 Jorge Valverde-Rebaza
Jorge Valverde-Rebaza Aram González
Aram González Octavio Navarro-Hinojosa
Octavio Navarro-Hinojosa Julieta Noguez
Julieta Noguez
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Educ. , 08 August 2024
Sec. Leadership in Education
Volume 9 - 2024 | https://doi.org/10.3389/feduc.2024.1418006
This article is part of the Research Topic Continuing Engineering Education for a Sustainable Future View all 19 articles
Introduction: In recent years, numerous AI tools have been employed to equip learners with diverse technical skills such as coding, data analysis, and other competencies related to computational sciences. However, the desired outcomes have not been consistently achieved. This study aims to analyze the perspectives of students and professionals from non-computational fields on the use of generative AI tools, augmented with visualization support, to tackle data analytics projects. The focus is on promoting the development of coding skills and fostering a deep understanding of the solutions generated. Consequently, our research seeks to introduce innovative approaches for incorporating visualization and generative AI tools into educational practices.
Methods: This article examines how learners perform and their perspectives when using traditional tools vs. LLM-based tools to acquire data analytics skills. To explore this, we conducted a case study with a cohort of 59 participants among students and professionals without computational thinking skills. These participants developed a data analytics project in the context of a Data Analytics short session. Our case study focused on examining the participants' performance using traditional programming tools, ChatGPT, and LIDA with GPT as an advanced generative AI tool.
Results: The results shown the transformative potential of approaches based on integrating advanced generative AI tools like GPT with specialized frameworks such as LIDA. The higher levels of participant preference indicate the superiority of these approaches over traditional development methods. Additionally, our findings suggest that the learning curves for the different approaches vary significantly. Since learners encountered technical difficulties in developing the project and interpreting the results. Our findings suggest that the integration of LIDA with GPT can significantly enhance the learning of advanced skills, especially those related to data analytics. We aim to establish this study as a foundation for the methodical adoption of generative AI tools in educational settings, paving the way for more effective and comprehensive training in these critical areas.
Discussion: It is important to highlight that when using general-purpose generative AI tools such as ChatGPT, users must be aware of the data analytics process and take responsibility for filtering out potential errors or incompleteness in the requirements of a data analytics project. These deficiencies can be mitigated by using more advanced tools specialized in supporting data analytics tasks, such as LIDA with GPT. However, users still need advanced programming knowledge to properly configure this connection via API. There is a significant opportunity for generative AI tools to improve their performance, providing accurate, complete, and convincing results for data analytics projects, thereby increasing user confidence in adopting these technologies. We hope this work underscores the opportunities and needs for integrating advanced LLMs into educational practices, particularly in developing computational thinking skills.
Artificial Intelligence (AI) is permeating an ever-growing array of domains within daily life, and its utilization is on the rise in professional contexts such as healthcare (Alhashmi et al., 2024), marketing (Haleem et al., 2022), education (Chen et al., 2020; Zhang and Aslan, 2021), and beyond. AI tools in education have revolutionized the educational landscape by providing personalized learning experiences and assisting in administrative tasks such as assessment and the customization of instructional strategies. Thus, from intelligent tutoring systems to chatbots and virtual assistants, AI tools in education enhance learning experiences by fostering efficiency, adaptability, and inclusivity (Laupichler et al., 2022; Srinivasan, 2022; Wolters et al., 2024).
Programming education has made significant advancements in recent decades. Once perceived as a skill limited to a select few with strong computational thinking competencies, programming has evolved into a critical tool for tackling complex real-world challenges, and driving innovation (Nouri et al., 2020). As a result, proficiency in programming has become indispensable for success across various sectors, especially in the business domain (Yilmaz and Yilmaz, 2023), proving its resilience even in global crises such as the COVID-19 pandemic (Pesonen and Hellas, 2022). This growing recognition of the importance of programming skills has led to their inclusion in university and continuing education courses.
Despite the increasing interest in programming education, learning to program remains a hard, and intricate endeavor for many individuals. Consequently, a considerable number of learners discontinue their learning journey before achieving proficiency (Rouhani et al., 2022; Saqr and López-Pernas, 2024). AI tools effectively address challenges such as the requirement for comprehensive guidance and support, the complexities of debugging code errors, and, most crucially, the comprehension of underlying concepts. Despite their capability, these challenges persist (Pedro et al., 2019).
The introduction of ChatGPT in November 2022 marked a pivotal moment in the landscape of AI tools, marking a clear delineation between the pre- and post-eras of AI tools (OpenAI, 2022). ChatGPT, as an application of Large Language Models (LLMs), has captivated the world with its remarkable capability to execute highly intricate tasks and its notable aptitude for engaging in natural conversation. This includes seamlessly responding to user inquiries and providing feedback, stimulating ongoing dialogue through continuous interaction. Such capabilities distinguish ChatGPT from previous AI tools, offering users a uniquely immersive experience (Rospigliosi, 2023; Mai et al., 2024). Thus, ChatGPT shaped and popularized generative AI tools, encompassing platforms such as Google Bard, Falcon, Cohere, Llama, Bing Chat, Gemini, and others.
In the realm of teaching and learning, the emergence of ChatGPT and other generative AI tools has elicited diverse perspectives among educators, as their potential applications have the capacity to revolutionize existing educational methodologies. Thus, in < 2 years since these technologies became widely accessible, numerous studies have already emerged exploring their opportunities and threats (Mai et al., 2024), significance and impact (Kasneci et al., 2023), ethical implications (Vaccino-Salvadore, 2023), risk factors (Morales-García et al., 2024), and other aspects.
Due to its ability to generate content, define terms, and serve as a programming assistant, ChatGPT and other generative AI tools have the potential to contribute significantly to the process of teaching and learning programming skills in ways that previous chatbots could not achieve (Yilmaz and Yilmaz, 2023; da Silva et al., 2024). Furthermore, generative AI tools can play a significant role in teaching and learning more advanced computational skills, which typically demand higher levels of abstraction or computational thinking capacity, such as building data analytics solutions (Ellis and Slade, 2023; Bringula, 2024; Xing, 2024) and, even more, helping to understand what is being programmed (Nam et al., 2024).
Despite the advantages that potentially position ChatGPT and other generative AI tools as technologies that democratize support for teaching and learning programming and data analytics skills, new challenges arise, especially when instructing learners who lack computational thinking competencies. Therefore, in this work, we investigate how the utilization of technologies that integrate generative AI tools directly into learners' data analytics projects can support the learning process of programming and data analytics skills in contrast to the traditional use of generative AI tools.
For this study, we employ LIDA (Dibia, 2023), a novel tool designed to comprehend the semantics of data to set pertinent visualization objectives and produce visualization specifications, infographics, and data narratives. LIDA can be used with various LLM providers, including OpenAI, Azure OpenAI, PaLM, Cohere, and Huggingface, allowing for seamless incorporation into the user's data analytics projects. This approach simplifies programming by leveraging natural language prompts to generate code snippets that are effortlessly integrated into the existing codebase. This approach enables learners to concentrate more on crafting solutions for their projects rather than delving into the intricate details of programming. This paper aims to provide a perspective into how educators can leverage LIDA, or similar technologies, in conjunction with generative AI tools to enhance learning outcomes related to programming and data analytics skills. This is particularly valuable in contexts where learners do not yet possess advanced computational thinking abilities.
The structure of this article is organized as follows: Section 2 provides a comprehensive review of the existing literature on innovation in education focusing on the use of tools based on LLMs. Section 3 details the methodology employed in this study, including a thorough description of the case study utilized. Section 4 presents the findings from our case study, incorporating an exploratory analysis of the collected data. Finally, Section 5 concludes with a discussion of our findings, highlighting the implications and potential impact of this research.
In this section, we present the evolution of AI tools in education, focusing on tools that facilitate teaching and acquiring computational thinking skills, particularly those related to data analytics.
Effective learning methods in programming education can enhance how students learn and interact with computer programming and coding environments. These methods encourage learners to progress further and embark on the development of data analytics and data science projects (Saqr and López-Pernas, 2024). The integration of AI into these methodologies can significantly enhance this process. Popenici and Kerr (2017) reviewed AI's potential impact in higher education, noting its benefits, such as augmenting human capabilities, personalizing learning, and supporting skill development in critical thinking and problem-solving. Authors also highlighted risks, including educator replacement, bias reinforcement, job displacement, loss of human interaction, and reduced critical thinking due to over-reliance on technology.
Similar concerns, and additional recommendations, have been raised after the introduction of ChatGPT (Baidoo-Anu and Ansah, 2023; Chinonso et al., 2023; Kasneci et al., 2023; Rahman and Watanobe, 2023). The integration of ChatGPT as well as other generative AI tools into educational settings has the potential to revolutionize programming instruction by providing personalized learning experiences, formative assessments, and enhanced teaching strategies. Kiesler and Schiffner (2023) assessed the performance of ChatGPT-3.5 and ChatGPT-4 on 72 Python tasks from CodingBat using unit tests. The LLMs achieved high accuracy, with 94.4–95.8% correct responses, highlighting their effectiveness in solving introductory programming tasks.
Additionally, LLMs' capability to generate code and provide textual explanations offers new opportunities for integrating them into educational settings. These capabilities enable the design of programming tasks, the provision of formative feedback, support for novice learners, and offer accessibility and inclusivity by aiding students with disabilities or those who struggle with traditional methods. However, LLMs' present limitations in addressing more complex problems that require a deeper understanding of programming concepts (Chinonso et al., 2023; Kiesler and Schiffner, 2023; da Silva et al., 2024).
