 Fanbo Zhuo
Fanbo Zhuo Xiaocheng Zhang1,2,3
Xiaocheng Zhang1,2,3- 1The State Key Laboratory of Robotics, Shenyang Institute of Automation, Shenyang, China
- 2The Institutes for Robotics and Intelligent Manufacturing, Chinese Academy of Sciences, Shenyang, China
- 3School of Computer Science and Technology, The University of Chinese Academy of Sciences, Beijing, China
Introduction: Brain computer interfaces (BCI), which establish a direct interaction between the brain and the external device bypassing peripheral nerves, is one of the hot research areas. How to effectively convert brain intentions into instructions for controlling external devices in real-time remains a key issue that needs to be addressed in brain computer interfaces. The Riemannian geometry-based methods have achieved competitive results in decoding EEG signals. However, current Riemannian classifiers tend to overlook changes in data distribution, resulting in degenerated classification performance in cross-session and/or cross subject scenarios.
Methods: This paper proposes a brain signal decoding method based on Riemannian transfer learning, fully considering the drift of the data distribution. Two Riemannian transfer learning methods based log-Euclidean metric are developed, such that historical data (source domain) can be used to aid the training of the Riemannian decoder for the current task, or data from other subjects can be used to boost the training of the decoder for the target subject.
Results: The proposed methods were verified on BCI competition III, IIIa, and IV 2a datasets. Compared with the baseline that without transfer learning, the proposed algorithm demonstrates superior classification performance. In contrast to the Riemann transfer learning method based on the affine invariant Riemannian metric, the proposed method obtained comparable classification performance, but is much more computationally efficient.
Discussion: With the help of proposed transfer learning method, the Riemannian classifier obtained competitive performance to existing methods in the literature. More importantly, the transfer learning process is unsupervised and time-efficient, possessing potential for online learning scenarios.
1 Introduction
Brain-computer interface (BCI) establishes a direct communication between the brain and external devices, providing a new way for the brain to interact with the external world. It allows humans to interact with their surroundings without the intervention of any peripheral nerve or muscle. BCI extracts brain signals and decodes them into control commands to manipulate external devices (such as wheelchairs) while also provides feedback inputs to the brain, such as visual and electrical stimuli. Consequently, in BCI research, brain signals decoding is indispensable.
There are various ways to collect brain signals, such as electroencephalography (EEG), magnetoencephalography (MEG), and magnetic resonance imaging (MRI). Among these methods, EEG is most easily accepted by both users and practitioners as it has many merits. First, it is non-invasive. EEG signals are obtained by placing multiple electrodes over the scalp of the brain, which reflect its electrophysiological activities. Second, the equipment of EEG is relatively small and thus transportable. Third, the EEG device is relatively cheap and is affordable even for small research groups. Therefore, EEG-based BCI systems hold significant potential for widespread application.
However, EEG signals are non-stationary, non-linear, and characterized by weak amplitudes, low spatiotemporal resolution, low signal-to-noise ratio, and inter-individual diversity, making the decoding of EEG signals very challenging (Lotte et al., 2018). Existing methods for decoding EEG signals can be broadly categorized into three groups, including classical signal processing-based methods, deep learning-based methods, and Riemannian geometry or tensor-based methods (Lotte et al., 2018).
Riemannian geometry-based methods represent EEG signals as covariance matrices, transforming them into the Riemannian space of symmetric positive definite (SPD) matrices. Riemannian classifiers are then established to recognize them. Riemannian geometry-based methods have many advantages over other methods. First, they are robust to noise. Moreover, they are applicable to all commonly used EEG paradigms, including P300, steady state visually evoked potential (SSVEP), and motor imagery (Abiri et al., 2019). Finally, they only require small training samples. Consequently, Riemannian geometry-based methods are a promising group of approaches for brain signal decoding (Congedo et al., 2013).
However, current Riemannian geometry-based methods tend to overlook issues related to changes in data distribution and inter-individual variability. Though these methods exhibit good robustness, taking the factors of data distribution differences into consideration might lead to even better recognition performance.
Data distribution changes often occur in cross-session and cross-subject learning within BCI systems. For instance, the same subject may display distribution disparities resulting from variations in electrode positions or changes in the subject's physiological state between two experimental sessions. Additionally, experiments involving different subjects may be impacted by individual biological distinctions, potentially leading to a decline in performance. To conquer this problem, the standard approach in BCIs involves recalibrating classifiers at the beginning of each experiment through a series of calibration trials. Unfortunately, this approach is a time-consuming process that may make subject fatigue and obtain suboptimal performance since it fails to utilize information from past experiments.
To address above issues, transfer learning is commonly adopted in BCIs (Lotte et al., 2018), which can circumvent the recalibration process. Transfer learning targets to help boost the learning of the task in the target domain using the knowledge in the source domain and the source task (Pan and Yang, 2010). In BCIs, the learning setting of domain adaptation is often encountered, where the feature space between the source domain and the target domain is the same, but the marginal probability distributions of the input data are different.
Multiple domain adaptation methods have been proposed to reduce the distribution divergence (Du et al., 2023; Luo, 2023). Existing domain adaptation methods can be generally divided into three categories, including the sample alignment-based methods, the feature adaptation-based methods, and the deep learning model-based methods (Luo, 2023). The first type of methods try to align the averaged covariance matrix of samples from both the target domain and source domain to the identity matrix and thus brings the marginal probability distributions of input data in two domains closer. The second type of methods leverage mathematical transformations to map the input data from the source domain and target domain into a common feature space, where a classifier trained on transformed source data will generalize well to target data. The deep learning model-based methods use conversational neural networks (CNN) for feature extraction from samples and include feature alignment or adversarial techniques in the training process to encourage the learning of domain-invariant features. However, the feature adaptation-based methods are usually constrained by the feature representations, while deep learning-based method demands high computational resources and imposes stringent requirements on domain discrepancy. Therefore, this study focuses on the sample alignment-based methods.
In the Riemannian framework of sample alignment-based methods, data distribution changes manifest as geometric transformations of covariance matrices, which are referred to as “covariance shift” by He and Wu (2018). To eliminate the shift problem, Zanini et al. (2018) propose to utilize the affine transformation to map the covariance matrices to a reference covariance matrix. Li and Zhang (2019) design a covariance matching approach for semi-supervised domain adaptation. Zheng and Lu (2016) build a personalized EEG-based affective model for transfer learning in an unsupervised manner. Rodrigues et al. (2019) employ procrustes analysis on the SPD Riemannian space, further addressing the covariance shift problem.
In the light of the acknowledged work of sample alignment-based methods, we propose a new transfer learning approach based on procrustes analysis (PA) (Maybank, 2005). PA is a common approach of distribution matching for aligning two data distributions in Euclidean space. It has been extended to Riemannian space for the application of EEG classification, which is termed as Riemannian Procrustes Analysis (RPA) (Rodrigues et al., 2019). However, RPA utilizes affine invariant Riemannian metrics (AIRM), which is computationally intensive. To alleviate the computational burden, this study proposes to use more computationally efficient Log-Euclidean Metric (LEM).
The main contributions in this study are summarized as follows:
• We generalize the Euclidean PA to the Riemannian manifold of SPD matrices equipped with log-Euclidean metric, which is termed as PA-LEM. Due to the nice properties of log-Euclidean metric, the resulted method is equivalent to map the SPD matrices into their logarithm domain and then apply Euclidean PA in the mapped space.
• We augment the RPA with AIRM by LEM to boost the computation of the distribution matching. With LEM, the mean and dispersion of samples are more efficiently obtained. Thus, the proposed RPA with LEM (RPA-LEM) becomes much more computationally efficient.
• We combine the proposed transfer learning approaches with the Riemannian classifier termed as probabilistic learning vector quantization with log-Euclidean metric learning (PLVQ-LEML) (Zhang and Tang, 2022) and validate the performance on two motor imagery EEG datasets. The proposed transfer learning approaches significantly improve the performance of PLVQ-LEML. Compared with RPA, the proposed approach improves the performance of the classifier greater with less computational time.
The remainder of this article is organized as follows. Section 2 briefly introduces the concepts of LEM, PLVQ-LEM, and Procrustes analysis. In Section 3, we derive the proposed methods. Section 4 describes the experiment setup and the results. Section 5 concludes the main contributions of this study.
2 Related Work
In this section, we briefly introduce the related concepts of log-Euclidean metric, the Riemannian classifier–probabilistic learning vector quantization with log-Euclidean metric learning (PLVQ-LEML), and the Procrustes analysis that targets for aligning data in Euclidean space.
2.1 Log-Euclidean Metric
Riemannian approaches transform the original EEG signal matrices to SPD matrices by calculating the covariance matrices. These SPD matrices live on a curved manifold instead of the flat Euclidean space (Tang et al., 2021a). SPD manifold is a differential manifold equipped with Riemannian metric, defining smoothly varying inner products on tangent spaces. Riemannian metric enables the measurement of angles and lengths of tangent vectors and is crucial for quantifying distances and curves on the manifold.
