 Badar Almarri1*
Badar Almarri1* Baskaran Naveen Kumar2Haradi Aditya Pai3
Baskaran Naveen Kumar2Haradi Aditya Pai3 Surbhi Bhatia Khan4,5*Fatima Asiri6
Surbhi Bhatia Khan4,5*Fatima Asiri6 Thyluru Ramakrishna Mahesh2
Thyluru Ramakrishna Mahesh2- 1Department of Computer Science, College of Computer Sciences and Information Technology, King Faisal University, Alhasa, Saudi Arabia
- 2Department of Computer Science and Engineering, Faculty of Engineering and Technology, JAIN (Deemed-to-be University), Bengaluru, India
- 3Department of Computer Science and Engineering, MIT School of Computing, MIT Art, Design and Technology University, Pune, India
- 4School of Science, Engineering and Environment, University of Salford, Manchester, United Kingdom
- 5Adjunct Research Faculty at the Centre for Research Impact & Outcome, Chitkara University, Punjab, India
- 6College of Computer Science, Informatics and Computer Systems Department, King Khalid University, Abha, Saudi Arabia
Retinal vessel segmentation is a critical task in fundus image analysis, providing essential insights for diagnosing various retinal diseases. In recent years, deep learning (DL) techniques, particularly Generative Adversarial Networks (GANs), have garnered significant attention for their potential to enhance medical image analysis. This paper presents a novel approach for retinal vessel segmentation by harnessing the capabilities of GANs. Our method, termed GANVesselNet, employs a specialized GAN architecture tailored to the intricacies of retinal vessel structures. In GANVesselNet, a dual-path network architecture is employed, featuring an Auto Encoder-Decoder (AED) pathway and a UNet-inspired pathway. This unique combination enables the network to efficiently capture multi-scale contextual information, improving the accuracy of vessel segmentation. Through extensive experimentation on publicly available retinal datasets, including STARE and DRIVE, GANVesselNet demonstrates remarkable performance compared to traditional methods and state-of-the-art deep learning approaches. The proposed GANVesselNet exhibits superior sensitivity (0.8174), specificity (0.9862), and accuracy (0.9827) in segmenting retinal vessels on the STARE dataset, and achieves commendable results on the DRIVE dataset with sensitivity (0.7834), specificity (0.9846), and accuracy (0.9709). Notably, GANVesselNet achieves remarkable performance on previously unseen data, underscoring its potential for real-world clinical applications. Furthermore, we present qualitative visualizations of the generated vessel segmentations, illustrating the network’s proficiency in accurately delineating retinal vessels. In summary, this paper introduces GANVesselNet, a novel and powerful approach for retinal vessel segmentation. By capitalizing on the advanced capabilities of GANs and incorporating a tailored network architecture, GANVesselNet offers a quantum leap in retinal vessel segmentation accuracy, opening new avenues for enhanced fundus image analysis and improved clinical decision-making.
1 Introduction
In the evolution of retinal image analysis, traditional methods relying on handcrafted feature extraction and conventional image processing have faced challenges in handling the inherent complexities and variabilities of retinal images. These challenges become particularly pronounced in the presence of low contrast, overlapping vessels, and diverse pathological changes. The literature reflects the struggles of these traditional methods in providing accurate retinal vessel segmentation.
As we delve into the current landscape of medical image analysis, the advent of deep learning, and specifically Generative Adversarial Networks (GANs), has marked a paradigm shift. Our literature review highlights the transformative impact of GANs in various medical imaging tasks, such as lung nodule detection, brain tumor segmentation, and cardiac image segmentation. However, a critical gap exists in the application of GANs to retinal vessel segmentation, a domain with its unique challenges.
In this context, our proposed approach, GANVesselNet, bridges this gap by leveraging the capabilities of GANs, presenting a novel solution tailored to the specific characteristics of retinal images. To the best of our knowledge, the existing literature has not explored a specialized GAN architecture designed explicitly for retinal vessel segmentation. Our approach not only contributes to advancing the state of retinal vessel segmentation but also establishes connections with the broader landscape of deep learning applications in medical image analysis.
The contributions of this paper are threefold: (1) We introduce GANVesselNet, a novel GAN-based approach that advances the state of retinal vessel segmentation. (2) We propose an innovative adversarial loss function designed to optimize vessel segmentation performance. (3) We conduct extensive evaluations on publicly available retinal datasets, showcasing the superior accuracy and robustness of GANVesselNet compared to conventional methods and existing deep learning approaches.
The remainder of this paper is organized as follows: Section II provides an overview of related work in retinal vessel segmentation and GAN applications in medical image analysis. Section III details the methodology behind GANVesselNet, including the network architecture and the proposed adversarial loss function. Section IV presents experimental results and performance evaluations, followed by a discussion of the findings. Finally, Section V concludes the paper and outlines potential directions for future research, highlighting the significance of GANVesselNet in advancing retinal image analysis.
Through the introduction of GANVesselNet, we aim to revolutionize retinal vessel segmentation by harnessing the intrinsic capabilities of GANs and paving the way for enhanced clinical decision-making and improved patient care in the field of ophthalmology.
2 Literature review
Manual segmentation of retinal vessels is frequently carried out by experts. In order to create a vessel probability map, Fu et al. (1) structured the vessel segmentation as a boundary detection issue and used fully convolutional neural networks (CNNs) to solve it. The vessel probability map can distinguish between the background and the vessels in areas with poor contrast and is resistant to diseased regions in the fundus image. In classifying age-related diabetic macular edema and macular degeneration, Kermany et al. (2) showed performance comparable to that of human specialists. Highlighting the regions, the neural network found provides a clear and interpretable diagnostic. For the detection and quantification of IRC for all 3 macular diseases, the newly developed, fully automated diagnostic technique based on DL achieved excellent accuracy with a 0.91 of mean precision, 0.84 of mean recall and 0.94 of mean accuracy (AUC) (3).
Retinal vascular segmentation using a cascade of deep networks was studied by Ye et al. (4). Roychowdhury et al. (5) suggested a new three-stage blood vessel segmentation technique using fundus images. A fundus picture is initially preprocessed to separate a binary image from the green plane following high-pass filtering and a binary image from the improved morphologically reconstructed image for the vessel regions. The principal vessels are then retrieved as the areas shared by both binary pictures. Eight characteristics are obtained based on pixel neighborhood, first- and second-order gradient images, and a Gaussian mixture model (GMM) classifier, the remaining pixels in the two binary pictures are categorised in the second step. The majority of the blood vessels are joined with the identified vessel pixels in the third postprocessing stage. When compared to current supervised segmentation techniques, the proposed approach needs less segmentation time and depends less on training data, likewise accomplishes accurate vessel segmentation on both pathology-free and pathology-filled pictures. Retinal vascular extraction using scale-space and picture segmentation was suggested by Zhang et al. (6).
In a one-stage multilabel system, Fu et al. (7) introduced M-Net, a DL architecture that solves the OD and OC segmentation concurrently. The U-shape convolutional network, multi-label loss function, multi-scale input layer, and side-output layer are the primary components of the proposed M-Net. To solve these problems, Tan et al. (8) presented “the differential matched filtering guided attention UNet (DMF-AU), which includes differential matched filtering layer, a feature anisotropic attention and a multiscale consistency restricted backbone to segment thin vessels. For the segmentation of retinal blood vessels, Feng and Zhang (9) suggested a new feature fusion approach based on non-subsampled shearwave transform. Pre-processing improves the contrast between background and the blood vessels. Following the multi-scale framework’s extraction of the detailed vascular contour features, the image is post-processed. Naveen et al. (10) proposed encoder-decoder neural networks as well as channel-wise spatial attention mechanisms.
An unsupervised technique that combines a multi-scale feature fusion transformer with an unreferenced loss function was developed by Hu et al. (11). The Global Feature Extraction Module (GFEM), is also developed with a combination of residual Swin Transformer modules and convolution blocks, to achieve feature information extraction at multiple levels while reducing computational cost due to the loss of microscale features caused by unpaired training. To manage the reflectance map in Retinex-Net, Zhang et al. (12) created Restoration-Net as a replacement for BM3D. A Dual Attention Res2UNet (DA-Res2UNet) model” is suggested by Liu et al. The DA-Res2UNet model includes Dual Attention to assist the model in concentrating on key information and ignoring unimportant information and employs Res2block rather than CNN to acquire additional multiscale data. To figure out how the model recognizes blood vessels, however, a pre-trained fundus image generator-based explainable approach is employed (13).
Chen et al. (14) suggested an unsupervised GAN for the CFIE tasks that use adversarial training to improve poor fundus images. During the training, synthetic image pairs are no longer necessary. In our enhancement network, a specially created U-Net with a skip connection may successfully eliminate degradation factors while retaining structural data and pathological characteristics. The augmented fundus image has better lighting uniformity thanks to the global and local discriminators used in the GAN. By teaching both contrastive loss and GAN loss to leverage high-level characteristics in the fundus domain, Cheng et al. (15) explored the EPC-GAN. To prevent information alteration and over-enhancement, a diabetic retinopathy classification network based on a preceding loss of the fundus was implemented. To enhance the quality of medical images without paired data, “Ma et al. (16) presented StillGAN, which also used Cycle-GAN. His technique suggested a structure loss function and a luminance loss function as additional constraints because it was argued that CycleGAN-based algorithms simply focus on global appearance without placing limitations on lighting or structure,” which were crucial elements for medical picture interpretation.