Despite their advantages, generative AI tools are not without their limitations and potential drawbacks (Azaria et al., 2024). They may generate inaccurate information, perpetuate biases from their training data, and raise privacy concerns when handling sensitive student data. Additionally, their contextual understanding is often limited, leading to potentially incorrect or irrelevant results in specific searches. Moreover, the outputs from these tools might be difficult to interpret, posing challenges for inexperienced users (Phung et al., 2023). Furthermore, studies suggest that an over-reliance on AI-powered tools could diminish students' critical thinking skills, as they increasingly rely on technology for problem-solving (Ifelebuegu et al., 2023; Memarian and Doleck, 2023; Mosaiyebzadeh et al., 2023).
Thus, to fully leverage the advantages of generative AI tools in programming education, educators and students should collaborate on establishing guidelines for responsible AI integration and usage. Both parties should also focus on addressing the associated limitations and explore integrating these tools with complementary technologies to effectively handle more extensive or complex tasks.
The power afforded by LLMs can be decisively harnessed to support the teaching and learning of comprehensive skills within the context of computational thinking. Specifically, ChatGPT and other generative AI tools can support the acquisition of skills that facilitate the rapid and consistent execution of projects in data analytics, data science, data mining, and related fields.
Since the emergence of LLMs, several authors have developed strategies to leverage the potential of generative AI tools to enhance data analytics education. Tu et al. (2023) explored the transformative potential of LLMs in data science education, highlighting their ability to amplify human intelligence, foster critical thinking, and promote ethical awareness. By streamlining repetitive tasks such as data cleaning and machine learning model building, LLMs allow students to concentrate on higher-level concepts and provide contextually relevant examples, exercises, and explanations tailored to individual needs. Zheng (2023) reported that ChatGPT enhances the understanding of new and existing complex technical concepts related to data science and data analytics and improves coding skills by generating code for common algorithms and tasks. Furthermore, ChatGPT facilitates learning at an individual's pace through simple prompts in their native language.
Despite the potential of LLMs to support data analytics education, few studies in the literature, to the best of our knowledge, report concrete and formal efforts in this direction. Therefore, one of the objectives of this work is to contribute to narrowing this gap.
While ChatGPT and other generative AI tools have been used as assistants in programming education, new tools have emerged to enhance this process. Chen et al. (2023) developed GPTutor, an extension for Visual Studio Code that leverages the uses OpenAI's GPT API to offer detailed code explanations by integrating relevant source code into its prompts, delivering more precise and concise insights compared to existing code explainers. Yang et al. (2024) introduced the Conversational REpair Framework—(CREF), which employs LLMs to semi-automatically repair programs by integrating augmented information and human guidance aiming to improve productivity, elevate code quality, facilitate interactive learning, and broaden access to high-quality programming education.
Prasad and Sane (2024) proposed a self-regulated learning (SRL) framework for programming problem-solving using generative AI technologies like LLMs. They emphasize the importance of SRL skills in effectively leveraging LLMs and explore how these technologies influence students' problem-understanding, solution evaluation, and regulation strategies. Their SRL framework provides a theoretical foundation for educational interventions that enhance SRL skills, improving students' ability to use AI-powered tools in programming tasks. A key advantage of this framework is its ability to promote self-regulation by encouraging deep problem analysis, fostering problem decomposition skills, and enhancing computational thinking through prompt engineering and conversational AI. Other efforts include LLM-based assistants like Code Interpreter by OpenAI (2024) and Open Interpreter by Lucas (2023). Both tools work as Python code assistants using GPT, facilitating programming tasks.
However, these generative AI tools primarily support the teaching and learning of programming-related skills. Few tools have been specifically designed for developing skills focused on supporting data analytics or data science learning. One of the pioneering tools in this area is LIDA, a novel tool for generating grammar-agnostic visualizations and infographics. Developed by Dibia (2023), LIDA approaches visualization generation as a multi-stage process, arguing that well-orchestrated pipelines based on LLMs and Image Generation Models (IGMs) are effective for addressing data analytics tasks. LIDA leverages the language modeling and code writing capabilities of state-of-the-art LLMs to enable four core automated visualization capabilities: (i) Summarizer, which converts data into a rich but compact natural language summary; (ii) Goal Explorer, which enumerates visualization goals based on the data; (iii) VisGenerator, which generates, refines, executes, and filters visualization code; and, (iv) Infographer, which produces data-faithful stylized graphics using IGMs. Additionally, LIDA's data visualization capabilities extend to four operations on existing visualizations: explanation, self-evaluation, automatic repair, and recommendation. LIDA's characteristics make it a direct support tool for both, development and education-related, activities.
Recently, Hong et al. (2024) introduced Data Interpreter, an LLM-based agent that emphasizes three pivotal techniques to enhance problem-solving in data science: (i) dynamic planning using hierarchical graph structures for real-time data adaptability; (ii) dynamic tool integration to improve code proficiency during execution, thereby enriching the necessary expertise; and (iii) identification of logical inconsistencies in feedback and efficiency enhancement through experience recording. Although it is possible to direct Data Interpreter toward educational purposes, the agent primarily focuses on automating the development of data science and data analytics projects in an agile and reliable manner.
Our objective is to measure the impact of generative AI tools on the learning process of data analytics. To achieve this, we conducted a case study involving students and professionals with minimal or underdeveloped computational thinking skills. Below, we detail the research model, study group, and case study conditions.
This article examines how learners perform and their perspectives when using traditional tools versus LLM-based tools to acquire data analytics skills. To explore this, we employed the case study method. A case study entails a thorough examination and analysis of an individual, group, organization, or event. It delves deeply into a specific topic, elucidating a phenomenon or seeking to understand the efficacy of certain strategies or approaches in a particular situation (Yilmaz and Yilmaz, 2023).
Participants developed a data analytics project in the context of a Data Analytics short session as described in Section 3.4. Thus, our case study focused on examining the participants' performance while also considering the instructors' opinions on the quality of the solutions developed as presented in Section 3.5.
We conducted a case study with a cohort of 59 participants affiliated with higher education programs at Tecnologico de Monterrey, a private university in Mexico. The cohort included 43 undergraduate students enrolled in a Data Analytics course and 16 professionals from a continuing education course focused on Data Analytics. It is important to highlight that our analysis was guided by the perspective of the participants' roles, specifically distinguishing between students and professionals.
To examine potential differences in responses due to the gender gap in motivation for developing computational competencies, the study documented the gender distribution of the participants (Jung Won Hur and Marghitu, 2017; Kurti et al., 2024). From our cohort, 32 participants identified as female, 27 as male, and 1 preferred not to disclose. Figure 1 presents the distribution of gender across different roles among the participants in our case study.
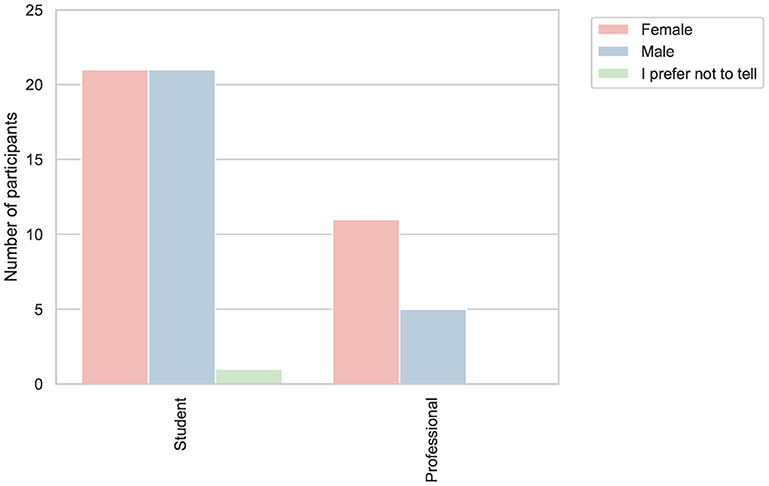
Figure 1. Distribution of participants by role and gender.
All participants were affiliated with different departments, ensuring diversity in areas of expertise and indicating the depth of their computational background. Specifically, 88% of participants came from fields such as finance, business, social sciences, and others, while the remaining 12% were from engineering disciplines including sustainable engineering, chemical engineering, biomedical engineering, and industrial engineering. This distribution is detailed in Figure 2.
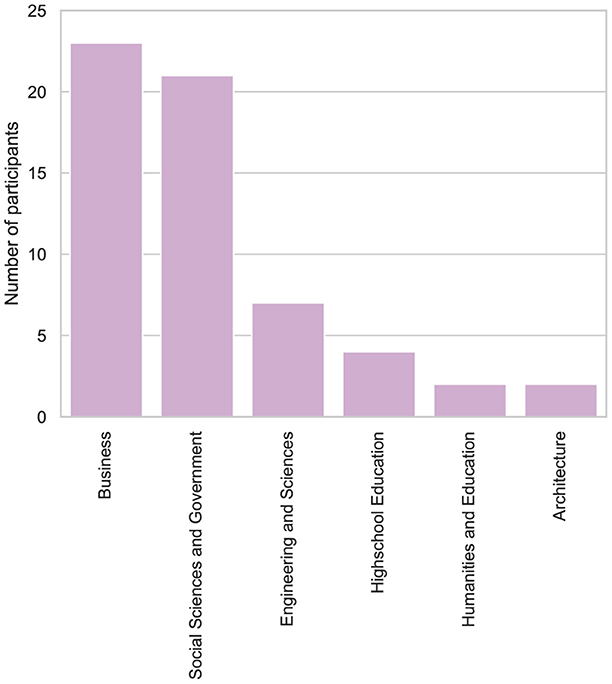
Figure 2. Distribution of participants by affiliation.
