 Yanling Yang1,2
Yanling Yang1,2 Zezhou Hao
Zezhou Hao Liang Zhou
Liang Zhou Xufeng Yao
Xufeng Yao
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurosci., 24 March 2025
Sec. Brain Imaging Methods
Volume 19 - 2025 | https://doi.org/10.3389/fnins.2025.1546559
This article is part of the Research TopicInnovative imaging in neurological disorders: bridging engineering and medicineView all 3 articles
Introduction: Human brain activities are always difficult to recognize due to its diversity and susceptibility to disturbance. With its unique capability of measuring brain activities, magnetoencephalography (MEG), as a high temporal and spatial resolution neuroimaging technique, has been used to identify multi-task brain activities. Accurately and robustly classifying motor imagery (MI) and cognitive imagery (CI) from MEG signals is a significant challenge in the field of brain-computer interface (BCI).
Methods: In this study, a graph-based long short-term memory-convolutional neural network (GLCNet) is proposed to classify the brain activities in MI and CI tasks. It was characterized by implementing three modules of graph convolutional network (GCN), spatial convolution and long short-term memory (LSTM) to effectively extract time-frequency-spatial features simultaneously. For performance evaluation, our method was compared with six benchmark algorithms of FBCSP, FBCNet, EEGNet, DeepConvNets, Shallow ConvNet and MEGNet on two public datasets of MEG-BCI and BCI competition IV dataset 3.
Results: The results demonstrated that the proposed GLCNet outperformed other models with the average accuracies of 78.65% and 65.8% for two classification and four classification on the MEG-BCI dataset, respectively.
Discussion: It was concluded that the GLCNet enhanced the model’s adaptability in handling individual variability with robust performance. This would contribute to the exploration of brain activates in neuroscience.
Magnetoencephalography (MEG) is a non-invasive neuroimaging technique that records dynamic spatiotemporal brain patterns with millisecond resolution by measuring the magnetic fields produced by neuronal activity (Yang et al., 2024). Revealing the developmental patterns of motor cognition requires brain magnetic measurement technology with high temporal and spatial resolution, and MEG is the ideal tool for detecting the complex and multifaceted development of cognitive abilities (Gross, 2019). Compared to other neuroimaging modalities, MEG offers substantial advantages, including high temporal resolution, the capacity for direct measurement of neuronal activity, real-time data acquisition, and precise localization of dynamic neural processes (Hämäläinen et al., 2020; Mellinger et al., 2007). Recent studies have demonstrated MEG’s effectiveness in classifying specific motor imagery (MI) and cognitive imagery (CI). For instance, MEG has been applied to classify upper limb movements (Hesse et al., 2007), recognize multiple gestures (Bu et al., 2023), and assess kinematic parameters (Kim et al., 2023), offering new possibilities for applications in fields such as neurorehabilitation and human-computer interaction (Halme and Parkkonen, 2018). These findings underscore MEG’s potential for enhanced classifying of brain activity and its applicability in diverse research and clinical settings.
Brain activities such as MI (Groß et al., 2002; Jerbi et al., 2007), CI (Leeuwis et al., 2021), motor execution (ME) (Solodkin et al., 2004), and emotional processing (Dumas et al., 2011) are key areas for understanding neural dynamics. Among them, MI holds promise in rehabilitation medicine, sports training, and neuroscience research (Chholak et al., 2019). MI involves mentally rehearsing movements without physically executing them (Phadikar et al., 2023), which is especially valuable for identifying movement intentions in patients with motor impairments and enables the implementation of closed-loop neurofeedback systems to support rehabilitation (Mane et al., 2020). CI is particularly significant for preventing cognitive decline and treating cognitive impairments (Hooda and Kumar, 2020). It involves activating specific brain regions through mental task simulation, generating interpretable neural patterns essential for both research and clinical practice. Till now, MEG decoding continues to face challenges in explaining complex brain activities and enhancing classification efficiency. While some progresses have been made in specific tasks, such as feature extraction from high-dimensional signals, understanding of brain activities, and accuracy improvement.
Classification of MEG signals in different task states can reveal brain region interactions and information processing processes (Nara et al., 2023; Lotte et al., 2018). However, challenges such as noise, high inter-trial variance, and limited training data, coupled with high intra-class variability of MI and CI, make MEG classification studies more difficult (Lotte et al., 2018; Roy et al., 2019). Previous studies on MI classification can be divided into two categories: classical machine learning (ML) and deep learning (DL) methods. Classical ML methods have mainly depended on manually crafted features derived from neurophysiological signals; however, these methods are frequently hindered by their time-consuming nature, dependency on individual subjects, and limited ability to extract effective features (Lotte et al., 2018). Handcrafted features can result in suboptimal classification performance due to the inherent limitations of individual expertise and experience. In contrast, DL enables the training of end-to-end models that directly map raw signals to categories, automatically extracting high-level features necessary for classification and thereby reducing the reliance on handcrafted features (Ju and Guan, 2022; Altaheri et al., 2023; Al-Saegh et al., 2021). DL models still struggle to meet the stringent demands for high accuracy and robust generalization required for emerging clinical applications (Sakhavi et al., 2018).
Among the classical ML methods, common spatial pattern (CSP) is a powerful method for constructing optimal spatial filters (Ramoser et al., 2000; Ang et al., 2008). As a result, several extended CSP variants have been developed, including filter bank CSP (FBCSP) (Ang et al., 2008) and discriminative filter bank CSP (DFBCSP) (Thomas et al., 2009). For feature classification, various classical classifiers are often employed, such as linear discriminant analysis (LDA) (Fisher, 1936), support vector machines (SVMs), and random forest (RF) (Breiman, 2001), are commonly used to classify MI tasks (Lu et al., 2010; Ang et al., 2012; Zheng et al., 2018). Rathee et al., (2021) used the FBCSP method for feature extraction, with low inter-session comparison accuracy and an average classification rate of about 69.35% for specific tasks (hand vs. word generation). Youssofzadeh et al. (2023) applied SVM classification to beta power decrements, achieving accuracy rates of 74% for MI tasks (Hand vs. Feet) and 68% for CI tasks (Word vs. Sub). Tang et al. (2024) employed SVM with a radial basis function (RBF) kernel to categorize features derived from Riemannian geometry, achieving an average accuracy of up to 80.47% in two-class cross-session MEG data tasks. Inspired by the success of EEGNet (Lawhern et al., 2018; Sarma et al., 2023) proposed MEGNet, a compact deep neural network model designed to improve single-trial decoding. MEGNet effectively captures essential spatiotemporal features and improves classification accuracy, which results showed that MEGNet outperforms traditional feature extraction methods, achieving a consistent mean accuracy of 64.76% for two classification. Bu et al. (2023) developed the MEG-RPSnet model, a convolutional neural network for decoding hand gestures from MEG signals, and achieving an average accuracy of 85.56% for Rock-Paper-Scissors gestures. Wang et al. (2024) performed unilateral movement decoding of the upper and lower limbs using MEG signals. Their study demonstrated that source-level analysis had achieved an averaged accuracy of 96.97% in classifying lower limb tasks, significantly outperforming sensor-level analysis.
MEG and electroencephalography (EEG) are non-invasive brain activity recording techniques with shared electromagnetic foundations, capturing electrical and magnetic fields from synchronized cortical neurons and providing complementary insights into brain dynamics (Hämäläinen et al., 1993; Cohen, 1972). Although there are limited studies applying DL to MEG classification, the data characteristics of MEG and EEG are similar and both reflect neural activities. Several DL-based EEG classification models have been proposed (Lawhern et al., 2018; Schirrmeister et al., 2017; Mane et al., 2021), thus providing a reference for MEG research based on DL.
Recent studies have investigated the potential of DL methods, with particular focus on convolutional neural networks (CNNs) (Mane et al., 2020) and recurrent neural networks (RNNs) (Luo et al., 2018), as promising solutions for EEG signal classification. Lawhern et al. (2018) introduced the EEGNet model, which uses a two-step convolutional sequence to learn spatial filters for each time filter, effectively extracting spatial features of specific frequencies. The results demonstrated that the model achieves four-class classification accuracy of 73.15%. Schirrmeister et al. (2017) designed the DeepConvNet, a deep convolutional network inspired by successful architectures in computer vision, to address the task of EEG decoding. The results demonstrated that DeepConvNet achieves four-class classification accuracy of 72.22%. Schirrmeister et al. (2017) developed Shallow ConvNet, drawing inspiration from the FBCSP approach, to capture the temporal dynamics of band power fluctuations within trials (Sakhavi et al., 2015). Mane et al. (2021) proposed FBCNet, which utilizes multi-view data representation and spatial filtering techniques to extract spectral-spatial features with discriminative power. The model achieved four-class classification accuracy of 76.20%. Furthermore, the integration of CNN with graph theory led to the development of the graph convolutional network (GCN), which incorporates the functional topological relationships of brain networks (Defferrard et al., 2016; Song et al., 2018; Wang et al., 2019). Hou et al. (2022) proposed GCNs-Net, designed to classify four-class MI tasks by leveraging the functional topological relationships between electrodes. This method demonstrated reliable convergence for both individual and group-level predictions, achieving an average accuracy of 93.06% on the PhysioNet dataset. RNNs and long short-term memory (LSTM) networks have also been proposed to capture temporal features for EEG classification (Yang et al., 2020; Hu et al., 2020; Wang et al., 2018). While GCN and LSTM have achieved high prediction accuracy, few researchers have explored this approach in the context of MEG classification.
To address the limitation of low accuracy in MEG multi-task classification, we developed a graph-based long short-term memory convolutional neural network (GLCNet) for the classification of MEG signals. Our model is characterized by the implementation of three main modules: the GCN module, which efficiently extracts spatial features; the spatial convolution module, performing spatial convolutions across all channels at each time point; and the LSTM module, capturing the temporal dynamics of the MEG signal, respectively. Finally, the spatial features extracted from the GCN and the spatiotemporal features captured from both the spatial convolution and LSTM modules are fed into a fully connected layer for precise classification results. Therefore, the time-frequency-spatial features of MEG signals are fully exploited by combining modules. The contributions are summarized as follows:
(1) An improved GLCNet model is proposed to efficiently classify MEG signals. This model integrates three key modules: GCN, spatial convolution, and LSTM. It effectively captures highly discriminative and robust features.
(2) An enhanced cross-entropy loss function will be added to focus the model on difficult samples, accelerating their correction and promoting faster convergence.
(3) Experiment results show that the GLCNet outperforms benchmark algorithms on the MEG-BCI datasets.
We evaluated the classification accuracy on two datasets, namely the MEG-BCI datasets (Rathee et al., 2021) and the BCI competition IV dataset 3.1
The dataset utilized in this study is an open-source MEG-BCI datasets designed for MI and CI tasks (Rathee et al., 2021). The dataset consists of 17 participants, of whom 14 are male (82.35%) and 3 are female (17.64%), with the median age being 28 years.
