 Yan Jiang
Yan Jiang Jie Zhang
Jie Zhang Shuangquan Liu
Shuangquan Liu- Yunnan Electric Power Dispatching and Control Center, Kunming, Yunnan, China
As a clean energy source, solar power plays an important role in reducing the high carbon emissions of China’s electricity system. However, the intermittent nature of the system limits the effective use of photovoltaic power generation. This paper addresses the problem of low accuracy of ultra-short-term prediction of distributed PV power, compares various deep learning models, and innovatively selects the Informer model with multi-head probability sparse self-attention mechanism for prediction. The results show that the CEEMDAN-Informer model proposed in this paper has better prediction accuracy, and the error index is improved by 30.88% on average compared with the single Informer model; the Informer model is superior to other deep learning models LSTM and RNN models in medium series prediction, and its prediction accuracy is significantly better than the two. The power prediction model proposed in this study improves the accuracy of PV ultra-short-term power prediction and proves the feasibility and superiority of the deep learning model in PV power prediction. Meanwhile, the results of this study can provide some reference for the power prediction of other renewable energy sources, such as wind power.
1 Introduction
Photovoltaic power generation can be divided into centralized photovoltaic power generation and distributed photovoltaic power generation. Distributed photovoltaic refers to the photovoltaic power generation technology that is built near the user side, and the user is self-sufficient and connects the excess electricity to the grid (Pazouki et al., 2020). Distributed photovoltaic power generation can be absorbed locally, reduce transportation losses, have strong flexibility and disaster prevention ability, and can also alleviate the problem of residential power shortage to a certain extent (Guermoui et al., 2020). With the rise of the “carbon neutral” concept, the development of distributed PV is gaining momentum.
China’s distributed PV power generation developed rapidly. From 2002 to 2006, China’s distributed photovoltaic power generation is in the initial pilot stage. In 2013, the state clearly put forward the subsidy policy for distributed power generation to further promote its development. The period 2016–2020 is the rapid development stage, with the installed capacity increasing rapidly. In 2021, the capacity of distributed photovoltaic power generation exceeds that of centralized power generation for the first time (Wang et al., 2023). In 2022, the state issued the 14th Five-Year Plan for the Modern Energy System, which clearly proposed to comprehensively promote solar power generation, give priority to local development and utilization, and accelerate the construction of distributed photovoltaic (Commission, 2022).
Although distributed photovoltaic power generation has many advantages, such as clean, green, low-carbon and flexible, it also has intermittent limitations that constrain its large-scale grid-connected power generation (Sabo et al., 2017; Xu et al., 2018). Therefore, accurate prediction of photovoltaic power generation is of great significance in alleviating the energy crisis, optimizing power dispatch and other aspects, which can improve the efficiency of photovoltaic power generation, maintain the stability of the power grid, alleviate the energy crisis and ensure the national energy security (Yang et al., 2023).
At present, there are many photovoltaic power generation prediction technologies for China. According to the time scale, it can be divided into ultra-short-term, short-term, medium-term and long-term prediction. Among them, ultra-short-term prediction is to predict the power generation of the photovoltaic power station in the next 0–4 h, and the time resolution is not less than 15 min, which is suitable for power system frequency modulation optimization, economic load scheduling and rotating standby regulation, etc. Short-term prediction is to predict the power of the photovoltaic station within 3 days from zero to the next day, and the time resolution is 15 min. It is suitable for formulation of pre-generation plan and reasonable dispatching of power grid resources. Medium- and long-term prediction is to predict the power generation of the photovoltaic station in the next few months or even years, which is suitable for the planning of the photovoltaic station, the maintenance of power transmission and transformation equipment, and the energy storage of power plants (Zheng et al., 2017).
For the study of ultra-short-term prediction, scholars mainly focus on the treatment of meteorological conditions. Tang et al. (2021) proposed a two-layer collaborative real-time correction ultra-short-term photovoltaic prediction model based on XGBoost, comparing with common prediction models, which effectively improved the prediction accuracy of sudden weather in ultra-short-term prediction. Li et al. (2023) proposed an Attention-LSTM model, solved the problem of missing meteorological data for distributed photovoltaic ultra-short-term prediction. Ding et al. (2023) also studied the improvement of the accuracy of the attention mechanism, and proposed two deep deterministic strategy gradient (DDPG) and cyclic deterministic strategy gradient (RDPG). Compared with the model without attention mechanism, the prediction error RMSE was reduced by 24.24% and 31.34%, which were 26.89% and 18.76% lower than the Attention-LSTM model, respectively (Ding et al., 2023). Compared with Li X et al.’s study, it further improved the accuracy of ultra-short-term prediction. It can be seen that the use of the attention mechanism can effectively improve the prediction accuracy of models.
Short-term prediction has been studied a lot. Among these studies, most of the models focus on improving the prediction accuracy. Liu et al. (2022) constructed the MIV-PSO-BPNN model to make a single-field prediction of the T2-2 photovoltaic power plant at Pudong International Airport, which proved that the model fits better in sunny days and can cope with the PV output mutation better than the BPNN model and SVM model in cloudy and rainy days (Liu et al., 2022). Wang and Deng (2023) proposed a comprehensive BPNN based on prediction-correction. Compared with traditional BPNN, based on the consideration of deterministic prediction, it took into account the uncertainty of short-term prediction and improved the accuracy of point prediction (Wang and Deng, 2023). Moreover, part of the research, in addition to improving the prediction accuracy, also sought to improve the operation speed and generalization ability of the model. Cang et al. (2023) used optimization LSTM model for the whole county distributed photovoltaic power interval prediction, reduced the model training time and reduced the demand of force, implemented the 48 h, 192 power only 2.32% average absolute error. More importantly, the model was universal and can be copied to other large power plants for prediction and use.