Moreover, the cohort included individuals from a wide range of age groups: 22 participants were between 18 and 20 years old, 19 were between 21 and 22, while smaller groups fell into older age brackets, with 2 participants each in the ranges of 23–25, 26–30, 31–35, and 36–40 years. Additionally, 4 participants were between 40 and 50 years old, and 5 were over 50 years old, as shown in Figure 3.
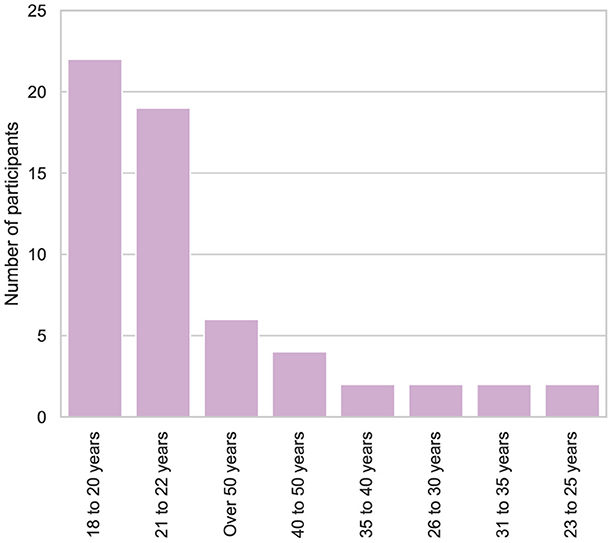
Figure 3. Distribution of participants by age.
Collecting data on participants' age, gender, and professional background enabled us to examine variations in responses influenced by these demographics. This information is crucial for analyzing the impact of generative AI tools on learners with varying levels of experience across different fields. All participants' responses were analyzed to assess their performance and perspectives on using traditional and LLM-based tools for developing data analytics skills, ensuring a comprehensive understanding of their effectiveness in diverse educational and professional contexts.
The focal point of our case study is centered on developing a single data analytics project for all participants. The following materials were defined for carrying out the case study:
1. Programming environment: We selected Google Colaboratory (2017), a collaborative programming environment hosted in the cloud, which allows users to focus on programming, without worrying about technical details such as package installation, programming configurations, memory management, etc. Participants required a free Google Colaboratory account to work on the project.
2. Datasets: We selected two well-established datasets from the literature: the Iris and the Wine datasets (Dua and Graff, 2019):
• Iris dataset: This dataset was used by the instructors to illustrate the development of a data analytics project.
• Wine dataset: This dataset is similar to the Iris dataset, and was given to learners to be worked on entirely by them.
While the datasets are commonly known, the instructors provided them directly to avoid confusion and variations.
3. Project methodology: The project was developed following the de-facto standard and industry-independent process model CRISP-DM (Schröer et al., 2021). Only 3 of the 6 phases of CRISP-DM were performed:
• Business understanding: The business situation should be assessed to get an overview of the available and required resources. The project's goal establishment is one of the most important aspects of this phase. Thus, the instructors formulated one goal (G1) for the project based on the Iris dataset and one goal (G2) for the one based on the Wine dataset. These goals were carefully put together to align with the analytical challenges faced by learners and the educational goals of our case study.
• Data understanding: Exploring and describing the dataset and checking the data quality are essential tasks in this phase. To make it more concrete, it is recommended to carry out a statistical exploratory analysis. Depending on the established goal, it is possible to reach a feasible solution at this point.
• Evaluation: The results are reviewed according to the established goal. Therefore, the results must be interpreted and further actions are defined. Furthermore, the process is to be reviewed in general.
It is recommended that participants have a basic understanding of data analytics projects' pipeline. Nevertheless, the instructors provided fundamental highlights.
4. ChatGPT: An LLM web application based on a model specifically trained to follow instructions from prompts and provide detailed responses (OpenAI, 2022). For this study, the participants required a free ChatGPT access account.
5. GPT via API: This is the core of ChatGPT, namely, the model itself, which can be accessed directly via API service (OpenAI, 2020). This is a technical resource primarily used in specialized software development projects. Due to the cost of accessing GPTs via API, the instructors provided an OpenAI token free of charge to facilitate access to this resource.
6. LIDA: An open-source library for generating data visualizations and data-faithful infographics, compatible with multiple LLM providers (Dibia, 2023).
A special 135-min session was scheduled for our participants, referred to as learners, to take part in the study. The session was led by the instructors, who are the authors of this work, following the step-by-step actions described below.
1. Presentation (5 min): The session begins with a welcome to the participants, an explanation of the session's purpose, and an overview of how the data regarding their performance and impressions will be collected.
2. Introduction (10 min): A brief overview of the development of data analytics projects following the CRISP-DM methodology is provided. It is noted that we will undertake a project using three different approaches: traditional development, utilizing ChatGPT, and employing LIDA in combination with GPT.
3. Approach 1—traditional development (30 min): A new project is initiated in Google Colaboratory, with development centered on achieving the defined goal (G1) on the Iris dataset: Is there a relationship between sepal length and petal width in different iris species?
This approach emphasizes the traditional development of a data analytics project using standard Python packages, including pandas, scikit-learn, matplotlib, and seaborn. Thus, the instructors provided the pre-developed source code and guided learners on every step throughout the entire process, from data reading to the interpretation of the results.
a. Activity proposal (5 min): The Wine dataset is presented to learners as well as the respective goal (G2): Do the chemical components of a wine allow us to identify the class of wine to which it belongs?
Learners are instructed about the Activity 1 which consists on develop the data analytics project to address G2 using standard Python packages. Participants are allocated 10 min to work on the project and are encouraged to progress as far as possible within this time frame.
b. Activity 1 development (10 min): Participants work on the project, focusing on solving G2 using Approach 1. During this period, no technical support is provided by the instructors.
4. Approach 2—ChatGPT-based development (20 min): A new chat window in ChatGPT is initiated. The instructor recommends using the most recent ChatGPT version. For this case study, the instructor gave the freedom for the learners to choose to use ChatGPT-3.5 or ChatGPT-4.
The instructor begins developing G1 again, this time with ChatGPT. Using prompt engineering, the instructor defines ChatGPT's role and outlines expectations. ChatGPT is informed about the programming environment, the dataset, and the desired goal. The source code responses generated by ChatGPT are copied to a new project in Google Colaboratory for execution. The results are observed and analyzed. The instructor then returns to the ChatGPT window to request explanations and interpretations of the results. The ChatGPT explanation is discussed and compared against the instructor's interpretation. New prompts may be made to adjust the results, enhance the visual aspects of the plots, and so on.
a. Activity proposal (3 min): Learners are instructed about the Activity 2, which consists on develop the data analytics project to address G2 using ChatGPT-based development. Participants are allotted a 10-min period to work on the project, during which they are encouraged to achieve as much progress as they could.
b. Activity 2 development (10 min): Participants work on the project, focusing on solving G2 using Approach 2. During this time, the instructors do not provide any technical assistance.
5. Approach 3—LIDA + GPT development (25 min): A new project is initiated in Google Colaboratory. Within this environment, instructors demonstrated how to install and configure LIDA. They also guided the integration of LIDA with the preferred GPT model using OpenAI's API, ensuring it aligned with the GPT model used in Approach 2.
This process included detailed instructions on how to create and use prompts directly from the Google Colaboratory programming environment by integrating LIDA + GPT to address G1. Given that this combined approach provides a compact and efficient solution for G1, we further explored its capabilities to refine and enhance the results.
a. Activity proposal (2 min): Learners are instructed about the Activity 3 which consists on develop the data analytics project to address G2 using LIDA + GPT development. Participants are given 10 min to advance the project and are encouraged to make as much progress as possible within the allotted time.
b. Activity 3 development (10 min): Participants worked on the project, focusing on solving G2 using Approach 3. During this time, the instructors do not offer any technical assistance.
6. Form filling and closing (15 min): Participants are directed to a Google Form questionnaire, specifically designed to capture their information. The session concluded after all the participants filled out the form.
The instructors can provide an additional 10–15 min for Q&A. Moreover, it is important to note that the objective of each of the three activities proposed to participants is, in addition to demonstrating different ways of solving a data analytics project, to measure the level of complexity of the technologies and the background required for their appropriate use.
In Activity 1, participants were tasked with completing the project using conventional Python programming techniques without any AI assistance. This activity aimed to set a baseline for comparing the effectiveness and efficiency of the other methods. In Activity 2, participants used ChatGPT as an external programming assistant. This setup allowed us to measure the impact of integrating a conversational AI assistant into the data analytics workflow. This activity also lets us analyze the advantages and potential challenges of using ChatGPT in a specialized context. Finally, in Activity 3, participants experienced the use of LIDA integrated with GPT as a specialized assistant for data-related projects. This approach aimed to create a workflow with assistance from an AI specialized in Data Analytics, all within the programming environment itself.