MEG data were acquired using a 306-channel whole-head neuromagnetometer system (Elekta Neuromag TRIUX; MEGIN Oy, Helsinki, Finland), consisting of 204 planar gradiometers and 102 magnetometers. The experiments were conducted in a shielded room, and the raw data were acquired with on-line filtering from 0.01 to 300 Hz at a sampling rate of 1,000 Hz. Head position tracking started and continued 20 s after the start of the experiment (Rathee et al., 2021).
The experimental paradigm included four mental imagery tasks: both hands movements (Hand), both feet movements (Feet), mathematical subtraction (Sub) and word generation (Word). The timing diagram of the MEG-BCI paradigm is shown in Figure 1. Each trial starts with a 2-s rest period, followed by a 5-s imagery task period (Rathee et al., 2021). Each subject’s two-session experiment was conducted on different days, and each session contained 200 trials (4 classes × 50trials).

Figure 1. Timing diagram of MEG-BCI paradigm.
BCI Competition IV dataset 3 includes MEG signals of two subjects, S1 and S2. The MEG changes during wrist movements in four directions with the right hand were measured by 10 MEG channels located above the motor areas. Those signals were filtered with a 0.5–100 Hz band-pass filter, and resampled at 400 Hz. There were 40 trials per target direction, resulting in a total of 160 labeled trials for each subject. The category labels of the four movement directions (right, forward, left, backward) were set to 1, 2, 3, and 4, respectively. The data format of MEG signal was represented as: number of experiments × number of time sampling points × number of channels. Here, the training data are 160 × 400 × 10 and 160 × 400 × 10, and the test data are 74 × 400 × 10 and 73 × 400 × 10 for S1 and S2, respectively.
For MEG-BCI datasets, we selected 16 subjects (excluding participant with ID ‘sub-2’, whose information is incomplete), resulting in a total of 6,400 samples (16 subjects × 2 sessions × 200 trials), MEG data from the 204 gradiometer sensors were utilized. Next, we performed preprocessing on the MEG data using MNE-Python (Gramfort et al., 2013). Bad channel detection, jump artifact correction, and head movement compensation were performed using signal space projection (SSP) and Maxwell filtering techniques. Following this, MEG data were downsampled to 500 Hz, signal space separation (SSS) removes external noise sources (such as power lines, wireless devices, etc.). The data were baseline corrected within the time window of −200 ms to 0 ms. Each trial spanned 5,000 ms, from 2,000 ms to 7,000 ms, followed by 0.5–40 Hz bandpass filtering and removal of artifacts using independent component analysis (ICA). For BCI competition IV dataset 3, we used the commonly used time window segmentation of [0, 4] s for data analysis.
As shown in Figure 2, the proposed GLCNet consists of five vital parts: multi-band layers, GCN module, spatial convolution module, LSTM module, and fully connected layer. The multi-band layer divides MEG signals into multiple frequency sub-bands for analyzing brain activities within specific frequency ranges; the GCN module obtains functional topological relationships between MEG channels relying on their relational properties; the spatial convolution module extracts spatial dependencies among neighboring channels; the LSTM module captures long-term temporal features by analyzing global correlations across time points. Finally, the fully connected layer integrates acquired features to yield predicted results.
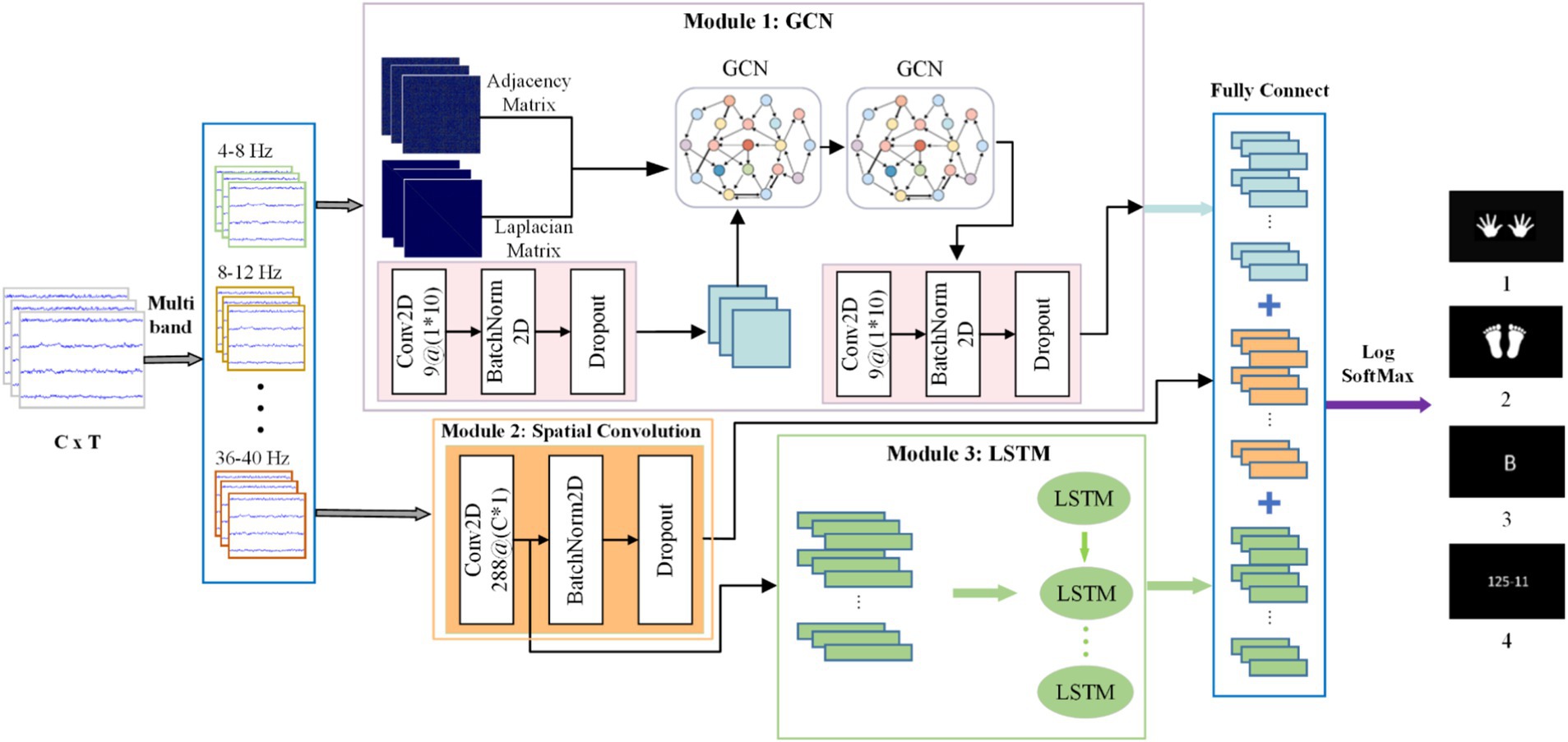
Figure 2. The framework of the proposed GLCNet.
The raw MEG data is first input into the multi-band layer to obtain multiple frequency sub-bands, which are then sequentially passed through the GCN module and spatial convolution module. The GCN outputs highly generalized MEG spatial features that capture graph correlations. Next, the spatial representations obtained from the spatial convolution module are input into the LSTM module, which outputs features with enhanced temporal correlations. Finally, the spatiotemporal features extracted by the GCN and spatial convolution-LSTM modules are integrated and forwarded to a fully connected layer to produce the classification results.
Table 1 contains the main parameters and layer configurations of each module of GLCNet. Here, C, T denote the number of channels and time points, respectively. F represents the number of filters in the convolutional layers, and K indicates the size of the convolution kernel. ELU and ReLU activation functions are applied to the convolution and classification layers, respectively. S represents stride; the probability parameter P in dropout refers to the probability of a single neuron being discarded; A represents the adjacency matrix, while D denotes the degree matrix. Nc represents category.

Table 1. Detailed framework and parameters of GLCNet.
This study applies a multi-band layer to decompose MEG signals into frequency sub-bands, generating multi-view representations that facilitate the analysis of frequency-specific brain activity. GLCNet employs a multi-view representation of the MEG data, x, generated by applying a filter bank with narrow-band temporal filters to the raw MEG signal. The filter bank F, comprising non-overlapping frequency bands (4–8, 8–12, …, 36–40 Hz) with 4 Hz bandwidths, utilizes a Chebyshev Type II filter for the filtering process. The design of this module is based on inspiration from the FBCSP algorithm (Ang et al., 2008), providing sufficient frequency resolution to capture spatial patterns within the signal’s frequency components. Frequency bands based on typical MEG signal distributions were chosen to capture distinct characteristics of brain activity. This approach significantly improves the recognition of spatial patterns across different frequency bands for providing richer neural activity details.
Due to the non-Euclidean spatial arrangement of MEG channels, graph-based data structures are highly effective for representing brain connectivity. We propose utilizing a GCN to capture the spatial relationships among MEG channels. By incorporating advancements in graph theory, the GCN efficiently captures spatial features in MEG signals by learning the underlying relationships between nodes. These spatial dependencies can be efficiently represented and visualized as graphs, with each channel corresponding to a node and edges indicating the connections between channels. GCN performs convolution operations on graph-structured data in non-Euclidean space, where the graph captures the spatial relationships, consists of nodes V and edges E. The adjacency matrix describes the connections between different nodes (Zhao et al., 2019). The MEG signal, comprising both time-domain and channel features, contains spatially distributed information across channels. Thus, applying graph convolution to the channel dimension is critical for enhancing model performance (Du et al., 2022). The convolutional propagation rule in GCN for updating node features at each layer is defined in Equation 1.
where is the adjacency matrix of the graph G plus the identity matrix, is the degree matrix, is the activation unit matrix of the l-th layer, is the parameter matrix of each layer, and σ represents the nonlinear activation function (Du et al., 2022). In this study, we use the phase lag index (PLI) matrix to replace the manually set adjacency matrix in the GCN (Piqueira, 2011).
The structure of the GCN module is illustrated in Figure 3. Multi band MEG input into GCN is represented as graph , where the nodes correspond to the set of MEG and E the edges with . E is represented as an adjacency matrix with , where d is the min-max normalized geodesic distance. L is represented as a Laplacian matrix. The CNN output, Z, represents the characteristic feature vectors of G, with the adjacency matrix, Laplacian matrix, and characteristic matrix sequentially introduced to capture the topological structure of the features as a graph. During forward propagation of the network, graph nodes are computed pointwise convolution is used to update node features based on the features of neighboring nodes, edge weights and learnable parameters. The architecture consists of two graph convolutional layers with dimensions (64,5) specified by the network’s design, followed by a CNN layer that aggregates node features into a single embedding vector of length 5.
