 Otto Halmesvaara1*
Otto Halmesvaara1* Marleena Vornanen1,2,3
Marleena Vornanen1,2,3 Helena Kääriäinen4
Helena Kääriäinen4 Markus Perola3,4
Markus Perola3,4 Kati Kristiansson3,4
Kati Kristiansson3,4 Hanna Konttinen1
Hanna Konttinen1- 1Social Psychology, Faculty of Social Sciences, University of Helsinki, Helsinki, Finland
- 2Motion Analysis Laboratory, Children’s Hospital, Helsinki University Hospital, Helsinki, Finland
- 3Research Program for Clinical and Molecular Metabolism, Faculty of Medicine, University of Helsinki, Helsinki, Finland
- 4Department of Public Health and Welfare, Finnish Institute for Health and Welfare, Helsinki, Finland
Receiving polygenic risk estimates of future disease through health care or direct-to-consumer companies is expected to become more common in the coming decades. However, only a limited number of studies have examined if such estimates might evoke an adverse psychosocial reaction in receivers. The present study utilized data from a sub-section of a personalized medicine project (the P5 study) that combines genomic and traditional health data to evaluate participants’ risk for certain common diseases. We investigated how communication of future disease risk estimates related to type 2 diabetes and coronary heart disease influenced respondents’ risk perception, self-efficacy, disease-related worry, and other emotions. A randomized controlled trial was conducted, where the experimental group (n = 714) received risk estimates based on traditional and polygenic risk factors and the control group (n = 649) based solely on traditional risk factors. On average, higher disease risk was associated with higher perceived risk (ps, <0.001, ηp2 = 0.087–0.071), worry (ps <0.001, ηp2 = 0.061–0.028), lower self-efficacy (p <0 .001, ηp2 = 0.012), less positive emotions (ps <0.04, ηp2 = 0.042–0.005), and more negative emotions (ps <0.048, ηp2 = 0.062–0.006). However, we found no evidence that adding the polygenic risk to complement the more traditional risk factors would induce any substantive psychosocial harm to the recipients (ps >0.06).
1 Introduction
Type 2 diabetes (T2D) and coronary heart disease (CHD) affect millions of people globally and are significant contributors to disability and mortality worldwide (Sanchis-Gomar et al., 2016; Zheng, Ley, and Hu, 2018). The etiology of T2D and CHD indicates that, besides lifestyle-related risk factors, the risk of diabetes or heart disease is influenced by genetics. (Roberts and Stewart, 2012; Fuchsberger et al., 2016). Currently, genomic risk scores estimating the risk of future diseases such as diabetes or coronary heart disease are not routinely used in public health care. However, genotyping has become considerably cheaper and faster than in previous years. It is expected that genomic risk estimates will become increasingly more common in clinical and commercial contexts alike (Krier, Kalia and Green, 2016; Abul-Husn and Kenny, 2019).
However, it is not clear how receiving such risk information is beneficial in disease prevention or health behavior change. Most studies concerning genomic risk information’s effect on health behavior have produced nonsignificant or mixed results (e.g., Hollands et al., 2016; Peterson et al., 2018). Influence on psychosocial factors, such as emotional reaction the results, has been studied less extensively, and a considerable heterogeneity exists in the quality and methodology of the relevant studies (for a summary, see Wade, 2019; and for meta-analysis, see Robinson et al., 2019). Moreover, since a large part of the studies has focused on cancer-related testing, not much is known concerning future disease risk estimates influence in the context of other common diseases such as diabetes and cardiovascular disease.
Consequently, it would be relevant to expand the scope from cancer risk-related information to include other diseases. The field would also benefit from more large-scale experimental studies related to the psychosocial outcomes of genomic risk estimates. Thus, the current study aims to improve knowledge on how communication of genomic risk information related to type 2 diabetes and coronary heart disease influences respondents’ risk perception, self-efficacy, disease-related worry, and other emotions in the context of a randomized controlled trial. T2D and CHD were selected as suitable conditions for the current study since both are common diseases in Finland, and risk mitigation is possible through lifestyle changes (Abouzeid et al., 2015; Salomaa et al., 2016). Furthermore, genome-wide polygenic scores have been published for both conditions (Khera et al., 2018).
Self-efficacy (i.e., persons subjective estimate of the amount of control they expect to have in any given situation; Bandura, 1997), perception of disease risk, and emotional responses to risk information are concepts widely utilized in common health behavioral models and are known antecedents of health behavior (for example, see Hagger et al., 2020). Besides theoretical interest, there is also an apparent practical value in studying psychosocial outcomes. Suppose genomic risk estimates are to be more widely distributed in the context of common diseases. In that case, it is crucial to investigate that no active harm is caused to recipients as a byproduct, especially since the benefits of receiving such information remain uncertain.
So far, relatively few randomized controlled trials (RCT) have rigorously assessed the psychosocial impact of receiving actual genomic risk estimates related to T2D or CHD. A small-scale RCT by Grant et al. (2013) offered a diabetes prevention program to all participants and then compared effects on an experimental group supplemented with a genetic risk score for T2D and a control group, which received no risk score. No difference was found between the groups for risk perception, motivation, or confidence in diabetes-related lifestyle changes. In 2015, Voils et al. found no effect for perceived risk when a comparison was made between an experimental group receiving lifestyle and phenotypic and genomic risk estimate for T2D and a control group receiving lifestyle and phenotypic risk for T2D and risk score for unrelated eye disease. Likewise, a study by McVay et al. (2015), using the same sample, found no long-term effects regarding control perceptions or self-efficacy relating to diabetes. In 2016, Godino et al. examined the effects of receiving either standard lifestyle advice (control group) or a combination of lifestyle advice and a genomic or a phenotypic risk estimate for type 2 diabetes. The study found no effect regarding anxiety or worry respondents felt after the test results. The perception of risk for type 2 diabetes was lower in both intervention groups. However, no difference was found between genomic and phenotypic risk scores (see also Silarova et al., 2018 concerning the same sample). In relation to CHD, Robinson et al. (2016) investigated, among other things, how the reception of genomic risk score in addition to conventional risk estimate influenced participants’ perceived personal control when compared to a group receiving only conventional risk estimate. Out of the three subscales tested, the experimental group had slightly higher perceived cognitive control than participants receiving only conventional risk estimates.
To sum up, earlier studies have not reported adverse effects on receiving genomic risk information concerning T2D or CHD. However, only a limited number of studies have been conducted, especially related to CHD, and mainly cognitive outcomes have been examined. The present study aims to confirm earlier findings concerning risk perception and self-efficacy and expand from previous studies by investigating the emotional reaction to the test results. Moreover, since the size of the disease risk varies individually, it is also relevant to inspect if different risk levels cause different reactions depending on what type of risk information the participants have received. For example, it is conceivable that if one’s risk for T2D or CHD is low, it might matter less whether the risk was calculated based on genomic or more traditional factors. However, the same might not apply if one is at high risk for the disease. Thus, the specific research questions are:
1. Does receiving T2D- and CHD-related risk estimates based on a combination of genome-wide polygenic and traditional risk factors influence risk perception, self-efficacy, disease-related worry, or other emotions differently compared to receiving estimates based solely on traditional risk factors?
2. Is the magnitude of disease risk differently associated with the psychosocial factors depending on whether the respondent received estimates based on a combination of genome-wide polygenic and traditional risk factors or solely on traditional risk factors (i.e., is there an interaction between the disease risk level and type of risk information)?
2 Materials and Methods
2.1 Participants and Procedure
The present study utilized data from a sub-section of the P5 study1. P5 is a personalized medicine project led by the Finnish Institute for Health and Welfare. The project combines genomic and traditional health data to evaluate participants’ risk for certain common diseases and then utilizes an internet portal to return the future disease risk estimates (see Marjonen et al., 2021). The current study extracted data from two time points in 2019–2020. Namely, just before the respondents had access to their risk estimates of future disease concerning type 2 diabetes (T2D) and coronary heart disease (CHD) and after the participants had seen their estimates and filled the post-results survey. Access to the risk estimates was granted on 19.11.2019 for the experimental group and 16.12.2019 for the control group (all participants also received a reminder to fill in the surveys on 28.1.2020). Before participants could see their results, they had to fill in the pre-results survey. Most participants (over 90%) returned the post-results survey either on the same day as they filled the pre-results survey (34%) or within 76 days after filling the pre-results survey (56%). The possible confounding effect of response time was checked with a sensitivity analysis where the number of days each respondent had between returning the first and second survey was added as a covariate in the models. The sensitivity analysis resulted in only minute differences, see Supplementary File S1.
