 Yiwen Zhang1†
Yiwen Zhang1† Ran Dai
Ran Dai Cheng Zheng
Cheng Zheng
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Nutr., 02 August 2023
Sec. Nutrition Methodology
Volume 10 - 2023 | https://doi.org/10.3389/fnut.2023.1215768
This article is part of the Research TopicBiochemical Biomarkers of Nutritional StatusView all 7 articles
Addressing systematic measurement errors in self-reported data is a critical challenge in association studies of dietary intake and chronic disease risk. The regression calibration method has been utilized for error correction when an objectively measured biomarker is available; however, biomarkers for only a few dietary components have been developed. This paper proposes to use high-dimensional objective measurements to construct biomarkers for many more dietary components and to estimate the diet disease associations. It also discusses the challenges in variance estimation in high-dimensional regression methods and presents a variety of techniques to address this issue, including cross-validation, degrees-of-freedom corrected estimators, and refitted cross-validation (RCV). Extensive simulation is performed to study the finite sample performance of the proposed estimators. The proposed method is applied to the Women's Health Initiative cohort data to examine the associations between the sodium/potassium intake ratio and the total cardiovascular disease.
The field of nutritional epidemiology plays a crucial role in understanding the impact of dietary patterns on human health. The ongoing exploration of associations between dietary components and chronic disease risks continually uncovers valuable insights. For instance, the well-established link between obesity and cancer risk (1) serves as a testament to the significance of this research. In order to effectively prevent and control chronic diseases, it is imperative to acquire detailed information on how key energy balance factors associate with the risks of major chronic illnesses [World Cancer Research Fund/American Institute for Cancer Research (2)]. Investigating the complex working mechanisms of these energy balance factors necessitates a comprehensive examination of the connections between multiple dietary components and disease risks. Establishing such associations, however, is far from simple. A major challenge stems from biases in dietary assessment, which are notoriously difficult to address (3). Strong evidence (4) suggests that the misreporting of dietary energy intake is associated with individual characteristics, such as body mass index (BMI). These systematic measurement errors result in estimation biases that cannot be automatically rectified (5). Moreover, correcting measurement errors becomes increasingly challenging when attempting to model dietary components jointly in the context of their relationships with chronic diseases.
Correcting measurement errors has been an important subject in statistical methodology development, greatly influencing nutritional studies (6). Various strategies have been developed to address these errors (7–15). One notable method, regression calibration, is particularly useful for handling covariate-dependent measurement errors and offers ease of implementation (16). Studies within the Women's Health Initiative (WHI) have demonstrated the effectiveness of joint regression calibration approaches in addressing measurement errors when objective biomarkers are available for all modeled dietary intakes (4, 17–19). These biomarkers inform calibration equations for self-reported measurements of exposure variables, which then provide calibrated intake estimates to better assess associations between dietary exposures and disease risks.
There is a significant research gap in generating reliable calibrated estimates for numerous nutritional and physical activity variables using single objective measurements. Consequently, regression models with multiple predictors have been developed from feeding studies to obtain calibrated estimates (4, 20). For instance, in the WHI Nutrition and Physical Activity Assessment Study (NPAAS), a regression-based biomarker has been established for a single dietary component or energy balance factors (21). To address the systematic measurement errors in self-reported food frequency questionnaire (FFQ) data from a large cohort, blood and urine measurements were collected for a subgroup, while a feeding study (NPAAS-FS) was conducted on another smaller subgroup where both blood and urine measurements and assessed dietary intake information were collected. This novel feeding study design aimed to improve the accuracy of capturing measurement errors in the FFQ (21). However, there are some challenges in building the regression calibration method, as the classical measurement error assumption will be violated by the feeding study-based biomarker development procedure, which regresses the consumed nutrient on blood and urine measurements and personal characteristics. This issue arises because the residual of the regression model is independent of the predicted value instead of the actual one. Ignoring this violation results in biased estimates of the calibrated dietary intake and the diet-disease association due to Berkson-type errors (22). When developing biomarkers for objectively measured variables with low dimensions, new calibration methods have been developed to account for Berkson-type errors in association studies of univariate nutritional variables (20). Zhang et al. (23) have extended this approach to multivariate nutritional variables, providing consistent estimators for disease associations of a single dietary component and valid confidence intervals for disease association parameters under rare disease settings. Nevertheless, for some macronutrient intakes, suitable biomarkers cannot be developed from low-dimensional measurements. High-dimensional metabolites offer an opportunity to establish valid biomarkers, but it remains an open question on how to obtain valid inferences for such biomarkers.
In this paper, we concentrate on high-dimensional objective measurements for a univariate exposure of interest, where the sample size is smaller than the dimension of the variables, in constructing a biomarker model. High-dimensional variable selection constitutes a significant portion of the rapidly advancing statistical frontiers today. Over the past few decades, numerous studies have been dedicated to understanding the performance of various variable selection techniques. Frank and Friedman (24) first proposed a technique called bridge regression. Breiman (25) introduced the nonnegative garrote for shrinkage estimation and variable selection. Lasso, an l-1 regularized least squares method, was studied and introduced by (26) for variable selection. Nonconcave penalized likelihood estimators, such as smoothly clipped absolute deviation (SCAD), were proposed by (27) and (28). Efron et al. (29) presented the least angle regression for variable selection and introduced the LARS algorithm. Zou and Li (30) proposed one-step sparse estimates for nonconcave penalized likelihood models and introduced the local linear approximation algorithm for optimizing non-concave penalized likelihoods.
Building a biomarker model with high-dimensional sparse data requires predictive performance that can effectively address the challenges associated with such data. One issue that arises when working with high-dimensional models is the collinearity among covariates, which can result in spurious correlations between variables (31). Numerous researchers have explored penalized regression techniques, such as Lasso and SCAD, to handle high-dimensional sparse data. Alternatively, variable selection can also be done by ranking predictive powers using random forest (RF) (32). Variance estimation in high dimensional models presents its own challenges, due to factors such as collinearity among covariates and the presence of spurious correlations. A variety of techniques have been proposed to address the issue of variance estimation in high-dimensional regression methods. Cross-validation (CV), a popular resampling technique, has been widely applied to assess the performance of different models and obtain unbiased variance estimates (33). The bootstrap, another resampling method, has been employed to estimate the variability of regression parameters (34). The degrees-of-freedom corrected estimators, such as the generalized degrees of freedom and the effective degrees of freedom, provide better error variance estimates by accounting for the complexity of the models (35, 36). The refitted cross-validation (RCV) method is a modification of the standard cross-validation procedure that improves the estimation of error variance in high-dimensional regression (37).
The remaining of the paper is organized as follows. In Section 2, we introduce the framework of the present study and the notation. In Section 3, we introduce different methods and detail variance estimation procedures. In Section 4, we conduct extensive simulations to evaluate the finite sample performance of our proposed estimators. In Section 5, we apply our method to the WHI data to estimate the effect of macronutrient intakes on the risk of various chronic diseases. Finally, in Section 6, we present our conclusions and discussions.
We aim to investigate the correlation between a particular type of dietary intake Z ∈ ℝ [such as the (log-transformed) ratio of dietary sodium to potassium] and the timeframe, T, to the emergence of a specific chronic illness. Nevertheless, rather than directly observing Z, we only gather information on self-reported dietary intake Q ∈ ℝ, which may deviate from Z depending on individual characteristics:
Here, a ∈ ℝ(2+q) is an unidentified parameter vector, and ϵq is a random error with a mean of 0 that is independent of Z and V. We also take into account potential confounding factors, referred to as personal characteristics V ∈ ℝq where q is the number of covariates. To model the hazard of the response, we employ a Cox model:
where , θz is the parameter we are interested in, and λ0(t) represents a “baseline” hazard function.
In the NPAAS feeding study (NPAAS-FS), we furnish participants' meals with standardized food, which closely mimicking their regular diet, has well-documented nutrient content (21). The true unobservable dietary intake within the 2-week feeding period is denoted as
In our current model, we assume that ϵx is independent of Z and V. However, condition (3) could be considered somewhat restrictive, given that the design of the feeding study is based on reported long-term dietary intake and not the actual diet. To address this, we have modified this assumption such that the true short-term unobserved diet X does not necessarily need to be centered around Z. Additional specifics can be found in Section 3. One intricate issue related to the feeding study is the measurement errors arising from food packaging. For example, a pack of chips labeled as 100 calories might in reality contain 101 calories. Consequently, the observed short-term dietary intake during the feeding study can be expressed as , where is independent of ϵx, Z, and V.
The study is organized into three stages: the feeding study (Sample 1) for biomarker development, the biomarker sub-study (Sample 2) for calibration equation development, and the association study (Sample 3) using the complete cohort to establish the disease association.
When self-reported intake Q data from feeding study samples is available, the bias of self-reported dietary intake can be directly calibrated (refer to Section 3.4). However, self-reported dietary intake Q is usually not available concurrently in Sample 1. To acquire that data, a long-term feeding study would be necessary, wherein participants report their dietary intake provided over preceding months (e.g., 3 months). Furthermore, the Q value obtained just prior to the feeding period in NPAAS-FS is not collected at the same time as biomarker W, and it might be inappropriately highly correlated with .
