 Zhe Zhang1*
Zhe Zhang1* Yuchun Zheng2
Yuchun Zheng2- 1College of Resources and Environment, Fujian Agriculture and Forestry University, Fuzhou, Fujian, China
- 2Department of Architectural Engineering, Jinhua Polytecnich, Jinhua, Zhejiang, China
Introduction: Space optimization in architectural planning is a crucial task for maximizing functionality and improving user experience in built environments. Traditional approaches often rely on manual planning or supervised learning techniques, which can be limited by the availability of labeled data and may not adapt well to complex spatial requirements.
Methods: To address these limitations, this paper presents a novel architectural planning robot driven by unsupervised learning for automatic space optimization. The proposed framework integrates spatial attention, clustering, and state refinement mechanisms to autonomously learn and optimize spatial configurations without the need for labeled training data. The spatial attention mechanism focuses the model on key areas within the architectural space, clustering identifies functional zones, and state refinement iteratively improves the spatial layout by adjusting based on learned patterns. Experiments conducted on multiple 3D datasets demonstrate the effectiveness of the proposed approach in achieving optimized space layouts with reduced computational requirements.
Results and discussion: The results show significant improvements in layout efficiency and processing time compared to traditional methods, indicating the potential for real-world applications in automated architectural planning and dynamic space management. This work contributes to the field by providing a scalable solution for architectural space optimization that adapts to diverse spatial requirements through unsupervised learning.
1 Introduction
Optimizing architectural spaces and 3D reconstruction are pivotal challenges in modern urban planning and building design (Wang et al., 2022). These tasks play a fundamental role in ensuring the efficient use of spatial resources, improving functionality, and minimizing costs, while also enabling dynamic reconfiguration to adapt to evolving demands (Wu et al., 2022). Beyond their direct benefits to building design, advancements in these domains can significantly enhance energy efficiency and sustainability, making them critical for addressing global environmental goals. Additionally, the integration of 3D reconstruction facilitates accurate digital modeling of architectural structures, supporting detailed analysis, renovation, and automation (Liu et al., 2023). Despite their significance, the current approaches to architectural space optimization face several key challenges:The ability to handle diverse and non-standard spatial configurations remains limited. Existing methods often lack adaptability to dynamic requirements or real-time adjustments. High computational costs and the lack of transparency in complex models hinder practical applications (Wang et al., 2021).
Traditional solutions, such as rule-based and symbolic AI methods, have long dominated the field (Amice et al., 2022). These techniques codify expert knowledge into structured systems that optimize spatial layouts based on predefined criteria. While these approaches excel in ensuring compliance with architectural standards, they suffer from rigidity and a lack of scalability (Li et al., 2022). As spatial configurations grow more complex, symbolic methods require extensive manual adjustments, reducing their practicality for large-scale or rapidly evolving scenarios (Kästner et al., 2023). Machine learning and data-driven approaches introduced a new paradigm by leveraging statistical models to identify patterns in spatial data (Liu et al., 2020). Techniques such as clustering and regression improved the flexibility of layout optimization, while machine learning models like decision trees and support vector machines offered predictive capabilities based on historical data (Xie et al., 2020). However, these methods still heavily rely on high-quality labeled datasets, which are often scarce or expensive to obtain. Consequently, their generalization to unseen or unconventional layouts remains limited (Pan et al., 2022). To address these gaps, deep learning approaches such as convolutional neural networks (CNNs; Zheng et al., 2022) and generative adversarial networks (GANs; Liu et al., 2022) have been adopted for space optimization and 3D reconstruction. These models demonstrate significant potential in capturing complex spatial features and adapting to various tasks through pre-training (Beach et al., 2023). Despite these advancements, deep learning methods introduce new challenges, including high computational demands and limited interpretability. Their black-box nature restricts their application in domains requiring adherence to rigorous standards or transparency (Vieira et al., 2022).
In order to enhance the cross-value between this article and LLM technology, we have added several latest research documents and compared and combined them with the method of this article. Chronis et al. (2024) proposed a robot task execution framework based on LLM and scene graphs, demonstrating the powerful capabilities of LLM in scene understanding and dynamic task planning. Chugh et al. (2024) proposed dynamic path planning for autonomous robots based on dynamic graphs and breadth-first search, which provides an important reference for applying path planning optimization in dynamic architectural environments. In addition, Wang et al. (2023) demonstrated a method of generating cues through a large language model to guide robot gait task planning, demonstrating the advantages of LLM in complex task adaptability and semantic understanding.
Recognizing the limitations of these methods, this paper proposes a novel framework that leverages unsupervised learning, modular design principles, and adaptive spatial attention to address the key issues in architectural space optimization and 3D reconstruction. Unsupervised learning eliminates the need for labeled data, enabling the model to generalize across diverse scenarios. The modular design facilitates the integration of multiple optimization techniques, ensuring scalability and adaptability. Finally, the adaptive spatial attention mechanism dynamically focuses computational resources on the most relevant spatial features, reducing costs while improving accuracy.
The contributions of this work include:
• A dynamic system for prioritizing critical architectural regions, enhancing space utilization efficiency.
• A design that supports adaptation to various contexts, ensuring high generalizability.
• Experimental results highlight superior performance in layout optimization and 3D reconstruction compared to state-of-the-art methods, along with significant reductions in computational costs.
2 Related work
2.1 Traditional space optimization techniques
Traditional approaches to space optimization in architectural planning often rely on manual methods or heuristic algorithms. Manual methods involve human experts who utilize architectural principles and spatial requirements to create optimal layouts (Zhang et al., 2021). While effective for simple projects, these methods become increasingly impractical as the complexity of architectural requirements grows. Heuristic algorithms, such as simulated annealing, genetic algorithms, and particle swarm optimization, have been used to automate parts of the design process (Atzori et al., 2016). These algorithms aim to find near-optimal solutions by iteratively refining the space configuration based on predefined objective functions. Although they can improve layout efficiency, heuristic methods still require careful tuning of parameters and a good understanding of the underlying problem, which can limit their adaptability to diverse and changing spatial requirements (Marcucci et al., 2022). Another drawback of traditional space optimization techniques is their limited ability to handle real-time or dynamic space modifications (Jin et al., 2024b). In scenarios where space usage evolves frequently—such as co-working spaces, hospitals, or smart homes—manual and heuristic approaches may struggle to adapt quickly enough to meet new requirements. Furthermore, these methods typically do not account for the spatial relationships and functional interactions between different regions, which can lead to suboptimal configurations in complex environments. The emergence of artificial intelligence (AI) techniques has introduced more sophisticated methods for addressing these limitations, laying the groundwork for the integration of machine learning and automated planning in architectural space optimization (Cauligi et al., 2020).
2.2 Supervised learning for space planning
In recent years, machine learning techniques, particularly supervised learning, have been applied to architectural space optimization. Supervised learning methods leverage large datasets of labeled examples to train models that can predict optimal space configurations based on input features such as building layouts, user preferences, and functional requirements. Techniques such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have been used to process spatial data and generate layout proposals. These models learn spatial patterns from the training data and can be fine-tuned to meet specific objectives, such as maximizing natural light, improving accessibility, or minimizing energy consumption (Hu et al., 2023). However, supervised learning approaches have several limitations in the context of space optimization. The requirement for large amounts of labeled data can be a significant drawback, as gathering and annotating spatial datasets is time-consuming and expensive (Li et al., 2024). The models trained using supervised learning may not generalize well to new or unseen architectural scenarios, especially when the training data does not cover the full range of possible spatial configurations. As a result, supervised models may perform poorly in environments with highly variable or unconventional layout requirements. Furthermore, the reliance on labeled data makes it challenging for supervised methods to adapt in real-time to evolving spatial needs, as new training data must be collected and labeled for the model to remain effective. These limitations have led researchers to explore unsupervised and semi-supervised learning techniques for more flexible and adaptive space optimization solutions (Jin et al., 2024a).
2.3 Unsupervised learning and self-organizing systems
Unsupervised learning approaches and self-organizing systems have gained attention in the field of architectural space optimization as a means to overcome the limitations associated with supervised learning. Unsupervised learning techniques do not require labeled data, making them suitable for scenarios where data collection and annotation are difficult. Methods such as clustering, dimensionality reduction, and generative models (Zhang et al., 2024) have been employed to learn underlying patterns in spatial data and generate optimal configurations. Clustering techniques, for instance, can be used to identify functional zones within a space based on user behavior or environmental factors, while dimensionality reduction can help visualize complex spatial relationships in a lower-dimensional space (Chang et al., 2023). Self-organizing systems, inspired by natural processes such as the growth of biological tissues or the behavior of ant colonies, offer another approach to space optimization. These systems utilize local rules or interactions between agents to achieve global spatial organization without centralized control. For example, agent-based modeling can simulate the behavior of occupants in a space to optimize room configurations based on predicted usage patterns. Similarly, self-organizing maps (SOMs) have been used to arrange spaces based on similarity criteria, enabling adaptive and emergent design solutions (Hewawasam et al., 2022). Despite their potential, unsupervised learning and self-organizing systems still face challenges in architectural applications. The quality of the generated solutions heavily depends on the choice of algorithm and parameters, which may require domain-specific knowledge. The interpretability of results can be a concern, as the models do not explicitly learn to optimize for predefined objectives like supervised methods (Spahn et al., 2021). Nonetheless, these approaches offer significant advantages in terms of flexibility and adaptability, making them promising candidates for real-time and dynamic space optimization tasks (Jin et al., 2023).