In terms of medium- and long-term prediction, scholars are not as regular as short-term prediction, which mostly adopt the idea of classification according to meteorological characteristics. Zhao et al. (2019) proposed a photovoltaic power prediction method based on the clustering method. For the medium- and long-term prediction according to the seasonal characteristics and weather characteristics of photovoltaic power, and the mean absolute percentage error ratio (MAPE) of the prediction results was 12.55% (Zhao et al., 2019). Babbar et al. (2021) combined the Adaboost algorithm with the LSTM algorithm to classify and predict the photovoltaic power under different weather types. The results showed that the combination of various techniques performed better than a single model and had a high degree of accuracy (Babbar et al., 2021). However, the prediction accuracy of the above two methods was not high, while Fang et al. (2022) used the LSTM model to solve the “long-term cycle dependence problem”. Compared with the actual value, the monthly error MAPE fluctuated around 3.5%, and the annual error MAPE fluctuated around 1.1%, indicating excellent prediction results of the model.
For a given photovoltaic system, the tilt angle of the photovoltaic module and the efficiency of the inverter remain essentially unchanged, and the corresponding meteorological conditions are the main factors affecting the output power. Many scholars at home and abroad have also studied this issue. Zhang et al. (2022) modeled the photovoltaic cell and selected five parameters: irradiation intensity, surface temperature of the photovoltaic cell, temperature coefficient, equivalent series resistance and equivalent parallel resistance. The effects of these parameters on the output power and conversion efficiency of the PV cell were investigated using a global sensitivity analysis method based on fuzzy theory (Zhang et al., 2022). However, Yuan et al. (2022) used dynamic time-bending algorithm to calculate that total irradiance and ambient temperature are more related than relative humidity, air pressure and component temperature.
In previous studies, combined methods are increasingly used because of their strong generalization ability and higher accuracy than single prediction methods (Kim et al., 2021). In addition, as far as current research is concerned, the research of domestic and foreign scholars on photovoltaic prediction mainly focuses on short-term research, and there are relatively few studies on ultra-short-term prediction, while the field of medium- and long-term prediction is almost empty (Wang et al., 2023).
In this paper, we compared various deep learning models and innovatively selected the Informer model with multi-head probability sparse self-attention mechanism for prediction, and then used three error indicators of root mean square error, mean absolute percentage error and mean absolute error to evaluate the accuracy of prediction results. For the problem that PV power supply capacity was greatly affected by meteorological factors, the influence of several weather indicators, such as irradiance, temperature and wind speed, on the prediction accuracy was investigated. In addition, considering the seasonal characteristics of PV power supply capacity, this study classified and predicted PV time series data according to seasons; for the characteristics of non-linear and non-smooth PV power data, CEEMDAN technique was used to decompose PV power data into multiple IMF and residual terms, and then each component was predicted together with meteorological factors using the prediction model to obtain the final prediction results. The technology roadmap for this paper is shown in Figure 1.
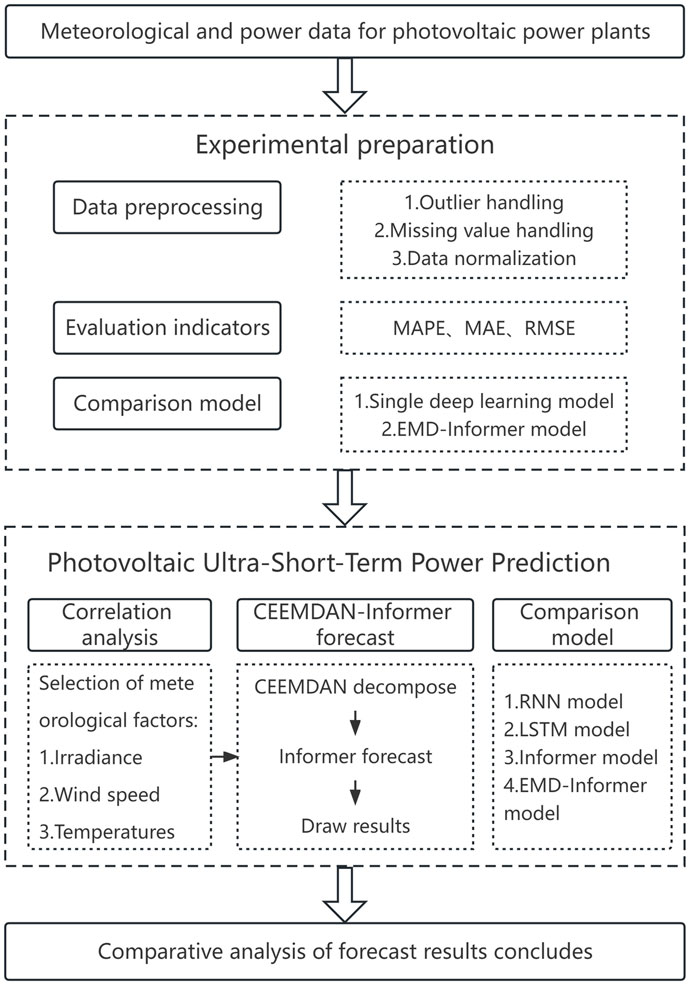
FIGURE 1. Technology roadmap.
This paper is organized as follows. Section 2 introduces the main theories and technologies: the basic model Transformer, the main model Informer of this paper, the decomposition technology CEEEMDAN, and the Pearson correlation coefficient used in this paper. Section 3 pre-processes the selected data. Section 4 describes the experimental component. Finally, we draw our conclusions in Section 5.
2 Key theories and techniques
2.1 Deep learning models
The current mainstream prediction methods can be roughly divided into statistical analysis method and artificial intelligence method. Statistical analysis includes regression analysis, time series method, etc., which is based on the analysis of historical data by statistical rules. It is suitable for linear and stable prediction, and has poor fit for non-linear and complex power prediction. Artificial intelligence method mainly includes traditional machine learning, deep learning, etc. Among them, deep learning is often used for power prediction due to its ability to process nonlinear, high-dimensional data independently (Wang et al., 2019; Peng et al., 2023).