In the context of EEG classification, two notable metrics are the log-Euclidean metric (LEM) and the affine-invariant Riemannian Metric (AIRM). LEM exhibits many useful properties. For example, it maintains distances invariant under operations such as the matrix inversion, logarithmic multiplication, or orthogonal transformation and scaling (Tang et al., 2023). The basic notations and mathmetical principles of LEM are introduced as follows:
Let 𝕊+(n) represents the space of all real-valued n × n symmetric positive definite matrices. 𝕊+(n) makes a Riemannian manifold if endowed with a Riemannian metric. Log-Euclidean metric (LEM) is a commonly used Riemannian metric on the SPD manifold 𝕊+(n). It is derived by exploiting the Lie group structure under group operation:
where exp represents the matrix exponential function, i.e., , and log denotes matrix logarithm—the inverse of the matrix exponential function.
The well-studied log-Euclidean metric on Lie group of SPD matrices (Arsigny et al., 2006, 2007) leads to the Euclidean metric in the logarithm domain of SPD matrices. Let 𝕊(n) denotes the space of all real-valued n × n symmetric matrices. For any symmetric matrix X ∈ 𝕊(n), a one-parameter subgroup in 𝕊+(n) is defined as
with derivative
The geodesics are then determined by translated versions of one-parameter subgroup, i.e., γ(t) = exp(V1 + tV2) for V1, V2 ∈ 𝕊(n). Therefore, the geodesic between and is the linear combination in the logarithmic domain:
By definition, the Riemannian exponential map is the mapping that projects a tangent vector V to the point on the geodesic at time 1, where the geodesic starts at time 0 from X (i.e., γ(0) = X) with an initial speed vector V, i.e., ExpX(V) = γ(1). By differentiating the geodesic given by Equation 1 at time 0, we obtain the initial speed vector:
With the initial speed vector V = X1 · (logX2 − logX1), the Riemannian exponential map ExpX1(V) needs to return to the point X2 on the manifold, i.e., ExpX1(V) = γ(1) = X2. We can rewrite X2 as a function of V as follows:
Then, the exponential map induced by the log-Euclidean metric is given as follows:
The Riemannian logarithmic map LogX1(X2) is the inverse map of the Riemannian exponential map. It gives the initial speed of the geodesic γ(t) starting from points X1 to X2, i.e., . Therefore, the logarithmic map induced by the log-Euclidean metric is as follows:
The metric at a point on the manifold can be obtained by translating the scalar product on the tangent space at the identity (Arsigny et al., 2007). Let be the logarithmic multiplication by X, that is, for any A ∈ 𝕊+(n), LX(A) = exp(logX + logA) = exp(logX) · exp(logA) = X⊙A. The identity matrix I ∈ 𝕊+(n) can be transported to a matrix X ∈ 𝕊+(n) by LX and any tangent vector Δ at the identity I can be transported to a tangent vector V at the point X ∈ 𝕊+(n) by the differential of LX, given by dLX(Δ) = XΔ. At the identity, the metric is defined as the usual scalar product 〈Δ1, Δ2〉I = Tr(Δ1Δ2). The log-Euclidean metric is required to be invariant by left- multiplication (Arsigny et al., 2007), i.e., 〈XΔ1, XΔ2〉X = 〈Δ1, Δ2〉I, which can only be satisfied with definition:
where Tr represents the trace operator. With log-Euclidean metric, the squared geodesic distance between two SPD matrices is given as follows:
which corresponds to a Euclidean distance in the logarithmic domain.
Based on Equations (1, 2), the geodesic emitted at the point X in the direction of , i.e., γLE(0) = X, , can be expressed as follows:
2.2 PLVQ-LEML
Probabilistic learning vector quantization with log-Euclidean metric learning (PLVQ-LEML) (Zhang and Tang, 2022) is a Riemannian classifier that is designed to classify the data points represented by symmetric positive definite (SPD) matrices. It is an extension of Euclidean robust soft learning vector quantization (Seo and Obermayer, 2003) to deal with such data points taking their non-linear Riemannian geometry into consideration. We will briefly introduce this method here. For more detailed information, please refer to Zhang and Tang (2022).
Consider a data set , where represents the input data and yi ∈ 1, ..., C denotes the corresponding class label. Here, C represents the number of classes. PLVQ-LEML is to learn M-labeled prototypes Wj, j = 1, ..., M that locate in the same space as the inputs Xi does, i.e., . The label of the prototype Wj is denoted as cj. Let , the marginal probability density function p(X) that generate the data in the Riemannian space 𝕊+(n) can be approximated by a Gaussian mixture model:
where P(j) represents the probability that data points are generated by a particular component j of the mixture and p(X ∣ j) denotes the conditional probability that the component j generates a particular data point X. Here, the conditional probability p(X ∣ j) is a Gaussian-like probability density function constructed using the Riemannian distance derived from the log-Euclidean metric learning (LEML) framework (Huang et al., 2015), as follows:
Here,
where σ2 is a user-defined constant represent the variance, while δ(X, Wj, Q) is the Remainnian distance between X and Wj parametrized by a learnable metric tensor Q derived from LEML, computed as follows:
The metric tensor Q is a symmetric semi-definite matrix of size n × n. Then, the probability density that a data point X is generated by the mixture model for the correct class can be given as follows:
With Bayes' theorem, the conditional probability of assigning label y to data X can be obtained as follows:
Then, for the dataset , the likelihood function is as follows:
The prototypes Wj, j = 1, ..., M and the metric tensor Q can be learned by minimizing the negative log-likelihood function as follows:
The updating rule of prototypes can be obtained by minimizing above loss function via Riemannian gradient descent algorithm on the Riemannian manifold of SPD matrices equipped with log-Euclidean metric, which is calculated as follows:
where Py(l|X) and P(l|X) are assignment probabilities:
and 0 < α < 1 is the learning rate for prototypes updates.
Similar to the method proposed by Biehl et al. (2015), the updating rule of the metric tensor Q obtained by minimizing the cost function via stochastic Riemannian gradient descent algorithm using the quotient geometry with the flat metric in the total space is given as follows:
where 0 < η < 1 is the learning rate for metric updates.
2.3 Procrustes analysis
Procrustes analysis (PA) (Gower and Dijksterhuis, 2004) is a widely used approach to align two data domains in the Euclidean space. Suppose we have two sets of data points that are from the same feature space but drawn from two different distributions, denoted as and , respectively, there exists a linear relationship between each pair of data points xi ∈ X and as follows:
where and m ∈ Rn represent the centers of the two data sets, respectively, U is an orthogonal matrix, representing the rotation between the two data sets, and d is a scalar denoting the dispersion difference between the two data sets. The objective of the PA process is to determine the values of in order to obtain new data set , where perfectly matches xi. Here, can be obtained as follows:
Through the process of the transformation 3, is first to be centralized to zero mean (subtracted ), stretched or compressed to unit variance (divided by d), then rotated (multiplied by UT), and finally recentralized to mean m (added by m). The last step that recentralizes to mean m is often replaced by centralizing xi to zero mean, which is to align two data sets of zero mean.
3 Riemannian transfer learning methods based on logarithmic euclidean metric
This section introduces our proposed transfer learning methods that are generalizations of Procrustes analysis to the Riemannian space of SPD matrices using log-Euclidean metric (LEM).
3.1 Problem formulation and notation
In this study, the EEG signals are represented in the SPD Riemannian manifold by covariance matrix. The i-th trial of EEG signals is presented as follows (Tang et al., 2021b):
where n and l denote the number of channels and sampled points, respectively. Usually after being bandpass filtered, the signals will become zero mean. Each trial of EEG signals is represented by the sample covariance matrix that can be computed as follows:
Then, EEG signals are represented by SPD matrices. The SPD matrice manifests the spatial power distribution of the EEG signals over the brain.
In the case of transfer learning, the source data set and the target set , where and represent the input SPD matrices of the two data sets, respectively, while yi ∈ {1, ..., C} and ỹi ∈ {1, ..., C} denote their corresponding class labels, respectively. Here, C represents the number of classes.
Suppose the data points are drawn from statistical distributions that can be parameterized solely by their geometric mean and the dispersion around neighboring points. To be more precisely, assume that the underlying statistical distribution generating the data set samples is a mixture of Riemannian Gaussian distributions on the SPD manifold with one mixture for each class (Said et al., 2017).
Under this condition, the statistical information of the source and target data sets can be parameterized by a set consisting of C + 2 elements, respectively, as follows:
Here, M denotes the geometric mean of the source data set , and represents the geometric mean of the target data set T, which are defined as follows:
where G represents the computation of the geodesic mean. d represents the dispersion of the data points Xi around the geometric mean M for the source data set , while denotes the dispersion of the data points around the geometric mean for the target data set . They are computed as follows:
where represents the squared Riemannian geometric distance function. Mk represents the geometric mean of the data points for a particular class k in the source data set , while represents the geometric mean of the data points for a particular class k in the target data set . They are computed as follows:
3.2 PA-LEM
The log-Euclidean metric constitutes a valid Riemannian metric in the original space of SPD matrices and also provides an equivalence Euclidean metric in the logarithm domain of the SPD matrices. Due to this nice property, a straight forward extension of PA to the Riemannian space of SPD matrices is to perform PA in its logarithm domain.