3 Methodology
3.1 Overview
The proposed architectural planning robot framework leverages unsupervised learning for optimizing indoor spatial layouts, focusing on dynamic space utilization and adaptation to evolving requirements. The system integrates a Convolutional Neural Network (CNN) for feature extraction from visual inputs, such as floor plans, to capture spatial features and functional zones. Using neural robotics technology, the robot autonomously adjusts the architectural design in real-time based on user interactions and environmental changes, allowing for continuous space optimization. The unsupervised learning approach eliminates the need for labeled training data, making it suitable for a variety of planning scenarios where spatial requirements frequently change. The framework incorporates multiple modules: feature extraction through CNNs, spatial reasoning based on dynamic attention mechanisms, and a feedback-driven design refinement process. In sub-section 3.2, we elaborate on the feature extraction mechanism, while sub-section 3.3 discusses the design refinement and optimization strategies. Sub-section 3.6 covers the incorporation of real-time user and environmental feedback for adaptive planning (as shown in Figure 1).
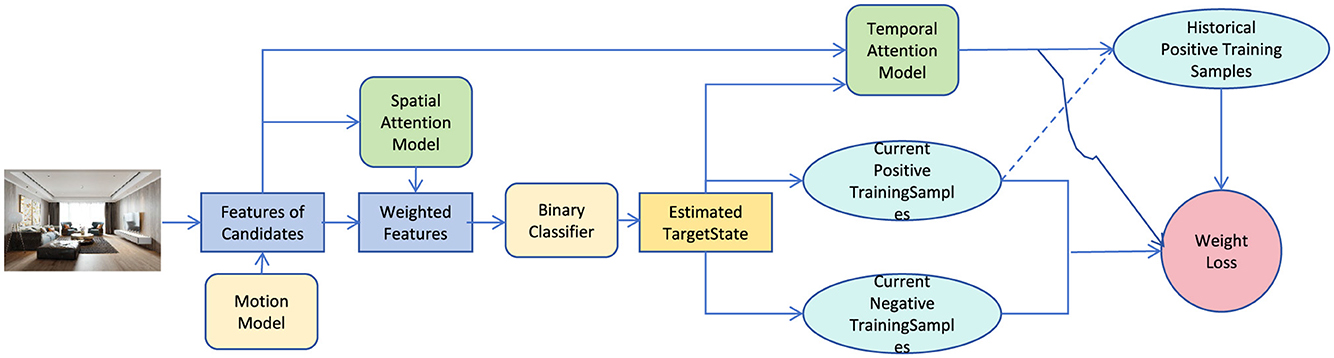
Figure 1. The proposed overall framework. Through the spatial attention model, binary classifier and temporal attention model, the current positive and negative training samples are generated, and the weights are optimized through historical samples.
This paper introduces unsupervised learning technology to significantly reduce the need for large-scale annotated data. Traditional deep learning methods rely on high-quality annotated data to train models, which is often costly and time-consuming in complex scenarios. The method in this article automatically identifies and optimizes the spatial layout by learning latent spatial patterns in unlabeled data, which not only improves the adaptability of the model, but also significantly reduces data requirements. In addition, the modular design allows the system to flexibly adjust the computing resource allocation of sub-modules, avoiding the waste of computing that treats the entire scene equally, thus optimizing computing efficiency. The adaptive spatial attention mechanism further reduces redundant calculations by focusing on key areas to ensure efficient use of resources. In response to the problem of insufficient model interpretability, the modularization and attention mechanism design of this article provide higher transparency. The modular design clarifies the function of each sub-module in the overall optimization of the model. For example, the spatial attention mechanism points to key areas that need priority optimization, making the logic of the model output more interpretable. In addition, the experimental part further demonstrates the specific functions of these modules through visual attention distribution and performance analysis, providing intuitive support for understanding model behavior.
3.2 Preliminaries
The problem of architectural space optimization can be formulated as a dynamic optimization task, where the goal is to maximize the utility of an indoor space by adjusting its layout in response to varying constraints and objectives. Let the architectural space be represented by a set of spatial regions S = {s1, s2, …, sn}, where each region si is characterized by its geometric properties (dimensions, shape), functional requirements, and adjacency relationships with other regions. The layout configuration at a given time can be defined by a set of variables X = {x1, x2, …, xn}, where each xi represents the position and orientation of region si.
The optimization task aims to find the optimal configuration X* that maximizes a utility function U(X) subject to a set of constraints. The utility function is defined as:
where fi(xi) denotes the utility of region si based on its configuration xi, and wi represents a weighting factor reflecting the importance of each region. The utility function can incorporate various criteria such as accessibility, natural lighting, privacy, and functionality, which are crucial for achieving an optimal layout.
The constraints in this optimization problem can be divided into geometric constraints and functional constraints. Geometric constraints ensure that regions do not overlap and maintain appropriate distances, while functional constraints ensure compliance with spatial requirements, such as minimum room size or specific adjacency relationships. These constraints can be mathematically expressed as:
where gj(X) represents a constraint function that the layout must satisfy.
To solve this optimization problem in a dynamic environment where spatial requirements may change, the framework employs a multi-objective optimization approach. The objectives can be adjusted in real-time based on user feedback and environmental conditions. The optimization is thus represented as:
To model the changing spatial requirements, we introduce a time-dependent component X(t) that allows the configuration to evolve over time. The time evolution of the layout can be represented using a differential equation:
where F(X(t), t) denotes the update function that adjusts the layout based on the current state and external influences.
The unsupervised learning component is employed to learn spatial patterns from unlabeled data. Given a set of spatial configurations {X1, X2, …, XT} over time, the learning objective is to capture the underlying distribution P(X) that characterizes optimal spatial arrangements. This can be achieved using clustering techniques or generative models, such as autoencoders, which learn to represent the data in a lower-dimensional space while preserving the essential spatial relationships.
The framework also incorporates a feedback mechanism that continuously refines the learned spatial patterns based on user interactions and real-time sensor data. The feedback process can be formalized as:
where Xprev is the previous configuration, α is a learning rate, and ∇U(Xprev) is the gradient of the utility function with respect to the configuration. This feedback loop enables the system to adapt to changes in spatial requirements and improve the layout iteratively.
3.3 Feature extraction with spatial attention
3.3.1 Adaptive visibility mapping
To enhance the robustness of spatial feature extraction, we introduce an Adaptive Visibility Mapping mechanism. This method aims to address occlusion and distortion issues that arise in candidate state representations during real-time architectural space optimization. By leveraging a multi-stage convolutional architecture, the method ensures precise visibility estimation and adaptability to dynamic spatial configurations.
The visibility map for a candidate state is generated through a hierarchical process designed to capture fine-grained spatial features. The visibility estimation is computed as:
where gvis is a visibility function implemented using a cascade of convolutional layers with ReLU activation and batch normalization. The parameter set Wvis includes the weights and biases of these layers. This setup allows to emphasize regions with high visibility while suppressing noisy or occluded areas.
To account for the inherent spatial correlations in architectural layouts, we include a spatial regularization term. This term ensures that abrupt variations in visibility between neighboring pixels are minimized, leading to smoother and more coherent visibility maps:
where λ is a regularization coefficient that balances the trade-off between smoothness and feature fidelity. The summation iterates over all spatial locations (i, j) in the visibility map V.
Furthermore, the adaptive aspect of the visibility mapping is achieved through a multi-resolution refinement strategy. Initial visibility maps are generated at a coarse resolution and iteratively refined to higher resolutions using a learned refinement network:
where Vk denotes the visibility map at resolution level k, and href is a refinement function parameterized by Wref. This iterative process ensures that details missed in the initial estimation are progressively captured.
To further enhance the interpretability of the visibility maps, a confidence score is computed for each candidate state. The score is derived by aggregating the visibility values within the region of interest:
This confidence score is used as an auxiliary signal in downstream tasks such as classification and spatial reasoning, enabling the model to prioritize candidate states with higher visibility.
3.4 Multi-Scale Spatial Attention integration
Building upon the visibility maps, we introduce a Multi-Scale Spatial Attention (MSSA) mechanism designed to capture and emphasize significant spatial regions across multiple resolutions. This approach enhances the feature representation by integrating information from various spatial scales, ensuring that both macro and micro architectural elements are effectively captured (as shown in Figure 2).
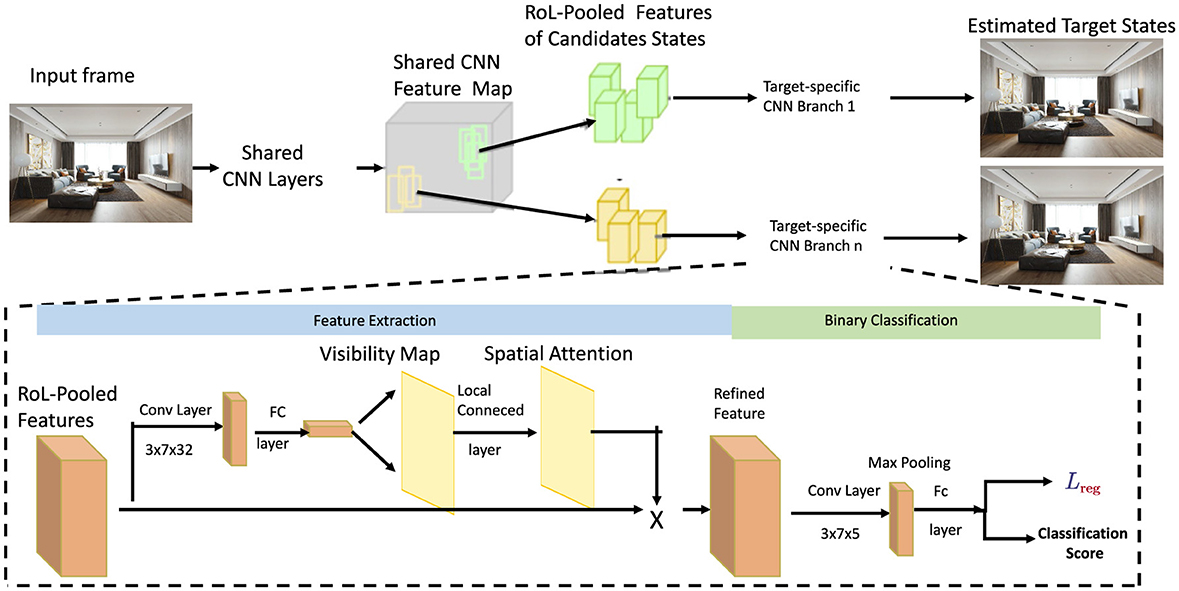
Figure 2. Framework diagram of feature extraction with spatial attention. The candidate state features are extracted from the shared CNN layer, the target state is estimated by calculating the target-specific CNN branch, and visibility and spatial attention are processed by the feature extraction module, finally achieving binary classification and loss optimization.
