 Qi An
Qi An Liang Huang
Liang Huang Chuan Wang
Chuan Wang Dongmei Wang
Dongmei Wang Yalan Tu
Yalan Tu
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Pharmacol. , 11 February 2025
Sec. Experimental Pharmacology and Drug Discovery
Volume 16 - 2025 | https://doi.org/10.3389/fphar.2025.1550158
Drug discovery plays a crucial role in medicinal chemistry, serving as the cornerstone for developing new treatments to address a wide range of diseases. This review emphasizes the significance of advanced strategies, such as Click Chemistry, Targeted Protein Degradation (TPD), DNA-Encoded Libraries (DELs), and Computer-Aided Drug Design (CADD), in boosting the drug discovery process. Click Chemistry streamlines the synthesis of diverse compound libraries, facilitating efficient hit discovery and lead optimization. TPD harnesses natural degradation pathways to target previously undruggable proteins, while DELs enable high-throughput screening of millions of compounds. CADD employs computational methods to refine candidate selection and reduce resource expenditure. To demonstrate the utility of these methodologies, we highlight exemplary small molecules discovered in the past decade, along with a summary of marketed drugs and investigational new drugs that exemplify their clinical impact. These examples illustrate how these techniques directly contribute to advancing medicinal chemistry from the bench to bedside. Looking ahead, Artificial Intelligence (AI) technologies and interdisciplinary collaboration are poised to address the growing complexity of drug discovery. By fostering a deeper understanding of these transformative strategies, this review aims to inspire innovative research directions and further advance the field of medicinal chemistry.
Medicinal chemistry is the interdisciplinary field that focuses on the design, development, and optimization of pharmaceutical compounds. It combines principles from chemistry, biology, and pharmacology to create bioactive molecules that can effectively treat diseases (Francesco, 2023). Key research contents include the synthesis of new compounds, structure-activity relationship (SAR) studies, optimization of drug properties (such as solubility and bioavailability), and the evaluation of pharmacological effects. The discovery and design of small molecule drugs have been pivotal in the field of medicinal chemistry, serving as the cornerstone for developing new therapeutics to combat a myriad of diseases (Campbell et al., 2018). Small molecules have historically played a critical role in the development of effective treatments for a wide range of diseases, including cancer, infectious diseases, and chronic illnesses (Zhong et al., 2021; Davis et al., 2020; Parra Sánchez et al., 2022). Despite their significance, the process of small molecule drug discovery is fraught with challenges, such as high attrition rates in clinical trials, the complexity of biological systems, and the need for precision-targeted therapies (Zhong et al., 2021; Keserü and Makara, 2009; Bedard et al., 2020). As such, there is a pressing need for innovative approaches that can enhance the efficiency and success of small molecule drug design.
One of the primary challenges in the drug discovery process is the vast chemical space that needs to be navigated (Saldívar-González and Medina-Franco, 2022). Traditional methods often rely on trial-and-error approaches, which are not only time-consuming but also resource-intensive. Additionally, the complexity of biological systems and the diverse nature of diseases necessitate a more targeted and strategic approach to drug design. In this context, several new methodologies have emerged, promising to transform the landscape of small molecule drug discovery.
Click Chemistry has garnered significant attention as a powerful tool in drug discovery. It enables the rapid synthesis of diverse compound libraries through highly efficient and selective reactions (Zhao et al., 2024; Wilson Lucas et al., 2023). Click chemistry’s modular nature allows for the straightforward incorporation of various functional groups, facilitating the optimization of lead compounds and enabling the creation of complex structures from simple precursors (Jiang et al., 2019). This approach not only accelerates the discovery process but also enhances the likelihood of identifying compounds with desirable pharmacological properties.
Targeted Protein Degradation (TPD) strategies represent another groundbreaking advancement in small molecule drug design (Wells and Kumru, 2024). Unlike traditional inhibitors that aim to block protein activity, TPD technologies employ small molecules to tag undruggable proteins for degradation via the ubiquitin-proteasome system or autophagic-lysosomal system (Song et al., 2023). This novel approach provides a means to address undruggable targets and offers a new therapeutic paradigm for conditions where conventional small molecules have fallen short. By harnessing the body’s own degradation machinery, TPD strategies enable the selective removal of disease-associated proteins, thereby providing an innovative pathway for drug discovery.
DNA-Encoded Libraries (DELs) have emerged as a widely used technology that allows for the high-throughput screening of vast chemical libraries (Peterson and Liu, 2023). DELs utilize DNA as a unique identifier for each compound, facilitating the simultaneous testing of millions of small molecules against biological targets (Dockerill and Winssinger, 2023). This technology not only streamlines the identification of potential drug candidates but also allows for the exploration of chemical diversity in an unprecedented manner. The ability to rapidly probe the interaction of small molecules with target proteins enhances the efficiency of lead discovery and optimization, making DELs an essential tool in modern drug development.
Computer-Aided Drug Design (CADD) has also significantly influenced the drug discovery landscape by employing computational methods to predict the binding affinity of small molecules and specific targets (Sadybekov and Katritch, 2023; Jiménez-Luna et al., 2021) This approach significantly reduces the time and resources required for experimental screening (Giordano et al., 2022). With advancements in artificial intelligence (AI), CADD is becoming increasingly sophisticated, enabling researchers to simulate complex biological interactions and refine drug design more effectively (You et al., 2022). This predictive capability not only accelerates the discovery process but also enhances the precision of drug design, addressing the critical need for tailored therapies.
Each approach brings unique advantages, addressing specific challenges in the drug development pipeline and paving the way for innovative therapeutic solutions. The integration of these technologies promises to enhance the efficiency of drug discovery, reduce attrition rates in clinical trials, and ultimately lead to the development of more effective and targeted therapies. This review aims to provide a comprehensive overview of recent advancements in these approaches, to explore their underlying principles, and their potential impact on the future of medicinal chemistry. To illustrate the utility of these techniques, we highlight exemplary small molecules developed over the past decade, emphasizing their role in accelerating drug development. Furthermore, we summarize representative marketed drugs and investigational new drugs, illustrating these technologies' direct contributions to clinical practice. Finally, we discuss the future prospects and challenges of each approach. By fostering an understanding of these emerging strategies, we aim to inspire new research directions and collaborations that will further advance the field of medicinal chemistry.
Click chemistry, a combinatorial methodology first introduced by Professor Sharpless in 2001, revolutionized the rapid synthesis of C-X-C atom frameworks (Kolb et al., 2001). This approach has since become an essential tool in the medicinal chemist’s toolbox, offering significant advantages such as broad substrate scope, high yield, stereospecificity, operational simplicity, and the formation of only benign by-products that can often be removed without chromatography (Caselli et al., 2015; Le Droumaguet et al., 2022). Additionally, click reactions are conducted using environmentally benign solvents, further enhancing their utility in drug discovery (Shankaraiah et al., 2019). In contrast to traditional drug design, click chemistry employs modular reactions to efficiently create new drug-like molecules. Moreover, these reactions serve as versatile linkers for small molecules and proteins. An example is their application in the synthesis of proteolysis targeting chimeras (PROTACs), where click chemistry links two pharmacophores via a specific scaffold to produce compounds with high target affinity (Wurz et al., 2017). Click chemistry is also instrumental in constructing diverse compound libraries, offering a robust platform for screening bioactive molecules and potential therapeutic agents. Importantly, target-templated in situ click chemistry allows for the direct generation of hits within the binding pocket of a target, streamlining the discovery of enzyme inhibitors and other bioactive compounds. This powerful method significantly accelerates both the synthesis and screening processes in drug discovery (Kugler et al., 2023; Glassford et al., 2016).
Conventional click chemistry has found widespread application in various domains of drug discovery, facilitating the modular synthesis of new drug-like molecules, serving as a linker for PROTACs or pharmacophore groups, and enabling the rapid construction of compound libraries. This efficient, chemo-selective synthesis method allows for the coupling of molecular fragments under mild reaction conditions, making it highly desirable in medicinal chemistry. Key reactions within click chemistry include the Cu-catalyzed azide-alkyne cycloaddition (CuAAC), strain-promoted azide-alkyne cycloaddition (SPAAC), thiol-ene reactions, inverse electron demand Diels–Alder reactions (IEDDA), hydrazone click chemistry, and the recently emerging sulfur fluoride exchange (SuFEx) reaction (Shankaraiah et al., 2019; Kim and Koo, 2019; Barrow et al., 2019). Since its introduction in 2001, click chemistry has become a prominent research focus, driving innovation in the development of bioactive compounds and therapeutic agents (Cai et al., 2023).
The discovery of Cu(I) catalyzed CuAAC in 2001 represented a pivotal advancement, transforming click chemistry from a theoretical concept into a widely accepted and practical methodology (Kolb et al., 2001). Among all click reactions, CuAAC has emerged as the most popular synthetic and coupling tool. This reaction offers exceptional application potential due to its ability to facilitate the functionalization of organic scaffolds with azides and alkynes (Jiang et al., 2019), which remain stable during subsequent transformations in the presence of highly functionalized biomolecules, molecular oxygen, water, and other common reaction conditions. In contrast to the uncatalyzed cycloaddition of azides and alkynes, which yields a mixture of 1,4- and 1,5-triazole regioisomers at elevated temperatures, CuAAC selectively combines organic azides and terminal alkynes to produce 1,4-disubstituted 1,2,3-triazoles exclusively under mild conditions (Figure 1A), thus eliminating the need to separate the 1,4- and 1,5-linked regioisomers using classical chromatographic techniques. The detailed reaction mechanisms underlying this transformation are illustrated in Figure 2A. Notably, the CuAAC reaction offers key advantages, including exceptional stereoselectivity, rapid reaction rates, and the ability to form intermolecular connections efficiently under mild conditions. These attributes have positioned CuAAC as a powerful and widely adopted tool in drug discovery. Compounds containing the 1,2,3-triazole moiety have demonstrated compelling biological activities, as illustrated by several approved drugs and drug candidates depicted in Figure 3A.
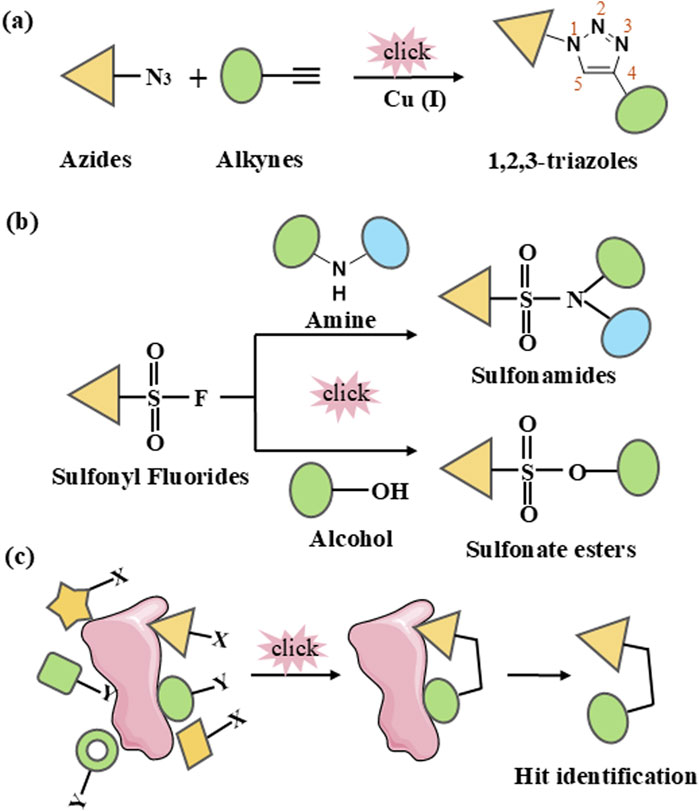
Figure 1. Schematic representation of click chemistry. (A) Cu-catalyzed azide-alkyne cycloaddition (CuAAC). (B) Sulfur (VI)-Fluoride Exchange (SuFEx). (C) In situ click chemistry approach.
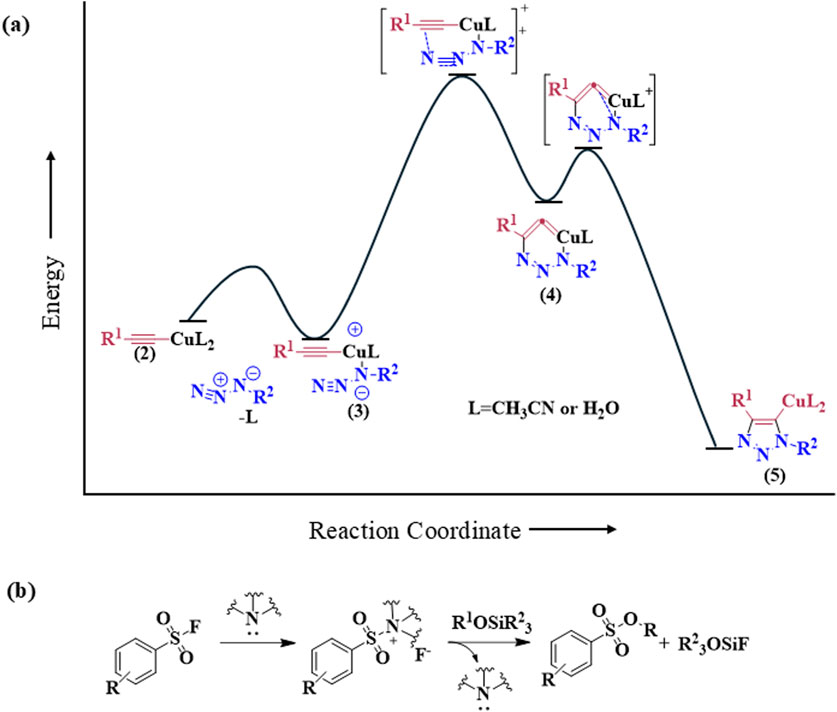
Figure 2. Reaction mechanisms of click chemistry of (A) Cu-catalyzed azide-alkyne cycloaddition (CuAAC) and (B) Sulfur (VI)-Fluoride Exchange.
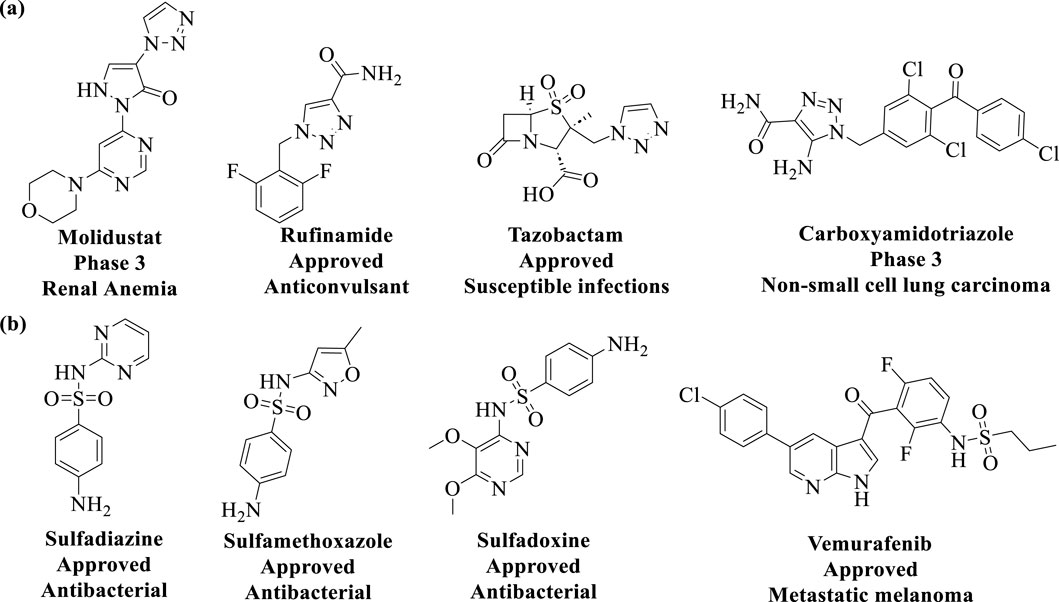
Figure 3. Chemical structures of approved drugs and drug candidates containing the (A) 1,2,3-triazole moiety, and (B) sulfonamides moiety.
Recent studies illustrate the utility of CuAAC click chemistry in drug discovery. For instance, Synta66 has been employed as a chemical probe to elucidate the role of store-operated calcium entry (SOCE) in cellular mechanisms. To identify drug-like SOCE inhibitors with improved pharmacokinetic profiles, Pirali et al. replaced the amide group in Synta66 with a triazole ring. Among the synthesized 1,2,3-triazoles, compound #1 (Figure 4A) exhibited significantly higher aqueous solubility (1,528 μg/mL vs. 0.28 μg/mL) compared to Synta66. Furthermore, compound #1 demonstrated potent inhibitory activity at nanomolar concentrations, favorable pharmacokinetic properties, and in vivo efficacy in a mouse model of acute pancreatitis (Serafini et al., 2020). In another study, Manera et al. designed, synthesized, and functionally characterized the first bitopic ligands for the cannabinoid receptor CB2 (CB2R). These ligands were synthesized through a click chemistry reaction between azido and alkyne derivatives. The most promising bitopic ligand, FD-22a (Figure 4A), exhibited anti-inflammatory activity in a human microglial cell inflammatory model and demonstrated antinociceptive effects in vivo in a mouse model of neuropathic pain (Gado et al., 2022). Additionally, Cee et al. reported a click chemistry approach as a reliable linking strategy for the synthesis of a 10-membered library of PROTACs (Figure 4A). This method enables the parallel synthesis of PROTAC libraries, contingent upon the availability of the requisite azides and alkynes. Conceptually, this platform represents a powerful new tool for accessing diverse PROTAC libraries, with principles that can be readily applied to other ligases and target proteins (Wurz et al., 2017).