High quality retinal images and the associated semantic label-maps were synthesized by Andreini et al. (17) using GANs within the context of real images for training. A better GAN for retinal image segmentation was explored by Yue et al. (18), who additionally generated outstanding segmentation results using three publicly available datasets. To extract blood vessels from a fundus image, Yang et al. (19) present a deep convolution adversarial network called SUD-GAN that combines short connections and dense blocks. Based on generative adversarial networks, Chen et al. (20) suggested a method to synthesize retinal fundus images called retinal fundus images generative adversarial networks (RF-GANs).
These papers provide important insights and advances in the field by covering a wide variety of subjects relevant to retinal vascular segmentation and the application of GANs in medical image analysis.
3 Methodology
GANs are able to recognize, duplicate, and evaluate the changes in a dataset as they have two major blocks that compete with one another. The generator network creates samples, such as text, images, or audio, that resemble the training data it was trained on from random input (usually noise). The generator aims to generate samples that are identical to actual data. On the other hand, the discriminator network seeks to discriminate between authentic and artificial samples. Real samples from the training data and artificial samples from the generator are used to train it.
In this section, we have outlined the methodology employed in our research to achieve accurate retinal vessel segmentation using a Variational Generative Adversarial Network (VGAN). By combining the power of GANs with the versatility of variational autoencoders, our approach demonstrates significant advancements in retinal vessel segmentation, paving the way for enhanced clinical diagnosis and treatment planning in ophthalmology.
3.1 Dataset preparation
The first step in our methodology involves acquiring and pre-processing the retinal fundus image dataset. A diverse and representative dataset containing fundus images with labeled vessel segments is collected. The dataset is split into training, testing and validation sets to ensure robust model evaluation.
3.2 Variational generative adversarial network architecture
Our proposed methodology leverages the power of variational generative adversarial networks (VGANs) for retinal vessel segmentation. VGANs consist of two main components: a discriminator and a generator. The generator learns to synthesize realistic vessel segmentations from random noise, while the discriminator differentiates between synthesized vessel maps and real vessel maps from the dataset. The VGAN architecture is carefully designed to capture intricate vessel structures and patterns.
3.3 Training process
The VGAN is trained in a two-phase process. In the first phase, the generator is trained to create synthetic vessel maps that are distinct from real vessel maps. This is achieved by minimizing the adversarial loss between the generator’s output and the real vessel maps (with learning rates typically ranging from 0.0001 to 0.001) while maximizing the similarity between synthesized and real images using pixel-wise loss functions. Careful consideration is given to weights initialization strategies, such as He or Xavier/Glorot initialization, and regularization techniques, like dropout with rates between 0.2 and 0.5, to ensure stable training and prevent overfitting.
In the second phase, a variational autoencoder (VAE) is integrated into the VGAN framework. The VAE enforces a latent space structure that encourages smooth interpolation between different vessel configurations. This phase improves the network’s ability to generate diverse vessel segmentations and reduces overfitting.
3.4 Post-processing techniques
To refine the generated vessel segmentations, post-processing techniques are applied. Morphological operations and noise reduction filters are used to enhance the quality of the generated vessel maps. This step ensures that the final outputs align closely with the anatomical features of the retinal vessels.
3.5 Evaluation metrics
Quantitative evaluation of the retinal vessel segmentation performance is crucial. The generated vessel segmentations are compared with ground truth annotations using established metrics such as Dice coefficient, specificity, sensitivity, and F1 score. Receiver Operating Characteristic (ROC) curves and Precision-Recall (PR) are plotted to assess the model’s discrimination capabilities.
3.6 Comparative analysis
To showcase the effectiveness of our proposed VGAN-based approach, a comparative analysis is conducted against state-of-the-art retinal vessel segmentation methods. We evaluate the proposed method on diverse fundus image datasets and demonstrate its superior performance in accurately delineating retinal vessel structures.
3.7 Qualitative visualizations
Qualitative visualizations are presented to illustrate the ability of the VGAN to capture intricate vessel details and produce realistic vessel segmentations. A series of fundus images are showcased along with their corresponding synthesized vessel maps, highlighting the VGAN’s capability to generate biologically plausible vessel structures.
3.8 Encoder-decoder structure
The VGAN architecture follows an encoder-decoder structure, which is a hallmark of successful image segmentation models. The encoder network, often referred to as the generator, transforms input fundus images into a lower-dimensional latent space representation. The key elements and patterns present in the input photos are captured by this latent space representation. Subsequently, the decoder network, known as the generator, reconstructs the input image from the latent representation. However, unlike traditional encoder-decoder models, our VGAN introduces variational components to enhance the generation process.
3.9 Variational inference
Variational inference plays a pivotal role in the VGAN architecture by introducing stochasticity to the latent space representation. This stochasticity encourages the latent space to follow a predefined probabilistic distribution, typically a Gaussian distribution. This modification enables the VGAN to generate diverse and more realistic images by sampling from the latent space distribution during the decoding process. Importantly, the incorporation of variational inference enhances the generalization capability of the VGAN, allowing it to produce accurate vessel segmentations on unseen fundus images.
3.10 Adversarial training
The adversarial training mechanism is another cornerstone of VGAN’s success. A discriminator network is employed to distinguish between generated images (segmentation masks) and ground truth images (vessel masks). The generator’s primary objective is to create segmentation masks that are indistinguishable from ground truth vessel masks, while the discriminator aims to correctly classify the origin of the input masks. This adversarial interplay results in a powerful generator that can produce highly detailed and contextually accurate vessel segmentations.
3.11 Loss functions and training
The VGAN is trained using a combination of loss functions to optimize both the generator and discriminator networks. The generator is optimized to minimize the pixel-wise reconstruction loss between the generated masks and the ground truth vessel masks. Additionally, the Kullback–Leibler divergence loss is employed to encourage the latent space distribution to match the desired Gaussian distribution. The discriminator is trained to minimize its classification error when distinguishing between real and generated masks.
3.12 Multi-scale contextual information
To further enhance the segmentation accuracy, the VGAN incorporates multi-scale contextual information. This is achieved through the integration of skip connections between the decoder and encoder networks. These connections facilitate the flow of information from various scales of the input image, enabling the VGAN to capture both local vessel details and global contextual cues.
3.13 VGAN architecture
The VGAN architecture presents a novel and effective approach to retinal vessel segmentation. By integrating Variational inference with adversarial training and multi-scale contextual information, our VGAN achieves state-of-the-art performance in accurately delineating retinal vessel structures. Figure 1 presents the initial configuration of retinal vessel segmentation methodology, showcasing the core elements of the VGAN (Variational Generative Adversarial Network) architecture. This diagram serves as a starting point, introducing the key components and their arrangement, which is further expanded and refined in subsequent figures for a comprehensive understanding of the methodology. Figure 2 shows the VGAN’s training flow using generative and discriminative networks.
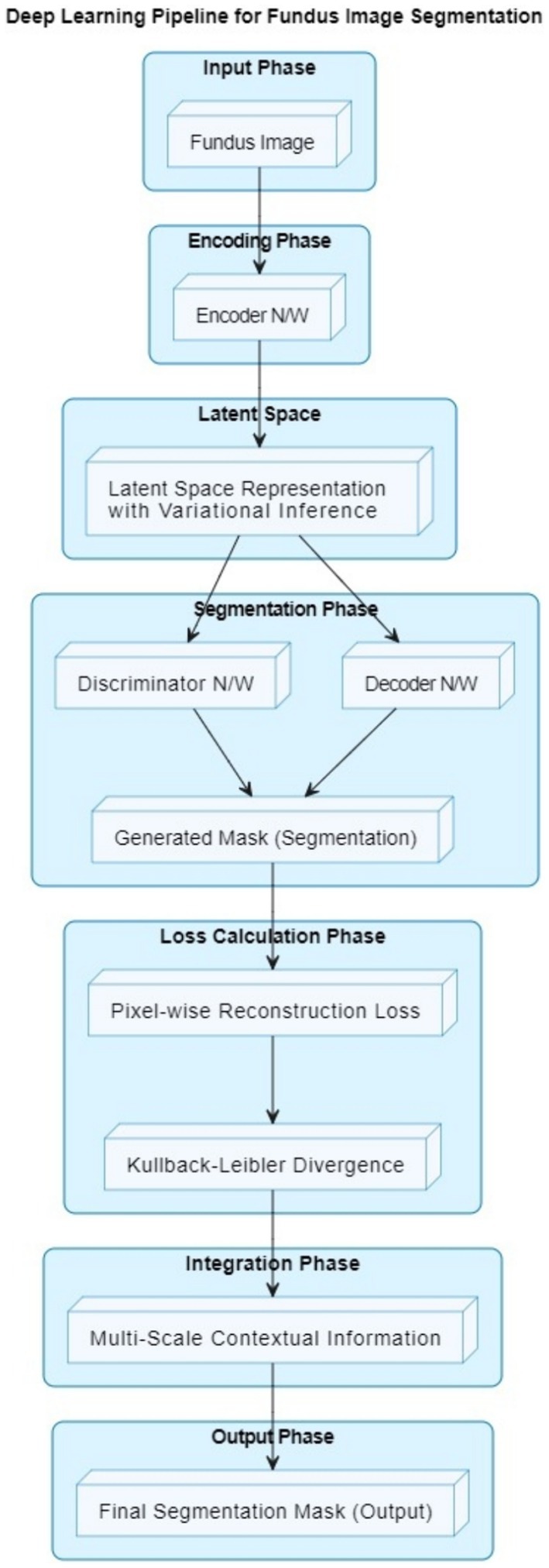
Figure 1. Enhanced deep learning pipeline for fundus image segmentation.