The future disease risk estimates were calculated based on respondents’ risk of developing T2D/CHD during the next 10-years. T2D risk was categorized to 4 levels (below 7.5% risk as low, 7.5–10% as elevated, 10–20% as high, and more than 20% as very high) and CHD risk in 3 levels (below 7.5% as low, 7.5–10% as elevated, and more than 10% as high). Participants also received information on selected single clinical variants (SCVs) related to CHD and venous thromboembolism (see Marjonen et al., 2021 for details). However, since the SCVs were not the main topic of the current study, respondents with one or more SCV were dropped from the final sample (n = 91). An exception was made regarding the pharmacogenetic variant of the SCL O 1B1 gene, which was found abundantly in the current sample (n = 1189), but which did not influence the risk for CHD or venous thromboembolism. Participants with the SCL O 1B1 variant were normally randomized to the experimental and the control group (N = 591 and 598, respectively).
The experimental group received disease risk estimates based on traditional risk factors and genome-wide polygenic scores (GPS), and the control group received estimates based solely on the traditional risk factors. Traditional risk factors included: BMI, total cholesterol, high-density lipoprotein, systolic blood pressure, blood pressure-lowering medication, lipid-lowering medication, self-reported family history, and smoking status. We used GPSes, previously published in the UK Biobank population, containing close to 7 million genomic variants for T2D and 6.6 million variants for CHD (Khera et al., 2018). To calculate the GPSes, all variants were collected from the imputed data and weighted by their corresponding genotype effect sizes. Imputed data contained 94% of the original variants in the T2D and CHD polygenic scores. After summing the variants together, the GPS was standardized using the mean and standard deviation (SD) of the GPS in an independent population sample. If a variant was missing from the imputed data (missingness 0.05%), the population average frequency of the genotype was used in the calculation instead.
The risk scores were presented as a number, accompanied with a short-written description of the risk score, and as a graph where participant’s risk was contrasted to the above-mentioned risk levels for the relevant disease (see Marjonen et al., 2021 for examples). In addition to the 10-years combined disease risk, the experimental group was provided with a graph showing their genome-wide polygenic risk scores separately. Also, a health report was given to all participants, which gave a more thorough explanation of the results and provided personal instructions on how the participants could influence their disease risk with lifestyle changes (see Marjonen et al., 2021). Finally, an interactive calculator was introduced, where respondents could test how changing their physical parameters (e.g., age) and lifestyle factors (e.g., smoking) would change their risk score (see Marjonen et al., 2021).
In total, 3449 respondents (drawn from a population-based survey of 8217; see Marjonen et al., 2021) consented to participate in the P5 study, and 3177 had risk results given to them (272 participants did not have genomic data available at the time of the RCT). 2290 respondents returned the pre-results survey, and 1368 out of 2290 the post-results survey (see Table 1 and Figure 1). To more formally access attrition, respondents who dropped (i.e., those randomized to experimental/control group but who did not return the post-survey; n = 1809) and who returned the post-survey (n = 1368) were compared with each other. The chi-square test of independence indicated that respondents who stayed and who dropped differed in terms of all the socio-demographic variables (ps < 0.03). However, the association’s size was relatively small in all cases (Cramer’s V = 0.04–0.21). Noteworthy, respondents who dropped were somewhat older (V = 0.21), less educated (V = 0.20), more likely to be pensioners (V = 0.16), had lower income (V = 0.17), and had a higher risk for CHD (V = 0.19). (See Supplementary File S1 for full results and Marjonen et al., 2021 for comparison of the population-based survey and the P5 study.).
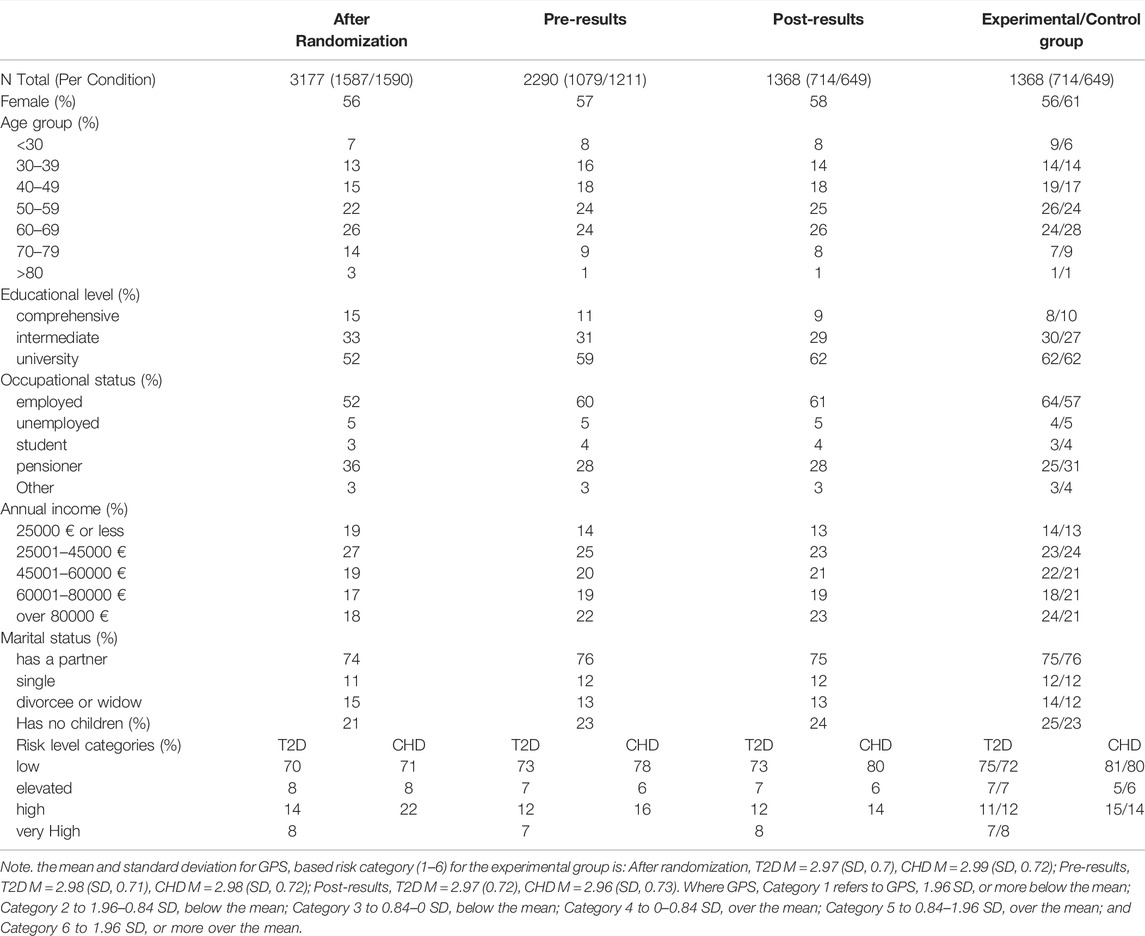
TABLE 1. Sample descriptives at three time points, and between the experimental and the control group after the post-results survey.
