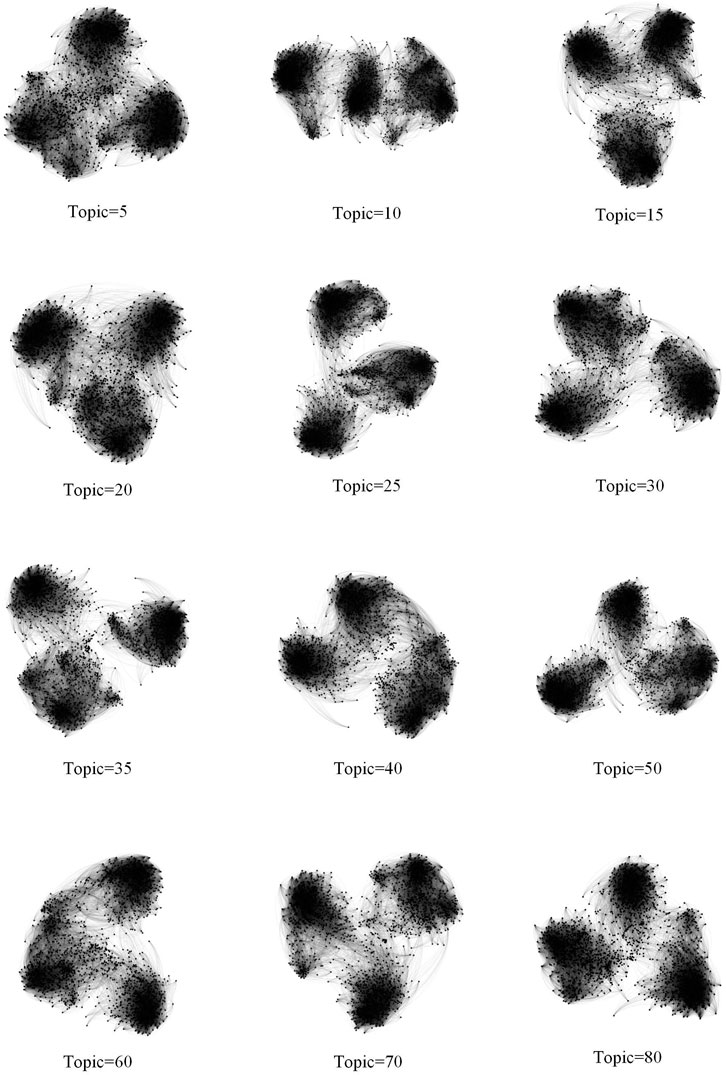
FIGURE 4. Relationship network diagram of different topic numbers.
After completing the construction of the social network, the results shown in Figure 5A are obtained using the σ-norm-based community detection algorithm proposed in this paper (where the initial value of the parameter ρ is set to 1, which is automatically adjusted according to the number of iterations, and ρ = ρ*2 when the connected component of the target matrix U is smaller than the number of communities k, and ρ = ρ/2 when it is larger than the number of communities k. The adaptive loss parameter is set to 0.1 according to [34]), with each color representing a community. Figure 5B then represents the correct community to which the node belongs. By comparing Figures 5A,B, it can be observed that the community detection algorithm proposed in this paper performs very well, and there are relatively few cases of misclassified communities, and only a small number of nodes are misclassified sporadically.

FIGURE 5. The results of community detection, (A) is the result of community detection algorithm based on σ-norm, (B) is the correct community class for all nodes.
To better validate the performance of the algorithm proposed in this paper, we compare it with three community detection algorithms, Normalized cut (Ncut) [42], Fast unfolding algorithm (Louvain) [43] and Clustering with Adaptive Neighbors (CAN) [44], on the Weibo dataset and the WebKB dataset1 [45]. Among them, Ncut is a classical graph-based approach; Louvain is a modularity-based community discovery algorithm; CAN is similar to the algorithm proposed in this paper and is an algorithm that learns both the data similarity matrix and the clustering structure. WebKB dataset is composed of approximately 6,000 web pages from computer science departments of four schools (Cornell, Texas, Washington, and Wisconsin), which are classified into seven categories.