The mean of the data sets in the logarithm domain can be expressed as follows:
Similarly, the dispersion d or in the original space corresponds to the variance denoted as d′ or in the logarithm domain, which can be computed as follows:
Thus, the PA method based on the log-Euclidean metric (PA-LEM) can be formulated as follows:
Rotation is not utilized here as it is found barely improves the performance on the target data set in EEG signal classification in the reference Rodrigues et al. (2019). The algorithm of PA-LEM is summarized in Algorithm 1. It is equivalent to normalize both the source data set and target data set to zero mean and unit variance. After the alignment performed by Algorithm 1, the Riemannian classifier PLVQ-LEML learned in the source data set can be directly applied to the target data set, reducing the learning effort on the target data set.

Algorithm 1. PA-LEM.
3.3 PRA-LEM
Riemannian Procrustes analysis (RPA) Rodrigues et al. (2019) is an extension of the Euclidean PA to the Riemannian manifold of SPD matrices equipped with affine-invariance Riemannian metric (AIRM) Zanini et al. (2018). The RPA method involves re-centering, stretching, and rotation based on the intrinsic geometric structure of the SPD manifold. Similar to PA, RPA also needs the computation of Riemannian distance and Riemannian geometric mean induced by AIRM, which involves the inverse of matrices that is very computational demanding. Thus, in this study, to boost the computation, the more computationally efficient LEM is utilized.
Under AIRM, the squared Riemannian distance between two points Xi and Xj in the space 𝕊+(n) is computed as follows:
where λk represents the eigenvalues of matrix . Note that, here, the compuation of the Riemannian distance induced by AIRM requires matrix inverse which is very time-consuming. The geometric mean of N data points {X1, …, XN} is obtained by minimizing their sum of squared Riemannian distance:
via stochastic Riemannian gradient descent algorithm Moakher (2008). Instead, the Riemannian geometric mean under LEM has closed solution, which is much more computationally efficient.
Here, we present how to adapt the Riemannian Procrustes analysis (RPA) under AIRM to RPA with LEM (RPA-LEM). Since the rotation operation performs poorly in motor imagery EEG signal recognition Rodrigues et al. (2019), we only employ the recentering and stretching operations.
3.3.1 Recenter
The purpose of this step is to recenter the dataset to the identity matrix, which serves as the spatial origin in the SPD manifold. Therefore, the first step of RPA-LEM involves calculating the Riemannian centroid of the original dataset:
Then, we transform the matrices in and so that they are both centered at the identity matrix:
After re-center, two new datasets become:
Note that the law of large numbers from statistics also applies to SPD matrices. If the elements of the dataset are drawn from a statistical distribution with a geometric mean of M, as the number of instances N increases, the centroid of these N matrices will converge to M. This implies that in experimental paradigms where experiments are conducted sequentially, it is reasonable to expect that with an increasing number of trials, increasingly accurate estimates of the geometric mean will be obtained.
3.3.2 Stretching
The purpose of this step is to adjust the distributions of the two datasets by stretching them so that their dispersion around the geometric mean becomes equal. According to the Riemannian distance formula based on the affine-invariant metric, this can be achieved as follows:
This means that we can adjust the dispersion of by simply moving each matrix along a geodesic path connected to the identity matrix, with the parameter s as a scaling factor. We achieve the matching of dispersion between the source and target datasets by stretching the target dataset as follows:
where d and are the dispersions of two datasets around their geometric centroids, respectively. Under log-Euclidean metric (LEM), the dispersions can be calculated as follows:
PRA-LEM introduces LEM into the Riemannian Procrustes analysis such that the Riemannian geometric mean and the data dispersions around the Riemannian geometric mean can be more efficiently computed. The computation process of RPA-LEM is summarized in Algorithm 2.

Algorithm 2. RPA-LEM.
Figure 1 illustrates the schematic steps of the Riemannian transfer learning method. Note that even though RPA-LEM and PA-LEM use the same way to compute the geometric mean and dispersion, they are inherently not the same. PA-LEM integrates Procrustes analysis (PA) with LEM by transforming the SPD (Symmetric Positive Definite) matrices into the logarithm space. This transformation allows for the application of classical Euclidean computations on the logarithmic domain of the dataset, leveraging the advantages of LEM in handling SPD matrices. However, as the original Euclidean PA did not take account the intrinsic geometry of the SPD manifold, neglecting its geometry-aware nature. Their differences arise from the distinction between LEM and AIRM. LEM emphasizes differences in eigenvalues between matrices, while AIRM emphasizes differences in the overall shape and orientation between matrices. Therefore, RPA-LEM will induce more significant transformations on the original matrix data as compared with PA-LEM. In theory, RPA-LEM should result in better performance. Subsequent experimental results also confirm this.
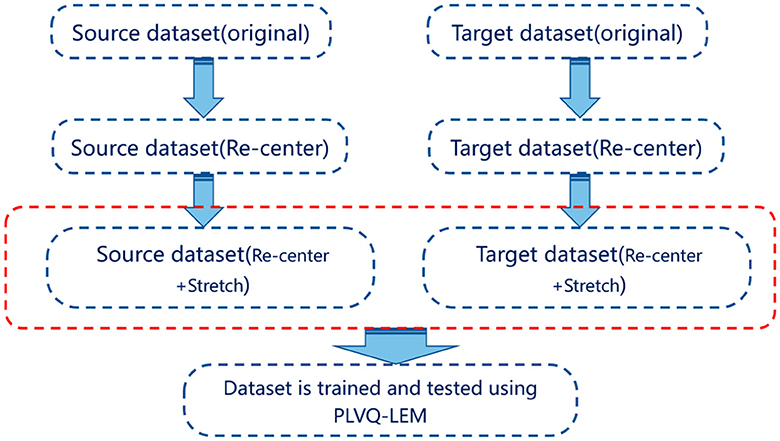
Figure 1. The diagram of Riemannian transfer learning method. Both source dataset and target dataset are processed using re-centering and stretching. Then, the proceeded datasets are utilized for training and testing, respectively.
Additionally, the advantage of computational efficiency brought by log-Euclidean metric mainly comes from the calculation of Riemannian mean and Riemannian distance. In the case of Riemannian mean, the time cost for affine invariant metric is O(K × N × M2) (assume the average iteration times of Riemannian mean is K), while the calculation cost of riemannian mean in log-Euclidean scenario is O(N × M2), as the riemmannian mean for LEM is a closed solution. As for the Riemannian distance, the LEM require no inverse operation and matrix multiplication like the AIM does. The time cost for LEM is O(N × M2), while the cost for AIM is O(N × M3). It is worth noting that these theoretical advantages have also been validated in experiments.
4 Experimental result
Two popular motor imagery EEG data sets were used to evaluate our proposed approach, namely, BCI competition III data set IIIa (BCI III IIIa) (Davoudi et al., 2017; Gaur et al., 2018) and BCI competition IV data set 2a (BCI IV 2a) (Tangermann et al., 2012). The two data sets (BCI III IIIa and BCI IV 2a) contain EEG signals extracted using n = 60 and n = 22 electrodes, respectively, which will be briefly described as follows.
BCI III IIIa data set comprises EEG data from three subjects who performed four different motor imagery tasks (left-hand, right-hand, foot, and tongue motor imagery) based on prompts. EEG signals were recorded using a Neuroscan 64-channel EEG signal amplifier with reference electrodes placed on the left and right mastoids, recording from 60 channels, and sampled at 250 Hz. The experiments were repeated across multiple runs (at least 6 runs), with each run containing 10 random presentations of each of the four motor imagery tasks, in total 40 trials per run. Thus, each subject had 240 trials, all conducted on the same date.
BCI IV 2a data set comprises EEG data from nine subjects who performed motor imagery tasks involving four types of motor imagery movement tasks including left-hand, right-hand, foot, and tongue motor imagery. Each subject participated in 576 trials, with each trial corresponding to a motor imagery task (144 trials per class). Half of the trials (4 × 72 trials) were conducted in the first session, and the other half (4 × 72 trials) in the second session conducted on different dates. EEG signals from 22 electrodes placed over the sensorimotor cortex of the subjects were recorded at a sampling rate of 250 Hz. During each trial, an arrow cue appeared, pointing left, right, down, or up, corresponding to one of the four classes, to instruct the subject to perform the respective motor imagery task. Motor imagery lasted for 4 s from the appearance of the cue.
For both data sets, recordings of each trial from 0.5 to 2.5 s starting from the presence of the cue were extracted for further analysis. The extracted signals were first bandpass-filtered between 10 and 30 Hz using a 5th-order Butterworth filter. Then, each trial of EEG signals is transformed into an SPD matrice using Equation (4). The inputs of the two datasets become elements of which live in 𝕊+(22) and 𝕊+(60), respectively.
