
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Environ. Sci. , 26 March 2025
Sec. Environmental Informatics and Remote Sensing
Volume 13 - 2025 | https://doi.org/10.3389/fenvs.2025.1562287
 Jinjing Zhu1*
Jinjing Zhu1* Ling Li2
Ling Li2Introduction: Accurate environmental image classification is essential for ecological monitoring, climate analysis, disaster detection, and sustainable resource management. However, traditional classification models face significant challenges, including high intra-class variability, overlapping class boundaries, imbalanced datasets, and environmental fluctuations caused by seasonal and lighting changes.
Methods: To overcome these limitations, this study introduces the Multi-Scale Attention-Based Environmental Classification Network (MABEC-Net), a novel deep learning framework that enhances classification accuracy, robustness, and scalability. MABEC-Net integrates multi-scale feature extraction, which enables the model to analyze both fine-grained local textures and broader environmental patterns. Spatial and channel attention mechanisms are incorporated to dynamically adjust feature importance, allowing the model to focus on key visual information while minimizing noise.In addition to the network architecture, we propose the Adaptive Environmental Training Strategy (AETS), a robust training framework designed to improve model generalization across diverse environmental datasets. AETS employs dynamic data augmentation to simulate real-world variations, domain-specific regularization to enhance feature consistency, and feedback-driven optimization to iteratively refine the model‘s performance based on real-time evaluation metrics.
Results: Extensive experiments conducted on multiple benchmark datasets demonstrate that MABEC-Net, in conjunction with AETS, significantly outperforms state-of-the-art models in terms of classification accuracy, robustness to domain shifts, and computational efficiency.
Discussion: By integrating advanced attention-based feature extraction with adaptive training strategies, this study establishes a cutting-edge AI-driven solution for large-scale environmental monitoring, ecological assessment, and sustainable resource management. Future research directions include optimizing computational efficiency for deployment in edge computing and resource-constrained environments, as well as extending the framework to multimodal environmental data sources, such as hyperspectral imagery and sensor networks.
Environmental monitoring plays a crucial role in addressing global challenges such as climate change, deforestation, and biodiversity loss (Maurício et al., 2023). The increasing availability of high-resolution imagery from satellites, drones, and ground-based sensors has led to significant advances in image classification for environmental applications (Tian et al., 2020). Accurate classification of environmental images is essential for tasks such as land cover analysis, ecosystem monitoring (Hong et al., 2020), and natural disaster assessment, where AI-driven solutions offer scalable and efficient alternatives to traditional methods (Yang et al., 2021).
Traditional environmental image classification methods, such as threshold-based segmentation, handcrafted feature extraction, and classical machine learning models like support vector machines and random forests (Sun et al., 2022), have been widely used in remote sensing applications. While these approaches perform well in specific domains, they often struggle with high intra-class variability (Rao et al., 2021), complex environmental patterns, and the presence of noise. Furthermore, handcrafted features lack generalization ability when applied to diverse and dynamic environmental conditions (Wang et al., 2022). With the rise of deep learning, convolutional neural networks have significantly outperformed classical methods in environmental classification tasks (Mai et al., 2021), demonstrating remarkable capabilities in feature extraction, hierarchical representation learning, and scalability (Azizi et al., 2021). Advanced CNN architectures such as ResNet, EfficientNet, and DenseNet have been widely applied to land use classification, vegetation monitoring, and pollution detection. However, CNN-based models often require large amounts of labeled training data and struggle to capture long-range dependencies in complex environmental images (Li et al., 2020).
Recent advancements in vision transformers and attention mechanisms have further improved the capability to model global spatial correlations in image data (Bhojanapalli et al., 2021). Vision transformers offer advantages in capturing long-range dependencies, making them particularly useful for monitoring wildfire spread (Kim et al., 2022), glacier retreat, and ecosystem degradation. However, their high computational demands and reliance on large-scale labeled datasets limit their applicability in real-time environmental monitoring (Zhang et al., 2020). To address these challenges, this study proposes MABEC-Net (Multi-Scale Attention-Based Environmental Classification Network) (Zhu et al., 2020), a novel deep learning framework that integrates multi-scale feature extraction and attention mechanisms to enhance the accuracy and robustness of environmental image classification. Unlike conventional CNN-based models (Ashtiani et al., 2021), MABEC-Net captures both local details and global context through a combination of spatial and channel attention mechanisms, improving classification performance in highly variable environmental settings (Chen et al., 2021).
This subsection provides an overview of how deep learning techniques, particularly Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), have been applied to environmental image classification (Masana et al., 2020). We discuss recent advancements and highlight the challenges faced, such as class imbalance, domain shifts, and interpretability (Vermeire et al., 2022). Here, we focus on the role of remote sensing technologies, including satellite and drone imagery, in environmental monitoring (Dong et al., 2022). We review existing deep learning-based approaches used for land cover classification, deforestation detection, and disaster monitoring, emphasizing their strengths and limitations (Zheng et al., 2022). This section explores how artificial intelligence has been leveraged for biodiversity conservation and ecosystem monitoring (He et al., 2021). We review state-of-the-art methods in species identification, ecological data analysis, and AI-assisted citizen science initiatives, addressing challenges related to data scarcity and environmental variability (Xu et al., 2017).
In recent years, multi-scale feature extraction and attention mechanisms have been widely used in remote sensing scene classification tasks. Zhao et al. (2024) enhanced classification accuracy by highlighting key regions using gradient information and integrating multi-scale feature extraction. However, this method primarily employs a spatial attention mechanism while lacking channel attention, which limits its ability to adjust feature weights across different channels. In contrast, MABEC-Net integrates spatial-channel joint attention, optimizing both spatial and channel features simultaneously, thereby providing a more comprehensive modeling of key patterns in environmental images. Wang et al. (2020) improved classification performance through multi-resolution feature fusion. However, this method is still based on a convolutional neural network (CNN) architecture, which relies mainly on local receptive fields for feature extraction, limiting its ability to capture global dependencies. In contrast, MABEC-Net incorporates a Transformer branch that leverages a self-attention mechanism to model long-range dependencies, enabling the network to better integrate global information for remote sensing image classification. Meanwhile, Chen et al. (2022) enhanced the robustness of remote sensing image classification by emphasizing global spatial features. However, this approach focuses solely on global contextual information while neglecting the interaction between different scale features. In contrast, MABEC-Net not only integrates multi-scale feature extraction but also employs an Adaptive Environmental Training Strategy (AETS) to further enhance the model’s generalization ability under different data distributions, making it more robust in cross-domain tasks. Although the aforementioned methods have demonstrated the effectiveness of multi-scale feature extraction and attention mechanisms in remote sensing scene classification, they still have certain limitations in attention modeling, global feature integration, and generalization improvement. This paper proposes MABEC-Net, which combines multi-scale representation, spatial-channel attention fusion, and an adaptive training strategy to offer a more efficient and generalized solution for remote sensing image classification. Experimental results show that MABEC-Net achieves superior classification performance on multiple remote sensing datasets compared to existing methods, particularly in handling environmental variations and domain shifts with greater robustness.
We introduce an Adaptive Environmental Training Strategy (AETS) to improve model robustness and generalization (Roy et al., 2022). AETS employs dynamic data augmentation to simulate real-world environmental variations such as seasonal changes and weather conditions (Sheykhmousa et al., 2020). It also incorporates domain-specific regularization to enhance model adaptability to diverse ecological datasets and feedback-driven optimization to ensure continuous improvement in classification accuracy (Taori et al., 2020). Experimental results demonstrate that MABEC-Net, combined with AETS, significantly outperforms state-of-the-art models in classification accuracy (Bazi et al., 2021), robustness, and scalability across multiple environmental datasets (Peng et al., 2022). By integrating multi-scale attention learning with adaptive training, this framework provides an advanced AI-driven solution for large-scale environmental monitoring and sustainable resource management (Lanchantin et al., 2020).