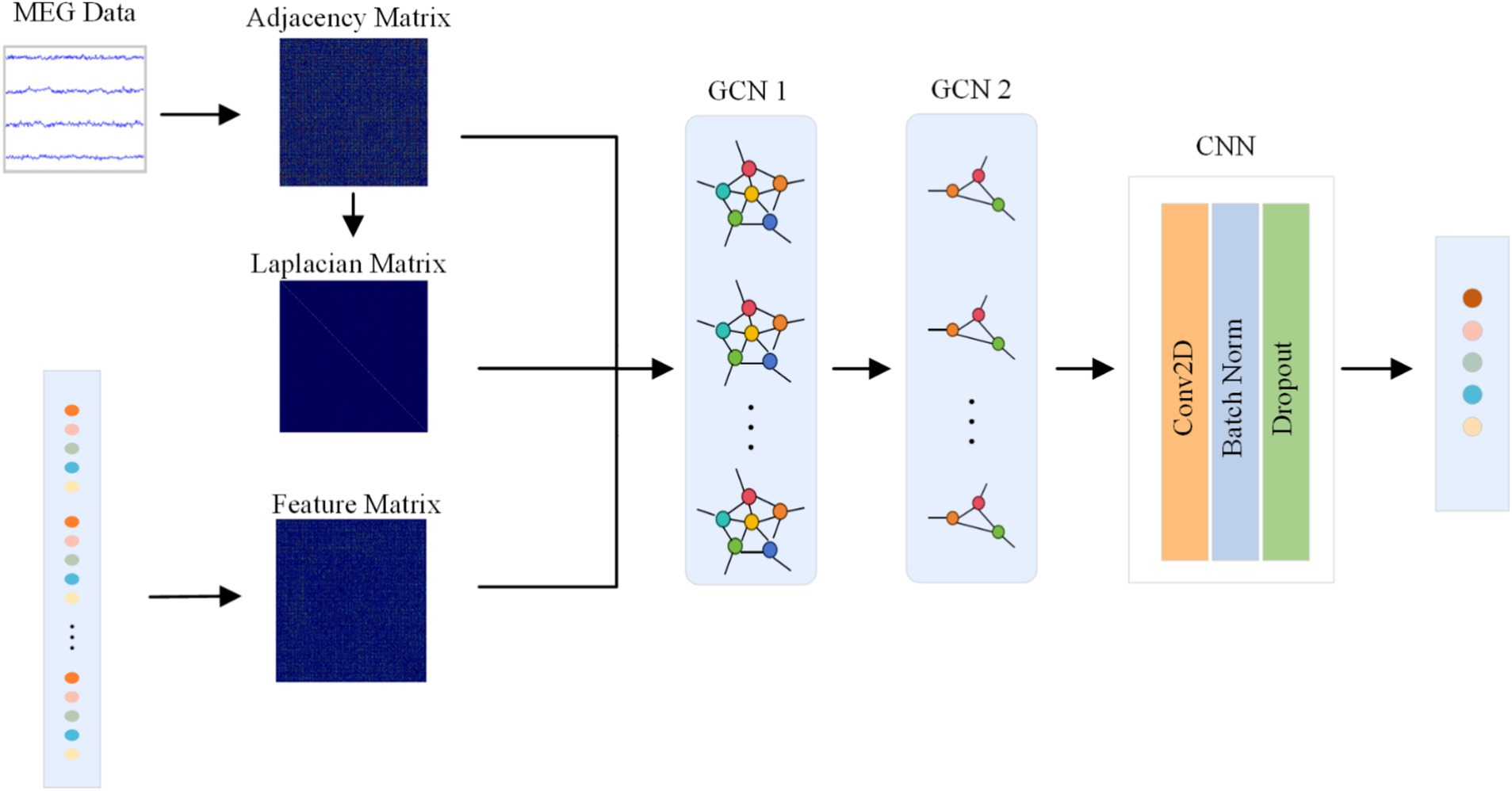
Figure 3. The structure of the GCN module.
The spatial convolution module draws inspiration from the spatial convolution block (SCB) layer of FBCNet (Mane et al., 2021). It applies convolutional filters across the spatial dimensions of MEG data to capture dependencies and relationships between channel locations. This module enhances the extraction of spatial features by capturing interactions between neighboring channels, thereby improving the identification of patterns and structures in the brain’s spatial activity domain. The spatial convolution module utilizes 2D convolution kernels to extract channel-specific spatial features (Peng et al., 2021). Following the 2D convolution, BatchNorm2D and dropout are applied to reduce overfitting.
The LSTM, a variant of RNN, incorporates storage units and a gating mechanism to replace standard hidden layer updates, effectively addressing the vanishing gradient issue in traditional RNNs. It excels in processing multivariate time series data, such as MEG signals, by capturing both short- and long-term dependencies to extract temporal features (Yu et al., 2019). The related formulas can be expressed in Equations 2–6, where and are the weights and biases of different layers in the memory, is sigmoid activation function, it,ft,ot,ct,ht are input gate, forget gate, out gate, cell state and hidden state (He et al., 2022; Saichand, 2021). Figure 4 illustrates the structure of the LSTM module.
In MEG signal processing, LSTM segments the signal into multiple time intervals and sequentially processes each segment to update internal states and generate outputs. This approach captures complex temporal features that reflect MEG signal dynamics. The resulting feature matrix from LSTM processing includes a feature vector for each segment, capturing both instantaneous values and temporal evolution. These features enhance classification accuracy and model robustness.
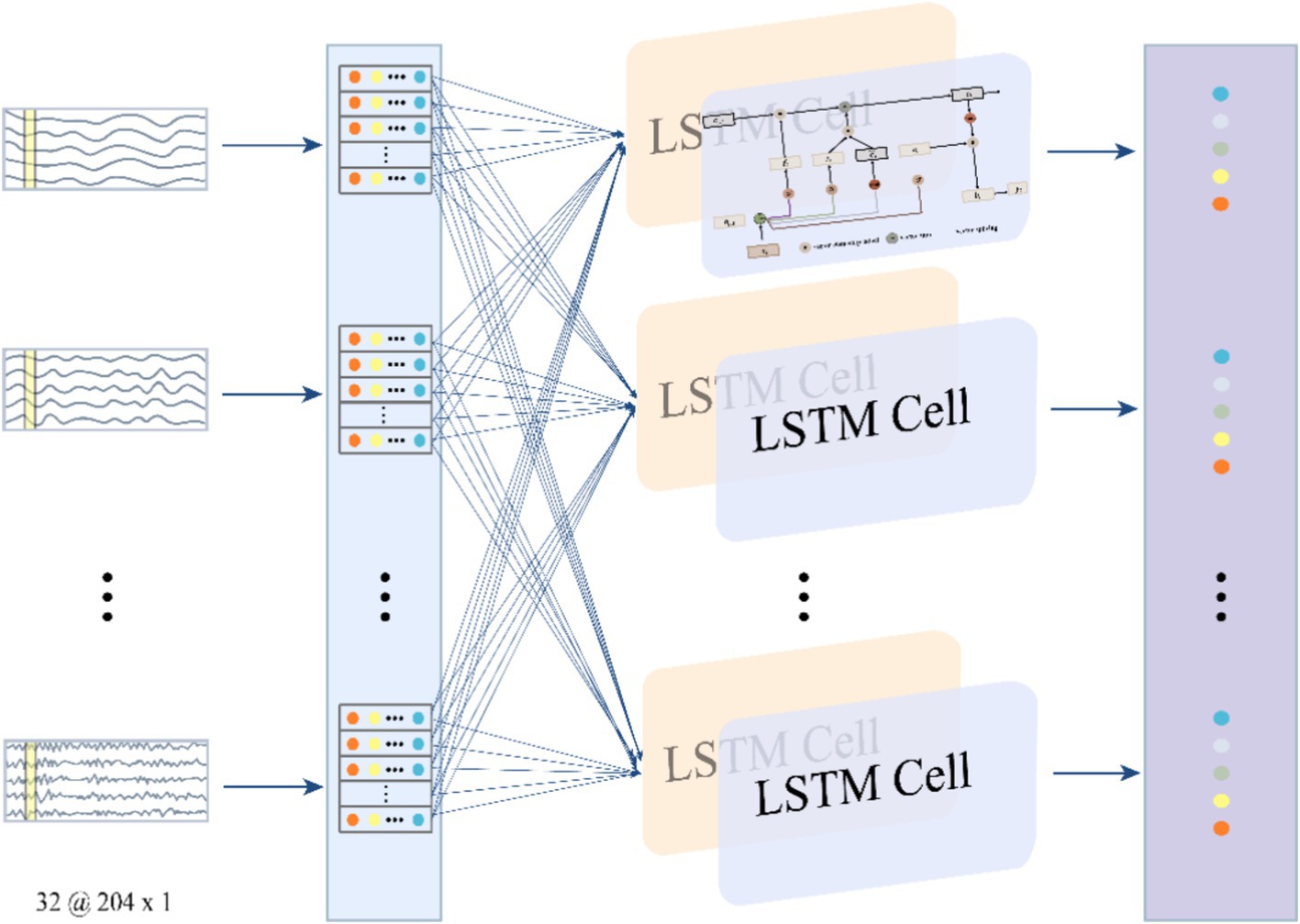
Figure 4. The structure of the LSTM module.
The loss function plays a crucial role in evaluating a model’s performance by quantifying the difference between predicted and actual outcomes. The cross-entropy (CE) loss function is widely used to measure the divergence between predicted and target probabilities (Ho and Wookey, 2019). The probability distribution p represents the true labels, and q the predicted outputs. The CE is given by , with the CE for multi-class classification computed as shown in Equation 7:
It can be observed that a smaller indicates a closer alignment between the two probability distributions, which signifies more accurate prediction results. In the MEG dataset, samples exhibit varying characteristics and can be categorized based on the ease with which the model can classify them. Some samples are straightforward for the model to predict, often referred to as “easy samples.” Conversely, others present more challenges and are known as “difficult samples.” While traditional CE yields small losses for easy samples, an abundance of such samples can dominate the overall loss, overshadowing the contributions from more difficult samples. The loss function should prioritize difficult samples, allowing the model to focus on them and improve MI classification accuracy (Ma et al., 2023).
To shift the model’s focus toward challenging samples, the CE formula has been refined, resulting in the introduction of the enhanced cross-entropy (ECE) loss function. The ECE introduces weights into the original formula, with smaller weights for easier samples and larger weights for more difficult samples, which is expressed as Equation 8.
In this formula, the larger the value of , the easier the sample is to classify. Consequently, a smaller value of indicates that this easy sample contributes less to the overall loss, while difficult samples, with larger values, contribute more significantly. By introducing the square root, the loss function is designed so that, for correctly predicted samples, is smaller than the traditional CE, whereas for incorrectly predicted samples, is larger. This adjustment directs the loss function to prioritize incorrectly predicted samples, accelerating the model’s error correction and promoting faster convergence.
The experiment consisted of two-class and four-class classifications. For MEG-BCI dataset, the two-class experiments included Hand vs. Feet, Hand vs. Word, Hand vs. Subtraction, Feet vs. Word, Feet vs. Subtraction, and Word vs. Subtraction. The four-class classification among Hand, Feet, Word, and Subtraction tasks was conducted. For BCI competition IV dataset 3, the two-class classification of 1 vs. 2, 1 vs. 3, 1 vs. 4, 2 vs. 3, 2 vs. 4, 3 vs. 4 and the four-class classification for 1, 2, 3, and 4 tasks were performed.