In this study, Kappa coefficient, one of the most commonly used metric to measure the performance of motor imagery EEG classification, was used. It effectively penalizes model bias and serves well for both consistency checks, evaluating classification effectiveness. For data of balanced classes involved in this study, Kappa is calculated as Kappa = (D − C)/(1 − 1/C), where D denotes classification accuracy, and C signifies the number of classes.
4.1 The choice of classifier and transfer strategies
To evaluate our proposed Riemannian transfer learning methods, a Riemannian classifier is needed. In this study, we chose our previously developed PLVQ-LEML method introduced in Section 2.2 as the Riemannian classifier. This classifier is selected mainly due to the following three considerations:
• The PLVQ-LEML classifier is developed based on Riemannian geometry, targeting to deal with data living on the manifold of SPD matrices. The proposed Riemannian transfer learning methods are also developed based on Riemannian geometry, in particular, geometric transformations that align distributions for data represented by points living on the manifold of SPD matrices. Thus, the combination of PLVQ-LEML with our proposed Riemannian transfer learning methods ensures compatibility and a natural extension of interpretability.
• The PLVQ-LEML classifier is developed using log-Euclidean metric, whose learning rule of prototypes is equivalent to perform the Euclidean updating rule in the logarithm domain. This enables an effective integration with the PA-LEM method.
• Due to the efficiency of log-Euclidean metric, the computation of PLVQ-LEML is very efficient compared with other Riemannian classifiers. The high computational efficiency provides the method higher potential to be used in BCI systems.
We performed a preliminary experiment to compare the classification performance of the PLVQ-LEML with minimum distance to Riemannian mean (MDRM), another computationally efficient Riemannian classifier.
All hyper-parameters were set following the same schedule as mentioned in the study by Zhang and Tang (2022). During training process, the learning rates are set to be decreased over iterations. The learning rate of the prototypes follows the annealing schedule , where n is the rank of the input matrix, ξ represents the number of prototypes per class, and T represents the training epochs. The learning rate for the distance matrix tensor Q follows the annealing schedule , where t0 is the start iteration index for updating the distance matrix Q. In order to stabilize the training process, η(t) is set to be smaller than α(t) and the distance matrix tensor was started to learn when the learning of the prototypes was table. t0 = 1 was used in this study.
The hyper-parameters N and σ2 were selected from {1, 2, 3, 4, 5, 6, 7, 8} and {0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4}, respectively, using five-fold cross validation on the training fold. The selected optimal hyper-parameters are shown in Tables 1, 2. The detailed information can be found in our previous published study of PLVQ-LEML Zhang and Tang (2022). Table 3 presents the averaged kappa values over all subjects within the dataset BCI IV 2a and BCI III IIIa. From Table 3, we can observe that the performance of PLVQ-LEML is much better than MDRM. Taking both classification performance and computationally efficiency into consideration, we choose PLVQ-LEML as the classifier in this study.
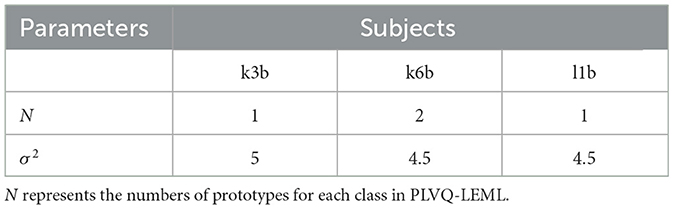
Table 1. Selected hyperparameters of PLVQ-LEML on BCI III IIIa data set.
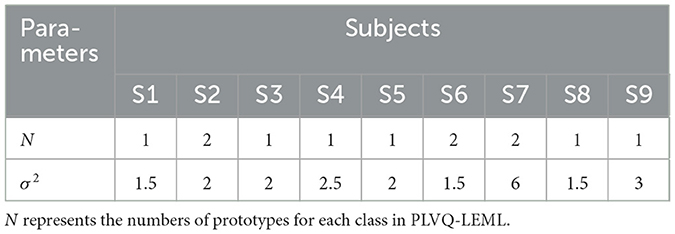
Table 2. Selected hyperparameters of PLVQ-LEML on BCI IV IIa data set.
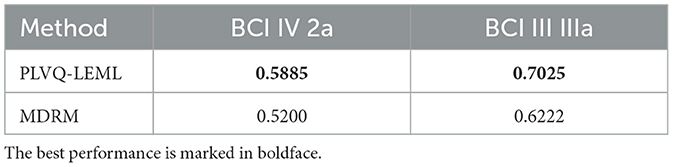
Table 3. Averaged kappa of PLVQ-LEML compared with that of MDRM.
We also performed a preliminary experiment to compare the transfer strategies. As we mentioned in Section 3, our transfer strategies involve two operations, namely, re-center (rct) and stretching (str). We compared the performance of the transfer learning approaches under different conditions, including using only re-center and combination of re-center and stretching in cross-session transfer setting. Tables 4, 5 demonstrate the performance comparison between the proposed method and RPA under different conditions on both BCI IV 2a and BCI III IIIa data sets. From Tables 4, 5, we can observe that the performance of re-center only performs slightly better than combining re-center with stretching operation. This also confirm the findings in the study by Rodrigues et al. (2019). Thus, in our following experiments, our proposed PA-LEM and RPA-LEM, together with the original RAP, only use re-center operation.
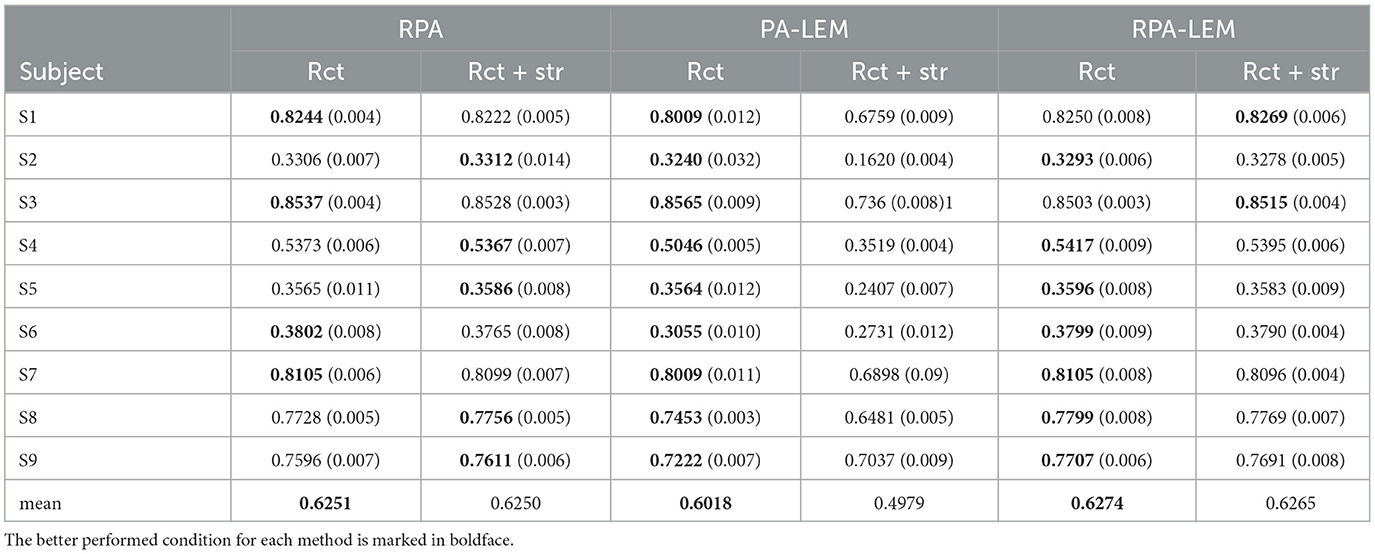
Table 4. Performance comparison between the proposed method and RPA under different conditions on the data set BCI IV 2a.
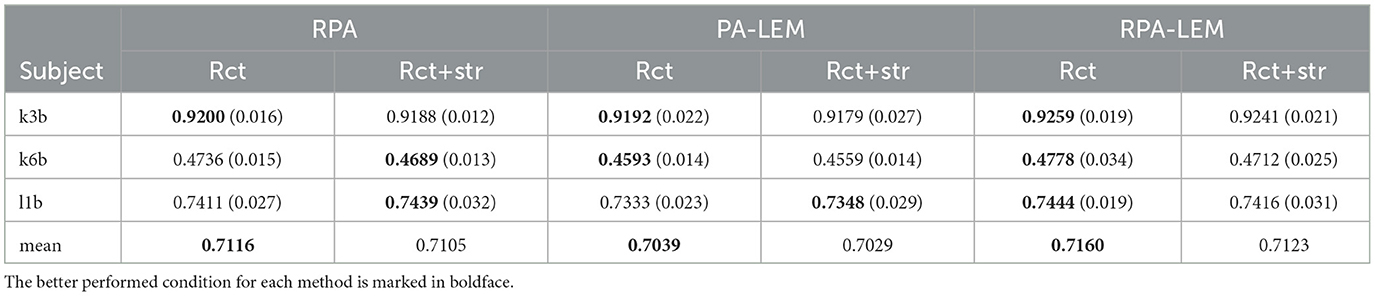
Table 5. Performance comparison between the proposed method and RPA under different conditions on the data set BCI III IIIa.
