 Sheng Ye
Sheng Ye Jue Wang
Jue Wang Mingmin Zhu2
Mingmin Zhu2 Linlin Zhuo
Linlin Zhuo Tiancong Chen
Tiancong Chen- 1The Second Affiliated Hospital of Wenzhou Medical University, Wenzhou, Zhejiang, China
- 2School of Laboratory Medicine and Life Sciences, Wenzhou Medical University, Wenzhou, Zhejiang, China
- 3Department of Clinical Laboratory, Shandong Provincial Third Hospital, Shandong University, Jinan, Shandong, China
- 4Department of Bioinformatics and Genomics, University of North Carolina at Charlotte, Charlotte, NC, United States
- 5School of Data Science and Artificial Intelligence, Wenzhou University of Technology, Wenzhou, Zhejiang, China
- 6Department of Rehabilitation, The Wenzhou Third Clinical Institute Affiliated to Wenzhou Medical University, Wenzhou People's Hospital, Wenzhou Maternal and Child Health Care Hospital, Wenzhou, Zhejiang, China
The growing microbial resistance to traditional medicines necessitates in-depth analysis of medicine-microbe interactions (MMIs) to develop new therapeutic strategies. Widely used artificial intelligence models are limited by sparse observational data and prevalent noise, leading to over-reliance on specific data for feature extraction and reduced generalization ability. To address these limitations, we integrate Kolmogorov-Arnold Networks (KANs), independent subspaces, and collaborative decoding techniques into the masked graph autoencoder (Mask GAE) framework, creating an innovative MMI prediction model with enhanced accuracy, generalization, and interpretability. First, we apply Bernoulli distribution to randomly mask parts of the medicine-microbe graph, advancing self-supervised training and reducing noise impact. Additionally, the independent subspace technique enables graph neural networks (GNNs) to learn weights independently across different feature subspaces, enhancing feature expression. Fusing the multi-layer outputs of GNNs effectively reduces information loss caused by masking. Moreover, using KANs for advanced nonlinear mapping enhances the learnability and interpretability of weights, deepening the understanding of complex MMIs. These measures significantly enhanced the accuracy, generalization, and interpretability of our model in MMI prediction tasks. We validated our model on three public datasets with results showing that our model outperformed existing leading models. The relevant data and code are publicly accessible at: https://github.com/zhuoninnin1992/MKAN-MMI.
1 Introduction
Traditional medicines have historically played a crucial role in safeguarding life and health. Its primary mechanisms involve inhibiting harmful bacteria, viruses, and other microorganisms, or promoting the growth of beneficial microorganisms. Microbes, including bacteria, viruses, fungi, and protozoa, are ubiquitous on Earth and have a profound impact on human life and health (Consortium, 2012). They play crucial roles in digestion and immune processes (Flint et al., 2012; Hooper et al., 2012), produce essential vitamins (LeBlanc et al., 2013), and defend against pathogens (Buffie and Pamer, 2013). While many microbes benefit the environment and human health, some can cause disease. For instance, bacteria like Staphylococcus aureus and Escherichia coli, typically harmless in the human body, can under certain conditions cause skin infections (Liu A. et al., 2024), food poisoning (Gencay et al., 2016; Glavin, 2003), and more serious diseases. Therefore, understanding the relationship between microbes and medicines is crucial in precision medicine. Traditionally, microbial resistance has been studied through clinical observations and laboratory experiments that identify resistant strains by exposing bacteria to antibiotics and observing their survival. However, these methods are time-consuming, costly, and limited in detection range. This limitation has driven the adoption of computational methods in studying microbial resistance. Currently, the core technologies for inferring microbial resistance include systems biology and network analysis, machine learning and deep learning, and graph neural networks.
The first strategy integrates bioinformatics technologies and theories to construct and analyze biological network models, studying potential interactions between microbes and antibiotics. This approach helps scientists understand the complex regulatory mechanisms of microbial resistance. Sara Green et al. used graph theory and dynamic systems theory to simulate biological networks, gaining deeper insights into the mechanisms of microbial resistance to antibiotics (Green et al., 2018). Roberta Bardini et al. utilized a multi-level Petri net (Nets-Within-Nets, NWN) computational model to simulate the effects of various antibiotic management rules on microbial resistance (Bardini et al., 2018). Liu et al. constructed and analyzed complex network models using high-throughput multi-omics data, revealing key interactions and functions in microbial communities and mechanisms affecting community structure and resistance (Liu et al., 2021). Additionally, network topology analysis identified microbes with decisive roles in microbial networks, offering new perspectives on the functions and interactions of microbes in biological systems. Wang et al. investigated the structure and function of Cladophora’s microbial community at different life cycle stages using high-throughput 16S rRNA gene sequencing and network analysis, and analyzed the key ecological processes these communities may participate in through a functional prediction database (Wang et al., 2023b). Network-based methods employs biological network models and graph theory to assist research in deciphering the complex regulatory mechanisms underlying microbe resistance. Network topology analysis enables the identification of microbes that play pivotal roles in medicine-microbe networks, providing insights into their functions and interactions within biological systems. James et al. summarized current challenges, including incomplete data, prediction errors, noise in network analysis, and limitations in experimental verification (James and Muñoz-Muñoz, 2022). These challenges limit the broader application of network analysis-based technologies.
The second strategy leverages the similarity networks of microbes and medicines, employing machine learning (Li et al., 2021) and deep learning (Guthrie et al., 2017; Bardini et al., 2018) methods to identify potential MMIs. With significant improvements in computing performance and data storage capacity, numerous databases relevant to MMI have been established. This offers a fundamental resource for exploring new interactions between microbes and medicines through machine learning technology. For instance, Zhu et al. calculated the GIP core similarity of microbes and medicines, analyzed the chemical structure similarity of medicines, constructed similarity networks and medicine-microbe interaction networks, and employed KATZ technology to identify unknown MMIs (Zhu et al., 2019). However, the KATZ method exhibits significant limitations, including poor data adaptability, high computational complexity, and parameter sensitivity. These issues may challenge the KATZ method, particularly with sparse, large-scale, and new datasets. Consequently, HeteSim was developed. HeteSim, designed for heterogeneous networks, minimizes computation and data dependence by focusing on specific and related paths, performing well in sparse situations (Shi et al., 2014). Long et al. integrated metapath2vec with bipartite network recommendation technology and devised a biased bipartite network projection algorithm to enhance MMI prediction accuracy (Long and Luo, 2020). Zhu et al. constructed a medicine similarity matrix and applied the Laplace regularized least squares technique to identify unknown MMIs (Zhu et al., 2021). Similarity network-based methods focus on extracting similarity data from multiple sources, significantly addressing the limitations of medicine-microbe network data. Additionally, they often propose more efficient feature fusion techniques to improve the representation of medicines and microbes. However, their strong reliance on specific feature extraction may limit these methods’ adaptability.
The third strategy employs GNN technology to capture complex interactions between microbes and medicines by extracting node representations from the medicine-microbe graph. Huang et al. proposed the Graph2MDA model, based on the variational graph autoencoder (VGAE), which integrates multi-source data and network topology to accurately identify unknown MMIs (Deng et al., 2022). This marks the first application of VGAE technology to MMI prediction, achieving notable results. Tian et al. proposed the SCSMDA model, which is based on the graph convolutional network (GCN) and self-supervised learning strategy and enhances node representation using meta-path technology, yielding positive results (Tian et al., 2023). Additionally, the model incorporates contrastive learning and adaptive negative sampling strategies to further enhance performance. Long et al. introduced the EGATMDA model, leveraging GCN and the graph attention network (GAT) to extract and dynamically optimize node representations by adjusting the importance of various nodes and network types (Long et al., 2020b). Wang et al. proposed the TNRGCN model, which begins by constructing a medicine-microbe-disease heterogeneous network and then employs the relational graph convolutional network (RGCN) to identify unknown MMIs (Wang et al., 2023a). The model also utilizes principal component analysis (PCA) to extract key information from multi-source similarity data. GNN-based methods effectively capture network topology information through message propagation and update operations on medicine-microbe networks, enabling accurate prediction of potential MMIs. However, these methods typically depend on uniform and dense topological networks, which are rarely encountered in real-world scenarios. Furthermore, the initial representation of medicines and microbes often fails to significantly enhance the performance of GNN-based methods.
