 Liu He
Liu He Hui Cheng1*
Hui Cheng1* Yunong Zhang
Yunong Zhang
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurorobot., 17 March 2025
Volume 19 - 2025 | https://doi.org/10.3389/fnbot.2025.1553623
This study addresses the distributed optimization problem with time-varying objective functions and time-varying constraints in a multi-agent system (MAS). To tackle the distributed time-varying constrained optimization (DTVCO) problem, each agent in the MAS communicates with its neighbors while relying solely on local information, such as its own objective function and constraints, to compute the optimal solution. We propose a novel penalty-based zeroing neural network (PB-ZNN) to solve the continuous-time DTVCO (CTDTVCO) problem. The PB-ZNN model incorporates two penalty functions: The first penalizes agents for deviating from the states of their neighbors, driving all agents to reach a consensus, and the second penalizes agents for falling outside the feasible range, ensuring that the solutions of all agents remain within the constraints. The PB-ZNN model solves the CTDTVCO problem in a semi-centralized manner, where information exchange between agents is distributed, but computation is centralized. Building on the semi-centralized PB-ZNN model, we adopt the Euler formula to develop a distributed PB-ZNN (DPB-ZNN) algorithm for solving the discrete-time DTVCO (DTDTVCO) problem in a fully distributed manner. We present and prove the convergence theorems of the proposed PB-ZNN model and DPB-ZNN algorithm. The efficacy and accuracy of the DPB-ZNN algorithm are illustrated through numerical examples, including a simulation experiment applying the algorithm to the cooperative control of redundant manipulators.
Recently, owing to the development of large-scale networks and advancements in big data theory, research on distributed optimization problems has garnered considerable attention due to its broad application prospects in science and engineering (Bahman and Jorge, 2014; Molzahn et al., 2017; Mao et al., 2023; Kang and Yang, 2023), such as resource allocation (Cai et al., 2024), energy management (Li et al., 2024), and economic dispatch (Huang et al., 2022). In a typical distributed optimization problem, the objective function of a multi-agent system (MAS) results from summing the local sub-objectives of each individual agent (Jia et al., 2024). In addition, during the search for an optimal solution, each agent only has access to its local sub-objective and constraints while communicating its own state to neighboring agents. Overall system convergence is achieved through consensus among the agents.
The aforementioned studies focus on distributed optimization problems with static objective functions. However, distributed time-varying constrained optimization (DTVCO) problems, where the objective functions and constraints change over time, are encountered in practical scenarios, such as the formation control of multi-robot systems (Sun et al., 2022), Nash equilibrium seeking for time-varying non-cooperative games (Ye and Hu, 2015), and distributed time-varying resource allocation (Cherukuri and Cortés, 2016). The DTVCO problem is more intricate than distributed static optimization since the optimal solution evolves over time. As a result, researchers have increasingly turned their attention to DTVCO (Zheng et al., 2017; Sun et al., 2023; Zhang et al., 2021a; Zhu and Wang, 2024; He et al., 2021). For example, Zheng et al. (2017) introduced a consensus-based control scheme employing second-order optimization methods to address DTVCO problems characterized by local objective functions with identical Hessians. Sun et al. (2023), introduced a distributed control algorithm comprising a sliding-mode consensus component and a Hessian-based optimization component, integrated with log-barrier penalty functions, to address the DTVCO problem. Zhu and Wang (2024) utilized the finite-time stability theory and graph theory to propose a novel class of distributed finite-time optimization algorithms that are independent to time derivatives of the gradients and Hessian information.
Due to the parallel computing characteristics, hardware implementation capabilities, and parallel distributed properties (Yang et al., 2020; Jin et al., 2022b; Qiu et al., 2021; Sun et al., 2020; Song et al., 2024), neural network-based methods provide an powerful approach for solving various challenging computational problems in real time. Recent advancements in neural networks have shown significant progress in tackling time-varying problems. For fault-tolerant motion planning of redundant manipulators, Jin et al. (2017) developed a different-level simultaneous minimization scheme by utilizing a discrete-time recurrent neural network to solve quadratic programming problems. Khan et al. (2020b) have developed a metaheuristic-based control framework for simultaneous tracking control and obstacle avoidance of redundant manipulators, unifying these tasks into a single constrained optimization problem. Enhancements to the beetle antennae search algorithm, called BAS-ADAM, have been proposed by Khan et al. (2020a) to improve convergence behavior and avoid local minima in highly non-convex objective functions. A distributed competitive and collaborative coordination approach has been established by (Liu et al., 2024) for multi-robot systems, optimizing system stability and resource utilization through a fusion of recurrent neural dynamics and distributed solvers. In addition, Zhang et al. (2018a) have proposed a novel recurrent neural network for kinematic control of redundant manipulators, addressing periodic input disturbances and physical constraints while optimizing a general quadratic performance index. These studies collectively highlight the innovation and potential of neural networks in addressing time-varying challenges in various applications. Another exciting direction in neural network-based control scheme is the data-driven model predictive control (MPC). The data-driven MPC impacted the field of robotic control, particularly in handling complex and dynamic environments. For example, one study by Yan et al. (2024) proposed a data-driven MPC algorithm that integrates neural dynamics for trajectory tracking in redundant manipulators with unknown models. Another research by Jin et al. (2024) introduced a cerebellum-inspired learning and control scheme using echo state networks to achieve precise joint velocity control in redundant manipulators.
Introduced by Zhang et al. (2002), since its inception, zeroing neural network (ZNN) method has been widely utilized to address a range of time-varying problems (Liao et al., 2022; Peng et al., 2022; Lan et al., 2023; Zuo et al., 2022; Dai et al., 2023; Chen et al., 2024; Hu et al., 2024; Jin et al., 2022a; Tan et al., 2023; Ding et al., 2018), such as time-varying matrix inversion (Dai et al., 2023), time-varying optimization (Chen et al., 2024), and time-varying Lyapunov equation solving (Zuo et al., 2022). Recent advancements in ZNN have illustrated their effectiveness in various robotic applications. (Sun et al., 2024b) have successfully applied ZNN to human-robot interaction and force control, improving estimation accuracy and ensuring safety in complex environments. In the realm of motion estimation, (Wang et al., 2024) have integrated ZNN into a multi-task parallel learning framework to reconstruct missing sEMG signals and estimate joint angles with high accuracy. In addition, (Xie et al., 2025) have utilized ZNN in obstacle avoidance schemes for redundant robots, leveraging deep reinforcement learning to enhance obstacle avoidance capabilities. Furthermore, Sun et al. (2024a) have developed a hybrid orthogonal repetitive motion and obstacle avoidance scheme for omnidirectional mobile robotic arms, achieving accurate obstacle avoidance and repetitive motion tasks. These studies collectively highlight the innovation and potential of ZNN in revolutionizing various aspects of robotics.
Despite the significant success of ZNN method in addressing time-varying problems, the ZNN models presented in the aforementioned works are limited to solve those problems in a centralized manner. There is a scarcity of existing research focusing on distributed ZNN. The most typical work of distributed ZNN is by Jin et al. In Jin et al. (2018), a ZNN-based control scheme is introduced to address the cooperative motion generation problem. This scheme facilitates cooperative motion generation within a distributed network of multiple redundant manipulators. However, for an individual manipulator, the computation results of neighbors' control inputs are required to compute its own control input. Therefore, the proposed control method is not a fully distributed scheme, as the control inputs for the entire system need to be computed collectively by all manipulators, rather than being computed independently by each manipulator.
Driven by the above discussions, a novel penalty-based ZNN (PB-ZNN) model is proposed. The PB-ZNN model solves a continuous-time DTVCO (CTDTVCO) problem in a semi-centralized manner. Then, to extend the application of ZNN models to distributed time-varying problems, a distributed penalty-based ZNN (DPB-ZNN) algorithm is designed on the basis of the proposed PB-ZNN model. The DPB-ZNN algorithm solves a discrete-time DTVCO (DTDTVTO) problem in a fully distributed manner.