4.2 Visualization
To better understand the issue in classification using cross-session or cross-subject EEG data, we visualized the data using the t-distributed stochastic neighbor embedding (t-SNE) technique. t-SNE maps data points in a high-dimensional space to a lower dimensional space while preserving the pairwise distances of the data points as much as possible. Thus, the utilization of t-SNE techniques can well preserve the Riemannian distances between data points that live on the Riemannian manifold of SPD matrices. Here, we project the data points on the Riemannian manifold of SPD matrices into a two-dimensional space for visual inspection.
The distribution improvement effects across all subjects are relatively similar. In this study, we have only displayed the comparison for one subject. Figure 2 displays the distribution of the two different sessions for subject 9 in the BCI IV 2a data set. From Figure 2, we can observe that the distribution of the two sessions are clearly different in the original feature space before RPA-LEM being applied. Even for the same subject, EEG signals collected on different dates exhibit significant distribution variations, making EEG signal recognition challenging. Classifiers trained on one session will not perform well in another session. However, after transfer via RPA-LEM, the distribution differences between sessions were noticeably reduced, which may significantly improve the performance of the classifier trained on one session but used on the other session.
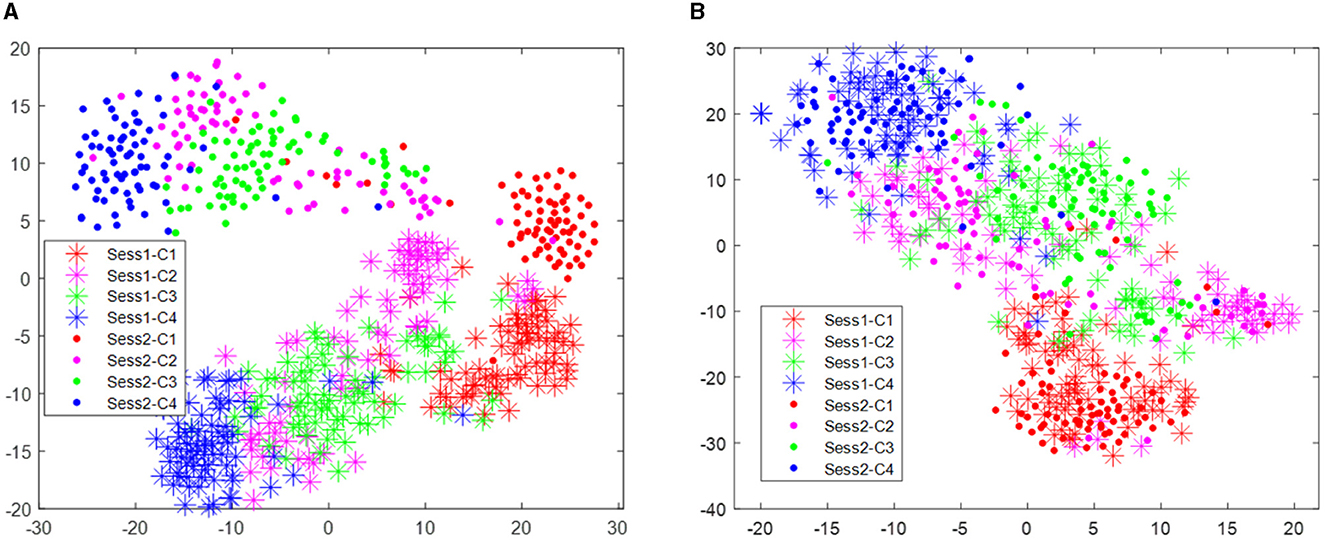
Figure 2. Distribution of the two sessions for subject 9 in the data set BCI IV 2a. Stars represent data points from session 1, while filled circles represent data points from session 2. Four different colors show four different classes. (A) Illustrates the distribution before transfer. (B) demonstrates the distribution after transfer by RPA-LEM.
Figure 3 visualizes the data from all subjects within the BCI IV 2a dataset, showing significant distribution differences among different subjects. These differences will make the classifier trained on one subject fail to obtain reasonable performance on another subject. However, after alignment via RAP-LEM, the distribution of data from subject 1 overlaps with that from subject 3, suggesting that RAP-LEM successfully matches the data from the two subjects. Thus, after alignment via RAP-LEM, the classifier trained on subject 1 will also give nice classification performance on subject 3.
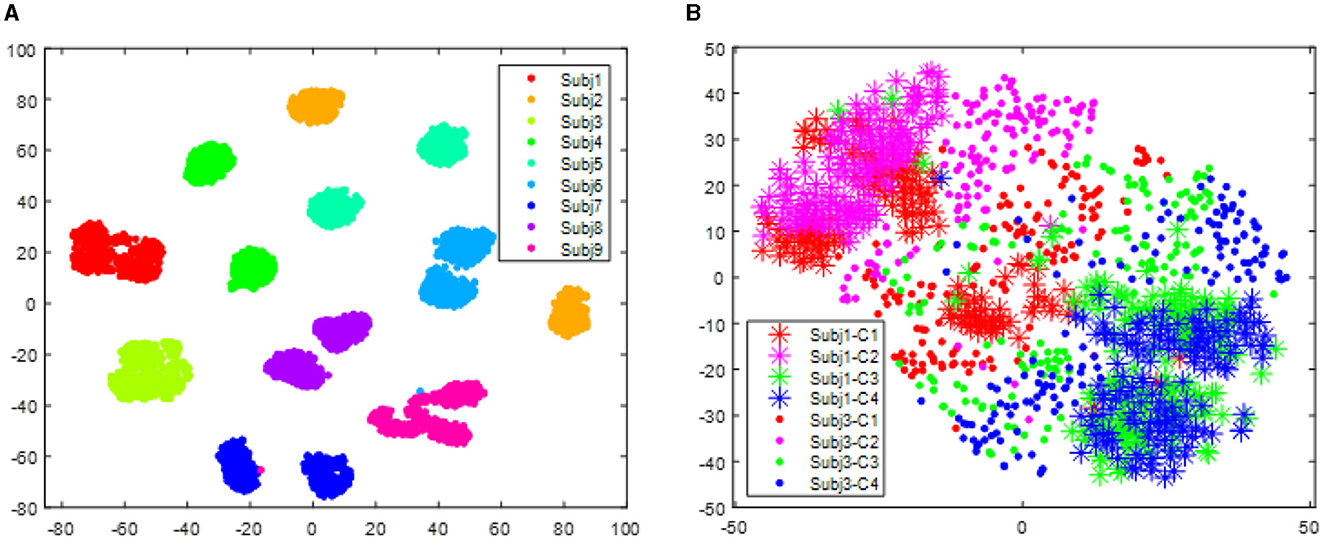
Figure 3. Distribution of data points for all subjects in the data set BCI IV 2a. (A) illustrates the distribution before transfer. Different color represents data comes from different subjects. (B) demonstrates the distribution of subject 1 and subject 3 after alignment by RPA-LEM.
With respect to the data set BCI III IIIa, as the EEG signals of each subject were collected within the same day, no distribution differences were expected. However, to give a clear illustration, we visualized the data treating the predefined training split and test split as two different sessions. As shown in Figure 4, no apparent distribution difference between two “sessions” was observed. Consequently, RPA-LEM will not provide significant improvement on classification results. However, as shown in Figure 5, the distribution disparities between subjects are significant. After applying RPA-LEM, the distribution disparities between subjects (e.g., k3b and l1b) can be significantly reduced.
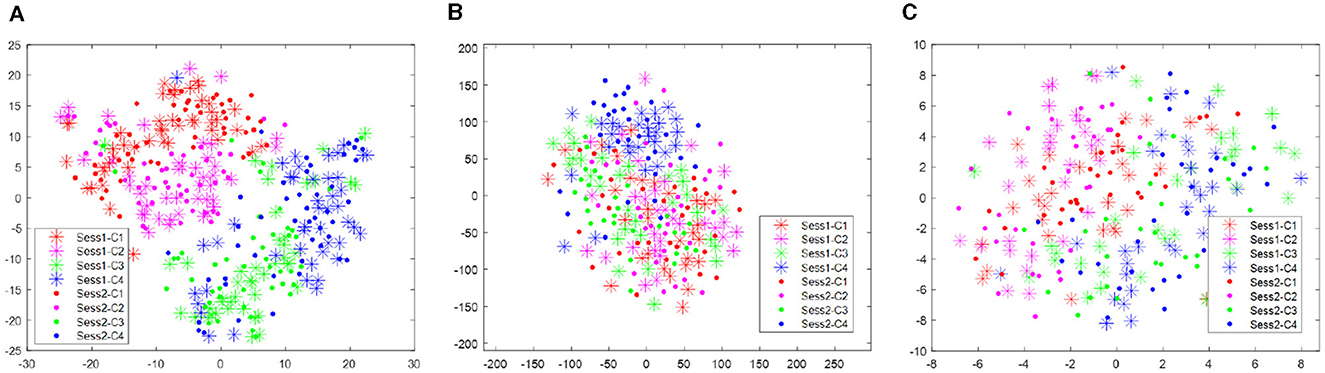
Figure 4. Distribution of the two “sessions” for the three subjects in the data set BCI IV 2a, respectively. Stars represent data points from session 1, while filled circles represent data points from session 2. Four different colors show four different classes. (A) illustrates the distribution for subject k3b. (B) demonstrates the distribution for subject k6b. (C) demonstrates the distribution for subject l1b.