As an alternative, we could employ a high-dimensional biomarker W ∈ ℝp, comprised of p blood and urine measurements obtained objectively, as a bridge between from the feeding study sample and Q from a separate, larger sample. We assume that the blood and urine measurements W are influenced by the short-term diet X, whereas the self-reported questionnaire data are directly impacted by the long-term diet Z. We assume that W is possibly high-dimensional and follows a parametric model:
where B ∈ ℝ(2+q) × p is a matrix of unknown parameters and is independent of .
In practical terms, our best option is to utilize the baseline Q gathered at a separate time (for instance, at baseline for Sample 3) for Sample 1. This baseline Q has been effectively used in studies concerning various dietary components [e.g., protein and carbohydrate; (22)]. However, a time gap exists between the data collection for this baseline Q and the timing of measurements in Sample 1. Consequently, there's a concern that the conditional distribution in Sample 1 may differ from Samples 2 and 3 for specific dietary components. Even when Q is available, the feeding study's sample size is usually restricted, which could lead to less than optimal efficiency for disease association estimates. In such instances, we consider Q as unavailable in Sample 1 and use W to predict .
The process of estimating the association between Z and T is divided into three stages, each utilizing distinct, non-overlapping samples derived from the same fundamental population: 1. the biomarker creation phase, 2. the calibration phase, and 3. the phase assessing the association. Each stage employs a different sample. The size of the sample used in stage k is denoted as nk. In Stage 1, there are n1 samples, and for each individual i, we have access to data and possibly Qi; in Stage 2, n2 samples are available, and for each individual i, we have ; in Stage 3, there are n3 samples, and for each individual i, we have and the composite outcome , where Ti is the time of disease occurrence, and Ci is a potential censoring time. Conventionally, Ti and Ci are assumed to be independent given .
During the first stage, we utilize data from the biomarker creation phase to develop the biomarker. This model can be constructed by regressing the observed short-term dietary intakes on one of the following:
(i) blood/urine measurements W and personal characteristics V;
(ii) blood/urine measurements W, self-reported dietary intake Q, and personal characteristics V;
(iii) self-reported dietary intake Q and personal characteristics V.
As earlier indicated, self-reported dietary intake Q may be deemed unavailable during Stage 1. If that's the case, we treat Q as unavailable and opt for choice (i) in Stage 1. When Q is accessible in Stage 1, choice (ii) might enhance the estimation of . If the biomarker W is not available, option (iii) directly models based on Q and V, but the effectiveness might be hampered by the limited sample size n1. In Stage 2, a calibration equation is developed using self-reported log-transformed dietary intake Q and personal characteristics V to predict actual intake X if options (i) or (ii) are implemented in Stage 1. If option (iii) is chosen, Stage 2 is bypassed, as the equation is already established in Stage 1. However, option (i) introduces Berkson-type error, which impacts regression calibration, thus necessitating new methodologies to address this characteristic. In Stage 3, we calibrate the self-reported dietary intake utilizing the Stage 2 calibration equation, conduct disease association analyses with the available data on Q, V, and the composite survival outcome (T*, Δ).
In summary, the high-dimensional regression calibration procedure has three stages: biomarker construction, calibration, and estimation. In Stage 1, the relationship between the true dietary intake X and high-dimensional biomarker W is established. If self-reported dietary intakes Q are not available, option (i) can be used. If Q is available in Stage 1, whether or not W is also available, relationships between X and Q can be directly established with option (iii). If both W and Q are available for Stage 1, one of the options from (i), (ii), and (iii) can be used. As discussed, (i) might lead to Berkson type error (38) and (iii) might have low efficiency. For Stage 2, we developed bias correction methods to account for the bias introduced by the Berkson type error. For Stage 3, we can use a multivariate approach to jointly study the associations between multiple dietary components and the disease risks.
we first consider the case where is known. We propose methods to estimate in the discussion section. In the real data analysis where is not available, we vary this parameter to perform sensitivity analysis.
With high-dimensional data on urine measurements (W), we first need to obtain estimated coefficients among n1 subjects in the biomarker discovery sample of the observed short-term dietary intake on high-dimensional blood and urine measurements (W) as well as subject characteristics (V). Three different approaches including Lasso, SCAD, and RF are used to conduct variable selection in high-dimensional statistical inference. We will describe each approach explicitly for every method in the following subsections.
In the first step, we need to fit a linear regression of on W and V:
With Lasso approach, the coefficients, , minimize the penalized least squares (PLLasso) as below:
Lasso performs variable selection by shrinking coefficient estimates toward zero leading to a sparse model. The tuning parameter λ is selected through cross-validation.
With the SCAD approach, a nonconvex penalty is given by:
The first derivatives of PLSCAD(β1j) is continuous and is given by
for some a > 2 and β1 > 0. Similar to Lasso, λ in SCAD is selected through cross-validation based on the smallest mean square error (MSE) whereas a is set to be 3.7 based on simulation results and Bayesian statistical point of view from (27).
Other than penalized regression as we described above, RF is another choice for variable selection. The basic concept is to grow regression trees in the general form below:
where R1, …, RM denotes a partition of feature space. Then we can repeat this procedure to build the RF by considering the approximate square root of the total number of predictors each time. The advantage of RF is we can see the contribution of each variable to the regression tree and their relative importance.
For each method, we did direct selection and post selection. For direct selection, we applied an estimated model from each approach to predict the long-term dietary intake straightly. For post selection, we performed linear regression afterward with selected variables (Ŝ) from each approach. Specifically, for Lasso and SCAD, we have:
For RF, the 10 most important variables are considered as the final selected variables. For both direct and post selection, we considered two ways to deal with W and V; one is to consider both W and V in the approach of variable selection while the other is to consider only W. To be more specific, in Lasso and SCAD, the penalization will be applied to (W, V) or to only W, respectively. In RF, the decision trees will be built by considering (W, V) or only W, respectively.
With estimated we had in the prior step, we can then compute to predict the long-term dietary intake (Z) among the n2 calibration samples and run a regression of on self-reported food frequency questionnaire data (Q) and V to build calibration equation using the n2 calibration samples to estimate the parameter
Using the Stage 3 sample, we then estimate Z as for i = n1 + n2 + 1, ⋯ , n1 + n2 + n3. Finally, we estimate the association between Z and the time-to-event endpoint (T*, Δ) by solving the score equation for Cox model:
where τ is a pre-specified large number and we assume P(C > τ) > 0, and . In application, τ is typically defined as the largest follow-up time in the Stage 3 sample.
As shown in (20), for low-dimension setting, Method 1 will lead to a bias factor in Ẑ1 when using and a bias-corrected estimator has been proposed. so for this high dimensional setting, we propose a similar bias-corrected estimator where
is an estimated version of the bias factor.
For direct selection, we used K-fold cross-validated errors to compute the in penalized regression and RF to obtain . Denote the predicted value for the k − th fold when using regression parameters from the other K − 1 training datasets as when using (W,V) as predictors and as when using V as predictors, then we have
With and , can be calculated as
For post selection, we first obtain the selected variables from the methods Lasso, SCAD, or RF. Afterward, we estimate the coefficients by refitting a linear regression. To facilitate interpretation, we consider both W and V in variable selection for the remainder of this subsection. Consequently, we have:
Subsequently, we can fit a low-dimensional model as below:
Here, Ws and Vs denote the selected W and V variables, while and βV represent the corresponding coefficients in the aforementioned equations. From there, BF can be estimated as:
where
As demonstrated above, obtaining a precise estimation of is crucial for a reliable estimation of BF. Chatterjee and Jafarov (39) revealed that the estimator , as mentioned earlier, leads to a downward bias when using Lasso. Therefore, we decide to compute and compare three different types of in our study involving post selection. We will provide a description of each type below.
(i) K-fold cross validation
We fit penalized regression or RF with the cross-validated training dataset and get predicted with selected (W, V) for each fold. Denote the selected subset as Sk for each training set .