The remainder of this study is organized into six sections. In Section 2, some preliminaries concerning graph theory and mathematical notations are provided. Then, in Section 3, the main results of this study are presented. The formulation of the CTDTVCO problem is presented in Section 3.1, and the detailed design process of PB-ZNN model is presented in Section 3.2. The formulation for the DTDTVCO problem and the detailed design process of DPB-ZNN algorithm is presented in Section 3.3. In Section 4, the theoretical proofs of the convergence of both PB-ZNN model and DPB-ZNN algorithm are provided. The efficacy and efficiency of the DPB-ZNN algorithm are illustrated in Section 5 through numerical examples, including a simulation experiment applying it to the cooperative control of redundant manipulators. Finally, the conclusion of this study is given in Section 6.
Before ending this section, the main contributions of this study are listed as follows.
• A novel PB-ZNN model is designed to address the CTDTVCO problem. By incorporating two penalty functions, the PB-ZNN model successfully solves the CTDTVCO problem in a semi-centralized manner.
• On the basis of the PB-ZNN model, a DPB-ZNN algorithm is designed. By incorporating the Euler formula, the proposed DPB-ZNN algorithm effectively solves the DTDTVCO problem in a fully distributed manner.
• The convergence properties of both PB-ZNN model and DPB-ZNN algorithm are proved. Further theoretical analyses prove that the maximum steady-state residual error (MSSRE) for the proposed DPB-ZNN algorithm is of O(τ2).
The notation ||·||2 represents the 2-norm of a vector or a matrix. Moreover, (·)T denotes the transpose of a matrix or a vector, In is the identity matrix of size n×n, , and ⊗ represents the Kronecker product (Golub and Loan, 2013).
Some principles from graph theory (Diestel, 2017) are introduced as follows.
The notation denotes a weighted graph, wherein represents the set of vertices, and denotes the set of edges. The adjacency matrix is denoted by , where aij>0 when and aij = 0 when , respectively. Moreover, the notation denotes the neighbor set of ith vertex. The graph is said to be connected and undirected when a path between any given pair of vertices within exists and when also indicates . The degree matrix D is defined as where . Finally, the Laplacian matrix is defined as L = D−A.
Assumption 1: Graph is undirected and connected.
In Subsection 3.1, the formulations of the CTDTVCO problem are provided. To address the CTDTVCO problem, two penalty functions are introduced. In Subsection 3.2, a PB-ZNN model is proposed to solve the CTDTVCO problem in a semi-centralized manner. Then, on the basis of the proposed PB-ZNN model, a novel DPB-ZNN algorithm is proposed to solve the DTDTVCO problem in a fully distributed manner in Subsection 3.3.
In this study, the CTDTVCO problem within graph is formulated as
where x(t) ∈ ℝd, and denotes the time-varying local objective function of the agent i and fi should be second-order differentiable and strongly convex for all i = 1, 2, ⋯ , n. Moreover, Ki(t)x(t) = bi(t) and Ji(t)x(t) ≤ ci(t) are the time-varying equality and inequality constraints associated with the agent i. For all i ∈ {1, 2, …, n}, the coefficient matrix is of full row rank and coefficient matrix Ji(t) is defined as . In addition, notations and denote the coefficient vectors. The above-mentioned matrices and vectors are assumed to be differentiable. It is worth pointing out that all contradictions among agents' equality constraints should be ruled out for the CTDTVCO problem to be solvable.
According to Assumption 1, the communication graph is both connected and undirected. Hence, the CTDTVCO problem (Equations 1–3) is reformulated as an equivalent problem described by the following Lemma 1.
Lemma 1: If graph is connected and undirected, then the CTDTVCO problem (Equations 1–3) is equivalent to the following optimization problem (Bahman and Jorge, 2014).
where
with , , and . The coefficient vectors b(t) and c(t) are defined as b(t)= , and , and the matrix . In addition, 0nd denotes an nd dimensional vector whose elements are 0.
Remark 1: Through Lemma 1, the consensus problem for the CTDTVCO problem (Equations 1–3) is reformulated as an equality constraint (Equation 7). Following the conventional ZNN design method, equality constraints are typically handled by applying the Lagrange function. However, this approach is not suitable for equality constraint (Equation 7), because the Laplacian matrix L is inherently rank-deficient. Consequently, setting L = L⊗Id also results in a rank-deficient matrix.
To obtain the optimal solution for the CTDTVCO problem (Equations 1–3), two penalty functions are introduced in this study. The definitions of these two penalty functions are as follows:
where Nj(xi(t)) = cij(t)−Jij(t)xi(t) with cij(t) being the jth element of vector ci(t) and Jij(t) being the jth row of matrix Ji(t). In addition, σ1, σ2>0 are two positive parameters that are sufficiently larege and parameter ρ>0 is positive and near zero.
• The first penalty function intuitively manages information exchange between agents and their neighbors, driving all agents to reach a consensus.
• The second penalty function is from Zhang et al. (2021b), and it addresses the distributed inequality constraints, ensuring that each agent's solution remains bounded.
It is evident that when Lx(t) → 0nd, the value of p1(x(t)) approaches zero. Furthermore, when inequality constraints (Equation 5) are met, the value of p2(x(t)) becomes a positive number very close to zero. This soft penalty allows slight violations of constraints while still promoting feasible solutions. Conversely, by choosing sufficiently large enough positive parameters σ1 and σ2, the values of p1(x(t)) and p2(x(t)) are magnified to serve as punishments for solution x(t) that fall outside the feasible range. Thus, the CTDTVCO problem (Equations 4–6) is transformed into an equivalent CTDTVCO problem with no inequality constraints as follows:
Therefore, by solving the CTDTVCO problem (Equations 10, 11), one acquires an approximate solution to the original CTDTVCO problem (Equations 1–3). To solve the CTDTVCO problem (Equations 10, 11), a Lagrange function is introduced:
where the Lagrange multiplier λ(t) is defined as , with being the Lagrange multiplier corresponding to the agent i. It is assumed that both ∂L(x(t), λ(t), t)/∂x(t) and ∂L(x(t), λ(t), t)/∂λ(t) exist and are continuous. The optimal solution must satisfy the following equations:
where
with the elements being
In addition, Φ(x(t)) is defined as
with
For convenience in computation, (Equation 13) is expressed as the following matrix equation:
where
The vector y(t) needs to be solved at all time. One sees that the CTDTVCO problem (Equations 1–3) is solved if the matrix equation (Equation 14) is solved.
In this subsection, a PB-ZNN model is proposed for the entire system to solve the matrix equation (Equation 14).
To obtain the solution of (Equation 14), an error function is defined as
To minimize the value of the error function ε(t) and approach zero, it is essential that the derivative of the error function (Equation 15) with respect to time t remains negative (Zhang et al., 2018b). Consequently, the ZNN design formula is employed as follows:
where Ψ(·):ℝnd+k↦ℝnd+k is an array consisting of activation functions ψ(·) and a positive parameter γ>0 is used to adjust the convergence rate. It is crucial that the activation function ψ(·) satisfies two properties: It must be monotonically increasing and an odd function. By substituting (Equation 16) into (Equation 15), the following model is obtained:
where and denote the derivatives with respect to time t of the matrix A(t) and the vector g(t), respectively.
Moreover, according to Equation 14, one obtains
where
with and
in which
with and ċij(t) = dcij/dt. In addition,
where for all i = 1, 2, …, n denotes the Hessian matrix of the agent i and the definition of Hi(xi(t), t) is as follows:
One notices the simultaneous presence of x(t) and in in Equation 19. This reflects the combined influence of both the state and its time derivative on the dynamics of the system. When numerically computing Equation 17, it becomes necessary to consolidate similar terms. Define two matrices, M1(t) and M2(t), and a vector h(t), as follows:
where for all i = 1, 2, …, n,
Hence, after a restructuring of the ZNN model (Equation 17), one has
where
with . In this study, the linear function (i.e., Ψ(x(t)) = x(t)) is chosen as the activation function for simplicity. Therefore, the PB-ZNN model for the whole system is given as
Thus, the design of PB-ZNN model that solves the CTDTVCO problem (Equations 1–3) is completed.