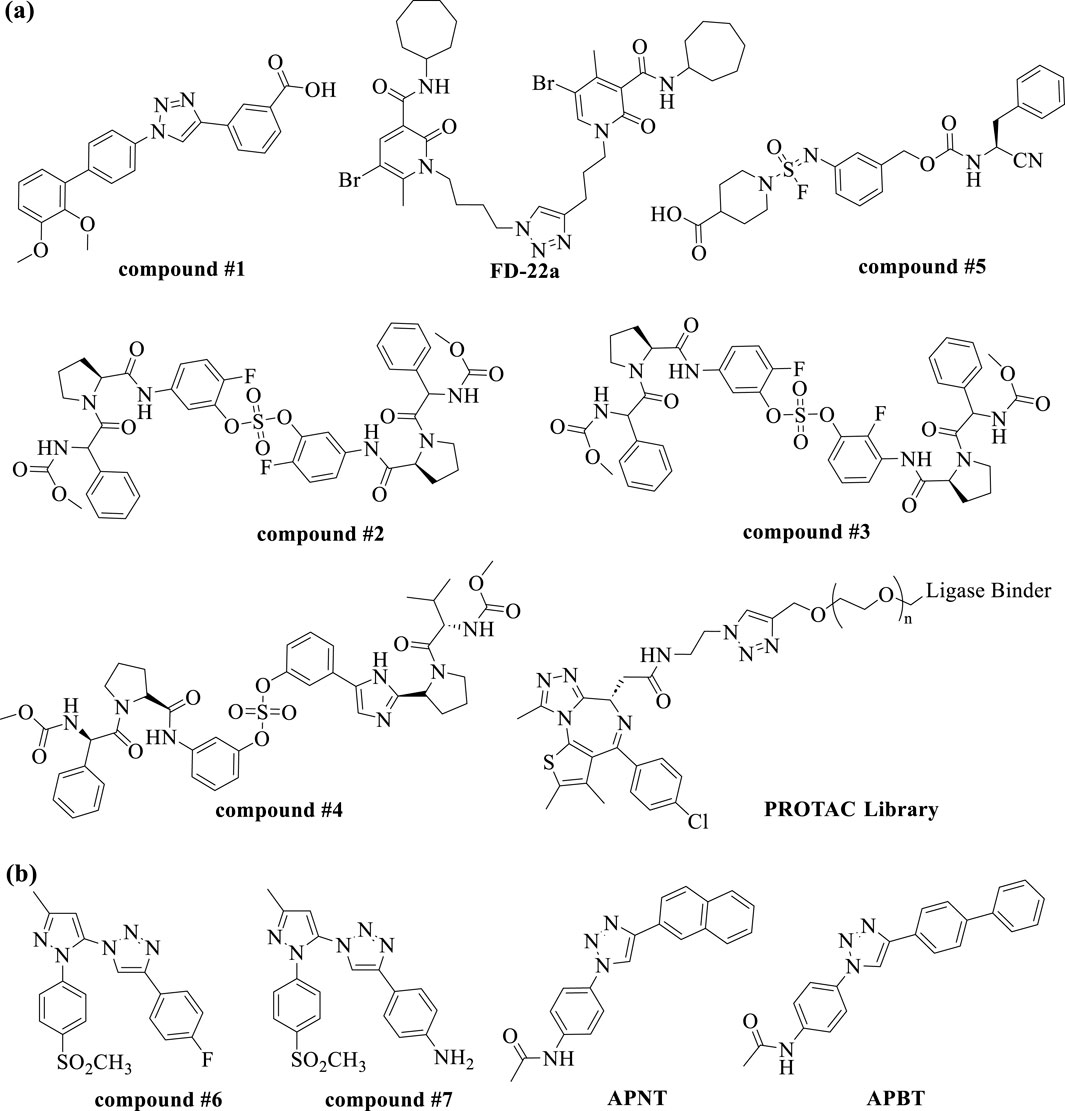
Figure 4. Chemical structures of small molecules discovered from (A) the conventional click chemistry and (B) in situ click chemistry.
In 2014, Sharpless and colleagues introduced the next advancement in click chemistry: SuFEx (Click-II) (Figure 1B). The detailed reaction mechanisms are shown in Figure 2B. SuFEx represents a recent set of ideal click chemistry transformations, characterized by metal-free reaction conditions. This approach utilizes sulfuryl fluoride (SO2F2) and thionyl tetrafluoride (SOF4) to synthesize two key S–F motifs: arylfluorosulfates (Ar–O–SO2–F) and iminosulfur oxydifluorides (R–NSOF2) (Barrow et al., 2019). Although the potential of SuFEx in drug discovery is just beginning to be explored, it holds promise. In contrast to the CuAAC reaction, which has been employed in proof-of-concept studies for lead optimization, only a limited number of drugs feature the 1,2,3-triazole linkage. Sulfonamides, however, are a common structural motif in drug design and represent the primary sulfur-based feature in clinically approved medications (Figure 3B). More than 150 sulfonamide drugs are available on the market (Zhao et al., 2019), encompassing a range of therapeutic activities including antibacterial, antitumor, anti-obesity, anti-thyroid, and analgesic effects for neuropathic pain. Furthermore, sulfonate esters (R–SO2–OR) and sulfate diesters (R–OSO2–OR) serve as excellent bioisosteric substitutes for carboxylic acids and esters. Despite their greater lipophilicity, these sulfonyl compounds maintain a polarized S–O bond, facilitating robust electrostatic interactions with target proteins (Hong et al., 2019). This positions SuFEx as a promising tool for the modular synthesis of functional libraries in drug discovery.
SuFEx click chemistry has emerged as a valuable tool in drug discovery. Kim, Jang, and colleagues successfully utilized SuFEx reactions in a click chemistry approach to synthesize biaryl sulfate core derivatives, demonstrating their efficacy as potent inhibitors of hepatitis C virus (HCV) nonstructural protein 5A (NS5A). Among the synthesized inhibitors, compounds #2, #3, and #4 (Figure 4A) exhibited impressive two-digit picomolar EC50 values against HCV genotype-1b (GT-1b) and single-digit or sub-nanomolar activities against the HCV genotype-2a (GT-2a) strain (You et al., 2018). A pioneering study by Wolan et al. showcased biocompatible SuFEx click chemistry as a proof-of-concept for a high-throughput process aimed at generating drug-like, biologically active molecules. Starting from a modest high-throughput screening hit against the bacterial cysteine protease SpeB, a SuFExable iminosulfur oxydifluoride [RN = S(O)F2] motif was introduced, leading to the rapid diversification into 460 analogs in overnight reactions. Direct screening of these products yielded drug-like inhibitors with up to 300-fold increased potency. Compound #5 (Figure 4A) is the first potent and selective SpeB inhibitor, useful for studying the protease’s role in cellular and animal models (Kitamura et al., 2020). More recently, the research groups of Moses et al. demonstrated the versatility and practicality of Accelerated SuFEx Click Chemistry (ASCC) for the late-stage derivatization of bioactive molecules. They employed ASCC to synthesize discrete compound libraries in a 96-well plate format, ensuring experimental consistency and significantly enhancing the efficiency of identifying potent hit molecules. Additionally, ASCC was utilized to create arrays of sulfonate ester-linked, high-potency microtubule-targeting agents (MTAs) that exhibited nanomolar anticancer activity against multidrug-resistant cancer cell lines. These findings highlight ASCC’s promise as a robust platform for advancing drug discovery (Homer et al., 2024).
The discovery of bioactive compounds hinges on the iterative generation of SAR data derived from the preparation and biological assays of hit congeners. However, traditional methods are often time-consuming and labor-intensive, leading to slow and costly hit-to-lead transitions. Target-guided synthesis (TGS) is a synthetic strategy for enzyme inhibitors that involves the selective assembly of complementary functional groups based on biological targets (e.g., enzymes) serving as templates (Hu and Manetsch, 2010a). The application of click chemistry in kinetic TGS, known as in situ click chemistry, represents an innovative synthesis process where a biological target facilitates the assembly of its own inhibitor through the guided selection of suitable building blocks (Hu and Manetsch, 2010a; Bhardwaj et al., 2017) (Figure 1C). This approach not only results in compounds with high binding affinity for the target but also offers a powerful strategy for rapidly preparing and characterizing compound libraries of bioactive molecules, greatly improving the efficiency of drug discovery. Fragment-based drug design plays a crucial role in drug discovery. In situ click chemistry provides a unique strategy for fragment modification and optimization. In this approach, chemical ligation depends on the close proximity and optimal spatial arrangement of reactive fragments (Bhardwaj et al., 2017). When these fragments bind simultaneously to the target’s binding sites, they facilitate the formation of irreversible bonds. Consequently, the selection of suitable combinatorial fragment libraries is a critical factor for the success of this method.
The general protocol for assembling and screening focused combinatorial fragment libraries using in situ click chemistry involves four key steps. First, suitable fragments are selected, typically featuring a common warhead—a core structure for interaction with a specific class of biological targets. These fragments should exhibit a variety of substituents and functional groups, as greater skeletal and stereochemical diversity within the chemical space increases the likelihood of identifying effective hits. Additionally, the fragments need to possess desirable properties such as stability, solubility, and cellular permeability to ensure compatibility with biological systems (Wang et al., 2016; Rzuczek et al., 2014; Hu and Manetsch, 2010b). Second, the reactant fragments are synthesized to include reactive groups such as azides, alkynes, or sulfonyl fluorides, which serve as warheads in the click chemistry reactions. Third, in situ screening is conducted, typically in 96- or 384-well plates, enabling high-throughput screening without further purification, thus streamlining the drug discovery process. Finally, interactions between the fragment molecules and target compounds are assessed based on preliminary screening data, such as percentage inhibition, with promising hits further validated through IC50 determination to confirm their potency (Wang et al., 2016).
In recent years, the rapid assembly and in situ screening of focused combinatorial fragment libraries using CuAAC and SuFEx click chemistry have emerged as robust and efficient strategies for generating bioactive molecules. In 2015, Wuest and colleagues demonstrated for the first time the use of CuAAC click chemistry in conjunction with the cyclooxygenase-2 (COX-2) active site as a reaction vessel for the in situ generation of highly specific inhibitors. This study led to the discovery of two highly potent and selective COX-2 isozyme inhibitors (compounds #6 and #7) (Figure 4B), which exhibited significantly greater in vivo anti-inflammatory activity compared to widely used selective COX-2 inhibitors. These findings provide a valuable tool for the economical and rapid screening of potential drug candidates (Bhardwaj et al., 2017). In 2016, Wang and colleagues introduced two cell-permeable O-GlcNAc transferase (OGT) inhibitors, APNT and APBT (Figure 4B), developed from low-activity precursors (IC50 > 1 mM) through a strategy termed “tethering in situ click chemistry” (TISCC). Among these, APNT exhibited a significantly enhanced inhibitory activity, with an IC50 of 66.7 ± 0.8 μM, representing over a 60-fold improvement. Notably, APNT’s potency was comparable to that of benzoxazolinone, an irreversible OGT inhibitor. However, benzoxazolinone’s high reactivity made it unsuitable as a selective OGT inhibitor for cellular applications. In contrast, both APNT and APBT effectively suppressed O-GlcNAcylation in cells without causing significant cytotoxicity. This highlights TISCC as a promising approach for optimizing low-activity precursors with millimolar IC50 values into potent and selective inhibitors (Wang Y. et al., 2017).
Click chemistry offers several advantages, including insensitive to oxygen and water, high yields, regioselectivity, and stereoselectivity. These properties enable researchers to rapidly prepare target compounds and build compound libraries. Furthermore, in situ click chemistry leverages enzymes as reaction templates, taking advantage of their favorable conformations under physiologically relevant conditions. This approach selectively connects individual building blocks to synthesize novel enzyme inhibitors. However, the application of click chemistry in drug discovery also presents challenges and should not be regarded as a universal solution. Firstly, when generating large numbers of compounds at a rapid pace, it remains uncertain whether click chemistry consistently yields compounds with desirable drug-like properties. As a result, further optimization of biological activity and drug-like characteristics can also be time-consuming. While copper species are among the simplest and most useful catalysts for the CuAAC click reaction, their introduction into biological systems raises concerns regarding potential toxicity, which may interfere with the screening of compound libraries utilizing biological targets as templates. In contrast, the SuFEx reaction is a metal-free procedure that shows promise for library screening. The synthesis of 1,2,3-triazole rings as pharmacophores or bioisosteres via CuAAC has significant potential in drug design for various diseases. However, the 1,2,3-triazole ring itself is not commonly utilized as a pharmacophore and is rarely found in marketed drugs, indicating certain limitations in its application as a drug molecule. Conversely, sulfonamides are a prevalent feature in drug structures and serve as the primary sulfur-based motif in clinically approved drugs, with over 150 sulfonamide drugs available in the market. Despite their stability, ease of synthesis, and potential as pharmacophores, sulfur-ester linkages remain notably underrepresented in drug molecules. Lastly, despite the decades since its inception, click chemistry encompasses only a limited number of reactions, resulting in the identification of multiple hits and leads for specific targets, but relatively few marketed drugs have been successfully discovered through this approach. Consequently, while click chemistry presents both advantages and disadvantages in medicinal chemistry and drug discovery, it also faces numerous challenges. Ongoing developments hold the promise of advancing this synthetic technique to meet the preclinical and clinical requirements of various systemic and localized diseases.
Targeting pathogenic proteins with small molecule inhibitors has become a widely adopted strategy for treating various diseases. However, many intracellular proteins are deemed “undruggable” due to the absence of accessible active sites, posing a significant challenge in the design and development of effective small molecule inhibitors (Xie et al., 2023). TPD is an emerging concept in drug discovery, first introduced in 1999 (Wickner et al., 1999). Recently, TPD has gained traction as a novel approach for targeting these previously undruggable proteins, utilizing proteasomal and lysosomal pathways (Ding et al., 2020; Zhang C. et al., 2024). Unlike traditional inhibitors, small molecule degraders do not require continuous exposure of the protein’s binding site, which enhances their therapeutic potential. Additionally, many degraders, such as PROTACs, operate catalytically, allowing for lower dosages to achieve the desired effects (Bondeson et al., 2015). Most TPD strategies, including PROTACs and molecular glues, primarily rely on the ubiquitin–proteasome system (UPS) and predominantly target intracellular proteins. In contrast, lysosome-dependent TPD strategies can degrade membrane proteins, extracellular proteins, and protein aggregates, significantly broadening the range of substrates that can be targeted (Zhao et al., 2022). The proper functioning of these two pathways is crucial for preventing or treating a variety of diseases, including tumors, neurodegenerative disorders, autoimmune diseases, and metabolic syndrome. Therefore, employing proteasomes and lysosomes to target pathogenic proteins represents a promising strategy in addressing these complex health challenges.
The UPS is a crucial pathway for protein degradation, playing a vital role in maintaining cellular homeostasis by facilitating the degradation of over 80% cellular proteins (Chen et al., 2016). This degradation process targets damaged proteins or those that are no longer needed. Ubiquitination is achieved through a cascade involving three key enzymes: an E1 activating enzyme, an E2 conjugating enzyme, and an E3 ligase. The E1 enzyme binds to a ubiquitin molecule in an ATP-dependent manner and subsequently transfers it to the E2 enzyme. The E3 ligase then catalyzes the transfer of the ubiquitin from E2 to the target substrate, leading to the polyubiquitination of the substrate (Eldridge and O'Brien, 2009). The accumulation of the polyubiquitin chain on a targeted protein serves as a signal for degradation by the proteasome. PROTACs and molecular glues are two prominent technologies that leverage the UPS for the targeted degradation of specific proteins of interest (POI), and will be the focus of our discussion.
The UPS, exemplified by PROTACs, offers a powerful strategy for degrading otherwise undruggable POI. PROTACs are synthetic heterobifunctional molecules composed of an E3-recruiting ligand, a POI-targeting warhead, and a flexible linker that connects the two (Konstantinidou et al., 2019). By promoting the formation of a ternary complex comprising the POI, PROTAC, and E3 ligase, these compounds enhance the ubiquitination of the POI, leading to its degradation via the UPS (Figure 5A). Unlike traditional inhibitors, PROTACs operate through an event-driven mechanism, acting as catalysts for selective protein degradation—one molecule of PROTAC can induce the ubiquitination of multiple target protein molecules (Burslem and Crews, 2020). Initially demonstrated by Crews and colleagues in 2001, the concept of PROTACs has since evolved into various innovative degradation technologies targeting kinases, nuclear receptors, epigenetic proteins, misfolded proteins, and even RNAs (Sakamoto et al., 2001; Schreiber, 1992). This broadens the spectrum of potential targets and enhances clinical applications for treating cancer, neurodegenerative diseases, and viral infections. Consequently, PROTAC technology is advancing into clinical settings, with over 15 targeted degraders currently in clinical trials (Figure 6A).
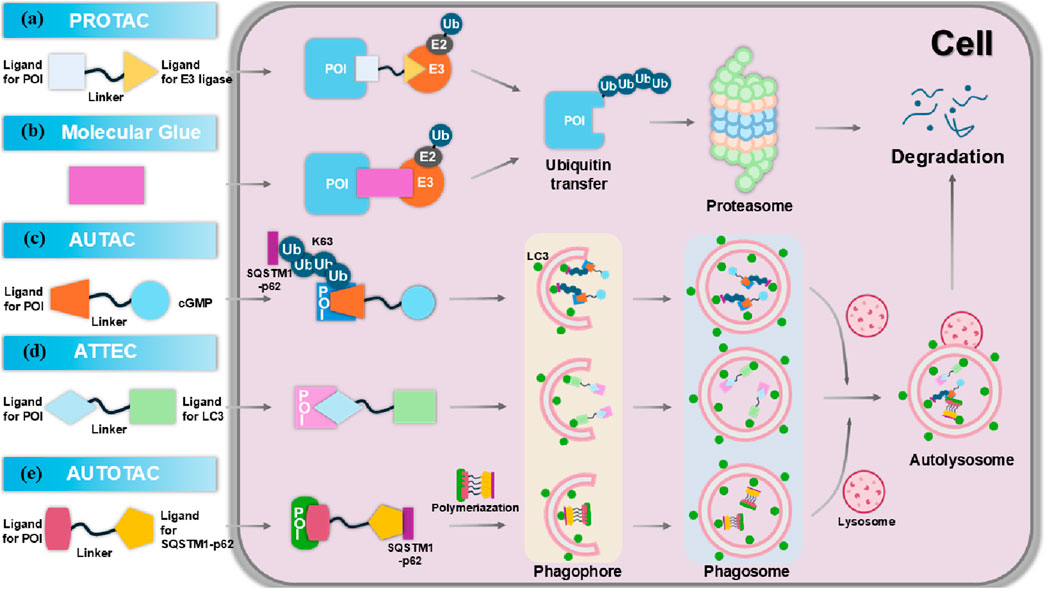
Figure 5. The molecular mechanism of targeted protein degradation (TPD). (A) Proteolysis targeting chimeras (PROTACs) are composed of an E3 ligase-targeting ligand, a linker, and a proteins of interest (POI)-binding ligand. By simultaneously interacting with both the POI and the E3 ligase, PROTACs promote the polyubiquitination of the POI, marking it for degradation via the proteasome. (B) Molecular glues bind to the E3 ubiquitin ligase, or the POI, facilitating their interaction and triggering the ubiquitination and degradation of the POI. (C) Autophagy-targeting chimeras (AUTACs) consist of a POI-targeting warhead, a linker, and a cGMP-based degradation tag. This tag promotes K63 polyubiquitination of the POI, leading to selective degradation via autophagy in the lysosome. (D) Autophagosome-tethering compounds (ATTECs) bind LC3 and the POI, (E) while AUTOphagy-TArgeting Chimeras (AUTOTACs) bind p62 and the POI, driving autophagosome formation, which then merge with lysosomes to degrade the targeted POI.

Figure 6. Chemical structures of proteasome-based degraders. Representational PROTACs currently in (A) clinical trials and (B) preclinical trials. Representational molecular glues currently in (C) clinical trials and (D) preclinical trials. Degradation tag and proteins of interest (POI) warheads are respectively marked in blue and red.
The PROTAC technology represents a promising therapeutic modality for treating various diseases. Here, we highlight some PROTACs that target specific proteins for degradation. A significant achievement in PROTAC technology is the development of orally bioavailable PROTACs that have progressed to clinical trials. Notably, the androgen receptor degrader ARV-110 (Clinical Trial No. NCT03888612) and the estrogen receptor degrader ARV-471 (Clinical Trial No. NCT05654623) have entered phase II and III clinical trials for prostate and breast cancer, respectively. The PROTAC approach, widely exploited in cancer research, also holds promise for antiviral development. In 2022, the Marazzi and Jin groups identified FM-74-103 (Figure 6B), a small-molecule degrader that inhibits infections from Influenza A virus (IAV), syndrome coronavirus 2 (SARS-CoV-2), and cytomegalovirus (CMV). FM-74-103 selectively degrades human G1 to S phase transition 1 (GSPT1), a translation termination factor, showcasing its potential as a host-directed antiviral that can degrade key factors controlling both RNA and DNA virus replication in host cells. This work highlights the broad utility of the PROTAC platform for rational design and development of next-generation antivirals (Zhao et al., 2023). Moreover, PROTACs can target undruggable proteins, significantly expanding the therapeutic prospects for refractory diseases. Tau protein accumulation is a hallmark of Alzheimer’s disease (AD) and related tauopathies; however, tau is a natively unfolded protein lacking well-defined folds and active sites. In 2021, Wang et al. discovered C004019 (Figure 6B), a novel small-molecule PROTAC that selectively promotes tau clearance, significantly improving synaptic and cognitive functions in various hTau cell models and in AD-like hTau and 3xTg transgenic mice. This work demonstrates that PROTACs can effectively induce the degradation of undruggable proteins, offering promising therapeutic avenues for AD and related tauopathies (Wang W. et al., 2021).