Despite the considerable success of current MMI inference methods based on deep learning or GNN, significant challenges remain. First, the model’s generalization ability is constrained by complex feature extractors and classifiers, with limited interpretability. Second, the observed data is vastly outnumbered by unknown drug-microbe pairs, leading to severe imbalance. Third, noisy data is inevitably introduced during the data collection process. To address these issues, we have integrated KAN, independent subspace, and collaborative encoding technologies into the Mask GAE framework to develop the new MMI prediction model MKAN-MMI. First, we mask portions of the input medicine-microbe graph to decrease the model’s noise sensitivity. Second, we employ independent subspace technology, allowing GNNs to independently learn weights within their respective feature subspaces during feature extraction. Specifically, we utilize polynomial technology to divide node features into distinct subspaces and allocate specific biases and weights to each, optimizing them independently. This avoids linear dependencies and improves the model’s adaptability to unknown data, thereby enhancing feature expression. Additionally, we collaboratively decode the outputs from multi-layer GNNs to minimize losses from masking operations. Subsequently, we incorporate KAN technology in the linear output layer to enhance weight learnability and interpretability, improving the model’s understanding of the complex interactions between microbes and medicines. These measures have significantly improved the model’s prediction accuracy, generalization ability, and interpretability. Our contributions can be summarized as follows:
1. Under the Mask GAE framework, we integrated KAN, independent subspace, and collaborative decoding technologies to develop a new MMI prediction model that achieved stable and reliable results.
2. We implemented independent subspace technology, enabling each feature subspace to independently learn weights and enhance expression capability.
3. We employed KAN technology to improve the learnability and interpretability of weights, thus enabling the model to capture detailed interactions between microbes and medicines.
4. We adopted collaborative decoding technology to integrate GNN’s multi-layer outputs, minimizing loss from masking.
2 Methods
The aim of this study is to identify potential MMIs among numerous unobserved medicine-microbe pairs, using observed MMIs as a basis. Since traditional biochemical or clinical experiments are often costly and time-consuming, developing efficient computational methods is crucial for rapidly identifying these unknown associations. The current research employs three main strategies: 1) integrating systems biology and network analysis, along with bioinformatics methods and mathematical modeling, to analyze the response mechanisms of microbes to drugs; 2) utilizing machine learning and deep learning techniques to extract similar features between microbes and drugs for predicting potential unknown interactions; and 3) applying GNN to extract topological features from known interactions, enhancing the representation of microbe and drug nodes. These strategies significantly enhance research efficiency for unknown MMIs and provide substantial support for understanding the complex interaction networks between microbes and drugs. However, these methods face practical challenges, particularly in terms of model generalization, which is often limited by the complexity of feature extractors and classifiers.
We integrated KAN, independent subspace, and collaborative decoding techniques into the Mask GAE framework to propose the MMI prediction model MKAN-MMI. Compared to traditional GNN-based MMI prediction models, our approach exhibits three main differences. First, we employ independent subspace technology, enabling subspaces to autonomously learn weights. This prevents weight sharing among subspaces and reduces linear correlations, thereby enhancing their expressiveness. Second, we apply collaborative decoding technology to conduct cross-Hadamard product operations on GNN’s multi-layer outputs, improving data utilization and the model’s adaptability to sparse data. Third, we utilize KAN technology to enhance the learnability and interpretability of weights, deepening our understanding of the complex interactions between medicines and microbes.
2.1 Model overview
Figure 1 illustrates the architecture of the MKAN-MMI model. In module (A), we gather observed MMIs along with original microbe and medicine information from the database to construct the initial medicine-microbe graph. Subsequently, we mask traversed MMIs by sampling nodes, employing a random walk strategy. In module (B), independent subspace technology is applied to learn weights for each subspace independently, facilitating the extraction of multi-layer representations of microbes and medicines. In module (C), the cross-Hadamard product is applied to the multi-layer output from module (B) to produce the final medicine-microbe pair representation. Subsequently, KAN technology predicts the score and reconstructs the medicine-microbe graph. Module (D) encapsulates the operating rules of KAN.
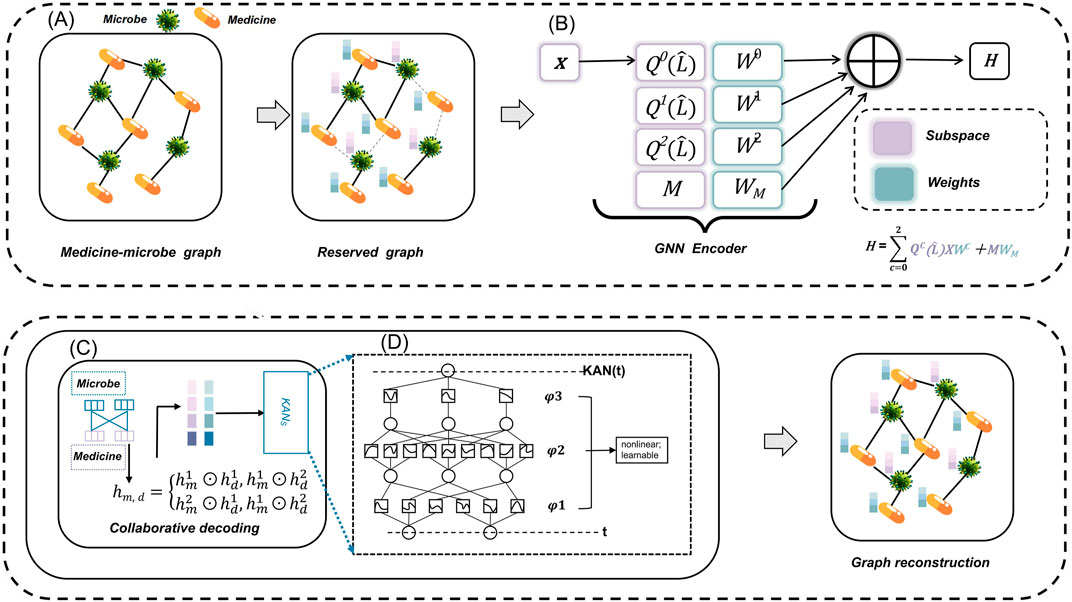
Figure 1. The MKAN-MMI model’s architecture comprises: (A) constructing and masking the medicine-microbe graph, (B) extracting microbe and medicine representations using independent subspace technology, (C) reconstructing the masked graph with collaborative decoding, and (D) employing KAN technology.
2.2 Masked graph autoencoders
Recently, GAE technology has achieved significant success due to its self-supervised nature. The architecture of GAE is straightforward, comprising only two main components: a GNN encoder and a decoder. The GAE process is well-defined: the GNN encoder extracts node embeddings from the input graph, and the decoder is trained to reconstruct based on known links. The objective function is defined as Equations 1–3:
where
Numerous studies have demonstrated that GAE exhibits enhanced performance following appropriate masking of the input graph (Devlin et al., 2019; He et al., 2022; Hou et al., 2022). Similarly, this study aims to identify potential MMIs from unknown medicine-microbe pairs using a self-supervised strategy within the Mask GAE framework. The observed medicine-microbe graph is represented as
where
where
2.3 Independent subspace
The GNN model accurately extracts node representations from the graph’s topological information, excelling in various graph tasks and attracting significant attention. The GNN model operates by performing multiple aggregation and update operations using the adjacency and feature matrices to extract features. Aggregation and update operations can be modified to create GNN variants suitable for various scenarios. While this model offers convenience, it also presents some challenges. Studies indicate that during the iteration of GNN models, feature subspaces are likely to exhibit approximate linear correlations (Sun et al., 2023). This significantly diminishes the subspace’s expressive power. The primary cause is the shared weights across multiple layers of feature subspaces (Sun et al., 2023). Inspired by these findings, we have integrated independent subspace technology into the Mask GAE framework to enhance the model’s feature extraction capabilities.