It is worth pointing out that, although the PB-ZNN model (Equation 20) is designed to address the CTDTVCO problem, it solves Equation 14 in a semi-decentralized manner. Upon examining matrix Q(t) in Equation 20, one observes that for agent i, due to the presence of L in Q(t), solving the time derivative ẋi(t) analytically requires information from its neighbors: ẋj(t) for . Therefore, if to be analytically solved, the information exchange among agents is distributed, but the PB-ZNN model (Equation 20) is computed in a centralized way.
In this subsection, a distributed PB-ZNN (DPB-ZNN) algorithm is developed for each agent to solve the DTDTVCO problem in a fully distributed manner.
First, let us consider the following DTDTVCO problem with a computational time interval [tk, tk+1):
where f(xk+1, tk+1) is generated or measured from the smoothly time-varying signal f(x(t), t) by sampling at the time instant t = (k+1)τ (which is denoted as tk+1), and τ denotes the sampling gap.
The DPB-ZNN algorithm is designed on the basis of the continuous-time PB-ZNN model (Equation 20). Therefore, the distributed form of PB-ZNN model (Equation 20) is given to lay the basis for the DPB-ZNN algorithm.
Through simple matrix computation, the distributed form of equation (Equation 14) for agent i to solve in continuous-time is given as
where
with Di = diId×d and di denotes the degree of the Laplacian matrix L associated with the agent i. In addition, . It is evident that the distributed solution [ẋ1(t);ẋ2(t);…;ẋn(t)] for equation (Equation 24) is equivalent to in equation (Equation 14).
Consequently, for the agent i, the distributed form of the error function is defined as
Therefore, following the same design process as the PB-ZNN model, one has
where
with . In addition, M1i(t), M2i(t), and hi(t) are defined in the same way as in Section 3.2. Therefore, for agent i, the distributed form of PB-ZNN model (Equation 20) is formulated as
Hence, the distributed discrete-time PB-ZNN model is formulated as
where Qik, Aik, Sik, gik, and uik are generated or measured from the smoothly time-varying signals Qi(t), Ai(t), Si(t), gi(t), and ui(t), respectively. Upon examining uik, one notices that is required for agent i to compute ẋik. However, ẋjk is unknown to agent i in a fully distributed manner. Therefore, an approximation for ėik is introduced.
In traditional methods that solve distributed optimization problems, agents exchange xik with their neighbors to address the consensus problem. In this study, an alternative approach is proposed. Instead of merely exchanging the information xik, each agent maintains a short memory of their neighbors' states. By using the Euler formula, agents approximate ẋjk for on the basis of the memories that they kept, and ultimately approximate ėik effectively.
The Euler formula used in this study is given as follows (Chen et al., 2024).
This formula approximates the derivative ẋik using the backward difference of xik over the time step τ. The term O(τ) represents the truncation error, indicating that the approximation becomes more accurate as τ approaches zero. Therefore, the approximation of ėi(t) is defined as
Here, ėik is approximated by summing the estimated derivatives of the neighbors' states , utilizing the stored state information to eliminate the need for continuous communication. Hence, the fully distributed DPB-ZNN algorithm that solves the DTDTVCO problem is given as
with
Hence, by choosing the linear function as the active function, one obtains
By introducing the 2-step time-discretization (TD) formula (Chen et al., 2024).
the DPB-ZNN algorithm is obtained as
where parameter h = τγ is used to scale the convergence rate. The proposed DPB-ZNN algorithm (Equation 31) solves the DTDTVCO problem in a fully distributed manner. Notably, information exchange between agents is strictly limited to their solutions xik. Local information, including each agent's own objective function and constraints, remains inaccessible to its neighbors.
In this section, the convergence theorems for the PB-ZNN model (Equation 31) and DPB-ZNN algorithm (Equation 26) are established and proved.
On the basis of the analyses presented in Subsection 3.1, the CTDTVCO problem (Equations 1–3) is reformulated as the matrix equation (Equation 15). Therefore, solving the CTDTVCO (Equations 1–3) is equivalent to solving the matrix equation (Equation 15).
Theorem 1: For the CTDTVCO problem (Equations 1–3), consider that a monotonically increasing odd activation function Ψ(·) is used. Starting from any initial state y(0) ∈ ℝnd+k, the residual error ||ε(t)||2 converges to zero, meaning .
Proof: Define a Lyapunov candidate function as
Hence, the time derivative of V(t) is
With Ψ(·) being monotonically increasing and odd, the following conditions hold true for ψi(·):
Therefore, it is guaranteed that εi(t)ψ(εi(t)) ≥ 0 always holds true, which means . According to the Lyapunov stability theorem (Khalil, 2002), one obtains that ||ε(t)||2 converges to zero, meaning . Thus, the proof is completed. ■
In this subsection, detailed theoretical analyses about the DPB-ZNN algorithm (Equation 31) are given. The DPB-ZNN algorithm is deemed as a linear 2-step method. For better understanding, some lemmas are introduced as follows (Chen et al., 2024).
Lemma 2: A linear N-step method is formulated as . The first and second characteristic polynomials of the linear multiple-step method are and , respectively. If all complex roots of the characteristic polynomial z(ι) ensure |ι| ≤ 1, and if there exists |ι| = 1 with the root that ensures |ι| = 1 is simple, then the corresponding N-step method is 0-stable.
Lemma 3: A linear N-step method is formulated as . The order of truncation error when synthesizing the N-step method can be checked by computing and . If wq ≠ 0 and wi = 0 with i < q, the N-step method, then the multiple-step method has truncation error of O(τq).
Lemma 4: A linear N-step method is formulated as . The first and second characteristic polynomials of the linear multiple-step method are and , respectively. If z(1) = 0 and ż(1) = ζ(1), with ż being the derivative of z(ι), the N-step method is consistent.
Lemma 5: A linear N-step method is formulated as . The N-step method is convergent, if and only if Lemmas 1 and 3 are satisfied. That is, an N-step method is convergent, if and only if it is 0-stable and consistent.
On the basis of the above lemmas, the theorem about the convergence property of DPB-ZNN algorithm (Equations 24) is proved.
Theorem 2: Consider the CTDTVO problem (Equations 1–3). Suppose that for every agent i, its local objective function fi(xi(t), t) has continuous 2nd order derivatives. With design parameter γ > 0 and sufficiently small sampling interval gap, the DPB-ZNN algorithm (Equation 31) is convergent with a truncation error O(τ2).
Proof: According to Lemma 5, if and only if the DPB-ZNN algorithm (Equation 24) is 0-stable and consistent, the DPB-ZNN algorithm (Equation 24) is convergent.
According to Lemma 2, the first characteristic polynomial of the DPB-ZNN algorithm (Equation 24) is formulated as
The root of the characteristic polynomial is ι = 1. One obtains that all roots ensure |ι| ≤ 1 and when|ι| = 1 the root is simple. Therefore, the DPB-ZNN algorithm (Equation 24) is 0-stable.
On the basis of (Equations 30, 31), the following equation for the DPB-ZNN algorithm (Equation 31) is formulated:
According to Lemma 3, . Hence, w2 is obtained as
One computes that wj = 0 for j = 0, 1. Therefore, according to Lemma 3, the DPB-ZNN algorithm (Equation 31) has a truncation error order O(τ2). In addition, the second characteristic polynomial of the DPB-ZNN algorithm (Equation 31) is formulated as ζ(ι) = 1. Hence, one has ż(1) = ζ(1) = 1. Thus, according to Lemma 4, the DPB-ZNN algorithm (Equation 31) is consistent order O(τ2).
According to Lemma 5, the DPB-ZNN algorithm (Equation 31) is convergent since it is 0-stable and consistent order O(τ2). Thus, the proof is completed. ■
Theorem 3: Consider the CTDTVO problem (Equations 1–3). Suppose that, for every agent i, its local objective function fi(xi(t), t) have continuous 2nd order derivatives. With design parameter γ>0 and sufficiently small sampling interval gap, the maximum steady-state residual error (MSSRE) synthesized by the DPB-ZNN algorithm (Equation 26) is of O(τ2).