2.1.1 Transformer
Transformer (Figure 2) is relatively easy to train in parallel compared to traditional RNN models. Its core is the self-attention mechanism, which enables the model to better capture dependencies, remote contexts and global semantics when processing sequential data, making the model more flexible and efficient. It has excellent performance in processing large data and long sequences, but also suffers from the difficulty of secondary processing, large memory consumption, and local limitations of the encoder-decoder architecture (Vaswani et al., 2017; Xiao et al., 2023).
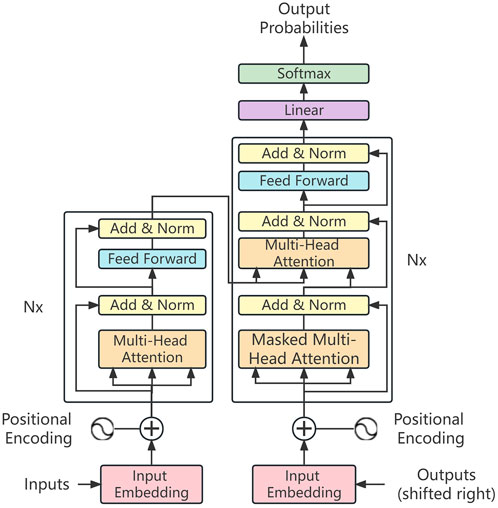
FIGURE 2. Structural diagram of the Transformer model.
The delivery patterns of many competitive neuron adopt an encoder-decoder architecture, whereby an input sequence combining elements such as
The Transformer adopts a complex architecture that organically combines the connection layer between the self-attention layer and the points, and realizes the functions on the left and right sides of Figure 2 through the cooperative work of the encoder and the decoder.
2.1.2 Information extractor model
Zhou et al. (2021) have invented a new LSTF model, Informer (Figure 3), which addresses the difficulty mentioned above.
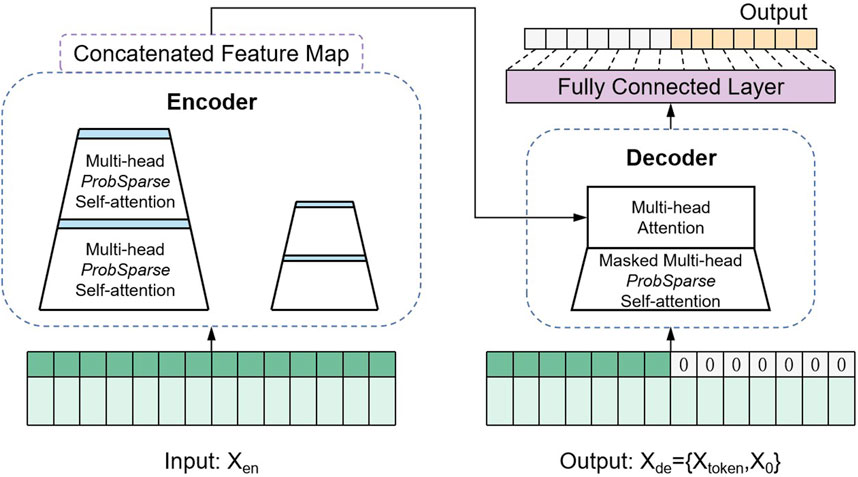
FIGURE 3. Structure diagram of the Informer model.
The Informer model adopts an “encoding-decoding” structure. As shown in Figure 3, the encoder on the left receives a long sequence of inputs and obtains feature mappings through the ProbSparse self-attention module. On the right is the decoder, which receives a long sequence of inputs with the target part of the prediction set to 0, interacts with the encoded features through multi-attention, and finally directly predicts the output target part (the orange part) at once.
Informer has three main advantages (Gong et al., 2022; Wei et al., 2023; Zou et al., 2023):
• It employs the ProbSparse self-attention mechanism that effectively reduces time complexity and memory usage.
• It highlights the dominant factor in the self-attention mechanism by halving the cascade layer inputs, effectively handling excessively long input sequences.
• It performs one-time prediction for long time series instead of stepwise prediction, which greatly improves the inference speed of long series prediction.
2.2 The empirical mode decomposition of fully adaptive noise sets
Due to the intermittent characteristics of photovoltaic power generation, the signal decomposition technology can be used to decompose the power time series to improve the accuracy and reliability of the prediction.
Empirical Mode Decomposition (EMD) is a form that can effectively convert complex data into a residual (RES) and multiple eigenmode functions (IMF), so as to better understand and deal with complex digital properties. Each IMF represents a frequency and amplitude component of the signal and satisfies two conditions:
(1) Over the entire length of the signal, the number of IMF extreme points is either equal or differs by no more than 1.
(2) At each extreme point, the mean value of the upper and lower envelope of the IMF should be zero.
The advantage of EMD is that it can decompose signals adaptively, and does not require any prior knowledge, without predicting the amplitude and frequency. It can also handle both nonlinear and non-stationary signals because it is a local decomposition method. However, EMD is sensitive to noise and has high computational complexity when processing high-dimensional data.
Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) is an improved model of EMD. It addresses the problem of modal aliasing and over decomposition present in EMD by introducing adaptive noise. Specifically, CEEMDAN adds some adaptive noise to the original signal and then decomposes it into multiple IMFs and a RES using EMD. The procedure is then repeated separately for each IMF and residual term until the stopping criterion is satisfied.
2.3 The Pearson correlation coefficient method
The Pearson correlation coefficient is used to measure the linear correlation between variables X and Y, and the value is between −1 and 1 (Schober et al., 2018). The formula is:
The larger its absolute value, the stronger the degree of correlation.
3 Data preprocessing and modeling
3.1 Data preprocessing
The Yulara Solar System was selected for this study. It was 1.8 MW distributed solar photovoltaic power plant located in Uluru, Central Australia. In this study, one of the stationary polysilicon power plants was used for data analysis and modelling at the 5-min level for the whole year 2020. Descriptive statistics of the data used were presented below (Table 1):

TABLE 1. Descriptive statistics of the power data.