Specifically, we introduce a new GNN architecture centered on using polynomial technology to deshare weights in feature subspaces. According to Chebyshev’s theorem, the aggregation function is expressed as Equation 7:
where
From the above equation, it is evident that the feature subspace is closely linked to the initial representation of microbes (medicines). In the medicine-microbe graph, the dimensionality of the initial representation may limit the formation of the feature space. Consequently, we apply singular value decomposition to the adjacency matrix as Equation 8:
where
As illustrated in Figure 1, with
2.4 Collaborative decoding
Given a microbe
where
Research indicates that connecting, adding, or multiplying the multi-layer outputs of GNNs can enhance the data processing. However, a major drawback of this strategy is the introduction of significant noise, which impacts the final microbe (medicine) representation. Drawing inspiration from prior research (Tan et al., 2023), we have implemented collaborative decoding technology and the cross-Hadamard product to integrate representations of microbes and medicines across each GNN layers as Equation 11:
where
2.5 Kolmogorov-arnold networks (KANs)
MLP is capable of describing nonlinear functions; its simplicity and feasibility have made it the most popular neural network currently. The core of MLP involves performing linear mapping on the input, often incorporating nonlinear activation functions. MLP has been integrated into various network architectures, including GNNs and convolutional neural networks. However, recent studies have highlighted significant challenges facing MLP that cannot be ignored. For instance, MLP often requires stacking, and typically has a large parameter scale. Moreover, MLP’s functionality relies entirely on the interplay of neurons, resulting in limited interpretability. Initially, MLP places the activation function at the neuron level, whereas KAN applies univariate and spline functions to the weights. This approach allows KAN to improve weight learnability and interpretability. KAN theory originates from the concept that multivariate continuous functions can be derived by combining univariate functions via binary addition, as Equation 12:
where
To achieve arbitrary depth with KAN, a straightforward approach is the integration of MLP with KAN theory, as Equation 13:
where
As depicted in Figure 1B, the MKAN-MMI model employs KAN to process the final representation of the medicine-microbe pair for predicting the final score. Subsequent experiments demonstrate that integrating KAN technology significantly enhances the model’s prediction performance.
3 Results
3.1 Data preparation
To verify the accuracy of the MKAN-MMI model in MMI prediction, we conducted evaluations across several publicly accessible MMI databases. Drawing on prior research (Long et al., 2020a), we selected three databases for evaluation: MDAD (Sun et al., 2018), DrugVirus (Andersen et al., 2020), and aBiofilm (Long et al., 2020a). The MDAD database comprises 1,373 medicines, 173 microbes, and 2,470 MMI in total. The aBiofilm database includes 1,720 medicines, 140 microbes, and 2,884 MMIs in total. The DrugVirus database contains 175 medicines, 95 microbes, and 933 MMIs in total.
Additionally, we gathered similarity data for microbes and medicines from previous studies (Tian et al., 2023). For microbes, we gathered functional similarity
3.2 Experiment setting
We compared the MKAN-MMI model against eight models, encompassing classic GNN models such as GCN (Li et al., 2018) and GAT (Veličković et al., 2018), as well as advanced models like DTI-CNN (Peng et al., 2020), NIMCGCN (Li et al., 2020), MMGCN (Tang et al., 2021), and DTIGAT (Wang et al., 2021), Graph2MDA (Deng et al., 2022), SCSMDA (Tian et al., 2023), and GCNMDA (Devlin et al., 2019). Notably, DTI-CNN (Peng et al., 2020), NIMCGCN (Li et al., 2020), MMGCN (Tang et al., 2021), and DTI-GAT (Wang et al., 2021) were not originally designed for MMI prediction tasks. Consequently, these models required modifications, including adjusting the input to the initial representation of microbes and medicines, and to the medicine-microbe graphs. To ensure fairness, the study maintained a consistent data partitioning ratio and conducted uniform 5-fold cross-validation across all experiments. The proposed MKAN-MMI model primarily considers the root node sampling rate, random walk length, and number of feature subspaces. Empirically, these parameters are set to 0.5, 3, and 3 by default. The training-to-test set ratio is set to 4:1, and the positive-to-negative sample ratio is also set to 1:1. The primary evaluation metrics employed were AUC (area under the ROC curve) and AUPR (area under the precision-recall curve). Additionally, for a comprehensive assessment, accuracy (ACC), precision (PRE), F1-score, and Matthews correlation coefficient (MCC) served as auxiliary metrics, similar to previous practice (Zhou et al., 2024; Wei et al., 2024; Wang et al., 2024; Ma et al., 2024; Xu et al., 2023).
3.3 Performance comparison
Under identical data partitioning conditions, we assessed the performance of the proposed model alongside that of existing comparison models. Table 1 displays the AUC and AUPR performance metrics of all models across the MDAD, DrugVirus, and aBiofilm datasets. Significantly, the MKAN-MMI model achieved the highest performance in both AUC and AUPR metrics across all datasets, ranking first. The SCSMDA model followed closely, securing the second rank. The DTI-CNN model, ranking third in the AUC metric, underscored the autoencoder’s advantage in feature extraction. However, it exhibited slightly inferior performance in the AUPR metric within the DrugVirus and aBiofilm datasets. The underperformance of other GNN models highlights the challenges of strategies relying solely on observed MMIs. GNN model designs heavily depend on network topology during aggregation and updates, often neglecting the nodes’ initial representations. Specifically, in the MDAD, DrugVirus, and aBiofilm datasets, the observed MMIs are significantly fewer than the unknown medicine-microbe pairs, suggesting the initial representation could play a crucial role in MMI prediction.
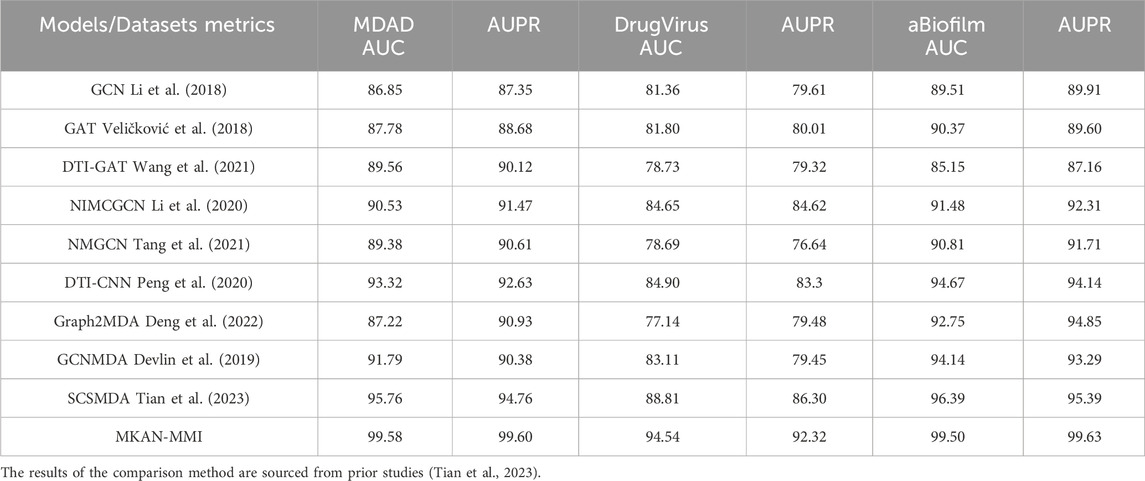
Table 1. Comparison of MKAN-MMI with other outstanding models (%).