The concept of molecular glue was first introduced Harvard chemical biologist Stuart Schreiber in the early 1990s (Schreiber, 1992). As a linker-free scaffold, molecular glues induce, stabilize, or enhance interactions between E3 ligases and their POI by modifying the surface of the E3 ubiquitin ligase, thereby promoting the ubiquitination of the POI (Zhou et al., 2023) (Figure 5B). This modality effectively hijacks the ubiquitin-proteasome pathway to degrade traditionally challenging therapeutic targets, thereby broadening the spectrum of druggable proteins. Unlike PROTACs, molecular glues are generally smaller (typically<500 Da) and lack clearly separable components like linkers or distinct chemical moieties for binding to each protein. While their smaller size and successful precedents suggest that molecular glues may exhibit better drug-like properties, their design poses significant challenges. However, the few molecular glues that have made it into clinical trials were largely discovered serendipitously (Ding et al., 2022) (Figure 6C). In 2014, Krönke et al. reported the first molecular glue, lenalidomide (a thalidomide analog), which induces the degradation of IKZF1/3 via the CUL4/CRBN pathway (Krönke et al., 2014). Since the discovery of thalidomide, over ten small molecular glues with similar structural motifs have been identified. Subsequent studies revealed that a series of aryl sulfonamides function as molecular glues, enhancing the interaction between the E3 ubiquitin ligase CUL4-DCAF15 (DDB1 CUL4 Associated Factor 15) and RBM39 (RNA binding motif protein 39), thereby promoting RBM39 degradation. Several aryl sulfonamides, including Indisulam, CQS, and E7820, have been evaluated in clinical trials as potential antitumor agents (Figure 6C) (Han et al., 2017; Uehara et al., 2017).
Molecular glue degraders have generated significant interest in the research community. To facilitate the discovery of molecular glue degraders targeting diverse proteins and binding modes, there is an urgent need for new screening methods and rational design strategies that transition from serendipitous discovery to systematic exploration. (1) Innovative Screening Technologies: Ebert et al. developed a method to mine correlations between the cytotoxicity of 4,518 clinical and preclinical small molecules and the expression levels of E3 ligase components across a wide range of human cancer cell lines. This led to the identification of CR8 as a molecular glue degrader that binds to CDK12–cyclin K, recruiting the DDB1–CUL4–RBX1 E3 ligase complex to ubiquitinate cyclin K (Figure 6D) (Słabicki et al., 2020; Kozicka et al., 2023). Similarly, through chemogenomic screening, Han et al. discovered HQ461, a novel molecular glue that binds the ATP pocket of CDK12 and promotes interaction with DDB1, triggering cyclin K degradation (Figure 6D) (Lv et al., 2020). (2) Optimization of Molecular Glue Design: Daniel et al. introduced a transposable chemical handle that can convert protein-targeting ligands into molecular degraders. Using the CDK4/6 inhibitor Ribociclib as a prototype, they identified a covalent handle capable of inducing CDK4 degradation. Further optimization led to the development of a “fumarate” handle, a universal modular chemical tool for generating molecular glue degraders (Figure 6D) (Toriki et al., 2023). Additionally, Rao et al. employed a dual-target, dual-mechanism design strategy to combine multiple mTOR inhibitors with E3 ligase ligands. After extensive screening, they discovered the bifunctional molecule YB-3-17, which selectively degrades GSPT1 while inhibiting mTOR (Figure 6D) (Liu Y. et al., 2024). These studies demonstrate the growing sophistication of molecular glue degrader design and expand their potential applications across various therapeutic targets.
More recently, new TPD strategies have been developed to hijack the lysosomal degradation pathway, the major degradation pathway independent of the proteasome. As a central “garbage disposal” mechanism within cells, lysosomes facilitate the breakdown of various biomacromolecules, including proteins, lipids, carbohydrates, and nucleic acids, through endocytic, phagocytic, and autophagic pathways (Saftig and Klumperman, 2009). The lysosomal degradation system comprises the endosome/lysosome and autophagy pathways, which operate both independently and synergistically to degrade intracellular and extracellular components. The endosome/lysosome pathway involves a series of membrane-bound compartments that mediate the processing of internalized material. Endocytosed substances are first incorporated into early endosomes, then transported through endosome carrier vesicles, late endosomes, and ultimately delivered to lysosomes for hydrolytic degradation (Ding et al., 2020). Autophagy, an evolutionarily conserved process, plays a critical role in maintaining cellular homeostasis by clearing unnecessary or damaged organelles and proteins via a lysosome-dependent mechanism. In this process, targeted organelles and proteins are encapsulated within double-membrane vesicles, known as autophagosomes (Zhao et al., 2022). These autophagosomes subsequently fuse with lysosomes, where their contents are broken down.
AUTAC is an innovative targeted protein degrader that harnesses the autophagy pathway to facilitate the selective degradation of intracellular proteins and organelle debris (Sakamoto et al., 2001). By inducing specific ubiquitin modifications, particularly K63-linked polyubiquitination, AUTAC molecules create a recognition signal that is effectively processed by the selective autophagy machinery. This K63 polyubiquitination is distinct from the more common K48-linked ubiquitination, which typically signals for proteasomal degradation (Figure 5C) (Takahashi et al., 2019). Structurally, AUTACs are heterobifunctional molecules comprising three key components: a degradation tag, which is often a guanine derivative responsible for initiating ubiquitination; a flexible linker that connects the degradation tag to the ligand; and a ligand warhead that selectively binds to the POI. Following binding, the targeted cellular components are sequestered into autophagosomes, which then fuse with lysosomes for degradation in the presence of lysosomal hydrolases. Despite the promise of AUTAC technology in drug discovery, significant gaps remain in understanding the detailed mechanisms underlying its efficacy, including the molecular interactions involved in the recognition and processing of ubiquitinated targets (Li et al., 2021). Currently, there are no clear examples of AUTACs in clinical trials, with research primarily focused on early preclinical assessments.
In 2019, Arimoto’s group introduced the concept of AUTAC, drawing inspiration from the antibacterial autophagy process. Since then, molecules of AUTACs 1–4 (Figure 7A) have been successfully employed to degrade various proteins, including methionine aminopeptidase 2 (MetAP2), FK506-binding protein (FKBP12), BET family proteins, translocator protein (TSPO), and others, alongside mitochondrial components, showcasing their remarkable degradation capabilities. Subsequent investigations have indicated that the degradation of mitochondria can trigger the elimination of additional pathogenic proteins (Takahashi et al., 2019). In 2023, the group conducted a SAR study, substituting L-Cysteine with pyrazole in the design of second-generation AUTACs. This modification resulted in a substantial enhancement of activity, with the tt44 (Figure 7A) of second-generation AUTACs achieving up to a 100-fold increase in potency compared to first-generation AUTACs, which were effective at concentrations of 10 μM (Takahashi et al., 2023). More recently, Schmitzer and colleagues developed an AUTAC-Biguanide compound (Figure 7A) by incorporating a biguanide functional group as a targeting moiety linked to the guanine scaffold. This strategic addition enables the selective targeting of the degradation process toward mitochondria. Notably, AUTAC-Biguanide exhibits superior antiproliferative properties compared to metformin and demonstrates enhanced selectivity for cancer cells (Vatté et al., 2024). This body of research underscores the potential of AUTAC molecules to effectively degrade cellular organelles, including damaged mitochondria, paving the way for novel therapeutic strategies.
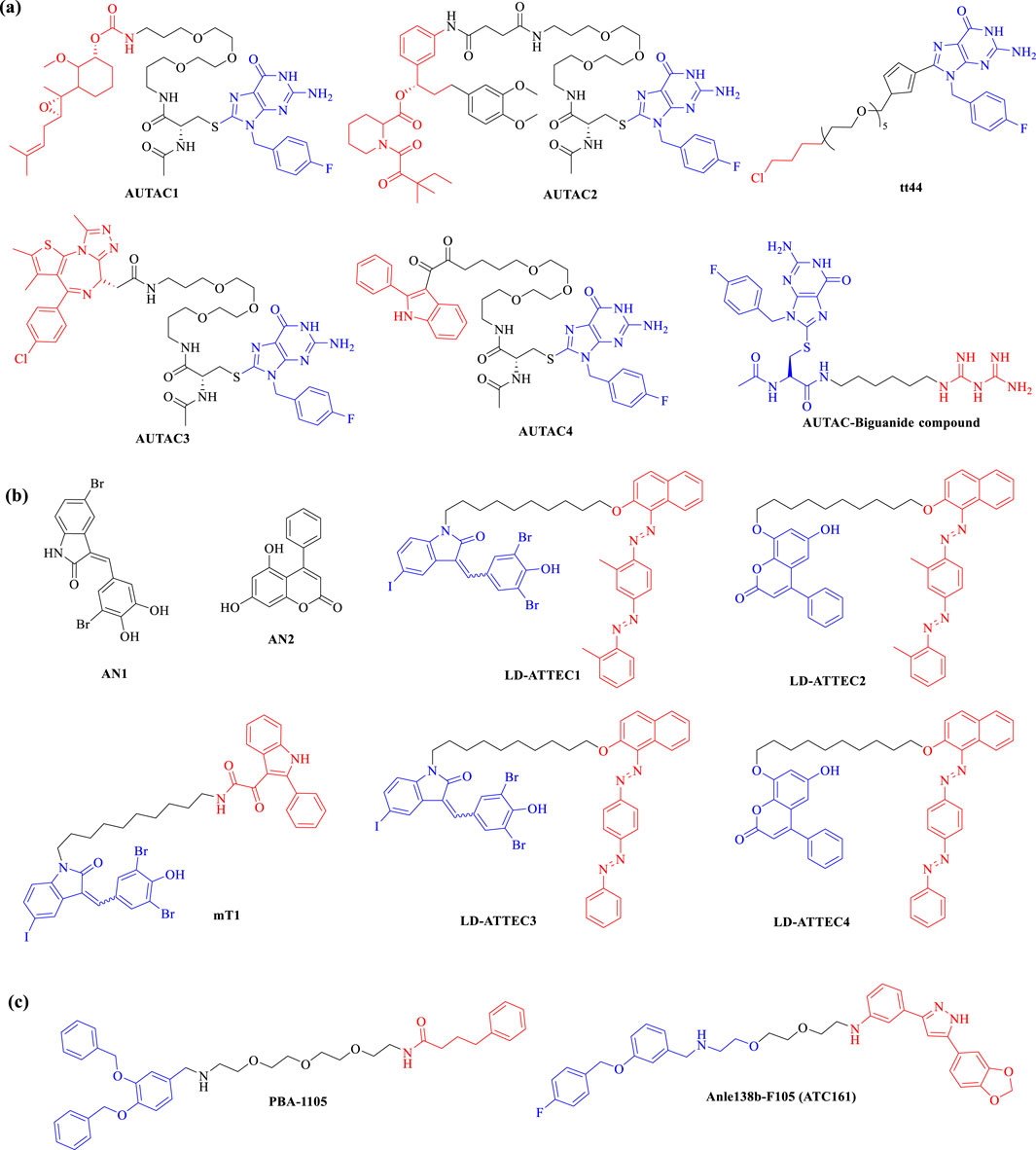
Figure 7. Chemical structures of lysosome-based degraders. Representational (A) AUTACs, (B) ATTECs and (C) AUTOTACs currently in preclinical trials. Degradation tag and proteins of interest (POI) warheads are respectively marked in blue and red.
ATTEC was first introduced in 2019 by Professor Boxun Lu of Fudan University (Li et al., 2019). Unlike PROTACs and AUTACs, which rely on ubiquitination for protein degradation, ATTEC molecules operate independently of this modification. Instead, ATTEC compounds function by tethering the POI to LC3, effectively directing disease-related targets to phagocytes for degradation (Figure 5D). This unique mechanism provides broad applicability across various disease contexts and target types (Zhang C. et al., 2024; Li et al., 2019). Distinct from PROTACs and AUTACs, which are characterized by two ligands connected via a linker, ATTEC molecules do not utilize a linker and can be likened to “molecular glue.” This innovative design allows for the precise and efficient recruitment of target proteins. In recent years, a series of novel ATTECs have been developed as heterobifunctional small molecules, enhancing their functionality. Given the diverse range of autophagic substrates, ATTEC technology holds significant promise for extending the applicability of protein degraders to non-proteinaceous biomolecules and organelles. This adaptability may pave the way for new therapeutic strategies targeting a wider array of biological processes, potentially transforming treatment approaches for various diseases.
In 2019, the Lu research group introduced ATTEC technology, developing ATTEC molecules capable of binding both the key autophagy protein LC3 and the mutant huntingtin protein (mHTT). This pioneering study demonstrated that molecules AN1 and AN2 (Figure 7B) effectively degrade mHTT in both cellular and in vivo animal models, successfully rescuing phenotypes associated with Huntington’s disease (Li et al., 2019). Building on this initial work, Lu and colleagues expanded the application of ATTEC technology by designing small molecules that target lipid droplets (LDs), which are implicated in various metabolic disorders such as obesity, type 2 diabetes, liver steatosis, and atherosclerosis. These novel ATTECs (LD-ATTECs C1-C4, shown in Figure 7B) bind to both LC3 and LDs, achieving near-complete clearance of LDs and rescuing LD-related phenotypes in cell cultures as well as in two independent mouse models (Fu et al., 2021). The proof-of-concept findings underscore the potential of ATTECs to facilitate the degradation of LDs. Most recently, Lu’s team has developed new bifunctional ATTEC (mT1, shown in Figure 7B) that simultaneously bind to the outer mitochondrial membrane protein TSPO and the autophagosome protein LC3. This innovative approach enhances the engulfment of damaged mitochondria by autophagosomes, promoting their subsequent autophagic degradation (Tan et al., 2023). This study not only confirms the ability of ATTECs to degrade organelles but also presents promising new strategies for intervening in mitochondria-related disorders. Conceptually, this approach could be extended to target a range of other proteins and non-protein entities, broadening the therapeutic potential of ATTEC technology.
In 2022, Kwon’s group introduced AUTOTACs, an innovative degrader technology that degrades UPS-resistant misfolded proteins and their oligomeric/aggregated species (Ji et al., 2022). AUTOTACs directly bind to the ZZ-type zinc finger (ZZ) domain of sequestosome 1 (SQSTM1)/p62, eliminating the need for polyubiquitination. This bifunctional molecule comprises two key components: a ligand that targets the POI and a ligand that directs the molecule to the autophagy pathway via the p62 protein (Figure 5E). By effectively linking these components through a flexible linker, AUTOTACs facilitate the simultaneous degradation of the target protein while enhancing autophagic flux. This dual functionality not only improves the efficiency of protein degradation but also promotes cellular health by ensuring the clearance of damaged or unnecessary proteins through autophagy, offering a promising strategy for therapeutic interventions in various diseases.
In 2022, the research team led by Yong Tae Kwon developed AUTOTAC compounds that features a module specifically designed to interact with the ZZ domain of p62, alongside a module targeting the POI. Both in vitro and in vivo studies demonstrated that these AUTOTACs (e.g., PBA-1105, Anle138b-F105, shown in Figure 7C) effectively targets the androgen receptor (AR) in prostate cancer cells and methionine aminopeptidase 2 (MetAP2) in glioblastoma cells, showcasing its powerful degradation capabilities (Ji et al., 2022). Building on this success, in 2023, Kwon’s group synthesized a series of AUTOTAC molecules that bind both p62/SQSTM1 and α-synuclein aggregates, which are implicated in the progression of Parkinson’s disease. One notable compound, ATC161 (Figure 7C), is an oral drug characterized by favorable pharmacokinetic and pharmacodynamic profiles. It selectively induces the degradation of α-synuclein aggregates in both in vitro and in vivo models (Lee et al., 2023). This research underscores the potential of the AUTOTAC platform for advancing drug discovery in the context of proteinopathies and related diseases.
TPD has emerged as a groundbreaking modality in drug discovery over the past 2 decades, with PROTACs and molecular glues representing the most advanced technologies in this field. In recent years, lysosome-based degrader technologies have begun to gain traction, significantly expanding the range of disease-related targets that can be addressed, thereby offering new strategies for clinical treatment. However, the development of lysosome-based TPD technologies remains in its infancy compared to the more established PROTAC and molecular glue approaches. While multiple PROTAC compounds have shown great promise in clinical trials, their development is not without challenges. First, synthesizing PROTACs requires not only the identification of a suitable ligand for the protein of interest but also converting that ligand into a functional PROTAC, which can be a time-intensive process demanding considerable expertise in synthetic and medicinal chemistry. Additionally, PROTACs often struggle with issues related to cell permeability and oral bioavailability, primarily due to their complex chemical structures. Furthermore, traditional methodologies do not provide a comprehensive understanding of the mechanisms of action of PROTACs, necessitating the implementation of complementary technologies for thorough evaluation. In contrast, molecular glues are generally smaller and more drug-like, which enhances their potential for clinical application. However, significant challenges remain, particularly during the later stages of optimization. While lysosome-based TPD technologies are still emerging, further research is essential to elucidate the molecular mechanisms and SAR of AUTACs, ATTECs, and AUTOTACs, and to establish their fundamental design principles. Despite these hurdles, TPD technologies hold immense potential to not only serve as powerful tools for biomedical research but also to enrich the medicinal chemist’s toolkit. With focused research and development efforts, these technologies could substantially broaden the spectrum of degradable targets, paving the way for exciting new avenues in therapeutic discovery.
DELs have emerged as a revolutionary tool in drug discovery, offering significant advantages in the identification of potential therapeutic candidates. Initially conceptualized by Brenner and Lerner in 1992, who proposed a theoretical framework for utilizing DNA to encode synthetic peptides (Brenner and Lerner, 1992), DEL technology saw practical application when Liu and Gartner employed DNA-templated synthesis to create small molecules with diverse chemical structures in 2001 (Gartner and Liu, 2001). DELs consist of combinatorial libraries of drug-like molecules, each uniquely barcoded with a DNA sequence that encodes the structure of the attached library member (Clark et al., 2009; Potowski et al., 2021). This innovative approach enables the preparation of libraries with unprecedented diversity and facilitates efficient screening for ligands that bind to specific protein targets. Traditional methods of synthesizing and screening individual molecules are often costly and complex, requiring substantial quantities of target protein, well-established bioassays, and intricate logistical arrangements. In contrast, DEL selections can be performed in just a few days, utilizing only tens of micrograms of protein and picomole amounts of DELs, along with next-generation DNA sequencing (NGS) technologies (Matsuo et al., 2023) (Figure 8). Compared to conventional compound libraries, DELs offer higher density, improved stability, and reduced costs, thereby opening up new avenues for the design and synthesis of complex molecules. This capability not only enhances the efficiency of the drug discovery process but also expands the range of chemical diversity that can be explored, ultimately contributing to the development of more effective therapeutics.