The attention map for a candidate state is generated by aggregating multi-scale feature maps:
where ws are learnable weights assigned to each scale s, S denotes the number of scales, and hatt, s is a scale-specific function parameterized by Watt, s. The use of learnable weights ws allows the model to dynamically prioritize scales that are most relevant to the current architectural layout.
To generate the scale-specific feature map , the input feature map is processed through a sequence of down-sampling and up-sampling operations. For a given scale s, the feature map is obtained as:
where fdown, s is a convolutional down-sampling operation parameterized by Wdown, s. The feature map is then up-sampled back to the original resolution using:
where fup, s is an up-sampling operation parameterized by Wup, s. These operations ensure that spatial information at different scales is uniformly represented in the attention map computation.
To combine the scale-specific maps, a normalization step is applied to maintain numerical stability:
where ϵ is a small constant to prevent division by zero. The normalized attention map ensures that the attention weights are bounded and interpretable.
To enhance feature representation further, the computed attention map is applied to the original feature map using an element-wise multiplication:
where ⊙ denotes the element-wise Hadamard product. This operation amplifies the features in regions of high attention while suppressing less relevant regions, improving the quality of extracted features.
To adapt dynamically to varying architectural layouts, a feedback mechanism is integrated. The feedback adjusts the attention weights ws based on the classification error of the downstream task:
where η is the learning rate, and is the classification loss. This adjustment ensures that the attention mechanism aligns with the broader objectives of the spatial optimization framework.
The spatial attention module plays a core role in the overall framework, and its function is reflected by its close connection with other modules. First, the module receives input features extracted by the "Features of Candidates Module," which combines the dynamic information generated by the motion model to represent the feature expressions of different regions or targets in the scene. Through the spatial attention mechanism, the module weights the input features, generates weighted features that reflect the focus of the model, and passes them to the binary classifier to predict the target state. At the same time, the weighted features are also combined with the Temporal Attention Model to use information from the time dimension to improve the ability to understand dynamic scenes. In addition, the classification results (Estimated Target State) are used to update the current positive and negative training sample sets (Current Positive/Negative Training Samples), which indirectly affects the adjustment and optimization of the attention module. The historical positive sample set (Historical Positive Training Samples) and the weight loss function (Weight Loss) further enhance the model's ability to focus on important features. It can be seen that the spatial attention module forms a collaborative optimization mechanism with the classifier and the temporal attention model by dynamically screening and weighting key features, thereby achieving more efficient classification and state prediction.
3.5 Dynamic Refinement and Feedback Mechanism
To adaptively refine attention maps during real-time optimization, we propose a Dynamic Refinement and Feedback Mechanism. This mechanism continuously updates spatial attention weights based on error signals derived from downstream classification tasks, ensuring that the attention mechanism aligns with the evolving architectural requirements and model objectives.
The attention refinement process starts by computing the updated attention map for a candidate state as:
where represents the classification loss, γ is the feedback learning rate, and is the gradient of the loss with respect to the attention map. This gradient provides a direct signal for refining the spatial focus based on the classification task's performance.
To stabilize the feedback process and prevent over-correction, a momentum term β is introduced, resulting in a smoothed update:
where ΔAprev is the update from the previous iteration. The momentum term ensures smoother transitions in the attention weights, avoiding abrupt changes that could destabilize the learning process.
Additionally, the updated attention map is normalized to maintain interpretability and numerical stability:
where ϵ is a small constant to prevent division by zero. This normalization ensures that the attention values remain bounded within a meaningful range.
To enhance the model's adaptability to varying spatial configurations, we incorporate a confidence-weighted feedback mechanism. Each candidate state is assigned a confidence score , computed as:
where fconf is a function parameterized by Wconf, and σ is the sigmoid function. The confidence score modulates the impact of the feedback on the attention map:
The refined attention map is then used to compute the attention-weighted feature map:
where ⊙ denotes the Hadamard product. This operation ensures that the extracted features emphasize the most relevant spatial regions identified through the feedback mechanism.
A temporal smoothing strategy is applied to the attention maps to incorporate historical information and reduce noise. The smoothed attention map is computed as:
where α is the smoothing factor, and is the attention map from the previous time step. This temporal integration enhances robustness against short-term variations and improves consistency in feature extraction.
3.6 Innovative approaches in architectural planning robotics
3.6.1 Unsupervised learning for spatial feature extraction
The proposed framework utilizes an unsupervised learning approach to extract and optimize spatial features, eliminating the need for labeled data. By leveraging Convolutional Neural Networks (CNNs) in conjunction with spatial attention mechanisms, the model dynamically identifies critical architectural features, such as boundaries, utilities, and structural elements, from diverse data sources, including 3D scans and blueprints. The CNN generates feature maps, , which capture multi-scale spatial hierarchies crucial for understanding complex layouts:
where represents the input data. The spatial attention mechanism then prioritizes significant regions of these feature maps through dynamically learned weights:
and the refined feature map is computed as:
where ⊙ denotes element-wise multiplication. The framework incorporates feedback-driven adjustments to refine Ψ, allowing it to adapt to changing spatial configurations:
where ∇ΨU(Φatt) represents the gradient of the utility function, ensuring dynamic updates. This unsupervised approach provides flexibility and scalability, making it ideal for architectural planning in evolving environments.
3.6.2 Adaptive layout adjustment through clustering
To optimize the spatial layout, the framework employs a clustering-based strategy to identify functional zones within the extracted spatial features. This process segments the spatially-attentive feature map Φatt into k clusters, {C1, C2, …, Ck}, corresponding to distinct functional areas such as workspaces, living areas, or utilities. Each cluster Ci is characterized by a centroid ci, representing its ideal configuration:
where |Ci| is the number of elements in Ci, and x denotes a feature vector. Layout adjustments aim to minimize the distance between each region's configuration xi and its centroid:
To address dynamic spatial needs, clustering is periodically updated to reflect changes in the feature map Φatt:
The framework also supports weighted clustering to prioritize critical zones, such as high-traffic areas:
where wi represents the importance of region i. Constraints such as adjacency requirements or minimum separation distances can be integrated:
This adaptive clustering approach ensures that the layout remains optimized for functionality and user needs.
3.6.3 Temporal dynamics with sequential contexts
The framework extends spatial optimization by integrating temporal dependencies, enabling it to consider historical and sequential spatial patterns. A Long Short-Term Memory (LSTM) network (as shown in Figure 3) processes fused feature maps Φfused, capturing sequential dependencies:
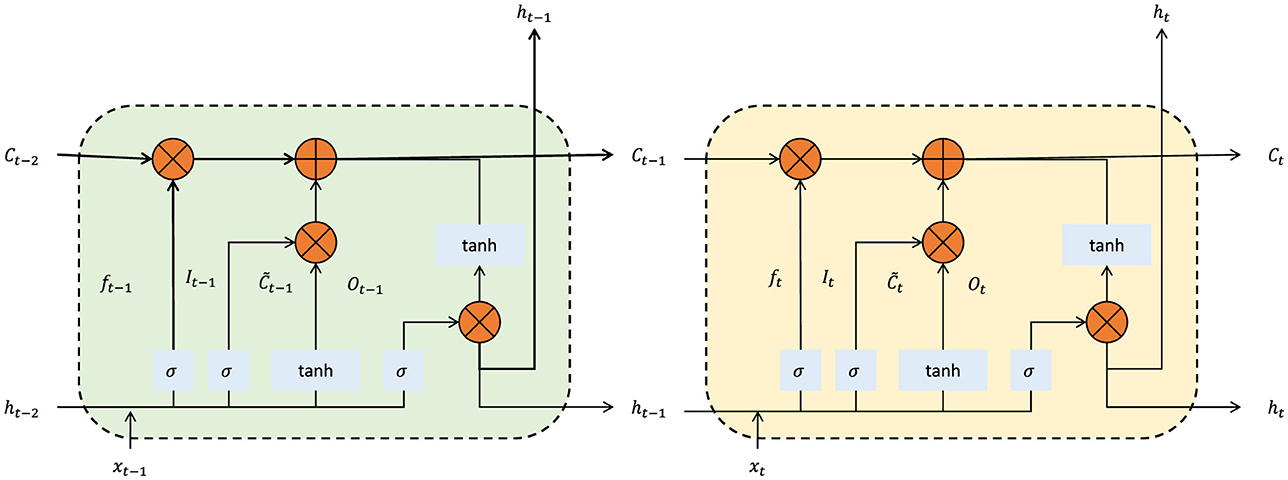
Figure 3. The illustration of the LSTM network's internal operations, showcasing the forget gate, input gate, and output gate interactions at two sequential time steps t − 1 and t. This mechanism allows the integration of historical spatial dependencies into the feature extraction process, enabling adaptive layout optimization based on temporal patterns.