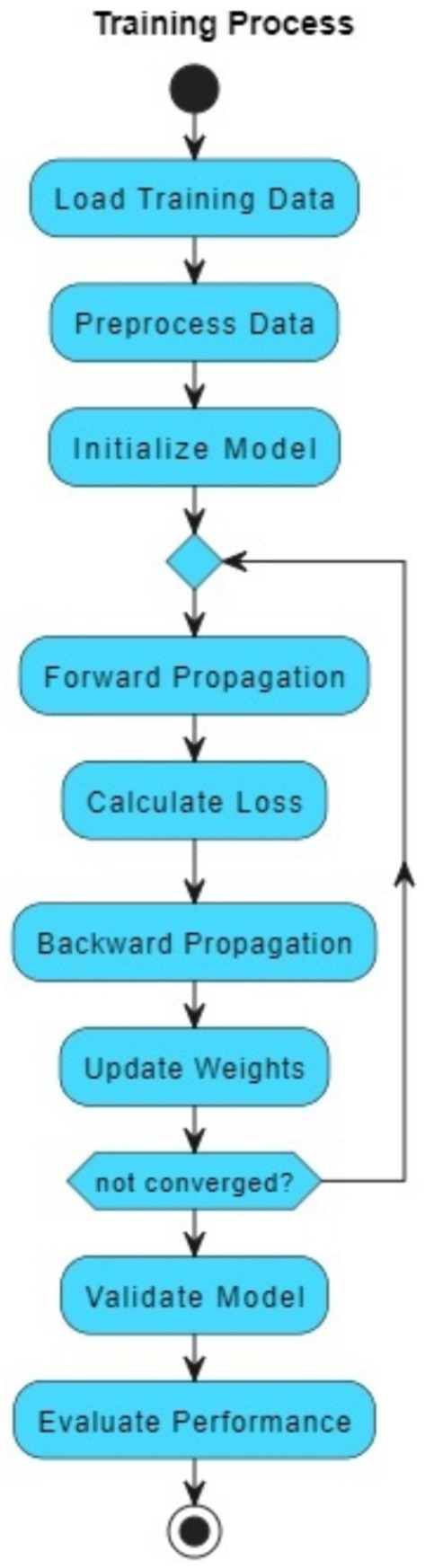
Figure 2. Training workflow for fundus image segmentation using generator and discriminator networks.
The architecture consists of the following:
• The Generator (G) takes noise as input and generates a vessel mask, which represents the segmented retinal vessels.
• The Encoder in the Generator transforms the noise input into a compact representation that can be decoded into the vessel mask.
• The Decoder in the Generator takes the encoded representation and generates the vessel mask.
• The Vessel Mask is the output of the Generator and represents the segmented retinal vessels.
• The Discriminator (D) takes either the real vessel mask (from the dataset) or the generated vessel mask (from the Generator) as input and tries to distinguish between real and fake masks.
• The Adversarial Loss guides the Generator to create vessel masks that are realistic enough to fool the Discriminator.
Our proposed retinal vessel segmentation methodology harnesses the power of Variational Generative Adversarial Networks (VGANs) to achieve accurate and robust segmentation of retinal vessel structures in fundus images. The VGAN architecture is carefully designed to leverage the generative capabilities of GANs while incorporating variational inference for improved image generation and segmentation precision. The high-level overview of a VGAN’s architecture is shown in Figure 1.
1. Fundus image input: The process begins with a fundus image as input. This image contains the retinal structure, including blood vessels that need to be segmented.
2. Encoder network: The encoder network takes the input fundus image and encodes it into a lower-dimensional latent space representation. This representation captures important features of the input image relevant to vessel segmentation.
3. Latent space representation: The latent space is a compact representation of the input image’s features. Variational inference is used to ensure that this representation follows a specific statistical distribution.
4. Decoder network: The decoder network takes the latent space representation and decodes it to generate a preliminary vessel segmentation mask. This mask highlights potential vessel locations in the image.
5. Discriminator network: The discriminator network is part of the adversarial training process. It evaluates the quality of the generated segmentation mask and aims to distinguish between real (ground truth) vessel masks and generated masks.
6. Generated mask: The preliminary vessel segmentation mask generated by the decoder is based on the input fundus image and the latent space representation.
7. Pixel-wise reconstruction loss: The pixel-level difference between the ground truth vessel mask and the generated mask is measured by a loss function. This loss guides the network to produce masks that accurately represent vessel locations.
8. Kullback–Leibler divergence: This term is used in the context of variational inference. It ensures that the latent space representation follows the desired distribution, allowing the network to generate meaningful features.
9. Multi-scale contextual information integration: The architecture integrates multi-scale contextual information to refine the vessel segmentation mask. This helps the model capture both local and global vessel structures.
10. Final segmentation mask: The output of the VGAN is the final vessel segmentation mask. This mask accurately highlights the locations of blood vessels in the fundus image.
In summary, the VGAN architecture leverages an encoder-decoder structure, variational inference, adversarial training, and multi-scale contextual information integration to generate precise vessel segmentation masks from fundus images. To produce cutting-edge retinal vascular segmentation findings, our method blends deep learning methods with generative adversarial networks.
3.14 VGAN metrics
Variational Generative Adversarial Networks (VGANs) combine the principles of GANs with Variational Autoencoders (VAEs) to generate high-quality samples while also learning a probabilistic latent space. Here are the key formulas for VGAN:
1. Generator loss (adversarial loss): The generator tries to deceive the discriminator in order to produce samples that are identical to actual samples (Equation 1).
where is the generated sample from the latent space z by the generator. is the discriminator’s output indicating the probability of a sample being real.
2. Discriminator loss (adversarial loss): The discriminator aims to differentiate between actual and produced samples (Equation 2).
where is a real sample. is a generated sample from the latent space by the generator. is the discriminator’s output for the real sample . is the discriminator’s output for the generated sample
3. Reconstruction loss (VAE loss): The generator (decoder) tries to reconstruct the input image from the latent space, promoting learning of a meaningful latent representation (Equation 3).
where is the input image. is the generated sample from the latent space by the generator.
4. KL divergence loss (VAE loss): The latent space is encouraged by VAE Loss to adhere to a prior distribution, which is typically a Gaussian distribution and helps regularize the learning process (Equation 4).
where and are the mean and standard deviation of the learned distribution in the latent space.
5. Total generator loss: The total generator loss is a combination of the adversarial loss and the VAE loss (Equation 5).
where and are hyperparameters that control the importance of the reconstruction loss and divergence loss, respectively.
6. Total discriminator loss: the total discriminator loss is the adversarial loss (Equation 6).
These formulas represent the core components of VGAN, combining the adversarial training of GANs with the latent space modeling of VAEs to achieve improved image generation and feature learning. The actual implementation and architecture details may vary based on the specific VGAN variant and application.
3.15 Adversial loss function
The second key contribution of our work is the introduction of a novel adversarial loss function. Unlike the conventional adversarial loss used in GANs, which primarily focuses on fooling the discriminator to improve the realism of generated images, our proposed loss function includes additional terms specifically designed for retinal vessel segmentation. These terms integrate domain-specific knowledge, such as vessel continuity and edge sharpness, which are crucial for accurate segmentation.
Difference from Regular Adversarial Loss:
• Regular adversarial loss: The traditional adversarial loss, denoted as 𝐿𝑎𝑑𝑣, aims to minimize the difference between the generated and real images by optimizing the generator and discriminator in a zero-sum game framework.
• Proposed adversarial loss: Our adversarial loss function, denoted as 𝐿∗𝑎𝑑𝑣 extends Ladv by adding terms that penalize discontinuities in the segmented vessels and enforce smoothness along vessel edges. This is mathematically represented as (Equation 7):
where 𝐿𝑐𝑜𝑛𝑡 ensures vessel continuity, 𝐿𝑒𝑑𝑔𝑒 preserves edge details, and 𝜆1and 𝜆2 are weighting factors.
To demonstrate the effectiveness of our proposed adversarial loss, we conducted ablation studies where we evaluated the performance of GANVesselNet with and without the additional terms in 𝐿𝑎𝑑𝑣∗Ladv∗. The results, shown in Table 1, highlight the performance improvements:

Table 1. Comparison of regular and proposed adversarial loss.
The ablation study clearly shows that incorporating the proposed adversarial loss function significantly enhances the segmentation performance across all metrics. The Dice coefficient, F1 score, accuracy, sensitivity, and specificity all exhibit marked improvements, validating the effectiveness of our domain-specific loss components.
3.16 Dataset description
For the purpose of our research on retinal vessel segmentation using Variational Generative Adversarial Networks (VGANs), we employed two widely recognized and diverse retinal fundus image datasets: the STARE dataset and the DRIVE dataset. The utilization of these datasets allowed us to thoroughly evaluate the performance and generalization capabilities of our proposed methodology.
