 Swetha Dhamercherla1
Swetha Dhamercherla1 Suresh Dara
Suresh Dara
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Genet., 21 March 2025
Sec. Computational Genomics
Volume 16 - 2025 | https://doi.org/10.3389/fgene.2025.1528810
Microarray gene expression data have emerged as powerful tools in cancer classification and diagnosis. However, the high dimensionality of these datasets presents significant challenges for feature selection, leading to the development of various computational methods. In this paper, we utilized the Eagle Prey Optimization (EPO), a novel genetically inspired approach for microarray gene selection in cancer classification. EPO draws inspiration from the remarkable hunting strategies of eagles, which exhibit unparalleled precision and efficiency in capturing prey. Similarly, our algorithm aims to identify a small subset of informative genes that can discriminate between cancer subtypes with high accuracy and minimal redundancy. To achieve this, EPO employs a combination of genetic mutation operator with EPO fitness function, to evolve a population of potential gene subsets over multiple generations. The key innovation of EPO lies in its incorporation of a fitness function specifically designed for cancer classification tasks. This function considers not only the discriminative power of selected genes but also their diversity and redundancy, ensuring the creation of compact and informative gene subsets. Moreover, EPO incorporates a mechanism for adaptive mutation rates, allowing the algorithm to explore the search space efficiently. To validate the effectiveness of EPO, extensive experiments were conducted on several publicly available microarray datasets representing different cancer types. Comparative analysis with state-of-the-art gene selection algorithms demonstrates that EPO consistently outperforms these methods in terms of classification accuracy, dimensionality reduction, and robustness to noise.
Cancer, one of the most formidable and devastating diseases afflicting humanity, is characterized by the uncontrolled growth and spread of abnormal cells within the body. Early and accurate diagnosis is paramount for effective treatment and improved patient outcomes. In the realm of cancer research, microarray gene expression profiling has emerged as a groundbreaking technology, offering insights into the intricate molecular mechanisms underlying various cancer subtypes. However, the high dimensionality of microarray data, characterized by thousands of gene features, poses a formidable challenge to the effective classification of cancer samples. In this context, the task of identifying a minimal subset of informative genes, while preserving the discriminative power of the data, becomes imperative. Gene selection, a critical preprocessing step in microarray analysis, aims to address this challenge by pinpointing the genes most relevant to the classification task. Numerous computational methods have been proposed to tackle this problem, ranging from filter-based approaches to wrapper-based algorithms. Nevertheless, the search for an optimal gene subset that maximizes classification accuracy and minimizes redundancy remains a complex and evolving area of research.
Whereas, the task of the feature selection is considered to be a fundamental and critical step in the process of data analysis, machine learning, and statistical modeling. It refers to the process of choosing a subset of relevant and informative features (or variables) from a larger pool of available features in a dataset. The primary objective of feature selection is to improve the performance of predictive models, reduce computational complexity, enhance interpretability, and mitigate the risk of overfitting. In real-world datasets, especially in fields such as biology, finance, image analysis, and natural language processing, it is common to encounter datasets with a multitude of features, some of which may be redundant, noisy, or irrelevant. The presence of such features can have adverse effects on the performance of machine learning algorithms. These effects include increased computational demands, reduced model generalization, and difficulty in understanding the underlying patterns in the data.
Feature selection offers a solution to these challenges by systematically identifying and retaining only those features that contribute the most to the predictive power of a model. By reducing the dimensionality of the data, feature selection simplifies the modeling process, often resulting in models that are easier to train, interpret, and deploy in practical applications.
Among the various available techniques for feature selection, the use of optimization techniques plays a pivotal role in feature selection. Feature selection involves choosing a subset of relevant features from a larger pool of variables to improve model performance, reduce computational complexity, and enhance interpretability. This process is essential for improving the efficiency and effectiveness of data analysis and modeling. Optimization methods offer a systematic and principled approach to tackling this challenging problem.
Firstly, optimization techniques provide a formal framework for defining and optimizing an objective function or criterion that quantifies the quality of a feature subset. The objective function can be tailored to the specific goals of feature selection, whether it is maximizing classification accuracy, minimizing computational cost, or achieving a trade-off between various performance metrics. Through this optimization process, one can systematically search through the space of all possible feature subsets to find the most promising subset that optimizes the chosen criterion.
Secondly, optimization methods enable the exploration of large and complex feature spaces efficiently. Given the exponential growth in the number of possible feature combinations with increasing data dimensionality, brute-force methods become computationally infeasible. Optimization algorithms, such as genetic algorithms, simulated annealing, or particle swarm optimization, offer efficient search strategies that can navigate through this vast feature space to identify relevant subsets, even in high-dimensional datasets.
Furthermore, optimization techniques allow for the incorporation of domain-specific knowledge and constraints into the feature selection process. Researchers and practitioners can encode their expertise or prior information into the optimization algorithm, ensuring that the selected feature subsets adhere to specific requirements or characteristics relevant to the problem domain.
Additionally, optimization-based feature selection methods facilitate the exploration of trade-offs between competing objectives. For instance, one might aim to simultaneously maximize classification accuracy while minimizing the number of selected features to reduce model complexity. Multi-objective optimization approaches can efficiently handle such scenarios, generating a range of Pareto-optimal solutions that represent the trade-off front between conflicting objectives.
Despite the advances in optimization algorithms for feature selection in microarray gene expression data, challenges remain in balancing exploration and exploitation to achieve efficient and effective gene selection. High-dimensional data, such as microarray data, poses inherent difficulties, including redundancy, noise, and the risk of overfitting in machine learning models. Existing meta-heuristic algorithms, while powerful, often suffer from premature convergence or excessive computational costs, especially when applied to datasets with high dimensionality and small sample sizes. This gap in achieving robust, efficient, and biologically interpretable solutions for cancer classification motivated the development of the Eagle Prey Optimization (EPO) algorithm. The inspiration behind EPO lies in the hunting strategies of eagles, which naturally balance global exploration and local exploitation.
In this context, Eagle Prey Optimization (EPO) emerges as a novel and genetically inspired approach designed to address the complex problem of microarray gene selection in cancer classification. EPO takes inspiration from the awe-inspiring hunting strategies of eagles, which are renowned for their precision and efficiency in capturing prey. In a similar vein, EPO seeks to identify a concise and informative set of genes that can effectively discriminate between different cancer subtypes while minimizing redundancy and maintaining robustness. This paper introduces the concept of Eagle Prey Optimization and presents its application in the domain of microarray gene selection for cancer classification. Through rigorous experimentation and comparative analysis with state-of-the-art algorithms, we demonstrate the superior performance of EPO in terms of classification accuracy, dimensionality reduction, and robustness to noise. Furthermore, we highlight the algorithm’s ability to unveil biologically relevant genes associated with cancer pathways, thereby contributing to our understanding of the molecular basis of cancer subtypes. The integration of EPO in cancer research not only enhances the diagnostic potential but also holds the promise of discovering novel biomarkers and therapeutic targets, ultimately advancing the field of precision medicine and improving the prognosis of cancer patients. This paper delves into the intricacies of Eagle Prey Optimization, its genetic-inspired mechanisms, and its potential to revolutionize microarray gene selection in cancer classification.
This paper presents several significant contributions that advance the field of cancer classification and microarray gene selection using the proposed EPO algorithm. The main contributions of the work are given as:
• Introduces Eagle Prey Optimization, a novel optimization algorithm inspired by the hunting strategies of eagles. EPO is specifically tailored for microarray gene selection in cancer classification, offering a unique approach to address the challenges associated with high-dimensional gene expression data.
• EPO leverages genetic-inspired mechanisms to evolve a population of potential gene subsets over multiple generations. This genetic inspiration allows EPO to explore the search space effectively and efficiently, mimicking the precision and efficiency of eagles in hunting prey.
• EPO incorporates a specialized fitness function designed for cancer classification tasks. This function takes into account not only the discriminative power of selected genes but also their diversity and redundancy, promoting the creation of compact and informative gene subsets that enhance classification accuracy.
• Provides comprehensive experimental results of the EPO using the various different cancer type datasets having high dimensional feature representation and comparing EPO with state-of-the-art gene selection algorithms.
The rest of the paper is organized as follows: Section 2 provides an overview of the existing literature on feature selection methods for microarray data in cancer classification. It discusses various optimization algorithms, genetic-inspired approaches, and their applications in gene selection. The paper delves into the details of the proposed EPO algorithm in Section 3. It explains the genetic-inspired mechanisms used in EPO and the dedicated fitness function for cancer classification is described in depth, highlighting its role in promoting the selection of informative and non-redundant gene subsets. The experimental methodology is presented in Section 4. It outlines the datasets used for validation, the performance metrics employed, and the results of the experiments conducted to evaluate the performance of EPO. The paper concludes by summarizing the key findings and contributions of the research in Section 6.