Proof: Let denotes the actual solution to the problem, i.e., εik+1 = 0 when . According to Theorem 3, the DPB-ZNN algorithm (Equation 31) has a truncation error of O(τ2), meaning . By applying the Taylor expansion, one further has
Hence, the MSSRE is deducted as
where||·||F represents the Frobenius norm of a matrix. Since is the actual solution, the partial derivative evaluates to a constant matrix, bounded due to the continuity of the second-order derivatives of fi. Therefore, the MSSRE synthesized by the DPB-ZNN algorithm (Equation 31) is of O(τ2). Thus, the proof is completed. ■
In this section, two numerical examples are presented. These examples serve to validate the effectiveness of the proposed DPB-ZNN algorithm (Equation 31) discussed in this study.
Consider a DTDTVCO problem with a MAS consisting of three agents. The formulation of the DTDTVCO problem is given as follows:
where . The communication topology of the network is shown in Figure 1. The detailed time-varying local objective functions fi and the corresponding time-varying local constraints are given through Tables 1, 2.
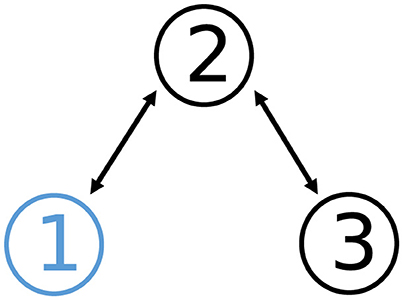
Figure 1. Communication topology of graph in Example 1, where is connected and undirected.
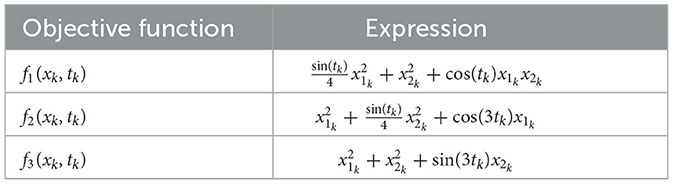
Table 1. Expressions of time-varying objective functions of all agents in Example 1.
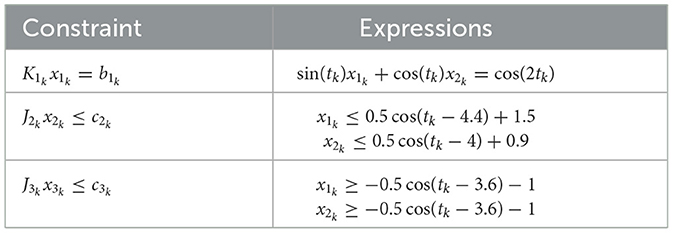
Table 2. Expressions of time-varying constraints of all agents in Example 1.
Before conducting the experiment, the parameters of the DPB-ZNN algorithm (Equation 31) must be properly configured. The total solving time is set to T = 10 s, the sampling gap τ is set to τ = 0.001 s, and h is set to 0.2. In this experiment, for the first penalty function, σ1 is set to 50. To guarantee that xik remains within the feasible region of the inequality constraints for any agent, σ2 is set to 100, while the parameter ρ is set to a value close to zero, specifically 0.001.
The initial states xi0 are set as , , and . The experimental results are illustrated through Figures 2, 3. In Figures 2, 3, the dashed red lines denote the inequality constraints J2kx2k ≤ c2k associated with the agent 2, and dashed purple lines denote the inequality constraints J3kx3k ≤ c3k associated with the agent 3.
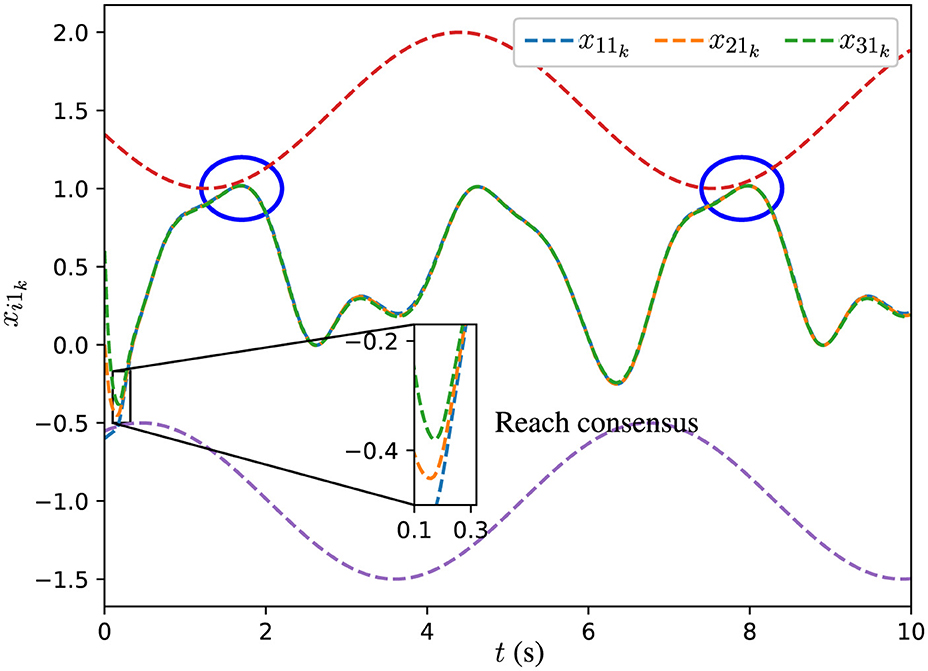
Figure 2. Trajectories of xi1k for all agents synthesized by DPB-ZNN algorithm (Equation 31).

Figure 3. Trajectories of xi2k for all agents synthesized by DPB-ZNN algorithm (Equation 31).
From Figures 2, 3, one sees that the three agents achieve consensus from different initial states. In Figures 2, 3, the distributed time-varying inequality constraints are denoted by the red and purple dashed lines. As pointed out by the blue circles in Figures 2, 3, for each agent, their solutions are constrained by the distributed time-varying inequality constraints.
In addition, several experiments are conducted with DPB-ZNN algorithm (Equation 31) solving the DTDTVCO problem (Equation 37) with different τ. The corresponding MSSREs ||εk||2 are presented in Figure 4, Table 3. In Figure 4, the MSSREs ||εk||2 with different τ are presented. Figure 4 includes three distinct trajectories corresponding to τ = 0.001 s (blue dashed line), τ = 0.0001 s (orange dashed line), and τ = 0.00001 s (green dashed line). The blue dashed line, for τ = 0.001 s, shows a decreasing MSSRE starting from approximately 102 to approximately 10−2. The orange dashed line, for τ = 0.0001 s, reflects a faster convergence with MSSRE reducing to 10−4. The green dashed line, for τ = 0.00001 s, presents the most rapid reduction, with MSSRE decreasing from 102 to 10−6, highlighting the advantage of very small time steps for precise updates. The figure reveals a clear trend: As τ decreases, the MSSRE also decreases, indicating improved performance of the algorithm with smaller τ values. From Figure 4, Table 3, one sees that the MSSRE ||εk||2 is of O(τ2), which corroborates the theoretical analyses.
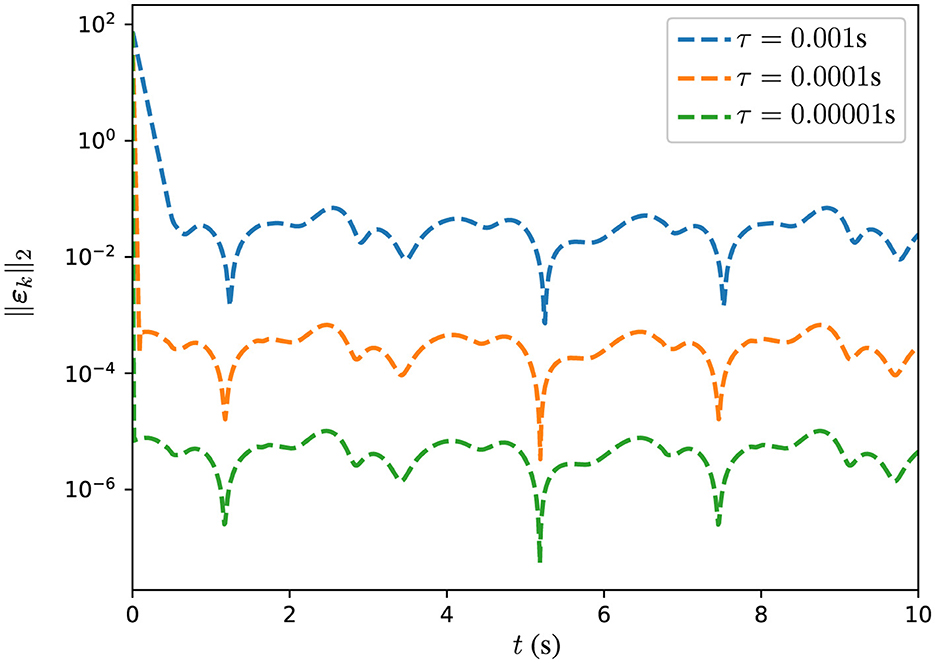
Figure 4. Trajectories of MSSRE ||εk||2 for DPB-ZNN algorithm in solving DTDTVCO problem (Equation 40), with different τ.