Figure 6 shows the performance of each algorithm in terms of AC, NMI and Q on the WebKB and Weibo datasets. By observing Figure 6, we can find that the community detection method proposed in this paper only has slightly lower NMI and Q values than Ncut in the Wisconsin dataset, but is in the leading position in all other aspects, and is significantly more stable than the Ncut algorithm, which can be applied to multiple types of datasets well. In the Weibo dataset, the performance of AC, NMI and Q is better than other methods, which indicates that the community detection algorithm proposed in this paper can be perfectly applied to social networks composed of individual semantic information as features, and provides high-quality preconditions for the subsequent extraction of online opinion leaders.
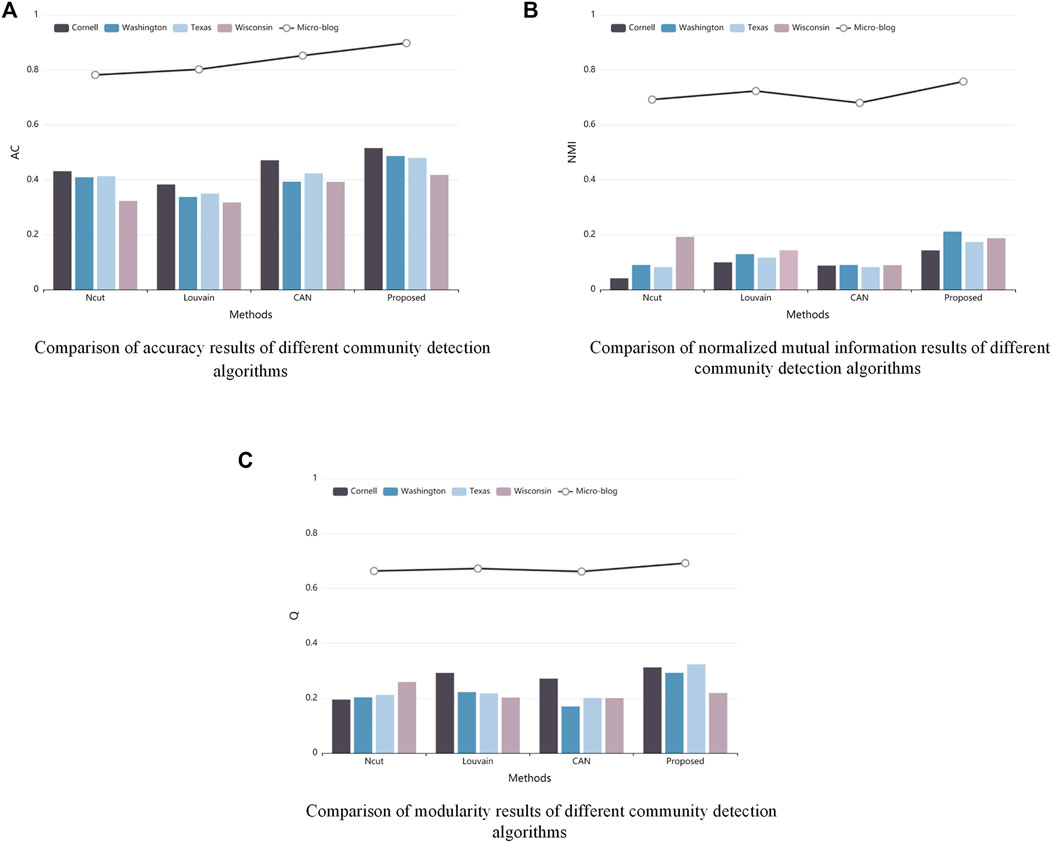
FIGURE 6. Comparative analysis of WebKB dataset and Micro-blog dataset based on AC, NMI and Q, (A) is comparison of accuracy results for different community detection algorithms, (B) is comparison of normalized mutual information results for different community detection algorithms, (C) is comparison of modularity results for different community detection algorithms.