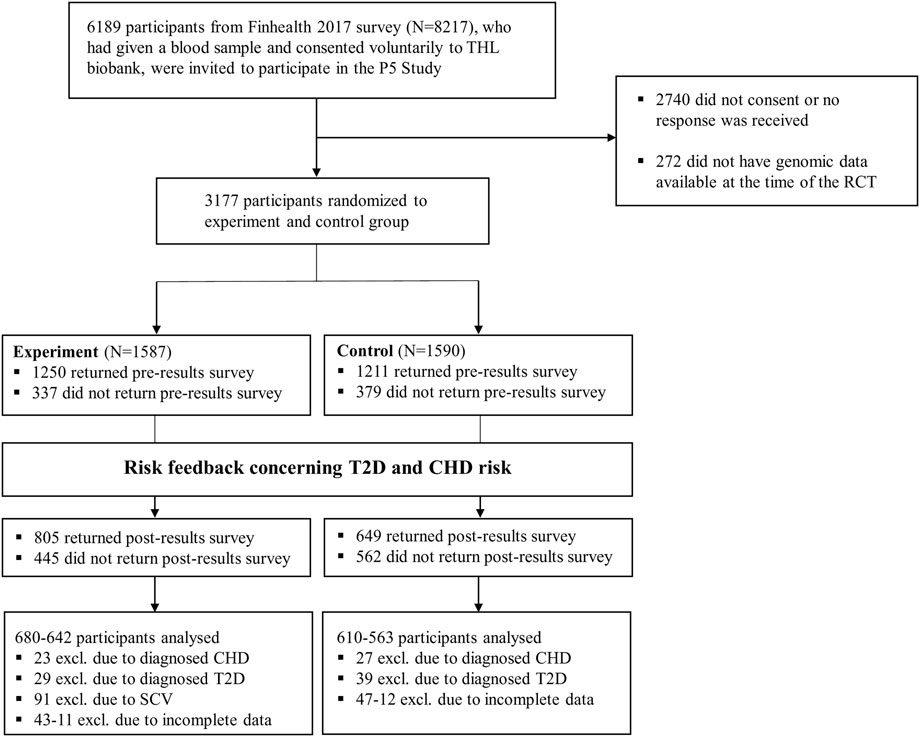
FIGURE 1. Flowchart for the current study.
Before the analyses were carried out, respondents with T2D already diagnosed (n = 68) or CHD already diagnosed (n = 50) were excluded from the relevant models (see Analysis and design). After listwise deletion was used, the final models included 1202–1290 respondents.
Moreover, since the number of available participants determined the sample size, no a priori power analysis could be done. Instead, a sensitivity power analysis for the two statistical models intended to be used, namely analysis of covariance (ANCOVA) and analysis of variance (ANOVA), was conducted with the (smallest) available sample size. G*Power software (Faul et al., 2007) indicated that when ANCOVA (n = 1231) with 1 covariate and 2 × 4 factorial design was used, the smallest effect for interaction that could be detected with 0.05 alpha and 80% power was Cohen’s f = 0.094. Similarly, for 2 × 4 factorial ANOVA (n = 1202) the smallest effect for interaction that could be detected with 0.05 alpha and 80% power was Cohen’s f = 0.095.
2.2 Measures
2.2.1 Perceived Risk
Perceived risk for T2D and CHD was measured with one item (per disease) before and after the risk scores were released. The wording was identical for both diseases: “How do you perceive your risk for T2D/CHD?” where 1 was “very small,” and 5 was “very large.”
2.2.2 Self-Efficacy
Similarly, self-efficacy was measured with one item before and after the risk scores were released: “To what extent do you feel that you can influence whether you develop T2D/CHD”, where 1 was “Not at all,” and 7 was “Very much.”
2.2.3 Risk-Related Worry
Different questions were used for risk-related worry in the pre- and post-results questionnaires. Before the risk scores were released, participants’ general worry of T2D/CHD risk was measured with one item: “How worried you are concerning your risk for T2D/CHD?”. Then, after the risk scores were released, separate items were used for worry related to genetic factors and worry related to traditional risk factors: “How worried you are concerning your risk for T2D/CHD based on “traditional” (e.g., cholesterol)/genetic risk factors.” That is, the pre-results questionnaire included two worry related questions (one for T2D and one for CHD), and the post-results questionnaire included four worry related questions (worry related to genetic risk/traditional risk factors for TD2/CHD). Each item was rated from 1 “Not at all” to 7 “Very much.”
2.2.4 Emotional Reactions (MICRA)
Participants’ immediate emotional reaction to the test results was measured with eight items selected from the Multidimensional Impact of Cancer Risk Assessment (MICRA; Cella et al., 2002) questionnaire, a well-established scale used to monitor patient concerns related to genetic testing for cancer. The selected items (items specific to cancer testing were excluded) reflected a range of emotional reactions respondents could experience due to their test results. The following items were included: “Feeling upset about my test result,” “Feeling sad about my test result,” “Feeling anxious or nervous about my test result,” “Feeling guilty about my test result,” “Feeling relieved about my test result,” “Feeling happy about my test result,” “Feeling a loss of control,” and “Having problems enjoying life because of my test result.” All items were rated from 1 (“Very little or not at all”) to 5 (“Very much”).
MICRA subscales were not utilized. The reason for this was twofold; for one, not all MICRA items were included in the study (e.g., cancer-specific items were excluded), making it difficult to estimate the proper aggregate scores. Secondly, we wanted to explore the diversity of people’s emotional reactions to polygenic risk scores, not just changes in more general emotional dispositions that MICRA subscales depict (e.g., positive/negative reaction).
See Marjonen et al. (2021) for all the scales used in the study.
2.3 Analysis and Design
Since the MICRA scale was used only after the respondents had seen their test results (as these questions specifically measured participants reaction to the test results) and all other items had an appropriate baseline score measured before the risk scores were released, different statistical models were applied to the MICRA items and the other dependent variables. Consistent with the sensitivity power analysis, a 0.05 alpha level was adopted for all statistical tests. All analyses were carried out with RStudio v1.4.1717.
2.3.1 Analysis of Perceived Risk, Self-Efficacy, and Risk-Related Worry
For a simple pretest-posttest design, ANCOVA is the typically preferred method (Huitema, 2011) and has shown to perform well in comparison to many alternatives (e.g., Egbewale et al., 2014; Zhang et al., 2014; Chausse et al., 2016; O'Connell et al., 2017). Thus, an ANCOVA model was selected for all the dependent variables with an appropriate baseline score. More specifically, a 2-way ANCOVA with the type of risk information received (only traditional/combination of traditional and genetic) and risk level (low, elevated, high, and very high for T2D, or low, elevated, and high for CHD) as factors, and score of the dependent variable in the pre-results survey as a covariate was used for each model. Dependent variables included perceived risk for T2D/CHD, worry concerning one’s risk for T2D/CHD based on traditional/genetic factors, and self-efficacy concerning one’s ability to prevent the development of T2D/CHD. In case of significant main effect, a pairwise comparison with estimated marginal means was implemented to test which groups differed from each other formally. If a significant interaction emerged, it was first plotted and eyeballed, and then pairwise comparisons were carried out for each factor within the levels of the other factor. Type 3 sums of squares were used in all ANCOVA models, as is recommended for designs where interaction between the factors is inspected (Huitema, 2011). Moreover, since multiple tests were performed, a Holm correction was applied in all ANCOVA models and in subsequent comparisons to assure appropriate control for the Type I error rate (Abdi, 2007). Partial eta squared (ηp2) was used as an effect size estimator for the F-test and Cohen’s d for pairwise comparisons of estimated marginal means (both estimated from the relevant test statistic and degrees of freedom).
2.3.2 Analysis of Emotional Reactions (MICRA)
As mentioned before, no covariate was available for the MICRA scale. Thus, an ANOVA model with each MICRA item as a dependent variable was used instead of the ANCOVA model. When significant effects emerged, a similar approach was utilized as described earlier with the ANCOVA models (i.e., Holm correction, pairwise comparison of marginal means, and so on). Moreover, since the MICRA items were not written in relation to either of the disease risks but asked solely how the respondents felt about their “test results,” it was not a priori clear if separate ANOVAs should be calculated for each disease risk or if both risks should be included in the same model. That being the case, it was first tested if any significant three-way interactions concerning the type of risk information received and T2D and CHD risk level would emerge (see Supplementary File S1 for three-way ANOVA results). When none was found, it was decided that for simplicity, each MICRA item would be analyzed with two 2-way ANOVAs. Once with T2D risk level and once with CHD risk level as a factor.