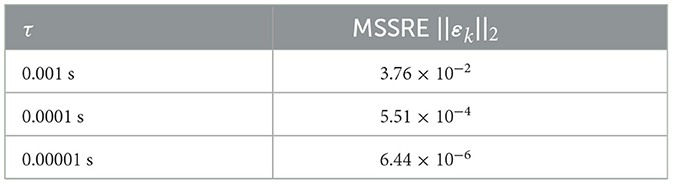
Table 3. MSSREs of DPB-ZNN algorithm (Equation 31) in solving DTDTVCO problem (Equation 37) with different τ.
Moreover, the gradient neural network (GNN) algorithm is often used to solve time-varying problems with constraints. Therefore, a comparison experiment between the GNN and the proposed DPB-ZNN algorithm is conducted.
First, for the agent i, a scalar-valued energy function is designed as follows:
where εik = Aikyik−gik. Then, by exploiting the gradient information of the energy function (Equation 38), one obtains
where the parameter γG is used to scale the convergence rate of the GNN algorithm (Zhang et al., 2021b). Hence, the GNN algorithm for solving the DTDTVCO problem is given as
Then, both the GNN algorithm (Equation 39) and the DPB-ZNN algorithm (Equation 31) are used to solve the DTDTVCO problem (Equation 37). For both the GNN algorithm and the DPB-ZNN algorithm, the parameters σ1, σ2, ρ, and the initial states are set the same. The corresponding experimental results are shown in Table 4, Figure 5.
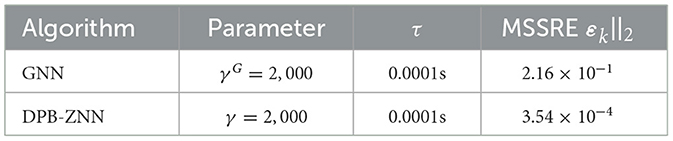
Table 4. Comparisons between GNN algorithm and DPB-ZNN algorithm in solving DTDTVCO problem.
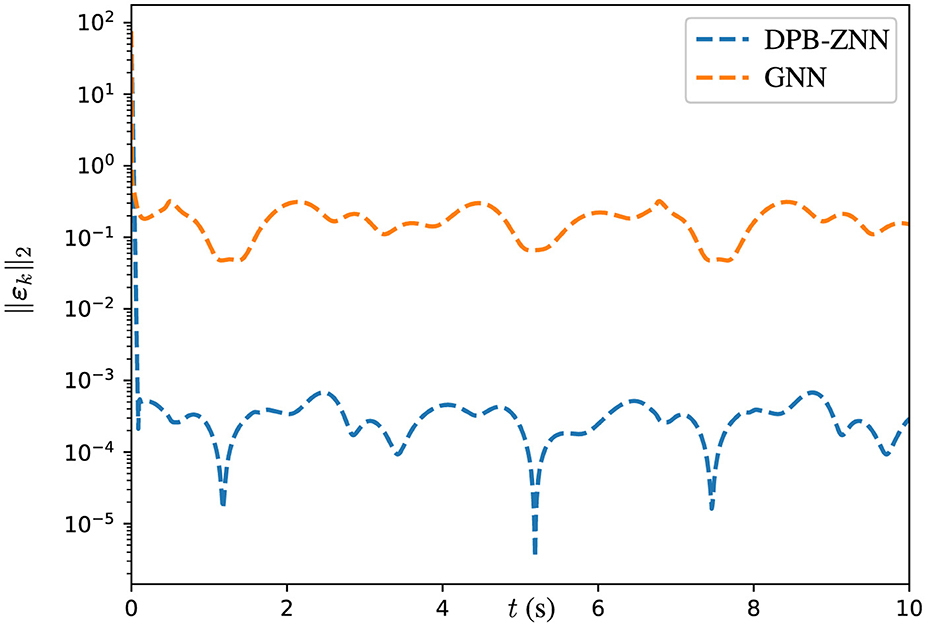
Figure 5. Trajectories of ||εk||2 of GNN and DPB-ZNN algorithms in solving DTDTVCO problem.
The MSSRE ||εk||2 along with the corresponding parameters for both GNN and DPB-ZNN algorithms are provided in Table 4. From Table 4 and Figure 5, one sees that, with the sampling time being the same τ = 0.0001 s, DPB-ZNN algorithm (Equation 31) achieves a higher accuracy with the MSSRE ||εk||2 being 3.54 × 10−4, while the MSSRE ||εk||2 of GNN algorithm is 2.16 × 10−1. To sum up, the DPB-ZNN algorithm (Equation 31) has a higher accuracy when solving DTDTVCO problem than the GNN algorithm.
In addition, to investigate the impact of model inaccuracies and measurement noise, numerical experiments on a DTVCO problem with noise, solved by the DPB-ZNN algorithm, are conducted. To lay the basis for further investigation on the robustness of DPB-ZNN algorithm under the pollution of unknown noises, one obtains the following equation:
where ϱik ∈ [−0.5, 0.5] denotes a discrete-time bounded unknown random noise that is uniformly distributed within the range [−0.5, 0.5]. The corresponding experimental results are presented in Figure 6. Except for the bounded random noise ϱik, the initial states and corresponding parameters are set to be the same as those in Subsection 5.1. The trajectories of the residual error ||εk||2 of the DPB-ZNN algorithm with different values of τ are illustrated in Figure 6.
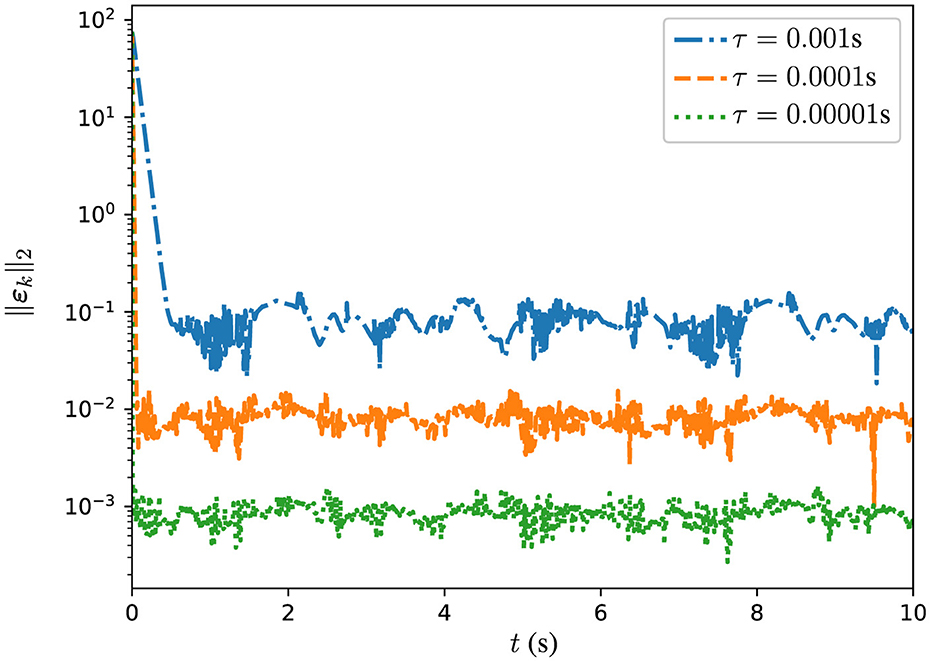
Figure 6. Trajectories of MSSRE ||εk||2 for DPB-ZNN algorithm in solving DTDTVCO problem with random noise and different τ.
