 Gregor Mönke1*†
Gregor Mönke1*† Tim Schäfer1†
Tim Schäfer1† Mohsen Parto-Dezfouli1†
Mohsen Parto-Dezfouli1† Diljit Singh Kajal1†
Diljit Singh Kajal1† Stefan Fürtinger1†Joscha Tapani Schmiedt2†Pascal Fries1,3,4†
Stefan Fürtinger1†Joscha Tapani Schmiedt2†Pascal Fries1,3,4†- 1Ernst Strüngmann Institute (ESI) for Neuroscience in Cooperation with Max Planck Society, Frankfurt, Germany
- 2Brain Research Institute, Universität Bremen, Bremen, Germany
- 3Donders Institute for Brain, Cognition and Behaviour, Radboud University Nijmegen, Nijmegen, Netherlands
- 4Max Planck Institute for Biological Cybernetics, Tübingen, Germany
We introduce an open-source Python package for the analysis of large-scale electrophysiological data, named SyNCoPy, which stands for Systems Neuroscience Computing in Python. The package includes signal processing analyses across time (e.g., time-lock analysis), frequency (e.g., power spectrum), and connectivity (e.g., coherence) domains. It enables user-friendly data analysis on both laptop-based and high-performance computing systems. SyNCoPy is designed to facilitate trial-parallel workflows (parallel processing of trials), making it an ideal tool for large-scale analysis of electrophysiological data. Based on parallel processing of trials, the software can support very large-scale datasets via innovative out-of-core computation techniques. It also provides seamless interoperability with other standard software packages through a range of file format importers and exporters and open file formats. The naming of the user functions closely follows the well-established FieldTrip framework, which is an open-source MATLAB toolbox for advanced analysis of electrophysiological data.
Introduction
In neuroscience, methods such as electroencephalography (EEG), magnetoencephalography (MEG), electrocorticography (ECoG), and microelectrode recordings are used to measure electromagnetic signals originating from brain activity. The high time resolution of these techniques enables the analysis of brain activity across a large frequency range, which is essential for the understanding of the functional interconnection of brain regions in systems neuroscience. Researchers in this field are typically interested in identifying brain activity related to certain experimental conditions, e.g., the onset of a stimulus presented to a subject. Therefore, experimental tasks are repeated many times, and the resulting trials are later averaged to reduce noise and variance. The trial repetitions combined with modern experimental setups using an increasing number of recording sites (channels), and high sampling rates can lead to very large (> 10 GB) datasets. With these datasets, standard algorithms such as all-to-all connectivity computations between channels can become impossible to carry out on laptops or desktop computers with limited memory and require workstations or high-performance computing (HPC) systems which can be complex to work with. Moreover, recently, there has been a significant surge of interest in using the scientific Python tech stack as an open-source environment for data analysis.
In this study, we present Systems Neuroscience Computing in Python (SyNCoPy), a Python package for the analysis of large-scale electrophysiology data that combines an easy-to-use, FieldTrip-like (Oostenveld et al., 2011) application programming interface (API) with inbuilt support for distributed workflows on HPC systems.
Related software packages
Scientific software packages for the analysis of neuro-electromagnetic data include FieldTrip, EEGLAB (Delorme et al., 2011; Delorme and Makeig, 2004), NUTMEG (Dalal et al., 2011), and Brainstorm (Tadel et al., 2011) for MATLAB, and MNE Python (Gramfort et al., 2013, 2014) and Elephant (Denker et al., 2023) for Python. SPM software (Litvak et al., 2011) also includes functionality for MEE/EEG analysis.
FieldTrip is a MATLAB toolbox that was first published in 2011 and has been actively evolving since then. Its features include preprocessing, multivariate time series and connectivity analysis, and source localization. It comes with a data browser, interactive data visualizations, and extensive documentation. The functional API consists of powerful main functions (e.g., ft_preprocessing, ft_freqanalysis, and ft_connectivityanalysis) and a number of smaller auxiliary functions. Most functions can be called with the input data and a config structure as input parameters and return an output data structure that includes a copy of the config, serving as a history of the operations applied to the data and a way to re-apply the analysis to different input data.
EEGLAB has been developed since at least 2004 and is an interactive MATLAB toolbox for processing continuous and event-related EEG, MEG, and other electrophysiological data. It includes both a graphic user interface (GUI) and an API and has support for user-contributed code via a plug-in interface. Features include interactive visualization, artifact removal, independent component analysis (ICA), time–frequency analysis, and source modeling.
Brainstorm software package is written in MATLAB and Java but can be run as a standalone application without the need for a MATLAB license. It focuses on a sophisticated GUI and provides some batch-processing functionalities.
Elephant is a Python library for the analysis of electrophysiological data with a focus on generic analysis functions for spike-train data and time-series recordings from electrodes.
MNE Python is a Python package that supports data preprocessing, source localization, statistical analysis, and estimation of functional connectivity between distributed brain regions. It is built on top of the scientific Python ecosystem, has many contributors, and is well integrated with other applications using the Neuromag FIF file format. MNE has extensive plotting capabilities and documentation, including publicly available example datasets and tutorials. It supports parallelization on multiple cores of a single machine via Python’s joblib module but currently no direct parallelization support for HPC systems. The API is a combination of fine-grained functions and methods defined directly on the data objects. MNE is focused on the analysis of EEG and MEG data and local field potentials (LFPs) and supports artifact removal, time/frequency analysis, and source modeling.