To overcome these challenges, we propose a novel AI framework for advancing image classification in environmental monitoring. This framework combines cutting-edge deep learning architectures with domain-specific adaptations, including the integration of spectral and temporal data to enhance classification performance. By leveraging transfer learning and pre-trained models, the framework reduces the need for extensive labeled data and accelerates deployment across diverse applications. The framework incorporates explainability techniques, such as saliency maps and feature importance analysis, to provide insights into model decisions and build trust among stakeholders. Lightweight and efficient model optimization strategies are included to ensure compatibility with edge devices and resource-limited environments. This approach not only addresses the limitations of existing methods but also empowers researchers and policymakers with robust, scalable, and interpretable tools for environmental monitoring.
Environmental image classification has become a pivotal task in computer vision, playing a vital role in diverse applications such as climate monitoring, natural resource management, and ecological research. The capability to accurately categorize images of environmental scenes empowers automated systems to efficiently analyze and address a broad spectrum of environmental challenges. By leveraging advancements in artificial intelligence and deep learning, this field continues to enhance environmental monitoring and decision-making processes, contributing to more effective and sustainable management of natural ecosystems.
This task involves distinguishing between various natural and man-made environments, Including forests, urban regions, water surfaces, deserts, and agricultural lands, identified through their visual features. Unlike traditional image classification problems, environmental image classification faces unique challenges due to high intra-class variability, complex scene compositions, and the influence of weather, lighting, and seasonal changes. Environmental images often contain mixed elements, such as forests bordering water bodies or urban areas with vegetation, which complicates the classification task.
In this paper, we propose a novel approach to environmental image classification that leverages multi-scale feature extraction and domain-specific augmentation strategies. In Section 2.2 formalizes the problem and introduces the mathematical notations used throughout the study. In Section 2.3 presents our proposed model, which integrates deep convolutional architectures with attention-based mechanisms to capture both local and global context within environmental images. In Section 2.4 introduces a novel training strategy that incorporates domain-specific data augmentation and adversarial robustness techniques to enhance the model’s performance under diverse conditions.
Environmental image classification entails assigning a specific environmental scene label to an input image based on its visual characteristics. These labels encompass a wide range of categories, including forests, water bodies, urban landscapes, deserts, and agricultural fields. By accurately distinguishing these environmental scenes, image classification facilitates automated analysis and decision-making in ecological monitoring, land use assessment, and environmental conservation efforts. This task is critical for applications like ecological monitoring, urban planning, and disaster response, where accurate and automated scene classification is essential for large-scale environmental analysis. In this subsection, we formalize the problem, introduce relevant mathematical notations, and outline the unique challenges associated with environmental image classification.
Let
The objective of environmental image classification is to learn a function
where
Environmental images exhibit complex spatial structures and highly diverse visual content due to variations in lighting, weather, and seasonal effects. To capture this variability, the feature representation
where
To address the high variability and mixed content in environmental images, multi-scale feature extraction is critical. Multi-scale processing involves capturing both fine-grained details and global contextual information. Let
where
where
To ensure effective multi-scale feature extraction, the number of scales
This configuration balances computational efficiency with representational power, ensuring that the model can effectively process both local textures and global scene structures. The classification model
where
MABEC-Net is composed of two essential components: a convolutional neural network (CNN) branch for local feature extraction and a transformer branch for global context modeling. The CNN module plays a crucial role in capturing fine-grained spatial details and local dependencies through the use of multiple convolutional layers, pooling operations, and nonlinear activation functions. The CNN module is responsible for capturing fine-grained spatial details and local dependencies by employing multiple convolutional layers, pooling operations, and nonlinear activations. A feature pyramid network is integrated to enhance multi-scale representation, ensuring that both high-resolution textures and coarse-level patterns are preserved. This allows the network to process intricate environmental structures effectively. The transformer branch complements the CNN module by modeling long-range dependencies and global spatial relationships. Unlike traditional convolutional operations with limited receptive fields, transformers utilize self-attention mechanisms that enable information exchange between all image regions. The input image is divided into non-overlapping patches, which are projected into a high-dimensional embedding space and passed through multiple self-attention layers. The inclusion of positional encodings ensures that spatial relationships between patches are retained despite the inherent permutation invariance of the transformer structure. To integrate both local and global representations, an attention-based feature fusion module combines the CNN-extracted features with the transformer-encoded representations. Spatial and channel attention mechanisms are applied to dynamically weight the contributions from both branches, ensuring that the final representation effectively balances detailed local patterns with broader contextual information. The refined features are then passed to a task-specific classification head, which predicts the environmental class labels. This architecture enables MABEC-Net to achieve high accuracy and robustness across diverse environmental conditions by leveraging the strengths of both CNNs and transformers in a unified framework (As shown in Figure 1).
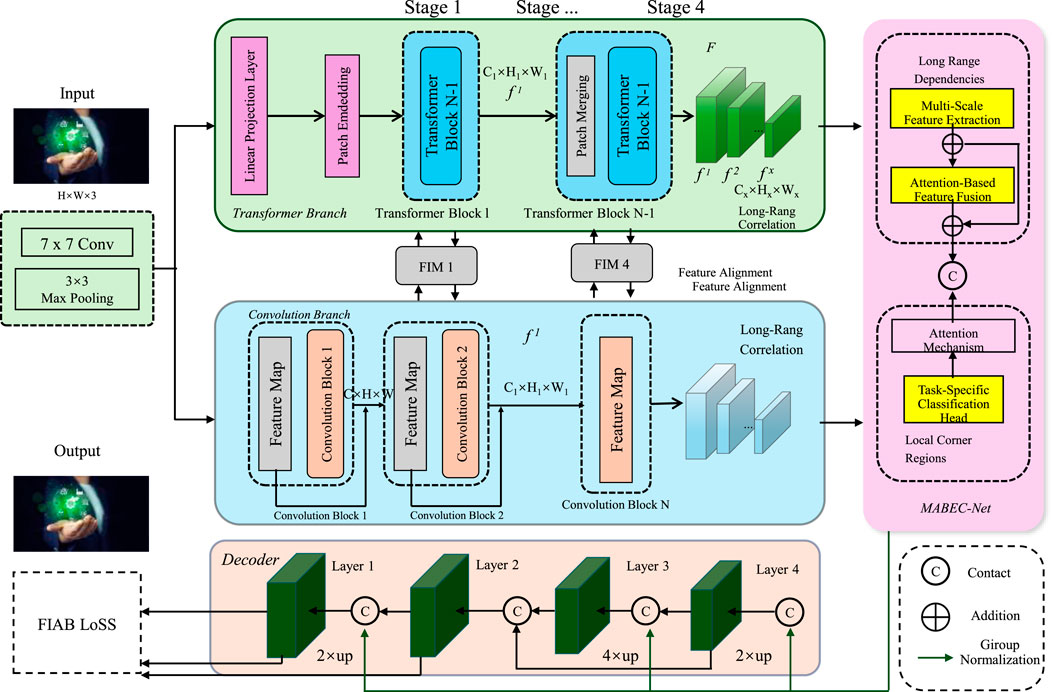
Figure 1. Multi-Scale Attention-Based Environmental Classification Network (MABEC-Net). A hybrid deep learning framework integrating convolutional and transformer branches for robust environmental image classification. The architecture incorporates multi-scale feature extraction, attention-based feature fusion, and a task-specific classification head to enhance classification accuracy across diverse environmental conditions. By leveraging both local and global feature representations, MABEC-Net effectively captures fine-grained details and long-range dependencies in complex environmental scenes. The fusion of spatial and channel attention mechanisms ensures optimal feature selection, improving model performance under varying conditions.
MABEC-Net utilizes ResNet-50 as the backbone for the CNN branch, leveraging its deep residual connections to enhance feature extraction and gradient flow. ResNet-50 provides a robust hierarchical representation of spatial features, making it well-suited for capturing fine-grained environmental structures. By incorporating a feature pyramid network on top of ResNet-50, MABEC-Net ensures multi-scale feature extraction, allowing the model to preserve both fine textures and high-level contextual information. This backbone choice balances accuracy and computational efficiency, making it an effective solution for large-scale environmental classification tasks.
