 Xu Wu
Xu Wu Xiangyu Ju
Xiangyu Ju Ming Li
Ming Li- College of Intelligence Science and Technology, National University of Defense Technology, Changsha, China
Background: Electroencephalogram (EEG) is widely used in emotion recognition due to its precision and reliability. However, the nonstationarity of EEG signals causes significant differences between individuals or sessions, making it challenging to construct a robust model. Recently, domain adaptation (DA) methods have shown excellent results in cross-subject EEG emotion recognition by aligning marginal distributions. Nevertheless, these methods do not consider emotion category labels, which can lead to label confusion during alignment. Our study aims to alleviate this problem by promoting conditional distribution alignment during domain adaptation to improve cross-subject and cross-session emotion recognition performance.
Method: This study introduces a multi-source domain adaptation common-branch network for EEG emotion recognition and proposes a novel sample hybridization method. This method enables the introduction of target domain data information by directionally hybridizing source and target domain samples without increasing the overall sample size, thereby enhancing the effectiveness of conditional distribution alignment in domain adaptation. Cross-subject and cross-session experiments were conducted on two publicly available datasets, SEED and SEED-IV, to validate the proposed model.
Result: In cross-subject emotion recognition, our method achieved an average accuracy of 90.27% on the SEED dataset, with eight out of 15 subjects attaining a recognition accuracy higher than 90%. For the SEED-IV dataset, the recognition accuracy also reached 73.21%. Additionally, in the cross-session experiment, we sequentially used two out of the three session data as source domains and the remaining session as the target domain for emotion recognition. The proposed model yielded average accuracies of 94.16 and 75.05% on the two datasets, respectively.
Conclusion: Our proposed method aims to alleviate the difficulties of emotion recognition from the limited generalization ability of EEG features across subjects and sessions. Though adapting the multi-source domain adaptation and the sample hybridization method, the proposed method can effectively transfer the emotion-related knowledge of known subjects and achieve accurate emotion recognition on unlabeled subjects.
1 Introduction
Emotion, as a complex subjective expression of humans, plays a crucial role in daily life, affecting work, learning, memory, and decision-making (Tyng et al., 2017; Alarcao and Fonseca, 2017; Yu et al., 2023). The generation of emotions involves intricate interactions among multiple brain regions, primarily including the prefrontal cortex, temporal lobe, and others, which are essential for the perception, expression, and regulation of emotions (AlShorman et al., 2020). However, emotions can be intentionally or unintentionally suppressed, leading many individuals to struggle with accurately describing their emotional states. This presents significant challenges for analyzing and assessing emotions (Guo et al., 2024).
These challenges highlight the need for accurate and objective emotion recognition, particularly in fields such as human-computer interaction (HCI), healthcare, mental health monitoring, and security. In these domains, utilizing physiological signals for emotion recognition has become an important area of research (Fiorini et al., 2020; Khare et al., 2024). Recent advancements in AI-enabled detection methods have further enhanced the ability to assess emotional states. For instance, AI techniques have been successfully applied to detect anxiety and psychological stress, showcasing their potential to improve emotion recognition performance (Pal et al., 2022; Heyat et al., 2022). Moreover, research has demonstrated a strong correlation between the generation of emotions and the electrical signals produced by cerebral cortex activity, allowing for the distinction of emotional states through signal decoding (Liu et al., 2017; Venkatraman et al., 2017; Malfliet et al., 2017). Electroencephalography (EEG), as a non-invasive physiological signal detection tool, objectively reflects the electrical activity of different brain regions (Parveen et al., 2023). Consequently, numerous studies have employed EEG-based methods for emotion recognition (Ran et al., 2023; Niu et al., 2023).
Nonetheless, the inherent nonstationarity of EEG signals poses significant challenges in EEG-based emotion recognition (Prabowo et al., 2023; Wu et al., 2020). This non-stationarity can cause significant variations in the EEG patterns between different subjects from the same emotional category and even between the same subject at different times, which increases the difficulty of designing effective and robust recognition models. In addition, when traditional machine learning-based methods are used for emotion analysis, the collection and precise annotation of a large amount of EEG data are required. However, limitations of low spatial resolution of the EEG, high noise interference ratio, and long calibration time during data collection make it particularly challenging to train models effectively using large-scale datasets.
Therefore, to alleviate the requirement for large-scale data collection and tedious annotation, an increasing number of studies have leveraged the concept of domain adaptation (DA) to optimize the EEG-based emotion recognition methods (Li W. et al., 2021; Wan et al., 2021). The DA method enables the utilization of labeled data from a source domain to empower predictions in an unlabeled target domain, thereby significantly enhancing learning performance in the target domain. Zheng et al. (2017) have found that there are consistent and stable patterns between different subjects and sessions, which has provided support for the DA implementation into emotion recognition tasks. The application of the DA methods has effectively reduced the need for a large number of labeled samples (Li Y. et al., 2019), pushing the field of EEG emotion recognition toward more efficient and practical directions.
However, in DA-based emotion recognition, the existing methods primarily focus on aligning the marginal distributions of target- and source-domain data, which neglects the risk that the target-domain data of unknown categories might be adapted to incorrect emotional categories, thus preventing effective matching of data with the same emotional category between the source and target domains. Therefore, a more reasonable approach is to reduce the conditional distribution discrepancy between the source domain and the target domain while considering the alignment of the marginal distributions. This will bring the joint distributions of the source and target domains closer together, thus improving the model's decoding performance on target domain data. However, promoting the alignment of conditional distributions between the source and target domains, and achieving effective adaptation for data with the same labels is a challenge.
In order to solve the above problem, guide the target-domain samples to transfer to the correct category, this study constructs the so-called hybrid sample sets and uses it to replace the source domain. The hybrid sample set consists of half the source domain samples and half the hybrid samples, with hybrid samples constructed by linear combination source domain samples with target domain samples that have the highest cosine similarity. These hybrid samples inherit information from both the source and target domain samples and retain the same category labels as the source-domain samples. During the training process, this method allows the model to naturally learn the features of target domain samples. Meanwhile, since the hybrid samples share labels with the source domain samples, they can guide target samples to transfer to their corresponding source-domain samples, which potentially belong to the same category as the target-domain samples. As a result, samples from the same category in both the source and target domains will exhibit similar feature distributions, increasing the probability that the target-domain samples are classified into the correct category, thus effectively achieving conditional distribution alignment between the target and source domains. Additionally, the hybrid sample set retains half of the source domain samples as stable references to help the model maintain a baseline performance.
This study applies this idea to EEG emotion recognition and constructs a sample hybridization-based multi-source DA method, which can achieve excellent performance in different tasks.
The primary contributions of this study can be condensed as follows:
(1) A sample hybridization method is proposed, where each hybrid sample is constructed by hybridizing a sample from the source domain with its most similar sample in the target domain. Hybrid samples incorporate the information from the source and target domain. As training progresses, the model can gradually adapt to the data distribution of the target domain;
(2) A multi-source DA network is designed. The proposed network takes into account the difference in marginal distribution between different domains, and achieves the marginal distribution alignment by using the maximum mean discrepancy (MMD) loss. In addition, a conditional entropy loss is introduced to adapt the feature distribution of the target domain;
(3) The experiments for cross-subject and cross-session emotion recognition are conducted on two publicly available emotion datasets, the SEED and SEED-IV datasets. The experimental results demonstrate the excellent performance of the proposed model.
The subsequent sections of this paper are structured as follows: Section 2 introduces some related works on domain adaptation based emotion recognition. Section 3 describes the details of the materials and methods proposed in this paper. Section 4 presents the results and compares the results with existing methods. Section 5 discusses the proposed method. Finally, Section 6 summarizes this work.
2 Related work
In recent years, with the deepening of the analysis and processing of brain electrophysiological signals, the field of affective computing has demonstrated great feasibility, sparking widespread research interest among researchers (Pan et al., 2023). Recent studies aimed to answer the question of the representation of emotions. Currently, there are two widely accepted representation models: the discrete model and the continuous model. Separately, in the discrete model, emotions are categorized into basic emotional states, such as happiness, neutrality, and sadness (Ekman and Friesen, 1971). In the continuous model, emotions are expressed continuously within a three-dimensional space, which is defined by arousal, valence, and dominance (Mehrabian, 1996). In this context, numerous studies have achieved remarkable progress in the field of affective computing using the domain adaptation (DA) method.
For instance, Chai et al. (2016) introduced an innovative subspace-aligned autoencoder (SAAE) that adopts an autoencoder structure capable of performing feature alignment between the source and target domains, enabling the trained classifier to classify emotions in unlabeled data from the target domain effectively. Sun and Saenko (2016) presented an unsupervised DA method to align linear transformations that correspond to the second-order statistics between the target and source distributions, thereby enhancing the generalization capabilities across domains. Wang Y. et al. (2021) designed a prototype-based symmetric positive definite matrix network architecture that can facilitate feature and sample adaptation between distributionally indistinguishable and centroid-aligned subjects. Similarly, Peng et al. (2022) employed the maximum mean discrepancy (MMD) (Borgwardt et al., 2006) method for joint distribution alignment and used graph-based adaptive label propagation for estimating target labels.
With the advancing progress and widespread adoption of deep learning, utilizing deep neural networks for decoding emotion-related EEG signals has emerged as the predominant approach. Li et al. (2018) presented the deep adaptation network (DAN) to address the challenge of generalization in cross-individual emotion recognition. By optimizing the effects of variations across individuals in EEG signals, the DAN can achieve significant performance improvement compared to baseline methods and other DA techniques. Later, Li et al. (2018) proposed a method that integrates adversarial training with associated domain adaptation (ADA) (Li J. et al., 2019) to address domain distribution discrepancy across domains. By enforcing similarity in feature representations between the target and source domains, this approach reduces the impact of domain shift and improves the model's effectiveness when applied to the target domain. Haeusser et al. (2017) introduced a multi-source collaborative adaptation framework, which considers the correlation between domains and features. The authors focused on achieving automatic emotion recognition across topics or datasets using the EEG features. Zhu et al. (2022) incorporated wasserstein adversarial training into the ADA framework within an autoencoder network, aiming to increase the resemblance between marginal and conditional distributions of different domains, ultimately leading to improved performance in domain adaptation tasks. More recently, Wang F. et al. (2021) developed a domain selection method, which could screen the most similar data from the source domain to the new subjects, thereby mitigating the overfitting issue and enhancing the network's generalization capabilities.