We developed SyNCoPy to complement some of MNE’s and Elephant’s features and offer an easy, FieldTrip-like API, support for time-discrete spike datasets, and built-in parallelization on HPC systems.
The SyNCoPy architecture
The mentioned software solutions are well-established and share different features with SyNCoPy. However, none of them is made for handling very large datasets and for distributed computing on HPC systems. SyNCoPy supports this use case through an architecture that supports trial-parallel out-of-core computations. SyNCoPy’s core data structures consist of metadata and a multi-dimensional data array, but the data array is not loaded into memory by default. Instead, when a computation is requested, the data are streamed trialwise from Hierarchical Data Format 5 (HDF5) containers stored on the hard disk, and the results are written back to disk in a similar fashion. Metadata is stored in JavaScript Object Notation (JSON) format. This approach allows for memory-efficient processing of very large datasets with many trials, as well as for easy trial-based parallelization. Parallelization is achieved by employing the well-established Dask (Rocklin, 2015) library, having each Dask job handle one trial at a time. On a standard computer, trials can be handled sequentially or in parallel using several cores, if enough memory is available. On HPC or cloud-based systems, the Dask scheduler typically distributes the compute jobs over several nodes to achieve parallelization. This means that large numbers of trials can be processed in parallel using today’s HPC systems.
SyNCoPy is started on a laptop (left) to process a multi-trial dataset. When a high-level SyNCoPy API function is executed in a Jupyter Notebook, SyNCoPy’s algorithms based on NumPy and SciPy are wrapped in a computational routine that connects to a high-performance compute cluster (or a local cluster on the laptop) via Dask and automatically distributes the trial-by-trial computations to the available resources. The jobs run in parallel (center), with each worker process handling one job at a time and writing the results for a trial into the proper slot of a single HDF5 container on disk. When all workers have finished their assigned jobs, the results on disk are complete and can be accessed from the SyNCoPy session on the laptop (right). The results can then be visualized with SyNCoPy’s plotting API based on matplotlib, exported to Neurodata Without Borders (NWB) format, or NumPy arrays can be extracted directly for custom post-processing using the standard scientific Python tech stack.
The internal architecture of SyNCoPy and the recommended setup for running parallel computations on large datasets is depicted in Figure 1. Users connect to a remote JupyterHub instance, for example, provided by an institutional high-performance computing (HPC) cluster. After creating a global Dask client, running SyNCoPy analyses will use the available computing resources. The input data should reside on fast storage accessible from the cluster, typically a file server. When the user starts a parallel computation, SyNCoPy automatically detects and uses the Dask cluster and distributes the work to the HPC cluster nodes. The nodes write the results to disk, and the SyNCoPy data structure returned by the SyNCoPy API function points to the data on disk. Note that the resulting data are never transferred directly over the network and are never loaded completely into memory. For post-processing, the API offers interfaces to matplotlib (Hunter, 2007) for plotting, and NumPy (Harris et al., 2020) and pyNWB (Rübel et al., 2022) for data export.
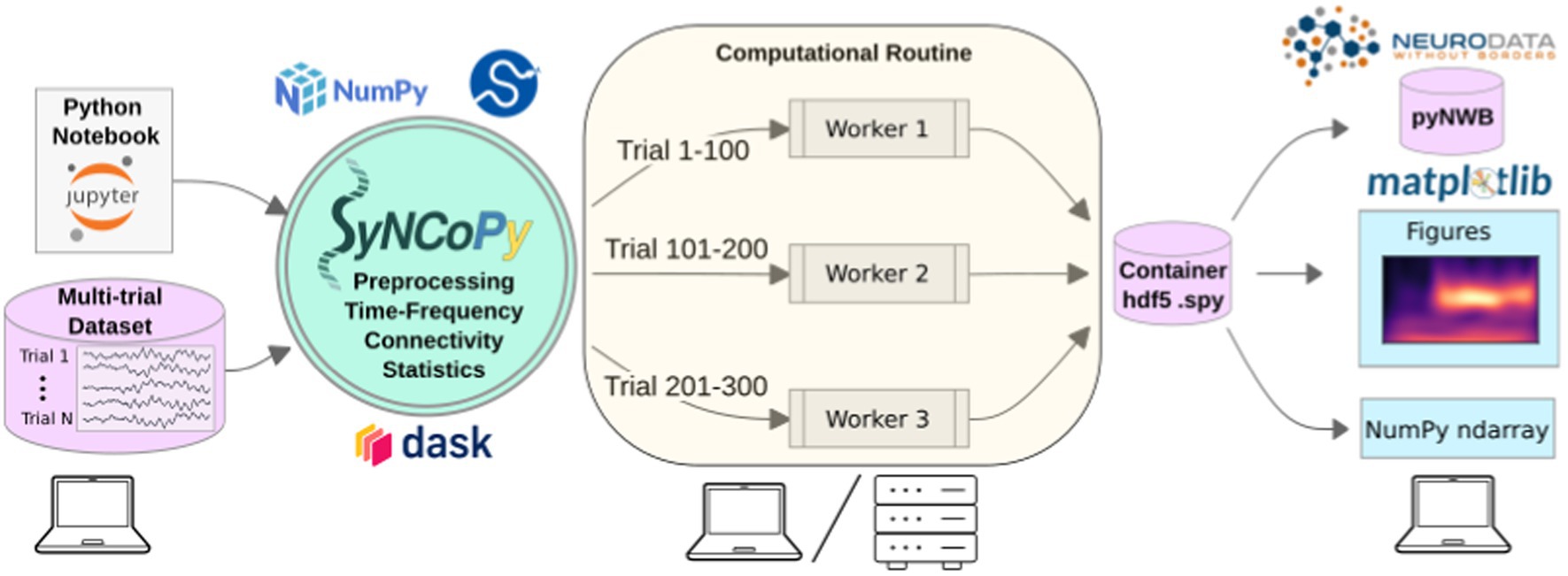
Figure 1. SyNCoPy architecture and a typical setup for parallel processing.