Microarray gene expression data analysis has significantly advanced our understanding of cancer biology and has played a pivotal role in cancer classification and diagnosis. However, the high dimensionality of microarray data, characterized by thousands of gene expression profiles, poses a major challenge. Feature selection techniques have become essential in addressing this challenge by identifying a subset of informative genes that are most relevant for cancer classification. In the past literature on microarray gene expression feature selection, extensive research has been conducted to develop and evaluate various methods and techniques. These methods aim to identify a subset of relevant genes from the large pool of gene expression data to improve the accuracy and interpretability of cancer classification models.
On a similar theme, the work introduced in (Peng et al., 2005), proposed a feature selection method that maximizes mutual information while minimizing redundancy among selected features, enhancing the informativeness of the selected genes for cancer classification. Whereas, a team of several authors also worked on the comparative analysis of feature selection (Almugren and Alshamlan, 2019; Mohd Ali et al., 2022; Remeseiro and Bolon-Canedo, 2019; Alhenawi et al., 2022). These studies evaluate various feature selection methods and multiclass classification algorithms for microarray-based tissue classification. They provide insights into the best approaches for accurate cancer subtype classification.
The work proposed in (Houssein et al., 2022), presents an integrated approach combining manta rays foraging optimization and support vector machine methods for gene selection and cancer classification, achieving improved classification performance. Using the strategy of optimization only, the work proposed in Othman et al. (2020) uses the gene selection algorithm inspired by the cuckoo search optimization algorithm with evolutionary operators for cancer microarray data. It demonstrates improved performance in terms of classification accuracy and feature selection efficiency. Also, the authors of Aziz (2022) use the hybrid approach, using cuckoo optimization as one algorithm for cancer classification. The use of the cuckoo search optimization algorithm is also found satisfactory in collaboration with other optimization algorithms, making a hybrid approach for various application areas (Priya et al., 2022; Senapati et al., 2023; Kalaiarasu and Anitha, 2020; Segera, 2021).
Several authors also showed the reliability of the genetic algorithm on microarray gene expression datasets for feature reduction and dimensionality reduction. One such work is proposed in Ram and Kuila (2019) where the authors present a genetic algorithm for microarray gene selection. It employs a feature ranking strategy to improve classification accuracy and reduce dimensionality. In addition to the genetic algorithms, the use of manifold learning is also utilized by some authors for cancer classification using the gene dataset (Wang et al., 2023). In a couple of recent works, the genetic algorithm is also used in the hybridization of the algorithms for the selection of the more robust features for high-dimensional cancer datasets (Ge et al., 2019; Ali and Saeed, 2023). The results from these research articles boost the interest in using hybrid algorithms as they improve classification accuracy. Besides this, the use of genetic algorithms is also found to enhance the effectiveness of similarity searching in ligand-based virtual screening which is proposed in Berrhail and Belhadef (2020). Some of the authors explored the use of the feature-thresholds guided genetic algorithm for feature scoring on high-dimensional datasets (Deng et al., 2023). This new variant of the genetic algorithm improves the classification accuracy by using a limited set of selected genes.
In one of the works on high-dimensional datasets, the literature introduces a distance ratio-based feature selection algorithm that considers both inter-class and intra-class distances to identify informative genes for cancer classification (Brankovic et al., 2018). Similarly in the article (Zhou et al., 2022), authors proposed a new approach using the mutual information with correlation coefficient for feature selection on high dimensional datasets. Whereas, the critical analysis of the various feature selection approaches and their stability prediction is presented in one of the current research studies (Khaire and Dhanalakshmi, 2022).
In some of the works, the authors proposed the use of the quantum approach with the optimization algorithms for reducing high dimensional data. On this, the work introduces a quantum binary particle swarm optimization algorithm tailored for feature selection in gene expression data, highlighting its ability to identify relevant genes for cancer classification with high efficiency (Wu et al., 2019). Similarly, in Ghosh et al. (2021) the authors proposed a quantum squirrel-inspired algorithm for gene selection in methylation and expression data of prostate cancer. The work claimed that the quantum-inspired algorithm variant provides good results with the selection of the relevant genes. Several other variants of the quantum-inspired form of various optimization algorithms were also present in the literature for the selection of the relevant genes from the high dimensional dataset (Dabba et al., 2020; Wang et al., 2020). Also, the details of the quantum meta-heuristic algorithms and their role in various engineering applications were also presented in the literature (Prakash, 2021).
In some of the recently published works on gene selection for cancer classification, authors have used a variety of approaches. One such approach is the use of hybridization. In Mahesh et al. (2024), authors have proposed the use of the hybrid model that integrates the strengths of Ant Colony Optimization (ACO) and Particle Swarm Optimization (PSO) to enhance feature selection and classification accuracy. The model’s effectiveness is demonstrated through its application in predicting leukemia, achieving a notable accuracy of 87.88% using a Support Vector Machine (SVM) for classification. In another recent work, proposed in 2024 (Sucharita et al., 2024), authors proposed a two-step hybrid approach that begins with an ensemble of filter-based heterogeneous feature selection methods. This initial step is crucial as filter methods are known for their efficiency in handling high-dimensional datasets by evaluating the relevance of features based on statistical measures without involving any classifier. In the second step, the selected features undergo a wrapper-based selection process. Here, the authors employ the Moth-Flame Optimization (MFO) algorithm, which is a bio-inspired optimization technique (Zamani et al., 2024). The fitness function for this optimization is based on an Extreme Learning Machine (ELM), which is known for its rapid learning capabilities and one-pass processing of samples. This characteristic of ELM allows for efficient training, making it suitable for scenarios where computational resources are limited.
In another work, an author used the two computational approaches for cell-type shared and specific binding (Zhang et al., 2023). Authors characterize cell-type-specific and shared binding sites by integrating multiple types of features, utilizing XGBoost and convolutional neural networks (CNNs). The integration of diverse features is found crucial in their study for enhancing model performance in biological contexts as evidenced by recent studies that highlight the importance of feature diversity in improving predictive accuracy for transcription factor (TF) binding sites. The experimental results demonstrate that both the XGBoost and CNN models significantly outperform existing methods across three classification tasks, supporting the assertion that advanced machine-learning techniques can effectively capture the complexities of biological data.
Besides the microarray gene expression data, there exists work in the literature on another class of dataset called next-generation sequencing (NGS) data. Optimization techniques can be applied to next-generation sequencing (NGS) data in various ways to extract valuable insights and enhance the analysis of biological and genomic information. NGS data optimization typically focuses on improving data quality, computational efficiency, and the extraction of biologically relevant information. Many authors worked on this domain recently to optimize the NGS data using optimization approaches.
One such different work is proposed in McNulty et al. (2019) on the NGS dataset. This research contributes to the field of cancer genomics by offering a data-driven and adaptable solution for filtering common germline polymorphisms from tumor-only NGS data. The optimized cutoffs provide a more reliable basis for somatic mutation identification, improving the precision and clinical relevance of cancer genomics research and personalized medicine.
In the work (Pellegrino et al., 2023), the authors used the fusion of Extreme Gradient Boosting and metaheuristic algorithms to provide a robust and effective framework for predicting pathogenicity in myeloid NGS onco-somatic variants. The integration of these techniques holds the potential to enhance our understanding of the genetic underpinnings of myeloid malignancies, supporting precision medicine initiatives and improving patient outcomes in the field of onco-hematology.
The work proposed by the authors of Halim (2020) considered the optimization of the DNA fragment assembly as a critical task in genomics and bioinformatics, where researchers aim to reconstruct the complete DNA sequence from a set of smaller overlapping fragments. The Overlap-Layout-Consensus (OLC) approach here is a fundamental method in this process, and metaheuristic-based techniques offer innovative ways to enhance the efficiency and accuracy of DNA fragment assembly. Whereas in MotieGhader et al. (2020), the research contributes to the advancement of breast cancer molecular subtype stratification by introducing a novel approach that integrates meta-heuristic optimization algorithms with feature selection criteria for mRNA and microRNA data. The results demonstrate the efficacy of this approach in enhancing classification accuracy and illuminating the biological underpinnings of breast cancer subtypes, ultimately paving the way for personalized treatment strategies.
Eagle prey hunting is a remarkable and highly efficient hunting strategy employed by various species of eagles, which are large and powerful birds of prey known for their exceptional hunting abilities. Eagles possess exceptional eyesight, with some species capable of spotting prey from great distances. Their acute vision allows them to identify potential targets with remarkable precision. Eagles often begin their hunts by soaring at high altitudes, scanning the ground below for potential prey. Their ability to see over large areas from a great height gives them a strategic advantage. Once a suitable target is spotted, eagles use their impressive speed and maneuverability to initiate a surprise attack. They typically approach their prey from above, diving down to catch their target off guard. Eagles have powerful talons with sharp claws designed to grip and immobilize their prey effectively. The talons are used to secure the prey and prevent it from escaping. They can adjust their trajectory and speed during the hunt to ensure a successful capture. Whereas, the choice of prey can vary from small mammals, birds, and fish, to even larger prey.