The SCSMDA model utilizes GCN technology and self-supervised learning strategies, incorporating meta-path and graph contrast learning techniques to enhance node representations, resulting in positive outcomes. However, the increased complexity of its architecture may hinder the model’s generalization. The proposed model adopts the encoder-decoder framework of GAE to reconstruct the medicine-microbe graph, demonstrating greater efficiency and accuracy in identifying unknown MMIs compared to the SCSMDA model. This improvement can be attributed to several factors. First, independent subspace technology is employed to enhance subspace representation capabilities. Second, collaborative decoding technology integrates multi-layer GNN outputs to improve node representations of medicines and microbes. Finally, the proposed model applies KAN technology to enhance its flexibility and generalization capabilities.
3.4 Parameter experiments
The proposed model incorporates several customizable parameters, including GNN encoder type, node sampling rate, and masked path length. We assessed the impact of different parameter settings on the MKAN-MMI model’s performance across three databases, confirming its adaptability to these parameters.
3.4.1 Node sampling rate analysis
The MKAN-MMI model offers a broad spectrum of node sampling rate settings to accommodate data of varying densities. Typically, dense data necessitates a higher sampling rate to mitigate overfitting, whereas sparse data benefits from a lower rate to minimize information loss. Prior to inputting the medicine-microbe graph into the MKAN-MMI model, we sampled nodes using a Bernoulli distribution at rates between 0.3 and 0.7. From the selected nodes, masked paths (MMIs) are established using a random walk strategy. In the experiments, the path length was consistently set to 3. Figure 2 displays the results, showing that the model’s performance improves with higher node sampling rates. This suggests that suitably masking observed MMIs can alleviate issues related to overfitting or noise. However, excessive sampling of nodes results in a correspondingly higher number of masked MMIs. The results indicate a noticeable decline in model performance. This suggests that excessive masking of key nodes or MMIs contributes to performance degradation.
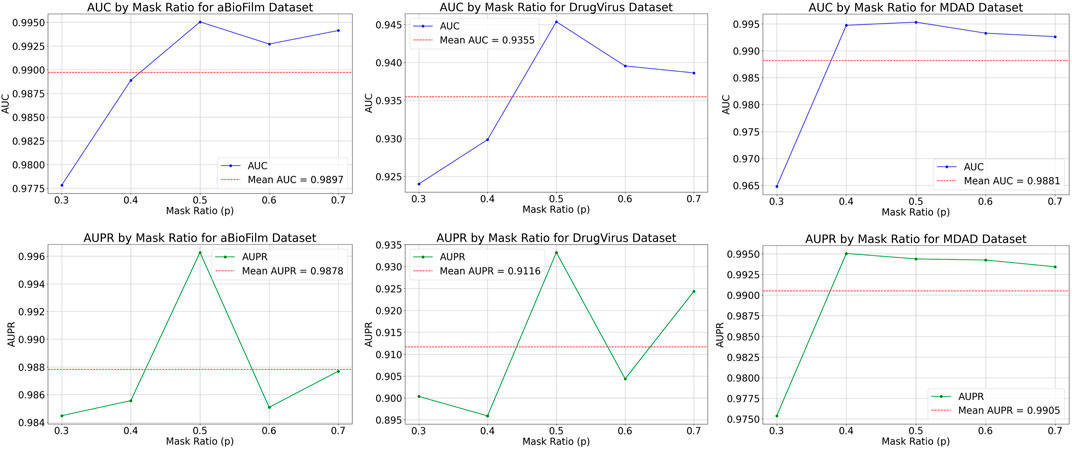
Figure 2. Results of MKAN-MMI model using different node sampling rates.
3.4.2 Walk length analysis
After sampling nodes at a predefined ratio, we mask the MMIs starting from these nodes using a pre-set length dictated by the random walk strategy. The MKAN-MMI model accommodates custom walk lengths to suit various data types. In the experiments, the sampling rate was consistently maintained at 0.5. Figure 3 illustrates that the model’s overall performance exhibits minimal fluctuations. The model achieves optimal performance when the walk length is set to 3. We deduce that the model’s performance is correlated with the walk length. A shorter masking length, such as 2, may lead to fewer masked MMIs, potentially limiting the model’s training effectiveness. Conversely, a longer masking length, such as 4, could result in more masked MMIs, risking significant loss of key information.
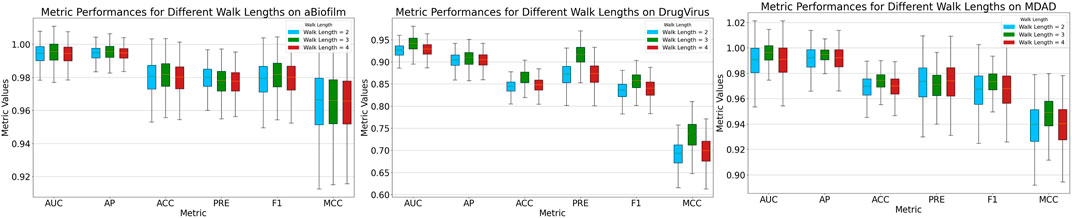
Figure 3. Results of MKAN-MMI model using different walk lengths.
3.4.3 GNN encoder analysis
Within the Mask GAE framework, the GNN encoder can be customized. In our experiments, we evaluated the performance of various GNN encoders integrated into the model. Figure 4 demonstrates that encoders based on independent subspaces significantly outperform other GNN models. Additionally, the GCN, GIN, and SAGE models generally outperform the GAT model. This could be attributed to GAT’s focus on edge weight information, which may be significantly lost when masking MMIs. These traditional GNN models employ a weight-sharing mechanism that leads to linear correlations among subspaces during iterations, severely constraining their expressive capabilities. We have integrated independent subspace technology into the model to enhance the autonomous learning capabilities of subspaces, thereby boosting model performance.
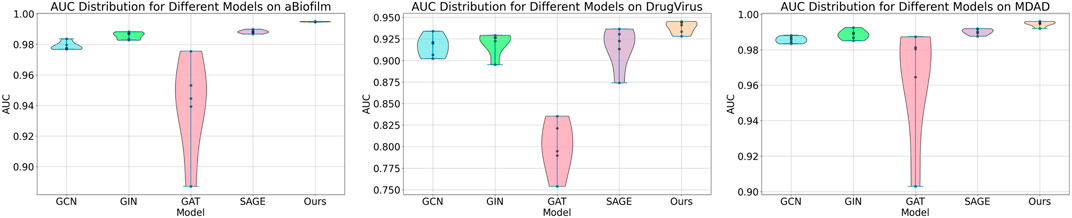
Figure 4. Results of MKAN-MMI model using different GNN encoders.
3.4.4 Feature subspace number analysis
Another key parameter in this study is the number of feature subspaces. We conducted experiments to explore the impact of this parameter on model performance. In these experiments, the sampling rate was fixed at 0.5 and the walk length at 3. As shown in Figure 5, the model’s overall performance exhibited little fluctuation on aBiofilm, DrugVirus, and MDAD datasets, sequentially. When the number of feature subspaces was set to 3, the model achieved optimal performance. We infer that the model’s performance is correlated with the number of feature subspaces. A smaller number, such as 2, may result in insufficient feature extraction, limiting the model’s training effectiveness, while a larger number, such as 4, may introduce redundant information, reducing performance.

Figure 5. Results of MKAN-MMI model using different subsapce numbers.