Denote WSk as selected W and VSk as selected V in the (K-1) training dataset for each fold, then we can fit a linear regression of on WSk, VSk and the predicted value is denoted as . Also, we can fit a linear regression of on Vk and the predicted value is denoted as . After doing this for all K folds, we get the estimated values of for the whole sample 1, that is,
With and , can be calculated as
(ii) Modified variance estimator
When performing penalized regression for variable selection, the choice of the regularization parameter λ is crucial for obtaining an accurate finite sample estimator. The value of λ influences both the number of variables selected and the extent to which their estimated coefficients are shrunk toward zero. If λ is set too large, not all signal variables will be selected, resulting in rapidly degrading performance (mainly characterized by a significant upward bias) as the true β becomes less sparse with a larger signal per element. Conversely, if λ is set too small, many noise variables will be selected, which allows spurious correlations to decrease our variance estimate, leading to considerable downward bias. Based on the simulation result in (40), there is a balance to be maintained when selecting the appropriate λ:
where ŝλ is the number of nonzero elements in at the regulation parameter λ selected with K-fold (usually 5–10) cross-validation. Then we have:
(iii) Refitted cross-validation estimator (RCV)
This estimator is derived from the RCV procedure proposed by (37). We first split the dataset into two roughly equal parts: and . We then perform penalized regression and RF on the first part. For penalized regression, we fit Lasso or SCAD on W and V with cross-validated to obtain the non-zero estimated coefficients for W and V. In the case of RF, we select the 10 most important variables based on the residual sum of squares (RSS). We then refit the model with the selected W and V to obtain the post selected estimators of their coefficients, denoted as . Subsequently, using the selected W and V in W(2) and V(2), we can compute the following variance estimate on the second part.
where ŝ(1) is the number of selected variables in the first part. Repeating the mirror image procedure on , we can obtain , selected W obtained from Lasso in the second part and . Last, can be derived as below:
With , we have . We can run a regression of on self-reported food frequency questionnaire data (Q) and V to build calibration equation using the n2 calibration samples to estimate the parameter
Using the Stage 3 sample, we then estimate Z as for i = n1 + n2 + 1, ⋯ , n1 + n2 + n3. Finally, we estimate the association of Z with the time-to-event endpoint (T*, Δ) by solving the score equation for Cox model:
For method 2 to work, we can relax Equation (3) to that the conditional mean 𝔼[Z|W,V] from sample 2 is the same as the conditional mean 𝔼[X|W,V] from sample 1.
If the self-reported data Q from the feeding study is accessible and we presume that the distributions of (Q|Z,V) remain consistent between the controlled feeding study and the cohort, the bias in the naive estimator can be rectified by simply incorporating Q into the biomarker development equation. This is because the inclusion of Q ensures that 𝔼[Ẑ|Q,V] = 𝔼[𝔼[Z|Q,V,W]|Q,V] = 𝔼[Z|Q,V].
The sequence of the first method remains unchanged, but in the first step of the regression model, the log-transformed self-reported food frequency questionnaire data (Q) is included. Specifically, for the first step, the predictors W, V, and Q are utilized to construct the biomarker. Following this, in the second step, we employ W, V, and Q to estimate Z. Lasso, SCAD, and RF, as previously described, are all applied in Method 3 for variable selection and effect estimation in high-dimensional statistical inference, considering both direct selection and post-selection.
With the estimated from the first step, , we can execute a regression of on the self-reported food frequency questionnaire data (Q) and V to construct a calibration equation using the n2 calibration samples to estimate the parameter
Using the Stage 3 sample, we then estimate Z as for i = n1 + n2 + 1, ⋯ , n1 + n2 + n3. Finally, we estimate the association of Z with the time-to-event endpoint (T*, Δ) by solving the score equation for Cox model:
For method 3 to work, we can relax Equation (3) to that the conditional mean 𝔼[Z|W, Q,V] from sample 2 is the same as the conditional mean 𝔼[X|W, Q,V] from sample 1.
We build the estimating equation by regressing on Q and V in the first step and directly apply it to the third step. Then we build the calibration equation using the feeding study by regressing on V and Q and use the calibration equation to predict Z and perform a Cox regression of Y on Z and V in the full cohort to estimate the association parameter. In other words, we have
and by solving estimating equations
For method 4 to work, we can relax Equation (3) to that the conditional mean 𝔼[Z|Q,V] from sample 3 is the same as the conditional mean 𝔼[X|Q,V] from sample 1.
We simulate data with varying levels of sparsity, effect size, and shape within the context of high-dimensional statistical inference. Our goal is to investigate how the sparsity, effect size, and shape among different measurements influence the bias and variance of various estimators. We compare the bias, empirical standard deviation (SD), estimated standard error (SE), and coverage rate for a nominal 95% confidence interval (CR) across different sample sizes, effect shapes, effect sizes, and correlation structures. Here the CR is computed from the asymptotic SE formula as shown in the Theorem 1 of (20) with the term estimated from 100 Bootstrap samples using data from the first two samples given that there is no closed-form variance formula for Σγk when W is of high-dimension. We examine both scenarios, with and without penalties applied to the personal characteristics V during the first stage of penalized regression. Time-to-event outcomes are generated using the Cox model.
where Z, V, X, and Q ∈ ℝ, while W ∈ ℝp is high-dimensional. In this study, ϵx and ϵq are independently sampled from normal distributions with mean zero and standard deviations σx and σq. The censoring time is sampled from a mixture of a uniform distribution Unif(0, 10) and a point mass at 10, with equal probability. Three settings are considered: (i) baseline setting, (ii) weak biomarker effect and strong self-reported data effect, and (iii) strong biomarker effect. We experiment with three sparsity levels of W (2, 5, and 10), and consider two different patterns of the effect size for W: equivalent and random. More details on the parameter settings can be found in Supplementary material (Section 1.1).
The bias, mean estimated standard error (SE), empirical standard deviation (SD), and coverage rate (CR) of 95% nominal confidence interval for all four methods from 100 simulations are listed in Tables 1, 2 with Lasso penalized regression. The performance of our proposed Method 2 varies under different scenarios. Post selection and direct selection are both performed for variable selection. The results are for the ones forcing personal characteristics (V) in the model while the results for not forcing V in the model can be found in Supplementary Tables 2, 3.
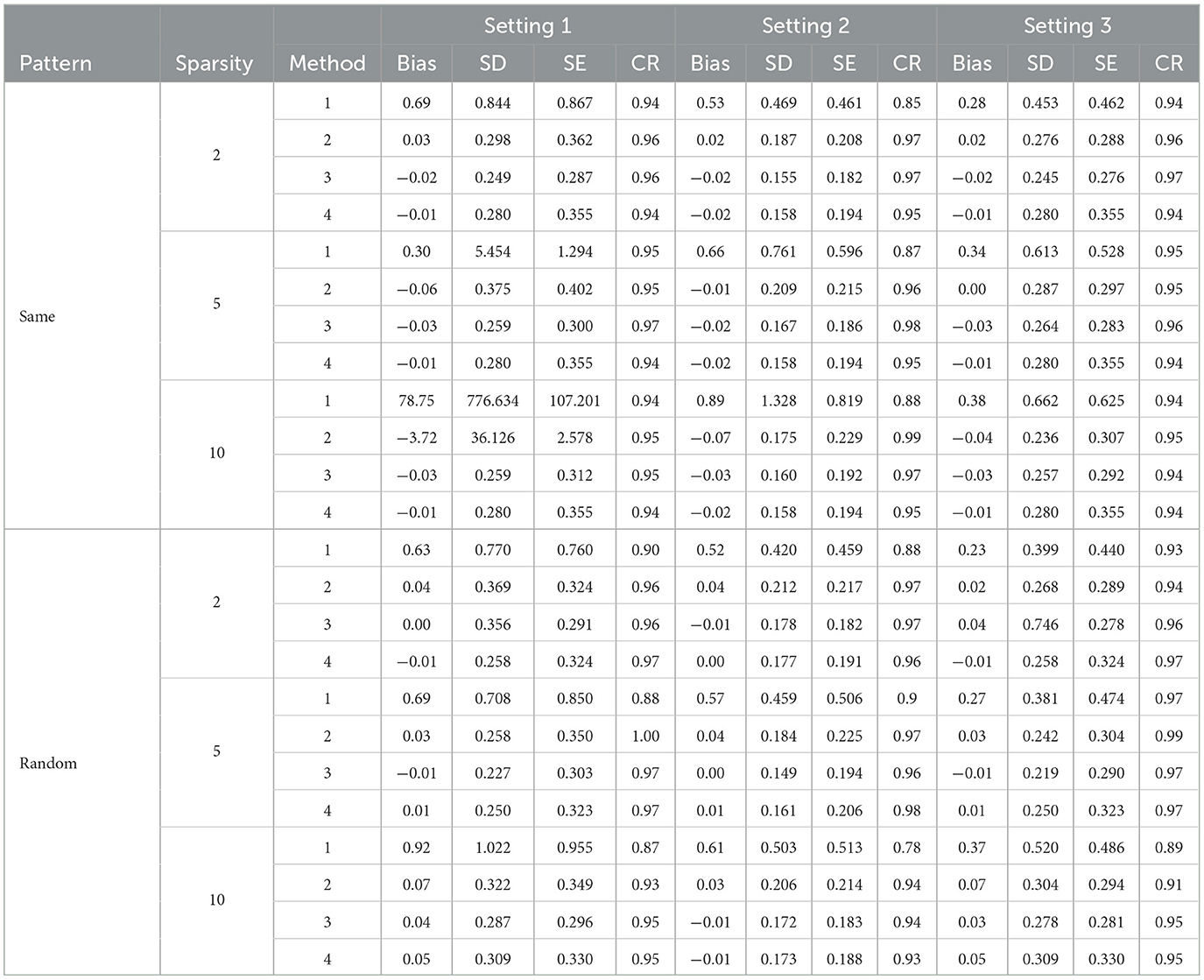
Table 1. Simulation results with direct Lasso selection forcing personal characteristics in the model.