5.4 Results of Online Opinion Leader Mining
After completing the community detection, each community structure can be considered as an opinion circle, from which the online opinion leaders are mined. Since the similarity matrix calculated by Eq. 8 uses a sparsity constraint, the sum of the edge weights of the nodes is 1, which will lead to the existence of some edges with very small weights (very low similarity between nodes) within the community structure, as well as nodes whose weight sizes and degrees do not reach a balance. Therefore, to obtain the optimal experimental results, we need to determine a similarity threshold ϕ and keep the edges with weights greater than ϕ. Figure 7 depicts the effects of using the opinion leader mining method proposed in this paper on the AC and F1-score metrics under different similarity thresholds. From Figure 7, we can find that the values of AC and F1-score increase and then decrease as ϕ increases, and when the ϕ reaches 0.1, the indicators in Science and Education communities reach the maximum value; when ϕ reaches 0.15, the indicators in Fashion community reach the maximum value. Therefore, the similarity threshold ϕ is set to 0.1 for Science and Education communities and 0.15 for Fashion communities. Also, to balance the size of the weight values of the nodes with the size of the degree, we found that multiplying the edge weights of each node by three performs best.
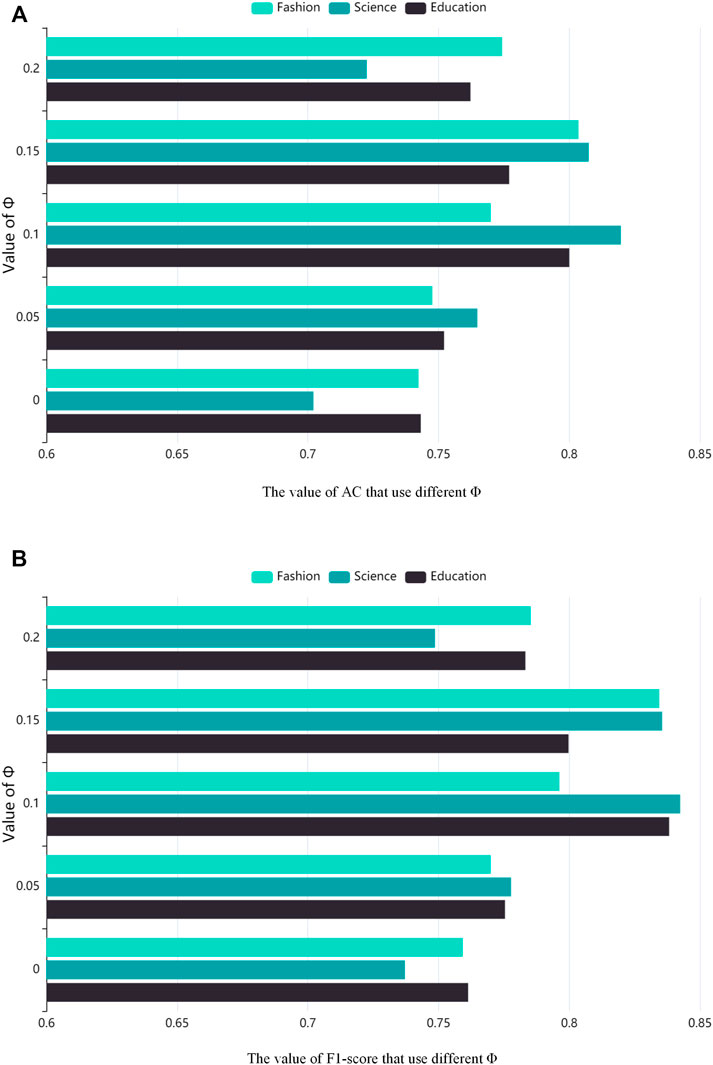
FIGURE 7. Accuracy and F1-score analysis of opinion leaders mining with different similarity thresholds ϕ, (A) is the value of AC that use different ϕ, (B) is the value of F1-score that use different ϕ.
Finally, it is also necessary to determine the optimal value of the parameter τ (Eq. 30) used in this online opinion leader mining method. Figure 8 depicts the effect of different τ on the AC and F1-score metrics, and it can be observed that the Fashion community reaches the maximum AC at τ equal to 0.7 and the maximum F1-score at τ equal to 0.8; the Science community reaches the maximum for each metric at τ equal to 0.8; the Education community reaches the maximum for each metric at τ equal to 1.1 maximum. Therefore, considering the magnitude of AC and F1-score indicators, the parameter τ is set to 0.7, 0.8, and 1.1 for Fashion, Science,and Education communities, respectively, for online opinion leader mining.