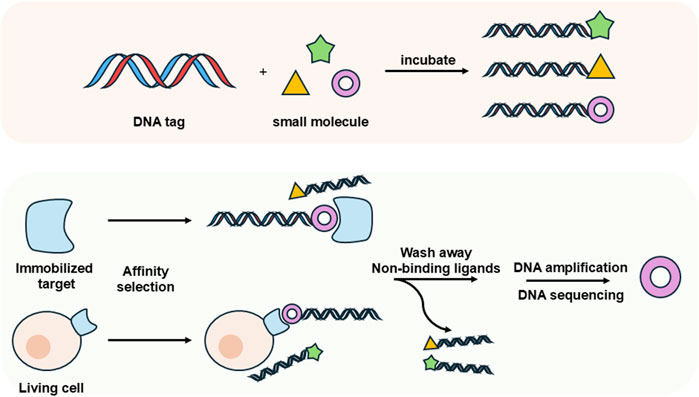
Figure 8. Schematic illustration of DNA-encoded libraries (DELs).
The application of DELs for small molecule discovery primarily involves affinity-based selections conducted on single immobilized targets in vitro. In these affinity-based selections, purified proteins equipped with affinity tags are immobilized on solid matrixes, such as magnetic beads or resin (Cochrane et al., 2021; Zhang Y. et al., 2024). This setup enables the effective separation of active library members that bind to the target from those that are weakly or non-binding and remain in solution. Following this, a series of washing steps is employed to remove inactive library members, ensuring that only those bound to the target remain attached. The target-bound library members can be eluted through various methods, including cleaving the target from the solid support, disrupting ligand-target interactions, or introducing an excess of a competitive ligand. In the context of DELs, the DNA sequences encoding the selected library members are then amplified via PCR. This amplified DNA can be subjected to additional rounds of in vitro selection, often under increasingly stringent conditions, to enrich the most active compounds (Scheuermann et al., 2006; Neri and Lerner, 2018). This straightforward yet effective methodology allows for the rapid evaluation of molecules with affinity for a target of interest. As such, it serves as a crucial starting point for further optimization, characterization, and eventual development of candidates for clinical trials. By leveraging the unique advantages of DEL technology, researchers can streamline the drug discovery process and enhance the likelihood of identifying promising therapeutic candidates.
Traditional workflows for DELs have proven effective in identifying multiple clinical candidates, with more than three candidates having progressed to clinical trials to date (Figure 9A). Gough, Bertin, and their collaborators developed extensive DNA-encoded small-molecule libraries using a split-and-pool strategy, resulting in approximately 7.7 billion diverse warheads across three cycles of building blocks. Utilizing these libraries, they discovered a novel series of highly potent benzoxazepinone inhibitors targeting receptor interacting protein 1 (RIP1) kinase. Notably, these inhibitors (e.g., compound #8, shown in Figure 9B) demonstrated complete selectivity against over 450 off-target kinases in a stereochemical-dependent manner. This series not only showcases high potency and kinase selectivity but also exhibits favorable pharmacokinetic profiles in rodent models (Harris et al., 2016). Building on this success, the team optimized a benzoxazepinone hit from their DNA-encoded library, leading to the discovery of the clinical candidate GSK2982772, which is currently undergoing phase 2 clinical trials for psoriasis, rheumatoid arthritis, and ulcerative colitis (Harris et al., 2017; Weisel et al., 2020). In a significant expansion of DEL technology, Dou et al. in 2022 adapted the approach for RNA targets. They initially faced challenges with false positive signals arising from unintended DNA-RNA interactions during their selection against the HIV-1 TAR (trans-acting responsive region) RNA. To mitigate this issue, they developed an optimized strategy incorporating RNA patches and competitive elution to minimize unwanted binding. Subsequent k-mer analysis and motif searches effectively filtered out false positives. This refined method was successfully applied to a DEL selection against the Escherichia coli FMN riboswitch, yielding compounds (e.g., HGC-1 and HGC-2, shown in Figure 9B) with nanomolar binding affinities and comparable potency in functional assays (Chen et al., 2022).
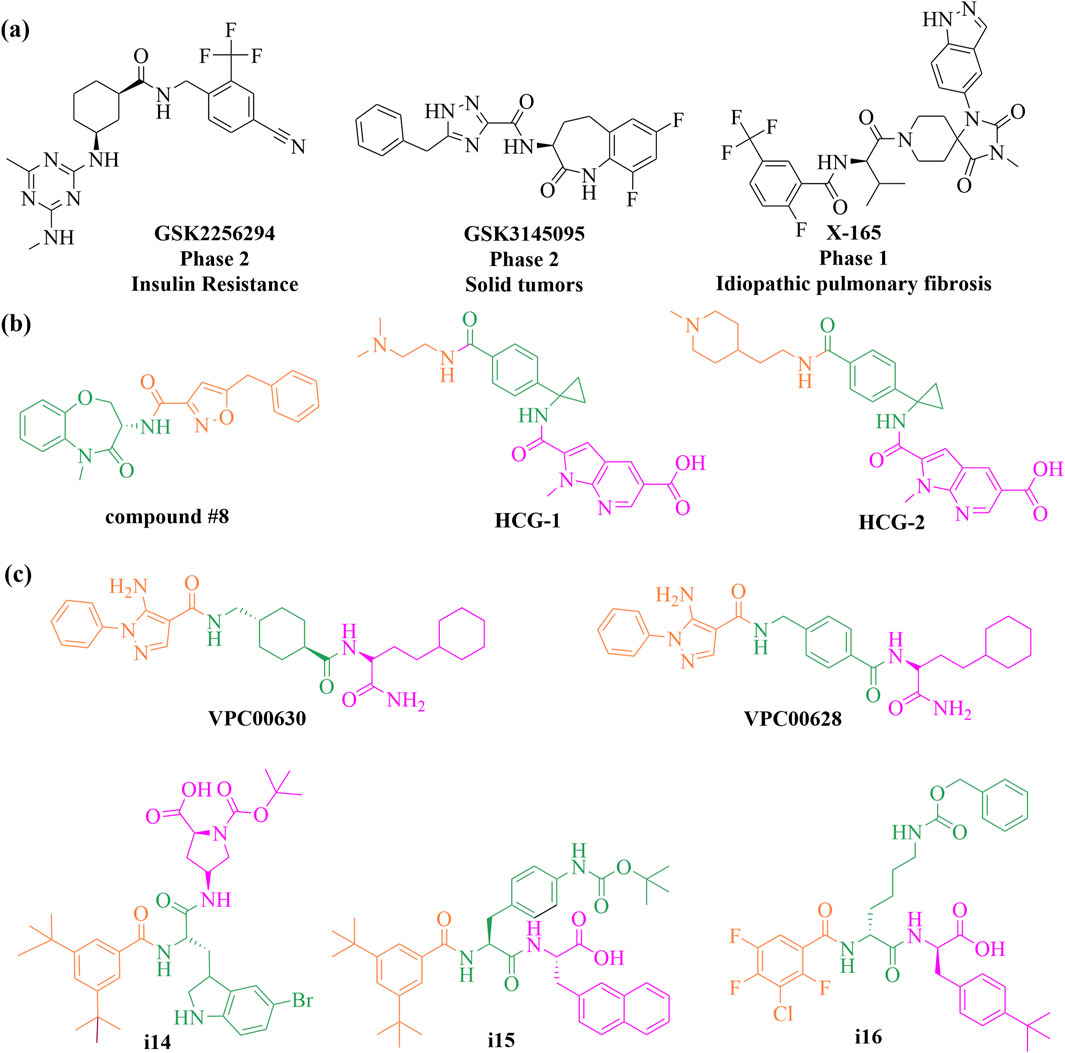
Figure 9. Chemical structures of small molecules discovered from DNA-encoded libraries (DELs). Representational small molecules currently in (A) clinical trials, and (B, C) preclinical trials.
Traditional DELs selection methods that rely on purified, immobilized protein targets face significant limitations when applied to many critical classes of drug targets. Certain proteins cannot be isolated or subjected to in vitro selection due to instability or the absence of established isolation protocols. Additionally, conventional DELs screening is conducted in dilute solutions containing primarily water, buffers, and salts, which fails to accurately replicate the complex cellular environment. The cytosol of living cells comprises 20%–30% (by weight) diverse macromolecules, creating a markedly different milieu compared to the dilute conditions used in traditional screening (Ellis, 2001). Consequently, there is a pressing need to perform ligand discovery directly in live cells (Figure 8). Developing approaches that enable the selection of DELs against targets within a cellular context would eliminate the challenges associated with requiring a pure, active protein and allow for the assessment of proteins in a more functionally relevant state. This would ensure that essential binding partners and post-translational modifications are preserved, ultimately leading to more effective drug discovery outcomes.
The Hansen group achieved a significant milestone by successfully screening a multimillion-member DELs within living cells, utilizing oocytes from the South African clawed frog, Xenopus laevis. They screened a DEL comprising 194 million members against three protein targets: mitogen-activated protein kinase 14 (p38α), human acetyl-coenzyme A synthetase 2 (ACSS2), and human dedicator of cytokinesis 5 (DOCK5). This effort yielded multiple chemical clusters and identified nanomolar-level potent hits (e.g., VCP00630 and VCP00628, shown in Figure 9C) for p38α, highlighting the potential of DELs to broaden target screening and reduce attrition rates in drug discovery (Petersen et al., 2021). In a separate study, a novel approach was introduced for identifying small molecule agonists for membrane proteins by selecting DELs on live cells. This method connects extracellular ligand binding to intracellular biochemical responses, thereby enhancing the likelihood of discovering agonists. It was demonstrated on three membrane proteins: epidermal growth factor receptor (EGFR), thrombopoietin receptor (TPOR), and insulin receptor (INSR), utilizing DELs containing 30 million and 1.033 billion compounds. This innovative approach successfully identified novel agonists (e.g., i14, i15 and i16, shown in Figure 9C) with sub-nanomolar affinities and micromolar cellular activities (Huang et al., 2024).
DELs present significant advantages in drug discovery, but they also face notable challenges. One major challenge is the delivery of DELs into target cells, as traditional methods often struggle with membrane permeability, limiting the effective screening of compounds in vivo. While advances have been made using techniques like electroporation and microinjection, achieving efficient delivery while maintaining cell viability remains a hurdle. Another issue is the complexity of interpreting the binding interactions between DEL members and target proteins. High background noise from endogenous proteins can confound results, making it difficult to distinguish between specific and nonspecific interactions. Additionally, the large size of DELs complicates the characterization of individual hits, as the multimeric nature of the libraries can obscure individual ligand properties. Furthermore, ensuring the stability and integrity of the DNA during the selection process is crucial, as degradation can affect the quality of the results. Lastly, while DELs enable high-throughput screening, the need for extensive bioinformatics resources to analyze and validate hits can be resource-intensive, posing a logistical challenge for many research teams. Addressing these challenges is essential for maximizing the potential of DELs in drug discovery and expanding their applicability to a broader range of targets.
In recent years, significant advancements have been made in the pharmaceutical field, driven by the rapid development of computer technology and artificial intelligence (AI). The policy for the evaluation of chemicals (Registration, Evaluation and Authorisation of Chemicals [REACH]) has strongly advocated for the adoption of in silico methods within the pharmaceutical industry (Neri and Lerner, 2018). This approach is particularly justified, as it enables a substantial reduction in the use of laboratory animals for in vivo testing and leads to considerable cost savings in research. Recent studies have established CADD is an indispensable tool for drug discovery and can speed up, especially, the early development stages of lead identification and optimization (Rusinko et al., 2024; Hsieh et al., 2023) (Figure 10). CADD primarily integrates traditional disciplines such as computational chemistry, molecular biology, and structural biology. By utilizing advanced algorithms and predictive models, it facilitates the assessment of interactions between drug molecules and biomolecules, thereby accelerating the drug design and optimization processes. Consequently, several small molecules discovered through CADD technology have been approved, as illustrated in Figure 11. Additionally, AI technologies—including machine learning (ML), deep learning (DL), and natural language processing—have been successfully implemented in real-world drug discovery (Liu G. et al., 2023; McNair, 2023).

Figure 10. A typical workflow for computer-aided drug design (CADD).
Figure 11. Chemical structures of approved small molecules discovered from CADD technology.
In structure-based drug design (SBDD), the binding interaction and binding site between target structure and ligand are determined using various techniques such as X-ray diffraction, NMR, or calculations involving molecular mechanics and dynamics techniques (Zhu et al., 2020; Sugiki et al., 2018; Defelipe et al., 2018). However, in SBVS, basing a three-dimensional (3D) structural model of the intended target macromolecule (usually a protein, or RNA structure) search and rank accessible chemical space for potential ligands (Maia et al., 2020). SBVS is widely employed to find small molecules that can bind to the active or allosteric site of the target, predicting potential drug candidates. SBVS involves docking of large and diverse virtual chemical libraries into an X-ray crystal structure or homology model of the target protein. The success of SBVS depends on the accuracy of both the target structure and the docking/scoring algorithms (Macalino et al., 2015). The integration of AI technologies in SBVS has influenced the field by improving the accuracy, speed, and scalability of virtual screening (Lima et al., 2016; Zhang et al., 2023).
The most employed SBVS technique in drug design studies is molecular docking. This method is a computational technique used to predict how small molecules (ligands) interact with a target macromolecule, typically a protein. Nowadays more than 227,000 biological macromolecular structures are deposited on Protein Data Bank (PDB) database (http://rcsb.org), covering more than 170,000 organisms and 190,000 distinct protein sequences. Molecular docking techniques have been popular in SBVS since the early 1980s (Kuntz et al., 1982). Molecular docking study prophesies the interaction energy between two molecules, and determines the interactions of ligand and target to find the conformation of ligand in the formed complex with overall binding free energy (Forli et al., 2016). In general, the process of molecular docking is performed according to the following steps: (i) obtain the 3D structure of the target macromolecule from crystal structure repositories (e.g., PDB); (ii) characterization of the binding sites and cavities; (iii) compound library construction, which involves several processes of characterization, filtering, and clustering; (iv) molecular docking of target with compounds supplemented with known actives and decoys followed by scoring; and (v) final evaluation and validation (Lionta et al., 2014). Some common tools are used in molecular docking, such as AutoDock and AutoDock Vina, Glide, GOLD (Genetic Optimization for Ligand Docking), DOCK, Surflex-Dock, LeDock and FlexX (Cheng et al., 2012; Shen et al., 2020). Moreover, AI-based enhancements in scoring, protein flexibility modeling, and ligand design have transformed molecular docking into a more efficient and reliable tool for drug discovery, making it possible to screen vast chemical libraries and optimize lead compounds with high precision. Molecular docking are superseded by tools like AtomNet, DeltaVina (AI-enhanced AutoDock Vina) and GNINA (Stafford et al., 2022; Wang and Zhang, 2017; McNutt et al., 2021).
In 2019, Xie et al. conducted a virtual screening of 2,004 clinical and preclinical drugs using AutoDock Vina to target multiple enzymes. Their study identified kinase inhibitors, particularly Lifirafenib (Figure 12A), as promising lead compounds for inhibiting the aroQ, phzG, and phzS enzymes, which are involved in the phenazine biosynthesis pathway. These findings highlight the potential of Lifirafenib in drug repurposing, though further experimental validation is necessary (Xie and Xie, 2019). The combination of molecular docking and drug repositioning strategies is proving effective in accelerating the discovery of new preclinical drug candidates. SBVS has been shown to enhance hit quality, especially as the number of compounds screened increases. Arthanari et al. developed VirtualFlow, an open-source platform for large-scale virtual screening capable of handling ultra-large libraries and multiple docking programs. VirtualFlow processed over one billion compounds using AutoDockTools, leading to the discovery of lead molecules such as iKeap1 (Figure 12A), which binds to Kelch-like ECH-associated protein 1 (KEAP1) with nanomolar affinity, demonstrating significant potential in drug discovery (Gorgulla et al., 2020). In 2023, Houston et al. introduced SCORCH, a new ML-based model designed to improve the scoring functions used in molecular docking. SCORCH showed superior performance in virtual screening and pose prediction compared to traditional scoring methods, with higher enrichment factors and improved pose ranking. This model’s increased accuracy, combined with uncertainty estimation, offers a promising approach to reducing drug discovery costs and timelines (McGibbon et al., 2023).
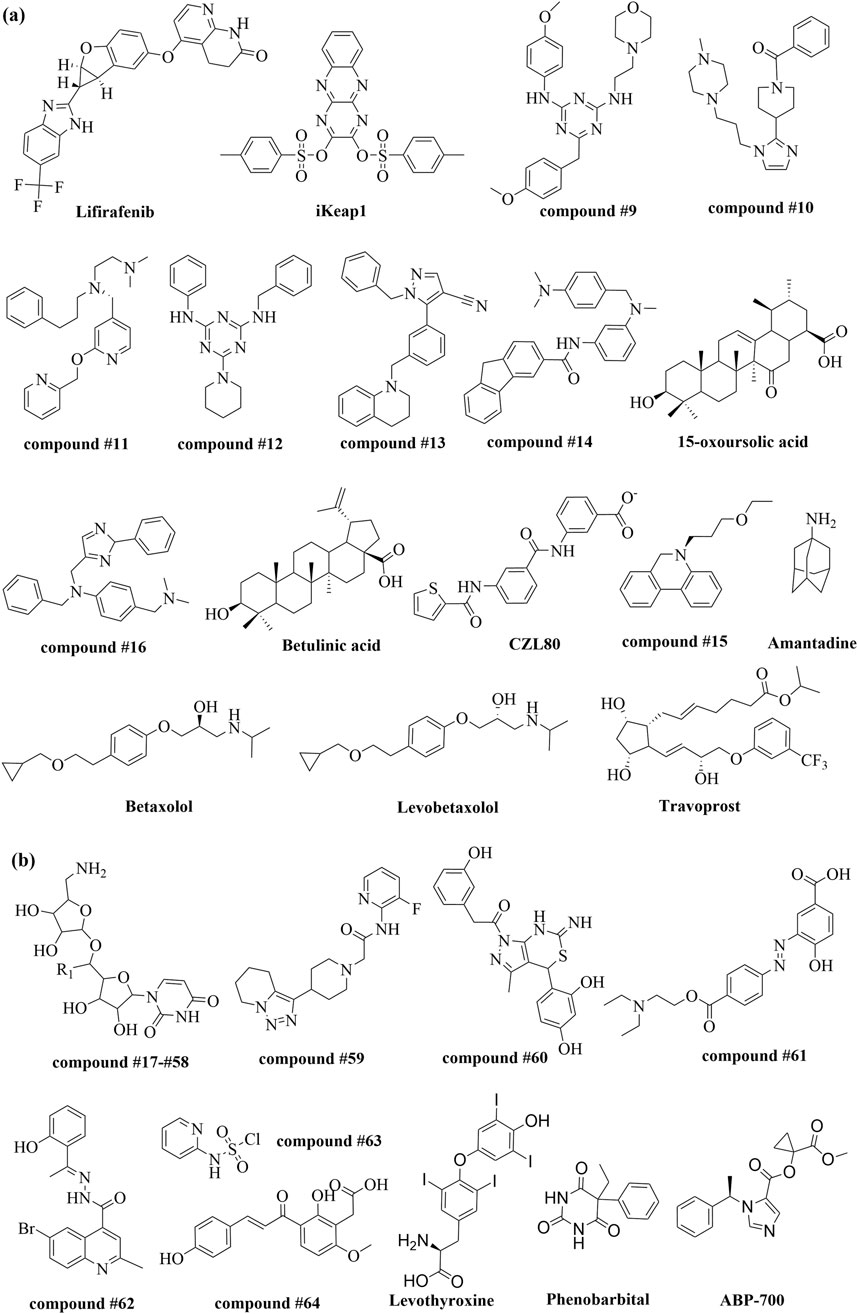
Figure 12. Chemical structures of small molecules discovered from virtual screening. (A) Exemplary small molecules by structure-based virtual screening (SBVS). (B) Exemplary small molecules by ligand-based virtual screening (LBVS).