Although the above studies have achieved significant results, most of them have primarily concentrated on the overall adaptation between the target domain and multiple source domains while overlooking the potential differences in distributions between various source domains, contributing to the poor generalization ability of the model.
Therefore, many recent studies have attempted to perform differentiated DA between the target domain and multiple source domains, using a common-branch network architecture to achieve one-to-one adaptation between different domains. For instance, Chen et al. (2021) developed a domain adaptation network with a common branch to extract domain-shared, low-level invariant features. In the branch network, they employed the MMD to reduce the differences in marginal distributions between different domains. Similarly, Cao et al. (2022) categorized the EEG data collected from diverse subjects into multiple source domains and incorporated various domain-specific feature extraction modules of differing dimensions within the branch network, thus enabling the extraction of richer and more diverse domain-specific feature representations. She et al. (2023) introduced a joint DA method in the branch network and improved recognition results by calculating domain similarity weights. Although the aforementioned methods are more comprehensive than merging multiple source domains for adaptation, they still lack an efficient method to mitigate the differences in conditional distributions between the target domain and multiple source domains, which can result in poor recognition performance when applied to the target domain.
Aiming to address the mentioned limitation, this paper proposes a sample hybridization-based multi-source DA (SH-MDA) network for EEG emotion recognition. A common-branch network architecture is adopted to achieve one-to-one DA between the target and source domains, and the MMD loss is utilized to measure the marginal distribution differences between different domains. Besides, to reduce the conditional distribution differences between the source and target domains, and considering the significant individual differences between subjects in different source domains, which make it challenging to construct a universal hybrid sample set applicable to all individual's feature distribution, the hybrid sample set is constructed for each source domain and replaces the source domain in model training.
For the construction of hybrid samples within the hybrid sample set, in the field of data augmentation, some data augmentation methods can serve as references. For instance, Zhang et al. (2017) introduced the Mixup method to generate more diverse samples by randomly combining two different samples in each training batch; Zhou et al. (2023) proposed the EEGmixup, which combines EEG data from the same trial to increase the number of samples in both the source and target domains; and, Wang et al. (2024) utilized prior knowledge on the channel distributions and generated new samples by exchanging the left and right hemisphere channels to achieve data augmentation. For simplicity, in our method, we construct hybrid samples by linearly combining the samples with the highest cosine similarity from the source and target domains.
Moreover, to improve the recognition performance of the model on the unlabeled samples of the target domain, this study introduces conditional entropy to make the model's decision boundary more adaptive to the target-domain feature distribution after model processing.
3 Materials and methods
This study was completed in several steps, as illustrated in Figure 1. These steps include the EEG datasets (utilizing publicly available EEG emotional datasets), data preprocessing, and model design, which details the proposed SH-MDA model. Finally, the proposed model is applied for emotion recognition in cross-subject and cross-session tasks.
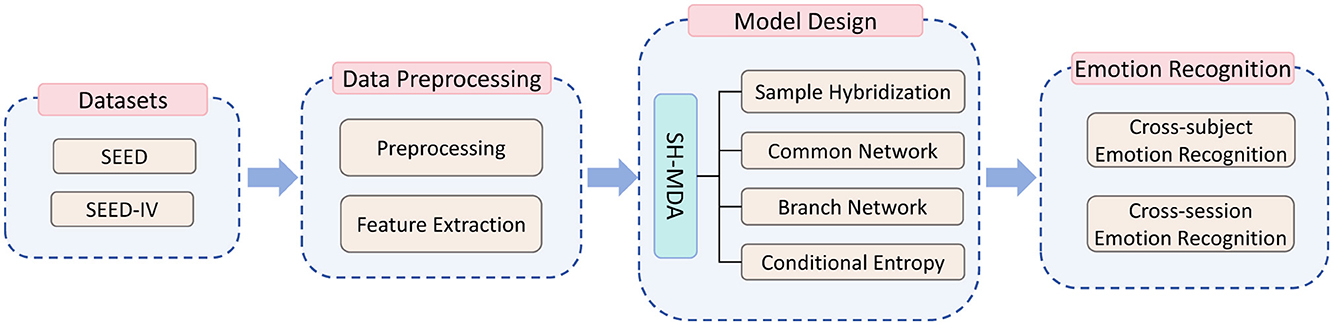
Figure 1. The flowchart of this study.
3.1 Datasets
In this study, the the Shanghai Jiao Tong University (SJTU) emotional EEG dataset (SEED) and its extended version SEED-IV are selected to validate the effectiveness of our proposed method, which are widely used in the field of EEG emotion recognition. The data acquisition and ethical considerations can be seen in Zheng and Lu (2015) and Zheng et al. (2018), all EEG data used in this paper are licensed, and for privacy protection, only numbers are used to represent different subjects. The brief description of the datasets are shown in Table 1.
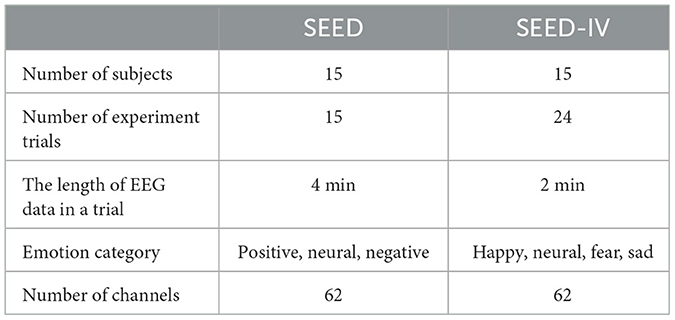
Table 1. The summary of the SEED and SEED-IV datasets.
3.1.1 SEED dataset
The SEED dataset comprises EEG recordings from 15 individuals, consisting of seven males and eight females. It employs video stimuli to evoke corresponding emotions. The video materials were derived from 15 emotional clips selected from movies, each ~4 min in length, with five clips representing each emotion. All subjects participated in three separate experiments conducted at one-week intervals. During each experiment, participants viewed the 15 emotional clips while their brain activity was recorded via EEG. After each video segment, participants had 45 s for self-assessment to ensure the effectiveness of the emotional induction.
3.1.2 SEED-IV dataset
The SEED-IV dataset contains the EEG data of four emotion categories: neutral, sad, fear, and happy. Its structure is similar to that of the SEED dataset; it also includes data from 15 subjects who completed three trials, each comprising 24 experimental trials. In each trial, participants were first presented with a 5-s cue intended to prime their emotional state. Following this cue, they watched a 2-min film segment specifically chosen to evoke the target emotion. After the film, a 45-s self-assessment period was included during which participants rated their emotional experiences.
3.2 Data preprocessing
3.2.1 Preprocessing
For the SEED dataset, the downsampling rate for raw EEG signals was set to 200 Hz, and the signals underwent preprocessing using band-pass filtering from 0 to 70 Hz. Subsequently, the EEG data was segmented using non-overlapping time windows, each 1 s in length. Finally, the number of samples per subject per experiment was 3,394.
The SEED-IV dataset utilizes a preprocessing approach similar to that of the SEED dataset, which initially employs a band-pass filtering step to isolate frequencies ranging from 1 to 75 Hz. Subsequently, the EEG data is segmented using a non-overlapping time window of 4-s length. Finally, the sample size for each subject across the three sessions is 851, 832, and 822, respectively.
3.2.2 Feature extraction
In the selection of input features for the model, recent studies have revealed that differential entropy (DE) features can effectively extract emotional information from EEG signals, thereby enhancing the classification performance of a model (Ju et al., 2024; Lu et al., 2023; Li et al., 2023; Liang et al., 2021). For a segment pre-processed time series EEG data X, which approximates a Gaussian distribution N(μ, σ2), DE features can be calculated as follows
The differential entropy is a simple measure of the time series complexity in a specific frequency band. In this study, for both the SEED and SEED-IV datasets, after dividing samples using different time windows, we extracted DE features for each sample across the δ (1–3 Hz), θ (4–7 Hz), α (8–13 Hz), β (14–30 Hz), and γ (31–50 Hz) frequency bands and normalize them by different channels. Finally, the feature dimension is 62 × 5 (channels × frequency bands).
3.3 Model design
3.3.1 The framework of SH-MDA
This study aims to construct an emotion recognition model using the DA method. The training procedure of the proposed SH-MDA model is shown in Figure 2. Suppose there are multiple labeled EEG data from source subjects (domains) and unlabeled EEG data from a target subject (domain), defined as and , where the N denotes the number of domains, Mi represents the number of samples in the i-th domain. Firstly, after preprocessing, the hybrid sample sets are constructed and replace the N source domains. Each hybrid sample set consist of half source domain samples and half hybrid samples. Then, the common domain-invariant features of the samples are extracted using the common feature extractor in the common network and reinforced through adversarial training with a domain discriminator. Subsequently, these extracted features are passed to different branch networks, which comprise branch feature extractors (BFEs) and branch task classifiers (BTCs). The BFEs extract domain-specific features for each domain and forward them to the BTCs that compute their respective prediction results. Finally, the loss functions are calculated to update the model.

Figure 2. The training process of the proposed framework of SH-MDA. N hybrid sample sets are constructed and replace the corresponding source domain. The hybrid sample set consists of half of the source domain samples and half of the hybrid samples. The common network is utilized to extract domain-invariant features, and the domain discriminator is used to strengthen the extraction through adversarial training. The multiple branch networks are employed to extract domain-specific features and achieve one-to-one adaptation.
In addition, in the stage of model prediction, the domain-invariant features of target domain samples extracted by common feature extractor are sent to N branch networks to obtain N probability distributions of emotion categories, and the final emotion recognition result is output by averaging these probability distributions.
3.3.2 Sample hybridization
Aiming to minimize the conditional distribution difference between source domains and the target domain, this study introduces a conditional alignment method that utilizes sample hybridization, as briefly illustrated in Figure 3.