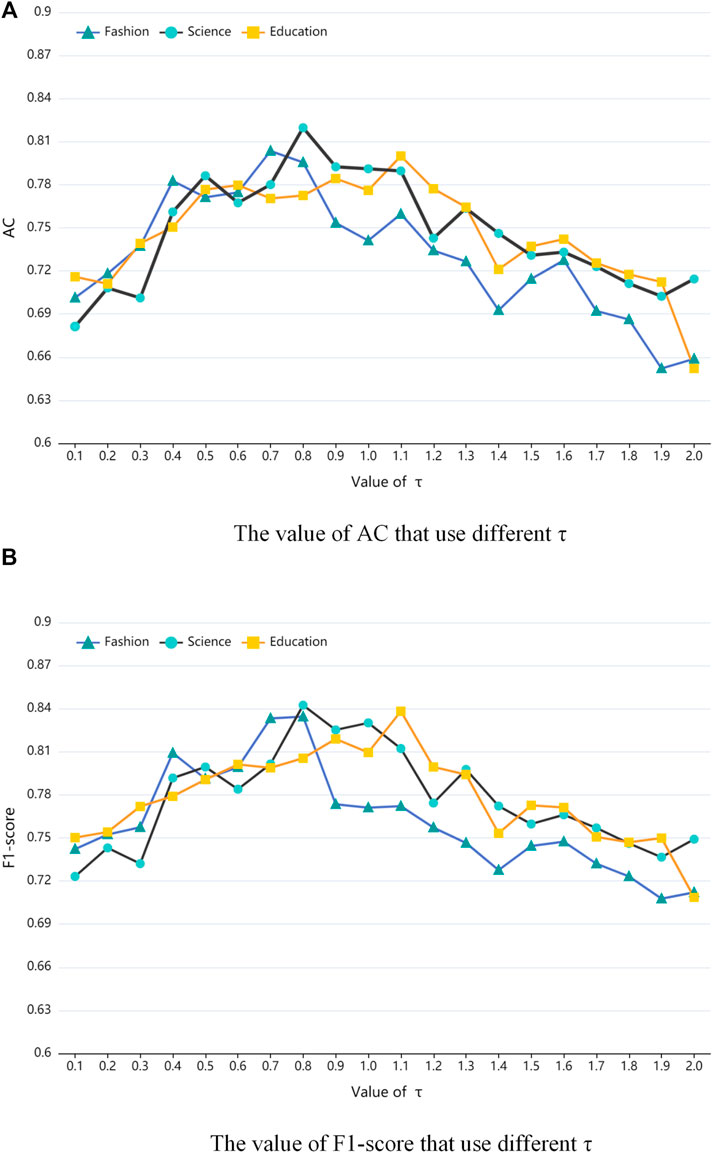
FIGURE 8. Accuracy and F1-score analysis of opinion leaders mining with different positive tuning parameters τ, (A) is the value of AC that use different τ, (B) is the value of F1-score that use different τ.
To verify the effectiveness and performance of the methods proposed in this paper, we compare the AC and F1-score metrics performance of the five methods on the Weibo dataset and further discuss the performance effectiveness of each method. Before giving the experimental results, a brief introduction of the five methods is given.
BC (Betweenness Centrality) [46]: The method uses betweenness centrality to mine opinion leaders. In most real networks, information flows randomly according to its intent rather than following the shortest path, so using betweenness centrality to measure node importance is not applicable in some networks.
CC (Closeness Centrality) [47]: This method is similar to betweenness centrality and combines the global and local effects of nodes in complex networks, effectively solving the complexity of node deletion methods and direct computation of betweenness centrality.
EC (Eigenvector Centrality) [48]: This method is based on the assumption that the importance of a node depends on the number of neighboring nodes and also on the influence of each neighboring node, so that the importance of the node is evaluated only from the other nodes connected to the node.
ProfitLeader (PL) [49]: This method ranks the key nodes in the network by measuring the profit that the nodes can provide.
PageRank (PR) [50]: This method ranks pages according to their link structure, i.e. the influence of a page depends on the number and quality of the other pages pointing to it. If a page has many high quality pages pointing to it, then it is also of high quality.