An interesting contradiction in drug discovery is the fact that 60%–70% of drugs on the market target integral membrane proteins, which to date have been unsuitable for structure-based approaches because of the enormous difficulties in producing suitable quantities of functional protein for crystallization trials (van Montfort and Workman, 2009). In the case of target proteins for which no direct crystallographic data are available, the construction and screening of homology models can be performed. Homology modeling is a computational method used to predict the 3D structure of a protein based on its amino acid sequence and an available structure of a homologous protein (a protein with a similar sequence). The homology modeling consists of five key steps: (i) find a suitable homologous protein structure to use as a template, (ii) align the sequence of the target protein with the sequence of the template protein, (iii) construct a 3D model of the target protein based on the template structure, (iv) improve the quality of the modeled structure, and (v) assess the quality and accuracy of the model (Lee et al., 2017). Homology modeling employs information from template structures of homologous proteins. Some common tools include BLAST, MODELLER, SWISS-MODEL, and PyMod (Bullock et al., 2013; Waterhouse et al., 2018; Janson and Paiardini, 2021). However, with the advance in the AI field, these methods are superseded by methods like AlphaFold, RoseTTAFold, ESMFold, and OmegaFold, which supersedes traditional homology modeling methods by offering greater accuracy, faster predictions, and the ability to model proteins for which no template is available (Lee et al., 2022; Song et al., 2024; Chen et al., 2024).
Overexpression of Forkhead box protein C2 (FOXC2) is associated with cancer progression and metastasis, making it a key target for anticancer drug development. In 2023, Tao et al. used the I-TASSER server for homology modeling to construct a 3D structure of full-length FOXC2. Ligand-based drug design (LBDD) identified MC-1-F2 analogues from 15 million compounds in the ChEMBL and ZINC databases, resulting in eight promising lead compounds (compounds #9-#16) (Figure 12A) through molecular dynamics (MD) simulations and molecular mechanics/generalized Born surface area (MM/GBSA) MM/GBSA calculations (Ibrahim et al., 2022). In 2024, Ali et al. utilized SWISS-MODEL to generate a homology model of the dengue virus non-structural 4B (NS4B) protein and validated it using multiple tools. Molecular docking revealed significant binding affinities of triterpenoids, including 15-oxoursolic acid and betulinic acid (Figure 12A), against NS4B (Ali et al., 2024). The same year, Darvishi et al. employed MODELLER 9v10 and AutoDock Vina for homology modeling and molecular docking to optimize Yarrowia lipolytica L-asparaginase. Three mutants—T171S, T171S-N60A, and T171A-T223A—exhibited increased affinity for L-asparagine and reduced affinity for L-glutamine. This study underscores the utility of combining homology modeling and molecular docking to identify therapeutic candidates with fewer side effects, providing valuable insights for enzyme optimization in drug development (Darvishi et al., 2024).
With advancements in AI, traditional homology modeling methods are being increasingly superseded by ML approaches. Svenningsson et al. compared virtual screenings using protein structures generated by AlphaFold, a ML method, and traditional homology modeling. By docking over 16 million compounds onto the trace amine-associated receptor 1 (TAAR1) model, they selected 30 and 32 highly ranked compounds from the AlphaFold and homology model screenings, respectively. The hit rate of AlphaFold screening (60%) was more than twice as high as that of the homology model, leading to the discovery of the most effective agonist (Díaz-Holguín et al., 2024). RoseTTAFold, inspired by AlphaFold, was tested by Tseng et al. on a collection of solved G-protein-coupled receptor (GPCR) structures in the PDB. They assessed the accuracy of the predictions using the root-mean-square deviation (RMSD) of backbone alpha-carbons, finding that AlphaFold outperformed RoseTTAFold in top-scored model accuracy, while RoseTTAFold showed a smaller variance in RMSDs (Lee et al., 2022). Meanwhile, single-sequence-based structure prediction methods, such as ESMFold and OmegaFold, offer a balance between inference speed and prediction accuracy. Lin et al. introduced ESMFold, a pre-trained language model for fast and accurate structure prediction, achieving accuracy comparable to AlphaFold2 while reducing inference time by up to 60 times (Lin et al., 2023).
MD simulations are a crucial computational tool either before or after docking to study deep insights into the dynamic interactions between potential drug molecules (ligands) and their target proteins (Liu et al., 2018). MD simulations have been long proposed to provide insight into protein dynamics beyond that available crystallographically, and unravel novel cryptic binding sites, expanding the druggability of the targets (Kuzmanic et al., 2020). MD simulations study protein-ligand interactions, facilitating SBDD and optimizing lead compounds by assessing binding affinities and stability. The MD process involves several key steps: (i) preparing the system (selecting molecules, solvation, and ionization), energy minimization, equilibration under controlled conditions, and conducting a production run where atomic positions are updated over time, (ii) data is collected for analysis, focusing on structural changes, binding interactions, and dynamic properties, and (iii) visualization tools are used to interpret results, leading to insights into molecular behavior and interactions in drug discovery (Yelshanskaya et al., 2020; Tang Y. et al., 2020). MD simulations utilize a variety of tools and software packages, with common examples including GROMACS, CHAPERON g, NAMD, VMD, and OpenMM (Yelshanskaya et al., 2020; Yekeen et al., 2023; Phillips et al., 2020; Eastman et al., 2017).
Amantadine (Figure 12A) has emerged as a promising candidate for COVID-19 treatment by inhibiting the ion channel activity of SARS-CoV-2 Proteins E and open reading frame (ORF) Protein 10. Rosenkilde et al. demonstrated that amantadine blocks Protein E-mediated currents, further elucidating its specific interaction profile through solution NMR and MD simulations (Toft-Bertelsen et al., 2021). Chen et al. identified caspase-1 as a key regulator in febrile seizures (FS), with caspase-1 knockout mice showing resistance to FS. Overexpression increased susceptibility, and MD simulations coupled with MM/GBSA binding free energy calculations identified CZL80 (Figure 12A) as a potent brain-penetrable, low molecular weight caspase-1 inhibitor. These findings emphasize the utility of MD simulations in virtual screening to uncover drug mechanisms (Tang Y. et al., 2020). Another study combined MD simulations and patch clamp electrophysiology to assess drug candidates targeting KIR6.2 wild-type (WT) and developmental delay, epilepsy, and neonatal diabetes (DEND) syndrome-related mutant channels. Betaxolol and Levobetaxolol (Figure 12A) were identified as effective pore blockers, exhibiting IC50 values ranging from 22 to 55 μM. Travoprost (Figure 12A) demonstrated the strongest inhibitory effect on WT and L164P channels. The MD simulations provided insight into the potential channel interaction and clarified the possible mechanisms shed light on mechanisms of the tested drug candidates (Houtman et al., 2022).
LBVS is a valuable computational approach in drug discovery, particularly useful when structural information on the target protein is unavailable (Yang et al., 2019). The core principle of LBVS involves analyzing the binding affinities and structural features of known ligands to design drug molecules with improved affinity and selectivity. Key methodologies in LBVS include QSAR modeling, which links chemical structures with biological activity, and pharmacophore modeling, which identifies critical spatial features necessary for binding (Lee et al., 2011). LBVS approach is especially beneficial in the early stages of drug discovery, enabling efficient screening of large compound libraries and prioritizing candidates for experimental testing. However, the effectiveness of LBVS depends on the availability of high-quality ligand data and may overlook potential drug candidates that lack significant structural similarity to known ligands (Pérez-Castillo et al., 2014). The integration of AI technologies has greatly enhanced LBVS by improving its accuracy and efficiency. ML and DL techniques are used to analyze large datasets, predict molecular interactions, and optimize ligand properties, allowing for more efficient exploration of chemical space and accelerating the identification of promising therapeutic agents (Bonanno and Ebejer, 2019; Wu et al., 2024).
QSAR models predict biological activity—such as toxicity, efficacy, or binding affinity—based on molecular properties like electronic, topological, steric, and hydrophobic features derived from a compound’s structure (Vyas et al., 2021). These models aid in designing compounds with improved therapeutic profiles. QSAR uses statistical methods such as multiple linear regression, support vector machines, and neural networks to correlate molecular features with biological outcomes (Tang W. et al., 2020). The QSAR modeling process involves several steps: (i) collecting compound data, (ii) representing molecular structures via descriptors, (iii) preprocessing the data, building and training the model using statistical techniques, and (iv) validating the model through internal and external validation methods (Lee et al., 2011). QSAR modeling employs tools like CoMFA, CoMSIA, HQSAR, Dragon, and PaDEL-Descriptor for molecular descriptor calculation (Sainy and Sharma, 2015; Wang Y. et al., 2021; Liu Z. et al., 2023), while platforms like AutoQSAR is used for model building (Yang et al., 2021; Arakal et al., 2021). Additionally, ML libraries such as R, Python (scikit-learn), and WEKA are crucial for statistical analysis and model development (Shah and Arumugam, 2024).
Khairullina and Martynova used GUSAR 2019 software, developed by the V.N. Orekhovich Institute, to perform QSAR analysis on derivatives of 5-ethyluridine, N2-guanine, and 6-oxopurine with anti-herpetic activity against Herpes simplex viruses (HSV) thymidine kinase. Twelve predictive models, based on quantitative neighborhoods of atoms (QNAs), multilevel neighborhoods of atoms (MNAs), and whole-molecule descriptors, demonstrated high accuracy in predicting pIC50 values. Virtual screening of the ChEMBL database using these QSAR models identified 42 new potential HSV-1 and HSV-2 TK inhibitors (compounds #17-#58) (Figure 12B) (Khairullina and Martynova, 2023). Similarly, Gaston-Mathé’s team evaluated a DL-based de novo design technology for generating lead compounds across 11 biological activity targets. Their QSAR models achieved precision between 0.67 and 1.0, and the AI algorithm generated 150 virtual compounds, with 11 synthesized compounds showing an 86% average success rate. One compound (compound #59) (Figure 12B) met all 11 objectives, while two met 10, highlighting the efficacy of combining AI-based de novo design with QSAR modeling for multi-parameter optimization (Perron et al., 2022). In the context of RNA-targeted drug discovery, Hargrove et al. developed QSAR models to predict binding parameters of small molecules to HIV-1 transactivation response (TAR) RNA. These models, built using multiple linear regression with feature selection, identified key properties influencing binding strength and kinetics, and were validated with new compounds, demonstrating their accuracy and broad applicability (Cai et al., 2022).
Recent advancements in AI techniques, particularly DL, along with the rapid expansion of molecular databases for virtual screening and significant improvements in computational power, have led to the emergence of a new field in QSAR applications, known as “deep QSAR” (Tropsha et al., 2024). One key advantage of “deep QSAR” over traditional methods is its ability to more effectively tackle multi-objective optimization tasks through knowledge transfer, leveraging diverse data sources to improve prediction accuracy across different tasks. For instance, Pérez-Castillo et al. developed a QSAR model based on DL strategies using hundreds of inhibitors of the SARS-CoV main protease (Mpro) (Tejera et al., 2020). This model was used to virtually screen a large number of drugs from the DrugBank database, followed by docking and molecular dynamics analysis of the top 20 candidates. The results identified Levothyroxine, Phenobarbital, and ABP-700 as the most promising inhibitors of the SARS-CoV-2 Mpro enzyme (Figure 12B). In a different approach, Ghosh et al. developed two supervised ML-based 3D-QSAR methods, CoMFA and CoMSIA, to analyze the structure-activity relationships of focal adhesion kinase inhibitors. Unlike 2D-QSAR, 3D-QSAR incorporates quantum chemical descriptors, molecular scaffolds, substitution constants, and various surface and volume descriptors, providing richer insights into the non-bonding interactions between receptors and ligands (Ghosh and Cho, 2023).
Pharmacophore modeling aims to identify the essential molecular features required for a ligand to interact with a biological target, typically a protein. These features include steric arrangements, electrostatic properties, aromatic rings, hydrogen bond donors and acceptors, and hydrophobic regions, which are abstracted into a pharmacophore—a 3D model representing the spatial arrangement of these key interactions necessary for binding and biological activity (van Drie, 2003). Pharmacophore modeling can identify key structural features shared by active ligands, which can then be used to screen for other molecules possessing these characteristics. To predict the activity of a new compound, QSAR models can be developed. While pharmacophore models highlight the essential features responsible for activity, QSAR provides a deeper understanding of how the chemical or physical properties of a ligand relate to its biological effect (Vyas et al., 2021). Pharmacophore models are useful for virtual screening, enabling the identification of new potential drug candidates by comparing large chemical libraries with the pharmacophore, thus accelerating hit identification, lead optimization, and drug design. The process typically involves identifying active compounds, extracting key molecular features, aligning them in 3D space, and generating a pharmacophore model to capture the essential interactions for biological activity (Lee et al., 2011). Tools like LigandScout, Discovery Studio, PharmMapper, and ZINCPharmer are commonly used to generate and evaluate pharmacophore models (Temml et al., 2014; Wang X. et al., 2017; Koes and Camacho, 2012).
Zhong et al. used MOE software to develop a pharmacophore model targeting Glucose Transporter 1 (GLUT1) and screened the National Cancer Institute (NCI) compound database, comprising 1,469 molecules. This screening identified 16 hit compounds, with four (compounds #60-#63) (Figure 12B) showing dose-dependent inhibition of glucose uptake and reduced colon cancer cell growth in vitro. Further results indicate that lead compound 57 was a GLUT inhibitor (Almahmoud et al., 2020). Similarly, Aulifa et al. performed an in silico study to evaluate the inhibitory activity of active compounds from the ashitaba plant compared to statins against the 3-hydroxy-3-methylglutaryl (HMG) Co-A reductase enzyme. Using pharmacophore modeling and docking simulations, 299 active HMG-CoA reductase inhibitors and 8,884 inactive compounds (decoys) were downloaded from the DUD-E database. Molecular docking revealed that 15 hit compounds exhibited low binding energy (∆G), suggesting potential inhibitory activity against HMG-CoA reductase. The lowest ∆G value was found in 3′-carboxymethyl-4,2′-dihydroxy-4′-methoxy chalcone (compound #64) (Figure 12B), which was lower than the ∆G value of the other comparator drugs, atorvastatin and simvastatin (Aulifa et al., 2024).
Traditional pharmacophore modeling relies on an effective pharmacophore with a protein-ligand eutectic structure as a reference, often depending on existing molecular libraries. However, obtaining these eutectic structures can be challenging, making de novo drug design difficult in many drug development projects (Giordano et al., 2022). To address this, Koes et al. proposed PharmRL, a novel approach that combines DL with geometric reinforcement learning to construct high-quality pharmacophores without requiring ligand information. Their algorithm demonstrated superior prospective virtual screening performance on the DUD-E dataset compared to randomly selecting ligand recognition features from eutectic structures. PharmRL was also tested on the COVID Moonshot dataset, effectively identifying potential lead molecules without fragment screening experiments (Aggarwal and D, 2024). Additionally, Imrie et al. introduced the DEVELOP model, which utilizes pharmacophore information to optimize precursor or lead compounds. By integrating the graph-based deep generative model DeLinker with a convolutional neural network, DEVELOP leverages 3D representations of molecules and target pharmacophores. Using the design of menin and mixed lineage leukemia (MLL) fusion protein inhibitors as a case study, they demonstrated that molecules generated by DEVELOP closely matched the input pharmacophore information (Imrie et al., 2021).
De novo drug design involves creating novel molecules without relying on existing compounds or natural products. Traditional methods, such as fragment-based approaches, generate new molecules from scratch but often face challenges due to the complexity of molecular structures, making them difficult to synthesize (Schneider et al., 2017). Compared to virtual screening, drug design from scratch, aided by new algorithms for molecular design and evaluation, allows for more efficient exploration of a wider chemical space. While molecules proposed through de novo drug design are typically far from final drug candidates, they serve as valuable starting points for medicinal chemistry development (Tang et al., 2024). De novo drug design methods can be classified into structure-based and ligand-based approaches, depending on the level of molecular characterization (Schneider, 2014). Early structure-based methods involved growing ligands within a binding pocket’s steric and electronic constraints, either directly from protein structures or inferred from known ligand properties (Schneider and Fechner, 2005). However, these approaches often resulted in compounds with poor drug-likeness and synthetic feasibility, limiting their practical application. In contrast, recent advancements in ligand-based de novo drug design have shown promise in generating compound libraries that can be further analyzed using scoring functions to evaluate properties such as biological activity, synthetic accessibility, metabolism, and pharmacokinetics (Thomas et al., 2021; Atz et al., 2024).
In 2022, Gaston-Mathé et al. demonstrated the use of DL for multi-parameter optimization in ligand-based de novo drug design (Perron et al., 2022). They employed DL generative models to accelerate the identification of lead compounds that satisfied 11 different biological activity objectives. Using Servier’s project dataset, they established QSAR models for all 11 objectives, achieving moderate to high performance. A de novo algorithm based on DL was combined with the QSAR models to generate 150 virtual compounds expected to be active against all 11 objectives. Among the synthesized compounds, mol 885 was active for all 11 indicators, while mol 886 and 887 were active for 10, with the last indicator within the detection error range (Figure 13A). In 2024, Gisbert Schneider’s research team developed the DRAGONFLY computational method, which integrates graph neural networks and chemical language models (CLMs) to generate compound libraries with specific biological activity, synthesizability, and structural novelty (Atz et al., 2024). Using DRAGONFLY, they designed new ligands targeting the human peroxisome proliferator-activated receptor (PPAR) gamma subtype. Two top-scoring compounds (1 and 2) were synthesized and characterized through computational, biophysical, and biochemical methods (Figure 13A). The results identified potent PPAR partial agonists with favorable activity and selectivity profiles for both nuclear receptors and off-target interactions.
Figure 13. Chemical structures of small molecules identified through (A) de novo drug design, (B) drug repurposing, and (C) ADMET predictions.
Drug repurposing, or the process of identifying new pharmacological effects for existing drugs, traditionally involved the labor-intensive task of analyzing vast amounts of medical literature and clinical data. This approach required interdisciplinary collaboration and was relatively inefficient. However, with the rapid expansion of bioinformatics and large-scale “omics” data, the time and cost associated with drug development have significantly decreased (Keiser et al., 2009). Computational drug repurposing has evolved from traditional methods based on chemical similarity and molecular docking to more advanced approaches that leverage systems biology for drug effect evaluation (Haupt and Schroeder, 2011; He et al., 2023). Recently, DL-based methods have shown great promise in automating the extraction of molecular structures, omics data, and clinical information, which improves the accuracy and interpretability of prediction models. These advances have accelerated drug repositioning. Several AI-driven platforms, such as DTINet, DEEPScreen, PandaOmics, PREDICT, SLAMS, and NetLapRLS, have been proposed to integrate heterogeneous data sources and identify potential drug repurposing opportunities (Luo et al., 2017; Rifaioglu et al., 2020; Liu B. H. M. et al., 2024; Gottlieb et al., 2011; Chen et al., 2021).