3.5 Ablation study
We anticipate that the proposed model will excel in the MMI prediction task, primarily due to the integration of independent subspace, collaborative decoding, and KAN techniques within the Mask GAE framework. To test this hypothesis, we conducted multiple experimental series on the MDAD database. Table 2 displays the outcomes of these experiments. “GCN” and “DG” signify that the MKAN-MMI model’s encoder employs GCN and independent subspace techniques, respectively. “CD” denotes that the MKAN-MMI model’s decoder utilizes collaborative decoding technology. “ID” represents that the model extracts the output of the last layer of the microbe and medicine, performs the Hadamard product, and predicts the medicine-microbe pair score. “KAN” and “MLP” show that the MKAN-MMI model employs KAN and MLP, respectively, to predict the medicine-microbe pair score. Observations reveal that the absence of independent subspace, collaborative decoding, or KAN technology in the MKAN-MMI model leads to reduced performance. This indicates that all three technologies contribute significantly to enhancing MMI prediction. The model’s performance is poorest when it lacks collaborative decoding technology. This suggests that collaborative decoding technology effectively mitigates data sparsity issues, thereby enhancing the model’s robustness. Performance slightly declines when the model operates without independent subspace technology. Performance significantly deteriorates when the model employs MLP technology in place of KAN.
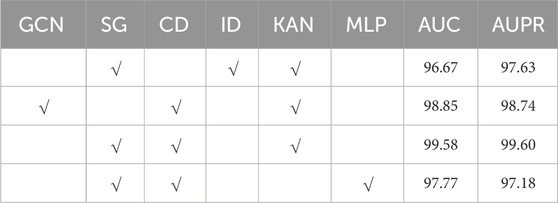
Table 2. Results of ablation study (%).
3.6 AUC-based statistical significance analysis
In this study, we employed one-way analysis of variance (ANOVA) (St and Wold, 1989) to systematically assess whether significant differences exist in the AUC performance of various MMI prediction models across the aBiofilm, DrugVirus, and MDAD datasets, as shown in Figures 6–8, respectively. The results indicate that on the MDAD dataset, our model demonstrates a significant advantage, with p-values below 1.0e-07 compared to most models, underscoring its statistical significance. Notably, when compared to the Graph2MDA and DTI-CNN models, our model achieved p-values of 1.00e-04 and 3.20e-03, respectively. While the differences are subtle, they remain statistically significant. On the DrugVirus dataset, our model also showed significance in most comparisons. However, when compared to the NIMCGCN model, the two models performed similarly, with p-values as high as 0.99, indicating their comparable predictive ability on this dataset. Nonetheless, in other comparisons, our model consistently demonstrates significant superiority, with p-values mostly below 1.0e-07. On the aBiofilm dataset, our model also maintains a significant performance advantage. In comparisons with NIMCGCN and Graph2MDA, p-values were 0.66 and 0.98, respectively, indicating that our model performs similarly to these models on some evaluation metrics. Overall, the p-values between our model and all comparison models remain well below the significance threshold of 0.05, further validating its superior performance.
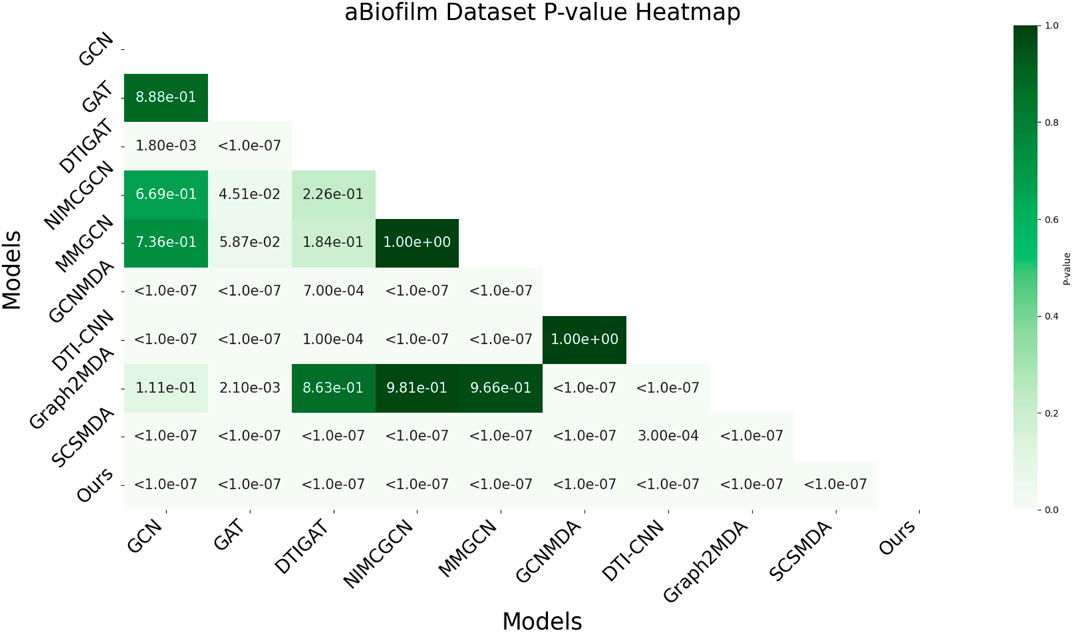
Figure 6. AUC-based statistical significance analysis on aBiofilm dataset.
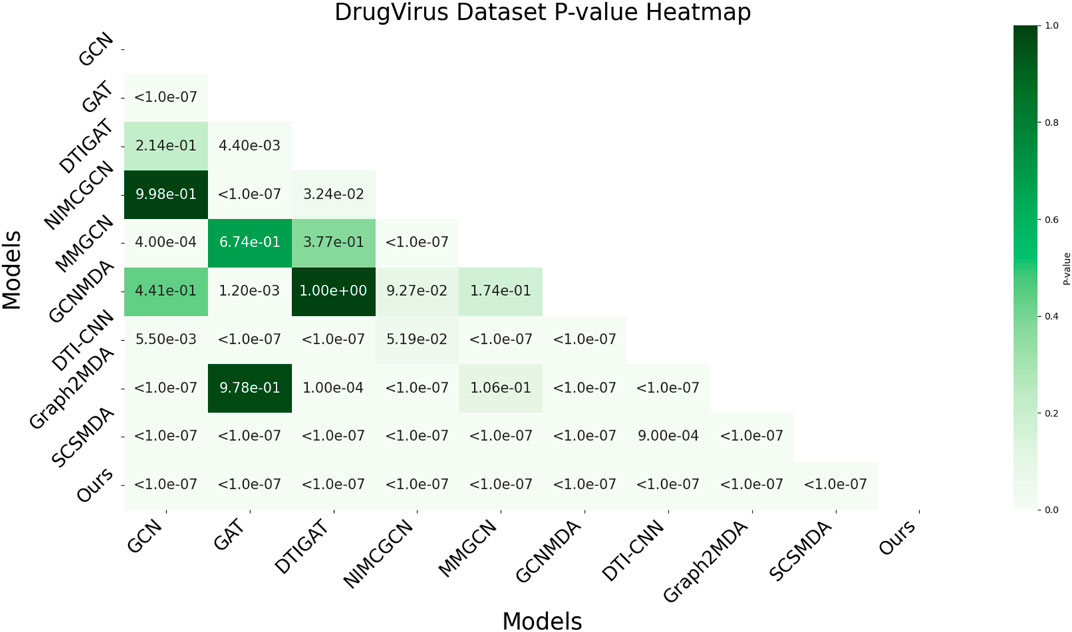
Figure 7. AUC-based statistical significance analysis on DrugVirus dataset.