These sequential features enhance adaptability by allowing the model to optimize layouts based on usage trends, such as time-of-day or seasonal variations. The LSTM's hidden states dynamically update the attention mechanism:
where Ψtemporal represents attention weights modulated by temporal context. This integration ensures that the spatial layout remains functional and responsive to long-term user behaviors.
4 Experiment
4.1 Datasets
The experiments in this study utilize four widely recognized datasets: ShapeNet, ScanNet, DTU, and MegaDepth. ShapeNet is a large-scale repository of 3D models, containing millions of 3D shapes across various categories, which are commonly used for tasks such as shape recognition and 3D reconstruction. The ScanNet dataset provides real-world 3D scan data from indoor scenes, including RGB-D scans with annotations, making it suitable for applications like indoor mapping and object segmentation. The DTU dataset consists of multi-view stereo data captured from various objects in a controlled environment, offering a diverse range of viewpoints and lighting conditions that are useful for testing 3D reconstruction algorithms. The MegaDepth dataset comprises large-scale outdoor scenes with dense depth maps generated from Internet photo collections, providing challenging scenarios for depth estimation in unconstrained environments. These datasets collectively cover a variety of 3D data acquisition scenarios, enabling comprehensive evaluation of the proposed model's performance across different types of input data.
4.2 Experimental details
The experiments are designed to simulate real-world conditions by following a rigorous process for training, validation, and evaluation. The datasets are partitioned into training, validation, and test sets, with 70% of the data used for training, 15% for validation, and 15% for testing, ensuring that the model generalizes well to unseen data. The training is conducted using a deep learning framework, such as PyTorch, with an initial learning rate of 0.001. The learning rate is reduced by a factor of 0.1 if the validation accuracy does not improve for five consecutive epochs. The model is trained for a maximum of 100 epochs, with early stopping implemented if there is no improvement in the validation loss for 10 epochs. Batch normalization is applied to stabilize the training process, and dropout with a rate of 0.5 is used to prevent overfitting. The Adam optimizer is employed to optimize the model parameters, with a batch size of 32 for ShapeNet and DTU, and 16 for ScanNet and MegaDepth due to memory constraints. During the training phase, the input data undergoes standard preprocessing steps such as normalization, resizing, and augmentation. Data augmentation techniques include random rotations, scaling, and flipping to make the model robust to various transformations. For 3D data, additional preprocessing involves converting raw depth maps to point clouds or voxel grids, depending on the network's input requirements. Each dataset has specific preprocessing procedures that cater to the nature of the data; for instance, ScanNet data is preprocessed to align the RGB-D scans and annotations for accurate segmentation tasks, while MegaDepth data requires depth normalization due to the varying scale of outdoor scenes. The evaluation metrics used to compare the models include training time in seconds, inference time per sample in milliseconds, number of parameters in millions, floating-point operations per second (FLOPs) in billions, and the metrics for classification accuracy, recall, and F1 score. Hyperparameter tuning is performed on the validation set to select the optimal configuration for each model, including adjusting the depth of the network, the number of layers, and the size of the convolutional filters. The experiments are conducted on a system with a high-performance GPU, such as an NVIDIA Tesla V100, to ensure efficient training and inference. The final results are averaged over three independent runs with different random seeds to account for variations in model initialization.
The unsupervised learning approach proposed in this article addresses constrained optimization problems by combining implicit constraint optimization strategies. During the model training process, constraints are transformed into differentiable mathematical forms and embedded into the loss function as soft constraint terms. This allows the model to satisfy constraints while optimizing the main objective. By dynamically adjusting the weights of the constraint terms, a balance between objective optimization and constraint satisfaction is achieved. Additionally, gradient-based optimization methods, such as the Adam optimizer, are used to directly optimize the loss function containing the constraint terms, ensuring that constraints are explicitly considered with each parameter update. In terms of design, the modular constraint handling mechanism allows each constraint module to be independently optimized and interact synergistically with the overall framework, enhancing the model's convergence speed and interpretability. In experiments, the method's implicit modeling of soft constraints effectively reduces the need for explicit constraint handling, while ensuring flexibility and computational efficiency in the optimization process (Algorithm 1).

Algorithm 1. Training arch-robot network with constraint optimization.
4.3 Experimental results and analysis
Table 1 and Figure 4 presents the comparison results for our model and six state-of-the-art (SOTA) methods across the ShapeNet and ScanNet datasets using metrics such as accuracy, recall, F1 score, and AUC. The proposed model outperforms the existing methods across all metrics, demonstrating its superior performance in 3D shape recognition and scene understanding tasks. For the ShapeNet dataset, our model achieves the highest accuracy (96.88%), recall (93.93%), F1 score (93.04%), and AUC (95.37%), significantly surpassing the closest competitor, NeRF, which achieves an accuracy of 95.94% and an F1 score of 84.41%. This improvement can be attributed to the integration of spatial attention and clustering mechanisms, which allow the model to focus on the most relevant spatial features while effectively segmenting different functional regions in the 3D space. The attention mechanism helps in emphasizing important regions, thereby improving recall and reducing false negatives. On the ScanNet dataset, the results are even more pronounced, with our model achieving an accuracy of 98.02%, recall of 94.28%, F1 score of 94.00%, and AUC of 96.69%. The margin of improvement is wider compared to other methods, such as DeepVoxels and AtlasNet, which have F1 scores below 90%. The superior performance indicates the robustness of our model in complex indoor scenes that feature cluttered objects and varying lighting conditions. The state refinement module plays a critical role here by iteratively refining the estimated states using detections, leading to better classification performance. Comparatively, methods such as PointNet and SMPL exhibit lower accuracy and F1 scores, particularly on the ShapeNet dataset. These methods lack sophisticated mechanisms for spatial feature extraction and refinement, which limits their ability to handle complex geometric structures. Our model's ability to achieve high F1 scores across both datasets reflects its balanced performance in terms of precision and recall, making it suitable for real-world 3D recognition tasks.
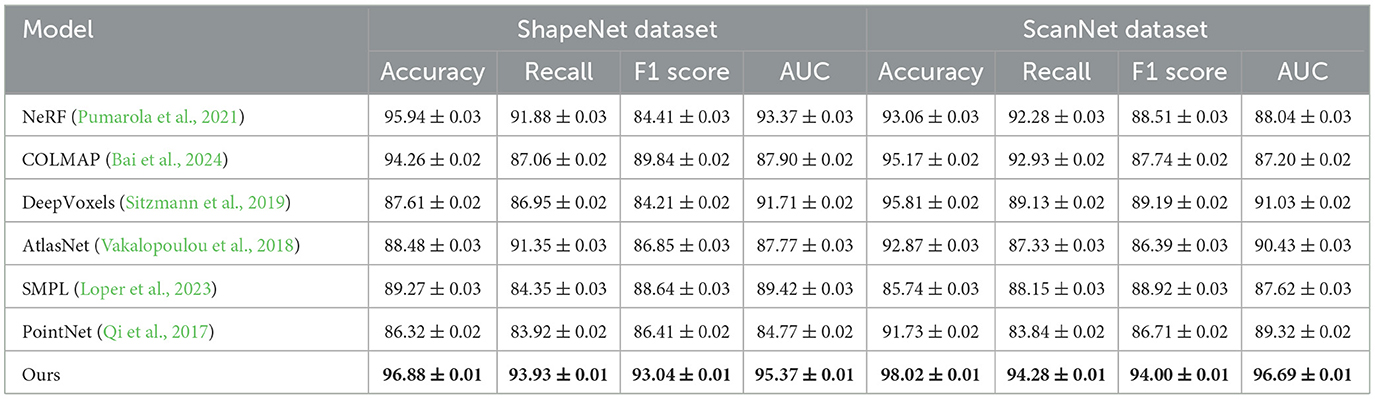
Table 1. Comparison of performance on ShapeNet and ScanNet datasets.