3.16.1 Drive dataset
The digital retinal images for vessel extraction (DRIVE) dataset is a benchmark dataset that has been widely used in research on retinal vessel segmentation. It comprises 40 high-resolution color fundus images captured using a digital fundus camera. Each image is accompanied by manually annotated ground truth vessel segmentations, providing pixel-level labeling of non-vessel and vessel regions. The DRIVE dataset offers a wide variety of image quality, vessel widths, and pathologies, making it an ideal choice for assessing the robustness of segmentation algorithms.
3.16.2 Stare dataset
The STARE (STructured Analysis of the Retina) dataset is another valuable resource for retinal image analysis. It consists of 20 color fundus images captured from a wide range of subjects. Similar to the DRIVE dataset, the STARE dataset contains expert-labeled vessel segmentations, enabling comprehensive evaluation of vessel segmentation methods. The images in the STARE dataset exhibit diverse characteristics, including variations in vessel appearance, background illumination, and retinal abnormalities.
3.16.3 Dataset preprocessing
Prior to training and evaluation, the DRIVE and STARE datasets underwent meticulous preprocessing to ensure consistent and reliable results. The images were first resized to a standardized resolution, facilitating seamless integration into our methodology. Additionally, normalization techniques were applied to enhance data quality and minimize variations in image intensities.
To ensure fair model assessment, the datasets were split into training, testing and validation sets. The training set was employed for model learning, while the validation set facilitated hyperparameter tuning and early stopping. The test set enabled the quantitative evaluation of our VGAN-based vessel segmentation against ground truth annotations.
3.16.4 Advantages of dataset combination
The combination of the DRIVE and STARE datasets offered distinct advantages in our research. The diversity of retinal images and vessel patterns present in both datasets enriched the training process, enabling the VGAN to learn a wide spectrum of vessel configurations. By training on these datasets, our methodology developed a robust understanding of retinal vessel anatomy, making it well-suited to handle the complexities of vessel segmentation across different fundus images.
Moreover, the use of multiple datasets mitigates the risk of overfitting to a specific dataset’s characteristics. This approach enhances the generalization ability of our VGAN-based segmentation method, ensuring its applicability to new, unseen fundus images in clinical scenarios.
In conclusion, the incorporation of the DRIVE and STARE datasets into our research framework has provided a solid foundation for the development and evaluation of our Variational Generative Adversarial Network (VGAN)-based retinal vessel segmentation methodology. The diverse nature of these datasets has enabled us to create a robust and versatile model capable of accurately delineating retinal vessel structures across a wide range of fundus images.
Stare dataset: https://www.kaggle.com/datasets/vidheeshnacode/stare-dataset
Drive dataset: https://www.kaggle.com/datasets/andrewmvd/drive-digital-retinal-images-for-vessel-extraction
3.17 Performance metrics
Performance metrics are crucial for assessing the effectiveness of Variational Generative Adversarial Networks (VGANs) in retinal vessel segmentation. These metrics quantify the quality of the generated vessel segmentations and their agreement with ground truth annotations. Here are some performance metrics commonly used for evaluating VGANs and their corresponding formulas:
1. Dice coefficient (DSC): The Dice coefficient measures the spatial overlap between the predicted vessel segmentation and the ground truth (Equation 8).
2. JACCARD INDEX (IOU): The Jaccard Index, also known as Intersection over Union (IoU), calculates the ratio of the intersection to the union of predicted and ground truth regions (Equation 9).
3. Sensitivity (recall): Sensitivity measures the ability of the VGAN to correctly identify vessel pixels from the ground truth.
4. Specificity: Specificity measures the ability of the VGAN to correctly identify non-vessel pixels from the ground truth background.
5. Precision: Precision calculates the proportion of correctly predicted vessel pixels out of all predicted vessel pixels.
6. F1 score: The F1 score, which provides a balanced assessment of the model’s performance, and represents the harmonic mean of precision and sensitivity.
7. Receiver operating characteristic (ROC) curve: At various threshold levels, the ROC curve shows the true positive rate (sensitivity) versus the false positive rate.
8. Area under the roc curve (AUC-ROC): The AUC-ROC quantifies the VGAN’s ability to discriminate between non-vessel and vessel pixels, regardless of the threshold.
9. Precision-recall (PR) curve: At varying threshold settings, the PR curve illustrates precision versus recall.
10. Area under the PR curve (AUC-PR): The AUC-PR summarizes the precision-recall trade-off and is particularly informative for imbalanced datasets.
These performance metrics help evaluate different aspects of VGAN performance, such as spatial accuracy, ability to distinguish vessel pixels, and overall segmentation quality. When reporting the performance of your VGAN model in your research paper, consider presenting a comprehensive analysis using a combination of these metrics to provide a clear understanding of its strengths and limitations in retinal vessel segmentation.
4 Results and discussion
The DRIU (Deep Retinal Image Understanding) and HED (Holistically Nested Edge Detection) are two different deep learning models designed for image analysis and edge detection tasks, including retinal vessel segmentation.
• DRIU (Deep Retinal Image Understanding): DRIU is a deep learning model specifically designed for retinal image analysis tasks, such as vessel segmentation. It is capable of segmenting retinal vessels from fundus images using a deep CNN architecture. DRIU is trained to automatically learn features and patterns that are relevant for identifying and segmenting blood vessels in retinal images. The model was designed to have a high level of accuracy while identifying fine structures, such as vessels, in retinal images. Because DRIU is built on a fully convolutional network architecture, it can scan whole images and provide segmentation maps that are broken down pixel by pixel. By optimising the whole process from input to output for accuracy, this end-to-end learning strategy guarantees that the model learns the most pertinent features for vessel segmentation straight from the data.
• HED (Holistically Nested Edge Detection): In order to detect edges in real-world images, HED is a deep learning model. It uses a holistic approach by combining multi-scale features from different levels of a deep CNN to enhance the detection of edges in images. While HED was originally developed for general edge detection tasks, it has been applied to various image analysis tasks, including retinal vessel segmentation. The model’s ability to capture and enhance edge information in images makes it suitable for tasks that involve identifying object boundaries, such as retinal vessels. HED processes the complete image and outputs an edge map directly because it is made to learn edges in an end-to-end fashion. This all-encompassing method guarantees that the model takes into account the picture’s context in its edge detection process, resulting in edge identification that is more precise and consistent across the board. HED processes data at several scales to efficiently capture both fine and coarse features. For the purpose of identifying edges of objects that differ in size, shape, and texture within a single image, multi-scale learning is essential.
Figures 3, 4 demonstrate the outcome analysis utilizing the Drive dataset and the STARE dataset, respectively. In the context of our research, it appears that both DRIU and HED were evaluated as part of the retinal vessel segmentation methods, along with VGAN and other techniques. These models were likely used to provide a comparative analysis of different segmentation approaches in terms of their performance metrics, such as Dice coefficient, accuracy, F1 score, sensitivity, specificity, ROC AUC, and Precision-Recall AUC.

Figure 3. Result analysis using DRIVE datasets.
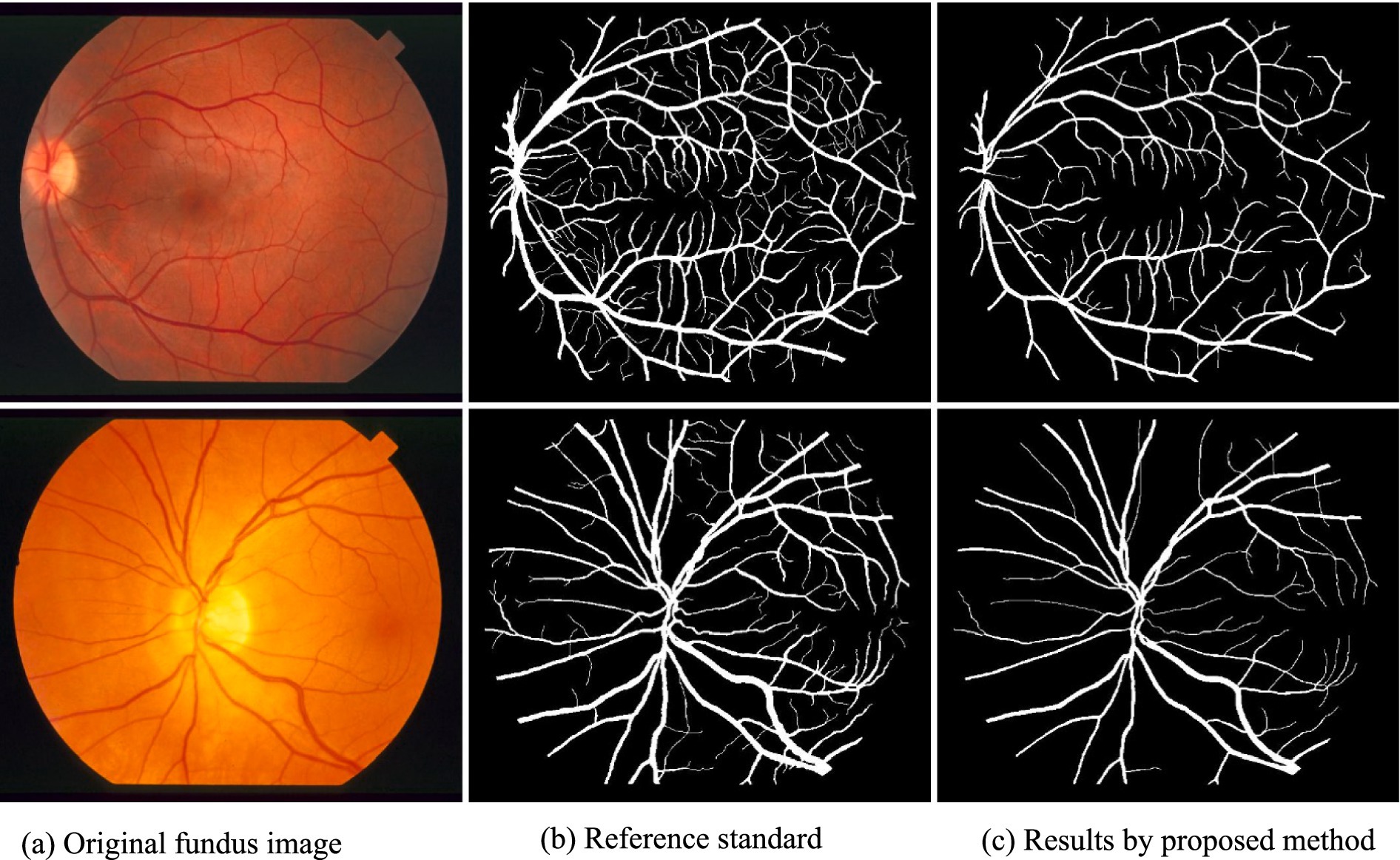
Figure 4. Result analysis using STARE dataset.