From the Figure 6, one observes that the MSSRE converges over time for all three sampling intervals, indicating that the DPB-ZNN algorithm effectively reduces the residual errors in the presence of noise. The trajectory with τ = 0.00001 s (green dash line) shows the fastest convergence, reaching the lowest error value within the shortest time, with MSSRE values dropping to approximately 10−4. The trajectory with τ = 0.0001 s (orange dashed line) also converges well but at a slightly slower rate, with MSSRE values reaching approximately 10−3. The trajectory with τ = 0.001 s (blue dashed line) converges the slowest, taking the longest time to reach a low error value, with MSSRE values approximately 10−2.
These experimental results illustrate the robustness of the DPB-ZNN algorithm as it consistently minimizes residual errors and converges effectively even in the presence of noise. The smaller sampling intervals τ lead to faster convergence and lower residual errors, highlighting the algorithm's ability to handle noise polluted time-varying challenges with high accuracy and efficiency.
To illustrate the efficacy of the proposed DPB-ZNN algorithm (Equation 31) in applications, a cooperative control experiment is simulated. In this experiment, we consider a group of four identical 5-joint planar redundant robot manipulators performing a cooperative control task. The communication topology of the four robot manipulators is shown in Figure 7.
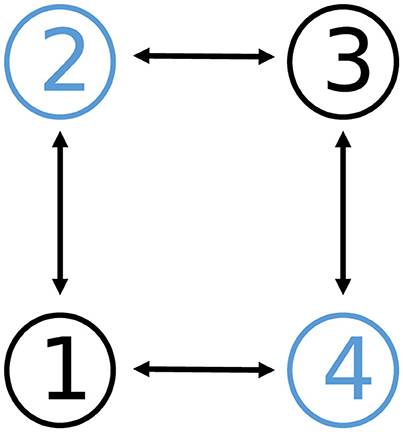
Figure 7. Communication topology of graph in Example 3, where is connected and undirected.
To control the redundant robot manipulators performing a cooperative control, for the entire system, a motion planning scheme for the entire system on the basis of the DTDTVCO problem is described as follows (Jin et al., 2018):
where ṙiwk denotes the time derivative of the desired trajectory of the end-effector position vector (i.e., reference), denotes the joint velocities of the ith manipulator, and denotes the Jacobian matrix of the manipulator i. In applications, limitations of joint velocities are often encountered. The boundary constraints are denoted as , where the lower and upper limits of the joint velocity are denoted as and , respectively. The bound constraints (Equation 44) are easily transformed into inequality constraints and , in which Ji1 = Id×d and Ji2 = −Id×d, respectively. It is worth pointing out that, as discussed in Section 3.1, the equality constraints of the robot manipulators should not be contradictory. In this particular experiment, manipulators 2 and 4 share the same equality constraint , whereas manipulators 1 and 3 do not have such constraints. This means that manipulators 2 and 4 have access to the desired path, while manipulators 1 and 3 do not. Then, the DPB-ZNN algorithm (Equation 31) is adopted to solve the aforementioned cooperative control problem with parameters h = 0.2, σ1 = 50, and σ2 = 50. The sampling time is set to τ = 0.001 s. The desired trajectory for the robot manipulators follows a Lissajous pattern. In this simulation experiment, the upper and lower joint velocity limits for each joint were set to 1.5 and −1.5 rad/s, respectively. The experimental results are presented in Figure 8 through Figure 10.
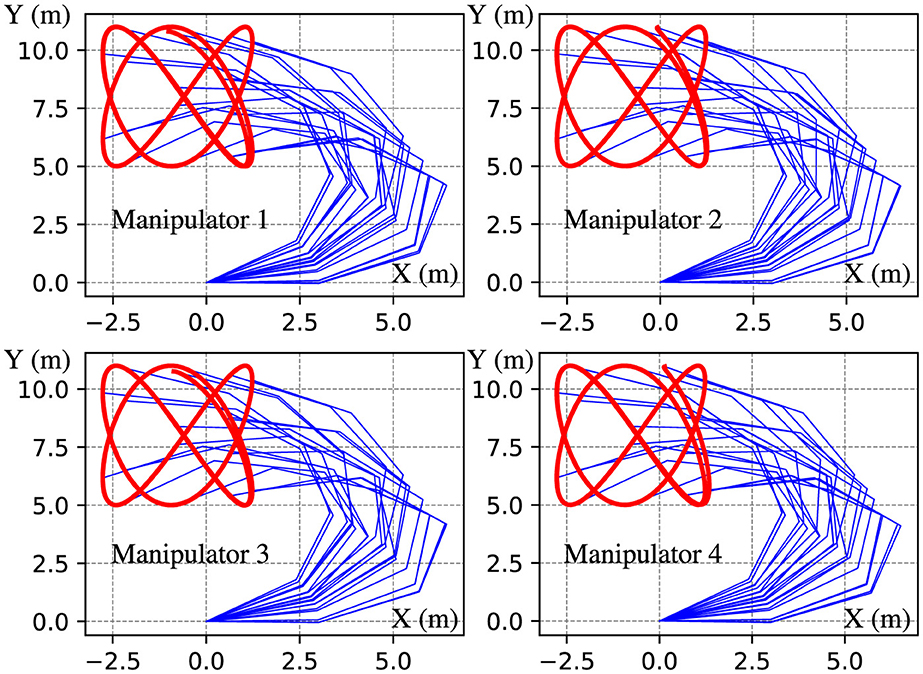
Figure 8. Trajectories of end effectors generated by DPB-ZNN algorithm (Equation 31) when robot manipulators track Lissajous pattern.
The experimental results depicted in Figure 8 showcase the trajectories of the end effectors generated by the DPB-ZNN algorithm, as the manipulators track a Lissajous pattern. Each subplot, corresponding to Manipulator 1 through Manipulator 4, exhibits that all manipulators track the Lissajous pattern successfully. The experimental results depicted in Figure 9 reveal the effectiveness of the proposed DPB-ZNN algorithm in driving the residual errors of all robot manipulators toward zero over time. Figure 9 fully illustrates the efficiency of the proposed DPB-ZNN algorithm for solving the cooperative control problem of robot manipulators with joint velocity limits.

Figure 9. Trajectories of residual error ||ϵik||2 of all robot manipulators.
From Figure 9, one sees that the residual error trajectories, presented in a logarithmic scale reaches the level of 10−4 m/s to 10−5 m/s over a 10-s period, illustrate a rapid reduction in error magnitude, particularly during the initial phase of the simulation, highlighting the algorithm's swift convergence capabilities. While minor fluctuations in the early stages reflect the dynamic adjustments made by the algorithm to adhere to time-varying constraints and achieve consensus among agents, the overall trend consistently shows convergence across all manipulators. The slight variations in the error reduction rate among the manipulators are likely due to differences in their initial states and local objective functions, yet these discrepancies diminish over time, emphasizing the algorithm's distributed nature and ability to enforce consensus and feasibility. In addition, one sees that despite the lack of information of the desired path, manipulator 1 and manipulator 3 track the desired path successfully, meaning the cooperative control problem is solved by the DPB-ZNN algorithm (Equation 31) effectively in a fully distributed manner.
Furthermore, the joint velocities of the robot manipulators solved by the DPB-ZNN algorithm (Equation 31) are presented in Figure 10. As shown in Figure 10, for all agents, all the joint velocities remain within the upper and lower joint velocity limits, which verify the effectiveness of DPB-ZNN algorithm in applying to the cooperative control problem of robot manipulators. To sum up, this experiment verifies the effectiveness and high accuracy of the proposed DPB-ZNN algorithm (Equation 31).