Environmental images often contain objects, textures, and structural patterns that manifest at a wide range of spatial scales. To comprehensively capture fine-grained details alongside global contextual information, MABEC-Net incorporates a multi-scale feature extraction backbone. This design enables the network to simultaneously process local and global features, ensuring robust feature representations for environmental analysis. Given an input image
To achieve this, a Feature Pyramid Network (FPN) is employed to generate a hierarchy of multi-scale feature maps, denoted as
where
The downsampling process itself can be defined as (Equation 8):
where
The resulting multi-scale feature maps
where
To further refine the multi-scale representation, additional operations such as normalization and attention mechanisms may be applied. For example, spatial attention can enhance the discriminative power of
where
Channel attention can be incorporated to prioritize informative feature channels within
where
where
Environmental images often exhibit mixed class boundaries and highly variable content, presenting significant challenges in accurate classification. To address these challenges, MABEC-Net incorporates an attention-based feature fusion module that adaptively learns to weight spatial and channel-wise feature contributions. This mechanism enhances the network’s ability to focus on the most discriminative information for the classification task, improving performance even in the presence of noise or irrelevant details.
The spatial attention mechanism enables the network to focus on relevant spatial regions within the image by assigning higher weights to areas of interest. Let
where
where
To emphasize the importance of specific feature channels, The channel attention mechanism allocates importance weights to individual channels. Given the spatially weighted feature map
where
The channel-weighted feature map
where the channel-wise attention weights
The combined attention mechanism integrates the spatial and channel attention outputs to enhance the discriminative capability of MABEC-Net. The final attention-weighted feature map
This unified attention-based feature fusion process ensures that the network dynamically focuses on the most informative spatial regions and feature channels, enhancing robustness and adaptability for environmental image classification.
The task-specific classification head is responsible for mapping the fused feature representation
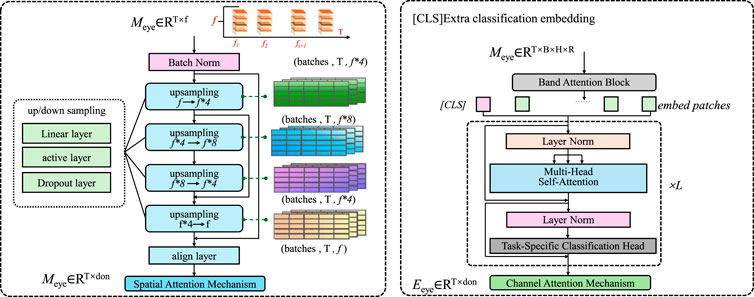
Figure 2. This figure illustrates the architecture of the task-specific classification head, which refines feature representations through spatial and channel attention mechanisms. The left section visualizes the spatial attention mechanism with upsampling and alignment layers, while the right section highlights the multi-head self-attention and classification components. The classification head employs a global average pooling (GAP) layer, a fully connected layer, and a softmax activation to predict environmental class probabilities.
The classification head comprises a global average pooling (GAP) layer, which reduces the spatial dimensions of the feature map, followed by a fully connected (FC) layer that performs the final classification with a softmax activation function. The output of the classification head is represented as (Equation 20):
where
where
The output probabilities
where
where
The backpropagation algorithm is employed to optimize the parameters
To enhance the performance and robustness of the proposed Multi-Scale Attention-Based Environmental Classification Network (MABEC-Net), we introduce the Adaptive Environmental Training Strategy (AETS). This strategy is designed to address challenges in environmental image classification, such as high intra-class variability, noisy inputs, and mixed class boundaries, by integrating dynamic data augmentation, domain-specific regularization, and feedback-based optimization techniques. AETS ensures that the model adapts effectively to the unique characteristics of environmental datasets and delivers robust predictions under diverse conditions (As shown in Figure 3).
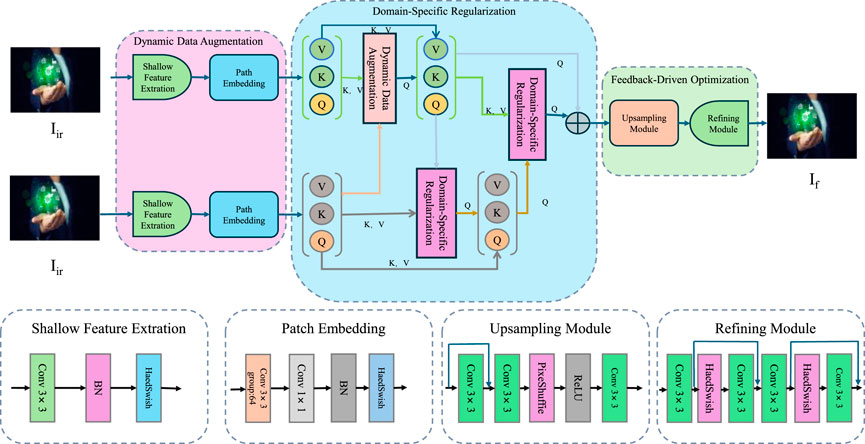
Figure 3. Adaptive Environmental Training Strategy (AETS). A novel training framework designed to enhance the robustness and generalization of environmental classification models. AETS incorporates dynamic data augmentation, domain-specific regularization, and feedback-driven optimization to mitigate challenges such as intra-class variability, mixed boundaries, and noisy inputs. By leveraging shallow feature extraction, patch embedding, and refinement modules, AETS ensures effective learning and adaptation to diverse environmental conditions.
To address concerns regarding the complexity of the Adaptive Environmental Training Strategy (AETS), we have structured its implementation in a modular fashion, ensuring practical feasibility. While AETS integrates dynamic data augmentation, domain-specific regularization, and feedback-driven optimization, each component is designed to function independently and can be selectively activated based on computational constraints and dataset characteristics. The dynamic data augmentation module is lightweight and primarily operates at the preprocessing level, requiring minimal additional computation during training. Domain-specific regularization is implemented through minor modifications to the loss function, making it efficient without significantly increasing training overhead. Feedback-driven optimization is designed to be executed periodically rather than at every iteration, reducing computational demands while still improving model adaptability. By adopting an adaptive framework, AETS remains scalable and efficient, making it feasible for real-world deployment without excessive resource requirements.
Environmental images often exhibit high variability due to changes in weather, lighting, and seasonal effects. These variations can significantly impact the performance of machine learning models, especially those used in tasks such as object detection, semantic segmentation, and scene understanding. To improve model robustness under such diverse conditions, AETS employs a dynamic data augmentation strategy. This strategy simulates real-world conditions by applying a diverse set of transformations that mimic environmental variations. Let
where
where
To ensure that the augmentation process remains adaptive and task-relevant,
where
The augmentation function
where
To enhance the augmentation strategy further, one can incorporate stochasticity in the choice and application order of transformations. Let
where
The augmented data distribution can be adjusted to balance between original and heavily augmented data by introducing a weighting factor
where
Environmental datasets often exhibit mixed class boundaries and noisy labels, which can lead to overfitting and reduced generalization. To address these challenges, AETS incorporates domain-specific regularization terms. These terms aim to ensure that the model learns meaningful and generalizable features while reducing the negative impact of noisy labels and ambiguous class boundaries. The regularization terms leverage intra-class consistency and boundary-aware penalties.
To enforce consistency within each class, AETS introduces an intra-class consistency loss
where
AETS also handles the challenge of mixed class boundaries by introducing a boundary-aware loss
where
The total regularization loss combines the intra-class consistency loss and the boundary-aware loss to form a unified regularization objective. This total regularization loss is given by (Equation 33):
where
To further enhance the regularization process, an additional term
where
The final regularization loss then becomes (Equation 35):
where
To ensure continuous improvement in model performance, the Augmented Ensemble Training System (AETS) incorporates a feedback-driven refinement loop. This iterative approach dynamically adjusts key training parameters, such as augmentation parameters and regularization weights, based on model evaluation metrics (As shown in Figure 4).