To evaluate the performance of GLCNet on the public MEG-BCI datasets, the performance of GLCNet was compared with six state-of-the-art benchmark algorithms of FBCSP (Ang et al., 2008), FBCNet (Mane et al., 2021), EEGNet (Lawhern et al., 2018), Deep ConvNets (Schirrmeister et al., 2017), Shallow ConvNet (Schirrmeister et al., 2017), and MEGNet (Sarma et al., 2023). In order to validate the effectiveness of GLCNet, we performed a technical validation of the four-classification model in terms of model training, ablation studies, feature visualization, comparison of ECE and CE accuracy, and statistical analysis. Among them, the ablation experiments are divided into three groups: (a) removal of the GCN module (without module 1); (b) removal of the spatial convolution module (without module 2); and (c) removal of the LSTM module (without module 3).
Two stage training method is employed where the dataset is divided separately into training set and validation set in the first stage. The model was trained using the training set, with early stopping criteria based on the validation accuracy. Training was terminated if no improvement in validation converges within 50 epochs. Setting the maximum number of iterations to 100 ensures sufficient training duration. Once the stopping criterion was met, the model parameters corresponding to the best validation accuracy were reinstated. In the second stage the validation set is added to the training set and the validation set loss is monitored and training stops when it is lower than the first stage.
The training method for GLCNet is shown in Algorithm 1. In the first stage, the input is processed through modules 1–3 to compute three feature sets (F1-F3), where F3 uses only the spatial convolution layer from module 2. These features are then fused by summation, and the resulting combined feature set is passed to a fully connected layer, which applies the ECE loss function to output the loss value of the fused feature set. In the second phase, the validation set is integrated with the training set, and the same training procedure as in the first phase is followed.

ALGORITHM 1. Training detail of proposed GLCNet.
The proposed GLCNet is implemented with PyTorch 1.13.1 on four NVIDIA GeForce RTX 3090 GPUs platform. The training process was configured with a batch size of 32, a learning rate of 0.001, and the ECE loss function. The Adam optimizer and ReLU activation function were employed, while Dropout with a rate of 0.25 was used to mitigate overfitting. These settings of hyperparameters were referenced from FBCNet (Mane et al., 2021) and Deep ConvNets (Schirrmeister et al., 2017). The running code is available on GitHub.2
Three metrics were used for performance evaluation, which are expressed in Equations 9–11.
, , , represent true positives, true negatives, false positives, and false negatives, respectively. Recall refers to the proportion of actual positive samples that are correctly identified as positive. Precision and recall are often considered opposing metrics. To account for both metrics, the F1-score was introduced. represents the accuracy of classification under random conditions. Additionally, the kappa value serves as a measure of agreement, providing an assessment of classification consistency.
The process involves two stages. In the first stage, prior to the 100th epoch, the validation set remains completely separate from the training set. During this stage, accuracy and loss converge quickly, with validation accuracy stabilizing around 80%, indicating that GLCNet is well-trained. In the second stage, following the 100th epoch, in order to make full use of all the training samples, the verification set is added to the training set as a new training set. Consequently, the validation data are incorporated into both training and validation processes, leading to validation accuracy approaching 100%. Additionally, the loss values for both the training and validation sets show a close alignment. The accuracy and loss trends of GLCNet during the training process are shown in Figure 5.
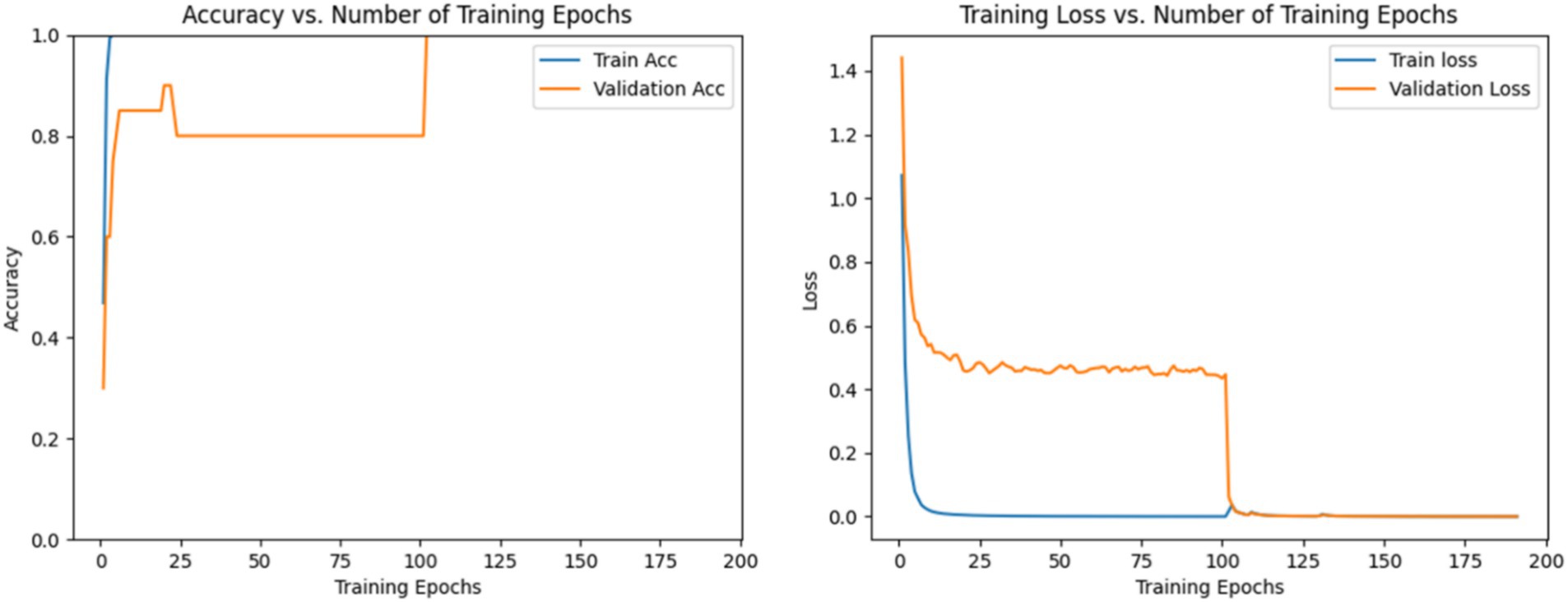
Figure 5. Accuracy and loss of GLCNet in the training and validation sets during training.
As shown in Table 2, removing any module results in a decrease in accuracy. Module 1 had the most significant impact, with recognition accuracy dropping by 9.00%. This module is primarily responsible for extracting spatial features; a 3.10% decrease after removing module 2, which extracts spatial convolution features; and a 5.70% decrease after removing module 3, responsible for temporal feature extraction. The positive impact of module 1 and 3 on model performance are evident, as the classification accuracy of GLCNet significantly declines when either module is excluded.

Table 2. The accuracy comparison in the ablation study on MEG-BCI dataset.
The t-distributed stochastic neighbor embedding (t-SNE) (Van Der Maaten and Hinton, 2008) is a popular visualization method, which is employed to generate a two-dimensional embedding of the learned MEG features. Figure 6 shows the t-SNE visualization (sub11) of the feature distributions produced by the different models for the four tasks: hand, feet, word generation and subtraction. Compared to the other models, GLCNet has a higher discrimination with the least overlap between classes.
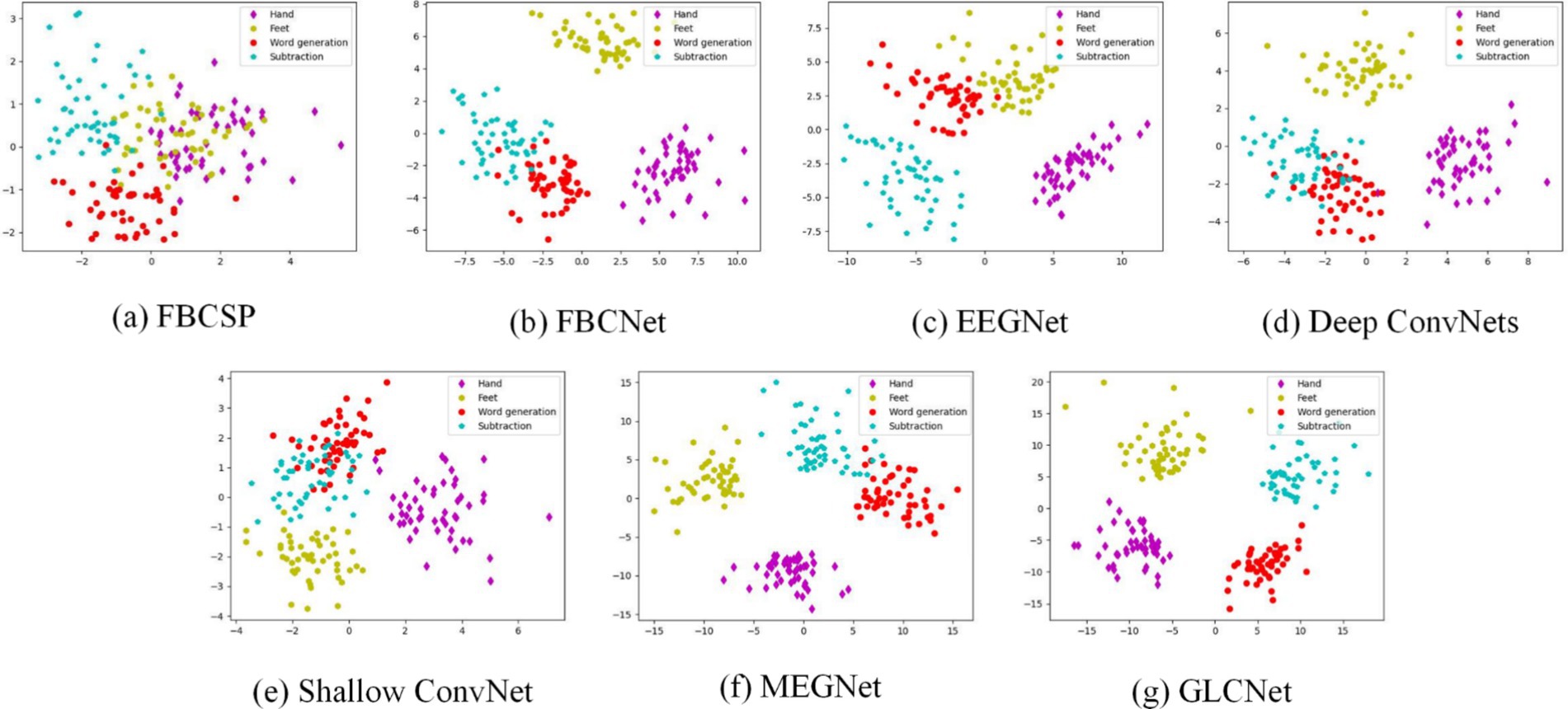
Figure 6. Visualization of t-SNE for sub 11 of MEG-BCI dataset. The four colors of dots represent Hand, Feet, Word Generation, and Subtraction.