Table 5 summarizes the time complexity of different influence calculation methods (

TABLE 5. Time Complexity of different evaluation methods.
Table 6 shows the performance results of the proposed method in this paper with the above five methods on the Weibo dataset. The AC and F1-score values are obtained by comparing the calculation results of each method with the actual network opinion leaders (the top 10% of important user nodes). We can find that the method in this paper has better results compared with other methods, and the AC and F1-score can reach more than 80% in all three community structures, which can prove the effectiveness and correctness of the method proposed in this paper. Table 7 lists the mining accuracy of our proposed method for opinion leaders ranked in the top k% of influence, and it can be found that the results tend to be smooth and do not have excellent performance only for mining opinion leaders in specific positions, so the method can be applied to mining opinion leaders with different percentage requirements.

TABLE 6. Comparison of AC and F1-score results with other evaluation methods.
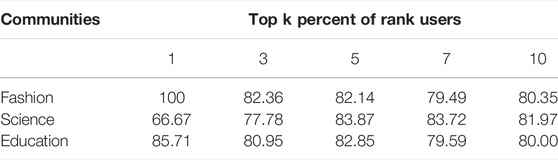
TABLE 7. The results of AC for different percentages of opinion leaders.
Table 8 presents the local influence, overall influence, and combined influence values of the top 15 users and the communities they belong to in the Weibo dataset using the results obtained from the proposed method. From Table 8, it can be found that as the ranking decreases, the values of both the local influence and the overall influence of the user show a relatively large decrease, which means that the user’s information interaction ability with other users and the influence of neighboring nodes on it are decreasing. This also verifies the scarcity of users with followers greater than 1000 W and OPE values greater than eight in the Weibo dataset, further illustrating the effectiveness of the network opinion leader mining method proposed in this paper.
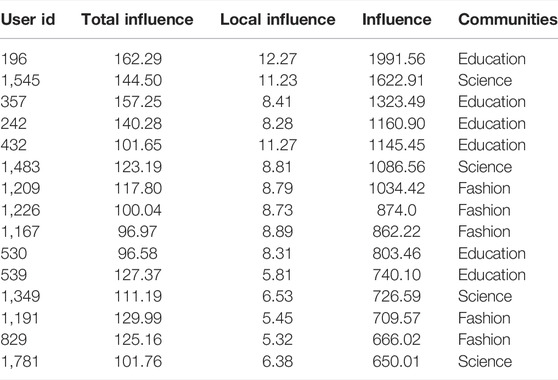
TABLE 8. The Top-15 users of influence evaluation results.
6 Conclusion
This paper studies the detection of local opinion leaders in semantic social networks. In the aspect of semantic information quantification, we introduce the LDA model to extract the global topics of network documents and construct the semantic feature representation of nodes by calculating the similarity between the global topics and the posts produced by users. To detect local opinion leaders, a community detection method based on σ-norm is presented to split the network and users with topic consistency create a public opinion circle. The proposed strategy efficiently prevents the exclusion of local opinion leaders with low global influence by taking into account local influence within the public opinion circle and global influence outside the public opinion circle. We conduct experiments on real social networks, and the results show that the proposed method is capable of a high-quality semantic social network partition and accurate mining of local opinion leaders. Future research will focus on the design of adaptive algorithms to achieve fast identification of opinion leaders in dynamic networks.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: http://www.cs.cmu.edu/∼WebKB/.
Author Contributions
HY proposed the core idea of the paper. QL and XD collected data and built the experimental platform. CC and LW wrote the main part of the paper and verified the performance of the algorithm. All authors listed approved the paper for publication.