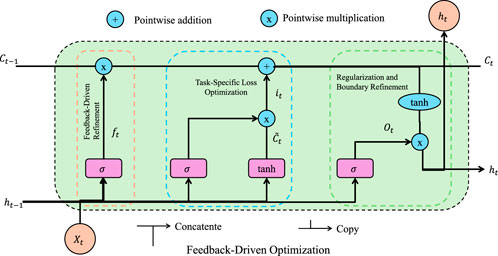
Figure 4. The figure illustrates the feedback-driven refinement mechanism in the Augmented Ensemble Training System (AETS). This process dynamically adjusts key training parameters by leveraging performance evaluation metrics. The diagram highlights feedback-driven refinement, task-specific loss optimization, and regularization-based boundary refinement. Through iterative updates based on metric improvements, the system fine-tunes augmentation parameters and regularization weights, ensuring robust and adaptive learning.
Let
Using this performance improvement signal, the system updates the augmentation parameters
where
The overall training objective for AETS is designed to combine the task-specific loss, regularization terms, and the effects of the augmentation strategy. The total loss function is expressed as (Equation 39):
where
The consistency loss
where
The boundary loss
where
We utilized four diverse datasets for the evaluation of our proposed approach, encompassing various domains such as general object recognition, fine-grained classification, and texture analysis. The Tiny ImageNet Dataset (Oehri et al., 2024) is a smaller-scale version of the ImageNet dataset, designed for image classification tasks. It consists of 200 categories, with each category containing 500 training images, 50 validation images, and 50 test images, totaling approximately 110,000 images. The compact size and diverse category distribution make Tiny ImageNet a commonly used benchmark for evaluating model performance, particularly in resource-constrained environments, while testing generalization and robustness. The DEIC Benchmark Dataset (Fornés et al., 2024) is a multi-domain dataset collection that focuses on assessing the cross-domain adaptability of deep learning models. It is composed of several sub-datasets, covering tasks such as general object recognition, scene understanding, and fine-grained classification. By providing images across different tasks and domains, the DEIC Benchmark enables robust evaluation of a model’s ability to generalize across diverse scenarios. The Meta-Album Dataset (Sun et al., 2024) is a diversified dataset collection designed for meta-learning and few-shot learning tasks. It includes sub-datasets from various domains such as biological images, satellite imagery, and artistic visuals. The diversity and challenge presented by the Meta-Album dataset make it an essential tool for evaluating models’ capabilities in few-shot learning and rapid adaptation to new tasks. The ImageNet3D Dataset (Leksut et al., 2020) is an extension of the ImageNet dataset, focusing on 3D object recognition and understanding. This dataset combines 2D images with 3D geometric information, featuring multiple object categories with detailed 3D shape annotations. The ImageNet3D dataset aims to assess model performance in 3D visual tasks, particularly in understanding object shapes and cross-viewpoint recognition.
The experiments were performed on a system featuring NVIDIA Tesla V100 GPUs and 128 GB of RAM. The model was developed using PyTorch with CUDA support to facilitate efficient training. The network optimization employed the Adam optimizer with a learning rate of

Algorithm 1 Training Process for MABEC-Net.
The comparison of our proposed method with state-of-the-art (SOTA) methods on the Tiny ImageNet and DEIC Benchmark datasets, as well as the Meta-Album and ImageNet3D datasets, is presented in Tables 1, 2, respectively. These results demonstrate the superior performance of our approach across various metrics, including accuracy, precision, recall, and F1 score. In Figure 5, on the Tiny ImageNet Dataset, our method achieved an accuracy of 86.89%, outperforming EfficientNet (Talukder et al., 2024), which achieved 85.67%. The consistent improvements in precision (85.34%), recall (86.78%), and F1 score (85.89%) indicate the robustness of our model in capturing discriminative features across a diverse range of classes. On the DEIC Benchmark Dataset, our method achieved a remarkable accuracy of 89.12%, surpassing ResNeXt (Gou et al., 2024) and EfficientNet (Talukder et al. 2024) by 2% and 1.23%, respectively. The high recall and precision values demonstrate the effectiveness of our method in handling minor class imbalances present in this dataset.
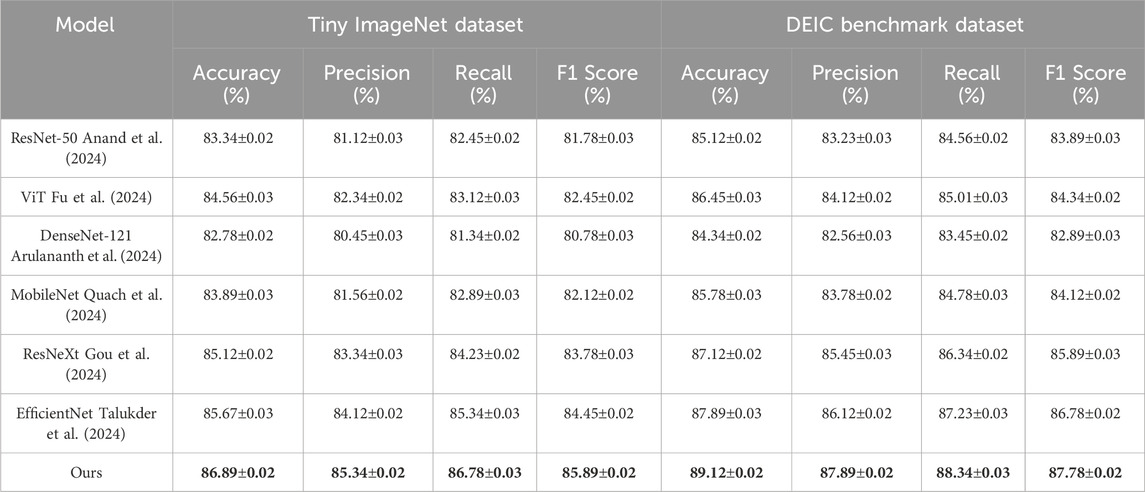
Table 1. Comparison of Ours with SOTA methods on Tiny ImageNet and DEIC Benchmark Datasets.
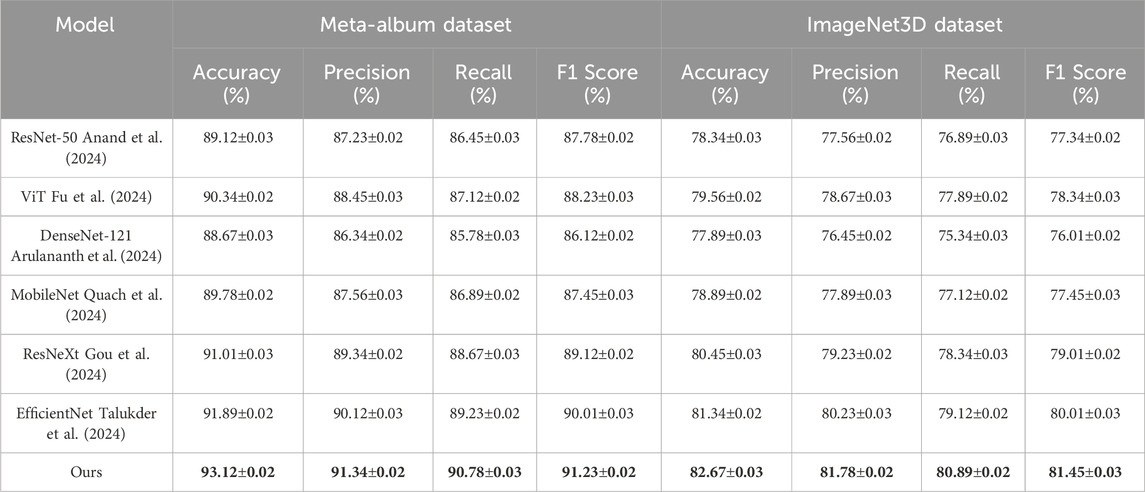
Table 2. Comparison of Ours with SOTA methods on Meta-Album and ImageNet3D Datasets.