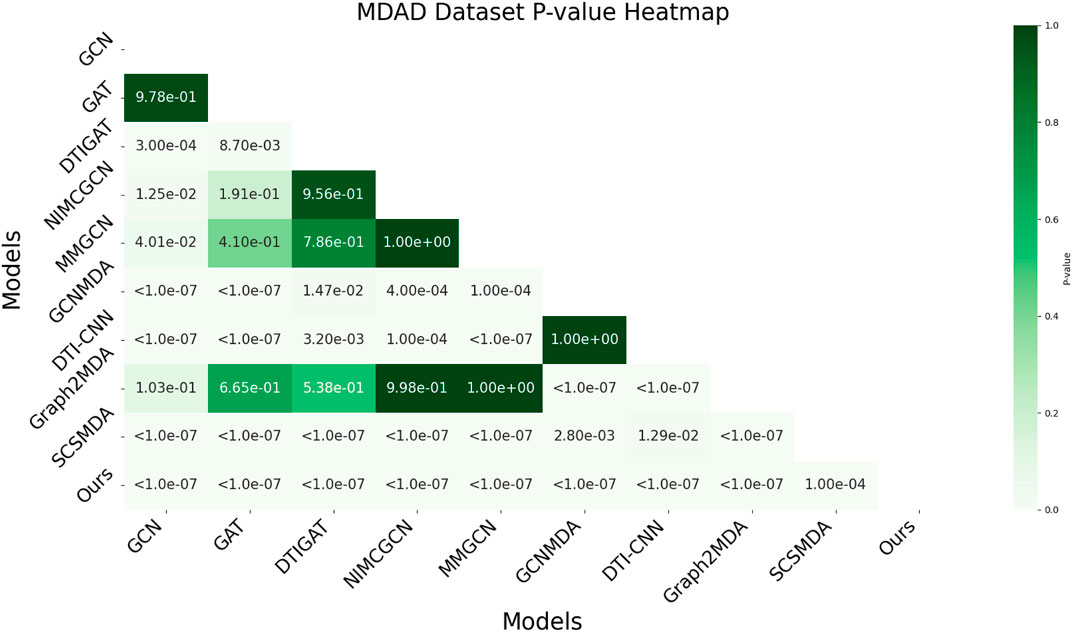
Figure 8. AUC-based statistical significance analysis on MDAD dataset.
The analysis results not only confirm the performance advantage of our model but also emphasize its stability and reliability across various data environments. Additionally, the results strongly support the application value of decoupled representation learning and multi-scale fusion technology in enhancing model generalization and addressing complex interaction prediction challenges.
3.7 Performance evaluation
This study employed a five-fold cross-validation method to assess the performance of the MKAN-MMI model across the MDAD, DrugVirus, and aBioFilm databases. As detailed in Table 3, the proposed model demonstrated stable performance on the MMI prediction task, surpassing the current state-of-the-art SCSMDA model. Specifically, the proposed model achieved an average AUC of 99.58% on the MDAD dataset, which is 4.43% higher than SCSMDA’s 95.15%. On the DrugVirus dataset, the proposed model recorded an average AUC of 94.54%, 0.87% higher than SCSMDA’s 93.67%. On the aBioFilm dataset, our model excelled with an average AUC of 99.50%, marking an increase of 1.27% over SCSMDA’s 98.23%. Additionally, for the AUPR metric, the proposed MKAN-MMI model significantly outperforms the SCSMDA model. These results underscore the model’s effectiveness and its robust generalization capability across various settings.
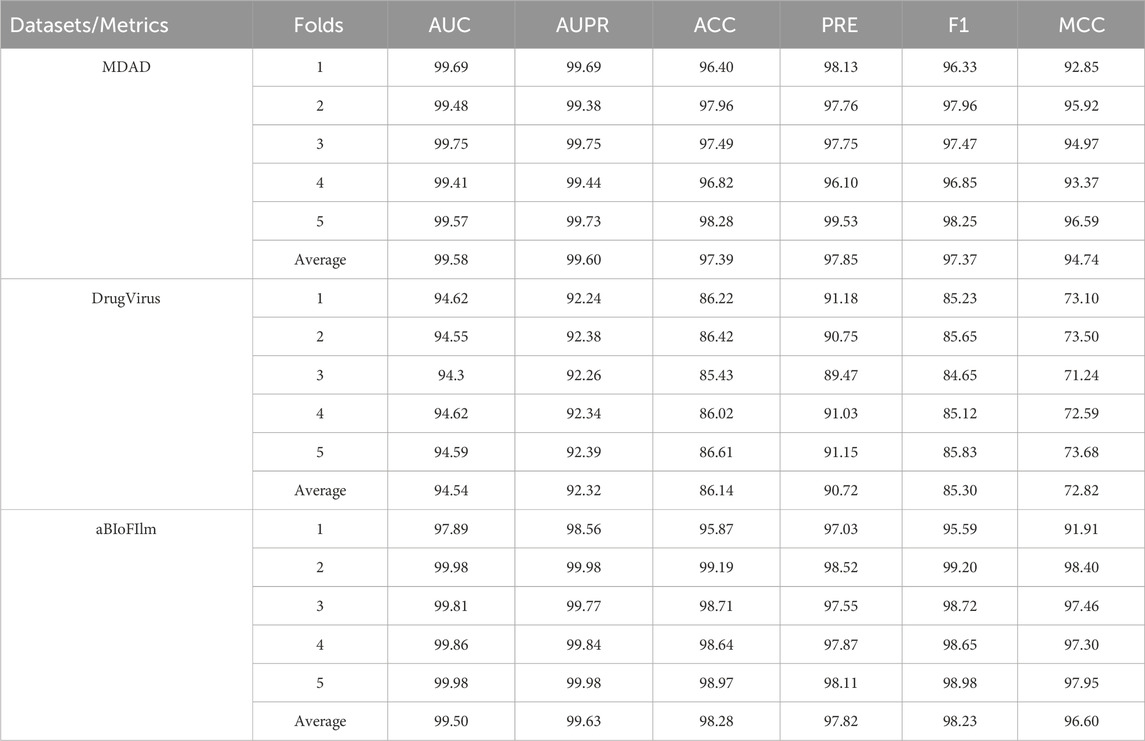
Table 3. Results of ablation study (%).
3.8 Case analysis
We conducted a series of case studies to assess the model’s performance under isolation. We chose the medicine Berberine from the DrugVirus database for analysis and validation. Berberine, an alkaloid derived from plants like Coptis chinensis and Phellodendron chinense, has been used historically to treat various diseases (Song et al., 2020). This medicine exhibits multiple biological activities, including antimicrobial, anti-inflammatory, antioxidant properties, and the regulation of blood sugar and lipids. Berberine inhibits protein synthesis in microbial cells, reduces inflammatory factor expression, enhances the antioxidant enzyme system, and activates AMP-activated protein kinase (AMPK). Consequently, it holds potential for treating type 2 diabetes, cardiovascular diseases, and gastrointestinal disorders. Although considered relatively safe, Berberine may interact with specific microbes. Thus, studying Berberine and its associated microbes is essential.
Epstein–Barr virus (EBV) is a
Specifically, we excluded Berberine, EBV and their associated MMIs from the dataset during model training. Subsequently, the trained model predicted the likelihood of interactions between all microbes (medicines) and Berberine (EBV). Following analysis, the top 10 microbes were identified, with results detailed in Table 4. It was confirmed that nine microbes interact with Berberine, as documented in the DrugVirus database. The results in Table 5 indicate that all 10 medicines predicted by the trained model interact with EBV and have been verified in DrugVirus. Therefore, the proposed model is demonstrably effective in independently identifying potential MMIs.
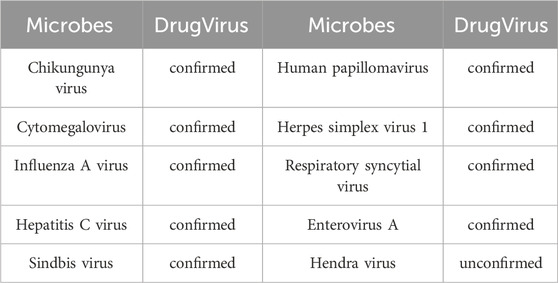
Table 4. The top 10 predicted microbes interacted with Berberine with the highest scores.
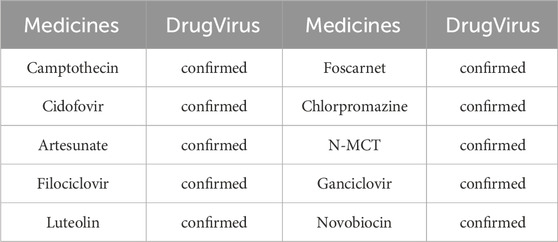
Table 5. The top 10 predicted medicines interacted with EBV with the highest scores.