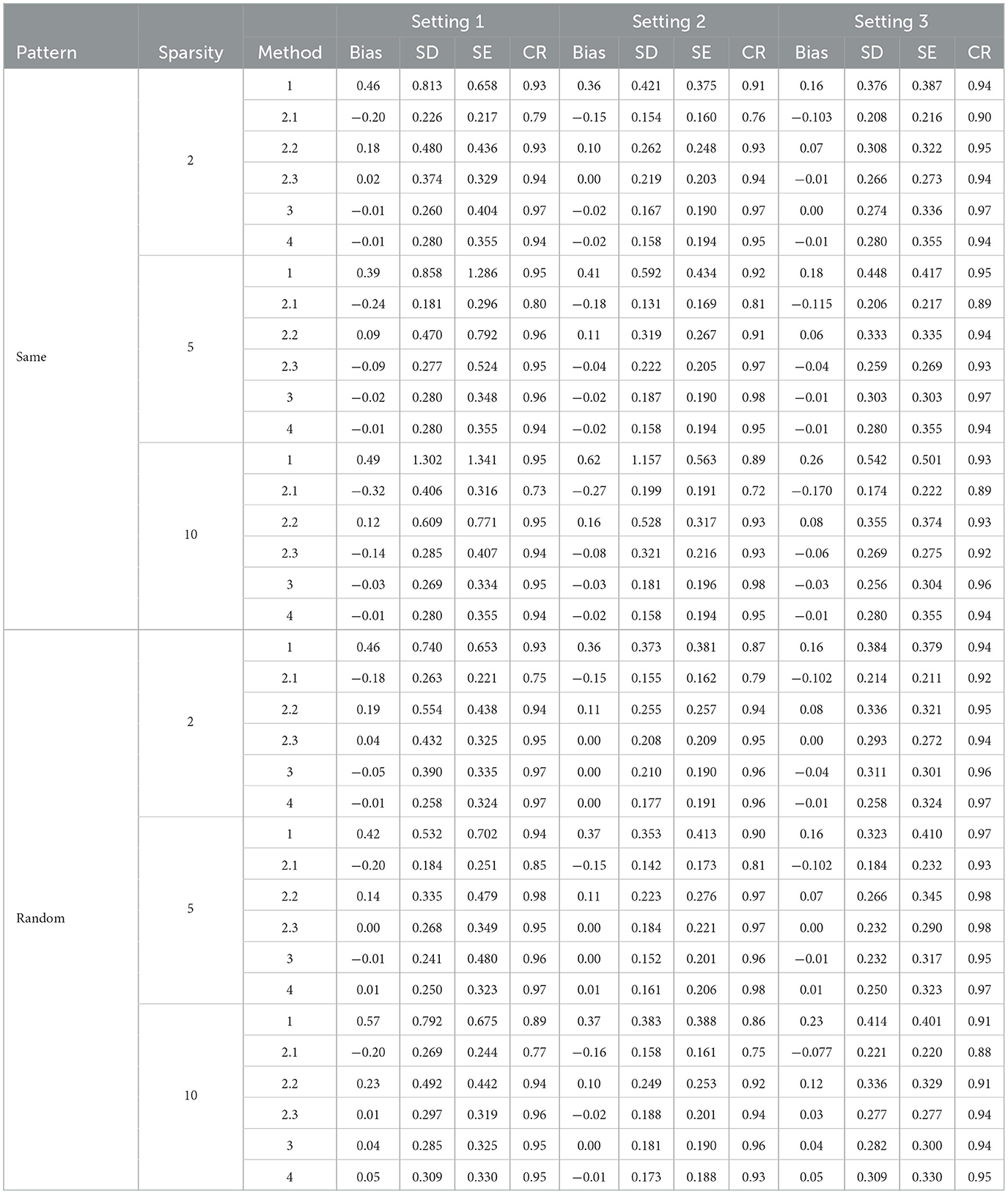
Table 2. Simulation results with post Lasso selection forcing personal characteristics in the model.
In general, the post selection methods perform slightly better than the direct-selection methods with lower SDs and SEs. For a few settings, the direct selection approach does not perform stably in terms of bias and SD. The direct selection not forcing the inclusion of personal characteristics showed more stable results compared with direct selection forcing the inclusion of personal characteristics for Method 2 but the variance is larger in general for all other methods. For the post selection approach, the performances of the three variance estimation methods, are shown as 2.1 (K-fold cross-validation), 2.2 (modified variance estimator), and 2.3 (RCV) in Tables 2, 4, 6. Method 2.3 (RCV estimation under post selection within Method 2) performs the best among all three approaches across different settings and patterns. Some key advantages of Method 2.3 include lower bias and smaller standard deviations (SD) and standard errors (SE), along with good coverage rates (CR).
Tables 1, 2 shows the results using Lasso penalized regression when forcing personal characteristics in the model. As the sparsity level increases, the performance of most methods seems to degrade, with higher biases and lower coverage rates. Methods 3 and 4 demonstrate good performances in most of the settings. However, when the strength of the biomarker is strong and the strength of FFQ is relatively weak (i,e., Setting 3), we can see Method 2 generally generated the most efficient result compared with Methods 3 and 4. When we have strong biomarker effects (Setting 3), Method 2.3 outperforms the other methods.
Tables 3, 4 present the results for SCAD penalized regression when personal characteristics are forced into the model. Corresponding results without forcing personal characteristics can be found in Supplementary Tables 4, 5. When comparing SCAD with Lasso, we can observe a similar trend in terms of bias control and standard deviation (SD) across various effect size patterns and settings. In addition, when comparing the three approaches for variance estimation in constructing the bias factor (BF) using Method 2 with post selection, the RCV approach continues to outperform the others in controlling bias and providing the most efficient results. With direct selection using SCAD in Method 2, the bias is generally well-controlled, and the confidence rate (CR) is promising when personal characteristics are not fixed for variable filtering. These results are comparable to those obtained with Lasso. However, when variables are post selected, SCAD's performance is not as strong as Lasso's. This is particularly noticeable in scenarios with large sparsity, where SCAD struggles to control bias effectively. In summary, Lasso demonstrates superior performance in variance estimation and bias control when compared to SCAD.
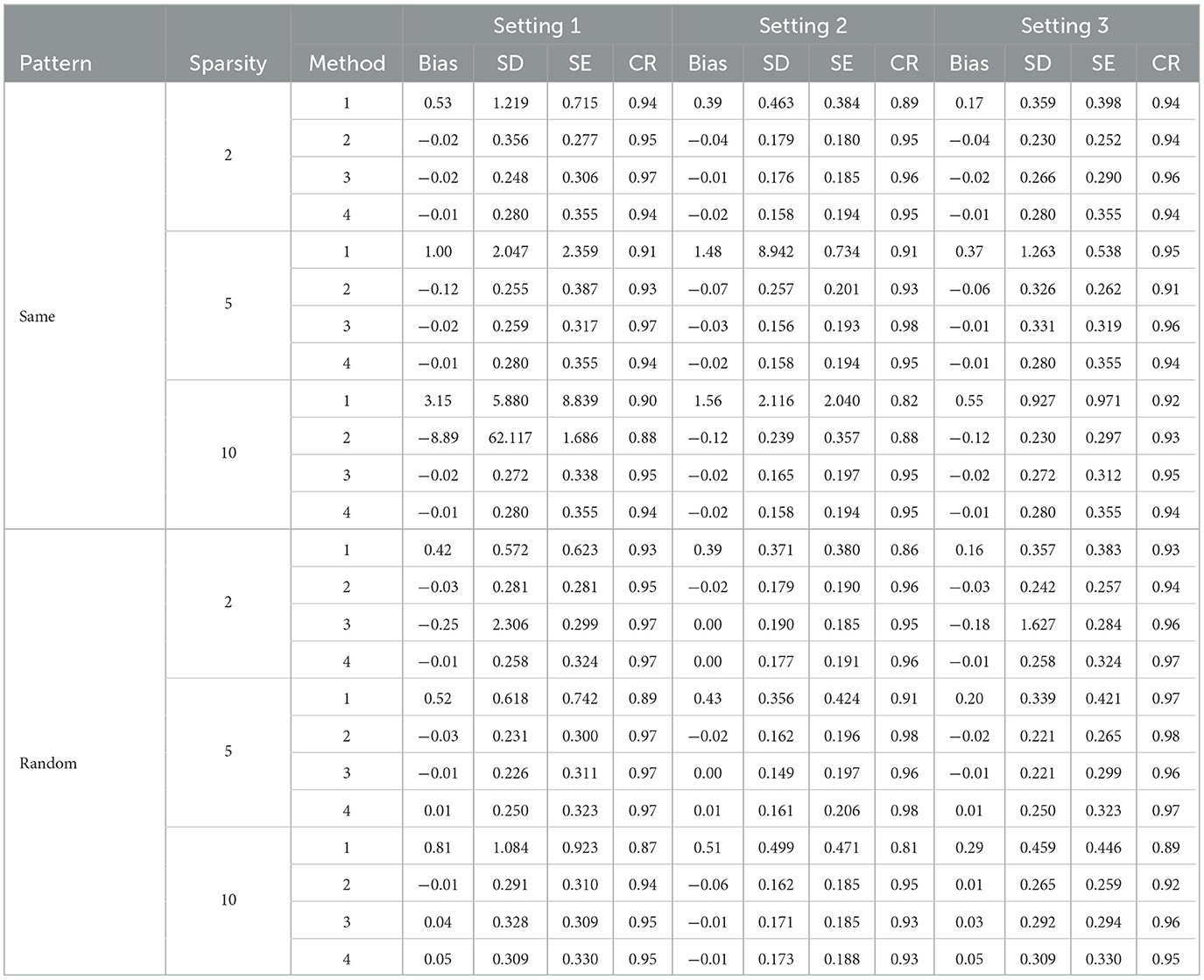
Table 3. Simulation results for direct SCAD selection forcing personal characteristics in the model.