Data collection was conducted immediately after the session concluded. The authors created an electronic questionnaire using Google Forms, and the link to the online form was distributed to the learners in the class. Learners were then instructed to complete the web form using their computers.
The questionnaire was prepared to collect sufficient data to generate a robust profile of each participant, encompassing three critical aspects: demographics, previous programming and data analytics experience, and data analytics learning experience during the session.
Regarding demographic information, the focus was on collecting data on gender, age, affiliation, and role, as detailed in Section 3.2. Regarding previous programming and data analytics experience, we collected the following data:
• Programming experience: To assess their technical background, we inquired about participants' prior experience in programming. This information is vital for evaluating how programming skills might influence their interactions with the analytical tools used in the study, as well as the speed at which participants developed the activities assigned during the session.
• Experience in data analytics: It is necessary to understand the participants' familiarity with data processing projects, as this could affect their ease of use and efficiency with different analytical methods.
• Experience using programming tools: It is necessary to assess the participants' knowledge and experience using programming tools, such as Google Colaboratory, to determine their potential proficiency with technologies related to data analytics.
• Experience with generative AI: We asked participants about their experience with generative AI technologies. This is crucial for understanding their readiness to leverage advanced AI tools to address professional challenges.
Regarding the data analytics learning experience during the session, we collected the following data:
• Developing time: Participants provided the time range required to complete the project for each approach. If a participant did not finish the activity within the allotted time, they were asked to estimate the additional time needed to complete it.
• Contribution to workflow development: Participants assessed the extent to which each approach contributed to the project's development concerning the specified goal, with a particular emphasis on the quality of the solution obtained.
• Ease of use: Participants were asked which approach they found easiest to use for developing the step-by-step process of a data analytics project. This helps identify the most user-friendly approach, which is critical for adoption in real-world settings.
• Result achievement speed: Participants were asked to indicate which approach enabled them to achieve results the quickest, providing insights regarding the efficiency of each approach in solving a data analytics challenge.
• Appropriateness. Participants evaluated which method they considered the most suitable for the type of work they were performing. This question assesses the perceived relevance and effectiveness of each approach.
• Correctness: We asked participants which approach they deemed most correct in relation to the progressive and overall obtaining of results. This question addresses their perceptions of the validity, quality, and reliability of the results obtained with each approach.
To evaluate participants' programming experience, they were asked: “Before today's session, have you had any experience with programming in any language?” The response options were: “yes,” “no,” and “some.” Analyzing this aspect by participant's roles, 65% of the students reported having programming experience, while the remaining 35% indicated they had some experience. Among the professionals, 69% stated they had programming experience, 25% reported having minimal experience, and 6% indicated they had no programming experience at all. Figure 4 shows these distributions.
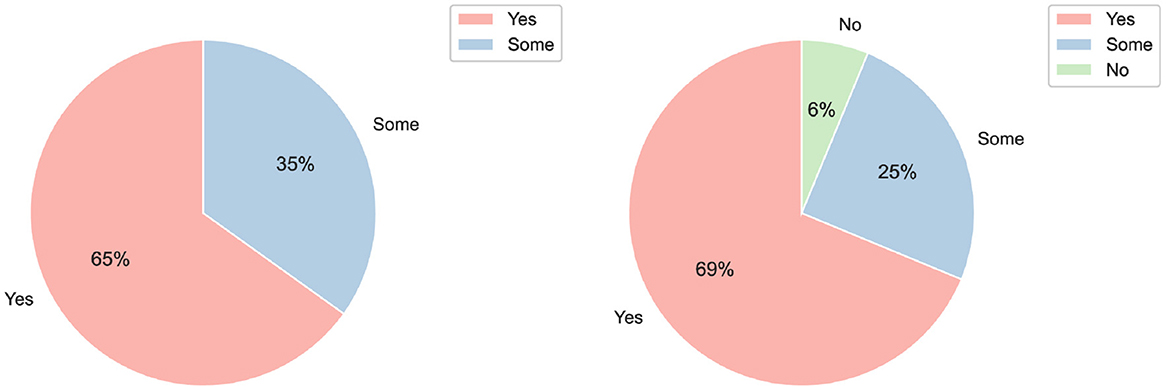
Figure 4. Distribution displaying participants' programming experience based on their roles as students (left), and professionals (right).
Since it is important to understand possible gaps in gender and age in the process of acquiring computational thinking-related skills, Figure 5 details the participants' experience based on these two demographic factors considering their roles. The figure shows no significant disparity in programming experience across all roles, genders, and age groups, except for professionals over 50 years, where we found participants identified as female with no prior programming experience. Additionally, among students, the youngest group (18–20 years old) shows a majority of identified as females with previous programming experience. In the 21–22 age range, the predominant group is such identified as male.
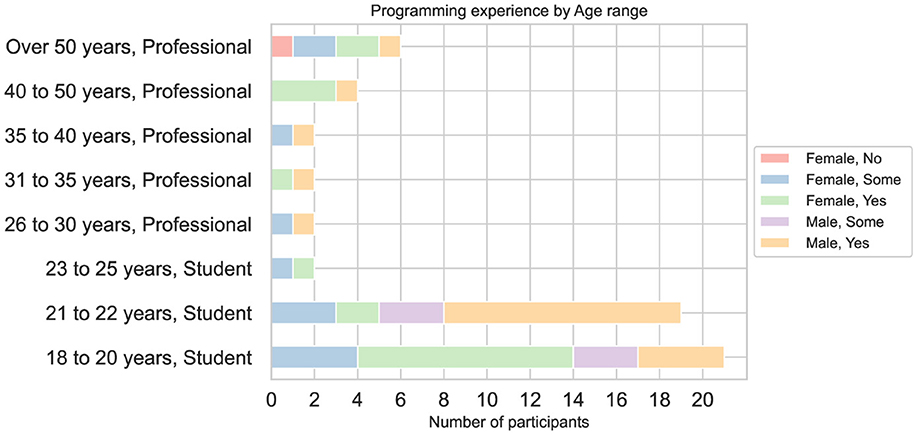
Figure 5. Distribution displaying participants' programming experience by role, ranging age, and gender.
To assess participants' experience in data analytics, they were asked: “Before today's session, had you had any experience developing any data analytics projects?” The response options were: “yes,” “no,” and “some.” Considering their roles, we observed that 56% had experience, 40% had no experience, and 5% had minimal experience. Among professionals, 50% of students had previous experience developing data analytics projects or related tasks, while 38% had no experience, and 12% had some experience. These distributions can be observed in Figure 6.
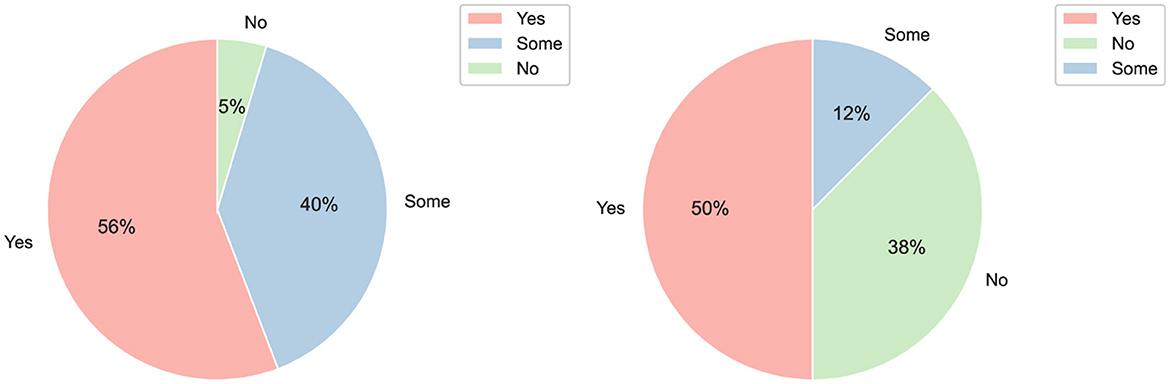
Figure 6. Distribution displaying participants' experience in developing data analytics projects based on their roles as students (left), and professionals (right).
Analyzing Figures 4, 6, we note that all students had at least some minimum experience in programming, while only 6% of professionals reported having no experience at all. However, participants with programming experience did not necessarily have experience in developing data analytics projects. Consequently, there is a greater number of participants with no prior experience in data analytics projects compared to those with programming experience. Furthermore, as shown in Figure 7, the gender group that presents the greatest disparity in data analytics-related skills is female across roles and age groups. This is most clearly seen in the younger groups, where half or more of the males have at least some experience in data analytics, while among females, half or fewer possess these skills.