Zeng et al. proposed DTINet, a novel computational pipeline for predicting drug-target interactions (DTIs) by building a large-scale heterogeneous network that integrates data from various sources, including target genes, drugs, drug side effects, diseases, and other relevant factors (Luo et al., 2017). Focusing on the top 150 predictions, DTINet identified novel interactions between the drugs telmisartan, chlorpromazine, and alendronate, and cyclooxygenase proteins. These predictions were experimentally validated, revealing the potential of these drugs as cyclooxygenase inhibitors in preventing inflammatory diseases. In 2020, Doğan et al. introduced DEEPScreen, a DTI prediction system based on deep convolutional neural networks (CNNs), which uses 2-D structural compound representations to predict protein targets for drugs (Rifaioglu et al., 2020). As a case study, DEEPScreen predicted JAK proteins as new targets for Cladribine, and this was experimentally validated in vitro on cancer cells through STAT3 phosphorylation (Figure 13B). Meanwhile, Wang et al. employed PandaOmics, an AI-driven target discovery engine, to analyze large-scale transcriptomic data and identify novel therapeutic targets for endometriosis, including guanylate binding protein 2 (GBP2) and hematopoietic kinase (HCK), as well as the drug reuse target integrin β 2 (ITGB2). The FDA-approved drug Lifitegrast, a small molecule integrin antagonist for dry eye syndrome, was identified as a potential treatment for endometriosis (Figure 13B). In vivo experiments showed that Lifitegrast effectively inhibited lesion growth in a mouse model of endometriosis, suggesting its repurposing potential for this condition (Liu B. H. M. et al., 2024).
In addition to pharmacological efficacy, an ideal drug must also exhibit favorable ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) properties. Imbalances in these characteristics are a leading cause of late-stage drug failures and the withdrawal of approved drugs (Morgan et al., 2012). CADD plays a vital role in predicting ADMET properties, employing simulation techniques to forecast how drugs will behave in the body and their potential toxicity. Accurate ADMET predictions are essential in the early stages of drug discovery, guiding optimization efforts (Ferreira and Andricopulo, 2019). Recent advancements in AI and DL technologies have significantly enhanced the precision and efficiency of ADMET predictions. A new generation of predictors based on DL and big data promises to further streamline the drug discovery process, from laboratory studies to clinical applications (Keutzer et al., 2022; Alsultan et al., 2020). Popular tools for ADMET prediction include ADMETlab, ADMET Predictor, SwissADME, OptADMET, FAF-Drugs4, and Hit Dexter (Fu et al., 2024; Sohlenius-Sternbeck and Terelius, 2022; Daina et al., 2017; Yi et al., 2024; Lagorce et al., 2017; Stork et al., 2019).
In 2022, Iqbal et al. employed a comprehensive computational approach to identify potent never in mitosis A (NIMA)-related kinase 7 (NEK7) inhibitors, using both Autodock 4.2 and Molecular Operating Environment (MOE) 2015.10 for docking studies (Aziz et al., 2022). Their top compounds, M7 and M12, demonstrated excellent binding affinities and were subsequently evaluated for ADMET properties using the ADMETlab 2.0 server (Figure 13C). Notably, both compounds showed superior human intestinal absorption (HIA) values compared to the standard HIV drug Dabrafenib (Figure 13C). In 2024, Cao et al. launched ADMETlab 3.0, an updated version of the web server that overcomes limitations of its predecessor by offering broader coverage, enhanced performance, improved API functionality, and better decision support (Fu et al., 2024).
CADD has greatly enhanced drug discovery, but several challenges remain. SBVS requires high-quality 3D structures of biological targets, which are often unavailable, especially for membrane-bound or flexible proteins. This can lead to inaccurate docking results. To overcome this, advances in techniques like cryo-electron microscopy and homology modeling are being used to improve target structure prediction. LBVS faces limitations in predicting novel compounds, as it depends on known ligand-target interactions. Hybrid methods that combine SBVS and LBVS are now being explored to enhance screening accuracy and broaden the search for new drugs. De novo drug design offers the potential to generate entirely novel compounds, but the challenge lies in optimizing them for drug-like properties such as synthetic feasibility and biological activity. AI and ML are now being applied to refine de novo designs, increasing their success rate. Drug repurposing, although an efficient strategy for identifying new uses for existing drugs, often struggles with predicting the binding affinity of repurposed compounds to new targets. The use of large-scale molecular databases and advanced AI models can help in this area. ADMET predictions remain imprecise, complicating early-stage drug development. Enhanced computational models and multi-parameter optimization techniques are being developed to better predict these properties and identify safer drug candidates.
This review highlights advanced strategies for the discovery and development of small-molecule drugs, delving into their underlying principles and examining their potential to the future of medicinal chemistry. As highlighted in this review, the integration of advanced techniques such as Click chemistry, TPD strategies, DELs technologies, and CADD has significantly improved the efficiency and effectiveness of drug discovery. Click Chemistry, with its rapid synthesis of diverse compound libraries, has reshaped how researchers approach the optimization of lead compounds. Its modular nature facilitates the incorporation of functional groups, allowing for the streamlined development of therapeutics tailored to specific targets. TPD technologies introduce a novel paradigm by utilizing the body’s natural degradation systems, enabling the targeting of previously undruggable proteins and expanding the therapeutic landscape. Similarly, DELs have transformed high-throughput screening by facilitating the parallel evaluation of millions of compounds, thereby accelerating the efficient identification of novel drug candidates. CADD represents a significant leap forward in the predictive capabilities of drug design, leveraging computational tools to refine candidate selection based on structural properties. This not only reduces the time and resources needed for experimental screening but also enhances the precision of drug design, aligning with the increasing demand for tailored therapies that meet individual patient needs.
Looking forward, the future of medicinal chemistry appears promising yet complex. The integration of AI into drug discovery processes is poised to further enhance the predictive capabilities and efficiency of these methodologies. However, challenges remain, particularly in terms of the biological validation of discovered compounds and the translation of preclinical findings into successful clinical applications. There is also a critical need to address the ethical implications and potential risks associated with these innovative approaches, ensuring that advancements are made responsibly. Additionally, by integrating multimodal data, including protein structure, sequence, and functional information, researchers can conduct a comprehensive analysis that provides deeper insights into drug design. This holistic approach enhances our understanding of molecular interactions and optimizes the development of targeted therapeutic drugs. Finally, to maximize the potential of these technologies, fostering interdisciplinary collaborations between chemists, biologists, pharmacologists, and data scientists will be essential. By combining expertise from various fields, the medicinal chemistry community can tackle the multifaceted challenges of drug discovery more effectively.
In conclusion, as we embrace these emerging strategies, there is a clear opportunity to inspire new research directions that not only advance our understanding of medicinal chemistry but also lead to the development of innovative therapeutic solutions. The integration of novel methodologies holds the potential to reshape the landscape of drug discovery, ultimately improving patient outcomes and addressing the pressing healthcare challenges of our time. By continuing to explore and refine these approaches, we can enhance our ability to combat a wide array of diseases, making significant strides towards more effective and targeted therapies.
QA: Conceptualization, Data curation, Formal Analysis, Software, Visualization, Writing–original draft. LH: Investigation, Software, Writing–original draft. CW: Conceptualization, Data curation, Writing–original draft. DW: Formal Analysis, Visualization, Writing–review and editing. YT: Funding acquisition, Investigation, Visualization, Writing–review and editing.
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by National Natural Science Foundation of China (No. 32401117) and Chengdu Municipal Science and Technology Program (2024-YF05-01305-SN).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declare that no Generative AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Aggarwal, R., and D, R. K. (2024). PharmRL: pharmacophore elucidation with deep geometric reinforcement learning. BMC Biol. 22, 301. doi:10.1186/s12915-024-02096-5
Ali, S., Ali, U., Safi, K., Naz, F., Jan, M. I., Iqbal, Z., et al. (2024). In silico homology modeling of dengue virus non-structural 4B (NS4B) protein and its molecular docking studies using triterpenoids. BMC. Infect. Dis. 24, 688. doi:10.1186/s12879-024-09578-5
Almahmoud, S., Jin, W., Geng, L., Wang, J., Wang, X., Vennerstrom, J. L., et al. (2020). Ligand-based design of GLUT inhibitors as potential antitumor agents. Bioorg. Med. Chem. 28, 115395. doi:10.1016/j.bmc.2020.115395
Alsultan, A., Alghamdi, W. A., Alghamdi, J., Alharbi, A. F., Aljutayli, A., Albassam, A., et al. (2020). Clinical pharmacology applications in clinical drug development and clinical care: a focus on Saudi Arabia. Saudi. Pharm. J. 28, 1217–1227. doi:10.1016/j.jsps.2020.08.012
Arakal, N. G., Sharma, V., Kumar, A., Kavya, B., Devadath, N. G., Kumar, S. B., et al. (2021). Ligand-based design approach of potential Bcl-2 inhibitors for cancer chemotherapy. Biomed 209, 106347. doi:10.1016/j.cmpb.2021.106347
Atz, K., Cotos, L., Isert, C., Håkansson, M., Focht, D., Hilleke, M., et al. (2024). Prospective de novo drug design with deep interactome learning. Nat. Commun. 15, 3408. doi:10.1038/s41467-024-47613-w
Aulifa, D. L., Amirah, S. R., Rahayu, D., Megantara, S., and Muchtaridi, M. (2024). Pharmacophore modeling and binding affinity of secondary Metabolites from Angelica keiskei to HMG Co-A reductase. Molecules 29, 2983. doi:10.3390/molecules29132983
Aziz, M., Ejaz, S. A., Tamam, N., Siddique, F., Riaz, N., Qais, F. A., et al. (2022). Identification of potent inhibitors of NEK7 protein using a comprehensive computational approach. Sci. Rep. 12, 6404. doi:10.1038/s41598-022-10253-5
Barrow, A. S., Smedley, C. J., Zheng, Q., Li, S., Dong, J., and Moses, J. E. (2019). The growing applications of SuFEx click chemistry. Chem. Soc. Rev. 48, 4731–4758. doi:10.1039/c8cs00960k
Bedard, P. L., Hyman, D. M., Davids, M. S., and Siu, L. L. (2020). Small molecules, big impact: 20 years of targeted therapy in oncology. Lancet 395, 1078–1088. doi:10.1016/s0140-6736(20)30164-1
Bhardwaj, A., Kaur, J., Wuest, M., and Wuest, F. (2017). In situ click chemistry generation of cyclooxygenase-2 inhibitors. Nat. Commun. 8, 1. doi:10.1038/s41467-016-0009-6
Bonanno, E., and Ebejer, J. P. (2019). Applying machine learning to Ultrafast Shape recognition in ligand-based virtual screening. Front. Pharmacol. 10, 1675. doi:10.3389/fphar.2019.01675
Bondeson, D. P., Mares, A., Smith, I. E. D., Ko, E., Campos, S., Miah, A. H., et al. (2015). Catalytic in vivo protein knockdown by small-molecule PROTACs. Nat. Chem. Biol. 11, 611–617. doi:10.1038/nchembio.1858
Brenner, S., and Lerner, R. A. (1992). Encoded combinatorial chemistry. Proc. Natl. Acad. Sci. U. S. A. 89, 5381–5383. doi:10.1073/pnas.89.12.5381
Bullock, C., Cornia, N., Jacob, R., Remm, A., Peavey, T., Weekes, K., et al. (2013). DockoMatic 2.0: high throughput inverse virtual screening and homology modeling. J. Chem. Inf. Model. 53, 2161–2170. doi:10.1021/ci400047w
Burslem, G. M., and Crews, C. M. (2020). Proteolysis-targeting chimeras as therapeutics and tools for biological discovery. Cell 181, 102–114. doi:10.1016/j.cell.2019.11.031
Cai, J. H., Zhu, X. Z., Guo, P. Y., Rose, P., Liu, X. T., Liu, X., et al. (2023). Recent updates in click and computational chemistry for drug discovery and development. Front. Chem. 11, 1114970. doi:10.3389/fchem.2023.1114970
Cai, Z., Zafferani, M., Akande, O. M., and Hargrove, A. E. (2022). Quantitative structure–activity relationship (QSAR) study predicts small-molecule binding to RNA structure. J. Med. Chem. 65, 7262–7277. doi:10.1021/acs.jmedchem.2c00254
Campbell, I. B., Macdonald, S. J. F., and Procopiou, P. A. (2018). Medicinal chemistry in drug discovery in big pharma: past, present and future. Drug. Discov. Today 23, 219–234. doi:10.1016/j.drudis.2017.10.007
Caselli, E., Romagnoli, C., Vahabi, R., Taracila, M. A., Bonomo, R. A., and Prati, F. (2015). Click chemistry in lead optimization of Boronic acids as β-Lactamase inhibitors. J. Med. Chem. 58, 5445–5458. doi:10.1021/acs.jmedchem.5b00341
Chen, P., Bao, T., Yu, X., and Liu, Z. (2021). A drug repositioning algorithm based on a deep autoencoder and adaptive fusion. BMC Bioinforma. 22, 532. doi:10.1186/s12859-021-04406-y
Chen, Q., Li, Y., Lin, C., Chen, L., Luo, H., Xia, S., et al. (2022). Expanding the DNA-encoded library toolbox: identifying small molecules targeting RNA. Nucleic. acids. Res. 50, e67. doi:10.1093/nar/gkac173
Chen, Y., Xu, Y., Liu, D., Xing, Y., and Gong, H. (2024). An end-to-end framework for the prediction of protein structure and fitness from single sequence. Nat. Commun. 15, 7400. doi:10.1038/s41467-024-51776-x
Chen, Y.-J., Wu, H., and Shen, X.-Z. (2016). The ubiquitin–proteasome system and its potential application in hepatocellular carcinoma therapy. Cancer. Lett. 379, 245–252. doi:10.1016/j.canlet.2015.06.023
Cheng, T., Li, Q., Zhou, Z., Wang, Y., and Bryant, S. H. (2012). Structure-based virtual screening for drug discovery: a problem-centric review. AAPS J. 14, 133–141. doi:10.1208/s12248-012-9322-0
Clark, M. A., Acharya, R. A., Arico-Muendel, C. C., Belyanskaya, S. L., Benjamin, D. R., Carlson, N. R., et al. (2009). Design, synthesis and selection of DNA-encoded small-molecule libraries. Nat. Chem. Biol. 5, 647–654. doi:10.1038/nchembio.211
Cochrane, W. G., Fitzgerald, P. R., and Paegel, B. M. (2021). Antibacterial discovery via phenotypic DNA-encoded library screening. ACS Chem. Bio. 16, 2752–2756. doi:10.1021/acschembio.1c00714
Daina, A., Michielin, O., and Zoete, V. (2017). SwissADME: a free web tool to evaluate pharmacokinetics, drug-likeness and medicinal chemistry friendliness of small molecules. Sci. Rep. 7, 42717. doi:10.1038/srep42717
Darvishi, F., Beiranvand, E., Kalhor, H., Shahbazi, B., and Mafakher, L. (2024). Homology modeling and molecular docking studies to decrease glutamine affinity of Yarrowia lipolytica L-asparaginase. Int. J. Biol. Macromol. 263, 130312. doi:10.1016/j.ijbiomac.2024.130312
Davis, J. S., Ferreira, D., Paige, E., Gedye, C., and Boyle, M. (2020). Infectious Complications of biological and small molecule targeted Immunomodulatory therapies. Clin. Microbiol. Rev. 33. doi:10.1128/cmr.00035-19
Defelipe, L. A., Arcon, J. P., Modenutti, C. P., Marti, M. A., Turjanski, A. G., and Barril, X. (2018). Solvents to fragments to drugs: MD applications in drug design. Molecules 23, 3269. doi:10.3390/molecules23123269
Díaz-Holguín, A., Saarinen, M., Vo, D. D., Sturchio, A., Branzell, N., Cabeza de Vaca, I., et al. (2024). AlphaFold accelerated discovery of psychotropic agonists targeting the trace amine-associated receptor 1. Sci. Adv. 10, eadn1524. doi:10.1126/sciadv.adn1524
Ding, Y., Fei, Y., and Lu, B. (2020). Emerging new concepts of degrader technologies. Trends. Pharmacol. Sci. 41, 464–474. doi:10.1016/j.tips.2020.04.005
Ding, Y., Xing, D., Fei, Y., and Lu, B. (2022). Emerging degrader technologies engaging lysosomal pathways. Chem. Soc. Rev. 51, 8832–8876. doi:10.1039/d2cs00624c
Dockerill, M., and Winssinger, N. (2023). DNA-encoded libraries: towards harnessing their full power with Darwinian evolution. Angew. Chem. Int. Ed. Engl. 62, e202215542. doi:10.1002/anie.202215542
Eastman, P., Swails, J., Chodera, J. D., McGibbon, R. T., Zhao, Y., Beauchamp, K. A., et al. (2017). OpenMM 7: rapid development of high performance algorithms for molecular dynamics. PLoS. Comput. Biol. 13, e1005659. doi:10.1371/journal.pcbi.1005659
Eldridge, A. G., and O'Brien, T. (2009). Therapeutic strategies within the ubiquitin proteasome system. Cell. death. Differ. 17, 4–13. doi:10.1038/cdd.2009.82