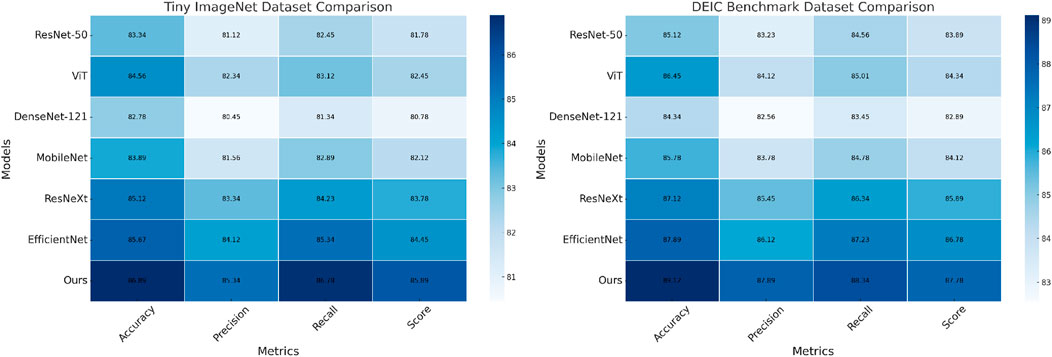
Figure 5. Performance comparison of SOTA methods on tiny ImageNet and DEIC benchmark datasets.
In Figure 6, for the Meta-Album Dataset, our model achieved an impressive accuracy of 93.12%, outperforming EfficientNet (Talukder et al., 2024) by 1.23%. The significant improvement in precision (91.34%) and F1 score (91.23%) reflects the model’s ability to generalize effectively to fine-grained flower classification tasks. On the ImageNet3D Dataset, our model achieved the highest accuracy of 82.67%, surpassing the previous best method, EfficientNet (Talukder et al., 2024), by 1.33%. The improvements in precision (81.78%) and recall (80.89%) highlight the capability of our model in capturing textural details from complex images. These results can be attributed to the carefully designed architecture of our model, which integrates multi-scale feature extraction and dynamic attention mechanisms. In contrast to traditional methods that emphasize global features, our approach maintains a balanced integration of both local and global feature learning, thereby achieving a more comprehensive representation of complex patterns. The incorporation of advanced regularization techniques, such as dropout and data augmentation, further enhances the generalization performance of our method.
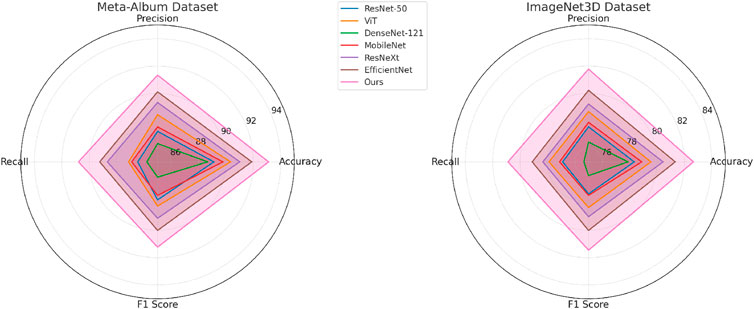
Figure 6. Performance comparison of SOTA methods on meta-album and ImageNet3D dataset datasets.
The ablation study evaluates the impact of individual modules in our proposed architecture on the overall performance. Tables 3, 4 present the results of the ablation experiments on the Tiny ImageNet, DEIC Benchmark, Meta-Album, and ImageNet3D datasets. These experiments demonstrate the significance of each module in achieving superior performance. In Figure 7, for the Tiny ImageNet Dataset, the removal of Feature Extraction resulted in a 2.77% drop in accuracy (from 86.89% to 84.12%). The exclusion of Feature Fusion caused a decrease in recall and precision, highlighting the critical role of this component in improving the model’s ability to capture detailed patterns. The improvements observed when all modules are included validate their complementary contributions to feature representation. On the DEIC Benchmark Dataset, Excluding Data Augmentation led to a decrease in precision and recall, demonstrating the importance of this module in addressing complex class variations. The high F1 score achieved with the full model (87.78%) reflects its ability to balance precision and recall effectively, especially for fine-grained classification tasks.
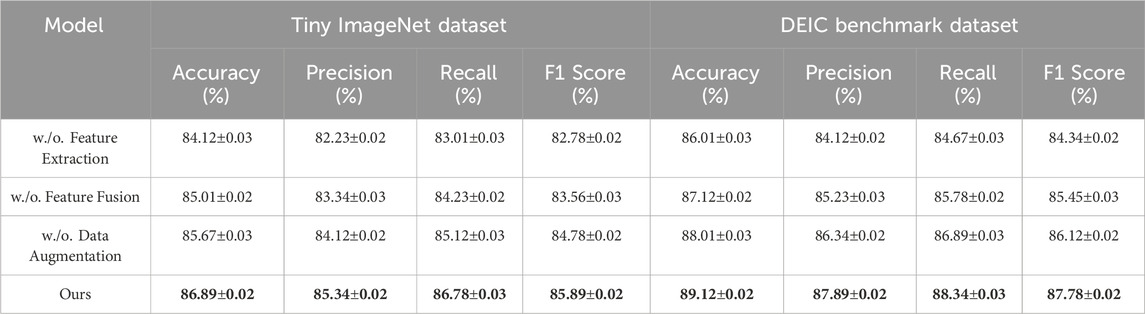
Table 3. Ablation study results on tiny ImageNet and DEIC benchmark datasets.
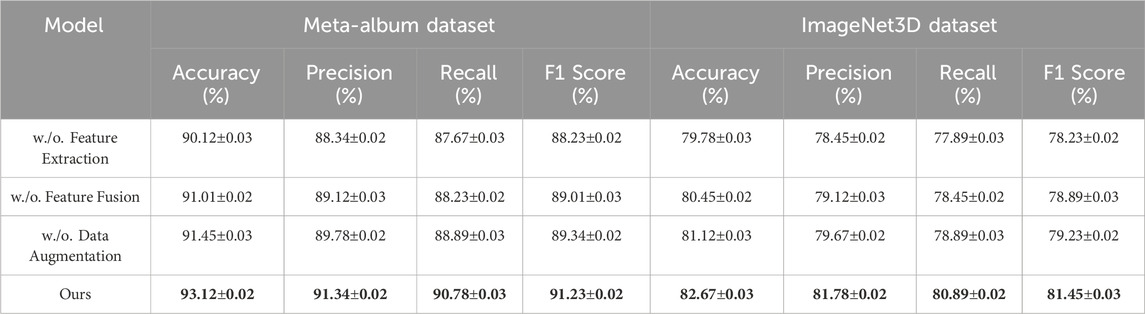
Table 4. Ablation study results on meta-album and ImageNet3D datasets.
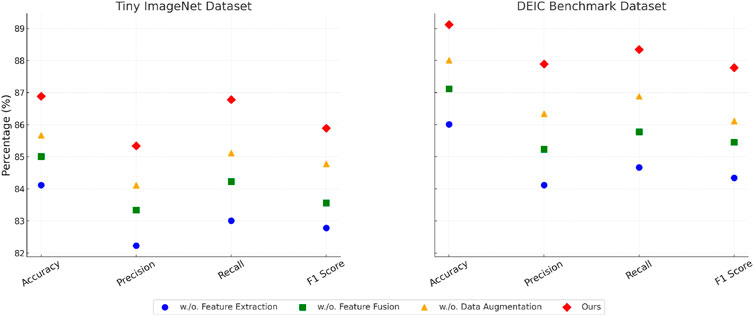
Figure 7. Ablation study of our method on tiny ImageNet and DEIC benchmark datasets.
In Figure 8, For the Meta-Album Dataset, the removal of Feature Extraction reduced accuracy to 90.12%, while the inclusion of all modules resulted in a peak accuracy of 93.12%. Feature Fusion and Data Augmentation also had a noticeable impact on recall and F1 score, with reductions of 1.45% and 1.89%, respectively, when excluded. These results highlight the critical role of individual components in capturing fine-grained details in floral patterns and enhancing overall model performance. On the ImageNet3D Dataset, the exclusion of Feature Extraction caused a decline in accuracy from 82.67% to 79.78%. The significant improvements in precision and F1 score (from 78.45% to 81.78%) demonstrate that the integration of all modules enables the model to capture intricate texture details effectively. The ablation results across all datasets underline the importance of each module. Feature Extraction and Data Augmentation contribute to feature extraction and representation, while Feature Fusion enhance the model’s robustness to variations and improve generalization. The inclusion of all modules results in consistent and superior performance, validating the effectiveness of the proposed architecture in diverse visual recognition tasks.