3 Results
3.1 Perceived Risk for T2D and CHD
Two separate 2-way ANCOVAs were calculated for perceived risk related to T2D and CHD. In both models, perceived risk, measured in the post-results survey, was used as a dependent variable, perceived risk in the pre-results survey a covariate, and participant’s risk level (low, elevated, high, and very high for T2D; and low, elevated, and high for CHD) and the type of risk information received (combination of genetic and traditional or traditional only) as factors. As can be seen from Table 2, risk level had a significant main effect in both disease conditions (both ps <0.001), but no significant effect was found for the type of risk information given or for the interaction between risk level and type of information (ps >0.12).
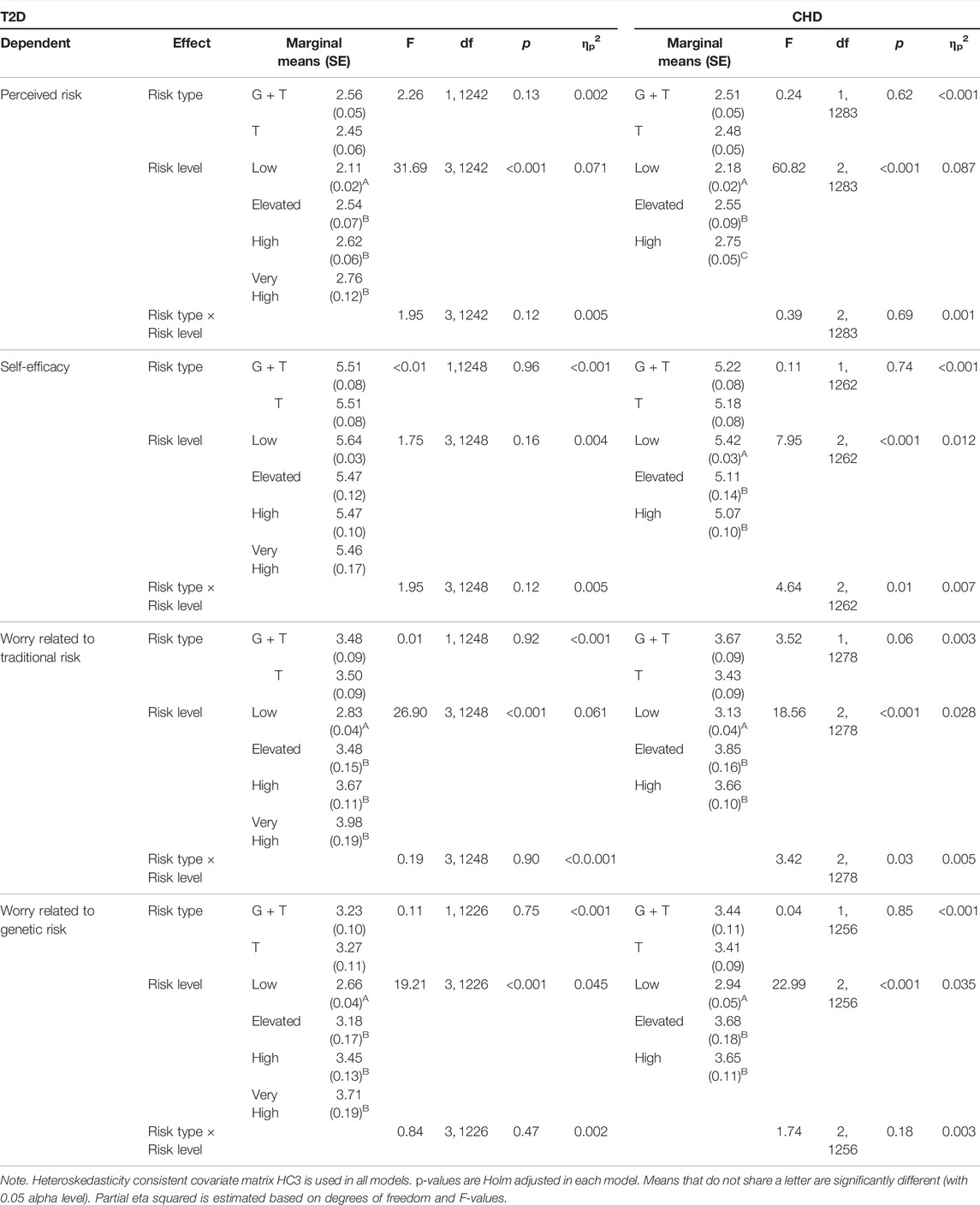
TABLE 2. Analysis of covariance main effects and interactions: Perceived risk, self-efficacy, and worry concerning T2D and CHD risk.
Estimated marginal means and pairwise comparisons were calculated to investigate the significant main effects further. When perceived risk related to T2D was inspected, participants with low risk also perceived their risk as lower compared to respondents with elevated (MD = 0.43 ± 0.08, d = 0.32), high (MD = 0.52 ± 0.07, d = 0.44), or very high (MD = 0.65 ± 0.13, d = 0.30) risk (ps <0.001). However, no differences were found when participants with elevated, high, or very high risk were compared to each other (ps > 0.34). A somewhat similar pattern emerged regarding perceived risk related to CHD. As before, respondents with low risk perceived their risk lower compared to participants with elevated or high risk (both ps <0.001, MD = 0.36–0.57 ± 0.09–0.05, d = 0.22–0.59). In addition, participants with elevated risk also perceived their risk lower compared to participants with high risk (p = 0.04, MD = 0.21 ± 0.10, d = 0.11).
3.2 Self-Efficacy Concerning One’s Ability to Prevent T2D and CHD
Similar 2-way ANCOVAs as described above were calculated concerning self-efficacy. As before, the type of risk information and level worked as factors, and self-efficacy score before the risk information was released was used as a covariate. In relation to self-efficacy and T2D, no statistically significant main effects or interaction emerged for the type of information received or for risk level (ps > 0.12). When CHD and self-efficacy were inspected, a nonsignificant main effect for type of risk (p = 0.74) and a significant main effect for risk level (p = <0.001) emerged. Moreover, an interaction between the type of risk information and risk level was found (p = 0.01).
Since the interaction effect was statistically significant, the main effect of risk level was not further investigated (see Table 2 for main effect results). Instead, the interaction between the risk level and type of information was plotted and eyeballed (see Figure 2A). Then pairwise comparisons were carried out for each factor within the levels of the other factor (i.e., low vs. elevated vs. high CHD risk comparisons made separately for both types of risk, and type of risk comparisons made separately within each CHD risk level). Within the group receiving only traditional risk information, it seemed that higher risk was associated consistently with lower self-efficacy. Pairwise comparisons indicated differences between respondents with low and high risk (p < 0.001, MD = 0.66 ± 0.17, d = 0.21), but not for other risk levels (ps > 0.15). As for the group receiving a combination of genetic and traditional risk, the plot indicated a V-shape trend: low- and high-risk participants seemed to have almost equal self-efficacy while respondents with elevated risk had relatively reduced self-efficacy. However, none of the differences reached statistical significance when pairwise comparisons were carried out (ps > 0.21).