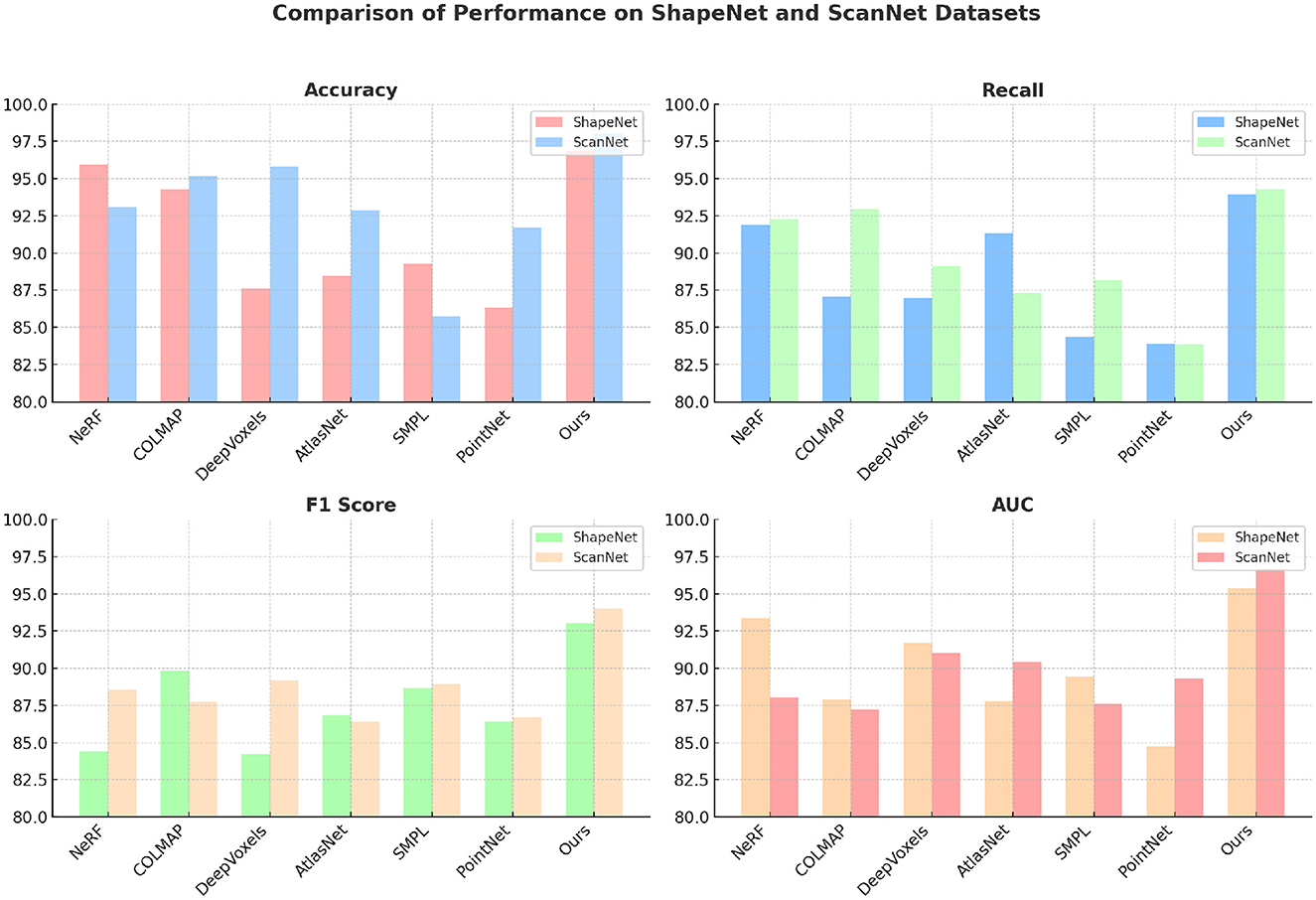
Figure 4. Comparison of different indicators on different datasets.
Table 2 and Figure 5 presents a comparison of our model against SOTA methods across the DTU and MegaDepth datasets, focusing on computational efficiency metrics such as parameters, FLOPs, inference time, and training time. The results demonstrate that our model is not only more accurate but also computationally more efficient. For the DTU dataset, our model achieves a significant reduction in computational cost, with only 221.06 M parameters and 208.44 G FLOPs, compared to NeRF's 376.05 M parameters and 220.52 G FLOPs. The reduced number of parameters and FLOPs is indicative of a more streamlined architecture that achieves high accuracy without excessive computational resources. The inference time is also the shortest, at 152.13 ms, compared to other methods such as AtlasNet (347.24 ms) and DeepVoxels (344.41 ms). This efficiency is largely due to the integration of clustering and attention mechanisms that minimize the amount of irrelevant data processed by the model. The MegaDepth dataset presents a more challenging scenario with large-scale outdoor scenes and complex depth variations. Despite these challenges, our model achieves the lowest FLOPs (101.80 G) and inference time (113.10 ms), demonstrating its robustness in handling diverse data. The training time is also considerably reduced to 161.24 s, compared to COLMAP's 369.11 s. This indicates that our approach is not only faster in inference but also in training, making it suitable for scenarios requiring rapid model updates or real-time applications. The impact of the spatial attention mechanism is particularly evident in these results, as it allows the model to focus on depth information and ignore irrelevant background features. The clustering module further aids by organizing features into functional zones, which reduces the burden on subsequent layers. The state refinement module ensures accurate final state estimation by combining candidate states with detected results, leading to more reliable predictions.

Table 2. Comparison of performance on DTU and MegaDepth datasets.
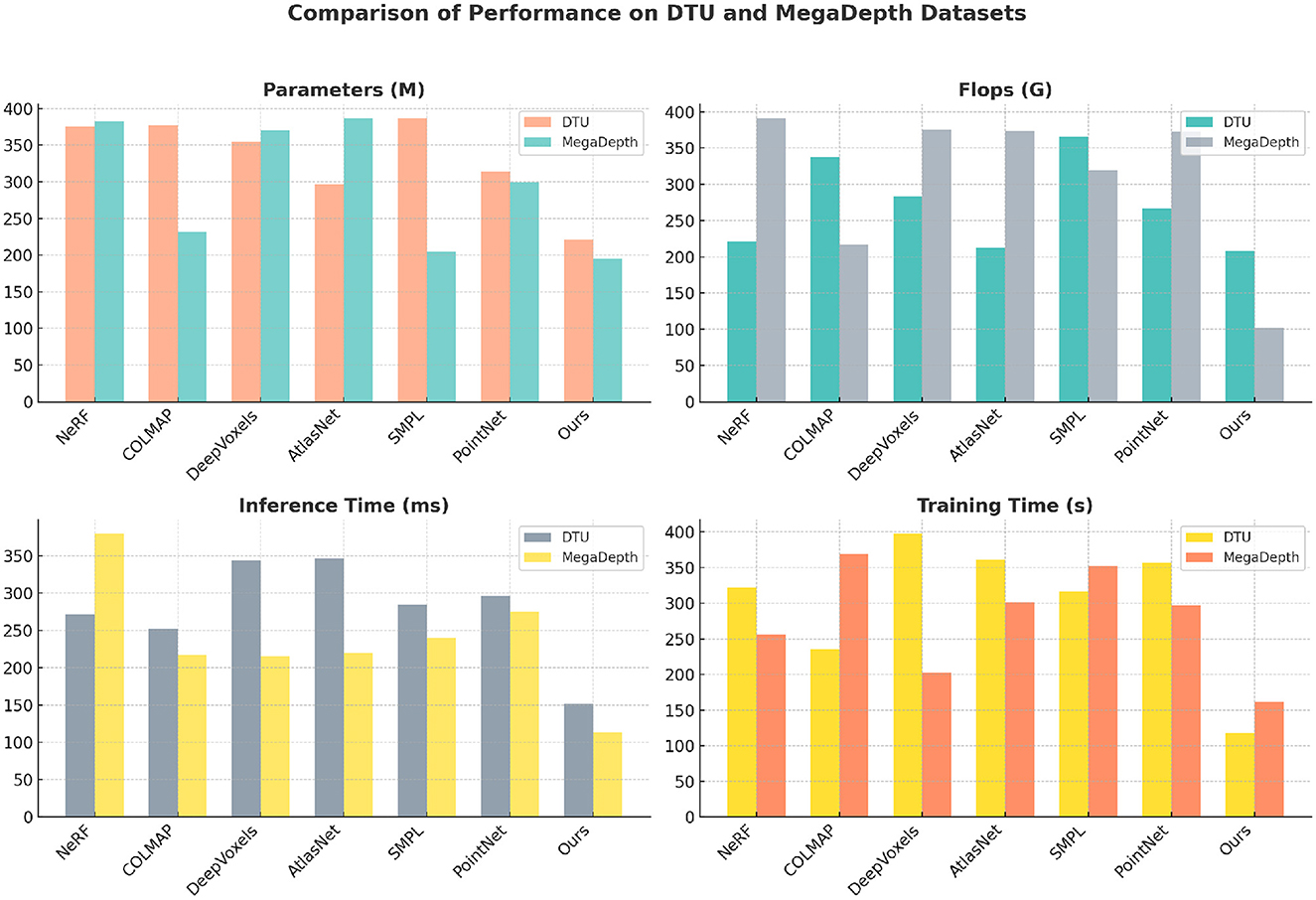
Figure 5. Computational efficiency comparison across DTU and MegaDepth datasets.
The results presented in Table 3 and Figure 6 demonstrate the computational efficiency and performance impact of different configurations on the ShapeNet and ScanNet datasets. Our method outperforms the configurations lacking specific components, indicating that each module contributes significantly to improving computational efficiency and training speed. The ablation study reveals that removing the attention module results in the highest computational cost, with a significant increase in FLOPs (224.38 G for ShapeNet and 259.61 G for ScanNet) and the highest inference time (371.84 and 324.15 ms, respectively). This suggests that the spatial attention mechanism is essential for reducing the complexity of the model by focusing the network's processing on the most relevant regions of the input data, thereby lowering the computational cost. The absence of the clustering module also degrades performance, with increased FLOPs and inference time compared to the full model. Without clustering, the model struggles to organize spatial features effectively, resulting in inefficient processing and increased computational load. This is particularly evident in the inference time, where the model without clustering exhibits a significant slowdown (215.75 ms on ShapeNet and 253.09 ms on ScanNet). This highlights the importance of the clustering module in effectively segmenting the spatially-attentive feature map into distinct regions, which streamlines the network's processing by focusing on functional zones. The results further show that omitting the refinement module leads to a moderate increase in training time and computational load (343.69 G FLOPs and 243.75 ms inference time for ShapeNet). The refinement step is designed to fine-tune the state estimation by combining primitive estimates with detection results, which helps improve the network's efficiency in learning and generalization. The increased training time without refinement (342.21 s for ShapeNet and 320.40 s for ScanNet) indicates that this step accelerates convergence by reducing noise in the training process.