Eagles employ a variety of hunting techniques depending on their species and the type of prey they are targeting. The hunting strategy of the eagles is known with some common situational conditions like:
• Aerial Hunting: Many eagle species are skilled aerial hunters. They soar at high altitudes, scanning the ground for potential prey. When a suitable target is spotted, the eagle dives down with incredible speed and accuracy to seize its prey. This technique is often used for hunting birds, which are captured mid-air.
• Perch and Wait: Some eagles, such as the African fish eagle, prefer to perch near water bodies. They wait patiently for fish or other aquatic prey to come close to the surface, then swoop down to capture them with their sharp talons.
• Surprise Attacks: Eagles are known for their ability to launch surprise attacks on their prey. They approach from behind obstacles or use the sun to blind their prey, making it harder for the prey to detect them until it is too late.
• Cooperative Hunting: Eagles engage in cooperative hunting, particularly when targeting larger prey. Bald eagles, for instance, may work together to capture larger fish. One eagle distracts the prey while the other swoops in for the capture.
• Still Hunting: Some eagle species, like the martial eagle, are known for “still hunting.” They perch inconspicuously in trees or on cliffs, silently waiting for ground-dwelling prey to come into their field of view. When the prey is within striking distance, the eagle pounces with great force.
• Scavenging: While eagles are primarily hunters, they are opportunistic and sometimes scavenge for carrion or steal food from other birds or predators. Bald eagles, for example, are known to scavenge fish from other birds or steal from otters.
• Hunting Grounds: Eagles tend to establish hunting grounds in their territories, often returning to the same locations repeatedly. They become familiar with the behavior of prey in their territory, improving their hunting success.
• Stalking and Ambushing: Some eagles stalk their prey on the ground, using cover and vegetation to approach undetected. Once in range, they swiftly ambush and capture their prey.
Based on the above-defined approaches, the eagle hunting strategies can indeed be summarized in a sequence of actions: that includes selecting the search space, searching for prey within that space, and executing an attack. This behavior of the eagle targeting the prey is shown diagrammatically in Figure 1.
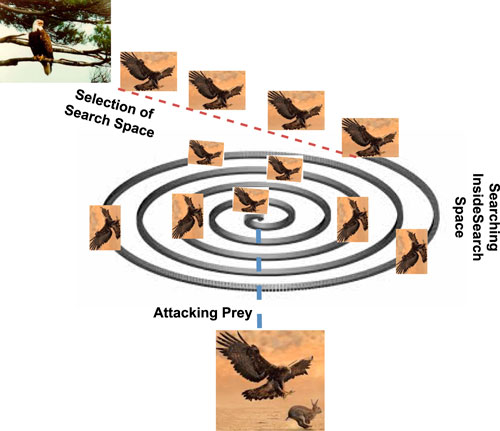
Figure 1. Prey hunting strategy of the eagle including the selection of the search space, searching prey in search space and executing an attack.
The eagles choose a certain region to start their quest for food and depart in a specified direction once they have settled on a target area. As a result, discovering the search space is accomplished through self-searching and tracking other birds. Eagles often begin their hunting expedition by ascending to a significant altitude, sometimes thousands of feet in the air. This altitude provides them with a broader view of the landscape and potential prey. The search space encompasses the area below the eagle, covering a wide territory. It is from this vantage point that eagles identify potential targets.
After selecting an appropriate search space, the eagles will start to search for the prey in the search space. Eagles have exceptional eyesight, and they scan the terrain for any signs of movement or potential prey items. Their keen vision enables them to detect even small or distant prey. They focus on specific characteristics, such as the size, shape, or behavior of animals on the ground and any movement that may indicate the presence of prey. The search often involves circling or gliding at various altitudes to cover a larger area effectively. Generally, the searching behaviors of the eagles are in spiral form with the selected search space.
After the scanning of the prey from the specific altitude and once a suitable prey item is identified within the search space, the eagle initiates its attack. The decision to attack is based on factors like the proximity and vulnerability of the prey. Eagles are known for their remarkable speed and agility during the attack phase. They may adjust their altitude, speed, and direction as needed to maintain the element of surprise and increase the accuracy of their strike. The attack typically involves a rapid descent, with the eagle using its sharp talons to grasp and immobilize the prey. The talons are designed to pierce and grip the prey securely, ensuring that it cannot escape.
Any nature-inspired meta-heuristic algorithm starts with the random initialization of the seed point. This seed point acts as a base parameter to start with and the corresponding objective function either needs to be minimized or maximized depending on the choice of the problem. Let us suppose that the sample space is defined using the 2-dimensional space of size m
where the symbolic representation of the used variables is defined as the total number of sample objects given by variable n, the problem dimension is represented by m,
In this sample space, the Eagle will select the hunting space heuristically and identify the region having the maximum possible chance of the prey, called the best position for hunting, called
where,
The process starts with random solutions of candidate solution as
Next, the second step of hunting is the searching of the prey in the selected region. As the eagle searches for its prey in the spiral form and thus at every temporal state this diameter of the spiral reduces by a factor till it swoops the prey. This process is mathematically given by Equation 3.
where,
Once the target is found, the eagle will shorten the spiral circle radius and focus on the prey to swoop. This process is known as narrowing exploration in the search space and mathematically is given by Equation 4.
where
Here u and v are selected randomly in the range of (0, 1), b is constant having a value of 1.5, and
Also, the Y and X are the coefficients that handle the spiral space of the eagle moment. The mathematical formulation of these is given in Equation 7.
where r(i) is given as,
Here, SC is the search cycle and holds a value in the range (0,5), and a is the rotation parameter in the range (2,10). Thus the parameters a and SC were used to handle the change in the spiral shape.
The next hunting phase of the eagle is called the exploitation phase where the eagle swoops the prey with a slow encounter which is mathematically given by Equation 8.
Here, the constants 0.1 and 0.2 are the adjustment parameters of the exploitation phase and are fixed using simulation results.
The other case is when the prey is large enough to swoop on the ground, Equation 8 is to be narrowed down as the hunt is more forced and speedy. The modified equation of the narrow exploitation phase is given by Equation 9.
Here (1-T) represents the amount of time the eagle spent to swoop the prey from the ground from the total time spent on hunting.
The stepwise explanation of the proposed algorithm is shown using the flowchart in Figure 2. Whereas, the pseudo-code of the proposed EPO algorithm is given in Algorithm 1.
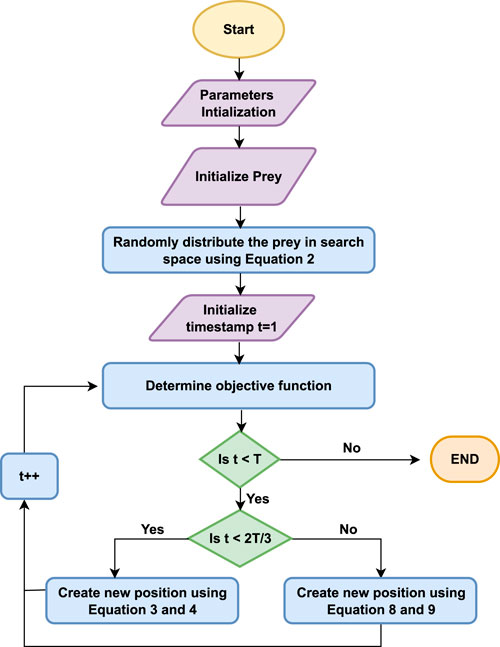
Figure 2. Flowchart of the proposed Eagle Prey Optimization algorithm.
The initial ranges of hyperparameters were selected based on prior literature and the nature of the optimization problem. The population size
A grid search was performed to fine-tune critical hyperparameters (
where
The fitness function
where

Algorithm 1. An algorithm of Proposed Eagle Prey Optimization.
The computational complexity of the EPO algorithm is determined by three primary components.
1. Initialization Phase: The algorithm starts with the initialization of a population of candidate solutions (prey) of size
2. Fitness Evaluation: The fitness of each candidate solution is computed using the defined fitness function, which includes evaluating a machine learning model on the subset of features, and the cost of training and validating the machine learning model depends on the size of the selected subset
For a single fitness evaluation the complexity is
3. Exploration and Exploitation Phases: In each iteration, the algorithm performs exploration and exploitation to update the positions of the candidate solutions. This involves calculating the movement of prey in the search space based on adaptive mechanisms and updating positions and recalculating fitness for
The algorithm performs these operations for a total of
To evaluate the performance of the proposed feature selection method, in the experimentation, the Microarray Gene Expression (MGE) dataset is taken into consideration. The dataset is available on the public data repository1 having 11 variants of the cancer genes supervised into binary to multi classes. Out of the 11 available gene expression datasets, we took 8 datasets (except ALL-AML, ALL-AML-3, and ALL-AML-4). The selected 8 datasets are in the. arff extension having gene counts, instances count, and number of class distribution information. The choice of the selection of this data repository is because of having the minimum gene count of 2000, which is a pre-screened criterion of dataset selection. The description of the dataset with the parameter information is presented in Table 1.