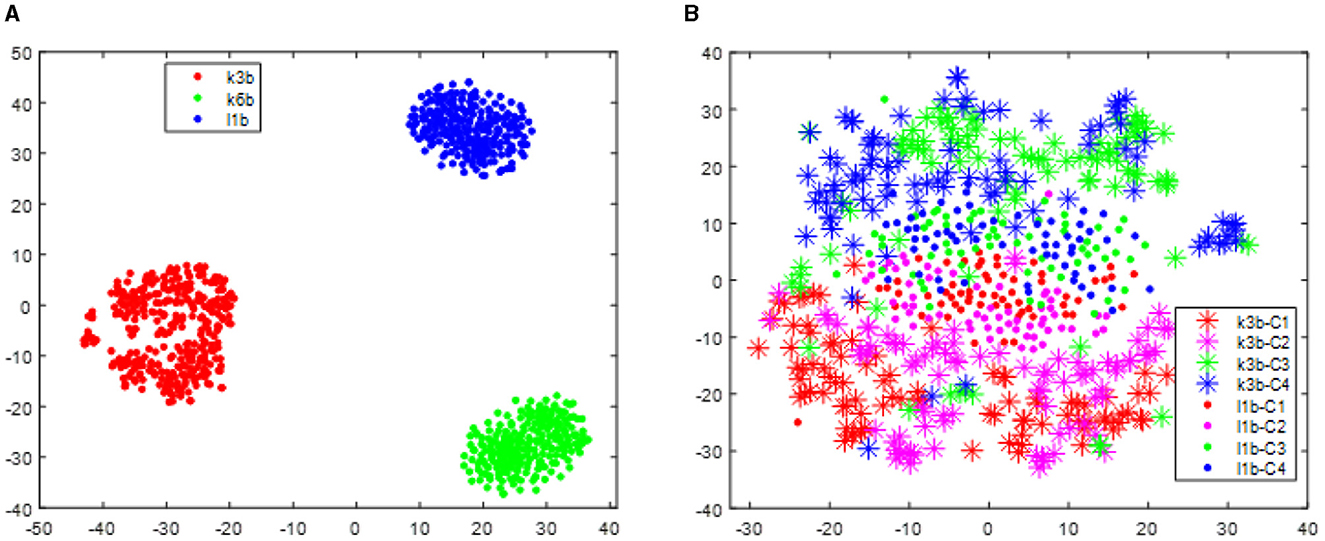
Figure 5. Distribution of data points for all subjects in the data set BCI III IIIa. (A) illustrates the distribution before transfer. Different colors represent data comes from different subjects. (B) demonstrates the distribution of subject k3b and subject l1b after alignment by RPA-LEM.
4.3 Model performance analysis
The performance of the proposed transfer learning approaches was evaluated on the BCI IV 2a and BCI III IIIa data sets using PLVQ-LEML as classifier. Then, we compared the performance of PLVQ-LEML with and without the proposed transfer learning approaches (PA-LEM and RPA-LEM) and the original RPA. We also compared the final performance with existing results in the literature.
4.3.1 BCI IV 2a
We first evaluated our proposed transfer learning approaches in the cross-session transfer setting, which matches the data distribution of the given testing session with that of the given training session for each subject in the data set BCI IV 2a. The experiments were repeated for 10 runs. The averaged test kappa values over 10 runs is shown in Table 6. The Riemannian classifier PLVQ-LEML was employed. The term “no-transfer” means classification using PLVQ-LEML without any transfer operations applied. The results in the table are organized in two parts, with high-quality subjects at the top and low-quality subjects at the bottom. From Table 6, we can observe that the inclusion of the transfer learning approaches generally outperformed the no transfer approach. Our proposed RPA-LEM approach performed slightly better than RPA on average, while our proposed PA-LEM performed worse than RPA. In general, for high-quality subjects, our approach RPA-LEM can improve the performance by a rate as high as 11.14%, on average, compared with no transfer, while for low-quality subjects, our approach RPA-LEM can only improve that by a rate of 2.5%. The overall performance of our proposed RPA-LEM is comparable to that of RPA. The PLVQ-LEML with our proposed RPA-LEM (PLVQ-LEML + RPA-LEM) obtained much better results compared with existing results, as shown in Table 7, suggesting the effectiveness of the proposed method.
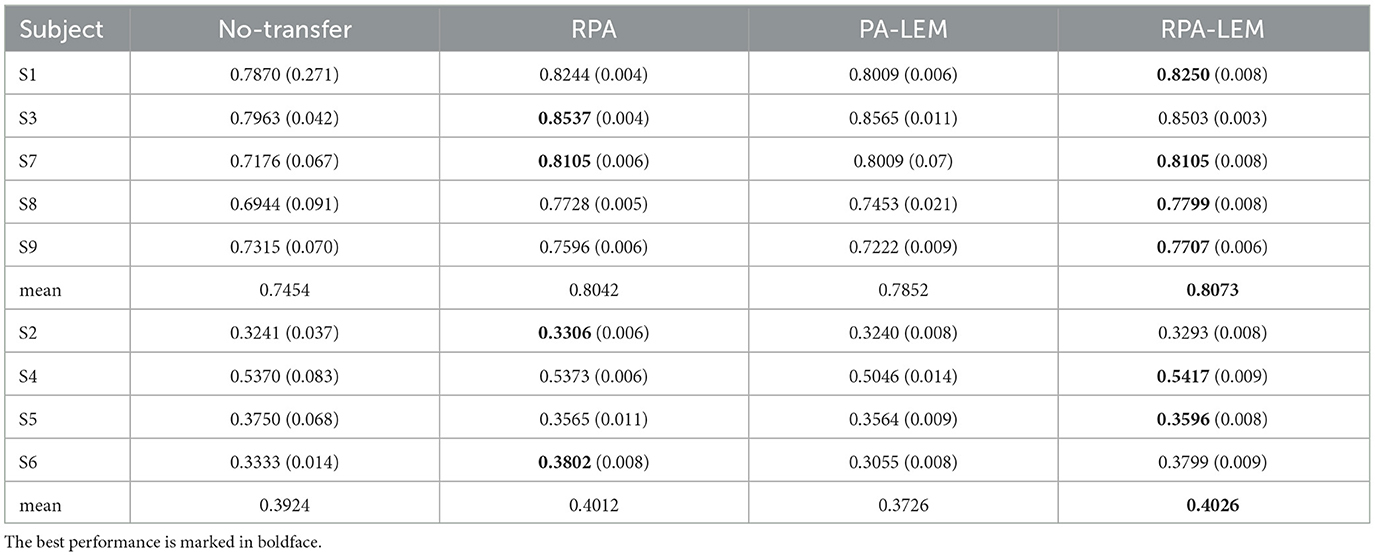
Table 6. Performance comparison between no-transfer and three transfer learning methods in cross-session transfer setting on the data set BCI IV 2a.
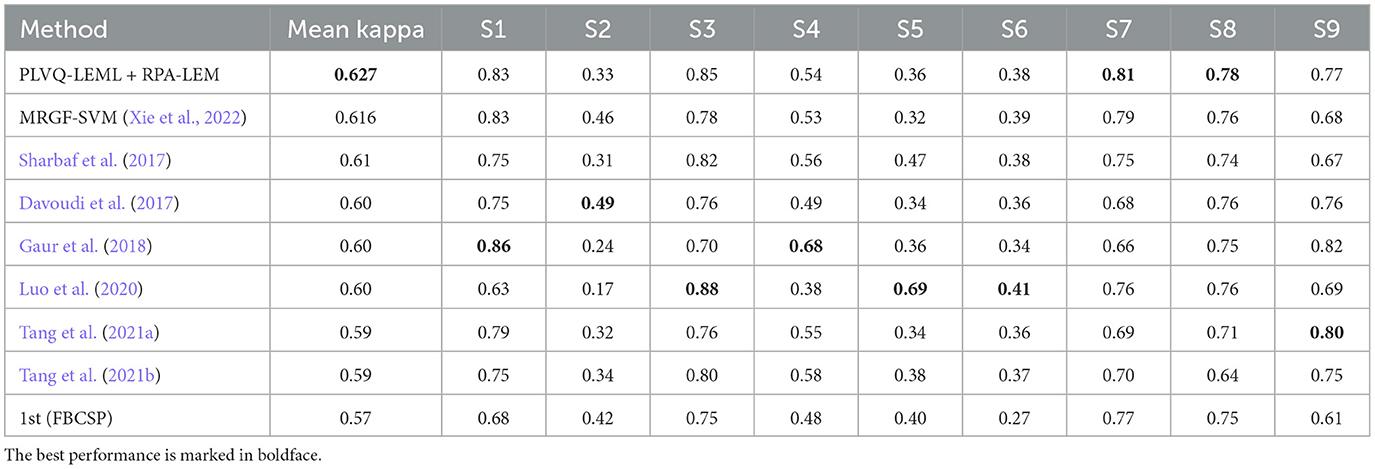
Table 7. Performance comparison between our method and existing methods on the data set BCI IV 2a.