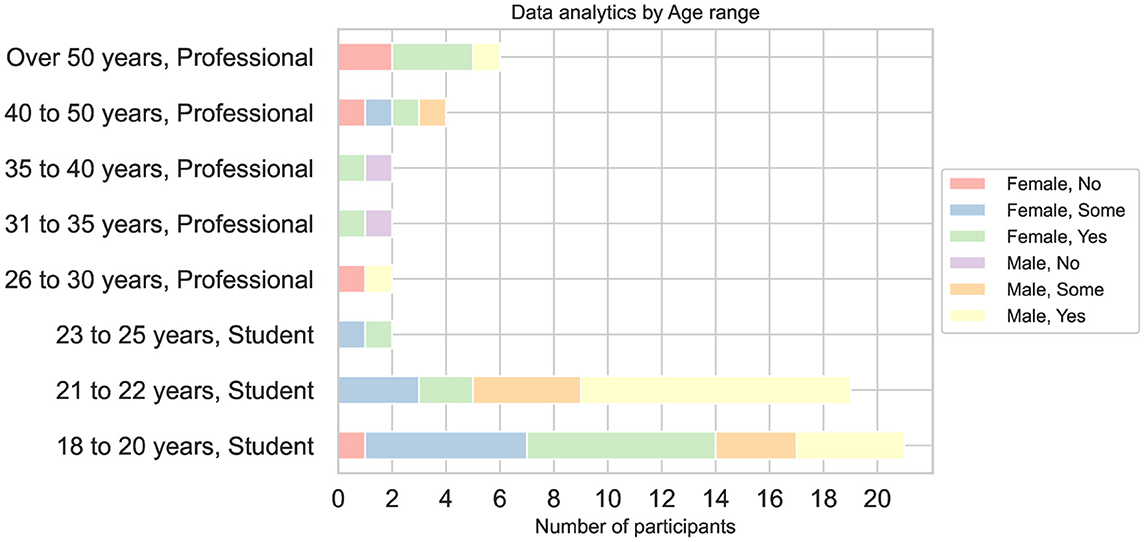
Figure 7. Distribution of participants' experience in data analytics-related skills by role, age range, and gender.
To assess participants' experience with programming tools, we asked, “Before today's session, were you familiar with programming tools like Google Colaboratory, Python, and others?” The response options were: “yes,” “no,” and “some.” As shown in Figure 8, only 8% of participants, regardless of their role, indicated they had no prior exposure to programming tools. This percentage is entirely represented by professionals who reported having none or minimal programming experience because they are just beginning their journey into acquiring these skills. Conversely, some students had already taken or were taking an introductory data analytics course that included programming tuition.
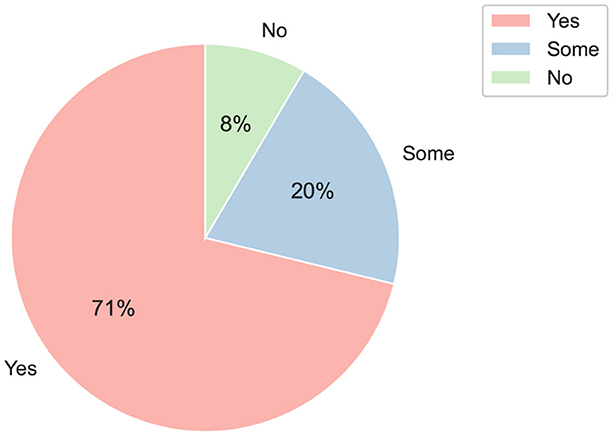
Figure 8. Displaying participants' experience in programming tools.
To assess participants' experience with generative AI, we asked four specific questions: “Before today's session, have you had any experience using ChatGPT to the extent of creating prompts on various topics?” “Before today's session, have you had any experience using ChatGPT for any programming tasks?” “Before today's session, have you had any experience using ChatGPT for any data analytics tasks?” and “Before today's session, have you had any experience using any OpenAI API or other generative AI provider's API?” For each question, the participants had to respond with one of the following options: “yes,” “no,” or “some.” Results for these four questions are shown in Figure 9.
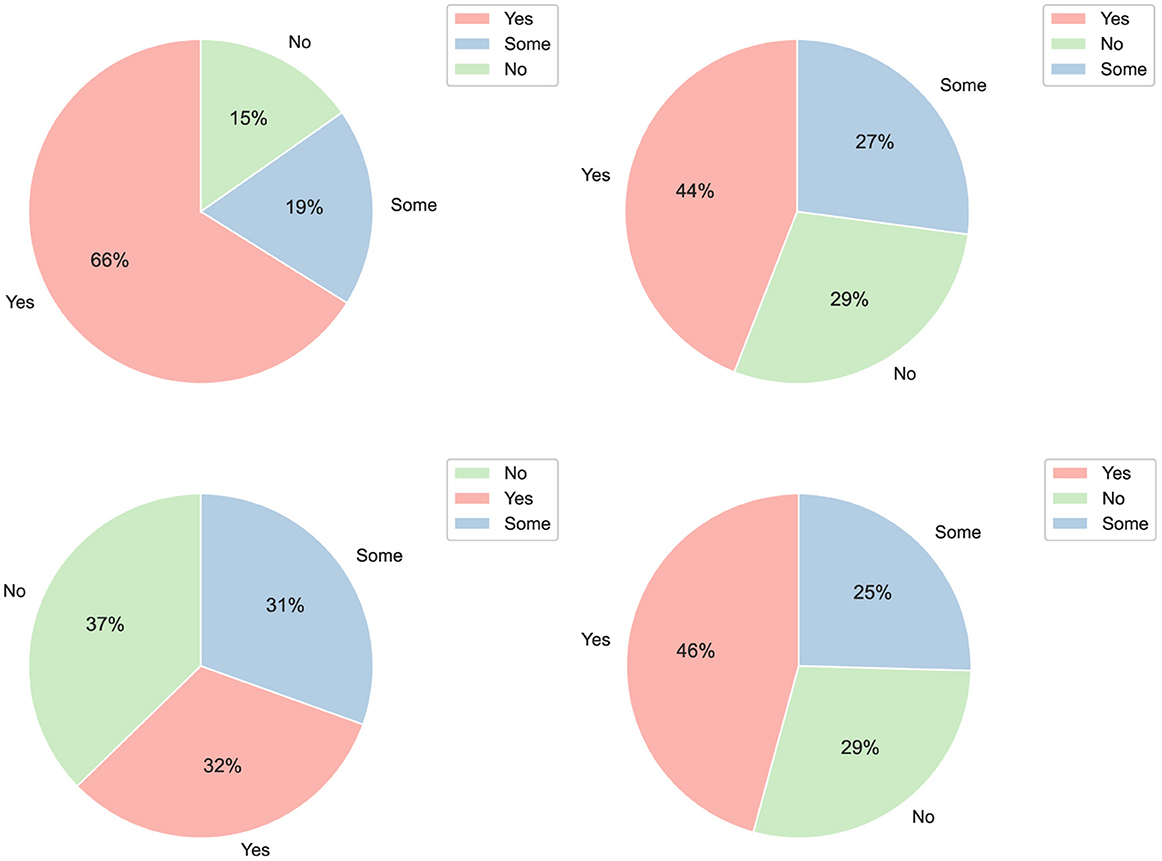
Figure 9. Distribution of participants' experience related to the use of generative AI tools like ChatGPT. (Top left corner) Distribution of participants who had previously used ChatGPT for general purposes. (Top right corner) Distribution of participants who had previously used ChatGPT for programming tasks. (Bottom left corner) Distribution of participants who had previously used ChatGPT for data analytics project development. (Bottom right corner) Distribution of participants who had previously used APIs from any LLM provider, such as OpenAI.
In Figure 9 we can observe an unexpected finding. Despite being just over 2 years since the launch of ChatGPT, given the popularity of the platform, one could assume that all participants would have had some prior experience with it. However, our data reveals that 15% of participants have had no prior interaction with this generative AI tool. More further insights are observed when found that a significant portion of the participants, 27%, had never used ChatGPT for programming tasks. Moreover, an even larger segment, 37%, had not utilized ChatGPT for data analytics project development. These results indicate that, contrary to expectations, a substantial number of participants were yet to integrate ChatGPT into their workflows for these specific tasks. Moreover, also is interesting to observe that a significant portion of participants with programming and data analytics experience also had some experience using generative AI APIs. This implies a considerable level of expertise that allows for a greater critical appreciation of the session that learners have taken.
The time each participant spent developing Activities 1, 2, and 3 is crucial for quantifying the effort required to tackle the same project using different approaches. As shown in Figure 10, only when using Approach 2, which relied on ChatGPT as an external programming assistant, and Approach 3, which integrated the LIDA framework with GPT via OpenAI's API, were some students and professionals able to complete the project in < 5 min. Conversely, when using Approach 1, which involved traditional programming packages, the majority of participants required more than 10 min to complete the project. This highlights the efficiency of Approaches 2 and 3 compared to Approach 1.
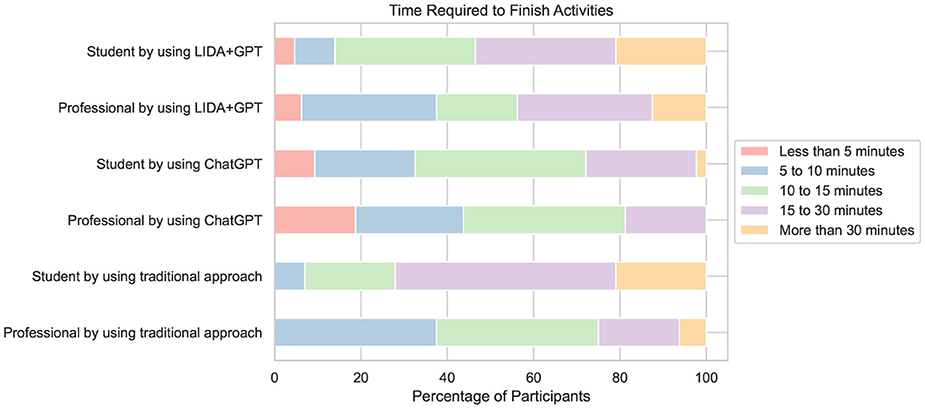
Figure 10. Distribution displaying the time spent by both students and professionals in developing the data analytics project using the three different approaches: Approach 1, which utilized traditional programming packages; Approach 2, which involved using ChatGPT as a programming assistant; and Approach 3, which integrated the LIDA framework with OpenAI's GPT via API connection.