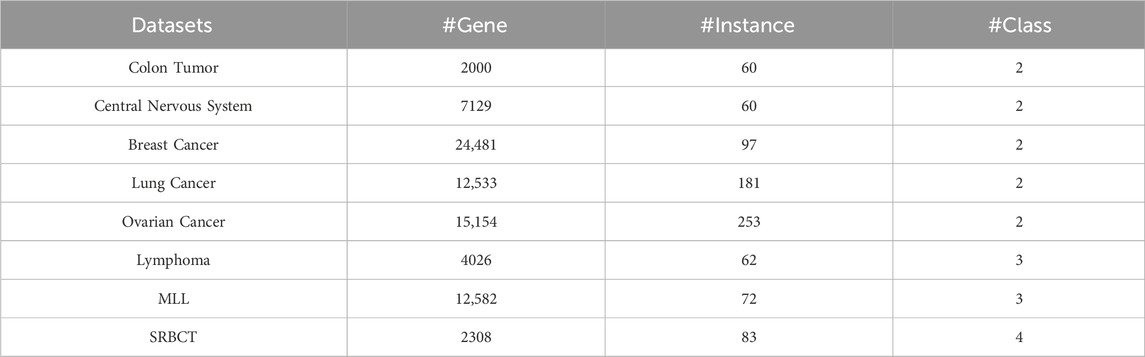
Table 1. Dataset Description with the associated parameter information.
In the machine learning system, while model training, the common practice is to subdivide the dataset into two parts i.e., Training and validation. To divide the dataset, the most commonly used approach is the 80-20 rule, where the randomly selected 80% dataset is used as a training set and the rest 20% as validation. But, with the smaller dataset having a limited sample size this approach is found appropriate, more especially with the MGE datasets as reported in Braga-Neto and Dougherty (2004). Thus, in this work, the dataset has experimented with the well-known Bootstrap method, called the 0.632+ estimator (Efron and Tibshirani, 1997).
Let’s say we wish to use the function f to forecast V using U such that f may depend on some parameters that are predicted from the data (V, U), i.e., f(U) =
where
As the function f tried to fix the data using the given sample
where
When using cross-validation, the value of k, or the number of folds to utilize, is crucial. The error estimates have an increase in the bias and lower variance with the decreasing value of k. On the other hand, the error estimate may have a significant variance but a very low bias when k is set to the number of instances. Once more, the bias-variance tradeoff may result from this. In such a condition we prefer the use of bootstrapping over cross-validation.
To estimate the extra-sample prediction error, we might utilize the bootstrap method rather than cross-validation. Any statistic’s sample distribution may be estimated via bootstrap resampling. We can consider picking B bootstrap samples (with replacement) from the set
where
The above Equation 14 addresses the overfitting issue, but retains bias. The non-distinct observations in the bootstrap samples, a consequence of replacement sampling, are the cause of this bias. Thus, for every sample size, the average number of unique observations can be around 0.632N (Efron and Tibshirani, 1997). Thus, the error computation using the 0.632+ estimator is given by Equation 15.
where,
and
Here, R measures the relative overfitting rate and
Performance evaluation and goodness-of-fit parameters are essential aspects of assessing the effectiveness of classification models. When evaluating the performance of a classification model, various metrics can be used to measure how well the model predicts the true classes of instances. The performance evaluation metrics that were used in the experimentation, were computed using the
• Accuracy: It is a widely used metric that measures the proportion of correctly classified instances out of the total instances. It is calculated as
• Precision (Positive Predictive Value): measures the accuracy of positive predictions. It is calculated as
• Recall (Sensitivity, True Positive Rate): measures the proportion of actual positives that were correctly predicted by the model. It is calculated as
• F1 Score: is the harmonic mean of precision and recall. It provides a balanced measure between precision and recall. It is calculated as
• Specificity (True Negative Rate): Specificity measures the ability of the model to correctly identify the negative instances. It is calculated as
• Area Under the Receiver Operating Characteristic (ROC) Curve (AUC-ROC): AUC-ROC measures the area under the ROC curve, which plots the true positive rate against the false positive rate. It provides an aggregate measure of the model’s ability to distinguish between classes.
In the experimentation, various machine learning models are used for classification tasks, each with its strengths and weaknesses depending on the nature of the data. A short description of these machine learning models is given as.
1. Decision Trees (DT): Decision Trees recursively split the dataset based on features, creating a tree structure. They are easy to interpret and can handle both categorical and numerical data. We have used the traditional gradient boosting technique that optimizes decision trees by minimizing loss functions in a sequential manner.
2. Random Forests (RF): Random Forests are an ensemble of decision trees. They build multiple trees and combine their predictions to improve accuracy and reduce overfitting.
3. Support Vector Machines (SVM): SVMs are effective for both binary and multiclass classification. They find the hyperplane that best separates classes in the feature space.
4. k-Nearest Neighbors (k-NN): k-NN classifies instances based on the majority class of their k nearest neighbors in the feature space. It is simple but can be computationally expensive for larger datasets.
5. Backpropagation neural network (BPNN): The backpropagation algorithm is a method that involves training a neural network to learn the mapping from input features to output classes with the updation of the weight parameters while backpropagation.
To evaluate the performance of the proposed feature selection algorithm on the selected 8 gene expression datasets we have used the six performance metrics and evaluated the performance using 5 machine learning classifiers. The experimental results of the proposed method are presented in Tables 2, 3. Based on the experimentation results it was observed that the performance of the SVM and the BPNN classifiers are found significant as compared with the other three classifiers. However, the datasets having binary class labels show the best performance (accuracy%) with the SVM classifier as compared with BPNN, which is marginally better. While the datasets have multi-class labels, show their best performance with the BPNN classifier, which shows an upregulation in the accuracy by approx 1%.
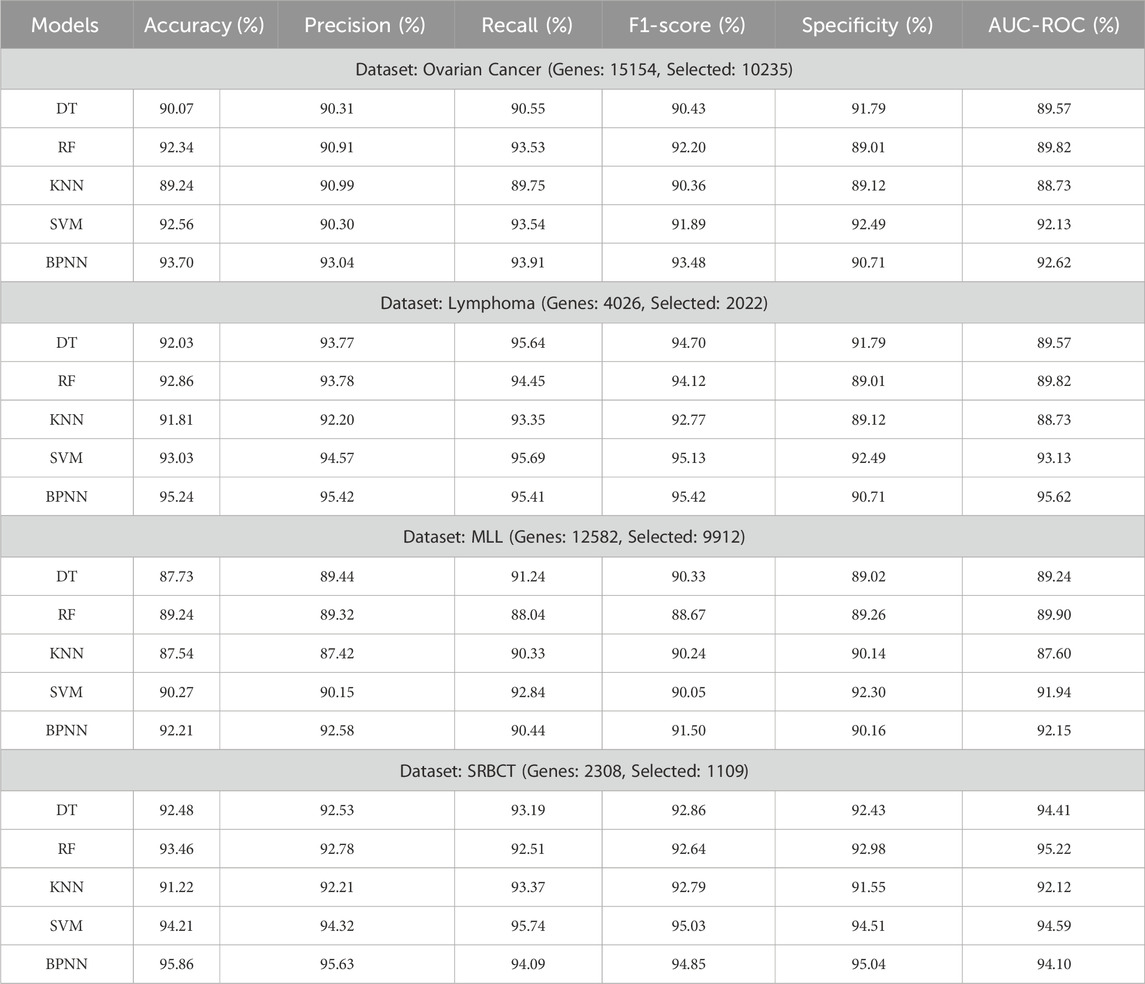
Table 2. Experimentation results of the proposed approach on Ovarian, Lymphoma, MLL, SRBCT Cancerous datasets using multi-classifiers.