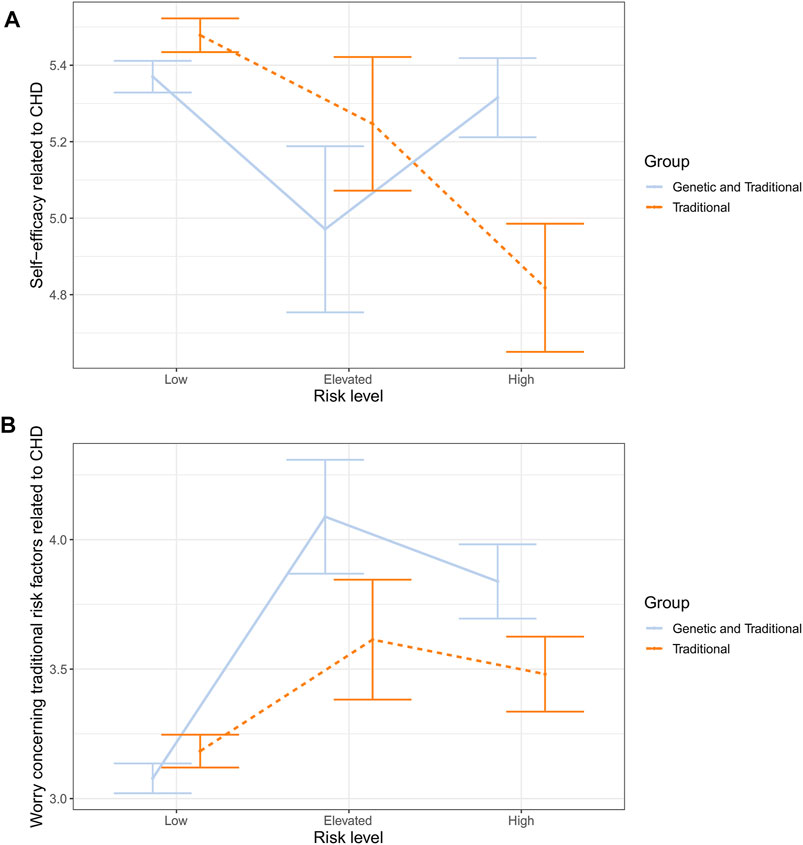
FIGURE 2. Estimated means and standard errors for interaction between risk type and risk level concerning CHD related self-efficacy (A) and worry (B).
When the effect of type of risk was, in turn, inspected in the classes of risk level, pairwise comparisons indicated that the group receiving a combination of traditional and genetic information had, compared to the control group, higher self-efficacy within the high-risk level (p = 0.01, MD = 0.50 ± 0.20, d = 0.14), while no difference was found within low or elevated risk levels (ps > 0.07).
3.3 Worry Related to T2D and CHD Risk Based on Traditional Risk Factors
Two separate two-way ANCOVAs were conducted. General worry concerning T2D/CHD measured in the pre-results survey was used as a covariate, and worry concerning traditional risk for T2D/CHD measured in the post-results survey was used as a dependent variable. Again, the type of risk and risk level worked as factors in both models. In relation to worry concerning traditional risk for T2D, no significant main effect was found for the type of risk information received (p = 0.92) or for the interaction between the risk type and risk level (p = 0.90). However, the risk level did have a significant main effect (p < 0.001). Likewise, in relation to CHD, no significant main effect was found for the type of risk information (p = 0.06). Significant effects did, however, emerge for the risk level (p <0 .001) and for the risk type and level interaction (p = 0.03).
Pairwise comparisons indicated that respondents with low risk for T2D were significantly less worried than participants who had elevated (MD = 0.64 ± 0.15, d = 0.24), high (MD = 0.84 ± 0.12, d = 0.39), or very high (MD = 1.44 ± 0.19, d = 0.34) risk for T2D (ps < 0.001). However, no differences were found when elevated-, high-, and very high-risk groups were compared to each other (ps > 0.10).
In relation to CHD, due to the significant interaction, the main effect of the risk level was not further investigated (see Table 2 for main effect results). As before, the interaction was first plotted and eyeballed, and then pairwise comparisons were made. Both the experiment and the control group showed a roughly similar pattern of results (see Figure 2B). CHD-related worry was the lowest at a low-risk level, then spiked up at an elevated risk level, and slightly dropped at a high-risk level. Although roughly similar, the pattern seemed more pronounced in the group receiving traditional and genetic risk information. However, when pairwise comparisons were conducted comparing the two groups at different risk levels, no differences emerged at any stage (all ps > 0.08). The only statistically significant differences emerged within the group receiving traditional and genetic risk information. Here, low-risk respondents were less worried than elevated- (MD = 1.01 ± 0.23, d = 0.25) or high-risk (MD = 0.76 ± 0.16, d = 0.27) participants (both ps <0.001).
3.4 Worry Related to T2D and CHD Risk Based on Genetic Risk Factors
Similar two-way ANCOVAs as described above were calculated for worry related to genetic risk factors. As before, type of risk and risk level worked as factors, and general worry related to T2D/CHD measured in the pre-results survey was used as a covariate. No significant main effects were found in either disease condition for the type of risk information received (ps > 0.75) or for the interaction between the type of risk and risk level (ps > 0.18). However, risk level did have a significant main effect in both disease conditions (both ps < 0.001).
Pairwise comparisons revealed that participants with low risk for T2D were less worried about their T2D risk related to genetic risk factors than respondents with elevated (MD = 0.53 ± 0.17, d = 0.17), high (MD = 0.79 ± 0.14, d = 0.33), or very high (MD = 1.05 ± 0.20, d = 0.30) risk (ps < 0.01). However, no significant differences were observed between elevated-, high-, and very high-risk groups (ps > 0.12). When the risk for CHD was inspected, participants with low risk were less worried concerning their risk related to genetic factors than respondents with elevated (MD = 0.74 ± 0.19, d = 0.22) or high (MD = 0.71 ± 0.11, d = 0.34) risk (ps < 0.001). Again, no difference emerged between elevated- and high-risk groups (p = 0.90).
3.5 Emotional Reactions to Test Results (MICRA)
Separate 2-way ANOVA models were conducted for the MICRA items. All models included the type of risk and risk level as factors. The analyses were carried out once with T2D risk level as a factor and once with CHD risk level as a factor (see Table 3).
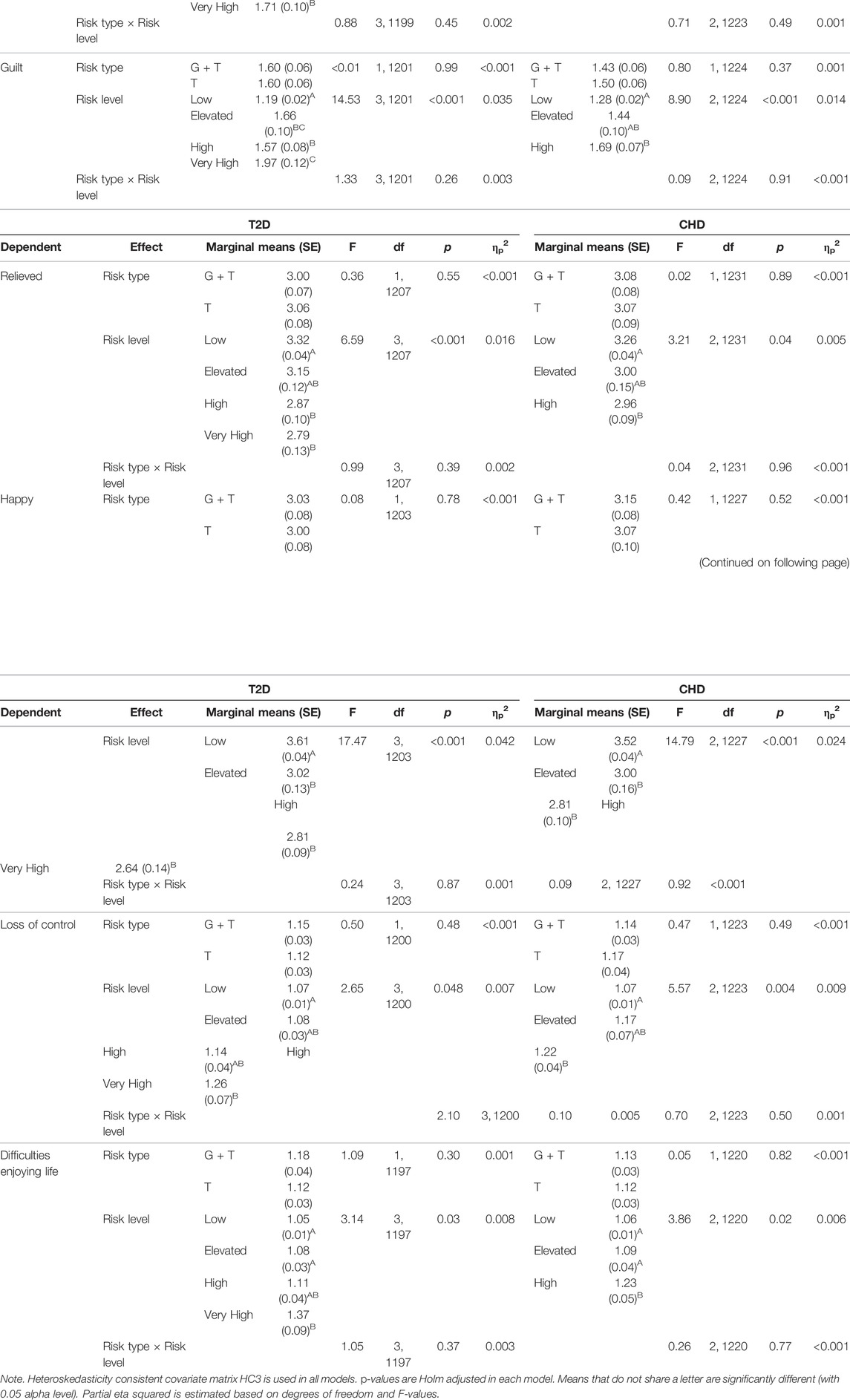
TABLE 3. Analysis of variance main effects and interactions: Emotional reaction to the test results concerning T2D and CHD risk.