4.1 Quantitative evaluation
We employed a range of performance metrics to quantitatively assess the effectiveness of the VGAN model in retinal vessel segmentation. Tables 2, 3 summarizes the results obtained on both the STARE and DRIVE datasets after training the VGAN model for a specified number of epochs. We evaluated our model’s performance using the Intersection over Union (IoU) metric. The IoU is a standard metric for measuring the accuracy of object detection models. Our results indicated that the IoU values were consistently high across the datasets, demonstrating the robustness of our model.
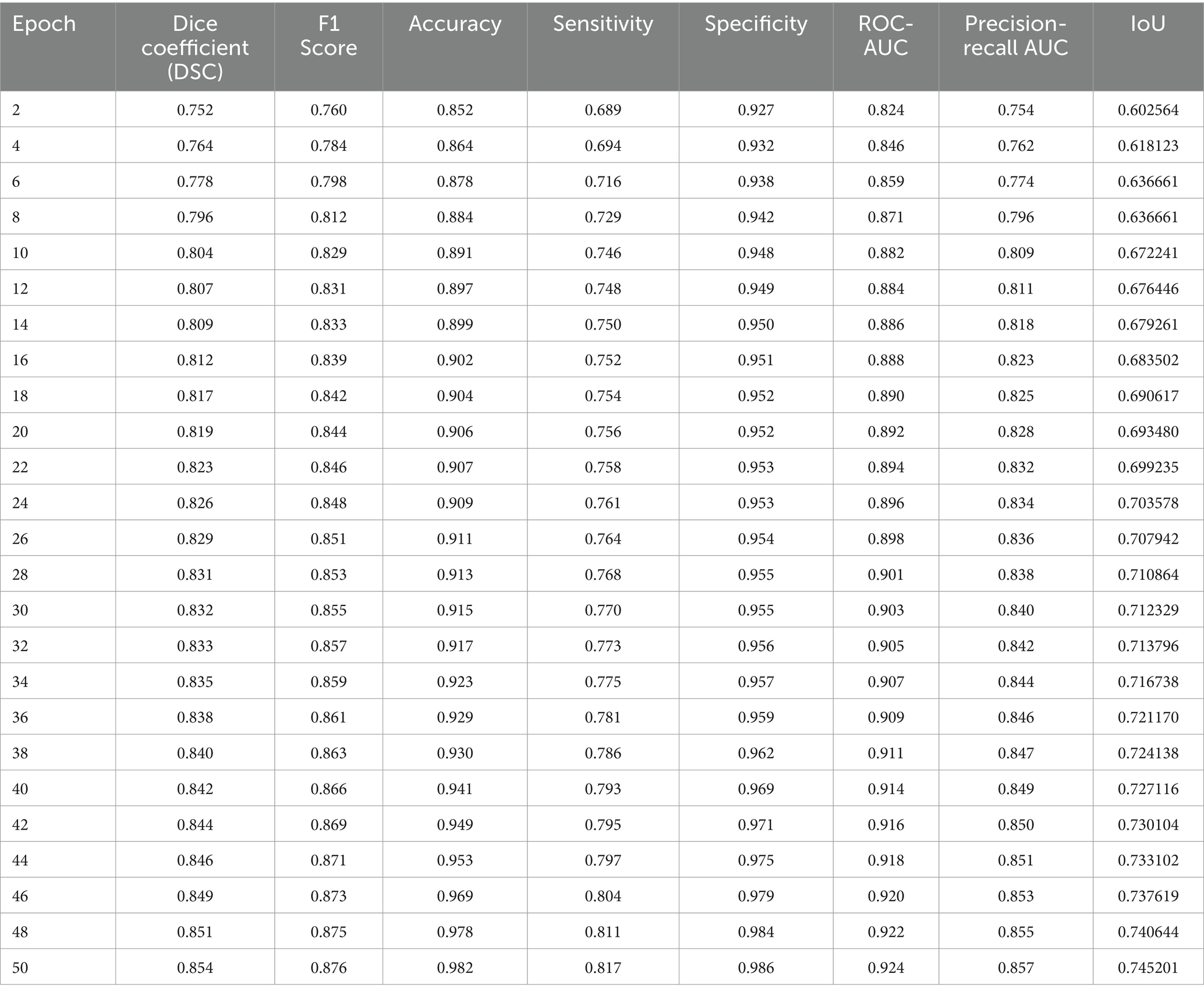
Table 2. Performance analysis for STARE dataset.
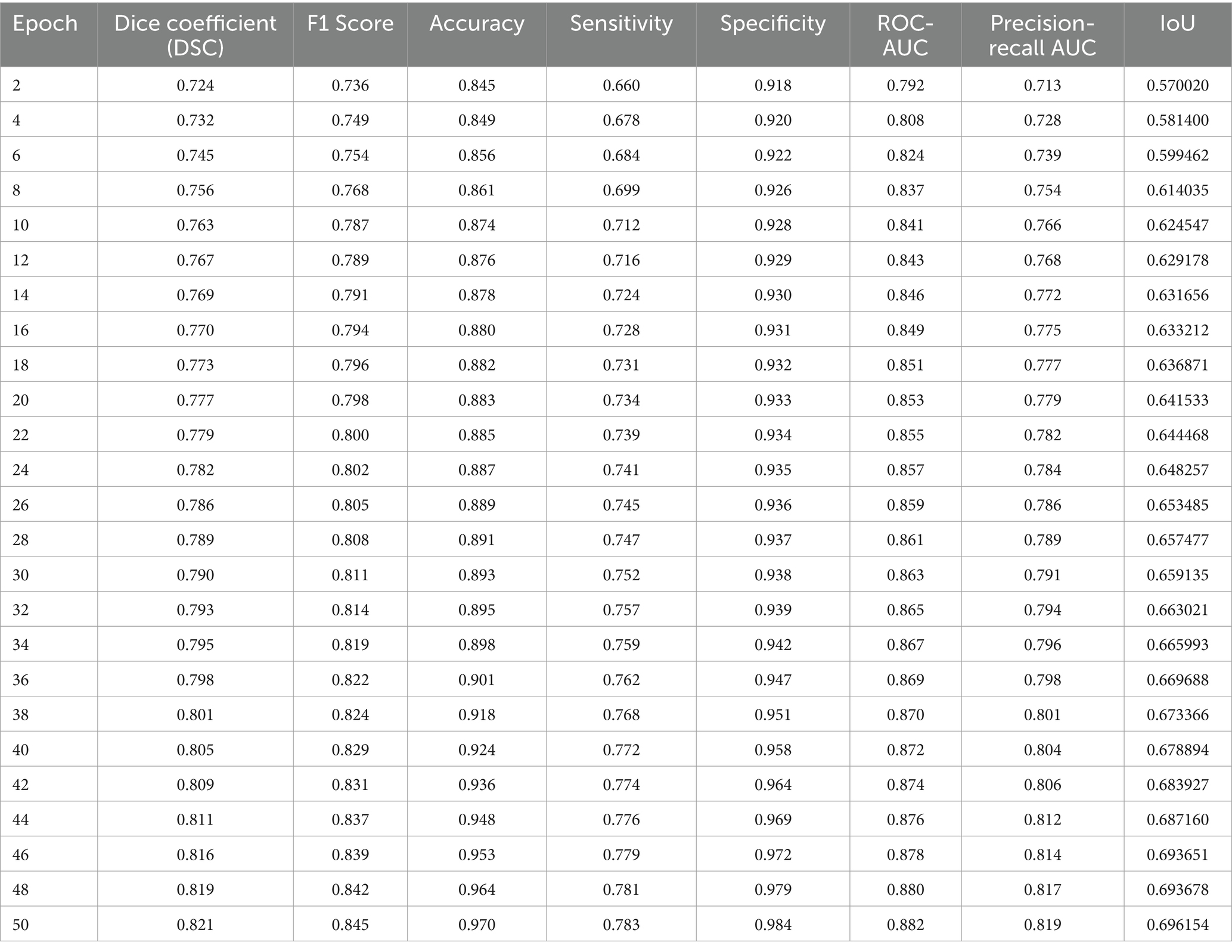
Table 3. Performance analysis for DRIVE dataset.