We then evaluated our proposed transfer learning approaches in the cross-subject transfer setting, treating data from one subject as training set and data from another subject as test set. To directly compare our methods with that is reported in the study by Zanini et al. (2018), which uses MDRM as classifier and RPA to reduce the distribution differences between the test subject and the training subject (MDRM+RPA), we followed their experimental setting that only utilizes the high-quality subjects (i.e., S1, S3, S7, S8, and S9). For each test subject, one subject among the remaining good subjects was used as the training subject. For each subject, the experiments were repeated until all the remaining good subjects were used as the training subject once. The mean kappa value together with standard deviation in bracket is shown in Table 8. From Table 8, we can observed that the incorporation of the Riemannian transfer learning significantly improved the classification performance. Our proposed RPA-LEM performed on par to the original RPA on this challenging task.

Table 8. Performance comparison between no-transfer and three transfer learning methods in the cross-subject transfer setting on the data set BCI IV 2a.
We finally compared the computational time (i.e., CPU time) of our proposed RPA-LEM with RPA. In BCI systems, real-time performance is crucial. Thus, when the classification performances are comparable, more computationally efficient methods are favorable. Figure 6 demonstrates the CPU time taken by our proposed RAP-LEM for the entire training and test process of one subject on the data set BCI IV 2a under both cross-session and cross-subject transfer settings. The reported CPU time is the averaged one over 10 runs, removing the randomness coming from the computing resource assignment. From Figure 6, we can observe that our proposed RPA-LEM is much more computationally efficient than RPA on both transfer settings.
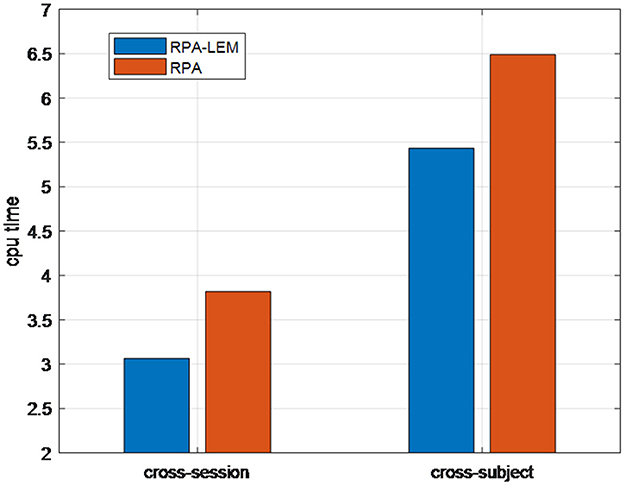
Figure 6. CPU time of RPA-LEM compared with RPA on the BCI IV 2a data set.
In summary, on the BCI IV 2a data set, our proposed RPA-LEM obtained slightly better or comparable classification performance to RPA under both cross-session and cross-subject transfer settings, with much higher computational efficiency.
4.3.2 BCI III IIIa
Similarly, we evaluated our proposed approaches in the cross-session transfer setting on the data set BCI III IIIa. The IIIa dataset is recorded in one single day. For cross-session evaluation, we split the dataset into two sessions in a random way. Repeated experiments of 10 times are conducted, and then, results are averaged to represent the experimental outcome. As Figure 4 illustrated, no apparent distribution differences were observed, since the data of each subject were recorded continuously at a single day. Thus, the performance of the classifier is not expected to be improved significantly by the transfer approaches. This is corroborated by our experimental results, as shown in Table 9. The performance of the classifier with transfer approaches remained similar to that without transfer. Again, our proposed RPA-LEM performed slightly better than our proposed PA-LEM but comparable to RPA. Additionally, PLVQ-LEML integrated with RPA-LEM obtained competitive performance to the existing methods, only seconded to the winner of the competition, as given in Table 10.

Table 9. Performance comparison between no-transfer and two transfer learning methods in the cross-“session” setting on the data set BCI III IIIa.
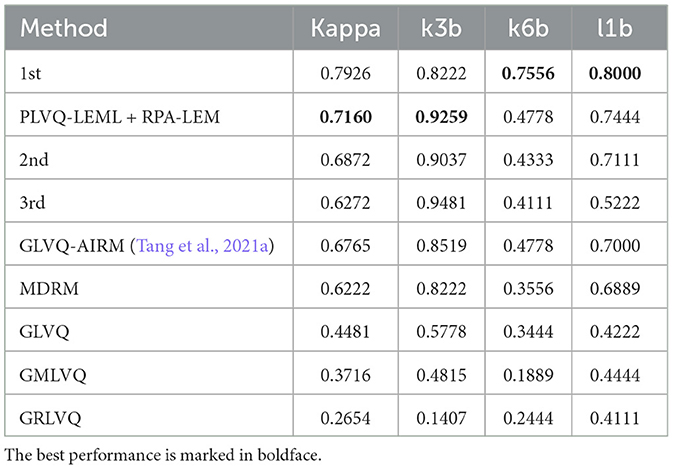
Table 10. Performance comparison between our method and existing methods on the data set BCI III IIIa.
Again, we evaluated our proposed approaches in the cross-subject transfer learning setting on the data set BCI III IIIa. Similarly, for every test subject, each of the remaining subjects works as the training subject once. The averaged kappa values together with the standard derivation in brackets are reported, see Table 11. From Table 11, we can observe that the classification performance of our proposed RPA-LEM is comparable to RPA but significantly better than that of no-transfer. More importantly, our proposed method is much computationally efficient than RPA in both settings, as shown in Figure 7.
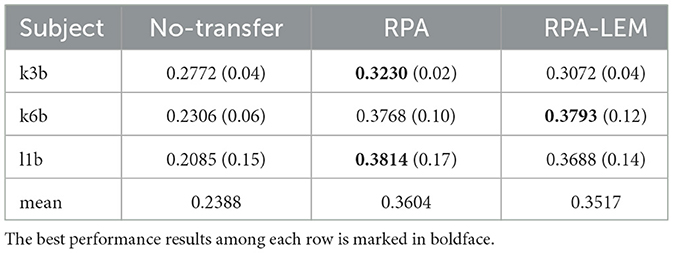
Table 11. Performance comparison of kappa between no-transfer and two transfer learning methods in the cross-subject transfer learning setting on the data set BCI III IIIa.
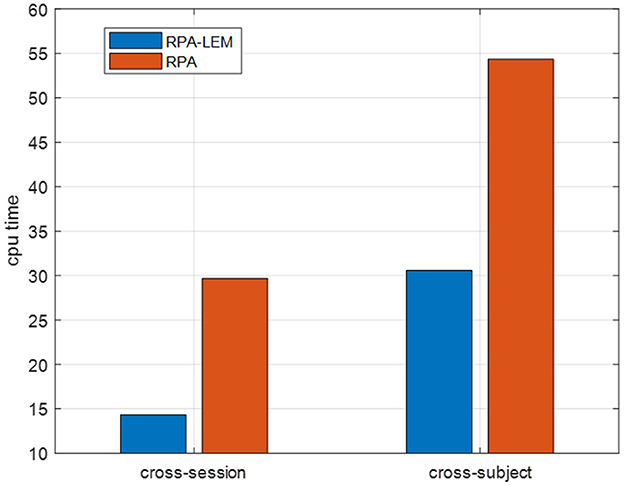
Figure 7. CPU time of RPA-LEM compared with RPA on the BCI III IIIa data set.
5 Conclusion
This paper introduces two Riemannian transfer learning methods based on log-Euclidean metric termed as PA-LEM and RPA-LEM to reduce the distribution differences between the source data and the target data, both of which are points living on the Riemannian space of symmetric positive definite (SPD) matrices, aiming to improve the classification performance of the Riemannian classifier PLVQ-LEML efficiently on the target data. PA-LEM is equivalent to perform Euclidean Procrustes analysis (PA) in the logarithm domain of the SPD matrix-valued data. RPA-LEM adapts RPA, which computes Riemannian mean and dispersion of samples under computationally demanding affine-invariant Riemannian metric (AIRM), by log-Euclidean metric, yielding slightly better classification performance than RPA, with much higher computational efficiency.