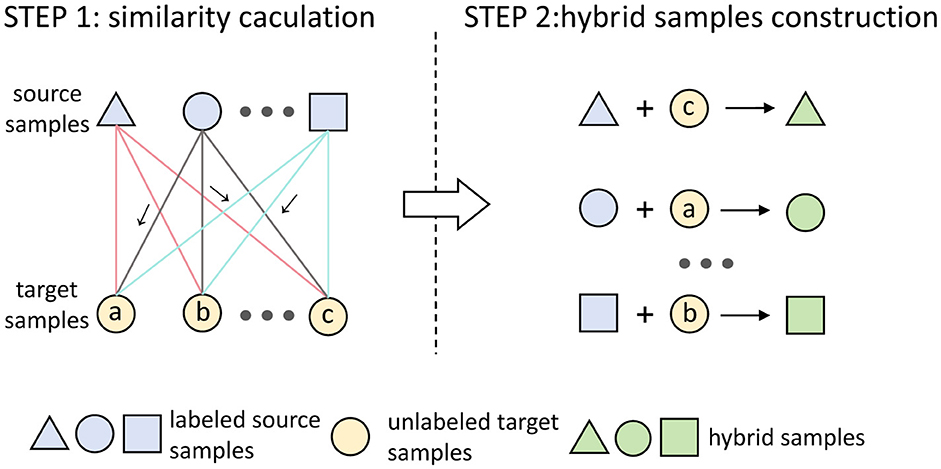
Figure 3. Illustration of sample hybridization, different graphs are used to represent different labels. The symbol “ → ” represent the highest similarity among the source sample and the target sample. The sample hybridization can be divided into two steps. STEP 1: Compute the cosine similarity between the source domain samples and the target domain samples. STEP 2: Linearly combine the source domain samples with their most similar samples in the target domain to construct hybrid samples, which share the same labels as the source domain samples.
Specifically, the sample hybridization can be divided into two steps. In the first step, the cosine similarity is used as a measurement to compute the similarity between samples in a given source domain and samples in the target domain. In a training batch, for the sample from the i-th source domain , where Mb denotes the batch size, m and d represent the number of channels and feature dimension per channel, the sj, k is defined as the cosine similarity between and the sample in the target domain , the sj, k can be calculated as
where ∥·∥ denotes the Euclidean norm. Next, the normalized cosine similarity between and Mb samples of the target domain in the training batch can be represented by a vector , and is calculated by
Furthermore, for the sample in Xi, b, by calculating the normalized similarity Dj, there is a target domain sample with the highest similarity. Theoretically, compared with the other samples in the target domain, sample is most likely to belong to the same emotional category as sample . However, due to the difference between the target and source domains (subject), there exists a significant risk that if the label of the source domain sample is directly utilized as the pseudo label for its most similar target domain sample to conduct domain adaptation, which might cause irreversible negative transfer and subsequently affect the effectiveness of domain adaptation.
Therefore, in the second step, we construct the hybrid samples through a linear combination of the source-domain samples and their most similar samples in the target domain, while sharing labels with the source-domain samples. This way, during training, these hybrid samples can provide feature information of the target domain samples and be classified into corresponding emotion categories based on the shared labels, enabling the model to gradually adapt to the data distribution of the target domain.
In the above, we introduced the construction process of hybrid samples. Finally, to ensure that the target domain data in the hybrid samples does not overly affect the source domain data and to maintain the dominance of the source domain data, we retain half of the source domain samples when constructing the hybrid sample set. These source domain samples will serve as a stable reference to help the model maintain baseline performance. For the i-th source domain, the hybrid sample set in a training batch can be defined as
where λ is the hybrid parameter, represents the sample with the highest cosine similarity to source domain sample in the target domain within the current training batch. Since a hybrid sample set Hi, b is composed of samples from the source and target domains with the highest similarity, which can be considered that samples from the source domain and samples obtained after hybridizing the source-domain samples have a high probability of belonging to the same emotional category. Therefore, the source-domain labels can as the pseudo labels of the hybrid sample set and the hybrid sample sets are defined as .
3.3.3 Common network
In the common network, this study designs a simple three-layer multilayer perceptron (MLP) common feature extractor EI, which aims to extract the domain-invariant features by mapping the input features from the original space to the common feature space, for the samples hi∈ℝm×d from i-th hybrid sample set Hi and the samples xt∈ℝm×d from target domain XT, the domain-invariant features and can be formulated as follows
where EI(·) represents the common feature extractor in the common network, and θI denotes its parameters. To enhance the capability of the model to extract domain-invariant features, the domain discriminator Ddis is introduced. Ddis consists of a fully connected layer, a softmax layer, and a gradient reversal layer (GRL), and the domain discrimination loss Ldis can be expressed as
where θD represents the parameter of Ddis, and Di denote the domain-invariant features and the domain label of i-th hybrid sample set. The optimization objective of the domain discriminator is to induce the common feature extractor to more effectively extract domain-invariant features through adversarial training, by minimizing the value of Ldis, the parameters of the common feature extractor are updated by the gradient reversal layer in the direction of the opposite gradient. This makes the extracted features more general.
3.3.4 Branch networks
In this paper, we design different branch networks to achieve one-to-one distribution alignment by mapping the features of each source domain and target domain into specific feature spaces. As shown in Figure 4, each branch network consists of a branch feature extractor (BFE) and a branch task classifier (BTC).
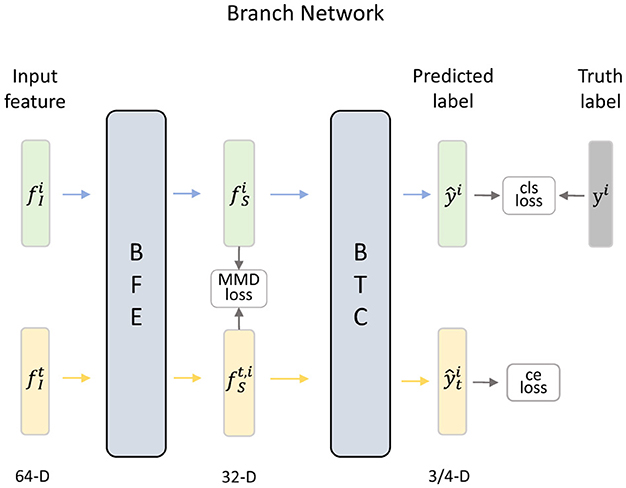
Figure 4. Details of the i-th branch network, which can achieve an effective alignment of the distribution between a specific hybrid sample set and the target domain by minimizing the loss functions.
Specifically, after extracting domain-invariant features and , the features of different hybrid sample set and target domain are fed into the corresponding branch network. In the branch network, the BFE employs a fully connected layer to map data into an individual latent space and obtains domain-specific features. In i-th BFE , the domain-specific features and are extracted by
in which denotes the parameters of . In addition, the Maximum Mean Discrepancy (MMD) loss is calculated to measure the differences in marginal distributions across domains. The formula of LMMD can be expressed as
where represents the domain-specific feature of the sample in the i-th hybrid sample set, denotes the domain-specific feature of the sample in the i-th branch network of the target domain, and Mi and Mt are the numbers of samples in the source domain and target domain, respectively. Then, the extracted domain-specific features of hybrid sample sets and target domain are sent to corresponding BTC to reduce feature dimensions to the number of emotion categories, and the softmax layer translates the output as probability distribution. The prediction of i-th BTC can be expressed as
Where represents the i-th branch task classifier, ŷi and denote the prediction results in i-th BTC. Furthermore, the classification loss is used to measure the difference between the predictions and the truth labels. During the training process, the calculation of classification loss Lcls can be expressed by cross-entropy as follows:
where p(·) is the indicator function, is the prediction of i-th hybrid sample set in c-th emotion category, yi represents the truth label of i-th source domain, C denotes the number of emotion categories. By minimizing the Lcls, the hybrid samples will exhibit a similar conditional distribution to that of the source domain samples. Since the hybrid samples incorporate information from the target domain samples, they can serve as a guide to align these target samples with the source domain samples, enhancing the model's adaptation effect, and improving the classification accuracy on the target domain.
3.3.5 Conditional entropy
In this study, the target domain data are unlabeled. Therefore, after training the classifiers using the data from source domain, the classifier might align more closely with the data distribution of the source domain while paying less attention to that of the target domain. Consequently, the decision boundary of classifier in the target domain could be inaccurate. To address this issue, this study introduces the conditional entropy loss Lce, which is defined by Shu et al. (2018):
where denotes the prediction result of the target-domain data output from i-th branch network. The conditional entropy loss measures the classification uncertainty of classifier. A high value of conditional entropy loss indicates that the classifier has a large uncertainty about the category belonging to input data. Therefore, by minimizing the conditional entropy loss, the classifier can be forced to make more certain predictions in the target domain, even though those predictions might not be completely accurate. In this way, the classifier's decision boundary will be pushed away from the high-density regions of the target domain data, reducing the probability of making uncertain predictions in these regions.
In summary, in the training stage, the proposed SH-MDA receives samples from source and target domains, and achieves distribution alignment between the source and target domains. The parameters of SH-MDA can be updated by minimizing the Ltotal :
where the λ1~λ3 is the balance parameters. The training procedure of SH-MDA model is presented in Algorithm 1.

Algorithm 1. The training procedure of SH-MDA.
3.4 Experiments
The proposed SH-MDA is implemented on PyTorch framework version 1.8.1 with the CUDA toolkit version 10.1, conducted cross-subject and cross-session experiments and compared with several state-of-the-art methods on two public emotion datasets. All the experiments were performed on a PC with an Intel (R) Core (TM) i9-10900X CPU, an NVIDIA GTX 2080Ti GPU, running the Windows 10 operating system. The codes of SH-MDA are available at https://github.com/Xitsuka/SH-MDA.
In the experiment, two validation paradigms were adopted: cross-subject and cross-session. In the common feature extractor, the extracted DE features were fed as the model input, and the feature dimension was reduced from 310 (62 × 5) to 64 after three layers of the MLP. In the three-layer MLP, a LeakyRelu (Xu et al., 2015) layer was used after each linear layer. In the domain discriminator, domain-invariant features pass through two fully connected layers, with the dimensionality reduced from 64 to the number of source domains. Next, in the BFE and BTC, only one fully connected layer was used; the BFE reduced the features from 64-D to 32-D, and then the BTC reduced the 32-D features to the number of categories. The Table 2 describes the network hyperparameters of SH-MDA.