According to the data analysis in the table, there should be 105,408 pieces of actual power data and more than 2,000 missing data, requiring missing values. The maximum power could reach 800 kW and the minimum power was −0.24 kW. The minimum power was negative because the photovoltaic modules not only had no output power at night, but also needed to consume part of the power to maintain their own operation. The standard deviation and variance of the actual power were large, indicating that the volatility of the photovoltaic power sequence was high, which also made prediction difficult. According to the literature review, unnecessary factors for predicting photovoltaic power in the original data set had been excluded, and seven indices of irradiance, air temperature, air pressure, wind speed, maximum wind speed, wind direction and rainfall had been retained.
At the same time, there were still some outliers in rainfall and other indicators. Since both missing values and outliers could affect the predictive power, the data with missing values and outliers were treated first.
Outlier handling: some outliers existed in the dataset for a variety of reasons, such as system malfunctions and unusual events. The anomalies were detected by using the interquartile range (IQR) (Rostami et al., 2022). We considered the values outside the “lower quartile−1.5 × IQR” and the “upper quartile + 1.5 × IQR” as outliers. After testing using this method, there were still a small number of outliers, so the data were located through the image and classified as outliers. Replaced the outlier value with the zero value.
Missing value processing: After outlier processing, there were still a large number of missing values in the data. These missing values fell into two categories. One was a small number of linear missing values, which were treated directly by linear interpolation; the other was multi-line continuous missing values. In the case of direct interpolation, it did not follow the fluctuation law and was still an outlier, so data from the same time on the previous day were used for replacement.
Normalization treatment: In order to reduce the effect of the index measurement unit on the predictive effect, the index needed to be normalized. This paper adopted the maximum and minimum normalization (Polat and Nour, 2020):
where x′ was the normalized data value and x was the non-normalized data value. The max(x) and min(x) represented the maximum and minimum values in the sequence, respectively.
Dataset division: Due to the seasonality of photovoltaic power (Raza et al., 2017), the dataset for 2020 was divided into four seasons: spring, summer, autumn and winter for the prediction. Divided January–March as spring, and so on for the rest of the season.
3.2 The CEEMDAN-Informer model
The CEEMDAN-Informer model was constructed as follows: First, the photovoltaic power data sets of different seasons were CEEMDAN-decomposed in the form of an IMF and a residual RES. Second, the Informer model parameters were adjusted to select the optimal training times, sequence length, prediction length, batch_size and learning rate. Finally, each IMF component, RES component and selected meteorological factors were input into the Informer model with adjusted parameters for training to obtain the final prediction results. The model framework was shown in Figure 4.
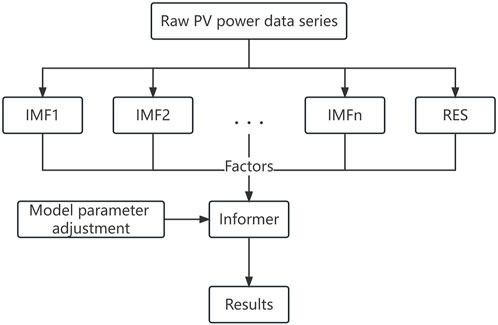
FIGURE 4. The prediction flow diagram of the CEEMDAN-Informer model.
3.3 Contrast model selection
To further validate the conclusions of this paper, the following models were used for comparison:
(1) Single deep learning model: A single RNN model, LSTM model and Informer model were used for comparison to verify the superiority of the Informer model over other deep learning models. At the same time, we could compare a single Informer model with the CEEMDAN-Informer model constructed in this paper to verify the improvement of the prediction accuracy of the model constructed in this paper.
(2) Combination of EMD decomposition technology and Informer model: EMD-Informer model was used as a comparison model to verify the superiority of the CEEMDAN model.
4 Discussion
4.1 Correlation analysis
The seven selected factors were first analyzed for correlation using the Pearson correlation coefficient method. As shown in Figure 5, through the Pearson correlation coefficient diagram, it could be found that the photovoltaic power had a strong positive linear correlation with irradiance, indicating that the power was most affected by irradiance. Second, the photovoltaic power had a moderate positive linear correlation with maximum wind speed, wind speed and air temperature. Of these, due to the high correlation between maximum wind speed and wind speed, only wind speed was retained in the prediction. Wind direction, pressure and precipitation were not linearly correlated with power.
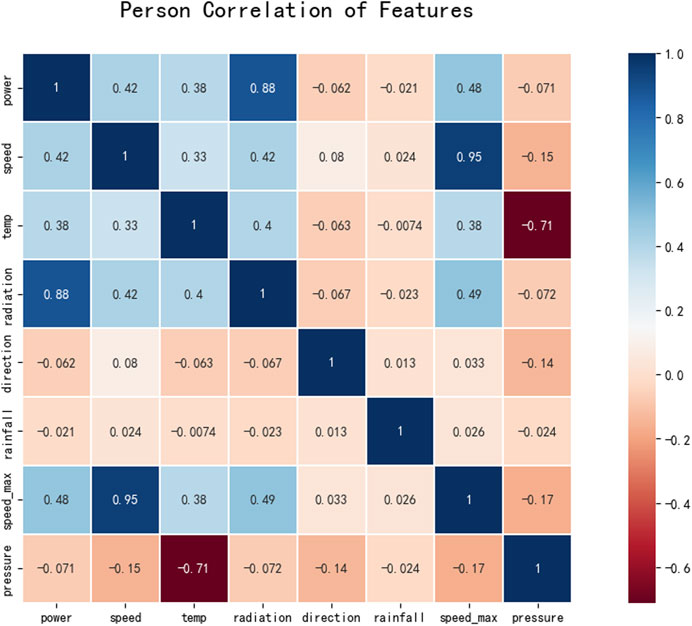
FIGURE 5. Pearson correlation of features.
4.2 Analysis of mode decomposition and power prediction results
First, CEEMDAN decomposed the photovoltaic power data sets in the form of multiple IMF and a residual RES. The decomposition results in spring were shown in Figure 6. The sequence in the first line in red was the trend diagram of the original photovoltaic power data, and the green part was the decomposed sequence. It could be seen that the original sequence was decomposed into 13 IMFs, ordered by their frequency from high to low, with no obvious modal aliasing phenomenon.