4 Conclusion
Microbes, existing in diverse forms across plants and animals, are integral to numerous life processes. Accurate identification of potential MMIs facilitates exploration of medicine resistance and side effects, and aids in developing new treatment strategies. This study examined various MMI prediction models and identified their key challenges. For instance, the often sparse and noisy observational data causes these models to overly rely on complex feature extraction, rendering them susceptible to overfitting and other issues. Consequently, we integrated independent subspaces, collaborative decoding, and KAN technologies into the Mask GAE framework, resulting in the proposed MMI prediction model, MKAN-MMI. Operating under the Mask GAE framework, this model mitigates the risks of overfitting and noise via masking rules. Simultaneously, the model employs independent subspace technology to prevent asymptotic correlation among subspaces, thereby enhancing their expressiveness. Furthermore, the model utilizes collaborative decoding technology to mitigate the impact of data sparsity. A series of designed experiments demonstrated the effectiveness of these measures in MMI prediction. Additionally, these results indicate that the proposed MKAN-MMI model is likely to be a valuable tool in studying microbes and medicines.
However, the proposed model faces challenges that cannot be overlooked. First, the known MMI data are too limited and highly imbalanced compared to the unknown medicine-microbe pairs. Second, there is currently no effective method to characterize microbes and medicines. Third, significant differences may exist between the newly generated data and the original dataset. To overcome these challenges, we propose the following approaches. First, leveraging large language models or pre-trained models to learn general knowledge about drugs and microorganisms to enhance node representation. Second, incorporating text descriptions, such as properties and functions of medicines and microbes, and multimodal methods like SMILES sequences, to integrate information. Third, applying transfer learning to capture the differences between new and old data, thereby improving model adaptability.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Author contributions
ShY: Methodology, Writing–original draft. JW: Methodology, Writing–original draft. MZ: Data curation, Formal Analysis, Writing–review and editing. SiY: Supervision, Writing–review and editing, Methodology. LZ: Data curation, Writing–review and editing. TC: Supervision, Writing–review and editing, Methodology. JG: Supervision, Writing–review and editing, Methodology.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Science and Technology Bureauof Wenzhou (Grant No. Y20240195).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Andersen, P. I., Ianevski, A., Lysvand, H., Vitkauskiene, A., Oksenych, V., Bjørås, M., et al. (2020). Discovery and development of safe-in-man broad-spectrum antiviral agents. Int. J. Infect. Dis. 93, 268–276. doi:10.1016/j.ijid.2020.02.018
Bardini, R., Di Carlo, S., Politano, G., and Benso, A. (2018). Modeling antibiotic resistance in the microbiota using multi-level petri nets. BMC Syst. Biol. 12, 108–179. doi:10.1186/s12918-018-0627-1
Buffie, C. G., and Pamer, E. G. (2013). Microbiota-mediated colonization resistance against intestinal pathogens. Nat. Rev. Immunol. 13, 790–801. doi:10.1038/nri3535
Cohen, J., Kimura, H., Nakamura, S., Ko, Y.-H., and Jaffe, E. (2009). Epstein–barr virus-associated lymphoproliferative disease in non-immunocompromised hosts: a status report and summary of an international meeting, 8–9 september 2008. Ann. Oncol. 20, 1472–1482. doi:10.1093/annonc/mdp064
Consortium, H. M. P. (2012). Structure, function and diversity of the healthy human microbiome. nature 486, 207–214. doi:10.1038/nature11234
Deng, L., Huang, Y., Liu, X., and Liu, H. (2022). Graph2mda: a multi-modal variational graph embedding model for predicting microbe–drug associations. Bioinformatics 38, 1118–1125. doi:10.1093/bioinformatics/btab792
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). “Bert: pre-training of deep bidirectional transformers for language understanding,” in Proceedings of NAACL-HLT, Minneapolis, Minnesota, June, 2019, 4171–4186.
Flint, H. J., Scott, K. P., Louis, P., and Duncan, S. H. (2012). The role of the gut microbiota in nutrition and health. Nat. Rev. Gastroenterology and hepatology 9, 577–589. doi:10.1038/nrgastro.2012.156
Gencay, Y. E., Ayaz, N. D., Copuroglu, G., and Erol, I. (2016). Biocontrol of shiga toxigenic escherichia coli o157: H7 in t urkish raw meatball by bacteriophage. J. Food Saf. 36, 120–131. doi:10.1111/jfs.12219
Girosi, F., and Poggio, T. (1989). Representation properties of networks: Kolmogorov’s theorem is irrelevant. Neural Comput. 1, 465–469. doi:10.1162/neco.1989.1.4.465
Glavin, M. O. (2003). A single microbial sea: food safety as a global concern. SAIS Rev. 23, 203–220. doi:10.1353/sais.2003.0012
Green, S., Şerban, M., Scholl, R., Jones, N., Brigandt, I., and Bechtel, W. (2018). Network analyses in systems biology: new strategies for dealing with biological complexity. Synthese 195, 1751–1777. doi:10.1007/s11229-016-1307-6
Guthrie, L., Gupta, S., Daily, J., and Kelly, L. (2017). Human microbiome signatures of differential colorectal cancer drug metabolism. NPJ biofilms microbiomes 3, 27. doi:10.1038/s41522-017-0034-1
Hattori, M., Tanaka, N., Kanehisa, M., and Goto, S. (2010). Simcomp/subcomp: chemical structure search servers for network analyses. Nucleic acids Res. 38, W652–W656. doi:10.1093/nar/gkq367
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., and Girshick, R. (2022). “Masked autoencoders are scalable vision learners,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, New Orleans, LA, June 18–24, 2022, 16000–16009.