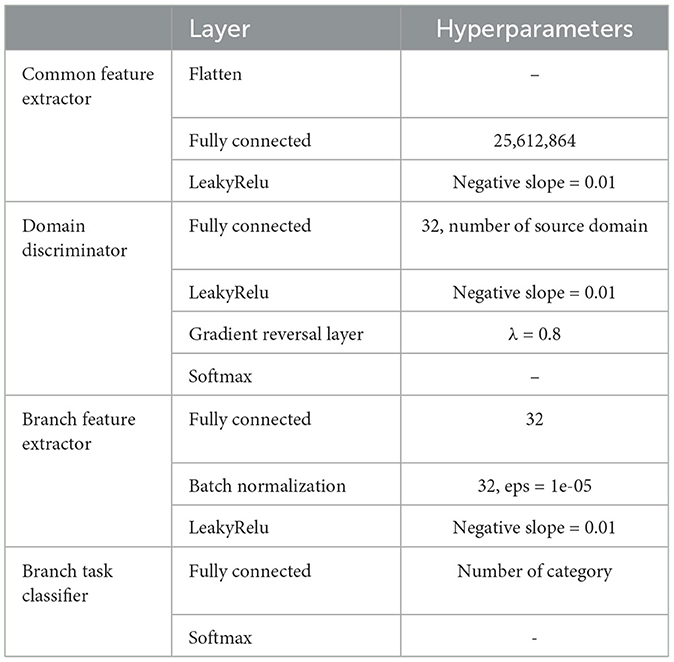
Table 2. Hyperparameters of proposed SH-MDA.
In the training process of SH-MDA, the Adam optimizer (Kingma and Ba, 2014) was used to update the network parameters. The balance parameter λ1 for Ldis was set to 0.1, selected from {0.01, 0.1, 0.5, 1.0} based on optimal performance. The LMMD used a dynamic parameter , as utilized in many studies (Chen et al., 2021; She et al., 2023), with its value increasing with the number of iterations. As the number of iterations progressed, the marginal distribution alignment between the source and target domains was gradually achieved. For λ3, we followed the setting from Shu et al. (2018); Jiménez-Guarneros and Fuentes-Pineda (2023), using a balance parameter of 0.1. The hybrid parameter λ was searched within the range of {0.4, 0.5, ..., 1.0}, and the optimal value is 0.8 in the cross-subject experiments and 0.6 in the cross-session experiments.
In addition, since the common feature extractor was updated by different domains, and the BFE and BTC received data only from the specific domains, the learning rate of the common feature extractor was set to a small value to ensure model stability. Particularly, the learning rate was set to 5e-4 for the common feature extractor, and 5e-3 for the domain discriminator and branch networks. The hyperparameters setting of experiments is described in Table 3 .
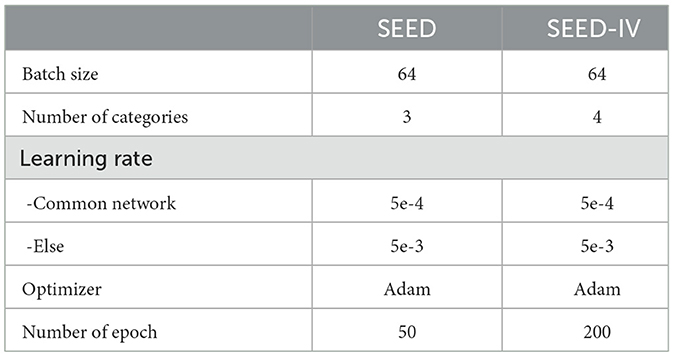
Table 3. The parameters setting for the experiments on SEED and SEED-IV datasets.
4 Results
4.1 Results of cross-subject experiments
In the cross-subject experiment, the leave-one-subject-out (LOSO) cross-validation strategy was used to evaluate the effectiveness of the model. In one session, a specific subject served as the target-domain data, while the data from that same session but originating from the other subjects was utilized as the source domain. The process of training and validation was repeated until each subject's sessions had been designated as the target once. For instance, in the SEED dataset, which contains data from 15 subjects, the data from one subject was designated as target-domain data, while the data from the other 14 subjects served as source-domain data, thus, there were 15 tasks in a single session. In this study, the average recognition accuracy of three sessions for each subject was used as the recognition accuracy of that subject, and the average accuracy of all the subjects was used as the final result of the cross-subject experiment of the model. The experiments on the SEED-IV dataset were conducted in the same way.
The accuracy for each subject is shown in Figure 5. The average recognition accuracy of the proposed model for each subject in the SEED dataset exceeded 80%, with a minimum of 80.37% and a maximum of 99.94%. Additionally, the recognition accuracy for eight out of the 15 subjects was higher than 90%. On the SEED-IV dataset, the proposed algorithm achieved a lowest average accuracy of 53.36%, a highest accuracy of 87.19%, and exceeded 70% accuracy for 11 subjects. In addition to accuracy, we analyzed the sensitivity, specificity, and F1 score of the model in cross-subject experiments. The results are presented in Table 4. On the SEED dataset, the sensitivity, specificity, and F1 score were 90.49, 95.71, and 90.24%, respectively; on the SEED-IV dataset, they were 74.29, 91.74 and 73.32%.
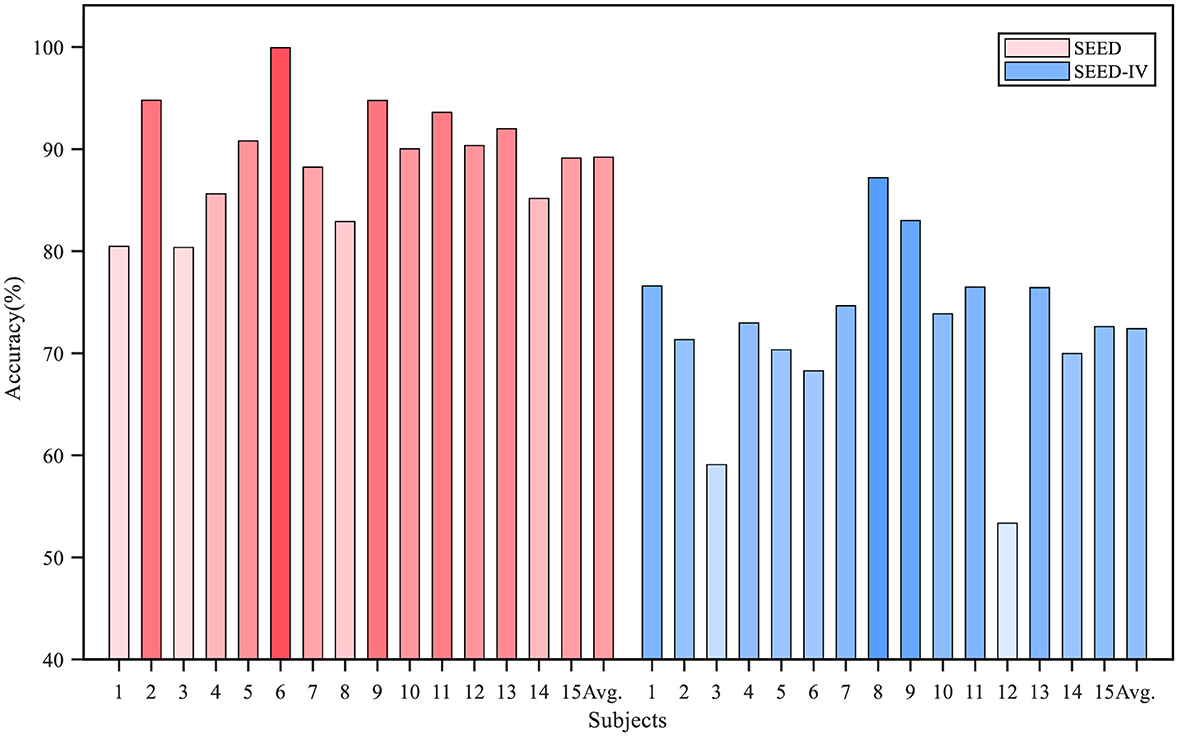
Figure 5. The recognition accuracy in the cross-subject experiment on the SEED and SEED-IV datasets. the i-th bar represents the average accuracy when i-th subject is selected as target domain.

Table 4. Performance of the propose method in cross-subject experiments.
4.2 Results of cross-session experiments
In the SEED and SEED-IV datasets, each subject conducted the experiment with three sessions. For each subject, in the cross-session experiments, the three sessions were used as the target domain in sequence, with each session serving as the target domain once while the other two served as the source domain. Finally, the average classification accuracy of the three sessions of all subjects was denoted as cross-session experimental result of the model.
The performance of the proposed model in the three sessions for each subject in the two datasets is shown in Figures 6, 7. The results demonstrated that in the cross-session experiment, where both the source and target domain were from the same subject's data, the difficulty of DA was reduced, and thus, the performance was better than that of the cross-subject experiment. On the SEED data set, the average accuracy of the three sessions was higher than 90%, and the accuracy of most sessions was higher than 80%. Meanwhile, the experiment results on the SEED-IV dataset also indicated good performance of the proposed model. The accuracy of the algorithm when the second and third sessions were used as a target domain was significantly higher than that when the first session was used, reaching 80.78 and 76.18%, respectively. Furthermore, as shown in Table 5, we also calculated the performance metrics of the model in cross-session experiments, including sensitivity, specificity, and F1 score. On the SEED dataset, these metrics were 94.18, 96.98, and 94.15%, while on the SEED-IV dataset, they were 75.69, 92.59, and 75.21%.