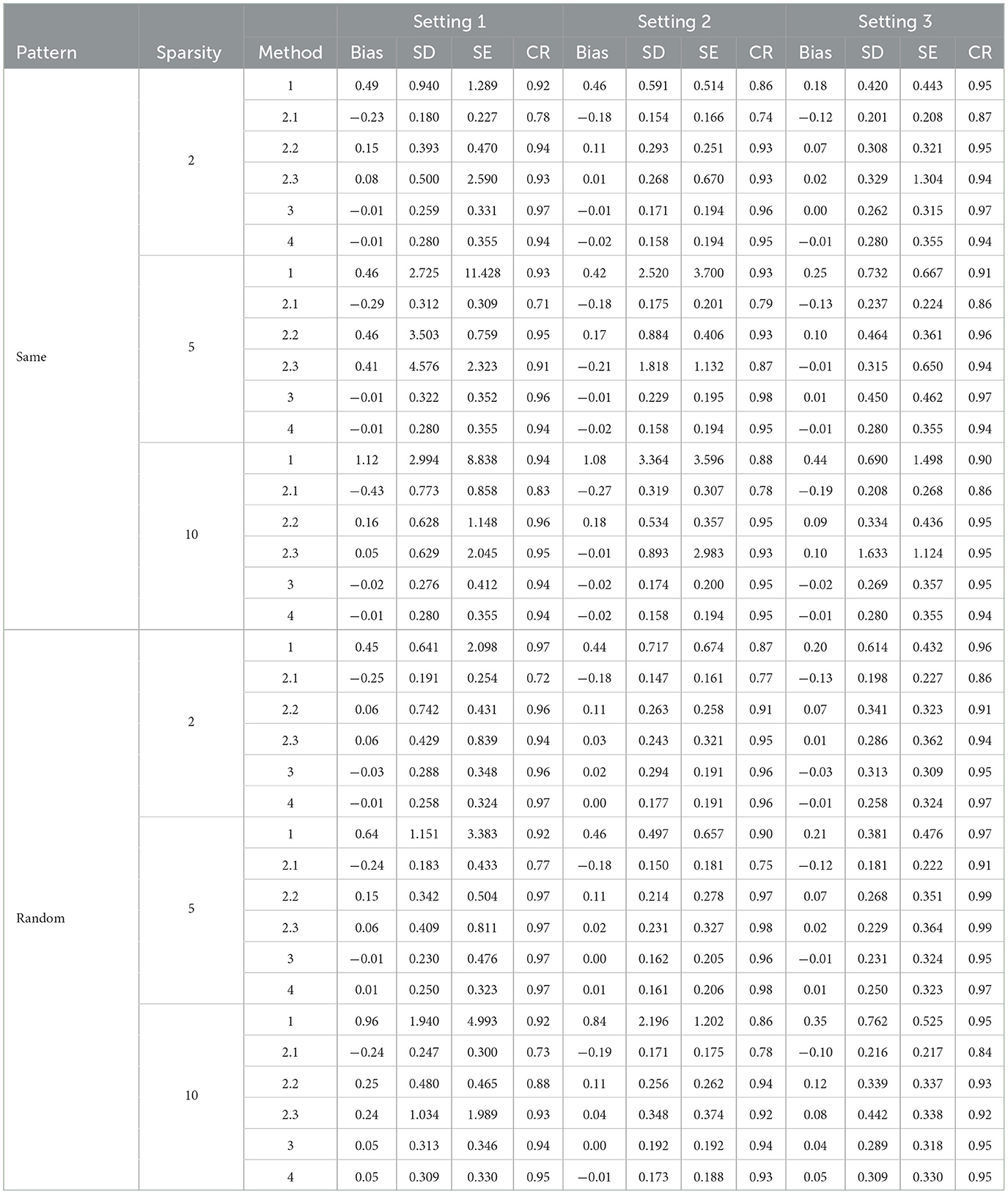
Table 4. Simulation results for post SCAD selection forcing personal characteristics in the model.
RF offers an alternative approach for constructing a biomarker prediction model in the second stage. Tables 5, 6 display the results obtained using RF. When the 10 most important variables are directly selected with RF, the estimated bias is considerably large in most scenarios. However, when post selection is applied to variables using RF, results with variance estimation approaches 2.2 and 2.3 both exhibit small bias and promising confidence rates (CR). These outcomes are comparable to those achieved with Lasso for Method 2 using the RCV estimation (2.3). In summary, while RF does not provide accurate estimations of associated parameters when using direct selection, its performance is similar to Lasso when post selection is employed.
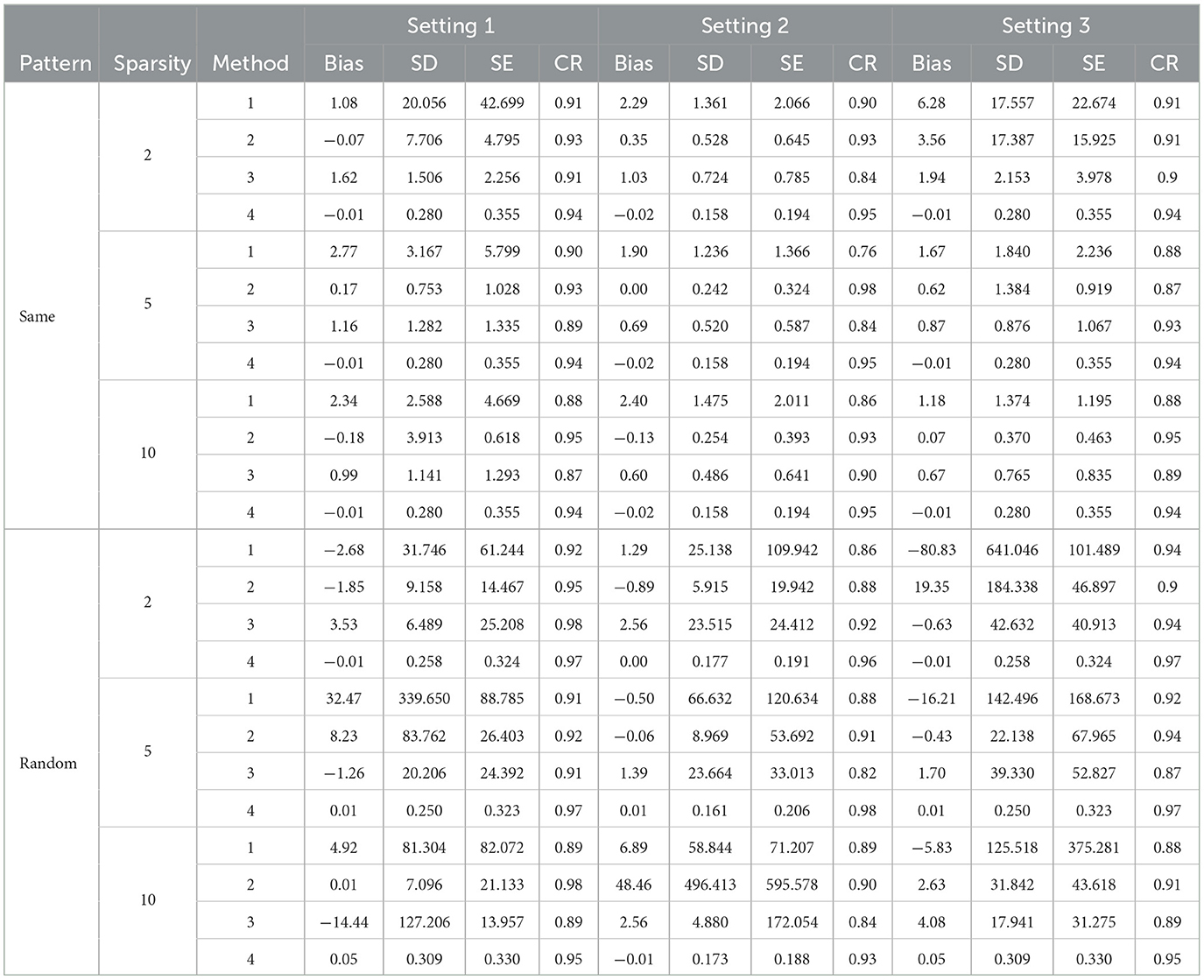
Table 5. Simulation results for direct RF selection not forcing personal characteristics in the model.