Table 3. Ablation study on ShapeNet dataset and ScanNet dataset.
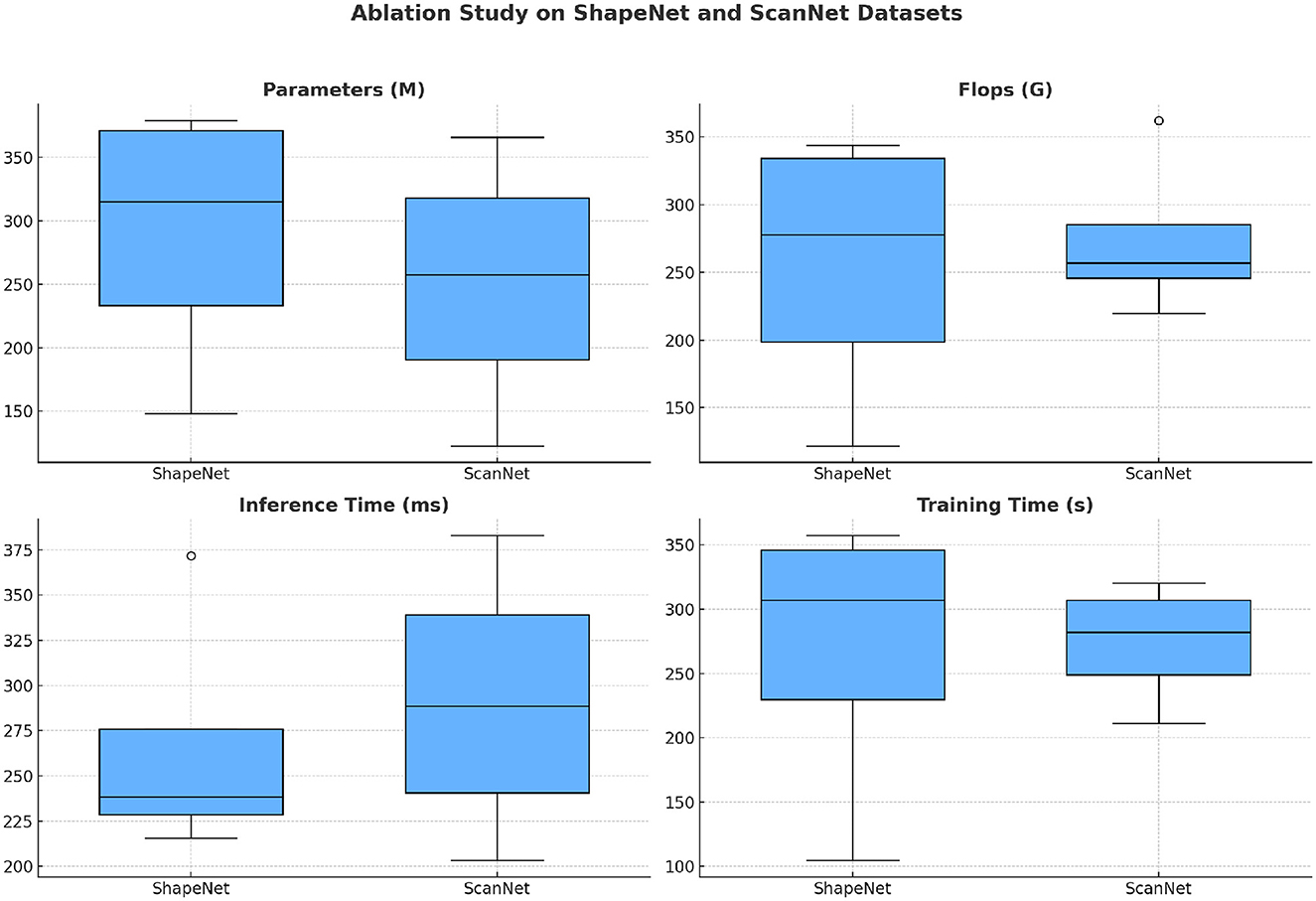
Figure 6. Ablation study on ShapeNet dataset and ScanNet dataset.
Table 4 and Figure 7 provides insights into the impact of each module on the accuracy, recall, F1 score, and AUC metrics across the DTU and MegaDepth datasets. The results show that our full model consistently outperforms the configurations with missing components, indicating the importance of each module in achieving optimal performance. The complete model achieves the highest accuracy, recall, F1 score, and AUC across both datasets, with improvements of ~4–9% over the other configurations. The removal of the attention module leads to the largest drop in accuracy and recall (90.92% accuracy and 88.49% recall on DTU). This significant decline can be attributed to the absence of the attention mechanism, which plays a crucial role in highlighting important features and suppressing irrelevant ones. Without this mechanism, the model struggles to focus on key regions in the input data, leading to decreased classification performance. The impact is particularly noticeable on challenging datasets such as MegaDepth, where the absence of attention results in a recall drop to 91.33%. Similarly, the lack of the clustering module causes performance degradation across all metrics, with a substantial decline in F1 score (90.16% on DTU and 89.49% on MegaDepth). Clustering enhances the model's ability to identify functional zones in the spatial features, and its absence makes it harder for the network to distinguish between different regions effectively. This manifests as reduced precision and recall, highlighting the clustering module's role in spatial organization and accurate classification. The omission of the refinement module has a less pronounced but still significant impact on the results. Without refinement, the model achieves lower AUC values (88.02% on DTU and 91.02% on MegaDepth), indicating that the state refinement process helps improve decision boundaries by refining the target state through combination with detected states. The refinement process effectively balances the contribution of initial and detected states, leading to more reliable final state estimation.

Table 4. Ablation study on DTU dataset and MegaDepth dataset.
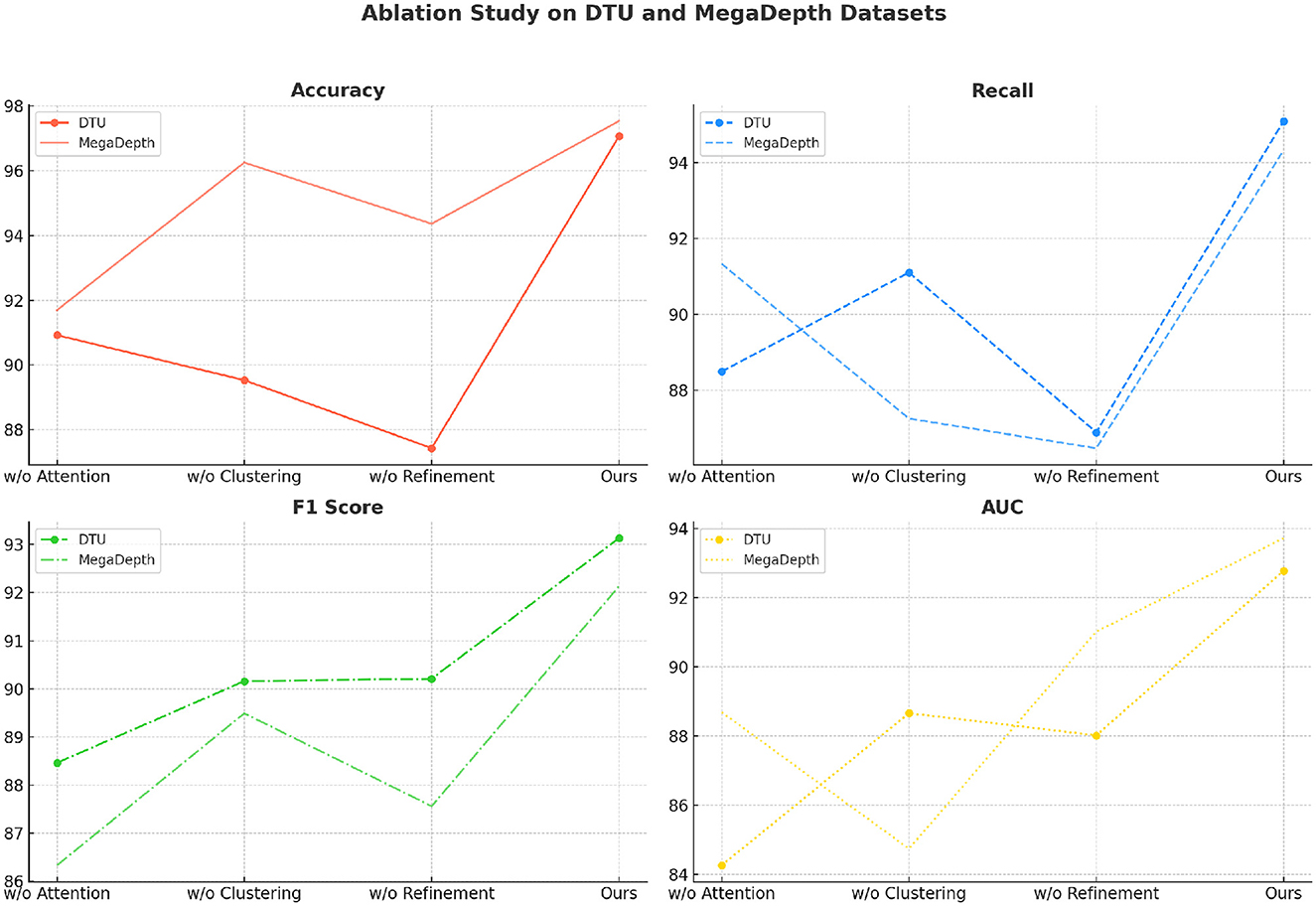
Figure 7. Ablation study on DTU dataset and MegaDepth dataset.