Ellis, R. J. (2001). Macromolecular crowding: obvious but underappreciated. Trends. biochem. Sci. 26, 597–604. doi:10.1016/s0968-0004(01)01938-7
Ferreira, L. L. G., and Andricopulo, A. D. (2019). ADMET modeling approaches in drug discovery. Drug. Discov. Today 24, 1157–1165. doi:10.1016/j.drudis.2019.03.015
Forli, S., Huey, R., Pique, M. E., Sanner, M. F., Goodsell, D. S., and Olson, A. J. (2016). Computational protein-ligand docking and virtual drug screening with the AutoDock suite. Nat. Protoc. 11, 905–919. doi:10.1038/nprot.2016.051
Francesco, Z. (2023). Looking back and moving forward in medicinal chemistry. Nat. Commun. 14, 4299. doi:10.1038/s41467-023-39949-6
Fu, L., Shi, S., Yi, J., Wang, N., He, Y., Wu, Z., et al. (2024). ADMETlab 3.0: an updated comprehensive online ADMET prediction platform enhanced with broader coverage, improved performance, API functionality and decision support. Nucleic. acids. Res. 52, W422–w431. doi:10.1093/nar/gkae236
Fu, Y., Chen, N., Wang, Z., Luo, S., Ding, Y., and Lu, B. (2021). Degradation of lipid droplets by chimeric autophagy-tethering compounds. Cell. Res. 31, 965–979. doi:10.1038/s41422-021-00532-7
Gado, F., Ferrisi, R., Polini, B., Mohamed, K. A., Ricardi, C., Lucarini, E., et al. (2022). Design, synthesis, and biological activity of new CB2 receptor ligands: from Orthosteric and allosteric Modulators to Dualsteric/bitopic ligands. J. Med. Chem. 65, 9918–9938. doi:10.1021/acs.jmedchem.2c00582
Gartner, Z. J., and Liu, D. R. (2001). The generality of DNA-templated synthesis as a basis for evolving non-natural small molecules. J. Am. Chem. Soc. 123, 6961–6963. doi:10.1021/ja015873n
Ghosh, S., and Cho, S. J. (2023). Three-dimensional-QSAR and relative binding affinity estimation of focal adhesion kinase inhibitors. Molecules 28, 1464. doi:10.3390/molecules28031464
Giordano, D., Biancaniello, C., Argenio, M. A., and Facchiano, A. (2022). Drug design by pharmacophore and virtual screening approach. Pharm. (Basel) 15, 646. doi:10.3390/ph15050646
Glassford, I., Teijaro, C. N., Daher, S. S., Weil, A., Small, M. C., Redhu, S. K., et al. (2016). Ribosome-templated azide-alkyne cycloadditions: synthesis of potent Macrolide Antibiotics by in situ click chemistry. J. Am. Chem. Soc. 138, 3136–3144. doi:10.1021/jacs.5b13008
Gorgulla, C., Boeszoermenyi, A., Wang, Z.-F., Fischer, P. D., Coote, P. W., Padmanabha Das, K. M., et al. (2020). An open-source drug discovery platform enables ultra-large virtual screens. Nature 580, 663–668. doi:10.1038/s41586-020-2117-z
Gottlieb, A., Stein, G. Y., Ruppin, E., and Sharan, R. (2011). PREDICT: a method for inferring novel drug indications with application to personalized medicine. Mol. Syst. Biol. 7, 496. doi:10.1038/msb.2011.26
Han, T., Goralski, M., Gaskill, N., Capota, E., Kim, J., Ting, T. C., et al. (2017). Anticancer sulfonamides target splicing by inducing RBM39 degradation via recruitment to DCAF15. Science. 356, eaal3755. doi:10.1126/science.aal3755
Harris, P. A., Berger, S. B., Jeong, J. U., Nagilla, R., Bandyopadhyay, D., Campobasso, N., et al. (2017). Discovery of a first-in-class receptor interacting protein 1 (RIP1) kinase specific clinical candidate (GSK2982772) for the treatment of inflammatory diseases. J. Med. Chem. 60, 1247–1261. doi:10.1021/acs.jmedchem.6b01751
Harris, P. A., King, B. W., Bandyopadhyay, D., Berger, S. B., Campobasso, N., Capriotti, C. A., et al. (2016). DNA-encoded library screening identifies Benzo[b] [1,4]oxazepin-4-ones as highly potent and Monoselective receptor interacting protein 1 kinase inhibitors. J. Med. Chem. 59, 2163–2178. doi:10.1021/acs.jmedchem.5b01898
Haupt, V. J., and Schroeder, M. (2011). Old friends in new guise: repositioning of known drugs with structural bioinformatics. Brief. Bioinform. 12, 312–326. doi:10.1093/bib/bbr011
He, H., Duo, H., Hao, Y., Zhang, X., Zhou, X., Zeng, Y., et al. (2023). Computational drug repurposing by exploiting large-scale gene expression data: strategy, methods and applications. Comput. Biol. Med. 155, 106671. doi:10.1016/j.compbiomed.2023.106671
Homer, J. A., Koelln, R. A., Barrow, A. S., Gialelis, T. L., Boiarska, Z., Steinohrt, N. S., et al. (2024). Modular synthesis of functional libraries by accelerated SuFEx click chemistry. Chem. Sci. 15, 3879–3892. doi:10.1039/d3sc05729a
Hong, B. T., Cheng, Y. E., Cheng, T. J., and Fang, J. M. (2019). Boronate, trifluoroborate, sulfone, sulfinate and sulfonate congeners of oseltamivir carboxylic acid: synthesis and anti-influenza activity. Eur. J. Med. Chem. 163, 710–721. doi:10.1016/j.ejmech.2018.12.027
Houtman, M. J. C., Friesacher, T., Chen, X., Zangerl-Plessl, E.-M., Heyden, M. A. G. v.d., and Stary-Weinzinger, A. (2022). Development of IKATP ion channel blockers targeting Sulfonylurea resistant mutant KIR6.2 based channels for treating DEND syndrome. Front. Pharmacol. 12, 814066. doi:10.3389/fphar.2021.814066
Hsieh, C. J., Giannakoulias, S., Petersson, E. J., and Mach, R. H. (2023). Computational chemistry for the identification of lead compounds for Radiotracer development. Pharm. (Basel) 16, 317. doi:10.3390/ph16020317
Hu, X., and Manetsch, R. (2010a). Kinetic target-guided synthesis. Chem. Soc. Rev. 39, 1316–1324. doi:10.1039/b904092g
Hu, X., and Manetsch, R. (2010b). Kinetic target-guided synthesis. Chem. Soc. Rev. 39, 1316–1324. doi:10.1039/b904092g
Huang, Y., Hou, R., Lam, F. S., Jia, Y., Zhou, Y., He, X., et al. (2024). Agonist discovery for membrane proteins on live cells by using DNA-encoded libraries. J. Am. Chem. Soc. 146, 24638–24653. doi:10.1021/jacs.4c08624
Ibrahim, M. T., Lee, J., and Tao, P. (2022). Homology modeling of Forkhead box protein C2: identification of potential inhibitors using ligand and structure-based virtual screening. Mol. Divers. 27, 1661–1674. doi:10.1007/s11030-022-10519-0
Imrie, F., Hadfield, T. E., Bradley, A. R., and Deane, C. M. (2021). Deep generative design with 3D pharmacophoric constraints. Chem. Sci. 12, 14577–14589. doi:10.1039/d1sc02436a
Janson, G., and Paiardini, A. (2021). PyMod 3: a complete suite for structural bioinformatics in PyMOL. Bioinforma. Oxf. 37, 1471–1472. doi:10.1093/bioinformatics/btaa849
Ji, C. H., Kim, H. Y., Lee, M. J., Heo, A. J., Park, D. Y., Lim, S., et al. (2022). The AUTOTAC chemical biology platform for targeted protein degradation via the autophagy-lysosome system. Nat. Commun. 13, 904. doi:10.1038/s41467-022-28520-4
Jiang, X., Hao, X., Jing, L., Wu, G., Kang, D., Liu, X., et al. (2019). Recent applications of click chemistry in drug discovery. Expert. Opin. Drug. Discov. 14, 779–789. doi:10.1080/17460441.2019.1614910
Jiménez-Luna, J., Grisoni, F., Weskamp, N., and Schneider, G. (2021). Artificial intelligence in drug discovery: recent advances and future perspectives. Expert. Opin. Drug. Discov. 16, 949–959. doi:10.1080/17460441.2021.1909567
Keiser, M. J., Setola, V., Irwin, J. J., Laggner, C., Abbas, A. I., Hufeisen, S. J., et al. (2009). Predicting new molecular targets for known drugs. Nature 462, 175–181. doi:10.1038/nature08506
Keserü, G. M., and Makara, G. M. (2009). The influence of lead discovery strategies on the properties of drug candidates. Nat. Rev. Drug. Discov. 8, 203–212. doi:10.1038/nrd2796
Keutzer, L., You, H., Farnoud, A., Nyberg, J., Wicha, S. G., Maher-Edwards, G., et al. (2022). Machine learning and Pharmacometrics for prediction of pharmacokinetic data: Differences, Similarities and challenges illustrated with Rifampicin. Pharmaceutics 14, 1530. doi:10.3390/pharmaceutics14081530
Khairullina, V., and Martynova, Y. (2023). Quantitative structure–activity relationship in the series of 5-ethyluridine, N2-guanine, and 6-oxopurine derivatives with Pronounced anti-herpetic activity. Molecules 28, 7715. doi:10.3390/molecules28237715
Kim, E., and Koo, H. (2019). Biomedical applications of copper-free click chemistry: in vitro, in vivo, and ex vivo. Chem. Sci. 10, 7835–7851. doi:10.1039/c9sc03368h
Kitamura, S., Zheng, Q., Woehl, J. L., Solania, A., Chen, E., Dillon, N., et al. (2020). Sulfur(VI) fluoride exchange (SuFEx)-Enabled high-throughput medicinal chemistry. J. Am. Chem. Soc. 142, 10899–10904. doi:10.1021/jacs.9b13652
Koes, D. R., and Camacho, C. J. (2012). ZINCPharmer: pharmacophore search of the ZINC database. Nucleic. acids. Res. 40, W409–W414. doi:10.1093/nar/gks378
Kolb, H. C., Finn, M. G., and Sharpless, K. B. (2001). Click chemistry: diverse chemical function from a few Good reactions. Angew. Chem. Int. Ed. Engl. 40, 2004–2021. doi:10.1002/1521-3773(20010601)40:11<2004::aid-anie2004>3.3.co;2-x
Konstantinidou, M., Li, J., Zhang, B., Wang, Z., Shaabani, S., Ter Brake, F., et al. (2019). PROTACs– a game-changing technology. Expert. Opin. Drug. Discov. 14, 1255–1268. doi:10.1080/17460441.2019.1659242
Kozicka, Z., Suchyta, D. J., Focht, V., Kempf, G., Petzold, G., Jentzsch, M., et al. (2023). Design principles for cyclin K molecular glue degraders. Nat. Chem. Biol. 20, 93–102. doi:10.1038/s41589-023-01409-z
Krönke, J., Udeshi, N. D., Narla, A., Grauman, P., Hurst, S. N., McConkey, M., et al. (2014). Lenalidomide causes selective degradation of IKZF1 and IKZF3 in multiple Myeloma cells. Science 343, 301–305. doi:10.1126/science.1244851
Kugler, M., Hadzima, M., Dzijak, R., Rampmaier, R., Srb, P., Vrzal, L., et al. (2023). Identification of specific carbonic anhydrase inhibitors via in situ click chemistry, phage-display and synthetic peptide libraries: comparison of the methods and structural study. RSC Med. Chem. 14, 144–153. doi:10.1039/d2md00330a
Kuntz, I. D., Blaney, J. M., Oatley, S. J., Langridge, R., and Ferrin, T. E. (1982). A geometric approach to macromolecule-ligand interactions. J. Mol. Biol. 161, 269–288. doi:10.1016/0022-2836(82)90153-x
Kuzmanic, A., Bowman, G. R., Juarez-Jimenez, J., Michel, J., and Gervasio, F. L. (2020). Investigating cryptic binding sites by molecular dynamics simulations. Acc. Chem. Res. 53, 654–661. doi:10.1021/acs.accounts.9b00613
Lagorce, D., Bouslama, L., Becot, J., Miteva, M. A., and Villoutreix, B. O. (2017). FAF-Drugs4: free ADME-tox filtering computations for chemical biology and early stages drug discovery. Bioinformatics 33, 3658–3660. doi:10.1093/bioinformatics/btx491
Le Droumaguet, B., Guerrouache, M., and Carbonnier, B. (2022). Contribution of the “click chemistry” toolbox for the design, synthesis, and resulting applications of innovative and efficient separative supports: time for assessment. Macromol. Rapid. Commum. 43, e2200210. doi:10.1002/marc.202200210
Lee, C., Su, B. H., and Tseng, Y. J. (2022). Comparative studies of AlphaFold, RoseTTAFold and Modeller: a case study involving the use of G-protein-coupled receptors. Brief. Bioinform. 23, bbac308. doi:10.1093/bib/bbac308
Lee, C.-H., Huang, H.-C., and Juan, H.-F. (2011). Reviewing ligand-based rational drug design: the search for an ATP Synthase inhibitor. Int. J. Mol. Sci. 12, 5304–5318. doi:10.3390/ijms12085304
Lee, J., Sung, K. W., Bae, E.-J., Yoon, D., Kim, D., Lee, J. S., et al. (2023). Targeted degradation of ⍺-synuclein aggregates in Parkinson’s disease using the AUTOTAC technology. Mol. Neurodegener. 18, 41. doi:10.1186/s13024-023-00630-7
Lee, Y., Basith, S., and Choi, S. (2017). Recent advances in structure-based drug design targeting class A G protein-coupled receptors utilizing crystal structures and computational simulations. J. Med. Chem. 61, 1–46. doi:10.1021/acs.jmedchem.6b01453
Li, H., Dong, J., Cai, M., Xu, Z., Cheng, X.-D., and Qin, J.-J. (2021). Protein degradation technology: a strategic paradigm shift in drug discovery. J. Hematol. Oncol. 14, 138. doi:10.1186/s13045-021-01146-7
Li, Z., Wang, C., Wang, Z., Zhu, C., Li, J., Sha, T., et al. (2019). Allele-selective lowering of mutant HTT protein by HTT–LC3 linker compounds. Nature 575, 203–209. doi:10.1038/s41586-019-1722-1
Lima, A. N., Philot, E. A., Trossini, G. H. G., Scott, L. P. B., Maltarollo, V. G., and Honorio, K. M. (2016). Use of machine learning approaches for novel drug discovery. Expert. Opin. Drug. Discov. 11, 225–239. doi:10.1517/17460441.2016.1146250
Lin, Z., Akin, H., Rao, R., Hie, B., Zhu, Z., Lu, W., et al. (2023). Evolutionary-scale prediction of atomic-level protein structure with a language model. Science. 379, 1123–1130. doi:10.1126/science.ade2574
Lionta, E., Spyrou, G., Vassilatis, D. K., and Cournia, Z. (2014). Structure-based virtual screening for drug discovery: principles, applications and recent advances. Curr. Top. Med. Chem. 14, 1923–1938. doi:10.2174/1568026614666140929124445
Liu, B. H. M., Lin, Y., Long, X., Hung, S. W., Gaponova, A., Ren, F., et al. (2024b). Utilizing AI for the identification and validation of novel therapeutic targets and repurposed drugs for endometriosis. Adv. Sci. (Weinh)., e2406565. doi:10.1002/advs.202406565
Liu, G., Catacutan, D. B., Rathod, K., Swanson, K., Jin, W., Mohammed, J. C., et al. (2023a). Deep learning-guided discovery of an antibiotic targeting Acinetobacter baumannii. Nat. Chem. Biol. 19, 1342–1350. doi:10.1038/s41589-023-01349-8
Liu, X., Shi, D., Zhou, S., Liu, H., Liu, H., and Yao, X. (2018). Molecular dynamics simulations and novel drug discovery. Expert. Opin. Drug. Discov. 13, 23–37. doi:10.1080/17460441.2018.1403419
Liu, Y., Sun, X., Liu, Q., Han, C., and Rao, Y. (2024a). A dual-target and dual-mechanism design strategy by combining inhibition and degradation Together. J. Am. Chem. Soc. 147, 3110–3118. doi:10.1021/jacs.4c11930
Liu, Z., Gao, J., Li, C., Xu, L., Lv, X., Deng, H., et al. (2023b). Application of QSAR models for acute toxicity of tetrazole compounds administrated orally and intraperitoneally in rat and mouse. Toxicology 500, 153679. doi:10.1016/j.tox.2023.153679
Luo, Y., Zhao, X., Zhou, J., Yang, J., Zhang, Y., Kuang, W., et al. (2017). A network integration approach for drug-target interaction prediction and computational drug repositioning from heterogeneous information. Nat. Commun. 8, 573. doi:10.1038/s41467-017-00680-8
Lv, L., Chen, P., Cao, L., Li, Y., Zeng, Z., Cui, Y., et al. (2020). Discovery of a molecular glue promoting CDK12-DDB1 interaction to trigger cyclin K degradation. eLife 9, e59994. doi:10.7554/eLife.59994
Macalino, S. J. Y., Gosu, V., Hong, S., and Choi, S. (2015). Role of computer-aided drug design in modern drug discovery. Arch. Pharm. Res. 38, 1686–1701. doi:10.1007/s12272-015-0640-5
Maia, E. H. B., Assis, L. C., de Oliveira, T. A., da Silva, A. M., and Taranto, A. G. (2020). Structure-based virtual screening: from classical to artificial intelligence. Front. Chem. 8, 343. doi:10.3389/fchem.2020.00343
Matsuo, B., Granados, A., Levitre, G., and Molander, G. A. (2023). Photochemical methods applied to DNA encoded library (DEL) synthesis. Acc. Chem. Res. 56, 385–401. doi:10.1021/acs.accounts.2c00778
McGibbon, M., Money-Kyrle, S., Blay, V., and Houston, D. R. (2023). SCORCH: improving structure-based virtual screening with machine learning classifiers, data augmentation, and uncertainty estimation. J. Adv. Res. 46, 135–147. doi:10.1016/j.jare.2022.07.001
McNair, D. (2023). Artificial intelligence and machine learning for lead-to-candidate decision-making and beyond. Annu. Rev. Pharmacol. Toxicol. 63, 77–97. doi:10.1146/annurev-pharmtox-051921-023255
McNutt, A. T., Francoeur, P., Aggarwal, R., Masuda, T., Meli, R., Ragoza, M., et al. (2021). GNINA 1.0: molecular docking with deep learning. J. Cheminform. 13, 43. doi:10.1186/s13321-021-00522-2
Morgan, P., Van Der Graaf, P. H., Arrowsmith, J., Feltner, D. E., Drummond, K. S., Wegner, C. D., et al. (2012). Can the flow of medicines be improved? Fundamental pharmacokinetic and pharmacological principles toward improving Phase II survival. Drug. Discov. Today 17, 419–424. doi:10.1016/j.drudis.2011.12.020
Neri, D., and Lerner, R. A. (2018). DNA-encoded chemical libraries: a selection system based on Endowing organic compounds with amplifiable information. Annu. Rev. Biochem. 87, 479–502. doi:10.1146/annurev-biochem-062917-012550
Parra Sánchez, A. R., Voskuyl, A. E., and van Vollenhoven, R. F. (2022). Treat-to-target in systemic lupus erythematosus: advancing towards its implementation. Nat. Rev. Rheumatol. 18, 146–157. doi:10.1038/s41584-021-00739-3
Pérez-Castillo, Y., Cruz-Monteagudo, M., Lazar, C., Taminau, J., Froeyen, M., Cabrera-Pérez, M. A., et al. (2014). Toward the computer-aided discovery of FabH inhibitors. Do predictive QSAR models ensure high quality virtual screening performance? Mol. Divers. 18, 637–654. doi:10.1007/s11030-014-9513-y
Perron, Q., Mirguet, O., Tajmouati, H., Skiredj, A., Rojas, A., Gohier, A., et al. (2022). Deep generative models for ligand-based de novo design applied to multi-parametric optimization. J. Comput. Chem. 43, 692–703. doi:10.1002/jcc.26826
Petersen, L. K., Christensen, A. B., Andersen, J., Folkesson, C. G., Kristensen, O., Andersen, C., et al. (2021). Screening of DNA-encoded small molecule libraries inside a living cell. J. Am. Chem. Soc. 143, 2751–2756. doi:10.1021/jacs.0c09213
Peterson, A. A., and Liu, D. R. (2023). Small-molecule discovery through DNA-encoded libraries. Nat. Rev. Drug Discov. 22, 699–722. doi:10.1038/s41573-023-00713-6
Phillips, J. C., Hardy, D. J., Maia, J. D. C., Stone, J. E., Ribeiro, J. V., Bernardi, R. C., et al. (2020). Scalable molecular dynamics on CPU and GPU architectures with NAMD. J. Chem. Phys. 153, 044130. doi:10.1063/5.0014475