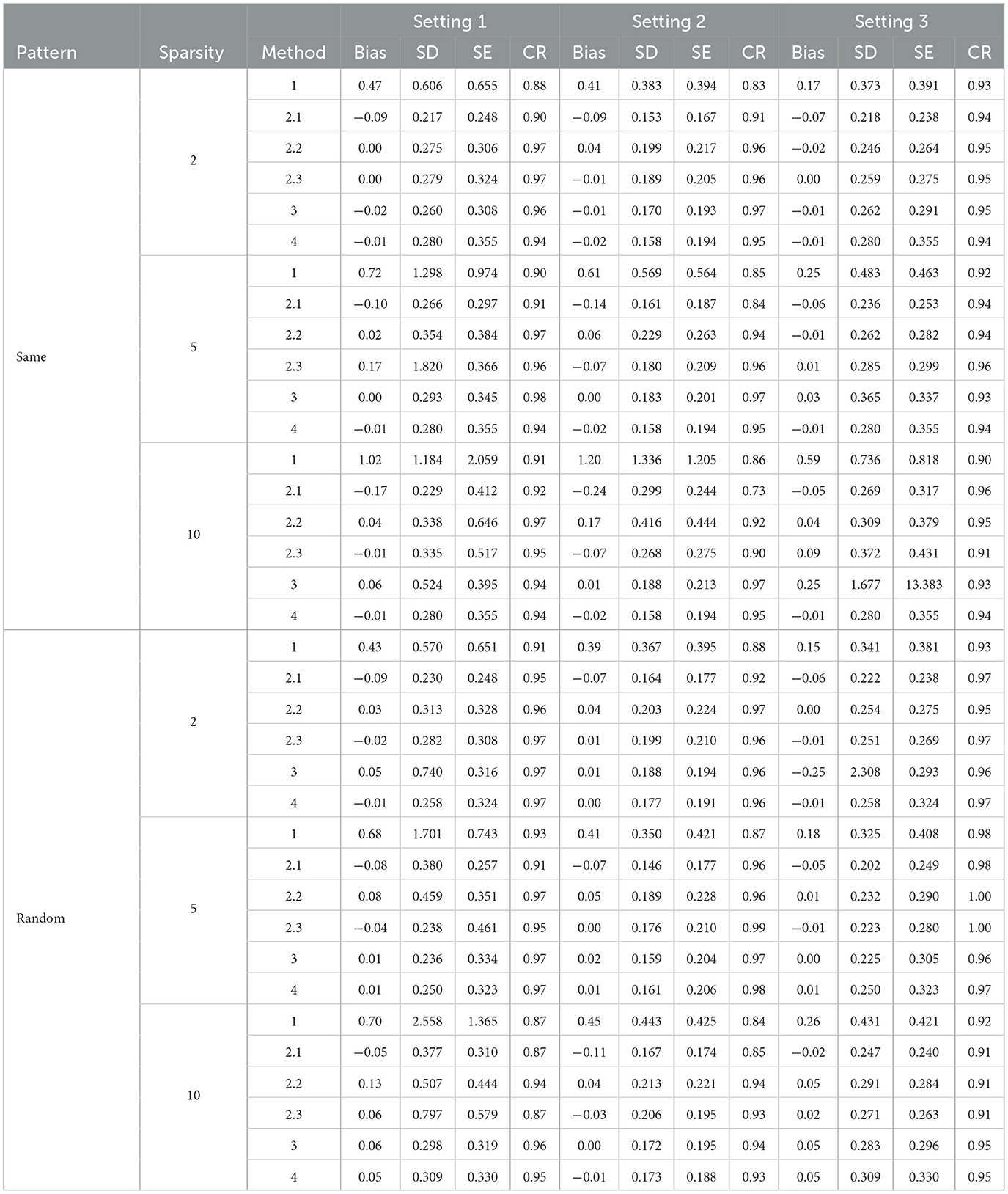
Table 6. Simulation results for post RF selection not forcing personal characteristics in the model.
Overall, with the linear settings, Lasso provides a consistent estimator in most cases and largely attenuates the bias compared with SCAD and RF. For more general model settings, RF has potential advantages when the linear model does not hold. The post selection option with RCV variance estimation for BF construction provides consistent estimation on associated parameters with stable CR and is recommended especially when we have sparse high-dimensional data structure.
We exemplify our methodologies utilizing data from the WHI NPAAS feeding study (n = 153), NPAAS biomarker study (n = 450), and the comprehensive WHI cohort data [comprising the WHI Observational Study (OS) and the Dietary Modification Trial Control Arm (DM-C), n = 122, 970]. A log-transformed self-reported ratio of sodium to potassium intake from FFQ serves as Q. Covariates such as age, BMI, race/ethnicity, education level, self-reported physical activity, and smoking status are considered as V. The high-dimensional 24 h urine measurements, acquired via nuclear magnetic resonance (NMR) and gas chromatography-mass spectrometry (GC-MS) platforms, are denoted as W. The disease outcome under consideration is total cardiovascular disease (CVD). The prevalence of CVD events is <10% (41), suggesting that the rare disease assumption is not substantially violated. Follow-up times commence at the moment of FFQ measurement (year-1 visit in DM-C and at enrollment in OS) and persist until the earliest of the specific CVD outcomes under consideration, death, loss to follow-up, or September 30, 2010, whichever occurs first. In our analytical process, hazard rates are modeled as implicitly conditioned on the continued survival of the study subject. This implies that death is not viewed as a source of censoring in our formulation. Rather, death merely constrains the follow-up period during which hazard rate information is collected for the subject. This differs from considering death as censoring non-fatal outcomes, which would be the case in a competing risk formulation.
We scrutinized the normality of the log-transformed self-reported intake (Q), the log-transformed metabolites from 24-hour urine measurements (W), and the log-transformed evaluated sodium/potassium ratio () utilizing the NPAAS-FS dataset. No evidence indicated a violation of any normality assumptions (B-H adjusted p value > 0.1) (42).
The estimated HR and corresponding 95% confidence interval according to a 20% increase in the sodium-potassium ratio are shown in Table 7 for the methods of Lasso, SCAD, and RF.
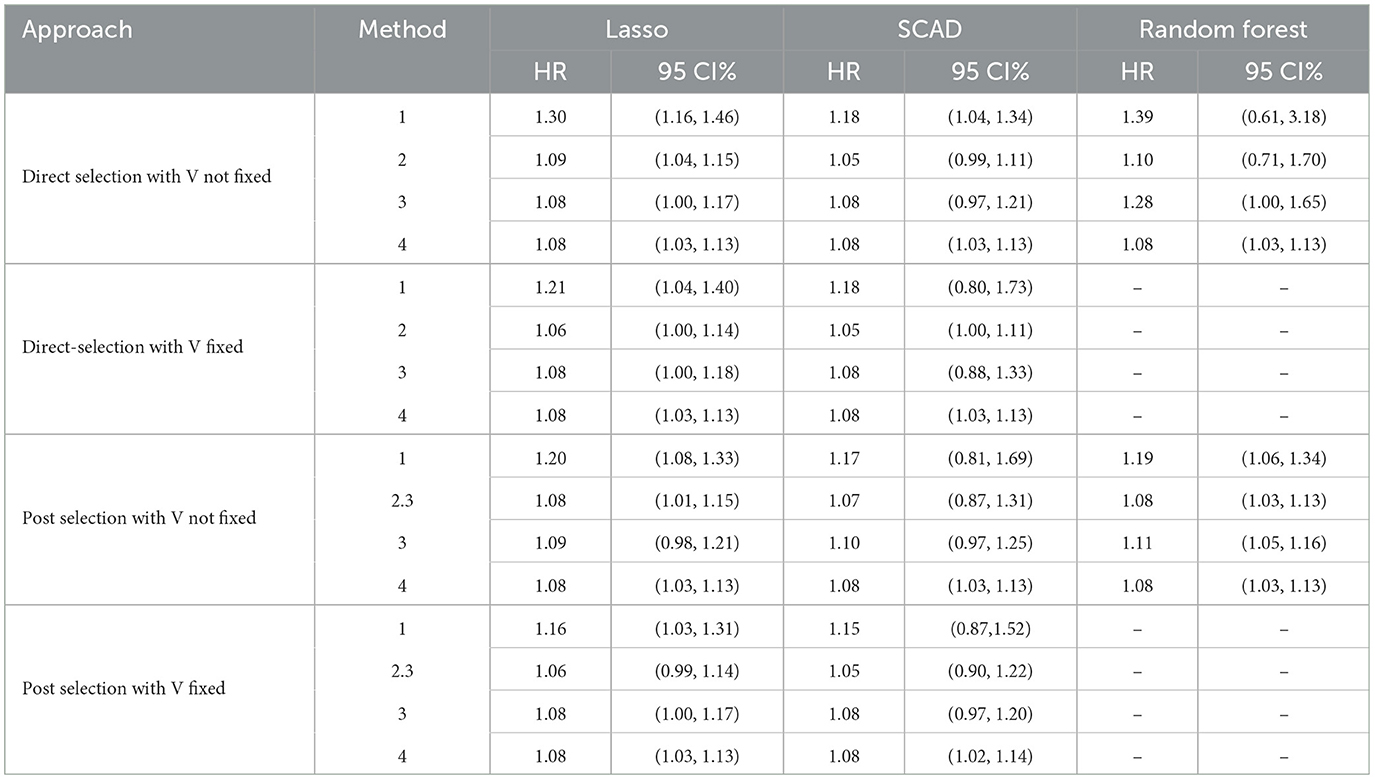
Table 7. Association between 20% increase in sodium-to-potassium ratio with total CVD in high-dimensional space under Lasso, SCAD, and RF approaches.