Funding
This work is sponsored by National Natural Science Foundation of China (No. 61402126, No. 62101163); Nature Science Foundation of Heilongjiang Province of China (No. F2016024, No. LH2021F029), China Postdoctoral Science Foundation (No. 2021M701020); Heilongjiang Postdoctoral Science Foundation (No. LBH-Z15095, No. LBH-Z20020); University Nursing Program for Young Scholars with Creative Talents in Heilongjiang Province (No. UNPYSCT-2017094); Fundamental Research Foundation for Universities of Heilongjiang Province (No. 2020-KYYWF-0341).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1http://www.cs.cmu.edu/∼WebKB/
References
1. Camacho D, Panizo-LLedot Á, Bello-Orgaz G, Gonzalez-Pardo A, Cambria E. The Four Dimensions of Social Network Analysis: An Overview of Research Methods, Applications, and Software Tools. Inf Fusion (2020) 63:88–120. doi:10.1016/j.inffus.2020.05.009
2. Camacho D, Luzón MV, Cambria E. New Research Methods & Algorithms in Social Network Analysis. Future Generation Comput Syst (2021) 114:290–3. doi:10.1016/j.future.2020.08.006
3. Bello-Orgaz G, Jung JJ, Camacho D. Social Big Data: Recent Achievements and New Challenges. Inf Fusion (2016) 28:45–59. doi:10.1016/j.inffus.2015.08.005
4. Hussain A, Cambria E. Semi-supervised Learning for Big Social Data Analysis. Neurocomputing (2018) 275:1662–73. doi:10.1016/j.neucom.2017.10.010
5. Zhang M, Wang W. Study on Public Opinion Propagation in Self media Age Based on Time Delay Differential Model. Proced Comput Sci (2017) 122:486–93. doi:10.1016/j.procs.2017.11.397
6. Chen X, Zhang W, Xu X, Cao W. A Public and Large-Scale Expert Information Fusion Method and its Application: Mining Public Opinion via Sentiment Analysis and Measuring Public Dynamic Reliability. Inf Fusion (2022) 78:71–85. doi:10.1016/j.inffus.2021.09.015
7. He W, Tian X, Tao R, Zhang W, Yan G, Akula V. Application of Social media Analytics: A Case of Analyzing Online Hotel Reviews. Online Inf Rev (2017) 41:1. doi:10.1108/oir-07-2016-0201
8. Ramakrishnan J, Mavaluru D, Srinivasan K, Mubarakali A, Narmatha C, Malathi G. Opinion Mining Using Machine Learning Approaches: A Critical Study. In: 2020 International Conference on Computing and Information Technology (ICCIT-1441). Tabuk, Saudi Arabia: IEEE (2020). p. 1–4. doi:10.1109/iccit-144147971.2020.9213747
9. Chen T, Shi J, Yang J, Cong G, Li G. Modeling Public Opinion Polarization in Group Behavior by Integrating Sirs-Based Information Diffusion Process. Complexity (2020) 2020. doi:10.1155/2020/4791527
10. Aleahmad A, Karisani P, Rahgozar M, Oroumchian F. Olfinder: Finding Opinion Leaders in Online Social Networks. J Inf Sci (2016) 42:659–74. doi:10.1177/0165551515605217
11. Walter S, Brüggemann M. Opportunity Makes Opinion Leaders: Analyzing the Role of First-Hand Information in Opinion Leadership in Social media Networks. Inf Commun Soc (2020) 23:267–87. doi:10.1080/1369118x.2018.1500622
12. Jain L, Katarya R, Sachdeva S. Recognition of Opinion Leaders Coalitions in Online Social Network Using Game Theory. Knowledge-Based Syst (2020) 203:106158. doi:10.1016/j.knosys.2020.106158
13. Chunaev P. Community Detection in Node-Attributed Social Networks: a Survey. Comput Sci Rev (2020) 37:100286. doi:10.1016/j.cosrev.2020.100286
14. Leskovec J, Lang KJ, Mahoney M. Empirical Comparison of Algorithms for Network Community Detection. In: WWW ’10: Proceedings of the 19th International Conference on World Wide Web. New York, NY: Association for Computing Machinery (2010). p. 631–40. doi:10.1145/1772690.1772755
15. Papadopoulos S, Kompatsiaris Y, Vakali A, Spyridonos P. Community Detection in Social media. Data Min Knowl Disc (2012) 24:515–54. doi:10.1007/s10618-011-0224-z
16. Chien I, Lin C-Y, Wang I-H. Community Detection in Hypergraphs: Optimal Statistical Limit and Efficient Algorithms. In: International Conference on Artificial Intelligence and Statistics (PMLR) (2018). p. 871–9.