SyNCoPy compute functions (running as a ComputationalRoutine) can attach to any running Dask client and hence harness the full flexibility of the Dask ecosystem, e.g., easy deployment to cloud resources.
SyNCoPy provides specialized data structures and a general method for implementing parallel out-of-core computations on it, the ComputationalRoutine. The user-exposed functions (high-level SyNCoPy API, such as syncopy.connectivityanalysis) internally evaluate user-specified configurations and then use the ComputationalRoutine mechanism to execute code that typically works on the data of a single trial. Depending on the global Python environment, the ComputationalRoutine executes the per-trial code sequentially or in parallel via Dask (see also esi-acme)1 to interact with a parallelization backend, e.g., a Slurm job scheduler running on an HPC cluster. SyNCoPy analysis scripts are agnostic about the hardware environment, meaning analyses can be developed and run locally on single machines such as laptops, and the same code can later be deployed on distributed computing resources.
Feature overview
The current features of SyNCoPy can be divided into the broad categories of data handling, preprocessing, time-locked analysis, frequency-domain analysis, and connectivity-based analysis.
Data structures and data handling
The data handling category includes functions for loading and saving data using SyNCoPy’s internal data formats, as well as some functions to convert data, i.e., import data and export them into other file formats. SyNCoPy’s core data structures generally contain a multidimensional data array and metadata. On disk, the data are represented as an HDF5 file, and when data are loaded into memory, they become available as NumPy arrays. SyNCoPy does not directly read files generated by electrophysiology recording systems; it currently supports importing data from files in NWB, HDF5, or NumPy formats. The data structures can be divided into data types for continuous data and discrete data. The AnalogData class is typically used to store raw electrophysiological data, i.e., multi-channel, regularly sampled, analog data with one or more trials. If no trial information is available in the data source, the user typically creates a trial definition to define the trials. For many analysis types, latency selections are applied to ensure that the data are time-locked to a certain event such as stimulus onset, which results in a TimeLockData instance. Algorithms that output real or complex spectral data store these results in instances of the SpectralData class, and those resulting in channel–channel interaction information (connectivity measures) return instances of the CrossSpectralData class. The discrete data classes SpikeData and EventData are used to store spikes and events, respectively. The SpikeData class can store spikes identified in external spike sorting software such as SpyKING CIRCUS (Yger et al., 2018), including the raw waveform around each spike. The EventData class is used to store event times and is typically used in combination with other data classes.
All data classes can be initialized from NumPy arrays and data type-specific metadata, such as the sampling frequency for AnalogData instances. To facilitate memory-safe data handling also during initialization, Python generators producing single-trial NumPy arrays can be fed directly into the respective SyNCoPy data class constructors. To improve interoperability with other software packages, functions to convert between the data structures of MNE Python and SyNCoPy are available. We also provide functions to save and load data in NWB format.
Preprocessing
SyNCoPy’s preprocessing functions work on AnalogData instances and support detrending, normalizing, and filtering signals, including low-pass, high-pass, band-pass, and band-stop filters. Resampling and downsampling of time-series data are also supported.
Time–frequency analysis
SyNCoPy provides functions for frequency analysis and time–frequency analysis on input of type AnalogData. The (multi-)tapered Fourier transform (MTMFFT) algorithms perform spectral analysis on time-series data using either a single taper window or many tapers based on the discrete prolate spheroidal sequence (DPSS). The effective frequency smoothing width can be directly controlled in Hertz with the tapsmofrq parameter as in FieldTrip. The single tapers available in SyNCoPy are imported from SciPy’s signal module (Virtanen et al., 2020). The resulting spectra can be post-processed using the FOOOF method (Fitting Oscillations and One-over-f) (Donoghue et al., 2020). A sliding window short-time Fourier transform is also available as well as Welch’s method for the estimation of power spectra based on time-averaging over short, modified periodograms (Welch, 1967). Both the non-orthogonal continuous wavelet transform (Torrence and Compo, 1998) and superlets, which can reveal fast transient oscillations with high resolution in both time and frequency (Moca et al., 2021), are available in SyNCoPy for time–frequency analysis.
Connectivity analysis
The connectivity analysis module reveals functional connectivity between channels. It provides algorithms for cross-spectral density estimation (CSD), coherence, pairwise phase consistency (PPC), (Vinck et al., 2010), non-parametric Granger causality (Dhamala et al., 2008), and cross-correlation. Running connectivity analysis requires SpectralData input. If an AnalogData instance is passed, an implicit MTFFT analysis is run with default parameters to obtain a SpectralData instance.
Statistics
SyNCoPy provides functions to compute the mean, median, standard deviation, and variance along arbitrary axes of its data classes. The inter-trial coherence can be computed for input of type SpectralData. Jackknifing (Richter et al., 2015) is also implemented and can be used to compute confidence intervals for coherence or Granger causality results. The peristimulus time histogram (PSTH) can be computed for SpikeData instances (Palm et al., 1988).