To validate the effectiveness of the proposed ECE loss function in classifying challenging samples in MEG data and enhancing classification accuracy, it is essential to demonstrate its practical impact on improving the model’s training performance. As illustrated in Figure 7, we compared the average accuracy of five benchmark algorithms and GLCNet using both the CE and ECE loss functions. The results show an approximately 2% improvement in the average classification accuracy for each model when using ECE. This indicates that the proposed ECE loss function is more effective in enhancing the classification accuracy, particularly for challenging samples.
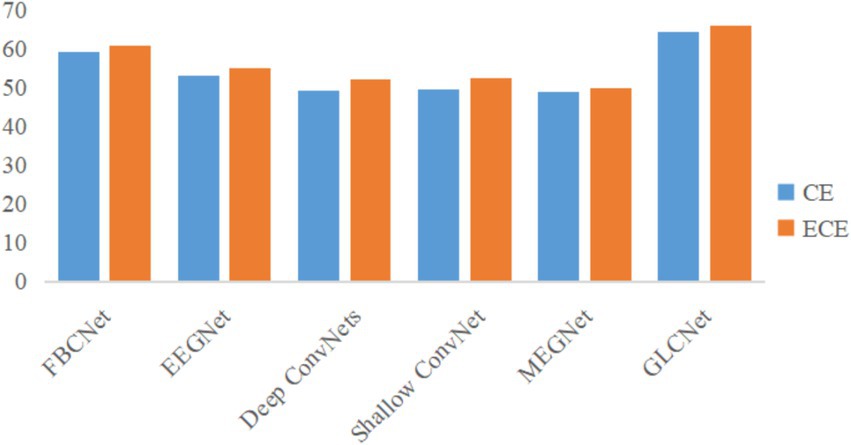
Figure 7. Comparison of loss functions of CE and ECE for GLCNet and other models.
Figure 8 compares the convergence curves of CE Loss and ECE Loss for the GLCNet model on sub 11 of MEG-BCI dataset. It is clear that the ECE Loss (orange curve) decreases more quickly than CE Loss (blue curve) along with epochs. This meant that the lower ECE Loss reflected more accurate predicted probabilities and exhibited stronger capabilities.

Figure 8. Comparison of convergence curves for CE and ECE on the sub 11 for MEG-BCI dataset.
The average comparison results of the six two-class classification tasks are presented in Table 3. Overall, for the classifications of Hand vs. Feet, Hand vs. Word, Hand vs. Subtraction, Feet vs. Subtraction, and Word vs. Subtraction, the GLCNet model achieves superior mean accuracies of 70.8, 82.7, 81.3, 81.7, and 78.9%, respectively, outperforming the other six algorithms. In Supplementary Table S1 (Hand vs. Feet), FBCNet, EEGNet and MEGNet achieve mean accuracies about 65%, while FBCSP, DeepConvNets, and ShallowConvNet achieve mean accuracies around 60%. In Supplementary Table S2 (Hand vs. Word), the mean accuracies for FBCSP, FBCNet, EEGNet, DeepConvNets, ShallowConvNet, and MEGNet were 66.3, 79.6, 72.4, 70.0, 70.2, and 72.0%, respectively. In Supplementary Table S3 (Hand vs. Subtraction), MEGNet accuracy around 77.0%, both DeepConvNets and ShallowConvNet recorded accuracies of 73%. While FBCNet and EEGNet showed steady performance, FBCSP consistently yielded lower classification results. In Supplementary Table S4 (Feet vs. Word), GLCNet achieves an average accuracy of 76.5%, slightly below FBCNet’s 77.9%. FBCSP, EEGNet, DeepConvNet and MEGNet achieved 61.4, 73.3, 68.5, and 71.63%, respectively. In Supplementary Table S5 (Feet vs. Subtraction), FBCSP recorded the lowest accuracy at 69.8%, FBCNet maintained approximately 77%, both EEGNet and ShallowNet reached 73%, MEGNet recorded the lowest accuracy at 50.3%. In Supplementary Table S6 (Word vs. Subtraction), FBCSP again recorded the lowest accuracy at 59.1%, FBCNet remained around 77%, and EEGNet, DeepConvNets, ShallowNet and MEGNet each scored approximately 70%.

Table 3. Comparison of accuracy, kappa and F1-score for two-class classification for proposed model and other models.
In conclusion, Figure 9 summarizes the results, showing that the proposed GLCNet achieved a maximum accuracy of 82.7% in two-class classification, demonstrating superior performance over the other six algorithms. Both FBCSP, EEGNet and MEGNet exhibited stable performance, while FBCNet maintained consistent accuracy across classifications. DeepConvNets and ShallowConvNet showed moderate classification performance, with FBCSP being the least effective among the algorithms tested.
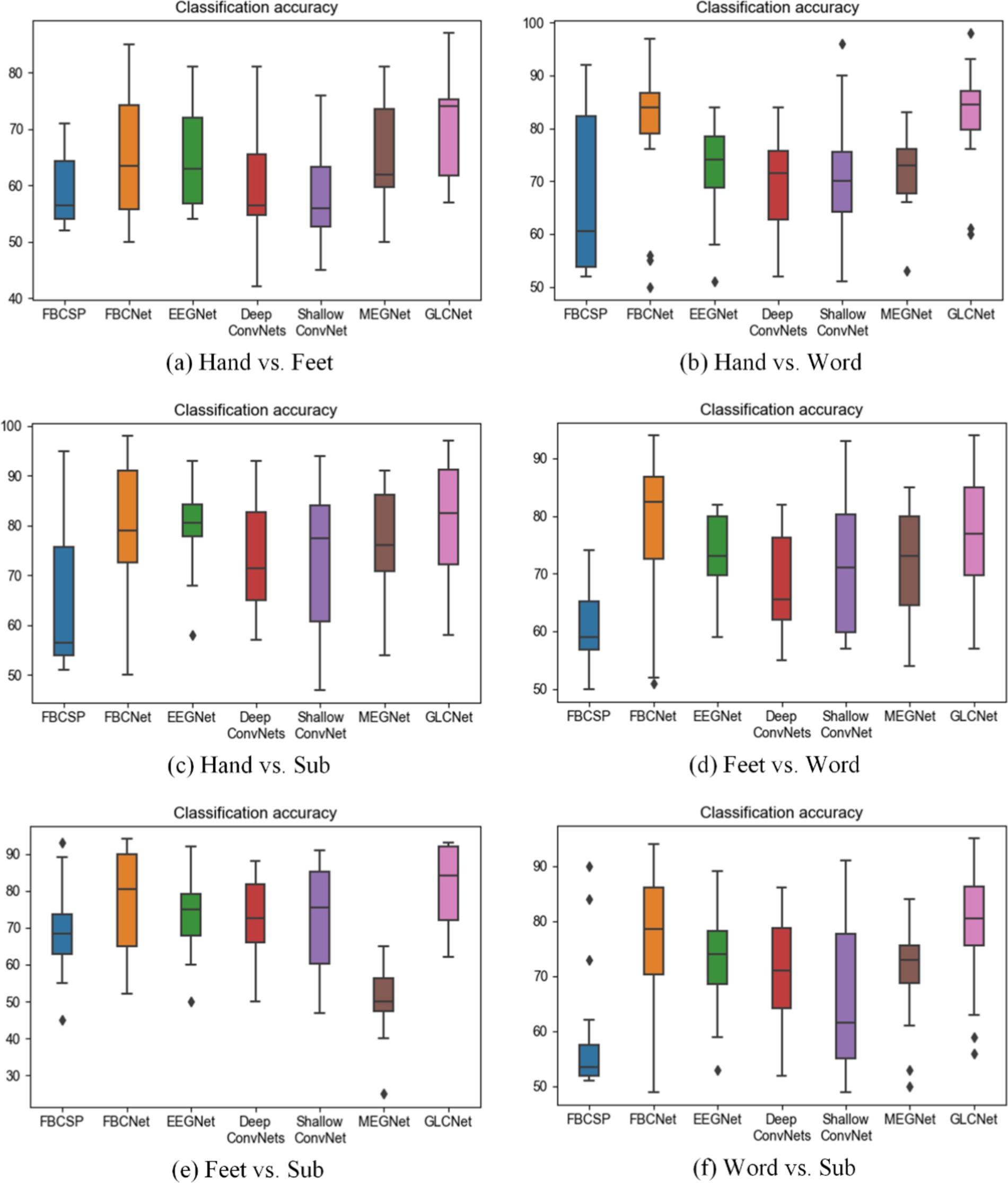
Figure 9. Comparison of two-class classification accuracy for GLCNet and other models. Black dots indicate outliers.
Table 4 and Figure 10 present the complete four-class classification results on the MEG-BCI dataset using the proposed GLCNet and other benchmark algorithms. Overall, GLCNet surpasses the benchmarks in average classification accuracy, achieving an average accuracy of 65.8%, a mean kappa value of 0.55, and a mean F1-score of 0.65. This represents improvements of 20.7, 6.7, 12.8, 16.7, 16.1, and 15.9% over FBCSP, FBCNet, EEGNet, DeepConvNets, ShallowConvNet, and MEGNet, respectively. Furthermore, the kappa value of 0.55, the highest among all methods, highlights the effectiveness of the proposed approach.