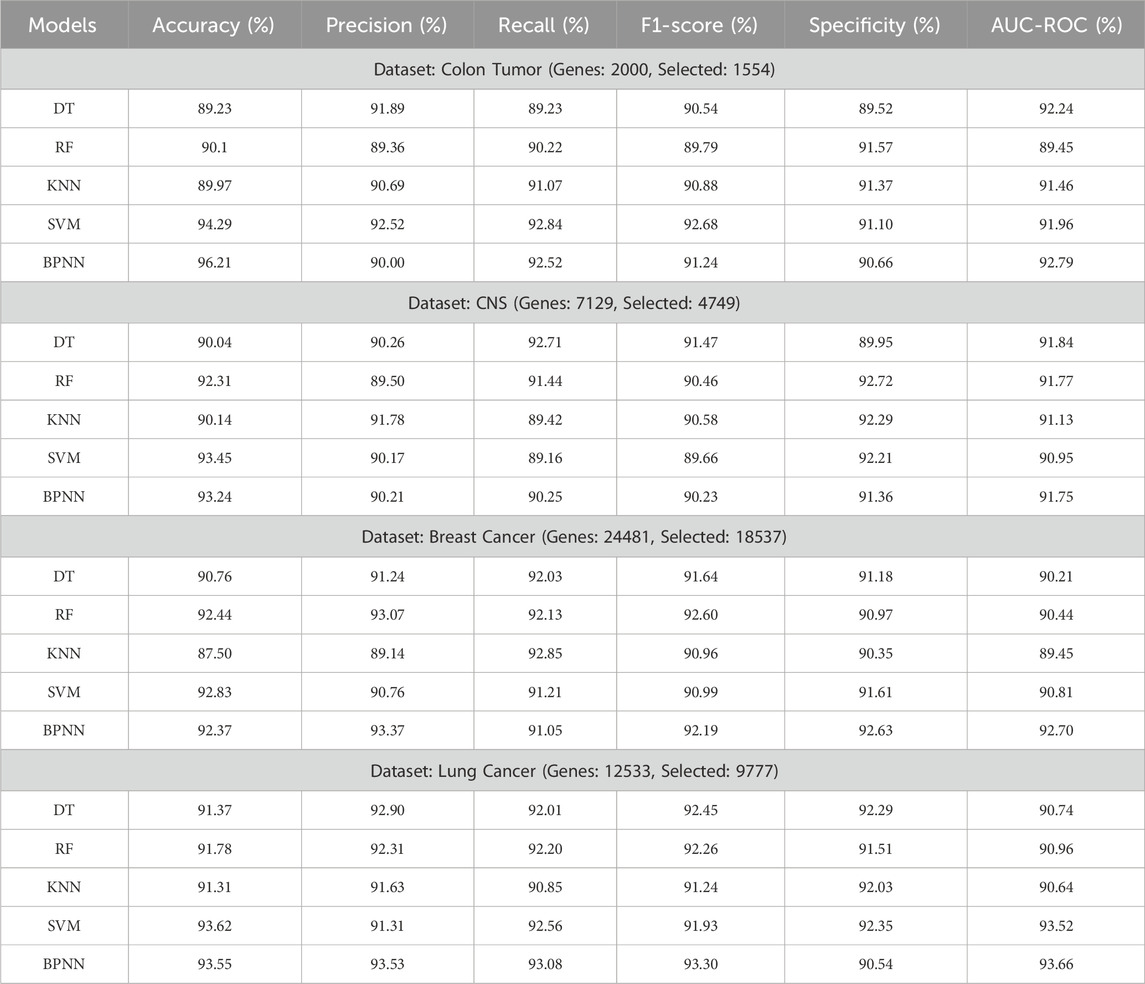
Table 3. Experimentation results of the proposed approach on Colon, CNS, Breast, and Lung Cancerous datasets using multi-classifiers.
The experimentation results show the impact of using the feature selection algorithm, especially showing its relevance on the used dataset, is presented in Table 4. The results show the experimentation values (accuracy%) on the used dataset with and without the feature selection algorithm. Based on the result values it was found that the performance of the machine learning models are much improved with the use of the proposed feature selection algorithm. While the results without feature selection algorithm was significantly on the lower side. Thus, the implication of the feature selection algorithm is found relevant in the study.
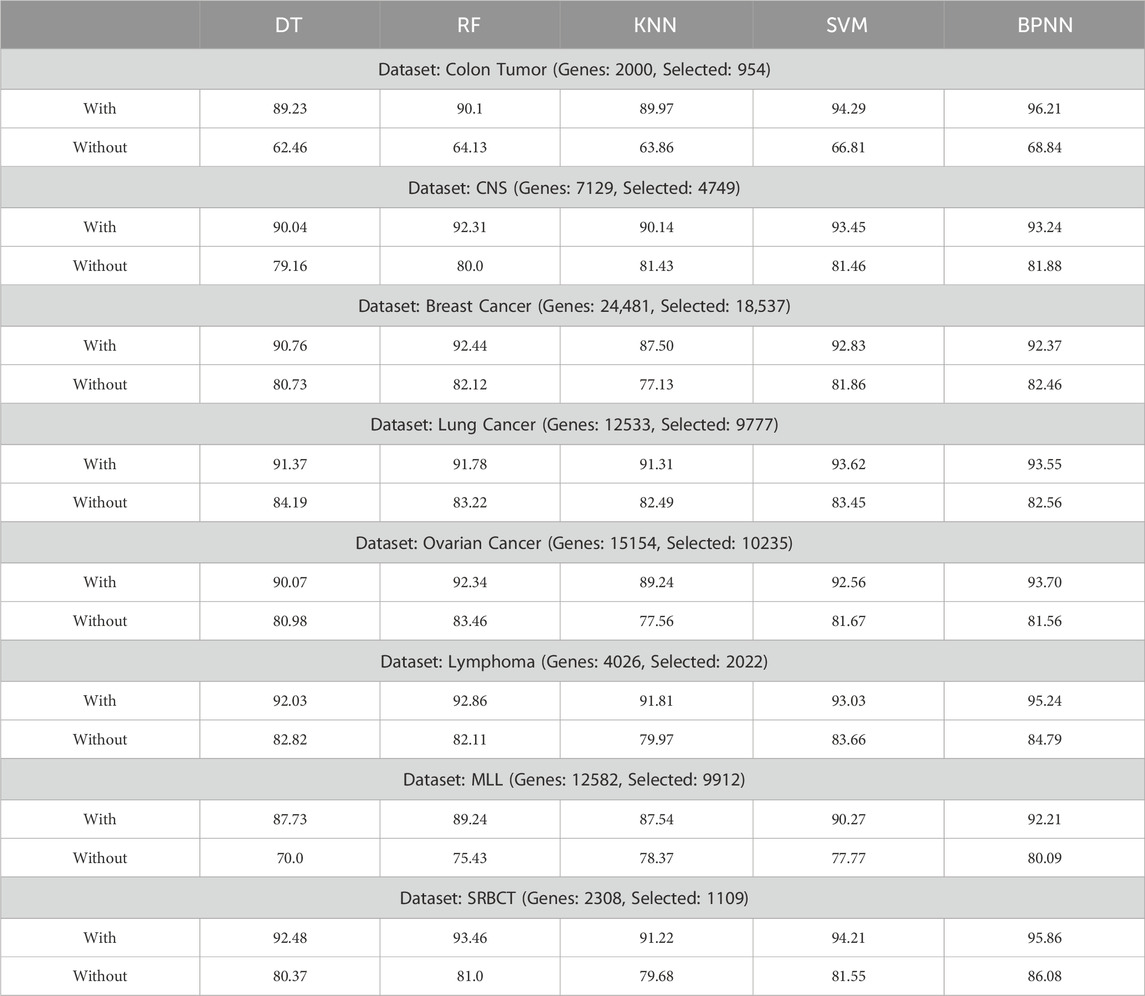
Table 4. Result showing the accuracy of the models with and without using the proposed feature selection algorithm.