Plotting and utility functions
We provide plotting functions for various SyNCoPy data types, including AnalogData, SpectralData, and SpikeData. The SyNCoPy plotting functions are intended to give scientists a quick and easy overview of their data during the development of the data analysis pipeline and for project presentations but not to provide publication-ready figures. The functions internally use matplotlib, and the resulting figures can be post-processed by users if needed.
The synthdata module in SyNCoPy contains utility functions to create synthetic datasets, which is useful for training purposes, and to test custom algorithms and assess their performance. Apart from standard processes such as white noise or Poisson shot noise to simulate spike data, we also offer red noise (AR(1) process) and a phase-diffusion algorithm (Schulze, 2005) to mimic experimental LFP signals.
Basic algebraic operations such as addition and multiplication are supported (and parallelized) for all SyNCoPy data classes and NumPy arrays, allowing for flexible synthetic data construction and standard operations such as baseline corrections.
Example of a step-by-step analysis pipeline for a real electrophysiological dataset
In the following, we present an example of a step-by-step analysis pipeline to demonstrate how to use SyNCoPy for analyzing extracellular electrophysiology data. For comparison, the same analysis was carried out in MATLAB with FieldTrip. The source code for the SyNCoPy version and the FieldTrip version is available online at https://github.com/frieslab/syncopy_paper.
Figure 2 depicts the analysis pipeline and SyNCoPy functions used to process a sample brain signal. The dataset used in the analyses is publicly available and comes from the Allen Institute Visual Coding—Neuropixels project2 and has been described previously (Siegle et al., 2021). In summary, LFP and spiking activity were simultaneously recorded through high-density Neuropixel extracellular electrophysiology probes. These recordings encompass various regions of the mouse brain during the processing of visual stimuli. The LFP data were recorded using Open Ephys (Siegle et al., 2017), and spike data were extracted with Kilosort (Pachitariu et al., 2024). During the experiment, mice were presented with different visual stimuli. In this study, the full-field flash stimulus with a duration of 250 ms was considered as the stimulus epoch, while the 250-ms period before stimulus onset was used as the baseline (Figure 2B). To evaluate connectivity analyses, two visual areas from one sample session were selected (Area A, in the Allen dataset, referred to as Area VISl, corresponding to the primary visual area, lateral part; Area B, in the Allen dataset, referred to as Area VISrl, corresponding to the primary visual area, rostral part). After preprocessing data for aligning the data to stimulus onset, the aforementioned time-domain and frequency-domain analyses were tested on the data. Figure 2C shows the LFP response averaged across different trials and channels of Area A. It indicates an evoked response with a short latency after visual stimulus presentation. Time-locked raster plots and the peristimulus time histogram (PSTH) of the spike trains are shown for 150 trials of a sample neuron (Figures 2D,E, respectively). Subsequently, we calculated the power spectrum of the LFP from Area A, the coherence spectrum between the LFPs of Area A and Area B, the pairwise phase consistency (PPC) spectrum between the LFPs of Area A and Area B, and the non-parametric Granger causality (GC) spectrum between the LFPs of Area A and Area B, as four common frequency-domain analyses.
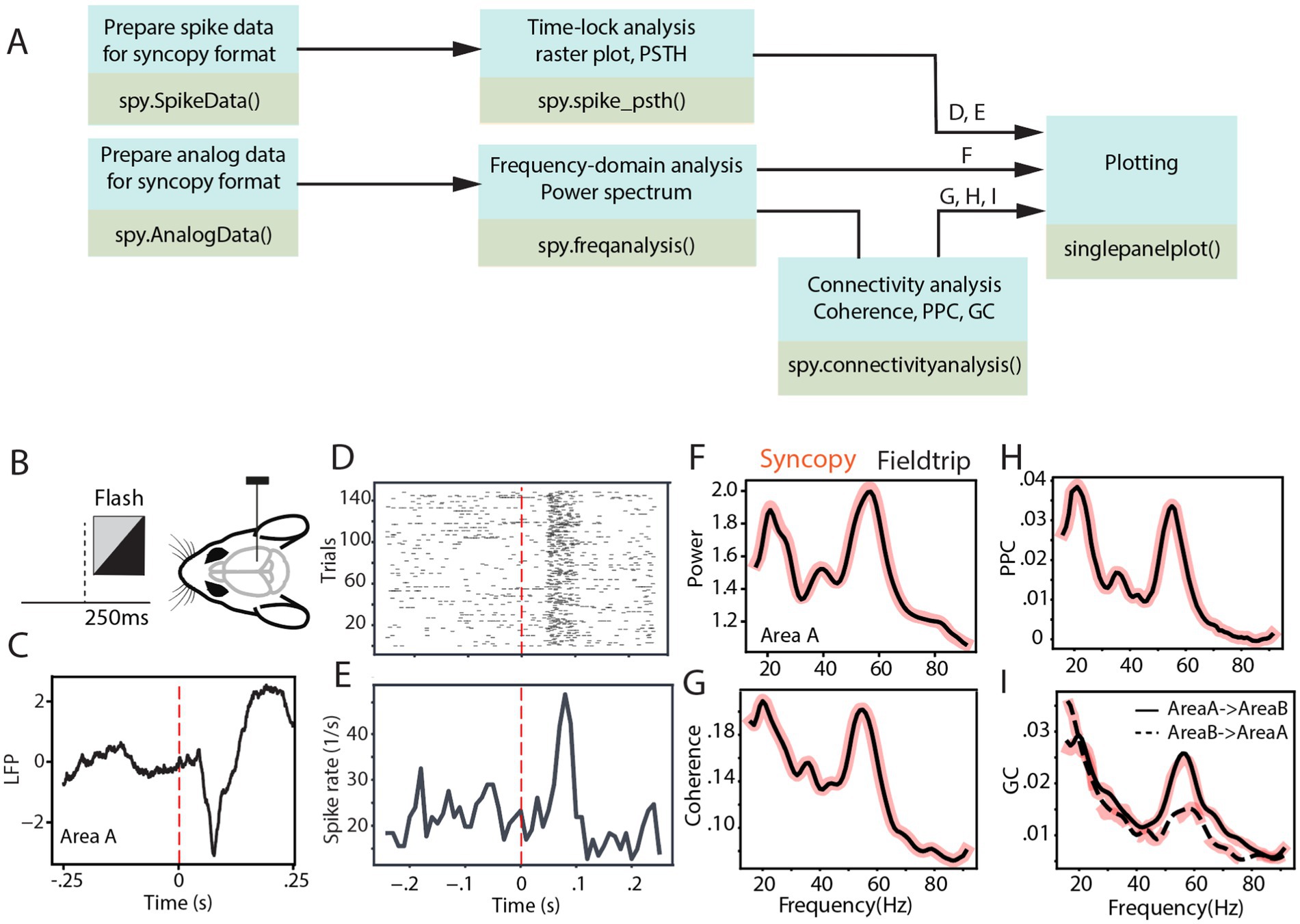