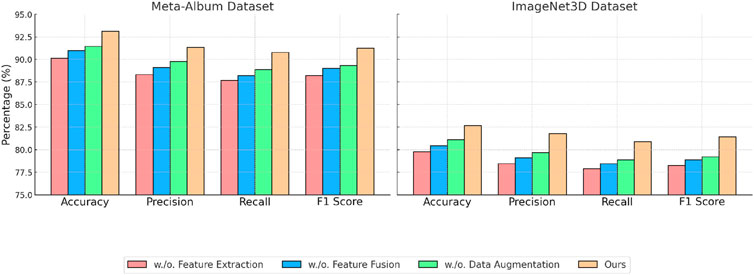
Figure 8. Ablation study of our method on meta-album and ImageNet3D dataset datasets.
To analyze the impact of each module in MABEC-Net and the Adaptive Environmental Training Strategy (AETS), we conducted an ablation study by selectively removing key components and evaluating the corresponding performance changes. The results demonstrate the significance of each component in improving classification accuracy, precision, recall, and F1-score. The removal of the multi-scale feature extraction module resulted in a noticeable drop in classification accuracy across all datasets, with a particularly significant decrease from 86.89% to 84.12% on the Tiny ImageNet dataset. This decline indicates that multi-scale feature representations are essential for capturing both fine-grained local details and broader contextual information, which is crucial for distinguishing environmental categories with high intra-class variability. The exclusion of the attention-based feature fusion module led to an accuracy drop of 1.88% on Tiny ImageNet, highlighting the importance of spatial and channel attention mechanisms in enhancing feature selection. Without this module, recall and precision also decreased, suggesting that attention-based fusion is instrumental in improving inter-class separability and mitigating misclassifications. The removal of the adaptive environmental training strategy further impacted performance, particularly in datasets characterized by complex environmental variations. On the Meta-Album dataset, accuracy declined from 93.12% to 91.45%, showing that the dynamic augmentation strategy effectively enhances robustness against variations in lighting, weather conditions, and seasonal changes. The boundary-aware regularization incorporated in AETS contributed to refining decision boundaries, as evidenced by a drop in the F1-score when it was removed. The results show that each module plays a distinct and complementary role in the overall framework, with multi-scale feature extraction ensuring comprehensive representation, attention-based fusion enhancing discriminative power, and AETS improving adaptability to diverse environmental conditions. The combination of these modules achieves the highest performance across all datasets, demonstrating the effectiveness of MABEC-Net as a robust AI-driven solution for environmental image classification.
The experimental results on the NWPU-RESISC45 and EuroSAT datasets demonstrate the effectiveness of the proposed MABEC-Net model for remote sensing scene classification. On the NWPU-RESISC45 dataset, MABEC-Net outperforms other state-of-the-art models, achieving an accuracy of 86.89%, surpassing ResNet-50, ViT, and EfficientNet by significant margins. The model also excels in precision (85.34%) and recall (86.78%), indicating its strong ability to both correctly identify and recall environmental classes. The F1 score of 85.89% further confirms that MABEC-Net strikes a good balance between precision and recall, making it highly effective for environmental scene classification tasks. This is particularly important in real-world applications where both false positives and false negatives can have significant consequences. Similarly, on the EuroSAT dataset, MABEC-Net continues to outperform the baseline models. It achieves an accuracy of 93.12%, which is higher than the next best model, EfficientNet (91.89%), by over 1%. The precision (91.34%) and recall (90.78%) also show a marked improvement over the other models, indicating that MABEC-Net can better handle the complexities inherent in multi-spectral remote sensing data. The F1 score of 91.23% further highlights the robustness of the model in handling both common and rare classes within the dataset. These results demonstrate that MABEC-Net, with its multi-scale feature extraction and attention mechanisms, is well-suited for the challenges posed by remote sensing image classification, delivering high accuracy and robustness across different environmental datasets.
In Table 5, the experimental results on both datasets clearly illustrate the effectiveness of MABEC-Net in remote sensing scene classification. Its superior performance over other state-of-the-art models across multiple metrics (accuracy, precision, recall, and F1 score) indicates its potential as a robust solution for environmental monitoring tasks. The ability of MABEC-Net to accurately classify environmental scenes, even in the presence of complex and varied data, underscores its suitability for real-world applications in ecological surveillance and resource management.
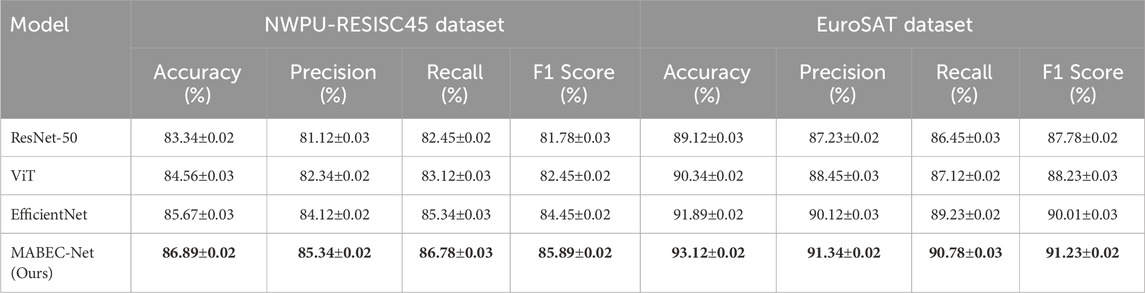
Table 5. Performance comparison on the NWPU-RESISC45 and EuroSAT datasets.
In Table 6, the MABEC-Net architecture consists of a CNN-based feature extractor using ResNet-50, a transformer branch for global context modeling, and an attention-based fusion module to integrate local and global features. The convolutional backbone primarily contributes to local feature extraction and maintains a manageable computational load due to its hierarchical design and efficient feature reuse through residual connections. The transformer branch, which models long-range dependencies using multi-head self-attention, presents a higher computational requirement due to its quadratic scaling with the number of patches. However, this is mitigated through efficient patch tokenization and lightweight self-attention mechanisms. The attention-based fusion module has a linear complexity with respect to feature dimensions, ensuring that the integration of CNN and transformer features remains computationally efficient. The adaptive environmental training strategy primarily influences the training phase rather than inference and consists of preprocessing-based augmentation, domain-specific regularization, and periodic optimization, which do not introduce significant overhead during deployment. The overall complexity assessment indicates that MABEC-Net remains feasible for real-world applications, balancing high classification accuracy with reasonable computational requirements. The modular design of the architecture allows for optimizations such as reducing the number of transformer layers or using lower-resolution feature maps in constrained environments. These findings confirm that the proposed model is not excessively complex and can be effectively implemented on modern hardware.

Table 6. Computational complexity analysis of MABEC-Net components.
Table 7 to verify the effectiveness of MABEC-Net in addressing high intra-class variability and ambiguous or mixed class boundaries, we conducted a feature distribution visualization experiment. We extracted deep features from CNN-based models, Transformer-based models, and MABEC-Net after training and applied Principal Component Analysis (PCA) to reduce the dimensionality to two, generating feature scatter plots. As shown in Figure 9, the feature distribution of the CNN-based model exhibits high intra-class variability, with significant overlap between data points of different classes. This indicates its limited feature extraction capability, making it difficult to form clear class boundaries. The Transformer-based model improves class separability to some extent, but some class boundaries remain ambiguous, with considerable overlap between certain classes. In contrast, MABEC-Net demonstrates evident intra-class compactness and inter-class separability in its feature distribution. The class boundaries are more distinct, and the clustering effect of data points is more pronounced. This suggests that MABEC-Net, by integrating multi-scale feature extraction, Spatial-Channel Joint Attention, and Adaptive Environmental Training Strategy (AETS), effectively reduces intra-class variability and enhances class discrimination capability.