As in the previous section it was found that the performance of the machine learning models were enhanced with the use of the feature selection algorithm. However, to validate the performance of the proposed algorithm further experimentation’s were made with the various other feature selection algorithms exist in the literature irrespective of their use on same datasets. Here we present the detailed comparative study of the proposed algorithm with the existing feature selection algorithms.
To evaluate the comparative results of the proposed feature selection algorithm with the benchmark meta-heuristic optimization algorithms, literature was studied to explore the existing algorithms that were used in various application areas for selecting relevant features. Based on the study, here 12 well known algorithms were selected to compare the result. These algorithms are Giant Trevally Optimizer (GTO), Backtracking Search Optimization Algorithm (BSA), Hunger Games Search (HGS) Optimization, Mean Variance Optimisation (MVO), Harris Hawks optimization (HHO), Particle Swarm Optimization (PSO), Cuckoo Search Optimization (CSO), Firefly Algorithm (FA), Bat Algorithm (BA), Flower Pollination Optimization (FPO), Whale Optimization Algorithm (WOA), and Grey Wolf Optimization (GWO). The parameter setting of these algorithms used in the experimentation is shown in Table 5.
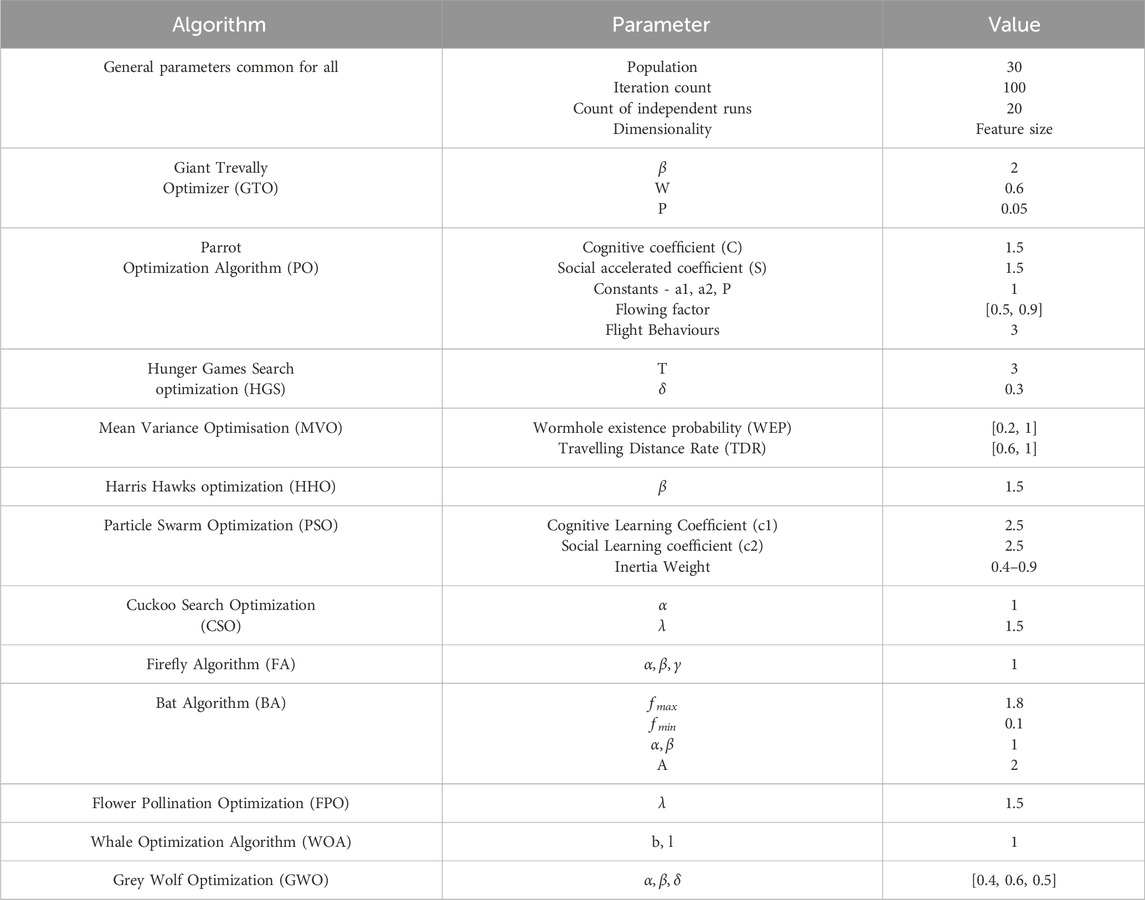
Table 5. Details of the selected optimization algorithms with their parameter settings and values.
The comparative analysis of the proposed EPO algorithm with the other benchmark meta-heuristic algorithms is presented in Tables 6, 7. The results presented in the table gives the computation accuracy of the various machine learning algorithms with optimization algorithms on the selected datasets. Based on the experimentation results it was concluded that the performance of the EPO algorithm is much better as compared with the other benchmark algorithms.
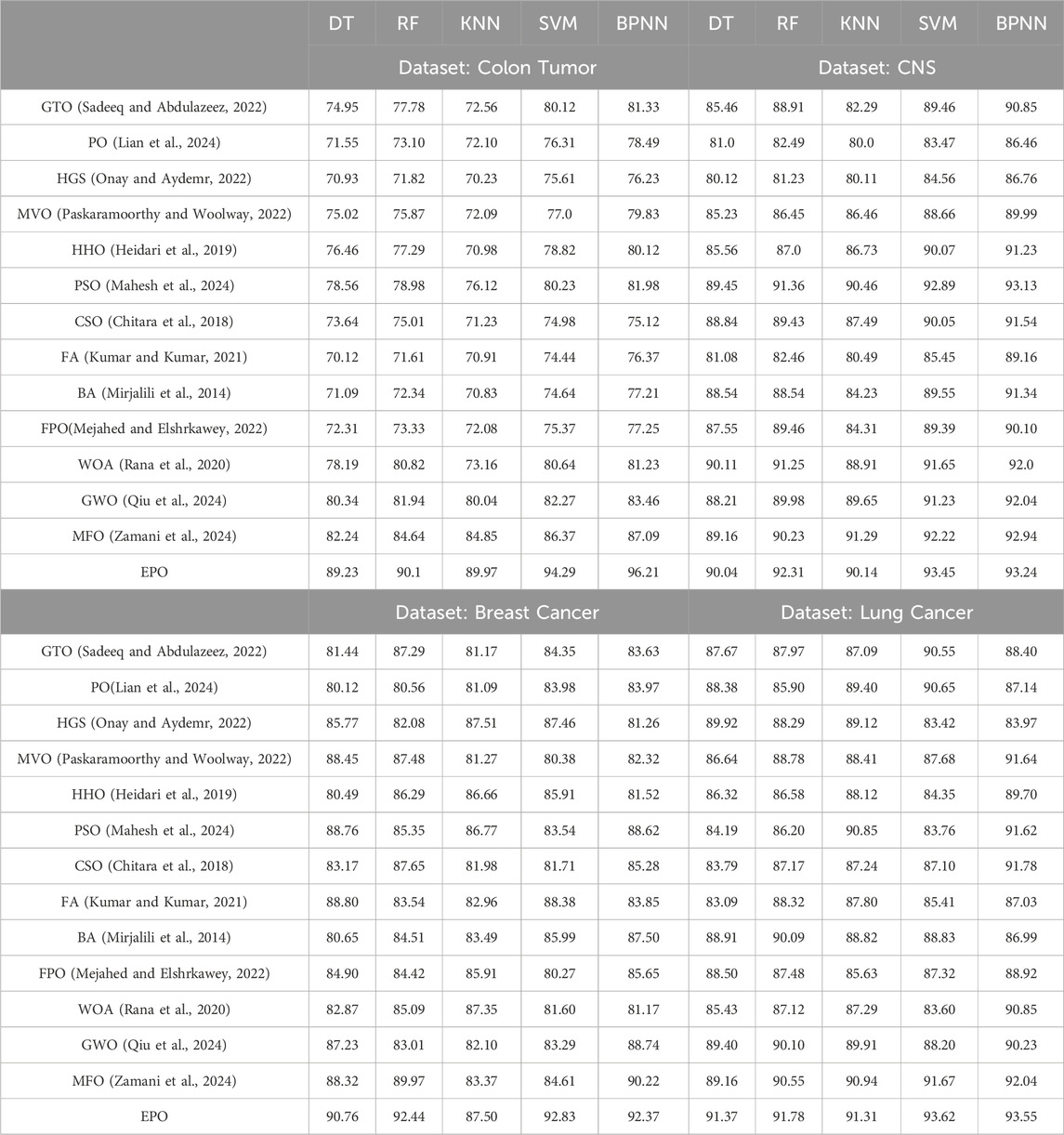
Table 6. Comparative analysis of the Proposed EPO algorithm with other meta-heuristic algorithms. The result presented here is the accuracy (%) on Colon, CNS, Breast, and Lung Cancerous datasets.