We observe that the estimated HR is >1 in all cases, indicating a higher risk of CVD with increased sodium-to-potassium ratios, regardless of the different high-dimensional approaches used. These findings are consistent with those reported in previously published studies (20). The most conservative estimate for , 0, is used to construct the BF in Method 2. Moreover, RCV variance estimation is employed to construct the BF for the post selection approach with Method 2. The estimation of the associated parameter derived from Method 2 is smaller in scale compared to Method 1 and is similar to Methods 3 and 4. We note that the 95% CI does not include an HR of 1 with Lasso and RF in most cases, indicating a significant association between calibrated dietary intake and the risk of CVD. Conversely, the 95% CI with SCAD exhibits less efficient results with larger variance, indicating a non-significant association between calibrated dietary intake and the risk of CVD in several instances.
We investigated the prerequisites for a valid biomarker in high-dimensional space for regression calibration purposes. Various methods to handle high-dimensional data (i.e., Lasso, SCAD, and RF) and approaches to variable selection (i.e., direct and post selection) were applied and compared across different scenarios, such as sparsity level and pattern of effect size. This paper offers researchers a comprehensive understanding of how to handle high-dimensional data in calibrated regression studies. Building linear regression models in high-dimensional space presents challenges, such as overfitting to samples and multicollinearity, which can lead to inadequate estimations.
In order to identify the most effective measurements associated with consumed dietary intakes in the feeding study, Lasso, SCAD, and RF were applied for variable selection within the high-dimensional dataset. Overall, Lasso demonstrated more stable results for variable selection compared to the other two approaches. Method 2, with the BF constructed using RCV estimation under the Lasso post selection approach, consistently provided good estimations in most cases.
It is worth noting that various factors, such as filtering conditions and methods for obtaining tuning parameters, can influence the accuracy of the biomarker prediction model when using penalized regression methods and RF. Depending on these choices, the accuracy of the estimated association parameters can vary significantly. Consequently, researchers should carefully consider these factors to achieve the most accurate and reliable results when working with high-dimensional data in calibrated regression studies.
Identifying effective measurements associated with consumed dietary intakes is crucial for biomarker construction. Statistical inference presents challenges with penalized estimators. In this paper, a bootstrapping approach was employed for variance estimation in high-dimensional data for penalized regression and RF. However, there are alternative approaches for variance estimation in high-dimensional data with penalized regression that could be considered in future analyses.
One issue with the estimated covariance matrix relates to zero components. Specifically, when coefficients are zero, the approximate covariance matrix results in zero for estimated variance. Although the estimation of non-zero components is robust, the signs of zero components can be either negative or positive. This issue is also present in the sandwich formula of the covariance matrix developed by (31). Wasserman and Roeder (43) proposed a two-stage procedure for valid inference. Their method involves randomly dividing the data into training and testing datasets. Penalized linear regression is used in the training data to select informative variables in the first stage, while ordinary least squares (OLS) are applied in the testing data to compute standard errors. A drawback of the single-split method is that results may depend on how the data is split. To address this, Meinshausen et al. (44) suggested a multi-split method, which repeats the single-split multiple times. Lockhart et al. (45) introduced the covariance test statistic to test the significance of predictor variables that enter the current Lasso model. For ultra-high-dimensional cases where the sample size is equal to or smaller than the variable dimension, the sure independent screening (SIS) technique proposed by (31) can be considered for variable screening in future work.
The data analyzed in this study is subject to the following licenses/restrictions: the data can only be accessed through the collaborative mode as described on the Women's Health Initiative website. Requests to access these datasets should be directed to www.whi.org.
RD and CZ designed the research and had primary responsibility for the final content. YZ, RD, and CZ derived the methods. YZ performed simulation studies and run the data analysis. RD drafted the paper. YH and RP revised the draft and provide critical feedback to the paper. All authors read and approved the final manuscript.
This work was supported in part by grants R01 CA119171 and R01 CA277133 from the U.S. National Cancer Institute and U54 GM115458 from the National Institute of General Medical Sciences. The WHI programs are funded by the National Heart, Lung, and Blood Institute, National Institutes of Health, U.S. Department of Health and Human Services through contracts, HHSN268201600018C, HHSN268201600001C, HHSN268201600002C, HHSN268201600003C, and HHSN268201600004C.
The authors acknowledge the following investigators in the Women's Health Initiative (WHI) Program: Program Office: Jacques E. Rossouw, Shari Ludlam, Dale Burwen, Joan McGowan, Leslie Ford, and Nancy Geller, National Heart, Lung, and Blood Institute, Bethesda, Maryland; Clinical Coordinating Center, Women's Health Initiative Clinical Coordinating Center: Garnet L. Anderson, Ross L. Prentice, Andrea Z. LaCroix, and Charles L. Kooperberg, Public Health Sciences, Fred Hutchinson Cancer Research Center, Seattle, Washington; Investigators and Academic Centers: JoAnn E. Manson, Brigham and Women's Hospital, Harvard Medical School, Boston, Massachusetts; Barbara V. Howard, MedStar Health Research Institute/Howard University, Washington, DC; Marcia L. Stefanick, Stanford Prevention Research Center, Stanford, California; Rebecca Jackson, The Ohio State University, Columbus, Ohio; Cynthia A. Thomson, University of Arizona, Tucson/Phoenix, Arizona; Jean Wactawski-Wende, University at Buffalo, Buffalo, New York; Marian C. Limacher, University of Florida, Gainesville/Jacksonville, Florida; Robert M. Wallace, University of Iowa, Iowa City/Davenport, Iowa; Lewis H. Kuller, University of Pittsburgh, Pittsburgh, Pennsylvania; and Sally A. Shumaker, Wake Forest University School of Medicine, Winston-Salem, North Carolina; Women's Health Initiative Memory Study: Sally A. Shumaker, Wake Forest University School of Medicine, Winston-Salem, North Carolina. For a list of all the investigators who have contributed to WHI science, please visit: https://www.whi.org/researchers/SitePages/WHI%20Investigators.aspx. Decisions concerning study design, data collection and analysis, interpretation of the results, the preparation of the manuscript, and the decision to submit the manuscript for publication resided with committees that comprised WHI investigators and included National Heart, Lung, and Blood Institute representatives.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The contents of the paper are solely the responsibility of the authors.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnut.2023.1215768/full#supplementary-material
1. Adams KF, Schatzkin A, Harris TB, Kipnis V, Morris T, Ballard-Barbash R. Overweight, obesity and mortality in a large prospective cohort of persons 50 to 71 years old. N Engl J Med. (2006) 355:763–78. doi: 10.1056/NEJMoa055643
2. World Cancer Research Fund/American Institute for Cancer Research (WCRF/AICR). Food, Nutrition and the Prevention of Cancer: A Global Perspective. Washington, DC: American Institute for Cancer Research (2007).