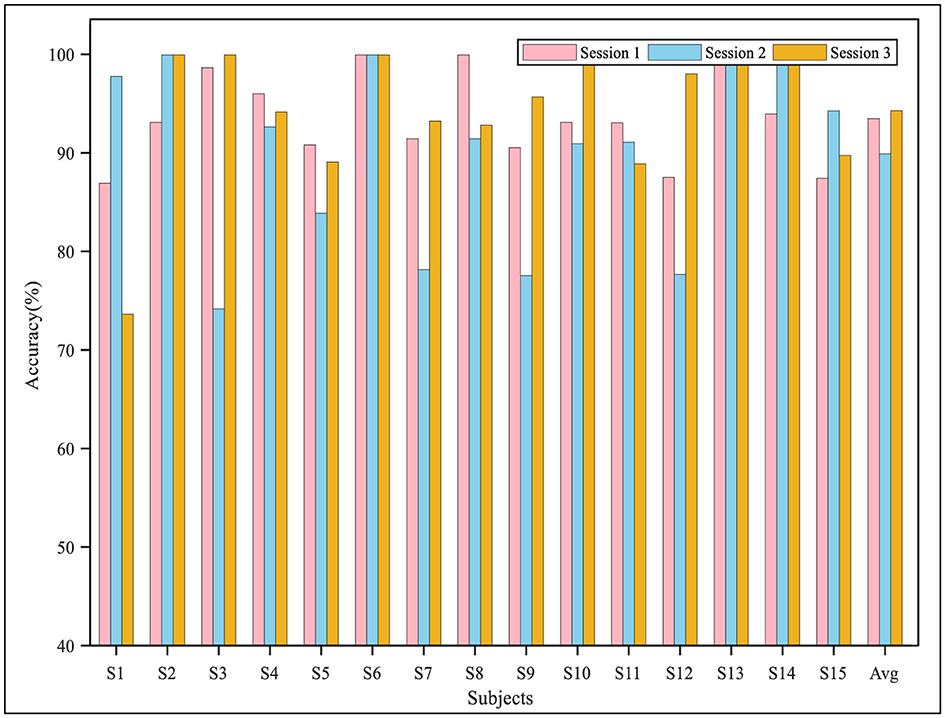
Figure 6. The classification accuracy in the cross-session experiment on the SEED dataset.
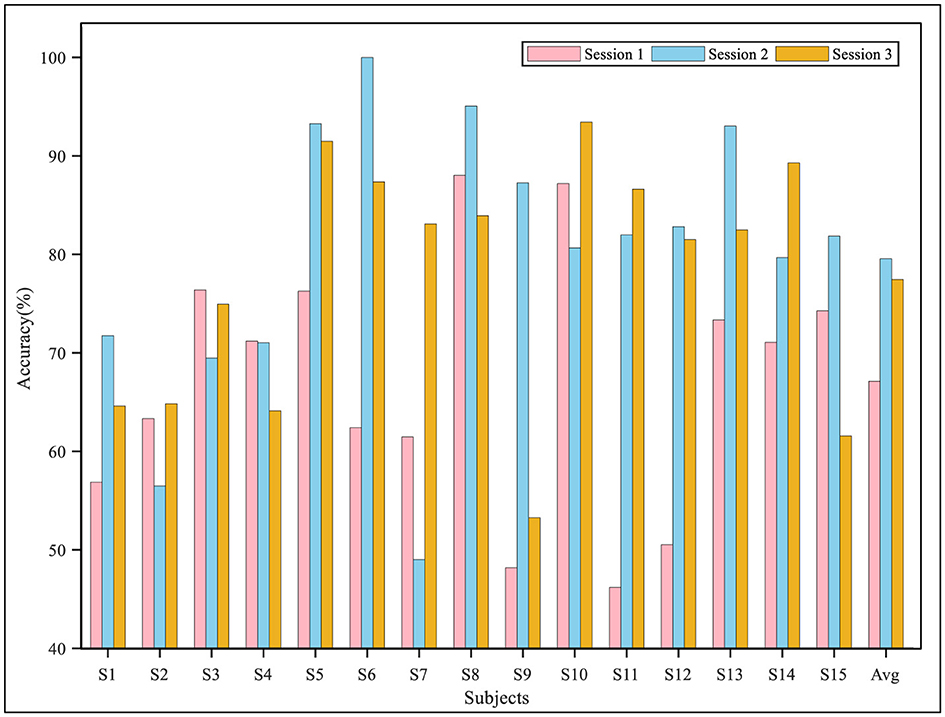
Figure 7. The classification accuracy in the cross-session experiment on the SEED-IV dataset.

Table 5. Performance of the propose method in cross-session experiments.
4.3 Comparison with the existing methods
To better demonstrate the performance of the model, the proposed method was compared with other optimal methods reported in existing studies. Table 6 shows the recognition accuracy and standard deviation of these methods across subjects in the SEED and SEED-IV datasets. Since the SEED dataset contained three emotion categories and the SEED-IV dataset contained four emotion categories, the classification accuracy of the model on the SEED-IV dataset was lower than that on the SEED dataset. For the SEED dataset, the proposed algorithm was significantly superior to the other algorithms, with an average accuracy of 90.27% in the three sessions, which was about 2% higher than that of the currently optimal algorithm. Meanwhile, the standard deviation of the proposed method was 5.56, which was also at the level of the existing best-performing method, demonstrating the stability of the proposed method. On the SEED-IV dataset, the proposed SH-MDA also showed better performance than the other methods, with an average accuracy of 73.41%, which was higher than the best accuracy reported in the related studies.
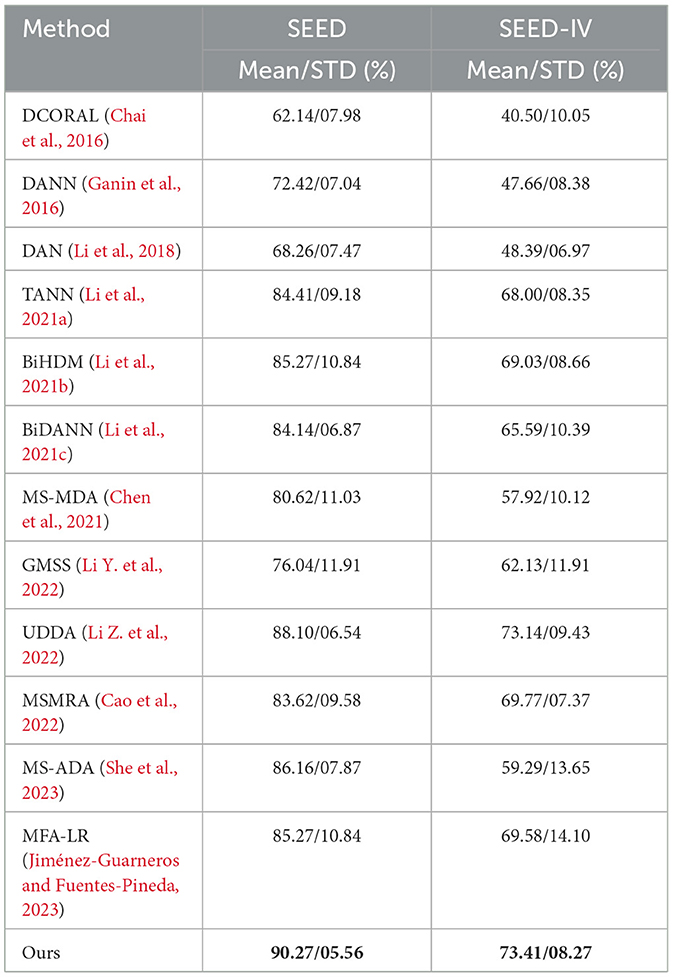
Table 6. Comparison of the accuracy in cross-subject experiments.
Table 7 illustrates the results of the proposed SH-MDA and other advanced methods in the cross-session experiments. The results indicated that, among all the algorithms, the proposed model achieved optimal performance on both public datasets. On the SEED dataset, the average accuracy of the proposed model stood at 94.16%, surpassing the MS-ADA model's accuracy by ~3%. However, the classification performance generally decreased due to the increased difficulty in classification on the SEED-IV dataset. The average accuracy of the SH-MDA method was 75.05%, which denoted an obvious performance improvement of 2.67% compared with the other algorithms.
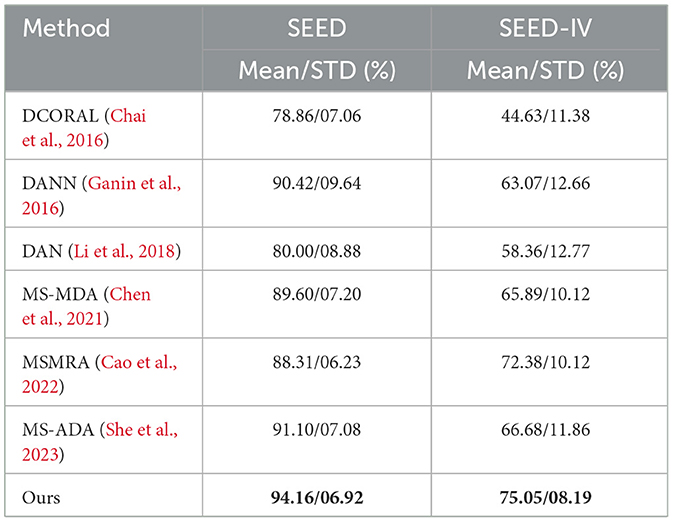
Table 7. Comparison of the accuracy in cross-session experiments.
4.4 Confusion matrix
The confusion matrices of the SH-MDA method for different datasets are presented in Figure 8. It should be noted that to ensure that the experimental results were convincing, the confusion matrix used data from three sessions. Figures 8A, B correspond to two different tasks on the SEED dataset. Obviously, in the cross-subject experiments, negative emotion was the most difficult to recognize, with an accuracy of 86.44%. In the two tasks, the model could easily confuse in the discrimination of neutral and negative emotions but maintained a high accuracy in the discrimination of positive emotions, with 95.36 and 97.02%.