Table 7. Comparative analysis of the proposed EPO algorithm with other meta heuristic algorithms. The result presented here is the accuracy (%) on Ovarian, Lymphoma, MLL, and SRBCT Cancerous datasets.
In this work, the performance of the proposed model is validated statistically using three statistical measures i.e., Paired t-Test, Wilcoxon Signed-Rank Test, and Effect Size (Cohen’s d). A paired t-test was conducted to compare the performance metrics precision, recall, and F1-score of the proposed Eagle Prey Optimization (EPO) approach with each of the benchmark algorithms. The test was performed across multiple runs (100 independent runs) for each algorithm to account for randomness in model initialization and data splitting. Since the distribution of the performance metrics might not always meet the assumptions of normality required for a t-test, we also performed the non-parametric Wilcoxon signed-rank test. This test is particularly suitable for comparing paired samples without assuming normality. To quantify the magnitude of the observed differences, we calculated the effect size using Cohen’s d. This provides a measure of practical significance, complementing the p-values from the statistical tests. The experimentation results of these tests are presented in Tables 8–10.

Table 8. Significance test results for precision.

Table 9. Significance test results for recall.

Table 10. Significance test results for F1-Score.
For precision, recall, and F1-score, the p-values obtained from both the paired t-test and Wilcoxon signed-rank test were less than 0.05, indicating that the improvements achieved by EPO over benchmark methods are statistically significant. The effect size calculations (Cohen’s d) further confirmed that the observed differences are meaningful, with medium to large effect sizes observed for most comparisons. The statistical tests thus provide strong evidence that the improvements in precision, recall, and F1-score achieved by EPO are not marginal or due to random variability. While some differences may appear small (1%–2%), their statistical significance highlights that they consistently hold across multiple runs and are therefore meaningful in practice.
In this study, we investigated the efficacy of Eagle Prey Optimization (EPO) as a meta-heuristic approach for microarray gene selection in cancer classification. Our evaluation included the application of EPO to five well-established machine learning classifiers, and the results were benchmarked against twelve state-of-the-art optimization algorithms commonly used in gene selection tasks. Our experiments demonstrated that Eagle Prey Optimization consistently exhibited robust performance across various machine learning classifiers, namely, Decision Tree, Random Forest, K-Nearest Neighbor, Support Vector Machine, and Back Propagation Neural Network. The adaptability of EPO to different classification models underscores its versatility in the context of microarray gene selection for cancer classification.
In comparison to twelve benchmark optimization algorithms, EPO showcased competitive or superior performance in terms of both convergence speed and solution quality. The results suggest that the unique search strategy inspired by the hunting behavior of eagles equips EPO with an effective exploration-exploitation balance, making it particularly well-suited for gene selection tasks in cancer classification. Also, the detailed analysis of the convergence curves and selected gene subsets provided insights into the behavior of EPO across different classifiers. The algorithm demonstrated a remarkable ability to identify biologically relevant gene subsets, contributing to enhanced cancer classification accuracy.
The findings of this study have significant practical implications for the field of bioinformatics and cancer research. The success of Eagle Prey Optimization in selecting informative gene subsets highlights its potential as a valuable tool for aiding in the identification of biomarkers associated with specific cancer types. Thus, using the collective results it was concluded that the proposed Eagle Prey Optimization emerges as a promising meta-heuristic approach for microarray gene selection in cancer classification. Its performance across various classifiers and benchmark algorithms positions it as a competitive and potentially transformative tool in the quest for accurate and interpretable cancer biomarkers.
While our study provides compelling evidence for the effectiveness of EPO in microarray gene selection, there is room for further exploration. Future work can focus on addressing several limitations of EPO in several ways. First, extending EPO to a distributed or cloud-based framework could significantly reduce computation time, enabling its application to larger and more diverse datasets. Second, incorporating an adaptive hyperparameter tuning strategy or integrating reinforcement learning mechanisms could enhance the algorithm’s efficiency and reduce manual intervention. Third, combining EPO with ensemble learning techniques could further improve classification performance and robustness. Lastly, validating the selected gene subsets across multiple independent datasets and exploring their biological implications through pathway enrichment and functional analysis would strengthen the translational impact of the study.
Publicly available datasets were analyzed in this study. This data can be found here: https://csse.szu.edu.cn/staff/zhuzx/datasets.html, accessed in October 2023.
SwD: Conceptualization, Data curation, Formal Analysis, Investigation, Methodology, Software, Validation, Visualization, Writing–original draft, Writing–review and editing. DR: Conceptualization, Formal Analysis, Investigation, Software, Supervision, Validation, Writing–review and editing, Writing–original draft. SuD: Conceptualization, Formal Analysis, Investigation, Methodology, Supervision, Writing–review and editing, Writing–original draft, and funding.
The author(s) declare that financial support was received for the research and/or publication of this article. Funds for Open Access is provided by VIT-AP University.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declare that no Generative AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1https://csse.szu.edu.cn/staff/zhuzx/datasets.html, accessed in October 2023.
Alhenawi, E., Al-Sayyed, R., Hudaib, A., and Mirjalili, S. (2022). Feature selection methods on gene expression microarray data for cancer classification: a systematic review. Comput. Biol. Med. 140, 105051. doi:10.1016/j.compbiomed.2021.105051
Ali, W., and Saeed, F. (2023). Hybrid filter and genetic algorithm-based feature selection for improving cancer classification in high-dimensional microarray data. Processes 11, 562. doi:10.3390/pr11020562
Almugren, N., and Alshamlan, H. (2019). A survey on hybrid feature selection methods in microarray gene expression data for cancer classification. IEEE access 7, 78533–78548. doi:10.1109/access.2019.2922987
Aziz, R. M. (2022). Cuckoo search-based optimization for cancer classification: a new hybrid approach. J. Comput. Biol. 29, 565–584. doi:10.1089/cmb.2021.0410
Berrhail, F., and Belhadef, H. (2020). Genetic algorithm-based feature selection approach for enhancing the effectiveness of similarity searching in ligand-based virtual screening. Curr. Bioinforma. 15, 431–444. doi:10.2174/1574893614666191119123935
Braga-Neto, U. M., and Dougherty, E. R. (2004). Is cross-validation valid for small-sample microarray classification? Bioinformatics 20, 374–380. doi:10.1093/bioinformatics/btg419
Brankovic, A., Hosseini, M., and Piroddi, L. (2018). A distributed feature selection algorithm based on distance correlation with an application to microarrays. IEEE/ACM Trans. Comput. Biol. Bioinforma. 16, 1802–1815. doi:10.1109/TCBB.2018.2833482
Chitara, D., Niazi, K. R., Swarnkar, A., and Gupta, N. (2018). Cuckoo search optimization algorithm for designing of a multimachine power system stabilizer. IEEE Trans. Industry Appl. 54, 3056–3065. doi:10.1109/tia.2018.2811725
Dabba, A., Tari, A., and Meftali, S. (2020). Gene selection and classification using quantum moth flame optimization algorithm. Am. J. Sci. and Eng. 1, 16–20. doi:10.15864/ajse.1204
Deng, S., Li, Y., Wang, J., Cao, R., and Li, M. (2023). A feature-thresholds guided genetic algorithm based on a multi-objective feature scoring method for high-dimensional feature selection. Appl. Soft Comput. 148, 110765. doi:10.1016/j.asoc.2023.110765
Efron, B., and Tibshirani, R. (1997). Improvements on cross-validation: the 632+ bootstrap method. J. Am. Stat. Assoc. 92, 548–560. doi:10.2307/2965703
Ge, J., Zhang, X., Liu, G., and Sun, Y. (2019). “A novel feature selection algorithm based on artificial bee colony algorithm and genetic algorithm,” in 2019 IEEE international conference on power, intelligent computing and systems (ICPICS) (IEEE), 131–135.