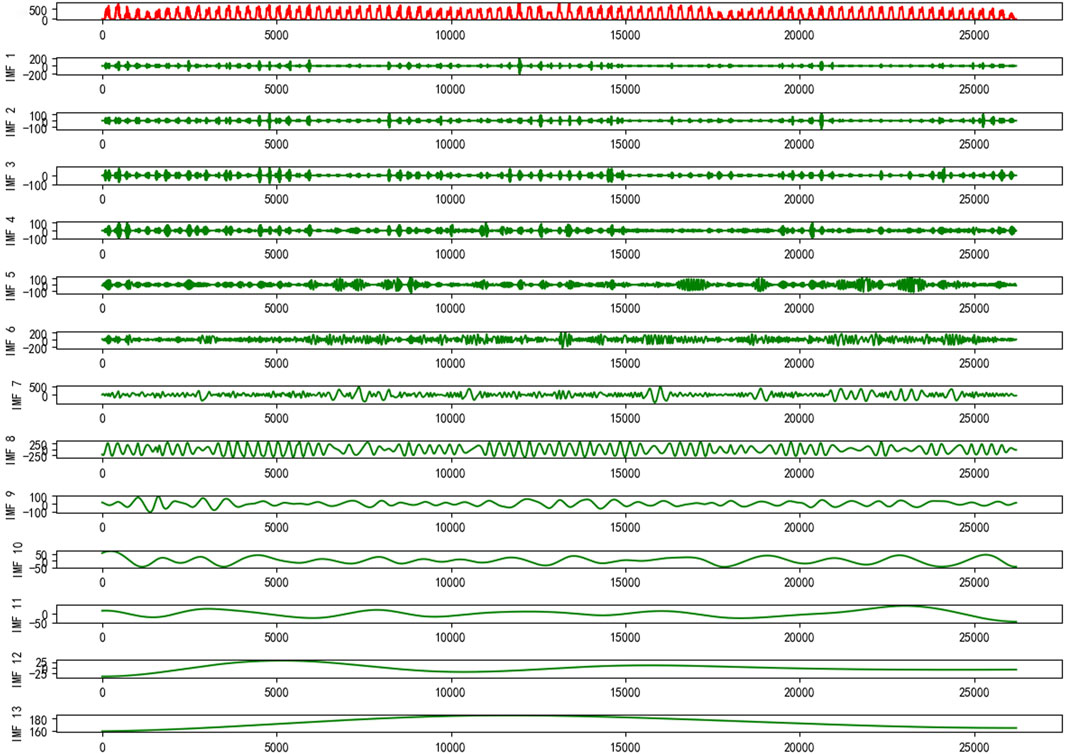
FIGURE 6. Power decomposition diagram of photovoltaic power generation in the spring of 2020.
Second, each IMF component was trained separately along with the RES component using the Informer model. In the Informer model prediction, the training set, test set and validation set were split 8:1:1, with training times epochs = 15, batch_size = 32, early stop mechanism patience = 3, learning rate learning_rate = 0.001, sequence length = 36, predict length = 9. The data time step was 5 min, which meant that the power data of the future 45 min was predicted for 9 time points with 36 historical time steps. Then the meteorological factor data set (NWP) was added, and the irradiance, wind speed and temperature were selected as the meteorological factor data and input into the model for training, and the final prediction results were obtained.
Using CEEMDAN-Informer model for the four data sets of spring, summer, autumn and winter. The results obtained were shown in Table 2:
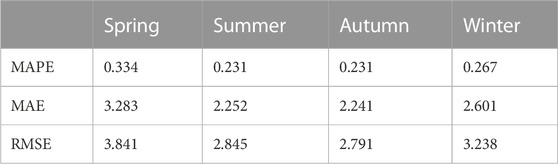
TABLE 2. Results of the CEEMDAN-Informer model prediction.
The prediction errors of the four datasets were within acceptable limits and the prediction effect was better in summer and autumn. This was due to the fact that the temperature in Australian summer and autumn (April–September) was appropriate, with less fluctuation (Figure 7). In spring and winter, the temperature fluctuated a lot, even more than 40°C in part of the time, which greatly reduced the photoelectric conversion efficiency of photovoltaic panels and thus affected their power output.
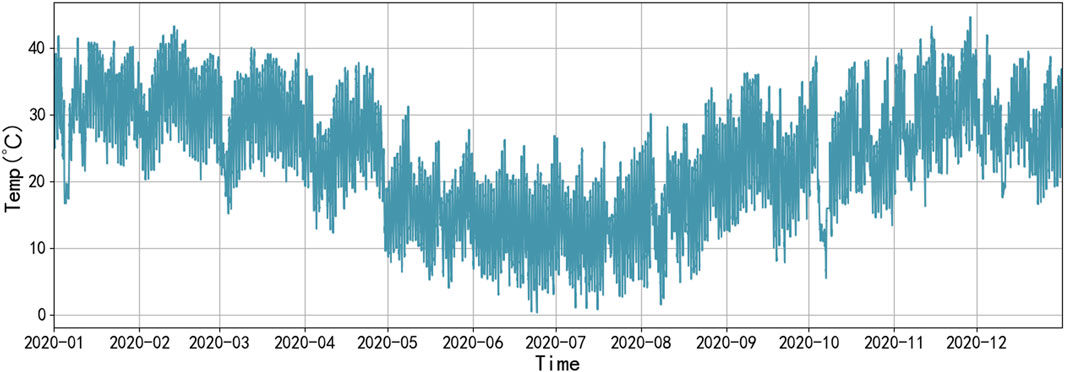
FIGURE 7. Trend chart of the annual temperature in Australia in 2020.