Our methods are unsupervised transfer learning methods that do not require knowledge of labels of the target domain and thus can be used for online learning setting. One of our future work is to adapt our method for online learning setting, which learns the Riemannian mean and dispersion can be computed in an online fashion. In such scenario, when more experiments are conducted, the target domain data gradually increases, the obtained geometric mean will tend toward true value. Thus, the improvement in the classification performance will gradually increase over time. Even though the proposed Riemannian transfer learning approach in this study is initially designed for EEG data, it is actually applicable for any learning scenarios, where the inputs can be represented by SPD matrices. One typical example is the image set classification, where a set of images is represented by their covariance matrix. Thus, one of our future studies is devoted to explore the application of our proposed method in other learning scenarios, such as image set classification.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
FZ: Data curation, Formal analysis, Investigation, Methodology, Software, Validation, Writing—original draft, Writing—review & editing, Visualization. XZ: Conceptualization, Formal analysis, Methodology, Software, Validation, Visualization, Writing—original draft, Writing—review & editing. FT: Writing—review & editing, Funding acquisition, Project administration, Resources, Supervision, Conceptualization. YY: Writing—review & editing, Validation, Data curation. LL: Project administration, Writing—review & editing, Conceptualization.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This study was supported by the National Natural Science Foundation of China (Grant No. 62273335), Shenyang Science and Technology Innovation Talent Program for Middle-aged and Young Scholars (Grant No. RC231112), and CAS Project for Young Scientists in Basic Research (Grant No. YSBR-041).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abiri, R., Borhani, S., Sellers, E. W., Jiang, Y., and Zhao, X. (2019). A comprehensive review of EEG-based brain-computer interface paradigms. J. Neural Eng. 16:011001. doi: 10.1088/1741-2552/aaf12e
Arsigny, V., Fillard, P., Pennec, X., and Ayache, N. (2006). Log-Euclidean metrics for fast and simple calculus on diffusion tensors. Magn. Reson. Med. 56, 411–421. doi: 10.1002/mrm.20965
Arsigny, V., Filllard, P., Pennec, X., and Ayache, N. (2007). Geometric means in a novel vector space structure on symmetric positive-definite matrices. SIAM J. Matrix Anal. Appl. 29, 328–347. doi: 10.1137/050637996
Biehl, M., Hammer, B., Schleif, F.-M., Schneider, P., and Villmann, T. (2015). “Stationarity of matrix relevance LVQ,” in 2015 International Joint Conference on Neural Networks (IJCNN) (Killarney: IEEE), 1–8. doi: 10.1109/IJCNN.2015.7280441
Congedo, M., Barachant, A., and Andreev, A. (2013). A new generation of brain-computer interface based on Riemannian geometry. arXiv preprint arXiv:1310.8115.
Davoudi, A., Ghidary, S. S., and Sadatnejad, K. (2017). Dimensionality reduction based on distance preservation to local mean for symmetric positive definite matrices and its application in brain-computer interfaces. Neural. Eng. 14:036019. doi: 10.1088/1741-2552/aa61bb
Du, Y., Zhou, D., Xie, Y., Lei, Y., and Shi, J. (2023). Prototype-guided feature learning for unsupervised domain adaptation. Pattern Recognit. 135:109154. doi: 10.1016/j.patcog.2022.109154
Gaur, P., Pachori, R. B., Wang, H., and Prasad, G. (2018). A multi-class EEG-based BCI classification using multivariate empirical mode decomposition based filtering and Riemannian geometry. Expert Syst. Appl. 95:201. doi: 10.1016/j.eswa.2017.11.007
Gower, J. C., and Dijksterhuis, G. B. (2004). Procrustes Problems. Oxford: Oxford University Press. doi: 10.1093/acprof:oso/9780198510581.001.0001
He, H., and Wu, D. (2018). Transfer Learning for Brain-Computer Interfaces: A Euclidean Space Data Alignment Approach. Ithaca, NY: Cornell University - arXiv.
Huang, Z., Wang, R., Shan, S., Li, X., and Chen, X. (2015). “Log-Euclidean metric learning on symmetric positive definite manifold with application to image set classification,” in ICML (IEEE), 720–729.
Li, L., and Zhang, Z. (2019). Semi-supervised domain adaptation by covariance matching. IEEE Trans. Pattern Anal. Mach. Intell. 41, 2724–2739. doi: 10.1109/TPAMI.2018.2866846
Lotte, F., Bougrain, L., Cichocki, A., Clerc, M., Congedo, M., Rakotomamonjy, A., et al. (2018). A review of classification algorithms for EEG-based brain-computer interfaces: a 10-year update. J. Neural Eng. 15:031005. doi: 10.1088/1741-2552/aab2f2
Luo, J., Gao, X., Zhu, X., Wang, B., Lu, N., Wang, J., et al. (2020). Motor imagery EEG classification based on ensemble support vector learning. Comput. Methods Programs Biomed. 193:105464. doi: 10.1016/j.cmpb.2020.105464
Luo, T.-j. (2023). Dual selections based knowledge transfer learning for cross-subject motor imagery EEG classification. Front. Neurosci. 17:1274320. doi: 10.3389/fnins.2023.1274320
Maybank, S. J. (2005). Procrustes problems. J. R. Stat. Soc. A: Stat. Soc. 168, 459–459. doi: 10.1111/j.1467-985X.2005.358_4.x
Moakher, M. (2008). A differential geometric approach to the geometric mean of symmetric positive-definite matrices. Siam J. Matrix Anal. Appl. 26, 735–747. doi: 10.1137/S0895479803436937
Pan, S. J., and Yang, Q. (2010). A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22, 1345–1359. doi: 10.1109/TKDE.2009.191
Rodrigues, P. L. C., Jutten, C., and Congedo, M. (2019). Riemannian procrustes analysis: transfer learning for brain-computer interfaces. IEEE Trans. Biomed. Eng. 66, 2390–2401. doi: 10.1109/TBME.2018.2889705
Said, S., Bombrun, L., Berthoumieu, Y., and Manton, J. H. (2017). Riemannian Gaussian distributions on the space of symmetric positive definite matrices. IEEE Trans. Inf. Theory 63, 2153–2170. doi: 10.1109/TIT.2017.2653803
Seo, S., and Obermayer, K. (2003). Soft learning vector quantization. Neural Comput. 15:1589. doi: 10.1162/089976603321891819
Sharbaf, M. E., Fallah, A., and Rashidi, S. (2017). “Shrinkage estimator based common spatial pattern for multi-class motor imagery classification by hybrid classifier,” in 2017 3rd International Conference on Pattern Recognition and Image Analysis (IPRIA) (Shahrekord: IEEE). doi: 10.1109/PRIA.2017.7983059
Tang, F., Fan, M., and Tiňo, P. (2021a). Generalized learning Riemannian space quantization: a case study on Riemannian manifold of spd matrices. IEEE Trans. Neural Netw. Learn. Syst. 32, 281–292. doi: 10.1109/TNNLS.2020.2978514
Tang, F., Feng, H., Tiňo, P., Si, B., and Ji, D. (2021b). Probabilistic learning vector quantization on manifold of symmetric positive definite matrices. Neural Netw. 142, 105–118. doi: 10.1016/j.neunet.2021.04.024
Tang, F., Tiňo, P., and Yu, H. (2023). Generalized learning vector quantization with log-Euclidean metric learning on symmetric positive-definite manifold. IEEE Trans. Cybern. 53, 5178–5190. doi: 10.1109/TCYB.2022.3178412
Tangermann, M., Müller, K. R., Aertsen, A., Birbaumer, N., Braun, C., Brunner, C. M., et al. (2012). Review of the BCI competition IV. Front. Neurosci. 6, 1–31. doi: 10.3389/fnins.2012.00055
Xie, X., Zou, X., Yu, T., Tang, R., Hou, Y., Qi, F., et al. (2022). Multiple graph fusion based on Riemannian geometry for motor imagery classification. Appl. Intell. 52, 9067–9079. doi: 10.1007/s10489-021-02975-2
Zanini, P., Congedo, M., Jutten, C., Said, S., and Berthoumieu, Y. (2018). Transfer learning: a Riemannian geometry framework with applications to brain-computer interfaces. IEEE Trans. Biomed. Eng. 65, 1107–1116. doi: 10.1109/TBME.2017.2742541
Zhang, X.-C., and Tang, F.-Z. (2022). Probabilistic Riemannian quantification method with log-Euclidean metric learning. Appl. Res. Comput. 39:8. doi: 10.19734/j.issn.1001-3695.2021.09.0353
Keywords: brain-computer interfaces, transfer learning, Riemannian spaces, EEG, motor imagery
Citation: Zhuo F, Zhang X, Tang F, Yu Y and Liu L (2024) Riemannian transfer learning based on log-Euclidean metric for EEG classification. Front. Neurosci. 18:1381572. doi: 10.3389/fnins.2024.1381572
Received: 04 February 2024; Accepted: 09 May 2024;
Published: 30 May 2024.
Edited by:
Nenggan Zheng, Zhejiang University, ChinaReviewed by:
Frank-Michael Schleif, University of Applied Sciences, Würzburg-Schweinfurt, GermanyHongmiao Zhang, Soochow University, China
Copyright © 2024 Zhuo, Zhang, Tang, Yu and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fengzhen Tang, dGFuZ2Zlbmd6aGVuQHNpYS5jbg==