Hooper, L. V., Littman, D. R., and Macpherson, A. J. (2012). Interactions between the microbiota and the immune system. Science 336, 1268–1273. doi:10.1126/science.1223490
Hou, Z., Liu, X., Cen, Y., Dong, Y., Yang, H., Wang, C., et al. (2022). “Graphmae: self-supervised masked graph autoencoders,” in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, August 14–18, 2022, 594–604. doi:10.1145/3534678.3539321
James, K., and Muñoz-Muñoz, J. (2022). Computational network inference for bacterial interactomics. Msystems 7, 014566–e1521. doi:10.1128/msystems.01456-21
Kamneva, O. K. (2017). Genome composition and phylogeny of microbes predict their co-occurrence in the environment. PLoS Comput. Biol. 13, e1005366. doi:10.1371/journal.pcbi.1005366
LeBlanc, J. G., Milani, C., De Giori, G. S., Sesma, F., Van Sinderen, D., and Ventura, M. (2013). Bacteria as vitamin suppliers to their host: a gut microbiota perspective. Curr. Opin. Biotechnol. 24, 160–168. doi:10.1016/j.copbio.2012.08.005
Li, R., Wang, S., Zhu, F., and Huang, J. (2018). Adaptive graph convolutional neural networks. Proc. AAAI Conf. Artif. Intell. 32. doi:10.1609/aaai.v32i1.11691
Li, J., Zhang, S., Liu, T., Ning, C., Zhang, Z., and Zhou, W. (2020). Neural inductive matrix completion with graph convolutional networks for mirna-disease association prediction. Bioinformatics 36, 2538–2546. doi:10.1093/bioinformatics/btz965
Li, X., Lin, Y., Meng, X., Qiu, Y., and Hu, B. (2021). An L_0 regularization method for imaging genetics and whole genome association analysis on alzheimer's disease. IEEE J. Biomed. Health Inf. 25, 3677–3684. doi:10.1109/jbhi.2021.3093027
Liu, A., Garrett, S., Hong, W., and Zhang, J. (2024). Staphylococcus aureus infections and human intestinal microbiota. Pathogens 13, 276. doi:10.3390/pathogens13040276
Liu, Z., Ma, A., Mathé, E., Merling, M., Ma, Q., and Liu, B. (2021). Network analyses in microbiome based on high-throughput multi-omics data. Briefings Bioinforma. 22, 1639–1655. doi:10.1093/bib/bbaa005
Liu, Z., Wang, Y., Vaidya, S., Ruehle, F., Halverson, J., Soljačić, M., et al. (2024). Kan: Kolmogorov-arnold networks. arXiv Prepr. arXiv:2404. doi:10.48550/arXiv.2404.19756
Long, Y., and Luo, J. (2020). Association mining to identify microbe drug interactions based on heterogeneous network embedding representation. IEEE J. Biomed. health Inf. 25, 266–275. doi:10.1109/JBHI.2020.2998906
Long, Y., Wu, M., Kwoh, C. K., Luo, J., and Li, X. (2020a). Predicting human microbe–drug associations via graph convolutional network with conditional random field. Bioinformatics 36, 4918–4927. doi:10.1093/bioinformatics/btaa598
Long, Y., Wu, M., Liu, Y., Kwoh, C. K., Luo, J., and Li, X. (2020b). Ensembling graph attention networks for human microbe–drug association prediction. Bioinformatics 36, i779–i786. doi:10.1093/bioinformatics/btaa891
Ma, X., Fu, X., Wang, T., Zhuo, L., and Zou, Q. (2024). Graphadt: empowering interpretable predictions of acute dermal toxicity with multi-view graph pooling and structure remapping. Bioinformatics 40, btae438. doi:10.1093/bioinformatics/btae438
Macsween, K. F., and Crawford, D. H. (2003). Epstein-barr virus—recent advances. Lancet Infect. Dis. 3, 131–140. doi:10.1016/s1473-3099(03)00543-7
Peng, J., Li, J., and Shang, X. (2020). A learning-based method for drug-target interaction prediction based on feature representation learning and deep neural network. BMC Bioinforma. 21, 394. doi:10.1186/s12859-020-03677-1
Poggio, T., Banburski, A., and Liao, Q. (2020). Theoretical issues in deep networks. Proc. Natl. Acad. Sci. 117, 30039–30045. doi:10.1073/pnas.1907369117
Shi, C., Kong, X., Huang, Y., Philip, S. Y., and Wu, B. (2014). Hetesim: a general framework for relevance measure in heterogeneous networks. IEEE Trans. Knowl. Data Eng. 26, 2479–2492. doi:10.1109/tkde.2013.2297920
Song, D., Hao, J., and Fan, D. (2020). Biological properties and clinical applications of berberine. Front. Med. 14, 564–582. doi:10.1007/s11684-019-0724-6
St, L., and Wold, S. (1989). Analysis of variance (anova). Chemom. intelligent laboratory Syst. 6, 259–272. doi:10.1016/0169-7439(89)80095-4
Sun, Y.-Z., Zhang, D.-H., Cai, S.-B., Ming, Z., Li, J.-Q., and Chen, X. (2018). Mdad: a special resource for microbe-drug associations. Front. Cell. Infect. Microbiol. 8, 424. doi:10.3389/fcimb.2018.00424
Sun, J., Zhang, L., Chen, G., Xu, P., Zhang, K., and Yang, Y. (2023). “Feature expansion for graph neural networks,” in International Conference on Machine Learning, Honolulu, Hawaii, July 23–29, 2023 (PMLR), 33156–33176.
Tan, Q., Liu, N., Huang, X., Choi, S.-H., Li, L., Chen, R., et al. (2023). “S2gae: self-supervised graph autoencoders are generalizable learners with graph masking,” in Proceedings of the sixteenth ACM international conference on web search and data mining, Singapore, February 27–March 3, 2023, 787–795.
Tang, X., Luo, J., Shen, C., and Lai, Z. (2021). Multi-view multichannel attention graph convolutional network for mirna–disease association prediction. Briefings Bioinforma. 22, bbab174. doi:10.1093/bib/bbab174
Tian, Z., Yu, Y., Fang, H., Xie, W., and Guo, M. (2023). Predicting microbe–drug associations with structure-enhanced contrastive learning and self-paced negative sampling strategy. Briefings Bioinforma. 24, bbac634. doi:10.1093/bib/bbac634
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., and Bengio, Y. (2018). Graph attention networks. Int. Conf. Learn. Represent. doi:10.48550/arXiv.1710.10903
Wang, H., Zhou, G., Liu, S., Jiang, J.-Y., and Wang, W. (2021). Drug-target interaction prediction with graph attention networks. arXiv Prepr. arXiv:2107.06099.
Wang, Y., Lei, X., and Pan, Y. (2023a). Microbe-disease association prediction using rgcn through microbe-drug-disease network. IEEE/ACM Trans. Comput. Biol. Bioinforma. 20, 3353–3362. doi:10.1109/TCBB.2023.3247035
Wang, Y., Zhou, P., Zhou, W., Huang, S., Peng, C., Li, D., et al. (2023b). Network analysis indicates microbial assemblage differences in life stages of cladophora. Appl. Environ. Microbiol. 89, e02112–e02122. doi:10.1128/aem.02112-22
Wang, R., Wang, T., Zhuo, L., Wei, J., Fu, X., Zou, Q., et al. (2024). Diff-amp: tailored designed antimicrobial peptide framework with all-in-one generation, identification, prediction and optimization. Briefings Bioinforma. 25, bbae078. doi:10.1093/bib/bbae078
Wei, J., Zhu, Y., Zhuo, L., Liu, Y., Fu, X., and Li, F. (2024). Efficient deep model ensemble framework for drug-target interaction prediction. J. Phys. Chem. Lett. 15, 7681–7693. doi:10.1021/acs.jpclett.4c01509
Xu, J., Xu, J., Meng, Y., Lu, C., Cai, L., Zeng, X., et al. (2023). Graph embedding and Gaussian mixture variational autoencoder network for end-to-end analysis of single-cell rna sequencing data. Cell Rep. Methods 3, 100382. doi:10.1016/j.crmeth.2022.100382
Young, L. S., and Rickinson, A. B. (2004). Epstein–barr virus: 40 years on. Nat. Rev. Cancer 4, 757–768. doi:10.1038/nrc1452
Zhou, Z., Liao, Q., Wei, J., Zhuo, L., Wu, X., Fu, X., et al. (2024). Revisiting drug–protein interaction prediction: a novel global–local perspective. Bioinformatics 40, btae271. doi:10.1093/bioinformatics/btae271
Zhu, L., Duan, G., Yan, C., and Wang, J. (2019). “Prediction of microbe-drug associations based on katz measure,” in 2019 IEEE international conference on bioinformatics and biomedicine (BIBM), San Diego, CA, November 18–21, 2019 (IEEE), 183–187.
Keywords: traditional medicine (TM), medicine-microbe interactions (MMIs), artificial intelligence models, masked graph autoencoder (mask GAE), kolmogorov-arnold networks (KANs)
Citation: Ye S, Wang J, Zhu M, Yuan S, Zhuo L, Chen T and Gao J (2024) MKAN-MMI: empowering traditional medicine-microbe interaction prediction with masked graph autoencoders and KANs. Front. Pharmacol. 15:1484639. doi: 10.3389/fphar.2024.1484639
Received: 22 August 2024; Accepted: 08 October 2024;
Published: 22 October 2024.
Edited by:
Junlin Xu, Hunan University, ChinaCopyright © 2024 Ye, Wang, Zhu, Yuan, Zhuo, Chen and Gao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sisi Yuan, c3l1YW40QGNoYXJsb3R0ZS5lZHU=; Tiancong Chen, dGlhbmNvbmdhQDE2My5jb20=; Jinjian Gao, Z2FvamluamlhbjcwQDEyNi5jb20=
†These authors have contributed equally to this work