Type of risk had a nonsignificant main effect in all models (ps > 0.30). Likewise, no statistically significant interaction between risk type and the risk level emerged concerning T2D risk (ps > 0.10) or CHD risk (ps > 0.14). However, a significant main effect did emerge for both CHD and T2D risk levels in all models (ps < 0.048).
As with the ANCOVA models, pairwise comparisons of estimated marginal means were carried out for the statistically significant effects. For the T2D risk level, the comparisons indicated a similar pattern of results concerning how upset, sad, nervous, or happy the respondents felt. Participants with low T2D risk were less upset (MD = 0.39–0.71 ± 0.10–0.12, d = 0.23–0.34), sad (MD = 0.40–0.52 ± 0.12–0.08, d = 0.22–0.39), nervous (MD = 0.28–0.54 ± 0.09–0.10, d = 0.18–0.30), and happier (MD = 0.60–0.80 ± 0.14–0.11, d = 0.25–0.43) than respondents with elevated, high, or very high risk (ps < 0.01). An almost similar pattern emerged concerning how much guilt the respondents felt due to their test results. Low-risk participants felt less guilt than respondents with elevated (MD = 0.47 ± 0.10, d = 27), high (MD = 0.38 ± 0.08, d = 0.28), or very high (MD = 0.78 ± 0.12, d = 37) risk (ps < 0.001). However, a statistically significant difference also emerged between respondents with high and very high risk (p = 0.02, MD = 0.40 ± 0.14, d = 0.16). Other differences related to upset, sadness, nervousness, guilt, happiness, and T2D risk level were statistically nonsignificant (ps > 0.07).
The amount of relief participants felt after seeing their results followed largely the same general pattern of the low-risk group producing the significant effects. However, no statistically significant effect was observed when low- and elevated-risk groups were compared to each other (p = 0.35, while other comparisons to low risk were again p < 0.001, MD = 0.54–0.46 ± 0.14–0.11, d = 0.22–0.24). When feelings of losing control were inspected, participants with low T2D risk felt more in control than participants with very high risk (p = 0.04, MD = 0.20 ± 0.07, d = 0.16). All other comparisons related to losing control were nonsignificant (ps > 0.07). Finally, when comparisons related to difficulties enjoying life were conducted, respondents with very high T2D risk had more difficulties compared to participants with low (MD = 0.32 ± 0.10, d = 0.20) or elevated (MD = 0.29 ± 0.10, d = 0.17) risk (ps < 0.02). All other comparisons were statistically nonsignificant (ps > 0.05).
Pairwise comparisons related to CHD risk and emotions produced reasonably similar results. Participants with low CHD risk were less upset (MD = 0.35–0.47 ± 0.11–0.07, d = 0.18–0.38), sad (MD = 0.32–0.49 ± 0.12–0.07, d = 0.16–0.40), and happier (MD = 0.52–0.72 ± 0.17–0.10, d = 0.18–0.41) than respondents with elevated or high risk (ps < 0.012), while all other differences were statistically nonsignificant (ps > 0.24). Likewise, respondents with low CHD risk felt less nervous (MD = 0.33 ± 0.07, d = 0.28), guilty (MD = 0.42 ± 0.07, d = 0.33), and loss of control (MD = 0.15 ± 0.04, d = 0.21) compared to respondents with high risk (ps < 0.01). However, no difference was found when low and elevated or high and elevated risk participants were compared to each other (ps > 0.07). Finally, when risk groups were compared in relation to how much difficulties they have enjoying life, respondents with low (MD = 0.17 ± 0.05, d = 0.20) or elevated (MD = 0.15 ± 0.06, d = 0.14) risk had less difficulties compared to high-risk participants (ps < 0.033), while no statistically significant difference emerged between participants with low and elevated risk (p = 0.54).
4 Discussion
An RCT was utilized to investigate the psychosocial effects of receiving a combination of traditional risk information and a genome-wide polygenic risk score concerning two common diseases. The experimental group was given a risk estimate related to type 2 diabetes (T2D) and coronary heart disease (CHD) based on a combination of genome-wide polygenic risk scores and traditional risk factors. The control group received risk estimates for the same diseases based solely on traditional risk factors. Afterward, the groups were compared in relation to perceived risk, self-efficacy, risk-related worry, and emotional reactions to the test results.
Type of risk (i.e., whether the respondents received future disease risk estimates based on a combination of genome-wide polygenic and traditional risk factors or traditional risk factors only) did not have a significant main effect in any comparisons made. Thus, our results are largely compatible with earlier studies concerning polygenic estimates of T2D and CHD risk, and polygenic risk scores more generally (e.g., Godino et al., 2016; Robinson et al., 2016; Robinson et al., 2019). Receiving a genome-wide polygenic risk in addition to more traditional risk factors for T2D or CHD does not, on average, seem to stir detrimental or any other kind of pronounced psychological reaction in the receivers when compared to receiving information based only on traditional risk factors.
However, two significant interaction effects were found when the type of risk information received was inspected alongside the risk level (i.e., how high respondents’ risk for T2D/CHD was). In relation to CHD risk and self-efficacy, the control group showed a linearly decreasing trend in self-efficacy as CHD risk increased. In the experimental group, low- and high-risk participants had very similar levels of self-efficacy, and participants with elevated risk had slightly lower self-efficacy. Multiple reasons could contribute to the observed pattern. For example, it has been suggested that genetic risk estimates might induce fatalistic beliefs concerning one’s chances of coming down with a certain disease (Claassen et al., 2010), which, in turn, might lead to insensitivity to actual risk.
However, empirical evidence that polygenic risk scores would inflict fatalistic beliefs in real-life situations has been scant (Collins et al., 2011). Moreover, at least at first glance, it seems peculiar that no such interaction was found for T2D risk and self-efficacy. Though, it is possible that the knowledge of not having certain CHD risk increasing SCVs (as participants with these SCVs present were excluded from the final sample and no information about T2D related SCVs were given) could contribute to the observed differences between the CHD and T2D interactions relating to self-efficacy. Thus, it seems that, for one, there could exist some uncharted and subtle (Cohen’s d = 0.14) phenomena between genome-wide polygenic risk and self-efficacy that do not manifest in the context of T2D risk. Alternatively, the effect could depend on knowledge of not having certain risk influencing SCVs. Lastly, it could be some combination of the two or a spurious finding. Consequently, we suggest that the current finding is first replicated in other studies before drawing more far-reaching conclusions about self-efficacy and genome-wide polygenic risk for CHD.
The second interaction also emerged only in the context of CHD risk. Here, worry related to traditional risk factors concerning CHD increased in both groups when low and elevated risk participants were compared and then slightly decreased when elevated and high risk participants were compared. Although the trend looked similar in both the control and experimental group, the upward spike from low to elevated risk was more pronounced in the group receiving genetic and traditional risk information. Moreover, pairwise comparisons indicated that the only significant differences were within the experimental group and not between the groups. Thus, it seems that there was more fluctuation between respondents’ reactions at different risk levels in the group receiving genetic and traditional risk information (producing significant within-group differences) but not enough to produce differences between the groups. That is, at any specific risk level, the control and experimental group did not formally differ from each other. Given that the observed pattern was only present in the context of CHD risk and not T2D risk, and no such effect emerged concerning worry related to genetic risk for either of the disease conditions, we suggest that the current finding is first replicated before drawing more firm conclusions.