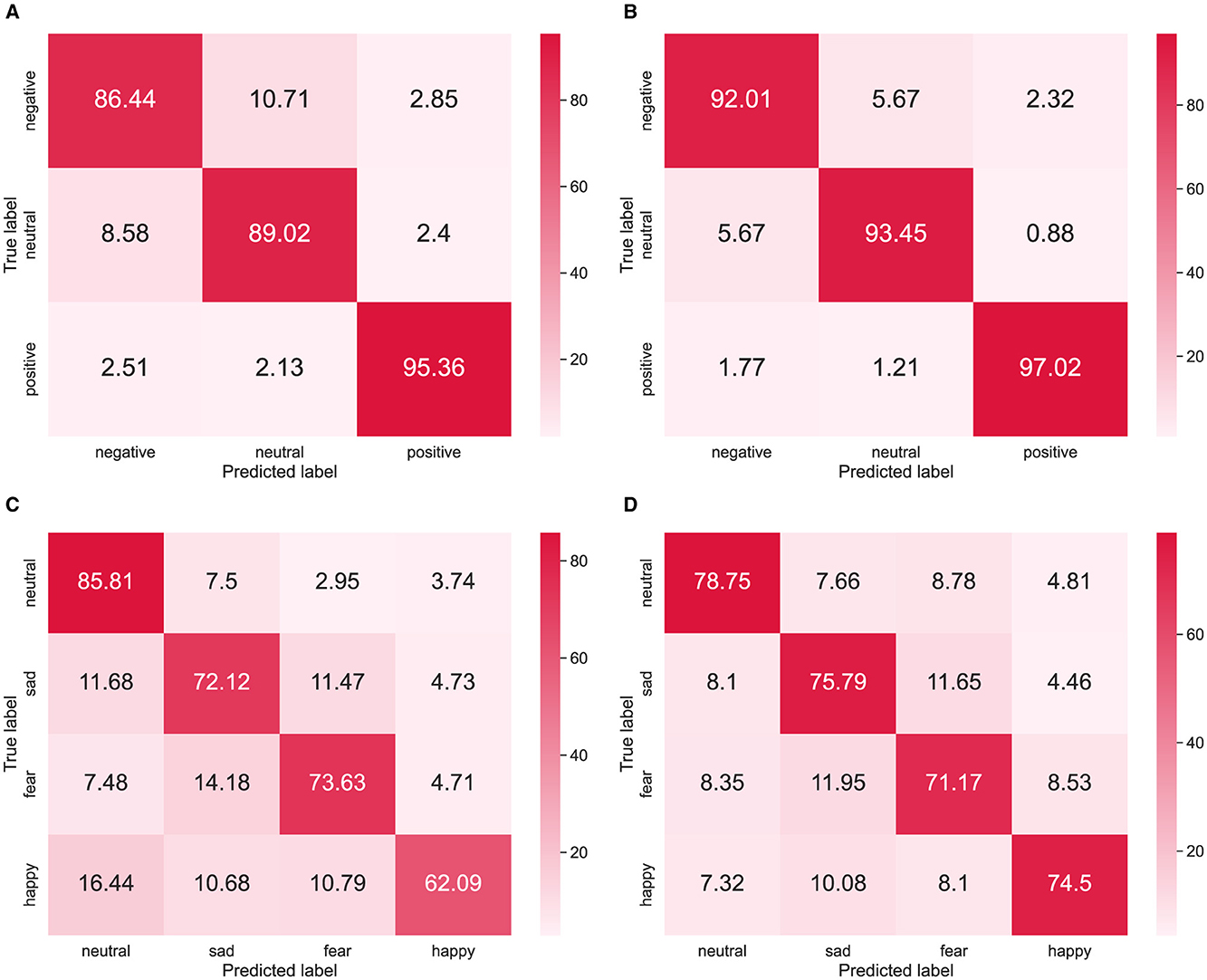
Figure 8. Confusion matrices of the SH-MDA in the cross-subject and cross-session experiments: (A, B) the results on the SEED dataset; (C, D) the results on the SEED-IV dataset.
Figures 8C, D show the confusion matrices on the SEED-IV dataset. The results indicated that the classification performance on the SEED-IV degraded compared with the SEED dataset. However, the model maintained good stability in recognizing each emotion category. In the two tasks,the model maintained high accuracy in the discrimination of neutral emotions, reaching 85.81 and 78.75%. Moreover, the model performed a high confusion probability in fear and sad emotion categories, which might indicate the potential relevance of the two emotions.
5 Discussion
5.1 Visualization
The t-SNE technology was used to visualize the changes of feature distribution of two dataset, which could reduce the data dimension while maintaining the data distribution in a low-dimensional space (Van der Maaten and Hinton, 2008). To simplify the experiment and enhance the visualization effects, the experiment was conducted only for the cross-subject task, and 100 EEG samples from each of the five subjects (domains) were randomly selected.
The changes in feature distribution of the SEED and SEED-IV datasets through the model are illustrated in Figure 9. Different colors represent different domains, and different graphs are used to represent different emotion categories. Figures 9A–C show the original feature distributions. To highlight the distribution of target samples, the target domain samples before model processing are represented in black. The original feature distribution indicated that there was a clear difference between the source-domain samples and the target-domain samples. In addition, category confusion existed in both target and source domains, which manifested in the SEED dataset as confusion between negative and neutral emotions; this was consistent with the confusion mentioned in the earlier confusion matrix. In the SEED-IV dataset, category confusion indicates mutual confusion between various emotion categories, which explained the observed decline in performance in this dataset.
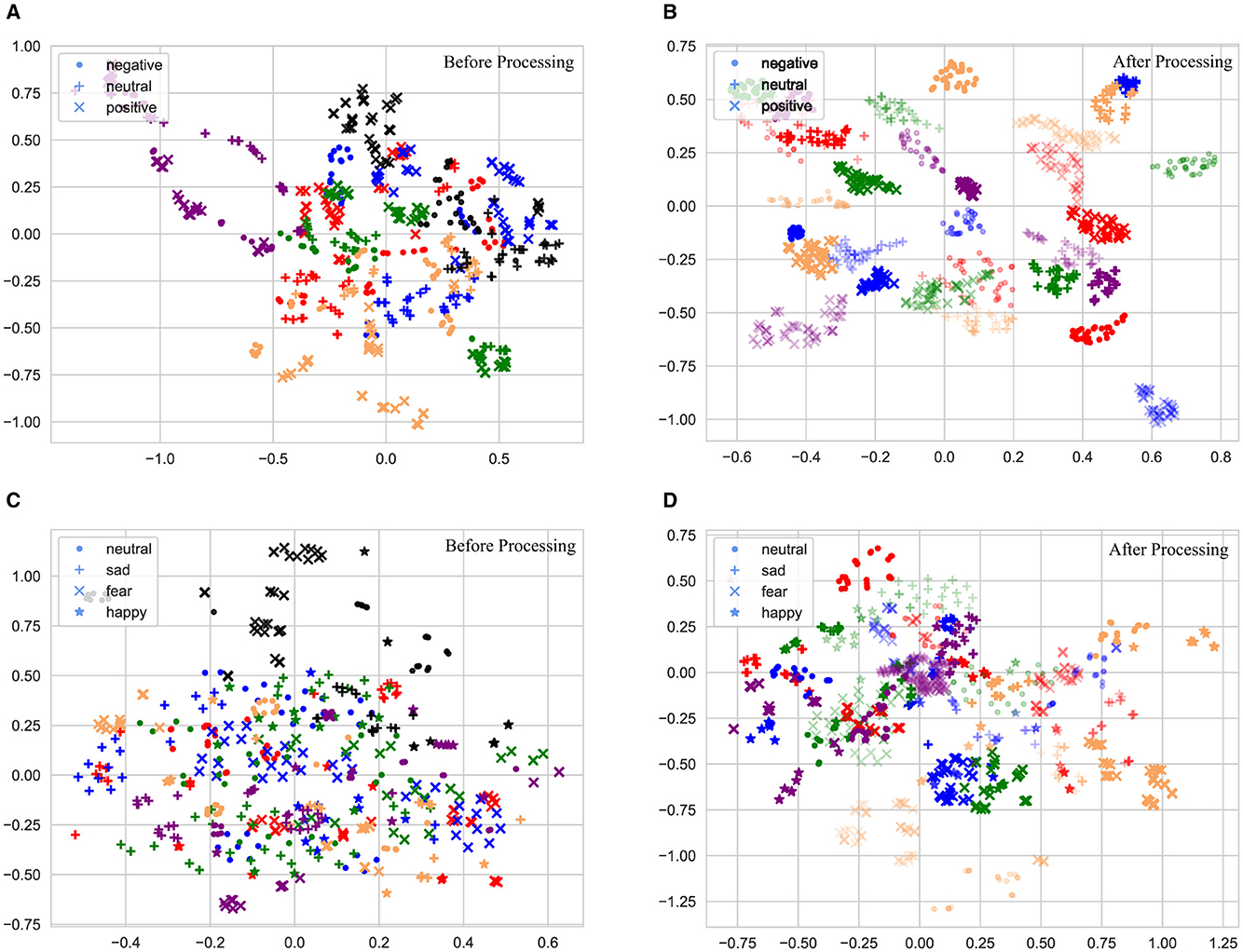
Figure 9. Scatter plot of feature distribution with the t-SNE on the SEED and SEED-IV datasets: (A, B) the feature distribution in the SEED dataset; (C, D) the feature distribution in the SEED-IV dataset.
The feature distributions after processing by the proposed model are displayed in Figures 9B–D; for better visualization, the processed target-domain samples are denoted as translucent while maintaining the same colors as their corresponding source-domain data for easy distinction. The results indicated that, the source-domain and target-domain samples exhibited a concentration of samples from the same category and separation of those from different categories, exemplifying the excellent performance of the proposed model in multi-source domain adaptation tasks.
5.2 Ablation experiment
In this article, the ablation experiments were conducted on two datasets. In the cross-subject and cross-session experiments, the average value of the three sessions was used as the result, as shown in Table 8.