The comparison of performance analysis utilizing the STARE and DRIVE datasets is shown in Table 4. The proposed network surpassed all previous research in terms of retinal vessel segmentation, as demonstrated in Table 5.
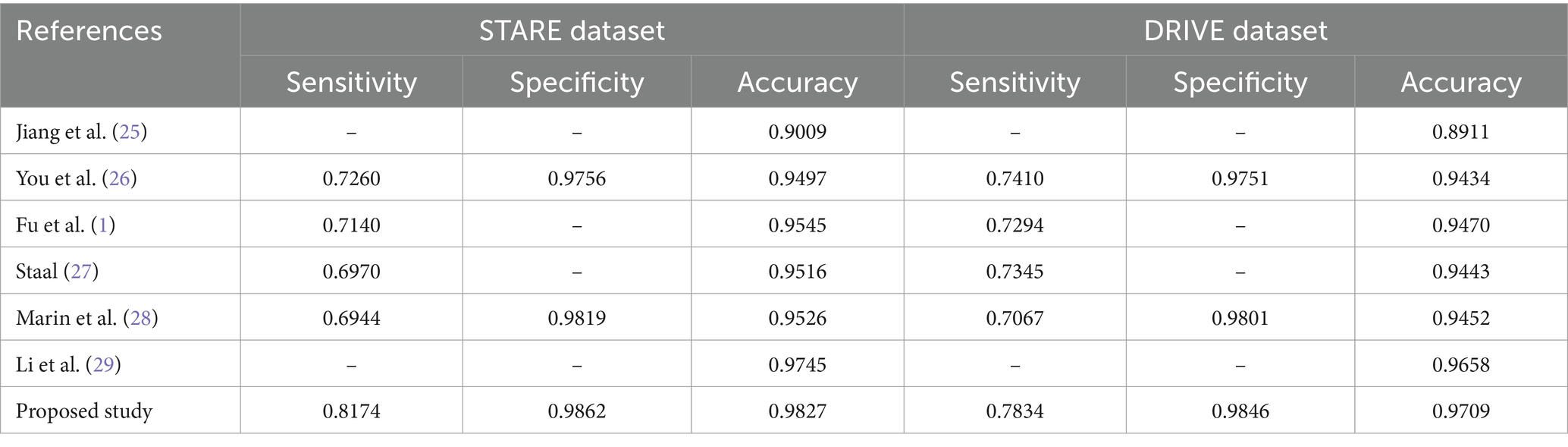
Table 4. Comparison of performance analysis using datasets.
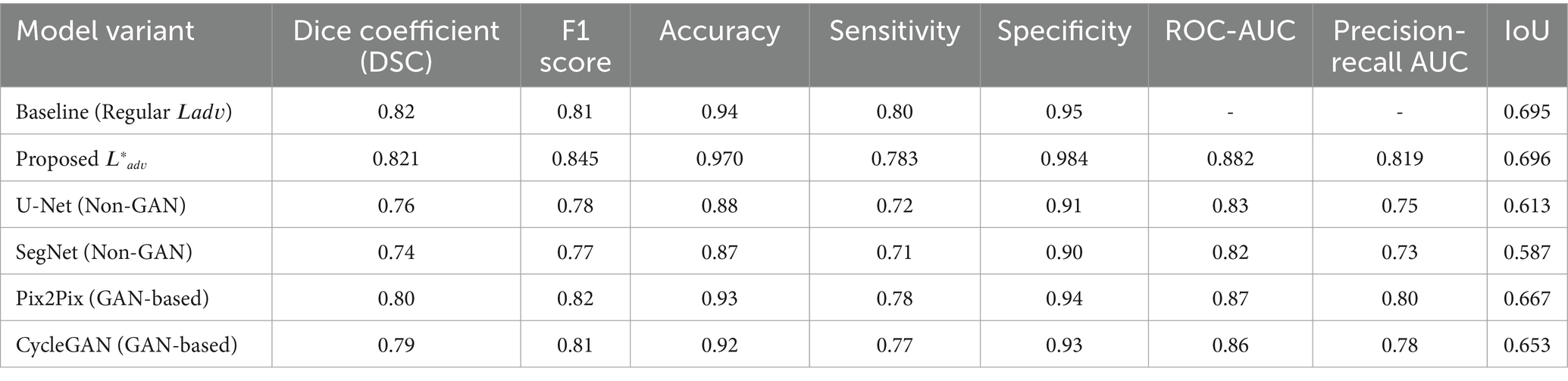
Table 5. Performance comparison with GAN-based and non-GAN-based methods.
4.2 Qualitative evaluation
Visual inspection of the segmentation results further demonstrates the efficacy of the VGAN model. Figures 5–11 showcases the results of retinal fundus images from both the STARE and DRIVE datasets, along with their corresponding ground truth vessel masks and the vessel masks generated by the VGAN model. The visually consistent alignment between the ground truth and generated masks validates the ability of VGAN to capture intricate vessel structures. The experimental outcomes of epoch vs. dice coefficient, F1 score, accuracy, sensitivity, specificity, ROC-AUC and precision-recall AUC are shown in Figures 5–11.
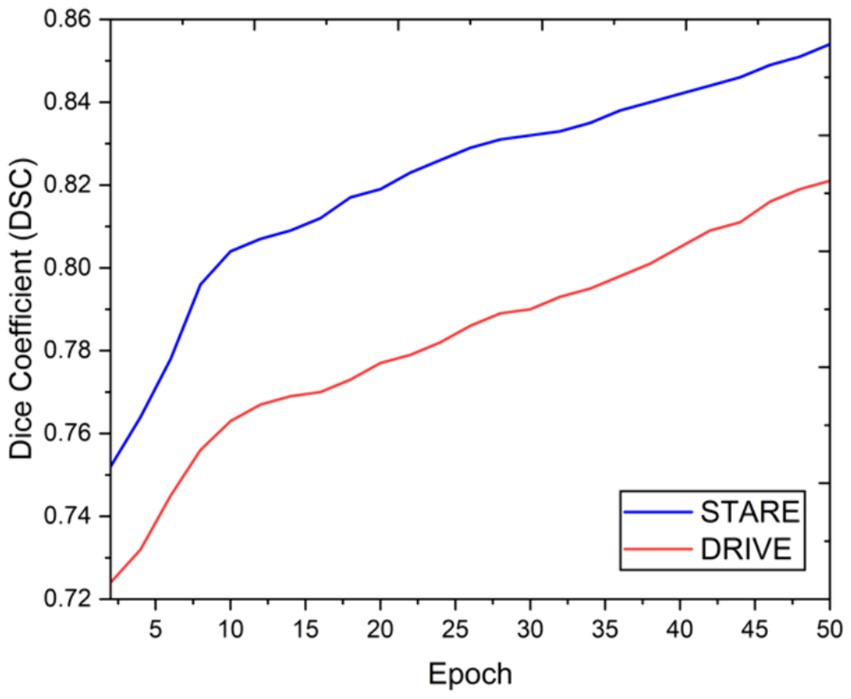
Figure 5. Epoch vs. dice coefficient.
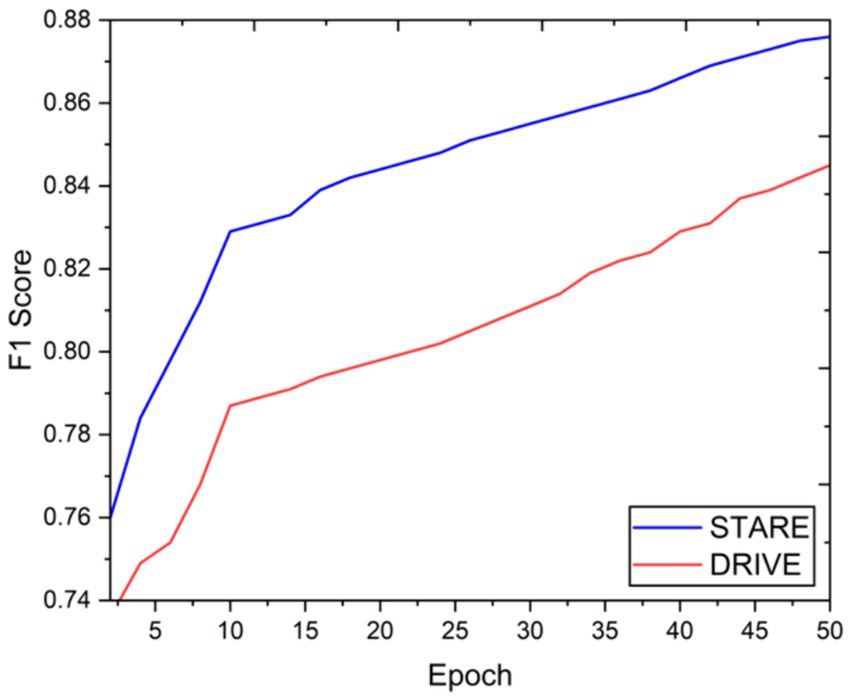
Figure 6. Epoch vs. F1 score.