Another noteworthy observation, as depicted in Figure 10, is that ~40% of professionals managed to develop the project within 10 min using either Approach 2 or Approach 3. This indicates a relatively high efficiency among professionals with these approaches. In contrast, students required more time and effort; only 35% of them completed the project in up to 10 min using Approach 2, and a mere 15% achieved this with Approach 3. This disparity suggests that professionals might be better equipped to leverage the capabilities of ChatGPT and the LIDA + GPT integration efficiently. Furthermore, professionals also spend less time working on Approach 1 to complete the project than students. This implies that, in general, professionals are more adept at tackling a data analytics project using any approach compared to students.
Additionally, in Figure 10, we can observe that 20% of students and 10% of professionals took more than 30 min to complete the project in Approach 3. This significant delay might indicate potential technical challenges associated with integrating LIDA with GPT via API. The extended time could reflect difficulties in configuring and effectively using the LLM, as the integration process still requires several complex setup steps. This suggests that while LIDA with GPT integration offers powerful capabilities, it also demands a higher level of technical proficiency or more refined implementation to avoid such delays.
We analyzed participants' perception of three approaches to solving the same data analytics project focusing on ease of use, speed in achieving results, appropriateness, and correctness. To obtain this perception, we asked four questions:
• Which of the approaches for developing an analytics project seemed easiest to you? Ease refers to a general understanding of the process and practical implementation of the activity. In which of the approaches do you consider you could develop a data analytics project more efficiently, focusing more on analytics rather than programming details?
• Which of the approaches for developing an analytics project seemed fastest to you? Speed refers to which approach allowed you to progress the most in the 10 min offered for the activity development. In which do you feel you progressed the most or could potentially advance faster to achieve the aimed results?
• Which of the approaches for developing an analytics project seemed most appropriate to you? Appropriateness refers to the development experience. Which of the approaches do you consider has a more analytics-focused approach, reducing the effort on programming details?
• Which of the approaches for developing an analytics project seemed most correct to you? Correctness refers to offering a coherent response that addresses the project goal in an objective, clear, visually appealing, and explanatory manner.
For each question, participants could respond with one of the following options: (i) Approach 1—Traditional method: Using standard Python libraries; (ii) Approach 2—ChatGPT as an external programming assistant; (iii) LIDA with GPT integration via API; and, (iv) None. Figures 11, 12 show the participants' perceptions regarding these four aspects, considering their roles and gender, respectively. Specifically in Figure 12, aiming to maintain the legibility of the chart, we opted to exclude the individual who chose not to disclose their gender.
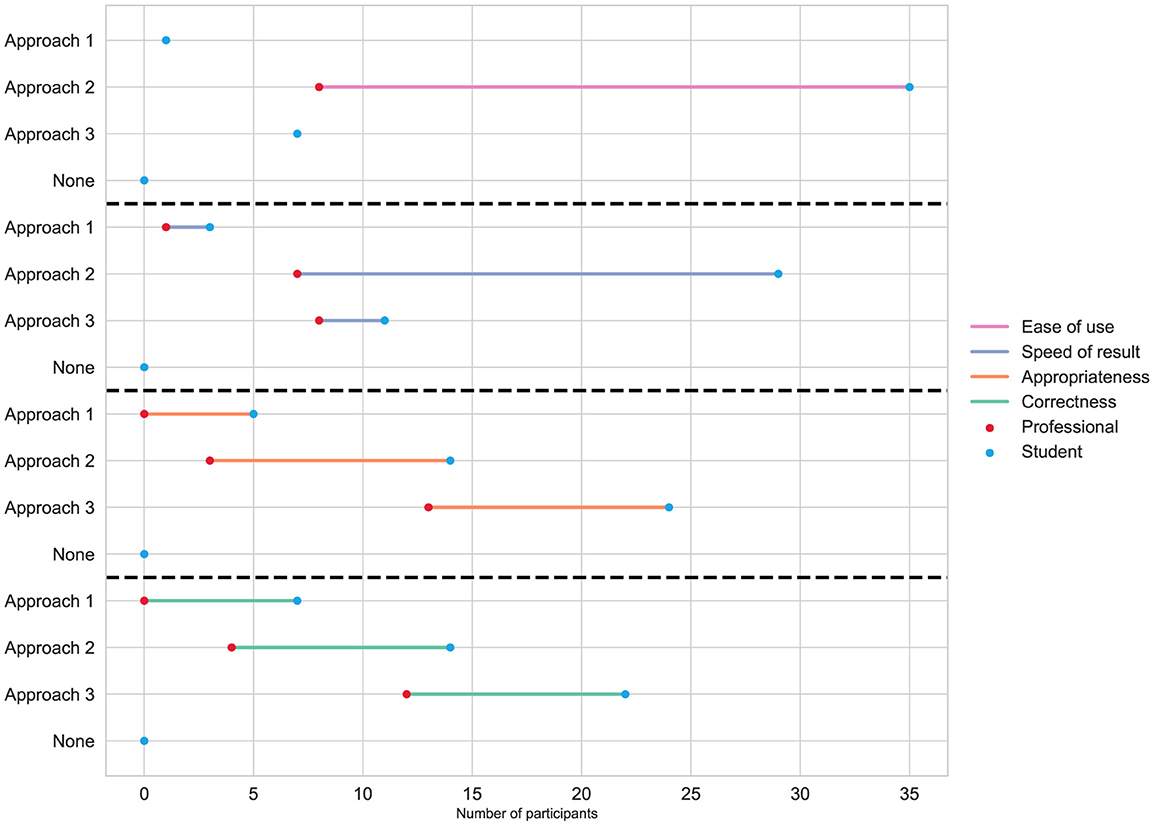
Figure 11. Perception of participants grouped by role regarding the ease of use, speed in achieving results, appropriateness, and correctness for each of the three approaches to solving data analytics projects.
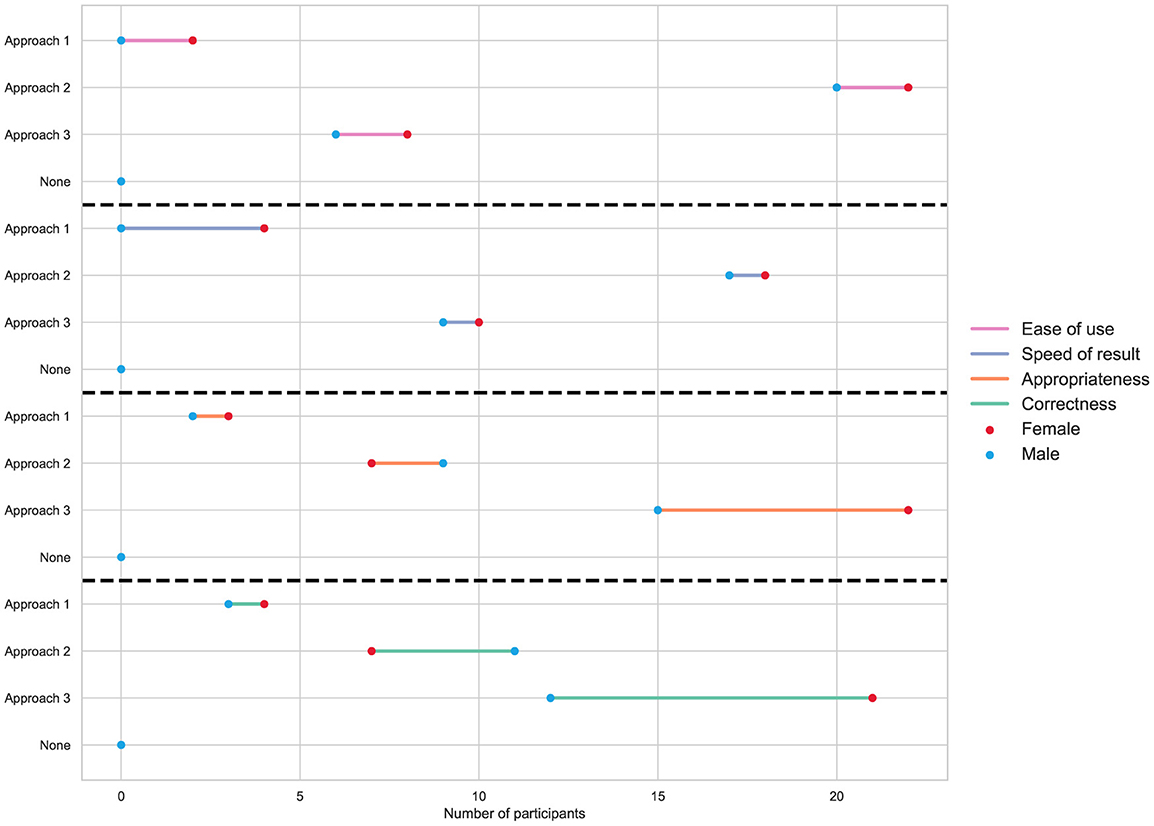
Figure 12. Perception of participants grouped by gender regarding the ease of use, speed in achieving results, appropriateness, and correctness for each of the three approaches to solving data analytics projects.