4.3 Comparative analysis of the model prediction accuracy
4.3.1 Single-model prediction contrast
The RNN, LSTM and Informer models were used to compare the performance of the prediction model. The settings for the Informer model were the same as above. For LSTM, we built a three-layer LSTM model with the number of hidden layers of 128, 64, 32 respectively, set the training times epochs = 150, and batch_size = 128, sequence length = 36, prediction length = 9, which meant the photovoltaic power of 45 min in the future. The RNN model was set in the same way as the LSTM model. The prediction results were shown in Table 3:
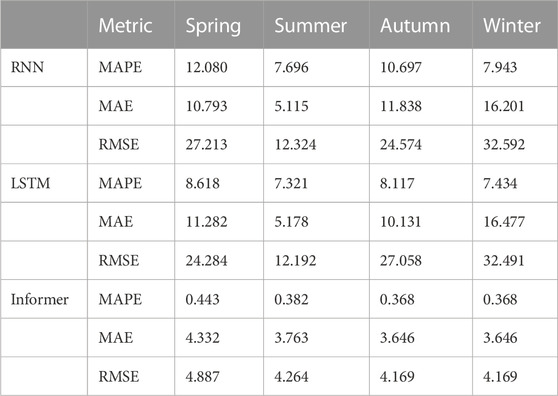
TABLE 3. Prediction results of RNN, LSTM, and Informer models.
The results showed that the RNN and LSTM models predicted almost as well, but overall the LSTM model predicted slightly better than the RNN. This was because the LSTM model was a modified version of the RNN model that added a gating mechanism and was better at capturing long-term memory. However, they only focus on the current state input and the state input at the previous moment, whereas the Informer model employed the multi-head self-attention mechanism, which could focus on multiple positions in the input sequence simultaneously, and the effect on long-term sequence prediction would be more significant. The average MAPE, MAE and RMSE values of the four seasons were only 0.39, 3.84 and 4.37, and the prediction accuracy was much higher than the traditional deep learning model, which proved that the Informer model had a good prediction effect in multi-step prediction.
However, comparing the prediction effect of CEEMDAN Informer model and single Informer model, the model proposed in this paper had better prediction effect, and the error index was reduced by 30.88% on average, which proved that the use of signal decomposition technology was helpful to improve the prediction accuracy.
4.3.2 EMD-Informer model prediction
According to the above analysis of the prediction results, we found that using the decomposition technique could reduce the prediction error, so we built the EMD Informer model for prediction and explored the effect of the decomposition technique on the accuracy of the model. The prediction process and parameter settings of Informer remained unchanged. The prediction results were shown in Table 4.
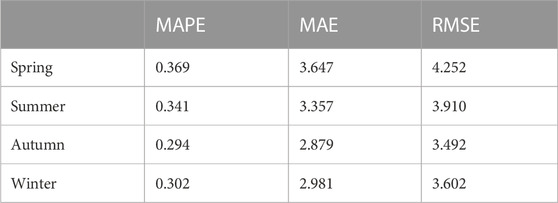
TABLE 4. Results of the EMD-Informer prediction.
As shown in Figure 8, when the prediction accuracy of different signal decomposition techniques was compared with the combined model composed of the Informer model, the prediction results of the Informer model, the EMD-Informer model and the CEEMDAN-Informer model were all relatively ideal. The prediction accuracy of each model using the signal decomposition technology was improved compared to a single Informer model, which proved that the signal decomposition technology could effectively improve the prediction accuracy of the model. In addition, the CEEMDAN Informer model had higher accuracy than the EMD Informer model. Among them, the improvement effect of summer prediction accuracy was the most obvious, the MAPE, MAE and RMSE values increased by 32.13%, 32.91% and 27.23% respectively; the improvement effect in spring was the worst, but the three indicators still increased by 9.49%, 9.97% and 9.71% respectively. The results showed that the CEEMDAN decomposition technology could improve the performance prediction effect better than the EMD technology.
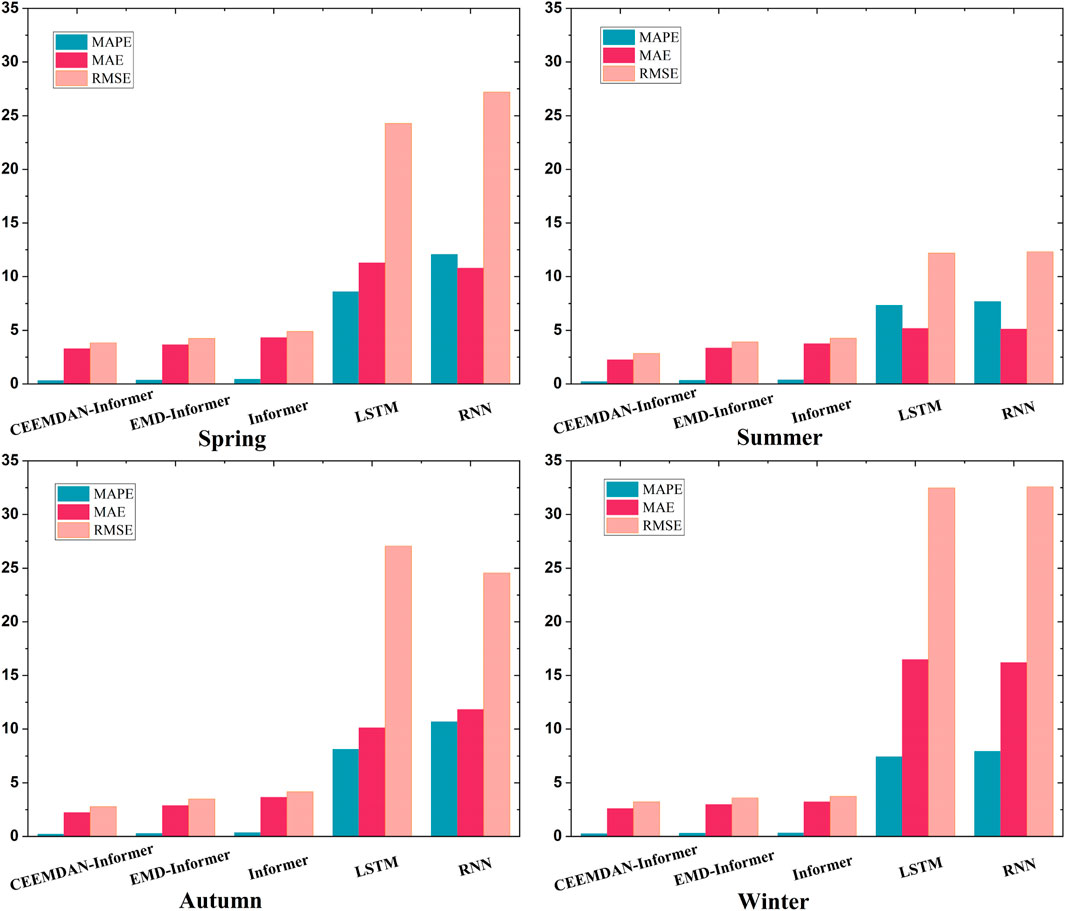
FIGURE 8. Comparison of prediction accuracy between different signal decomposition techniques and Informer combined models.