Figure 2. SyNCoPy analysis for an example of electrophysiological dataset. (A) Example analysis pipelines using SyNCoPy functions to process electrophysiological data. The different pipelines result in the plots shown in panels (D-I), as indicated above the arrows feeding into the final plotting routine. (B) During the presentation of the full-field flash stimulus lasting for 250 ms, LFP and spiking activity were recorded from different brain areas of awake mice. (C) The averaged LFP response over trials and channels of Area A, time-locked to stimulus onset. (D,E) Time-lock raster plot (D) and peristimulus time histogram (E) of spiking activity of 150 trials in a sample neuron. (F) Spectra of LFP power ratio between stimulus and baseline period in the frequency range of 1–95 Hz averaged over trials and channels of Area A. The black line reflects the FieldTrip result, and the red-shaded line corresponds to the SyNCoPy result. (G-I) Same as F but for coherence between LFPs of Area A and Area B (G), pairwise phase consistency between LFPs of Area A and Area B (H), Granger causality between the LFPs of Area A and Area B (I). Black lines are FieldTrip results, and red-shaded lines are SyNCoPy results. The solid line is feedforward, and the dashed line is feedback direction (I).
These analyses were calculated in both SyNCoPy and FieldTrip for demonstration purposes and to illustrate the comparability of the outputs. To this end, the data were first zero-padded. Then, based on the MTMFFT method and using the Hann window, the power spectrum was calculated during the stimulus period and the baseline period for each trial and recording channel. MTMFFT conducts frequency analysis on time-series trial data either by employing a single taper (such as Hann) or by utilizing multiple tapers derived from discrete prolate spheroidal sequences (DPSS). For each recording channel separately, the power spectra of the stimulus period and the baseline period were separately averaged, and the ratio of stimulus over baseline power was calculated. Subsequently, the power ratio spectra were averaged over channels (Figure 2F).
Similarly, the coherence (Figure 2G), PPC (Figure 2H), and Granger causality (Figure 2I) between the selected area pairs were measured after zero padding the signals. The results are essentially identical between SyNCoPy and FieldTrip for power, coherence, and PPC, and they are very similar for GC (Figures 2F–I).
Memory benchmarks
Peak memory consumption—methods
We investigated the peak memory consumption (PMC) of SyNCoPy for several algorithms in a typical usage scenario, i.e., during parallel processing on an HPC cluster. Specifically, the “small” queue of the Raven cluster at the Max Planck Computing and Data Facility (MPCDF) of the Max Planck Society was used. To assess the memory consumption as a function of the dataset size, we created synthetic datasets of increasing size with SyNCoPy’s synthdata module and processed them with SyNCoPy. We evaluated (1) preprocessing with a Butterworth + Hilbert filter, (2) the MTMFFT, (3) the MTMFFT f.t. algorithm (here, f.t. specifies that a fixed number of tapers was used for better comparison, as explained in more detail below), (4) wavelets, and (5) coherence. The starting dataset size was 10 trials, 5,000 samples per trial, and 50 channels, which requires approximately 10 MB of space. We created scripts to run each algorithm with different dataset sizes. After each call to a SyNCoPy API function, the Python garbage collector was called to ensure meaningful measurements. During each run, the PMC was monitored with the memory_profiler package3 for Python. The PMC is the highest amount of memory consumption of the submitting process and one worker that was measured during a run. We repeated the process 20 times for each unique combination of dataset size and algorithm to obtain robust results. We report the mean and the standard deviation over the 20 runs in Figure 3.