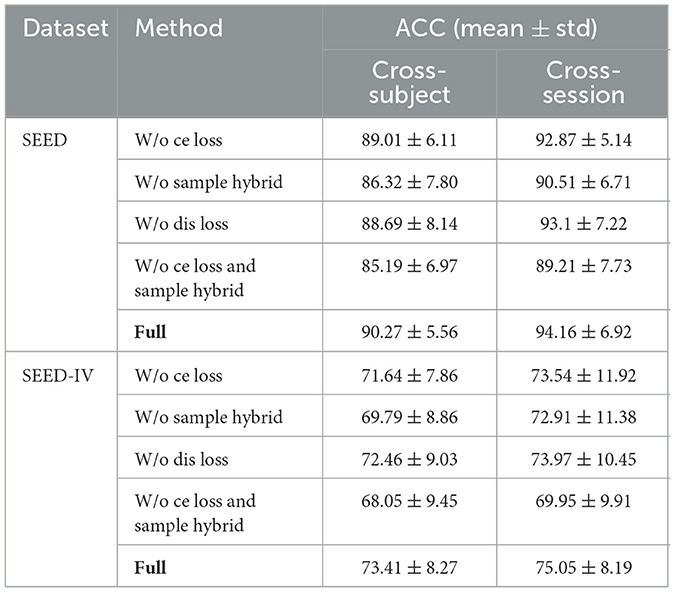
Table 8. The results of ablation experiments.
The last row in Table 8 presents the performance of the complete proposed model. First, during the training process, the conditional entropy loss was ablated. With a relatively small decrease in accuracy of about 1%, it was demonstrated that pushing the decision boundary away from the high-density regions in the target domain contributed to the model performance improvement. Moreover, even without the conditional entropy loss, the proposed model's results outperformed most of the comparative methods.
There was a substantial drop in model accuracy upon ablation of the hybrid method, with decreases of 3.95 and 3.65% on the SEED dataset and 3.62 and 2.14% on the SEED-IV dataset. This decline may stem from the model's inability to account for the alignment of inter-domain conditional distributions. Subsequently, discrimination loss was ablated, which also leads to the decline of the model performance. Finally, when both the conditional entropy loss and the hybrid loss were removed, the model was forced to focus only on the classification and MMD losses, and there was a significant decrease in performance compared with the full model. This result further substantiated the superiority of the proposed model.
5.3 Limitations
Although this study has achieved good recognition results, there are still certain limitations. First, The hybrid sample set is obtained by hybridizing the samples from the source domain and the samples from the target domain according to the hybrid parameter λ, however, this paper only performs global hybridizing without considering each sample, so the selection of this parameter may not always be optimal for each sample. Second, by minimizing the classification loss, the hybrid samples were compelled to be classified into the category of their associated source-domain samples, thus indirectly enhancing the likelihood of the target-domain samples being transferred to the correct category. However, although most target domain samples could be transferred to the corresponding categories with the guidance of hybrid samples, a small number of samples failed to adapt effectively to the correct categories due to their low similarity with the source-domain samples. Moreover, although our method was evaluated on two datasets, its generalization capability maybe needs to be further studied. The comparisons in this paper were limited to single-center data with a relatively small scale. Currently, a substantial amount of data comes from multiple centers. And due to differences in collection equipment, stimulus materials, experimental design, and other factors, significant variations exist among data from different centers. The performance of our algorithm when dealing with cross-center data has not yet been validated and requires further study.
Therefore, future work should focus on developing adaptive sample hybridization methods that allow the weights and targets of sample hybridization to be adjusted adaptively based on the differences between different source and target domains. Additionally, to enhance the model's ability to recognize emotions across centers, it is important to actively explore domain generalization methods and combine them with existing domain adaptation models to further improve the model's generalization capability and practicality.
6 Conclusion
This study proposes a novel multi-source domain adaptation EEG emotion recognition network model named SH-MDA, which aims to alleviate the difficulties of emotion recognition from the limited generalization ability of EEG features across subjects and sessions. In addition, a sample hybridization method that can effectively achieve the alignment of conditional distributions between the source and target domains is introduced. The cross-subject and cross-session experiment results demonstrate that, in comparison to other advanced methods, the proposed method can exhibit superior adaptability to multiple source domains and achieve optimal results on two different databases. Furthermore, the results of the ablation experiments validate the effectiveness of the proposed approach, and the results of the t-SNE visualization indicate that the SH-MDA can separate target-domain samples with different labels and cluster samples with the same label, thus enhancing the recognition performance. We proposed a novel multi-source domain adaptation method for emotion recognition tasks across subjects and sessions. This method can also be applied to other EEG classification tasks based on domain adaptation, such as motor imagery and fatigue state classification. Although the proposed method performs well, there are still some limitations. For instance, the sample hybridization in the model relies on hybrid weights and lacks cross-center recognition capability. Therefore, in future work, the adaptive sample hybridization and domain generalization methods should be investigated to further improve the domain adaptation effectiveness and generalization ability of this model.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://bcmi.sjtu.edu.cn/home/seed/seed.html.
Author contributions
XW: Writing – original draft, Writing – review & editing. XJ: Writing – review & editing. SD: Writing – review & editing. XL: Resources, Writing – review & editing. ML: Supervision, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Natural Science Foundation of China, grant number 62076248.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Alarcao, S. M., and Fonseca, M. J. (2017). Emotions recognition using EEG signals: a survey. IEEE Trans. Affect. Comput. 10, 374–393. doi: 10.1109/TAFFC.2017.2714671
AlShorman, O., Masadeh, M., Alzyoud, A., Heyat, M., Akhtar, F., and Rishipal (2020). “The effects of emotional stress on learning and memory cognitive functions: An EEG review study in education,” in 2020 Sixth International Conference on e-Learning (econf) (Sakheer: IEEE). doi: 10.1109/econf51404.2020.9385468
Borgwardt, K. M., Gretton, A., Rasch, M. J., Kriegel, H.-P., Schölkopf, B., and Smola, A. J. (2006). Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 22, e49–e57. doi: 10.1093/bioinformatics/btl242
Cao, J., He, X., Yang, C., Chen, S., Li, Z., and Wang, Z. (2022). Multi-source and multi-representation adaptation for cross-domain electroencephalography emotion recognition. Front. Psychol. 12:809459. doi: 10.3389/fpsyg.2021.809459
Chai, X., Wang, Q., Zhao, Y., Liu, X., Bai, O., and Li, Y. (2016). Unsupervised domain adaptation techniques based on auto-encoder for non-stationary EEG-based emotion recognition. Comput. Biol. Med. 79, 205–214. doi: 10.1016/j.compbiomed.2016.10.019
Chen, H., Jin, M., Li, Z., Fan, C., Li, J., and He, H. (2021). MS-MDA: multisource marginal distribution adaptation for cross-subject and cross-session eeg emotion recognition. Front. Neurosci. 15:778488. doi: 10.3389/fnins.2021.778488
Ekman, P., and Friesen, W. V. (1971). Constants across cultures in the face and emotion. J. Pers. Soc. Psychol. 17:124. doi: 10.1037/h0030377
Fiorini, L., Mancioppi, G., Semeraro, F., Fujita, H., and Cavallo, F. (2020). Unsupervised emotional state classification through physiological parameters for social robotics applications. Knowl. Based Syst. 190:105217. doi: 10.1016/j.knosys.2019.105217
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., et al. (2016). Domain-adversarial training of neural networks. J. Mach. Learn. Res. 17, 1–35. doi: 10.48550/arXiv.1505.07818
Guo, R., Guo, H., Wang, L., Chen, M., Yang, D., and Li, B. (2024). Development and application of emotion recognition technology—a systematic literature review. BMC. Psychol. 12:95. doi: 10.1186/s40359-024-01581-4
Haeusser, P., Frerix, T., Mordvintsev, A., and Cremers, D. (2017). “Associative domain adaptation,” in International Conference on Computer Vision (ICCV) (Venice: IEEE), 2765–2773.
Heyat, M., Akhtar, F., Abbas, S., Al-Sarem, M., Alqarafi, A., Stalin, A., et al. (2022). Wearable flexible electronics based cardiac electrode for researcher mental stress detection system using machine learning models on single lead electrocardiogram signal. Biosensors 12:427. doi: 10.3390/bios12060427
Jiménez-Guarneros, M., and Fuentes-Pineda, G. (2023). Learning a robust unified domain adaptation framework for cross-subject eeg-based emotion recognition. Biomed. Signal Process. Control 86:105138. doi: 10.1016/j.bspc.2023.105138
Ju, X., Li, M., Tian, W., and Hu, D. (2024). EEG-based emotion recognition using a temporal-difference minimizing neural network. Cogn. Neurodyn. 18, 405–416. doi: 10.1007/s11571-023-10004-w
Khare, S. K., Blanes-Vidal, V., Nadimi, E. S., and Acharya, U. R. (2024). Emotion recognition and artificial intelligence: a systematic review (2014-2023) and research recommendations. Inf. Fusion 102:102019. doi: 10.1016/j.inffus.2023.102019
Kingma, D. P., and Ba, J. (2014). Adam: a method for stochastic optimization. arXiv [preprint]. doi: 10.48550/arXiv.1412.6980
Li, H., Jin, Y.-M., Zheng, W.-L., and Lu, B.-L. (2018). “Cross-subject emotion recognition using deep adaptation networks,” In 25th International Conference on Neural Information Processing (ICONIP) (Springer), 403–413.