5 Conclusion
In this paper, we made point prediction for ultra-short-term photovoltaic power prediction based on CEEMDAN-Informer model and considered the meteorological influencing factors of photovoltaic power generation. Meanwhile, in the present study, the prediction results of CEEMDAN-Informer model were compared with other commonly used deep learning models. The research conclusions of this paper were summarized as follows:
(1) The relationship between the influencing factors of photovoltaic power generation and power generation was analyzed. First, through literature review, a number of indicators such as irradiance, wind speed and wind direction were possible factors; second, relevant meteorological data and photovoltaic power generation data were collected, and then analyzed using the Pearson correlation coefficient method to find that among the seven indicators selected in this paper, irradiance, wind speed, maximum wind speed and air temperature had a strong linear correlation with them; finally, the data were divided into different data sets and input into the prediction model, and the influence of season on the prediction accuracy was further investigated.
(2) The results showed that the CEEMDAN-Informer model had significant advantages over the traditional deep learning model in photovoltaic power prediction. Due to the intermittent nature of photovoltaic prediction, improving the prediction accuracy of the model had become the focus of ultra-short-term research. While many studies had proved that models using attention mechanisms could effectively improve the prediction accuracy. Therefore, in this paper, we selected the Informer model with the multi-head sparse self-attention mechanism as the prediction model, and combined with the CEEMDAN solution technology to build the CEEMDAN-Informer model as the main model for photovoltaic power prediction. A series of models including RNN, LSTM, Informer and EMD-Informer were used as comparison models. The results showed that the prediction accuracy of the CEEMDAN-Informer model was significantly higher than the other models.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author contributions
YJ: Writing–original draft, Writing–review and editing. KF: Writing–review and editing. WH: Writing–review and editing. JZ: Writing–original draft, Writing–review and editing. XL: Writing–review and editing. SL: Writing–review and editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This paper is supported by the Science and Technology Program of China Southern Power Grid Co., Ltd. (Grant No. YNKJXM20222173) and the Reserve Talents Program for Middle-aged and Young Leaders of Disciplines in Science and Technology of Yunnan Province, China (Grant No. 202105AC160014).
Conflict of interest
Authors YJ, KF, WH, JZ, XL, and SL were employed by Yunnan Electric Power Dispatching and Control Center.
The authors declare that this study received funding from Science and Technology Program of China Southern Power Grid Co., Ltd.
The funder had the following involvement in the study: study design, collection, analysis, interpretation of data, the writing of this article, and the decision to submit it for publication.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Babbar, S. M., Lau, C. Y., and Thang, K. F. (2021). Long term solar power generation prediction using Adaboost as a hybrid of linear and non-linear machine learning model. Int. J. Adv. Comput. Sci. Appl. 12, 536–545. doi:10.14569/ijacsa.2021.0121161
Cang, M., Zhai, X., Wang, J., Wu, S., and Chen, X. (2023). Study on comprehensive LSTM power prediction model of photovoltaic power generation in whole county. Technol. Industry 23 (06), 156–164.
Commission, N. D. R. (2022). 14th five-year plan for the modern energy system. https://neec.no/14th-five-year-plan-on-modern-energy-system-planning/.
Ding, Z., Fu, Q., Chen, J., Lu, Y., Wu, H., Fang, N., et al. (2023). Ultra-short-term photovoltaic power prediction by deep reinforcement learning based on attention mechanism. J. Comput. Appl. 43, 1647–1654.
Fang, P., Gao, Y., Pan, G., Ma, D., and Sun, H. (2022). Research on forecasting method of mid-and long-term photovoltaic power generation based on LSTM neural Network. Renesable Energy Resour. 40, 48–54.
Gong, M. J., Zhao, Y., Sun, J. W., Han, C., Sun, G., and Yan, B. (2022). Load forecasting of district heating system based on Informer. Energy 253, 124179. doi:10.1016/j.energy.2022.124179
Guermoui, M., Melgani, F., Gairaa, K., and Mekhalfi, M. L. (2020). A comprehensive review of hybrid models for solar radiation forecasting. J. Clean. Prod. 258, 120357. doi:10.1016/j.jclepro.2020.120357
Kim, B., Suh, D., Otto, M. O., and Huh, J. S. (2021). A novel hybrid spatio-temporal forecasting of multisite solar photovoltaic generation. Remote Sens. 13, 2605. doi:10.3390/rs13132605
Li, X., Xiao, N., Peng, B., Ai, Z., and Wang, Y. (2023). Frequency prediction after disturbance of grid-connected wind power systems based on WOA and Attention-LSTM. Energy Rep. 9, 208–216. doi:10.1016/j.egyr.2023.02.077
Liu, D., Liu, F., and Xu, Y. (2022). SHORT-TERM PHOTOVOLTAIC POWER FORECASTING BASED ON MIV-PSO-BPNN MODEL. Acta Energiae Solaris Sin. 43, 94–98.
Pazouki, S., Naderi, E., and Asrari, A. (2020). “Interconnected energy hubs including DERs targeted by FDI cyberattacks,” in 11th international green and sustainable computing workshop (IGSC) (Pullman, WA, USA: Electr Network).