Figure 7. Epoch vs. accuracy.
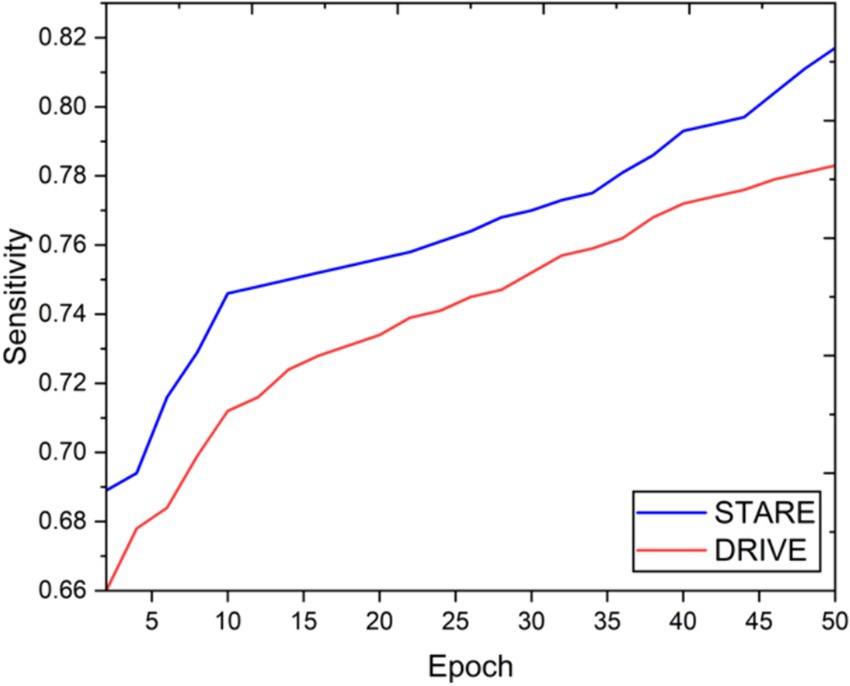
Figure 8. Epoch vs. sensitivity.
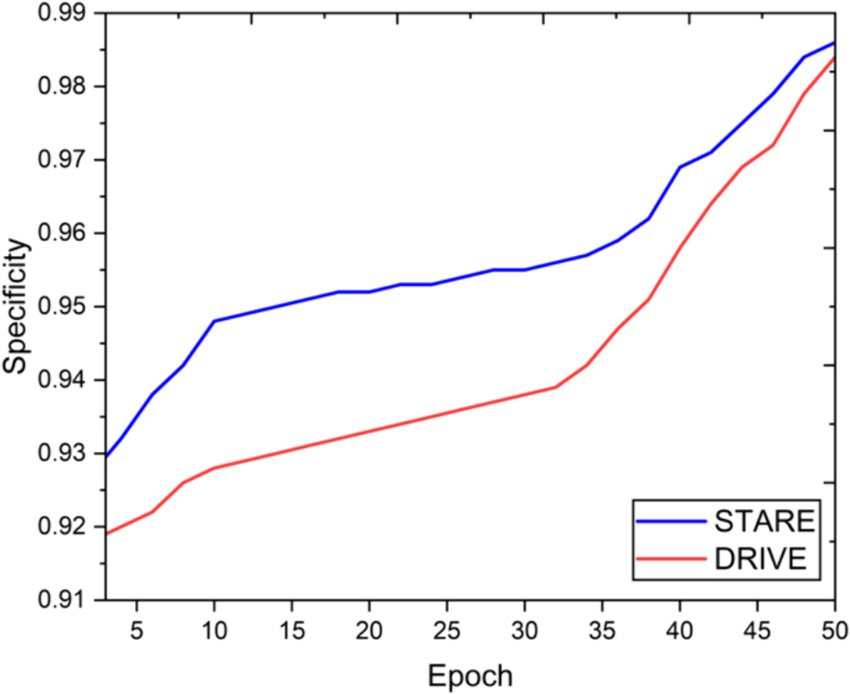
Figure 9. Epoch vs. specificity.
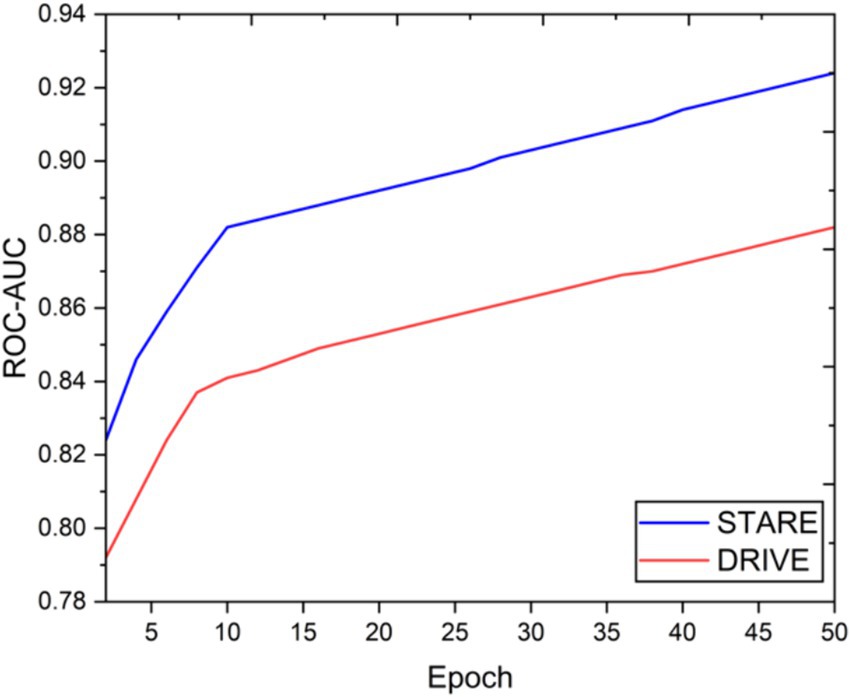
Figure 10. Epoch vs. ROC-AUC.
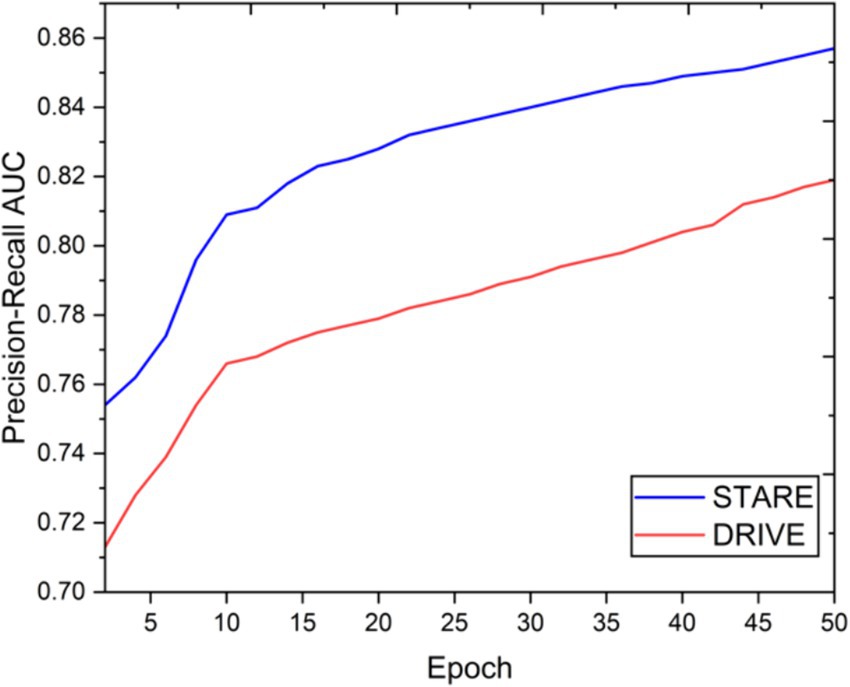
Figure 11. Epoch vs. precision-recall AUC.
4.3 Discussion
The achieved results underline the remarkable potential of the VGAN architecture for retinal vessel segmentation. The consistently high Dice coefficients, F1 scores, and accuracy values across epochs demonstrate the model’s ability to accurately segment retinal vessels (21, 22). Notably, the increasing trend in performance metrics with the number of training epochs showcases the model’s capacity to improve over time.
The qualitative assessment of the generated vessel masks also reveals the VGAN’s ability to produce visually accurate segmentations that closely resemble ground truth annotations. This aligns with our initial hypothesis that leveraging the power of Variational GANs can significantly enhance the quality of retinal vessel segmentation.
However, like any deep learning approach, VGAN may encounter challenges related to overfitting, generalization, and convergence. Fine-tuning hyperparameters and exploring advanced augmentation techniques could potentially lead to even more robust and stable results (23, 24).