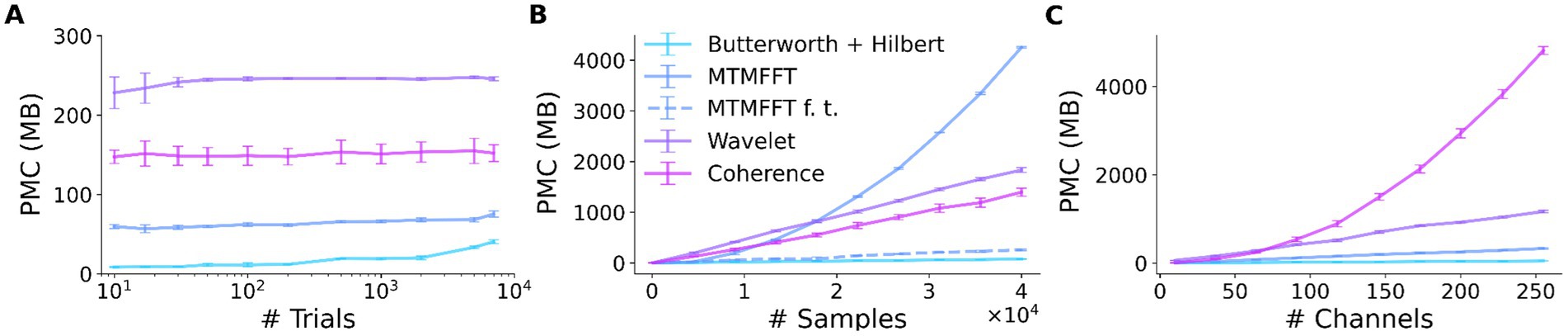
Figure 3. SyNCoPy memory efficiency. Peak memory consumption (PMC) as a function of input size for selected algorithms. The PMC measurements are based on synthetic data. The starting dataset size is 10 trials, 5,000 samples, and 50 channels. Each data point shows the PMC mean and standard deviation of 20 independent runs. (A) PMC is largely independent of the number of trials. The total size of the test dataset varied over almost three orders of magnitude (10 trials to 7,000 trials, ~10 MB to 7GB), while the size of a single trial was kept constant at 1 MB. (B) PMC depends on the number of samples per trial and the algorithm. The number of samples (length of the signals) varied from 10 to 40,000. (C) PMC depends on the number of channels and the algorithm. Channel numbers varied from 2 to 250.
Peak memory consumption—results
The results of the peak memory consumption (PMC) measurements are illustrated in Figure 3. First, we investigated the effect of the trial count on PMC (Figure 3A). We incrementally increased the number of trials from 10 up to 40,000 while keeping the samples per trial and the number of channels constant. At each data point, we performed 20 independent runs with the respective algorithm. The PMC stayed largely constant, irrespective of the trial count, for all algorithms. The PMC was lowest for the Butterworth filter, followed by the MTMFFT, Coherence, and Wavelets. Second, we demonstrate the effect of increasing the number of samples per trial on memory consumption (Figure 3B). We gradually increased the number of samples per trial from 10 to 40,000 while keeping the trial count and channel count constant. For the wavelets, the multi-taper analysis with a fixed number of tapers (MTMFFT f.t.), and coherence computation, a linear effect on the PMC is visible. For the Butterworth filter, memory consumption is essentially constant, as for this method we employ SciPy’s signal.sosfiltfilt implementation, which works on finite sections of the input data. For the full multi-taper analysis (MTMFFT), the PCM increases quadratically with the sample count: The FFT itself has a PMC that is a linear function of the number of samples, and the number of tapers needed to achieve a consistent frequency smoothing (tapsmofrq parameter) also scales with the number of samples. Finally, we observe the effect of increasing the number of channels on the PMC of the algorithms (Figure 3C). For the wavelets and the MTMFFT, a linear effect on the PMC is shown. For the Butterworth filter, the PMC again is almost constant. Coherence shows quadratic scaling of PMC with the number of channels, which directly follows from combinatorics.
Discussion
SyNCoPy is a Python package for the analysis of electrophysiological data, with a focus on extracellular electrophysiology. It stands out from similar software packages by its ability to scale easily from laptops to HPC systems and thus support very large datasets, and an API similar to FieldTrip. SyNCoPy’s support for big data is based on its architecture, which (1) allows for easy usage of typical HPC systems available at many scientific institutions, (2) streams data from disk to memory only when needed, and (3) isolates computations on the minimal amount of data required for independent computations. We demonstrated SyNCoPy’s memory efficiency by benchmarking peak memory consumption (PMC) for a number of algorithms. The results demonstrate that SyNCoPy’s architecture is indeed able to provide largely constant PMC, independent of the number of trials. Moreover, the PMC scales as expected for the respective algorithms with increases in single-trial size.
From a feature perspective, SyNCoPy currently focuses on the preprocessing of raw data, time–frequency analysis, and connectivity measures. We expect that neuroscience users may want to employ SyNCoPy in combination with other well-established software packages such as MNE Python, Elephant, and others that contain complementary functionality. To facilitate this, we provide support for converting MNE Python data structures and importing and exporting standard file formats such as NWB. In addition, the SyNCoPy file format is based on the open standards HDF5 and JSON and can thus be read by standard libraries available for a variety of languages.
SyNCoPy does not have a graphical user interface and relies on scripting. While this may require a certain initial time investment for users completely new to programming, we believe that the standardization and increased reproducibility offered by this approach pay off quickly. FieldTrip is largely based on the same approach and has reached a large user community. To help new users, SyNCoPy comes with full API documentation and includes a set of articles that demonstrate typical analysis workflows. Questions and issues can be reported and discussed on the SyNCoPy GitHub repository.4
Limitations
First, it is important to acknowledge that memory efficiency is a software requirement that, in some situations, conflicts with performance in the sense of processing speed: For a small dataset, it is faster to load everything into memory at once than to stream chunks of the data on demand. However, for large datasets, this computing strategy prevents the processing of datasets larger than (a certain fraction of) the machine’s RAM and thus is not feasible.