Peng, Z. K., Sun, N. Y., Cheng, J. F., Liu, W., Wang, C., Bi, Y., et al. (2023). A sequential strong PUF architecture based on reconfigurable neural networks (RNNs) against state-of-the-art modeling attacks. Integration-the Vlsi J. 92, 83–90. doi:10.1016/j.vlsi.2023.05.003
Polat, K., and Nour, M. (2020). Epileptic seizure detection based on new hybrid models with electroencephalogram signals. Irbm 41, 331–353. doi:10.1016/j.irbm.2020.06.008
Raza, M. Q., Nadarajah, M., and Ekanayake, C. (2017). Demand forecast of PV integrated bioclimatic buildings using ensemble framework. Appl. Energy 208, 1626–1638. doi:10.1016/j.apenergy.2017.08.192
Rostami, A., Akhoondzadeh, M., and Amani, M. (2022). A fuzzy-based flood warning system using 19-year remote sensing time series data in the Google Earth Engine cloud platform. Adv. Space Res. 70, 1406–1428. doi:10.1016/j.asr.2022.06.008
Sabo, M. L., Mariun, N., Hizam, H., Mohd Radzi, M. A., and Zakaria, A. (2017). Spatial matching of large-scale grid-connected photovoltaic power generation with utility demand in Peninsular Malaysia. Appl. Energy 191, 663–688. doi:10.1016/j.apenergy.2017.01.087
Schober, P., Boer, C., and Schwarte, L. A. (2018). Correlation coefficients: appropriate use and interpretation. Anesth. Analgesia 126, 1763–1768. doi:10.1213/ane.0000000000002864
Tang, Y., Lin, D., Ni, C., and Zhao, B. (2021). XGBoost based Bi-layer collaborative real-time calibration for ultra-short-term photovoltaic prediction. Automation Electr. Power Syst. 45, 18–27.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). “Attention is all you need,” in 31st annual conference on neural information processing systems (NIPS), Curran Associates, Inc, (Long Beach, CA, USA).
Wang, H. L. J., and Deng, Y. (2023). Short-term photovoltaic power forecasting based on predict-correct combination BP neural network. Smart Power 51 (03), 46–52.
Wang, H. Z., Lei, Z. X., Zhang, X., Zhou, B., and Peng, J. (2019). A review of deep learning for renewable energy forecasting. Energy Convers. Manag. 198, 111799. doi:10.1016/j.enconman.2019.111799
Wang, J., Wu, J., Huang, Y., Shao, S., Gao, F., Guan, X., et al. (2023). Optimal allocation of wind-photovoltaic-storage capacity in multi-area power grid based on distributed algorithm. J. Xi'an Jiaot. Univ. 57, 15–24.
Wei, H., Wang, W. S., and Kao, X. X. (2023). A novel approach to ultra-short-term wind power prediction based on feature engineering and informer. Energy Rep. 9, 1236–1250. doi:10.1016/j.egyr.2022.12.062
Xiao, H. G., Li, L., Liu, Q. Y., Zhu, X., and Zhang, Q. (2023). Transformers in medical image segmentation: a review. Biomed. Signal Process. Control 84, 104791. doi:10.1016/j.bspc.2023.104791
Xu, X. K., Guan, C. M., and Jin, J. Y. (2018). Valuing the carbon assets of distributed photovoltaic generation in China. Energy Policy 121, 374–382. doi:10.1016/j.enpol.2018.06.046
Yang, X. H., Wang, X. P., Leng, Z. Y., Deng, Y., Deng, F., Zhang, Z., et al. (2023). An optimized scheduling strategy combining robust optimization and rolling optimization to solve the uncertainty of RES-CCHP MG. Renew. Energy 211, 307–325. doi:10.1016/j.renene.2023.04.103
Yuan, J., Xie, B., He, B., Zhao, Z., Liu, Y., Liu, B., et al. (2022). SHORT TERM FORECASTING METHOD OF PHOTOVOLTAIC OUTPUT BASED ON DTW-VMD-PSO-BP. Acta Energiae Solaris Sin. 43, 58–66.
Zhang, F., Han, C., Wu, M. Y., Hou, X., and Wang, X. (2022). Global sensitivity analysis of photovoltaic cell parameters based on credibility variance. Energy Rep. 8, 7582–7588. doi:10.1016/j.egyr.2022.05.280
Zhao, S., Hu, L., Tian, J., and Xu, Z. (2019). Contract power decomposition model of multi-energy power system based on mid-long term wind power and photovoltaic electricity forecasting. Electr. Power Autom. Equip. 39, 13–19.
Zheng, C. W., Wang, Q., and Li, C. Y. (2017). An overview of medium-to long-term predictions of global wave energy resources. Renew. Sustain. Energy Rev. 79, 1492–1502. doi:10.1016/j.rser.2017.05.109
Zhou, H. Y., Zhang, S. H., Peng, J. Q., Zhang, S., Li, J. X., Xiong, H., et al. (2021). “Informer: beyond efficient transformer for long sequence time-series forecasting,” in 35th AAAI conference on artificial intelligence/33rd conference on innovative applications of artificial intelligence/11th symposium on educational advances in artificial intelligence (Electr Network), Pullman, WA, USA, 11106–11115.
Keywords: photovoltaic power prediction, ultra-short-term, Informer, deep learning, CEEMDAN
Citation: Jiang Y, Fu K, Huang W, Zhang J, Li X and Liu S (2023) Ultra-short-term PV power prediction based on Informer with multi-head probability sparse self-attentiveness mechanism. Front. Energy Res. 11:1301828. doi: 10.3389/fenrg.2023.1301828
Received: 25 September 2023; Accepted: 24 October 2023;
Published: 16 November 2023.
Edited by:
Qingrui Wang, Huazhong University of Science and Technology, ChinaReviewed by:
Hewen Zhou, Shandong University, ChinaCong Men, University of Science and Technology Beijing, China
Copyright © 2023 Jiang, Fu, Huang, Zhang, Li and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jie Zhang, amltaG9yc2UxOTc4QDE2My5jb20=