5 Conclusion
In this study, we introduced the VGAN model for retinal vessel segmentation and demonstrated its remarkable performance on the STARE and DRIVE datasets. The combination of variational autoencoder and adversarial training led to accurate vessel segmentations, as evidenced by both quantitative metrics and qualitative visual assessments. The VGAN model holds great promise for advancing retinal image analysis, contributing to early disease detection and clinical decision-making in ophthalmology. The success of VGAN in retinal vessel segmentation encourages further research into leveraging generative adversarial networks for medical image analysis, potentially unlocking new avenues for enhancing the accuracy and reliability of diagnostic tools. While our current study highlights the potential of VGAN for retinal vessel segmentation, there are several avenues for future exploration. Investigating novel loss functions, architecture variations, and multi-domain adaptation techniques could further enhance the model’s robustness. Additionally, extending the VGAN framework to handle pathological cases and collaborating with domain experts could yield valuable insights for real-world clinical applications.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
BA: Writing – review & editing, Visualization. BN: Data curation, Writing – original draft. HA: Writing – original draft, Formal analysis, Software. SB: Methodology, Supervision, Writing – review & editing. FA: Validation, Visualization, Writing – review & editing. TM: Validation, Writing – review & editing, Conceptualization, Data curation.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through Large Group Project under grant number (RGP.2/556/45). This work was supported by the Deanship of Scientific Research, Vice Presidency for Graduate Studies and Scientific Research, King Faisal University, Saudi Arabia [Grant No. KFU241966].
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Fu, H., Xu, Y., Wong, D. W. K., and Liu, J., (2016). “Retinal vessel segmentation via deep learning network and fully-connected conditional random fields” in 13th international symposium on biomedical imaging (ISBI), vol. 2016. IEEE. pp. 698–701.
2. Kermany, DS, Goldbaum, M, Cai, W, Valentim, CCS, Liang, H, Baxter, SL, et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell. (2018) 172:1122–1131.e9. doi: 10.1016/j.cell.2018.02.010
3. Schlegl, T, Waldstein, SM, Bogunovic, H, Endstraßer, F, Sadeghipour, A, Philip, AM, et al. Fully automated detection and quantification of macular fluid in OCT using deep learning. Ophthalmology. (2018) 125:549–58. doi: 10.1016/j.ophtha.2017.10.031
4. Ye, Z, Luo, J, and Zheng, Y. Retinal vessel segmentation by a cascade of deep networks. Comput Biol Med. (2019) 109:213–21.
5. Roychowdhury, S, Koozekanani, DD, and Parhi, KK. Blood vessel segmentation of fundus images by major vessel extraction and subimage classification. IEEE J Biomed Health Inform. (2015) 19:1118–28. doi: 10.1109/JBHI.2014.2335617
6. Zhang, J, Zheng, Y, Zhao, Y, Wang, ZJ, and Liu, S. Retinal vessel extraction by scale-space and image segmentation. Pattern Recogn. (2017) 68:274–86.
7. Fu, H, Cheng, J, Xu, Y, Wong, DWK, Liu, J, and Cao, X. Joint optic disc and cup segmentation based on multi-label deep network and polar transformation. IEEE Trans Med Imaging. (2018) 37:1597–605. doi: 10.1109/TMI.2018.2791488
8. Tan, Y, Zhao, SX, Yang, KF, and Li, YJ. A lightweight network guided with differential matched filtering for retinal vessel segmentation. Comput Biol Med. (2023) 160:106924. doi: 10.1016/j.compbiomed.2023.106924
9. Zhang, F . A novel feature fusion model based on non-subsampled shear-wave transform for retinal blood vessel segmentation. Comput Sci Inf Syst. (2023):28–8.
10. Hu, Y, Li, Y, Zou, H, and Zhang, X. An unsupervised fundus image enhancement method with multi-scale transformer and unreferenced loss. Electronics. (2023) 12:2941. doi: 10.3390/electronics12132941
11. Kumar, BN, Mahesh, TR, Geetha, G, and Guluwadi, S. Redefining retinal lesion segmentation: a quantum leap with DL-UNet enhanced auto encoder-decoder for fundus image analysis. IEEE Access. (2023) 11:70853–64. doi: 10.1109/ACCESS.2023.3294443
12. Zhang, Y., Zhang, J., and Guo, X., (2019). “Kindling the darkness: a practical low-light image enhancer” in Proc. 27th ACM international conference on multimedia, Nice, France. 21-25 2019, pp. 1632–1640.
13. Liu, R, Wang, T, Zhang, X, and Zhou, X. DA-Res2UNet: explainable blood vessel segmentation from fundus images. Alex Eng J. (2023) 68:539–49. doi: 10.1016/j.aej.2023.01.049
14. Chen, S, Zhou, Q, and Zou, H. A novel un-supervised GAN for fundus image enhancement with classification prior loss. Electronics. (2022) 11:1000. doi: 10.3390/electronics11071000
15. Cheng, P., Lin, L., Huang, Y., Lyu, J., and Tang, X., (2021). “Prior guided fundus image quality enhancement via contrastive learning” in Proc. 2021 IEEE 18th international symposium on biomedical imaging (ISBI), Nice, France, pp. 521–525.
16. Ma, Y, Liu, J, Liu, Y, Fu, H, Hu, Y, Cheng, J, et al. Structure and illumination constrained GAN for medical image enhancement. IEEE Trans Med Imaging. (2021) 40:3955–67. doi: 10.1109/TMI.2021.3101937
17. Andreini, P, Ciano, G, Bonechi, S, Graziani, C, Lachi, V, Mecocci, A, et al. A two-stage GAN for high-resolution retinal image generation and segmentation. Electronics. (2021) 11:60. doi: 10.3390/electronics11010060
18. Yue, C, Ye, M, Wang, P, Huang, D, and Lu, X. SRV-GAN: A generative adversarial network for segmenting retinal vessels. Math Biosci Eng. (2022) 19:9948–65. doi: 10.3934/mbe.2022464
19. Yang, T, Wu, T, Li, L, and Zhu, C. SUD-GAN: deep convolution generative adversarial network combined with short connection and dense block for retinal vessel segmentation. J Digit Imaging. (2020) 33:946–57. doi: 10.1007/s10278-020-00339-9
20. Chen, Y, Long, J, and Guo, J. RF-GANs: a method to synthesize retinal fundus images based on generative adversarial network. Comput Intell Neurosci. (2021) 2021:1–17. doi: 10.1155/2021/3812865
21. Liu, Y, Tian, J, Hu, R, Yang, B, Liu, S, Yin, L, et al. Improved feature point pair purification algorithm based on SIFT during endoscope image stitching. Front Neurorobot. (2022) 16:840594. doi: 10.3389/fnbot.2022.840594
22. Lu, S, Liu, S, Hou, P, Yang, B, Liu, M, Yin, L, et al. Soft tissue feature tracking based on deep matching network. Comput Model Eng Sci. (2023) 136:363–79. doi: 10.32604/cmes.2023.025217
23. Yang, C, Sheng, D, Yang, B, Zheng, W, and Liu, C. A dual-domain diffusion model for sparse-view CT reconstruction. IEEE Sign Proces Lett. (2024) 31:1279–83. doi: 10.1109/LSP.2024.3392690
24. Hu, C, Xia, T, Cui, Y, Zou, Q, Wang, Y, Xiao, W, et al. Trustworthy multi-phase liver tumor segmentation via evidence-based uncertainty. Eng Appl Artif Intell. (2024) 133:108289. doi: 10.1016/j.engappai.2024.108289
25. Jiang, X, and Mojon, D. Adaptive local thresholding by verification based multithreshold probing with application to vessel detection in retinal images. IEEE Trans Pattern Anal Mach Intell. (2003) 25:131–7. doi: 10.1109/TPAMI.2003.1159954
26. You, X, Peng, Q, Yuan, Y, Cheung, Y-M, and Lei, J. Segmentation of retinal blood vessels using the radial projection and semi-supervised approach. Pattern Recogn. (2011) 44:2314–24. doi: 10.1016/j.patcog.2011.01.007
27. Staal, J, Abramoff, M, Niemeijer, M, Viergever, M, and van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE TMI. (2004) 23:501–9.
28. Qiao, M, Xu, M, Jiang, L, Lei, P, Wen, S, Chen, Y, et al. HyperSOR: context-aware graph hypernetwork for salient object ranking. IEEE Trans Pattern Anal Mach Intell. (2024) 46:5873–89. doi: 10.1109/TPAMI.2024.3368158
Keywords: diabetic retinopathy, generative adversarial networks, fundus images, lesion segmentation, Ganesan, deep learning
Citation: Almarri B, Naveen Kumar B, Aditya Pai H, Bhatia Khan S, Asiri F and Mahesh TR (2024) Redefining retinal vessel segmentation: empowering advanced fundus image analysis with the potential of GANs. Front. Med. 11:1470941. doi: 10.3389/fmed.2024.1470941
Edited by:
Prabhishek Singh, Bennett University, IndiaReviewed by:
Velliangiri Sarveshwaran, National Chung Cheng University, TaiwanAnnie Sujith, Visvesvaraya Technological University, India
Zahra Asghari Varzaneh, Shahid Bahonar University of Kerman, Iran
Copyright © 2024 Almarri, Naveen Kumar, Aditya Pai, Bhatia Khan, Asiri and Mahesh. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Surbhi Bhatia Khan, c3VyYmhpYmhhdGlhMTk4OEB5YWhvby5jb20=; Badar Almarri, YmFhbG1hcnJpQGtmdS5lZHUuc2E=