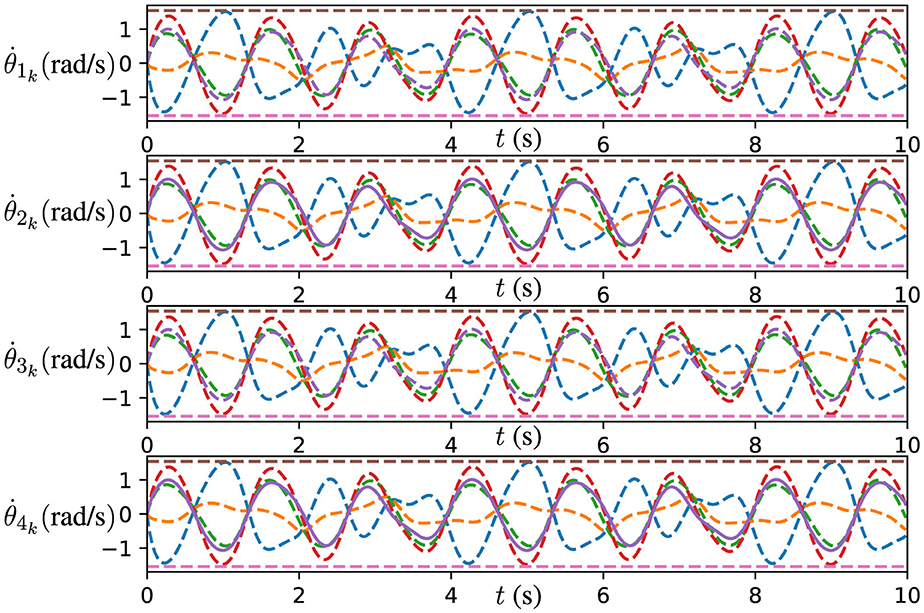
Figure 10. Trajectories of for four robot manipulators generated by DPB-ZNN algorithm (Equation 31) when robot manipulators track Lissajous pattern.
Aiming at solving the CTDTVCO problem with both time-varying equality and inequality constraints, a novel PB-ZNN model has been designed in this study by incorporating two penalty functions. The proposed PB-ZNN model solves the CTDTVCO problem in a semi-centralized manner. Then, on the basis of the PB-ZNN model, a DPB-ZNN algorithm has been proposed. By adopting an approximation formula, the DPB-ZNN algorithm solves the DTDTVCO problem in a fully distributed manner. The global convergence theorems of the proposed PB-ZNN model and DPB-ZNN algorithm have been proved. Numerical experiment results have illustrated the efficacy and efficiency of the proposed DPB-ZNN algorithm, including a simulation experiment applying it to the cooperative control of redundant robot manipulators.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
LH: Conceptualization, Data curation, Methodology, Software, Validation, Writing – original draft, Writing – review & editing. HC: Conceptualization, Supervision, Validation, Writing – review & editing. YZ: Validation, Writing – review & editing.
The author(s) declare financial support was received for the research and/or publication of this article. This research was supported by the China National Key R&D Program (with number 2022YFB3903804), the National Natural Science Foundation of China (with number 62376290), and Natural Science Foundation of Guangdong Province (with number 2024A1515011016).
The authors wish to express their sincere thanks to Sun Yat-sen University for its support and assistance in this study.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declare that no Gen AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Bahman, G., and Jorge, C. (2014). Distributed continuous-time convex optimization on weight-balanced digraphs. IEEE Trans. Automat. Contr. 59, 781–786. doi: 10.1109/TAC.2013.2278132
Cai, Y., Yu, W., Nie, X., Cheng, Q., and Cui, T. (2024). Joint resource allocation for ris-assisted heterogeneous networks with centralized and distributed frameworks. IEEE Trans. Circuits Syst. I Regul. Pap. 71, 2132–2145. doi: 10.1109/TCSI.2023.3325262
Chen, J., Pan, Y., and Zhang, Y. (2024). Znn continuous model and discrete algorithm for temporally variant optimization with nonlinear equation constraints via novel td formula. IEEE Trans. Syst. Man Cybern. Syst. 54, 3994–4004. doi: 10.1109/TSMC.2024.3374754
Cherukuri, A., and Cortés, J. (2016). Initialization-free distributed coordination for economic dispatch under varying loads and generator commitment. Automatica 74, 183–193. doi: 10.1016/j.automatica.2016.07.003
Dai, J., Tan, P., Xiao, L., Jia, L., He, Y., and Luo, J. (2023). A fuzzy adaptive zeroing neural network model with event-triggered control for time-varying matrix inversion. IEEE Trans. Fuzzy Syst. 31, 3974–3983. doi: 10.1109/TFUZZ.2023.3272653
Ding, L., Xiao, L., Liao, B., Lu, R., and Peng, H. (2018). An improved recurrent neural network for complex-valued systems of linear equation and its application to robotic motion tracking. Front. Neurorobot 11:45. doi: 10.3389/fnbot.2017.00045
Golub, G. H., and Loan, C. F. V. (2013). Matrix Computations. Baltimore: John Hopkins Univesity Press.
He, S., He, X., and Huang, T. (2021). A continuous-time consensus algorithm using neurodynamic system for distributed time-varying optimization with inequality constraints. J. Franklin I. 358, 6741–6758. doi: 10.1016/j.jfranklin.2021.07.007
Hu, Y., Zhang, C., Wang, B., Zhao, J., Gong, X., Gao, J., et al. (2024). Noise-tolerant znn-based data-driven iterative learning control for discrete nonaffine nonlinear mimo repetitive systems. IEEE-CAA J. Automatic 11, 344–361. doi: 10.1109/JAS.2023.123603
Huang, B., Zou, Y., Chen, F., and Meng, Z. (2022). Distributed time-varying economic dispatch via a prediction-correction method. IEEE Trans. Circuits Syst. I Regul. Pap. 69, 4215–4224. doi: 10.1109/TCSI.2022.3185398
Jia, W., Huang, T., and Qin, S. (2024). A collective neurodynamic penalty approach to nonconvex distributed constrained optimization. Neural Netw. 171, 145–158. doi: 10.1016/j.neunet.2023.12.011
Jin, J., Zhao, L., Chen, L., and Chen, W. (2022a). A robust zeroing neural network and its applications to dynamic complex matrix equation solving and robotic manipulator trajectory tracking. Front. Neurorobot 16:1065256. doi: 10.3389/fnbot.2022.1065256
Jin, J., Zhu, J., Gong, J., and Chen, W. (2022b). Novel activation functions-based znn models for fixed-time solving dynamirc sylvester equation. Neural Comput. Applic. 34, 14297–14315. doi: 10.1007/s00521-022-06905-2
Jin, L., Huang, R., Liu, M., and Ma, X. (2024). Cerebellum-inspired learning and control scheme for redundant manipulators at joint velocity level. IEEE Trans. Cybern. 54, 6297–6306. doi: 10.1109/TCYB.2024.3436021
Jin, L., Li, S., Xiao, L., Lu, R., and Liao, B. (2018). Cooperative motion generation in a distributed network of redundant robot manipulators with noises. IEEE Trans. Syst. Man Cybern. Syst. 48, 1715–1724. doi: 10.1109/TSMC.2017.2693400
Jin, L., Liao, B., Liu, M., Xiao, L., Guo, D., and Yan, X. (2017). Different-level simultaneous minimization scheme for fault tolerance of redundant manipulator aided with discrete-time recurrent neural network. Front. Neurorobot. 11:50. doi: 10.3389/fnbot.2017.00050
Kang, J., and Yang, G. G. G. (2023). Distributed optimization of uncertain multiagent systems with disturbances and actuator faults via exosystem observer-based output regulation. IEEE Trans. Circuits Syst. I Regul. Pap. 70, 897–909. doi: 10.1109/TCSI.2022.3221097
Khan, A. H., Cao, X., Li, S., Katsikis, V. N., and Liao, L. (2020a). BAS-ADAM: an adam based approach to improve the performance of beetle antennae search optimizer. IEEE/CAA J. Autom. Sinica 7, 461–471. doi: 10.1109/JAS.2020.1003048
Khan, A. H., Li, S., and Luo, X. (2020b). Obstacle avoidance and tracking control of redundant robotic manipulator: An rnn-based metaheuristic approach. IEEE Trans. Ind. Informat. 16, 123–134. doi: 10.1109/TII.2019.2941916
Lan, X., Jin, J., and Liu, H. (2023). Towards non-linearly activated znn model for constrained manipulator trajectory tracking. Front. Phys. 11:1159212. doi: 10.3389/fphy.2023.1159212
Li, J., Lu, J., Liu, Y., and Cao, J. (2024). Optimal energy management for networked microgrids via distributed neurodynamic. IEEE Trans. Circuits Syst. I Regul. Pap. 71, 2182–2192. doi: 10.1109/TCSI.2024.3351942