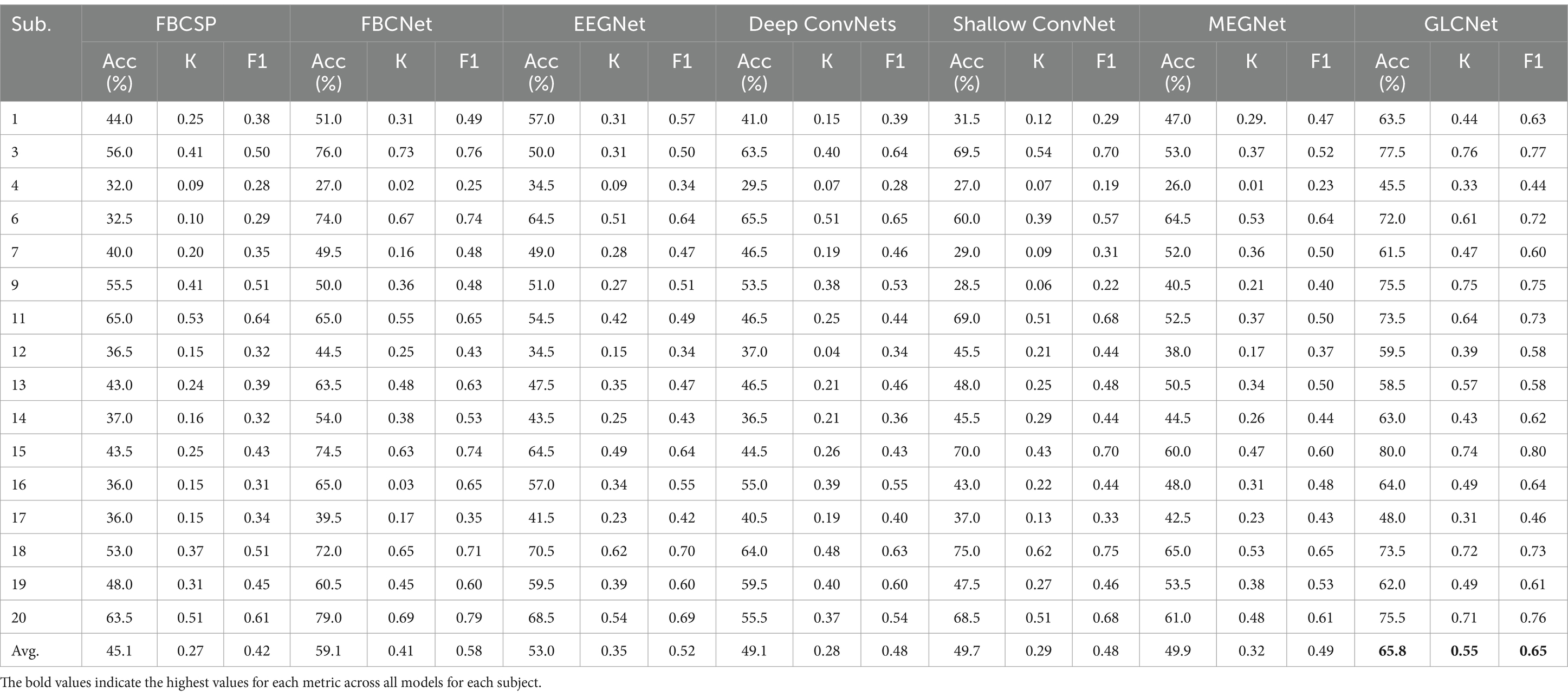
Table 4. Comparison of accuracy, kappa and F1-score for four-class classification for proposed model and other models.
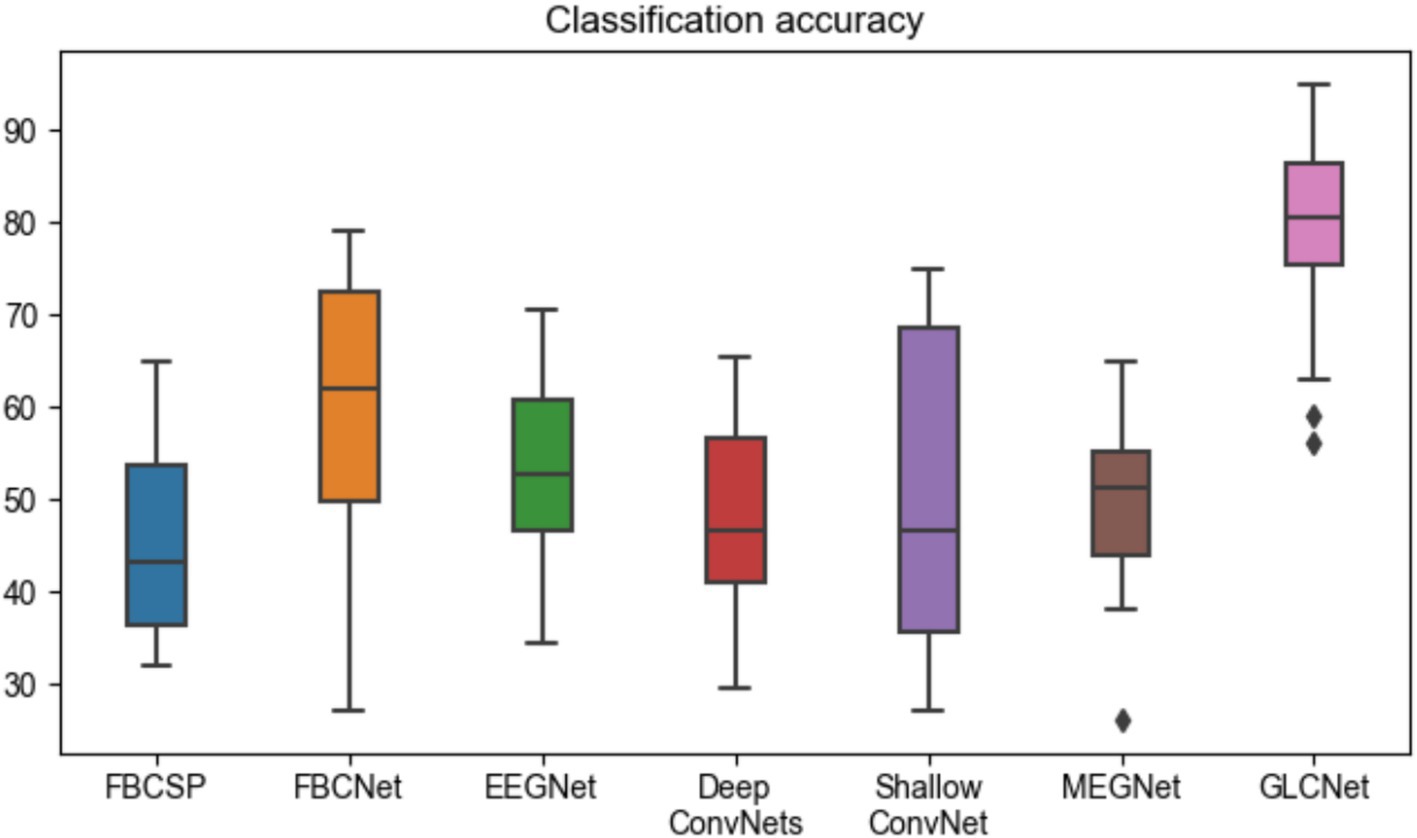
Figure 10. Comparison of four-class classification accuracy for GLCNet and other models. Black dots indicate outliers.
Table 5 presents the statistical significance of GLCNet compared to other models. With the exception of FBCNet, the classification results of the remaining four benchmark algorithms differ significantly from GLCNet (p < 0.001), indicating that GLCNet performs significantly better than these benchmark algorithms.

Table 5. ANOVA statistical analysis results of GLCNet and other models.
This study compares six benchmark models for two-class and four-class classification on the BCICIV-3 dataset. In Table 6, the GLCNet obtained the highest accuracies, particularly in the tasks 1 vs. 2, 2 vs. 3, 2 vs. 4, 3 vs. 4, and 1 vs. 2 vs. 3 vs. 4, achieving the accuracies of 76.5, 75.1, 78.1, 77.5, and 59.9%, respectively; the MEGNet also performed well in the tasks of 1 vs. 3 and 1 vs. 4, with the accuracies of 82.9 and 78.1%, respectively. Meanwhile, it was indicated that the FBCNet and FBCSP gave worst results.
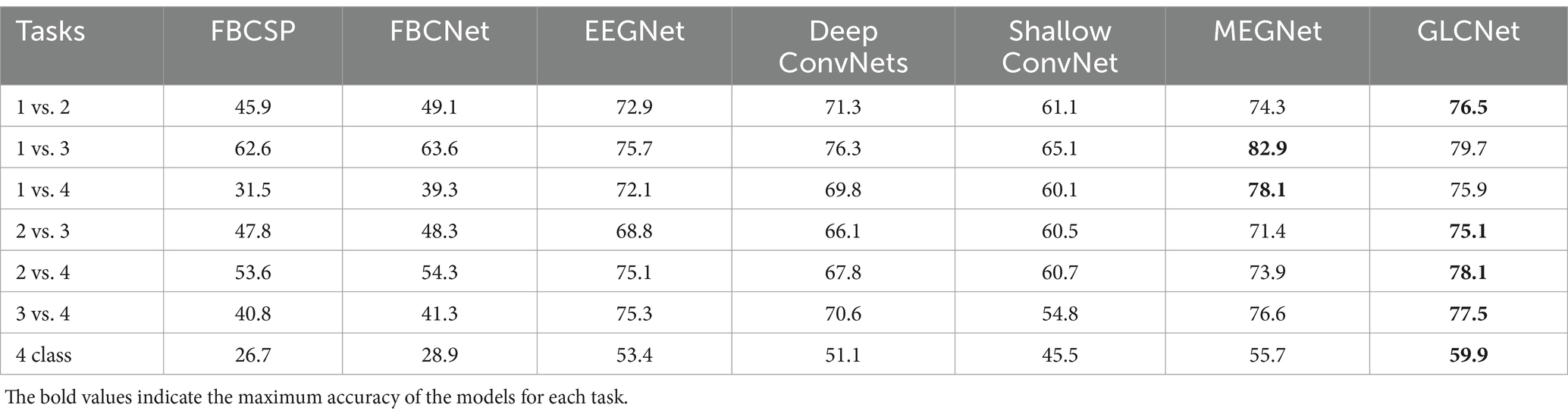
Table 6. Accuracies (%) of benchmark models for the BCICIV-3 dataset.
This study introduced GLCNet, a novel end-to-end CNN architecture designed for MEG signal classification, combining GCN for spatial feature extraction and LSTM for temporal continuity. Through evaluation on MEG-BCI datasets and BCI competition IV dataset 3, GLCNet outperforms state-of-the-art benchmark algorithms in both classification accuracy and model robustness. Beyond classification accuracy, GLCNet demonstrated strong performance in model training, ablation experiments, feature visualization, comparison of ECE and CE accuracy, and ANOVA analysis. This comprehensive performance highlights GLCNet’s robustness and versatility in MEG signal classification and related analyses. GLCNet serving as a powerful tool for MEG signal classification and advancing its applications in intelligent diagnostics and neuroscience research.
MEG data features high spatial and temporal resolution, making it an ideal modality for investigating intricate brain activity. While traditional CNNs use spatial convolution layers to extract spatial features, they face limitations in handling complex spatial topologies and long-range dependencies. Accordingly, the six chosen benchmark approaches exhibited several challenges. Especially, the FBCSP (Ang et al., 2008) mainly relied on manually designed features, and limited its generalizability across tasks and subjects; the FBCNet (Mane et al., 2021) and EEGNet (Lawhern et al., 2018) were prone to overfitting when decoding MI tasks; the Shallow ConvNet (Schirrmeister et al., 2017) demonstrated high variability in reflecting task-dependent performance; the Deep ConvNets (Schirrmeister et al., 2017) incorporated complexity and failed to capture subtle patterns; the MEGNet (Sarma et al., 2023) effectively identified prominent features but might overlook details in more complex tasks. To address these challenges, this paper introduces GCN for enhanced spatial feature learning, effectively capturing non-Euclidean structures and inter-channel correlations within MEG signals, thus uncovering comprehensive spatial information. Additionally, integrating LSTM, which captures long-term dependencies and complex temporal patterns, improves the continuity of time-series information and effectively manages temporal signal changes and dynamic features. GLCNet combines topological connectivity and convolutional features to deeply explore channel topological structures in the spatial domain while capturing temporal characteristics and signal variations. The inclusion of multi-band layers allows the model to focus on specific frequency ranges, capturing frequency components and their spatial patterns to maximize information utilization. By integrating above modules in parallel, GLCNet enhances classification performance, leveraging the rich temporal, frequency, and spatial information in MEG signals. This multidimensional approach enables more precise analysis of complex brain activity, improving the accuracy and robustness of neural data interpretation.