Potowski, M., Kunig, V. B. K., Eberlein, L., Vakalopoulos, A., Kast, S. M., and Brunschweiger, A. (2021). Chemically stabilized DNA Barcodes for DNA-encoded chemistry. Angew. Chem. Int. Ed. Engl. 60, 19744–19749. doi:10.1002/anie.202104348
Rifaioglu, A. S., Nalbat, E., Atalay, V., Martin, M. J., Cetin-Atalay, R., and Doğan, T. (2020). DEEPScreen: high performance drug-target interaction prediction with convolutional neural networks using 2-D structural compound representations. Chem. Sci. 11, 2531–2557. doi:10.1039/c9sc03414e
Rusinko, A., Rezaei, M., Friedrich, L., Buchstaller, H. P., Kuhn, D., and Ghogare, A. (2024). AIDDISON: Empowering drug discovery with AI/ML and CADD tools in a secure, web-based SaaS platform. J. Chem. Inf. Model. 64, 3–8. doi:10.1021/acs.jcim.3c01016
Rzuczek, S. G., Park, H., and Disney, M. D. (2014). A toxic RNA catalyzes the in cellulo synthesis of its own inhibitor. Angew. Chem. Int. Ed. Engl. 53, 10956–10959. doi:10.1002/anie.201406465
Sadybekov, A. V., and Katritch, V. (2023). Computational approaches streamlining drug discovery. Nature 616, 673–685. doi:10.1038/s41586-023-05905-z
Saftig, P., and Klumperman, J. (2009). Lysosome biogenesis and lysosomal membrane proteins: trafficking meets function. Nat. Rev. Mol. Cell. Bio. 10, 623–635. doi:10.1038/nrm2745
Sainy, J., and Sharma, R. (2015). QSAR analysis of thiolactone derivatives using HQSAR, CoMFA and CoMSIA. Sar. QSAR. Environ. Res. 26, 873–892. doi:10.1080/1062936x.2015.1095238
Sakamoto, K. M., Kim, K. B., Kumagai, A., Mercurio, F., Crews, C. M., and Deshaies, R. J. (2001). Protacs: chimeric molecules that target proteins to the Skp1-Cullin-F box complex for ubiquitination and degradation. Proc. Natl. Acad. Sci. U. S. A. 98, 8554–8559. doi:10.1073/pnas.141230798
Saldívar-González, F. I., and Medina-Franco, J. L. (2022). Approaches for enhancing the analysis of chemical space for drug discovery. Expert. Opin. Drug. Discov. 17, 789–798. doi:10.1080/17460441.2022.2084608
Scheuermann, J., Dumelin, C. E., Melkko, S., and Neri, D. (2006). DNA-encoded chemical libraries. J. Biotechnol. 126, 568–581. doi:10.1016/j.jbiotec.2006.05.018
Schneider, G., and Fechner, U. (2005). Computer-based de novo design of drug-like molecules. Nat. Rev. Drug. Discov. 4, 649–663. doi:10.1038/nrd1799
Schneider, G., Funatsu, K., Okuno, Y., and Winkler, D. (2017). De novo drug design - Ye olde scoring problem Revisited. Mol. Inf. 36. doi:10.1002/minf.201681031
Schreiber, S. L. (1992). Immunophilin-sensitive protein phosphatase action in cell signaling pathways. Cell 70, 365–368. doi:10.1016/0092-8674(92)90158-9
Serafini, M., Cordero-Sanchez, C., Di Paola, R., Bhela, I. P., Aprile, S., Purghè, B., et al. (2020). Store-operated calcium entry as a therapeutic target in acute pancreatitis: discovery and development of drug-like SOCE inhibitors. J. Med. Chem. 63, 14761–14779. doi:10.1021/acs.jmedchem.0c01305
Shah, M., and Arumugam, S. (2024). Exploring putative drug properties associated with TNF-alpha inhibition and identification of potential targets in cardiovascular disease using machine learning-assisted QSAR modeling and virtual reverse pharmacology approach. Mol. Divers. 28, 2263–2287. doi:10.1007/s11030-024-10921-w
Shankaraiah, N., Sakla, A. P., Laxmikeshav, K., and Tokala, R. (2019). Reliability of click chemistry on drug discovery: a Personal Account. Chem. Rec. 20, 253–272. doi:10.1002/tcr.201900027
Shen, C., Wang, Z., Yao, X., Li, Y., Lei, T., Wang, E., et al. (2020). Comprehensive assessment of nine docking programs on type II kinase inhibitors: prediction accuracy of sampling power, scoring power and screening power. Brief. Bioinform. 21, 282–297. doi:10.1093/bib/bby103
Słabicki, M., Kozicka, Z., Petzold, G., Li, Y.-D., Manojkumar, M., Bunker, R. D., et al. (2020). The CDK inhibitor CR8 acts as a molecular glue degrader that depletes cyclin K. Nature 585, 293–297. doi:10.1038/s41586-020-2374-x
Sohlenius-Sternbeck, A. K., and Terelius, Y. (2022). Evaluation of ADMET predictor in early discovery drug metabolism and pharmacokinetics project work. Drug. Metab. Dispos. 50, 95–104. doi:10.1124/dmd.121.000552
Song, J., Hu, M., Zhou, J., Xie, S., Li, T., and Li, Y. (2023). Targeted protein degradation in drug development: recent advances and future challenges. Eur. J. Med. Chem. 261, 115839. doi:10.1016/j.ejmech.2023.115839
Song, Y., Yuan, Q., Chen, S., Zeng, Y., Zhao, H., and Yang, Y. (2024). Accurately predicting enzyme functions through geometric graph learning on ESMFold-predicted structures. Nat. Commun. 15, 8180. doi:10.1038/s41467-024-52533-w
Stafford, K. A., Anderson, B. M., Sorenson, J., and van den Bedem, H. (2022). AtomNet PoseRanker: Enriching ligand pose quality for dynamic proteins in virtual high-throughput screens. J. Chem. Inf. Model. 62, 1178–1189. doi:10.1021/acs.jcim.1c01250
Stork, C., Chen, Y., Šícho, M., and Kirchmair, J. (2019). Hit Dexter 2.0: machine-learning models for the prediction of Frequent Hitters. J. Chem. Inf. Model. 59, 1030–1043. doi:10.1021/acs.jcim.8b00677
Sugiki, T., Furuita, K., Fujiwara, T., and Kojima, C. (2018). Current NMR techniques for structure-based drug discovery. Molecules 23, 148. doi:10.3390/molecules23010148
Takahashi, D., Moriyama, J., Nakamura, T., Miki, E., Takahashi, E., Sato, A., et al. (2019). AUTACs: Cargo-specific degraders using selective autophagy. Mol. Cell. 76, 797–810. doi:10.1016/j.molcel.2019.09.009
Takahashi, D., Ora, T., Sasaki, S., Ishii, N., Tanaka, T., Matsuda, T., et al. (2023). Second-generation AUTACs for targeted autophagic degradation. J. Med. Chem. 66, 12342–12372. doi:10.1021/acs.jmedchem.3c00861
Tan, S., Wang, D., Fu, Y., Zheng, H., Liu, Y., and Lu, B. (2023). Targeted clearance of mitochondria by an autophagy-tethering compound (ATTEC) and its potential therapeutic effects. Sci. Bull. (Beijing). 68, 3013–3026. doi:10.1016/j.scib.2023.10.021
Tang, W., Li, Y., Yu, Y., Wang, Z., Xu, T., Chen, J., et al. (2020b). Development of models predicting biodegradation rate rating with multiple linear regression and support vector machine algorithms. Chemosphere 253, 126666. doi:10.1016/j.chemosphere.2020.126666
Tang, Y., Feng, B., Wang, Y., Sun, H., You, Y., Yu, J., et al. (2020a). Structure-based discovery of CZL80, a caspase-1 inhibitor with therapeutic potential for febrile seizures and later enhanced epileptogenic susceptibility. Br. J. Pharmacol. 177, 3519–3534. doi:10.1111/bph.15076
Tang, Y., Moretti, R., and Meiler, J. (2024). Recent advances in automated structure-based de novo drug design. J. Chem. Inf. Model. 64, 1794–1805. doi:10.1021/acs.jcim.4c00247
Tejera, E., Munteanu, C. R., López-Cortés, A., Cabrera-Andrade, A., and Pérez-Castillo, Y. (2020). Drugs repurposing using QSAR, docking and molecular dynamics for possible inhibitors of the SARS-CoV-2 M(pro) protease. Molecules 25, 5172. doi:10.3390/molecules25215172
Temml, V., Kaserer, T., Kutil, Z., Landa, P., Vanek, T., and Schuster, D. (2014). Pharmacophore modeling for COX-1 and -2 inhibitors with LigandScout in comparison to discovery Studio. Future. Med. Chem. 6, 1869–1881. doi:10.4155/fmc.14.114
Thomas, M., Smith, R. T., O'Boyle, N. M., de Graaf, C., and Bender, A. (2021). Comparison of structure- and ligand-based scoring functions for deep generative models: a GPCR case study. J. Cheminform. 13, 39. doi:10.1186/s13321-021-00516-0
Toft-Bertelsen, T. L., Jeppesen, M. G., Tzortzini, E., Xue, K., Giller, K., Becker, S., et al. (2021). Amantadine has potential for the treatment of COVID-19 because it inhibits known and novel ion channels encoded by SARS-CoV-2. Commun. Biol. 4, 1347. doi:10.1038/s42003-021-02866-9
Toriki, E. S., Papatzimas, J. W., Nishikawa, K., Dovala, D., Frank, A. O., Hesse, M. J., et al. (2023). Rational chemical design of molecular glue degraders. ACS Cent. Sci. 9, 915–926. doi:10.1021/acscentsci.2c01317
Tropsha, A., Isayev, O., Varnek, A., Schneider, G., and Cherkasov, A. (2024). Integrating QSAR modelling and deep learning in drug discovery: the emergence of deep QSAR. Drug. Discov. 23, 141–155. doi:10.1038/s41573-023-00832-0
Uehara, T., Minoshima, Y., Sagane, K., Sugi, N. H., Mitsuhashi, K. O., Yamamoto, N., et al. (2017). Selective degradation of splicing factor CAPERα by anticancer sulfonamides. Nat. Chem. Biol. 13, 675–680. doi:10.1038/nchembio.2363
van Drie, J. H. (2003). Pharmacophore discovery--lessons learned. Curr. Pharm. Des. 9, 1649–1664. doi:10.2174/1381612033454568
van Montfort, R. L. M., and Workman, P. (2009). Structure-based design of molecular cancer therapeutics. Trends. Biotechnol. 27, 315–328. doi:10.1016/j.tibtech.2009.02.003
Vatté, J., Bourdeau, V., Ferbeyre, G., and Schmitzer, A. R. (2024). Gaining insight into mitochondrial targeting: AUTAC-biguanide as an anticancer agent. Molecules 29, 3773. doi:10.3390/molecules29163773
Vyas, V. K., Bhati, S., Patel, S., and Ghate, M. (2021). Structure- and ligand-based drug design methods for the modeling of antimalarial agents: a review of updates from 2012 onwards. J. Biomol. Struct. Dyn. 40, 10481–10506. doi:10.1080/07391102.2021.1932598
Wang, C., and Zhang, Y. (2017). Improving scoring-docking-screening powers of protein-ligand scoring functions using random forest. J. Comput. Chem. 38, 169–177. doi:10.1002/jcc.24667
Wang, W., Zhou, Q., Jiang, T., Li, S., Ye, J., Zheng, J., et al. (2021a). A novel small-molecule PROTAC selectively promotes tau clearance to improve cognitive functions in Alzheimer-like models. Theranostics 11, 5279–5295. doi:10.7150/thno.55680
Wang, X., Huang, B., Liu, X., and Zhan, P. (2016). Discovery of bioactive molecules from CuAAC click-chemistry-based combinatorial libraries. Drug. Discov. today 21, 118–132. doi:10.1016/j.drudis.2015.08.004
Wang, X., Shen, Y., Wang, S., Li, S., Zhang, W., Liu, X., et al. (2017b). PharmMapper 2017 update: a web server for potential drug target identification with a comprehensive target pharmacophore database. Nucleic. acids. Res. 45, W356-W360–w360. doi:10.1093/nar/gkx374
Wang, Y., Yang, X., Zhang, S., Guo, T. L., Zhao, B., Du, Q., et al. (2021b). Polarizability and aromaticity index govern AhR-mediated potencies of PAHs: a QSAR with consideration of freely dissolved concentrations. Chemosphere 268, 129343. doi:10.1016/j.chemosphere.2020.129343
Wang, Y., Zhu, J., and Zhang, L. (2017a). Discovery of cell-permeable O-GlcNAc transferase inhibitors via tethering in situ click chemistry. J. Med. Chem. 60, 263–272. doi:10.1021/acs.jmedchem.6b01237
Waterhouse, A., Bertoni, M., Bienert, S., Studer, G., Tauriello, G., Gumienny, R., et al. (2018). SWISS-MODEL: homology modelling of protein structures and complexes. Nucleic. acids. Res. 46, W296-W303–w303. doi:10.1093/nar/gky427
Weisel, K., Berger, S., Papp, K., Maari, C., Krueger, J. G., Scott, N., et al. (2020). Response to inhibition of receptor-interacting protein kinase 1 (RIPK1) in active Plaque psoriasis: a Randomized Placebo-controlled study. Clin. Pharmacol. Ther. 108, 808–816. doi:10.1002/cpt.1852
Wells, J. A., and Kumru, K. (2024). Extracellular targeted protein degradation: an emerging modality for drug discovery. Nat. Rev. Drug Discov. 23, 126–140. doi:10.1038/s41573-023-00833-z
Wickner, S., Maurizi, M. R., and Gottesman, S. (1999). Posttranslational quality control: folding, refolding, and degrading proteins. Science 286, 1888–1893. doi:10.1126/science.286.5446.1888
Wilson Lucas, S., Zijian Qin, R., Rakesh, K. P., Sharath Kumar, K. S., and Qin, H. L. (2023). Chemical and biology of sulfur fluoride exchange (SuFEx) click chemistry for drug discovery. Bioorg. Chem. 130, 106227. doi:10.1016/j.bioorg.2022.106227
Wu, H., Liu, J., Zhang, R., Lu, Y., Cui, G., Cui, Z., et al. (2024). A review of deep learning methods for ligand based drug virtual screening. Fundam. Res. 4, 715–737. doi:10.1016/j.fmre.2024.02.011
Wurz, R. P., Dellamaggiore, K., Dou, H., Javier, N., Lo, M.-C., McCarter, J. D., et al. (2017). A “click chemistry platform” for the rapid synthesis of Bispecific molecules for inducing protein degradation. J. Med. Chem. 61, 453–461. doi:10.1021/acs.jmedchem.6b01781
Xie, L., and Xie, L. (2019). Pathway-Centric structure-based multi-target compound screening for anti-Virulence drug repurposing. Int. J. Mol. Sci. 20, 3504. doi:10.3390/ijms20143504
Xie, X., Yu, T., Li, X., Zhang, N., Foster, L. J., Peng, C., et al. (2023). Recent advances in targeting the “undruggable” proteins: from drug discovery to clinical trials. Signal. Transduct. Target. Ther. 8, 335. doi:10.1038/s41392-023-01589-z
Yang, X., Wang, Y., Byrne, R., Schneider, G., and Yang, S. (2019). Concepts of artificial intelligence for computer-assisted drug discovery. Chem. Rev. 119, 10520–10594. doi:10.1021/acs.chemrev.8b00728
Yang, Z. Y., Fu, L., Lu, A. P., Liu, S., Hou, T. J., and Cao, D. S. (2021). Semi-automated workflow for molecular pair analysis and QSAR-assisted transformation space expansion. J. Cheminform. 13, 86. doi:10.1186/s13321-021-00564-6
Yekeen, A. A., Durojaye, O. A., Idris, M. O., Muritala, H. F., and Arise, R. O. (2023). CHAPERONg: a tool for automated GROMACS-based molecular dynamics simulations and trajectory analyses. Comput. Struct. Biotechnol. J. 21, 4849–4858. doi:10.1016/j.csbj.2023.09.024
Yelshanskaya, M. V., Singh, A. K., Narangoda, C., Williams, R. S. B., Kurnikova, M. G., and Sobolevsky, A. I. (2020). Structural basis of AMPA receptor inhibition by trans-4-butylcyclohexane carboxylic acid. Br. J. Pharmacol. 179, 3628–3644. doi:10.1111/bph.15254
Yi, J., Shi, S., Fu, L., Yang, Z., Nie, P., Lu, A., et al. (2024). OptADMET: a web-based tool for substructure modifications to improve ADMET properties of lead compounds. Nat. Protoc. 19, 1105–1121. doi:10.1038/s41596-023-00942-4
You, Y., Kim, H. S., Park, J. W., Keum, G., Jang, S. K., and Kim, B. M. (2018). Sulfur(vi) fluoride exchange as a key reaction for synthesizing biaryl sulfate core derivatives as potent hepatitis C virus NS5A inhibitors and their structure–activity relationship studies. RSC Adv. 8, 31803–31821. doi:10.1039/c8ra05471a
You, Y., Lai, X., Pan, Y., Zheng, H., Vera, J., Liu, S., et al. (2022). Artificial intelligence in cancer target identification and drug discovery. Signal. Transduct. Target. Ther. 7, 156. doi:10.1038/s41392-022-00994-0
Zhang, C., Liu, Y., Li, G., Yang, Z., Han, C., Sun, X., et al. (2024a). Targeting the undruggables—the power of protein degraders. Sci. Bull. 69, 1776–1797. doi:10.1016/j.scib.2024.03.056
Zhang, X., Zhang, O., Shen, C., Qu, W., Chen, S., Cao, H., et al. (2023). Efficient and accurate large library ligand docking with KarmaDock. Nat. Comput. Sci. 3, 789–804. doi:10.1038/s43588-023-00511-5
Zhang, Y., Lin, L., Qiao, S., Zhao, X., Li, T., and Liang, Q. (2024b). Screening and evaluation of the hit compound from a DNA-encoded library derived from natural products based on immobilized endothelin receptor A. Int. J. Biol. Macromol. 256, 128206. doi:10.1016/j.ijbiomac.2023.128206
Zhao, C., Rakesh, K. P., Ravidar, L., Fang, W. Y., and Qin, H. L. (2019). Pharmaceutical and medicinal significance of sulfur (S(VI))-Containing motifs for drug discovery: a critical review. Eur. J. Med. Chem. 162, 679–734. doi:10.1016/j.ejmech.2018.11.017
Zhao, L., Zhao, J., Zhong, K., Tong, A., and Jia, D. (2022). Targeted protein degradation: mechanisms, strategies and application. Signal. Transduct. Target. Ther. 7, 113. doi:10.1038/s41392-022-00966-4
Zhao, N., Ho, J. S. Y., Meng, F., Zheng, S., Kurland, A. P., Tian, L., et al. (2023). Generation of host-directed and virus-specific antivirals using targeted protein degradation promoted by small molecules and viral RNA mimics. Cell. host. Microbe. 31, 1154–1169.e10. doi:10.1016/j.chom.2023.05.030
Zhao, R., Zhu, J., Jiang, X., and Bai, R. (2024). Click chemistry-aided drug discovery: a retrospective and prospective outlook. Eur. J. Med. Chem. 264, 116037. doi:10.1016/j.ejmech.2023.116037
Zhong, L., Li, Y., Xiong, L., Wang, W., Wu, M., Yuan, T., et al. (2021). Small molecules in targeted cancer therapy: advances, challenges, and future perspectives. Signal. Transduct. Target. Ther. 6, 201. doi:10.1038/s41392-021-00572-w
Zhou, Q.-Q., Xiao, H.-T., Yang, F., Wang, Y.-D., Li, P., and Zheng, Z.-G. (2023). Advancing targeted protein degradation for metabolic diseases therapy. Pharmacol. Res. 188, 106627. doi:10.1016/j.phrs.2022.106627
Keywords: drug discovery, click chemistry, targeted protein degradation (TPD), DNA-encoded libraries (DELs), computer-aided drug design (CADD)
Citation: An Q, Huang L, Wang C, Wang D and Tu Y (2025) New strategies to enhance the efficiency and precision of drug discovery. Front. Pharmacol. 16:1550158. doi: 10.3389/fphar.2025.1550158
Received: 23 December 2024; Accepted: 22 January 2025;
Published: 11 February 2025.
Edited by:
Yuxiang Dong, University of Nebraska Medical Center, United StatesReviewed by:
Ammara Saleem, Government College University, Faisalabad, PakistanCopyright © 2025 An, Huang, Wang, Wang and Tu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dongmei Wang, aGVycmluZ2RvbmdAMTI2LmNvbQ==; Yalan Tu, dHlsOTUwMzMwQDE2My5jb20=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.