As stated in Figure 11, regarding the ease of use aspect, both students and professionals agree that Approach 2 offers greater advantages. Some students attribute this advantage to Approach 3, while very few students consider Approach 1 to be easier to use. Here it is important to notice that all professionals completely agree that using ChatGPT as a programming assistant is the easiest way to tackle data analytics projects, while students' opinions are diverse. This perception is also reflected from a gender perspective, as depicted in Figure 12, which illustrates that both males and females predominantly consider Approach 2 to be the easiest to use. This preference suggests that regardless of gender and role, participants found ChatGPT to be more user-friendly and easier to use compared to the other approaches.
When we look at the speed factor of obtaining results in both Figures 11, 12, we see that most students and professionals, whether male or female, consider Approach 2 to be faster. Here we observe that a significant number of participants consider Approach 3, which integrates LIDA with GPT via OpenAI's API, to be the fastest method for developing the project. This suggests that the streamlined workflow provided by this integration can be highly efficient. However, it is important to note that the speed advantage of Approach 3 is somewhat nuanced. The immediate response to a prompt in ChatGPT is inherently quicker because it bypasses the additional steps required for integrating and configuring the prompt to work within the LIDA + GPT environment. This additional setup in Approach 3 can introduce delays, even though the overall approach might offer superior functionality and efficiency once fully operational.
When Figures 11, 12 examine the appropriateness of different approaches in minimizing the effort required on programming details for data analytics projects, both by role and by gender, Approach 3 emerges as the preferred method. This indicates that integrating LIDA with GPT is widely recognized for its potential to streamline programming efforts effectively. However, it is noteworthy that a significant proportion of students also find Approach 2 to be a competitive option in this regard. This suggests that while the advanced integration capabilities of Approach 3 are appreciated, the straightforward and immediate assistance provided by ChatGPT in Approach 2 remains highly valued, particularly among students.
In examining the correctness of results across different approaches, as shown in Figures 11, 12, Approach 3 consistently emerges as the preferred choice among participants, irrespective of their role or gender. However, it is noteworthy that there is a closer alignment of preferences with Approach 2 and, surprisingly, also with Approach 1. Given that this factor assesses the quality of results produced by each approach, it is expected that Approach 3 would be preferred for its specialized support in data analytics projects provided by the integration of LIDA with GPT. This preference underscores its effectiveness in delivering high-quality outcomes with minimal manual programming effort. Approach 2 also received a favorable reception due to its capability to provide valuable assistance, though ChatGPT requires participants to craft precise prompts and possess expertise in data analytics project development. It is noteworthy that some participants, particularly students identified as female, found Approach 1, which relies on traditional programming packages, to offer greater correctness in results. This might reflect their comfort and familiarity with conventional methods or a preference for the precision and control that manual coding provides. Overall, while advanced and integrated approaches such as Approaches 2 and 3 are favored for their efficiency and support in data analytics, traditional methods like Approach 1 still hold significant value for certain participant groups regarding perceived correctness and reliability.
Finally, evaluations were conducted on the projects optionally submitted by the participants. From the instructors' perspective, projects utilizing Approach 3 demonstrated enhanced comprehension and application of data analytics concepts among participants, irrespective of their computational background. Integrating LIDA with a GPT led to project solutions of higher quality, indicating a heightened proficiency in data management and application development. Moreover, instructors considered that Approach 3 fostered an immersive and engaging learning experience in learners, significantly more so than those developed using other approaches. Such enriched narrative elements improve the project's clarity and impact. Those elements also contribute to a more compelling presentation of data insights, highlighting the added value of integrating advanced generative AI tools with traditional data analytics frameworks.
This work highlights the potential of employing generative AI-based tools to revolutionize the development of data analytics competencies among students and professionals, regardless of their computational background. To this end, we presented a case study that, to our knowledge, is the first to evaluate the use of these technologies in the data analytics learning process, comparing them with each other and with traditional approaches based on programming packages.
A key lesson from our case study is the transformative potential of approaches based on integrating advanced generative AI tools like GPT with specialized frameworks such as LIDA. The higher levels of participant preference indicate the superiority of these approaches over traditional development methods. However, it is important to highlight that when using general-purpose generative AI tools such as ChatGPT, users must be aware of the data analytics process and take responsibility for filtering out potential errors or incompleteness in the requirements of a data analytics project. These deficiencies can be mitigated by using more advanced tools specialized in supporting data analytics tasks, such as LIDA with GPT. However, users still need advanced programming knowledge to properly configure this connection via API.
Additionally, our findings suggest that the learning curves for the different approaches vary significantly. Since learners encountered technical difficulties in developing the project and interpreting the results, Approach 1 has a steep learning curve. Approach 2, which involves consolidating the ChatGPT responses into a cohesive project, has a shallow learning curve due to the challenge of verifying the suitability of the solution. Approach 3, using LIDA integrated with GPT, has a J-curve pattern, with initial developing difficulties related to establish the connection via API and configuring the LLM, followed by a smooth and efficient process once set up.
It is important not to disregard that some users may feel insecure about the solutions generated by AI tools, leading them to prefer the traditional approach to developing data analytics projects. Therefore, there is a significant opportunity for generative AI tools to improve their performance, providing accurate, complete, and convincing results for data analytics projects, thereby increasing user confidence in adopting these technologies.
Some limitations concerning this work include the heterogeneity of participants' affiliations and ages, the short time allocated for completing activities for each approach, and the need for further studies to address the insecurity aspects related to the use of AI-based tools by some participants. Additionally, more extensive validation is required to assess the acquisition of critical thinking skills.
Nevertheless, we hope this work highlights the opportunities and needs for integrating advanced LLMs into educational practices, particularly in developing computational thinking skills. Our findings suggest that such integration can significantly enhance the learning of advanced skills, especially those related to data analytics. We aim to establish this study as a foundation for the methodical adoption of generative AI tools in educational settings, paving the way for more effective and comprehensive training in these critical areas. In future work, we plan to replicate this study with a larger participant pool and compare LIDA with similar technologies. Additionally, we intend to evaluate performance across various LLMs beyond GPT.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving humans were approved by Cynthia Karyna López Botello, Tecnologico de Monterrey. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
JV-R: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Supervision, Writing – original draft, Writing – review & editing. AG: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Validation, Writing – review & editing. ON-H: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Validation, Writing – review & editing. JN: Conceptualization, Formal analysis, Methodology, Validation, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was partially supported by the NOVUS grant: 2023-419283 (PEP No. PHHT085-23ZZNV041).
We would like to thank the Writing Lab from the Institute for the Future of Education for helping in the publication of this work. We also thank the Cyber Learning Lab and the Computer Department of Tecnologico de Monterrey, Mexico City Region.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The handling editor GC declared a shared affiliation with the authors at the time of review.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/feduc.2024.1418006/full#supplementary-material
Alhashmi, S. M., Hashem, I. A. T., and Al-Qudah, I. (2024). Artificial Intelligence applications in healthcare: a bibliometric and topic model-based analysis. Intell. Syst. Appl. 21:200299. doi: 10.1016/j.iswa.2023.200299
Azaria, A., Azoulay, R., and Reches, S. (2024). ChatGPT is a remarkable tool–for experts. Data Intell. 6, 240–296. doi: 10.1162/dint_a_00235
Baidoo-Anu, D., and Ansah, L. O. (2023). Education in the era of generative artificial intelligence (AI): Understanding the potential benefits of chatgpt in promoting teaching and learning. Soc. Sci. Res. Netw. 2023:4337484. doi: 10.2139/ssrn.4337484
Bringula, R. (2024). ChatGPT in a programming course: benefits and limitations. Front. Educ. 9:1248705. doi: 10.3389/feduc.2024.1248705
Chen, E., Huang, R., Chen, H. S., Tseng, Y. H., and Li, L. Y. (2023). “GPTutor: a ChatGPT-powered programming tool for code explanation,” in International Conference on Artificial Intelligence in Education. Available at: https://link.springer.com/chapter/10.1007/978-3-031-36336-8_50
Chen, L., Chen, P., and Lin, Z. (2020). Artificial intelligence in education: a review. IEEE Access 8, 75264–75278. doi: 10.1109/ACCESS.2020.2988510
Chinonso, O. E., Theresa, A. M. E., and Aduke, T. C. (2023). ChatGPT for teaching, learning and research: prospects and challenges. Glob. Acad. J. Human. Soc. Sci. 5, 33–40. doi: 10.36348/gajhss.2023.v05i02.001
da Silva, C. A. G., Ramos, F. N., de Moraes, R. V., and dos Santos, E. L. (2024). ChatGPT: challenges and benefits in software programming for higher education. Sustainability 16:31245. doi: 10.3390/su16031245
Dibia, V. (2023). LIDA: a tool for automatic generation of grammar-agnostic visualizations and infographics using large language models,” in Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics: System Demonstrations (ACL), 113–126. Available at: https://aclanthology.org/2023.acl-demo.11/
Dua, D., and Graff, C. (2019). UCI Machine Learning Repository. Available at: Iris dataset: https://archive.ics.uci.edu/ml/datasets/Iris (accessed June 23, 2024) and Wine dataset: https://archive.ics.uci.edu/ml/datasets/Wine (accessed June 23, 2024).