Li, J., Pan, W., Huang, H., Pan, J., and Wang, F. (2023). STGATE: spatial-temporal graph attention network with a transformer encoder for EEG-based emotion recognition. Front. Hum. Neurosci. 17:1169949. doi: 10.3389/fnhum.2023.1169949
Li, J., Qiu, S., Du, C., Wang, Y., and He, H. (2019). Domain adaptation for EEG emotion recognition based on latent representation similarity. Cogn. Syst. Res. 12, 344–353. doi: 10.1109/TCDS.2019.2949306
Li, W., Huan, W., Hou, B., Tian, Y., Zhang, Z., and Song, A. (2021). Can emotion be transferred?—a review on transfer learning for eeg-based emotion recognition. IEEE Trans. Cogn. Dev. Syst. 14, 833–846. doi: 10.1109/TCDS.2021.3098842
Li, Y., Chen, J., Li, F., Fu, B., Wu, H., Ji, Y., et al. (2022). GMSS: graph-based multi-task self-supervised learning for EEG emotion recognition. IEEE Trans. Affect. Comput. 14, 2512–2525. doi: 10.1109/TAFFC.2022.3170428
Li, Y., Fu, B., Li, F., Shi, G., and Zheng, W. (2021a). A novel transferability attention neural network model for eeg emotion recognition. Neurocomputing 447, 92–101. doi: 10.1016/j.neucom.2021.02.048
Li, Y., Wang, L., Zheng, W., Zong, Y., Qi, L., and Cui, Z. (2021b). A novel bi-hemispheric discrepancy model for EEG emotion recognition. IEEE Trans. COGN. DEV. SYST 13, 354–367. doi: 10.1109/TCDS.2020.2999337
Li, Y., Zheng, W., Wang, L., Zong, Y., and Cui, Z. (2019). From regional to global brain: a novel hierarchical spatial-temporal neural network model for EEG emotion recognition. IEEE Trans. Affect. Comput. 13, 568–578. doi: 10.1109/TAFFC.2019.2922912
Li, Y., Zheng, W., Zong, Y., Cui, Z., Zhang, T., and Zhou, X. (2021c). A bi-hemisphere domain adversarial neural network model for EEG emotion recognition. IEEE Trans. Affect. Comput 12, 494–504. doi: 10.1109/TAFFC.2018.2885474
Li, Z., Zhu, E., Jin, M., Fan, C., He, H., Cai, T., et al. (2022). Dynamic domain adaptation for class-aware cross-subject and cross-session EEG emotion recognition. IEEE J. Biomed. Health 26, 5964–5973. doi: 10.1109/JBHI.2022.3210158
Liang, Z., Zhou, R., Zhang, L., Li, L., Huang, G., Zhang, Z., et al. (2021). EEGFUseNet: hybrid unsupervised deep feature characterization and fusion for high-dimensional EEG with an application to emotion recognition. IEEE Trans. Neural Syst. Rehabil. Eng. 29, 1913–1925. doi: 10.1109/TNSRE.2021.3111689
Liu, Y.-J., Yu, M., Zhao, G., Song, J., Ge, Y., and Shi, Y. (2017). Real-time movie-induced discrete emotion recognition from EEG signals. IEEE Trans. Affect. Comput. 9, 550–562. doi: 10.1109/TAFFC.2017.2660485
Lu, W., Liu, H., Ma, H., Tan, T.-P., and Xia, L. (2023). Hybrid transfer learning strategy for cross-subject EEG emotion recognition. Front. Hum. Neurosci. 17:1280241. doi: 10.3389/fnhum.2023.1280241
Malfliet, A., Coppieters, I., Van Wilgen, P., Kregel, J., De Pauw, R., Dolphens, M., et al. (2017). Brain changes associated with cognitive and emotional factors in chronic pain: a systematic review. Eur. J. Pain 21, 769–786. doi: 10.1002/ejp.1003
Mehrabian, A. (1996). Pleasure-arousal-dominance: a general framework for describing and measuring individual differences in temperament. Curr. Psychol. 14, 261–292. doi: 10.1007/BF02686918
Niu, W., Ma, C., Sun, X., Li, M., and Gao, Z. (2023). A brain network analysis-based double way deep neural network for emotion recognition. IEEE Trans. Neural Syst. Rehabil. Eng. 31, 917–925. doi: 10.1109/TNSRE.2023.3236434
Pal, R., Adhikari, D., Heyat, M., Guragai, B., Lipari, V., Ballester, J., et al. (2022). A novel smart belt for anxiety detection, classification, and reduction using iiomt on students' cardiac signal and msy. Bioengineering 9:793. doi: 10.3390/bioengineering9120793
Pan, D., Zheng, H., Xu, F., Ouyang, Y., Jia, Z., Wang, C., et al. (2023). MSFR-GCN: a multi-scale feature reconstruction graph convolutional network for eeg emotion and cognition recognition. IEEE Trans. Neural Syst. Rehabil. Eng. 31, 3245–3254. doi: 10.1109/TNSRE.2023.3304660
Parveen, S., Heyat, M., Akhtar, F., Parveen, S., Asrafali, B., Singh, B., et al. (2023). “Interweaving artificial intelligence and bio-signals in mental fatigue: unveiling dynamics and future pathways,” in 2023 20th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Volume 21 (Chengdu: IEEE), 1–9. doi: 10.1109/iccwamtip60502.2023.10387132
Peng, Y., Wang, W., Kong, W., Nie, F., Lu, B.-L., and Cichocki, A. (2022). Joint feature adaptation and graph adaptive label propagation for cross-subject emotion recognition from EEG signals. IEEE Trans. Affect. Comput. 13, 1941–1958. doi: 10.1109/TAFFC.2022.3189222
Prabowo, D. W., Nugroho, H. A., Setiawan, N. A., and Debayle, J. (2023). A systematic literature review of emotion recognition using EEG signals. IEEE Trans. Cogn. Dev. Syst. 82:101152. doi: 10.1016/j.cogsys.2023.101152
Ran, S., Zhong, W., Duan, D., Ye, L., and Zhang, Q. (2023). SSTM-IS: simplified stm method based on instance selection for real-time EEG emotion recognition. Front. Hum. Neurosci. 17:1132254. doi: 10.3389/fnhum.2023.1132254
She, Q., Zhang, C., Fang, F., Ma, Y., and Zhang, Y. (2023). Multisource associate domain adaptation for cross-subject and cross-session EEG emotion recognition. IEEE Trans. Instrum. Meas. 72:3277985. doi: 10.1109/TIM.2023.3277985
Shu, R., Bui, H. H., Narui, H., and Ermon, S. (2018). A DIRT-T approach to unsupervised domain adaptation. arXiv [preprint]. doi: 10.48550/arXiv.1802.08735
Sun, B., and Saenko, K. (2016). “Deep coral: correlation alignment for deep domain adaptation,” in 16th European Conference on Computer Vision (ECCV) (Amsterdam: Springer), 443–450.
Tyng, C. M., Amin, H. U., Saad, M. N., and Malik, A. S. (2017). The influences of emotion on learning and memory. Front. Psychol. 8:235933. doi: 10.3389/fpsyg.2017.01454
Van der Maaten, L., and Hinton, G. (2008). Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605.
Venkatraman, A., Edlow, B. L., and Immordino-Yang, M. H. (2017). The brainstem in emotion: a review. Front. Neuroanat. 11:15. doi: 10.3389/fnana.2017.00015
Wan, Z., Yang, R., Huang, M., Zeng, N., and Liu, X. (2021). A review on transfer learning in eeg signal analysis. Neurocomputing 421, 1–14. doi: 10.1016/j.neucom.2020.09.017
Wang, F., Zhang, W., Xu, Z., Ping, J., and Chu, H. (2021). A deep multi-source adaptation transfer network for cross-subject electroencephalogram emotion recognition. Neural Comput. Appl. 33, 9061–9073. doi: 10.1007/s00521-020-05670-4
Wang, Y., Qiu, S., Ma, X., and He, H. (2021). A prototype-based SPD matrix network for domain adaptation EEG emotion recognition. Pattern Recognit. 110:107626. doi: 10.1016/j.patcog.2020.107626
Wang, Z., Li, S., Luo, J., Liu, J., and Wu, D. (2024). Channel reflection: knowledge-driven data augmentation for eeg-based brain–computer interfaces. Neural Netw. 176:106351. doi: 10.1016/j.neunet.2024.106351
Wu, D., Xu, Y., and Lu, B.-L. (2020). Transfer learning for EEG-based brain-computer interfaces: a review of progress made since 2016. IEEE Trans. Cogn. Dev. Syst. 14, 4–19. doi: 10.1109/TCDS.2020.3007453
Xu, B., Wang, N., Chen, T., and Li, M. (2015). Empirical evaluation of rectified activations in convolutional network. arXiv [preprint]. doi: 10.48550/arXiv.1505.00853
Yu, W.-W., Jiang, J., Yang, K.-F., Yan, H.-M., and Li, Y.-J. (2023). LGSNet: a two-stream network for micro-and macro-expression spotting with background modeling. IEEE Trans. Affect. Comput. 15, 223–240. doi: 10.1109/TAFFC.2023.3266808
Zhang, H., Cissé, M., Dauphin, Y., and Lopez-Paz, D. (2017). mixup: beyond empirical risk minimization. arXiv [preprint]. doi: 10.48550/arXiv.1710.09412
Zheng, W.-L., Liu, W., Lu, Y., Lu, B.-L., and Cichocki, A. (2018). Emotionmeter: a multimodal framework for recognizing human emotions. IEEE Trans. Cybern. 49, 1110–1122. doi: 10.1109/TCYB.2018.2797176
Zheng, W.-L., and Lu, B.-L. (2015). Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks. IEEE Trans. Auton. Ment. Dev. 7, 162–175. doi: 10.1109/TAMD.2015.2431497
Zheng, W.-L., Zhu, J.-Y., and Lu, B.-L. (2017). Identifying stable patterns over time for emotion recognition from EEG. IEEE Trans. Affect. Comput. 10, 417–429. doi: 10.1109/TAFFC.2017.2712143
Zhou, R., Ye, W., Zhang, Z., Luo, Y., Zhang, L., Li, L., et al. (2023). EEGMatch: learning with incomplete labels for semi-supervised EEG-based cross-subject emotion recognition. arXiv [preprint]. doi: 10.48550/arXiv.2304.06496
Keywords: electroencephalogram, emotion recognition, multi-source domain adaptation, sample hybridization, brain computer interaction
Citation: Wu X, Ju X, Dai S, Li X and Li M (2024) Multi-source domain adaptation for EEG emotion recognition based on inter-domain sample hybridization. Front. Hum. Neurosci. 18:1464431. doi: 10.3389/fnhum.2024.1464431
Received: 14 July 2024; Accepted: 15 October 2024;
Published: 31 October 2024.
Edited by:
Zohreh Mousavi, Southern University of Science and Technology, ChinaReviewed by:
Mirsaeed Abdollahi, Tabriz University of Medical Sciences, IranZhipeng He, Sun Yat-sen University, China
Lei Su, Kunming University of Science and Technology, China
Belal Bin Heyat, Westlake University, China
Copyright © 2024 Wu, Ju, Dai, Li and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ming Li, bGltaW5nNzhAbnVkdC5lZHUuY24=