While the type of risk information received did not produce consistent effects, the magnitude of risk (i.e., T2D/CHD risk level) did have a clear impact on nearly all the psychosocial variables studied. The effects generally flowed in the direction of what would be expected: on average, the higher risk was associated with higher perceived risk, worry, lower self-efficacy, and with less positive emotions and with more negative emotions. Effects concerning risk perception had the highest effect sizes (ηp2 = 0.07–0.09), and extreme adverse reactions, such as respondents having difficulties enjoying life or feeling that they are losing control, had the smallest effect sizes (ηp2 < 0.01). In general, adverse reactions to the risk estimates were subdued regardless of the risk level (e.g., the highest marginal mean observed concerning reactions with negative valence was M = 3.98 ± 0.19 for T2D related worry, which is just slightly above the middle point of the scale used).
It is possible that respondents with high or very high risk were already conscious of their heightened risk (e.g., due to lifestyle factors or family history), which might have made the emotional impact of the results less extreme. Likewise, since both conditions are actionable and the offered risk projection was for 10 years, respondents might have felt they still had time to make the necessary lifestyle changes and were thus not overly worried about their test results at present. Indeed, along with the risk estimates, participants were given information concerning lifestyle changes that could mitigate their disease risk. Importantly, the interactive calculator tangibly demonstrated how changing physical parameters and lifestyle factors could influence one’s risk for T2D and CHD. It is also conceivable that even when respondents had a high relative risk (i.e., risk contrasted with the population average), they might not have considered their absolute risk (e.g., 10–20%) to be high enough to cause great concern. Finally, it should be noted that only 34% of participants returned the pre-and post-survey on the same day. Thus, most respondents had some time to process the results, which might have softened the initial reaction.
To sum up, we did not find consistent evidence that distributing risk estimates based on a combination of genome-wide polygenic and traditional risk would cause psychological harm to the respondents. The presence of genome-wide polygenic risk did not seem to influence risk perception or cause an adverse emotional reaction. Likewise, self-efficacy and disease-related worry remained, for most parts, unaltered. The minute changes that did emerge (The highest ηp2 for significant effect involving the experimental and control group was 0.007, and the highest d was 0.14) could not be interpreted as harmful per se. As such, our results are largely in line with other studies concerning T2D (Grant et al., 2013; McVay et al., 2015; Voils et al., 2015; Godino et al., 2016) and CHD (Robinson et al., 2016) risk scores and with studies concerning polygenic risk scores more generally (Robinson et al., 2019; Wade, 2019). Results concerning the magnitude of the disease risk were consistent with expectations, albeit subdued.
Several limitations should be considered when interpreting the results as with any study. For one, absence of evidence is not evidence of absence (Altman and Bland, 1995). It is thus difficult to conclude with certainty that there are no harmful effects in receiving genome-wide polygenic risk information. However, given the sensitivity power analysis, our study does indicate that if these effects exist, they are likely relatively small in magnitude. Secondly, significant attrition occurred between the randomization and the post-survey (approximately 55% of respondents dropped), which exposed the sample to additional bias. Even though the observed differences in the measured socio-demographic variables were reasonably modest between those who dropped and stayed, the dropouts tended to be from groups that already suffer from underrepresentation in health surveys (e.g., less educated and with lower socioeconomic status; Reinikainen et al., 2018). Moreover, it is possible that the groups might also differ substantially from each other regarding some unmeasured factor. Thus, special caution should be applied when generalizing the results. Thirdly, as with most studies conducted in a real-life setting, the set-up included multiple potentially confounding factors. Notably, in the current study, respondents received multiple risk scores simultaneously (including SCV results), and response time was not strictly controlled (i.e., after receiving the notification, respondents themselves decided when to check their results and answer the survey questions). Although the sensitivity analyses did not indicate notable confounding effects, caution should still be applied when generalizing the results into a different context. Finally, it is important to keep in mind that when the risk estimates were communicated, the respondents also received information about risk-mitigating lifestyle strategies. The absence of this information or a change in the feedback could influence the results.
Data Availability Statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://thl.fi/en/web/thl-biobank/for-researchers, THL Biobank.
Ethics Statement
The study was reviewed and approved by Coordinating Ethics Committee of the Hospital District of Helsinki and Uusimaa. The participants provided their written informed consent to participate in this study.
Author Contributions
All authors contributed to conception and design of the study. OH performed the statistical analysis. OH wrote the first draft of the manuscript. All authors reviewed and commented on the article.
Funding
The study was supported by Emil Aaltonen Foundation and Yrjö Jahnsson Foundation.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We want to thank all the P5 participants for taking part in the study. We thank Marketta Taimi and Erika Perola for their help in collecting the P5 consent and questionnaire data. Last, we would like to pay our gratitude and our respects in memory of our dear colleague Ari Haukkala, who showed a great importance in the implementation of the study.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2022.881349/full#supplementary-material
Footnotes
1https://thl.fi/en/web/thlfi-en/research-and-development/research-and-projects/the-p5.fi-study-genetic-information-for-health-support?redirect = %2Fen%2Fweb%2Fthlfi-en%2Fresearch-and-expertwork%2Fprojects-and-programmes%2Fcurrent-research-and-projects.
References
Abdi, H. (2007). Bonferroni and Šidák Corrections for Multiple Comparisons. Encycl. Meas. statistics 3, 103–107.
Abouzeid, M., Wikström, K., Peltonen, M., Lindström, J., Borodulin, K., Rahkonen, O., et al. (2015). Secular Trends and Educational Differences in the Incidence of Type 2 Diabetes in Finland, 1972-2007. Eur. J. Epidemiol. 30 (8), 649–659. doi:10.1007/s10654-015-0008-7
Abul-Husn, N. S., and Kenny, E. E. (2019). Personalized Medicine and the Power of Electronic Health Records. Cell 177 (1), 58–69. doi:10.1016/j.cell.2019.02.039
Altman, D. G., and Bland, J. M. (1995). Statistics Notes: Absence of Evidence Is Not Evidence of Absence. BMJ 311 (7003), 485. doi:10.1136/bmj.311.7003.485
Cella, D., Hughes, C., Peterman, A., Chang, C.-H., Peshkin, B. N., Schwartz, M. D., et al. (2002). A Brief Assessment of Concerns Associated with Genetic Testing for Cancer: the Multidimensional Impact of Cancer Risk Assessment (MICRA) Questionnaire. Health Psychol. 21 (6), 564–572. doi:10.1037/0278-6133.21.6.564
Chaussé, P., Liu, J., and Luta, G. (2016). A Simulation-Based Comparison of Covariate Adjustment Methods for the Analysis of Randomized Controlled Trials. Ijerph 13 (4), 414. doi:10.3390/ijerph13040414
Claassen, L., Henneman, L., De Vet, R., Knol, D., Marteau, T., and Timmermans, D. (2010). Fatalistic Responses to Different Types of Genetic Risk Information: Exploring the Role of Self-Malleability. Psychol. Health 25 (2), 183–196. doi:10.1080/08870440802460434
Collins, R. E., Wright, A. J., and Marteau, T. M. (2011). Impact of Communicating Personalized Genetic Risk Information on Perceived Control over the Risk: a Systematic Review. Genet. Med. 13 (4), 273–277. doi:10.1097/GIM.0b013e3181f710ca
Egbewale, B. E., Lewis, M., and Sim, J. (2014). Bias, Precision and Statistical Power of Analysis of Covariance in the Analysis of Randomized Trials with Baseline Imbalance: a Simulation Study. BMC Med. Res. Methodol. 14, 49. doi:10.1186/1471-2288-14-49
Faul, F., Erdfelder, E., Lang, A.-G., and Buchner, A. (2007). G*Power 3: a Flexible Statistical Power Analysis Program for the Social, Behavioral, and Biomedical Sciences. Behav. Res. Methods 39 (2), 175–191. doi:10.3758/bf03193146
Fuchsberger, C., Flannick, J., Teslovich, T. M., Mahajan, A., Agarwala, V., Gaulton, K. J., et al. (2016). The Genetic Architecture of Type 2 Diabetes. Nature 536 (7614), 41–47. doi:10.1038/nature18642
Godino, J. G., van Sluijs, E. M. F., Marteau, T. M., Sutton, S., Sharp, S. J., and Griffin, S. J. (2016). Lifestyle Advice Combined with Personalized Estimates of Genetic or Phenotypic Risk of Type 2 Diabetes, and Objectively Measured Physical Activity: A Randomized Controlled Trial. PLoS Med. 13 (11), e1002185. doi:10.1371/journal.pmed.1002185
Grant, R. W., O’Brien, K. E., Waxler, J. L., Vassy, J. L., Delahanty, L. M., Bissett, L. G., et al. (2013). Personalized Genetic Risk Counseling to Motivate Diabetes Prevention. Diabetes Care 36 (1), 13–19. doi:10.2337/dc12-0884
M. S. Hagger, L. D. Cameron, K. Hamilton, N. Hankonen, and T. Lintunen (Editors) (2020). The Handbook of Behavior Change. Cambridge Handbooks in Psychology (Cambridge: Cambridge University Press), i–ii.