17. Garcia JO, Ashourvan A, Muldoon S, Vettel JM, Bassett DS. Applications of Community Detection Techniques to Brain Graphs: Algorithmic Considerations and Implications for Neural Function. Proc IEEE (2018) 106:846–67. doi:10.1109/jproc.2017.2786710
18. Cao J, Bu Z, Wang Y, Yang H, Jiang J, Li H-J. Detecting Prosumer-Community Groups in Smart Grids from the Multiagent Perspective. IEEE Trans Syst Man Cybern, Syst (2019) 49:1652–64. doi:10.1109/tsmc.2019.2899366
19. Bu Z, Li H-J, Zhang C, Cao J, Li A, Shi Y. Graph K-Means Based on Leader Identification, Dynamic Game, and Opinion Dynamics. IEEE Trans Knowledge Data Eng (2019) 32:1348–61.
20. Cao J, Wang Y, Bu Z, Wang Y, Tao H, Zhu G. Compactness Preserving Community Computation via a Network Generative Process. IEEE Trans Emerging Top Comput Intelligence (2021). doi:10.1109/tetci.2021.3110086
21. Zhao Y, Kou G, Peng Y, Chen Y. Understanding Influence Power of Opinion Leaders in E-Commerce Networks: An Opinion Dynamics Theory Perspective. Inf Sci (2018) 426:131–47. doi:10.1016/j.ins.2017.10.031
22. Liu X, Liu C. Information Diffusion and Opinion Leader Mathematical Modeling Based on Microblog. IEEE Access (2018) 6:34736–45. doi:10.1109/access.2018.2849722
23. Jain L, Katarya R. Identification of Opinion Leader in Online Social Network Using Fuzzy Trust System. In: 2018 IEEE 8th International Advance Computing Conference (IACC). Greater Noida, India: IEEE (2018). p. 233–9. doi:10.1109/iadcc.2018.8692095
24. Wang C, Du YJ, Tang MW. Opinion Leader Mining Algorithm in Microblog Platform Based on Topic Similarity. In: 2016 2nd IEEE International Conference on Computer and Communications (ICCC). Chengdu: IEEE (2016). p. 160–5. doi:10.1109/compcomm.2016.7924685
25. Dewi FK, Yudhoatmojo SB, Budi I. Identification of Opinion Leader on Rumor Spreading in Online Social Network Twitter Using Edge Weighting and Centrality Measure Weighting. In: 2017 Twelfth International Conference on Digital Information Management (ICDIM). Fukuoka, Japan: IEEE (2017). p. 313–8. doi:10.1109/icdim.2017.8244680
26. Yang L, Qiao Y, Liu Z, Ma J, Li X. Identifying Opinion Leader Nodes in Online Social Networks with a New Closeness Evaluation Algorithm. Soft Comput (2018) 22:453–64. doi:10.1007/s00500-016-2335-3
27. Su J, Xu J, Qiu X, Huang X. Incorporating Discriminator in Sentence Generation: a Gibbs Sampling Method. In: Proceedings of the AAAI Conference on Artificial Intelligence (2018). vol. 32.
28. Nie F, Wang X, Jordan M, Huang H. The Constrained Laplacian Rank Algorithm for Graph-Based Clustering. In: Proceedings of the AAAI conference on artificial intelligence (2016). vol. 30.
29. Wright J, Yang AY, Ganesh A, Sastry SS, Ma Y. Robust Face Recognition via Sparse Representation. IEEE Trans Pattern Anal Mach Intell (2008) 31:210–27. doi:10.1109/TPAMI.2008.79
30. Zhang R, Nie F, Guo M, Wei X, Li X. Joint Learning of Fuzzy K-Means and Nonnegative Spectral Clustering with Side Information. IEEE Trans Image Process (2018) 28:2152–62. doi:10.1109/TIP.2018.2882925
32. Fan K. On a Theorem of Weyl Concerning Eigenvalues of Linear Transformations: Ii. Proc Natl Acad Sci (1950) 36:31–5. doi:10.1073/pnas.36.1.31
33. Bertsekas DP. Constrained Optimization and Lagrange Multiplier Methods. Cambridge, MA: Academic Press (2014).
34. Nie F, Wang H, Huang H, Ding C. Adaptive Loss Minimization for Semi-supervised Elastic Embedding. In: Twenty-Third International Joint Conference on Artificial Intelligence (2013).