3. Paeratakul S, Popkin BM, Kohlmeier L, Hertz-Picciotto I, Guo X, Edwards LJ. Measurement error in dietary data: implications for the epidemiologic study of the diet-disease relationship. Eur J Clin Nutr. (1998) 52:722–7. doi: 10.1038/sj.ejcn.1600633
4. Prentice RL, Mossavar-Rahmani Y, Huang Y, Horn LV, Beresford SAA, Caan B, et al. Evaluation and comparison of food records, recalls, and frequencies for energy and protein assessment by using recovery biomarkers. Am J Epidemiol. (2011) 174:591–603. doi: 10.1093/aje/kwr140
5. Carroll RJ, Ruppert D, Stefanski LA, Crainiceanu CM. Measurement Error in Nonlinear Models: A Modern Perspective. Boca Raton, FL: CRC Press (2006). doi: 10.1201/9781420010138
6. Freedman LS, Schatzkin A, Midthune D, Kipnis V. Dealing with dietary measurement error in nutritional cohort studies. J Natl Cancer Instit. (2011) 103:1086–92. doi: 10.1093/jnci/djr189
7. Huang Y, Wang CY. Cox regression with accurate covariate unascertainable: a nonparametric-correction approach. J Am Stat Assoc. (2000) 45:1209–19. doi: 10.1080/01621459.2000.10474321
8. Kipnis V, Midthune D, Freedman L, Bingham S, Schatzkin A, Subar A, et al. Bias in dietary-report instruments and its implications for nutritional epidemiology. Public Health Nutr. (2002) 5:915–23. doi: 10.1079/PHN2002383
9. Song X, Huang X. On corrected score approach for proportional hazards model with covariatemeasurement error. Biometrics. (2005) 61:702–14. doi: 10.1111/j.1541-0420.2005.00349.x
10. Carroll RJ, Midthune D, Subar AF, Shumakovich M, Freedman LS, Thompson FE, et al. Taking advantage of the strengths of 2 different dietary assessment instruments to improve intake estimates for nutritional epidemiology. Am J Epidemiol. (2012) 175:340–7. doi: 10.1093/aje/kwr317
11. Yan Y, Yi GY. A corrected profile likelihood method for survival data with covariate measurement error under the Cox model. Can J Stat. (2015) 43:454–80. doi: 10.1002/cjs.11258
12. Li Y, Ryan L. Inference on survival data with covariate measurement error-An imputationapproach. Scand J Stat. (2006) 33:169–90. doi: 10.1111/j.1467-9469.2006.00460.x
13. Prentice RL, Huang Y, Tinker LF, Beresford SA, Neuhouser ML, Pettinger M, et al. Regression calibration in nutritional epidemiology: example of fat density and total energy in relationship to postmenopausal breast cancer. Am J Epidemiol. (2013) 178:1663–72. doi: 10.1093/aje/kwt198
14. Keogh RH, White IR. A toolkit for measurement error correction, with a focus on nutritional epidemiology. Stat Med. (2014) 33:2137–55. doi: 10.1002/sim.6095
15. Bartlett JW, Keogh RH. Bayesian correction for covariate measurement error: a frequentist evaluation and comparison with regression calibration. Stat Methods Med Res. (2018) 27:1695–708. doi: 10.1177/0962280216667764
16. Rosner B, Spiegelman D, Willett WC. Correction of logistic regression relative risk estimates and confidence intervals for measurement error: the case of multiple covariates measured with error. Am J Epidemiol. (1990) 132:734–45. doi: 10.1093/oxfordjournals.aje.a115715
17. Shaw PA, Prentice RL. Hazard ratio estimation for biomarker-calibrated dietary exposures. Biometrics. (2012) 68:397–407. doi: 10.1111/j.1541-0420.2011.01690.x
18. Prentice RL. Covariate measurement errors and parameter estimation in a failure time regression model. Biometrika. (1982) 69:331–42. doi: 10.1093/biomet/69.2.331
19. Zheng C, Beresford SAA, Horn LV, Tinker LF, Thomson CA, Neuhouser ML, et al. Simultaneous association of total energy consumption and activity-related energy expenditure with cardiovascular disease, cancer, and diabetes risk among postmenopausal women. Am J Epidemiol. (2014) 180:526–35. doi: 10.1093/aje/kwu152
20. Zheng C, Zhang Y, Huang Y, Prentice R. Using controlled feeding study for biomarker development in regression calibration for disease association estimation. Stat Biosci. (2023) 15:57–113. doi: 10.1007/s12561-022-09349-3
21. Lampe JW, Huang Y, Neuhouser ML, Tinker LF, Song X, Schoeller DA, et al. Dietary biomarker evaluation in a controlled feeding study in women from the Women's Health Initiative cohort. Am J Clin Nutr. (2017) 105:466–75. doi: 10.3945/ajcn.116.144840
22. Prentice R, Pettinger M, Neuhouser M, Raftery D, Zheng C, Gowda N, et al. Biomarker-calibrated macronutrient intake and chronic disease risk among postmenopausal women. J Nutr. (2021) 151:2330–41. doi: 10.1093/jn/nxab091
23. Zhang Y, Dai R, Huang Y, Prentice R, Zheng C. Using simultaneous regression calibration to study the effect of multiple error-prone exposures on disease risk utilizing biomarkers developed from a controlled feeding study. Ann Appl Stat. (2023). [Epub ahead of print].
24. Frank LE, Friedman JH. A statistical view of some chemometrics regression tools. Technometrics. (1993) 35:109–35. doi: 10.1080/00401706.1993.10485033
25. Breiman L. Better subset regression using the nonnegative garrote. Technometrics. (1995) 37:373–84. doi: 10.1080/00401706.1995.10484371
26. Tibshirani R. Regression shrinkage and selection via the lasso. J R Stat Soc Ser B. (1996) 58:267–88. doi: 10.1111/j.2517-6161.1996.tb02080.x
27. Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. J Am Stat Assoc. (2001) 96:1348–60. doi: 10.1198/016214501753382273
28. Fan J, Peng H. Nonconcave penalized likelihood with a diverging number of parameters. Ann Stat. (2004) 32:928–61. doi: 10.1214/009053604000000256
29. Efron B, Hastie T, Johnstone I, Tibshirani R. Least angle regression. Ann Stat. (2004) 32:407–99. doi: 10.1214/009053604000000067
30. Zou H, Li R. One-step sparse estimates in nonconcave penalized likelihood models. Ann Stat. (2008) 36:1509–33. doi: 10.1214/009053607000000802
31. Fan J, Lv J. Sure independence screening for ultrahigh dimensional feature space. J R Stat Soc Ser B. (2008) 70:849–911. doi: 10.1111/j.1467-9868.2008.00674.x
33. Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. New York, NY: Springer Science & Business Media (2009). doi: 10.1007/978-0-387-84858-7
34. Efron B, Tibshirani RJ. An Introduction to the Bootstrap. Boca Raton, FL: Chapman & Hall; CRC Press (1993). doi: 10.1007/978-1-4899-4541-9
35. Zou H, Hastie T, Tibshirani R. On the “degrees of freedom” of the lasso. Ann Stat. (2007) 35:2173–92. doi: 10.1214/009053607000000127
36. Reid S, Tibshirani R, Friedman J. A study of error variance estimation in lasso regression. Stat Sin. (2014) 24:35–67.
37. Fan J, Guo S, Hao N. Variance estimation using refitted cross-validation in ultrahigh dimensional regression. J R Stat Soc Ser B. (2012) 74:37–65. doi: 10.1111/j.1467-9868.2011.01005.x
38. Carroll RJ, Ruppert D, Stefanski LA. Measurement Error in Nonlinear Models Chapman and Hall London. New York, NY: Springer-Verlag (1995). doi: 10.1007/978-1-4899-4477-1
39. Chatterjee S, Jafarov J. Prediction error of cross-validated lasso. arXiv preprint arXiv:150206291. (2015). doi: 10.48550/arXiv.1502.06291
40. Reid S, Tibshirani R, Friedman J. A study of error variance estimation in lasso regression. Stat Sin. (2016) 26:35–67. doi: 10.5705/ss.2014.042
41. Prentice RL, Huang Y, Neuhouser ML, Manson JE, Mossavar-Rahmani Y, Thomas F, et al. Associations of biomarker-calibrated sodium and potassium intakes with cardiovascular disease risk among postmenopausal women. Am J Epidemiol. (2017) 186:1035–43. doi: 10.1093/aje/kwx238
42. Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc Ser B. (1995) 57:289–300. doi: 10.1111/j.2517-6161.1995.tb02031.x
43. Wasserman L, Roeder K. High dimensional variable selection. Ann Stat. (2009) 37:2178–201. doi: 10.1214/08-AOS646
44. Meinshausen N, Meier L, Bühlmann P. P-values for high-dimensional regression. J Am Stat Assoc. (2009) 104:1671–81. doi: 10.1198/jasa.2009.tm08647
Keywords: measurement error, regression calibration, feeding study, biomarker, high-dimensional data
Citation: Zhang Y, Dai R, Huang Y, Prentice RL and Zheng C (2023) Regression calibration utilizing biomarkers developed from high-dimensional metabolites. Front. Nutr. 10:1215768. doi: 10.3389/fnut.2023.1215768
Received: 02 May 2023; Accepted: 17 July 2023;
Published: 02 August 2023.
Edited by:
Alessandra Durazzo, Council for Agricultural Research and Economics, ItalyReviewed by:
Mário Sousa-Pimenta, Instituto Português de Oncologia, PortugalCopyright © 2023 Zhang, Dai, Huang, Prentice and Zheng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ran Dai, cmFuLmRhaUB1bm1jLmVkdQ==; Cheng Zheng, Y2hlbmcuemhlbmdAdW5tYy5lZHU=
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.