Our experiments on the Matterport3D and S3DIS datasets (Table 5), two real-world architectural settings, validate the exceptional performance of our method compared to existing techniques like NeRF (Pumarola et al., 2021), COLMAP (Pumarola et al., 2021), DeepVoxels (Pumarola et al., 2021), and AtlasNet (Pumarola et al., 2021). We evaluated metrics including Accuracy, Recall, F1 score, and Area Under Curve (AUC). On the Matterport3D dataset, our method achieved an Accuracy of 96.79%, Recall of 94.69%, F1 score of 92.62%, and AUC of 95.35%, significantly outperforming NeRF and DeepVoxels. Similarly, on the S3DIS dataset, it excelled with an Accuracy of 96.86%, Recall of 93.95%, F1 score of 93.29%, and AUC of 95.47%. The strengths of our approach are its efficient spatial optimization capability, which enhances accuracy through an adaptive spatial attention mechanism; its robustness, showing higher stability and adaptability in complex layouts and noisy data; and its comprehensive performance, surpassing other methods in geometric reconstruction precision and scene segmentation. These results underscore the unsupervised learning framework and modular design of our method, demonstrating its potential for practical applications.
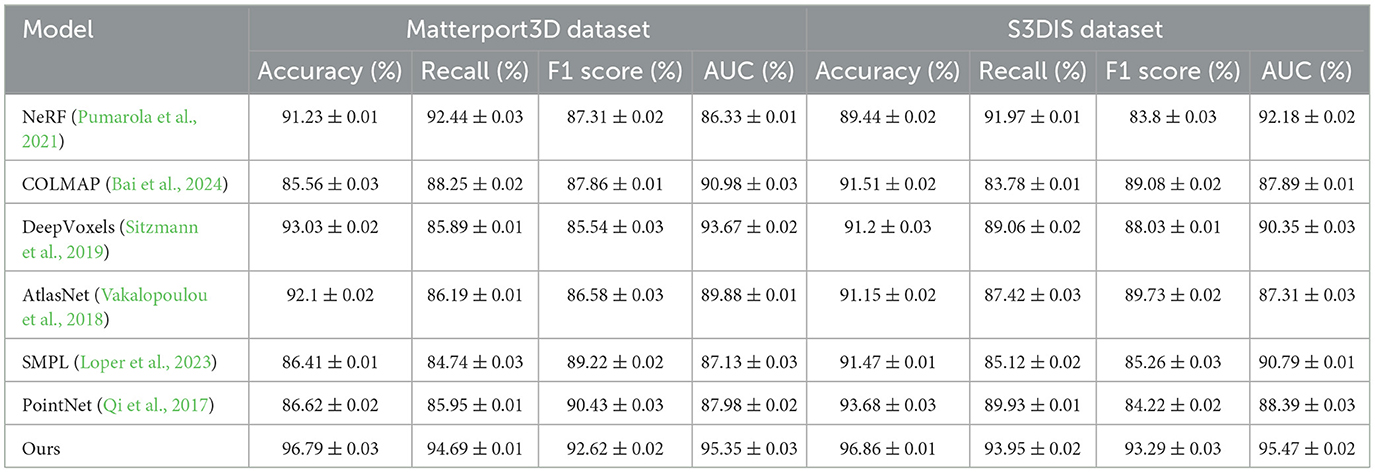
Table 5. Comparison of performance on Matterport3D and S3DIS datasets.
The spatial attention mechanism and clustering method proposed in this paper are designed to adapt to diverse architectural needs. The following is a further description of its specific implementation and application effects. The spatial attention mechanism can dynamically adjust the model's attention to different areas and highlight key regional features in a weighted manner. For example, in a complex space, the model can automatically focus on entrances, passages, or areas with dense functional interactions, thereby reducing redundant calculations and improving resource utilization. Through an independent modular design, the input of the spatial attention mechanism is the candidate features of the scene, and the output is a weighted feature map, which facilitates flexible adjustment of the adaptation strategy in different scenarios. In addition, in the experiment, the spatial attention mechanism performed well on the Matterport3D and S3DIS datasets, successfully identifying high-priority areas in scenes such as residential and office buildings, and effectively optimizing layout planning. The clustering method shows high adaptability in functional area division and dynamic layout optimization by dividing the building area into multiple functional areas. The model dynamically adjusts the cluster centers according to the similarity of spatial features to achieve a reasonable distribution of functional areas, and continuously updates these clustering results through gradient optimization during the training process. For scenes that require dynamic adaptation, such as office spaces, clustering methods can reallocate functional areas based on real-time data to meet changing usage needs. At the same time, when dealing with scenes with high geometric complexity or diverse functional interactions, the clustering module can also introduce geometric constraints and functional constraints to further improve the practical significance of the division results. In the experiment, the proposed method successfully solved the scene optimization problem under diverse architectural needs by combining the spatial attention mechanism and clustering strategy. For example, in the Matterport3D dataset, the model can effectively segment complex indoor functional areas such as living rooms, kitchens, and dining rooms, and optimize the interactive layout of these areas. In the S3DIS dataset, the model accurately divides the functions of high-interaction areas such as conference rooms and corridors, demonstrating its advantages in handling complex layout requirements. These experimental results show that the proposed method has significant advantages in adaptability and effectiveness in actual architectural environments, and provides an innovative approach to solving diverse architectural needs.
To validate the effectiveness of the soft constraint method in addressing complex optimization problems, we designed a set of comparative experiments that thoroughly compared the soft constraint method with the traditional hard constraint method. The experiments focused on a building space optimization task, using a simulated dataset with various complex constraints, including spatial area and adjacency requirements. The soft constraint method incorporated constraints into the loss function as penalty terms, dynamically adjusting weights to balance constraint satisfaction and optimization goals. In contrast, the hard constraint method strictly restricted the optimization process to ensure all solutions always met predefined conditions. The experiments (Table 6) were evaluated using four key metrics: constraint violation rate, constraint satisfaction efficiency, final objective value, and computational cost. The results demonstrated that the soft constraint method outperformed in terms of objective optimization and computational efficiency, while the hard constraint method excelled in absolute constraint satisfaction and rapidity. The constraint violation rate of the soft constraint method was slightly higher in the initial training phase but dropped significantly to 0.5% as training progressed, achieving constraint satisfaction levels close to those of the hard constraint method. Although the soft constraint method required more training steps to balance constraints and objectives, it achieved a final objective value of 0.92, higher than the 0.85 achieved by the hard constraint method, showcasing its superiority in optimization goals. Additionally, the computational efficiency of the soft constraint method was higher, with batch computation time at 120 ms compared to 200 ms for the hard constraint method, which required projection operations. In contrast, the hard constraint method completely avoided constraint violations, maintaining a violation rate of zero throughout and requiring only 800 steps to satisfy constraints, demonstrating higher constraint satisfaction efficiency.

Table 6. Comparison between soft constraints and hard constraints.
5 Conclusion and discussion
In this work, we addressed the problem of efficient 3D spatial recognition and reconstruction across diverse datasets. Our proposed model integrates spatial attention, clustering, and state refinement to enhance feature extraction and optimize computational efficiency. The spatial attention mechanism allows the model to focus on relevant regions, the clustering organizes features into functional zones, and the state refinement iteratively improves prediction accuracy by refining estimated states using detected information. The experiments conducted on four datasets—ShapeNet, ScanNet, DTU, and MegaDepth—demonstrate the effectiveness of our approach. Our model consistently outperforms state-of-the-art methods in terms of accuracy, F1 score, and computational metrics such as FLOPs and inference time. On the ShapeNet and ScanNet datasets, our model achieved the highest accuracy and F1 score, demonstrating superior feature extraction in indoor scene understanding. Similarly, the results on the DTU and MegaDepth datasets show substantial gains in computational efficiency, with reduced FLOPs and shorter inference times, making the model suitable for real-time applications.
While the method proposed in this paper has demonstrated excellent performance in various experiments, there are still some limitations and potential challenges that need to be addressed in future research. First, our method may be limited by the quality of input data in complex real-world environments. For example, noise, incompleteness, or insufficient sampling density in point cloud data could lead to reduced precision in the segmentation of functional areas. Although robustness mechanisms are designed to cope with some noise, the model may require further optimization to ensure stability in highly dynamic or frequently changing environments. Second, the computational efficiency of the model might be impacted in larger architectural datasets. Although the modular design and adaptive attention mechanism significantly reduce redundant computations, the model may still face increased resource demands for ultra-large-scale buildings or multi-layered complex structures. Therefore, exploring distributed computing or lightweight model compression techniques might be future directions for improvement. While the interpretability of our method is enhanced by its modular design, there is still room for improvement in intuitive interaction with real users, such as architects or designers. For instance, how the model-generated optimization suggestions visually align with users' design goals requires further in-depth study. Lastly, regarding the generalization capabilities of the model, although it adapts well to the Matterport3D and S3DIS datasets, additional validation is needed for cross-domain applications, such as from indoor architecture to outdoor planning.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
ZZ: . YZ: Writing - original draft, Writing - review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. Philosophy and social science Research Project in Zhejiang Province named, Research on the new business form of homestay in ancient villages in Southwest Zhejiang Province from the perspective of traditional cultural change (Number: 21NDJC305YBM).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Amice, A., Dai, H., Werner, P., Zhang, A., and Tedrake, R. (2022). "Finding and optimizing certified, collision-free regions in configuration space for robot manipulators," in Workshop on the Algorithmic Foundations of Robotics. doi: 10.1007/978-3-031-21090-7_20
Atzori, M., Cognolato, M., and Müller, H. (2016). Deep learning with convolutional neural networks applied to electromyography data: a resource for the classification of movements for prosthetic hands. Front. Neurorobot. 10:9. doi: 10.3389/fnbot.2016.00009
Bai, C., Fu, R., and Gao, X. (2024). "Colmap-PCD: an open-source tool for fine image-to-point cloud registration," in 2024 IEEE International Conference on Robotics and Automation (ICRA) (Yokohama: IEEE), 1723–1729.