Ellis, A. R., and Slade, E. (2023). A new era of learning: considerations for ChatGPT as a tool to enhance statistics and data science education. J. Stat. Data Sci. Educ. 31, 128–133. doi: 10.1080/26939169.2023.2223609
Google Colaboratory (2017). Google Colaboratory. Available at: https://colab.research.google.com/ (accessed June 23, 2024).
Haleem, A., Javaid, M., Qadri, M. A., Singh, R. P., and Suman, R. (2022). Artificial Intelligence (AI) applications for marketing: a literature-based study. Int. J. Intell. Netw. 3, 119–132. doi: 10.1016/j.ijin.2022.08.005
Hong, S., Lin, Y., Liu, B., Wu, B., Li, D., Chen, J., et al. (2024). Data interpreter: an LLM agent for data science. arXiv [Preprint]. arXiv:2402.18679.
Ifelebuegu, A. O., Kulume, P., and Cherukut, P. (2023). Chatbots and AI in Education (AIEd) tools: the good, the bad, and the ugly. J. Appl. Learn. Teach. 6:29. doi: 10.37074/jalt.2023.6.2.29
Jung Won Hur, C. E. A., and Marghitu, D. (2017). Girls and computer science: experiences, perceptions, and career aspirations. Comput. Sci. Educ. 27, 100–120. doi: 10.1080/08993408.2017.1376385
Kasneci, E., Sessler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., et al. (2023). ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Diff . 103:102274. doi: 10.1016/j.lindif.2023.102274
Kiesler, N., and Schiffner, D. (2023). Large language models in introductory programming education: ChatGPT's performance and implications for assessments. arXiv.org. doi: 10.48550/arXiv.2308.08572
Kurti, E., Ferati, M., and Kalonaityte, V. (2024). Closing the gender gap in ICT higher education: exploring women's motivations in pursuing ICT education. Front. Educ. 9:1352029. doi: 10.3389/feduc.2024.1352029
Laupichler, M. C., Aster, A., Schirch, J., and Raupach, T. (2022). Artificial intelligence literacy in higher and adult education: a scoping literature review. Comput. Educ. 3:100101. doi: 10.1016/j.caeai.2022.100101
Lucas, K. (2023). Open-Interpreter: A Natural Language Interface for Computers. Available at: https://github.com/OpenInterpreter/open-interpreter (accessed June 24, 2024).
Mai, D. T. T., Da, C. V., and Hanh, N. V. (2024). The use of chatgpt in teaching and learning: a systematic review through Swot analysis approach. Front. Educ. 9:1328769. doi: 10.3389/feduc.2024.1328769
Memarian, B., and Doleck, T. (2023). Chatgpt in education: methods, potentials and limitations. Comput. Hum. Behav. 2023:100022. doi: 10.1016/j.chbah.2023.100022
Morales-García, W. C., Sairitupa-Sanchez, L. Z., Morales-García, S. B., and Morales-García, M. (2024). Development and validation of a scale for dependence on artificial intelligence in university students. Front. Educ. 9:1323898. doi: 10.3389/feduc.2024.1323898
Mosaiyebzadeh, F., Pouriyeh, S., Parizi, R. M., Dehbozorgi, N., Dorodchi, M., and Batista, D. M. (2023). Exploring the role of chatgpt in education: applications and challenges. Conf. Inform. Technol. Educ. 2023:3611445. doi: 10.1145/3585059.3611445
Nam, D., Macvean, A., Hellendoorn, V., Vasilescu, B., and Myers, B. (2024). “Using an LLM to help with code understanding,” in 2024 IEEE/ACM 46th International Conference on Software Engineering, ICSE 2024 (IEEE), 881–881. doi: 10.1145/3597503.3639187
Nouri, J., Zhang, L., Mannila, L., and Norén, E. (2020). Development of computational thinking, digital competence and 21st century skills when learning programming in K-9. Educ. Inq. 11, 1–17. doi: 10.1080/20004508.2019.1627844
OpenAI (2020). Openai API. Available at: https://openai.com/index/openai-api/ (accessed June 23, 2024).
OpenAI (2022). Introducing ChatGPT. Available at: https://openai.com/index/chatgpt/ (accessed June 23, 2024).
OpenAI (2024). Code Interpreter. Available at: https://platform.openai.com/docs/assistants/tools/code-interpreter/ (accessed June 24, 2024).
Pedro, F., Subosa, M., Rivas, A., and Valverde, P. (2019). Artificial Intelligence in Education: Challenges and Opportunities for Sustainable Development. UNESDOC Digital Library. Available at: https://unesdoc.unesco.org/ark:/48223/pf0000366994
Pesonen, H., and Hellas, A. (2022). “On things that matter in learning programming: towards a scale for new programming students,” in 2022 IEEE Frontiers in Education Conference (FIE), 1–9. Available at: https://doi.ieeecomputersociety.org/10.1109/FIE56618.2022.9962572
Phung, T., Pădurean, V. A., Cambronero, J., Gulwani, S., Kohn, T., Majumdar, R., et al. (2023). Generative AI for programming education: benchmarking ChatGPT, GPT-4, and human tutors. Int. Comput. Educ. Res. Workshop 2023:3603476. doi: 10.1145/3568812.3603476
Popenici, S. A. D., and Kerr, S. (2017). Exploring the impact of artificial intelligence on teaching and learning in higher education. Res. Pract. Technol. Enhanc. Learn. 12:13. doi: 10.1186/s41039-017-0062-8
Prasad, P., and Sane, A. (2024). “A self-regulated learning framework using generative AI and its application in CS educational intervention design,” in Technical Symposium on Computer Science Education. doi: 10.1145/3626252.3630828
Rahman, M. M., and Watanobe, Y. (2023). ChatGPT for education and research: opportunities, threats, and strategies. Appl. Sci. 13, 5783–5783. doi: 10.3390/app13095783
Rospigliosi, P. (2023). Artificial intelligence in teaching and learning: what questions should we ask of ChatGPT? Interact. Learn. Environ. 31, 1–3. doi: 10.1080/10494820.2023.2180191
Rouhani, M., Lillebo, M., Farshchian, V., and Divitini, M. (2022). “Learning to program: an in-service teachers' perspective,” in 2022 IEEE Global Engineering Education Conference (EDUCON), 123–132. Available at: https://ieeexplore.ieee.org/document/9766781
Saqr, M., and López-Pernas, S. (2024). Learning Analytics Methods and Tutorials: A Practical Guide Using R. Berlin: Springer.
Schröer, C., Kruse, F., and Gómez, J. M. (2021). A systematic literature review on applying CRISP-DM process model. Proc. Comput. Sci. 181, 526–534. doi: 10.1016/j.procs.2021.01.199
Srinivasan, V. (2022). AI and learning: a preferred future. Comput. Educ. 3:100062. doi: 10.1016/j.caeai.2022.100062
Tu, X., Zou, J., Su, W., and Zhang, L. (2023). What should data science education do with large language models? Harvard Data Sci. Rev. 6. doi: 10.1162/99608f92.bff007ab
Vaccino-Salvadore, S. (2023). Exploring the ethical dimensions of using ChatGPT in language learning and beyond. Languages 8:301091. doi: 10.3390/languages8030191
Wolters, A., Arz Von Straussenburg, A. F., and Riehle, D. M. (2024). “AI literacy in adult education—a literature review,” in Proceedings of the 57th Hawaii International Conference on System Sciences, HICSS 2024 (Baltimore, MD: ScholarSpace, Hamilton Library), 6888–6897.
Xing, Y. (2024). Exploring the use of ChatGPT in learning and instructing statistics and data analytics. Teach. Stat. 2024:12367. doi: 10.1111/test.12367
Yang, B., Tian, H., Pian, W., Yu, H., Wang, H., Klein, J., et al. (2024). “CREF: an LLM-based conversational software repair framework for programming tutors,” in ISSTA 2024: The ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). Available at: https://2024.issta.org/details/issta-2024-papers/71/CREF-An-LLM-based-Conversational-Software-Repair-Framework-for-Programming-Tutors
Yilmaz, R., and Yilmaz, F. G. K. (2023). Augmented intelligence in programming learning: examining student views on the use of chatgpt for programming learning. Comput. Hum. Behav. 1:100005. doi: 10.1016/j.chbah.2023.100005
Zhang, K., and Aslan, A. B. (2021). Ai technologies for education: recent research and future directions. Comput. Educ. 2:100025. doi: 10.1016/j.caeai.2021.100025
Keywords: ChatGPT, data analytics learning, generative AI tools, programming skills development, large language models in education, educational innovation, higher education, professional education
Citation: Valverde-Rebaza J, González A, Navarro-Hinojosa O and Noguez J (2024) Advanced large language models and visualization tools for data analytics learning. Front. Educ. 9:1418006. doi: 10.3389/feduc.2024.1418006
Received: 15 April 2024; Accepted: 18 July 2024;
Published: 08 August 2024.
Edited by:
Guillermo M. Chans, Monterrey Institute of Technology and Higher Education (ITESM), MexicoReviewed by:
Vanessa Camilleri, University of Malta, MaltaCopyright © 2024 Valverde-Rebaza, González, Navarro-Hinojosa and Noguez. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jorge Valverde-Rebaza, anZhbHZlcnJAdGVjLm14
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.