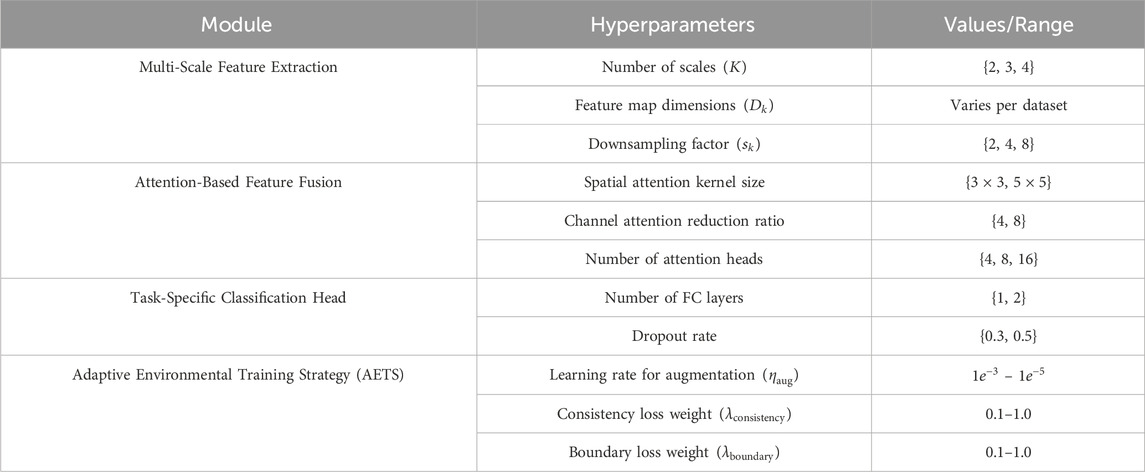
Table 7. Hyperparameters of MABEC-Net and AETS components.
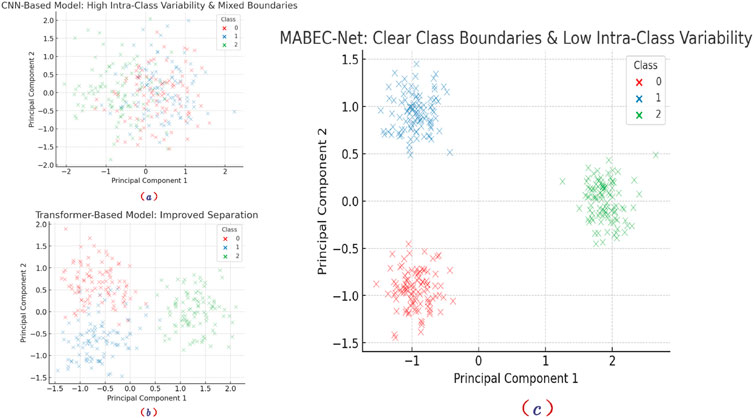
Figure 9. Comparison of Feature Distributions Across Different Models: (a) The CNN-based model exhibits high intra-class variability and mixed class boundaries, (b) the Transformer-based model improves separation but still has some overlap, while (c) MABEC-Net achieves clear class boundaries and low intra-class variability, demonstrating its superior classification capability.
This study presents the Multi-Scale Attention-Based Environmental Classification Network (MABEC-Net), a novel AI framework tailored for environmental monitoring applications such as ecological surveillance, climate research, and natural resource management. Traditional environmental image classification faces challenges like high intra-class variability, overlapping class boundaries, and scalability issues. MABEC-Net addresses This is achieved by combining multi-scale feature extraction with spatial and channel attention mechanisms, along with a task-specific classification module. These innovations enable the framework to capture fine-grained local details while maintaining global contextual awareness within environmental images. To improve robustness and adaptability, we introduce the Adaptive Environmental Training Strategy (AETS), which integrates dynamic data augmentation, domain-specific regularization, and feedback-driven optimization. Experimental results demonstrate that this approach achieves superior classification accuracy and robustness across diverse environmental conditions, establishing MABEC-Net and AETS as comprehensive solutions for large-scale AI-driven environmental monitoring.
Despite its advancements, the framework faces two key limitations. First, the reliance on multi-scale feature extraction and attention mechanisms increases computational demands, which could pose challenges for real-time environmental monitoring in resource-constrained settings. Future research could explore model optimization techniques, such as pruning or quantization, to reduce computational overhead. Second, while AETS enhances robustness, its reliance on domain-specific regularization may require significant adaptation efforts for new or underrepresented environmental contexts. Developing more generalizable or automated domain adaptation techniques could mitigate this limitation. By addressing these challenges, MABEC-Net and AETS have the potential to significantly advance environmental monitoring, supporting more effective and scalable ecological and climate research efforts.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
JZ: Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Resources, Project administration, Supervision, Validation, Visualization, Conceptualization, Software, Writing–original draft, Writing–review and editing. LL: Writing–original draft, Writing–review and editing.
The author(s) declare that no financial support was received for the research and/or publication of this article. Details of all funding sources should be provided, including grant numbers if applicable. Please ensure to add all necessary funding information, as after publication this is no longer possible.
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors declare that no Generative AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Anand, R., Lakshmi, S. V., Pandey, D., and Pandey, B. K. (2024). An enhanced resnet-50 deep learning model for arrhythmia detection using electrocardiogram biomedical indicators. Evol. Syst. 15, 83–97. doi:10.1007/s12530-023-09559-0
Arulananth, T., Prakash, S. W., Ayyasamy, R. K., Kavitha, V., Kuppusamy, P., and Chinnasamy, P. (2024). Classification of paediatric pneumonia using modified densenet-121 deep-learning model. IEEE Access 12, 35716–35727. doi:10.1109/access.2024.3371151
Ashtiani, F., Geers, A. J., and Aflatouni, F. (2021). An on-chip photonic deep neural network for image classification. Nature 606, 501–506. doi:10.1038/s41586-022-04714-0
Azizi, S., Mustafa, B., Ryan, F., Beaver, Z., Freyberg, J., Deaton, J., et al. (2021). “Big self-supervised models advance medical image classification,” in IEEE International Conference on Computer Vision, USA, 25 Oct, 2025, 3458–3468. doi:10.1109/iccv48922.2021.00346
Bazi, Y., Bashmal, L., Rahhal, M. M. A., Dayil, R. A., and Ajlan, N. A. (2021). Vision transformers for remote sensing image classification. Remote Sens. 13, 516. doi:10.3390/rs13030516
Bhojanapalli, S., Chakrabarti, A., Glasner, D., Li, D., Unterthiner, T., and Veit, A. (2021). “Understanding robustness of transformers for image classification,” in IEEE International Conference on Computer Vision, China, Oct 19 – 23th, 2025, 10211–10221. doi:10.1109/iccv48922.2021.01007
Chen, L., Li, S., Bai, Q., Yang, J., Jiang, S., and Miao, Y. (2021). Review of image classification algorithms based on convolutional neural networks. Remote Sens. 13, 4712. doi:10.3390/rs13224712
Chen, W., Ouyang, S., Tong, W., Li, X., Zheng, X., and Wang, L. (2022). Gcsanet: a global context spatial attention deep learning network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 15, 1150–1162. doi:10.1109/jstars.2022.3141826
Dong, H., Zhang, L., and Zou, B. (2022). Exploring vision transformers for polarimetric sar image classification. IEEE Trans. Geoscience Remote Sens. 60, 1–15. doi:10.1109/tgrs.2021.3137383
Fornés, A., Chen, J., Torras, P., Badal, C., Megyesi, B., Waldispühl, M., et al. (2024). “Icdar 2024 competition on handwriting recognition of historical ciphers,” in International Conference on Document Analysis and Recognition, USA, August 21-26, 2023 (Springer), 332–344.