Second, SyNCoPy is focused on trial-parallel processing, which is from our perspective a very common scenario in Neuroscience. However, in some situations or for certain algorithms, it may be beneficial to support parallelization along different axes. While SyNCoPy does have built-in support for parallelization over channels for some algorithms, it does not in general support parallelization along an arbitrary axis of the dataset.
Third, the extension of SyNCoPy with new algorithms is possible by creating a custom computational routine, but this process currently requires a good understanding of both parallel computing and some SyNCoPy internals and is thus intended for more advanced users.
Fourth, the target audience of SyNCoPy consists of neuroscientists who need to process larger datasets. The exact limitation for the size of the dataset depends on the specific algorithms and the settings used, of course, but what always holds is that a single trial must easily fit into the RAM of the machine, i.e., typically the HPC cluster node that runs the computations. It is important to understand that certain operations used while loading and saving data, or in the algorithms themselves, will need to create one, or in some cases even more, copies of the trial data in memory. Therefore, working with a dataset that has almost the size of the RAM is not feasible in reality. This is not a limitation of SyNCoPy but applies to all operations on computers, including the standard NumPy and SciPy libraries used internally by SyNCoPy to implement or run the algorithms on the data of a single trial. The required memory typically is a small multiple of the single-trial size.
Conclusion
SyNCoPy provides seamless scaling of trial-based workflows for the analysis of large electrophysiology datasets in Python. In this study, we demonstrated its ability to scale to very large datasets by measuring the peak memory consumption over a range of algorithms for datasets with varying numbers of trials, samples per trial, and channels. Furthermore, we illustrated how to use SyNCoPy on a real-world dataset, along with a direct comparison of the same analyses carried out with the well-established FieldTrip toolbox.
SyNCoPy was built to integrate into the current ecosystem of neuroscience tools. We hope that it will help researchers work with large datasets in a reproducible way and reduce the barriers to fully utilizing existing HPC resources in neuroscience.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found at: https://allensdk.readthedocs.io/en/latest/visual_coding_neuropixels.html.
Author contributions
GM: Conceptualization, Project administration, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing, Formal analysis. TS: Data curation, Methodology, Software, Writing – original draft, Writing – review & editing, Conceptualization. MP-D: Data curation, Investigation, Validation, Visualization, Writing – review & editing, Formal analysis. DK: Data curation, Validation, Writing – review & editing. SF: Conceptualization, Methodology, Project administration, Resources, Software, Writing – review & editing. JS: Conceptualization, Methodology, Software, Writing – review & editing. PF: Conceptualization, Funding acquisition, Methodology, Project administration, Resources, Validation, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by DFG (FR2557/7-1-DualStreams) and by the Ernst Strüngmann Institute.
Acknowledgments
The authors would like to thank Robert Oostenveld and Jan-Mathijs Schoffelen for their invaluable input and insightful feedback throughout the development of SyNCoPy, Mukesh Dhamala for providing help with the Python implementation of the Granger causality algorithm, and Katharine Shapcott and Muad Abd El Hay for early testing of software, suggestions, and discussions. In addition, the authors acknowledge the Max Planck Computing and Data Facility (MPCDF) and the IT team at ESI for providing generous access to high-performance computing resources.
Conflict of interest
PF has a patent on thin-film electrodes and is a member of the Advisory Board of CorTec GmbH (Freiburg, Germany).
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^https://github.com/esi-neuroscience/acme
2. ^https://allensdk.readthedocs.io/en/latest/visual_coding_neuropixels.html
References
Dalal, S. S., Zumer, J. M., Guggisberg, A. G., Trumpis, M., Wong, D. D. E., Sekihara, K., et al. (2011). MEG/EEG source reconstruction, statistical evaluation, and visualization with NUTMEG. Comput. Intell. Neurosci. 2011:758973. doi: 10.1155/2011/758973
Delorme, A., and Makeig, S. (2004). EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 134, 9–21. doi: 10.1016/j.jneumeth.2003.10.009
Delorme, A., Mullen, T., Kothe, C., Akalin Acar, Z., Bigdely-Shamlo, N., Vankov, A., et al. (2011). EEGLAB, SIFT, NFT, BCILAB, and ERICA: new tools for advanced EEG processing. Comput. Intell. Neurosci. 2011:e130714. doi: 10.1155/2011/130714
Denker, M., Köhler, C., Jurkus, R., Kern, M., Kurth, A. C., Kleinjohann, A., et al. (2023). Elephant 0.13.0. Zenodo. doi: 10.5281/zenodo.8144467