Ghosh, M., Sen, S., Sarkar, R., and Maulik, U. (2021). Quantum squirrel inspired algorithm for gene selection in methylation and expression data of prostate cancer. Appl. soft Comput. 105, 107221. doi:10.1016/j.asoc.2021.107221
Halim, Z. (2020). Optimizing the dna fragment assembly using metaheuristic-based overlap layout consensus approach. Appl. Soft Comput. 92, 106256. doi:10.1016/j.asoc.2020.106256
Heidari, A. A., Mirjalili, S., Faris, H., Aljarah, I., Mafarja, M., and Chen, H. (2019). Harris hawks optimization: algorithm and applications. Future gener. Comput. Syst. 97, 849–872. doi:10.1016/j.future.2019.02.028
Houssein, E. H., Hassan, H. N., Al-Sayed, M. M., and Nabil, E. (2022). Gene selection for microarray cancer classification based on manta rays foraging optimization and support vector machines. Arabian J. Sci. Eng. 47, 2555–2572. doi:10.1007/s13369-021-06102-8
Kalaiarasu, M., and Anitha, J. (2020). Modified cuckoo search-support vector machine (mcs-svm) gene selection and classification for autism spectrum disorder (asd) gene expression. NeuroQuantology 18, 01–13. doi:10.14704/nq.2020.18.11.nq20228
Khaire, U. M., and Dhanalakshmi, R. (2022). Stability of feature selection algorithm: a review. J. King Saud University-Computer Inf. Sci. 34, 1060–1073. doi:10.1016/j.jksuci.2019.06.012
Kumar, V., and Kumar, D. (2021). A systematic review on firefly algorithm: past, present, and future. Archives Comput. Methods Eng. 28, 3269–3291. doi:10.1007/s11831-020-09498-y
Lian, J., Hui, G., Ma, L., Zhu, T., Wu, X., Heidari, A. A., et al. (2024). Parrot optimizer: algorithm and applications to medical problems. Comput. Biol. Med. 172, 108064. doi:10.1016/j.compbiomed.2024.108064
Mahesh, T., Santhakumar, D., Balajee, A., Shreenidhi, H., Kumar, V. V., and Annand, J. R. (2024). Hybrid ant lion mutated ant colony optimizer technique with particle swarm optimization for leukemia prediction using microarray gene data. IEEE Access 12, 10910–10919. doi:10.1109/access.2024.3351871
McNulty, S. N., Parikh, B. A., Duncavage, E. J., Heusel, J. W., and Pfeifer, J. D. (2019). Optimization of population frequency cutoffs for filtering common germline polymorphisms from tumor-only next-generation sequencing data. J. Mol. Diagnostics 21, 903–912. doi:10.1016/j.jmoldx.2019.05.005
Mejahed, S., and Elshrkawey, M. (2022). A multi-objective algorithm for virtual machine placement in cloud environments using a hybrid of particle swarm optimization and flower pollination optimization. PeerJ Comput. Sci. 8, e834. doi:10.7717/peerj-cs.834
Mirjalili, S., Mirjalili, S. M., and Yang, X.-S. (2014). Binary bat algorithm. Neural Comput. Appl. 25, 663–681. doi:10.1007/s00521-013-1525-5
Mohd Ali, N., Besar, R., and Ab. Aziz, N. A. (2022). Hybrid feature selection of breast cancer gene expression microarray data based on metaheuristic methods: a comprehensive review. Symmetry 14, 1955. doi:10.3390/sym14101955
MotieGhader, H., Masoudi-Sobhanzadeh, Y., Ashtiani, S. H., and Masoudi-Nejad, A. (2020). Mrna and microrna selection for breast cancer molecular subtype stratification using meta-heuristic based algorithms. Genomics 112, 3207–3217. doi:10.1016/j.ygeno.2020.06.014
Onay, F. K., and Aydemr, S. B. (2022). Chaotic hunger games search optimization algorithm for global optimization and engineering problems. Math. Comput. Simul. 192, 514–536. doi:10.1016/j.matcom.2021.09.014
Othman, M. S., Kumaran, S. R., and Yusuf, L. M. (2020). Gene selection using hybrid multi-objective cuckoo search algorithm with evolutionary operators for cancer microarray data. IEEE Access 8, 186348–186361. doi:10.1109/access.2020.3029890
Paskaramoorthy, A., and Woolway, M. (2022). An empirical evaluation of sensitivity bounds for mean-variance portfolio optimisation. Finance Res. Lett. 44, 102065. doi:10.1016/j.frl.2021.102065
Pellegrino, E., Camilla, C., Abbou, N., Beaufils, N., Pissier, C., Gabert, J., et al. (2023). Extreme gradient boosting tuned with metaheuristic algorithms for predicting myeloid ngs onco-somatic variant pathogenicity. Bioengineering 10, 753. doi:10.3390/bioengineering10070753
Peng, H., Long, F., and Ding, C. (2005). Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. pattern analysis Mach. Intell. 27, 1226–1238. doi:10.1109/TPAMI.2005.159
Prakash, K. B. (2021). Quantum meta-heuristics and applications. Cognitive Engineering for next generation computing: a practical analytical approach, 265–297.
Priya, R. D., Sivaraj, R., Anitha, N., and Devisurya, V. (2022). Tri-staged feature selection in multi-class heterogeneous datasets using memetic algorithm and cuckoo search optimization. Expert Syst. Appl. 209, 118286. doi:10.1016/j.eswa.2022.118286
Qiu, Y., Yang, X., and Chen, S. (2024). An improved gray wolf optimization algorithm solving to functional optimization and engineering design problems. Sci. Rep. 14, 14190. doi:10.1038/s41598-024-64526-2
Ram, P. K., and Kuila, P. (2019). Feature selection from microarray data: genetic algorithm based approach. J. Inf. Optim. Sci. 40, 1599–1610. doi:10.1080/02522667.2019.1703260
Rana, N., Latiff, M. S. A., Abdulhamid, S. M., and Chiroma, H. (2020). Whale optimization algorithm: a systematic review of contemporary applications, modifications and developments. Neural Comput. Appl. 32, 16245–16277. doi:10.1007/s00521-020-04849-z
Remeseiro, B., and Bolon-Canedo, V. (2019). A review of feature selection methods in medical applications. Comput. Biol. Med. 112, 103375. doi:10.1016/j.compbiomed.2019.103375
Sadeeq, H. T., and Abdulazeez, A. M. (2022). Giant trevally optimizer (gto): a novel metaheuristic algorithm for global optimization and challenging engineering problems. IEEE Access 10, 121615–121640. doi:10.1109/access.2022.3223388
Segera, R. D. (2021). An excited cuckoo search-grey Wolf adaptive kernel svm for effective pattern recognition in dna microarray cancer chips. University of Nairobi. Ph.D. thesis.
Senapati, S. K., Shrivastava, M., and Mahapatra, S. (2023). “Pcsvm: a hybrid approach using particle swarm optimization and cuckoo search for effective cancer diagnosis,” in 2023 2nd edition of IEEE Delhi section flagship conference (DELCON), 1–5. doi:10.1109/DELCON57910.2023.10127354
Sucharita, S., Sahu, B., Swarnkar, T., and Meher, S. K. (2024). Classification of cancer microarray data using a two-step feature selection framework with moth-flame optimization and extreme learning machine. Multimedia Tools Appl. 83, 21319–21346. doi:10.1007/s11042-023-16353-2
Wang, D., Chen, H., Li, T., Wan, J., and Huang, Y. (2020). A novel quantum grasshopper optimization algorithm for feature selection. Int. J. Approx. Reason. 127, 33–53. doi:10.1016/j.ijar.2020.08.010
Wang, Z., Zhou, Y., Takagi, T., Song, J., Tian, Y.-S., and Shibuya, T. (2023). Genetic algorithm-based feature selection with manifold learning for cancer classification using microarray data. BMC Bioinforma. 24, 139. doi:10.1186/s12859-023-05267-3
Wu, Q., Ma, Z., Fan, J., Xu, G., and Shen, Y. (2019). A feature selection method based on hybrid improved binary quantum particle swarm optimization. Ieee Access 7, 80588–80601. doi:10.1109/access.2019.2919956
Zamani, H., Nadimi-Shahraki, M. H., Mirjalili, S., Soleimanian Gharehchopogh, F., and Oliva, D. (2024). A critical review of moth-flame optimization algorithm and its variants: structural reviewing, performance evaluation, and statistical analysis. Archives Comput. Methods Eng. 31, 2177–2225. doi:10.1007/s11831-023-10037-8
Zhang, Q., Teng, P., Wang, S., He, Y., Cui, Z., Guo, Z., et al. (2023). Computational prediction and characterization of cell-type-specific and shared binding sites. Bioinformatics 39, btac798. doi:10.1093/bioinformatics/btac798
Keywords: feature optimization, microarray gene selection, cancer classification, meta-heuristic optimization, feature selection
Citation: Dhamercherla S, Reddy Edla D and Dara S (2025) Cancer classification in high dimensional microarray gene expressions by feature selection using eagle prey optimization. Front. Genet. 16:1528810. doi: 10.3389/fgene.2025.1528810
Received: 19 November 2024; Accepted: 20 February 2025;
Published: 21 March 2025.
Edited by:
Chunhou Zheng, Anhui University, ChinaCopyright © 2025 Dhamercherla, Reddy Edla and Dara. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Suresh Dara, ZGFyYXN1cmVzaEBsaXZlLmlu
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.