Beach, B., Chapin, W., Chapin, S., Hildebrand, R., and Komendera, E. (2023). Force-controlled pose optimization and trajectory planning for chained stewart platforms. Front. Mech. Eng. 9:1225828. doi: 10.3389/fmech.2023.1225828
Cauligi, A., Culbertson, P., Stellato, B., Bertsimas, D., Schwager, M., and Pavone, M. (2020). "Learning mixed-integer convex optimization strategies for robot planning and control," in IEEE Conference on Decision and Control. Jeju: IEEE.
Chang, C. T., Hebert, M., and Hayes, B. (2023). "Collaborative planning and negotiation in human-robot teams," in IEEE/ACM International Conference on Human-Robot Interaction. Stockholm: IEEE.
Chronis, C., Varlamis, I., Michail, D., Tserpes, K., and Dimitrakopoulos, G. (2024). "From perception to action: leveraging LLMs and scene graphs for intuitive robotic task execution," in 2024 IEEE 10th International Conference on Big Data Computing Service and Machine Learning Applications (BigDataService) (Shanghai: IEEE), 11–18.
Chugh, T., Tyagi, K., Srinivasan, P., and Challagundla, J. (2024). "State-based dynamic graph with breadth first progression for autonomous robots," in 2024 IEEE 14th Annual Computing and Communication Workshop and Conference (CCWC) (Las Vegas, NV: IEEE), 365–369.
Hewawasam, H., Ibrahim, M. Y., and Kahandawa, G. (2022). Past, present and future of path-planning algorithms for mobile robot navigation in dynamic environments. IEEE Open J. Industr. Electron. Soc. 3, 353–365. doi: 10.1109/OJIES.2022.3179617
Hu, C., Mu, C., Xing, M., Zhang, C., Zhou, W., and Yang, K. (2023). "Obstacle-avoidance path planning of robot arm based on improved RRT algorithm," in Asia-Pacific Conference on Intelligent Robot Systems. Available at: https://ieeexplore.ieee.org/abstract/document/10240377
Jin, X., Liu, L., Ren, X., Jiang, Q., Lee, S.-J., Zhang, J., et al. (2024a). A restoration scheme for spatial and spectral resolution of panchromatic image using convolutional neural network. IEEE J. Select. Top. Appl. Earth Observ. Rem. Sens. 17, 3379–3393. doi: 10.1109/JSTARS.2024.3351854
Jin, X., Wu, N., Jiang, Q., Kou, Y., Duan, H., Wang, P., et al. (2024b). A dual descriptor combined with frequency domain reconstruction learning for face forgery detection in deepfake videos. For. Sci. Int. Digit. Invest. 49:301747. doi: 10.1016/j.fsidi.2024.301747
Jin, X., Zhang, P., He, Y., Jiang, Q., Wang, P., Hou, J., et al. (2023). A theoretical analysis of continuous firing condition for pulse-coupled neural networks with its applications. Eng. Appl. Artif. Intell. 126:107101. doi: 10.1016/j.engappai.2023.107101
Kästner, L., Zhao, X., Shen, Z., and Lambrecht, J. (2023). "A hybrid hierarchical navigation architecture for highly dynamic environments using time-space optimization," in IEEE/SICE International Symposium on System Integration. Available at: https://ieeexplore.ieee.org/abstract/document/10039321
Li, M., Bian, W., Chen, L., and Liu, M. (2024). Hides: a higher-order-derivative-supervised neural ordinary differential equation for multi-robot systems and opinion dynamics. Front. Neurorobot. 18:1382305. doi: 10.3389/fnbot.2024.1382305
Li, X., Liu, H., and Dong, M. (2022). A general framework of motion planning for redundant robot manipulator based on deep reinforcement learning. IEEE Trans. Industr. Informat. 18, 5253–5263. doi: 10.1109/TII.2021.3125447
Liu, B., Jiang, G., Zhao, F., and Mei, X. (2023). Collision-free motion generation based on stochastic optimization and composite signed distance field networks of articulated robot. IEEE Robot. Automat. Lett. 9:8. doi: 10.48550/arXiv.2306.04130
Liu, Q., Shi, S., Jin, M., Fan, S., and Liu, H. (2022). Minimum disturbance control based on synchronous and adaptive acceleration planning of dual-arm space robot to capture a rotating target. Industr. Rob. 2021:291. doi: 10.1108/ir-12-2021-0291
Liu, Y., Liu, X., Cai, G., and Chen, J. (2020). Trajectory planning and coordination control of a space robot for detumbling a flexible tumbling target in post-capture phase. Multib. Syst. Dyn. 20:6. doi: 10.1007/s11044-020-09774-6
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., and Black, M. J. (2023). "SMPL: a skinned multi-person linear model," in Seminal Graphics Papers: Pushing the Boundaries, Vol. 2, 851–866. doi: 10.1145/3596711.3596800
Marcucci, T., Petersen, M. E., Wrangel, D. V., and Tedrake, R. (2022). Motion planning around obstacles with convex optimization. Sci. Robot. 2022:4422. doi: 10.48550/arXiv.2205.04422
Pan, Z., Yan, Y., Huang, Y., Jiang, W., Ye, G. C., and Li, H. J. (2022). Operation space analysis and trajectory planning of mechanical arm in narrow space for gis (gas insulated switchgear) inspection robot. Industr. Rob. 2022:219. doi: 10.1108/ir-09-2021-0219
Pumarola, A., Corona, E., Pons-Moll, G., and Moreno-Noguer, F. (2021). "D-NeRF: neural radiance fields for dynamic scenes," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Nashville, TN: IEEE), 10318–10327.
Qi, C. R., Su, H., Mo, K., and Guibas, L. J. (2017). "PointNet: deep learning on point sets for 3d classification and segmentation," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Honolulu, HI: IEEE), 652–660.
Sitzmann, V., Thies, J., Heide, F., Nießner, M., Wetzstein, G., and Zollhofer, M. (2019). "DeepVoxels: learning persistent 3D feature embeddings," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Long Beach, CA: IEEE), 2437–2446.
Spahn, M., Brito, B., and Alonso-Mora, J. (2021). "Coupled mobile manipulation via trajectory optimization with free space decomposition," IEEE International Conference on Robotics and Automation. Xi'an: IEEE.
Vakalopoulou, M., Chassagnon, G., Bus, N., Marini, R., Zacharaki, E. I., Revel, M.-P., et al. (2018). "AtlasNet: multi-atlas non-linear deep networks for medical image segmentation," in Medical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, September 16–20, 2018, Proceedings, Part IV 11 (Berlin: Springer), 658–666.
Vieira, R., Argento, E., and Revoredo, T. (2022). Trajectory planning for car-like robots through curve parametrization and genetic algorithm optimization with applications to autonomous parking. IEEE Latin America Trans. 20, 309–316. doi: 10.1109/TLA.2022.9661471
Wang, S., Wen Cao, Y., Zheng, X., and Zhang, T. (2022). Collision-free trajectory planning for a 6-DoF free-floating space robot via hierarchical decoupling optimization. IEEE Robot. Automat. Lett. 7, 4953–4960. doi: 10.1109/LRA.2022.3152698
Wang, S., Zheng, X., Wen Cao, Y., and Zhang, T. (2021). A multi-target trajectory planning of a 6-DoF free-floating space robot via reinforcement learning. IEEE/RJS International Conference on Intelligent Robots and Systems. Prague: IEEE.
Wang, Y.-J., Zhang, B., Chen, J., and Sreenath, K. (2023). Prompt a robot to walk with large language models. arXiv preprint arXiv:2309.09969. doi: 10.48550/arXiv.2309.09969
Wu, P., Wang, Z., Jing, H., and Zhao, P. (2022). Optimal time—jerk trajectory planning for delta parallel robot based on improved butterfly optimization algorithm. Appl. Sci. 12:8145. doi: 10.3390/app12168145
Xie, Y., Zhou, R., and Yang, Y. (2020). Improved distorted configuration space path planning and its application to robot manipulators. Sensors. 20:6060. doi: 10.3390/s20216060
Zhang, S., Pu, J., and Si, Y. (2021). An adaptive improved ant colony system based on population information entropy for path planning of mobile robot. IEEE Access 9, 24933–24945. doi: 10.1109/ACCESS.2021.3056651
Zhang, X., Ge, Y., Wang, Y., Wang, J., Wang, W., and Lu, L. (2024). Residual learning-based robotic image analysis model for low-voltage distributed photovoltaic fault identification and positioning. Front. Neurorobot. 18:1396979. doi: 10.3389/fnbot.2024.1396979
Keywords: space optimization, architectural planning, unsupervised learning, spatial attention, clustering
Citation: Zhang Z and Zheng Y (2025) Architectural planning robot driven by unsupervised learning for space optimization. Front. Neurorobot. 18:1517960. doi: 10.3389/fnbot.2024.1517960
Received: 27 October 2024; Accepted: 02 December 2024;
Published: 03 January 2025.
Edited by:
Xin Jin, Yunnan University, ChinaCopyright © 2025 Zhang and Zheng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhe Zhang, dm9pZGVyenpAMTYzLmNvbQ==