Hollands, G. J., French, D. P., Griffin, S. J., Prevost, A. T., Sutton, S., King, S., et al. (2016). The Impact of Communicating Genetic Risks of Disease on Risk-Reducing Health Behaviour: Systematic Review with Meta-Analysis. BMJ 352, i1102. doi:10.1136/bmj.i1102
Huitema, B. E. (2011). The Analysis of Covariance and Alternatives: Statistical Methods for Experiments, Quasi-Experiments, and Single-Case Studies. Hoboken, N.J.: Wiley.
Khera, A. V., Chaffin, M., Aragam, K. G., Haas, M. E., Roselli, C., Choi, S. H., et al. (2018). Genome-wide Polygenic Scores for Common Diseases Identify Individuals with Risk Equivalent to Monogenic Mutations. Nat. Genet. 50 (9), 1219–1224. doi:10.1038/s41588-018-0183-z
Krier, J. B., Kalia, S. S., and Green, R. C. (2016). Genomic Sequencing in Clinical Practice: Applications, Challenges, and Opportunities. Dialogues Clin. Neurosci. 18 (3), 299–312. doi:10.31887/dcns.2016.18.3/jkrier
Marjonen, H., Marttila, M., Paajanen, T., Vornanen, M., Brunfeldt, M., Joensuu, A., et al. (2021). A Web Portal for Communicating Polygenic Risk Score Results for Health Care Use-The P5 Study. Front. Genet. 12, 763159. doi:10.3389/fgene.2021.763159
McVay, M. A., Beadles, C., Wu, R., Grubber, J., Coffman, C. J., Yancy, W. S., et al. (2015). Effects of Provision of Type 2 Diabetes Genetic Risk Feedback on Patient Perceptions of Diabetes Control and Diet and Physical Activity Self-Efficacy. Patient Educ. Couns. 98, 1600–1607. doi:10.1016/j.pec.2015.06.016
O Connell, N. S., Dai, L., Jiang, Y., Speiser, J. L., Ward, R., Wei, W., et al. (2017). Methods for Analysis of Pre-Post Data in Clinical Research: A Comparison of Five Common Methods. J. Biom Biostat. 08 (1), 1–8. doi:10.4172/2155-6180.1000334
Peterson, E. B., Chou, W.-y. S., Gaysynsky, A., Krakow, M., Elrick, A., Khoury, M. J., et al. (2018). Communication of Cancer-Related Genetic and Genomic Information: A Landscape Analysis of Reviews. Transl. Behav. Med. 8 (1), 59–70. doi:10.1093/tbm/ibx063
Reinikainen, J., Tolonen, H., Borodulin, K., Härkänen, T., Jousilahti, P., Karvanen, J., et al. (2018). Participation Rates by Educational Levels Have Diverged during 25 Years in Finnish Health Examination Surveys. Eur. J. Public Health 28 (2), 237–243. doi:10.1093/eurpub/ckx151
Roberts, R., and Stewart, A. F. R. (2012). Genes and Coronary Artery Disease. J. Am. Coll. Cardiol. 60 (18), 1715–1721. doi:10.1016/j.jacc.2011.12.062
Robinson, C. L., Jouni, H., Kruisselbrink, T. M., Austin, E. E., Christensen, K. D., Green, R. C., et al. (2016). Disclosing Genetic Risk for Coronary Heart Disease: Effects on Perceived Personal Control and Genetic Counseling Satisfaction. Clin. Genet. 89 (2), 251–257. doi:10.1111/cge.12577
Robinson, J. O., Wynn, J., Biesecker, B., Biesecker, L. G., Bernhardt, B., Brothers, K. B., et al. (2019). Psychological Outcomes Related to Exome and Genome Sequencing Result Disclosure: a Meta-Analysis of Seven Clinical Sequencing Exploratory Research (CSER) Consortium Studies. Genet. Med. 21 (12), 2781–2790. doi:10.1038/s41436-019-0565-3
Salomaa, V., Pietilä, A., Peltonen, M., and Kuulasmaa, K. (2016). Changes in CVD Incidence and Mortality Rates, and Life Expectancy: North Karelia and National. gh 11 (2), 201–205. doi:10.1016/j.gheart.2016.04.005
Sanchis-Gomar, F., Perez-Quilis, C., Leischik, R., and Lucia, A. (2016). Epidemiology of Coronary Heart Disease and Acute Coronary Syndrome. Ann. Transl. Med. 4 (13), 256. doi:10.21037/atm.2016.06.33
Silarova, B., Douglas, F. E., Usher-Smith, J. A., Godino, J. G., and Griffin, S. J. (2018). Risk Accuracy of Type 2 Diabetes in Middle Aged Adults: Associations with Sociodemographic, Clinical, Psychological and Behavioural Factors. Patient Educ. Couns. 101 (1), 43–51. doi:10.1016/j.pec.2017.07.023
Voils, C. I., Coffman, C. J., Grubber, J. M., Edelman, D., Sadeghpour, A., Maciejewski, M. L., et al. (2015). Does Type 2 Diabetes Genetic Testing and Counseling Reduce Modifiable Risk Factors? A Randomized Controlled Trial of Veterans. J. Gen. Intern Med. 30 (11), 1591–1598. doi:10.1007/s11606-015-3315-5
Wade, C. H. (2019). What Is the Psychosocial Impact of Providing Genetic and Genomic Health Information to Individuals? an Overview of Systematic Reviews. Hastings Cent. Rep. 49 (Suppl. 1), S88–S96. doi:10.1002/hast.1021
Zhang, S., Paul, J., Nantha-Aree, M., Buckley, N., Shahzad, U., Cheng, J., et al. (2014). Empirical Comparison of Four Baseline Covariate Adjustment Methods in Analysis of Continuous Outcomes in Randomized Controlled Trials. Clep 6, 227–235. doi:10.2147/CLEP.S56554
Keywords: polygenic risk, type 2 diabetes, coronary heart disease, Emotions, randomized controlled Trial
Citation: Halmesvaara O, Vornanen M, Kääriäinen H, Perola M, Kristiansson K and Konttinen H (2022) Psychosocial Effects of Receiving Genome-Wide Polygenic Risk Information Concerning Type 2 Diabetes and Coronary Heart Disease: A Randomized Controlled Trial. Front. Genet. 13:881349. doi: 10.3389/fgene.2022.881349
Received: 22 February 2022; Accepted: 28 April 2022;
Published: 30 May 2022.
Edited by:
Manuel Corpas, Cambridge Precision Medicine, United KingdomReviewed by:
Daiva Nielsen, McGill University, CanadaElizabeth Hauser, Duke University, United States
Copyright © 2022 Halmesvaara, Vornanen, Kääriäinen, Perola, Kristiansson and Konttinen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Otto Halmesvaara, b3R0by5oYWxtZXN2YWFyYUBoZWxzaW5raS5maQ==