Liao, B., Wang, Y., Li, J., Guo, D., and He, Y. (2022). Harmonic noise-tolerant znn for dynamic matrix pseudoinversion and its application to robot manipulator. Front. Neurorobot. 16:928636. doi: 10.3389/fnbot.2022.928636
Liu, M., Li, Y., Chen, Y., Qi, Y., and Jin, L. (2024). A distributed competitive and collaborative coordination for multirobot systems. IEEE Trans. Mobile Comput. 23, 11436–11448. doi: 10.1109/TMC.2024.3397242
Mao, S., Yang, M., Yang, W., Tang, Y., Zheng, W., Gu, J., et al. (2023). Differentially private distributed optimization with an event-triggered mechanism. IEEE Trans. Circuits Syst. I Regul. Pap. 70, 2943–2956. doi: 10.1109/TCSI.2023.3266358
Molzahn, D. K., Dörfler, F., Sandberg, H., Low, S. H., Chakrabarti, S., Baldick, R., et al. (2017). A survey of distributed optimization and control algorithms for electric power systems. IEEE Trans. Smart Grid 8:2941–2962. doi: 10.1109/TSG.2017.2720471
Peng, J., Fan, B., and Liu, W. (2022). Penalty-based distributed optimal control of dc microgrids with enhanced current regulation performance. IEEE Trans. Circuits Syst. I Regul. Pap. 69, 3026–3036. doi: 10.1109/TCSI.2022.3167790
Qiu, B., Guo, J., Li, X., and Zhang, Y. (2021). New discretized zeroing neural network models for solving future system of bounded inequalities and nonlinear equations aided with general explicit linear four-step rule. IEEE Trans. Industr. Inform. 17, 5164–5174. doi: 10.1109/TII.2020.3032158
Song, F., Zhou, Y., Xu, C., and Sun, Z. (2024). A novel discrete zeroing neural network for online solving time-varying nonlinear optimization problems. Front. Neurorobot. 18:1446508. doi: 10.3389/fnbot.2024.1446508
Sun, S., Xu, J., and Ren, W. (2023). Distributed continuous-time algorithms for time-varying constrained convex optimization. IEEE Trans. Automat. Contr. 68, 3931–3946. doi: 10.1109/TAC.2022.3198113
Sun, S., Zhang, Y., Lin, P., Ren, W., and Farrell, J. A. (2022). Distributed timevarying optimization with state-dependent gains: algorithms and experiments. IEEE Trans. Control Syst. Technol. 30, 416–425. doi: 10.1109/TCST.2021.3058845
Sun, Z., Shi, T., Wei, L., Sun, Y., Liu, K., and Jin, L. (2020). Noise-suppressing zeroing neural network for online solving time-varying nonlinear optimization problem: a control-based approach. Neural Comput. Appl. 32, 11505–11520. doi: 10.1007/s00521-019-04639-2
Sun, Z., Tang, S., Fei, Y., Xiao, X., Hu, Y., and Yu, J. (2024a). An orthogonal repetitive motion and obstacle avoidance scheme for omnidirectional mobile robotic arm. IEEE Trans. Ind. Electron. 2024, 1–12. doi: 10.1109/TIE.2024.3451063
Sun, Z., Xu, C., Jin, L., Pang, Z., and Yu, J. (2024b). Human–robot interaction force control of series elastic actuator-driven upper limb exoskeleton robot. IEEE Trans. Ind. Electron. 71, 11449–11461. doi: 10.1109/TIE.2024.3468711
Tan, N., Yu, P., Zhong, Z., and Zhang, Y. (2023). Data-driven control for continuum robots based on discrete zeroing neural networks. IEEE Trans. Industr. Inform. 19, 7088–7098. doi: 10.1109/TII.2022.3204307
Wang, G., Jin, L., Zhang, J., Duan, X., Yi, J., Zhang, M., et al. (2024). Recurrent neural network enabled continuous motion estimation of lower limb joints from incomplete semg signals. IEEE Trans. Neural Syst. Rehabil. Eng. 32, 1–10. doi: 10.1109/TNSRE.2024.3459924
Xie, Z., Liu, M., Su, Z., Sun, Z., and Jin, L. (2025). A data-driven obstacle avoidance scheme for redundant robots with unknown structures. IEEE Trans. Ind. Informat. 21, 1793–1802. doi: 10.1109/TII.2024.3488775
Yan, J., Jin, L., and Hu, B. (2024). Data-driven model predictive control for redundant manipulators with unknown model. IEEE Trans. Cybern. 54, 5901–5911. doi: 10.1109/TCYB.2024.3408254
Yang, M., Zhang, Y., Hu, H., and Qiu, B. (2020). General 7-instant dcznn model solving future different-level system of nonlinear inequality and linear equation. IEEE Trans. Neural Netw. Learn. Syst. 31, 3204–3214. doi: 10.1109/TNNLS.2019.2938866
Ye, M., and Hu, G. (2015). Distributed seeking of time-varying nash equilibrium for non-cooperative games. IEEE Trans. Automat. Contr. 60, 3000–3005. doi: 10.1109/TAC.2015.2414817
Zhang, W., Zhao, Y., He, W., and Wen, G. (2021a). Time-varying formation tracking for multiple dynamic targets: Finite- and fixed-time convergence. IEEE Trans. Circuits Syst. II Express Briefs 68, 1323–1327. doi: 10.1109/TCSII.2020.3025199
Zhang, Y., Jiang, D., and Wang, J. (2002). A recurrent neural network for solving sylvester equation with time-varying coefficients. IEEE Trans. Neural Netw. 13, 1053–1063. doi: 10.1109/TNN.2002.1031938
Zhang, Y., Li, S., Kadry, S., and Liao, B. (2018a). Recurrent neural network for kinematic control of redundant manipulators with periodic input disturbance and physical constraints. IEEE Trans. Cybern. 49, 4194–4205. doi: 10.1109/TCYB.2018.2859751
Zhang, Z., Lin, Y., Li, S., Li, Y., Yu, Z., and Luo, Y. (2018b). Tricriteria optimization-coordination motion of dual-redundant-robot manipulators for complex path planning. IEEE Trans. Control Syst. Technol. 26, 1345–1357. doi: 10.1109/TCST.2017.2709276
Zhang, Z., Yang, S., and Zheng, L. (2021b). A penalty strategy combined varying-parameter recurrent neural network for solving time-varying multi-type constrained quadratic programming problems. IEEE Trans. Neural Netw. Learn. Syst. 32, 2993–3004. doi: 10.1109/TNNLS.2020.3009201
Zheng, Y., Liu, Q., and Wang, J. (2017). A specified-time convergent multiagent system for distributed optimization with a time-varying objective function. IEEE Trans. Automat. Contr. 62, 1590–1605. doi: 10.1109/TAC.2016.2593899
Zhu, W., and Wang, Q. (2024). Distributed finite-time optimization of multi-agent systems with time-varying cost functions under digraphs. IEEE Trans. Netw. Sci. Eng. 11, 556–565. doi: 10.1109/TNSE.2023.3301900
Keywords: distributed optimization, zeroing neural network, equality and inequality constraints, time-varying, cooperative control
Citation: He L, Cheng H and Zhang Y (2025) A distributed penalty-based zeroing neural network for time-varying optimization with both equality and inequality constraints and its application to cooperative control of redundant robot manipulators. Front. Neurorobot. 19:1553623. doi: 10.3389/fnbot.2025.1553623
Received: 31 December 2024; Accepted: 28 February 2025;
Published: 17 March 2025.
Edited by:
Ming-Feng Ge, China University of Geosciences Wuhan, ChinaReviewed by:
Bolin Liao, Jishou University, ChinaCopyright © 2025 He, Cheng and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hui Cheng, Y2hlbmdoOUBtYWlsLnN5c3UuZWR1LmNu
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.