Dhamala, M., Rangarajan, G., and Ding, M. (2008). Analyzing information flow in brain networks with nonparametric granger causality. NeuroImage 41, 354–362. doi: 10.1016/j.neuroimage.2008.02.020
Donoghue, T., Haller, M., Peterson, E. J., Varma, P., Sebastian, P., Gao, R., et al. (2020). Parameterizing neural power spectra into periodic and aperiodic components. Nat. Neurosci. 23:12. doi: 10.1038/s41593-020-00744-x
Gramfort, A., Luessi, M., Larson, E., Engemann, D., Strohmeier, D., Brodbeck, C., et al. (2013). MEG and EEG data analysis with MNE-python. Front. Neurosci. 7:267. doi: 10.3389/fnins.2013.00267
Gramfort, A., Luessi, M., Larson, E., Engemann, D. A., Strohmeier, D., Brodbeck, C., et al. (2014). MNE software for processing MEG and EEG data. NeuroImage 86, 446–460. doi: 10.1016/j.neuroimage.2013.10.027
Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., et al. (2020). Array programming with NumPy. Nature 585:7825. doi: 10.1038/s41586-020-2649-2
Hunter, J. D. (2007). Matplotlib: a 2D graphics environment. Comp. Sci. Eng. 9, 90–95. doi: 10.1109/MCSE.2007.55
Litvak, V., Mattout, J., Kiebel, S., Phillips, C., Henson, R., Kilner, J., et al. (2011). EEG and MEG data analysis in SPM8. Comput Intell Neurosci. 2011:852961. doi: 10.1155/2011/852961
Moca, V. V., Bârzan, H., Nagy-Dăbâcan, A., and Mureșan, R. C. (2021). Time-frequency super-resolution with superlets. Nat. Commun. 12:1. doi: 10.1038/s41467-020-20539-9
Oostenveld, R., Fries, P., Maris, E., and Schoffelen, J.-M. (2011). FieldTrip: open source software for advanced analysis of MEG, EEG, and invasive electrophysiological data. Comput. Intell. Neurosci. 1:1. doi: 10.1155/2011/156869
Pachitariu, M., Sridhar, S., and Pennington, J. (2024). Spike sorting with Kilosort4. Nat Methods. 21, 914–921. doi: 10.1038/s41592-024-02232-7
Palm, G., Aertsen, A. M. H. J., and Gerstein, G. L. (1988). On the significance of correlations among neuronal spike trains. Biol. Cybern. 59, 1–11. doi: 10.1007/BF00336885
Richter, C. G., Thompson, W. H., Bosman, C. A., and Fries, P. (2015). A jackknife approach to quantifying single-trial correlation between covariance-based metrics undefined on a single-trial basis. NeuroImage 114, 57–70. doi: 10.1016/j.neuroimage.2015.04.040
Rocklin, M. (2015). Dask: Parallel computation with blocked algorithms and task scheduling, 126–132.
Rübel, O., Tritt, A., Ly, R., Dichter, B. K., Ghosh, S., Niu, L., et al. (2022). The Neurodata without Borders ecosystem for neurophysiological data science. eLife 11:e78362. doi: 10.7554/eLife.78362
Siegle, J. H., Jia, X., Durand, S., Gale, S., Bennett, C., Graddis, N., et al. (2021). Survey of spiking in the mouse visual system reveals functional hierarchy. Nature 592:7852. doi: 10.1038/s41586-020-03171-x
Siegle, J. H., López, A. C., Patel, Y. A., Abramov, K., Ohayon, S., and Voigts, J. (2017). Open Ephys: an open-source, plugin-based platform for multichannel electrophysiology. J. Neural Eng. 14:045003. doi: 10.1088/1741-2552/aa5eea
Tadel, F., Baillet, S., Mosher, J. C., Pantazis, D., and Leahy, R. M. (2011). Brainstorm: a user-friendly application for MEG/EEG analysis. Comput. Intell. Neurosci. 2011:e879716. doi: 10.1155/2011/879716
Torrence, C., and Compo, G. P. (1998). A practical guide to wavelet analysis. Bull. Am. Meteorol. Soc. 79, 61–78. doi: 10.1175/1520-0477(1998)079<0061:APGTWA>2.0.CO;2
Vinck, M., van Wingerden, M., Womelsdorf, T., Fries, P., and Pennartz, C. M. A. (2010). The pairwise phase consistency: a bias-free measure of rhythmic neuronal synchronization. NeuroImage 51, 112–122. doi: 10.1016/j.neuroimage.2010.01.073
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., et al. (2020). SciPy 1.0: fundamental algorithms for scientific computing in python. Nat. Methods 17:3. doi: 10.1038/s41592-019-0686-2
Welch, P. (1967). The use of fast Fourier transform for the estimation of power spectra: a method based on time averaging over short, modified periodograms. IEEE transactions on audio and electroacoustics
Keywords: spike train, local field potential (LFP), magnetoencephalography (MEG), electroencephalography (EEG), power spectra, coherence spectra, Granger causality spectra, big data
Citation: Mönke G, Schäfer T, Parto-Dezfouli M, Kajal DS, Fürtinger S, Schmiedt JT and Fries P (2024) Systems Neuroscience Computing in Python (SyNCoPy): a python package for large-scale analysis of electrophysiological data. Front. Neuroinform. 18:1448161. doi: 10.3389/fninf.2024.1448161
Edited by:
Andrew P. Davison, UMR9197 Institut des Neurosciences Paris Saclay (Neuro-PSI), FranceReviewed by:
Alberto Antonietti, Polytechnic University of Milan, ItalyFernando S. Borges, Downstate Health Sciences University, United States
Copyright © 2024 Mönke, Schäfer, Parto-Dezfouli, Kajal, Fürtinger, Schmiedt and Fries. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gregor Mönke, Z3Jncm1vZW5rZUBnbWFpbC5jb20=
†ORCID: Gregor Mönke, https://orcid.org/0000-0002-3521-715X
Tim Schäfer, https://orcid.org/0000-0002-3683-8070
Mohsen Parto-Dezfouli, https://orcid.org/0000-0002-9064-2212
Diljit Singh Kajal, https://orcid.org/0000-0002-0176-5342
Stefan Fürtinger, https://orcid.org/0000-0002-8118-036X
Joscha Tapani Schmiedt, https://orcid.org/0000-0001-6233-1866
Pascal Fries, https://orcid.org/0000-0002-4270-1468