In this study, we utilized data from the 204 gradiometer sensors while excluding data from the 102 magnetometers. This was because that the gradiometers typically exhibited a higher signal-to-noise ratio (SNR), which improved their sensitivity in detecting cortical activity. Additionally, the gradiometers could provide superior spatial resolution for precise localization of cortical activity (Rathee et al., 2021). The proposed GLCNet model was tested on MEG-BCI and BCI competition IV dataset 3, achieving the highest classification accuracy in both two-class and four-class tasks, except in the Feet vs. Word classification, where FBCNet outperformed GLCNet by 1.4%, and in the 1 vs. 3 and 1 vs. 4 tasks, where MEGNet outperformed GLCNet by 3.2 and 2.2%, respectively. Compared to benchmark algorithms on the MEG-BCI dataset, GLCNet’s average accuracy improved by 8.65% for two-class classification and 14.6% for four-class classification. As the number of tasks grows, the complexity of classification also increases, resulting in a significant performance decline in comparison algorithms for multi-task classification. This highlights the superior performance of GLCNet. Ablation experiments demonstrated that the highest classification performance was obtained when both GCN and LSTM were employed simultaneously. The t-SNE feature distribution visualization confirmed that the GLCNet module enhanced the model’s recognition capabilities. Furthermore, the loss function analysis underscored the benefits of the proposed ECE in improving classification accuracy, particularly for challenging samples.
Our study has several limitations. First, the training samples is very limited. This may affect the generalizability of our proposed approaches in cases of other datasets or populations. Second, the proposed model faces the challenges of long training times and high computational complexity. Third, only one kind of MEG modality was used in our study. The fusion of MEG with multimodal data, such as EEG and/or fMRI would be hopeful for the potential applications in BCI applications.
There are four aspects in our future studies. At first, more samples should be enrolled and even more types of multi-center datasets should be involved. The detailed parameter analyses of age, gender, and health status of samples should be considered in performance evaluation, too. Besides, more data augmentation techniques, such as temporal transformation and frequency filtering, could be tried to resolve the limitation of data size (He and Wu, 2020; Zhang et al., 2021; Ma et al., 2024).
Secondly, more kinds of lightweight alternatives should be explore to alleviate the problem of high training costs, such as model compression (Buciluǎ et al., 2006), knowledge distillation (Gou et al., 2021), and the substitution of lightweight modules (Lahiri et al., 2020) for model simplification.
Thirdly, the fusion of MEG with other modalities, such as EEG and fMRI, is sure to be a potential application in BCI. The multimodal decoding could help to improve model performance by optimizing signal quality, feature extraction (Li et al., 2023). This would assist a lot in the cognitive assessment of clinical applications in neurorehabilitation and cognitive training (Wang et al., 2024).
Finally, the medical ethics would be strictly obeyed in data acquirement, experimental setup and clinical procedures in our further studies. It is true that the MEG would become an important tool in neuroscience, and even in the field of BCI.
The proposed GLCNet, an advanced end-to-end CNN network, could extract effectively distinguished features from MEG data, and it was concluded that the GLCNet had demonstrated robust capabilities for the classification of MI and CI tasks. It was hopeful to be used in MEG-BCI systems. Future work will pay more attention to enhance the decoding capabilities and explore the potentials of the fused multimodal model in BCI applications.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
YY: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Writing – original draft, Writing – review & editing. HZ: Data curation, Investigation, Project administration, Writing – original draft. ZH: Software, Writing – review & editing, Methodology. CS: Methodology, Software, Writing – review & editing. LZ: Validation, Writing – review & editing. XY: Supervision, Writing – review & editing, Validation, Visualization.
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by Shanghai Municipal Commission of Science and Technology for Capacity Building for Local Universities (Grant number: 23010502700); the National Natural Science Foundation of China (Grant Number: 61971275, 81830052, 82072228, and 62376152).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors declare that no Gen AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2025.1546559/full#supplementary-material
Al-Saegh, A., Dawwd, S. A., and Abdul-Jabbar, J. M. (2021). Deep learning for motor imagery EEG-based classification: a review. Biomed. Signal Proc. Control 63:102172. doi: 10.1016/j.bspc.2020.102172
Altaheri, H., Muhammad, G., Alsulaiman, M., Amin, S. U., Altuwaijri, G. A., Abdul, W., et al. (2023). Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: a review. Neural Comput. & Applic. 35, 14681–14722. doi: 10.1007/s00521-021-06352-5
Ang, K. K., Chin, Z. Y., Wang, C., Guan, C., and Zhang, H. (2012). Filter bank common spatial pattern algorithm on BCI competition IV datasets 2a and 2b. Front. Neurosci. 6:39. doi: 10.3389/fnins.2012.00039
Ang, K. K., Chin, Z. Y., Zhang, H., and Guan, C. (2008). Filter bank common spatial pattern (FBCSP) in brain-computer interface. Proceeding of the 2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence): IEEE), Hong Kong, China. 2390–2397.
Bu, Y., Harrington, D. L., Lee, R. R., Shen, Q., Angeles-Quinto, A., Ji, Z., et al. (2023). Magnetoencephalogram-based brain–computer interface for hand-gesture decoding using deep learning. Cereb. Cortex 33, 8942–8955. doi: 10.1093/cercor/bhad173
Buciluǎ, C., Caruana, R., and Niculescu-Mizil, A. (2006). “Model compression”, Proceedings of the 12th ACM SIGKDD international conference on knowledge discovery and data mining, Association for Computing Machinery. 535–541.
Chholak, P., Niso, G., Maksimenko, V. A., Kurkin, S. A., Frolov, N. S., Pitsik, E. N., et al. (2019). Visual and kinesthetic modes affect motor imagery classification in untrained subjects. Sci. Rep. 9:9838. doi: 10.1038/s41598-019-46310-9
Cohen, D. (1972). Magnetoencephalography: detection of the brain's electrical activity with a superconducting magnetometer. Science 175, 664–666. doi: 10.1126/science.175.4022.664
Defferrard, M., Bresson, X., and Vandergheynst, P. (2016). Convolutional neural networks on graphs with fast localized spectral filtering. Curran Associates Inc. 3844–3852.
Du, G., Su, J., Zhang, L., Su, K., Wang, X., Teng, S., et al. (2022). A multi-dimensional graph convolution network for EEG emotion recognition. IEEE Trans. Instrum. Meas. 71, 1–11. doi: 10.1109/TIM.2022.3204314
Dumas, T., Attal, Y., Dubal, S., Jouvent, R., and George, N. (2011). Detection of activity from the amygdala with magnetoencephalography. IRBM 32, 42–47. doi: 10.1016/j.irbm.2010.11.001
Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Ann. Eugenics 7, 179–188. doi: 10.1111/j.1469-1809.1936.tb02137.x
Gou, J., Yu, B., Maybank, S. J., and Tao, D. (2021). Knowledge distillation: a survey. Int. J. Comput. Vis. 129, 1789–1819. doi: 10.1007/s11263-021-01453-z
Gramfort, A., Luessi, M., Larson, E., Engemann, D. A., Strohmeier, D., Brodbeck, C., et al. (2013). MEG and EEG data analysis with MNE-Python. Front. Neuroinform. 7:267. doi: 10.3389/fnins.2013.00267
Gross, J. (2019). Magnetoencephalography in cognitive neuroscience: a primer. Neuron 104, 189–204. doi: 10.1016/j.neuron.2019.07.001
Groß, J., Timmermann, L., Kujala, J., Dirks, M., Schmitz, F., Salmelin, R., et al. (2002). The neural basis of intermittent motor control in humans. Proc. Natl. Acad. Sci. 99, 2299–2302. doi: 10.1073/pnas.032682099
Halme, H.-L., and Parkkonen, L. (2018). Across-subject offline decoding of motor imagery from MEG and EEG. Sci. Rep. 8:10087. doi: 10.1038/s41598-018-28295-z
Hämäläinen, M., Hari, R., Ilmoniemi, R. J., Knuutila, J., and Lounasmaa, O. V. (1993). Magnetoencephalography—theory, instrumentation, and applications to noninvasive studies of the working human brain. Rev. Mod. Phys. 65, 413–497. doi: 10.1103/RevModPhys.65.413
Hämäläinen, M., Huang, M., and Bowyer, S. M. (2020). Magnetoencephalography signal processing, forward modeling, inverse source imaging, and coherence analysis. Neuroimaging Clin. 30, 125–143. doi: 10.1016/j.nic.2020.02.001
He, J., Cui, J., Zhang, G., Xue, M., Chu, D., and Zhao, Y. (2022). Spatial–temporal seizure detection with graph attention network and bi-directional LSTM architecture. Biomed. Signal Process. Control 78:103908. doi: 10.1016/j.bspc.2022.103908
He, H., and Wu, D. (2020). Different set domain adaptation for brain-computer interfaces: a label alignment approach. IEEE Trans. Neural Syst. Rehabil. Eng. 28, 1091–1108. doi: 10.1109/TNSRE.2020.2980299
Hesse, C., Oostenveld, R., Heskes, T., and Jensen, O. (2007). On the development of a brain--computer interface system using high--density magnetoencephalogram signals for real--time control of a robot arm. IEEE.