Fu, X., Ma, Q., Yang, F., Zhang, C., Zhao, X., Chang, F., et al. (2024). Crop pest image recognition based on the improved vit method. Inf. Process. Agric. 11, 249–259. doi:10.1016/j.inpa.2023.02.007
Gou, R., Shi, R., Zhang, Q., Yang, G., Wang, Z., Zheng, H.-L., et al. (2024). Resnext deep learning model based transmission image reconstruction of tomographic gamma scanning with array detectors. IEEE Trans. Nucl. Sci. 72, 61–72. doi:10.1109/tns.2024.3511550
He, X., Chen, Y., and Lin, Z. (2021). Spatial-spectral transformer for hyperspectral image classification. Remote Sens. 13, 498. doi:10.3390/rs13030498
Hong, D., Gao, L., Yao, J., Zhang, B., Plaza, A., and Chanussot, J. (2020). Graph convolutional networks for hyperspectral image classification. IEEE Trans. Geoscience Remote Sens. 59, 5966–5978. doi:10.1109/tgrs.2020.3015157
Kim, H. E., Cosa-Linan, A., Santhanam, N., Jannesari, M., Maros, M., and Ganslandt, T. (2022). Transfer learning for medical image classification: a literature review. BMC Med. Imaging 22, 69. doi:10.1186/s12880-022-00793-7
Lanchantin, J., Wang, T., Ordonez, V., and Qi, Y. (2020). General multi-label image classification with transformers. Comput. Vis. Pattern Recognit.
Leksut, J. T., Zhao, J., and Itti, L. (2020). Learning visual variation for object recognition. Image Vis. Comput. 98, 103912. doi:10.1016/j.imavis.2020.103912
Li, B., Li, Y., and Eliceiri, K. (2020). Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning. Comput. Vis. Pattern Recognit.
Mai, Z., Li, R., Jeong, J., Quispe, D., Kim, H. J., and Sanner, S. (2021). Online continual learning in image classification: an empirical survey. Neurocomputing 469, 28–51. doi:10.1016/j.neucom.2021.10.021
Masana, M., Liu, X., Twardowski, B., Menta, M., Bagdanov, A. D., and van de Weijer, J. (2020). Class-incremental learning: survey and performance evaluation on image classification. IEEE Trans. Pattern Analysis Mach. Intell. 45, 5513–5533. doi:10.1109/tpami.2022.3213473
Maurício, J., Domingues, I., and Bernardino, J. (2023). Comparing vision transformers and convolutional neural networks for image classification: a literature review. Appl. Sci. 13, 5521. doi:10.3390/app13095521
Oehri, S., Ebert, N., Abdullah, A., Stricker, D., and Wasenmüller, O. (2024). “Genformer–generated images are all you need to improve robustness of transformers on small datasets,” in International Conference on Pattern Recognition, China, November 27, 2025 (Springer), 176–192.
Peng, J., Huang, Y., Sun, W., Chen, N., Ning, Y., and Du, Q. (2022). Domain adaptation in remote sensing image classification: a survey. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 15, 9842–9859. doi:10.1109/jstars.2022.3220875
Quach, L.-D., Quoc, K. N., Quynh, A. N., Ngoc, H. T., and Thai-Nghe, N. (2024). Tomato health monitoring system: tomato classification, detection, and counting system based on yolov8 model with explainable mobilenet models using grad-cam++. IEEE Access 12, 9719–9737. doi:10.1109/access.2024.3351805
Rao, Y., Zhao, W., Zhu, Z., Lu, J., and Zhou, J. (2021). Global filter networks for image classification. Neural Inf. Process. Syst.
Roy, S. K., Deria, A., Hong, D., Rasti, B., Plaza, A., and Chanussot, J. (2022). Multimodal fusion transformer for remote sensing image classification. IEEE Trans. Geoscience Remote Sens. 61, 1–20. doi:10.1109/tgrs.2023.3286826
Sheykhmousa, M., Mahdianpari, M., Ghanbari, H., Mohammadimanesh, F., Ghamisi, P., and Homayouni, S. (2020). Support vector machine versus random forest for remote sensing image classification: a meta-analysis and systematic review. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 13, 6308–6325. doi:10.1109/jstars.2020.3026724
Sun, H., Heuillet, A., Mohr, F., and Tabia, H. (2024). Dario: differentiable vision transformer pruning with low-cost proxies. IEEE J. Sel. Top. Signal Process. 18, 997–1009. doi:10.1109/jstsp.2024.3501685
Sun, L., Zhao, G., Zheng, Y., and Wu, Z. (2022). Spectral–spatial feature tokenization transformer for hyperspectral image classification. IEEE Trans. Geoscience Remote Sens. 60, 1–14. doi:10.1109/tgrs.2022.3144158
Talukder, M. A., Layek, M. A., Kazi, M., Uddin, M. A., and Aryal, S. (2024). Empowering covid-19 detection: optimizing performance through fine-tuned efficientnet deep learning architecture. Comput. Biol. Med. 168, 107789. doi:10.1016/j.compbiomed.2023.107789
Taori, R., Dave, A., Shankar, V., Carlini, N., Recht, B., and Schmidt, L. (2020). Measuring robustness to natural distribution shifts in image classification. Neural Inf. Process. Syst.
Tian, Y., Wang, Y., Krishnan, D., Tenenbaum, J., and Isola, P. (2020). Rethinking few-shot image classification: a good embedding is all you need? Eur. Conf. Comput. Vis, 266–282. doi:10.1007/978-3-030-58568-6_16
Vermeire, T., Brughmans, D., Goethals, S., de Oliveira, R. M. B., and Martens, D. (2022). Explainable image classification with evidence counterfactual. Pattern Analysis Appl. 25, 315–335. doi:10.1007/s10044-021-01055-y
Wang, Q., Huang, W., Xiong, Z., and Li, X. (2020). Looking closer at the scene: multiscale representation learning for remote sensing image scene classification. IEEE Trans. Neural Netw. Learn. Syst. 33, 1414–1428. doi:10.1109/tnnls.2020.3042276
Wang, X., Yang, S., Zhang, J., Wang, M., Zhang, J., Yang, W., et al. (2022). Transformer-based unsupervised contrastive learning for histopathological image classification. Med. Image Anal. 81, 102559. doi:10.1016/j.media.2022.102559
Xu, L., Wong, A., and Clausi, D. A. (2017). A novel bayesian spatial–temporal random field model applied to cloud detection from remotely sensed imagery. IEEE Trans. Geoscience Remote Sens. 55, 4913–4924. doi:10.1109/tgrs.2017.2692264
Yang, J., Shi, R., Wei, D., Liu, Z., Zhao, L., Ke, B., et al. (2021). Medmnist v2 - a large-scale lightweight benchmark for 2d and 3d biomedical image classification. Sci. Data 10, 41. doi:10.1038/s41597-022-01721-8
Zhang, C., Cai, Y., Lin, G., and Shen, C. (2020). Deepemd: few-shot image classification with differentiable earth mover’s distance and structured classifiers. Comput. Vis. Pattern Recognit.
Zhao, Y., Gong, M., Qin, A. K., Zhang, M., Hu, Z., Gao, T., et al. (2024). Gradient-guided multi-scale focal attention network for remote sensing scene classification. IEEE Trans. Geoscience Remote Sens. 62, 1–18. doi:10.1109/tgrs.2024.3424489
Zheng, X., Sun, H., Lu, X., and Xie, W. (2022). Rotation-invariant attention network for hyperspectral image classification. IEEE Trans. Image Process. 31, 4251–4265. doi:10.1109/tip.2022.3177322
Keywords: environmental image classification, multi-scale processing, attention mechanisms, adaptive training, robust AI, deep learning
Citation: Zhu J and Li L (2025) Advancements in image classification for environmental monitoring using AI. Front. Environ. Sci. 13:1562287. doi: 10.3389/fenvs.2025.1562287
Received: 22 January 2025; Accepted: 26 February 2025;
Published: 26 March 2025.
Edited by:
Sawaid Abbas, University of the Punjab, PakistanCopyright © 2025 Zhu and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jinjing Zhu, emh1amluamluZ0BodXZ0Yy5lZHUuY24=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.