35. Li H-J, Bu Z, Wang Z, Cao J, Shi Y. Enhance the Performance of Network Computation by a Tunable Weighting Strategy. IEEE Trans Emerg Top Comput Intell (2018) 2:214–23. doi:10.1109/tetci.2018.2829906
36. Opsahl T, Agneessens F, Skvoretz J. Node Centrality in Weighted Networks: Generalizing Degree and Shortest Paths. Social networks (2010) 32:245–51. doi:10.1016/j.socnet.2010.03.006
37. Sheng J, Dai J, Wang B, Duan G, Long J, Zhang J, et al. Identifying Influential Nodes in Complex Networks Based on Global and Local Structure. Physica A: Stat Mech its Appl (2020) 541:123262. doi:10.1016/j.physa.2019.123262
38. Kynkäänniemi T, Karras T, Laine S, Lehtinen J, Aila T. Improved Precision and Recall Metric for Assessing Generative Models. arXiv preprint arXiv:1904.06991 (2019).
39. Zhang P. Evaluating Accuracy of Community Detection Using the Relative Normalized Mutual Information. J Stat Mech (2015) 2015:P11006. doi:10.1088/1742-5468/2015/11/p11006
40. Fawcett T. An Introduction to Roc Analysis. Pattern recognition Lett (2006) 27:861–74. doi:10.1016/j.patrec.2005.10.010
41. Newman ME, Girvan M. Finding and Evaluating Community Structure in Networks. Phys Rev E Stat Nonlin Soft Matter Phys (2004) 69:026113. doi:10.1103/PhysRevE.69.026113
42. Cour T, Benezit F, Shi J. Spectral Segmentation with Multiscale Graph Decomposition. In: 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05). San Diego, CA, USA: IEEE (2005). p. 1124–31. vol. 2.
43. Blondel VD, Guillaume J-L, Lambiotte R, Lefebvre E. Fast Unfolding of Communities in Large Networks. J Stat Mech (2008) 2008:P10008. doi:10.1088/1742-5468/2008/10/p10008
44. Nie F, Wang X, Huang H. Clustering and Projected Clustering with Adaptive Neighbors. In: Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining (2014). p. 977–86. doi:10.1145/2623330.2623726
45. Getoor L. Link-based Classification. In: Advanced Methods for Knowledge Discovery from Complex Data. Berlin, Germany: Springer (2005). p. 189–207.
46. Freeman LC. Centrality in Social Networks Conceptual Clarification. Soc networks (1978) 1:215–39. doi:10.1016/0378-8733(78)90021-7
47. Okamoto K, Chen W, Li X-Y. Ranking of Closeness Centrality for Large-Scale Social Networks. In: International Workshop on Frontiers in Algorithmics. Berlin, Germany: Springer (2008). p. 186–95.
48. Solá L, Romance M, Criado R, Flores J, García del Amo A, Boccaletti S. Eigenvector Centrality of Nodes in Multiplex Networks. Chaos (2013) 23:033131. doi:10.1063/1.4818544
49. Yu Z, Shao J, Yang Q, Sun Z. Profitleader: Identifying Leaders in Networks with Profit Capacity. World Wide Web (2019) 22:533–53. doi:10.1007/s11280-018-0537-6
Keywords: social networks, local opinion leader, influence calculation, semantic representation, community detection
Citation: Yang H, Liu Q, Ding X, Chen C and Wang L (2022) Detecting Local Opinion Leader in Semantic Social Networks: A Community-Based Approach. Front. Phys. 10:858225. doi: 10.3389/fphy.2022.858225
Received: 19 January 2022; Accepted: 02 March 2022;
Published: 30 March 2022.
Edited by:
Peican Zhu, Northwestern Polytechnical University, ChinaReviewed by:
Erik Cambria, Nanyang Technological University, SingaporeJie Cao, Nanjing University of Finance and Economics, China
Copyright © 2022 Yang, Liu, Ding, Chen and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hailu Yang, eWFuZ2hhaWx1QGhyYnVzdC5lZHUuY24=; Qian Liu, NTI5NTcyNTc4QHFxLmNvbQ==