Ho, Y., and Wookey, S. (2019). The real-world-weight cross-entropy loss function: modeling the costs of mislabeling. IEEE Access 8, 4806–4813. doi: 10.1109/ACCESS.2019.2962617
Hooda, N., and Kumar, N. (2020). Cognitive imagery classification of EEG signals using CSP-based feature selection method. IETE Tech. Rev. 37, 315–326. doi: 10.1080/02564602.2019.1620138
Hou, Y., Jia, S., Lun, X., Hao, Z., Shi, Y., Li, Y., et al. (2022). GCNs-net: a graph convolutional neural network approach for decoding time-resolved eeg motor imagery signals. IEEE Trans. Neural Netw. Learn. Syst. 35, 7312–7323. doi: 10.1109/TNNLS.2022.3202569
Hu, X., Yuan, S., Xu, F., Leng, Y., Yuan, K., and Yuan, Q. (2020). Scalp EEG classification using deep Bi-LSTM network for seizure detection. Comput. Biol. Med. 124:103919. doi: 10.1016/j.compbiomed.2020.103919
Jerbi, K., Lachaux, J.-P., N’Diaye, K., Pantazis, D., Leahy, R. M., Garnero, L., et al. (2007). Coherent neural representation of hand speed in humans revealed by MEG imaging. Proc. Natl. Acad. Sci. 104, 7676–7681. doi: 10.1073/pnas.0609632104
Ju, C., and Guan, C. (2022). Tensor-cspnet: a novel geometric deep learning framework for motor imagery classification. IEEE Trans. Neural Netw. Learn. Syst. 34, 10955–10969. doi: 10.1109/TNNLS.2022.3172108
Kim, H., Kim, J. S., and Chung, C. K. (2023). Identification of cerebral cortices processing acceleration, velocity, and position during directional reaching movement with deep neural network and explainable AI. Neuro Image 266:119783. doi: 10.1016/j.neuroimage.2022.119783
Lahiri, A., Bairagya, S., Bera, S., Haldar, S., and Biswas, P. K. (2020). Lightweight modules for efficient deep learning based image restoration. IEEE Trans. Circuits Syst. Video Technol. 31, 1395–1410. doi: 10.1109/TCSVT.2020.3007723
Lawhern, V. J., Solon, A. J., Waytowich, N. R., Gordon, S. M., Hung, C. P., and Lance, B. J. (2018). EEGNet: a compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 15:056013. doi: 10.1088/1741-2552/aace8c
Leeuwis, N., Paas, A., and Alimardani, M. (2021). Vividness of visual imagery and personality impact motor-imagery brain computer interfaces. Front. Hum. Neurosci. 15:634748. doi: 10.3389/fnhum.2021.634748
Li, X., Chen, J., Shi, N., Yang, C., Gao, P., Chen, X., et al. (2023). A hybrid steady-state visual evoked response-based brain-computer interface with MEG and EEG. Expert Syst. Appl. 223:119736. doi: 10.1016/j.eswa.2023.119736
Lotte, F., Bougrain, L., Cichocki, A., Clerc, M., Congedo, M., Rakotomamonjy, A., et al. (2018). A review of classification algorithms for EEG-based brain–computer interfaces: a 10 year update. J. Neural Eng. 15:031005. doi: 10.1088/1741-2552/aab2f2
Lu, H., Eng, H.-L., Guan, C., Plataniotis, K. N., and Venetsanopoulos, A. N. (2010). Regularized common spatial pattern with aggregation for EEG classification in small-sample setting. IEEE Trans. Biomed. Eng. 57, 2936–2946. doi: 10.1109/TBME.2010.2082540
Luo, T.-J., Zhou, C.-L., and Chao, F. (2018). Exploring spatial-frequency-sequential relationships for motor imagery classification with recurrent neural network. BMC Bioinformatics 19, 1–18. doi: 10.1186/s12859-018-2365-1
Ma, J., Ma, W., Zhang, J., Li, Y., Yang, B., and Shan, C. (2024). Partial prior transfer learning based on self-attention CNN for EEG decoding in stroke patients. Sci. Rep. 14:28170. doi: 10.1038/s41598-024-79202-8
Ma, W., Wang, C., Sun, X., Lin, X., and Wang, Y. (2023). A double-branch graph convolutional network based on individual differences weakening for motor imagery EEG classification. Biomed. Signal Process. Control 84:104684. doi: 10.1016/j.bspc.2023.104684
Mane, R., Chew, E., Chua, K., Ang, K. K., Robinson, N., Vinod, A. P., et al. (2021). FBCNet: a multi-view convolutional neural network for brain-computer interface. arXiv [Preprint]. doi: 10.48550/arXiv.2104.01233
Mane, R., Chouhan, T., and Guan, C. (2020). BCI for stroke rehabilitation: motor and beyond. J. Neural Eng. 17:041001. doi: 10.1088/1741-2552/aba162
Mane, R., Robinson, N., Vinod, A. P., Lee, S.-W., and Guan, C. (2020). A multi-view CNN with novel variance layer for motor imagery brain computer interface. Proceedings of the 2020 42nd annual international conference of the IEEE engineering in medicine & biology society (EMBC). IEEE. 2950–2953.
Mellinger, J., Schalk, G., Braun, C., Preissl, H., Rosenstiel, W., Birbaumer, N., et al. (2007). An MEG-based brain–computer interface (BCI). NeuroImage 36, 581–593. doi: 10.1016/j.neuroimage.2007.03.019
Nara, S., Raza, H., Carreiras, M., and Molinaro, N. (2023). Decoding numeracy and literacy in the human brain: insights from MEG and MVPA. Sci. Rep. 13:10979. doi: 10.1038/s41598-023-37113-0
Peng, H., Gong, W., Beckmann, C. F., Vedaldi, A., and Smith, S. M. (2021). Accurate brain age prediction with lightweight deep neural networks. Med. Image Anal. 68:101871. doi: 10.1016/j.media.2020.101871
Phadikar, S., Sinha, N., and Ghosh, R. (2023). Unsupervised feature extraction with autoencoders for EEG based multiclass motor imagery BCI. Expert Syst. Appl. 213:118901. doi: 10.1016/j.eswa.2022.118901
Piqueira, J. R. C. (2011). Network of phase-locking oscillators and a possible model for neural synchronization. Commun. Nonlinear Sci. Numer. Simul. 16, 3844–3854. doi: 10.1016/j.cnsns.2010.12.031
Ramoser, H., Muller-Gerking, J., and Pfurtscheller, G. (2000). Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans. Rehabil. Eng. 8, 441–446. doi: 10.1109/86.895946
Rathee, D., Raza, H., Roy, S., and Prasad, G. (2021). A magnetoencephalography dataset for motor and cognitive imagery-based brain-computer interface. Sci. Data 8:120. doi: 10.1038/s41597-021-00899-7
Roy, Y., Banville, H., Albuquerque, I., Gramfort, A., Falk, T. H., and Faubert, J. (2019). Deep learning-based electroencephalography analysis: a systematic review. J. Neural Eng. 16:051001. doi: 10.1088/1741-2552/ab260c
Saichand, N. V. (2021). Epileptic seizure detection using novel multilayer LSTM discriminant network and dynamic mode Koopman decomposition. Biomed. Signal Process. Control 68:102723. doi: 10.1016/j.bspc.2021.102723
Sakhavi, S., Guan, C., and Yan, S. (2018). Learning temporal information for brain-computer interface using convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 29, 5619–5629. doi: 10.1109/TNNLS.2018.2789927
Sakhavi, S., Guan, C., and Yan, S. (2015). Parallel convolutional-linear neural network for motor imagery classification. Proceedings of the 2015 23rd European signal processing conference (EUSIPCO), Nice, France. 2736–2740.
Sarma, M., Bond, C., Nara, S., and Raza, H. (2023). MEGNet: a MEG-based deep learning model for cognitive and motor imagery classification. Proceedings of the 2023 IEEE international conference on bioinformatics and biomedicine (BIBM), Istanbul, Turkiye. 2571–2578.
Schirrmeister, R. T., Springenberg, J. T., Fiederer, L. D. J., Glasstetter, M., Eggensperger, K., Tangermann, M., et al. (2017). Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 38, 5391–5420. doi: 10.1002/hbm.23730
Solodkin, A., Hlustik, P., Chen, E. E., and Small, S. L. (2004). Fine modulation in network activation during motor execution and motor imagery. Cereb. Cortex 14, 1246–1255. doi: 10.1093/cercor/bhh086
Song, T., Zheng, W., Song, P., and Cui, Z. (2018). EEG emotion recognition using dynamical graph convolutional neural networks. IEEE Trans. Affect. Comput. 11, 532–541. doi: 10.1109/TAFFC.2018.2817622
Tang, C., Gao, T., Wang, G., and Chen, B. (2024). Coherence-based channel selection and Riemannian geometry features for magnetoencephalography decoding. Cogn. Neurodyn. 18, 3535–3548. doi: 10.1007/s11571-024-10085-1
Thomas, K. P., Guan, C., Lau, C. T., Vinod, A. P., and Ang, K. K. (2009). A new discriminative common spatial pattern method for motor imagery brain–computer interfaces. IEEE Trans. Biomed. Eng. 56, 2730–2733. doi: 10.1109/TBME.2009.2026181
Van Der Maaten, L., and Hinton, G. (2008). Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605.
Wang, P., Jiang, A., Liu, X., Shang, J., and Zhang, L. (2018). LSTM-based EEG classification in motor imagery tasks. IEEE Trans. Neural Syst. Rehabil. Eng. 26, 2086–2095. doi: 10.1109/TNSRE.2018.2876129
Wang, Z., Tong, Y., and Heng, X. (2019). Phase-locking value based graph convolutional neural networks for emotion recognition. IEEE Access 7, 93711–93722. doi: 10.1109/ACCESS.2019.2927768
Wang, X., Zheng, Y., Wang, F., Ding, H., Meng, J., and Zhuo, Y. (2024). Unilateral movement decoding of upper and lower limbs using magnetoencephalography. Biomed. Signal Process. Control 93:106215. doi: 10.1016/j.bspc.2024.106215
Yang, J., Huang, X., Wu, H., and Yang, X. (2020). EEG-based emotion classification based on bidirectional long short-term memory network. Proc. Comput. Sci. 174, 491–504. doi: 10.1016/j.procs.2020.06.117
Yang, Y., Luo, S., Wang, W., Gao, X., Yao, X., and Wu, T. (2024). From bench to bedside: overview of magnetoencephalography in basic principle, signal processing, source localization and clinical applications. Neuro Image Clin. 42:103608. doi: 10.1016/j.nicl.2024.103608
Youssofzadeh, V., Roy, S., Chowdhury, A., Izadysadr, A., Parkkonen, L., Raghavan, M., et al. (2023). Mapping and decoding cortical engagement during motor imagery, mental arithmetic, and silent word generation using MEG. Hum. Brain Mapp. 44, 3324–3342. doi: 10.1002/hbm.26284
Yu, Y., Si, X., Hu, C., and Zhang, J. (2019). A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 31, 1235–1270. doi: 10.1162/neco_a_01199
Zhang, K., Robinson, N., Lee, S.-W., and Guan, C. (2021). Adaptive transfer learning for EEG motor imagery classification with deep convolutional neural network. Neural Netw. 136, 1–10. doi: 10.1016/j.neunet.2020.12.013
Zhao, L., Song, Y., Zhang, C., Liu, Y., Wang, P., Lin, T., et al. (2019). T-GCN: a temporal graph convolutional network for traffic prediction. IEEE Trans. Intell. Transp. Syst. 21, 3848–3858. doi: 10.1109/TITS.2019.2935152
Keywords: magnetoencephalography (MEG), motor imagery (MI), cognitive imagery (CI), graph convolutional network (GCN), long short-term memory (LSTM), spatial convolution
Citation: Yang Y, Zhao H, Hao Z, Shi C, Zhou L and Yao X (2025) Recognition of brain activities via graph-based long short-term memory-convolutional neural network. Front. Neurosci. 19:1546559. doi: 10.3389/fnins.2025.1546559
Edited by:
Mostafa Elhosseini, Mansoura University, EgyptReviewed by:
Abdelmoniem Helmy, Taibah University, Saudi ArabiaCopyright © 2025 Yang, Zhao, Hao, Shi, Zhou and Yao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xufeng Yao, eWFvNjYzNjMyOUBob3RtYWlsLmNvbQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.